1. Introduction
The Efficient XML Interchange (EXI) format is a very compact, high
performance XML representation that was designed to work well for a
broad range of applications. It simultaneously improves performance
and significantly reduces bandwidth requirements without compromising
efficient use of other resources such as battery life, code size,
processing power, and memory.
EXI uses a grammar-driven approach that achieves very efficient
encodings using a straightforward encoding algorithm and a small set
of data types. Consequently, EXI processors are relatively simple and
can be implemented on devices with limited capacity.
EXI is schema
"informed", meaning that it can utilize available schema
information to improve compactness and performance, but does not
depend on accurate, complete or current schemas to work. It supports
arbitrary schema extensions and deviations and also works very
effectively with partial schemas or in the absence of any schema. The
format itself also does not depend on any particular schema language,
or format, for schema information.
[Definition:] A program module
called an EXI processor, whether it is part of a software or
a hardware, is used by application programs to encode their structured data
into EXI streams and/or to decode
EXI streams to make the structured
data accessible to them. This document not only specifies the
EXI format, but also defines errors that EXI processors are required to
detect and behave upon.
The primary goal of this document is to define the EXI format completely without leaving ambiguity so as to make it feasible for implementations to interoperate. As such, the document lends itself to describing the design and features of the format in a systematic manner, often declaratively with relatively few prosaic annotations and examples. Those readers who prefer a step-by-step introduction to the EXI format design and features are suggested to start with the non-normative [EXI Primer].
1.1 History and Design
EXI is the result of extensive work carried out by the W3C's XML
Binary Characterization (XBC) and Efficient XML Interchange (EXI)
Working Groups. XBC was chartered to investigate the costs and
benefits of an alternative form of XML, and formulate a way to objectively
evaluate the potential of a substitute format for XML. Based on XBC's
recommendations, EXI was chartered, first to measure, evaluate, and
compare the performance of various XML technologies (using metrics
developed by XBC [XBC Measurement Methodologies]), and then, if it appeared
suitable, to formulate a recommendation for a W3C format
specification. The measurements results and analyses, are presented
elsewhere [EXI Measurements Note]. The format described in this
document is the specification so recommended.
The functional requirements of the EXI format are those that were
prepared by the XBC WG in their analysis of the desirable properties
of a high performance encoding for XML [XBC Properties].
Those properties were derived from a very broad set of use cases also
identified by the XBC working group [XBC Use Cases].
The design of the format presented here, is largely based on the
results of the measurements carried out by the group to evaluate the
performance characteristics (mainly of processing efficiency and
compactness) of various existing formats. The EXI format is based on
Efficient XML [Efficient XML], including for example the basis heuristic grammar approach,
compression algorithm, and resulting entropy encoding. Present work
centers around evaluating and integrating some features from other
measured format technologies into EXI (see Appendix F Format Features Under Consideration).
EXI is compatible with XML at the XML Information Set [XML Information Set] level, rather than at the XML syntax level. This
permits it to encapsulate an efficient alternative syntax and grammar
for XML, while facilitating at least the potential for minimizing the
impact on XML application interoperability.
1.2 Notational Conventions and Terminology
The key words MUST, MUST NOT, REQUIRED, SHALL, SHALL NOT, SHOULD,
SHOULD NOT, RECOMMENDED, MAY, and OPTIONAL, when they appear
EMPHASIZED in this document, are to be interpreted as described in RFC
2119 [IETF RFC 2119]. Other terminology used to describe the EXI
format is defined in the body of this specification.
The term event and stream is used throughout this document to denote EXI event and EXI stream respectively unless the words are qualified differently to mean otherwise.
This document specifies an abstract grammar for EXI. In grammar notation, all terminal
symbols are represented in plain text and all non-terminal symbols are
represented in italics. Grammar productions are
represented as follows:
|
LeftHandSide :
Event NonTerminal |
A set of one or more grammar productions that share the same
left-hand-side non-terminal symbol are often presented together along
with event codes that uniquely
identify events among the collocated productions as follows:
|
LeftHandSide : |
| |
Event 1 NonTerminal
1 | EventCode1 |
| |
Event 2 NonTerminal
2 | EventCode2 |
| |
Event 3 NonTerminal
3 | EventCode3 |
| | ... | |
| |
Event n NonTerminal
n | EventCoden |
Section 8.1 Grammar Notation introduces additional notations for describing productions and event codes in grammars. Those additional notations facilitates concise representation of the EXI grammar system.
Terminal symbols that are qualified with a qname permit the use of a wildcard symbol (*) in place of a qname. The terminal symbol SE (*) matches a start element (SE) event with any qname. Similarly, the terminal symbol AT (*) matches an attribute (AT) event with any qname.
Several prefixes are used throughout this document to designate certain namespaces. The bindings shown below are assumed, however, any prefixes can be used in practice if they are properly bound to the namespaces.
| Prefix | Namespace Name |
|---|
| exi |
http://www.w3.org/2007/07/exi |
| xml |
http://www.w3.org/XML/1998/namespace |
| xsd |
http://www.w3.org/2001/XMLSchema |
| xsi |
http://www.w3.org/2001/XMLSchema-instance |
In describing the layout of an EXI format construct, a pair of square brackets [ ] are used to surround the name of a field to denote that the occurrence of the field is optional in the structure of the part or component that contains the field.
In arithmetic expressions, the notation ⌈x⌉ where x represents a real number denotes the ceiling of x, that is, the smallest integer greater than or equal to x.
2. Design Principles
The following design principles were used to guide the development of EXI and encourage consistent design decisions. They are listed here to provide insight into the EXI design rationale and to anchor discussions on desirable EXI traits.
- General:
One of primary objectives of EXI is to maximize the number of systems, devices and applications that can communicate using XML data. Specialized approaches optimized for specific use cases should be avoided.
- Minimal:
To reach the broadest set of small, mobile and embedded applications, simple, elegant approaches are preferred to large, analytical or complex ones.
- Efficient:
EXI must be competitive with hand-optimized binary formats so it can be used by applications that require this level of efficiency.
- Flexible:
EXI must deal flexibly and efficiently with documents that contain arbitrary schema extensions or deviate from their schema. Documents that contain schema deviations should not cause encoding to fail.
- Interoperable:
EXI must integrate well with existing XML technologies, minimizing the changes required to those technologies. It must be compatible with the XML Information Set [XML Information Set], without significant subsetting or supersetting, in order to maintain interoperability with existing and prospective XML specifications.
3. Basic Concepts
EXI achieves broad generality, flexibility, and performance, by unifying concepts from formal language theory and information theory into a single, relatively simple algorithm. The algorithm uses a grammar to determine what is likely to occur at any given point in an XML document and encodes the most likely alternatives in fewer bits. The fully generalized algorithm works for any language that can be described by a grammar (e.g., XML, Java, HTTP, etc.); however, EXI is optimized specifically for XML languages.
The built-in EXI grammar accepts any XML document or fragment and may be augmented with productions derived from XML Schemas [XML Schema Structures][XML Schema Datatypes], RELAX NG schemas [ISO/IEC 19757-2:2003], DTDs [XML 1.0] or other sources of information about what is likely to occur in a set of XML documents. The EXI encoder uses the grammar to map a stream of XML information items onto a smaller, lower entropy, stream of events.
The encoder then represents the stream of events using a set of simple variable length codes called event codes. Event codes are similar to Huffman codes [Huffman Coding], but are much simpler to compute and maintain. They are encoded directly as a sequence of values, or if additional compression is desired, they are passed to the EXI compression algorithm, which replaces frequently occurring event patterns to further reduce size.
When schemas are used, EXI also supports a user-customizable set of typed encodings for efficiently encoding typed values.
4. EXI Streams
[Definition:] An EXI stream is an EXI header followed by an EXI stream body. It is the EXI stream body that carries the content of the document, while the EXI header amongst its roles communicates the options that were used for encoding the EXI stream body. Section
5. EXI Header describes the EXI header. Values in an EXI stream are packed into bytes most significant bit first.
Applications that use EXI streams embedded in a container data format that discerns it is an EXI stream, dictates the EXI format version and the EXI Options used for its encoding, may with to omit the EXI header. Although an EXI Body is not a valid EXI stream, EXI processors MAY provide a capability to process an EXI stream body independent of an EXI stream.
[Definition:] The building block of an EXI stream body is an EXI event. An EXI stream body consists of a sequence of EXI events representing an EXI document or an EXI fragment.
The EXI events permitted at any given position in an EXI stream are determined by the EXI grammar. The events occur in a well-formed manner with matching start element and end element events in the same fashion as XML. The EXI grammar incorporates knowledge of the XML grammar and may be augmented and refined using schema information and fidelity options. EXI grammar is formally specified in section 8. EXI Grammars.
The following table summarizes the EXI events and associated content that occur in an EXI stream. In addition, the table includes the grammar notation used to represent each event in this specification. Each event in an EXI stream participates in a mapping system that relates events to XML Information Items so that an EXI document as a whole serves to represent an XML Information Set. The table shows XML Information Items relevant to each EXI event type. Appendix B Infoset Mapping describes the mapping system in detail.
Section
6. Encoding EXI Streams describes the algorithm used to encode events in the EXI stream.
As indicated in the table above, there are some event types that carry content with their event instances while other event types function as markers without content. A grammar production may match a specific Element or Attribute by qname or match any Element or Attribute using wildcard notation. When a grammar matches an Element or Attribute by qname, the qname is not part of the content. When a grammar matches an Element or Attribute using wildcard notation, the qname is part of the content.
SE events may be followed by a series of NS events. Each NS event either associates a prefix with an URI, assigns a default namespace, or in the case of a namespace declaration with an empty URI, rescinds one of such associations in effect at the point of its occurrence. The effect of the association or disassociation caused by a NS event stays in effect until the corresponding EE event occurs. The series of NS events may include at most one NS event that carries an indicator value of 1. When the indicator has the value of 1, the prefix of the NS is used as the effective prefix of the element's qname. The uri of an NS event with an indicator value of 1 MUST match the uri of the associated SE event.
Each item in the event content has a data type associated with it as shown in the following table. The content of each event, if any, is encoded as a sequence of items each of which being encoded according to its data type in order starting with the first item followed by subsequent items.
Content items other than value have their inherent, fixed data types independent of their uses. The data type that governs each occurrence of the value item depends on the schema type if any that is in effect for the value in question. The type xsd:anySimpleType is used for values that do not have an associated schema-type, are schema-invalid, or occur in mixed content. Section
7. Representing Event Content describes how each of the types listed above are encoded in an EXI stream.
5. EXI Header
Each EXI stream begins with an EXI header. The EXI header
distinguishes EXI documents from text XML documents, identifies the
version of the EXI format being used, and can specify the options used to encode
the body of the EXI stream. The EXI header has the following
structure:
The EXI Options field within an EXI header is optional. Its presence is indicated by
the value of the presence bit that follows Distinguishing Bits. The presence and absence is indicated by the value 1 and 0, respectively.
When either compression or
alignment of the EXI stream is turned on
dictated by EXI options, padding bits of minumum length required to make the whole length of
the header byte-aligned are added at the end of the header.
The following sections describe the remaining three parts of the header.
5.1 Distinguishing Bits
[Definition:]
An EXI header starts with Distinguishing Bits part,
which is a two bit field used to distinguish EXI documents from text
XML documents. The first bit
contains the value 1 and the second bit contains the value 0, as follows.
This 2 bit sequence is the minimum that suffices to distinguish EXI
documents from XML documents since it is the minimum length bit
pattern that cannot occur as the first two bits of a well-formed XML
document represented in any one of the conventional character
encodings, such as UTF-8, UTF-16, UCS-2, UCS-4, EBCDIC, ISO 8859,
Shift-JIS and EUC, according to XML 1.0 [XML 1.0]. Therefore, XML
Processors are expected to reject an EXI stream as early as they read
and process the first byte from the stream.
Systems that use EXI documents as well as XML documents can look at
the Distinguishing Bits to determine whether to interpret a particular
stream as XML or EXI.
| Editorial note | |
|
In addition to distinguishing EXI from XML, the 2 bit distinguishing
bit pattern given above can distinguish EXI streams from quite a broad
range of popular content types that occur on the web, like PNG.
However, the working group is actively considering the introduction of
larger set of bits, such as a magic cookie, to distinguish EXI from a
broader range of data types.
|
5.2 EXI Format Version
[Definition:]
The third part in the EXI header is the EXI Format Version, which identifies the version
of the EXI format being used.
EXI format version numbers are integers. Each version of the EXI Format Specification specifies the corresponding EXI format version number to be used by conforming implementations. The EXI format version number that corresponds with this version of the EXI format specification is 0 (zero).
The first bit of the version field indicates whether the version is a preview or final version of the EXI format.
A value of 0 indicates this is a final version and a value of 1 indicates this is a preview
version. Final versions correspond to final, approved versions of the EXI format specification.
An EXI processor that implements a final version of the EXI format specification is REQUIRED to process EXI streams that have a version field with its first bit set to 0 followed by a version number that corresponds to the version of the EXI specification the processor implements.
Preview versions of the EXI format are useful for
gaining implementation and deployment experience prior to finalizing a
particular version of the EXI format. While preview versions may match drafts of this specification, they are not governed by this specification and the behaviour of EXI processors encountering preview versions of the EXI format is implementation dependent. Implementers are free to coordinate to achieve interoperability between different preview versions of the EXI format.
Following the first bit of the version is a sequence of one or more
4-bit unsigned integers representing the version number. The version
number is determined by summing this sequence of 4-bit unsigned
values. The sequence is terminated by any 4-bit unsigned integer with
a value in the range 0-14. As such, the first 15 version numbers are
represented by 4 bits, the next 15 are represented by 8 bits, etc.
Given an EXI stream with its stream cursor positioned just past the first bit of the EXI format version field, the EXI format version number can be computed by going through the following steps with version number initially set to 1.
- Read next 4 bits as an unsigned integer value.
- Add the value that was just read to the version number.
- If the value is 15, go to step 1, otherwise (i.e. the value being in the range of 0-14), use the current value of the version number as the EXI version number.
The following are example EXI format version numbers.
| EXI Format Version Field | Description |
|---|
| 1 0000 | Preview version 1 |
| 0 0000 | Final version 1 |
| 0 1110 | Final version 15 |
| 0 1111 0000 | Final version 16 |
| 0 1111 0001 | Final version 17 |
EXI processors conforming with the final version of this
specification MUST use the 5-bit value 0 0000 as the version
number.
5.3 EXI Options
[Definition:] The fourth part of the EXI
header is the EXI Options, which provides a way to specify the
options used to encode the body of the EXI stream.
[Definition:]
The EXI Options are represented as an EXI Options document, which is an XML document encoded using the EXI format described in this specification.
This results in a very compact header
format that can be read and written with very little additional software.
The presence of EXI Options in its entirety is optional in EXI header,
and it is predicated on the value of the presence bit that follows the
Distinguishing Bits.
When EXI Options are present in the header, an EXI Processor MUST observe the
specified options to process the EXI stream that follows. Otherwise,
an EXI Procesor may obtain the EXI options using another mechanism.
EXI processors MAY provide external means for applications or users to
specify EXI Options when the EXI header is absent.
Such EXI processors are typically used in controlled systems
where the knowledge about the effective EXI Options is shared prior to
the exchange of EXI documents. The mechanism to communicate out-of-bound
EXI Options and their representation used in such systems are implementation dependent.
The following table describes the EXI options specified in the
options field.
Table 5-1. EXI Options in Options Field| EXI Option | Description | Default Value |
|---|
|
alignment
|
Alignment of event codes and content items
|
bit-packed
|
| compression | EXI compression is used to achieve better compactness |
false
|
| fragment | Body is encoded as an EXI fragment instead of an EXI document |
false
|
| preserve | Specifies whether comments, pis, etc. are preserved |
all false
|
| schemaID | Identify the schema information, if any, used to encode the body |
none
|
| codecMap | Identify pluggable CODECs used to encode body |
none
|
| blockSize | Specifies the block size used for EXI compression |
1,000,000
|
| [user defined] | User defined headers may be added |
none
|
Appendix C XML Schema for EXI Options Header provides an XML Schema
describing
the EXI Options document.
This schema is
designed to produce smaller headers
for option combinations used when compactness is critical.
The EXI Options document is
encoded as an EXI body using the default options specified by the following XML document:
<header xmlns="http://www.w3.org/2007/07/exi">
</header>
| Editorial note | |
|
The above EXI Options document for encoding EXI Options documents will be revised to use "strict" option when the feature is specified in this specification. |
[Definition:] The alignment option is used to control the alignment of event codes and content items. The value is one of bit-packed, byte-alignment or pre-compression, of which bit-packed is the default value assumed when the "alignment" element is absent in the EXI Options document.
[Definition:] Alignment option value bit-packed indicates that the the event codes and associated content are packed in bits without any paddings in-between.
[Definition:] Alignment option value byte-alignment indicates that the event codes and associated content are aligned on byte boundaries. While byte-alignment generally results in EXI streams of larger sizes compared with their bit-packed equivalents, byte-alignment may provide a help in some use cases that involve frequent copying of large arrays of scalar data directly out of the stream. It can also make it possible to work with data in-place and can make it easier to debug encoded data by allowing items on aligned boundaries to be easily located in the stream.
[Definition:] Alignment option value pre-compression alignment indicates that all steps involved in compression (see section 9. EXI Compression) are to be done with the exception of the final step of applying the DEFLATE algorithm. The primary use case of pre-compression is to avoid a duplicate compression step when compression capability is built into the transport protocol. In this case, pre-compression just prepares the stream for later compression.
[Definition:] The compression option is a Boolean used to increase compactness using additional computational resources. The default value "false" is assumed when the "compression" element is absent in the EXI Options document.
When set to true, the event codes and associated content are compressed according to 9. EXI Compression regardless of the alignment option value.
