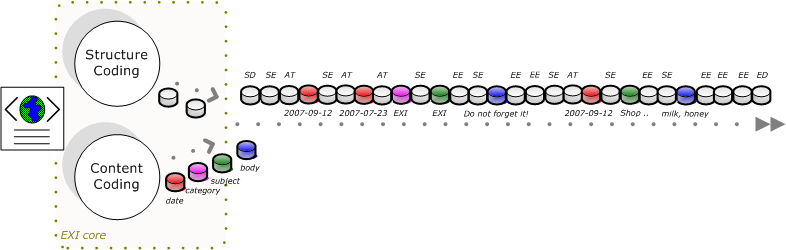
EXI streams are the basic structure of EXI documents. As shown below, an EXI
stream consists of an EXI header followed by an EXI body.
The EXI header conveys format version information and may also include the set of
options that were used during encoding; if these options are omitted, then it is
assumed that the decoder has access to them out of band. The EXI body comprises
an event sequence describing the document (or document fragment) that is
encoded. The following two sections describe the EXI header and EXI body in more
detail.
2.1.1 EXI Header
The header communicates encoding properties that are needed to decode the EXI
body. The default settings can be represented in a single byte. This keeps
the overhead and complexity to a minimum and does not sacrifice compactness,
especially for small documents where a header can introduce a large constant
factor.
The structure of an EXI header is depicted in the following figure. Note that
even though EXI is a bit aligned format, the header is padded to the next
byte to support fast header interpretation.
Table 2-2. EXI Header Structure| Distinguishing Bits | Presence Bit for EXI Options | EXI Format Version | EXI Options | [Padding Bits] |
|---|
The EXI header, and hence every EXI document, starts with a pair of Distinguishing
Bits that can be used to recognize an EXI document from a textual XML
document. The two bit-sequence (1 0) is sufficient to distinguish EXI
streams from XML streams based on a broad range of character encodings.
| Editorial note | |
| The integration of a magic cookie is under consideration by the EXI
WG. A magic cookie would allow distinguishing an EXI document from
formats other than XML or from future character encodings. |
The Presence Bit for EXI Options follows the distinguishing bits. The value
of this single bit is used to indicate the presence or absence of the EXI
Options that appear later in the header.
The EXI Format Version identifies the version of EXI in use and allows
future improvements and modifications. A leading 0 (zero) bit indicates that
the document is encoded according to the final version of the
recommendation, while a leading 1 (one) indicates that it is a preview
version. The differentiation is introduced to facilitate early releases of
preview versions with less strict interoperability requirements. Only final
versions are required to be processed by compliant processors. The leading
bit is followed by one or more 4-bit sequences which are collectively
interpreted as a format version number starting at 1. For example, the 4-bit
sequence 0000 is interpreted as version 1 and the two 4-bit sequences 1111
0001 is interpreted as 15 + 2 or version 17.
The EXI Options specify
how the body of an EXI stream is encoded and, as stated earlier, their
presence is controlled by the present bit earlier in the header. The
overhead introduced by the EXI options is comparatively small given that
they are formally described using an XML schema and can therefore be encoded
using EXI as well. The following table describes the EXI options that can be
specified in the EXI header.
Table 2-3. EXI Options| EXI Option | Description |
|---|
| alignment | Alignment of event codes and content items |
| compression | Indicates if EXI compression is to be used for better
compactness |
| fragment | Indicates if the body is to be encoded as an EXI fragment
instead of an EXI document |
| preserve | A set of options that controls whether comments, processing
instructions, etc. are preserved |
| schemaID | Identifies the schema used during encoding |
| codecMap | Identifies any pluggable CODECs used to encode the body |
| blockSize | Specifies the block size used for EXI compression |
| [user defined] | User defined headers may be added |
Most of the options are straightforward and act as boolean values to enable
or disable a feature. They are represented using optional XML elements which
are also encoded using EXI. For more information on the XML schema that is
used to encode these options, the reader is referred to XML Schema for EXI
Options Header.
The preserve options shown in the table above is really a family of options
that control what XML items are preserved and what XML items are ignored.
These are collectively known as fidelity options. These options
can be used to eliminate the associated overhead of communicating unused XML
items. Certain XML items such as processing instructions or DTDs may never
occur (like in SOAP) or are simply unimportant to the use case or
application domain. Fidelity options are used to manage filters for certain
XML items as shown in the following table.
