Intended audience: SVG content authors implementing SVG Tiny pages in right-to-left scripts such as Arabic and Hebrew, or having to deal with embedded right-to-left script text. This material is applicable whether you create documents in an editor, or via scripting.
Updated
Why should you read this?
Right-to-left scripts include Arabic, Hebrew, Thaana and N'ko, and are used by a large number of people around the world. If you are new to dealing with bidirectional text, getting it to display correctly can sometimes appear complex and confusing, but it need not be so. If you have
struggled with this or have yet to start, this tutorial should help you adopt the best approach to marking up your content. It will also explain enough of how
the bidirectional algorithm works for you to understand much better the root causes of most problems. We will also address some common
misconceptions about ways to deal with markup for bidirectional content.
Creating examples of bidi text in source code is problematic, since most source text editors don't apply markup semantics to the content, or keep the markup separate from the content as you edit. This means that the source code you write may not look the same as the code examples shown in this tutorial. For the sake of clarity, these examples keep markup and content separate, and render content as you would expect to see it ultimately displayed.
By following this tutorial you should be able to:
create effective SVG Tiny 1.2 content containing text written in the Arabic or Hebrew (or other right-to-left) scripts,
understand the basics of how the Unicode bidirectional algorithm works, so that you can understand why bidirectional text behaves the
way it does, and how to work around problems,
take decisions about the appropriateness of alternatives to markup.
Add direction="rtl" to the svg tag to set the base direction for the document any time the overall document direction is right-to-left. The base direction establishes the overall directional context for the text inside the element where it is declared.
You don't need to explicitly define the base direction for documents that are predominantly left-to-right, since this is the
default.
Having done this, you may not need any further directional markup in your content. The direction property value set on the svg element is inherited by text-related elements throughout the whole document. Much of the reordering that is needed to display text is automatically taken care of by the Unicode Bidirectional Algorithm ('bidi algorithm'). This can be illustrated by the example below.
Example: The direction property set on the svg tag. [live code]
This will display the text in the following (correct) order, if the implementation supports bidi text handling:
Without the direction property, the text would have looked like this:
Of course, there are situations where you may need to apply more markup, and we will describe those below. Also, adding direction="rtl" to the svg element will lead to some automatic effects on text-align and text-anchor properties which we will also describe shortly.
Language tagging.
While you are declaring the directionality of the document in the svg tag, don't forget to declare the
language of the document using the xml:lang attribute (see Language tags in HTML and XML).
However, do not make the mistake of assuming that language declarations indicate directionality, or vice versa!
Even if a script subtag is used in the language attribute value, this has no implication with regards to the directionality of the
text in the user agent. You must always declare the direction using the dir attribute.
Visual ordering of Hebrew text was common in (very) old HTML user agents that didn't support the Unicode bidirectional
algorithm. Text was stored in the source code in the same order you would expect to see it displayed. (It was not so common for Arabic script text, because it messes up the way Arabic characters join together.)
With logical ordering, text is stored in memory in the order in which it would normally be typed (and
usually pronounced). The Unicode bidirectional algorithm is then applied by the browser to render the correct visual display. Nowadays almost all text on the Web is in logical order.
You should always type your right-to-left content in logical order, and rely on the bidirectional algorithm and markup to make it display correctly. If you don't, it won't be possible to search your text, re-use the text, easily maintain your content, etc.
Example
In the picture below, the phrase "פעילות הבינאום, W3C" (at the top in blue) appears as it would normally appear
when displayed in a right-to-left paragraph. The numbered arrows show the reading direction. You read the sequences in the order of the numbers.
Logical and visual storage order contrasted.
The 2nd line shows the order of characters in memory in logical encoding order (assuming that the first character in memory is on the
left, the next to its right, and so on).
The 3rd line shows the order of characters in memory in visual encoding order (with the same assumptions
about order in memory).
Having established the base direction at the level of the svg element, you should not use the direction property on other elements unless you want to change the base direction for that element.