[Definition:] The fragment option is a Boolean that indicates whether the EXI body is an EXI document or an EXI fragment. When set to true, the EXI body is an EXI fragment. Otherwise, the EXI body is an EXI document. [Definition:] EXI fragments are analogous in concept to external general parsed entitiesXML in XML in that they consist of a sequence of elements, processing instructions and comments in containers of their own that are physically separate from the documents in which they are to be used. An EXI fragment is formally defined in terms of its grammar in Section 8.4.2 Built-in Fragment Grammar. The XML Information Set an EXI stream is mapped onto contains a document information item if the stream represents an EXI document, otherwise, the XML Information Set does not have a document information item if the stream represents an EXI fragment. The order among elements, processing instructions and comments that appear at the root in an EXI fragment is deemed significant and MUST be preserved by EXI processors.
[Definition:] The preserve option is a set of Booleans that can be set independently to control whether certain information items are preserved in the EXI stream. 6.3 Fidelity Options describes the set of information items effected by the preserve option.
[Definition:] The schemaID option may be used to identify the schema information used to encode the EXI body. When the schemaID is nil, no schema information was used to encode the EXI body. When the schemaID option is absent (i.e., undefined), no statement is made about the schema information used to encode the EXI body and it is assumed this information is communicated out of band.
[Definition:] The codecMap option identifies pluggable CODECs used to encode the EXI body as described in 7.4 Pluggable CODECS.
[Definition:] The blockSize option specifies the block size used for EXI compression. When the blockSize option is absent, the default blocksize of 1,000,000 is used. The default blockSize is intentionally large but can be reduced for processing large documents on devices with limited memory.
6. Encoding EXI Streams
The rules for encoding a series of events as an EXI stream are very
simple and are driven by a declarative set of grammars that describes
the structure of an EXI stream. Every event in the stream is
encoded using the same set of encoding rules, which are summarized as
follows:
- Get the next event to be encoded
- If fidelity options indicate this event type is not processed,
go to step 1
- Use the grammars to determine the event code of the event
- Encode the event code followed by the event content
- Evaluate the grammar production matched by the event
- Repeat until the End Document (ED) event is encoded
Namespace (NS) events are encoded before attribute (AT) events in the stream following the associated start element (SE) event.
When built-in element grammars are used, attribute events can occur in any order. Otherwise, when schema-informed grammars are used for processing an element, AT(xsi:type) event comes first if present, followed by the AT(xsi:nil) event if present, followed by the rest of the attribute (AT) events in lexical order sorted first by qname's local-name then by qname's URI. Namespace (NS) events can occur in any order regardless of the grammars used for processing the associated element.
EXI uses the same simple procedure described above, to encode well-formed documents, document fragments, schema-valid information items, schema-invalid information items, information items partially described by schemas and information items with no schema at all. Only the grammars that describe these items differ. For example, an element with no schema information is encoded according to the XML grammar defined by the XML specification, while an element with schema information is encoded according to the more specific grammar defined by that schema.
[Definition:] An event code is a sequence of 1 to 3 non-negative integers called parts. Each production in a grammar has an event code that distinguishes its event from that of other productions that share the same left-hand-side non-terminal symbol.
Section
6.1 Determining Event Codes describes in detail how the grammar is used to determine the event code of an event. Section
6.2 Representing Event Codes describes in detail how event codes are represented as bits. Section
6.3 Fidelity Options describes available fidelity options and how they effect the EXI stream. Section
7. Representing Event Content describes how the typed event contents are represented as bits.
6.1 Determining Event Codes
The structure of an EXI stream is described by the EXI grammars, which are formally specified in section
8. EXI Grammars. Each grammar defines which events are permitted to occur at any given point in the EXI stream and provides a pre-assigned event code for each event.
For example, the grammar productions below describe the events that can occur in a schema-informed EXI stream after the Start-Document (SD) event provided there are four global elements defined in the schema and provide an event code for each event:
| Syntax | Event Code |
|---|
| DocContent |
| | SE ("A")
DocEnd | 0 |
| | SE ("B")
DocEnd | 1 |
| | SE ("C")
DocEnd | 2 |
| | SE ("D")
DocEnd | 3 |
| | SE (*)
DocEnd | 4.0 |
| | DT
DocContent | 4.1 |
| | CH
DocContent | 4.2 |
| | CM
DocContent | 4.3.0 |
| | PI
DocContent | 4.3.1 |
At the point in an EXI stream where the above grammar productions are in effect, the event code of Start Element "A" (i.e. SE("A")) is 0. The event code of a DOCTYPE (DT) event at this point in the stream is 4.1, and so on.
6.2 Representing Event Codes
Each event code is represented by a sequence of 1 to 3 parts that uniquely identify an event.
Event code parts are encoded in order starting with the first part followed by subsequent parts.
When EXI compression and alignment are not in effect for the current processing of the stream,
the ith part of an event code is encoded using the minimum number of bits required to distinguish it from the ith part of the other sibling event codes in the current grammar. Specifically, the
ith part of an event code is encoded as an n-bit unsigned integer (7.1.9 n-bit Unsigned Integer), of which
n is ⌈ log 2 m ⌉ where m is the number of distinct values used as the
ith part of its own and all its sibling event codes in the current grammar.
Two event codes are siblings at the ith part if and only if they share the same values in all preceding parts. All event codes are siblings at the first part.
When the EXI events are subsequently subject to EXI compression or alignment,
the ith part of an event code is encoded using the minimum number of bytes instead of
bits required to distinguish it from the ith part of the other sibling event codes in
the current grammar. Each part is encoded as an n-bit unsigned integer
(7.1.9 n-bit Unsigned Integer), of which
n is ⌈ log 2 m ⌉ where m is the
number of distinct values used as the
ith part of its own and all its sibling event codes in the current grammar.
The number of bytes used for the n-bit unsigned integer representation in this case
is equal to ⌈ n / 8 ⌉.
Regardless of the EXI compression and alignment options, if there is only one distinct value for a given part, the part is omitted (i.e., encoded in log 2 1 = 0 bits = 0 bytes).
For example, the nine event codes shown in the
DocContent grammar above have a value ranging from 0 to 4 for their first part. There are five distinct values needed to identify the first part of these event codes. Therefore, when EXI compression and alignment are not in effect, the first part can be encoded in ⌈ log 2 5 ⌉ = 3 bits. In the same fashion, the number of bits used for encoding second and third part (if present) are calculated as ⌈ log 2 4 ⌉ = 2 bits and ⌈ log 2 2 ⌉ = 1 bits, respectively.
On the other hand, when EXI compression or alignment is in effect, the number of bytes used for each part is ⌈ 3 / 8 ⌉ = 1 bytes for the first part, ⌈ 2 / 8 ⌉ = 1 bytes for the second part and ⌈ 1 / 8 ⌉ = 1 bytes for the third part.
The table below illustrates how the event codes of each event in the
DocContent grammar above is encoded.
Table 6-1. Example event code encoding when EXI compression and alignment are not in effect| Event | Part values | Event Code Encoding | # bits |
|---|
| SE ("A") | 0 | | | 000 | 3 |
| SE ("B") | 1 | | | 001 | 3 |
| SE ("C") | 2 | | | 010 | 3 |
| SE ("D") | 3 | | | 011 | 3 |
| SE (*) | 4 | 0 | | 100 00 | 5 |
| DT | 4 | 1 | | 100 01 | 5 |
| CH | 4 | 2 | | 100 10 | 5 |
| CM | 4 | 3 | 0 | 100 11 0 | 6 |
| PI | 4 | 3 | 1 | 100 11 1 | 6 |
| # distinct values (
m) | 5 | 4 | 2 | | |
| # bits per part | | ⌈ log 2 m ⌉ |
| 3 | 2 | 1 | | |
Table 6-2. Example event code encoding when EXI compression or alignment is in effect| Event | Part values | Event Code Encoding | # bytes |
|---|
| SE ("A") | 0 | | | 00000000 | 1 |
| SE ("B") | 1 | | | 00000001 | 1 |
| SE ("C") | 2 | | | 00000010 | 1 |
| SE ("D") | 3 | | | 00000011 | 1 |
| SE (*) | 4 | 0 | | 00000100 00000000 | 2 |
| DT | 4 | 1 | | 00000100 00000001 | 2 |
| CH | 4 | 2 | | 00000100 00000010 | 2 |
| CM | 4 | 3 | 0 | 00000100 00000011 00000000 | 3 |
| PI | 4 | 3 | 1 | 00000100 00000011 00000001 | 3 |
| # distinct values (m) | 5 | 4 | 2 | | |
| # bytes per part | | ⌈ (log 2 m) / 8 ⌉ |
| 1 | 1 | 1 | | |
6.3 Fidelity Options
Some XML applications do not require the entire XML feature set and would prefer to eliminate the overhead associated with unused features. For example, the SOAP 1.2 specification
[SOAP 1.2] prohibits the use of XML processing-instructions. In addition, there are many data-exchange use cases that do not require XML comments or DTDs.
Applications can use a set of fidelity options to specify the XML features they require. As specified in section
8.3 Pruning Unneeded Productions, EXI processors MUST use these fidelity options to prune the events that are not required from the grammars, improving compactness and processing efficiency.
The table below lists the fidelity options supported by this version of the EXI specification and describes the effect setting these options has on the EXI stream.
Table 6-3. Fidelity options| Fidelity option | Effect |
|---|
| Preserve.comments | CM events are preserved |
| Preserve.pis | PI events are preserved |
| Preserve.dtd | DOCTYPE and ER events are preserved |
| Preserve.prefixes | NS events and namespace prefixes are preserved |
| Preserve.lexicalValues | Lexical form of element and attribute values is preserved |
EXI processors may report an error if the application attempts to encode events that have been pruned from the grammar or may simply ignore these events.
7. Representing Event Content
The content of each event in an EXI body is represented according to its type (see Table 4-2). In the absence of external type information or when the preserve.lexicalValues option is set to true, all attribute and character
values are typed as String.
[Definition:] EXI defines a minimal set of data types called Built-in EXI datatypes that define how values are represented in EXI streams as described in 7.1 Built-in EXI Datatypes Representation. The following table lists the built-in EXI datatypes, associated type identifiers and the XML Schema Language [XML Schema Datatypes] built-in types each is used to represent by default.
Table 7-1. Built-in EXI Datatypes| Built-in EXI Datatype | EXI Datatype ID |
XML Schema DatatypesXS2
|
|---|
|
Binary
| xsd:base64Binary | base64Binary |
| xsd:hexBinary | hexBinary |
|
Boolean
| xsd:boolean | boolean |
|
Date-Time
| xsd:dateTime | dateTime, time, date, gYearMonth, gYear, gMonthDay, gDay, gMonth |
|
Decimal
| xsd:decimal | decimal |
|
Float
| xsd:double | float, double |
|
Integer
| xsd:integer | integer without minInclusive or minExclusive facets, or with minInclusive or minExclusive facet of negative value |
|
Unsigned Integer
| nonNegativeInteger or integer with minInclusive or minExclusive facet value of 0 or above |
|
n-bit Unsigned Integer
|
integer with bounded range of 4095 or smaller as determined by the values of minInclusive, minExclusive, maxInclusive and maxExclusive facets.
|
|
String
| xsd:string | string, anySimpleType, anyURI, duration, All types derived by union |
|
List
| | All types derived by list, including
IDREFS and ENTITIES |
|
QName
| |
|
By default, types derived from the XML Schema types above are also represented by the associated built-in EXI datatype. When there are more than one XML Schema types above from which a type is derived directly or indirectly, the closest ancestor is used to determine the built-in EXI datatype. For example, a value of XML Schema type xsd:int is represented by the same built-in type as for XML Schema type xsd:integer. Although xsd:int is derived indirectly from xsd:integer and also further from xsd:decimal, a value of xsd:int is processed as an instance of xsd:integer because xsd:integer is closer to xsd:int than xsd:decimal is in the datatype inheritance hierarchy.
Each EXI datatype identifier above is a QName. Datatype identifiers uniquely identify one of the built-in EXI datatypes. They are used by Pluggable CODECS to designate XML Schema types to built-in EXI datatypes different from the ones that are associated by default. Not all built-in EXI datatypes are assigned datatype identifiers. Only those that have identifiers are usable by Pluggable CODECS for designating alternative representations.
The rules used to represent values of String depend on the content items to which the values belong. There are certain content items whose value representation involve the use of string tables while other content items are represented using the encoding rule described in 7.1.10 String without involvement of string tables. The content items that use string tables and how each of such content items uses string tables to represent their values are described in 7.3 String Table.
Schemas can provide one or more enumerated values for types. EXI exploits those pre-defined values when they are available to represent values of such types in a more efficient manner than it would otherwise using built-in EXI datatypes. The encoding rule for representing a type of enumerated values is described in 7.2 Enumerations. Types that are derived from other types by union and their subtypes are always represented as String regardless of the availability of enumerated values. Representation of values of which the schema type is one of QName, Notation or a type derived therefrom by restriction are also not affected by enumerated values if any.
7.1 Built-in EXI Datatypes Representation
The following sections describe the encoding rules for representing built-in EXI datatypes.
7.1.1 Binary
Values typed as Binary are represented as a length-prefixed sequence of octets representing the binary content. The length is represented as an Unsigned Integer (see
7.1.6 Unsigned Integer).
7.1.2 Boolean
The number of distinct values that a Boolean can represent depends on the presence of pattern facets in the associated schema datatype. Those values are zero (0) and one (1) in the absence of patterns, whereas they are zero (0), one (1), two (2) and three (3) when patterns are available. With patterns, the value set is able to distinguish values not only arithmetically (0 or 1) but also between lexical variances. The following table shows the possible Boolean values as well as what each value represents with/without patterns in comparison.
| Boolean value | without patterns | with patterns |
|---|
| 0 | 0 ("false" or "0") | 0 ("false") |
| 1 | 1 ("true" or "1") | 0 ("0") |
| 2 | N/A | 1 ("true") |
| 3 | 1 ("1") |
| # of distinct values (N) | 2 | 4 |
When the value of compression option is false and
the value bit-packed is used for alignment options,
values typed as Boolean
are represented using n-bit unsigned integer (7.1.9 n-bit Unsigned Integer) where
n equals to log2(N) given the number of distinct values which is 2 or 4
depending on the presence of pattern facets as shown in the above table. Otherwise, they are represented using one byte.
7.1.3 Decimal
Values typed as Decimal are represented as a Boolean sign (see 7.1.2 Boolean) followed by two Unsigned Integers (see 7.1.6 Unsigned Integer). A sign value of zero (0) is used to represent positive Decimal values and a sign value of one (1) is used to represent negative Decimal values. The first Unsigned Integer represents the integral portion of the Decimal value. The second Unsigned Integer represents the fractional portion of the Decimal value with the digits in reverse order to preserve leading zeros.
7.1.4 Float
Values typed as Float are represented as two consecutive Integers (see
7.1.5 Integer). The first Integer represents the mantissa of the floating point number and the second Integer represents the base-10 exponent of the floating point number. The range of the mantissa is - (263) to 263-1 and the range of the exponent is - (214-1) to 214-1. Values typed as Float with a mantissa or exponent outside the accepted range are represented as schema-invalid values.
The exponent value -(214) is used to indicate one of the special values: infinity, negative infinity and not-a-number (NaN). An exponent value -(214) with mantissa values 1 and -1 represents
positive infinity (INF) and negative infinity (-INF) respectively. An exponent value -(214) with any other mantissa value represents NaN.
A value represented as Float can be decoded by going through the following steps.
- Retrieve the mantissa value using the procedure described in 7.1.5 Integer.
- Retrieve the exponent value using the procedure described in 7.1.5 Integer.
- If the exponent value is -(214), the mantissa value 1 represents INF, the mantissa value -1 represents -INF and any other mantissa value represents NaN. If the exponent value is not -(214), the float value is m × 10e where m is the mantissa and e is the exponent obtained in the preceding steps.
Note:
Support for IEEE float representation is currently under consideration. (See F.2 IEEE Floats)
7.1.5 Integer
The Integer type supports signed integer numbers of arbitrary magnitude. Values typed as Integer are represented as a Boolean sign (see 7.1.2 Boolean) followed by an Unsigned Integer (see 7.1.6 Unsigned Integer). A sign value of zero (0) is used to represent positive integers and a sign value of one (1) is used to represent negative integers. For non-negative values, the Unsigned Integer holds the magnitude of the value. For negative values, the Unsigned Integer holds the magnitude of the value minus 1.
7.1.6 Unsigned Integer
The Unsigned Integer type supports unsigned integer numbers of arbitrary magnitude. Values typed as Unsigned Integer are represented using a sequence of octets. The sequence is terminated by an octet with its most significant bit set to 0. The value of the unsigned integer is stored in the least significant 7 bits of the octets as a sequence of 7-bit bytes, with the least significant byte first.
A value represented as Unsigned Integer can be decoded by going through the following steps with the initial value set to 0 and the initial multiplier set to 1.
- Read the next octet.
- Multiply the value of the unsigned number represented by the 7 least significant bits of the octet by the current multiplier and add the result to the current value.
- Multiply the multiplier by 128.
- If the most significant bit of the octet was 1, go back to step 1.
| Editorial note | |
|
EXI also provides a modified representation for Integers that will not fit within a 64-bit integer to facilitate processing by devices that do not support big integers. This capability has not yet been specified.
|
7.1.7 QName
Values of type QName are encoded as a sequence of values representing the URI, local-name and prefix components of the QName in that order, where the prefix component is present only when the preserve.prefixes option is set to true.
When the QName value is specified by a schema-informed grammar using the SE(qname) or AT(qname) terminal symbols, URI and local-name are implicit and are omitted.
Otherwise, URI and local-name components are encoded as Strings (see
7.1.10 String) per the rules defined for uri content item and a local-name content item, respectively.
If the QName is in no namespace, the URI is represented by a zero length String.
When present, prefixes are represented as n-bit unsigned integers (7.1.9 n-bit Unsigned Integer), where n is log2(N) and N is the number of unique prefixes specified for the URI of the QName by preceding NS events in the EXI stream. Each unique prefix is assigned a unique n-bit integer (0 ... N-1) according to the order in which the associated NS event occurs in the EXI stream. If there are no prefixes specified for the URI of the QName by preceding NS events in the EXI stream, the prefix is undefined. An undefined prefix is represented using zero bits (i.e., omitted).