Table 2-4. Fidelity Options| Fidelity Option | Effect |
|---|
| Preserve.comments | Productions of CM (Comment) events are preserved in
grammars |
| Preserve.pis | Productions of PI (Processing Instruction) events are preserved
in grammars |
| Preserve.dtd | Productions of DOCTYPE and ER (Entity Reference) events are
preserved |
| Preserve.prefixes | NS (Namespace Declaration) events and namespace prefixes are
preserved |
| Preserve.lexicalValues | Lexical form of element and attribute values are preserved |
Naturally, XML items that are discarded at encoding time (due to a
particular setting of the fidelity options) cannot be reconstructed at
decoding time. The next section deals with the EXI Body and discusses in
more detail the effects of enabling and disabling fidelity options.
2.1.2 EXI Body
The body of an EXI document is composed of a sequence of EXI events. The
notion of an event in this context is similar to that in the
StAX and SAX APIs. XML items are encoded into one or more EXI events; for
example, an attribute named foo can be encoded as AT("foo") and an element
named bar as the pair of events SE("bar") and EE. EXI events may have
additional content associated with them. For example, the attribute event
AT("foo") may have an attribute value foo1 associated with it.
The following table shows all the possible event types together with their
associated content.
Table 2-5. EXI Event types| EXI Event Type | Grammar Notation | Information Items |
|---|
| Structure | Content |
|---|
|
(+) Fidelity Options
can be used to prune events from the EXI stream to realize a
more compact representation.
|
| Start Document | SD | | |
|---|
| End Document | ED | | |
| Start Element | SE (qname) | | |
| SE (*) |
qname
| |
| End Element | EE | | |
| Attribute | AT ( qname ) | |
value
|
| AT (*) |
qname
|
| Characters | CH | |
value
|
| Namespace Declaration |
(+)
| NS |
prefix, uri, indicator
| |
| Comment | CM |
text
| |
| Processing Instruction | PI |
name, text
| |
| DOCTYPE | DT |
name, public, system, text
| |
| Entity Reference | ER |
name
| |
For named XML items, such as element and attributes, there are two types of
events: SE(qname) and SE(*) as well as AT(qname)
and AT(*). These events differ in their associated content: when
SE(qname) or AT(qname) are used, the actual
qname of the XML item is not encoded as part of event. The
decision to use one type of event over the other will be explained later
after introducing the notion of EXI grammars.
The fidelity options introduced in Section 2.1.1 EXI Header may be
used to prune EXI events like NS, CM, PI, DT (DocType) or ER (Entity
Reference). Grammar pruning simplifies the encoding and decoding process and
also improves compactness by filtering out unused event types.
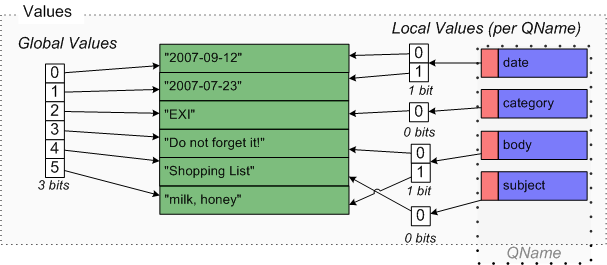
Consider a simple XML document from a notebook application:
<?xml version="1.0" encoding="UTF-8"?>
<notebook date="2007-09-12">
<note date="2007-07-23" category="EXI">
<subject>EXI</subject>
<body>Do not forget it!</body>
</note>
<note date="2007-09-12">
<subject>Shopping List</subject>
<body>milk, honey</body>
</note>
</notebook>
The sequence of EXI events corresponding to the body of this XML document is
shown below.
This sequence of EXI events can be easily mapped to the structure of the XML
document shown above. Every document begins with a SD and ends with an ED.
The order in which attributes are encoded may be different in schema-less
and schema-informed modes, as is the exact content associated with each
event.
The actual number of bits used to represent each type of event, excluding its
content, differs depending on context. The more event types that can occur
in a certain context, the larger the number of bits required to represent an
event in that context. What constitutes a context in this case is more
formally defined by an EXI grammar production in the next section.
2.1.3 EXI Grammars
EXI is a knowledge based encoding that uses a set of grammars to determine
which events are most likely to occur at any given point in an EXI stream
and encodes the most likely alternatives in fewer bits. It does this by
mapping the stream of events to a lower entropy set of representative values
and encoding those values using a set of simple variable length codes or an
EXI compression algorithm.
