Abstract
This model provides authors of specifications, software developers, and content
developers a common reference for interoperable text manipulations on the
World Wide Web. Topics addressed include encoding identification, early uniform
normalization, string identity matching, string indexing, and
URI conventions, building
on the Universal Character Set
(UCS) (refer to
[ISO10646] and [Unicode]).
Some introductory material on characters and character encodings is also
provided.
Status of this document
This is a W3C Working Draft for review by W3C members and other interested
parties. It is a draft document and may be updated, replaced, or obsoleted
by other documents at any time.
While this document addresses W3C Working Groups explicitly, other groups
outside of W3C are strongly encouraged to incorporate the relevant parts
of this model into their Web specifications and software.
This document is published as part of the
W3C Internationalization
Activity by the Internationalization Working Group (I18N WG), with the
help of the Internationalization Interest Group (I18N IG). Various parts
of this document are in different states of development. The I18N WG will
not allow early implementation to constrain its ability to make changes to
this specification prior to final release. It is inappropriate to use W3C
Working Drafts as reference material or to cite them as other than "work
in progress". A list of current W3C working drafts can be found at
http://www.w3.org/TR/.
Comments to this Working Draft are very welcome. Comments intended for public
discussion and archival should be sent to
www-international@w3.org. Comments
to the editors should be sent to
i18n-editor@w3.org (archived for
access by W3C member organizations).
Table of Contents
-
Introduction
-
Why is this document necessary?
-
Document Conventions
-
Conformance
-
Characters
-
Characters as seen by Humans
-
Characters and their Digital Representation
-
Choice and Identification of Character Encodings
-
The UCS as a Common Reference
-
Reference Processing Model
-
References to ISO 10646/Unicode
-
Character Escaping
-
Character Data Exchange: Early Uniform
Normalization
-
W3C Text Normalization
-
Application of Early Uniform
Normalization
-
String Identity Matching
-
Compatibility Equivalents and Control Characters
-
String Indexing
-
Character Encoding in URI References
-
Language Identification
-
Appendix: Change Log
-
Glossary
-
Acknowledgments
-
References
The 'character model' described in this document provides authors of
specifications, software developers, and content developers with a common
reference for interoperable text manipulations on the World Wide Web. Working
together, these three groups can build a more international Web. Topics addressed
include encoding identification, early uniform normalization, string identity
matching, string indexing, and
URI conventions, building
on the Universal Character Set
(UCS) (refer to
[ISO10646] and [Unicode]).
Some introductory material on characters and character encodings is also
provided. The model will allow Web documents authored in the world's scripts
(and on different platforms) to be exchanged, read, and searched by Web users
around the world.
Although Web developers in general are encouraged to follow the specifications
of this document, the document targets W3C Working Groups specifically and
lists requirements to ensure interoperability of W3C specifications (refer
to the section on conformance). Some of W3C Working
Groups and Activities that should be integrating this model into their work
are:
Outside of W3C, some areas of work where this document , and in particular
Section 4, Character Data Exchange: Early Uniform
Normalization, may apply, include:
-
Identifiers in Java
-
String handling in ECMAScript
-
Filenames in FTP
-
Folder names in
IMAP
-
Usenet newsgroup names
-
Identifiers in
ACAP
Starting with
[RFC 2070], the Web community has recognized the need
for a character model for the World Wide Web. W3C's first step towards building
this model was the adoption of the UCS (Universal Character Set )(refer to
[ISO10646] and [Unicode])as
the document character set for
HTML 4.0. This choice
was motivated by the fact that the UCS:
-
is the only universal character repertoire available,
-
covers the widest possible range,
-
provides a way of referencing characters independent of the encoding of a
resource,
-
is being updated/completed carefully,
-
is widely accepted and implemented by industry.
The UCS meant that HTML documents were not limited to containing
ASCII
characters. After HTML 4.0, W3C adopted the UCS for other specifications
such as XML [XML 1.0] and
CSS 2 [CSS2]. UCS now serves as a common
reference for W3C's specifications and applications.
Where data transfer on the Web remained unidirectional (from server to browser)
, and where the main purpose was to render documents, the use of the UCS
without specifying additional details sufficed. However, the Web has grown:
-
Data transfers among servers, proxies, and clients, in all directions, have
increased,
-
Non-ASCII characters are being used in more and more places,
-
Data transfers between different protocol/format elements (such as
element/attribute names, URI components, and textual content) have increased,
-
People are defining more and more
APIs, and not just protocols and formats.
In short, the Web may be seen as a single, very large application
[Nicol], rather than as a collection of independent
small applications.
While these developments strengthen the requirement that UCS be the basis
of a character model for the Web, they also create the need for additional
specifications on the application of UCS to the Web. Some properties of the
UCS that require additional specification for the Web include:
-
Choices of binary encoding forms (UTF-8, UTF-16, UCS-4)
-
Variable length encodings (e.g., due to the use of combining characters,
surrogates, etc.)
-
Duplicate encodings (e.g., precomposed vs. decomposed)
-
Control codes for various purposes (e.g., bidirectionality control, symmetric
swapping, etc.)
It should be noted that such properties also exist in legacy encodings, and
in many cases have been inherited by the UCS in one way or another from such
legacy encodings.
The remainder of this document presents the additional specifications and
requirements to ensure an interoperable character model for the Web.
Section 1.2 explains some of the conventions and
notation used in the document. Section 2 defines conformance for different
consumers of this document.
Section 3 defines a general character model, e.g., in the sense of the reference
processing model in [RFC 2070], and general guidelines,
e.g., similar to those in [RFC 2130] and
[RFC 2277]. Much of section 3 is introductory material
for readers who might not be familiar with the complexity of the topic.
Section 4 discusses Early Uniform Normalization, Section 5 string indexing.
Section 6 deals with Character Encoding in URI References, Section 7 with
Language Identification.
UCS codepoints are denoted as U+hhhh, where hhhh
is a sequence of hexadecimal digits.
Where this specification contains procedural descriptions, they are understood
to be a way to specify the desired external behavior. As long as observable
behavior is not affected, implementations may use some other way of achieving
the same results.
In order to conform to this document, all requirements must be satisfied.
Requirements vary for content providers, software developers, and specification
writers.
Requirements are expressed using the key words "MUST", "MUST NOT", "REQUIRED",
"SHALL", and "SHALL NOT". Recommendations are expressed using the key words
"SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL". Key words are
used in accordance with [RFC2119].
The word character is used in many contexts and with different meanings.
In the context of texts and digital representations of texts, it can roughly
be defined as a small logical unit of a text. See later sections of this
chapter for examples.
A text is then defined as sequences of characters. While such a definition
is sufficient to create or capture a common understanding in many cases,
it is also sufficiently open to create misunderstanding as soon as details
start to matter. It is very important to understand where misunderstanding
can occur in order to write appropriate specifications, protocol implementations,
and software for end users. The term 'character' is used in a variety of
contexts and thus leads to confusion when used outside of these contexts.
Why is so difficult to give one definition to the term "character"? There
are a number of dimensions to characters that lend themselves to conflicting
interpretations:
-
Characters as they are perceived by various end users versus characters as
units of digital text storage.
-
Characters as logical units versus glyphs used to represent them visually
(e.g., on paper or on screen).
-
Characters as logical units versus bytes and other physical storage units,
as well as e.g., integers as logical units used to represent them.
-
Characters with a visible representation versus so-called "control characters".
-
Characters used to represent text directly versus characters used to represent
protocol or format structure or to represent other characters indirectly
(see Character Escaping)
Consider, for example, how the different dimensions relate to
string indexing. Due to the wide variability of scripts
and characters, and because of tradeoffs between user friendliness and
implementation efficiency, indexing operations, as well as other operations,
may be more efficiently carried out at a particular layer.
