- Full Axis Feature
-
A conforming XQuery implementation that supports the Full
Axis Feature MUST support all
the optional
axes.
- Gregorian
-
In the operator mapping tables, the term Gregorian refers
to the types xs:gYearMonth, xs:gYear,
xs:gMonthDay, xs:gDay, and
xs:gMonth.
- NaN
-
NaN specifies the string used for the NaN-symbol, which
is used to represent the value NaN (not-a-number); the default
value is the string NaN
- Prolog
-
A Prolog is a series of declarations and imports that
define the processing environment for the module that contains the Prolog.
- QName
-
Lexically, a QName consists of an optional namespace
prefix and a local name. If the namespace prefix is present, it is
separated from the local name by a colon.
- SequenceType matching
-
During evaluation of an expression, it is sometimes necessary to
determine whether a value with a known dynamic type "matches" an expected
sequence
type. This process is known as SequenceType
matching.
- URI
-
Within this specification, the term URI refers to a
Universal Resource Identifier as defined in [RFC3986] and extended in [RFC3987] with the new name IRI.
- XDM instance
-
The term XDM instance is used, synonymously with the term
value, to denote an unconstrained sequence of nodes and/or atomic values in the data model.
- XPath 1.0 compatibility mode
-
XPath 1.0 compatibility mode. This
component must be set by all host languages that include XPath 2.0
as a subset, indicating whether rules for compatibility with XPath
1.0 are in effect. XQuery sets the value of this component to
false.
- XQuery 1.0 Processor
-
An XQuery 1.0 Processor processes a query according to
the XQuery 1.0 specification.
- XQuery 1.1 Processor
-
An XQuery 1.1 Processor processes a query according to
the XQuery 1.1 specification.
- atomic
value
-
An atomic value is a value in the value space of an
atomic type, as defined in [XML
Schema].
- atomization
-
Atomization of a sequence is defined as the result of
invoking the fn:data function on the sequence, as
defined in [XQuery 1.0 and XPath
2.0 Functions and Operators].
- available collections
-
Available collections. This is a mapping of strings onto
sequences of nodes. The string represents the absolute URI of a
resource. The sequence of nodes represents the result of the
fn:collection function when that URI is supplied as
the argument.
- available documents
-
Available documents. This is a mapping of strings onto
document nodes. The string represents the absolute URI of a
resource. The document node is the root of a tree that represents
that resource using the data model. The document node is returned by
the fn:doc function when applied to that URI.
- axis step
-
An axis step returns a sequence of nodes that are
reachable from the context node via a specified axis. Such a step
has two parts: an axis, which defines the "direction of
movement" for the step, and a node test, which selects nodes based on their
kind, name, and/or type annotation.
- base URI
-
Base URI. This is an absolute URI, used when necessary in
the resolution of relative URIs (for example, by the
fn:resolve-uri function.)
- base
URI declaration
-
A base URI declaration specifies the base URI property of the static context. The
base URI property is
used when resolving relative URIs within a module.
- binding sequence
-
In a for clause or window clause, when
an expression is preceded by the keyword in, the value
of that expression is called a binding sequence.
- boundary whitespace
-
Boundary whitespace is a sequence of consecutive
whitespace characters within the content of a direct
element constructor, that is delimited at each end either by
the start or end of the content, or by a DirectConstructor, or by an
EnclosedExpr. For this
purpose, characters generated by character references such as
  or by CdataSections are not considered to
be whitespace characters.
- boundary-space declaration
-
A boundary-space declaration sets the boundary-space policy in the
static
context, overriding any implementation-defined default.
Boundary-space policy controls whether boundary
whitespace is preserved by element constructors during
processing of the query.
- boundary-space policy
-
Boundary-space policy. This component controls the
processing of boundary whitespace by direct
element constructors, as described in 3.7.1.4 Boundary Whitespace.
- built-in function
-
The built-in functions supported by XQuery 1.1 are
defined in [XQuery 1.0 and XPath
2.0 Functions and Operators].
- character reference
-
A character reference is an XML-style reference to a
[Unicode] character, identified by its
decimal or hexadecimal code point.
