5.3.3.1 Responsibility Record
To promote take-up, PROV-DM offers a mild version of responsibility
in the form of a relation to represent when an agent acted on another
agent's behalf. So in the example of someone running a mail program,
the program is an agent of that activity and the person is also an
agent of the activity, but we would also add that the mail software
agent is running on the person's behalf. In the other example, the
student acted on behalf of his supervisor, who acted on behalf of the
department chair, who acts on behalf of the university, and all those
agents are responsible in some way for the activity to take place but
we don't say explicitly who bears responsibility and to what
degree.
We could also say that an agent can act on behalf of several other
agents (a group of agents). This would also make possible to
indirectly reflect chains of responsibility. This also indirectly
reflects control without requiring that control is explicitly
indicated. In some contexts there will be a need to represent
responsibility explicitly, for example to indicate legal
responsibility, and that could be added as an extension to this core
model. Similarly with control, since in particular contexts there
might be a need to define specific aspects of control that various
agents exert over a given activity.
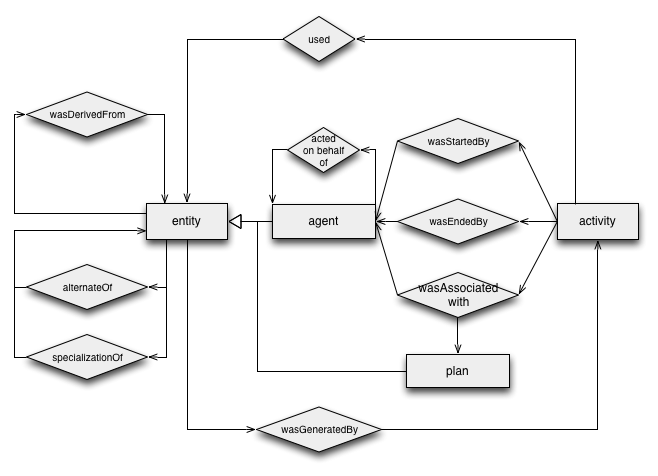
Given an activity association record wasAssociatedWith(a,ag2,attrs),
a responsibility record, written actedOnBehalfOf(id,ag2,ag1,a,attrs) in PROV-ASN, has the following constituents:
- id: an optional identifier id identifying the responsibility record;
- subordinate: an identifier ag2 for an agent record, which represents an agent associated with an activity, acting on behalf of the responsible
agent;
- responsible: an identifier ag1 for an agent record, which represents the agent on behalf of which the subordinate agent ag2
acts;
- activity: an optional identifier a of an activity record for which the responsibility record holds;
- attributes: an optional set of attribute-value pairs attrs that describe the modalities of this relation.
responsibilityRecord ::=
actedOnBehalfOf
(
identifier,
agIdentifier
,
agIdentifier
,
aIdentifier
optional-attribute-values
)
In the following example, a programmer, a researcher and a funder agents are asserted. The programmer and researcher are associated with a workflow activity. The programmer acts on behalf
of the researcher (delegation) encoding the commands specified by the researcher; the researcher acts on behalf of the funder, who has an contractual agreement with the researcher. The terms
'delegation' and 'contact' used in this example are domain specific.
activity(a,[prov:type="workflow"])
agent(ag1,[prov:type="programmer"])
agent(ag2,[prov:type="researcher"])
agent(ag3,[prov:type="funder"])
wasAssociatedWith(a,ag1,[prov:role="loggedInUser"])
wasAssociatedWith(a,ag2)
actedOnBehalfOf(ag1,ag2,a,[prov:type="delegation"])
actedOnBehalfOf(ag2,ag3,a,[prov:type="contract"])
5.3.3.2 Derivation Record
In PROV-DM, a derivation record is a representation that some entity is transformed from, created from, or affected by another entity in the world.
Examples of derivation include the transformation of a canvas into a painting, the transportation of a person from London to New York, the transformation of a relational table into a
linked data set, and the melting of ice into water.
According to Section Conceptualization, for an entity to be transformed from, created from, or affected by another in some way, there must be some
underpinning activities performing the necessary actions resulting in such a derivation.