-
Layer 1: Physical representation. This is necessary for APIs that expose
a physical representation of string data. Example: For the
[DOM] Level 1, UTF-16 was chosen based on current widespread
implementation practice. To avoid problems with duplicates, it is assumed
that the data is normalized according to Section 3.2.
-
Layer 2: Indexing based on abstract codepoints. Example: UCS codepoints should
be chosen, in accordance with
Production [2] of
[XML 1.0], the
SGML
declaration of [HTML 4.0], and the character model
of [RFC 2070]. This is the highest layer of
abstraction that ensures interoperability with very low implementation effort.
To avoid problems with duplicates, it is assumed that the data is normalized
according to Section 3.2.
-
Layer 3: Combining sequences, user-relevant. This layer groups (or in some
cases may separate) codepoints from Layer 2 in order to obtain 'characters'
that are as close as possible to what the user perceives as characters, but
in a way that is still language-independent. While we think that an exact
definition of this layer should be possible, such a definition does not currently
exist.
-
Layer 4: Depending on language and operation. This layer is least suited
for interoperability, but is necessary for certain operations, e.g. sorting.
Perceptions of characters by end users can vary widely based on script, language,
function, and context, or just individual differences. In some scripts and
languages, in particular in English, such perception differences are almost
nonexistent. In other cases the differences are more evident, but even in
these cases, the context usually present in human discourse can make it rather
difficult to become aware of the fact that even the same person can use the
term "character" in slightly or vastly different senses without necessarily
been misunderstood. Misunderstanding does not arise due to imperfect technology
(i.e., "Unicode just didn't get it right."). Instead, it comes from the high
flexibility and creativity of the human mind and the long tradition of writing
as an important part of human cultural heritage.
Specification writers using the term "character" MUST specify which meaning(s)
they intend. Specification writers SHOULD avoid the use of the term "character"
if a more specific term is available. Otherwise, there are many potential
sources of misunderstanding, including:
-
Scripts
-
Japanese Hiragana/Katakana are syllabaries, not phonemic alphabets. A character
in these scripts is therefore not a phoneme, but a syllable. Korean Hangul
combines symbols for phonemes into square syllabic blocks. Depending on the
user and the application, both the individual symbols as well as the syllabic
clusters can be called characters. Indic scripts use semi-regular or irregular
ways to combine consonants and vowels into clusters. Depending on the user
and the application, both individual consonants and vowels as well as consonant
clusters or consonant-vowel clusters can be seen as characters.
-
Languages
-
"ö" is considered as a character completely independent from "o" in
Swedish, as an extra character quite related to "o" in German, and as an
"o" having to be modified in certain contexts in order to make sure it stays
an "o" by itself in French or English.
-
Functionality
-
Users interact with characters in a number of ways that raise issues about
their definition, including:
-
Character input (e.g., through a keyboard). The limited number of
keys available on keyboards may make it necessary to input some characters
with special modifier keys, as composing sequences, or with even more complex
methods involving selective user interaction. On the other hand, some character
combinations may be available on the keyboard for more convenient input.
To ensure generality, developers SHOULD NOT assume a one-to-one mapping when
implementing user interface components (keyboard-related, display-related,
etc.).
-
Sorting. Sorting rules can both aggregate a character sequence into
a single unit given its own position in the sorting order, or can separate
various aspects of a character to be sorted separately. An example of the
former are the Spanish "ch" and "ll", an example of the later is alphabetic
sorting that ignores case difference on its first pass. Although Spanish
sorting, and to some extent Spanish everyday use, treat "ch" as a character,
digital encodings treat it as two characters, and keyboards do the same.
To ensure generality, developers SHOULD NOT use a binary sort or a one-to-one
mapping when implementing a functionality such as sorting.
-
String identity matching.Discussed in Section 5.
-
Display as a function is discussed separately under Section 3.2.
Note. The current version of this document only gives
lists of topics to be addressed for each subsection; the WG plans to address
the topics in more detail in the next version of this document.
To be of any use in computers, in computer communications and in particular
on the World Wide Web, characters must be encoded. In fact, much
of the information processed by computers over the last few decades has been
encoded text, exceptions being images, audio, video and numeric data. To
achieve text encoding, a large variety of encoding schemes have been devised,
which can be loosely defined as mappings between the character sequences
that users manipulate and the sequences of bits that computers manipulate.
Given the complexity of text encoding and the large variety of schemes for
character encoding invented throughout the computer age, however, a more
formal description of the encoding process is felt to be useful. Text encoding
can be described as follows (see
[UTR #17] for a more thorough description):
-
First, a set of characters to be encoded is identified. The units of encoding,
the characters, are pragmatically chosen as appropriate to express text and
allow various text processes in one or more target languages. They may not
correspond exactly to what users perceive as letters and other characters.
The set is called a repertoire.
Note.Where one way of looking at characters in a given script
is predominant, and corresponds for all or most functions, it is rather easy
to choose this for the actual digital encoding. For example, nobody has seriously
proposed to use syllable-based encoding for the Latin script, and nobody
has seriously proposed phoneme-based encoding for Japanese Hiragana and Katakana.
Where there is more than one way to perceive, identify, and encode the characters
of a given script, it is important to realize that:
-
Choosing a single encoding has vast benefits over having to deal with multiple
encodings.
-
The choice of encoding has to take into account the various languages and
functions without being biased towards one language or function to the extent
that the others become overly difficult to realize. In this sense, the choice
of encoding is often a technical compromise.
-
In many cases, the choice of encoding is also to a certain extent a political
compromise.
-
Each character of the repertoire is then associated with a (abstract,
mathematical) non-negative integer, the character number or code point. The
result, a mapping from the repertoire to the set of non-negative integers,
is called a coded character set, abbreviated CCS.
-
To enable use in computers, a suitable base datatype is identified (byte,
16-bit wyde or other) and a character encoding form is
devised, which encodes the abstract integers of a CCS into sequences of the
base datatype. The encoding form can be extremely simple (for instance, it
encodes the integers of the CCS into the natural representation of integers
of the chosen datatype of the computing platform) or arbitrarily complex
(variable number of base datatype units, value of each unit a non-trivial
function of the encoded integer, etc.)
-
To enable transmission or storage using byte-oriented devices, a
serialization scheme or character encoding scheme (CES)
is next devised. A CES maps the integers of one or more CCSes to well-defined
sequences of bytes, taking into account the necessary specification of byte-order
for multi-byte base datatypes and including in some cases switching schemes
between multiple CCSes (for instance ISO 2022). A CES, together with the
CCSes that it is used with, is what is identified by an
IANA
charset identifier. Given a sequence
of bytes representing text and a charset identifier, one can
unambiguously recover the sequence of characters of the text.
In some cases, the whole encoding process can be collapsed to a single step,
a trivial one-to-one mapping from characters to bytes; this is the case,
for instance, for US-ASCII and ISO/IEC 8859-1. It should be clear, however,
that characters and bytes are very different entities that SHOULD NOT be
confused: in general, the relationship is many-to-many.
Input and rendering (display, printing) of text are two other areas where
complexities occur. In keyboard input, it is not the case
that keystrokes and input character correspond one-to-one. Many writing systems
have too many characters to allow such a correspondence and must rely on
more complex input methods which transform keystroke sequences into
character sequences. Thus specification writers and software developers SHOULD
NOT assume that a single keystroke results in a single character, nor that
a single character can be input with a single keystroke (even with modifiers),
nor that keyboards are the same all over the world.
