The Resource Description Framework RDF
allows you to describe Web documents and resources from the real
world—people, organisations, things—in a computer-processable way.
Publishing such descriptions on the Web creates the Semantic Web. URIs (Uniform Resource Identifiers) are very
important, forming the link between RDF and the Web. This article presents
guidelines for their effective use. We discuss two strategies, called 303
URIs and hash URIs. We give pointers to several Web sites that
use these solutions, and briefly discuss why several other proposals have
problems.
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.
This is a First Public Working Draft of an intended W3C
Interest Group Note giving a tutorial explaining decisions of the TAG for
newcomers to Semantic Web technologies. It was initially based on the
DFKI
Technical Memo TM-07-01, Cool URIs for the Semantic Web and was reviewed
informally by the Technical Architecture Group
(TAG) and the Semantic Web
Deployment Group (SWD). This document was
developed by the Semantic Web
Education and Outreach (SWEO) Interest Group.
Please send comments about this document to public-sweo-ig@w3.org (with public
archive). Publication of this document as Working Group Note is planned for
1 February 2008, comments should possibly be sent until 21 January 2008.
Most issues found in TAG and SWD reviews have been addressed, known
remaining issues with this document are listed in the
changelog section.
Publication as an Working Draft does not imply endorsement by the
W3C Membership. This is a draft document and may be updated, replaced or
obsoleted by other documents at any time. It is inappropriate to cite this
document as other than work in progress.
This document was produced by a group operating under the 5 February 2004 W3C Patent Policy. The group does not expect this document to become a W3C Recommendation. W3C maintains a public list of any patent disclosures made in connection with the deliverables of the group; that page also includes instructions for disclosing a patent. An individual who has actual knowledge of a patent which the individual believes contains Essential Claim(s) must disclose the information in accordance with section 6 of the W3C Patent Policy.
This document is a practical guide for implementers of the RDF
specification. It explains two approaches for RDF data hosted on HTTP servers. Intended audiences are Web and ontology
developers who have to decide how to model their RDF URIs for use with HTTP.
Applications using non-HTTP URIs are not covered. This document is an
informative guide covering selected aspects of previously published, detailed
technical specifications. We assume that you are familiar with the basics of the RDF
data model [RDFPrimer]. We also
assume some familiarity with the HTTP protocol [RFC2616]. Wikipedia's article [WP-HTTP] serves as a good primer.
The Semantic Web is envisioned as a decentralised world-wide information
space for sharing machine-readable data with a minimum of integration costs.
Its two core challenges are the distributed modelling of the world with a
shared data model, and the infrastructure where data and schemas can be
published, found and used. A basic question is thus how to publish
information about resources in a way that allows interested users and
software applications to find them.
On the Semantic Web, all information has to be expressed as
statements about resources, like the members of the
company Example.com are Alice and Bob or Bob's telephone number is
"+1 555 262 or this Web page was created by Alice. Resources
are identified by Uniform Resource Identifiers (URIs) [RFC3986]. This modelling approach is at the
heart of Resource Description Framework (RDF) [RDFPrimer].
@@ check if this explains the semantic web for the intended
audience or if more is needed@@
Using RDF, the statements can be published on the website of the company.
Others can read the data and publish their own information, linking to
existing resources. This forms a distributed model of the world.
At the same time, Web documents have always been addressed with URIs (in common parlance often referred as Uniform
Resource Locators, URLs). This is
useful because it means we can easily make RDF statements about Web pages,
but also dangerous because we can easily mix up Web pages and the things, or
resources, described on the page.
So the question is, what URIs should we use in RDF? As an example, to
identify the frontpage of the Web site of Example Inc., we may use
http://www.example.com/. But what URI identifies the company as an
organisation, not a Web site? Do we have to serve any content—HTML pages,
RDF files—at those URIs? In this document we will answer these questions
according to relevant specifications. We explain how to use URIs for things
that are not Web pages, such as people, products, places, ideas and concepts
such as ontology classes. We give detailed examples how the Semantic Web can
(and should) be realised as a part of the Web.
Let us begin with an example. Assume that Example Inc., a fictional
company producing "Extreme Guitar Amplifiers", has a Web
site at http://www.example.com/. Part of the site is a white-pages
service listing the names and contact details of the employees. Alice and Bob
both work at Example Inc.. The structure of the Web site might thus be:
- http://www.example.com/
- the homepage of Example Inc.