- collation
-
A collation is a specification of the manner in which
strings and URIs are compared and, by extension, ordered. For a
more complete definition of collation, see [XQuery 1.0 and XPath 2.0 Functions and
Operators].
- comma operator
-
One way to construct a sequence is by using the comma
operator, which evaluates each of its operands and concatenates
the resulting sequences, in order, into a single result
sequence.
- computed element constructor
-
A computed element constructor creates an element node,
allowing both the name and the content of the node to be
computed.
- construction declaration
-
A construction declaration sets the construction
mode in the static context, overriding any
implementation-defined default.
- construction mode
-
Construction mode. The construction mode governs the
behavior of element and document node constructors. If construction
mode is preserve, the type of a constructed element
node is xs:anyType, and all attribute and element
nodes copied during node construction retain their original types.
If construction mode is strip, the type of a
constructed element node is xs:untyped; all element
nodes copied during node construction receive the type
xs:untyped, and all attribute nodes copied during node
construction receive the type xs:untypedAtomic.
- constructor function
-
The constructor function for a given type is used to
convert instances of other atomic types into the given type. The
semantics of the constructor function call T($arg) are
defined to be equivalent to the expression (($arg) cast as
T?).
- content expression
-
The final part of a computed constructor is an expression
enclosed in braces, called the content expression of the
constructor, that generates the content of the node.
- context
item
-
The context item is the item currently being processed.
An item is either an atomic value or a node.
- context item static type
-
Context item static type. This component defines the
static type of
the context item within the scope of a given expression.
- context
node
-
When the context item is a node, it can also be referred to as
the context node.
- context position
-
The context position is the position of the context item
within the sequence of items currently being processed.
- context
size
-
The context size is the number of items in the sequence
of items currently being processed.
- copy-namespaces declaration
-
A copy-namespaces declaration sets the value of copy-namespaces mode in the
static
context, overriding any implementation-defined default.
Copy-namespaces mode controls the namespace bindings that are
assigned when an existing element node is copied by an element
constructor or document constructor.
- copy-namespaces mode
-
Copy-namespaces mode. This component controls the
namespace bindings that are assigned when an existing element node
is copied by an element constructor, as described in 3.7.1 Direct Element
Constructors. Its value consists of two parts:
preserve or no-preserve, and
inherit or no-inherit.
- current
dateTime
-
Current dateTime. This information represents an
implementation-dependent point
in time during the processing of a
query, and includes an explicit timezone. It can be
retrieved by the fn:current-dateTime function. If
invoked multiple times during the execution of a query, this function always returns the same
result.
- data
model
-
XQuery 1.1 operates on the abstract, logical structure of an XML
document, rather than its surface syntax. This logical structure,
known as the data model, is defined in [XQuery/XPath Data Model (XDM)].
- data model schema
-
For a given node in an XDM instance, the data model
schema is defined as the schema from which the type annotation of
that node was derived.
- decimal-format declaration
-
A decimal-format declaration defines statically known decimal formats,
which define the properties used to format numbers using the
fn:format-number() function
- decimal-separator
-
decimal-separator specifies the character used for the
decimal-separator-sign; the default value is the period character
(.)
- default collation
-
Default collation. This identifies one of the collations
in statically known collations as the
collation to be used by functions and operators for comparing and
ordering values of type xs:string and
xs:anyURI (and types derived from them) when no
explicit collation is specified.
- default collation
declaration
-
A default collation declaration sets the value of the
default
collation in the static context, overriding any
implementation-defined default.
- default collection
-
Default collection. This is the sequence of nodes that
would result from calling the fn:collection function
with no arguments.
- default element/type namespace
-
Default element/type namespace. This is a namespace URI
or "none". The namespace URI, if present, is used for any
unprefixed QName appearing in a position where an element or type
name is expected.
- default
function namespace
-
Default function namespace. This is a namespace URI or
"none". The namespace URI, if present, is used for any unprefixed
QName appearing in a position where a function name is
expected.
- default order for empty
sequences
-
Default order for empty sequences. This component
controls the processing of empty sequences and NaN
values as ordering keys in an order by clause in a
FLWOR expression, as described in 3.8.8 Order By Clause.