Rendering, or at least the visual forms of rendering, introduces the notion
of a glyph, which can be defined as the components used to generate
the visible representation of a sequence of characters. This definition points
to the unsurprising fact that there is not, again, a one-to-one correspondence
between characters and glyphs: a single character can be represented by multiple
glyphs (each glyph is then part of the representation of that character);
a single glyph may also represent multiple characters (this is the case of
ligatures, among others). A set of glyphs makes up a font. Glyphs can be
construed as the basic units of organization of the visual rendering of text,
just as characters are the basic unit of organization of encoded text.
A few examples will help make sense of all this complexity (which is mostly
a reflexion of the complexity of human writing systems). Let us start with
a very simple example: a user, equipped with a US-English keyboard, types
"Foo", which the computer encodes as 16-bit values (the UTF-16 encoding of
the UCS) and displays on the screen.
Example 3.1: Basic Latin
| Keystrokes |
Shift-f |
o |
o |
| Input characters |
F |
o |
o |
Encoded characters
(byte values in hex) |
0x0046 |
0x006F |
0x006F |
| Display |
Foo |
The only complexity here is the use of a modifier (Shift) to input the capital
F. A slightly more complex example is a user typing "çé" on
a French-Canadian keyboard, which the computer encodes in fully decomposed
UTF-16 and displays.
Example 3.2: Latin with diacritics
| Keystrokes |
¸ c |
é |
| Input characters |
ç |
é |
Encoded characters
(byte values in hex) |
0x0063 0x0327 |
0x0065 0x0301 |
| Display |
çé |
A few interesting things are happening here: when the user types the cedilla
(¸), nothing happens except for a change of state of the keyboard driver;
the cedilla is a dead key. When the driver gets the c, it provides
a complete ç character to the system, which encodes it as two characters:
a c and a combining cedilla, each represented by a single 16-bit unit. These
two characters are then displayed as one ç glyph. The user then presses
the dedicated é key, which results in, again, two characters represented
by two bytes. Most systems will display this pair as one glyph, but it is
also possible to combine two glyphs (the base letter and the accent) to obtain
the same rendering.
Note. If Unicode Normalization Form C (precomposed, see
section 4.1) had been used in this example, only two characters would have
been encoded. If ISO/IEC 8859-1 encoding had been used, those two characters
would have encoded as one byte each; this is certainly simpler, but the
representable repertoire is very limited. If UTF-8 encoding (fully decomposed)
had been used, the result would have been the same four characters as above,
but with the first and third encoded as one byte and the second and fourth
encoded as two bytes.
On to a Japanese example: our user employs an input method to type
"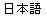 ", which the computer
encodes in UTF-16 and displays.
", which the computer
encodes in UTF-16 and displays.
Example 3.3: Japanese
| Keystrokes |
n i h o n g o <space><return> |
| Input characters |
 |
 |
 |
Encoded characters
(byte values in hex) |
0x65E5 |
0x672C |
0x8A9E |
| Display |
|
The interesting aspect here is input, where the user has to type a total
of nine keystrokes before the three characters are produced, which are then
encoded and displayed rather trivially. An Arabic example will show different
phenomena:
Example 3.4: Arabic
| Keystrokes |
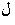 |
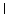 |
 |
 |
|
| Input characters |
|
|
|
|
|
|
Encoded characters
(byte values in hex) |
0x0644 |
0x0627 |
0x0644 |
0x0627 |
0x0639 |
0x0639 |
| Display |
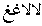 |
Here the first two keystrokes each produce an input character and an encoded
character, but the pair is displayed as a single glyph
(, a lam-alif ligature).
The next keystroke is a lam-alif, which some Arabic keyboards have; it produces
the same two characters which are displayed similarly, but this second lam-alif
is placed to the left of the first one. The last two keystrokes
produce two identical characters which are rendered by two different glyphs
(a medial form followed to its left by a final form). We thus have 5 keystrokes
producing 6 characters and 4 glyphs laid out right-to-left.
A final example in Tamil, typed with an
ISCII keyboard, will illustrate
some additional phenomena:
Example 3.5: Tamil
| Keystrokes |
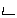 |
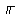 |
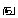 |
 |
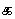 |
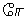 |
| Input characters |
|
|
|
|
|
|
Encoded characters
(byte values in hex) |
0x0B9F |
0x0BBE |
0x0B99 |
0x0BCD |
0x0B95 |
0x0BCB |
| Display |
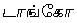 |
Here input is straightforward, but note that contrary to the preceding accented
Latin example, the diacritic
(virama,
vowel killer) is entered after the
to which it applies. Rendering
is interesting for the last two characters. The last one
() clearly consists of two
glyphs which surround the glyph of the next to last character
().
A number of operations routinely performed on text can be impacted by the
complexities of the world's writing systems. Let us take selection of on-screen
text by the mouse as an example, in a bidirectional (bidi) context. First,
let's have some bidi text, in this case Arabic letters (written right-to-left)
mixed with Arabic-Hindi digits (left-to-right):
Example 3.6: Bidirectional text
| In memory |
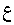
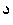 <space>
<space> 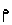
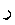
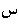 <space>
<space> 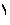
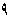
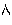
|
| On screen |
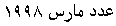 |
In the presence of bidi text, two possible selection modes must be considered.
The first is logical selection mode, which selects all the characters
logically located between the end-points of the user's mouse
gesture. Here the user selects from between the first and second letters
of the second word to the middle of the number. Logical selection looks like
this:
Example 3.7: Example of logical selection
| In memory |
|
| On screen |
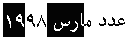 |
It is a consequence of the bidirectionality of the text that a single, continuous
logical selection in memory results in a discontinuous selection appearing
on the screen. This discontinuity, as well as the somewhat unintuitive behaviour
of the cursor, makes many users prefer a visual selection mode,
which selects all the characters visually located between
the end-points of the user's mouse gesture. With the same mouse gesture as
before, we now obtain:
Example 3.8: Example of visual selection
| In memory |
|
| On screen |
 |
In this mode, popular with users, a single visual selection range results
in two logical ranges [Issue: can there be more?], which MUST be accommodated
by protocols, APIs and implementations.
Note. In the next version of this document, the WG plans
to address the following topics in this subsection:
-
Where to define things in terms of characters, where in terms of bytes or
other coding units.
Section 3.2 discussed the relationship between characters and the underlying
representation, called character encoding. Because encoded text
cannot be interpreted and processed without knowing the
encoding, it is vitally important that the character encoding is known at
all times and places where text is exchanged or stored.
The existence of a large number of character encodings often brings to the
forefront the question of choosing one (or more) encodings when designing
a data format, a protocol, an API, when implementing these or simply when
editing a document. One aspect of this question is the following: should
multiple encodings be allowed, or only one mandated (by a data format for
instance)?
Mandating a unique character encoding has strong virtues of simplicity,
efficiency and robustness. After choosing this unique encoding, a protocol
or data format does not have to deal with provisions for character encoding
tagging, since the encoding is known implicitly from usage of such protocol
or data format. If the data is to be transferred other than electronically
(e.g. written on an envelope or a billboard, like URIs), then there is no
way to carry around encoding tags and a unique encoding is the only solution.
With a unique encoding, implementations do not have to deal with recognizing
encoding tags, nor with encoding conversions and other complexities inherent
in working with multiple encodings. Efficiency can seriously enhanced, especially
when small pieces of text are involved such as in short headers where encoding
identification tags would occupy space comparable with the data itself.