- http://www.example.com/people/alice
- the homepage of Alice
- http://www.example.com/people/bob
- the homepage of Bob
Like everything on the traditional Web, each of the pages mentioned above
are Web documents. Every Web document has its own URI. Note that a
Web document is not the same as a file: a single Web document can be
available in many different formats and languages, and a single file, for
example a PHP script, may be responsible for generating a large number of Web
documents with different URIs. A Web document is defined as something that
has a URI and can return representations (responses in a format such
as HTML or JPEG or RDF) of the identified resource in response to HTTP
requests. In technical literature, such as Architecture of the
World Wide Veb, Volume One [AWWW], the term Information Resource is
used instead of Web document.
On the traditional Web, URIs were used primarily for Web
documents—to link to them, and to access them in a browser. In short, to
locate a Web document—hence the term URL (Uniform
Resource Locator). The notion of resource identity was not so
important on the traditional Web, a URL simply identifies whatever we see
when we type it into a browser.
Web clients and servers use the HTTP protocol [RFC2616] to request representations of Web
documents and send back the responses. HTTP has a powerful mechanism for
offering different formats and language versions of the same Web document
known as content negotiation.
When a user agent (such as a browser) makes an HTTP request, it sends along
some HTTP headers to indicate what data formats and language it prefers. The
server then selects the best match from its
file system or generates the desired content on demand, and sends it back
to the client. For example, a browser could send this HTTP request to
indicate that it wants an HTML or XHTML version of
http://www.example.com/people/alice in English or German:
GET /people/alice HTTP/1.1
Host: www.example.com
Accept: text/html, application/xhtml+xml
Accept-Language: en, de
The server could answer:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Language: en
followed by the content of the HTML document in English. Content
negotiation [TAG-Alt] is often
implemented with a twist: Instead of a direct answer, the server
redirects to another URL where the appropriate version is found:
HTTP/1.1 302 Found
Location: http://www.example.com/people/alice.en.html
The redirect is indicated by a special Status Code, here 302
Found. The client would now send another HTTP request to the new URL. By
having separate URLs for different versions, this approach allows Web authors
to link directly to a specific version.
@@DannyAyers: ...and treat them as
independent resources? @@Leo: they may be several representions of the
same resource, the term "independent" may be misleading.
RDF/XML, the standard serialisation format of RDF, has its own content
type, application/rdf+xml. Content negotiation thus allows
publishers to serve HTML versions of a Web document to traditional Web
browsers and RDF versions to Semantic Web-enabled user agents. This also
allows servers to provide alternative RDF serialisation formats like Notation3 [N3] or TriX
[TriX].
@@ TAG suggest to rephrase the next sentence to "With the advent of
semantic web technologies, the web is extended so that (http:?) URIs can
identify not just web documents but also ..
@@ Danny Ayers: It's long been possible to identify things, and
RDF etc aren't strictly necessary
@@ LeoSauermann: hesitate to change the document based on this general comment.
On the Semantic Web, URIs identify not just Web documents, but also
real-world objects like people and cars, and even abstract ideas and
non-existing things like a mythical unicorn. We call all these real-world
objects or (according to WWW-Arch) non-information resources.
@@Danny Ayers: I believe it came in a recent thread on semantic-web@w3.org
that "non-information resource" wasn't defined in WebArch, though I
haven't checked. If so, should be reworded. My suggestion for rewording is to delete that last sentence
@@ Leo Sauermann: there is no other term offered. Suggestion: remove "(according to WWW.Arch)"
Given such a URI, how can we find out what resource it identifies? We need
some way to answer this question, because otherwise it will be hard to
achieve interoperability between independent information systems. We could
imagine a service where we can look up a description of the identified
resource, similar to today's search engines. But such a single point of
failure is against the Web's decentralised nature.
Instead, we should use the Web itself—an extremely robust and scalable
information publishing system—as a lookup service for resource
descriptions. Whenever a URI is mentioned, we can look it up to retrieve a
description containing relevant information and links to related data. This
is so important that we make it our number one requirement for good URIs:
- 1. Be on the Web.
