1
Introduction
The primary purpose of XPath is to address
parts of an [XML] document. XPath uses a
compact, non-XML syntax to facilitate use of XPath within
URIs and XML attribute values. XPath gets its name from its
use of a path notation as in URLs for navigating through
the hierarchical structure of an XML document.
[Definition: XPath operates on the
abstract, logical structure of an XML document, rather than
its surface syntax. This logical structure is known as the
data model, which is defined in the [XQuery 1.0 and XPath 2.0 Data Model]
document.]
XPath is designed to be embedded in a
host language such as [XSLT 2.0]
or [XQuery]. XPath has a natural
subset that can be used for matching (testing whether or
not a node matches a pattern); this use of XPath is
described in [XSLT 2.0].
XQuery Version 1.0 is an extension of XPath Version 2.0.
Any expression that is syntactically valid and executes
successfully in both XPath 2.0 and XQuery 1.0 will return the
same result in both languages. Since these languages are so
closely related, their grammars and language descriptions are
generated from a common source to ensure consistency, and the
editors of these specifications work together closely.
XPath also depends on and is closely related to the
following specifications:
This document specifies a grammar for XPath, using the
same Basic EBNF notation used in [XML],
except that grammar symbols always have initial capital
letters. Unless otherwise noted (see A.2 Lexical structure),
whitespace is not significant in the grammar. Grammar
productions are introduced together with the features that
they describe, and a complete grammar is also presented in
the appendix [A XPath
Grammar].
In the grammar productions in this document, nonterminal
symbols are underlined and literal text is enclosed in double
quotes. Certain productions (including the productions that
define DecimalLiteral, DoubleLiteral, and StringLiteral)
employ a regular-expression notation. The following example
production describes the syntax of a function call:
The production should be read as follows: A function call
consists of a QName followed by an open-parenthesis. The
open-parenthesis is followed by an optional argument list.
The argument list (if present) consists of one or more
expressions, separated by commas. The optional argument list
is followed by a close-parenthesis. The symbol
ExprSingle denotes an expression that does not
contain any top-level commas (since top-level commas in a
function call are used to separate the function
arguments).
Certain aspects of language processing are described in
this specification as implementation-defined or
implementation-dependent.
-
[Definition:
Implementation-defined indicates an aspect that
may differ between implementations, but must be specified
by the implementor for each particular
implementation.]
-
[Definition:
Implementation-dependent indicates an aspect that
may differ between implementations, is not specified by
this or any W3C specification, and is not required to be
specified by the implementor for any particular
implementation.]
2 Basics
The basic building block of XPath is the
expression. The language provides several kinds of
expressions which may be constructed from keywords, symbols,
and operands. In general, the operands of an expression are
other expressions. [Definition: XPath is a
functional language which means that expressions can
be nested with full generality. ] [Definition: XPath is also a
strongly-typed language in which the operands of
various expressions, operators, and functions must conform to
the expected types.]
Like XML, XPath is a case-sensitive language. All keywords
in XPath use lower-case characters.
The value of an expression is always a sequence.[Definition: A
sequence is an ordered collection of zero or more
items.] [Definition: An item is
either an atomic value or a node.] [Definition: An
atomic value is a value in the value space of an XML
Schema atomic type, as defined in [XML Schema] (that is, a simple type that is
not a list type or a union type).] [Definition: A node is an
instance of one of the seven node kinds described in
[XQuery 1.0 and XPath 2.0 Data
Model].] Each node has a unique node identity.
Some kinds of nodes have typed values, string values, and
names, which can be extracted from the node. The typed value of a
node is a sequence of zero or more atomic values. The
string
value of a node is a value of type
xs:string. The name of a node is a value
of type xs:QName.
[Definition: A sequence
containing exactly one item is called a singleton
sequence.] An item is identical to a singleton sequence
containing that item. Sequences are never nested--for
example, combining the values 1, (2, 3), and ( ) into a
single sequence results in the sequence (1, 2, 3). [Definition: A sequence containing
zero items is called an empty sequence.]
In this document, the namespace prefixes xs:
and xsi: are considered to be bound to the XML
Schema namespaces
http://www.w3.org/2001/XMLSchema and
http://www.w3.org/2001/XMLSchema-instance,
respectively (as described in [XML
Schema]), and the prefix fn: is considered
to be bound to the namespace of XPath/XQuery functions,
http://www.w3.org/2003/05/xpath-functions
(described in [XQuery 1.0
and XPath 2.0 Functions and Operators]). In some cases,
where the meaning is clear and namespaces are not important
to the discussion, built-in XML Schema typenames such as
integer and string are used without
a namespace prefix. Also, this document assumes that the
default function namespace is set to the
namespace of XPath/XQuery functions, so function names
appearing without a namespace prefix can be assumed to be in
this namespace.
2.1 Expression
Context
[Definition: The expression
context for a given expression consists of all the
information that can affect the result of the expression.]
This information is organized into two categories called
the static context and the dynamic
context.
2.1.1 Static Context
[Definition: The static
context of an expression is the information that is
available during static analysis of the expression, prior
to its evaluation.] This information can be used to
decide whether the expression contains a static error.
If analysis of an expression relies on some component of
the static context that has not been
assigned a value, a static error is raised.[err:XP0001]
The individual components of the static
context are summarized below. Further rules governing
the semantics of these components can be found in
C.1 Static
Context Components.
-
[Definition: XPath 1.0
compatibility mode. This value is
true if rules for backward compatibility
with XPath Version 1.0 are in effect; otherwise it is
false.]
-
[Definition: In-scope
namespaces. This is a set of (prefix, URI) pairs.
The in-scope namespaces are used for resolving
prefixes used in QNames within the expression.]
-
[Definition: Default
element/type namespace. This is a namespace URI.
This namespace is used for any unprefixed QName
appearing in a position where an element or type name
is expected.] The initial default element/type
namespace may be provided by the external
environment.
-
[Definition:
Default function namespace. This is a
namespace URI. This namespace URI is used for any
unprefixed QName appearing as the function name in a
function call. The initial default function namespace
may be provided by the external environment.]
-
[Definition: In-scope
schema definitions. This is a generic term for
all the element, attribute, and type definitions that
are in scope during processing of an expression.] It
includes the following three parts:
-
[Definition:
In-scope type definitions. The in-scope
type definitions always include the predefined
types listed in 2.1.1.1 Predefined
Types. Additional type definitions may be
provided by the host language
environment.]
XML Schema distinguishes named types,
which are given a QName by the schema designer,
must be declared at the top level of a schema,
and are uniquely identified by their QName, from
anonymous types, which are not given a
name by the schema designer, must be local, and
are identified in an implementation-dependent
way. Both named types and anonymous types can be
present in the in-scope type definitions.
-
[Definition:
In-scope element declarations. Each
element declaration is identified either by a
QName (for a top-level element) or by an
implementation-defined element identifier (for a
local element). An element declaration includes
information about the substitution groups
to which this element belongs.]
-
[Definition: In-scope
attribute declarations. Each attribute
declaration is identified either by a QName (for
a top-level attribute) or by an
implementation-defined attribute identifier (for
a local attribute). ]
-
[Definition: In-scope
variables. This is a set of (QName, type) pairs.
It defines the set of variables that are available
for reference within an expression. The QName is the
name of the variable, and the type is the static type
of the variable.]
An expression that binds a variable (such as a
for, some, or
every expression) extends the in-scope
variables of its subexpressions with the new bound
variable and its type.
-
[Definition: In-scope
functions. This component defines the set of
functions that are available to be called from within
an expression. Each function is uniquely identified
by its expanded QName and its arity (number of
parameters). Each function in in-scope
functions has a function signature
and a function
implementation.] [Definition: The
function signature specifies the name of the
function and the static types of its parameters
and its result.] [Definition: The
function implementation enables the function
to map instances of its parameter types into an
instance of its result type. ]
For each atomic type in the in-scope type definitions, there
is a constructor function in the in-scope functions.
Constructor functions are discussed in 3.10.4 Constructor
Functions.
-
[Definition: In-scope
collations. This is a set of (URI, collation)
pairs. It defines the names of the collations that
are available for use in function calls that take a
collation name as an argument.] A collation may be
regarded as an object that supports two functions: a
function that given a set of strings, returns a
sequence containing those strings in sorted order;
and a function that given two strings, returns true
if they are considered equal, and false if not.
-
[Definition: Default
collation. This collation is used by string
comparison functions when no explicit collation is
specified.]
-
[Definition: Base URI. This
is an absolute URI, used when necessary in the
resolution of relative URIs (for example, by the
fn:resolve-uri function.)]
-
[Definition:
Statically-known documents. This is a mapping
from strings onto types. The string represents the
absolute URI of a resource that is potentially
accessible using the fn:doc function.
The type is the type of the document node that would
result from calling the fn:doc function
with this URI as its argument. ] If the argument to
fn:doc is anthing other than a string
literal that is present in statically-known
documents, then the static type of
fn:doc is
document-node()?.
-
[Definition:
Statically-known collections. This is a
mapping from strings onto types. The string
represents the absolute URI of a resource that is
potentially accessible using the
fn:collection function. The type is the
type of the sequence of nodes that would result from
calling the fn:collection function with
this URI as its argument.] If the argument to
fn:collection is anthing other than a
string literal that is present in statically-known
collections, then the static type of
fn:collection is
node()?.
2.1.1.1 Predefined Types
The in-scope type definitions in the
static context are initialized
with certain predefined types, including all the
built-in types of [XML
Schema]. These built-in types are in the namespace
http://www.w3.org/2001/XMLSchema,
which is
represented in this document by the
prefix xs. Some examples of
built-in schema types include xs:integer,
xs:string, and xs:date.
Element and attribute definitions in the
xs namespace are not implicitly included
in the static context.
In addition, the predefined types of XPath include
the types listed below. All these predefined types are
in the namespace
http://www.w3.org/2003/05/xpath-datatypes,
which is
represented in this document by the
prefix xdt.
-
xdt:anyAtomicType is an abstract
type that includes all atomic values (and no values
that are not atomic). It is a subtype of
xs:anySimpleType, which is the base
type for all simple types, including atomic, list,
and union types. All specific atomic types such as
xs:integer, xs:string,
and xdt:untypedAtomic, are subtypes of
xdt:anyAtomicType.
-
xdt:untypedAtomic is a specific
atomic type used for untyped data, such as text
that is not given a specific type by schema
validation. It has no subtypes.
-
xdt:dayTimeDuration is a subtype of
xs:duration whose lexical
representation contains only day, hour, minute, and
second components.
-
xdt:yearMonthDuration is a subtype
of xs:duration whose lexical
representation is restricted to contain only year
and month components.
For more details about predefined types, see
[XQuery 1.0 and XPath
2.0 Functions and Operators].
2.1.2
Dynamic Context
[Definition: The dynamic
context of an expression is defined as information
that is available at the time the expression is
evaluated.] If evaluation of an expression relies on some
part of the dynamic context that has not
been assigned a value, a dynamic error is
raised.[err:XP0002]
The individual components of the dynamic
context are summarized below. Further rules governing
the semantics of these components can be found in
C.2
Dynamic Context Components.
The dynamic context consists of all
the components of the static context, and the
additional components listed below.
[Definition: The first three components of
the dynamic context (context item,
context position, and context size) are called the
focus of the expression. ] The focus enables the
processor to keep track of which nodes are being
processed by the expression.
Certain language constructs, notably the path
expression E1/E2 and the predicate
expression E1[E2], create a new focus for
the evaluation of a sub-expression. In these constructs,
E2 is evaluated once for each item in the
sequence that results from evaluating E1.
Each time E2 is evaluated, it is evaluated
with a different focus. The focus for evaluating
E2 is referred to below as the inner
focus, while the focus for evaluating E1
is referred to as the outer focus. The inner focus
exists only while E2 is being evaluated.
When this evaluation is complete, evaluation of the
containing expression continues with its original focus
unchanged.
-
[Definition: The context
item is the item currently being processed in a
path expression. An item is either an atomic value or
a node.][Definition: When the
context item is a node, it can also be referred to as
the context node.] The context item is
returned by the expression ".". When an
expression E1/E2 or E1[E2]
is evaluated, each item in the sequence obtained by
evaluating E1 becomes the context item
in the inner focus for an evaluation of
E2.
-
[Definition: The context
position is the position of the context item
within the sequence of items currently being
processed in a path expression. ]It changes whenever
the context item changes. Its value is always an
integer greater than zero. The context position is
returned by the expression
fn:position(). When an expression
E1/E2 or E1[E2] is
evaluated, the context position in the inner focus
for an evaluation of E2 is the position
of the context item in the sequence obtained by
evaluating E1. The position of the first
item in a sequence is always 1 (one). The context
position is always less than or equal to the context
size.
-
[Definition: The context
size is the number of items in the sequence of
items currently being processed in a path
expression.] Its value is always an integer greater
than zero. The context size is returned by the
expression last(). When an expression
E1/E2 or E1[E2] is
evaluated, the context size in the inner focus for an
evaluation of E2 is the number of items
in the sequence obtained by evaluating
E1.
-
[Definition: Dynamic
variables. This is a set of (QName, value) pairs.
It contains the same QNames as the in-scope
variables in the static context for the
expression. The QName is the name of the variable and
the value is the dynamic value of the variable.]