This desirable solution, however, is often felt to be unacceptable because
of the need for compatibility with existing data, systems, protocols and
applications, which use various encodings. Nevertheless, specification writers
and implementors are strongly encouraged to consider its adoption: it is
often the case that multiple encodings can be dealt with at the boundaries
or outside a protocol or API, as was done for the [DOM],
resulting in much greater simplicity and uniformity in the API itself.
If more than a single encoding is allowed, the question of granularity arises:
in a data format or a protocol, should a single 'entity' (document, message,
etc.) be allowed to be encoded in multiple encodings, with encoding transitions
within the entity? In an API, should a single argument to a procedure be
allowed to be so multi-encoded? Should different arguments of the same procedure
be allowed to be in different encodings? In an object model, should a
text-containing object be allowed to contain multi-encoded text? Should distinct
objects representing a 'document' (such as a DOM tree) be allowed to be in
different encodings? In general the answer is no, unless there exists a very
strong requirement to do so.
Multi-encoding requires provisions for in-text encoding identifications and
breaks the model of text-based protocols and data formats, since in the absence
of an underlying encoding, one cannot rely on characters
for effecting the encoding transitions and the requisite identification.
There exist examples of such protocols, MIME being a prominent one. Since
a MIME message may contain any number of attachments in different encodings,
it has provisions for multipart messages that take care of proper encoding
labeling, using headers outside the parts themselves. But MIME also has a
way to use multiple encodings in a single header (see RFC 2047 in
[MIME]). The in-text encoding identification mechanism
of RFC 2047 is delicate and hard to implement correctly, and experience has
shown that it does not work reliably, thereby showing
prominently the limits of such multi-encoding schemes. Consequently,
specification writers SHOULD restrict the basic entities of their specifications
to a single encoding.
If the unique encoding approach is adopted, the chosen encoding MUST be such
that it covers the needs of the largest possible audience, including coverage
for as many human languages as possible. In practice, this will most likely
mean that the choice will be one of the standard encodings of
ISO 10646/Unicode. If some
measure of compatibility with ASCII is desired, UTF-8 (see
[RFC 2279]) is most probably the UCS encoding of choice;
on the Internet, the IETF Charset Policy [RFC 2277]
specifies that "Protocols MUST be able to use the UTF-8 charset". Another
UCS encoding very worthy of consideration, especially for APIs, is UTF-16
(see [UTF-16]).
If the unique encoding approach is not chosen, then it is crucial to provide
for proper identification of character encoding at all times. For protocols,
the
[MIME] Internet specification has established a
standard way to proceed. First specified for Internet email, the MIME mechanism
has also been adopted by
HTTP [RFC 2616] and some aspects
of it adapted to other protocols. The MIME mechanism consists in having in
the protocol a Content-Type header which indicates the nature
or format of the protocol payload; when the content type is textual, a parameter
called charset is added to the Content-Type header,
with a value indicating the character encoding. The charset
parameter is defined such that it provides sufficient information to
unambiguously decode the sequence of bytes of the payload into a sequence
of characters. The values are drawn from the [IANA] registry.
Note. ISO 10646/Unicode designate certain ranges of code
points as the Private Use Area (PUA), a set of positions guaranteed never
to be allocated to standard characters and available for use by private
arrangement between creator and consumer. Since the characters in the PUA
are not, by definition, standardized, the values of the charset
parameter registered by IANA for UCS encodings do not take them into account
and do not contain enough information to unambiguously decode
a data stream containing PUA characters. Consequently, the standard, registered
charset parameter values may not be used to label entities
containing PUA characters.
The term charset derives from "character set", an expression with
a long and tortured history that is best avoided (see
[Connolly] for a discussion). Specification writers
SHOULD avoid using the expression "character set", as well as the term "charset"
except when referring to the MIME charset parameter or its
IANA-registered values.
Given the importance of proper character encoding identification, specification
writers MUST provide mechanisms such that the encoding of text can always
be reliably determined. When choosing which encodings may or must be supported
in a specification, designers MUST make sure that the UTF-8 and/or UTF-16
encodings of ISO 10646/Unicode are admissible encodings and SHOULD choose
at least one of UTF-8 or UTF-16 as mandated encodings (encodings that MUST
be supported by implementations of the specification). Reliance on defaults
and, most of all, on heuristics MUST be avoided; an exception is defaulting
to UTF-8 or UTF-16. Implementors of software MUST fully support such mechanisms
and SHOULD make it easy to use them (for instance in HTTP servers). Content
developers MUST make use of the offered facilities by always indicating character
encoding (for instance in XML encoding declarations).
The [IANA] registry constitutes the closest thing there
is to a standard for character encoding names. Specification writers SHOULD
mandate the use of those names, and in particular of the MIME preferred
names, to designate character encodings in protocols, data formats and
APIs. The use of the "x-" convention for unregistered names SHOULD be
discouraged, having led to abuse (use of x- for character encodings that
were widely used, even long after there was an official registration) in
the past. Content developers and software that tags textual data MUST use
one of the names mandated by the appropriate specification and SHOULD use
the MIME preferred name of an encoding to tag data in that encoding. An
IANA-registered charset name MUST NOT be used to tag textual
data in another encoding than the one identified in the IANA registration
of that name.
Receiving software (which must determine the encoding from available
information) MUST be able to recognize the name(s) of any encoding(s) mandated
by the specification it implements and SHOULD be able to recognize as many
names (in particular aliases of the MIME preferred name) as practicable;
it is best to provide a field-upgradable aliasing mechanism for this purpose.
In addition, receiving software SHOULD recognize the names and support as
many non-mandated encodings as practicable. [ISSUE: should we list a set
of encodings that implementors really, really SHOULD support?] When a
charset name is recognized, receiving software MUST interpret
the received data according to the encoding associated with the name in the
IANA registry.
In the absence of suitable information from the protocol, data format or
API, receiving software MAY use heuristics to attempt to determine the encoding,
realizing however that such heuristics cannot be 100% reliable and may not
be advisable in mission-critical applications, especially in situations where
there is not a human user present to verify de visu the
correct encoding identification. Such heuristics can be a nice feature in
a browser, but may be unadvisable when automatically processing a purchase
order.
Note. In the next version of this document, the WG
plans to address the following topics in this subsection:
-
Considerations for [MIME] headers and bodies [Anything
left?]
Many Internet protocols and data formats, most notably the very important
Web formats HTML, CSS and XML, are based on text. In those formats, everything
is text but the relevant specifications impose a structure on the text, giving
meaning to certain constructs so as to obtain functionality in addition to
that provided by plain text. HTML and XML are markup languages,
defining entities entirely composed of text but with conventions allowing
the separation of this text into markup and character data.
Citing from the [XML 1.0],
section 2.4:
Text consists of intermingled character data and markup. Markup takes the
form of start-tags, end-tags, empty-element tags, entity references, character
references, comments, CDATA section delimiters, document type declarations,
and processing instructions. All text that is not markup constitutes the
character data of the document.
For the purposes of this section, the important aspect is that everything
is text, that is, a sequence of characters. HTML is similarly constructed;
in fact, both XML and HTML inherit this structure from SGML. A CSS style
sheet, although not SGML-based, is also defined as a sequence of characters,
as are formats such as TEX, troff/nroff and many others. Protocols
are also often defined in terms of text, with the important benefit that
the protocol is then far easier to debug using simple tools such as
telnet.