Given either a n-bit unsigned integer m that represents the prefix value or an undefined prefix, the effective prefix value is determined by following the rules described below in order. A QName is in error if it has an undefined prefix that cannot be resolved by the rules below.
- If the prefix is defined, select the m-th prefix value associated with the URI of the QName as the candidate prefix value. Otherwise, there is no candidate prefix value.
- If the QName value is part of an SE event followed by an associated NS event with an indicator value of 1, the prefix value is the prefix of such NS event. Otherwise, the prefix value is the candidate value, if any, selected in step 1 above.
7.1.8 Date-Time
Values typed as Date-Time are encoded as a sequence
of values representing the individual components of the Date-Time. The
following table specifies each of the possible date-time components
along with how they are encoded.
Table 7-2. Date-Time components| Component | Value | Type |
|---|
| Year | Offset from 2000 | Integer (
7.1.5 Integer) |
| MonthDay | Month * 31 + Day | 9-bit Unsigned Integer (7.1.9 n-bit Unsigned Integer) where day is a value in the range 0-30 and month is a value in the range 1-12. |
| Time | ((Hour * 60) + Minutes) * 60 + seconds | 17-bit Unsigned Integer (7.1.9 n-bit Unsigned Integer) |
| FractionalSecs | Fractional seconds | Unsigned Integer (
7.1.6 Unsigned Integer) representing the fractional part of the seconds with digits in reverse order to preserve leading zeros |
| TimeZone | TZHours * 60 + TZMinutes | 11-bit Unsigned Integer (7.1.9 n-bit Unsigned Integer) representing a signed integer offset by 840 ( = 14 * 60 ) |
| presence | Boolean presence indicator | Boolean (7.1.2 Boolean) |
The variety of components that constitute a value and their appearance order depend on the XML Schema type associated with the value. The following table shows which components are included in a value of each XML Schema type that is relevant to Date-Time datatype. Items listed in square brackets are included if and only if the value of its preceding presence indicator (specified above) is set to true.
Table 7-3. Assortment of Date-Time components| XML Schema Type | Included Components |
|---|
| gYearXS2 | Year, presence, [TimeZone] |
| gYearMonthXS2 | Year, MonthDay, presence, [TimeZone] |
| dateXS2 |
| dateTimeXS2 | Year, MonthDay, Time, presence, [FractionalSecs], presence, [TimeZone] |
| gMonthXS2 | MonthDay, presence, [TimeZone] |
| gMonthDayXS2 |
| gDayXS2 |
| timeXS2 | Time, presence, [FractionalSecs], presence, [TimeZone] |
7.1.9 n-bit Unsigned Integer
When the value of compression option is false and
the value bit-packed is used for alignment options,
values of type
n-bit Unsigned Integer are represented as an unsigned binary integer using n bits.
Otherwise, they are represented as an unsigned integer using the minimum number of bytes required to store
n bits. Bytes are ordered with the least significant byte first.
The n-bit unsigned integer encoding is also used to encode bounded integers.
These are integer values that have been constrained explicitly through the use of schema facets
(for example, XML schema minInclusive and maxInclusive facets) or implicitly through the use
of a restricted data type (for example, the XML schema unsignedByte type).
A bounded integer value is encoded as an offset (or delta) from the minimum value in the range.
It is encoded in the minimum number of bits that would be necessary to hold any value within the
full range. For example, if an integer is constrained to have a value between 3 and 10
(inclusively) and the value to be encoded is 7, the number encoded would be 7 - 3 = 4 and the
number of bits needed would be 3.
If the range defined by the bounds is large, the average number of bits needed to encode a
set of values can be larger than the number of bits needed if those values are encoded as
variable-length integers (see 7.1.5 Integer). For this reason, a maximum
range value is imposed such that if the value to be encoded is larger than this maximum,
variable-length integer encoding is done. The maximum range value is 4095 which equates to a
bit field length of no more than 12 bits.
7.1.10 String
Values of type String are represented as a length prefixed sequence of
characters. The length indicates the number of characters in the
string and is represented as an Unsigned Integer (see 7.1.6 Unsigned Integer). If a restricted character set is defined for the string (see 7.1.10.1 Restricted Character Sets), each character is represented as an n-bit Unsigned Integer (see 7.1.9 n-bit Unsigned Integer). Otherwise, each character is represented by its UCS code point encoded as an Unsigned Integer (see 7.1.6 Unsigned Integer).
EXI uses a string table to represent certain
content items more efficiently. Section 7.3 String Table
describes the string table and how it is applied to different content
items.
7.1.10.1 Restricted Character Sets
If a string value is associated with a schema datatype and one or more of the datatypes in its datatype hierarchy has one or more pattern facets, there may be a restricted character set defined for the string value. The following steps are used to determine the restricted character set, if any, defined for a given string value associated with such a schema datatype.
First, determine the character set for each datatype in the datatype hierarchy of the string value that has one or more pattern facets according to section E Deriving Character Sets from XML Schema Regular Expressions. For each datatype with more than one pattern facet, compute the restricted character set based on the union of the regular expressions specified by its pattern facets. If the restricted character set for a datatype contains at least 255 characters or contains non-BMP characters, the character set of the datatype is not restricted and can be omitted from further consideration.
Then, compute the restricted character set for the string value as the intersection of all the character sets computed above. If the resulting character set contains less than 255 characters, the string value has a restricted character set and each character is represented using an n-bit Unsigned Integer (see 7.1.9 n-bit Unsigned Integer), where n is log2(N + 1) and N is the number of characters in the restricted character set.
The characters in the restricted character set are sorted by UCS code point and represented by integer values in the range (0 ... N-1) according to their ordinal position in the set. Characters that are not in this set are represented by the integer N followed by the UCS code point of the character represented as an Unsigned Integer.
The figure below illustrates an overview of the process for determining and using restricted character sets described in this section.
7.2 Enumerations
Values of enumerated types are encoded as
n-bit Unsigned Integers (7.1.9 n-bit Unsigned Integer) where n = ⌈ log 2 m ⌉ and m is the number of items
in the enumerated type. The value assigned to each item corresponds to
its ordinal position in the enumeration in schema-order starting with
position zero (0).
Exceptions are for schema types derived from others by union and their subtypes, QName or Notation and types derived therefrom by restriction. The values of such types are processed by their respective built-in EXI datatypes instead of being represented as enumerations.
7.3 String Table
EXI uses a string table to assign "compact identifiers" to some
string values. Occurrences of string values found in the string table
are represented using the associated compact identifier rather than
encoding the entire "string literal". The string table is initially pre-populated with
string values that are likely to occur in certain contexts and is
dynamically expanded to include additional string values encountered
in the document. The following content items are encoded using a
string table:
The uris and local-names used in qname content items are also encoded using a string table. When a string value is found in the string table, the value is encoded
using the compact identifier and no changes are made to the string table as a result.
When a string value is not found in the string table, its string literal is encoded
as a String without using a compact identifier, only after which
the string table is augmented by including the string value with an assigned
compact identifier.
The string table is divided into partitions and each partition is
optimized for more frequent use of either compact identifiers or string literals
depending on the purpose of the partition. Section 7.3.1 String Table Partitions describes how EXI string table is
partitioned. Section 7.3.2 Partitions Optimized for Frequent use of Compact Identifiers
describes how string values are encoded when the associated partition
is optimized for more frequent use of compact identifiers. Section 7.3.3 Partitions Optimized for Frequent use of String Literals describes how string values are
encoded when the associated partition is optimized for more frequent use
of string literals.
The life cycle of a string table spans the processing of
a single EXI stream. String tables are not represented in an EXI stream or exchanged
between EXI processors. A string table cannot be reused across multiple EXI streams;
therefore, EXI processors MUST use a string table that is equivalent to
the one that would have been newly created and pre-populated with initial
values for processing each EXI stream.
7.3.1 String Table Partitions
The string table is organized into partitions
so that the indices assigned to compact identifiers can stay relatively small.
Smaller number of indices results in improved average compactness and the efficiency
of table operations. Each partition has a separate set of compact identifiers and
content items are assigned to specific partitions as described below.
Uri content items and the URI portion of qname content items are assigned to the uri
partition. The uri partition is optimized for frequent use of compact identifiers and is
pre-populated with initial entries as described in D.1 Initial Entries in Uri Partition.
When a schema is provided, the uri partition is also pre-populated with
the name of each namespace URI declared in the schema,
appended in lexicographical order.
Prefix content items are assigned to partitions based
on their associated namespace URI. Partitions containing
prefix content items are optimized for frequent use of compact identifiers and the
string table is pre-populated with entries as described in
D.2 Initial Entries in Prefix Partitions.
Local-name content items and the local-name portion of qname content items are assigned to partitions based
on the namespace URI of the NS event or qname content item of which the local-name is a part. Partitions containing local-name
content items are optimized for frequent use of string literals and the string table is pre-populated
with entries as described in D.3 Initial Entries in Local-Name Partitions.
When a schema is provided, the string table is also pre-populated with the
local name of each attribute, element and type declared in the
schema, partitioned by namespace URI and sorted lexicographically.
Value
content items are assigned simultaneously to the global value partition
as well as to the "local" value partition that corresponds to the
qname of the attribute or element in context at the time
when the string table is looked up and the string value is not found in both global and local value partitions.
Partitions containing value
content items are optimized for frequent use of string literals and are initially empty.
7.3.2 Partitions Optimized for Frequent use of Compact Identifiers
String table partitions that are expected to contain a relatively
small number of entries used repeatedly throughout the document are
optimized for the frequent use of compact identifiers. This includes the uri partition and
all partitions containing prefix content items.
When a string value is found in a partition optimized for frequent use of compact identifiers,
the string value is represented as the value (i+1)
encoded as an n-bit Unsigned Integer (7.1.9 n-bit Unsigned Integer), where
i is the value of the compact identifier, n is
⌈ log2 (m+1) ⌉ and m is the number of
entries in the string table partition at the time of the operation.
When a string value is not found in a partition optimized for frequent use of compact identifiers,
the String value is represented as zero (0) encoded as an
n-bit Unsigned Integer, followed by the string literal
encoded as a String (7.1.10 String). After
encoding the String value, it is added to the string table partition
and assigned the next available compact identifier m.
7.3.3 Partitions Optimized for Frequent use of String Literals
The remaining string table partitions are optimized for
the frequent use of string literals. This includes all string table partitions containing
local-name content items
and all string table partitions containing value content
items.
When a string value is found in the partitions containing
local-name content items, the
string value is represented as zero (0) encoded as an Unsigned Integer (see
7.1.6 Unsigned Integer) followed by an the compact
identifier of the string value. The compact identifier of the string
value is encoded as an n-bit unsigned integer (7.1.9 n-bit Unsigned Integer), where
n is ⌈ log2 m ⌉ and m is
the number of entries in the string table partition at the time of the operation.
When a string value is not found in the partitions containing
local-name content items, its
string literal is encoded as a String (see 7.1.10 String) with the length of the string is incremented
by one. After encoding the string value, it is added to the string
table partition and assigned the next available compact
identifier m.
As described above, value content items are assigned
to two partitions, a "local" value partition and the global
value partition. When a string value is found in the "local" value partition,
the string value is represented as zero (0) encoded as an Unsigned Integer (see
7.1.6 Unsigned Integer) followed by the compact identifier
of the string value in the "local" value partition.
When a string value is found in the global value partition, but not in the "local" value
partition, the String value is represented as one (1) encoded as an
Unsigned Integer (see 7.1.6 Unsigned Integer) followed by the compact
identifier of the String value in the global value
partition. The compact identifier is encoded as an n-bit
unsigned integer (7.1.9 n-bit Unsigned Integer), where n is ⌈ log2m ⌉ and m is the number of entries in the
associated partition at the time of the operation.
When a string value is not found in the global or "local"
value partition, its string literal is encoded as a
String (see 7.1.10 String) with the length
incremented by two. After encoding the string value, it is added to
both the associated "local" value string table partition and the global value
string table partition.
7.4 Pluggable CODECS
By default, each typed value in an EXI stream is represented by the
associated built-in EXI data type (e.g., seeTable 7-1). However, [Definition:] EXI processors MAY provide the capability to
specify different built-in types or user-defined encoder/decoders
(CODECS) for representing specific schema types. This capability is
called Pluggable CODECS.
EXI processors that support Pluggable CODECS MAY provide
external means to define and install user-defined CODECS, of which EXI
processors are free to choose implementation dependent mechanisms. EXI
processors MAY also provide means for applications or users to specify
alternate built-in types or user-defined CODECS for representing
specific schema types, the mechanisms of which are again
implementation dependent.
When an EXI processor encodes an EXI stream using Pluggable CODECS,
it MUST specify
in the EXI header each schema type that is not represented using the
default built-in type and the alternate built-in type or user-defined
CODEC used for each one unless the whole EXI Options part of the header is omitted.
An EXI processor that attempts to decode an
EXI stream that specifies a user-defined CODEC in the EXI header that
it does not recognize MAY report a warning, but this is not an
error. However, when an EXI processor encounters a typed value that
was encoded by a user-defined CODEC that it does not support, it MUST
report an error.
The EXI options header, when it appears in an EXI stream, MUST include a codecMap element for each
schema type that is not represented using the default built-in
type. The codecMap element includes two child elements. The QName of
the first child element identifies the schema type that is not
represented using the default built-in type and the QName of the
second child element identifies the alternate built-in type or
user-defined CODEC used to represent that type. Built-in types are
identified by the type identifiers in Table 7-1.
For example, the following codecMap element indicates all values of
type xsd:decimal in the EXI stream are represented using the built-in
String type, which has the type ID xsd:string:
<codecMap xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:decimal/>
<xsd:string/>
</codecMap>
It is the responsibility of an EXI processor to interface with a particular implementation of built-in types or user-defined CODECs properly. In the example above, an EXI processor may need to provide a string value of the data being processed that is typed as xsd:decimal in order to interface with a built-in String type. In such a case, some EXI processors may have started with a decimal value and such processors may well translate the value into a string before passing the data to the built-in String type while other EXI processors may already have a string value of the data so that it can pass the value directly to the built-in String type without any translation.
As another example, the following codecMap element indicates all
values of the used-defined type geo:geometricSurface are represented
using the user-defined CODEC geo:geometricInterpolator:
<codecMap xmlns:geo="http://www.example.com/Geometry">
<geo:geometricSurface/>
<geo:geometricInterpolator/>
</codecMap>
Note:
EXI only defines a way to indicate the use of user-defined CODECs for representing values of specific types. CODECs which are assigned to types by QNames, are omnipresent only if the QName is one of those that represent built-in EXI datatypes. For CODECs of other QNames, EXI does not provide nor suggest a method by which they are identified and shared between EXI Processors. Therefore, its use needs to be restrained by weighing alternatives and considering the consequences of each in pros and cons, in order to avoid unruly proliferation of documents that use custom CODECs. Those applications that ever find Pluggable CODECS useful should make sure that they exchange such documents only among the parties that are pre-known or discovered to be able to process the user-defined CODECs that are in use. Otherwise, if it is not for certain if a receiver undestands the particular user-defined CODECs, the sender should never attempt to send documents that use user-defined CODECs to that recipient.
8. EXI Grammars
EXI is a knowledge based encoding that uses a set of grammars to
determine which events are most likely to occur at any given point in
an EXI stream and encodes the most likely alternatives in fewer
bits. It does this by mapping the stream of events to a lower entropy
set of representative values and encoding those values using a set of
simple variable length codes or an EXI compression algorithm.
The result is a very simple, small algorithm that uniformly handles
schema-less encoding, schema-informed encoding, schema deviations,
and any combination thereof in EXI streams. These variations do
not require different algorithms or different parsers, they are simply
informed by different combinations of grammars.
The following sections describe the grammars used to inform the EXI encoding.
Note:
The grammar semantics in this specification are written for clarity and generality. They do not prescribe a particular implementation approach.
8.1 Grammar Notation
8.1.1 Fixed Event Codes
Each grammar production has an event code, which is represented by a sequence of one to three parts separated by periods ("."). Each part is an unsigned integer. The following are examples of grammar productions with event codes as they appear in this specification.
| Productions | Event Codes |
|---|
| |
|
LeftHandSide 1 : |
| |
Event 1
NonTerminal 1 | 0 |
| |
Event 2
NonTerminal 2 | 1 |
| |
Event 3
NonTerminal 3 | 2.0 |
| |
Event 4
NonTerminal 4 | 2.1 |
| |
Event 5
NonTerminal 5 | 2.2.0 |
| |
Event 6
NonTerminal 6 | 2.2.1 |
| |
|
LeftHandSide 2 : |
| |
Event 1
NonTerminal 1 | 0 |
| |
Event 2
NonTerminal 2 | 1.0 |
| |
Event 3
NonTerminal 3 | 1.1 |
The number of parts in a given event code is called the event code's length. No two productions with the same non-terminal symbol on the left-hand-side are permitted to have the same event code.
8.1.2 Variable Event Codes
Some non-terminal symbols are used on the right-hand-side in a production without an event prefixed to them. Such non-terminal symbols are macros and they are used to capture some recurring set of productions into symbols so that a symbol can be used in the grammar representation instead of including all the productions the macro represents in place every time it is used.
|
ABigProduction 1 : |
| |
Event 1
NonTerminal 1 | 0 |
| |
Event 2
NonTerminal 2 | 1 |
| |
LEFTHANDSIDE 1 (2.0) | 2.0 |
| |
|
ABigProduction 2 : |
| |
Event 1
NonTerminal 1 | 0 |
| |
LEFTHANDSIDE 1 (1.1) | 1.1 |
| |
Event 2
NonTerminal 2 | 1.2 |
Because non-terminal macros are injected into the right-hand-side of more than one production,
the event codes of productions with these macro non-terminals on the left-hand-side are not fixed, but will have different event code values depending on the context in which the macro non-terminal appears. This specification calls these variable event codes and uses variables in place of individual event code parts to indicate the event code parts are determined by the context. Below are some examples of variable event codes:
|
LEFTHANDSIDE 1 (n.m) : |
| |
EVENT 1 NONTERMINAL
1 |
n.0 |
| |
EVENT 2 NONTERMINAL
2 |
n.1 |
| |
EVENT 3 NONTERMINAL
3 |
n.
m+2 |
| |
EVENT 4 NONTERMINAL
4 |
n.
m+3 |
| |
EVENT 5 NONTERMINAL
5 |
n.
m+4.0 |
| |
EVENT 6 NONTERMINAL
6 |
n.
m+4.1 |
Unless otherwise specified, the variable
n evaluates to the event code of the production in which the macro non-terminal
LEFTHANDSIDE
1 appears on the right-hand-side. Similarly, the expression
n.
m represents the first two parts of the event code of the production in which the macro non-terminal
LEFTHANDSIDE
1 appears on the right-hand-side.