EXI grammars are regular grammars in which productions are associated with
event codes. An EXI encoder, driven by an XML event stream,
matches grammar productions and uses their associated event codes to
represent an XML document or XML fragment. Since EXI grammars are regular
grammars, the sequence of event codes written by an encoder corresponds to a
path in the finite automaton that accepts the grammar. In reality, given
that XML is not a regular language, a single grammar cannot be used to
represent an entire XML event stream. Instead, an EXI encoder uses a stack
of grammars, one for each element content model (just like an XML Schema
validator would).
An event code is represented by a sequence of one to three parts, where each
part is a non-negative integer. Event codes in an EXI grammar are assigned
to productions in such a way that shorter event codes are used to represent
more likely to occur productions. Conversely, longer event codes are used to
represent less likely to occur productions. EXI grammars are designed so
that the average number of bits needed to represent each
production is less than that for a grammar in which more likely and less
likely productions are not distinguished. The following tables illustrate
this principle via an example.
Table 2-6. Event Code Assignment
| Event | Indicator | | #bits |
|---|
| AT("category") | 0 | | 4 | | AT("date") | 1 | | EE | 2 | | AT(*) | 3 | | NS | 4 | | SE(*) | 5 | | CH | 6 | | CM | 7 | | PI | 8 | | | #distinct values | 9 | |
|---|
| |
| Event | EventCode | | #bits |
|---|
| AT("category") | 0 | | | | 2 | | AT("date") | 1 | | | | EE | 2 | 0 | | 2 + 3 | | AT(*) | 2 | 1 | | | NS | 2 | 2 | | | SE(*) | 2 | 3 | | | CH | 2 | 4 | | | CM | 2 | 5 | 0 | 2 + 3 + 1 | | PI | 2 | 5 | 1 | | | #distinct values | 3 | 6 | 2 | |
|---|
|
|---|
| Naive Event Code Assignment | vs. | EXI Event Code Assignment |
In the first table, where productions are not separated according to their
popularity, a 4-bit code is needed to represent each entry. In the second
table, on the other hand, code lengths vary from 2 bits to 6 bits after
productions are group based on their likelihood to occur. Assuming the
content model for the element being encoded corresponds to the sequence
AT("category") AT("date") (i.e., the element declares two attributes) then
the encoding of all the event codes will be 4 bits shorter using the second
table.
EXI grammars take advantage of a priori knowledge of the kind of data being
encoded, namely, XML documents and XML fragments. In particular, EXI
grammars can take advantage of the fact that, on any given grammar, certain
XML items are more popular than others. For example, by simple inspection of
documents in the wild, it is easy to verify that attributes occur more
frequently than processing instructions and should therefore receive shorter
event codes.
Further improvements in how grammars are designed are possible if schema
information is also known at encoding time. In this case, we can not only
take advance of generic XML knowledge but also of knowledge that is specific
to the type of documents being encoded. For example, as shown in the tables
above, we can add specific productions such as AT("category") and AT("date")
with shorter event codes than AT(*).
The following two sections describe the differences between the built-in
grammars and the schema-informed grammars. Note that an EXI encoder may only
have partial schema information in which case it will use a
combination of built-in and schema-informed grammars during encoding.
2.1.3.1 Built-In Grammar
EXI uses a set of built-in grammars to encode XML documents and XML
fragments when no schema information is available. There are built-in
grammars to encode documents, fragments and elements. Document grammars
and fragment grammars describe the top-level structure, while element
grammars describe the structure of every element. Fragment grammars are
more lenient than document grammars; for example, they allow multiple
top-level elements to be encoded as siblings. For more information on
these grammars, the reader is referred to Built-in XML
Grammars.
The EXI format describes a mechanism by which built-in grammars are
dynamically extended using information from the actual instance being
encoded. Stated differently, the EXI format describes a
learning mechanism to further improve efficiency when no
schema information is available statically. Newly learned productions
are assigned short event codes, improving compactness for every
subsequent use of those productions. In addition, by adding new
productions to the grammar, certain data associated with an event only
needs to be encoded once. For example, if an element named notebook is
matched by SE(*) and subsequently matched by SE("notebook"), the actual
string "notebook" is only encoded once as part of the SE(*) event.