In the early days of the Web, HTML was defined in terms of ISO Latin-1 (see
[ISO 8859]), which severely limited the repertoire
of characters usable in Web documents and, consequently, the human languages
that could be accommodated. During efforts to internationalize HTML and break
free of that restriction, it was realized that advantage could be taken of
the SGML concept of document character set to decouple the definition
in terms of characters from the encoding of those characters. This led to
the development of a Reference Processing Model for HTML, first
described in [RFC 2070], in which the document character
set is defined to be ISO 10646 while actual entities (documents) are allowed
to be encoded in any character encoding compatible with the UCS (i.e. any
encoding whose repertoire is a subset of that of the UCS). This model has
been embraced by XML and CSS and is applicable to any data format or protocol
that is text-based as described above, not only formats derived from SGML.
The essence of the model can be described as follows:
-
The specification is defined in terms of characters, which are themselves
defined to be the same as UCS characters.
-
The specification may allow use of any UCS-compatible character encoding
for its text entities (but may choose to disallow or deprecate some encodings
and to make others mandatory), provided the behavior is the same as if the
processing happened as follows:
-
the encoding of any text entity received by the application implementing
the specification is determined and the text entity is interpreted as a sequence
of UCS characters. This is equivalent to transcoding the entity to some encoding
of the UCS and then considering that the entity was received in that encoding;
-
all processing takes place on this sequence of UCS characters;
-
if text is output by the application, the sequence of UCS characters is encoded
as described in Section 3.2, using an encoding chosen among those allowed
by the specification.
-
If the specification is such that multiple text entities are involved (such
as an XML document referring to external parsed entities), it may choose
to allow these entities to be in different character encodings. In all cases
processing is uniformly done in terms of UCS characters since the entities
are (virtually) transcoded to some UCS encoding before processing takes place.
Note. It is noteworthy that for a specification to use the
Reference Processing Model does not require that implementations
actually use ISO 10646/Unicode. The requirement is only that the implementations
behave as if the processing took place as described above.
Note. All specifications that derive from XML automatically
inherit this Reference Processing Model. XML is entirely defined in terms
of UCS characters and mandates the UTF-8 and UTF-16 encodings while allowing
any other encoding for parsed entities.
[To do: make normative statements.]
Specifications often need to make references to the ISO 10646 or Unicode
standards. Such references must be made with care, especially when normative.
One problematic area is the distinction between ISO 10646 and Unicode and
the question of whether a specification should reference one, the other or
both. Another is the fact that both standards are still evolving, in particular
with new characters being added to achieve the goal of a truly Universal
Character Set.
ISO 10646 (actually ISO/IEC 10646) is a de jure standard,
developed and published jointly by ISO (the
International Organisation for Standardisation) and
IEC (the International Electrotechnical
Commission). Unicode is a de facto standard developed
and published by the Unicode Consortium,
an organization of major computer corporations, software producers, database
vendors, research institutions, international agencies, various user groups,
and interested individuals. Unicode is therefore much more than a vendor
"standard", is comparable in influence to W3C recommendations but does not
have a de jure status.
ISO 10646 and Unicode define exactly the same CCS (same repertoire, same
character numbers) and encodings. This synchronism is actively maintained
by liaisons and common membership between the relevant technical committees.
But there are differences between the two standards; in fact, were it not
for those differences, Unicode would be pointless given the status of ISO
10646 as an International Standard. In addition to the jointly defined CCS
and encodings, the Unicode Standard adds normative and informative lists
of character properties, normative character equivalence and normalization
specifications, a normative algorithm for bidirectional text and a large
amount of useful implementation information. In short, Unicode adds semantics
to the characters that ISO 10646 merely enumerates.
Since specifications in general need both a definition for their characters
and the semantics associated with these characters, specification writers
SHOULD include normative references to both ISO/IEC 10646 and the Unicode
Standard. If a normative reference to Unicode is not considered appropriate,
an informative reference should nevertheless be provided so that implementors
can still benefit from the wealth of information provided in the standard
and on the Unicode Consortium Web site.
The fact that both ISO 10646 and Unicode are evolving (in synchronism) raises
the issue of versioning: should a specification refer to a specific version
of the standard, or should it make a generic reference, so that the normative
reference is to the version current at the time of reading the
specification? In general the answer is both. A generic
reference MUST be made so that characters allocated after a specification
is published are usable with that specification. But a specific reference
MAY be included to ensure that functionality depending on a particular version
is available and will not change over time (an example would be the set of
characters acceptable as Name characters in XML 1.0, which is an enumerated
list that parsers must implement to validate names).
One notable aspect of the history of ISO 10646 is Amendment 5. This amendment,
published in 1998 and reflected in Unicode 2.0 (1996), created an incompatible
change in the standard: a few thousand characters (all Korean Hangul syllables)
were moved, i.e. their character numbers were changed, causing
incompatibility with any anterior implementations and data involving Hangul.
The reason such a change was deemed acceptable was that no serious amount
of such data, and no widely available implementations, did exist at the time.
Because of this incompatibility all references to ISO 10646 and Unicode MUST
explicitly refer to Amendment 5 and all references to Unicode MUST be to
version 2.0 or later.
This incompatible change also points to the danger of generic references:
a specification could be endangered, should such a change occur in the future.
The relevant committees have pledged never to let that happen again, but
specification writers SHOULD protect against this risk by qualifying
generic references to either ISO 10646 or Unicode with a statement to the
effect that the reference excludes incompatible changes. An example is the
reference to ISO 10646 from HTML 4.01 [To do: add link when HTML 4.01 becomes
Rec]:
"Information Technology -- Universal Multiple-Octet Coded Character Set (UCS)
-- Part 1: Architecture and Basic Multilingual Plane", ISO/IEC 10646-1:1993.
This reference refers to a set of codepoints that may evolve as new characters
are assigned to them. This reference therefore includes future amendments
as long as they do not change character assignments up to
and including the first five amendments to ISO/IEC 10646-1:1993. Also, this
reference assumes that the character sets defined by ISO 10646 and Unicode
remain character-by-character equivalent. This reference also includes future
publications of other parts of 10646 (i.e., other than Part 1) that define
characters in planes 1-16.
Whether such a reference is included in the bibliography section of a
specification, or a simpler reference with explanatory text in the body of
the specification, is an editorial matter best left to each specification.
Examples of the latter, as well as a discussion of the versioning issue with
respect to MIME charset parameters for UCS encodings, can be
found in [RFC 2279] and
[UTF-16].
In a document format such as HTML or an XML application and in protocols,
some characters act as text data while others are used to indicate protocol
or format functions. In order to work correctly, a protocol or format has
to make a clear distinction between the text data characters and the functional
characters. In some cases, the distinction is based on position, for example
in TCP headers, or the first character in each line in a Fortran program.
In other cases, certain characters are designated as having certain specific
protocol/format functions in certain contexts (e.g. the "<" and the "&"
have very specific functions in HTML and XML). If there are such syntactically
relevant characters, then these characters cannot at the same time serve
to represent themselves in text data in the same way as all other characters
do. Also, often formats are represented in an encoding that does not allow
to represent all characters directly. For such cases, a technique called
escaping is used.
Escaping a character in a protocol or format means representing it by other
characters. This works by creating an additional syntactic construct, defining
additional characters, or defining character sequences that have special
meaning.
For specification authors: When designing potential future W3C protocols
and formats, the following points MUST be followed. When revising existing
W3C protocols and formats, the following points SHOULD be followed.
-
Use only one way of escaping characters.
Counter-example: For historic reasons, both HTML and XML have both decimal
(&#ddddd;) and hexadecimal (&#xhhhh;) escapes.
-
Use explicit end-delimiters: the form \uABCD where the end delimiter is a
space or any character other than [01-9A-F] should be avoided at all costs:
it is not clear visually, and it can cause an editor to insert spurious
line-breaks when word-wrapping on spaces. A form like SPREAD's &UABCD;
or XML's ꯍ is much better.
