1. Introduction
The W3C Architecture allows for markup languages for different
application areas such as graphics, multimedia, maths and hypertext to be
defined separately, and then to be combined into applications using the
facilities defined in those markup languages. Examples of use of this
approach include XHTML+Math+SVG, Joost, and XSmiles.
However, since these markup languages are defined to a degree in
isolation from the other markup languages that they are used with, it can
arise that some incompatibilities become apparent on combining them.
Examples that have arisen include how events are used, accessibility
concerns, and how data is submitted from forms.
The initial remit of the Backplane XG was to identify and explore these areas, and to
investigate the possibility of defining central facilites that application
markups could use and plug into, without having to redefine them.
During the period of its working the XG actually started implementing its ideas, and what
evolved was a plan for an architecture of implementing XML-based applications
within current-day browsers, using Javascript as a definition language, the
idea being if you could define a standard method of allowing the subparts to
communicate, you could define both the syntax and the semantics of markup
languages without those languages knowing about each other's existence, and
they could be combined and work together without further intervention.
2. Rich web platforms and formats
Web users today seek ever increasing interactivity and responsiveness
in Web applications, particularly as those applications expand in scope
and function to provide increasing levels of capability ("richness")
in presentation, control, and data management. The drive for richness stems
from a desire for authors to address greater functional goals in their
applications -- moving from web content to commerce to collaborative
services. The means for achieving richness stem largely from migrating
function back to the client that historically has been resident on the
server -- we do not seek to re-establish a world of client-server computing
but rather to increasingly leverage client capabilities in an era of greatly
expanded distributed computing and online services.
The Rich Web Application Backplane Incubator Group (XG) has had as its goal
understanding, demonstrating, and documenting two areas of work: (1) authoring
patterns for increased client-side capabilities in not only rich presentation
or graphics but also in navigation control and data management for
high-function web applications, and (2) techniques for extending current
browser runtimes to support these authoring patterns across a variety of markup
formats beyond the variants of HTML supported natively by existing browsers.
Following the introductory material of this XG report, we continue in Section 3
to illustrate the manner in which a variety of markup formats
including XHTML, SVG, XForms, SMIL,
and other emerging formats such as the Open Document Format (ODF) may come together
providing each of the model, view, and controller artifacts of a Rich Web Application.
In Section 4, we describe an approach to implementing many of these
formats in current browser platforms. We have come to focus on this point
significantly in the XG's work since we believe
that in the evolution of the web today it is not sufficient only to propose
improved formats without corresponding emphasis on pragmatic routes to
adoption.
Section 5 outlines some ways in which the accessibility requirements in ARIA
could benefit from the browser implementation techniques just reviewed.
Section 6 illustrates a set of authoring patterns using
existing markup formats for RIAs. In many cases the patterns we describe have
been known for some time but have not reached critical mass in the developer
community due to lack of convenient runtime support rather than lack of
consensus as to their utility. We are excited at this point as to the potential
for greater cross-format adoption of concepts such as MVC data binding,
event-based coordination, implicit creation of the UI through repeats over queries on the active
client data, and so on precisely since we now see and are actively involved
in the creation of practical, performant, and deployable techniques for their
use in current browser technologies.
Finally, the Conclusions section, along with Section 4.7 on Standardization, suggest possible follow-on actions
within the W3C to support a broader and interoperable use of the patterns and markup implementation
techniques discussed in this paper.
3. Structure of a rich web document
Figure 1 shows a cut-away view of the layers of a running Rich Internet Application
(RIA) document. Richness of interaction results from
increased client-side support for presentation, data, and control.
Multiple markup formats have been defined specializing in
each of these application concerns, as follows from top to bottom of the
figure:
- Concrete presentation is managed by HTML, SVG, VoiceXML, etc.
- Abstract presentation can be described by XForms UI controls or other vocabularies that express intent independent
of presentation.
- Control involves both sequencing of user interaction and calculation on
model data. XForms binds provide calculation, constraint, and validation
control. SMIL may be used for synchronous
multimedia and State Chart XML (SCXML)
for state-machine based control.
- Finally, model data may be stored in a variety of formats including both
XML instances in XForms and JSON structures in Javascript.
As a result, RIAs will increasingly be authored as a composition of multiple
markup formats as shown in the diagram -- not as separable "modalities" of a
mashed-up application, but as a single coherent user experience.
4. Rich web applications in the browser: extensibility
The markups outlined above are examples of multiple formats which
collectively describe the structure and behavior of rich web applications.
Markups for RIAs will in general be interactive formats, i.e. have processing
models controlling behavior in addition to content models defining structure.
Rather than authoring-time formats intended for mapping into HTML (applicable at best for a subset of the
concrete presentation formats and irrelevant for control and data formats),
we need methods to support the behavior of extensible formats directly in
the browser as runtime vocabularies.
It's also important to track emerging markup formats from sources other than
the W3C and ask whether they might be of
interest as components of web-based applications. Our example below shows one
such format, from OASIS -- the Open Document Text format used as a concrete
presentation markup. There are potentially other emerging formats, particularly
in the space of industry vertical standards, which may similarly be of interest
for use client-side with first-class implementation of their behaviors. Examples
might include HL7 and Clinical Document Architecture (CDA) from the healthcare industry, ACORD
from insurance, and XBRL from the finance industry. These
formats are of potential interest not just as data-exchange formats but to the
extent they have interactive behaviors also as components of client-side web
applications.
In the discussion below we consider various approaches to supporting both
the structural and behavioral requirements of non-HTML markups without requiring plug-ins or extension components in
the browser.
4.1 Server-side transcoding
Historically, the preferred approach to supporting "foreign"
markups has been to transcode them to HTML
on the server and either associate event handlers either to
implement markup semantics client side in script or to delegate user events
to the server to update remotely the running page. While popular (having
been used to implement XForms, ODF, and a
number of specialized formats) this approach suffers from the obvious
performance handicap of remote event processing and corresponding lack of
scalability of server middleware. Some implementations (e.g. EMC XForms) include
complete client-side implementations of the required lifecycle support, for
example in a Javascript engine loaded alongside the transcoded markup.
