Deutsch English Español Français Italiano Nederlands Português Українська
Ускоряющая клавиша n предназначена для пропусков при навигации по страницам. Пропуск для перехода на начало контента.
Данный документ является переводом. В случае каких-либо несоответствий и ошибок последняя версия документа на английском языке должна рассматриваться в качестве официальной. Первоначальное авторское право принадлежит W3C, как то указано ниже.
Переводчик: Alexandr Shlapak (Олександр Шлапак)
http://www.w3.org/International/tutorials/svg-tiny-bidi/
Предполагаемая аудитория: авторы контента SVG, которые применяют небольшие SVG страницы в скриптах, которые выравниваются справа налево: Арабский и Иврит, или те кто имеют дело с встроенным скриптовым текстом, который выравнивается справа налево. Этот материал можно применить при создании документы в редакторе или с помощью скриптов.
Cкрипты, которые выравниваются справа налево включают Арабский, Иврит, Тана и Нко, и используются большим количеством людей по всему миру. Если вы новичок в настройке двунаправленного текста, то заставить его правильно отображаться иногда может показаться сложной и запутанной задачей, но это не так. Если вы уже пытались это сделать либо еще и не начинали, то это руководство должно помочь вам принять наилучший подход относительно разметки вашего контента. Оно также четко объясняет, как работает двунаправленный алгоритм, чтобы лучше понять основные причины большинства проблем. Мы также рассмотрим некоторые общие недоразумение с разметкой для двустороннего контента.
Прочитав это руководство вы сможете:
Обратите внимание, что SVG Tiny 1.2 спецификация была опубликована в качестве Рекомендации 22 декабря 2008 года. Возможно пройдет некоторое время, прежде чем функциональные возможности описанные в данном руководстве станут широко распространенными.
В этом разделе:
Додайте direction="rtl" к svg тэгу для установки основного направления документа - справа налево. Базовое направление устанавливает общую направленность контекста для текста внутри элемента, в котором оно назначенное.
Вам не нужно явно определять базовое направление для документов, которые преимущественно выравниваются слева направо, так как это является умолчанием.
Сделав это, вам не потребуется дополнительная разметка направленности в вашем контенте. Значение свойства direction устанавливается в svg элементе и наследуется элементами, относящимися к тексту на протяжении всего документа. Большая часть переупорядочивания, которая необходима для отображения текста автоматически происходит за счет двунаправленного алгоритма Unicode ('bidi алгоритм'). Это можно проиллюстрировать на примере ниже.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="fa">
<title>...</title>
<desc>...</desc>
<text x="200" y="200"
font-size="10">داستان SVG Tiny 1.2 طولا ني است.</text>
</svg>
Это будет отображать текст в следующем (правильном) порядке, если реализация поддерживает bid обработку текста:
![]()
Без свойства direction, текст выглядел бы так:
![]()
Конечно, есть ситуации, когда вам может понадобиться применить больше разметок, и мы опишем их ниже. Кроме того, добавление direction="rtl" к svg элементу приведет к некоторым автоматическим воздействиям на свойства text-align и text-anchor, которые мы вскоре также будем описывать.
Хотя вы назначаете направленность документа в svg тэге, не забудьте назначить
язык документа используя атрибут xml:lang (смотрите Языковые тэги в HTML и XML).
Однако, не делайте ошибку, считая, что назначения языка указывают направленность текста, или наоборот!
Даже если скриптовый subtag используется в значении атрибута языка, это не влияет на направленность
текста в клиентском приложении. Вы должны всегда определять направления используя атрибут dir.
Визуальное расположение текста на Иврите было распространено в (очень) старых HTML клиентских приложениях, которые не поддерживали двунаправленный алгоритм Unicode. Текст хранится в исходном коде в том же порядке в котором можно ожидать его при отображении. (Это было не так часто в тексте написанном на Арабском скрипте, так как это портит взаимосвязь между символами.)
Текст с логическим расположением, сохраняется в памяти в том же порядке, в котором он, как правило, был напечатан (и обычно произносится). Двунаправленный алгоритм Unicode затем применяется в браузере, чтобы воспроизвести правильное визуальное отображение. В настоящее время почти весь текст в Сети находится в логическом порядке.
Вам следует размещать ваш контент, который выравнивается справа налево в логическом порядке, и полагаться на двунаправленный алгоритм и разметку, чтобы сделать так, чтобы он отображался правильно. Если вы этого не сделаете, то нельзя будет осуществлять поиск вашего текста, повторное использование текста, легко поддерживать ваш контент, и т.д.
На рисунке ниже, фраза "פעילות הבינאום, W3C" (синяя сверху) появляется так как она обычно появляется при отображении в параграфе, выравнивается справа налево. Пронумерованные стрелки показывают направление чтения. Вы читаете последовательности по порядку.
Противопоставление логического и визуального порядка расположения.