- delimiting terminal symbol
-
The delimiting terminal symbols are: S, "!=", StringLiteral, "#)", "$", "(",
"(#", ")", "*", "+", (comma), "-", "-->", (dot), "..", "/",
"//", "/>", (colon), "::", ":=", (semi-colon), "<",
"<!--", "<![CDATA[", "</", "<<", "<=", "<?",
"=", ">", ">=", ">>", "?", "?>", "@", "[", "]",
"]]>", "{", "|", "}"
- deterministic function
-
deterministic function is a function that always
evaluates to the same result if it is invoked with the same
arguments.
- digit-sign
-
digit-sign specifies the character used for the
digit-sign in the picture string; the default value is the number
sign character (#)
- direct element constructor
-
A direct element constructor is a form of element
constructor in which the name of the constructed element is a
constant.
- document order
-
Informally, document order is the order in which nodes
appear in the XML serialization of a document.
- dynamic context
-
The dynamic context of an expression is defined as
information that is available at the time the expression is
evaluated.
- dynamic error
-
A dynamic error is an error that must be detected during
the dynamic evaluation phase and may be detected during the static
analysis phase. Numeric overflow is an example of a dynamic
error.
- dynamic evaluation phase
-
The dynamic evaluation phase is the phase during which
the value of an expression is computed.
- dynamic
type
-
A dynamic type is associated with each value as it is
computed. The dynamic type of a value may be more specific than the
static type of
the expression that computed it (for example, the static type of an
expression might be xs:integer*, denoting a sequence
of zero or more integers, but at evaluation time its value may have
the dynamic type xs:integer, denoting exactly one
integer.)
- effective boolean
value
-
The effective boolean value of a value is defined as the
result of applying the fn:boolean function to the
value, as defined in [XQuery 1.0
and XPath 2.0 Functions and Operators].
- effective case
-
The effective case in a typeswitch
expression is the first case clause such that the
value of the operand expression matches the SequenceType in the
case clause, using the rules of SequenceType matching.
- empty order declaration
-
An empty order declaration sets the default order for empty sequences in
the static
context, overriding any implementation-defined default. This
declaration controls the processing of empty sequences and
NaN values as ordering keys in an order
by clause in a FLWOR expression.
- empty sequence
-
A sequence containing zero items is called an empty
sequence.
- encoding declaration
-
If present, a version declaration may optionally include an
encoding declaration. The value of the string literal
following the keyword encoding is an encoding name,
and must conform to the definition of EncName
specified in [XML 1.0] [err:XQST0087]. The purpose of an encoding
declaration is to allow the writer of a query to provide a string
that indicates how the query is encoded, such as
"UTF-8", "UTF-16", or
"US-ASCII".
- error
value
-
In addition to its identifying QName, a dynamic error may also
carry a descriptive string and one or more additional values called
error values.
- expanded QName
-
An expanded QName consists of an optional namespace URI
and a local name. An expanded QName also retains its original
namespace prefix (if any), to facilitate casting the expanded QName
into a string.
- expression context
-
The expression context for a given expression consists of
all the information that can affect the result of the
expression.
- extension expression
-
An extension expression is an expression whose semantics
are implementation-defined.
- external function
-
External functions are functions that are implemented
outside the query environment.
- filter expression
-
A filter expression consists simply of a primary
expression followed by zero or more predicates. The result of the filter expression
consists of the items returned by the primary expression, filtered
by applying each predicate in turn, working from left to right.
- focus
-
The first three components of the dynamic context (context item,
context position, and context size) are called the focus of
the expression.
- function depends
-
A function f1 depends on a variable
$y or a function f2 if a reference to
$y or f2 appears in the body of
f1, or if there exists a variable $z or a
function f3 such that f1 depends on
$z or f3 and $z or
f3 depends on $y or
f2.
- function implementation
-
Function implementations. Each function in function
signatures has a function implementation that enables the
function to map instances of its parameter types into an instance
of its result type. For a user-defined function,
the function implementation is an XQuery expression. For a
built-in
function or external function, the function
implementation is implementation-dependent.
- function signature
-
Function signatures. This component defines the set of
functions that are available to be called from within an
expression. Each function is uniquely identified by its expanded QName and
its arity (number of parameters).
- grouping
key
-
The atomized value of a grouping variable is called a
grouping key.