However, asserters may not assert or have knowledge of these activities and associated details: they may not assert or know their number, they may not assert or know their identity, they may
not assert or know the attributes characterizing how the relevant entities are used or generated. To accommodate the varying circumstances of the various asserters, PROV-DM allows more or
less precise records of derivation to be asserted. Hence, PROV-DM uses the terms precise and imprecise to characterize the different kinds of derivation record. We note
that the derivation itself is exact (i.e., deterministic, non-probabilistic), but it is its description, expressed in a derivation record, that may be imprecise.
The lack of precision may come from two sources:
- the number of activities that underpin a derivation is not asserted or known, or
- any of the other details that are involved in the derivation is not asserted or known; these include activity identities, generation and usage records, and their attributes.
Hence, we can consider two axis. An activity number axis that has values single, multiple, and unknown, respectively representing the case where one activity
is known to have occurred, more than one activities are known to have occurred, or an unknown number of activities have occurred. Likewise, we can consider another axis to cover other
details (identities, generation and usage records, attributes), with values asserted and not asserted. We can then form a matrix of possible derivations. Out of the six
possibilities,
PROV-DM offers three forms of derivation derivation records to cater for five othem, while the remaining one is not meaningful. The following table summarises names for the three kinds of
derivation, which we then explain.
- The asserter asserts that derivation is due to exactly one activity, and all the details are asserted. We call this a precise-1 derivation record.
- The asserter asserts that derivation is due to exactly one activity, but other details, whether known or unknown, are not asserted. We call this an imprecise-1 derivation record.
- The following cases are captured by an imprecise-n derivation record.
- The asserter knows that multiple activities are involved or ignores the number of activities involved in the derivation, and other details are not asserted.
- The asserter knows that multiple activities are involved in the derivation, and all their details are asserted. In this case, these activities are connected by means of generated and
used intermediary entities. Despite all activities and details being known, there is no guarantee that any of these activities plays an active role in the derivation; hence, this case is
also regarded as imprecise. Instead, precise derivations need to be expressed between these intermediary entities.
We note that the last theoretical cases cannot occur, since
asserting the details of an unknown number of activities is a contradiction.
In order to represent the number of activities in a derivation, we introduce a PROV-DM attribute steps, which can take two possible values: single and any.
When prov:steps="single", derivation is due to one activity; when prov:steps="any", the number of activities is multiple or not known.
The three kinds of derivation records are successively introduced. Making use of the attribute steps, we can distinguish the various derivation types.
A precise-1 derivation record, written wasDerivedFrom(id, e2, e1, a, g2, u1, attrs) in PROV-ASN, contains:
- id: an optional identifier id identifying the derivation record;
- generatedEntity: the identifier e2 of an entity record, which is a representation of the generated entity;
- usedEntity: the identifier e1 of an entity record, which is a representation of the used entity;
- activity: an identifier a of an activity record, which is a representation of the activity using and generating the above entities;
- generation: an identifier g2 of the generation record pertaining to e2 and a;
- usage: an identifier u1 of the usage record pertaining to e1 and a.
- attributes: an optional set of attribute-value pairs attrs that describe the modalities of this derivation, optionally including the attribute-value
pair prov:steps="single".
It is optional to include the attribute prov:steps in a precise-1 derivation since the record already refers to the one and only one activity underpinning the
derivation.
An imprecise-1 derivation record, written wasDerivedFrom(id, e2,e1, t, attrs) in PROV-ASN, contains:
- id: an optional identifier id identifying the derivation record;
- generatedEntity: the identifier e2 of an entity record, which is a representation of the generated entity;
- usedEntity: the identifier e1 of an entity record, which is a representation of the used entity;
- time: an optional "generation time" t, the time at which the entity denoted by e2 was created;
- attributes: a set of attribute-value pairs attrs that describe the modalities of this derivation; it must include the attribute-value pair prov:steps="single".
An imprecise-1 derivation must include the attribute prov:steps, since it is the only means to distinguish this record from an imprecise-n derivation
record.
An imprecise-n derivation record, written wasDerivedFrom(id, e2, e1, t, attrs) in PROV-ASN, contains:
- id: an optional identifier id identifying the derivation record;
- generatedEntity: the identifier e2 of an entity record, which is a representation of the generated entity;
- usedEntity: the identifier e1 of an entity record, which is a representation of the used entity;
- time: an optional "generation time" t, the time at which the entity denoted by e2 was created;
- attributes: an optional set of attribute-value pairs attrs that describe the modalities of this derivation; it optionally includes the attribute-value pair prov:steps="any".