Unnecessary use of the direction property impacts bandwidth and potentially creates unnecessary additional work for
page maintenance.
The base direction that is established by the direction property does, however, affect the way mixed language text and punctuation is ordered within a text or textArea element (this will be described in detail a little further on). From time to time you may want to change the base direction for one of these elements, if it is in a different language that the rest of the page.
To do so, simply use the direction property on that element, or on a grouping element that surrounds the relevant content.
Example: Changing the direction of a block element. [live code]
In this example, we use a grouping element around several text elements that need a base direction of left-to-right to look correct. Using a grouping element reduces the amount of work we have to do to achieve the desired result. The direction set is inherited by the enclosed text elements.
The text-align property is used with the textArea element, and its values are start, middle and end. It is important to remember that the first and last of these values relate to the text in a logical, rather than physical way.
start means the place where you would normally begin reading a line given the current base direction. When the base direction is left-to-right, that means to the left of the textArea element. If, on the other hand, the base direction is right-to-left, it means the right side of the textArea element.
For end, just reverse that.
This is intuitive if you have been using CSS with HTML, since the direction property in CSS automatically right-aligns text in a block element.
Example: text-align set to start for RTL text. [live code]
In this Urdu example the right-to-left direction that is set on the svg element is inherited by the textArea element.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="ur">
<title>...</title>
<desc>...</desc>
<textArea x="20" y="20" width="200">
فعالیت بینالمللیسازی، W3Cنا
عالمگیر ویب کو حقیقی طور پر عالمگیر بنانا
</textArea>
</svg>
On display, the text should look right-aligned within the textArea box, as shown below, since the default value of text-align is start, which for a right-to-left base direction means right-aligned.
The text-anchor property is used with the text element, and its values are also start, middle and end. Again, the first and last of these values relate to the text in a logical, rather than physical way.
If you have not specified any base direction, or you have specified direction="ltr", and if text-anchor is set to start, text will extend to the right of the x coordinate. If you have set direction="rtl", then text will extend to the left of the x coordinate. By default text-anchor is set to start.
For end, the opposite is true.
Example: Text-anchor in different text with different base directions. [live code]
In this English/Arabic example, we use two text elements, both with the same x coordinate, and both using the default value for text-anchor.
Although the x coordinate for both text elements is the same, this will display the text something like this:
You should bear in mind that the direction in which the text extends away from the x point (see the previous example) depends on the base direction, ie. the value of the direction property, and not on whether you are dealing with Latin or Arabic (or Hebrew) text. This is important.
It means that, for example, a list of terms containing both Latin and Middle Eastern words does not unexpectedly misalign the items.
Example: Script is not significant for text-align. [live code]
The following example contains alternating lines in Hebrew and Latin script:
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="he">
<title>...</title>
<desc>...</desc>
<text x="200" y="20"
font-size="10">W3C ,פעילות הבינאום</text>
<text x="200" y="30" xml:lang="en"
font-size="7">(Internationalization Activity, W3C)</text>
<text x="200" y="50"
font-size="10">ליצור מהרשת רשת כלל עולמית באמת</text>
<text x="200" y="60" xml:lang="en"
font-size="7">(Making the World Wide Web worldwide)</text>
</svg>
All the items in the address list will still appear right-aligned. We don't need to do anything special to the Latin-only lines so that they line up with the rest:
What you do need to remember, however, is that if you, for some reason, apply direction="ltr" for one of the text elements, you need to also specify text-anchor="end" for that item, so that it will continue to line up with the others.
In earlier sections we have mentioned that occasionally it is not sufficient to just add direction information to the svg tag. In this section we will look at why and when more control is required, and in particular we'll look at how to mark up tspan elements for direction (for which we need to introduce the unicode-bidi property).
The result of applying the bidirectional algorithm depends on the overall base direction of the
phrase, paragraph, block or page in which it is applied. The base direction establishes a directional context which the bidi algorithm refers to at various points to decide how to handle the text.