- grouping variable
-
A group by clause consists of the keywords
group by followed by one or more variables called
grouping variables.
- grouping-separator
-
grouping-separator specifies the character used for the
grouping-sign, which is typically used as a thousands separator;
the default value is the comma character (,)
- ignorable whitespace
-
Ignorable whitespace consists of any whitespace characters that may
occur between terminals,
unless these characters occur in the context of a production marked
with a ws:explicit
annotation, in which case they can occur only where explicitly
specified (see A.2.4.2
Explicit Whitespace Handling).
- implementation dependent
-
Implementation-dependent indicates an aspect that may
differ between implementations, is not specified by this or any W3C
specification, and is not required to be specified by the
implementor for any particular implementation.
- implementation defined
-
Implementation-defined indicates an aspect that may
differ between implementations, but must be specified by the
implementor for each particular implementation.
- implicit
timezone
-
Implicit timezone. This is the timezone to be used when a
date, time, or dateTime value that does not have a timezone is used
in a comparison or arithmetic operation. The implicit timezone is
an implementation-defined value of
type xs:dayTimeDuration. See [XML
Schema] for the range of legal values of a timezone.
- in-scope
attribute declarations
-
In-scope attribute declarations. Each attribute
declaration is identified either by an expanded QName (for a top-level
attribute declaration) or by an implementation-dependent
attribute identifier (for a local attribute declaration).
If the Schema Import Feature is supported,
in-scope attribute declarations include all attribute declarations
found in imported schemas.
- in-scope element
declarations
-
In-scope element declarations. Each element declaration
is identified either by an expanded QName (for a top-level element
declaration) or by an implementation-dependent element
identifier (for a local element declaration). If the Schema Import Feature is supported,
in-scope element declarations include all element declarations
found in imported schemas.
- in-scope namespaces
-
The in-scope namespaces property of an element node is a
set of namespace bindings, each of which associates a
namespace prefix with a URI, thus defining the set of namespace
prefixes that are available for interpreting QNames within the
scope of the element. For a given element, one namespace binding
may have an empty prefix; the URI of this namespace binding is the
default namespace within the scope of the element.
- in-scope schema
definitions
-
In-scope schema definitions. This is a generic term for
all the element declarations, attribute declarations, and schema
type definitions that are in scope during processing of an
expression.
- in-scope schema
type
-
In-scope schema types. Each schema type definition is
identified either by an expanded QName (for a named type)
or by an implementation-dependent type
identifier (for an anonymous type). The in-scope schema
types include the predefined schema types described in 2.5.1 Predefined Schema Types.
If the Schema Import Feature is supported,
in-scope schema types also include all type definitions found in
imported schemas.
- in-scope variables
-
In-scope variables. This is a set of (expanded QName,
type) pairs. It defines the set of variables that are available for
reference within an expression. The expanded QName is the name of the
variable, and the type is the static type of the variable.
- infinity
-
infinity specifies the string used for the
infinity-symbol; the default value is the string Infinity
- initializing expression
-
If a variable declaration includes an expression, the expression
is called an initializing expression.
- item
-
An item is either an atomic value or a node.
- kind test
-
An alternative form of a node test called a kind test can
select nodes based on their kind, name, and type
annotation.
- library module
-
A module that does not contain a Query Body is called a library module. A
library module consists of a module declaration followed by a
Prolog.
- literal
-
A literal is a direct syntactic representation of an
atomic value.
- main
module
-
A main module consists of a Prolog followed by a Query Body.
- may
-
MAY means that an item is truly optional.
- minus-sign
-
minus-sign specifies the character used for the
minus-symbol; the default value is the hyphen-minus character (-,
#x2D). The value must be a single character.
- module
-
A module is a fragment of XQuery code that conforms to
the Module grammar and can
independently undergo the static analysis phase described in
2.2.3 Expression
Processing. Each module is either a main module or a library module.
- module declaration
-
A module declaration serves to identify a module as a library module. A
module declaration begins with the keyword module and
contains a namespace prefix and a URILiteral.
- module feature
-
A conforming XQuery implementation that supports the Module
Feature allows a query Prolog to contain a Module Import
and allows library modules to be created.
- module
import
-
A module import imports the function declarations and
variable declarations from one or more library modules into the function
signatures and in-scope variables of the importing
module.