-
[Definition:
Current date and time. This information
represents an implementation-dependent point in time
during processing of a query or transformation. It
can be retrieved by the fn:current-date,
fn:current-time, and
fn:current-dateTime functions. If
invoked multiple times during the execution of a
query or transformation, these functions always
returns the same result.]
-
[Definition: Implicit
timezone. This is the timezone to be used when a
date, time, or dateTime value that does not have a
timezone is used in a comparison or in any other
operation. This value is an instance of
xdt:dayTimeDuration that is implementation
defined. See [ISO 8601]
for the range of legal values of a timezone.]
-
[Definition: Accessible
documents. This is a mapping of strings onto
document nodes. The string represents the absolute
URI of a resource. The document node is the
representation of that resource as an instance of the
data model, as returned by the fn:doc
function when applied to that URI. ]The set of
accessible documents may be the same as, or a subset
or superset of, the set of statically-known
documents, and it may be empty.
-
[Definition:
Accessible collections. This is a mapping of
strings onto sequences of nodes. The string
represents the absolute URI of a resource. The
sequence of nodes represents the result of the
fn:collection function when that URI is
supplied as the argument. ] The set of accessible
collections may be the same as, or a subset or
superset of, the set of statically-known collections,
and it may be empty.
2.2 Processing Model
XPath is defined in terms of the data model and in terms of the
expression
context.
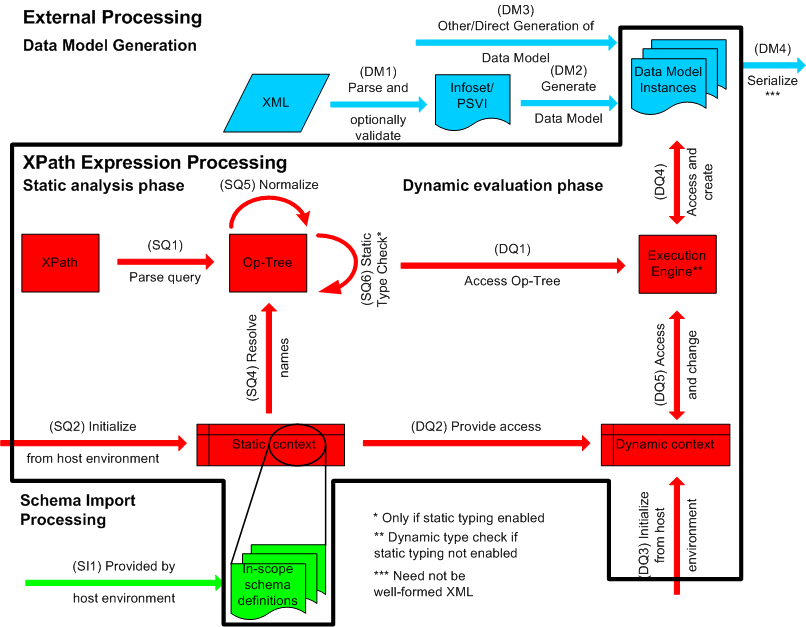
Figure 1: Processing Model Overview
Figure 1 provides a schematic overview of the processing
steps that are discussed in detail below. XPath
distinguishes between the external processing domain, which
includes generation of the data model (see 2.2.1 Data Model
Generation), schema import processing (see 2.2.2 Schema Import
Processing) and serialization (see 2.2.4 Serialization), and
the query processing domain, which includes the static
analysis and dynamic evaluation phases (see 2.2.3 Expression
Processing). Consistency constraints on the query
processing domain are defined in 2.2.5 Consistency
Constraints.
| Editorial
note |
|
| There is an
open issue on how much of the external processing
domain is considered normative (open issue 561). |
2.2.1 Data Model
Generation
Before an expression can be processed, the input
documents to be accessed by the expression must be
represented in the data model. Figure 1 depicts the
steps by which an XML document may be converted to the
data
model:
-
A document may be parsed using an XML parser that
generates an XML Information Set (see [XML Infoset]). The parsed document may
then be validated against one or more schemas. This
process, which is described in [XML Schema], results in an abstract
information structure called the Post-Schema
Validation Infoset (PSVI). If a document has no
associated schema, its Information Set is preserved.
(See DM1 in Fig. 1.)
-
The Information Set or PSVI may be transformed
into the data model by a process described
in [XQuery 1.0 and XPath 2.0
Data Model]. (See DM2 in Fig. 1.)
The above steps provide an example of how a data model instance
might be constructed. A data model instance might also be
synthesized directly from a relational database, or
constructed in some other way (see DM3 in Fig. 1.) XPath
is defined in terms of operations on the data model, but it
does not place any constraints on how the input data model instance
is constructed.
Each atomic value, element node, and attribute node in
the data
model is annotated with its dynamic type. The dynamic
type specifies a range of values -- for example, an
attribute named version might have the
dynamic type xs:decimal, indicating that it
contains a decimal value. For example, if the data model was
derived from an input XML document, the dynamic types of
the elements and attributes are derived from schema
validation.
The value of an attribute is represented directly
within the attribute node. An attribute node whose type
is unknown (such as might occur in a schemaless document)
is annotated with the dynamic type
xdt:untypedAtomic.
The value of an element is represented by the children
of the element node, which may include text nodes and
other element nodes. The dynamic type of an element node
indicates how the values in its child text nodes are to
be interpreted. An element whose type is unknown (such as
might occur in a schemaless document) is annotated with
the type xdt:untypedAny.
An atomic value of unknown type is annotated with the
type xdt:untypedAtomic.
2.2.2 Schema Import
Processing
2.2.3 Expression
Processing
XPath defines two phases of processing called the
static analysis phase and the
dynamic evaluation phase
(see Fig. 1).
2.2.3.1 Static Analysis
Phase
[Definition: The static
analysis phase depends on the expression itself and
on the static context. The static
analysis phase does not depend on any input data.]
During the static analysis phase, the query is
parsed into an internal representation called the
operation tree (step SQ1 in Figure 1). A parse
error is raised as a static error.[err:XP0003] The
static context is initialized
by the implementation (step SQ2). The static
context is used to resolve type names, function
names, namespace prefixes and variable names.
The operation tree is then normalized
by making explicit the implicit operations such as
atomization, type
promotion and extraction of Effective
Boolean Values (step SQ5). The normalization
process is described in [XQuery 1.0 and XPath 2.0
Formal Semantics]. An implementation is free to use
any strategy or algorithm whose result conforms to
these specifications.
If the Static Typing
Feature is supported, each expression is assigned a
static
type (step SQ6). [Definition:
The static type of an expression may be either a
named type or a structural description--for example,
xs:boolean? denotes an optional occurrence
of the xs:boolean type. The rules for
inferring the static types of various
expressions are described in [XQuery 1.0 and XPath 2.0
Formal Semantics].] In some cases, the static type is
derived from the lexical form of the expression; for
example, the static type of the literal
5 is xs:integer. In other
cases, the static type of an expression is
inferred according to rules based on the static types
of its operands; for example, the static type of
the expression 5 + 1.2 is
xs:decimal.
During the analysis phase, if the
Static Typing Feature is in
effect and an operand of an expression is found to have
a static
type that is not appropriate for that operand, a
type
error is raised.[err:XQ0004] If static type checking
raises no errors and assigns a static type T to an
expression, then execution of the expression on valid
input data is guaranteed either to produce a value of
type T or to raise a dynamic error.
During the static analysis phase, if the
static
type assigned to an expression other than
() is empty, a static error is
raised.[err:XQ0005] This catches cases in
which a query refers to an element or attribute that is
not present in the in-scope
schema definitions, possibly because of a spelling
error.
The purpose of type-checking during the static
analysis phase is to provide early detection of
type
errors and to infer type information that may be
useful in optimizing the evaluation of an
expression.
2.2.3.2 Dynamic Evaluation
Phase
[Definition: The dynamic
evaluation phase is performed only after successful
completion of the static analysis phase.
The dynamic evaluation phase depends on the
operation tree of the expression being evaluated
(step DQ1), on the input data (step DQ4), and on the
dynamic context (step DQ5),
which in turn draws information from the external
environment (step DQ3) and the static
context (step DQ2).] Execution of the evaluation
phase may create new data-model values (step DQ4) and
it may extend the dynamic context (step
DQ5)--for example, by binding values to variables.
|
Editorial note |
|
| This is
an open issue. It would be possible to evaluate an
expression containing a static type error, and this
might be quite useful because static analysis is
conservative. Static type analysis could be used to
warn of potential errors without inhibiting
execution of an expression. |
[Definition: A dynamic type
is associated with each value as it is computed. The
dynamic type of a value may be either a structural type
(such as "sequence of integers") or a named type. The
dynamic type of a value may be more specific than the
static
type of the expression that computed it (for
example, the static type of an expression
might be "zero or more integers or strings," but at
evaluation time its value may have the dynamic type
"integer.")]
If an operand of an expression is found to have a
dynamic type that is not appropriate for that operand,
a type
error is raised.[err:XP0006]
Even though static typing can catch many type errors
before an expression is executed, it is possible for an
expression to raise an error during evaluation that was
not detected by static analysis. For example, an
expression may contain a cast of a string into an
integer, which is statically valid. However, if the
actual value of the string at run time cannot be cast
into an integer, a dynamic error will result.
Similarly, an expression may apply an arithmetic
operator to a value whose static type is
xdt:untypedAtomic. This is not a static
error, but at run time, if the value cannot be
successfully cast to a numeric type, a dynamic
error will be raised.
It is also possible for static analysis of an
expression to raise a type error, even though execution
of the expression on certain inputs would be
successful. For example, an expression might contain a
function that requires an element as its parameter, and
the analysis phase might infer the static type of
the function parameter to be an optional element. This
case would be treated as a static type error, even though the
function call would be successful for input data in
which the optional element is present.
2.2.5 Consistency
Constraints
In order for an expression to be well defined, the
expression, its static context, and its
dynamic context must be
mutually consistent. The consistency constraints listed
below are prerequisites for correct functioning of an
XPath implementation. Enforcement of these consistency
constraints is beyond the scope of this
specification.
-
For each item type (i.e., element, attribute, or
type name) referenced in an instance of the data model
whose expanded name matches a name in the in-scope
schema definitions (ISSD), the corresponding element,
attribute, or type definition in the ISSD must be
equivalent to the definition originally provided in
the PSVI from which the data model instance was
created.
-
Every item type (i.e., every element, attribute,
or type name) referenced in in-scope
variables or in-scope functions must be in the
in-scope schema definitions.
-
Every name used in a SequenceType must be in the
in-scope schema definitions.
-
The element declaration for every element name
referenced in a SequenceType or
KindTest must be in the in-scope element declarations.
-
The attribute declaration for every attribute name
referenced in a SequenceType or
KindTest must be in the in-scope attribute
declarations.
-
For each mapping of a string to a document node in
accessible documents, if
there exists a mapping of the same string to a
document type in statically-known documents, the
document node must match the document type, using the
matching rules in 2.4.1.1 SequenceType
Matching.
-
For each mapping of a string to a sequence of
nodes in accessible
collections, if there exists a mapping of the
same string to a type in statically-known
collections, the sequence of nodes must match the
type, using the matching rules in 2.4.1.1 SequenceType
Matching.
-
The dynamic variables in the dynamic
context and the in-scope variables in the
static context must
correspond as follows:
2.3 Important Concepts
The concepts described in this section are normatively
defined in [XQuery 1.0 and XPath 2.0
Data Model] and [XQuery 1.0 and XPath 2.0
Functions and Operators]. They are summarized here
because they are of particular importance in the processing
of expressions.
2.3.1 Document
Order
[Definition: Document order
defines a total ordering among all the nodes seen by the
language processor and is defined formally in the
data
model.] Informally, document order corresponds to a
pre-order, depth-first, left-to-right traversal of the
nodes in the data model.
Within a given document, the document node is the
first node, followed by element nodes, text nodes,
comment nodes, and processing instruction nodes in the
order of their representation in the XML form of the
document (after expansion of entities). Element nodes
occur before their children, and the children of an
element node occur before its following siblings. The
namespace nodes of an element immediately follow the
element node, in implementation-defined order. The
attribute nodes of an element immediately follow its
namespace nodes, and are also in implementation-defined
order.
The relative order of nodes in distinct documents is
implementation
dependent but stable within a given query or
transformation. Given two distinct documents A and B, if
a node in document A is before a node in document B, then
every node in document A is before every node in document
B. The relative order among free-floating nodes (those
not in a document) is also implementation
dependent but stable.
2.3.2 Typed Value and String
Value
Nodes have a typed value and a string value.
[Definition: The typed value
of a node is a sequence of atomic values and can be
extracted by applying the fn:data function
to the node. The typed value for each kind of node is
defined by the dm:typed-value accessor in
[XQuery 1.0 and XPath 2.0 Data
Model]. ] [Definition:
The string value of a node is a string and can be
extracted by applying the the fn:string
function to the node. The string value for each kind of
node is defined by the dm:string-value
accessor in [XQuery 1.0 and XPath
2.0 Data Model].] [Definition: Element and
attribute nodes have a type annotation, which
represents (in an implementation-dependent way) the
dynamic
(run-time) type of the node.] XPath does not provide
a way to directly access the type annotation of an
element or attribute node.