Note. In the next version of this document, the WG plans
to address the following topics in this subsection:
-
Distinguish different requirements, use the same escaping, avoid overlaps
-
Use only one form of escaping, uniformly (i.e. transcoder does not need to
parse)
-
How to handle escaping of escaping
-
Existing forms of escaping, don't create new ones
-
Rationale for the above points
-
Examples of where the above works, and where not
-
Normalization of escape sequences: see Section 4.1
-
Requirements for potential future W3C formats
Make explicit cases of interaction between escaping, legacy encodings with
decomposed notations, code table switching and early normalization,...
Character data interchange using W3C protocols and formats is based on the
principle of early normalization, which defines the exact form to
which text data has to be normalized, and the cases in which normalization
must be applied. This document encourages Web components that generate content
to normalize text for the following reasons:
-
The number of Web components that generate and significantly process text
is considerably smaller than the number of components that have to implement
functionalities that specifically require normalization, such as those that
perform identify matching.
-
The Web components that generate and process text are in a much better position
to do normalization than other components; in particular, they may be aware
that they deal with a restricted repertoire only.
-
Not all components of the Web that implement functionalities such as string
matching can reasonably be expected to do normalization. This in particular
applies to very small components and components in the lower layers of the
architecture.
-
Forward-compatibility issues can be dealt with more easily: Less software
needs to be updated, namely only the software that uses new non-normalized
characters.
-
It allows you to
be conservative in what you send
(see
[CharReq,
subsection 2.8]).
-
It improves matching in cases where the character encoding is partly undefined,
such as URIs [RFC 2396].
-
It is a prerequisite for canonicalization (see
[CharReq,
subsection 2.7]).
-
It simplifies definitions and implementations for string indexing (see
[CharReq,
subsection 4.6]).
-
It increases interoperability and predictability if e.g. string data has
to be exposed in an API.
Text data is in normalized form according to this specification if all of
the following apply:
-
[Issue: Normalizing out escapings] All escapings that are not syntactically
relevant and that are not needed because of the limitations of the encoding
used are replaced by the actual characters.
-
It is in Unicode Canonical Composition (Normalization Form C) according to
[UTR #15]. Note: The cutoff version is Version 3.0 of
the Unicode Standard (planned to be identical to the next edition of ISO/IEC
10646-1). Using Version 3.0 of the Unicode Standard as a cutoff version for
Normalization Form C does not mean that characters not in Version
3.0 cannot be used in Web documents; it just means that precomposed characters
added after Version 3.0 will have to be represented as decomposed.
-
It does not include some strongly discouraged codepoints. The exact definition
of these codepoints is planned to be given in [UXML].
Note: The list of control codepoints to exclude, and of others to advise
against, is still under discussion.
Text data is also considered to be in normalized form for the purpose of
this specification if all of the following apply:
-
The text data is in a legacy encoding.
-
The escapings in the text data that reference UCS are normalized as specified
above.
-
The text data appears at a place where that legacy encoding is allowed.
-
The character encoding of the text data is appropriately identified (see
Section 3.3).
Note. It is possible that legacy encodings also exhibit
the problem of duplicate encodings. In this case, it would be appropriate
if a corresponding normalization were applied. Examples are ISO 6937 with
multiple accents, and some uses of ISO 2022.
Note. There are legacy encodings that do not exhibit the
problem of duplicate encodings, but that do not allow one-to-one conversion
of individual codepoints. An example is ISO 6937, which does not use
precomposition and places combining marks before the base character. [Issue:
Should back-conversion use escaping, or should it do one-to-many/many-to-many
conversion?]
The term "normalized form" in this section refers to the form defined
in Section 4.1.
Applications or tools transcoding from a legacy encoding to an encoding based
on UCS MUST ensure that their output is in normalized form.
The producer of text data MUST ensure that data is produced or sent out in
normalized form. For the purpose of W3C specifications and their implementations,
the producer of text data is the sender of the data in the case of protocols.
In the case of formats, it is the tool that produces the data.
Implementors of producer software in the above sense are encouraged to delegate
normalization to their respective data sources wherever possible. (Examples
of data sources would be: operating system, libraries, keyboard drivers.)
If any intermediate recipient of text data applies any operations, it MUST
ensure that the results of these operations is again in normalized form,
provided the incoming data is in that form. Intermediate recipients may provide
additional normalization towards the normalization form, as a side-effect
of their operations and/or as an additional service.
If intermediate recipients do not touch the data but just pass it on, they
are not required to check normalization or to normalize data. (Example: caching
proxies)
The recipients of text data SHOULD assume that data is normalized. Recipients
MAY provide normalization as an add-on service and safety measure. Recipients
SHOULD [Issue: MUST?] provide a way to switch off normalization.[Issue: change
to MUST NOT, to always fail?] If a producer and a recipient work as one unit,
normalization MUST be applied in the producer part but MUST be switched off
in the recipient part.
Example: Authoring tools frequently are extensions to browsers, and the browser
software components are used to display the results of editing. Such tools
should normalize all the text that is produced, but must not provide
normalization for the operations that are the same as in a browser, in order
to catch potential normalization problems, e.g. differences with documents
not edited by the tool, early.
Tools or operations that just do string identity matching, and that have
both strings to be matched available in the same encoding, SHOULD do so by
binary comparison.
Note. Producers, intermediate recipients, and transcoders
must support a repertoire of Unicode codepoints that is complete with respect
to normalization, i.e. if any arbitrary sequence of codepoints in the repertoire
is normalized, the codepoints needed for the normalization must also be part
of the repertoire.
One important operation that depends on early normalization is string
identity matching [CharReq]. String identity
matching (a frequent operation) is a subset of the more general problem of
string matching. There are various degrees of specificity for string matching,
from approximate matching such as regular expressions or phonetic matching
for English, to more specific matches such as accent-insensitive or
case-insensitive matching. String identity matching is concerned only with
strings that contain no user-identifiable distinctions.
At various places in the Web infrastructure, strings, and in particular
identifiers, are compared for identity. If different places use different
definitions of string identity matching, or if they rely on different mechanisms
to test identity, the results are undesired unpredictability and unnecessary
conversions. To solve the problem of string identity matching, the following
issues have to be addressed:
-
Which representations to treat as equivalent (and which not)
-
Which components in the Web architecture to make responsible for equivalence:
-
Each individual component that performs a string identity check has to take
equivalents into account (late normalization)
-
Duplicates and ambiguities are removed as close to their source as possible
(early normalization)
-
Which way to normalize (in the case that early normalization is needed)
String identity matching on the World Wide Web is based on the following
steps:
-
Early uniform normalization
-
Conversion to an encoding of UCS
-
Binary comparison
Conversion to UCS, and to the same encoding for both strings, assures that
text strings and not just bytes are compared. Early normalization gives the
responsibility of avoiding duplicate encodings to the data producer; it ensures
that a minimum of effort is spent on solving the problem.
This specification does not address compatibility equivalents. Compatibility
as listed in the Unicode database covers a wide range of
similarities/distinctions. Depending on the situation, some distinctions
are needed, and others will be confusing. To specify all these situations
in a single place seems premature. In the absence of any further specifications,
implementations are advised to generate the non-compatibility equivalent
if they do not explicitly need the compatibility character. A compatibility
character here is a character that disappears when applying Unicode Compatibility
Composition (Normalization Form CC of Unicode [UTR #15]).
A non-compatibility equivalent is the character resulting from applying Unicode
Compatibility Composition. [Issue: This needs to be worded more carefully,
not all compatibility characters have canonical equivalents.] [Issue: Some
details are already available in [UXML]. How much do
we need to leave here?]