It is optional to include the attribute prov:steps in an imprecise-n derivation record. It defaults to prov:steps="any".
None of the three kinds of derivation is defined to be transitive. Domain-specific specializations of these derivations may be defined in such a way that the transitivity property
holds.
In PROV-ASN, a derivation record's text matches the derivationRecord production of the grammar defined in this specification document.
derivationRecord ::=
wasDerivedFrom
(
identifier,
eIdentifier
,
eIdentifier
,
aIdentifier
,
gIdentifier
,
uIdentifier
optional-attribute-values
)
|
wasDerivedFrom
(
identifier,
eIdentifier
,
eIdentifier
,
time
optional-attribute-values
)
The first clause of the alternative, where the activity, generation and usage record identifiers are present formalizes a derivation record is precise-1. The second clause of the alternative, with optional time formalizes imprecise records. The distinction between imprecise-1 and imprecise-n is made by the
attribute prov:steps.
The following assertions state the existence of derivations.
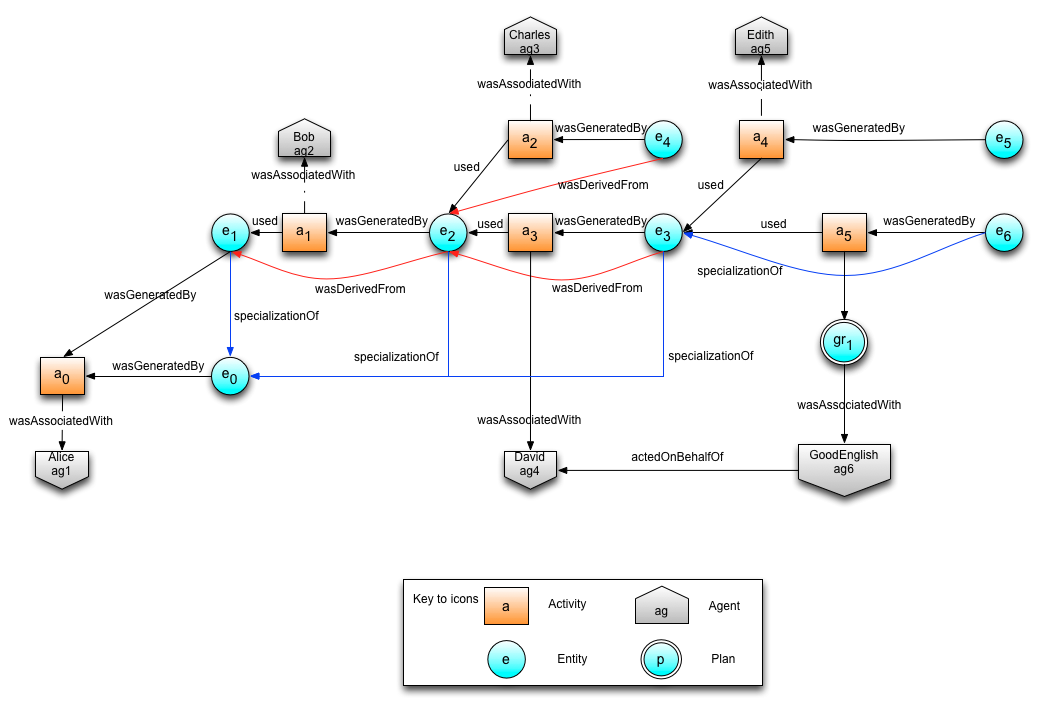
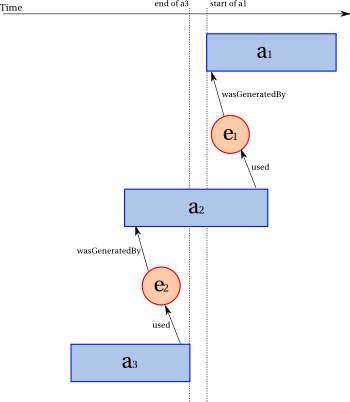
wasDerivedFrom(e5,e3,a4,g2,u2)
wasDerivedFrom(e5,e3,a4,g2,u2,[prov:steps="single"])
wasDerivedFrom(e3,e2,[prov:steps="single"])
wasDerivedFrom(e2,e1,[])
wasDerivedFrom(e2,e1,[prov:steps="any"])
wasDerivedFrom(e2,e1,2012-01-18T16:00:00, [prov:steps="any"])
The first two are precise-1 derivation records expressing that the activity represented by the activity a4, by
using the entity denoted by e3 according to usage record u2
derived the
entity denoted by e5 and generated it according to generation record
g2.