The relationship between the typed value and the
string value for various kinds of nodes is described and
illustrated by examples below.
-
For text, document, comment, processing
instruction, and namespace nodes, the typed value of
the node is the same as its string value, as an
instance of xdt:untypedAtomic. (The
string value of a document node is formed by
concatenating the string values of all its descendant
text nodes, in document order.)
-
The typed value of an attribute node with the type
annotation xdt:untypedAtomic is the same
as its string value, as an instance of
xdt:untypedAtomic. The typed value of an
attribute node with any other type annotation is
derived from its string value and type annotation in
a way that is consistent with schema validation.
Example: A1 is an attribute having string value
"3.14E-2" and type annotation
xs:double. The typed value of A1 is the
xs:double value whose lexical
representation is 3.14E-2.
Example: A2 is an attribute with type annotation
IDREFS, which is a list type derived
from IDREF. Its string value is
"bar baz faz". The typed value of A2 is
a sequence of three atomic values
("bar", "baz",
"faz"), each of type IDREF.
The typed value of a node is never treated as an
instance of a named list type. Instead, if the type
annotation of a node is a list type (such as
IDREFS), its typed value is treated as a
sequence of the underlying base type (such as
IDREF).
-
For an element node, the relationship between
typed value and string value depends on the node's
type annotation, as follows:
-
If the type annotation is
xs:anyType, or denotes a complex
type with mixed content, then the typed value of
the node is equal to its string value, as an
instance of xdt:untypedAtomic.
Example: E1 is an element node having type
annotation xs:anyType and string
value "1999-05-31". The typed value
of E1 is "1999-05-31", as an
instance of xdt:untypedAtomic.
Example: E2 is an element node with the type
annotation formula, which is a
complex type with mixed content. The content of
E2 consists of the character "H", a
child element named subscript with
string value "2", and the character
"O". The typed value of E2 is
"H2O" as an instance of
xdt:untypedAtomic.
-
If the type annotation denotes a simple type
or a complex type with simple content, then the
typed value of the node is derived from its
string value and its type annotation in a way
that is consistent with schema validation.
Example: E3 is an element node with the type
annotation cost, which is a complex
type that has several attributes and a simple
content type of xs:decimal. The
string value of E3 is "74.95". The
typed value of E3 is 74.95, as an
instance of xs:decimal.
Example: E4 is an element node with the type
annotation hatsizelist, which is a
simple type derived by list from the type
hatsize, which in turn is derived
from xs:integer. The string value of
E4 is "7 8 9". The typed value of E4
is a sequence of three values (7,
8, 9), each of type
hatsize.
-
If the type annotation denotes a complex type
with empty content, then the typed value of the
node is the empty sequence.
-
If the type annotation denotes a complex type
with non-mixed complex content, then the typed
value of the node is undefined. The
fn:data function raises a type error
[err:XP0007] when applied to such
a node.
Example: E5 is an element node with the type
annotation weather, which is a
complex type whose content type specifies
elementOnly. E5 has two child
elements named temperature and
precipitation. The typed value of E5
is undefined, and the fn:data
function applied to E5 raises an error.
2.3.3 Input Sources
XPath has a set of functions that provide access to
input data. These functions are of particular importance
because they provide a way in which an expression can
reference a document or a collection of documents. The
input functions are described informally here, and in
more detail in [XQuery
1.0 and XPath 2.0 Functions and Operators].
An expression can access input documents either by
calling one of the input functions or by referencing some
part of the expression context that is initialized by the
external environment, such as a variable or a
pre-initialized context item.
The input functions supported by XPath are as
follows:
-
The fn:doc function takes a string
containing a URI that refers to an XML document, and
returns a document node whose content is the
data
model representation of the given document.
-
The fn:collection function returns
the nodes found in a collection. A collection may be
any sequence of nodes. A collection is identified by
a string, which must be a valid URI. For example, the
expression
fn:collection("http://example.org")//customer
identifies all the customer elements
that are descendants of nodes found in the collection
whose URI is http://example.org.
If a given input function is invoked repeatedly with
the same arguments during the scope of a single query or
transformation, each invocation returns the same
result.
2.4 Types
XPath is a strongly typed language with a type system
based on [XML Schema]. The XPath
type system is formally defined in [XQuery 1.0 and XPath 2.0 Formal
Semantics]. During the analysis phase, if static type
checking is in effect and an expression has a static type that
is not appropriate for the context in which the expression
is used, a type
error is raised.[err:XQ0004] During the evaluation phase,
if the type of a value is incompatible with the expected
type of the context in which the value is used, a type error is
raised.[err:XP0006] A type error may be detected and
reported either during the static analysis phase or
during the dynamic evaluation phase.
2.4.1 SequenceType
[Definition: When it is necessary
to refer to a type in an XPath expression, the syntax
shown below is used. This syntax production is called
SequenceType, since it describes the type of an
XPath value, which is a sequence.]
SequenceType
QNames appearing in a SequenceType have their prefixes
expanded to namespace URIs by means of the in-scope
namespaces and the default element/type namespace.
It is a static error [err:XP0008] to use a
name in a SequenceType if that name is not found in the
appropriate part of the in-scope
schema definitions. If the name is used as an element
name, it must appear in the in-scope element declarations; if it
is used as an attribute name, it must appear in the
in-scope attribute declarations; and
if it is used as a type name, it must appear in the
in-scope type definitions.
Here are some examples of SequenceTypes that might be
used in XPath expressions:
-
xs:date refers to the built-in Schema
type date
-
attribute()? refers to an optional
attribute
-
element() refers to any element
-
element(po:shipto, po:address) refers
to an element that has the name
po:shipto (or is in the substitution
group of that element), and has the type annotation
po:address (or a subtype of that
type)
-
element(po:shipto, *) refers to an
element named po:shipto (or in the
substitution group of po:shipto), with
no restrictions on its type
-
element(*, po:address) refers to an
element of any name that has the type annotation
po:address (or a subtype of
po:address). If the keyword
nillable were used following
po:address, that would indicate that the
element may have empty content and the attribute
xsi:nil="true", even though the
declaration of the type po:address has
required content.
-
node()* refers to a sequence of zero
or more nodes of any type
-
item()+ refers to a sequence of one
or more nodes or atomic values
2.4.1.1 SequenceType
Matching
[Definition: During
evaluation of an expression, it is sometimes necessary
to determine whether a given value matches a type that
was declared using the SequenceType syntax. This
process is known as SequenceType matching.] For
example, an instance of expression returns
true if a given value matches a given
type, or false if it does not.
SequenceType matching
between a given value and a given SequenceType is
performed as follows:
If the SequenceType is empty(), the
match succeeds only if the value is an empty sequence.
If the SequenceType is an ItemType with no
OccurrenceIndicator, the match succeeds only if the
value contains precisely one item and that item matches
the ItemType (see below). If the SequenceType contains
an ItemType and an OccurrenceIndicator, the match
succeeds only if the number of items in the value is
consistent with the OccurrenceIndicator, and each of
these items matches the ItemType. As a consequence of
these rules, a value that is an empty sequence matches
any SequenceType whose occurrence indicator is
* or ?.
An OccurrenceIndicator indicates the number
of items in a sequence, as follows:
-
? indicates zero or one items
-
* indicates zero or more items
-
+ indicates one or more items
As stated above, an item may be a node or an atomic
value. The process of matching a given item against a
given ItemType is performed as follows
-
The ItemType item() matches any
single item. For example, item()
matches the atomic value 1 or the
element <a/>.
-
If an ItemType consists simply of a QName, that
QName must be the name of an atomic type that is in
the in-scope type definitions;
otherwise a static error is raised. An
ItemType consisting of the QName of an atomic type
matches a value if the dynamic type of the value is
the same as the named atomic type, or is derived
from the named atomic type by restriction. For
example, the ItemType xs:decimal
matches the value 12.34 (a decimal
literal); it also matches a value whose dynamic
type is shoesize, if
shoesize is an atomic type derived by
restriction from xs:decimal. The named
atomic type may be a generic type such as
xdt:anyAtomicType. (Note that names of
non-atomic types such as xs:IDREFS are
not accepted in this context, but can often be
replaced by an atomic type with an occurrence
indicator, such as xs:IDREF*.)
-
The following ItemTypes (referred to generically
as KindTests) match nodes:
-
node() matches any node.
-
text() matches any text
node.
-
processing-instruction()
matches any processing instruction node.
-
processing-instruction(N
) matches any processing instruction
node whose name (called its "PITarget" in XML)
is equal to N, where N is an
NCName. Example:
processing-instruction(xml-stylesheet)
matches any processing instruction whose
PITarget is xml-stylesheet.
For backward compatibility with XPath 1.0,
the PITarget of a processing instruction in a
KindTest may also be expressed as a string
literal, as in this example:
processing-instruction("xml-stylesheet").
-
comment() matches any comment
node.
-
document-node() matches any
document node.
-
document-node(E)
matches any document node whose content
consists of exactly one element node that
matches E, where E is an
ElementTest (see below),
mixed with zero or more comments and processing
instructions. Example:
document-node(element(book))
matches any document node whose content
contains exactly one element node named
book, that conforms to the schema
declaration for the top-level element
book (possibly mixed with comments
and processing instructions).
-
An ElementTest (see below)
matches an element node, optionally qualifying
the node by its name, its type, or both.
-
An AttributeTest (see
below) matches an attribute node, optionally
qualifying the node by its name, its type, or
both.
[Definition: An ElementTest
is used to match an element node by its name and/or
type.] An ElementTest may take one of the following
forms:
-
element(), or
element(*), or
element(*,*). All these forms of
ElementTest are equivalent, and they all match any
single element node, regardless of its name or
type.
-
element(N,
T), where N is a
QName and T is a QName optionally followed
by the keyword nillable. In this case,
T must be the name of a top-level type
definition in the in-scope type definitions. The
ElementTest matches a given element node if:
-
the name of the given element node is equal
to N (expanded QNames match), or is
equal to the name of any element in a
substitution group headed by a top-level
element with the name N; and:
-
the type annotation of the given element
node is T, or is a named type that is
derived by restriction or extension from
T. However, this test is not satisfied
if the given element node has the
nilled property and T
does not specify nillable.
The following examples illustrate this form of
ElementTest, matching an element node whose name is
person and whose type annotation is
surgeon (the second example permits
the element to have
xsi:nil="true"):
element(person, surgeon)
element(person, surgeon nillable)
-
element(N),
where N is a QName. This form is very
similar to the previous form, except that the
required type, rather than being named explicitly,
is taken from the top-level declaration of element
N. In this case, N must be the
name of a top-level element declaration in the
in-scope element declarations.
The ElementTest matches a given element node
if:
-
the name of the given element node is equal
to N (expanded QNames match), or is
equal to the name of any element in a
substitution group headed by N;
and:
-
the type annotation of the given element
node is the same as, or derived by restriction
or extension from, the type of the top-level
declaration for element N. The types
to be compared may be either named types
(identified by QNames) or anonymous types
(identified in an implementation-dependent
way). However, this test is not satisfied if
the given element node has an attribute
xsi:nil="true" and the top-level
declaration for element N does not
specify nillable.
The following example illustrates this form of
ElementTest, matching an element node whose name is
person and whose type annotation
conforms to the top-level person
element declaration in the in-scope element
declarations:
-
element(N,
*), where N is a QName. This
ElementTest matches a given element node if the
name of the node is equal to N (expanded
QNames match), or is equal to the name of any
element in a substitution group headed by a
top-level element with the name N. The
given element node may have any type
annotation.
The following example illustrates this form of
ElementTest, matching any element node whose name
is person or is in the
person substitution group, regardless
of its type annotation:
-
element(*,
T), where T is a
QName optionally followed by the keyword
nillable. In this case, T
must be the name of a top-level type definition in
the in-scope type definitions. The
ElementTest matches a given element node if the
node's type annotation is T, or is a named
type that is derived by restriction or extension
from T. However, this test is not
satisfied if the given element node has an
attribute xsi:nil="true" and
T does not specify
nillable.
The following examples illustrate this form of
ElementTest, matching any element node whose type
annotation is surgeon, regardless of
its name (the second example permits the element to
have xsi:nil="true"):
element(*, surgeon)
element(*, surgeon nillable)
-
element(P),
where P is a valid schema context path
beginning with a top-level element name or type
name in the in-scope schema definitions and
ending with an element name. This ElementTest
matches a given element node if:
-
the name of the given element node is equal
to the last name in the path (expanded QNames
match), and:
-
the type annotation of the given element
node is the same as the type of the element
represented by the schema path P.
The following examples illustrate this form of
ElementTest, matching element nodes whose name is
person. In the first example, the node
must conform to the schema definition of a
person element in a staff
element in a hospital element. In the
second example, the node must conform to the schema
definition of a person element within
the top-level type schedule:
element(hospital/staff/person)
element(type(schedule)/person)
[Definition: An
AttributeTest is used to match an attribute node
by its name and/or type.] An AttributeTest may take one
of the following forms:
-
attribute(), or
attribute(@*), or
attribute(@*,*). All these forms of
AttributeTest are equivalent, and they all match
any single attribute node, regardless of its name
or type.
-
attribute(@N,
T), where N and
T are QNames. In this case, T
must be the name of a top-level simple type
definition in the in-scope type definitions. This
AttributeTest matches a given attribute node
if:
-
the name of the given attribute node is
equal to N (expanded QNames match),
and:
-
the type annotation of the given attribute
node is T, or is a named type that is
derived by restriction from T.