- Given only a URI, machines and people should be able to retrieve a
description about the resource identified by the URI from the Web. Such
a look-up mechanism is important to establish shared understanding of
what a URI identifies. Machines should get RDF data and humans should
get a readable representation, such as HTML. The standard Web transfer
protocol, HTTP, should be used.
Let's assume Example Inc. wants to publish contact data of their employees
on the Semantic Web so their business partners can import it into their
address books. For example, the published data would contain these statements
about Alice, written here in N3 syntax [N3]:
<URI-of-alice> a foaf:Person;
foaf:name "Alice";
foaf:mbox <mailto:alice@example.com>;
foaf:homepage <http://www.example.com/people/alice> .
What URI should we use instead of the placeholder
<URI-of-alice>? Certainly not
http://www.example.com/people/alice, because that would confuse a
person with a Web document, leading to misunderstandings: Is the homepage of
Alice also named “Alice”? Has the homepage an email address? And why has
the homepage a homepage? So we need another URI. (For in-depth treatments of
this issue, see What
HTTP URIs Identify? [HTTP-URI2] and
Four
Uses of a URL: Name, Concept, Web Location and Document Instance [Booth]).
Therefore our second requirement:
- 2. Don't be ambiguous.
- There should be no confusion between identifiers for documents and
identifiers for other resources. URIs are meant to identify only one
thing, so one URI can't stand for both a Web-retrievable document and
another real-world object.
We note that our requirements seem to conflict with each other. If we
can't use URIs of documents to identify real-world object, then how can we
retrieve a description about real-world objects based on their URI? The
challenge is to find a solution that allows us to find the describing
documents if we have just the resource's URI, using standard Web
technologies.
The following picture shows the desired relationships between a resource
and its describing documents:
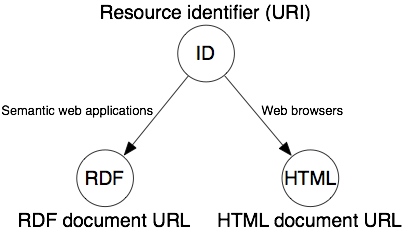
@@ The next paragraphs address a recommendation by TAG to weaken
our "err on the side of caution" recommendation by explaning the problem
better. TAG members may verify if their recommendation was met by our explanation.
Above we assumed that there is a distinction between web documents
(information resources) andreal-world, non-document objects
(non-information resources). The question is where to draw the line
between them.
According to W3C guidelines ([AWWW], section 2.2.), we have an information
resource if all its essential characteristics can be conveyed in a
message. Examples are a Web page, an image or a product catalog, which we
call Web documents in this document. The URI identifies both the entity and
indirectly the message that conveys
the characteristics. Real-world objects (non-information resources) are
therefore entities whose characteristics can not be conveyed in a message,
but are entities on their own. The key to understand the difference, is that
an information resource often describes a non-information resource.
For example the person Alice is described in an information resource, Alice's
homepage. We may not like the look of the homepage, but this opinion does not
relate to the person.
The problem now is that web documents are also part of our perceived
world, hence they are real-world objects in their own right. The document you
are reading right now is an entity of the real world you perceive.
Our recommendation is to err on the side of caution: Whenever an
object of interest is not clearly and obviously a document (all its
essential characteristics can be conveyed in a message), then it's better
to use two distinct URIs, one for the resource and another one for the
document describing it.
There are two solutions that meet our requirements for identifying
real-world objects: 303 URIs and hash URIs. Which one to
use depends on the situation, both have advantages and disadvantages.
The solutions described in the following apply to deployment scenarios in
which the RDF data and the HTML data is served separately, such as a
standalone RDF/XML document along with an HTML document. The metadata can
also be embedded in HTML, using technologies such as RDFa [RDFa Primer], microformats and other documents to
which the GRDDL [GRDDL] mechanisms can be applied. In those cases the RDF
data is extracted from the returned HTML document.
The first solution is to use “hash URIs” for non-document resources.
URIs can contain a fragment, a special part that is separated from
the rest of the URI by a hash symbol (“#”).
