
The work funded by DARPA and done by MIT and W3C under DAML project between 2002 and 2005 provided key steps in the research in the Semantic Web technology, and also played an essential role in delivering the technology to industry and government in the form of open W3C standards. The chief products of research was the development of the SWELL logic language, instantiated as the Notation3 language; the experience of its use, and of the software tools such as cwm developed around it. These tools, released as open source, have formed an on-ramp for many newcomers to the semantic web technology. Despite these successes, the semantic web has a long way to go, both in terms of research of the higher layers and deployment. The report discusses factors which may have affected deployment speed, and concludes with an outline of ongoing effort which would be appropriate.
The DAML project was an important effort by DARPA driving an early step in the development of the Semantic Web. Specifically, in the much-quoted 'layer cake' roadmap,
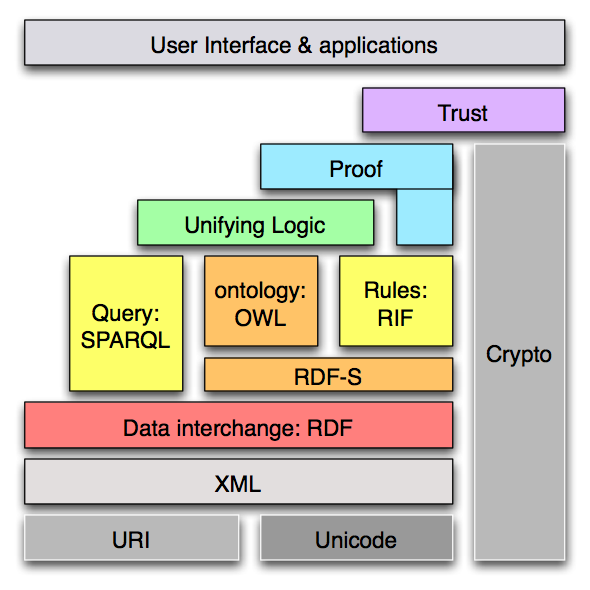
the step is the development from research project to common widely shared standard of the Web Ontology Language, initially referred to as the DARPA Agent Markup Language. The roadmap calls for languages of various levels of expressivity to be developed in such a way that information expressed in these various languages can be shared, and can express things about the same unbounded set of things and concepts. This sharing is enabled by using the global URI address space to refer to all things and concepts.
During the project's lifespan, different layers of the cake required different levels of work. The XML, URI, Unicode and RDF layers were all already well established standards. The DAML/OWL layer had been the subject of many research projects in the US and Europe, and the task addressed was to come to a clear understanding of the types of logic involved, and bring it to the level of a common standard. Meanwhile, the higher layers such as rule and query languages were the subject of research but also wide deployment of non-standard languages which were not yet deemed ready for standardization. The layers such as proof exchange and policy-aware and transparent accountable systems ("trust") continued to exist only at the research level.
The project described here involved participation in test activities as appropriate levels. A software platform was developed as a workbench for research, as a test implementation of standards, and as a openly available (open source) toolkit to promote the technology by making an easy on-ramp for developers new to the field. Also, various test scenarios were implemented to test that the concepts of integration of data between diverse applications were in fact practical. These tests were typically based either on the personal information management space, or on the enterprise automation space, using the W3C itself as the test enterprise.