The base direction is either set explicitly by the nearest parent element that uses the direction property, or, in the absence of such a parent, it is inherited from the default directionality of the svg tag, which is left-to-right.
Note that for block elements a base direction of right-to-left can only be set by using the direction property.
We already know that a sequence of Latin characters is rendered (ie. displayed) one after the other from left to right (we can see
that on this page). On the other hand, the bidi algorithm will render a sequence of strongly typed RTL (right-to-left) characters one after the other
from right to left.
This is independent of the current base direction, and works because each character in Unicode has an associated directional property. Most letters are strongly
typed as LTR. Letters from right-to-left scripts are strongly typed as RTL.
When text with different directionality is mixed inline, the bidi algorithm renders each sequence of characters with the same
directionality as a separate directional run.
So in the following example there are three directional runs:
Directional runs.
Another way of looking at this is that changes in direction mark the boundaries of directional runs. Note that you don't need
any markup or styling to make this happen.
It is particularly important to understand that order in which directional runs are displayed across the page depends on the prevailing base direction.
The words on the picture below are separate directional runs. The top line is in a context where the base direction is LTR; the bottom, RTL. The characters in both lines in the picture are stored in memory in exactly the same
order, but the visual ordering of the directional runs, when displayed, is reversed.
The effect of base direction on display of directional runs.
Spaces and punctuation are not strongly typed as either LTR or RTL in Unicode, because they may be used in either type of script.
They are therefore classed as neutral.
This is where things begin to get interesting. When the bidi algorithm encounters characters with neutral directional properties (such
as spaces and punctuation) it works out how to handle them by looking at the surrounding characters.
A neutral character between two strongly typed characters with the same directional type will also assume that directionality. So a neutral character between two strongly typed RTL characters will be treated as a RTL character itself, and will have the effect of
extending the directional run. This is why the three arabic words in this LTR phrase (separated only by spaces, which have neutral directionality)
are read from right to left as a single directional run. (The first Arabic word you read is مفتاح then معايير then الويب.)
Neutral characters as part of the directional run.
Note that you still don't need any markup or styling for this. And that there are still only three directional runs here.
The really interesting part comes when a space or punctuation falls between two strongly typed characters with different
directionality, ie. at the boundary between directional runs. In such a case the neutral character, or characters, will be treated as if they have the directionality of the base direction.
Even if there are several neutral characters between the two different strongly typed characters, they will all be treated in the same
way.
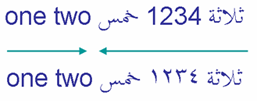
Numbers in RTL scripts run left-to-right within the right-to-left flow, but they are handled a little differently than words by the
bidi algorithm. They are said to have weak directionality. The two examples in the picture illustrate this
difference.
Digits.
The first example uses European digits, '1234', the second expresses the same number using Arabic-Indic digits, ١٢٣٤. In
both cases, the digits in the number are read left-to-right.
Because it is weakly typed, the number is seen as part of the Arabic text, so the two Arabic words that surround the number are
treated as part of the same directional run – even though the sequence of digits runs LTR on screen.
Note also that, alongside a number, certain otherwise neutral characters, such as currency symbols, will be treated as part of the
number rather than a neutral.
The bidi algorithm will handle text perfectly well in most situations, and typically no special markup or other device is needed other
than to set the overall direction for the document. You would be very lucky, however, if you got off that easily all the time. Here is our first
example of a situation where the bidirectional algorithm needs a little help.
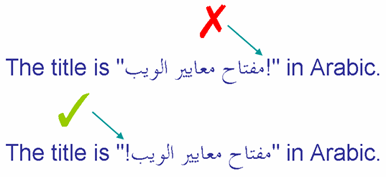
The first line on this picture shows an exclamation mark, that is part of the embedded Arabic text, appearing in the wrong place. The
second line shows the desired result.
Neutrals between directional runs may end up where they shouldn't.