A significant drawback for RIAs, and for the accessibility of their
documents, is that the client-side document structure resulting from
transcoding bears little or no resemblance in general to the document as
authored. Transcoding algorithms may be driven by convenience in terms of
output markup placement, style, and naming conventions. For authors of other
components on the page interested in mashing up with transcoded content these
issues can pose significant barriers to knowing where to dispatch events and
how to update page content dynamically. The principle of "view source"
is important not just for offline designers but also for page execution at
runtime.
4.2 Progressive enhancement and unobtrusive javascript
An approach very common to AJAX libraries (e.g. Dojo,
YUI) is the "progressive enhancement" of a
browser page with CSS, Javascript, and other style or behavior-related extensions
through artifacts separated from the original, sparse, source document. This
"unobtrusive" style provides a separation of concerns that allows in
principle for the original source document to run correctly on backlevel
browsers, but more generally for the required enhancements needed by RIAs to
be factored away from the application-specific document markup.
As in the server-side transcoding discussion, the main concern from this
approach results from an under-specified or non-standard relationship (1)
between the original source markup and its generated (or "shadow") content, and
(2) in the mechanisms for matching on source patterns and triggering the
generation of enhanced content.
Implementors of AJAX frameworks have considerable latitude in managing the
mapping between source elements and generated content. Ignoring accessibility
issues, preserving the semantic structure of the input document is not in
general critical to providing an effective visual experience to the end-user
looking only at what is presented "on the glass". Generated markup may
be placed under the source element, may replace the source element, or may
appear in totally unrelated sections of the document and be displayed out of
document order under control of dynamic positioning attributes.
Further, there is currently no standard (outside of XBL, see below) for the
naming, structure, or behavior of shadow content relative to its parent.
Authors wanting to dispatch events or register listeners on generated widget
content have in general no guidance as to the relationship between internal
widget behavior and its originating source element. We see in practice authors
violating good principles of abstraction by falling back on detailed knowledge
of widget internals -- a coding practice obviously fragile in terms of changes
in the underlying framework.
Implementors of AJAX frameworks also have considerable latitude in pattern
matching and progressive enhancement mechanisms. Various page loading events,
perhaps differing by browser, may be used to trigger queries to find content to
be enhanced. Triggering enhancement only at page loading time precludes
incremental enhancement as content is created dynamically -- or requires
different triggering mechanisms for those cases. Various combinations of
element name, attributes, and often CSS
classes may be used -- with little standardization -- to signal content
needing enhancement. Finally, as described above, the result of that
enhancement may appear in various locations throughout the document with
underspecified mapping to the original content.
While in general it is possible to load and execute multiple AJAX libraries
in the same document (provided the underlying script code adheres to best
practices for naming and function patterns), for authors there may be less
reuse of content across those libraries given the nonstandard conventions for
enhancing their content.
4.3 Client-side pre-processors
Client-side pre-processors differ from progressive enhancement in that
the source document is not seen as executable directly in any form without
transcoding, for example to HTML. The
source is a design-time artifact, and the runtime artifact is generated to
match the capabilities of a given target platform.
Client-side transcoding will in general suffer the same issues
surrounding transparent page content as server-based approaches. Client
processors rarely maintain a relationship between the original input
content and its transcoded result. Bi-directional mappings between source
and target formats would be needed to permit interactive editing or
dynamic modification of the original content incrementally to update the
running page.
4.4 Client-based tab library frameworks
In practice many client-side transcoders do not preserve the original
document markup nor link it to generated HTML
content as required to support such an interactive relationship. A
framework implementing tag libraries as "code behind" the HTML DOM (e.g. AmpleSDK) does
maintain the runtime identity of the elements in the custom namespace --
typically in a parallel DOM associated by
event handlers with generated HTML
content.
4.5 XBL
XBL formalizes the client-side tag library
mechanism by defining both the structural and behavioral relationship
between source content and shadow content. XBL
bindings define properties, fields, methods and events linking source
and shadow content. The semantic structure of the original source document
is preserved, as is recommended for accessibility and to support transparent
attachment of associated components in mash-ups or for document automation
(help wizards, navigation aids, etc.).
XBL bindings may be applied recursively
allowing for content to be defined initially as part of applications, i.e. as root document content, and then driven into
XBL bindings for reuse.
4.6 Cross-platform client-side behaviors
The Ubiquity framework achieves many of the
objectives of XBL by attaching executable
"behaviors" directly to the original source document elements. The
technique used for this behavioral "decoration" varies by browser
but such differences are localized to page loading time and are not visible
to page authors as they continue to see a common document structure
consistent with its originally authored structure (view source is what is
running not transcoded into HTML) and
consistent behavior in all browsers supported by this library (currently
Internet Explorer 7, FireFox 3, and the Safari/Chrome WebKit-based
rendering engines).
Indeed, we see this approach to using Javascript as an important
implementation technique for extensible markup elements whether they are
XML or HTML-based. The examples we have given are from XML vocabularies but a script-based "tag
library" mechanism would be interesting for supporting incremental
modules of HTML5, for example, as they appear in working drafts or perhaps
separable Recommendations -- and also as a means to accelerate their
implementation and adoption in a broad developer community before
"native" implementations in each browser are fully available.
4.7 Standardization
Currently there is only one interoperable extension method available in
mainstream browsers - using Javascript to add semantics to markup within a
DOM tree. There are several methods for
attaching the Javascript to the tree, for instance using XBL, or directly adding it to the tree by hand,
or indirectly via Javascript calls; however, once that is done, there is
no further standard or agreement, except by particular libraries, on how to
ensure that different parts of the Javascript work amicably together.