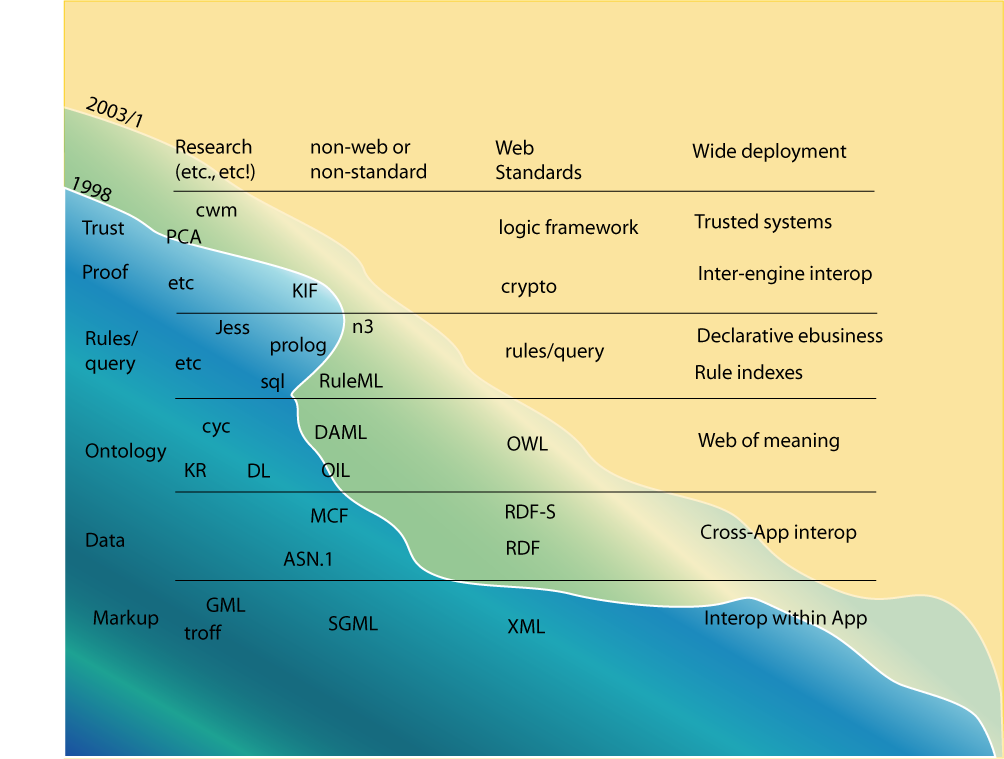
The eventual success criteria for the project, indeed for the DAML work as a whole, will be in the long term a strong wide and generally adopted semantic web technology which provides humanity with the ability to reuse data and logical information in an unprecedented way. Only in perhaps a decade will be able to judge this transition retrospectively, but we can at this stake (2006) note that the roadmap has indeed been followed, with new layers moving from research to standardization every few years. Some of the factors affecting this speed are discussed below.
At the immediate scale, the success criteria can be judged in terms of the development of the software as outlined in the proposal, and the creation of languages, such as the Semantic Web Logic Language (SWeLL), also described in the proposal. This software and the languages developed are inextricably interconnected in terms of mutual influence. In this report we take the arbitrary choice of discussing the languages first, then the software platform.
Introduction
The proposal called for the development of a suitable logic language for use on an open and unbounded semantic web. This language, described as SWeLL in the proposal, was actually delivered as a language now known as Notation 3.
This is a language which is a compact and readable alternative to RDF's XML syntax, but also is extended to allow greater expressiveness. It has subsets, one of which is RDF 1.0 equivalent, and one of which is RDF plus a form of RDF rules.
N3 is described in more detail elsewhere, and so here we give only an overview of its role in the project and in the goals of semantic web development. The N3 home page is a general introduction and a center for other resources. The developer learning N3 is invited to try the A tutorial, while implementers looking for for a particular detail of the definition of the logic are steered toward the operational semantics. There is also a list of other N3 resources.
The aims of the language were:
The language achieves these with the following features:
The following needs were seen initially as driving the devlopment of the system, as a result of its being intended for communication between agents whose only shared context is an unbounded web of information. We design the system such that all data sources are considered as having a (possibly empty) N3 semantics: that is, for each resource on the web there is an N3 formula which expresses at least a subset of the intent of the publisher of that resource.
On the web, it is of course quite unreasonable to belive anything one reads. So it is on the semantic web; an agent may read many things, but in general it is aware always of the provenance of data. We starting the project convinced that the many systems which roughly divide agents or data into "trusted" and "untrusted", or gradations thereof, we fundamentally naive. In practice, we demanded the ability to trust a certain source for statements of a certain form only under certain conditions, or even to deduce a separate fact from the presence of difference on in a specific source. (e.g. "If MIT says x is a student then x is a human being")
The systems we build are designed to operate in an open unbounded web of data, and logic. At no time does any agent in such an environment ever consider that it knows everything which anything has said about everything. Therefore the Closed World Assumption (CWA) in which a system is allowed to assume something is false if it not manifestly true from the given data, becomes quite unusable as it stands. Any such assumption, if it is to be shared with other agents, can only be shared if the actual scope of the data involved in the assumption is well defined.
The Web is seen, from the point of view of an agent processing N3, as a function which maps a URI into its N3 semantics, that is, an RDF graph or rather in general, an N3 formula. It is clearly necessary to make this function available for use in rules and information processing in general.
The success of N3 as a result of the DAML project can be judged as follows:
We now consider the requirements of operation in a semantic web context are met.
This requirement forced the extension of RDF to N3 so as to include quoted
graphs within a graph. These are known as N3 formulae. The
log:includes function expresses the constraint that one formula
includes (strictly, N3-entails) another.
To meet this requirement, there is no CWA form of negation. The only
negations available are that the built-in operators have negative forms.