Given our earlier discussion of the bidi algorithm, we can easily understand why this happened. Because the exclamation mark was typed in
between the last RTL letter 'ب' (on the left) and the LTR letter 'i' (of the word 'in') its directionality is determined by the base direction of
the paragraph (here LTR). Note that it makes no difference that there are actually two punctuation characters and a space in this position - they are
all neutrals and so are all affected the same way. Because the exclamation mark is seen as LTR it joins the directional run that includes the text
'in Arabic'.
So how do we get the punctuation in the right place?
One answer is to put the Arabic
quotation in a tspan element and use the direction property to change the base direction within the tspan to RTL.
Unlike the container elements we looked at before, tspan requires you to specify the unicode-bidi property, as well as the direction property, in order for the change in base direction to be effective. The value you need is embed. (We will look at the use of bidi-override later.)
<text>The title is "<tspan direction="rtl" unicode-bidi="embed" xml:lang="ar"> ... !</tspan>" in
Arabic.</text>
The editing environment you use may not show the exclamation mark in the right place in the code source, but it should look right when displayed.
Note carefully how the span tag falls inside the quote marks - the quotes are part of the surrounding English text.
Another possibility would be to type an invisible, strongly-typed RTL character after the exclamation mark. That way the
exclamation mark would be interpreted as RTL and join the Arabic directional run.
It just so happens that there is such a character - the Unicode character U+200F, called the RIGHT-TO-LEFT MARK (RLM). There is a
similar character, U+200E, called the LEFT-TO-RIGHT MARK (LRM). Because the character is invisible you may prefer to actually type in a numeric character reference (‏)
Adding this character just after the exclamation mark will produce the desired result.
<text>The title is "... !‏" in
Arabic.</text>
If there is already markup around the quotation, it probably makes sense to just use direction on that, rather than the control character. Otherwise it may be easier to use the control character.
The top line of the following picture shows what would happen to a list of RTL items within a LTR sentence if we relied solely on the
bidirectional algorithm (ie. if we didn't use the direction property to establish the base direction). In our example the list order is incorrect because the first two Arabic words should be reversed and the intervening comma,
which is part of the English text, should appear immediately to the right of the first word.
The second line in the picture shows the desired result.
Neutrals between same direction text may be inappropriately interpreted as part of a single
run.
The reason for the failure is that, with a strongly typed right-to-left (RTL) character on either side, the bidirectional algorithm
sees the neutral comma* as part of the Arabic text. It is interpreting the first two arabic words and the comma as a list in Arabic. In fact the comma
is part of the English text, and should mark the boundary of two directional runs in Arabic.
Actually the space adjacent to the comma is also a neutral character, and is treated in the same way as the comma, although we only mention the comma in the text for the sake of simplifying the explanation.
In the previous section the neutral character thought it was part of the directional context established by the base direction, but wasn't; in this section the
neutral character thinks it is part of the directional run, when it is really part of the overall directional context.
A simple solution is to use another invisible Unicode character, this time the LEFT-TO-RIGHT MARK, next to the comma. This puts our
neutral punctuation between strongly typed RTL and LTR characters and forces it to take on the directionality of the base direction, which is the
left-to-right of the English text. This breaks the Arabic words into two separate directional runs, which are ordered LTR in accordance with the prevailing direction
of the paragraph.
<text>The names of these states in Arabic are ...,‎ ... and ... respectively.</text>
Again, you may prefer to use an NCR (‎) for the sake of visibility.
The next picture shows another example where markup is not necessary, and a Unicode control character does the job much more simply.
Again, the top blue line in the picture shows the result of relying solely on the bidirectional algorithm, and the second line shows the desired
result.
The desired result was achieved by placing ‏ alongside the parenthesis that was supposed to be part of the Hebrew context, but
which appears between two spans of Latin text. The effect of the RLM mark is to break the Latin text into three separate directional runs, which are
ordered according to the RTL base direction.
Another example of the use of RLM or LRM, this time in a Hebrew context.
You may have noticed that, in addition to changing position, one of the parentheses in the previous example actually changed shape,
too. This was completely automatic, and happens because these characters are what are known as mirrored characters in
Unicode.