The following example illustrates this form of
AttributeTest, matching an attribute node whose
name is price and whose type
annotation is currency:
attribute(@price, currency)
-
attribute(@N),
where N is a QName. This form is very
similar to the previous form, except that the
required type, rather than being named explicitly,
is taken from the top-level attribute declaration
with name N.In this case, N must
be the name of a top-level attribute declaration in
the in-scope attribute
declarations. This AttributeTest matches a
given attribute node if:
-
the name of the given attribute node is
equal to N (expanded QNames match),
and:
-
the type annotation of the given attribute
node is the same as, or derived by restriction
from, the type of the top-level attribute
declaration for N. The types to be
compared may be either named types (identified
by QNames) or anonymous types (identified in an
implementation-dependent way).
The following example illustrates this form of
AttributeTest, matching an attribute node whose
name is price and whose type
annotation conforms to the schema declaration for a
top-level price attribute:
-
attribute(@N,
*), where N is a QName. This
AttributeTest matches a given attribute node if the
name of the node is equal to N (expanded
QNames match). The given attribute node may have
any type annotation.
The following example illustrates this form of
AttributeTest, matching any attribute node whose
name is price, regardless of its type
annotation:
-
attribute(@*,
T), where T is a
QName. In this case, T must be the name of
a top-level simple type definition in the in-scope type definitions. This
AttributeTest matches a given attribute node if the
node's type annotation is T, or is a
named type that is derived by restriction from
T.
The following example illustrates this form of
AttributeTest, matching any attribute node whose
type annotation is currency,
regardless of its name:
-
attribute(P),
where P is a valid schema context path
beginning with a top-level element name or type
name in the in-scope schema definitions,
and ending with an attribute name (preceded by
@). This AttributeTest matches a given
attribute node if:
-
the name of the given attribute node is
equal to the last name in the path (expanded
QNames match), and:
-
the type annotation of the given attribute
node is the same as the type of the attribute
represented by the schema path P.
The following examples illustrate this form of
AttributeTest, matching attribute nodes whose name
is price. In the first example, the
node must conform to the schema definition of a
price attribute in a
product element in a
catalog element. In the second
example, the node must conform to the schema
definition of a price attribute within
the top-level type plan:
attribute(catalog/product/@price)
attribute(type(plan)/@price)
2.4.2 Type Conversions
Some expressions do not require their operands to
exactly match the expected type. For example, function
parameters and returns expect a value of a particular
type, but automatically perform certain type conversions,
such as extraction of atomic values from nodes, promotion
of numeric values, and implicit casting of untyped
values. The conversion rules for function parameters and
returns are discussed in 3.1.5 Function Calls.
Other operators that provide special conversion rules
include arithmetic operators, which are discussed in
3.4 Arithmetic
Expressions, and value comparisons, which are
discussed in 3.5.1
Value Comparisons.
2.4.2.1 Atomization
Type conversions sometimes depend on a process
called atomization. [Definition: Atomization is
applied to a value when the value is used in a context
in which a sequence of atomic values is required. The
result of atomization is either a sequence of atomic
values or a type error. Atomization of a
sequence is defined as the result of invoking the
fn:data function on the sequence, as
defined in [XQuery 1.0
and XPath 2.0 Functions and Operators].]
The semantics of fn:data are repeated
here for convenience. The result of
fn:data is the sequence of atomic values
produced by applying the following rules to each item
in the input sequence:
-
If the item is an atomic value, it is
returned.
-
If the item is a node, it is replaced by its
typed
value.
Atomization may be used in processing the following
types of expressions:
2.4.2.2 Effective
Boolean Value
Under certain circumstances (listed below), it is
necessary to find the effective
boolean value of a value. [Definition: The effective boolean
value of a value is defined as the result of
applying the fn:boolean function to the
value, as defined in [XQuery 1.0 and XPath 2.0
Functions and Operators].]
The semantics of fn:boolean are
repeated here for convenience. fn:boolean
returns false if its operand is any of the
following:
-
An empty sequence.
-
The boolean value false.
-
A zero-length string ("").
-
A numeric value that is equal to zero.
-
The double or float
value NaN.
Otherwise, fn:boolean returns
true.
The effective boolean value of a sequence is
computed implicitly during processing of the following
types of expressions:
-
Logical expressions (and,
or)
-
The fn:not function
-
Certain types of predicates, such as
a[b].
-
Conditional expressions (if)
-
Quantified expressions (some,
every)
Note that the definition of effective
boolean value is not used when casting a value to
the type xs:boolean.
2.5 Error
Handling
2.5.1 Kinds of Errors
As described in 2.2.3 Expression
Processing, XPath defines an analysis phase, which does not
depend on input data, and an evaluation phase, which does
depend on input data. Errors may be raised during each
phase.
[Definition: A static error
is an error that must be detected during the analysis
phase. A syntax error is an example of a static error.
The means by which static errors are reported during
the analysis phase is implementation
defined. ]
[Definition: A dynamic error
is an error that must be detected during the evaluation
phase and may be detected during the analysis phase.
Numeric overflow is an example of a dynamic error. ]
[Definition: A type error may
be raised during the analysis or evaluation phase. During
the analysis phase, a type error occurs when the static type of
an expression does not match the expected type of the
context in which the expression occurs. During the
evaluation phase, a type error occurs when the dynamic
type of a value does not match the expected type of the
context in which the value occurs. ]
The result of the analysis phase is either
success or one or more type errors and/or static
errors.
The result of the evaluation phase is
either a result value, a type error, or a dynamic
error. If evaluation of an expression yields a value
(that is, it does not raise an error), the value must be
the value specified by the dynamic semantics defined in
[XQuery 1.0 and XPath
2.0 Formal Semantics].
If any expression (at any level) can be evaluated
during the analysis phase (because all its explicit
operands are known and it has no dependencies on the
dynamic context), then any error in performing this
evaluation may be reported as a static error. However,
the fn:error() function must not be
evaluated during the analysis phase. For example, an
implementation is allowed (but not required) to treat the
following expression as a static error, because it calls
a constructor function with a constant string that is not
in the lexical space of the target type:
[XQuery 1.0 and XPath
2.0 Formal Semantics] defines the set of static,
dynamic, and type errors. In addition to these
errors, an XPath implementation may raise implementation defined
warnings, either during the analysis phase or the
evaluation phase. The circumstances in which warnings are
raised, and the ways in which warnings are handled, are
implementation
defined.
In addition to the errors defined in this
specification, an implementation may raise a dynamic
error if insufficient resources are available for
processing a given expression. For example, an
implementation may specify limitations on the maximum
numbers or sizes of various objects. These limitations,
and the consequences of exceeding them, are implementation
defined.
2.5.2 Handling Dynamic
Errors
Except as noted in this document, if any operand of an
expression raises a dynamic error, the expression
also raises a dynamic error. If an expression
can validly return a value or raise a dynamic error, the
implementation may choose to return the value or raise
the dynamic error. For example, the
logical expression expr1 and expr2 may
return the value false if either operand
returns false, or may raise a dynamic
error if either operand raises a dynamic error.
If more than one operand of an expression raises an
error, the implementation may choose which error is
raised by the expression. For example, in this
expression:
($x div $y) + xs:decimal($z)
both the sub-expressions ($x div $y) and
xs:decimal($z) may raise an error. The
implementation may choose which error is raised by the
"+" expression. Once one operand raises an
error, the implementation is not required, but is
permitted, to evaluate any other operands.
A dynamic error carries an
error
value. [Definition: An error
value is a single item or the empty sequence.] For
example, an error value might be an integer, a string, a
QName, or an element. An implementation may provide a
mechanism whereby an application-defined error handler
can process error values and produce diagnostics; in the
absence of such an error handler, the string-value
of the error value may be used directly as an error
message.
A dynamic error may be raised by a
built-in function or operator. For example, the
div operator raises an error if its second
operand equals zero.
An error can be raised explicitly by calling the
fn:error function, which only raises an
error and never returns a value. The
fn:error function takes an optional item as
its parameter, which is the error value. For example, the
following function call raises a dynamic error whose error
value is a string:
fn:error(fn:concat("Unexpected value ", fn:string($v)))
2.5.3 Errors and
Optimization
Because different implementations may choose to
evaluate or optimize an expression in different ways, the
detection and reporting of dynamic errors is implementation
dependent.
When an implementation is able to evaluate an
expression without evaluating some subexpression, the
implementation is never required to evaluate that
subexpression solely to determine whether it raises a
dynamic
error. For example, if a function parameter is never
used in the body of the function, an implementation may
choose whether to evaluate the expression bound to that
parameter in a function call.
In some cases, an optimizer may be able to achieve
substantial performance improvements by rearranging an
expression so that the underlying operations such as
projection, restriction, and sorting are performed in a
different order than that specified in [XQuery 1.0 and XPath 2.0 Formal
Semantics]. In such cases, dynamic errors may be
raised that would not have been raised if the expression
were evaluated as written. For example, consider the
following expression:
$N[@x castable as xs:date]
[xs:date(@x) gt xs:date("2000-01-01")]
This expression cannot raise a casting error if it is
evaluated exactly as written (i.e., left to right). An
implementation is permitted, however, to reorder the
predicates to achieve better performance (for example, by
taking advantage of an index). This reordering could
cause the above expression to raise an error. However, an
expression must not be rearranged in a way that causes it
to return a result value that is different from the
result value defined by [XQuery 1.0 and XPath 2.0 Formal
Semantics].
To avoid unexpected errors caused by reordering of
expressions, tests that are designed to prevent dynamic
errors should be expressed using conditional expressions,
as in the following example:
$N[if (@x castable as xs:date)
then xs:date(@x) gt xs:date("2000-01-01")
else false()]
In the case of a conditional expression, the
implementation is required not to evaluate the
then branch if the condition is false, and
not to evaluate the else branch if the
condition is true. Conditional expressions are the only
expressions that provide guaranteed conditions under
which a particular subexpression will not be
evaluated.
2.6 Optional Features
XPath 2.0 defines an optional feature
called the Static Typing Feature. An
implementation that includes this feature is required to
detect type errors during the static
analysis phase. If an expression contains one or more
static errors or type errors, then a Static Typing
implementation must raise at least one of these errors
during the static analysis phase.
3
Expressions
This section introduces each of the basic kinds of
expression. Each kind of expression has a name such as
PathExpr, which is introduced on the left side
of the grammar production that defines the expression. Since
XPath is a composable language, each kind of expression is
defined in terms of other expressions whose operators have a
higher precedence. In this way, the precedence of operators
is represented explicitly in the grammar.
The order in which expressions are discussed in this
document does not reflect the order of operator precedence.
In general, this document introduces the simplest kinds of
expressions first, followed by more complex expressions. For
a complete overview of the grammar, see the Appendix
[A XPath Grammar].
The highest-level
(goal) symbol in the XPath grammar is
XPath.
The XPath operator that has lowest precedence is the comma
operator, which is used to concatenate two operands to form a
sequence. As shown in the grammar, a general expression
(Expr) can consist of two operands (ExprSingle) separated by
a comma. The name ExprSingle denotes an expression that does
not contain a top-level comma operator (despite its name, an
ExprSingle may evaluate to a sequence containing more than
one item.)
The symbol ExprSingle is used in various places in the
grammar where an expression is not allowed to contain a
top-level comma. For example, each of the arguments of a
function call must be an ExprSingle, because commas are used
to separate the arguments of a function call.
After the comma, the expressions that have next lowest
precedence are ForExpr, QuantifiedExpr, IfExpr, and
OrExpr. Each of these expressions is described in a separate
section of this document.
3.1 Primary Expressions
[Definition: Primary
expressions are the basic primitives of the language.
They include literals, variables, function calls,
constructors, and the use of parentheses to control
precedence of operators. ]
3.1.1
Literals
[Definition: A literal is a direct
syntactic representation of an atomic value.] XPath
supports two kinds of literals: numeric literals and
string literals.
The value of a numeric literal containing no
"." and no e or E
character is an atomic value whose type is
xs:integer and whose value is obtained by
parsing the numeric literal according to the rules of the
xs:integer datatype. The value of a numeric
literal containing "." but no e
or E character is an atomic value whose type
is xs:decimal and whose value is obtained by
parsing the numeric literal according to the rules of the
xs:decimal datatype. The value of a numeric
literal containing an e or E
character is an atomic value whose type is
xs:double and whose value is obtained by
parsing the numeric literal according to the rules of the
xs:double datatype.
The value of a string literal is an atomic
value whose type is xs:string and whose
value is the string denoted by the characters between the
delimiting apostrophes or quotation marks. If the literal
is delimited by apostrophes, two adjacent apostrophes
within the literal are interpreted as a single
apostrophe. Similarly, if the literal is delimited by
quotation marks, two adjacent quotation marks within the
literal are interpreted as one quotation mark.
Note:
If a string literal is used in an XPath expression
contained within the value of an XML attribute, the
characters used to delimit the literal should be
different from the characters that are used to delimit
the attribute.
Here are some examples of literal expressions:
-
"12.5" denotes the string containing
the characters '1', '2', '.', and '5'.
-
12 denotes the integer value
twelve.