Importantly, this includes the log:includes operator which has a
negative form log:notIncludes. This allows one to make a
condition that something has not been said by a given source. For example,
"If the order form gives no color, the color is black". This is the open
non-CWA form of the unacceptable: "If there is no color then the color is
black".
The web function is given the uri log:semantics. The software
platform evaluates it in real time.
Also, the cwm system can operate in modes such that when a symbol occurs during processing, it will be dereferenced on the web so that any published information about the symbol may be loaded. This is described more fully below.
The N3 design allows logical operators to be introduced simply as new properties, just as RDF allows new languages (effectively) to be designed just by the introduction of new RDF Properties. While the logical operators may then be simply regarded as an ontology for logic, in fact the language equipped with these operations becomes, effectively, a logic language, which we refer to as N3 logic.
Cwm (pronounced coom) is a general-purpose data processor for the semantic web, somewhat like sed, awk, etc. for text files or XSLT for XML. It is a forward chaining reasoner which can be used for querying, checking, transforming and filtering information. Its core language is RDF, extended to include rules, and it uses RDF/XML or RDF/N3 (see Notation3 Primer) serializations as required. Cwm is written in python. Like all the code developed in this project, it is released under an open source license, the W3C Software License.
The CWM platform is a general purpose semantic web development platform written in Python. It has been used as a library with a python API , but is chief goal was to serve as a general purpose data manipulation tool for semantic web languages, just as sed, awk and grep served as basic data manipulation tools in a unix line-oriented environment. It is also designed as a proof of concept, and a platform for proofs of new and varied concepts. To this end, the emphasis was on extensibility, and not on optimization for speed. The result has been that some projects have been started which conveniently used cwm, but which took longer and longer to run as the data sizes grew. This has lead to pressure to produce cwm-compatible systems which run faster, and we would note that work is in progress to integrate the rete-based pychinko reasoner with the cwm code itself.
The software module high-level structure is shown below.
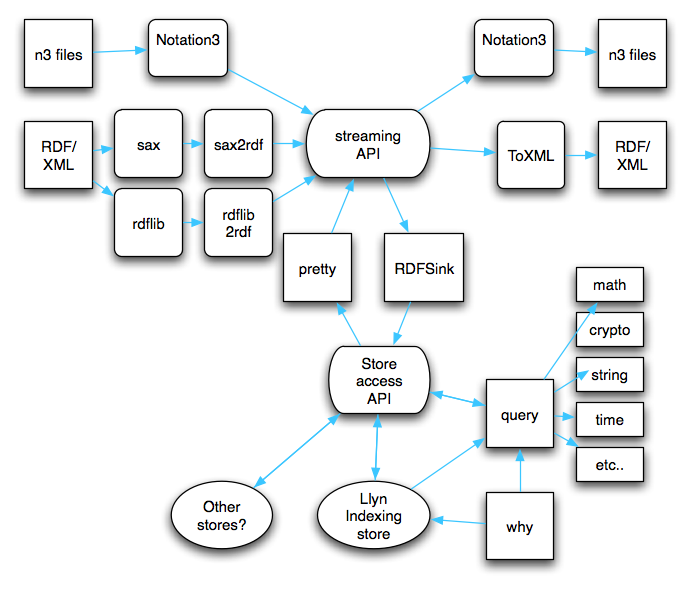
The N3 and RDF languages are grammatically similar, to the extent that it is possible to translate one into the other in a streaming mode. The efficiencies evident from this mode of operation led to a design of an abstract syntax interface which parsers and serializers supported. This is still in use, but experience was that as the N3 language became more sophisticated, the streaming interface became more burdensome to support as an output format for the serialization module.
The store (llyn.py) is a triple store, extended to cover the full N3 language, and also to record the provenance of each statement. A statement therefore is stored as the subject, predicate and object of RDF, plus the 'context' the identity of the formula in which the statement is, and a record of the reason object which stores the reason for the statement having been added to the store.
The store was originally designed and built with four indices, so that list was kept of each statement in which a given term occurred as, respectively, the subject, predicate, object or context. When there was a need to improve performance, this was changed so than now 7 indexes are used, as every combination of subject , predicate, object pattern with wildcards are indexed. This of course increases the time to load the store, and it is questionable whether the improvement in access is worth the effort of indexing. A design goal was to make the store module switchable so that tasks with specific profiles could use the most efficient form of store, but this was not given priority.
The inference engine is at heart a simple forward chaining reasoner for rules. A rule is stored as a statement whose predicate is log:implies. in the form
{ ?x parent ?y. ?y sister ?z } log:implies { ?x aunt ?z }.