- must
-
MUST means that the item is an absolute requirement of
the specification.
- name expression
-
When an expression is used to specify the name of a constructed
node, that expression is called the name expression of the
constructor.
- name test
-
A node test that consists only of a QName or a Wildcard is
called a name test.
- namespace declaration
-
A namespace declaration declares a namespace prefix and
associates it with a namespace URI, adding the (prefix, URI) pair
to the set of statically known namespaces.
- namespace declaration attribute
-
A namespace declaration attribute is used inside a direct
element constructor. Its purpose is to bind a namespace prefix or
to set the default element/type namespace for the
constructed element node, including its attributes.
- namespace-sensitive
-
A value is namespace-sensitive if it includes an item
whose dynamic
type is xs:QName or xs:NOTATION or is
derived by restriction from xs:QName or
xs:NOTATION.
- node
-
A node is an instance of one of the node kinds
defined in [XQuery/XPath Data Model
(XDM)].
- node test
-
A node test is a condition that must be true for each
node selected by a step.
- non-delimiting terminal symbol
-
The non-delimiting terminal symbols are: IntegerLiteral, NCName, DecimalLiteral, DoubleLiteral, QName, "NaN", "ancestor",
"ancestor-or-self", "and", "as", "ascending", "at", "attribute",
"base-uri", "boundary-space", "by", "case", "cast", "castable",
"catch", "child", "collation", "comment", "construction",
"context", "copy-namespaces", "count", "decimal-format",
"decimal-separator", "declare", "default", "descendant",
"descendant-or-self", "descending", "deterministic", "digit",
"div", "document", "document-node", "element", "else", "empty",
"empty-sequence", "encoding", "end", "eq", "every", "except",
"external", "following", "following-sibling", "for", "function",
"ge", "greatest", "group", "grouping-separator", "gt", "idiv",
"if", "import", "in", "infinity", "inherit", "instance",
"intersect", "is", "item", "lax", "le", "least", "let", "lt",
"minus-sign", "mod", "module", "namespace", "namespace-node", "ne",
"next", "no-inherit", "no-preserve", "node", "nondeterministic",
"of", "only", "option", "or", "order", "ordered", "ordering",
"outer", "parent", "pattern-separator", "per-mille", "percent",
"preceding", "preceding-sibling", "preserve", "previous",
"processing-instruction", "return", "satisfies", "schema",
"schema-attribute", "schema-element", "self", "sliding", "some",
"stable", "start", "strict", "strip", "text", "then", "to",
"treat", "try", "tumbling", "typeswitch", "union", "unordered",
"validate", "variable", "version", "when", "where", "window",
"xquery", "zero-digit"
- nondeterministic function
-
nondeterministic function is a function that is not
guaranteed to always return the same result when it is invoked with
the same arguments.
- numeric
-
When referring to a type, the term numeric denotes the
types xs:integer, xs:decimal,
xs:float, and xs:double.
- numeric predicate
-
A predicate whose predicate expression returns a numeric type is
called a numeric predicate.
- operator function
-
For each operator and valid combination of operand types, the
operator mapping tables specify a result type and an operator
function that implements the semantics of the operator for the
given types.
- option declaration
-
An option declaration declares an option that affects the
behavior of a particular implementation. Each option consists of an
identifying QName and a StringLiteral.
- optional axis
-
The following axes are designated as optional axes:
ancestor, ancestor-or-self,
following, following-sibling,
preceding, and preceding-sibling.
- ordering mode
-
Ordering mode. Ordering mode, which has the value
ordered or unordered, affects the
ordering of the result sequence returned by certain path expressions,
FLWOR expressions, and union, intersect,
and except expressions.
- ordering mode declaration
-
An ordering mode declaration sets the ordering mode in the
static
context, overriding any implementation-defined default.
- path expression
-
A path expression can be used to locate nodes within
trees. A path expression consists of a series of one or more
steps, separated by
"/" or "//", and optionally beginning
with "/" or "//".