Non-terminal macros are used in this specification for notational convenience only.
They are not non-terminals, even though they are used in place of non-terminals.
Productions that use non-terminal macros on the right-hand-side need to be expanded by macro substitution before such productions are interpreted.
Therefore, ABigProduction 1 and ABigProduction 2 shown in the preceding example are equivalent to the following set of productions derived by expanding the non-terminal macro symbol LEFTHANDSIDE
1 and evaluating the variable event codes.
|
ABigProduction 1 : |
| |
Event 1
NonTerminal 1 | 0 |
| |
Event 2
NonTerminal 2 | 1 |
| |
EVENT 1 NONTERMINAL
1 | 2.0 |
| |
EVENT 2 NONTERMINAL
2 | 2.1 |
| |
EVENT 3 NONTERMINAL
3 | 2.2 |
| |
EVENT 4 NONTERMINAL
4 | 2.3 |
| |
EVENT 5 NONTERMINAL
5 | 2.4.0 |
| |
EVENT 6 NONTERMINAL
6 | 2.4.1 |
| |
|
ABigProduction 2 : |
| |
Event 1
NonTerminal 1 | 0 |
| |
EVENT 1 NONTERMINAL
1 | 1.0 |
| |
EVENT 2 NONTERMINAL
2 | 1.1 |
| |
Event 2
NonTerminal 2 | 1.2 |
| |
EVENT 3 NONTERMINAL
3 | 1.3 |
| |
EVENT 4 NONTERMINAL
4 | 1.4 |
| |
EVENT 5 NONTERMINAL
5 | 1.5.0 |
| |
EVENT 6 NONTERMINAL
6 | 1.5.1 |
8.2 Grammar Event Codes
Each production rule in the EXI grammar includes an event code value that approximates the likelihood the associated production rule will be matched over the other productions with the same left-hand-side non-terminal symbol. Ultimately, the event codes determine the value(s) by which each non-terminal symbol will be represented in the EXI stream.
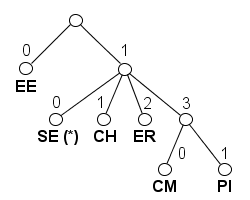
To understand how a given event code approximates the likelihood a given production will matched, it is useful to visualize the event codes for a set of production rules that have the same non-terminal symbol on the left-hand-side as a tree. For example, the following set of productions:
|
ElementContent : |
| | EE | 0 |
| | SE (*)
ElementContent | 1.0 |
| | CH
ElementContent | 1.1 |
| | ER
ElementContent | 1.2 |
| | CM
ElementContent | 1.3.0 |
| | PI
ElementContent | 1.3.1 |
represents a set of information items that might occur as element content after the start tag. Using the production event codes, we can visualize this set of productions as follows:
where the non-terminal symbols are represented by the leaf nodes of the tree and the event code of each production rule that contains a non-terminal symbol defines a path from the root of the tree to the node associated with that symbol. We call this the event code tree for a given set of productions.
An event code tree is similar to a Huffman tree [Huffman Coding] in that shorter paths are generally used for symbols that are considered more likely. However, event code trees are far simpler and less costly to compute and maintain. Event code trees are shallow and contain at most three levels. In addition, the length of each event code in the event code tree is assigned statically without analyzing the data. This classification provides some of the benefits of a Huffman tree without the cost.
8.3 Pruning Unneeded Productions
As discussed in section
6.3 Fidelity Options, applications MAY provide a set of fidelity options to specify the XML features they require. EXI processors MUST use these fidelity options to prune the events that are not required from the grammars, improving compactness and processing efficiency.
For example, the following set of productions represent the set of information items that might occur as element content after the start tag.
|
ElementContent : |
| | EE | 0 |
| | SE (*)
ElementContent | 1.0 |
| | CH
ElementContent | 1.1 |
| | ER
ElementContent | 1.2 |
| | CM
ElementContent | 1.3.0 |
| | PI
ElementContent | 1.3.1 |
If an application sets the fidelity options preserve.comments, preserve.pis and preserve.dtd to false, the productions matching comment (CM), processing instruction (PI) and entity reference (ER) events are pruned from the grammar, producing the following set of productions:
|
ElementContent : |
| | EE | 0 |
| | SE (*)
ElementContent | 1.0 |
| | CH
ElementContent | 1.1 |
Removing these productions from the grammar tells EXI processors that comments and processing instructions will never occur in the EXI stream, which reduces the entropy of the stream allowing it to be encoded in fewer bits.
Each time a production is removed from a grammar, the event codes of the other productions with the same non-terminal symbol on the left-hand-side MUST be adjusted to keep them contiguous if its removal has left the remaining productions with non-contiguous event codes.
8.4 Built-in XML Grammars
This section describes the built-in XML grammar used by EXI when no additional information is available to describe the contents of the EXI stream. The built-in XML grammar is used when no schema exists, for elements with unrestricted types (e.g., xsd:anyType) and for schema extensions and deviations that are not declared by the schema.
A built-in XML grammar is self-evolving. The built-in grammar continuously reflects the knowledge being learned while processing an EXI stream onto itself in order to keep refining itself for subsequent use of the grammar within the extent of processing a single stream.
8.4.1 Built-in Document Grammar
In the absence of additional information about the content of the EXI stream, the following grammar describes the events that will occur in an EXI document.
| Syntax | Event Code |
|---|
| |
|
Document : |
| | SD
DocContent | 0 |
| |
|
DocContent : |
| | SE (*)
DocEnd | 0 |
| | DT
DocContent | 1.0 |
| | CM
DocContent | 1.1.0 |
| | PI
DocContent | 1.1.1 |
| |
|
DocEnd : |
| | ED | 0 |
| | CM
DocEnd | 1.0 |
| | PI
DocEnd | 1.1 |
All productions in the built-in Document grammars of the form
LeftHandSide : SE (*) RightHandSide
are evaluated as follows:
- Let qname be the qualified name of the element matched by SE (*)
- If a grammar does not exist for element
qname, create one based on the Built-in Element Grammar
- Evaluate the element contents using a built-in grammar for element qname
- Evaluate the remainder of event sequence using RightHandSide.
8.4.2 Built-in Fragment Grammar
In the absence of additional information about the contents of an EXI stream, the following grammar describes the events that will occur in an EXI fragment. The grammar shown below represents the initial set of productions that belong to a built-in fragment grammar at the start of a stream processing, which is supplemented by the semantic description that explains the rules used to evolve the built-in fragment grammar to continuously improve it and be better prepared for subsequent uses of the same grammar during the rest of the processing of the stream.
| Syntax | Event Code |
|---|
| |
|
Fragment : |
| | SD
FragmentContent | 0 |
| |
|
FragmentContent : |
| | SE (*)
FragmentContent | 0 |
| | ED | 1 |
| | CM
FragmentContent | 2.0 |
| | PI
FragmentContent | 2.1 |
All productions in the built-in Fragment grammars of the form
LeftHandSide : SE (*) RightHandSide
are evaluated as follows:
- Let qname be the qualified name of the element matched by SE (*)
- If a grammar does not exist for element
qname, create one based on the Built-in Element Grammar
- Evaluate the element contents using a built-in grammar for element qname
- Create a production of the form LeftHandSide : SE (qname) RightHandSide with an event code 0
- Increment the first part of the event code of each production in the current grammar with the non-terminal LeftHandSide on the left hand side.
- Add the production created in step 4 to the grammar
- Evaluate the remainder of event sequence using RightHandSide.
All productions of the form LeftHandSide : SE (qname) RightHandSide that were previously added to the grammar upon the first occurrence of the element that has the qualified name qname are evaluated as follows when they are matched:
- Evaluate the element contents using a built-in grammar for element qname
- Evaluate the remainder of event sequence using RightHandSide.
8.4.3 Built-in Element Grammar
[Definition:] EXI defines a built-in element grammar that is used in the absence of additional information about the contents of an EXI element prior to its processing. A built-in element grammar shown below is prescibed by EXI to reflect the events that will occur in an element and the order amongst them in general without any further constraint about what is likely or not likely to occur inside elements.
A single instance of built-in element grammar is shared by those elements in a stream that have the same qualified name and do not have additional a priori constraints as to their content. A separate instance of built-in element grammar is assigned to each qualified name upon the first occurrence of the elements of the same qualified name, thereafter the grammar continuously evolves by reflecting the knowledge learned while processing the content of those elements. The grammar shown below represents the initial set of productions that belong to a built-in element grammar at the time when a new instance is created, which is supplemented by the semantic description that explains the rules that are applied by the grammar onto itself to evolve and be better prepared for subsequent uses of the same grammar instance during the rest of the processing of the stream.
| Syntax | Event Code |
|---|
| |
|
StartTagContent : |
| | EE | 0.0 |
| | AT (*)
StartTagContent | 0.1 |
| | NS
StartTagContent | 0.2 |
| |
ChildContentItems (0.3) | |
| |
|
ElementContent : |
| | EE | 0 |
| |
ChildContentItems (1.0) | |
| |
|
ChildContentItems (n.m) : |
| | SE (*) ElementContent |
n.
m |
| | CH ElementContent |
n.(m+1) |
| | ER ElementContent |
n.(m+2) |
| | CM ElementContent |
n.(m+3).0 |
| | PI ElementContent |
n.(m+3).1 |
All productions in the built-in Element grammar of the form
LeftHandSide: AT (*)
RightHandSide are evaluated as follows:
- Let
qname be the qualified name of the attribute matched by AT (*)
- Create a production of the form
LeftHandSide : AT (qname) StartTagContent
with an event code 0 and increment the first part of the event code of each production in the current grammar with the non-terminal LeftHandSide on the left hand side
- Add the production created in the previous step to the grammar
- Evaluate the remainder of event sequence using RightHandSide.
All productions in the built-in Element grammars of the form
LeftHandSide : SE (*) RightHandSide are evaluated as follows:
- Let qname be the qualified name of the element matched by SE (*)
- If a grammar does not exist for element
qname, create one based on the Built-in Element Grammar
- Evaluate the element contents using a built-in grammar for element qname
- Create a production of the form LeftHandSide : SE (qname) RightHandSide with an event code 0
- Increment the first part of the event code of each production in the current grammar with the non-terminal LeftHandSide on the left hand side.
- Add the production created in step 4 to the grammar
- Evaluate the remainder of event sequence using RightHandSide.
All productions of the form LeftHandSide : SE (qname) RightHandSide that were previously added to the grammar upon the first occurrence of the element that has the qualified name qname are evaluated as follows when they are matched:
- Evaluate the element contents using a built-in grammar for element qname
- Evaluate the remainder of event sequence using RightHandSide.
All productions in the built-in Element grammar of the form
LeftHandSide : CH
RightHandSide are evaluated as follows:
- If a production of the form,
LeftHandSide : CH
RightHandSide with an event code of length 1 does not exist in the current element grammar, create one with event code 0 and increment the first part of the event code of each production in the current grammar with the non-terminal
LeftHandSide on the left hand side.
- Add the production created in step 1 to the grammar
- Evaluate the remainder of event sequence using RightHandSide.
8.5 Schema-informed Grammars
This section describes the schema-informed grammars used by EXI when schema information is available to describe the contents of the EXI stream. Schema-informed grammars are independent of any particular schema language and can be derived from W3C XML Schemas, RELAX NG schemas, DTDs or other regular languages for describing what is likely to occur in an EXI stream.
Schema-informed grammars accept all XML documents and fragments regardless of whether and how closely they match the schema. The encoder encodes individual events using schema-informed grammars where they are available and falls back to the built-in XML grammars where they are not. In general, events for which a schema-informed grammar exists will be encoded more efficiently.
Unlike built-in XML grammars, schema-informed grammars are static and do not evolve, which permits the reuse of schema-informed grammars across the processing of multiple EXI streams. This is a single outstanding difference between the two grammar systems.
With such differences, however, their uses are not exclusive, but are connected together at individual grammar level. Of particular note is that built-in grammars that are called upon for schema-deviated parts or elements with unrestricted types (e.g. xsd:anyType) are still subject to dynamic grammar learning during the rest of the EXI stream processing as is described in 8.4.2 Built-in Fragment Grammar.
8.5.1 Schema-informed Document Grammar
When schema information is available to describe the contents of an EXI stream, the following grammar describes the events that will occur in an EXI document.
| Syntax | Event Code |
|---|
| |
|
Document : |
| | SD
DocContent | 0 |
| |
|
DocContent : |
| | SE (G 0) DocEnd | 0 |
| | SE (G 1) DocEnd | 1 |
| | ⋮ | ⋮ |
| | SE (G n-1) DocEnd | n-1 |
| | SE (*)
DocEnd |
n.0 |
| | DT
DocContent |
n.1 |
| | CM
DocContent |
n.2.0 |
| | PI
DocContent |
n.2.1 |
| |
|
|
| - The variable
n in the grammar above is the number of global elements declared in the schema.
G 0, G 1, ... G n-1 represent all the qnames of global elements sorted lexicographically, first by localName, then by uri.
- The terminal symbol SE (*) is only matched if a more specific match does not exist among SE(G 0), SE(G 1), ... SE(G n-1).
|
|
DocEnd : |
| | ED | 0 |
| | CM
DocEnd | 1.0 |
| | PI
DocEnd | 1.1 |
All productions in the schema-informed document grammars of the form
LeftHandSide : SE (*)
RightHandSide are evaluated as follows:
- Let
qname be the qualified name of the element matched by SE (*)
- If a grammar does not exist for Element
qname, create one based on the Built-in Element Grammar
- Evaluate the element contents using the SE (qname) grammar
8.5.2 Schema-informed Fragment Grammar
When schema information is available to describe the contents of an EXI stream, the following grammar describes the events that will occur in an EXI fragment.
| Syntax | Event Code |
|---|
| |
|
Fragment : |
| | SD
FragmentContent | 0 |
| |
|
FragmentContent : |
| | SE (F 0) FragmentContent | 0 |
| | SE (F 1) FragmentContent | 1 |
| | ⋮ | ⋮ |
| | SE (F n-1) FragmentContent | n-1 |
| | ED |
n |
| | SE (*)
FragmentContent | (n+1).0 |
| | CM
FragmentContent | (n+1).1.0 |
| | PI
FragmentContent | (n+1).1.1 |
| |
|
|
|
- The variable n in the grammar above is the number of unique element qnames declared in the schema. F 0, F 1, ... F n-1 represent all the unique qnames of elements sorted lexicographically, first by localName, then by uri. If there is more than one element with the same qname, the qname is included only once with a relaxed grammar that accepts any content.
- The terminal symbol SE (*) is only matched if a more specific match does not exist among SE(F 0), SE(F 1), ... SE(F n-1).
|
All productions in the schema-informed fragment grammars of the form
LeftHandSide : SE (*)
RightHandSide are evaluated as follows:
- Let
qname be the qualified name of the element matched by SE (*)
- If a grammar does not exist for Element
qname, create one based on the Built-in Element Grammar
- Evaluate the element contents using the SE (qname) grammar
8.5.3 Schema-informed Element and Type Grammars
[Definition:] When one or more XML Schema is available to describe the contents of an EXI stream, a schema-informed element grammar Element i is derived for each element declaration E i described by the schemas, where 0 ≤ i < n and n is the number of element declarations in the schema.
[Definition:] When one or more XML Schema is available to describe the contents of an EXI stream, a schema-informed type grammar Type i is derived for each named type declaration T i described by the schemas, where 0 ≤ i < n and n is the number of type declarations in the schema.
Each schema-informed element grammar and type grammar is constructed according to the following four steps:
- Create a proto-grammar that describes the content model according to available schema information (see section 8.5.3.1 EXI Proto-Grammars).
- Normalize the proto-grammar into an EXI grammar (see section 8.5.3.2 EXI Normalized Grammars).
- Assign event codes to each production in the normalized EXI grammar (see section 8.5.3.3 Event Code Assignment).
- Add additional productions to the normalized EXI grammar to represent events that may occur in the EXI stream, but are not described by the schema, such as comments, processing-instructions, schema-deviations, etc. (see section 8.5.3.4 Undeclared Productions).
Each element grammar Element i includes a sequence of n non-terminals Element i, j , where 0 ≤ j < n. The content of the entire element is described by the first non-terminal Element i, 0 . The remaining non-terminals describe portions of the element content. Likewise, each type grammar Type i includes a sequence of n non-terminals Type i, j and the content of the entire type is described by the first non-terminal Type i, 0 .
The algorithms expressed in this section provide a concise and formal description of the EXI grammars for a given set of XML Schema definitions. More efficient algorithms likely exist for generating these EXI grammars and EXI implementations are free to use any algorithm that produces grammars and event codes that generate EXI encodings that match those produced by the grammars described here.
8.5.3.1 EXI Proto-Grammars
This section describes the process for creating the EXI proto-grammars from XML Schema declarations and definitions. EXI proto-grammars differ from normalized EXI grammars in that they may contain productions of the form:
|
LeftHandSide : |
| | RightHandSize |
where LeftHandSide and RightHandSide are both non-terminals. Whereas, all productions in a normalized EXI grammar contain exactly one terminal symbol and at most one non-terminal symbol on the right hand side. This is a restricted form of Greibach normal form [Greibach Normal Form].
EXI proto-grammars are derived from XML Schema in a straight-forward manner and can easily be normalized with simple algorithm (see 8.5.3.2 EXI Normalized Grammars).
8.5.3.1.1 Grammar Concatenation Operator
Proto-grammars are specified in a modular, constructive fashion. XML Schema components such as terms, particles, attribute uses are transformed each into a distinct proto-grammar, leveraging proto-grammars of their sub-components. At various stages of proto-grammar construction, two or more of proto-grammars are concatenated one after another to form more composite grammars.