The matching engine which runs the rules operates simply by recursive search, with some optimizations. Firstly, the rule set is analyzed to determine which rules can possible affect the output of which other rules. A partial ordering is found, which for example in some cases will produce a pipeline. Otherwise, where rules can interact, they are tried repeatedly until no further rule firings occur. The second optimization is that, when matching a graph template, which is a series of template statements, the statements are ordered for processing as a function of the length of the index which would have to be searched, doing the smallest indexes first. This provides a significant improvement in many real-world examples where the data is very asymmetrical, in that some areas of the graph are dense and tabular in form, and others sparsely connected.
The inference engine also performs two extensions to its normal role, these being the execution of built-in functions, and the delegation of parts of the query to remote systems or remote documents.
Cwm uses rdf collections extensively, and puts a stronger interpretation than RDF, so that they can be used as triples. The cwm system assumes:
Lists work, therefore, as a compound data type. (Formula is another compound data type). They can contain variables. They are used, among other things, as argument lists for Nary functions, for example:
( 1 2 ) math:sum 3.
Cwm does not use the rdf concepts of bag, and sequence. These were found to be awkward in that their reification as RDF uses an infinite set of properties such as rdf:_1, rdf:2, etc.; and deficient in that there is no record of number of members of the bag.
There is some support for sets. We belive that distinguishing between ordered lists and unordered sets is in general going to be very important for data on the semantic web. Too often, XML documents leave the question of whether the order of data is important as implicit and not always understood. Too often, in N3, we are tempted to use a list because of its simple LISP-like syntax, when in fact we are describing an unordered set. However, operations on unordered and ordered sets are quite different. We use owl:oneOf to create a set as the class which has just the members of a list as members. (This form of set is used for the reification of N3, when describing the sets of variables and statements associated with a formula.)
Many reasoning engines have an ability to perform arithmetic, but arithmetic facts are separated out from the facts of the knowledge base as being fundamentally different things. In cwm, this is not the case: arithmetic facts, as with all other facts where the validity can be checked or the result evaluated by machine, are represented as RDF properties. This is done for various reasons. Philosophically, the design was not prepared to commit to a partitioning of knowledge into two parts in this fashion. It was felt necessary to be able to reason about these functions as well as to evaluate them. We understand that this causes problems for a Description Logic based systems, but this is not a DL system. It was also done for architectural simplicity. Making this simple decision allows all the language support for RDF and N3 to be immediately adopted for the arithmetic expressions; the store can store them, the serializer can output them and so on. Contrast this with the situation in for example the SPARQL language, in which a special place in the query expression is reserved for filter expressions, and a whole separate syntax is supported for it.
Within the reasoner, built-in functions are made part of the query. During query optimization, light builtins (such as negation of an integer) are assumed to be faster than searching the store, and are performed the moment they can be, while heavy builtins, such as accessing the Web, making a remote query, or recursively invoking the reasoner itself, are assumed to take a long time, and are postponed until anything faster, including searching the local store, as been done.
Nary functions are implemented using lists, as mentioned above. This was found to be very satisfactory.
The cwm system can operate in modes such that when a symbol occurs during processing, it will be dereferenced on the web so that any published information about the symbol may be loaded.
These may in the software be enabled individually. They operate recursively. The first form, looking up predicates, creates what we call the Ontological Closure of a graph. It is the case in practice that the ontological closure of documents is finite, and contains useful information.
The second and third forms are in general not guaranteed to terminate except within a deliberately designed dataset with no links to the public Semantic Web in general. They were not found to be very useful.
The fourth, fifth and sixth modes quickly look up new variables as they occur in query processing and do not suffer from the tendency to bring in the entire web. A query is evaluated by matching a graph template to the graph of data which can be found on the web. If each node in the graph has useful and relevant information associated with it, and that information is loaded by the query engine when the node is first mentioned, then it is possible for the query to successively bring in documents which together form the parts of a large graph as it is needed.
These modes of operation, and ones like them, are, we belive, important to the development of the semantic web. Future research should be directed toward protocols which involve conventions for the sort of information which is published against the URIs used as symbols for arbitrary things in the semantic web.
There are times when a particular document on the web contains all cases of a particular relation. For example, the relationship between a US state and its two letter code exists in 50 cases. Another document might for example store a definitive list of the MIT course numbers.
In this case, queries involving these properties become self-answering according to the following protocol. The query processor looks up the ontology for the property when it find it in a query. The ontology file mentions that there is a definitive document for the property, with a statement like, for example:
state:code log:definitiveDocument <stateCodes.rdf>.
The client then converts any query or query part of the form ?s
state:code ?y into a query on that document.