-
12.5 denotes the decimal value twelve
and one half.
-
125E2 denotes the double value twelve
thousand, five hundred.
-
"He said, ""I don't like it."""
denotes a string containing two quotation marks and
one apostrophe.
The boolean values true and
false can be represented by calls to the
built-in functions fn:true() and
fn:false(), respectively.
Values of other XML Schema built-in types can be
constructed by calling the constructor for the given
type. The constructors for XML Schema built-in types are
defined in [XQuery 1.0
and XPath 2.0 Functions and Operators]. In general,
the name of a constructor function for a given type is
the same as the name of the type (including its
namespace). For example:
-
xs:integer("12") returns the integer
value twelve.
-
xs:date("2001-08-25") returns an item
whose type is xs:date and whose value
represents the date 25th August 2001.
-
xdt:dayTimeDuration("PT5H") returns
an item whose type is
xdt:dayTimeDuration and whose value
represents a duration of five hours.
It is also possible to construct values of various
types by using a cast expression. For
example:
3.1.2
Variables
A variable reference is a QName preceded by a
$-sign. Two variable references are equivalent if their
local names are the same and their namespace prefixes are
bound to the same namespace URI in the in-scope
namespaces. An unprefixed variable reference is in no
namespace.
Every variable reference must match a name in the
in-scope
variables, which include variables from the following
sources:
-
A variable may be added to the in-scope variables
by the host language environment.
-
A variable may be bound by an XPath expression.
The kinds of
expressions that can bind variables are
for expressions (3.7 For Expressions)
and quantified expressions (3.9 Quantified
Expressions).
Every variable binding has a static scope. The scope
defines where references to the variable can validly
occur. It is a static error [err:XP0016] to
reference a variable that is not in scope. If a variable
is bound in the static context for an
expression, that variable is in scope for the entire
expression.
If a variable reference matches two or more bindings
that are in scope, then the reference is taken as
referring to the inner binding, that is, the one whose
scope is smaller. At evaluation time, the value of a
variable reference is the value of the expression to
which the relevant variable is bound. The scope of a
variable binding is defined separately for each kind of
expression that can bind variables.
3.1.3 Parenthesized
Expressions
Parentheses may be used to enforce a particular
evaluation order in expressions that contain multiple
operators. For example, the expression (2 + 4) *
5 evaluates to thirty, since the parenthesized
expression (2 + 4) is evaluated first and
its result is multiplied by five. Without parentheses,
the expression 2 + 4 * 5 evaluates to
twenty-two, because the multiplication operator has
higher precedence than the addition operator.
Empty parentheses are used to denote an empty
sequence, as described in 3.3.1 Constructing
Sequences.
3.1.4 Context Item
Expression
A context item expression evaluates to the
context item, which may be either a node (as in the
expression
fn:doc("bib.xml")//book[count(./author)>1])
or an atomic value (as in the expression (1 to
100)[. mod 5 eq 0]).
3.1.5 Function Calls
A function call consists of a QName followed by
a parenthesized list of zero or more expressions, called
arguments. If the QName in the function call has
no namespace prefix, it is considered to be in the
default function namespace.
If the expanded QName and number of arguments in a
function call do not match the name and arity of an
in-scope function in the static
context, an
error is raised (the host language environment may define
this error as either a static or a dynamic
error.)[err:XP0017]
A function call is evaluated as follows:
-
Each argument expression is evaluated, producing
an argument value. The order of argument evaluation
is implementation-dependent and a function need not
evaluate an argument if the function can evaluate its
body without evaluating that argument.
-
Each argument value is converted by applying the
function conversion rules listed below.
-
The function is executed using the converted
argument values. The result is a value of the
function's declared return type.
The function conversion rules are used to
convert an argument value to its expected type; that is,
to the declared type of the function parameter. The
expected type is expressed as a SequenceType. The function
conversion rules are applied to a given value as
follows:
-
If XPath 1.0 compatibility mode is
true, then one of the following
conversions is applied:
-
If the expected type is xs:string
or xs:string?, then the given value
V is effectively replaced by
fn:string(fn:subsequence(V, 1,
1)).
-
If the expected type is xs:double
or xs:double?, then the given value
V is effectively replaced by
fn:number(fn:subsequence(V, 1,
1)).
-
If the expected type is a (possibly optional)
node or item, then the given value V
is effectively replaced by
fn:subsequence(V, 1, 1).
-
Otherwise, the given value is unchanged.
-
If the expected type is a sequence of an atomic
type (possibly with an occurrence indicator
*, +, or ?),
the following conversions are applied:
-
Atomization is applied to
the given value, resulting in a sequence of
atomic values.
-
Each item in the atomic sequence that is of
type xdt:untypedAtomic is cast to
the expected atomic type.
-
For each numeric item in the atomic sequence
that can be promoted to the expected
atomic type using the promotion rules in B.1 Type Promotion, the
promotion is done.
-
If, after the above conversions, the resulting
value does not match the expected type according to
the rules for SequenceType
Matching, a type error is raised.[err:XP0006] Note
that the rules for SequenceType Matching permit a
value of a derived type to be substituted for a value
of its base type.
A core library of functions is defined in [XQuery 1.0 and XPath 2.0
Functions and Operators]. Additional functions may be
provided in the static
context.
Since the arguments of a function call are separated
by commas, any argument expression that contains a
top-level comma operator must be enclosed in parentheses.
Here are some illustrative examples of function
calls:
-
three-argument-function(1, 2, 3)
denotes a function call with three arguments.
-
two-argument-function((1, 2), 3)
denotes a function call with two arguments, the first
of which is a sequence of two values.
-
two-argument-function(1, ()) denotes
a function call with two arguments, the second of
which is an empty sequence.
-
one-argument-function((1, 2, 3))
denotes a function call with one argument that is a
sequence of three values.
-
one-argument-function(( )) denotes a
function call with one argument that is an empty
sequence.
-
zero-argument-function( ) denotes a
function call with zero arguments.
3.1.6 XPath
Comments
XPath comments can be used to provide informative
annotation. These comments are lexical constructs only,
and do not affect the processing of an expression.
Comments are delimited by the symbols (: and
:). Comments may be nested.
Comments may be used anywhere that ignorable
whitespace is allowed. See A.2 Lexical structure for
the exact lexical states where comments are
recognized.
The following is an example of a comment:
(: Houston, we have a problem :)
3.2 Path Expressions
A path expression can be used to locate nodes
within a tree.
A path expression consists of a series of one or more
steps, separated by "/" or
"//", and optionally beginning with
"/" or "//". An initial
"/" or "//" is an abbreviation
for one or more initial steps that are implicitly added to
the beginning of the path expression, as described
below.
A path expression consisting of a single step is
evaluated as described in 3.2.1
Steps.
Each occurrence of // in a path expression
is expanded as described in 3.2.4
Abbreviated Syntax, leaving a sequence of steps
separated by /. This sequence of steps is then
evaluated from left to right. Each operation
E1/E2 is evaluated as follows: Expression
E1 is evaluated, and if the result is not a
sequence of nodes, a type error is raised.[err:XP0019] Each node
resulting from the evaluation of E1 then
serves in turn to provide an inner focus for an
evaluation of E2, as described in 2.1.2 Dynamic Context. Each
evaluation of E2 must result in a sequence of
nodes; otherwise, a type error is raised.[err:XP0019] The
sequences of nodes resulting from all the evaluations of
E2 are merged, eliminating duplicate nodes
based on node identity and sorting the results in document
order.
As an example of a path expression,
child::div1/child::para selects the
para element children of the div1
element children of the context node, or, in other words,
the para element grandchildren of the context
node that have div1 parents.
A "/" at the beginning of a path expression
is an abbreviation for the initial step
fn:root(self::node()) treat as
document-node(). The effect of this initial step is
to begin the path at the root node of the tree that
contains the context node. If the context item is not a
node, a type
error is raised.[err:XP0020] At evaluation time, if the
root node above the context node is not a document node, a
dynamic
error is raised.[err:XP0050]
A "//" at the beginning of a path
expression is an abbreviation for the initial steps
fn:root(self::node()) treat as
document-node()/descendant-or-self::node(). The
effect of these initial steps is to establish an initial
node sequence that contains all nodes in the same tree as
the context node. This node sequence is then filtered by
subsequent steps in the path expression. If the context
item is not a node, a type error is raised.[err:XP0020] At
evaluation time, if the root node above the context node is
not a document node, a dynamic error is raised.[err:XP0050]
3.2.1
Steps
A step generates a sequence of items and then
filters the sequence by zero or more predicates.
The value of the step consists of those items that
satisfy the predicates. Predicates are described in
3.2.2 Predicates.
XPath provides two kinds of step, called a filter
step and an axis step.
A filter step consists simply of a primary
expression followed by zero or more predicates. The
result of the filter expression consists of all the items
returned by the primary expression for which all the
predicates are true. If no predicates are specified, the
result is simply the result of the primary expression.
This result may contain nodes, atomic values, or any
combination of these. The ordering of the items returned
by a filter step is the same as their order in the result
of the primary expression.
The result of an axis step is always a sequence
of zero or more nodes, and these nodes are always
returned in document order. An axis step may be either a
forward step or a reverse step, followed by
zero or more predicates. An axis step might be thought of
as beginning at the context node and navigating to
those nodes that are reachable from the context node via
a specified axis. Such a step has two parts: an
axis, which defines the "direction of movement"
for the step, and a node test, which selects nodes
based on their kind, name, and/or type. If the context
item is not a node, a type error is raised.[err:XP0020]
In the abbreviated syntax for a step, the axis
can be omitted and other shorthand notations can be used
as described in 3.2.4 Abbreviated
Syntax.
The unabbreviated syntax for an axis step consists of
the axis name and node test separated by a double colon.
The result of the step consists of the nodes reachable
from the context node via the specified axis that have
the node kind, name, and/or type specified by the node
test. For example, the step child::para
selects the para element children of the
context node: child is the name of the axis,
and para is the name of the element nodes to
be selected on this axis. The available axes are
described in 3.2.1.1 Axes. The
available node tests are described in 3.2.1.2 Node Tests. Examples of
steps are provided in 3.2.3
Unabbreviated Syntax and 3.2.4 Abbreviated Syntax.
3.2.1.1 Axes
| [52] |
ForwardAxis |
::= |
("child" "::")
| ("descendant" "::")
| ("attribute" "::")
| ("self" "::")
| ("descendant-or-self" "::")
| ("following-sibling" "::")
| ("following" "::")
| ("namespace" "::") |
| [53] |
ReverseAxis |
::= |
"parent" "::"
| "ancestor" "::"
| "preceding-sibling" "::"
| "preceding" "::"
| "ancestor-or-self" "::" |
XPath defines a set of full set of
axes for traversing documents, but a host
language may define a subset of these axes. The
following axes are defined:
-
the child axis contains the
children of the context node
-
the descendant axis contains the
descendants of the context node; a descendant is a
child or a child of a child and so on; thus the
descendant axis never contains attribute or
namespace nodes
-
the parent axis contains the parent
of the context node, if there is one
-
the ancestor axis contains the
ancestors of the context node; the ancestors of the
context node consist of the parent of context node
and the parent's parent and so on; thus, the
ancestor axis will always include the root node,
unless the context node is the root node
-
the following-sibling axis contains
all the following siblings of the context node; if
the context node is an attribute node or namespace
node, the following-sibling axis is
empty
-
the preceding-sibling axis contains
all the preceding siblings of the context node; if
the context node is an attribute node or namespace
node, the preceding-sibling axis is
empty
-
the following axis contains all
nodes, in the same tree as the context node, that
are after the context node in document order,
excluding any descendants and excluding attribute
nodes and namespace nodes
-
the preceding axis contains all
nodes, in the same tree as the context node, that
are before the context node in document order,
excluding any ancestors and excluding attribute
nodes and namespace nodes
-
the attribute axis contains the
attributes of the context node; the axis will be
empty unless the context node is an element
-
the self axis contains just the
context node itself
-
the descendant-or-self axis
contains the context node and the descendants of
the context node
-
the ancestor-or-self axis contains
the context node and the ancestors of the context
node; thus, the ancestor-or-self axis will always
include the root node
-
the namespace axis contains the
namespace nodes of the context node; this axis is
empty unless the context node is an element node.
The namespace axis is deprecated in
XPath 2.0. Whether an implementation supports the
namespace axis is implementation
defined. An implementation that does not
support the namespace axis must raise
a static error [err:XP0021] if
it is used. Applications needing information about
the namespaces of an element should use the
functions fn:get-in-scope-namespaces
and fn:get-namespace-uri-for-prefix
defined in [XQuery
1.0 and XPath 2.0 Functions and Operators].
Axes can be categorized as forward axes and
reverse axes. An axis that only ever contains
the context node or nodes that are after the context
node in document order is a forward axis. An axis that
only ever contains the context node or nodes that are
before the context node in document order is a reverse
axis.
The parent, ancestor,
ancestor-or-self, preceding,
and preceding-sibling axes are reverse
axes; all other axes are forward axes. The
ancestor, descendant,
following, preceding and
self axes partition a document (ignoring
attribute and namespace nodes): they do not overlap and
together they contain all the nodes in the
document.