Вторая строка показывает порядок символов в памяти в логическом порядке кодировки (предполагается, что первый символ памяти находится слева, тот который рядом с ним справа, и т.д.).
Третья строка показывает порядок символов в памяти в визуальном порядке кодировки (с тем же предположением о порядке расположения в памяти).
В этом разделе:
Установив, базовое направление на уровне элемента svg, вы не должны использовать свойство direction в других элементах, если только вы не хотите изменить базовое направление для того элемента.
Ненужное использование свойства direction влияет на пропускную способность и потенциально создает ненужную дополнительную работу по
обслуживании страницы.
Базовое направление, установленное свойством direction тем не менее, влияет на то, как расположен смешанный текст и пунктуация внутри элемента text или textArea (это будет подробно описано чуть дальше). Иногда, возможно, вы захотите изменить базовое направление для одного из этих элементов, если он написан на другом языке чем остальные страницы.
Для этого просто используйте свойство direction в том элементе, или в элементе группировки, который окружает соответствующий контент.
В этом примере мы используем элемент группировки вокруг нескольких элементов text, которым чтобы выглядеть правильно необходимо установить основное направление слева направо. Использование элемента группировки уменьшает объем работы, которую мы должны сделать, чтобы достичь желаемого результата. Заданное направление наследуется закрытыми элементами text.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="he">
<title>...</title>
<desc>...</desc>
<text x="200" y="20"
font-size="10">כתובת לפניות באנגליה:</text>
<g direction="ltr">
<text x="100" y="40"
font-size="10">3, Tennyson House</text>
<text x="100" y="50"
font-size="10">17 Clairbourne Road,</text>
<text x="100" y="60"
font-size="10">Harpenden AL5 4SD</text>
</g>
</svg>
Без разметки направления в элементе g, текст будет отображаться вроде этого:
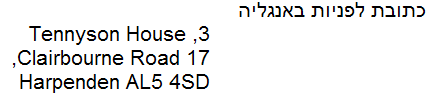
С установленным свойством direction, текст будет выглядеть как назначенный.

Вы могли заметить, что выравнивание текста по отношению к координате x различны для двух примеров приведенных выше. Мы обсудим это далее.
Свойство text-align используется с элементом textArea, и имеет следующие значения: start, middle и end. Важно помнить, что первое и последнее из этих значений связанные с текстом логично, а не физически.
start означает место, где обычно начинается чтение строки, задающей текущее базовое направление. Когда базовое направление слева направо, то это значит - слева от элемента TextArea. Если наоборот - базовое направление справа налево, то это означает - справа от элемента TextArea.
Для end, просто наоборот.
Это интуитивно, если вы использовали CSS с HTML, так как свойство direction в CSS автоматически выравнивает текст справа в блочном элементе.
В этом примере Урду выравнивание справа налево, что установлено в элементе svg наследуется элементом textArea.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="ur">
<title>...</title>
<desc>...</desc>
<textArea x="20" y="20" width="200">
فعالیت بینالمللیسازی، W3Cنا
عالمگیر ویب کو حقیقی طور پر عالمگیر بنانا
</textArea>
</svg>
На экране, текст должен выглядеть по правому краю в пределах области textArea, как показано ниже, так как значения по умолчанию text-align установлено start, то для базового направления справа налево это означает выравнивание по правому краю.

Свойство text-anchor используется с элементом text, и его значениями также являются: start, middle и end. Опять же, первое и последнее из этих значений связанные с текстом логично, а не физически.
Если вы не указали базового направления, или вы указали direction="ltr", и если значение text-anchor установлено как start, текст будет распространяться на право по оси координат х. Если вы установили direction="rtl", тогда текст будет распространяться на лево по оси координат х. По умолчанию значение text-anchor установлено - start.
Для end - наоборот.
В этом Английском/Арабском примере, мы используем два элемента text, оба с той же координатой х, а также с одинаковым значением по умолчанию для text-anchor.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
xml:lang="en">
<title>...</title>
<desc>...</desc>
<text x="200" y="10"
font-size="10">Internationalization activity, W3C</text>
<text direction="rtl" x="200" y="20"
font-size="10">نشاط التدويل، W3C</text>
</svg>
Хотя координата x для обоих элементов text одинаковая, текст будет отображаться вроде этого:

Вы должны иметь в виду, что направление, в котором текст распространяется от точки х (смотрите предыдущий пример) зависит от базового направления, то есть значение свойства direction, и not от того, имеете ли вы дело с Латинским или с Арабским текстом (или текстом на Иврит). Это важно.
Это означает, что, например, список терминов, содержащий Латинские и Ближневосточные слова ожидаемо испортит выравнивание элементов.
Следующий пример содержит переменные строки на Иврите и на Латинице:
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="he">
<title>...</title>
<desc>...</desc>
<text x="200" y="20"
font-size="10">W3C ,פעילות הבינאום</text>
<text x="200" y="30" xml:lang="en"
font-size="7">(Internationalization Activity, W3C)</text>
<text x="200" y="50"
font-size="10">ליצור מהרשת רשת כלל עולמית באמת</text>
<text x="200" y="60" xml:lang="en"
font-size="7">(Making the World Wide Web worldwide)</text>
</svg>
Все элементы в адресном списке отображаются по правому краю. Нам не нужно делать ничего особенного для строк написанных только на Латинском языке, так что они выстраиваются в линию с остальными:

То, что вы должны помнить, однако, если вы по каким причинам, применяете direction="ltr" для одного с элементов text, вы должны также указать text-anchor="end" для этого элемента, так что он будет продолжать выстраиваться с другими.
В этом разделе:
В предыдущих главах мы уже упоминали, что иногда недостаточно просто добавить информацию о направлении в svg тэге. В этом разделе мы рассмотрим, когда и почему нужно больше контроля, и в частности, мы рассмотрим, как размечать элементы tspan для направления (для которого необходимо ввести свойство unicode-bidi).
Результат применения двунаправленного алгоритма зависит от общего базового направления фразы, абзаца, блока или страницы, в которых он применяется. Базовое направление устанавливает направленный контекст, который bidi алгоритм направляет к разным точкам, чтобы решить, как обращаться с текстом.
Базовое направление либо устанавливается явно ближайшим родительским элементом, который использует свойство direction, либо, при отсутствии таких родительских элементов, он наследует направленность svg тэга по умолчанию - слева направо.
Заметим, что для блочных элементов основное направление справа налево можно установить только с помощью свойства direction.
Мы уже знаем, что последовательность Латинских символов предоставляется (то есть показывается) друг за другом слева направо (мы можем увидеть это на этой странице). Кроме того, bidi алгоритм даст последовательность строго типизированных RTL (справа налево) символов один за другим справа налево.
Это не зависит от текущего базового направления, и работает, так как каждый символ в Unicode имеет связанное направленное свойство. Большинство букв строго типизированные как LTR. Буквы в скриптах, которые выравниваются справа налево строго типизированные как RTL.
Направленное введение.

Когда текст с разной направленностью предоставляется встроенным, алгоритмом bidi визуализирует каждую последовательность символов, с той же направленностью что и отдельное направленное действие.
Таким образом, в следующем примере есть три направленные действия:
Направленные действия.

Другой способ посмотреть на это, является то что изменения в направлении отмечают пределы направленных действий. Обратите внимание, чтобы это сделать вам не нужна никакая разметка или стилизация.
Особенно важно понимать, что порядок, в котором отображаются направленные действия на странице зависит от базового направления, которому отдают предпочтение.
Слова на картинке ниже отделяют направленные действия. Верхняя строка находится в контексте, в котором основное направление - LTR; внизу - RTL. Символы в обеих строках на рисунке хранятся в памяти точно в таком же порядке, но визуальный порядок направленных действий, при отображении, меняется на противоположный.
Влияние базового направления на отображение направленных действий.

Пробелы и знаки препинания не являются строго типизированными как LTR либо RTL в Unicode, так как они могут быть использованы в любом типе скрипта. Поэтому они классифицируются как нейтральные.
Что интересно? Когда алгоритм bidi встречает символы со свойствами нейтральной направленности (такие, как пробелы и знаки препинания), он определяет как их обработать, глядя на окружающие символы.
Нейтральный символ между двумя строго типизированными символами с тем же типом направленности будет иметь такую же направленность. Так нейтральный символ между двумя строго типизированными RTL символами будет рассматриваться как RTL символ, и будет иметь эффект расширения направленного действия. Вот почему три Арабских слова в этой фразе LTR (разделены только пробелом, который имеет нейтральную направленность) читаются справа налево, как единственное направленное действие. (Первое Арабское слово, что вы читаете это مفتاح потом معايير потом الويب.)
Нейтральные символы как часть направленного действия.