When a client wants to retrieve a hash URI, then the HTTP protocol
requires the fragment part to be stripped off before requesting the URI from
the server. This means a URI that includes a hash cannot be retrieved
directly, and therefore cannot identify a Web document. But we can use them
to identify other, non-document resources, without creating ambiguity.
If Example Inc. adopts this solution, then they could use these URIs to
represent the company, Alice, and Bob:
- http://www.example.com/about#exampleinc
- Example Inc., the company
- http://www.example.com/about#bob
- Bob, the person
- http://www.example.com/about#alice
- Alice, the person
Clients will always strip off the fragment part before requesting any of
these URIs, resulting in a request to this URI:
- http://www.example.com/about
- RDF document describing Example Inc., Bob, and Alice
At this URI, Example Inc. could serve an RDF document that contains
descriptions of all three resources, using the original hash URIs to identify
the resources.
The following picture shows the hash URI approach without content
negotiation:
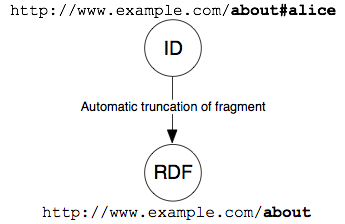
Alternatively, content negotiation (see Section
2.1.) could be employed to redirect from the about URI to
separate HTML and RDF documents. Again, the 303 See Other status
code must be used. (Otherwise, a client could conclude that the hash URI
refers to a part of the HTML document.)
The following picture shows the hash URI approach with content
negotiation:
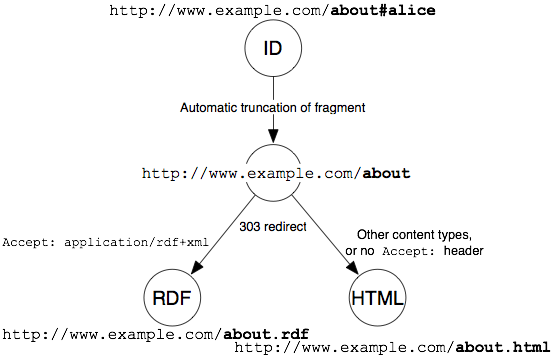
The second solution is to use a special HTTP status code, “303 See
Other”, to give an indication that the requested resource is not a
regular Web document. Web architecture tells you that for a non-information
resource it is inappropriate to return a 200 because there is, in fact, no
suitable representation for those resources. However, it is useful to provide
information about those resources. The W3C's Technical Architecture Group
proposes in its httpRange-14
resolution [httpRange] document
a solution that is to direct you to a different (information) resource which
can be represented as a document and can give you the information that you
want. By doing this we avoid ambiguity between the original, non-information
resource and the resource that describes it.
Since 303 is a redirect status code, the server can also give the location
of a document that describes the resource. If, on the other hand, a request
is answered with one of the usual status codes in the 2XX range, like 200
OK, then the client knows that the URI identifies a Web document.
If Example Inc. adopts this solution, they could use these URIs to
represent the company, Alice and Bob:
- http://www.example.com/id/exampleinc
- Example Inc., the company
- http://www.example.com/id/bob
- Bob, the person
- http://www.example.com/id/alice
- Alice, the person
The Web server would be configured to answer requests to all these URIs
with a 303 status code and a Location HTTP header that provides the
URL of a document that describes the resource.
The following picture shows the redirects for a possible 303 URI
solution:
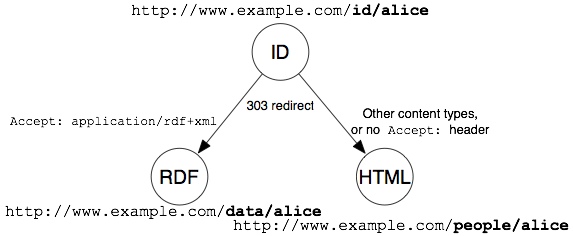
The server could employ content negotiation (see Section
2.1.) to send either the URL of an HTML description or RDF. HTTP requests
for HTML content would be redirected to the HTML URLs we gave in Section 2. Requests for RDF data would be redirected to
RDF documents, such as:
- http://www.example.com/data/exampleinc
- RDF document describing Example Inc., the company
- http://www.example.com/data/bob
- RDF document describing Bob, the person
- http://www.example.com/data/alice
- RDF document describing Alice, the person
Each of the RDF documents would contain statements about the appropriate
resource, using the original URI, e.g.
http://www.example.com/id/alice, to identify the described
resource.