In a sequence of nodes selected by a step, the
context positions of the nodes are determined in a way
that depends on the axis. If the axis is a forward
axis, context positions are assigned to the nodes in
document order. If the axis is a reverse axis, context
positions are assigned to the nodes in reverse document
order. In either case, the first context position is
1.
3.2.1.2
Node Tests
A node test is a condition that must be true
for each node selected by a step. The condition may be
based on the kind of the node (element, attribute,
text, document, comment, processing instruction, or
namespace), the name of the node, or (in the case of
element and attribute nodes), the type
annotation of the node.
Every axis has a principal node kind. If an
axis can contain elements, then the principal node kind
is element; otherwise, it is the kind of nodes that the
axis can contain. Thus:
-
For the attribute axis, the principal node kind
is attribute.
-
For the namespace axis, the principal node kind
is namespace.
-
For all other axes, the principal node kind is
element.
A node test that consists of a QName is called a
name test. A name test is true if and only if
the kind of the node is the principal node kind
and the expanded-QName of the node is equal to the
expanded-QName specified by the name test. For example,
child::para selects the para
element children of the context node; if the context
node has no para children, it selects an
empty set of nodes. attribute::abc:href
selects the attribute of the context node with the
QName abc:href; if the context node has no
such attribute, it selects an empty set of nodes.
A QName in a name test is expanded into an
expanded-QName using the in-scope namespaces in the
expression context. It is a static error [err:XP0008] if the
QName has a prefix that does not correspond to any
in-scope namespace. An unprefixed QName, when used as a
name test on an axis whose principal node kind is
element, has the namespaceURI of the default element/type
namespace in the expression context; otherwise, it
has no namespaceURI.
A name test is not satisfied by an element node
whose name does not match the QName of the name test,
even if it is in a substitution group whose head is the
named element.
A node test * is true for any node of
the principal node kind. For example,
child::* will select all element children
of the context node, and attribute::* will
select all attributes of the context node.
A node test can have the form NCName:*.
In this case, the prefix is expanded in the same way as
with a QName, using the in-scope namespaces in the
static context. If the prefix
is not found in the in-scope namespaces, a static error
is raised.[err:XP0008] The node test is true for
any node of the principal node kind whose
expanded-QName has the namespace URI to which the
prefix is bound, regardless of the local part of the
name.
A node test can also have the form
*:NCName. In this case, the node test is
true for any node of the principal node kind whose
local name matches the given NCName, regardless of its
namespace.
An alternative form of a node test is called a
KindTest, which can select nodes based on their
kind, name, and type annotation. The syntax and
semantics of a KindTest are described in 2.4.1 SequenceType. When
a KindTest is used in a node test, only those nodes on
the designated axis that match the KindTest are
selected. Shown below are several examples of KindTests
that might be used in path expressions:
-
node() matches any node.
-
text() matches any text node.
-
comment() matches any comment
node.
-
element() matches any element
node.
-
element(person) matches any element
node whose name is person (or is in
the substitution group headed by
person), and whose type annotation
conforms to the top-level schema declaration for a
person element.
-
element(person, *) matches any
element node whose name is person (or
is in the substitution group headed by
person), without any restriction on
type annotation.
-
element(person, surgeon) matches
any element node whose name is person
(or is in the substitution group headed by
person), and whose type annotation is
surgeon.
-
element(*, surgeon) matches any
element node whose type annotation is
surgeon, regardless of its name.
-
element(hospital/staff/person)
matches any element node whose name and type
annotation conform to the schema declaration of a
person element in a staff
element in a top-level hospital
element.
-
attribute() matches any attribute
node.
-
attribute(@price, *) matches any
attribute whose name is price,
regardless of its type annotation.
-
attribute(@*, xs:decimal) matches
any attribute whose type annotation is
xs:decimal, regardless of its
name.
-
document-node() matches any
document node.
-
document-node(element(book))
matches any document node whose content consists of
a single element node that satisfies the KindTest
element(book), mixed with zero or more
comments and processing instructions.
3.2.2
Predicates
A predicate consists of an expression, called a
predicate expression, enclosed in square brackets.
A predicate serves to filter a sequence, retaining some
items and discarding others. For each item in the
sequence to be filtered, the predicate expression is
evaluated using an inner focus derived from that
item, as described in 2.1.2
Dynamic Context. The result of the predicate
expression is coerced to a Boolean value, called the
predicate truth value, as described below. Those
items for which the predicate truth value is
true are retained, and those for which the
predicate truth value is false are
discarded.
The predicate truth value is derived by applying the
following rules, in order:
-
If the value of the predicate expression is an
atomic value of a numeric type, the predicate truth
value is true if the value of the
predicate expression is equal to the context
position, and is false otherwise.
-
Otherwise, the predicate truth value is the
effective boolean value of the
predicate expression.
Here are some examples of axis steps that
contain predicates:
-
This example selects the second
chapter element that is a child of the
context node:
-
This example selects all the descendants of the
context node whose name is "toy" and
whose color attribute has the value
"red":
descendant::toy[attribute::color = "red"]
-
This example selects all the employee
children of the context node that have a
secretary subelement:
child::employee[secretary]
Here are some examples of filter steps that
contain predicates:
3.2.3
Unabbreviated Syntax
This section provides a number of examples of path
expressions in which the axis is explicitly specified in
each step. The syntax used in these examples is called
the unabbreviated syntax. In many common cases, it
is possible to write path expressions more concisely
using an abbreviated syntax, as explained in
3.2.4 Abbreviated
Syntax.
-
child::para selects the
para element children of the context
node
-
child::* selects all element children
of the context node
-
child::text() selects all text node
children of the context node
-
child::node() selects all the
children of the context node, whatever their node
type
-
attribute::name selects the
name attribute of the context node
-
attribute::* selects all the
attributes of the context node
-
parent::* selects the parent of the
context node. If the context node is an attribute
node, this expression returns the element node (if
any) to which the attribute node is attached.
-
descendant::para selects the
para element descendants of the context
node
-
ancestor::div selects all
div ancestors of the context node
-
ancestor-or-self::div selects the
div ancestors of the context node and,
if the context node is a div element,
the context node as well
-
descendant-or-self::para selects the
para element descendants of the context
node and, if the context node is a para
element, the context node as well
-
self::para selects the context node
if it is a para element, and otherwise
selects nothing
-
child::chapter/descendant::para
selects the para element descendants of
the chapter element children of the
context node
-
child::*/child::para selects all
para grandchildren of the context
node
-
/ selects the root of the node
hierarchy that contains the context node
-
/descendant::para selects all the
para elements in the same document as
the context node
-
/descendant::list/child::member
selects all the member elements that
have a list parent and that are in the
same document as the context node
-
child::para[fn:position() = 1]
selects the first para child of the
context node
-
child::para[fn:position() =
fn:last()] selects the last para
child of the context node
-
child::para[fn:position() =
fn:last()-1] selects the last but one
para child of the context node
-
child::para[fn:position() > 1]
selects all the para children of the
context node other than the first para
child of the context node
-
following-sibling::chapter[fn:position() =
1]selects the next chapter
sibling of the context node
-
preceding-sibling::chapter[fn:position() =
1]selects the previous chapter
sibling of the context node
-
/descendant::figure[fn:position() =
42] selects the forty-second
figure element in the document
-
/child::doc/child::chapter[fn:position() =
5]/child::section[fn:position() = 2]selects
the second section of the fifth
chapter of the doc document
element
-
child::para[attribute::type="warning"]selects
all para children of the context node
that have a type attribute with value
warning
-
child::para[attribute::type='warning'][fn:position()
= 5]selects the fifth para child
of the context node that has a type
attribute with value warning
-
child::para[fn:position() =
5][attribute::type="warning"]selects the fifth
para child of the context node if that
child has a type attribute with value
warning
-
child::chapter[child::title='Introduction']selects
the chapter children of the context node
that have one or more title children
with string-value equal to
Introduction
-
child::chapter[child::title] selects
the chapter children of the context node
that have one or more title children
-
child::*[self::chapter or
self::appendix] selects the
chapter and appendix
children of the context node
-
child::*[self::chapter or
self::appendix][fn:position() = fn:last()]
selects the last chapter or
appendix child of the context node
3.2.4 Abbreviated
Syntax
The abbreviated syntax permits the following
abbreviations:
-
The most important abbreviation is that the axis
name can be omitted from an axis step. If the
axis name is omitted from an axis step, the default
axis is child unless the axis step
contains an AttributeTest; in that case,
the default axis is attribute. For
example, the path expression
section/para is an abbreviation for
child::section/child::para, and the path
expression section/@id is an
abbreviation for
child::section/attribute::id. Similarly,
section/attribute(@id) is an
abbreviation for
child::section/attribute::attribute(@id).
Note that the latter expression contains both an axis
specification and a node test.
-
There is also an abbreviation for attributes:
attribute:: can be abbreviated by
@. For example, a path expression
para[@type="warning"] is short for
child::para[attribute::type="warning"]
and so selects para children with a
type attribute with value equal to
warning.
-
// is effectively replaced by
/descendant-or-self::node()/ during
processing of a path expression. For example,
//para is an abbreviation for
/descendant-or-self::node()/child::para
and so will select any para element in
the document (even a para element that
is a document element will be selected by
//para since the document element node
is a child of the root node); div1//para
is short for
div1/descendant-or-self::node()/child::para
and so will select all para descendants
of div1 children.
Note that the path expression
//para[1] does not mean the
same as the path expression
/descendant::para[1]. The latter selects
the first descendant para element; the
former selects all descendant para
elements that are the first para
children of their parents.
-
A step consisting of .. is short for
parent::node(). For example,
../title is short for
parent::node()/child::title and so will
select the title children of the parent
of the context node.
Here are some examples of path expressions that use
the abbreviated syntax:
-
para selects the para
element children of the context node
-
* selects all element children of the
context node
-
text() selects all text node children
of the context node
-
@name selects the name
attribute of the context node
-
@* selects all the attributes of the
context node
-
para[1] selects the first
para child of the context node
-
para[fn:last()] selects the last
para child of the context node
-
*/para selects all para
grandchildren of the context node
-
/doc/chapter[5]/section[2] selects
the second section of the fifth
chapter of the doc
-
chapter//para selects the
para element descendants of the
chapter element children of the context
node
-
//para selects all the
para descendants of the document root
and thus selects all para elements in
the same document as the context node
-
//list/member selects all the
member elements in the same document as
the context node that have a list
parent
-
.//para selects the para
element descendants of the context node
-
.. selects the parent of the context
node
-
../@lang selects the
lang attribute of the parent of the
context node
-
para[@type="warning"] selects all
para children of the context node that
have a type attribute with value
warning
-
para[@type="warning"][5] selects the
fifth para child of the context node
that has a typeattribute with value
warning
-
para[5][@type="warning"] selects the
fifth para child of the context node if
that child has a type attribute with
value warning
-
chapter[title="Introduction"] selects
the chapter children of the context node
that have one or more title children
with string-value equal to
Introduction
-
chapter[title] selects the
chapter children of the context node
that have one or more title children
-
employee[@secretary and @assistant]
selects all the employee children of the
context node that have both a secretary
attribute and an assistant attribute
-
book/(chapter|appendix)/section
selects every section element that has a
parent that is either a chapter or an
appendix element, that in turn is a
child of a book element that is a child
of the context node.
-
book/fn:id(publisher)/name returns
the same result as
fn:id(book/publisher)/name.
-
If E is any expression that returns a
sequence of nodes, then the expression
E/. returns the same nodes in document
order, with duplicates eliminated based on node
identity.
3.3 Sequence Expressions
XPath supports operators to construct and combine
sequences of
items. Sequences are
never nested--for example, combining the values 1, (2, 3),
and ( ) into a single sequence results in the sequence (1,
2, 3).
3.3.1
Constructing Sequences
One way to construct a sequence is by using the comma
operator, which evaluates each of its operands and
concatenates the resulting values, in order, into a
single result sequence. Empty parentheses can be used to
denote an empty sequence. In places where the grammar
calls for ExprSingle, such as the arguments of a function
call, any expression that contains a top-level comma
operator must be enclosed in parentheses.
A sequence may contain duplicate values or nodes, but
a sequence is never an item in another sequence. When a
new sequence is created by concatenating two or more
input sequences, the new sequence contains all the items
of the input sequences and its length is the sum of the
lengths of the input sequences.
Here are some examples of expressions that construct
sequences:
-
This expression is a sequence of five
integers:
-
This expression constructs one sequence from the
sequences 10, (1, 2), the empty sequence (), and (3,
4):
It evaluates to the sequence:
10, 1, 2, 3, 4
-
This expression contains all salary
children of the context node followed by all
bonus children:
-
Assuming that $price is bound to the
value 10.50, this expression:
evaluates to the sequence
10.50, 10.50
A RangeExpr can be used to construct a sequence
of consecutive integers. Each of the operands of the
to operator is converted as though it was an
argument of a function with the expected parameter type
xs:integer. A type error [err:XP0006] is raised if the
operand cannot be converted to a single integer. A
sequence is constructed containing the two integer
operands and every integer between the two operands. If
the first operand is less than the second, the sequence
is in increasing order, otherwise it is in decreasing
order.
-
This example uses a range expression as one
operand in constructing a sequence:
It evaluates to the sequence:
10, 1, 2, 3, 4
-
This example constructs a sequence of length
one:
It evaluates to a sequence consisting of the
single integer 10.