Since extension via Javascript is such an core and widely-used technology,
it seems an essential area for standardization, especially for allowing
independent technologies to work together in one page. Using the experience
based on Ubiquity, a submission could be made to W3C
as a basis for such standardization.
5. Accessibility and Rich Internet Applications
Persons with disabilities often interact with their computers using
third-party assistive software such as speech synthesis, braille output,
screen magnification, voice input or an on-screen keyboard. Even in
environments where multi-modal output is natively supported by the user's
underlying operating system, assistive technology is only
capable of providing an equivalent user experience with a Rich Internet
Application if there exist explicit bindings between
scripted objects or routines and regions of the RIA which are dynamically
updated. When a script manipulates the contents of a page, assistive
technology cannot be relied upon to update the user of the new data or
content output by a scripted process, because the script, and not the
underlying declarative framework utilized for the RIA, directly generates
the output. Where declarative markup languages lack the semantics to convey
rich controls to assistive technologies, as they are typically composed of
a series of images and styling so that the controls in the RIA visually
look like traditional desktop widgets. Furthermore, sudden focus changes
by the user agent in response to scripted action is extremely disorienting
and inherently confusing for those not only using dedicated assistive
technologies, but also for those using the user agent's default screen
magnification mechanism "zoom". Such obtrusive focus methods --
such as alerts, as well as the common practice of moving focus to a part of
the RIA which has been updated -- disrupts the user's current workflow,
with no defined mechanism to retain or restore focus where the user last
interacted with the RIA prior to the generation of an alert or dynamically updated
content.
5.1 ARIA: Accessible Rich Internet Applications
The W3C has developed a technology to address these issues:
Accessible Rich Internet Applications (ARIA). ARIA
enables multi-modal navigation and interaction with scripted objects and
their output, through the use of explicit role and state properties which
can be bound to the declarative framework upon which a javascripted object
or element is presented to the user. ARIA also provides focus management
mechanisms, which are critical to an assistive technology users'
understanding of, and ability to interact with, the RIA. In the absence
of ARIA bindings, scripted objects and the changes to a web document
caused by scripting, constitute perceptual and functional black holes.
Thus, the additional semantics provided by ARIA allows authors to
restructure and substitute alternative content in an RIA and ensures that
assistive technologies can communicate changes of "role",
"state", or "property" caused by scripting, as well as
ensuring that dynamically updated content is accessible to the user of an
assistive technology.
While there are a handful of markup languages that explicitly separate
presentation from content -- in particular XForms and MathML -- and
provide explicit binding mechanisms, the overwhelming majority of RIAs currently
implemented on the web use a generic markup language, such as HTML or XHTML.
Even when using a declarative markup language which has been designed so as
to be natively accessible to persons with disabilities, there is still a
need for ARIA bindings in order to facillitate multi-modal exposition of
the content and interactivity provided by the RIA through the use of
scripting, as javascript overrides the default user agent behavior at the
DOM node when manipulating and/or managing
data, the content, and/or the style of an RIA in response to events
caused either by user interaction or by background scripts which produce
custom widgets and update specific areas of the RIA.
ARIA is intended to be used as a supplement for native language
semantics, not a replacement. When the host language provides a feature
that is equivalent to the ARIA feature, the host language feature
should be used. ARIA should be used in cases where the
host language lacks the needed role, state and/or property indicator.
Authors are advised to first use a host language feature that is as
similar as possible to an ARIA feature, then refine the meaning of the
feature by adding ARIA. This allows for the best possible fallback for
user agents that do not support ARIA and preserves the integrity of the
host language semantics. ARIA also enables a user to control the behavior
of an element in response to user input events such as from the keyboard
and the mouse. Authors are advised to use device-independent events with
supporting javascript to handle user interaction.
5.2 ARIA live regions and politeness levels
In RIAs, alerts and dialogs are often used to convey important messages
and feedback to the user. ARIA provides mechanisms which ensure that a
user, no matter what her means of interacting with the web, is notified of
dynamic changes to a RIA's content by processing the alert or dialog as a
"live region". An example of a live region is a section of an RIA
that reflects dynamic data management, such as auto-updating stock quotes or
updating a designated region on an interactive financial form. ARIA
contains attributes specific to live regions, using the
aria-live attribute, which may be applied to any element. Use
of the aria-live attribute indicates that content changes may
occur without the element to which the content change is bound receiving
focus, thereby providing an assistive technology with sufficient information
on how to process those content updates by first Indicating that an element
will be updated, and describes the types of updates which the user agent,
the assistive technology and individual users can expect from the live region.
The aria-live attribute is the primary determination for the
order of presentation of changes to live regions. ARIA describes live regions
in terms of "politeness levels". Regions specified as
polite will notify users of updates, but do not generally
interrupt the current task. ARIA's assertive value is used when
the update needs to be communicated to the user more urgently; for example,
warning or error messages in a form that performs immediate validation for
each form field.
Politeness levels are essentially an ordering mechanism for updates and
serve as a strong suggestion to the user agent or assistive technology. The
value may be overridden by the user agent, assistive technology, or user.
Since different users have different needs, it is up to the user to tweak
his or her assistive technology's response to a live region with a certain
politeness level from the commonly defined baseline.
Implementations must also consider the default level of politeness in a
role when the aria-live attribute is not set in the ancestor
chain (for example, log changes are polite by default). Items
which are assertive should be presented immediately, followed by polite
items. An assistive technology is thus able to implement increasing and
decreasing levels of granularity so that the user can exercise control
over queues, interruptions and dynamic updates, which -- without ARIA
bindings -- would be imperceptible to the user of assistive technology.