The grammar concatenation operator ⊕ is a binary, associative operator that creates a new grammar from its left and right grammar operands. The new grammar accepts any set of symbols accepted by its left operand followed by any set of symbols accepted by its right operand.
Given a left operand Grammar L and a right operand Grammar R, the following operation
creates a combined grammar by replacing each production of the form
where 0 ≤ k < n and n is the number of non-terminals that occur on the left hand side of productions in Grammar L, with a production of the form
connecting each accept state of Grammar L with the start state of Grammar R.
8.5.3.1.2 Element Grammars
This section describes the process for creating an EXI element grammar from an XML Schema element declarationXS1.
Given an element declaration E i , with properties {name}, {target namespace}, {type definition}, {scope} and {nillable}, create a corresponding EXI grammar Element i for evaluating the contents of elements in the specified {scope} with qname localName = {name} and qname uri = {target namespace} .
If the {type definition} of E i is a simple type definition, follow the procedures defined in section 8.5.3.1.3 SimpleType Grammars to generate the grammar Element i describing the content model of E i . If the {type definition} of E i is a complex type definition, follow the procedures defined in 8.5.3.1.4 Complex Type Grammars to generate the grammar Element i describing the content model of E i .
8.5.3.1.3 SimpleType Grammars
This section describes the process for creating an EXI type grammar from an XML Schema simple type definitionXS1.
Given a simple type definition T i , with properties {name} and {target namespace}, create a new EXI grammar Type i for evaluating instances of types with qname localName = {name} and qname uri = {target namespace}.
Add the following grammar productions to Type i :
| Syntax: | |
|---|
|
Type i, 0 : |
| | CH [schema-valid] Type i, 1 |
|
Type i, 1 : |
| | EE |
| |
| Note: |
|---|
|
Productions of the form LeftHandSide : CH [schema-valid] RightHandSide represent typed character data that is valid with respect to the schema. Schema-invalid character data is represented by productions of the form LeftHandSide : CH [schema-invalid] RightHandSide described in section 8.5.3.4.2 Undeclared Terminal Symbols.
|
8.5.3.1.4 Complex Type Grammars
This section describes the process for creating an EXI type grammar from an XML Schema complex type definitionXS1.
Given a complex type definition T i , with properties {name}, {target namespace}, {base type definition}, {derivation method}, {abstract}, {attribute uses}, {attribute wildcard} and {content type}, create an EXI grammar Type i for evaluating instances of types with qname localName = {name} and qname uri = {target namespace}.
Generate a grammar Attribute i , for each attribute use A i in {attribute uses} according to section 8.5.3.1.5 Attribute Uses. If an {attribute wildcard} is specified, add the following production to each grammar Attribute i generated above:
|
Attribute i, 0 : |
| | AT(*) Attribute i, 0 |
Sort the attribute grammars first by qname localName, then by qname uri to form a sequence of grammars G 0 , G 1 , …, G n-1 , where n is the number of attribute uses in {attribute uses}.
If {content type} is a simple type definition, generate a grammar Content i according to section 8.5.3.1.3 SimpleType Grammars. Otherwise, if {content type} has a content model particle, generate a grammar Content i according to section 8.5.3.1.6 Particles.
If an {attribute wildcard} is specified and {content type} is not empty, add the following production to the Content i grammar generated above:
|
Content i, 0 : |
| | AT(*) Content i, 0 |
Note that productions of the form LeftHandSide : AT(*) RightHandSide are only matched if a more specific match for the current event does not exist in the grammar.
Then, create the grammar Type i by combining the sequence of attribute use grammars constructed above and the Content i grammar using the grammar concatenation operator defined in section 8.5.3.1.1 Grammar Concatenation Operator as follows:
|
Type i = G 0 ⊕ G 1 ⊕ … ⊕ G n-1 ⊕ Content i
|
8.5.3.1.5 Attribute Uses
Given an attribute use A i with properties {required} and {attribute declaration}, where {attribute declaration} has properties {name}, {target namespace} and {scope}, generate a new EXI grammar Attribute i for evaluating attributes in the specified {scope} with qname localName = {name} and qname uri = {target namespace}. Add the following grammar productions to Attribute i :
|
Attribute i, 0 : |
| | AT(qname) Attribute i, 1 |
| |
|
Attribute i, 1 : |
| | EE |
If the {required} property of A i is false, add the following grammar production to indicate this attribute occurrence may be omitted from the content model.
8.5.3.1.6 Particles
Given a particle P i with {min occurs}, {max occurs} and {term} properties, generate a grammar Particle i for evaluating instances of P i as follows.
If {term} is an element declaration, generate the grammar Term 0 according to section 8.5.3.1.7 Element Terms. If {term} is a wildcard, generate the grammar Term 0 according to section 8.5.3.1.8 Wildcard Terms Wildcard Terms. If {term} is a model group, generate the grammar Term 0 according to section 8.5.3.1.9 Model Group Terms.
Create {min occurs} copies of Term 0 .
|
G 0 , G 1 , …, G {min occurs}-1
|
If {max occurs} is not unbounded, create {max occurs} – {min occurs} additional copies of Term 0 ,
|
G {min occurs} , G {min occurs}+1 , …, G {max occurs}-1
|
Add the following productions to each of the grammars that do not already have a production of this form.
|
G i, 0 : |
| | EE where {min occurs} ≤ i < {max occurs} |
indicating these instances of Term 0 may be omitted from the content model. Then, create the grammar for Particle i using the grammar concatenation operator defined in section 8.5.3.1.1 Grammar Concatenation Operator as follows:
|
Particle i = G 0 ⊕ G 1 ⊕ … ⊕ G {max occurs}-1
|
Otherwise, if {max occurs} is unbounded, generate one additional copy of Term 0 , G {min occurs} and replace all productions of the form:
with productions of the form:
|
G {min occurs}, k : |
| | G {min occurs}, 0 |
indicating this term may be repeated indefinitely. Then if there is no production of the form:
add one after the other productions with the non-terminal G {min occurs}, 0 on the left hand side, indicating this term may be omitted from the content model. Then, create the grammar for Particle i using the grammar concatenation operator defined in section 8.5.3.1.1 Grammar Concatenation Operator as follows:
|
Particle i = G 0 ⊕ G 1 ⊕ … ⊕ G {min occurs}
|
8.5.3.1.7 Element Terms
Given a particle {term} PT i that is an element declaration with properties {name} and {target namespace}, create a grammar ParticleTerm i containing the following grammar productions:
| Syntax: |
|---|
| |
|
ParticleTerm i, 0 : |
| |
SE(qname) ParticleTerm i, 1
|
| |
|
ParticleTerm i, 1 :
|
| |
EE
|
| |
|
where qname localname and qname uri are {name} property and {target namespace} property of the element declaration, respectively.
|
| |
In a schema-informed grammar, all productions of the form LeftHandSide : SE(qname) RightHandSide are evaluated as follows:
- Evaluate the element contents using the SE(qname) grammar.
- Evaluate the remainder of the event sequence using RightHandSide
8.5.3.1.8 Wildcard Terms
Given a particle {term} PT i that is a wildcard, create a grammar ParticleTerm i containing the following grammar productions:
| Syntax: |
|---|
| |
|
ParticleTerm i, 0 :
|
| |
SE(*) ParticleTerm i, 1
|
| | | |
|
ParticleTerm i, 1 :
|
| |
EE
|
| |
|
Note that productions of the form LeftHandSide : SE(*) RightHandSide are only matched if a more specific match for the current event does not exist in the grammar.
|
| |
| Semantics: |
|---|
| |
|
In a schema-informed grammar, all productions of the form LeftHandSide : SE(*) RightHandSide are evaluated as follows:
|
- Let qname be the qualified name of the element matched by SE (*)
- If a grammar does not exist for Element qname, create one based on the Built-in Element Grammar.
- Evaluate the element contents using the SE(qname) grammar.
- Evaluate the remainder of the event sequence using RightHandSide
8.5.3.1.9 Model Group Terms
8.5.3.1.9.1 Sequence Model Groups
Given a particle {term} PT i that is a model group with {compositor} equal to "sequence" and a list of n {particles} P 0 , P 1 , …, P n-1 , create a grammar ParticleTerm i as follows:
If the value of n is 0, add the following productions to the grammar ParticleTerm i .
Otherwise, generate a sequence of grammars Particle 0 , Particle 1 , …, Particle n-1 corresponding to the list of particles P 0 , P 1 , …, P n-1 according to section 8.5.3.1.6 Particles. Then combine the sequence of grammars using the grammar concatenation operator defined in section 8.5.3.1.1 Grammar Concatenation Operator as follows:
|
ParticleTerm i = Particle 0 ⊕ Particle 1 ⊕ … ⊕ Particle n-1 |
8.5.3.1.9.2 Choice Model Groups
Given a particle {term} PT i that is a model group with {compositor} equal to "choice" and a list of n {particles} P 0 , P 1 , …, P n-1 , create a grammar ParticleTerm i as follows:
If the value of n is 0, add the following productions to the grammar ParticleTerm i .
Otherwise, generate a sequence of grammar productions Particle 0 , Particle 1 , …, Particle n-1 corresponding to the list of particles P 0 , P 1 , …, P n-1 according to section 8.5.3.1.6 Particles. Then create the grammar ParticleTerm i with the following grammar productions:
|
ParticleTerm i, 0 :
|
| |
Particle 0, 0
|
| |
|
| |
Particle 1, 0
|
| |
⋮
|
| |
Particle n-1, 0
|
indicating the grammar for the term may accept any one of the given {particles}.
8.5.3.1.9.3 All Model Groups
Given a particle {term} PT i that is a model group with {compositor} equal to "all" and a list of n {particles} P 0 , P 1 , ..., P n-1 , create a grammar ParticleTerm i as follows:
Generate a set of grammars S 0 = { Particle 0 , Particle 1 , ..., Particle n-1 } corresponding to the list of particles P 0 , P 1 , ..., P n-1 according to section 8.5.3.1.6 Particles. Then, generate the grammar ParticleTerm i from the set S 0 by applying the following rules.
- Given a newly created grammar G and a set of m grammars, S = {G 0 , G 1 , …, G m-1 }, the productions of G are derived from S by the following steps.
- If the value of m is 0, add the following productions to the grammar G, which completes the grammar G.
- Otherwise, if m > 0, generate a sequence of grammars:
Part j = C j ⊕ All(S – {G j }) where 0 ≤ j < m, C j is a copy of G j and All(S – {G j }) is the All grammar for the set (S – {G j }) created by applying this sequence of rules recursively starting step 1. Then add the following productions to the grammar G:
| |
|
G :
|
| |
Part 0, 0
|
| |
Part 1, 0
|
| |
⋮
|
| |
Part m-1, 0
|
Note:
Although the algorithm used for constructing
all model group grammars presented above is well suited for clearly describing the grammar system in an implementation-independent manner, implementations may choose a more efficient method for grammar construction because the number of grammars the algorithm would generate tends to grow exponentially relative to the number of particles.
An example alternative grammar generation strategy that may lend better to implementation would be to use an array of boolean values each of which corresponds one of the particles to keep track of the particle occurrences and construct the grammars at run-time based on those particles that have yet to occur at the time of evaluation.
This sort of simplified special handling of
all model groups might be appealling given that
all model group instances are properly disconnected from another model group instances in that
all model group can only appear as the immediate content model of a complex type and the particles that they contain have always element terms, not model group terms. Implementations are free to choose or invent any method or any combination of methods to construct grammars for
all model groups.
8.5.3.2 EXI Normalized Grammars
This section describes the process for converting an EXI proto-grammar derived from an XML Schema in accordance with section 8.5.3.1 EXI Proto-Grammars into an EXI normalized grammar. Each production in an EXI normalized grammar has exactly one non-terminal symbol on the left hand side and one terminal symbol on the right hand side followed by at most one non-terminal symbol on the right hand side. In addition, EXI normalized grammars contain no two grammar productions with the same non-terminal on the left side and the same terminal symbol on the right-hand-side. This is a restricted form of Greibach normal form [Greibach Normal Form].
EXI proto-grammars differ from normalized EXI grammars in that they may contain productions of the form:
|
LeftHandSide :
|
| |
RightHandSize
|
where LeftHandSide and RightHandSide are both non-terminals. Therefore, the first step of the normalization process focuses on replacing productions in this form with productions that conform to the EXI normalized grammar rules. This process can produce a grammar that has more than one production with the same non-terminal on the left hand side and the same terminal symbol on the right hand side. Therefore, the second step focuses on eliminating such productions.
The first step of the normalization process is described in Section 8.5.3.2.1 Eliminating Productions with no Terminal Symbol. The second step is described in section 8.5.3.2.2 Eliminating Duplicate Terminal Symbols. Once these two steps are completed, the grammar will be an EXI normalized grammar.
8.5.3.2.1 Eliminating Productions with no Terminal Symbol
Given an EXI proto-grammar G i , with non-terminals G i, 0 , G i, 1 , …, G i, n-1 , replace each production of the form:
|
G i, j :
|
| |
G i, k where 0 ≤ j < n and 0 ≤ k < n
|
with a set of productions:
|
G i, j :
|
| |
RHS(G i, k ) 0
|
| |
RHS(G i, k ) 1
|
| |
⋮
|
| |
RHS(G i, k ) m-1
|
where RHS(G i, k ) 0 , RHS(G i, k ) 1 , …, RHS(G i, k ) m-1 represents the right hand side of each production in G i that has the non-terminal G j, k on the left hand side and m is the number of such productions.
Repeat this process until there are no more production of the form:
|
G i, j :
|
| |
G i, k where 0 ≤ j < n and 0 ≤ k < n
|
in the grammar G i .
8.5.3.2.2 Eliminating Duplicate Terminal Symbols
Given an EXI proto-grammar G i , with non-terminals G i, 0 , G i, 1 , …, G i, n-1 , identify all pairs of productions that have the same non-terminal on the left hand side and the same terminal symbol on the right hand side of the form:
|
G i, j :
|
| |
Terminal G i, k
|
| |
Terminal G i, l
|
where k ≠ l and Terminal represents a particular terminal symbol and replace them with a single production:
|
G i, j :
|
| |
Terminal G i, k ⊔ l
|
where G i, k ⊔ l is a distinct non-terminal that accepts the inputs accepted by G i, k and the inputs accepted by G i, l .
Here the notation " k ⊔ l " denotes a union set of integers and is used to uniquely identify the index of such a non-terminal.
If the non-terminal G i, k ⊔ l does not exist, create it as follows:
|
G i, k ⊔ l :
|
| |
RHS(G i, k ) 0
|
| |
RHS(G i, k ) 1
|
| |
⋮
|
| |
RHS(G i, k ) m-1
|
| |
|
| |
|
| |
RHS(G i, l ) 0
|
| |
RHS(G i, l ) 1
|
| |
⋮
|
| |
RHS(G i, l ) n-1
|
where RHS(G i, k ) 0,
RHS(G i, k ) 1,
…,
RHS(G i, k ) m-1
and
RHS(G i, l ) 0,
RHS(G i, l ) 1,
…,
RHS(G i, l ) n-1
represent the right hand side of each production in the Grammar G i that has the non-terminals G j, k and G j, l on the left hand side respectively and m and n are the number of such productions.
Repeat this process until there are no more productions in the grammar G i of the form:
|
G i, j :
|
| |
Terminal G i, k
|
| |
Terminal G i, l
|
Then, identify any identical productions of the following form:
|
G i, j :
|
| |
Terminal G i, k
|
| |
Terminal G i, k
|
where 0 ≤ k < n, n is the number of productions in G i and Terminal represents a specific terminal symbol, then remove one of them until there are no more productions remaining in the grammar G i of this form.
8.5.3.3 Event Code Assignment
This section describes the process for assigning unique event codes to each production in a normalized EXI grammar. Given a normalized EXI grammar G i , apply the following process to each unique non-terminal G i, j that occurs on the left hand side of the productions in G i where 0 ≤ j < n and n is the number of such non-terminals in G i .
Sort all productions with G i, j on the left hand side in the following order:
-
All productions with AT(qname) on the right hand side sorted lexically by qname localName, then by qname uri, followed by
-
any production with AT(*) on the right hand side, followed by
-
all productions with SE(qname) on the right hand side sorted in schema order, followed by
-
any production with CH on the right hand side, followed by
-
any production with EE on the right hand side
Given the sorted list of productions P 0 , P 1 , … P n with the non-terminal G i, j on the left hand side, assign event codes to each of the productions as follows:
| Productions | Event Code |
|---|
| | |
|
P 0
|
0
|
|
P 1
|
1
|
|
⋮
|
⋮
|
|
P n-1
|
n-1
|
8.5.3.4 Undeclared Productions
The normalized element and type grammars derived from a schema describe the sequences of child elements, attributes and character events that may occur in a particular EXI stream. However, there are additional events that may occur in an EXI stream that are not described by the schema, for example events representing comments, processing-instructions, schema deviations, etc.
This section describes the process for augmenting the normalized element and type grammars with productions that describe events that may occur in the EXI stream, but are not explicitly declared in the schema.
8.5.3.4.1 Adding Productions
For each normalized element grammar Element i , identify the first non-terminal Element i, content that includes no productions with the non-terminal AT (qname) on the right hand side. Create a copy Element i, content2 of Element i, content and add the following productions to each non-terminal Element i, j , such that 0 ≤ j ≤ content.
| Syntax | Event Code |
|---|
| | | | |
|
Element i, j :
|
| |
UndeclaredEE (n.m)
|
n.m
|
| |
UndeclaredStartTagItems (n.m+1) Element i, j
|
n.m+1
|
| |
UndeclaredContentItems (n.m+6) Element i, content2 |
n.m+6
|
where n.m represents the next available event code with length 2 and UndeclaredEE, UndeclaredStartTagItems and UndeclaredContentItems represent the set of terminal symbols defined in section 8.5.3.4.2 Undeclared Terminal Symbols. The production UndeclaredEE is only included if the element grammar does not already include a production of the form Element i, j : EE.