Обратите внимание, что вам для этого по-прежнему не нужны никакие разметка либо стилизация. И, что здесь до сих пор есть только три направленные действия.
Действительно интересное наступает тогда, когда пробел либо знак препинания ставится между двумя строго типизированными символами с разной направленностью, то есть на границе между направленными действиями. В таком случае нейтральный символ, либо символы будут рассматриваться так, будто они имеют базовое направление.
Даже если есть несколько нейтральных символов между двумя различными строго типизированными символами, то они будут рассматриваться в базовом направлении.
Нейтральные символы.

Цифры в RTL скриптах выравниваются слева направо в пределах потока, который выравнивается справа налево, но они обрабатываются bidi алгоритмом немного по-другому, чем слова. Они, как говорят, имеют слабую направленность. Два примера на рисунке показывают это различие.
Цифры.
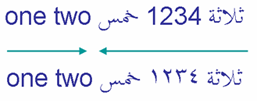
Первый пример использует европейские цифры, '1234', второй выражает то же число, используя Арабско-Индийские цифры, ١٢٣٤. В обоих случаях цифры в номере читаются слева направо.
Так как число слабо типизированное, то число рассматривается как часть текста на арабском языке, так что два арабских слова, которые окружают номер рассматриваются как часть того же направленного действия, хотя на экране последовательность цифр - LTR.
Отметим также, что, наряду с числом, такие определенные в противном случае нейтральные символы как символы валют, будут рассматриваться как часть числа, а не нейтральные символы.
Алгоритм bidi будет хорошо обрабатывать текст в большинстве ситуаций, и, как правило не требуется специальной разметки либо другого устройства, и нужен для другого, а не для установки общего направления документа. Вам бы очень повезло, если бы постоянно все было бы так легко. Вот наш первый пример ситуации, когда двунаправленному алгоритму нужно немного помочь.
Первая строка на этом рисунке показывает восклицательный знак, который является частью встроенного Арабского текста, который появляется в неправильном месте. Вторая строка показывает желаемый результат.
Нейтральные символы между направленными действиями могут заканчиваться там, где их быть не должно.
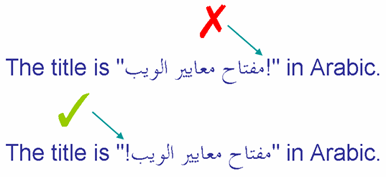
Учитывая наши предыдущие обсуждения алгоритма bidi, мы легко можем понять, почему это произошло. Потому что восклицательный знак был введен между последней RTL буквой 'ب' (слева) и LTR буквой 'i' (слова 'in') его направленность определяется основным направлением параграфа (здесь LTR). Обратите внимание, что не важно, что есть фактически два знака препинания и пробел в этой позиции - они все нейтральные символы и поэтому это влияет на них одинаково. Так как восклицательный знак рассматривается как LTR он присоединяется к направленному действию, которое включает текст на 'Арабском языке'.
Так как же мы получаем знаки препинания в нужном месте?
Один из ответов это поместить Арабскую
цитату в элемент tspan и использовать свойство direction, чтобы изменить базовое направление в пределах элемента tspan на RTL.
В отличие от элементов контейнера, которые мы рассмотрели ранее, элемент tspan требует от вас указать как свойство unicode-bidi, так и свойство direction, для того, чтобы изменение базового направления было эффективным. Значение которое вам нужно - это embed. (Позднее мы рассмотрим использование bidi-override.)
<text>The title is "<tspan direction="rtl" unicode-bidi="embed" xml:lang="ar"> ... !</tspan>" in
Arabic.</text>Среда редактирования, которую вы используете не может показать, восклицательный знак в нужном месте в исходном коде, но он должен выглядеть правильно при отображении.
Обратите внимание как span тэг попадает внутрь кавычек - кавычки являются частью окружающего Английского текста.
Другая возможность - ввести невидимый, строго типизированный RTL символ после восклицательного знака. Таким образом, восклицательный знак будет интерпретироваться как RTL и присоединится к Арабскому направленному действию.
Просто так получилось, что есть такой символ Unicode, как U+200F, который называется RIGHT-TO-LEFT MARK (метка справа налево) (RLM). Есть
похожий символ, U+200E, что называется LEFT-TO-RIGHT MARK (метка слева направо) (LRM). Поскольку символ невидимый вы можете отдать предпочтение фактическому введению числовой ссылки (‏)
Добавление этого символа сразу после восклицательного знака будет выдавать желаемый результат.
<text>The title is "... !‏" in
Arabic.</text>Если уже есть разметка вокруг цитаты, вероятно, есть смысл здесь использовать только свойство direction, а не управляющий символ. В противном случае проще может быть использование управляющего символа.
Верхняя строка следующего рисунка показывает что произойдет со список RTL элементов внутри LTR предложения, если мы будем опираться исключительно на
двунаправленный алгоритм (то есть, если мы не использовали свойство direction для того, чтобы установить базовое направление). В нашем примере порядок в списке неверный, так как первые два арабских слова следует поменять местами, и промежуточные запятые,
, являющиеся частью Английского текста, должны появиться сразу справа от первого слова.
Вторая строка на рисунке показывает желаемый результат.
Нейтральные символы между текстом одинакового направления могут быть неправильно интерпретированы в качестве части единого действия.