3.3.2
Combining Sequences
XPath provides several operators for combining
sequences of nodes. The union and
| operators are equivalent. They take two
node sequences as operands and return a sequence
containing all the nodes that occur in either of the
operands. The intersect operator takes two
node sequences as operands and returns a sequence
containing all the nodes that occur in both operands. The
except operator takes two node sequences as
operands and returns a sequence containing all the nodes
that occur in the first operand but not in the second
operand. All of these operators return their result
sequences in document order without duplicates based on
node identity. If an operand of union,
intersect, or except contains
an item that is not a node, a type error is raised.[err:XP0006]
Here are some examples of expressions that combine
sequences. Assume the existence of three element nodes
that we will refer to by symbolic names A, B, and C.
Assume that $seq1 is bound to a sequence
containing A and B, $seq2 is also bound to a
sequence containing A and B, and $seq3 is
bound to a sequence containing B and C. Then:
-
$seq1 union $seq1 evaluates to a
sequence containing A and B.
-
$seq2 union $seq3 evaluates to a
sequence containing A, B, and C.
-
$seq1 intersect $seq1 evaluates to a
sequence containing A and B.
-
$seq2 intersect $seq3 evaluates to a
sequence containing B only.
-
$seq1 except $seq2 evaluates to the
empty sequence.
-
$seq2 except $seq3 evaluates to a
sequence containing A only.
In addition to the sequence operators described
here,[XQuery 1.0 and
XPath 2.0 Functions and Operators] includes functions
for indexed access to items or sub-sequences of a
sequence, for indexed insertion or removal of items in a
sequence, and for removing duplicate values or nodes from
a sequence.
3.4
Arithmetic Expressions
XPath provides arithmetic operators for addition,
subtraction, multiplication, division, and modulus, in
their usual binary and unary forms.
The binary subtraction operator must be preceded by
whitespace if it could otherwise be interpreted as part of
the previous token. For example, a-b will be
interpreted as a name, but a - b will be
interpreted as an arithmetic operation.
An arithmetic expression is evaluated by applying the
following rules, in order, until an error is raised or a
value is computed:
-
Atomization is applied to each
operand.
-
If either operand is now an empty sequence, the
result of the operation is an empty sequence.
-
If either operand is now a sequence of length
greater than one, then:
-
If XPath 1.0 compatibility mode is
true, any items after the first item
in the sequence are discarded.
-
[err:XP0006] Otherwise, a
type
error is raised.[err:XP0006]
-
If either operand is now of type
xdt:untypedAtomic, it is cast to the
default type for the given operator. The default type
for the idiv operator is
xs:integer; the default type for all other
arithmetic operators is xs:double. If the
cast fails, a dynamic error is
raised.[err:XP0021]
-
If the operand types are now valid for the given
operator, the operator is applied to the operands,
resulting in an atomic value or a dynamic
error (for example, an error might result from
dividing by zero.) The combinations of atomic types
that are accepted by the various arithmetic operators,
and their respective result types, are listed in
B.2 Operator Mapping
together with the functions in [XQuery 1.0 and XPath 2.0
Functions and Operators] that define the semantics
of the operation for each type.
-
If the operand types are not valid for the given
operator, and XPath 1.0 compatibility mode is
true, and the operator is not
idiv, then each operand is further
converted according to the rules in 3.1.5 Function Calls as
if it were a function argument with the expected type
xs:double. The operator is then applied to
the operands, resulting in an atomic value or a
dynamic error.[err:XQ0004][err:XP0006]
-
If the operand types are still not valid for the
given operator, a type error is raised.
XPath supports two division operators named
div and idiv. The
div operator accepts operands of any numeric
types. The type of the result of the div
operator is the least common type of its operands; however,
if both operands are of type xs:integer,
div returns a result of type
xs:decimal. The idiv operator, on
the other hand, requires its operands to be of type
xs:integer and returns a result of type
xs:integer, rounded toward zero.
Here are some examples of arithmetic expressions:
-
The first expression below returns
-1.5, and the second expressions returns
-1:
-
Subtraction of two date values results in a value of
type xdt:dayTimeDuration:
$emp/hiredate - $emp/birthdate
-
This example illustrates the difference between a
subtraction operator and a hyphen:
$unit-price - $unit-discount
-
Unary operators have higher precedence than binary
operators, subject of course to the use of
parentheses:
-($bellcost + $whistlecost)
3.5
Comparison Expressions
Comparison expressions allow two values to be compared.
XPath provides four kinds of comparison expressions, called
value comparisons, general comparisons, node comparisons,
and order comparisons.
When an XPath expression is written
within an XML document, the XML escaping rules for
special characters must be followed; thus
"<" must be written as
"<".
3.5.1 Value Comparisons
Value comparisons are intended for comparing single
values. The result of a value comparison is defined by
applying the following rules, in order:
-
Atomization is applied to each
operand. If the result, called an atomized
operand, does not contain exactly one atomic
value, a type error is raised.[err:XQ0004][err:XP0006]
-
Any atomized operand that has the dynamic type
xdt:untypedAtomic is cast to the type
xs:string.
-
The result of the comparison is true
if the value of the first operand is (equal, not
equal, less than, less than or equal, greater than,
greater than or equal) to the value of the second
operand; otherwise the result of the comparison is
false. B.2
Operator Mapping describes which combinations
of atomic types are comparable, and how comparisons
are performed on values of various types. If the
value of the first atomized operand is not comparable
with the value of the second atomized operand, a
type
error is raised.[err:XQ0004][err:XP0006]
Here are some examples of value comparisons:
-
The following comparison is true only if
$book1 has a single author
subelement and its value is "Kennedy":
$book1/author eq "Kennedy"
-
The following comparison is true if
hatsize and shoesize are
both user-defined types that are derived by
restriction from a primitive numeric type:
hatsize(5) eq shoesize(5)
3.5.2 General
Comparisons
General comparisons are existentially quantified
comparisons that may be applied to operand sequences of
any length. The result of a general comparison that does
not raise an error is always true or
false.
Atomization is applied to each
operand of a general comparison. The result of the
comparison is true if and only if there is a
pair of atomic values, one belonging to the result of
atomization of the first operand and the other belonging
to the result of atomization of the second operand, that
have the required magnitude relationship.
Otherwise the result of the general comparison is
false. The magnitude relationship
between two atomic values is determined as follows:
-
If either atomic value has the dynamic type
xdt:untypedAtomic, that value is cast to
a required type, which is determined as follows:
-
If the dynamic type of the other atomic value
is a numeric type, the required type is
xs:double.
-
If the dynamic type of the other atomic value
is xdt:untypedAtomic, the required
type is xs:string.
-
Otherwise, the required type is the dynamic
type of the other atomic value.
If the cast to the required type fails, a
dynamic error is
raised.[err:XP0021]
-
If XPath 1.0 compatibility mode is
true, and at least one of the atomic
values has a numeric type, then both atomic values
are cast to to the type xs:double.
-
After any necessary casting, the atomic values are
compared using one of the value comparison operators
eq, ne, lt,
le, gt, or ge,
depending on whether the general comparison operator
was =, !=,
<, <=,
>, or >=. The values
have the required magnitude relationship if
the result of this value comparison is
true.
When evaluating a general comparison in which either
operand is a sequence of items, an implementation may
return true as soon as it finds an item in
the first operand and an item in the second operand for
which the underlying value comparison is
true. Similarly, a general comparison may
raise a dynamic error as soon as it
encounters an error in evaluating either operand, or in
comparing a pair of items from the two operands. As a
result of these rules, the result of a general comparison
is not deterministic in the presence of errors.
Here are some examples of general comparisons:
-
The following comparison is true if the value of
any author subelement of
$book1 has the string value
"Kennedy":
$book1/author = "Kennedy"
-
The following example contains three general
comparisons. The value of the first two comparisons
is true, and the value of the third
comparison is false. This example
illustrates the fact that general comparisons are not
transitive.
(1, 2) = (2, 3)
(2, 3) = (3, 4)
(1, 2) = (3, 4)
-
Suppose that $a, $b, and
$c are bound to element nodes with type
annotation xdt:untypedAtomic, with
string values "1", "2", and
"2.0" respectively. Then ($a, $b)
= ($c, 3.0) returns false,
because $b and $c are
compared as strings. However, ($a, $b) = ($c,
2.0) returns true, because
$b and 2.0 are compared as
numbers.
3.5.3 Node Comparisons
The result of a node comparison is defined by applying
the following rules, in order:
-
Each operand must be either a single node or an
empty sequence; otherwise a type error is
raised.[err:XQ0004][err:XP0006]
-
If either operand is an empty sequence, the result
of the comparison is an empty sequence.
-
A comparison with the is operator is
true if the two operands are nodes that
have the same identity; otherwise it is
false. A comparison with the
isnot operator is true if
the two operands are nodes that have different
identities; otherwise it is false. See
[XQuery 1.0 and XPath 2.0 Data
Model] for a discussion of node identity.
Use of the is operator is illustrated
below.
3.5.4 Order Comparisons
The result of an order comparison is defined by
applying the following rules, in order:
-
Both operands must be either a single node or an
empty sequence; otherwise a type error is
raised.[err:XQ0004][err:XP0006]
-
If either operand is an empty sequence, the result
of the comparison is an empty sequence.
-
A comparison with the <<
operator returns true if the first
operand node is earlier than the second operand node
in document order; otherwise it returns
false.
-
A comparison with the >>
operator returns true if the first
operand node is later than the second operand node in
document order; otherwise it returns
false.
Here is an example of an order comparison:
3.6 Logical Expressions
A logical expression is either an
and-expression or an or-expression. If a
logical expression does not raise an error, its value is
always one of the boolean values true or
false.
Logical
Expressions
The first step in evaluating a logical expression is to
find the effective boolean value of each of its
operands (see 2.4.2.2 Effective
Boolean Value).
The value of an and-expression is determined by the
effective boolean values (EBV's) of its operands. If an
error is raised during computation of one of the effective
boolean values, an and-expression may raise a
dynamic
error, as shown in the following table:
| AND: |
EBV2 =
true |
EBV2 =
false |
error in
EBV2 |
| EBV1 =
true |
true |
false |
error |
| EBV1 =
false |
false |
false |
false or error |
| error in
EBV1 |
error |
false or error |
error |
The value of an or-expression is determined by the
effective boolean values (EBV's) of its operands. If an
error is raised during computation of one of the effective
boolean values, an or-expression may raise a
dynamic
error, as shown in the following table:
| OR: |
EBV2 =
true |
EBV2 =
false |
error in
EBV2 |
| EBV1 =
true |
true |
true |
true or error |
| EBV1 =
false |
true |
false |
error |
| error in
EBV1 |
true or error |
error |
error |
The order in which the operands of a logical expression
are evaluated is implementation-dependent. The tables above
are defined in such a way that an or-expression can return
true if the first expression evaluated is
true, and it can raise an error if evaluation of the first
expression raises an error. Similarly, an and-expression
can return false if the first expression
evaluated is false, and it can raise an error if evaluation
of the first expression raises an error. As a result of
these rules, a logical expression is not deterministic in
the presence of errors, as illustrated in the examples
below.
Here are some examples of logical expressions:
-
The following expressions return
true:
-
The following expression may return either
false or raise a dynamic error:
-
The following expression may return either
true or raise a dynamic error:
-
The following expression must raise a dynamic
error:
In addition to and- and or-expressions, XPath provides a
function named not that takes a general
sequence as parameter and returns a boolean value. The
not function reduces its parameter to an
effective
boolean value. It then returns true if the
effective boolean value of its parameter is
false, and false if the effective
boolean value of its parameter is true. If an
error is encountered in finding the effective boolean value
of its operand, not raises the same dynamic error.
The not function is described in [XQuery 1.0 and XPath 2.0
Functions and Operators].
3.7 For Expressions
XPath provides an iteration facility called a for
expression.
A for expression is evaluated as
follows:
-
If the for expression uses multiple
variables, it is first expanded to a set of nested
for expressions, each of which uses only
one variable. For example, the expression for
$x in X, $y in Y return $x + $y is expanded to
for $x in X return for $y in Y return $x +
$y.
-
In a single-variable for expression,
the variable is called the range variable, the
value of the expression that follows the
in keyword is called the input
sequence, and the expression that follows the
return keyword is called the return
expression. The result of the for
expression is obtained by evaluating the
return expression once for each item in
the input sequence, with the range variable bound to
that item. The resulting sequences are concatenated
in the order of the items in the input sequence from
which they were derived.
The following example illustrates the
use of a for expression in restructuring
an input document. The example is based on the
following input:
<bib>
<book>
<title>TCP/IP Illustrated</title>
<author>Stevens</author>
<publisher>Addison-Wesley</publisher>
</book>
<book>
<title>Advanced Unix Programming</title>
<author>Stevens</author>
<publisher>Addison-Wesley</publisher>
</book>
<book>
<title>Data on the Web</title>
<author>Abiteboul</author>
<author>Buneman</author>
<author>Suciu</author>
</book>
</bib>
The following example transforms the input document
into a list in which each author's name appears only
once, followed by a list of titles of books written by
that author. This example assumes that the context item
is the bib element in the input
document.
for $a in distinct-values(//author)
return ($a,
for $b in //book[author = $a]
return $b/title)
The result of the above expression consists of the
following sequence of elements. The ordering of
author elements in the result is
implementation-dependent.