5.3 Implications of browser extension methodologies for
supporting ARIA
ARIA cites several key characteristics of authoring style which lead to
accessible applications: using native markup when possible, preserving
semantic document structure, and building and maintaining stable relationships
between elements and maintaining focus. A key opportunity for
standardization is thus to document approaches to browser extensibility
which maintain the characteristics of document structure under
transformations for progressive enhancement or attachment of dynamic
behaviors. We list several possibilities above and suggest follow-on work to
this XG to evaluate and formalize such
techniques. RIA authors are advised to consult the suite of ARIA documents available from the W3C.
In this section we present authoring patterns found in a number of existing
markup formats which we suggest are useful more broadly additional formats
needed for RIAs.
Our goal is to make explicit common patterns specifically cutting across
multiple working groups in the W3C but also
including others (e.g. ODF)
where additional awareness, discussion, and re-factoring of specifications
could lead to improved interoperability and easier authoring of composite
applications making use of multiple formats at one time.
We highlight common approaches to data management, mapping of data to
abstract and concrete presentation, and interaction control. These patterns
form the essentials of what we have come to call the rich web
"backplane" in that they provide a structural underpinning to a
client-side web document independent of the particular content type being
presented, facilitate the separation of concerns such as data versus
presentation versus control, and hence provide a common skeleton -- a.k.a. backplane -- assisting in
the composition of more complex web applications from a collaborating set of
more primitive components.
While there are many widget or other component architectures emerging some
of which (e.g. iWidget)
also facilitate cross-component data sharing and communication, these
approaches are coarser-grained units of composition than what we describe.
The patterns which follow are embedded directly into the behavior of
individual elements and groups of elements of their host languages and hence
we view them as inherently integrated in those vocabularies rather than
layered on top as is typical for widgets.
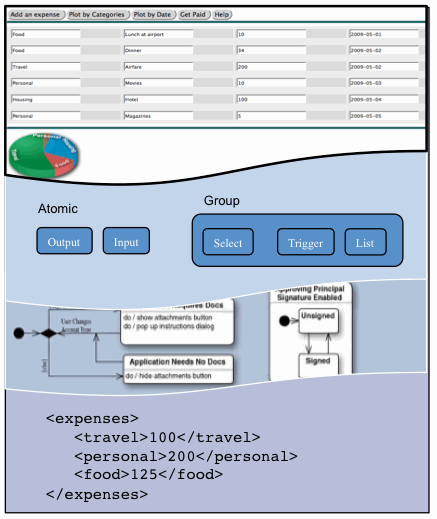
6.1 A simple example: Tracking expenses
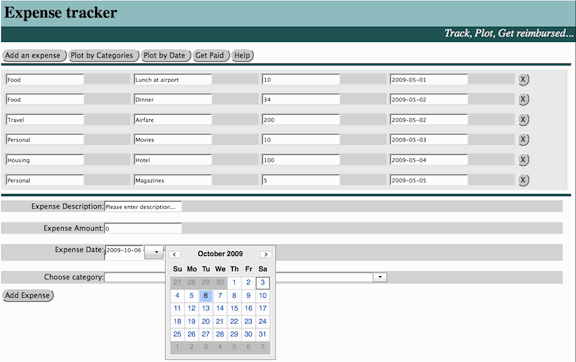
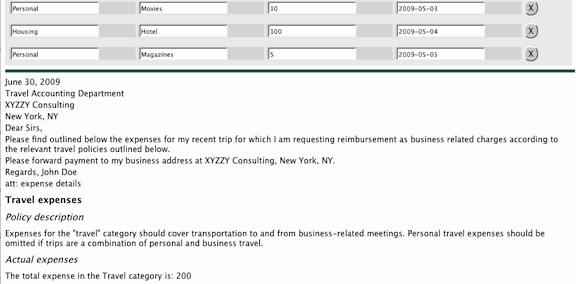
Figure 2 shows the main page of a simple expense tracking web application
that we will use to illustrate authoring patterns and runtime integration of
multiple markup formats. A list of expenses can be entered with a category,
description, date, and amount for each. Expenses are stored in an XForms data
model bound to this list. All of the XForms, ODF, and SMIL features of this
application have been implemented using the javascript Ubiquity and Ubiquity-XForms open source
libraries.
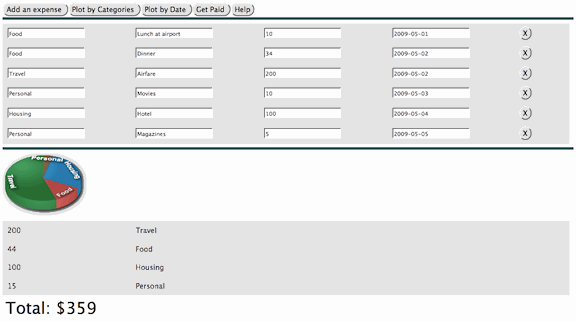
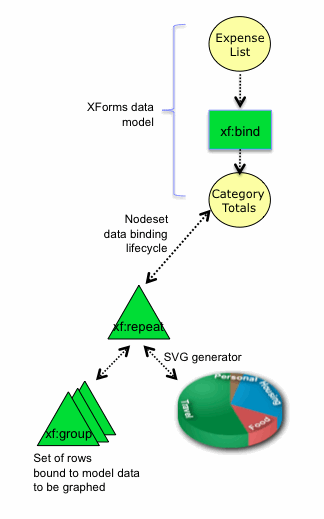
Figure 3 shows a graphical view of expenses aggregated
by category and drawn using an SVG piechart.
The expense categories included in the piechart are determined dynamically
by a data-driven aggregation of all non-zero categories from the underlying
expense list as described and illustrated in markup in the next section.