Причиной отказа является то, что с помощью строго типизированного справа налево (RTL) символа с обеих сторон, двунаправленный алгоритм видит нейтральную кому* как часть Арабского текста. Он интерпретирует первые два Арабских слова и кому в виде списка на Арабском языке. На самом деле кома является частью Английского текста, и должна отмечать границу двух направленных действий в Арабской языке.
В предыдущем разделе мы считали нейтральный символ частью направленного контекста установленного базовым направлением, но это не так; в этом разделе нейтральный символ должен быть частью направленного действия, в то время как он является действительно частью общего направленного контекста.
Простое решение заключается в использовании другого невидимого символа Unicode, на этот раз LEFT-TO-RIGHT MARK, рядом с запятой. Это ставит наши нейтральные знаки препинания между строго типизированными RTL и LTR символами и заставляет их взять на себя направленность базового направления, которое является слева направо в Английском тексте. Это разбивает Арабские слова на два отдельных направленных действия, которые располагаются LTR согласно преобладающему направлению параграфа.
<text>The names of these states in Arabic are ...,‎ ... and ... respectively.</text>Опять же, ради видимости вы можете отдать предпочтение использованию NCR (‎).
Следующая картина показывает другой пример, где разметка не нужна, и управляющий символ Unicode делает работу намного проще. Опять же, верхняя строка голубого цвета на рисунке показывает результат, когда вы будете полагаться только на двунаправленный алгоритм, а вторая строка показывает желаемый результат.
Желаемый результат был достигнут путем размещения ‏ рядом с скобкой, которая должна была стать частью контекста на Иврите, но
которая появляется между двумя интервалами Латинского текста. Эффект метки RLM - разделить Латинский текст на три отдельные направленные действия, которые
размещены в соответствии с базовым направлением RTL.
Другой пример использования RLM либо LRM, на этот раз в контексте на Иврите.

Возможно, вы заметили, что в дополнение к изменению позиции, одна из круглых скобок в предыдущем примере, также фактически изменила и форму. Это было полностью автоматическим, и случается, потому что эти символы - так называемые зеркальные символы в Unicode.
Зеркальные символы, как правило, пары символов, такие как круглые скобки, квадратные скобки и т.д., форма которых при отображении зависит от того, частью которого контекста они есть: LTR либо RTL. Вам не нужно изменять символ для изменения формы. Концы открытой круглой скобки всегда смотрят в сторону текстового потока. На картинке ниже, в верхней строке скобка обведена красным смотрит вправо, так как она рассматривается как открывающая скобка некоторого Латинского текста. В нижнем варианте текста, такой же символ (опять обведен красным) рассматривается как открывающая скобка, относящийся к Еврейскому тексту (то есть развернутое название следует за сокращением в порядке чтения), и поэтому выглядит иначе.
Зеркальные символы.

Это означает, что или сохранен контент на Арабском языке/Иврите или на Латинице, вы все равно в начале текста, который находится в скобках должны использовать тот же символ LEFT
PARENTHESIS (левая круглая скобка). Иными словами, относитесь к зеркальным символам так, как будто любое слово
left (лево) в названии означает 'opening' (открытие), и right (право) означает 'closing' (закрытие).
Unicode алгоритм bidi и LRM/RLM метки работают достаточно хорошо, когда есть только один уровень смешанного текста. Если у вас есть ситуации, когда имеется два или более уровней вложенности направленного текста вам нужно другое решение. Эта картина показывает Латинское предложение, что содержит цитату на Иврите, которая, в свою очередь, содержит как Иврит так и Латинский текст ('W3C').
Порядок двух слов на Иврите правильный, но текст 'W3C' должен появиться в левой части цитаты и запятая должна появиться между Еврейским текстом и 'W3C'.
Достижение желаемого отображения с помощью разметки, чтобы открыть новый уровень вложения.