Which approach is better? It depends. The hash URIs have the advantage of
reducing the number of necessary HTTP round-trips, which in turn reduces
access latency. A family of URIs can share the same non-hash part. The
descriptions of http://www.example.com/about#exampleinc,
http://www.example.com/about#product123, and
http://www.example.com/about# product456 are retrieved with a single
request to http://www.example.com/about. However this approach has a
downside. A client interested only in #product123 will inadvertently
load the data for all other resources as well, because they are in the same
file. 303 URIs, on the other hand, are very flexible because the redirection
target can be configured separately for each resource. There could be one
describing document for each resource, or one large document for all of them,
or any combination in between. It is also possible to change the policy later
on. But the large number of redirects may cause higher latency.
To address scalability issue with the management of a large set of URIs in
case of the 303 solution, the usage of a SPARQL endpoint or comparable
services is advised. Note also, that both 303 and Hash can be
combined, allowing to spread a large dataset into multiple parts and have
an identifier for a non-document resource. An example for a combination of
303 and Hash is:
- http://www.example.com/bob#this
- Bob, the person with a combined URI.
Any fragment identifier is valid, this in above URI is a
suggestion you may want to copy for your implementations.
- Conclusion.
- Hash URIs should be preferred for rather small and stable sets of
resources that evolve together. An ideal case are RDF Schema
vocabularies and OWL ontologies, where the terms are often used
together, and the number of terms is unlikely to grow much in the
future.
Hash URIs without content negotiation can be implemented by simply
uploading static RDF files to a Web server, without any special server
configuration. This makes them popular for quick-and-dirty RDF
publication.
303 URIs should be used for large sets of data that are, or may
grow, beyond the point where it is practical to serve all related
resources in a single document.
If in doubt, it's better to use the more flexible 303 URI
approach.
The best resource identifiers don't just provide descriptions for people
and machines, but are designed with simplicity, stability and manageability
in mind, as explained by Tim Berners-Lee in Cool URIs don't change
and by the W3C Team in Common HTTP
Implementation Problems (sections 1 and 3):
- Simplicity.
- Short, mnemonic URIs will not break as easily when sent in emails and
are in general easier to remember, e.g. when debugging your Semantic
Web server.
- Stability.
- Once you set up a URI to identify a certain resource, it should
remain this way as long as possible. Think about the next ten years.
Maybe twenty. Keep implementation-specific bits and pieces such as
.php and .asp out of your URIs, you may want to
change technologies later.
- Manageability.
- Issue your URIs in a way that you can manage. One good practice is to
include the current year in the URI path, so that you can change the
URI-schema each year without breaking older URIs. Keeping all 303 URIs
on a dedicated subdomain, e.g. http://id.example.com/alice,
eases later migration of the URI-handling subsystem.
All the URIs related to a single real-world object—resource identifier,
RDF document URL, HTML document URL—should also be explicitly linked with
each other to help information consumers understand their relation. For
example, in the 303 URI solution for Example Inc., there are three URIs
related to Alice:
- http://www.example.com/id/alice
- Identifier for Alice, the person
- http://www.example.com/people/alice
- Alice's homepage
- http://www.example.com/data/alice
- RDF document with description of Alice
Two of them are Web document URLs. The RDF document located at
http://www.example.com/data/alice might contain these statements
(expressed in N3):
<http://www.example.com/id/alice>
foaf:page <http://www.example.com/people/alice>;
rdfs:isDefinedBy <http://www.example.com/data/alice>;
a foaf:Person;
foaf:name "Alice";
foaf:mbox <mailto:alice@example.com>;
...
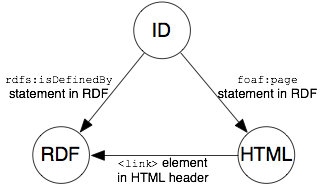
The document makes statements about Alice, the person, using the resource
identifier. The first two properties relate the resource identifier to the
two document URIs. The foaf:page statement links it to the HTML
document. This allows RDF-aware clients to find a human-readable version of
the resource, and at the same time, by linking the page to its topic, defines
useful metadata about that HTML document. The rdfs:isDefinedBy
statement links the person to the document containing its RDF description and
allows RDF browsers to distinguish this main resource from other auxiliary
resources that just happen to be mentioned in the document. We use
rdfs:isDefinedBy instead of its weaker superproperty
rdfs:seeAlso because the content at /data/alice is
authoritative. The remaining statements are the actual white pages data.