Specifications are advised to exclude compatibility characters in the syntactic
elements of the formats they define if this is reasonable (e.g. exclusion
of compatibility characters for GIs in XML). In the future, compatibility
characters should be replaced by appropriate style or markup information
wherever possible.
This specification does not address any further equivalents, such as case
equivalents, the equivalence between katakana and hiragana, the equivalence
between accented and un-accented characters, the equivalence between full
characters and fallbacks (e.g., "ö" vs. "oe" in German), and the equivalence
between various spellings and morphological forms (e.g., color vs. colour).
Such equivalence is on a higher level; whether and where it is needed depends
on the language, the application, and the preferences of the user.
On many occasions, in order to access a substring or a character, it is necessary
to identify positions (between "characters"or other appropriate units) in
a text string/sequence/array. Where such indices are exchanged between components
of the Web, there is a need for a uniform definition of string indexing in
order to ensure consistent behavior. The requirements for string indexing
are discussed in [CharReq,
section 4].
Depending on the requirements, indexing can occur on any of the Layers defined
at the start of Section 3. In particular, Layer 1 is recommended if the primary
concern is efficient internal operation. Layer 2 is recommended if the primary
concern is interaction with the formal definition of a format, e.g. XML.
Layer 3 will be recommended (once it is well defined) where the primary concern
is user interaction while maintaining interoperability.
Note: In many cases, it is highly preferable to use non-numeric ways of
identifying substrings. The specification of string indexing for the Web
should not be seen as a general recommendation for the use of string indexing
for substring identification. As an example, in the case of translation of
a document from one language to another, identification of substrings based
on document structure can be expected to be much more stable than identification
based on string indexing.
Note: The issue of indexing origin, i.e. whether the first character in a
string is indexed as character number 0 or as character number 1, is not
addressed explicitly here. In general, even individual characters should
be understood and processed as substrings, identified by a position before
and a position after the substring. Understanding indices as boundary positions
between the units indexed makes it easier to relate the indices for the various
Layers to each other. In the case of using boundary points, starting with
an index of 0 for the position at the start of the string is the best solution.
According to the current definition [RFC 2396], URI
references are restricted to a subset of US-ASCII. There is also an escaping
mechanism to encode arbitrary byte values using the %HH convention. However,
because [RFC 2396] does not define the mapping from
characters to bytes, the %HH convention by itself is of limited use. To avoid
future incompatibilities, W3C specifications for new protocol/format elements
MUST include the following paragraph by reference:
For all syntactic elements in the format/protocol which are being interpreted
as URI references, characters that are syntactically not allowed by the generic
URI syntax (all non-ASCII characters, plus the excluded characters in
[RFC 2396, Section 2.4.] except "#" and "%") MUST
be treated as follows: Each such character is converted to UTF-8 as one or
more bytes, each of these bytes is escaped with the URI escaping mechanism
(i.e. converted to %HH, where HH is the hexadecimal notation of the byte
value), and the original character is replaced by the resulting character
sequence.
Example: In the URI <http://www.w3.org/People/Dürst/>, the character
"ü" is not allowed. The representation of "ü" in UTF-8 consists
of two bytes with the values 0xC3 and 0xBC. The URI is therefore converted
to <http://www.w3.org/People/D%C3%BCrst/>.
Note: The intent of this is not to freeze the definitions of URI references
to a subset of US-ASCII characters forever, but to assure that W3C technology
correctly and predictably interacts with systems that are based on the current
definition of URI references while not inhibiting a future extension of the
URI reference definition.
Note: This provision does not affect the ability to use URI references with
other encodings than UTF-8. However, in such a case, the URI reference has
to always be given in its escaped form. As an example, if the http server
at www.w3.org would only use ISO-8859-1, the above URI would always have
to be given as <http://www.w3.org/People/D%FCrst/>, because "ü"
in ISO-8859-1 is 0xFC.
Note: Current W3C specifications already contain provisions in accordance
with the above. For [XML 1.0], please see Section 4.2.2,
External Entities. For [HTML 4.0], please see Appendix
B.2.1: Non-ASCII characters in URI attribute values, which also contains
some provisions for backwards compatibility. Further information and links
can be found at [I18NURI].
[Issue: What to do about [] for IPV6 addresses?]
In the next version of this document, the WG plans to address the following
topics in this subsection:
-
Languages, dialects, foreign words,...
-
Functions depending on language
-
Language tagging: Benefits and limits
-
Language tagging and text structure
-
Language tags to use: RFC 1766 and followers
Language tagging benefits Web accessibility. When content developers mark
up natural language changes in a document, speech synthesizers and Braille
devices can automatically switch to the new language, making the document
more accessible to multilingual users. Content developers SHOULD always identify
the predominant script of a document's content (e.g., through markup or HTTP
headers).
In addition to helping assistive technologies, natural language markup allows
search engines to find key words and identify documents in a desired language.
Natural language markup also improves readability of the Web for all people,
including those with learning disabilities, cognitive disabilities, or people
who are deaf.
Added François Yergeau as an editor. Changed sequence of lists for
comments in Status of this Document, mention how i18n-editor@w3.org is archived.
Some rewriting of Abstract and Introduction.
Fleshed out Section 3.2 "Characters and their digital representation" and
Section 3.3 "Identification of Character Encodings". A couple of existing
paragraphs in 3.3 (about benefits of unique encoding) moved to 3.2. Fleshed
out section 3.4.
Changed normalization to not mention Unicode Version 3.0 normatively anymore,
because this is part of UTR#15 now. Added annotation characters to list of
prohibited characters in. Later moved to [UXML], and
removed some material. Added issue about normalization and escaping.
Moved definition of layers to Section 3, changed to 4 layers. Made string
indexing refer to the general model in Section 3. Clarified use of boundary
points for indexing and use of 0-based indexing (needs more detail work).
In Section 6: Changed "represented" to "converted". Added
Note to explain that URIs (always escaped) can still be used with servers
not using UTF-8. Changed to apply to URI references so that it includes fragment
identifiers. Added # and % as characters allowed in URI references. Changed
"W3C specifications MUST" to "W3C specifications, for new protocol/format
elements, MUST". Changed "in accordance with" to "very similar to".
Added "Language identification" as Section 2.5, later moved to Section 7.
Minor work in Acknowledgements, Glossary.
Added references to UTR #17, Unicode 3.0, HTTP 1.1, UTF-16 I-D, Connolly's
"Character Set Considered Harmful". Expanded reference to MIME to include
all five RFCs (needed 2047 for section 3.3). Separated out Normative and
Other references.
Added <acronym> elements throughout for accessibility. Various typos
fixed throughout.
This glossary does not provide exact definitions of terms but gives some
background on how certain words are used in this document.
-
Character
-
Used in a loose sense to denote small units of text, where the exact definition
of these units is still open.
-
Early Normalization
-
See Early Uniform Normalization.
-
Early Uniform Normalization
-
Duplicates and ambiguities are removed as close to their source as possible.
This is done by normalizing them to a single representation. Because the
normalization is not done by the component that carries out the identity
check, normalization has to be done uniformly for all the components of the
Web.
-
Encoding based on UCS
-
An encoding that uses UCS codepoints in a reasonably simple manner. Examples:
UTF-8, UTF-7 (deprecated), UTF-16, UCS-2, UCS-4. (Note: For the later three,
an encoding definition also needs to include provisions for defining and
identifying the serialization of 16-bit or 31-bit values into byte sequences.)