Add the following productions to Element i, content2 and to each non-terminal Element i, j , such that content < j < n, where n is the number of non-terminals in Element i .
| Syntax | Event Code |
|---|
| | | | |
|
Element i, j :
|
| |
UndeclaredEE (n)
|
n
|
| |
UndeclaredContentItems (n.m) Element i, j
|
n.m
|
where n represents the next available event code with length 1, n.m represents the next available event code with length 2 and UndeclaredEE and UndeclaredContentItmes represent the set of terminal symbols defined in section 8.5.3.4.2 Undeclared Terminal Symbols. The production UndeclaredEE is only included if the element grammar does not already include a production of the form Element i, j : EE.
Apply the process described above for element grammars to each normalized type grammar Type i .
8.5.3.4.2 Undeclared Terminal Symbols
The following set of terminal symbols is added to each element and type non-terminal that describes a portion of the EXI stream where attributes events may occur:
| Syntax | Event Code |
|---|
| | | | |
|
UndeclaredStartTagItems (n.m) :
|
| |
AT (xsi:type)
|
n.m
|
| |
AT (xsi:nil)
|
n.(m+1)
|
| |
AT (*)
|
n.(m+2)
|
| |
AT (D 0 )
|
n.(m+3).0
|
| |
AT (D 1 )
|
n.(m+3).1
|
| |
⋮
|
⋮
|
| |
AT (D x-1 )
|
n.(m+3).(x-1)
|
| |
AT (*) [schema-invalid]
|
n.(m+3).(x)
|
| |
NS
|
n.(m+4)
|
| Note: |
|---|
|
|
-
The variable x above represents the number of attributes declared in the schema for this context.
|
-
AT (xsi:type) matches an xsi:type attribute that specifies a schema-valid type for the current element. The value of an AT (xsi:type) event is represented as a QName (see 7.1.7 QName). An xsi:type attribute that specifies a schema-invalid type for the current element is matched by the AT(*) terminal symbol. The terminal symbol AT (*) is only matched if a more specific match for the current event does not exist in the grammar.
|
-
AT (D i ) where i is a number of the range 0 ≤ i < n matches an attribute with qname D i that was declared in the schema for this context, but has a value that is schema-invalid. The value of an attribute that matches AT (D i ) is encoded as a String regardless of the schema-type associated with the qname D i .
|
-
AT (*) [schema-invalid] matches any attribute declared in the schema that is not permitted in this context and has a schema-invalid value.
|
| Semantics: |
|---|
|
|
|
When using schemas, all productions of the form LeftHandSide : AT (xsi:type) are evaluated as follows:
|
|
|
-
Let qname be the value of the xsi:type attribute
- Evaluate the element contents using the grammar for the qname type instead of the declared type for the current element
|
|
|
The following set of non-terminal symbols are added to every element non-terminal and type non-terminal in the EXI grammar:
| Syntax | Event Code |
|---|
| | | | |
|
UndeclaredContentItems (n.m):
|
| |
SE (*)
|
n.m
|
| |
CH [schema-invalid]
|
n.(m+1)
|
| |
ER
|
n.(m+2)
|
| |
CM
|
n.(m+3).0
|
| |
PI
|
n.(m+3).1
|
| Note: |
|---|
|
|
-
Productions of the form LeftHandSide : CH [schema-valid] RightHandSide match schema-invalid character data that is represented as un-typed data in the EXI stream. Schema-valid character data is represented as typed data in the EXI stream matched by productions of the form LeftHandSide : CH [schema-valid] RightHandSide described in section 8.5.3.1.3 SimpleType Grammars.
|
-
The terminal symbol SE (*) is only matched if a more specific match for the current event does not exist in the grammar.
|
The following non-terminal symbol is added to each element and type non-terminal that does not already include a production with the non-terminal symbol EE on the right hand side.
| Syntax | Event Code |
|---|
| | | | |
|
UndeclaredEE ( eventcode ) :
|
| |
EE
|
eventcode
|
8.5.3.5 Schema-informed Grammar Examples
As an example to exercise the process to produce schema-informed element grammars, consider the following XML Schema fragment declaring two complex-typed elements, <product> and <order>:
<xs:element name="product">
<xs:complexType>
<xs:sequence maxOccurs="2">
<xs:element name="description" type="xs:string" minOccurs="0"/>
<xs:element name="quantity" type="xs:integer" />
<xs:element name="price" type="xs:float" />
</xs:sequence>
<xs:attribute name="sku" type="xs:string" use="required" />
<xs:attribute name="color" type="xs:string" use="optional" />
</xs:complexType>
</xs:element>
<xs:element name="order">
<xs:complexType>
<xs:sequence>
<xs:element ref="product" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
</xs:element>
Section 8.5.3.5.1 Proto-Grammar Examples guides you through the process of deriving EXI proto-grammars from the schema components available in the example schema above. EXI grammars in the normalized form that correspond to the proto-grammars are shown in section 8.5.3.5.2 Normalized Grammar Examples. Section 8.5.3.5.3 Complete Grammar Examples shows the complete EXI grammars for elements <product> and <order>.
8.5.3.5.1 Proto-Grammar Examples
Grammars for element declaration terms "description", "quantity" and "price" are as follows. See section 8.5.3.1.7 Element Terms for the rules used to derive grammars from element terms.
| Term_description |
|---|
| |
|
Term_description 0 : |
| |
SE("description") Term_description 1
|
| |
|
Term_description 1 :
|
| |
EE
|
| |
| Term_quantity |
|---|
| |
|
Term_quantity 0 : |
| |
SE("quantity") Term_quantity 1
|
| |
|
Term_quantity 1 :
|
| |
EE
|
| |
| Term_price |
|---|
| |
|
Term_price 0 : |
| |
SE("price") Term_price 1
|
| |
|
Term_price 1 :
|
| |
EE
|
| |
Grammars for element particle "description" are derived from Term_description given { minOccurs } value of 0 and { maxOccurs } value of 1. See section 8.5.3.1.6 Particles for the rules used to derive grammars from particles.
| Particle_description |
|---|
| |
|
Term_description 0 : |
| |
SE("description") Term_description 1
|
| |
EE
|
| |
|
Term_description 1 :
|
| |
EE
|
| |
Grammars for element particle "quantity" and "prices" are the same as those of their terms (Term_quantity and Term_price, respectively) because { minOccurs } and { maxOccurs } are both 1.
| Particle_quantity |
|---|
| |
|
Term_quantity 0 : |
| |
SE("quantity") Term_quantity 1
|
| |
|
Term_quantity 1 :
|
| |
EE
|
| |
| Particle_price |
|---|
| |
|
Term_price 0 : |
| |
SE("price") Term_price 1
|
| |
|
Term_price 1 :
|
| |
EE
|
| |
Grammars for the sequence group term in <product> element declaration is derived from the grammars of subordinate particles as follows. See section 8.5.3.1.9.1 Sequence Model Groups for the rules used to derive grammars from a sequence group.
which yields the following grammars for Term_sequence.
| Term_sequence |
|---|
| |
|
Term_description0 :
|
| |
SE("description") Term_description1
|
| |
Term_quantity 0
|
| |
|
Term_description 1 :
|
| |
Term_quantity 0
|
| |
|
Term_quantity 0 :
|
| |
SE("quantity") Term_quantity 1
|
| |
|
Term_quantity 1 :
|
| |
Term_price 0
|
| |
|
Term_price 0 :
|
| |
SE("price") Term_price 1
|
| |
|
Term_price 1 :
|
| |
EE
|
| |
Grammars for the particle that is the content model of element <product> are derived from Term_sequence (shown above) given { minOccurs } value of 1 and { maxOccurs } value of 2. See section 8.5.3.1.6 Particles for the rules used to derive grammars from particles.
| Particle_sequence |
|---|
| |
|
Term_description0,0 :
|
| |
SE("description") Term_description0,1
|
| |
Term_quantity0,0
|
| |
|
Term_description0,1 :
|
| |
Term_quantity0,0
|
| |
|
Term_quantity0,0 :
|
| |
SE("quantity") Term_quantity0,1
|
| |
|
Term_quantity0,1 :
|
| |
Term_price0,0
|
| |
|
Term_price0,0 :
|
| |
SE("price") Term_price0,1
|
| |
|
Term_price0,1 :
|
| |
Term_description1,0
|
| |
|
Term_description1,0 :
|
| |
SE("description") Term_description1,1
|
| |
Term_quantity1,0
|
| |
EE
|
| |
|
Term_description1,1 :
|
| |
Term_quantity1,0
|
| |
|
Term_quantity1,0 :
|
| |
SE("quantity") Term_quantity1,1
|
| |
|
Term_quantity1,1 :
|
| |
Term_price1,0
|
| |
|
Term_price1,0 :
|
| |
SE("price") Term_price1,1
|
| |
|
Term_price1,1 :
|
| |
EE
|
| |
Grammars for attribute uses of attributes "sku" and "color" are as follows. See section 8.5.3.1.5 Attribute Uses for the rules used to derive grammars from attribute uses.
| Use_sku |
|---|
| |
|
Use_sku 0 :
|
| |
AT("sku") Use_sku 1
|
| |
|
Use_sku 1 :
|
| |
EE
|
| |
| Use_color |
|---|
| |
|
Use_color 0 :
|
| |
AT("color") Use_color 1
|
| |
EE
|
| |
|
Use_color 1 :
|
| |
EE
|
| |
Note the subtle difference between grammars Use_sku and Use_color. In the first grammar of each, only Use_color contains a production of which the right hand side starts with EE, which stems from the difference in their occurrence optionality as defined in the schema.
Finally, grammars for the element <product> is derived from the grammars of its attribute uses and content model particle as follows. See section 8.5.3.1.4 Complex Type Grammars for the rules used to derive grammars from a complex type.
which yields the following grammars for element <product>.
| ProtoG_ProductElement |
|---|
| |
|
Use_color 0 :
|
| |
AT("color") Use_color 1
|
| |
Use_sku 0
|
| |
|
Use_color 1 :
|
| |
Use_sku 0
|
| |
|
Use_sku 0 :
|
| |
AT("sku") Use_sku 1
|
| |
|
Use_sku 1 :
|
| |
Term_description0,0
|
| |
|
Term_description0,0 :
|
| |
SE("description") Term_description0,1
|
| |
Term_quantity0,0
|
| |
|
Term_description0,1 :
|
| |
Term_quantity0,0
|
| |
|
Term_quantity0,0 :
|
| |
SE("quantity") Term_quantity0,1
|
| |
|
Term_quantity0,1 :
|
| |
Term_price0,0
|
| |
|
Term_price0,0 :
|
| |
SE("price") Term_price0,1
|
| |
|
Term_price0,1 :
|
| |
Term_description1,0
|
| |
|
Term_description1,0 :
|
| |
SE("description") Term_description1,1
|
| |
Term_quantity1,0
|
| |
EE
|
| |
|
Term_description1,1 :
|
| |
Term_quantity1,0
|
| |
|
Term_quantity1,0 :
|
| |
SE("quantity") Term_quantity1,1
|
| |
|
Term_quantity1,1 :
|
| |
Term_price1,0
|
| |
|
Term_price1,0 :
|
| |
SE("price") Term_price1,1
|
| |
|
Term_price1,1 :
|
| |
EE
|
| |
The other element declaration <order> can be processed in the same fashion as was seen done above for element <product>, which would generate the following proto-grammars.
| |
|
|
Term_product 0,0 :
|
| |
SE("product") Term_product 0,1
|
| |
|
Term_product 0,1 :
|
| |
Term_product 1,0
|
| |
|
Term_product 1,0 :
|
| |
SE("product") Term_product 1,1
|
| |
EE
|
| |
|
Term_product 1,1 :
|
| |
Term_product 1,0
|
| |
In the above grammars, two grammars Term_product 0,1 and Term_product 1,1 are redundant because they serve for no other purpose than simply relaying one non-terminal to another. Though it is not required, the uses of non-terminals Term_product 0,1 and Term_product 1,1 are each replaced by Term_product 1,0 and Term_product 1,0, which produces the following modified proto-grammars.
| ProtoG_OrderElement |
|---|
|
|
| |
|
| |
|
Term_product 0,0 :
|
| |
SE("product") Term_product 1,0
|
| |
|
Term_product 0,1 :
|
| |
Term_product 1,0
|
| |
|
Term_product 1,0 :
|
| |
SE("product") Term_product 1,0
|
| |
EE
|
| |
|
Term_product 1,1 :
|
| |
Term_product 1,0
|
| |
8.5.3.5.2 Normalized Grammar Examples
The element proto-grammars ProtoG_ProductElement and ProtoG_OrderElement produced in the previous section can be turned into their normalized forms which are shown below with an event code assigned to each production. See section 8.5.3.2 EXI Normalized Grammars for the process that converts proto-grammars into normalized grammars, and section 8.5.3.3 Event Code Assignment for the rules that determine the event codes of productions in normalized grammars.
| NormG_ProductElement |
|---|
| Event Code |
|---|
|
Use_color 0 :
|
| |
AT("color") Use_color 1
| 0 |
| |
AT("sku") Use_sku 1
| 1 |
| |
|
Use_color 1 :
|
| |
AT("sku") Use_sku 1
| 0 |
| |
|
Use_sku 1 :
|
| |
SE("description") Term_description0,1
| 0 |
| |
SE("quantity") Term_quantity0,1
| 1 |
| |
|
Term_description0,1 :
|
| |
SE("quantity") Term_quantity0,1
| 0 |
| |
|
Term_quantity0,1 :
|
| |
SE("price") Term_price0,1
| 0 |
| |
|
Term_price0,1 :
|
| |
SE("description") Term_description1,1
| 0 |
| |
SE("quantity") Term_quantity1,1
| 1 |
| |
EE
| 2 |
| |
|
Term_description1,1 :
|
| |
SE("quantity") Term_quantity1,1
| 0 |
| |
|
Term_quantity1,1 :
|
| |
SE("price") Term_price1,1
| 0 |
| |
|
Term_price1,1 :
|
| |
EE
| 0 |
| |
| NormG_OrderElement |
|---|
| Event Code |
|---|
|
Term_product 0,0 :
|
| |
SE("product") Term_product 1,0
| 0 |
| |
|
Term_product 1,0:
|
| |
SE("product") Term_product 1,0
| 0 |
| |
EE
| 1 |
| |
Note that some grammars that were present in the proto-grammars have been removed in the normalized grammars. Those grammars were culled upon the completion of grammar normalization because their LeftHandSide are not referenced from RightHandSide of any available productions.
8.5.3.5.3 Complete Grammar Examples
The normalized grammars NormG_ProductElement and NormG_OrderElement are augumented with undeclared productions to become complete grammars which are shown below. See section 8.5.3.4 Undeclared Productions for the process that augments normalized grammars with productions that represent terminal symbols not declared in schemas.
| CompleteG_ProductElement |
|---|
| Event Code |
|---|
|
Use_color 0 :
|
| |
AT("color") Use_color 1
| 0 |
| |
AT("sku") Use_sku 1
| 1 |
| |
UndeclaredEE
| 2.0 |
| |
UndeclaredStartTagItems (2.1) Use_color 0
| 2.1 |
| |
UndeclaredContentItems (2.6) Use_sku 1
| 2.6 |
| |
|
Use_color 1 :
|
| |
AT("sku") Use_sku 1
| 0 |
| |
UndeclaredEE
| 1.0 |
| |
UndeclaredStartTagItems (1.1) Use_color 1
| 1.1 |
| |
UndeclaredContentItems (1.6) Use_sku 1
| 1.6 |
| |
|
Use_sku 1 :
|
| |
SE("description") Term_description0,1
| 0 |
| |
SE("quantity") Term_quantity0,1
| 1 |
| |
UndeclaredEE
| 2 |
| |
UndeclaredContentItems (3.0) Use_sku 1
| 3.0 |
| |
|
Term_description0,1 :
|
| |
SE("quantity") Term_quantity0,1
| 0 |
| |
UndeclaredEE
| 1 |
| |
UndeclaredContentItems (2.0) Term_description0,1
| 2.0 |
| |
|
Term_quantity0,1 :
|
| |
SE("price") Term_price0,1
| 0 |
| |
UndeclaredEE
| 1 |
| |
UndeclaredContentItems (2.0) Term_quantity0,1
| 2.0 |
| |
|
Term_price0,1 :
|
| |
SE("description") Term_description1,1
| 0 |
| |
SE("quantity") Term_quantity1,1
| 1 |
| |
EE
| 2 |
| |
UndeclaredContentItems (3.0) Term_price0,1
| 3.0 |
| |
|
Term_description1,1 :
|
| |
SE("quantity") Term_quantity1,1
| 0 |
| |
UndeclaredEE
| 1 |
| |
UndeclaredContentItems (2.0) Term_description1,1
| 2.0 |
| |
|
Term_quantity1,1 :
|
| |
SE("price") Term_price1,1
| 0 |
| |
UndeclaredEE
| 1 |
| |
UndeclaredContentItems (2.0) Term_quantity1,1
| 2.0 |
| |
|
Term_price1,1 :
|
| |
EE
| 0 |
| |
UndeclaredContentItems (1.0) Term_price1,1
| 1.0 |
| |
| CompleteG_OrderElement |
|---|
| Event Code |
|---|
|
Term_product 0,0 :
|
| |
SE("product") Term_product 1,0
| 0 |
| |
UndeclaredEE
| 1.0 |
| |
UndeclaredStartTagItems (1.1) Term_product 0,0
| 1.1 |
| |
UndeclaredContentItems (1.6) Term_product 2 0,0
| 1.6 |
| |
|
Term_product 2 0,0 :
|
| |
SE("product") Term_product 1,0
| 0 |
| |
UndeclaredEE
| 1 |
| |
UndeclaredContentItems (2.0) Term_product 2 0,0
| 2.0 |
| |
|
Term_product 1,0 :
|
| |
SE("product") Term_product 1,0
| 0 |
| |
EE
| 1 |
| |
UndeclaredContentItems (2.0) Term_product 1,0
| 2.0 |
| |
9. EXI Compression
The use of
EXI compression
increases
compactness utilizing additional computational resources. EXI compression combines knowledge of XML with a widely adopted, standard compression algorithm to achieve higher compression ratios than would be achievable by applying compression to the entire stream.