- pattern-separator-sign
-
pattern-separator-sign specifies the character used for
the pattern-separator-sign, which separates positive and negative
sub-pictures in a picture string; the default value is the
semi-colon character (;)
- per-mille-sign
-
per-mille-sign specifies the character used for the
per-mille-sign; the default value is the Unicode per-mille
character (#x2030)
- percent-sign
-
percent-sign specifies the character used for the
percent-sign; the default value is the percent character (%)
- positional variable
-
A positional variable is a variable that is preceded by
the keyword at.
- pragma
-
A pragma is denoted by the delimiters (# and
#), and consists of an identifying QName followed by
implementation-defined
content.
- predefined entity
reference
-
A predefined entity reference is a short sequence of
characters, beginning with an ampersand, that represents a single
character that might otherwise have syntactic significance.
- predicate
-
A predicate consists of an expression, called a
predicate expression, enclosed in square brackets. A
predicate serves to filter a sequence, retaining some items and
discarding others.
- primary expression
-
Primary expressions are the basic primitives of the
language. They include literals, variable references, context item
expressions, constructors, and function
calls. A primary expression may also be created by enclosing any
expression in parentheses, which is sometimes helpful in
controlling the precedence of operators.
- principal node kind
-
Every axis has a principal node kind. If an axis can
contain elements, then the principal node kind is element;
otherwise, it is the kind of nodes that the axis can contain.
- query
-
A query consists of one or more modules.
- query
body
-
The Query Body, if present, consists of an expression
that defines the result of the query.
- reverse document order
-
The node ordering that is the reverse of document order is
called reverse document order.
- schema
import
-
A schema import imports the element declarations,
attribute declarations, and type definitions from a schema into the
in-scope
schema definitions.
- schema import feature
-
The Schema Import Feature permits the query Prolog to
contain a schema
import.
- schema
type
-
A schema type is a type that is (or could be) defined
using the facilities of [XML Schema]
(including the built-in types of [XML
Schema]).
- schema validation feature
-
The Schema Validation Feature permits a query to contain
a validate expression (see 3.14 Validate Expressions.)
- sequence
-
A sequence is an ordered collection of zero or more
items.
- sequence type
-
A sequence type is a type that can be expressed using the
SequenceType syntax.
Sequence types are used whenever it is necessary to refer to a type
in an XQuery 1.1 expression. The term sequence type suggests
that this syntax is used to describe the type of an XQuery 1.1
value, which is always a sequence.
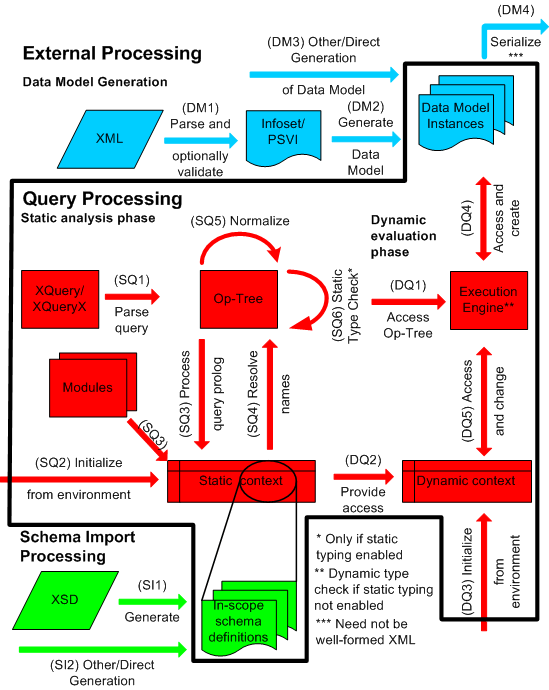
- serialization
-
Serialization is the process of converting an XDM instance into
a sequence of octets (step DM4 in Figure 1.)
- serialization feature
-
A conforming XQuery implementation that supports the
Serialization Feature MUST
provide means for serializing the result of a query, as specified
in 2.2.4 Serialization.
- setter
-
Setters are declarations that set the value of some
property that affects query processing, such as construction mode,
ordering mode, or default collation.
- should
-
SHOULD means that there may exist valid reasons in
particular circumstances to ignore a particular item, but the full
implications must be understood and carefully weighed before
choosing a different course.
- singleton
-
A sequence containing exactly one item is called a
singleton.