The modes mentioned above allow cwm to pick up data while it is processing
a query, by loading RDF or N3 documents. We were also interested in
applications in which large quantities of existing data were in live SQL
databases. The cwm query engine has the ability to pick up metadata from the
schemas (the ontological closure above) which directs it, for certain
specific Properties, to convert that part of the query into an SQL query.
This is done by making the assertion that the property has a
log:definitiveService whose URI is a made up form of mySQL URI
which carries the information on how to access the data.
The implementation is a proof of concept only: it operates only with mySQL databases. We would recommend that, now (2006) that SPARQL will soon be available as a standard, that future designs implement this functionality by converting the query into SPARQL. In this way, systems of federated SPARQL servers should be set up. This is a very interesting direction for future research, specifically the protocols for defining the conditions under which a given server should be contacted for a given form of query.
A practical need in semantic web systems is for human readable output, most typically for web-based use as either xHTML for text documents, or SVG for diagrams. A simple hook was added to cwm to allow report generation using rules, as follows:
The rules generate statements of the form
?k log:outputString ?s.
where ?k is a key giving the ordering of the output, and
?s is a string, typically a fragment of XML source. The rules
are then run in a cwm session which uses the --strings argument to select
string output rather than N3 or RDF serialization.
Another sometimes very effective way of presenting relatively small amounts of interconnected data is as a graph. The ATT GraphViz open source program automatically draws graphs. We developed a small ontology equivalent to the GraphViz input format, so that N3 rules could be used to generate graphs, including a style ontology to define the mapping between classes of object and the color and shape of displayed nodes. At least one hardened XML opinion leader was converted to the RDF world just by ability to display such graphs.
The original proposal mentions the devlopment of tools:
The first goal was effectively met by the fact that N3 was designed as a very easily writable language. In almost all cases the data needed, as well as the rules, were simply authored by hand in N3. In addition to this, we put significant effort into the conversion of non-RDF data into RDF. This was important from the point of view of feasibility of deployment of semantic web systems on top of existing data, so experience over a wide range of formats is important. It also encouraged various communities to start using RDF technology. This work is elaborated on below.
The proof generation facility is an integral part of the CWM software. For a cwm command line which would have produced a given result, adding --why to the command line produces instead a proof of that result.
A separate program, check.py, is used to validate a proof. The intention was for check.py to share as little code with the proof generator as possible, but the built-in functions and the unification algorithm were not worth coding independently.
The access control scenario was modelled, although it was not installed on the live W3C web site. The access control scenario implemented was one using delegated authority implemented using publick key cryptography. This drove the development of cryptographic builtin functions.
The use of RDF to define definitions of policies around the use of code is something enabled by the cwm functionality. During the period of the DAML project we did not develop these areas as far as we would have liked. However, we are, under future funding (Policy Aware Web (PAW) and Transparent Accountable Datamining Initiative (TAMI)), implementing these ideas much more fully.
DAML and OIL languages were developed during this time, in the United States and Europe respectively, and the results transferred to the W3C to form the Web Ontology Language (OWL). This was the major thrust of the program, and the transfer and successful development of the language at W3C into a global common interoperable standard for government, academia and industry may be considered be the princple claim to success of the DAML program.
We participated actively in all stages, in the design of the language (both in the ad hoc joint committee and the later W3C working group) and in the coordination and oversight of the process of building consensus around the new langauge at W3C. The commendable vision and leadership of the DARPA program managers, particularly the inital P.M., Prof. J. Hendler, provided that the effort would be sufficiently resourced through these stages without loss of momentum.
OWL becaome a W3C Recommendation on 10 February 2004.
The N3 language developed by this project demonstrated the power of rule-based systems in processing semantic web data. It also demonstrated that, when expressed in a suitably architected semantic web language, rules themselves could have the same ability to be shared as data has when expressed in RDF.
The status of rule languages at the time was that a group of those interested had already worked for several years on RuleML, a common but non-standard interchange language. The project provided effort in analysis of the state of development and the relationships of various products, and, through meetings and a W3C workshop, the bringing together of academics from the DAML community among others, and industrial rule-based system providers. This has resulted in the chartering of a working group aiming to produce a standard language which will meet th e requirements of all the players. This is a challenging task, perhaps even more challenging than the OWL development, but we are optimistic. We note, however, the absence of ongoing DARPA support comparable to that of the OWL work.
The semantic web we design is very declarative in nature, and a natural choice of implementation language would appear to be prolog. The SemWalker tool is a implementation in prolog of the basic RDF library functionality, including parsers, store, and query. SemWalker was created in order to provide a general user interface platform for directly browsing semantic web data.