Mirrored characters are usually pairs of characters, such as parentheses, brackets, and the like, whose shape when displayed is dependent upon whether it is part of a LTR or RTL context. You do not have
to change the character for the shape to change. The ends of an opening parenthesis always face in the direction of the text flow. In the picture below, the parenthesis circled in red faces to the right in the top line because it is being treated as the opening parenthesis of some Latin text. In the lower version of the text, the same character (again circled in red) is treated as a opening parenthesis related to the Hebrew text (ie. the expanded name follows the acronym in reading order), and therefore faces the other way.
Mirrored characters.
This means that, whether the stored content is in Arabic/Hebrew or Latin script, you would use the same LEFT
PARENTHESIS character at the beginning of the parenthesized text. In other words, treat mirrored characters as if any word left in the name meant 'opening', and right meant 'closing'.
The Unicode bidi algorithm and the LRM/RLM marks work quite well when there is only a single level of mixed text. If you have a
situation where there are two or more nested levels of directional text you will need a different solution. This picture shows a Latin sentence that
contains a Hebrew quote which, in turn, contains both Hebrew and Latin text ('W3C').
The order of the two Hebrew words is correct, but the text 'W3C' should appear on the left hand side of the quotation and the comma
should appear between the Hebrew text and 'W3C'.
Achieving the desired display by using markup to open up a new embedding level.
The problem arises because the directional flows are being ordered according to the LTR base direction of the paragraph. Inside the Hebrew
quotation, however, the correct default ordering should be RTL.
To resolve this problem we need to open a new embedding level. To do this you need to wrap the quotation with a tspan element and assign it a directionality of RTL using the direction and unicode-bidi properties.
<text>The title says "<tspan direction="rtl" unicode-bidi="embed"> ... </tspan>" in Hebrew.</text>
There are also Unicode control characters you could use to achieve the same result, but because they establish a base direction for a range of text with invisible
boundaries this is not recommended.
In summary, whereas you just use the direction property on container elements such as svg, g, text and textArea, you need to use both direction and unicode-bidi="embed" on tspan elements, since they are inline.
The other useful value of unicode-bidi is bidi-override. You will not need to use that very often. It is described in the next section.
There may be occasions where you don't want the bidi algorithm to do its reordering work at all. In these cases you need some additional
markup to surround the text you want left unordered.
In SVG this is achieved using the bidi-override value of the unicode-bidi property along with the direction property. Again, there are Unicode control characters you could
use to achieve the same result, but because they create states with invisible boundaries this is not recommended.
An example of text where you want to override the bidirectional algorithm.
The example in the picture shows Hebrew text as ordered in memory. You can use the unicode-bidi property to achieve that effect, ie.
Unicode provides special, invisible formatting codes to build on or override the outcome of the bidirectional algorithm in plain text, in
the same way as the SVG markup described in this tutorial.
There are a number of control characters in Unicode that can be used to create the same effect as markup for inline bidirectional text. These
are listed in the following table:
There are, however, some situations where Unicode control characters provide the only means to express directionality. This is the case for plain text elements such as title and desc. These element are defined to support only characters, no markup. It is therefore not
possible to use the direction or unicode-bidi properties on a part of the element content.
Attribute text, too, cannot be marked up for directionality, so Unicode control characters have to be used to indicate
directionality.
Note that other things, such as language, cannot be marked up for parts of plain text content or attribute values either.
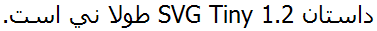
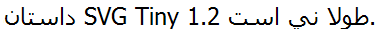

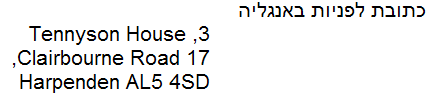













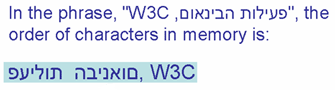
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}