Проблема возникает потому что, направленные потоки в настоящее время упорядочены согласно базовому направлению LTR. Однако, внутри цитаты на Иврите, правильным расположением по умолчанию должно быть RTL.
Для решения этой проблемы мы должны открыть новый уровень вложения. Для этого вам нужно поместить цитату в элемент tspan и назначить его направленность RTL используя свойства direction и unicode-bidi.
<text>The title says "<tspan direction="rtl" unicode-bidi="embed"> ... </tspan>" in Hebrew.</text>Есть также управляющие символы Unicode которые вы можете использовать для того, чтобы достичь того же результата, но потому, что они устанавливают базовую направленность фрагмента текста с помощью невидимых границ это не рекомендуется.
аким образом, в то время как вы просто используете свойство direction на таких контейнерных элементах, как svg, g, text и textArea, вы должны использовать как direction так и unicode-bidi="embed" в элементах tspan, так как они являются встроенными.
Другое полезное значение unicode-bidi - это bidi-override. Вам не нужно будет его использовать очень часто. Оно описанное в следующем разделе.
Могут быть случаи, когда вы вообще не хотите, чтобы bidi алгоритм делал свою работу по изменению порядка. В этих случаях вам понадобятся дополнительные разметки, чтобы окружить текст, который хотите оставить неупорядоченным.
В SVG это достигается с помощью использования значения bidi-override свойства unicode-bidi рядом со свойством direction. Опять же, есть управляющие символы Unicode которые вы можете
использовать, чтобы достичь того же результата, но потому, что они создают области с невидимыми границами, это
не рекомендуется.
Пример текста, где вы хотите переопределить двунаправленный алгоритм.
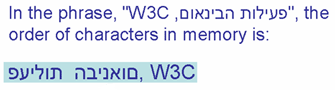
Например, на рисунке показан текст на Иврит как упорядоченный в памяти. Для достижения этого эффекта вы можете использовать свойство unicode-bidi.
<text x="20" y="80" direction="ltr" unicode-bidi="bidi-override"> ... </text>Unicode предоставляет специальные, невидимые коды форматирования для построения либо переопределения результата двунаправленного алгоритма в виде простого текста, так же, как описана SVG разметка в данном руководстве.
Есть целый ряд управляющих символов в Unicode, которые можно использовать для создания такого же эффекта как разметка для встроенного двунаправленного текста. Они перечислены в таблице:
| Символ | Код | Эквивалентная разметка |
|---|---|---|
| RLE | U+202B | <tspan direction="rtl" unicode-bidi="embed"> |
| LRE | U+202A | <tspan direction="ltr" unicode-bidi="embed" |
| RLO | U+202E | <tspan direction="rtl" unicode-bidi="bidi-override" |
| LRO | U+202D | <tspan direction="ltr" unicode-bidi="bidi-override" |
| U+202C | </tspan> |
Unicode в Языках Разметки советует не использовать их, когда доступна разметка, и, в частности не рекомендует смешивать управляющие коды и разметку.
Для получения дополнительной информации по этой теме смотрите Управляющие символы Unicode или разметка для поддержки bidi на сайте W3C Интернационализации.
Однако, есть некоторые ситуации, когда управляющие символы Unicode являются единственным средством для выражения направленности. Это тот случай, для таких текстовых элементов, как title и desc. Эти элементы определены для поддержки только символов, а не разметки. Поэтому не
можно использовать свойства direction или unicode-bidi в части контента элемента.
Атрибут text, тоже не может быть отмечен по направленности, поэтому символы управления Unicode должны быть использованы для того, чтобы указать, направленность.
Обратите внимание, что другие вещи, такие как язык, не могут быть размечены для части простого текстового контента либо для значений атрибутов.
Выскажите своё мнение (по-английски).
Перевод с английского: 2009-01-07. Последнее внесение изменений в перевод: 2011-12-08 20:00 GMT
Для просмотра истории внесения изменений нажмите tutorial-svg-tiny-bidi в блоге i18n.
Copyright © 2009-2011 W3C® (MIT, ERCIM, Keio, Beihang), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}