The SemWalker platform was used to create a web-based portal for viewing ontologies, known as Ontaria. The system included prolog-based semantic web crawler and indexer.
SemWalker is a toolkit for building browsers for Semantic Web data. SemWalker includes a data store and an RDF/OWL harvester. It is intended to run as a server-side application and implements user interfaces via HTML so that users use common Web browsers to connect to SemWalker applications. SemWalker has some preliminary work to support specialized views of objects based on their (RDF) Class.
Ontaria is a searchable and browsable directory of OWL ontologies built on SemWalker. The focus of Ontaria is on people who are creating RDF content and wish to find existing vocabularies they can use. The views implemented in Ontaria are customized for the purpose of browsing OWL ontologies.
The results of the SemWalker work provided insight into human interface issues for generic semantic web browsers, and indeed the architecture SemWalker used, of generic browsing with specific more crafted views available for special cases is the basis of later work on browsers such as PiggyBank and Isaviz which are driven by the embryonic Fresnel language, and by our own later Tabulator browser.
Development of the Semwalker prolog-based platform was discontinued, partly due to lack of a community of prolog users who would benefit from the open source code, but mainly in order to prioritize work on a standard rule language.
The Haystack project has been focusing on the development of general purpose user interfaces for arbitrary semantic web data. Any individual may contribute new types of information to the semantic web, and it will be difficult, if not impossible, for application developers to produce visualizations for all those new information type, especially given the many different uses to which individuals may wish to put the information they have gathered from multiple semantic web sources. Therefore, we have begun developing frameworks to let end users of semantic web information specify appropriate visualizations, and more generally to create their own information management applications over the semantic web, choosing precisely which information objects they want to work with and how they want to view and manipulate those objects. Such “end user application development” would let end users create workspaces designed specifically to solve their specific information management problems. Our approach combines three elements:
We have implemented our system as part of the Haystack information management platform. This tool provides a set of cooperating technologies and tools supporting end-user creation, visualization and manipulation of Semantic Web content, as well as application development for the Semantic Web
Annotea was an experiment in shared, collaborative annotations of Web documents using RDF. It provides a basic metadata query protocol for asking multiple servers for metadata about a named resource. In the case of Annotea the named resource is a Web document and the expected metadata is RDF describing annotations concerning that document. The user interface to Annotea was integrated into the W3C Amaya editor/browser. The form of annotation RDF data supported by the Amaya interface is HTML text with pointers to specific segments of the annotated document. Annotea annotations are stored externally to the annotated documents; write access to the documents is neither necessary nor expected.
The Annotea metadata query protocol is tuned to allow clients to issue a simple HTTP request to the metadata server to request the known metadata about a given Web document. In conjunction with Annotea we designed and implemented the Algae query language and persistent RDF database to be a general-purpose query language for RDF. Underlying the simple access protocol of Annotea, the Algae system provides s full-function data store and triple pattern-matching query interface. The Algae work was important input to the W3C Data Access Working Group and was incorporated into the W3C standard SPARQL Semantic Web query language for RDF.
The World Wide Web Consortium is an industry consortium with 400 member organizations (vendors, research organizations, and end-user organizations) participating in 38 working groups. These working groups publish their formal output as W3C Technical Reports. Regular news bulletins and periodic reports to the Membership inform the Members of the status of the work in each group. The formal workflow of the Consortium lends itself nicely to be a testbed for Semantic Web deployment.
W3C At A Glance was an early aggregator of information in RSS/RDF form from various parts of the W3C, presenting a view of related information using a hierarchical structure gleaned from the data. A novel feature of At A Glance was its integration with the RDF-based page access control system deployed on the W3C web site. Users of At A Glance are presented different aggregate views of the information based on their access rights to the original sources of the data. At A Glance was separately funded but the work was conducted in close collaboration with the DAML Semantic Web Development project.
The W3C Technical Reports index lists the formal work product of each W3C Working Group categorized by one of six "maturity levels". The maturity levels indicate the state of the work, from (first) working draft to adopted standard (called "W3C Recommendation"). The W3C Process defines the formal steps necessary for a document to advance in maturity level.
For many years the Technical Reports index had been maintained manually and the critical workflow data that it contained was not available in machine processable form. Checking the prerequisites for each maturity advancement was entirely manual. As part of a separately-funded workflow automation project, the W3C pages listing the Working Groups, their chartered time periods, their deliverables, and the Technical Reports index itself were all turned into authoritative sources of Semantic Web data by adding semantic markup to the existing HTML and using the following ontologies:
Data extraction tools were then written to allow cwm to check some of the dependencies and prerequisites at the time a new document is proposed for publication. The W3C Technical Reports index is now built automatically by cwm and is available to users in multiple views as well as in machine-processable RDF form, allowing a variety of analyses to be performed.