The HTML document at http://www.example.com/people/alice should
contain in its header a <link /> element that points to the
corresponding RDF document:
<html xmlns="http://www.w3.org/1999/xhtml" lang="en">
<head>
<title>Alice's Homepage</title>
<link rel="alternate" type="application/rdf+xml"
title="RDF Version"
href="http://www.example.com/data/alice" />
</head> ...
This allows RDF-aware Web clients to discover the RDF information. The
approach is recommended
in the RDF/XML specification ([RDFXML], section 9). If the information on the
Web page differs significantly from the RDF version, then we recommend using
rel="meta" instead of rel="alternate".
The following illustration shows how the RDF and HTML documents should
relate the three URIs to each other:
The W3C's Semantic Web Best Practices and Deployment Working Group has
published a document that describes how to implement the solutions presented
here on the Apache Web server. The Best Practice
Recipes for Publishing RDF Vocabularies [Recipes] mostly discuss the publication of
RDF vocabularies, but the ideas can also be applied to other kinds
of small RDF datasets that are published from static files.
Not all projects that work with Semantic Web technologies make their data
available on the Web. But a growing number of projects follow the practices
described here. This section gives a few examples.
ECS Southampton. The School of Electronics and Computer
Science at University of Southampton has a Semantic Web site that employs
the 303 solution and is a great example of Semantic Web engineering. It is
documented in the ECS URI
System Specification [ECS].
Separate subdomains are used for HTML documents, RDF documents, and resource
identifiers. Take these examples:
- http://id.ecs.soton.ac.uk/person/1650
- URI for Wendy Hall, the person
- http://www.ecs.soton.ac.uk/people/wh
- HTML page about Wendy Hall
- http://rdf.ecs.soton.ac.uk/person/1650
- RDF about Wendy Hall
Entering the first URI into a normal Web browser redirects to an HTML page
about Wendy Hall. It presents a Web view of all available data on her. The
page also links to her URI and to her RDF document.
D2R
Server is an open-source application that can be used to publish
data from relational databases on the Semantic Web in accordance with these
guidelines. It employs the 303 solution and content negotiation. For example,
the D2R Server
publishing the DBLP Bibliography Database publishes several 100k
bibliographical records and information about their authors. Example URIs,
again connected via 303 redirects:
- http://www4.wiwiss.fu-berlin.de/dblp/resource/person/315759
- URI for Chris Bizer, the person
- http://www4.wiwiss.fu-berlin.de/dblp/page/person/315759
- HTML page about Chris Bizer
The RDF document for Chris Bizer is a SPARQL query result from the
server's SPARQL endpoint:
http://www4.wiwiss.fu-berlin.de/dblp/sparql?query=
DESCRIBE+\%3Chttp\%3A\%2F\%2Fwww4.wiwiss.fu-berlin.de
\%2Fdblp\%2Fresource\%2Fperson\%2F315759\%3E
The SPARQL query encoded in this URI is:
DESCRIBE <http://www4.wiwiss.fu-berlin.de/dblp/resource/person/315759>
This shows how a SPARQL endpoint can be used as a convenient method of
serving resource descriptions.
Semantic
MediaWiki is an open-source Semantic Wiki engine. Authors can
use special wiki syntax to put semantic attributes and relationships into
wiki articles. For each article, the software generates a 303 URI that
identifies the article's topic, and serves RDF descriptions generated from
the attributes and relationships. Semantic MediaWiki drives the OntoWorld wiki. It has an article about the
city of Karlsruhe:
- http://ontoworld.org/wiki/Karlsruhe
- the article, an HTML document
- http://ontoworld.org/wiki/_Karlsruhe
- the city of Karlsruhe
- http://ontoworld.org/index.php/Special:ExportRDF/Karlsruhe?xmlmime=rdf
- RDF description of Karlsruhe
The URI of the RDF description is less than ideal, because it exposes the
implementation (php) and refers redundantly to RDF in the path and in the
query. A better URI would be for example
http://ontoworld.org/rdf/Karlsruhe.