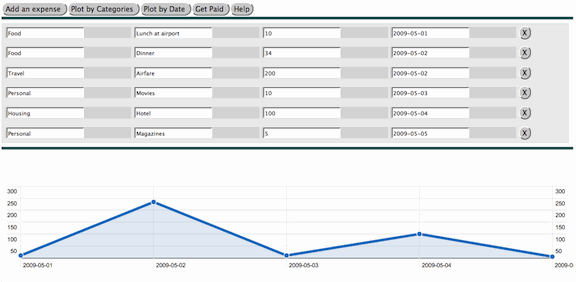
Figure 4 similarly shows a projection of expense entries
by date again using SVG. The importance of
the use of SVG in these examples is not in
that format per se, as SVG is already achieving considerable adoption natively in many
browsers. Rather, as discussed below, our interest is in treating SVG and other graphical widgets as concrete
presentation markups managed by abstract UI
controls with model bindings providing their data context and update
behavior.
A set of expenses, once entered, may be submitted for
re-imbursement by a report-generation tab implemented using the Open
Document Format (ODF) text format as shown in Figure 5. Open Document text
(ODT) elements are used to define a template for expense reimbursement with
the actual expense document containing only those categories with non-zero
expenses. ODF documents in the OASIS 1.0
specification may include XForms data models. As shown in Figure 4 we use
this capability to bind the expense report directly to data in the
underlying expense tracker's data model. Finally, entries for a table of
contents are computed dynamically across the sections dynamically found in the
document. Of particular note in this example is this enablement of ODF as a
web-centric markup format participating directly in the overall page lifecycle
with other web formats such as XHTML, XForms,
and SVG.
The schematic document structure for this
expense-tracing example is shown shown in Example 1 and includes
the following markup formats:
- HTML provides the root document
container and lifecycle.
- Embedded in HTML is an XForms
data model referenced both by the XForms UI for the master/detail view and by the ODF form controls and drawing elements
used to produce the expense report.
- Constraints and calculations (
xf:bind elements) in
the XForms model maintain running category totals used dynamically
to generate SVG markup as concrete
implementations of data-bound XForms repeats over those
totals. Script-based transformations are used similarly to generate
totals for daily expenses (support for iteration is a requirement for
future extensions to the XForms dependency mechanism and would allow
this to be done declaratively as well).
- Abstract ODF Form fields. These fields
define abstract behavior, bind to data, and are displayed in the ODF content layer, below.
- HTML and XForms UI controls for the main application shell, and master/detail
view.
- SVG category view, implemented as
data-bound XForms
repeat.
- SVG graph view, implemented as
data-bound XForms
repeat.
- ODF expense report, drawing ODF form fields embedded in running ODF text content.
<html>
<body class="yui-skin-sam">
<xforms:model id="model">
<xforms:instance id="expenses"/>
<!-- other instances for record keeping, etc -->
<!-- xforms binds to compute totals and transform data for charting/graphing -->
</xforms:model>
<!-- ODF-related form declarations -->
<office:forms>
<form:form>
<form:text form:name="TextBox" xforms:bind="travel_bind"
form:id="control1" form:current-value="100">
</form:text>
<!-- etc...other fields -->
</form:form>
</office:forms>
<!-- HTML and XForms UI controls for master expense list -->
<xforms:repeat nodeset="instance('expenses')/expense" id="expenseTable" startindex="1">
<!-- ... -->
</xforms:repeat>
<xforms:switch>
<xforms:case id="add_expense">
<!-- detail fields for adding expenses -->
</xforms:case>
<xforms:case id="SVG_by_category">
<xforms:repeat nodeset="instance('categories')/category[total!=0]" role="output-proportional">
<xforms:output ref="total" role="value"></xforms:output>
<xforms:output ref="name" role="label"></xforms:output>
</xforms:repeat>
</xforms:case>
<xforms:case id="SVG_by_date">
<xforms:repeat nodeset="instance('date_rollup')/point" role="output-trend">
<xforms:output ref="value" role="value"></xforms:output>
<xforms:output ref="date" role="label"></xforms:output>
</xforms:repeat>
</xforms:case>
<xforms:case id="ODF_invoice">
<!-- ODF-based expense report -->
<!-- intro boiler-plate text -->
<text:h text:outline-level="1">Travel expenses</text:h>
<text:h text:outline-level="2">Policy description </text:h>
<text:p>The total expense in the Travel category is:
<draw:control draw:name="Control1" draw:control="control1"></draw:control>
</text:p>
<!-- remaing expense categories in ODF... -->
</xforms:case>
</xforms:switch>
</body>
</html>
|
| Example 1: Expense application document
structure |
6.2 XML Events:
Transparent composition patterns
We begin with a simple observation as to the importance of transparent
control within web pages. By "transparent" we mean the ability for
one component in a page to observe, participate, and potentially alter the
execution of another component in the page. This capability is desirable
for authors adding function to an existing page, e.g. in "mashing up" content, in that it allows for their
incremental content not only to provide additional presentation but also
to augment the interactive behavior of the page in previously unanticipated
(by the original author) ways.
The principle means for observing and augmenting control is through a
consistent adoption of an event-based pattern of cross-component control rather
than direct invocation of methods or procedures within a page. Direct
invocation, while commonly used and simple to author, results in hidden paths
of control which can not be observed or intercepted by code elsewhere on the
page.
An event-based pattern, on the other hand, begins with a signaling phase
in which external observers are notified as to the impending execution of
the "default action" of the event. Handlers called at either capture
or bubbling phases may inject additional logic to prepare for or as a
consequence of the default action.
For those events which are cancelable, handlers may suppress the default
action perhaps replacing it with logic of their own. A familiar example is the
default action of selecting an anchor tag is to traverse the link. Canceling
that event does not stop its propagation to notify other handlers, but does
prevent traversal of the link at the end of the bubble phase.
One can think of this pattern as a partial "aspect oriented"
programming within web pages where event propagation prior to the default
action provides hooks for injecting code at various points in the event
lifecycle. The potential utility of a secondary capture/bubble phase
following default action execution (completing the analogy with AOP)
probably lacks sufficient use cases to balance the increased expense of
additional event propagation.