The third record is an imprecise-1 derivation, which is similar for e3 and e2, but it leaves the activity record and associated attributes implicit. The fourth and fifth records are imprecise-n derivation records between e2 and e1, but no information is provided as to the number and identity of activities underpinning the derivation. The six derivation records extends the fifth with the derivation time of e2.
An precise-1 derivation record is richer than an imprecise-1 derivation record, itself, being more informative that an imprecise-n derivation record. Hence, the following implications
hold.
Given two entity records denoted by e1 and e2, if the assertion wasDerivedFrom(e2,
e1, a, g2, u1, attrs)
holds for some generation record identified by g2, and usage record identified by u1, then wasDerivedFrom(e2,e1,[prov:steps="single"] ∪ attrs) also holds.
Given two entity records denoted by e1 and e2, if the assertion wasDerivedFrom(e2,
e1, [prov:steps="single"] ∪ attrs)
holds, then wasDerivedFrom(e2,e1,attrs) also holds.
The imprecise-1 derivation has the same meaning as the precise-1
derivation, except that an activity
is known to exist, though it does not need to be
asserted. This is formalized by the following inference rule,
referred to as activity introduction:
If wasDerivedFrom(e2,e1) holds,
then there exist an activity record identified by
a, a usage record identified by
u, and a generation record identified by
g
such that:
activity(a,aAttrs)
wasGeneratedBy(g,e2,a,gAttrs)
used(u,a,e1,uAttrs)
for sets of attribute-value pairs
gAttrs,
uAttrs, and
aAttrs.
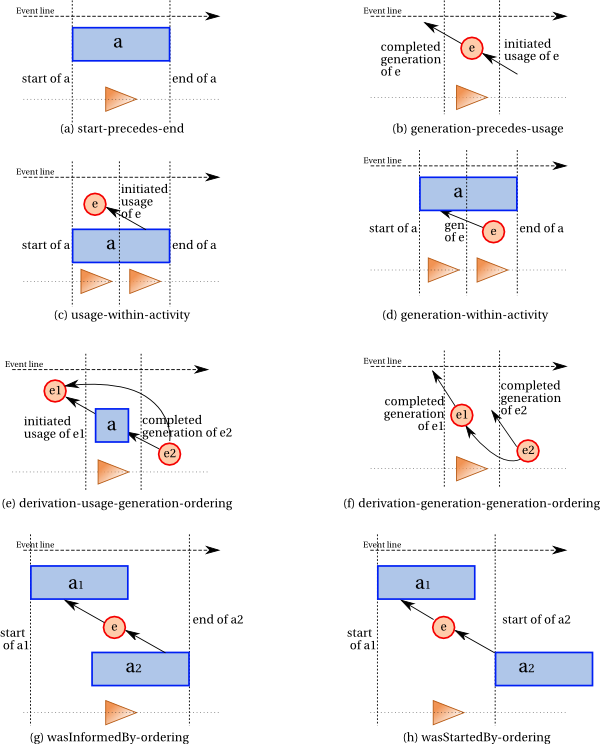
Note that inferring derivation from usage and generation does not hold
in general. Indeed, when a generation wasGeneratedBy(g, e2, a, attrs2)
precedes used(u, a, e1, attrs1), for
some e1, e2, attrs1, attrs2, and a, one
cannot infer derivation wasDerivedFrom(e2, e1, a, g, u)
or wasDerivedFrom(e2,e1) since
of e2 cannot possibly be derived from
e1, given the creation of e2 precedes the use
of e1.
In PROV-DM, the effective placeholder for an entity generation time is the generation record. The presence of
time information in imprecise derivation records is merely a convenience notation for a timeless derivation record and a generation record with this generation time information.
If wasDerivedFrom(e2,e1,t,attrs) holds, then the following records also hold:
wasDerivedFrom(e2,e1,attrs) and wasGeneratedBy(e2,t).
Should derivation have a time? Which time? This is
ISSUE-43.
This is now addressed in this text. Optional time in derivation is generation time. See also ISSUE-205.Several points were raised about the attribute steps.
Its name, its default value
ISSUE-180.
ISSUE-179.