As pointed out in the previous section, EXI grammars are always regular
and can, therefore, be accepted by finite automata (FA). To provide a
more operational view of an EXI processor, we will opt for the use of FA
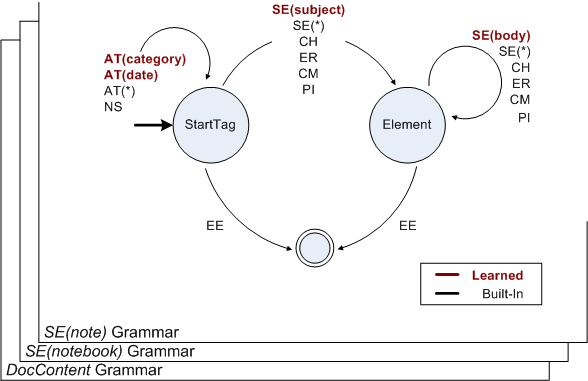
to explain how grammars work. The following figure shows a stack of
grammars in which the top-level grammar accepts "note" elements. State
transitions in black correspond to the built-in element grammar; state
transitions in red have been learned as a result of encoding the element
before.
The built-in element automaton has two distinguished states: StartTag and
Element. The former accepts attribute and namespace events that must
occur before any element content; the latter accepts only element
content which excludes attribute and namespace events. This separation
enables the use of short codes which improves compactness and processing
time.
As stated earlier, transitions in red are extensions to the built-in
element grammar based on knowledge acquired about the element "note".
Notice how AT("category"), AT("date") and SE("subject") have been added
out of the StartTag state while SE(body) has been added out of the
Element state. In particular, this suggests that SE("subject") is
expected to occur before SE("body"), and that both of these SE events
are expected to occur after any AT event. In addition, notice that both
AT(*) and SE(*) are still available to enable future learning.
2.1.3.2 Schema-informed Grammar
EXI grammars can be further improved if schema information is known
statically. Schema information can be interpreted in two different ways
or encoding modes: strict and non-strict. In
strict mode, the instances being encoded must be valid with respect to
the schema; any deviation from the schema will result in an encoding
error. In non-strict mode, deviations are accepted and encoded using
more generic events. Examples of deviations are attributes whose actual
values do not match the type defined in the schema or elements whose
structure does not correspond to that in the schema. Given that strict
grammars have fewer productions (no need for SE(*) or AT(*) in most
cases) shorter event codes can be used to encode each option.
Instead of being dynamically extensible as the built-in grammars,
schema-informed grammars are created statically based on the information
in the available schema. This process will add productions of the form
AT(qname) or SE(qname) guided by the
attribute and element declarations in the schema. Let us continue the
example from the previous section by assuming the following schema is
available statically.
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified">
<xs:element name="notebook">
<xs:complexType>
<xs:sequence maxOccurs="unbounded">
<xs:element name="note" type="Note"/>
</xs:sequence>
<xs:attribute ref="date" />
</xs:complexType>
</xs:element>
<xs:complexType name="Note">
<xs:sequence>
<xs:element name="subject" type="xs:string"/>
<xs:element name="body" type="xs:string"/>
</xs:sequence>
<xs:attribute ref="date" use="required" />
<xs:attribute name="category" type="xs:string"/>
</xs:complexType>
<xs:attribute name="date" type="xs:date" />
</xs:schema>
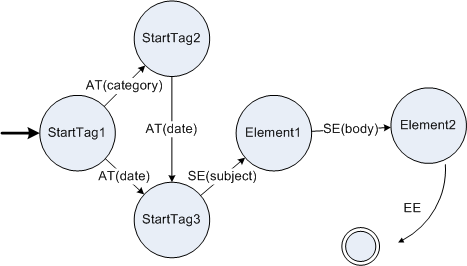
The schema for the element "note" states that it has a mandatory
attribute "date" and an optional attribute "category", and that its
structure is composed of an element "subject" followed by an element
"body". An automaton that corresponds to the strict grammar
for this element is shown next.
Note that AT("category") is accepted before AT("date") even though their
order is reversed in the schema. This is because attributes in
schema-informed grammars must be lexicographically sorted first by local
name and then by namespace URI. Attribute sorting reduces the number of
options which, in turn, greatly simplifies grammar creation and improves
compactness. Since this automaton does not include transitions on AT(*)
or SE(*) any deviations from the schema will result in an encoding
error.