From a "backplane" perspective, the importance of this
discussion is not due to the novelty of event-based patterns. Indeed, web
authors are quite familiar with adding handlers to click,
onload, and other HTML-related
page events. Rather, since extensibility through the creation of new
elements rather than script-based code has not been the norm to date on
the web we don't see authors readily creating custom elements and hence
extending their pages with custom events conforming to a transparent
event-based pattern. Providing a well-defined means for declarative
extension of web pages may provide the corresponding incentive to adopt
more aspect-like patterns of composition as well.
6.2.1 Subsetting the DOM Event lifecycle
We observe that DOM and XML events, and hence the above composition
pattern, are feasible even for formats that do not specify explicitly
their conformance with DOM event behavior.
SMIL 3.0, for example, treats
event implementations flexibly, adapting to the specific requirements of
its host language -- whether DOM oriented
or not. However, we think it is useful to consider such cases as in fact
more strictly DOM conformant with the
provision that the DOM event lifecycle has
been subsetted to support just those behaviors appropriate to the markup
format in question.
For example, one could define SMIL as
DOM conformant by restricting listeners to
register and be called only on target-phase processing, omitting capture
and bubble processing. In this way, composition patterns elsewhere on the
page could continue to use DOM or XML event registration, as well as default action
cancellation when desired, to achieve greater interoperability among
formats in a document.
6.3 XForms: client-side rich data patterns
Moving additional data and its associated calculation, transformation,
and validation to the client is a key feature of rich web applications.
Often, however, this aspect of interactivity is overlooked in comparison
to the rich presentational impact of raster or vector graphics or video in
adding dynamic behavior to client-side web documents. This section focuses,
therefore, on various patterns which add "rich data" behavior to
web applications in a manner we see as applying horizontally to an
increasing number of web formats.
The XForms data model is well described elsewhere
and we do not repeat that discussion here. Rather, we focus on the emerging
use of that format beyond conventional "forms" applications for data
maangement in web applications and indeed beyond that context to formats
such as Open Document not traditionally thought of as web document markups.
Again from a "backplane" perspective, it is clear to us that the
ability to store "instances" of data (whether XML or otherwise), to validate that data, compute over it to
derive related data, and to associate metadata indicating the validity,
relevance, and required states of that data are features of not only forms,
but of rich web applications generally and also of rich document
applications based for example on ODF.
6.3.1 Data transformations
A key feature of assisting user interaction with complex data is
adapting the format and structure of that data for more convenient
presentation and input. Often, data is stored in back-end systems in a
structure convenient for database performance or perhaps to conform to
standards defined in a given industry. Such data may be inconvenient
for display or input by being decomposed into too many separate fields,
or conversely by being aggregated into too few compact fields (think
ISO
date-time, for example). Data extracted from back-end systems is typically
encoded using internal key values which also require translation for
external display and input.
End-to-end rich web applications thus typically contain a pipeline of
data transformations between back-end and on-the-glass presentation.
Example 2 shows a set of transformations in the expense tracking scenario
which maintain subtotals over each expense category. These constraints are
expressed in a declarative form as a set of data-driven XPath expressions
linking inputs in the instance values to computed outputs elsewhere in the
data model. The model maintains a dependency graph of these constraints and
re-evaluates them as necessary whenever input values change driving
corresponding updates to other fields on the client.
<xforms:model id="model">
<xforms:instance id="expenses">
<expenses xmlns="">
<expense>
<description>Lunch at airport</description>
<amount>10</amount>
<date>2009-05-01</date>
<category>Food</category>
</expense>
<!-- etc... -->
</expenses>
</xforms:instance>
<xforms:instance id='categories'>
<categories>
<category><name>Travel</name><total>0</total></category>
<category><name>Entertainment</name><total>0</total></category>
<!-- etc -->
</categories>
</xforms:instance>
<xforms:bind nodeset="instance('categories')/category[name='Travel']/total"
calculate="sum(instance('expenses')/expense[category='Travel']/amount)"></xforms:bind>
<!-- etc -->
</xforms:model>
|
| Example 2: XForms data transformations using
bind elements |
The current capabilities of this calculation engine allow for scalar
dependencies (i.e. individual element values)
for inputs and outputs and do not support iteration. We can thus compute
subtotals over known expense categories as in Example 2, but currently do
not have a declarative notation for example to project expenses onto a set
of dates where the date ranges and values are not known (or conveniently
expressed) at authoring time. The graphical view of expenses by date in
Figure 4, therefore, is computed procedurally by iterating over the
instance data and creating output instance data in the desired format for
use by subsequent stages in the transformation or display pipeline.
From a backplane perspective, we are interested in the ability to
connect to the data model capabilities of maintaining instance values,
computing derived values, and computing metadata (so-called
Model-Item-Properties for validity, relevance, etc., see [XForms MIPs]) as a generic capability -- i.e. independent of any particular markup
vocabulary for a user interface view, or indeed as a means to bind other
elements of markup such as fragments of controller logic in SMIL (see below).
6.4.1 Single node data binding
The xf:ref and xf:bind attributes define a
lifecycle for model-view binding which can be applied not only to those
elements defined in the XForms set of atomic and container level controls
but indeed in any UI vocabulary needing data
and MIP connectivity.