W3C conducts all of its Working Group business by teleconference and simultaneous text chat (irc). The collaboration metadata around teleconferences are data that can be merged with other W3C enterprise data; the teleconference calendar is published as dynamic RDF data, as are data about in-progress teleconferences (active participants and agenda state). A Semantic Web-enabled agent, Zakim, was implemented which participates in the teleconference through the shared text chat. Zakim assists the meeting chairperson by reporting arriving and departing participants in real time, accepting requests for agenda items, and tracking 'hand raising' requests to address the meeting.
The Web integrated a variety of documentation systems so that now we can follow links from tutorial articles to reference documentation, across organizations, with one click. But for data, we are still pre-Web. Airline reservation systems are online, but when you book an itinerary, getting the data to your personal calendar application often involves manually copying each field across. We explored the use of Semantic Web techniques to address these problems.
| Topic | Format | Ontology | RDF Tools |
|---|---|---|---|
| Calendar | iCalendar (.ics) | RDF Calendar | toIcal.py, fromIcal.py |
| Handheld PDA | Danger OS XMLRPC | palmagent/danger | palmagent |
| PalmOS .db files | palm calendar, datebook | ||
| Handheld GPS | Garmin | fromGarmin.py | |
| Travel Itineraries | telex | various | grokTravItin.pl, cityLookup.n3, |
| Addressbook/Contact Information | vCard | swap/contact | mso2vcard.n3 |
| Personal Finance | OFX, QIF | swap/fin | qfx2n3.sed, qif2n3.py |
| Photo metadata | EXIF | jhead (as adapted) | |
| RFC822 | swap/email | mid_proxy.py, aboutMsg.py | |
| Software dependencies | makefile | make2n3.py | |
| dpkg | fink2n3.py |
The IETF proposed standard for calendar information is iCalendar (RFC 2445). It is supported by Apple's iCal and similar applications.
We developed
A number of collaborators joined in development of these tools. They are about as robust as other state-of-the-art iCalendar tools; that is: some issues around timezones and recurring events remain, but for most uses, they work well.
See
We explored import/export and synchronization of data from Palm OS devices and Danger Hiptop devices in the palmagent tools.
We developed fromGarmin.py, which combines with pygarmin to produce RDF data from a GPS device.
We developed grokTravItin.pl which converts data from SABRE telex format to RDF, as well as N3 rules to look up latitude, longitude, and timezones of airports, and used these in combination with calendar tools and PDA import tools. We used cwm's reporting features to write xearth files that can be used to visualize trips.
We presented this as part of our Semantic Web Tutorial Using N3 at WWW2003 and WWW2004.
We developed lookout.py, a tool demonstrating how to export Microsoft Outlook data to RDF/N3.
OFX is a format starting to be deployed by banking institutions to provide customer's data upon request. qfx2n3.sed is a demonstration of converting OFX (Open Financial Exchange) data to RDF. qif2n3.py is a demonstration of converting QIF (Quicken Interchange Format) data to RDF. These were combined with a transcription of the IRS 1040 rules into N3 for preparing taxes.
We also experimented with converting Quicken reports to RDF calendar and .ics formats via the hCalendar microformat.
Apple iTunes music data are stored in Apple OS/X Plist (property list) files (as are Safari bookmarks). We developed plist2rdf.xsl, which converts them to RDF.
We developed aboutMsg.py to convert email header data to RDF. We combined this with N3 rules for tracking cwm bugs as well as for tracking issues against the OWL and SPARQL specifications.
We also experimented with mid_proxy.py, which demonstrates an IMAP to HTTP gateway, with RDF support.
In Making a map of the photos, we adapted the jhead tool to produce RDF and combined the resulting data with GPS data to plot photos on a map.
Many of these tools were developed to address personal needs of the developers, who used the tools on the data from their personal lives. In only a few cases did we manage to publish anonymized data for others to use for demonstration and test purposes.
Toward the goal of promoting the wide availability of semantic web data, we developed a stand-alone program to export an existing SQL database as RDF data on the web. Known as dbview.py, this facility exports a series of interlinked RDF files, automatically generating URLs for all the objects (basically, rows) and properties (basically, columns) involved.
This facility was not given a lot of priority, being developed to the point that it demonstrated the feasibility of this technique. The hope was that database software vendors would adopt the idea, and provide their own products. There have indeed been several research projects such as D2RQ. , and suggestions more recently that include commercial implementations.