-
Late Normalization
-
Each individual component that performs a string identity check has to take
equivalence into account. This would be done by normalizing each string to
a preferred representation that eliminates duplicates and ambiguities. Because,
with late normalization, normalization is done locally and on the fly, there
is no need to specify a webwide uniform normalization.
-
Legacy Encoding
-
An encoding not based on UCS. Examples: ISO-8859-1, EUC-KR, and many others.
-
String Identity Matching
-
Exact matching of strings, except for encoding duplicates indistinguishable
to the user. See Section 4.3.
-
String Indexing
-
Indexing into a string to address a character or a sequence of characters.
See Section 5.
-
Transcoding
-
The process of changing text data from one character encoding to another.
-
UCS
-
Universal Character Set, the Coded Character Set (CCS) defined in parallel
by [ISO 10646] and [Unicode].
-
URI
-
Uniform Resource Identifier, see [RFC 2396]. According
to RFC 2396, an URI does not include a fragment identifier (the part after
a potential '#'). In colloquial usage, URI is often used for URI reference.
-
URI reference
-
URI with potentially attached fragment identifier (the part after '#'). See
[RFC 2396].
-
Web
-
World Wide Web, the collection of technologies built up starting with HTML,
HTTP, and URIs, the corresponding software (servers, browsers,...), and/or
the corresponding content.
Special thanks go to Ian Jakobs for serious help with editing. Tim Berners-Lee
and James Clark provided important details in the section on URIs. The W3C
I18N WG and IG, as well as others, provided many comments and suggestions.
-
[IANA]
-
(Internet Assigned Numbers Authority) K. Simonsen et al., Official Names
for Character Sets, See
ftp://ftp.isi.edu/in-notes/iana/assignments/character-sets.
-
[ISO 10646]
-
ISO/IEC 10646-1:1993,
Information technology -- Universal Multiple-Octet Coded Character Set
(UCS) -- Part 1: Architecture and Basic Multilingual Plane.
-
[RFC 2119]
-
S. Bradner, Key words for use in RFCs to Indicate Requirement Levels,
<http://www.ietf.org/rfc/rfc2119.txt>.
-
[UTR #15]
-
Mark Davis, Martin Dürst, Unicode Normalization Forms, Unicode
Technical Report #15, September 1999,
<http://www.unicode.org/unicode/reports/tr15/tr15-17.html>.
-
[Unicode 3.0]
-
The Unicode Consortium,
The Unicode
Standard --
Version
3.0, ISBN 0-201-61633-5.
-
[Connolly]
-
D. Connolly, Character Set Considered Harmful, W3C Note 2-May-1995
<http://www.w3.org/MarkUp/html-spec/charset-harmful>
-
[CSS2]
-
Bert Bos, Håkon Wium Lie, Chris Lilley, Ian Jacobs, Eds., Cascading
Style Sheets, level 2 (CSS2 Specification), W3C Recommendation 12-May-1998,
<http://www.w3.org/TR/REC-CSS2>.
-
[DOM]
-
Vidur Apparao et al., Document Object Model (DOM) Level 1
Specification, W3C Recommendation 1 October, 1998,
<http://www.w3.org/TR/REC-DOM-Level-1/>.
-
[I18NURI]
-
Internationalization: URIs and other identifiers
<http://www.w3.org/International/O-URL-and-ident>.
-
[ISO 6937]
-
ISO/IEC 6937:1994,
Information technology -- Coded graphic character set for text communication
-- Latin alphabet.
-
[ISO 8859]
-
ISO 8859
(various
parts and publication dates), Information technology -- 8-bit single-byte
coded graphic character sets.
-
[HTML 4.0]
-
Dave Raggett, Arnaud Le Hors, Ian Jacobs, Eds., HTML 4.0
Specification, W3C Recommendation 18-Dec-1997 (revised on 24-Apr-1998),
<http://www.w3.org/TR/REC-html40/>.
-
[MIME]
-
Multipurpose Internet Mail Extensions (MIME). Part One: Format of Internet
Message Bodies, N. Freed, N. Borenstein, RFC 2045, November 1996,
<http://www.ietf.org/rfc/rfc2045.txt>.
Part Two: Media Types, N. Freed, N. Borenstein, RFC 2046, November
1996. Part Three: Message Header Extensions for Non-ASCII Text,
K. Moore, RFC 2047, November 1996. Part Four: Registration Procedures,
N. Freed, J. Klensin, J. Postel, RFC 2048, November 1996. Part Five:
Conformance Criteria and Examples, N. Freed, N. Borenstein, RFC 2049,
November 1996.
-
[Nicol]
-
Gavin Nicol, The Multilingual World Wide Web, Chapter 2: The
WWW As A Multilingual Application,
<http://www.mind-to-mind.com/documents/i18n/multilingual-www.html#ID-2A08F773>.
-
[CharReq]
-
Martin J. Dürst, Requirements for String Identity and Character
Indexing Definitions for the WWW,
<http://www.w3.org/TR/WD-charreq>.
-
[RFC 2616]
-
R. Fielding, J. Gettys, J. Mogul, H. Frystyk, T. Berners-Lee, Hypertext
Transfer Protocol -- HTTP/1.1,
<http://www.ietf.org/rfc/rfc2616.txt>.
-
[RFC 2070]
-
F. Yergeau, G. Nicol, G. Adams, M. Dürst, Internationalization of
the Hypertext Markup Language, RFC 2070, January 1997,
<http://www.ietf.org/rfc/rfc2070.txt>.
-
[RFC 2130]
-
C. Weider, C. Preston, K. Simonsen, H. Alvestrand, R. Atkinson, M. Crispin,
P. Svanberg, The Report of the IAB Character Set Workshop held 29 February
- 1 March, 1996, RFC 2130, April 1997,
<http://www.ietf.org/rfc/rfc2130.txt>.
-
[RFC 2277]
-
H. Alvestrand, IETF Policy on Character Sets and Languages, RFC
2277 / BCP 18, January 1998,
<http://www.ietf.org/rfc/rfc2277.txt>.
-
[RFC 2279]
-
F. Yergeau, UTF-8, a transformation format of ISO 10646, RFC 2279,
January 1998,
<http://www.ietf.org/rfc/rfc2279.txt>.
-
[RFC 2396]
-
T. Berners-Lee, R. Fielding, L. Masinter, Uniform Resource Identifiers
(URI): Generic Syntax, August 1998,
<http://www.ietf.org/rfc/rfc2396.txt>.
-
[UTF-16]
-
P. Hoffman, F. Yergeau, UTF-16, an encoding of ISO 10646, Work in
progress,
<draft-hoffman-utf16-05.txt>.
-
[Unicode 2.0]
-
The Unicode Consortium,
The Unicode
Standard, Version
2.0, Addison-Wesley, Reading, MA, 1996.
-
[Unicode 2.1]
-
Lisa Moore, Unicode Technical Report # 8, The Unicode Standard, Version 2.1,
September 1998,
<http://www.unicode.org/unicode/reports/tr8.html>.
-
[UTR #17]
-
Ken Whistler, Mark Davis, Character Encoding Model, Proposed Draft
Unicode Technical Report #17, October 1998,
<http://www.unicode.org/unicode/reports/tr17/>.
-
[UXML]
-
Martin Dürst, Mark Davis, Hideki Hiura, and Asmus Freytag, Unicode
in XML and other Markup Languages, Proposed DRAFT Unicode Technical
Report #20 and W3C Working Draft,
<http://www.w3.org/TR/unicode-xml>.
-
[XML 1.0]
-
Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, Eds., Extensible Markup
Language (XML) 1.0, W3C Recommendation 10-February-1998,
<http://www.w3.org/TR/REC-xml>.