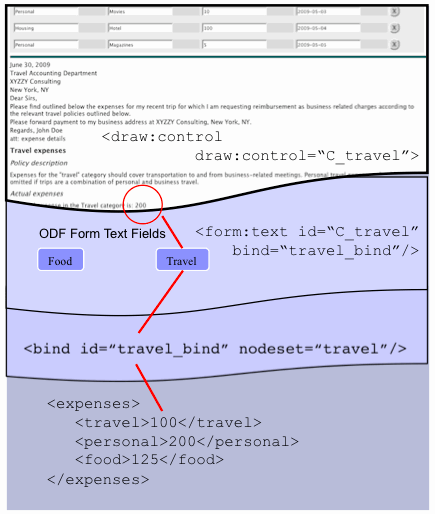
ODF is an example of a
specification that today uses this pattern of single-node-binding (we'll
consider binding to sets of data in the next section). ODF allows authors to include an XForms model in
text, spreadsheet, and presentation documents and to insert model data
values into formatted content using a two-layer field and drawing
architecture shown in Figure 6. ODF
fields are not XForms controls but they do bind to data using the
xf:bind attribute and therefore obtain the value-change and
MIP lifecycle behavior implied by that
binding. We illustrate this capability in the expense tracker by including
an implementation of a subset of ODF
elements sufficient as a proof-of-concept of mixing ODF behavior in web documents.
Figure 6 shows the ODF binds selecting
instance values in the data model. This, and all other ODF markup, was generated by use of production ODF editors such as Open
Office and IBM Symphony and inserted into this
web application with modification only to alter the placement of the data
model in the root web page rather than in the ODF subtree. This extension does not alter the mechanism of data
binding but is reflective of the use of ODF
content in a mixed document rather than as a stand-alone office format.
ODF fields are abstract
form fields which use xf:bind to connect to instance data but
do not themselves draw that data directly in formatted content. ODF provides a separate draw:control
element to manage that final layer of concrete presentation as described
below in the discussion on mapping between layers of presentation. Thus
ODF fields play a role similar to XForms
abstract UI controls which are intended in
general to be embedded in a host language for concrete styling and
interaction control.
6.4.2 Container level controls and data binding
Single node data binding can be used as well with container-level
controls, i.e. those that do not display
or input data directly but have children which do. Container controls use
xf:ref and xf:bind to set an evaluation context
allowing for relative data binding expressions in their children but
importantly also to receive MIP events for
relevance, validation, and required status. This status is then inherited
to child elements allowing, for example, for sections of ODF content in the expense reimbursement markup to
display conditionally whenever the expense data in the category it is bound
to is non-zero.
6.4.3 Nodeset binding
UI controls can bind to collections of data
in addition to individual nodes using the "nodeset" level of data
binding. Nodesets are constructed by XPath queries over instance data and
the associated UI content is treated as a
template to be repeated for each entry in the set. Relative binding (either
nested nodesets or single node binding) applies within the set to continue
the template expansion as many levels as required. The behavior of nodeset
binding is particularly powerful as changes to the query are tracked
dynamically and additional template content is instantiated, or existing
content removed, accordingly to maintain a current relationship between data
model and view. This mechanism provides an implicit, or data-driven,
declaration of the structural relationship between model and view over and
above the two-way data synchronization provided by single node bindings.
Continuing our use of ODF as an example
host language for data-aware web applications, two of us (Boyer, Wiecha)
have proposed extensions to the ODF
forms vocabulary to support repeating content as well as static
form fields. We see use cases both for xf:repeat as a container
control around existing ODF field elements
such as those shown in Figure 6, as well as the extension of the ODF forms vocabulary to allow for XForms controls to
be used directly in repeats or elsewhere in ODF
forms. Similarly, we would be interested to explore xf:repeat as
a data-driven UI template for other UI vocabularies
such as SVG, VoiceXML, and potentially for
generating more dynamic content for controller vocabularies such as SMIL and SCXML.
6.5 Embedding existing presentation formats in the Backplane
While not required, typically, UI controls
that bind to data are abstract controls in that they provide data
connections, manage the behavior of their local interaction state (working
data entry fields, selection status of single or multiple selection lists,
etc.), but do not present their bound data
directly. Rather, some means of mapping between abstract controls and one or
more concrete controls accomplishes this "last mile" to the user.
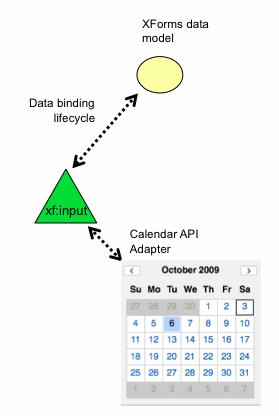
6.5.1 AJAX widgets
In Figure 2, abstract UI controls are extended
dynamically at page load time (or following element creation as the page is
later extended incrementally during execution). The runtime structure of the
xf:input element bound to a data value with type xsd:date
is shown in Figure 7. In this case, the YUI calendar widget is used to
provide the concrete realization of an interaction technique appropriate for
the bound data type, but the synchronization behavior with the backplane data
model is abstracted away into the xf:input parent element.
A second example leverages the increasing availability of
SVG as a native UI
format in modern browsers. The piechart and expense charting shown above
are drawn dynamically by javascript functions attached as event listeners
to data model change notifications received by their controlling
xf:repeat elements. Both SVG
examples are cases where the concrete presentation subtrees are built as
siblings of the abstract xf:repeat container element to avoid
conflict with the existing behavior of xf:repeat as it manages
the set of replicated data as its own children.
6.5.3 ODF
The ODF draw:control
element is responsible for surfacing data model values into formatted
content (whether text, spreadsheets, or presentations). Rather than
achieving this embedding syntactically by nesting ODF fields directly in
formatted content, the draw:control element is another
example of sibling mapping resolved using cross-references by ID between abstract form fields and drawn content.
The draw:control elements, like the SVG content in xf:repeats, function as listeners
to data model changes and redraw their content as necessary.
6.6 SMIL
and SCXML:
controller patterns
Along with the migration of function from server to client typical in a
rich web application there comes a corresponding need for control over the
resulting increased level of complexity of behavior. Rich web documents may
have multiple interacting components on the same page, requiring coordination
to achieve a coherent aggregate user experience. Rich web documents very
often have asynchronous interactions with remote services, also requiring
coordination to track requests and update client-side data or UI as responses are received.
Many AJAX-based applications today share this behavior but implement
their controller logic directly in a scripting language such as Javascript.