EXI compression is applied when compression is turned on or when alignment is set to pre-compression. Byte-aligned representations of event codes and content items are more amenable to compression algorithms compared to unaligned representations because most compression algorithms operate on series of bytes to identify redundancies in the octets. Therefore, when EXI compression is used, event codes and content items of EXI events are encoded as aligned bytes in accordance with 6.2 Representing Event Codes and 7. Representing Event Content.
EXI compression splits a sequence of EXI events into a number of contiguous blocks of events.
Events that belong to the same block are transformed into lower entropy groups of similar values called channels, which are individually well suited for standard compression algorithms. To reduce compression overhead, smaller channels are combined before compressing them, while larger channels are compressed independently. The criteria EXI compression uses to define and combine channels is intentionally simple to facilitate implementation, reduce processing overhead, and avoid the need to encode channel ordering or grouping information in the format. The figure below presents a schematic view of the steps involved in EXI compression.
In the following sections, 9.1 Blocks defines blocks and explains how EXI events are partitioned into blocks.
Section 9.2 Channels defines channels, their organization as well as how a group of channels correlate to its corresponding block of events.
Section 9.3 Compressed Streams describes how some channels are combined as needed in preparation for applying compression algorithms on channels.
9.1 Blocks
EXI compression partitions the sequence of EXI events into a sequence of one or more non-overlapping blocks. Each block preceding the final block contains the minimum set of consecutive events that have exactly blockSize Attribute (AT) and Character (CH) values, where blockSize is the block size of the EXI stream (see 5.3 EXI Options). The final block contains no more than blockSize Attribute (AT) and Character (CH) values.
9.2 Channels
Events inside each block are multiplexed into channels. The first channel of each block is the structure channel described in Section 9.2.1 Structure Channel. The remaining channels in each block are value channels described in Section 9.2.2 Value Channels.
The diagram below presents an exemplary view of the transformation in which events within a block are multiplexed into channels in one way and channels are demultiplexed into events in the other way.
9.2.1 Structure Channel
The structure channel of each block defines the overall order and structure of the events in that block. It contains the event codes and associated content for each event in the block, except for Attribute (AT) and Character (CH) values, which are stored in the value channels. In addition, there are two attribute events whose values are stored in the structure channel instead of in value channels, which are xsi:nil and xsi:type attributes that match a schema-informed grammar production. These attribute events are intrinsic to the grammar system thus are essential in processing the structure channel because their values affect the grammar to be used for processing the rest of the elements on which they appear. All event codes and content in the structure stream occur in the same order as they occur in the EXI event sequence.
9.2.2 Value Channels
The values of the Attribute (AT) and Character (CH) events in each block are organized into separate channels based on the qname of the associated attribute or element. Specifically, the value of each Attribute (AT) event is placed in the channel identified by the qname of the Attribute and the value of each Character (CH) event is placed in the channel identified by the qname of its parent Start Element (SE) event. Each block contains exactly one channel for each distinct element or attribute qname that occurs in the block. The values in each channel occur in the order they occur in the EXI event sequence.
9.3 Compressed Streams
The channels in a block are further organized into compressed streams. Smaller channels are combined into the same compressed stream, while others are each compressed separately. Below are the rules applied within the scope of a block used to determine the channels to be combined together, the order of the compressed streams and the order amongst the channels that are combined into the same compressed stream.
If the block contains at most 100 values, the block will contain only 1 compressed stream containing the structure channel followed by all of the value channels. The order of the value channels within the compressed stream is defined by the order in which the first value in each channel occurs in the EXI event sequence.
If the block contains more than 100 values, the first compressed stream contains only the structure channel. The second compressed stream contains all value channels that contain no more than 100 values. And the remaining compressed streams each contain only one channel, each having more than 100 values. The order of the value channels within the second compressed stream is defined by the order in which the first value in each channel occurs in the EXI event sequence. Similarly, the order of the compressed streams following the second compressed stream in the block is defined by the order in which the first value of the channel inside each compressed stream occurs in the EXI event sequence.
When the value of the compression option is set to true, each compressed
stream in a block is stored using the standard DEFLATE Compressed Data Format defined by
RFC 1951 [IETF RFC 1951]. Otherwise, when the value of the alignment option is set to pre-compression, each compressed stream in a block is stored directly without the DEFLATE algorithm.
10. Conformance
Note:
Description of EXI processor classes will be provided in this section.
There will be classes of EXI processors each of which represents either the whole or some limited capacity of the capability defined in the preceding sections. The set of capability that may drive processor classification include schema processing, pluggable codecs.
A References
A.1 Normative References
- IETF RFC 1951
-
DEFLATE Compressed Data Format Specification version 1.3, P. Deutsch, Author. Internet
Engineering Task Force, May 1996. Available at
http://www.ietf.org/rfc/rfc1951.txt.
- IETF RFC 2119
-
Key words for use in RFCs to Indicate
Requirement Levels, S. Bradner, Author. Internet
Engineering Task Force, June 1999. Available at
http://www.ietf.org/rfc/rfc2119.txt.
- ISO/IEC 10646
-
ISO/IEC 10646-1:2000. Information technology — Universal Multiple-Octet Coded Character Set (UCS) — Part 1: Architecture and Basic Multilingual Plane and ISO/IEC 10646-2:2001. Information technology — Universal Multiple-Octet Coded Character Set (UCS) — Part 2: Supplementary Planes, as, from time to time, amended, replaced by a new edition or expanded by the addition of new parts. [Geneva]: International Organization for Standardization. (See http://www.iso.ch for the latest version.)
- XML 1.0
-
Extensible Markup Language (XML) 1.0 (Fourth Edition),
T. Bray, J. Paoli, C. M. Sperberg-McQueen, and E. Maler, Editors.
World Wide Web Consortium, 10 February 1998, revised 16 August 2006.
This version is http://www.w3.org/TR/2006/REC-xml-20060816.
The latest version is available at
http://www.w3.org/TR/REC-xml.
- XML Information Set
-
XML Information Set (Second Edition),
J. Cowan and R. Tobin, Editors. World Wide Web Consortium,
24 October 2001, revised 4 February 2004.
This version is http://www.w3.org/TR/2004/REC-xml-infoset-20040204.
The latest version is available at
http://www.w3.org/TR/xml-infoset.
- XML Schema Structures
-
XML Schema Part 1: Structures Second
Edition, H. Thompson, D. Beech, M. Maloney, and
N. Mendelsohn, Editors. World Wide Web Consortium, 2 May
2001, revised 28 October 2004.
This version is http://www.w3.org/TR/2004/REC-xmlschema-1-20041028.
The latest version is available at
http://www.w3.org/TR/xmlschema-1.
- XML Schema Datatypes
-
XML Schema Part 2: Datatypes Second
Edition, P. Byron and A. Malhotra,
Editors. World Wide Web Consortium, 2 May 2001, revised 28
October 2004.
This version is http://www.w3.org/TR/2004/REC-xmlschema-2-20041028.
The latest version is available at
http://www.w3.org/TR/xmlschema-2.
A.2 Other References
- Efficient XML
-
Efficient XML, part of [EXI Measurements Note] independently referenced.
The latest version is available at
http://www.w3.org/TR/exi-measurements/#contributions-efx.
- EXI Measurements Note
-
Efficient XML Interchange Measurements Note,
Greg White, Jaakko Kangasharju, Don Brutzman and Stephen Williams, Editors.
World Wide Web Consortium.
The latest version is available at
http://www.w3.org/TR/exi-measurements/.
- EXI Primer
-
Efficient XML Interchange (EXI) Primer
,
Daniel Peintner, Santiago Pericas-Geertsen, Editors.
World Wide Web Consortium.
The latest version is available at
http://www.w3.org/TR/exi-primer/.
- Greibach Normal Form
-
A New Normal-Form Theorem for Context-Free Phrase Structure Grammars
,
Sheila A. Greibach, Author.
Journal of the ACM Volume 12 Issue 1, January 1965, pp. 42–52.
- Huffman Coding
-
A Method for the Construction of
Minimum-Redundancy Codes, D. A. Huffman,
Author. Proceedings of the I.R.E., September 1952, pp.
1098-1102.
- ISO/IEC 19757-2:2003
-
Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- SOAP 1.2
-
SOAP Version 1.2 Part 1: Messaging
Framework, M. Gudgin, M. Hadley, N. Mendelsohn,
J-J. Moreau, H. Frystyk Nielsen, Editors. World Wide Web
Consortium, 24 June 2003.
This version is http://www.w3.org/TR/2003/REC-soap12-part1-20030624/.
The latest version is available at
http://www.w3.org/TR/soap12-part1/.
- XBC Measurement Methodologies
-
XML Binary Characterization Measurement
Methodologies, S. D. Williams and P. Haggar,
Editors. World Wide Web Consortium, 31 March 2005.
This version is http://www.w3.org/TR/2005/NOTE-xbc-measurement-20050331/.
The latest version is available at
http://www.w3.org/TR/xbc-measurement.
- XBC Use Cases
-
XML Binary Characterization Use Cases,
Mike Cokus and Santiago Pericas-Geertsen, Editors.
World Wide Web Consortium, 31 March 2005.
This version is http://www.w3.org/TR/2005/NOTE-xbc-use-cases-20050331/.
The latest version is available at
http://www.w3.org/TR/xbc-use-cases.
- XBC Properties
-
XML Binary Characterization Properties,
Mike Cokus and Santiago Pericas-Geertsen, Editors.
World Wide Web Consortium, 31 March 2005.
This version is http://www.w3.org/TR/2005/NOTE-xbc-properties-20050331/
The latest version is available at
http://www.w3.org/TR/xbc-properties/.
B Infoset Mapping
This appendix contains the mappings between the XML Information
Set [XML Information Set] model and the EXI format.
Starting from the document information item,
each information item definition is mapped to its respective
unordered set of EXI event types. The actual order amongst information set items when it is relevant reflects the occurrence order of EXI events or their references in an EXI stream that correlate to the infoset items. As used in the XML Information
Set specification, the Infoset property names are shown in square
brackets, [thus].
B.1 Document Information Item
A document information item maps to a pair of SD and ED event with each of its properties subject to further mapping as shown in the following table.
Table B-1. Mapping between the document information item properties to EXI event types| Property | EXI event types |
|---|
| [children] | CM* PI* DT? [SE, EE] |
| [document element] | [SE, EE] |
| [notations] | Computed based on text content item of DT to which each notation information set item maps to. |
| [unparsed entities] | Computed based on text content item of DT to which each unparsed entity information set item maps to. |
| [base URI] | The base URI of the EXI stream |
| [character encoding scheme] | N/A |
| [standalone] | Not available |
| [version] | Not available |
| [all declarations processed] | True if all declarations contained directly or indirectly in DT are processed, otherwise false, which is the processor quality as opposed to the information provided by the format. |
B.2 Element Information Items
An element information item maps to a pair of a SE event and the corresponding EE event with each of its properties subject to further mapping as shown in the following table.
Table B-2. Mapping of the element information item properties to EXI event types| Property | EXI event types |
|---|
| [namespace name] | SE |
| [local name] | SE |
| [prefix] | SE |
| [children] | [SE, EE]* PI* CM* CH* ER* |
| [attributes] | AT* |
| [namespace attributes] | NS* |
| [in-scope namespaces] |
The namespace information items computed using the [namespace attributes]
properties of this information item and its ancestors
|
| [base URI] | The base URI of the element information item |
| [parent] | Computed based on the last SE event encountered that did
not get a matching EE event if any, or computed based on the SD event |
B.3 Attribute Information Item
An attribute information item maps to an AT event with each of its properties subject to further mapping as shown in the following table.
Table B-3. Mapping of the attribute information item properties to EXI event types| Property | EXI event types |
|---|
| [namespace name] | AT |
| [local name] | AT |
| [prefix] | AT |
| [normalized value] | The value of AT |
| [specified] | True if the item maps to AT, otherwise false |
| [attribute type] |
Computed based on AT and DT
|
| [references] |
Computed based on [attribute type] and value of AT
|
| [owner element] | Computed based on the last SE event encountered that did
not get a matching EE event |
B.4 Processing Instruction Information Item
A processing instruction information maps to a PI event with each of its properties subject to further mapping as shown in the following table.
Table B-4. Mapping of the processing instruction information item properties to EXI event types| Property | EXI event types |
|---|
| [target] | PI |
| [content] | PI |
| [base URI] | The base URI of the processing information item |
| [notation] |
Computed based on the availability of the internal DTD subset
|
| [parent] | Computed based on the last SE event encountered that did
not get a matching EE event type |
B.5 Unexpanded Entity Reference Information item
An unexpanded entity reference information item maps to an ER with each of its properties subject to further mapping as shown in the following table.
Table B-5. Mapping of the entity reference information item properties to
the EXI event types| Property | EXI event types |
|---|
| [name] | ER |
| [system identifier] | Based on the availability of the internal DTD subset |
| [public identifier] | Based on the availability of the internal DTD subset |
| [declaration base URI] | The base URI of the unexpanded entity reference information item |
| [parent] | Computed based on the last SE event encountered that did
not get a matching EE event type |
B.6 Character Information item
A character information item maps to the individual characters contained in a CH event following a SE event that did not get a matching EE event.
Table B-6. Mapping of the character information item properties and the EXI event types| Property | EXI event types |
|---|
| [character code] | Each character in CH |
| [element content whitespace] | Computed based on [parent] and DT |
| [parent] | Computed based on the last SE event encountered that did
not get a matching EE event |
B.7 Comment Information item
A comment information item maps to a CM event with each of its properties subject to further mapping as shown in the following table.
Table B-7. Mapping of the comment information item properties and the EXI event types| Property | EXI event types |
|---|
| [content] | text content item of CM |
| [parent] | Computed based on the last SE event encountered that did
not get a matching EE event, or the SD event |
B.8 Document Type Declaration Information item
A document type declaration information item maps to a DT event with each of its properties subject to further mapping as shown in the following table.
Table B-8. Mapping of the document type declaration information item properties to the EXI event types| Property | EXI event types |
|---|
| [system identifier] | DT |
| [public identifier] | DT |
| [children] | Computed based on text content item of DT |
| [parent] | Computed based on the SD event |
B.9 Unparsed Entity Information Item
An unparsed entity information item maps to part of the
text content item of DT event with each of its properties subject to further mapping as shown in the following table.
Table B-9. Mapping of the unparsed entity information item properties to EXI event types| Property | EXI event types |
|---|
| [name] | Computed based on text content item of DT |
| [system identifier] | Computed based on text content item of DT |
| [public identifier] | Computed based on text content item of DT |
| [declaration base URI] | The base URI of the unparsed entity information item |
| [notation name] | Computed based on text content item of DT |
| [notation] | Computed based on text content item of DT |
B.10 Notation Information Item
An notation information item maps to part of the
text content item of DT event with each of its properties subject to further mapping as shown in the following table.
Table B-10. Mapping of the notation information item properties to EXI event types| Property | EXI event types |
|---|
| [name] | Computed based on text content item of DT |
| [system identifier] | Computed based on text content item of DT |
| [public identifier] | Computed based on text content item of DT |
| [declaration base URI] | The base URI of the notation information item |
B.11 Namespace Information Item
An namespace information item ismaps toa NS event with each of its properties subject to further mapping as shown in the following table.
Table B-11. Mapping of the namespace information item properties to EXI event types| Property | EXI event types |
|---|
| [prefix] | NS |
| [namespace name] | NS |
C XML Schema for EXI Options Header
The following schema describes the EXI options header. It is
designed to produce smaller headers for option combinations used when
compactness is critical.
<xsd:schema targetNamespace="http://www.w3.org/2007/07/exi"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified">
<xsd:element name="header">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="lesscommon" minOccurs="0">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="uncommon" minOccurs="0">
<xsd:complexType>
<xsd:sequence>
<xsd:any namespace="##other" minOccurs="0" maxOccurs="unbounded" />
<xsd:element name="alignment" minOccurs="0">
<xsd:complexType>
<xsd:choice>
<xsd:element name="byte">
<xsd:complexType />
</xsd:element>
<xsd:element name="pre-compress">
<xsd:complexType />
</xsd:element>
</xsd:choice>
</xsd:complexType>
</xsd:element>
<xsd:element name="codecMap" minOccurs="0" maxOccurs="unbounded">
<xsd:complexType>
<xsd:sequence>
<xsd:any namespace="##other" /> <!-- schema type -->
<xsd:any namespace="##other" /> <!-- CODEC -->
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="preserve" minOccurs="0">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="dtd" minOccurs="0">
<xsd:complexType />
</xsd:element>
<xsd:element name="prefixes" minOccurs="0">
<xsd:complexType />
</xsd:element>
<xsd:element name="lexicalValues" minOccurs="0">
<xsd:complexType />
</xsd:element>
<xsd:element name="comments" minOccurs="0">
<xsd:complexType />
</xsd:element>
<xsd:element name="pis" minOccurs="0">
<xsd:complexType />
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="blockSize" minOccurs="0">
<xsd:simpleType>
<xsd:restriction base="xsd:unsignedInt" />
</xsd:simpleType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="common" minOccurs="0">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="compression" minOccurs="0">
<xsd:complexType />
</xsd:element>
<xsd:element name="fragment" minOccurs="0">
<xsd:complexType />
</xsd:element>
<xsd:element name="schemaId" minOccurs="0" nillable="true">
<xsd:simpleType>
<xsd:restriction base="xsd:string" />
</xsd:simpleType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="strict" minOccurs="0">
<xsd:complexType />
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
D Initial Entries in String Table Partitions
D.1 Initial Entries in Uri Partition
The following table lists the entries that are initially populated in uri partitions, where partition name URI denotes that they are entries in the uri partition.
Table D-1. Initial values in uri partition| Partition | String ID | String Value |
|---|
| URI | 0 | "" [empty string] |
| URI | 1 | "http://www.w3.org/XML/1998/namespace" |
| URI | 2 | "http://www.w3.org/2001/XMLSchema-instance" |
When XML Schemas are used to inform the grammars for processing EXI body, there is an additional entry that is appended to the uri partition.