- stable
-
Document order is stable, which means that the relative
order of two nodes will not change during the processing of a given
query, even if this order is implementation-dependent.
- static analysis phase
-
The static analysis phase depends on the expression
itself and on the static context. The static analysis
phase does not depend on input data (other than schemas).
- static context
-
The static context of an expression is the information
that is available during static analysis of the expression, prior
to its evaluation.
- static
error
-
A static error is an error that must be detected during
the static analysis phase. A syntax error is an example of a
static
error.
- static
type
-
The static type of an expression is a type such that,
when the expression is evaluated, the resulting value will always
conform to the static type.
- static typing extension
-
A static typing extension is an implementation-defined type
inference rule that infers a more precise static type than that
inferred by the type inference rules in [XQuery 1.0 and XPath 2.0 Formal
Semantics].
- static typing feature
-
The Static Typing Feature provides support for the static
semantics defined in [XQuery 1.0
and XPath 2.0 Formal Semantics], and requires implementations
to detect and report type errors during the static analysis
phase.
- statically known decimal
formats
-
Statically known decimal formats. This is the set of
known decimal formats. Each format is used for serializing decimal
numbers using fn:format-number().
- statically known collections
-
Statically known collections. This is a mapping from
strings onto types. The string represents the absolute URI of a
resource that is potentially available using the
fn:collection function. The type is the type of the
sequence of nodes that would result from calling the
fn:collection function with this URI as its
argument.
- statically
known documents
-
Statically known documents. This is a mapping from
strings onto types. The string represents the absolute URI of a
resource that is potentially available using the
fn:doc function. The type is the static type of a call to
fn:doc with the given URI as its literal argument.
- statically known collations
-
Statically known collations. This is an implementation-defined set of
(URI, collation) pairs. It defines the names of the collations that
are available for use in processing queries
and expressions.
- statically known default
collection type
-
Statically known default collection type. This is the
type of the sequence of nodes that would result from calling the
fn:collection function with no arguments.
- statically known namespaces
-
Statically known namespaces. This is a set of (prefix,
URI) pairs that define all the namespaces that are known during
static processing of a given expression.
- step
-
A step is a part of a path expression that generates a sequence
of items and then filters the sequence by zero or more predicates. The value of the
step consists of those items that satisfy the predicates, working
from left to right. A step may be either an axis step or a filter
expression.
- string
value
-
The string value of a node is a string and can be
extracted by applying the fn:string function to the
node.
- substitution group
-
Substitution groups are defined in [XML Schema] Part 1, Section 2.2.2.2. Informally,
the substitution group headed by a given element (called the
head element) consists of the set of elements that can be
substituted for the head element without affecting the outcome of
schema validation.
- subtype substitution
-
The use of a value whose dynamic type is derived from an expected
type is known as subtype substitution.
- symbol
-
Each rule in the grammar defines one symbol, using the
following format:
- symbol
separators
-
Whitespace and
Comments function as symbol
separators. For the most part, they are not mentioned in the
grammar, and may occur between any two terminal symbols mentioned
in the grammar, except where that is forbidden by the /* ws: explicit */ annotation in the EBNF, or by
the /* xgs: xml-version */
annotation.
- target namespace
-
Each imported schema or module is identified by its target
namespace, which is the namespace of the objects (such as
elements or functions) that are defined by the schema or
module.
- terminal
-
A terminal is a symbol or string or pattern that can
appear in the right-hand side of a rule, but never appears on the
left hand side in the main grammar, although it may appear on the
left-hand side of a rule in the grammar for terminals.
- tuple
-
A tuple is a set of zero or more named variables, each of
which is bound to a value that is an XDM instance.
- tuple stream
-
A tuple stream is an ordered sequence of zero or more
tuples.
- type annotation
-
Each element node and attribute node in an XDM instance has
a type annotation (referred to in [XQuery/XPath Data Model (XDM)] as its
type-name property.) The type annotation of a node is
a schema type
that describes the relationship between the string value of the node and its
typed value.
- type declaration
-
A variable binding may be accompanied by a type
declaration, which consists of the keyword as
followed by the static type of the variable, declared using the
syntax in 2.5.3 SequenceType
Syntax.