<author>Stevens</author>
<title>TCP/IP Illustrated</title>
<title>Advanced Programming in the Unix environment</title>
<author>Abiteboul</author>
<title>Data on the Web</title>
<author>Buneman</author>
<title>Data on the Web</title>
<author>Suciu</author>
<title>Data on the Web</title>
The following example illustrates a for
expression containing more than one variable:
for $i in (10, 20),
$j in (1, 2)
return ($i + $j)
The result of the above expression, expressed as a
sequence of numbers, is as follows: 11, 12, 21,
22
The scope of a variable bound in a for
expression comprises all subexpressions of the
for expression that appear after the
variable binding. The scope does not include the
expression to which the variable is bound. The following
example illustrates how a variable binding may reference
another variable bound earlier in the same
for expression:
for $x in $z, $y in f($x)
return g($x, $y)
Note that the focus for evaluation of the
return clause of a for
expression is the same as the focus for evaluation of the
for expression itself. The following
example, which attempts to find the total value of a set
of order-items, is therefore incorrect:
sum(for $i in order-item return @price * @qty)
Instead, the expression must be written to use the
variable bound in the for clause:
sum(for $i in order-item
return $i/@price * $i/@qty)
3.8
Conditional Expressions
XPath supports a conditional expression based on the
keywords if, then, and
else.
Conditional
Expression
The expression following the if keyword is
called the test expression, and the expressions
following the then and else
keywords are called the then-expression and
else-expression, respectively.
The first step in processing a conditional expression is
to find the effective boolean value of the test
expression, as defined in 2.4.2.2
Effective Boolean Value.
The value of a conditional expression is defined as
follows: If the effective boolean value of the test
expression is true, the value of the
then-expression is returned. If the effective boolean value
of the test expression is false, the value of
the else-expression is returned.
Conditional expressions have a special rule for
propagating dynamic errors. If the effective
value of the test expression is true, the
conditional expression ignores (does not raise) any dynamic
errors encountered in the else-expression. In this case,
since the else-expression can have no observable effect, it
need not be evaluated. Similarly, if the effective value of
the test expression is false, the conditional
expression ignores any dynamic errors encountered in the
then-expression, and the then-expression need not be
evaluated.
Here are some examples of conditional expressions:
-
In this example, the test expression is a comparison
expression:
if ($widget1/unit-cost < $widget2/unit-cost)
then $widget1
else $widget2
-
In this example, the test expression tests for the
existence of an attribute named
discounted, independently of its
value:
if ($part/@discounted)
then $part/wholesale
else $part/retail
3.9 Quantified
Expressions
Quantified expressions support existential and universal
quantification. The value of a quantified expression is
always true or false.
A quantified expression begins with a
quantifier, which is the keyword some
or every, followed by one or more in-clauses
that are used to bind variables, followed by the keyword
satisfies and a test expression. Each
in-clause associates a variable with an expression that
returns a sequence of values. The in-clauses generate
tuples of variable bindings, using values drawn from the
Cartesian product of the sequences returned by the binding
expressions. Conceptually, the test expression is evaluated
for each tuple of variable bindings. Results depend on the
effective boolean values of the test expressions, as
defined in 2.4.2.2 Effective Boolean
Value. The value of the quantified expression is
defined by the following rules:
-
If the quantifier is some, the
quantified expression is true if at least
one evaluation of the test expression has the
effective boolean value true;
otherwise the quantified expression is
false. This rule implies that, if the
in-clauses generate zero binding tuples, the value of
the quantified expression is false.
-
If the quantifier is every, the
quantified expression is true if every
evaluation of the test expression has the effective
boolean value true; otherwise the
quantified expression is false. This rule
implies that, if the in-clauses generate zero binding
tuples, the value of the quantified expression is
true.
The scope of a variable bound in a quantified expression
comprises all subexpressions of the quantified expression
that appear after the variable binding. The scope does not
include the expression to which the variable is bound.
The order in which test expressions are evaluated for
the various binding tuples is implementation defined. If
the quantifier is some, an implementation may
return true as soon as it finds one binding
tuple for which the test expression has an effective
Boolean value of true, and it may raise a
dynamic
error as soon as it finds one binding tuple for which
the test expression raises an error. Similarly, if the
quantifier is every, an implementation may
return false as soon as it finds one binding
tuple for which the test expression has an effective
Boolean value of false, and it may raise a
dynamic
error as soon as it finds one binding tuple for which
the test expression raises an error. As a result of these
rules, the value of a quantified expression is not
deterministic in the presence of errors, as illustrated in
the examples below.
Here are some examples of quantified expressions:
-
This expression is true if every
part element has a discounted
attribute (regardless of the values of these
attributes):
every $part in //part satisfies $part/@discounted
-
This expression is true if at least one
employee element satisfies the given
comparison expression:
some $emp in //employee satisfies ($emp/bonus > 0.25 * $emp/salary)
-
In the following examples, each quantified
expression evaluates its test expression over nine
tuples of variable bindings, formed from the Cartesian
product of the sequences (1, 2, 3) and
(2, 3, 4). The expression beginning with
some evaluates to true, and
the expression beginning with every
evaluates to false.
some $x in (1, 2, 3), $y in (2, 3, 4)
satisfies $x + $y = 4
every $x in (1, 2, 3), $y in (2, 3, 4)
satisfies $x + $y = 4
-
This quantified expression may either return
true or raise a type error, since its test
expression returns true for one variable
binding and raises a type error for another:
some $x in (1, 2, "cat") satisfies $x * 2 = 4
-
This quantified expression may either return
false or raise a type error, since its test
expression returns false for one variable
binding and raises a type error for another:
every $x in (1, 2, "cat") satisfies $x * 2 = 4
3.10 Expressions on
SequenceTypes
SequenceTypes are used in instance
of, cast, castable, and
treat expressions.
3.10.1 Instance Of
The boolean operator instance of returns
true if the value of its first operand
matches the type named in its second operand, according
to the rules for SequenceType Matching; otherwise
it returns false. For example:
-
5 instance of xs:integer
This example returns true because the
given value is an instance of the given type.
-
5 instance of xs:decimal
This example returns true because the
given value is an integer literal, and
xs:integer is derived by restriction
from xs:decimal.
-
. instance of element()
This example returns true if the
context item is an element node.
3.10.2 Cast
Occasionally it is necessary to convert a value to a
specific datatype. For this purpose, XPath provides a
cast expression that creates a new value of
a specific type based on an existing value. A
cast expression takes two operands: an
input expression and a target type. The
type of the input expression is called the input
type. The target type must be a named atomic type,
represented by a QName, optionally followed by the
occurrence indicator ? if an empty sequence
is permitted. If the target type has no namespace prefix,
it is considered to be in the default element/type
namespace. The semantics of the cast
expression are as follows:
-
Atomization is performed on the
input expression.
-
If the result of atomization is a sequence of more
than one atomic value, a type error is raised.[err:XQ0004][err:XP0006]
-
If the result of atomization is an empty
sequence:
-
If ? is specified after the
target type, the result of the cast
expression is an empty sequence.
-
If ? is not specified after the
target type, a type error is
raised.[err:XQ0004][err:XP0006]
-
If the result of atomization is a single atomic
value, the result of the cast expression depends on
the input type and the target type. In general, the
cast expression attempts to create a new value of the
target type based on the input value. Only certain
combinations of input type and target type are
supported. The rules are listed below. For the
purpose of these rules, we use the terms
subtype and supertype in the following
sense: if type B is derived from type A by
restriction, then B is a subtype of A, and A
is a supertype of B.
-
cast is supported for the
combinations of input type and target type listed
in [XQuery 1.0
and XPath 2.0 Functions and Operators]. For
each of these combinations, both the input type
and the target type are built-in schema types.
For example, a value of type
xs:string can be cast into the type
xs:decimal. For each of these
built-in combinations, the semantics of casting
are specified in [XQuery 1.0 and XPath
2.0 Functions and Operators].
-
cast is supported if the input
type is a derived atomic type and the target type
is a supertype of the input type. In this case,
the input value is mapped into the value space of
the target type, unchanged except for its type.
For example, if shoesize is derived
by restriction from xs:integer, a
value of type shoesize can be cast
into the type xs:integer.
-
cast is supported if the target
type is a derived atomic type and the input type
is xs:string or
xdt:untypedAtomic. The input value
is first converted to a value in the lexical
space of the target type by applying the
whitespace normalization rules for the target
type; a dynamic error [err:XP0029] is
raised if the resulting lexical value does not
satisfy the pattern facet of the target type. The
lexical value is then converted to the value
space of the target type using the schema-defined
rules for the target type; a dynamic
error[err:XP0029] is raised if the
resulting value does not satisfy all the facets
of the target type.
-
cast is supported if the target
type is a derived atomic type and the input type
is a supertype of the target type. The input
value must satisfy all the facets of the target
type (in the case of the pattern facet, this is
checked by generating a string representation of
the input value, using the rules for casting to
xs:string). The resulting value is
the same as the input value, but with a different
dynamic type.
-
If a primitive type P1 can be cast into a
primitive type P2, then any subtype of P1 can be
cast into any subtype of P2, provided that the
facets of the target type are satisfied. First
the input value is cast to P1 using rule (b)
above. Next, the value of type P1 is cast to the
type P2, using rule (a) above. Finally, the value
of type P2 is cast to the target type, using rule
(d) above.
-
For any combination of input type and target
type that is not in the above list, a
cast expression raises a type
error.[err:XQ0004][err:XP0006]
If casting from the input type to the target type is
supported but nevertheless it is not possible to cast the
input value into the value space of the target type, a
dynamic
error is raised.[err:XP0021] This includes the case when
any facet of the target type is not satisfied. For
example, the expression "2003-02-31" cast as
xs:date would raise a dynamic error.
3.10.3
Castable
XPath provides a form of Boolean expression that tests
whether a given value is castable into a given target
type. The expression V castable as T returns
true if the value V can be
successfully cast into the target type T by
using a cast expression; otherwise it
returns false. The castable
predicate can be used to avoid errors at evaluation time.
It can also be used to select an appropriate type for
processing of a given value, as illustrated in the
following example:
if ($x castable as hatsize)
then $x cast as hatsize
else if ($x castable as IQ)
then $x cast as IQ
else $x cast as xs:string
3.10.4 Constructor
Functions
Constructor functions provide an alternative syntax
for casting.
For every built-in atomic type T that is
defined in [XML Schema], as well
as the predefined types xdt:dayTimeDuration,
xdt:yearMonthDuration, and
xdt:untypedAtomic, a built-in constructor
function is provided. The signature of the built-in
constructor function for type T is as
follows:
The constructor function for type T accepts
any single item (either a node or an atomic value) as
input, and returns a value of type T (or raises
a dynamic error). Its semantics are
exactly the same as a cast expression with
target type T. The built-in constructor
functions are described in more detail in [XQuery 1.0 and XPath 2.0
Functions and Operators]. The following are examples
of built-in constructor functions:
-
This example is equivalent to "2000-01-01"
cast as xs:date.
-
This example is equivalent to ($floatvalue *
0.2E-5) cast as xs:decimal.
xs:decimal($floatvalue * 0.2E-5)
-
This example returns a
dayTimeDuration value equal to 21 days.
It is equivalent to "P21D" cast as
xdt:dayTimeDuration.
xdt:dayTimeDuration("P21D")
For each user-defined top-level atomic type T
in the in-scope type definitions that is in a
namespace, a constructor function is effectively defined.
Like the built-in constructor functions, the constructor
functions for user-defined types have the same name
(including namespace) as the type, accept any item as
input, and have semantics identical to a
cast expression with the user-defined type
as target type. For example, if usa:zipcode
is a user-defined top-level atomic type in the in-scope
type definitions, then the expression
usa:zipcode("12345") is equivalent to the
expression "12345" cast as usa:zipcode.
User-defined atomic types that are not in a namespace
do not have implicit constructor functions. To construct
an instance of such a type, it is necessary to use a
cast expression. For example, if the
user-defined type apple is derived from
xs:integer but is not in a namespace, an
instance of this type can be constructed as follows:
3.10.5
Treat
XPath provides an expression called treat
that can be used to modify the static type of its
operand.
Like cast, the treat
expression takes two operands: an expression and a
SequenceType. Unlike
cast, however, treat does not
change the dynamic type or value of its operand. Instead,
the purpose of treat is to ensure that an
expression has an expected type at evaluation time.
The semantics of expr1 treat as type1 are
as follows:
-
During static analysis:
The static type of the
treat expression is type1.
This enables the expression to be used as an argument
of a function that requires a parameter of
type1.
-
During expression evaluation:
If expr1 matches type1,
using the SequenceType Matching rules in 2.4.1 SequenceType, the
treat expression returns the value of
expr1; otherwise, it raises a dynamic
error.[err:XP0006] If the value of
expr1 is returned, its identity is
preserved. The treat expression ensures
that the value of its expression operand conforms to
the expected type at run-time.
-
Example:
$myaddress treat as element(*, USAddress)
The static type of
$myaddress may be element(*,
Address), a less specific type than
element(*, USAddress). However, at
run-time, the value of $myaddress must
match the type element(*, USAddress)
using SequenceType Matching rules; otherwise a
dynamic error is
raised.[err:XP0050]