Table D-2. Additional entry when XML Schemas are used| Partition | String ID | String Value |
|---|
| URI | 3 | "http://www.w3.org/2001/XMLSchema" |
D.2 Initial Entries in Prefix Partitions
The following table lists the entries that are initially populated in prefix partitions,
where XML-PF represents the partition for prefixes in
the "http://www.w3.org/XML/1998/namespace" namespace and XSI-PF
represents the partition for prefixes in the
"http://www.w3.org/2001/XMLSchema-instance" namespace.
Table D-3. Initial
prefix string table entries| Partition | String ID | String Value |
|---|
| "" | 0 | "" [empty string] |
| XML-PF | 0 | "xml" |
| XSI-PF | 0 | "xsi" |
D.3 Initial Entries in Local-Name Partitions
The following table lists the entries that are initially populated in local-name partitions,
where XML-NS represents the partition for local-names
in the "http://www.w3.org/XML/1998/namespace" namespace, XSI-NS
represents the partition for local-names in the
"http://www.w3.org/2001/XMLSchema-instance" namespace, and XSD-NS
represents the partition for local-names in the
"http://www.w3.org/2001/XMLSchema" namespace.
Table D-4. Initial local-name string table entries| Partition | String ID | String Value |
|---|
| XML-NS | 0 | "space" |
| XML-NS | 1 | "lang" |
| XML-NS | 2 | "id" |
| XML-NS | 3 | "base" |
| XSI-NS | 0 | "type" |
| XSI-NS | 1 | "nil" |
| XSD-NS | 0 | "anyType" |
| XSD-NS | 1 | "anySimpleType" |
| XSD-NS | 2 | "string" |
| XSD-NS | 3 | "normalizedString" |
| XSD-NS | 4 | "token" |
| XSD-NS | 5 | "language" |
| XSD-NS | 6 | "Name" |
| XSD-NS | 7 | "NCName" |
| XSD-NS | 8 | "ID" |
| XSD-NS | 9 | "IDREF" |
| XSD-NS | 10 | "IDREFS" |
| XSD-NS | 11 | "ENTITY" |
| XSD-NS | 12 | "ENTITIES" |
| XSD-NS | 13 | "NMTOKEN" |
| XSD-NS | 14 | "NMTOKENS" |
| XSD-NS | 15 | "duration" |
| XSD-NS | 16 | "dateTime" |
| XSD-NS | 17 | "time" |
| XSD-NS | 18 | "date" |
| XSD-NS | 19 | "gYearMonth" |
| XSD-NS | 20 | "gYear" |
| XSD-NS | 21 | "gMonthDay" |
| XSD-NS | 22 | "gDay" |
| XSD-NS | 23 | "gMonth" |
| XSD-NS | 24 | "boolean" |
| XSD-NS | 25 | "base64Binary" |
| XSD-NS | 26 | "hexBinary" |
| XSD-NS | 27 | "float" |
| XSD-NS | 28 | "double" |
| XSD-NS | 29 | "anyURI" |
| XSD-NS | 30 | "QName" |
| XSD-NS | 31 | "NOTATION" |
| XSD-NS | 32 | "decimal" |
| XSD-NS | 33 | "integer" |
| XSD-NS | 34 | "nonPositiveInteger" |
| XSD-NS | 35 | "negativeInteger" |
| XSD-NS | 36 | "long" |
| XSD-NS | 37 | "int" |
| XSD-NS | 38 | "short" |
| XSD-NS | 39 | "byte" |
| XSD-NS | 40 | "nonNegativeInteger" |
| XSD-NS | 41 | "positiveInteger" |
| XSD-NS | 42 | "unsignedLong" |
| XSD-NS | 43 | "unsignedInt" |
| XSD-NS | 44 | "unsignedShort" |
| XSD-NS | 45 | "unsignedByte" |
E Deriving Character Sets from XML Schema Regular Expressions
XML Schema datatypes specification [XML Schema Datatypes] defines its regular expression syntax for use in pattern facets of simple type definitions. Pattern facets are applied to values literally to constrain the set of valid values to those that lexically matches the specified regular expression. Though regular expression syntax is defined by dozens of productions, after all, they are character sets that constitute a regular expression at the finest granularity of the grammar, which are leveraged such as being combined, concatenated, complemented or subtracted in a bottom-up fashion to form a regular expression. In this regard, a regular expression can be seen as a sort of micro-schema that suggests a concrete character set to which characters in a string are likely to belong. The remainder of this section describes a method for deriving a character set from an XML Schema regular expression. Hereinafter, "character set" and "XML Schema regular expression" are referred to as "charset" and "regex", respectively.
At the top level, regexp syntax is summarized by the following three productions, excerpted here from [XML Schema Datatypes]. Note the notation used for the numbers that tag the productions. "XSD:" is prefixed to the original numeric tags to make it easier to discern them as belonging to XML Schema specification.
[XSD:1] regExp ::= branch ( '|' branch )*
[XSD:2] branch ::= piece*
[XSD:3] piece ::= atom quantifier?
|
These productions indicate that the charset of a regexp (i.e. regExp above) equals to the union of all the charsets each of which corresponds to an atom that participates in the regExp. There are exceptions which are based on empirical observations that are introduced here to identify certain regexps that are not subject to the computation of charsets.
If any atom itself is or contains one of the following character groups directly or indirectly, the charset of the whole regexp is defined to be the entire set of XML characters.
WildcardEsc (i.e. meta-character '.'). See [XSD:37a].
MultiCharEsc that is one of '\S', '\I', '\C', '\D' and '\w'. See [XSD:37].
complEsc (examples of which are '\P{ L }' and '\P{ N }' ). See [XSD:26].
negCharGroup as indicated by meta-character '^'. See [XSD:15].
Most regexps that contain one of the character groups listed above result in a very large number of characters, and even in such rare cases where it is not necessarily the case, there are usually alternative ways to describe the same effect more intuitively using none of the above constructs.
Shown below is the rule for assembling the charset of a regExp given a list of atoms that are contained directly in the regExp, excluding those atoms contained in sub-regexp parenthesized within the regExp (i.e. '(' regExp ')' in [XSD:9]) in which case the sub-regexp itself is the atom that is included in the list. Note the pseudo-function notation of the form CS(arg) with arg being a regexp construct denotes the method of obtaining the character set of the argument.
[1] CS(regExp) :=
union of every CS(atom[0...N-1]) (if *neither* WildcardEsc nor negCharGroup
are present)
where N represents the number of atoms
or
entire XML Charseter set (Otherwise, i.e. if WildcardEsc or negCharGroup
are present)
|
There are three kinds of atoms per its definition [XSD:9].
[XSD:9] atom ::= Char | charClass | ( '(' regExp ')' )
|
This production directly translates to the following rule for acquiring the charset of an atom.
[2] CS(atom) :=
a single char represented by Char (if atom is Char)
or
CS(charClass) (if atom is charClass. See rule [3])
or
CS(regExp) (if atom is sub-regexp. See rule [1])
|
Similarly, there are three choices for charClass per its definition [XSD:11] below, which is followed by the corresponding rule for acquiring the charset of a charClass.
[XSD:11] charClass ::= charClassEsc | charClassExpr | WildcardEsc
|
[3] CS(charClass) :=
CS(charClassEsc) (if charClass is charClassEsc. See [XSD:23] that defines
the characters contained in CS(charClassEsc) for each kind
of charClassEsc)
CS(charClassExpr) (if charClass charClassExpr. See rule [3])
|
Note that there is no rule specified above for a charClass that is a WildcardEsc. This is because the presence of a WildcardEsc causes to conclude the charset of the regExp that contains this charClass to be the entire XML charset (See rule [1] above).
A charClassExpr is either posCharGroup, negCharGroup or charClassSub per production [XSD:12] and [XSD:13] as excerpted below.
[XSD:12] charClassExpr ::= '[' charGroup ']'
[XSD:13] charGroup ::= posCharGroup | negCharGroup | charClassSub
|
This directly translates to the rule for charClassExpr charset as shown below.
[4] CS(charClassExpr) :=
CS(posCharGroup) (if charClassExpr is posCharGroup. See rule [5])
CS(charClassSub) (if charClassExpr is charClassSub. See rule [6])
|
Note that there is no rule specified above for a charClassExpr that is a negCharGroup. This is because the presence of a negCharGroup causes to conclude the charset of the regExp that contains this charClassExpr to be the entire XML charset (See rule [1] above).
posCharGroup is defined to be a sequence of charRange and charClassEsc per production [XSD:14].
[XSD:14] posCharGroup ::= ( charRange | charClassEsc )+
|
The above production translates to the following rule for acquiring the charset of a posCharGroup.
[5] CS(posCharGroup) := union of every CS(charRange[0...M-1]) and
every CS(charClassEsc[0...N-1])
where M and N represent the number of charRanges and charClassEscs
contained in the posCharGroup, respectively.
|
Lastly, charClassSub is defined using a subtraction operation as follows.
[XSD:16] charClassSub ::= ( posCharGroup | negCharGroup ) '-' charClassExpr
|
Because the presence of negCharGroup would have resulted in the containing regExp to have the entire XML charset in the first place, negCharGroup can be pruned from the above production, which makes the following reduced version of [XSD:16].
[XSD:16'] charClassSub ::= posCharGroup '-' charClassExpr
|
The above production translates to the following rule for acquiring the charset of a charClassSub.
[6] CS(charClassSub) := characters that are found
in CS(posCharGroup) (See rule [5])
but not in CS(charClassExpr) (See rule [4])
|
F Format Features Under Consideration (Non-Normative)
This section describes format features that, at the time of
writing, are under consideration by the WG. The list of proposed
features and extensions under consideration is actually longer,
only those that have been discussed by the WG are included here.
Most of these features are intended to address the format's
compactness, but some may also improve the processing efficiency
of a format's processor. The feature of F.1 Strict Schemas will be described in a normative part of the
specification once the details of its definition have been settled. The
others will each be tested in order to collect data to determine
whether their value outweighs the additional cost and complexity
they would introduce into the format.
F.1 Strict Schemas
| Editorial note | |
|
This feature has been adopted and will be added to a future version of this specification.
|
A strict schema fidelity option can be supported whereby an
encoder can be informed of the validity of the document being processed.
Strict schema coding would likely improve compactness for use cases
where documents are known to be valid according to a given schema,
or where it is known that a non-valid part of a document is of
no relevance to the decoder. This fidelity option is unlikely
to impact the runtime performance since it only affects an
encoder's initialization phase. However, this additional information
will likely benefit compactness by reducing the number of productions
in the grammar and, consequently, the number of bits needed to
encode event codes.
One of the usages of strict schemas would be for processing the EXI document representing the EXI Options in an EXI header. It can be encoded using the schema in Appendix C XML Schema for EXI Options Header
with the options specified by the following XML document:
<header xmlns="http://www.w3.org/2007/07/exi">
<strict/>
</header>
F.2 IEEE Floats
At least two of the use cases identified in the XML Binary
Characterization Use Cases document suggested efficient
support for floating point data aggregates such as arrays and
matrices. The most popular representation for floating point
values is that defined by the IEEE 754 standard. Native
support for this standard datatype in EXI could result in
significant performance improvements for those applications
that manipulate large amounts of numerical data. In such XML
applications, a lot of time can be spent converting to and
from IEEE 754. We will determine whether such direct support for
IEEE 754 and numerical aggregates is significantly greater than use of the
existing mechanism for floats in EXI described above.
Even though the IEEE 754 is extremely popular, it is not
supported in all platforms, for instance low and mid-end cell
phones. Therefore, if support for this datatype is
made mandatory in EXI, some conversion software would be
needed in those platforms to fully support the
format. However, having support for encoding and decoding IEEE
754 values should not be considered to be dependent on the
availibility of a full IEEE 754 native library since it was
estimated that a platform independent decode routine would
take about 300 bytes of machine code.
F.3 Bounded Tables
When previously unseen content (such as strings, elements or attributes) is encountered
during EXI encoding, it is always added to a string table or a grammar. The bounded
tables feature sets an a priori bound on the sizes of the string table partitions
and grammars. This feature is intended to improve the space efficiency of
EXI processors. Assuming a bound on the sizes of strings in the document,
this feature will allow the estimation of an absolute bound on space usage.
Fixing a processor's table sizes can negatively impact compactness in certain cases
given that a
string or grammar rule that would have been present under normal EXI rules may
not exist. However, without this feature, it may be impossible for certain
documents to be processed on devices with limited memory capabilities.
F.4 Grammar Coalescence
Schema-informed grammars are constructed primarily from structural constraints expressed
in a schema (e.g., an XML Schema) by considering those events that are expected to happen at a certain state as being more likely to occur than other events. These
primary events are assigned an event code of length 1 to ensure that they are
represented in fewer bits. On the other hand, other
events such as unexpected elements, unexpected attributes, unexpected end-of-elements,
comments and processing instructions are considered less likely to occur relative to the
primary events, and are thus assigned event codes of length 2 or 3 to reflect their
occurrence expectancy.
A schema can be regarded as a template. It follows that a
schema-informed EXI encoding defines a way of representing an instance of an XML infoset
relative to a template. This aspect of schema as a template
opens up a path to the proposed feature of coalesced grammars, whereby
EXI events convey not only an atomic event (such as an element or an
attribute) but also a sequence thereof in a single coalesced event.
Based on the constraints expressed in a schema, these events
are construed to occur more frequently together than not.
As an example, it may be possible to learn from a schema that the
element <order> is always followed by the element <product>,
which in turn is always followed by the element <description>.
Based on this knowledge, it is possible to assign an event code
to the sequence SE("order") SE("product") SE("description") by
inserting a new, coalesced production into the grammar. This new
production can be used in place of the existing productions for
each event, thus using a single event code to represent them.
Note
that this coalescing technique is not restricted to SE events;
it applies to any sequence of events that can be shown to
occur frequently, for which the use of a single event
code can provide obvious benefits. For example, an SE event
followed by multiple AT events can also be
combined using a single event code. To improve coalescing, the
lexicographical order currently defined for attributes in EXI
may need to be revisited so that required attributes are
placed before optional ones. This additional requirement will
enable better grouping and, consequently, better compactness.
F.5 Indexed Elements
Some use cases would benefit from the ability to jump to specific locations in an EXI stream and begin reading events at those locations without reading any data prior to that point in the stream. To address this requirement, a user or application may identify a set of elements in an EXI stream that are Indexed Elements. Indexed Elements are self contained, meaning their content has no dependencies on external events or any impact those events may have had on context sensitive structures, such as string tables and learned content models. Indexed Elements are also byte aligned to facilitate seeking to their location in an EXI stream using common stream implementations.
A variety of higher level functions can be implemented on top of Indexed Elements, including random access of EXI streams and accelerated sequential access of EXI streams using skip-pointers. As an example application, an electronic document system could choose to index all the pages in the document and store the page locations in a global index. Applications and users could then jump directly to page 500 of a large document and display it immediately without reading or storing any of the preceding pages of the document.
F.6
Further Features Under Consideration
The following proposals - mostly from external feedback to the WG - are also under consideration. As with all other format features, the intention is to examine their effect on efficiency (compactness and processing efficiency) and specification complexity before deciding how to proceed further, ideally by sample code that can be run over the W3C EXI test suite.
-
Numeric representations - examine alternative representations of integers or decimals.
-
Date & time representations - examine alternative representations of date and time related types.
-
xsi:type in schema-less mode - examine the opportunity to use typed values in schema less mode.
-
String representation - examine more conventional string encodings.
-
Compression - examine the effect of an alternative non-packetized deflate step in the compression mode.
G Example Encoding (Non-Normative)
EXI Primer [EXI Primer] contains a section that explains the workings of EXI format using simple example documents. Those examples are intended to serve as a tool to confirm the understanding of the EXI format in action by going through encoding and decoding processes step by step.
H
Changes from First Public Working Draft
(Non-Normative)
-
Described how QNames are represented with prefixes when prefix preservation is turned on (see section 7.1.7 QName).
-
Described how the presence of pattern facets affects the encoding of EXI Boolean (see section 7.1.2 Boolean) and EXI String (see section 7.1.10 String) representation.
-
Values typed as integer with bounded range of 4095 or smaller are now represented as n-bit Unsigned Integers (see section 7.1.9 n-bit Unsigned Integer).
I Acknowledgements (Non-Normative)
This document is the work of the Efficient XML Interchange (EXI) WG.
Members of the Working Group are (at the time of writing, sorted alphabetically by last name):
- Carine Bournez, W3C/ERCIM (staff contact)
- Don Brutzman, Web3D Consortium
- Alex Ceponkus, AgileDelta, Inc.
- Michael Cokus, MITRE Corporation
- Roger Cutler, Chevron
- Ed Day, Objective Systems, Inc.
- Philippe de Cuetos, Expway
- Rajul Gupta, OSS Nokalva, Inc.
- Joerg Heuer, Siemens AG
- Alan Hudson, Web3D Consortium
- Takuki Kamiya, Fujitsu Laboratories of America, Inc.
- Jaakko Kangasharju, University of Helsinki
- Don McGregor, Web3D Consortium
- Daniel Peintner, Siemens AG
- Santiago Pericas-Geertsen, Sun Microsystems, Inc.
- Liam Quin, W3C/MIT (staff contact)
- Kimmo Raatikainen, Nokia
- Rich Rollman, AgileDelta, Inc.
- Paul Sandoz, Sun Microsystems, Inc.
- John Schneider, AgileDelta, Inc.
- Cedric Thienot, Expway
- Paul Thorpe, OSS Nokalva, Inc.
- Daniel Vogelheim, Siemens AG (co-chair)
- Yun Wang, Intel Corporation
- Greg White, Stanford University (co-chair)
- Stephen Williams, High Performance Technologies, Inc.
The EXI Working Group would like to acknowledge the following former members of the group for their leadership, guidance and expertise they provided throughout their individual tenure in the WG. (sorted alphabetically by last name)
- Robin Berjon, Expway (former co-chair) (until 17 October 2006)
- Oliver Goldman, Adobe Systems, Inc. (former co-chair) (until 08 June 2006)
- Peter Haggar, IBM (until 07 March 2007)