- type
error
-
A type error may be raised during the static analysis
phase or the dynamic evaluation phase. During the static analysis
phase, a type error
occurs when the static type of an expression does not match
the expected type of the context in which the expression occurs.
During the dynamic evaluation phase, a type error occurs when the dynamic type of a value
does not match the expected type of the context in which the value
occurs.
- type
promotion
-
Under certain circumstances, an atomic value can be promoted
from one type to another. Type promotion is used in
evaluating function calls (see 3.1.5 Function Calls), order by clauses (see 3.8.8 Order By Clause), and
operators that accept numeric or string operands (see B.2 Operator Mapping).
- typed
value
-
The typed value of a node is a sequence of atomic values
and can be extracted by applying the fn:data function
to the node.
- user-defined function
-
User defined functions are functions that contain a
function body>, which provides the implementation of the
function as an XQuery expression.
- value
-
In the data
model, a value is always a sequence.
- variable depends
-
A variable $x depends on a variable
$y or a function f2 if a reference to
$y or f2 appears in the initializing
expression of $x, or if there exists a variable
$z or a function f3 such that
$x depends on $z or
f3 and $z or f3 depends on
$y or f2.
- variable reference
-
A variable reference is a QName preceded by a $-sign.
- variable values
-
Variable values. This is a set of (expanded QName, value)
pairs. It contains the same expanded QNames as the in-scope
variables in the static context for the expression. The
expanded QName is the name of the variable and the value is the
dynamic value of the variable, which includes its dynamic type.
- version declaration
-
A version declaration can identify the applicable XQuery
syntax and semantics for a module, as well as its encoding.
- warning
-
In addition to static errors, dynamic errors, and type errors, an XQuery 1.1
implementation may raise warnings, either during the
static
analysis phase or the dynamic evaluation phase. The
circumstances in which warnings are raised, and the ways in which
warnings are handled, are implementation-defined.
- whitespace
-
A whitespace character is any of the characters defined
by [http://www.w3.org/TR/REC-xml#NT-S].
- window
-
A window is a sequence of consecutive items drawn from
the binding
sequence.
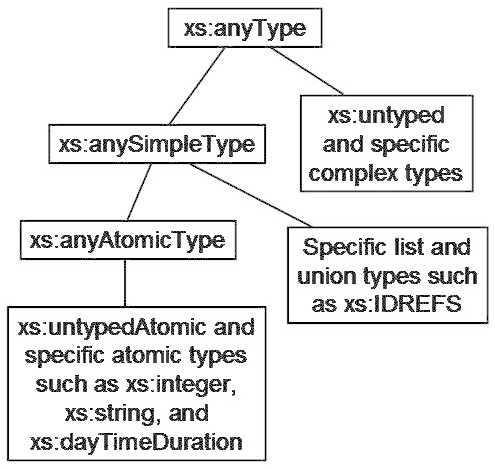
- xs:anyAtomicType
-
xs:anyAtomicType is an atomic type that includes
all atomic values (and no values that are not atomic). Its base
type is xs:anySimpleType from which all simple types,
including atomic, list, and union types, are derived. All primitive
atomic types, such as xs:decimal and
xs:string, have xs:anyAtomicType as their
base type.
- xs:dayTimeDuration
-
xs:dayTimeDuration is derived by restriction from
xs:duration. The lexical representation of
xs:dayTimeDuration is restricted to contain only day,
hour, minute, and second components.
- xs:untyped
-
xs:untyped is used as the type annotation of
an element node that has not been validated, or has been validated
in skip mode.
- xs:untypedAtomic
-
xs:untypedAtomic is an atomic type that is used to
denote untyped atomic data, such as text that has not been assigned
a more specific type.
- xs:yearMonthDuration
-
xs:yearMonthDuration is derived by restriction from
xs:duration. The lexical representation of
xs:yearMonthDuration is restricted to contain only
year and month components.
- zero-digit
-
zero-digit specifies the character used for the
digit-zero-sign; the default value is the digit zero (0). This
character must be a digit (category Nd in the Unicode property
database), and it must have the numeric value zero. This attribute
implicitly defines the Unicode character that is used to represent
each of the values 0 to 9 in the final result string: Unicode is
organized so that each set of decimal digits forms a contiguous
block of characters in numerical sequence.