Emphasize the notion of 'affected by'
ISSUE-133.
5.3.3.3 Alternate and Specialization Records
This section is currently under revision and in flux
The purpose of the record types defined in this section is to establish a relationship between two entities, which asserts that they provide a different characterization of the same thing.
Consider for example three entities:
- e1 denoting "Bob, the holder of facebook account ABC",
- e2 denoting "Bob, the holder of twitter account XYZ",
- e3 denoting "Bob, the person".
One may make several assertions to establish that these entities refer to the same the real-world thing Bob, either in different contexts, or at different levels of abstraction. For example:
- Entity denoted by e1 provides a more concrete characterization of Bob than e3 does;
- Entity denoted by e2 provides a more concrete characterization of Bob than e3 does;
- The entities denoted by e1 and e2 provide two different characterizations of the same thing, i.e., Bob.
Two relations are introduced to express these assertions:
- e2 is a specialization of e1, written specializationOf(e2,e1) captures the intent of assertion (1) and (2);
- e2 is an alternative characterization of e1, written alternateOf(e2,e1) captures the intent of assertion (3).
In order to further convey the intended meaning, the following properties are associated to these two relations.
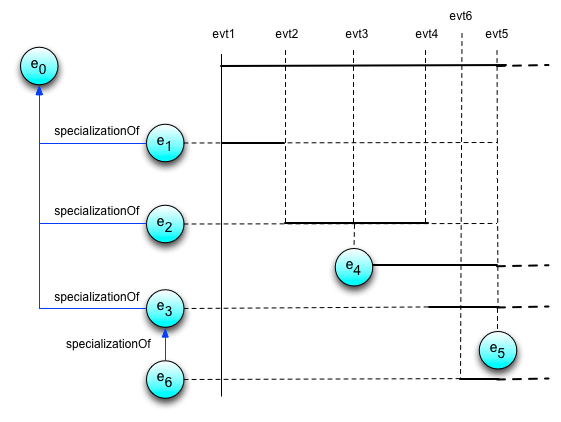
- specializationOf(e2,e1) is transitive: specializationOf(e3,e2) and specializationOf(e2,e1) implies specializationOf(e3,e1).
- specializationOf(e2,e1) is anti-symmetric: specializationOf(e2,e1) implies that specializationOf(e1,e2) does not hold.
- alternateOf(e2,e1) is symmetric: alternateOf(e2,e1) implies alternateOf(e1,e2).
There are proposals to make alternateOf a transitive property. This is still under discussion and the default is for alternateOf not to be transitive, and this is what the current text reflects.
A alternate record, written alternateOf(alt1, alt2, attrs) in PROV-ASN, has the following constituents:
- first alternate: an identifier alt1 of the first of the two entities
- second alternate: an identifier alt2 of the second of the two entities
- attrs: an optional set attrs of attribute-value pairs to further describe this record.
A specialization record written specializationOf(sub, super, attrs) in PROV-ASN, has the following constituents:
- specialised entity: an identifier sub of the specialised entity
- general entity: an identifier super of the entity that is being specialised
- attrs: an optional set attrs of attribute-value pairs to further describe this record.
An entity record identifier can optionally be accompanied by an account identifier. When this is the case, it becomes possible to use the alternateOf relation to
link two entity record identifiers that are appear in different accounts. (In particular, the entity identifiers in two different account are allowed to be the same.). When account
identifiers are not available, then the linking of entity records through alternateOf can only take place within the scope of a single account.
In PROV-ASN, an alternate record's text matches the alternateRecord production of the grammar defined in this specification document.
alternateRecord ::=
alternateOf
(
eIdentifier
,
eIdentifier
,
optional-attribute-values
)
|
alternateOf
(
eIdentifier
,
accIdentifier
,
eIdentifier
,
accIdentifier
,
optional-attribute-values
)
In PROV-ASN, a specialization record's text matches the specializationRecordproduction of the grammar defined in this specification document.
specializationRecord ::=
specializationOf
(
eIdentifier
,
eIdentifier
,
optional-attribute-values
)
|
specializationOf
(
eIdentifier
,
accIdentifier
,
eIdentifier
,
accIdentifier
,
optional-attribute-values
)
A discussion on alternative definition of these relations has not reached a satisfactory conclusion yet. This is
ISSUE-29. Also
ISSUE-96.
{kind=link}