While perfectly functional, there may be categories of control logic that
are particularly suited to special-purpose controller formats. Two of these
are explored in this section and their implementations as modules leveraging
the Ubiquity extension framework are detailed in the Appendix below.
6.6.1 SMIL
SMIL is a format centered on time-based control
abstractions, useful as a stand-alone web format (i.e., as the root document type) as well as a controller embedded
in other formats such as the XHTML/ODF compound document used in our expense tracker
application. Time based control is particularly prevalent in multimedia
presentations and demonstrations, for example in kiosks and online
training.
The NYC
tour in Figure 9 consists of a coordinated set of images, audio, and
captions. Each set is played in parallel, with the next set shown when the
previous one has finished. The overall control structure of this simple
example is then a sequence of parallel sections, each containing audio,
image, and caption.
This markup for this example is executable directly in the Safari,
Chrome, IE, and FireFox browsers
using the proof-of-concept SMIL Ubiquity
implementation jsambulant.
SMIL control can not only be time-based
but also event-based, to allow for user interaction within a SMIL presentation. SMIL
also has a data model, shared with XForms, to allow stateful presentations.
In a rich web document, these features allow creation of an adaptive
multimedia presentation that reacts to things happening elsewhere in the
document. Example 3 is an example of this (referring back to the data model
of Figure 7): it will play a warning message -- once only -- whenever your
entertainment costs go over $100.
<smil:par>
<smil:video begin="stateChange(instance('categories')/category/total)"
expr="instance('categories')/category[name='Entertainment']/total > 100"
src="expense_warning.ogv"
restart="never" />
<!-- rest of SMIL presentation -->
</smil:par>
|
| Example 3: SMIL reacting to data model
changes |
The event model and the data model, augmented with XForms facilities
like xf:dispatch and xf:send, enable the use of
SMIL as a controller language. The
temporal logic of the application could be specified in SMIL, using the data or event model to drive other
components of the application. This pattern can be used on various scales.
As an example of a small-scale use, think of things like a wizard
controller, where it drives the order of a number of sequenced forms. Large
scale examples would be things like courseware, quizzes or games.
6.6.2 SCXML
The State Chart XML (SCXML) format being defined
by the Voice Browser Working Group is centered around reactive systems
modeled conveniently by state machine-based semantics. Reactive systems
are particularly prevalent in less modal UIs
where multiple components, agents, or avatars
interact concurrently and where cross-component coordination is required.
While we have a small subset of SCXML
implemented in Javascript we have not to date based this on the Ubiquity
library nor explored its integration with scenarios such as the expense
tracker.
Like SMIL, State Chart XML offers
interesting possibilities as an embedded controller for rich web
applications. Indeed, achieving coherent user experience in a web
application assembled as a mash-up of multiple components is a challenge
in that they need to share not only data (accomplished by binding to
common data model elements as above) but control. When selecting a stock
symbol and date range in an input dialog, for example, not only does the
related stock widget need to accept those values but also to trigger the
"Get Quote" operation as well. A controller such as SMIL or SCXML
can conveniently add this control layer over and above the implicit data
synchronization provided by shared model state.
7. Conclusions
W3C
has dedicated significant resources to developing XML interaction formats as a modular, extensible architecture which has proved itself
in the market place. However, a new deployment technique is emerging of
implementing the XML interaction stack in the browser,
using Javascript as the implementation language. For this to be useful as
intended in the XML architecture, there
needs to be agreement on how implementations of particular markup-languages
use the Javascript facilities, so that different modules can be used
together without prior agreement -- avoiding potential pitfalls such as collision among multiple
javascript frameworks used in the same page, code generation lifecycles and location of generated
code in the document, mapping between events in generated and source code markup, and so on.
Note that Javascript-based libraries are, of course, effective means for implementing emerging
non-XML markup formats as well as XML-based ones. New features of HTML5, or later versions of HTML,
might be implemented in Javascript-based libraries to speed their adoption in the marketplace in advance
of the availability of native browser implementations.
The Backplane XG recommends that a workshop
be organized bringing together interested parties with an aim to creating
a Working Group to define a standardized architecture and
API for
XML and HTML interaction formats implemented in Javascript.
References
- [HTML+MATH+SVG]
- "An XHTML + MathML + SVG Profile", [1]
- [Joost]
- "Joost", [2]
- [XSmiles]
- "X-SMILES, an open XML browser for exotic devices", [3]
- [ODF]
- "OASIS Open Document Format for Office Applications", [4]
- [HL7]
- "Health Level Seven", [5]
- [CDA]
- "Clinical Document Architecture", [6]
- [ACORD]
- "ACORD Insurance Data Standards", [7]
- [XBRL]
- "eXtensible Business Reporting Language", [8]
- [EMC XForms]
- "The EMC Documentum XForms Engine", [9]
- [Dojo]
- "Dojo: The javascript toolkit", [10]
- [YUI]
- "YUI Library", [11]
- [Ample SDK]
- "Ample SDK: Open-source GUI Framework", [12]
- [XBL]
- "XML Binding Language", [13]
- [Ubiquity Library]
- " Ubiquity: Application Framework", [14]
- [Ubiquity XForms]
- " Ubiquity-XForms: XForms in Web Browsers and Presentational Ajax Libraries", [15]
- [ARIA]
- "Accessible Rich Internet Applications", [16]
- [iWidget]
- "iWidget v1.0 Specification", [17]
- [XForms 1.1]
- "XForms 1.1", [18]
- [Open Office]
- "Open Office", [19]
- [IBM Symphony]
- "IBM Lotus Symphony", [20]
- [ODF Next]
- "Enriching the interactive user experience of open document format", [21]
- [SMIL 3.0]
- "Synchronized Multimedia Integration Language (SMIL 3.0)", [22]
- [SCXML]
- "State Chart XML (SCXML): State Machine Notation for Control Abstraction", [23]