We hope to develop dbview further in future projects, as we conclude that there is still a strong need for simple paths from SQL data to the Semantic Web.
We look at the effects of the work in two parts, the specific deliverables of the project and the overall goal of the promotion and furtherance of the Semantic Web as a powerful deployed technology.
The semantic web technology is undergoing a steady uptake. A frequent question is why, when after 5 years the Web technology was, in 1995, well deployed and generally public understanding, after 5 years in 2006 the Semantic Web technology is not. There are several reasons which one might imagine would account for this.
The HTML language as initially proposed was extremely simple. There were no particular mathematical properties it had to have, compared to the languages of RDF, OWL, SPARQL and RIF in which choices had to made between logics, and the languages carefully checked for consistency and appropriate power. This has been much more complex.
The technology layer above OWL consists of query and rule languages. The roadmap we put forward involved waiting until the data language (RDF) and the ontology language for defining terms (OWL) were settled before work started on query and rules. This is partly because of dependencies, but also partly because of limited resources. However, we have for the last 5 years been doing the equivalent of developing relational databases without SQL. The query language, SPARQL, now in the final stages of standardization, is for many people a key to the usability of semantic web data. The SPARQL work has not benefitted from any US government funding.
Network systems such as the telephone, electronic mail, the Web and the Semantic Web are subject to Metcalfe's law, that the value of one component is strongly dependent on the number of other components. Such a system cannot get started until a critical mass of adopters have invested to populate a certain proportion of the system. DARPA's investment in the semantic web is an excellent example of this. The effort involved in getting, say, 10% of people to adopt a technology is much easier in a small community than a large one. The Web spread among High Energy Physicists, who were perfect early adopters: they had a major problem of disconnected information systems; they are bright, flexible people, and they already had the most advanced technology in terms of workstations and networking. For the last 5 years, the semantic web has not benefitted from this small incubator community. Now, however , it looks as though today's exciting leading edge scientific discipline, Life Science, is taking on that role, as judged from the deployment of ontologies and data, and the excitement at conferences and in interest groups. (It is possible that the defense industry may also be an early adopter, as it has strong needs, the ability and the resources, although the results of such work are often too sensitive to be available to inspire to those outside.)
For the hypertext WWW, a growth enabler was the immediate benefit to anyone putting up HTML pages was that they could see the web pages in any browser. For the last 5 years, the semantic Web has not really had a generic data browser. Certainly, there have been many browsers, but the powerful ones with an intuitive user interface have been specific to, and tailored for, applications [longwell, and CS AKTive] and the generic ones have typically had limited property-list or circle-and-arrow graph views not capable of seriously providing a powerful view of large amounts of data. MIT hoped to undergo future work based on Haystack and the new Tabulator project to make data immediately available in a compelling fashion, increasing the incentive to publish data, and also to allow early verification and correcting of obvious errors.
The development of the semantic web languages, particularly OWL, has been done under the architectural constraint that URIs are used for all global symbols. While this has indeed produced a language with the hoped-for qualities of supporting links between data and between ontologies, the custom in the community has been to develop project-wide data stores which are amassed from various sources, and then subjected to inference, query and visualization in situ. The result has been that the individual URIs are not supported in the sense that one can take one and look it up and get a reasonable set of data about the object.
Just as on the HTML web, it is important to get reasonable information on dereferencing a URI, it is also important with semantic web data. The actual value added by WWW or SW technology is the unexpected re-use of data. That can only occur if things are identified by URIs and these URIs are supported by servers serving appropriate data in RDF (and/or SPARQL query services).
In general, this analysis suggests that SW uptake will take place at a steady pace, but will be accelerated by funding in the areas of:
At this time it also seems appropriate to investigate the properties of the semantic webs we are planning to create on a large scale, both webs of interconnected data and web is rules from different rule sets.
The work described above was proposed by the W3C group of the Laboratory for Computer Science at MIT. Since that time, two organizational changes have take place. LCS merged with the Artificial Intelligence Laboratory at MIT to form a new combined Computer Science and Artificial Intelligence Laboratory, CSAIL (say "sea-sail"). Further, the need was felt to distinguish between the standards-level work done by W3C and the advanced research work. A new group was therefore created, the Decentralized Information Group (DIG) to investigate the and build systems which have web-like structures in general, including the WWW, the Semantic Web, and both technical and social aspects of decentralized systems one might envisage in the future.
CWM, a general purpose processor for the Semantic Web
The Broad Area Announcement BAA 00-07 [No longer served by DARPA] (cached)
Last change $Id: 31-daml-final.html,v 1.68 2006/06/02 22:10:22 timbl Exp $
Tim Berners-Lee, Ralph Swick