Many other approaches have been suggested over the years. While most of
them are appropriate in special circumstances, we feel that they do not fit
the criteria from Section 3, which are to be on the
Web and don't be ambiguous. Therefore they are not adequate as
general solutions for building a standards-based, non-fragmented,
decentralized Semantic Web. We will discuss two of these approaches in some
detail.
HTTP URIs already identify Web resources and Web documents, not other
kinds of resources. Shouldn't we create a new URI scheme to identify other
resources? Then we could easily distinguish them from Web documents just by
looking at the first characters of the URI. For example, the info
scheme can be used to identify books based on a LCCN number:
info:lccn/2002022641.
Here are examples of such new URI schemes. A longer list is provided by
Thompson and Orchard in URNs,
Namespaces and Registries [TAG-URNs].
- Magnet is an open
URI scheme enabling seamless integration between Web sites and
locally-running utilities, such as file-management tools. It is based on
hash-values, a URI looks like this:
magnet:?xt=urn:sha1:YNCKHTQCWBTRNJIV4WNAE52SJUQCZO5C.
- The info: URI
scheme is proposed to identify information assets that have
identifiers in existing public namespaces. Examples are URIs for LCCN
numbers (
info:lccn/2002022641) and the Dewey decimal system
(info:ddc/22/eng//004.678).
- The idea of Tag
URIs is to generate collision-free URIs by using a domain
name and the date when the URI was allocated. Even if the domain changes
ownership at a later date, the URI remains unambiguous. Example:
tag:hawke.org,2001-06-05:Taiko.
- XRI
defines a scheme and resolution protocol for abstract identifiers. The
idea is to use URIs that contain wildcards, to adapt to changes of
organizations, servers, etc.
Examples are @Jones.and.Company/(+phone.number) or
xri://northgate.library.example.com/(urn:isbn:0-395-36341-1).
To be truly useful, a new scheme must also define a protocol how to access
more information about the identified resource. For example, the
ftp:// URI scheme identifies resourcse (files on an FTP server), and
also comes with a protocol for accessing them (the FTP protocol).
Some of the new URI schemes provide no such protocol at all. Others
provide a Web service that allows retrieval of descriptions using the HTTP
protocol. The identifier is passed to the service, which looks up the
information in a central database or in a federated way. The problem here is
that a failure in this service renders the system unusable.
Another drawback can be a dependence on a standardization body. To
register new parts in the info: space, a standardization body has to
be contacted. This, or paying a license fee before creating a new URI, slows
down adoption. In cases a standardization body is desirable to ensure that
all URIs are unique (e.g. with ISBNs). But this can be achieved using HTTP
URIs inside an HTTP namespace owned and managed by the standardization
organization.
The problems with new URI schemes are discussed at length in URNs,
Namespaces and Registries.
This approach radically solves the URI problem by doing away with URIs
altogether: Instead of naming resources with a URI, anonymous
nodes are used, and are described with information that allows
us to find the right one. A person, for example, could be described with her
name, date of birth, and social security number. These pieces of information
should be sufficient to uniquely identify a person.
A popular practice is the use of a person's email address as a uniquely
identifying piece of information. The foaf:mbox property is used in
Friend of a Friend
(FOAF) profiles for this purpose. In
OWL, this kind of property is known as an Inverse Functional
Property (IFP). When an agent encounters two resources with the same
email address, it can infer that both refer to the same person and can treat
them as one.
But how to be on the Web with this approach? How to enable agents
to download more data about resources we mention? There is a best practice to
achieve this goal: Provide not only the IFP of the resource (e.g. the
person's email address), but also an rdfs:seeAlso property that
points to a Web address of an RDF document with further information about it.
We see that HTTP URIs are still used to identify the location where to
download more information.
Furthermore, we now need several pieces of information to refer to a
resource, the IFP value and the RDF document location. The simple act of
linking by using a URI has become a process involving several moving parts,
and this increases the risk of broken links and makes implementation more
cumbersome.
Regarding FOAF's practice of avoiding URIs for people, we agree with Tim Berners-Lee's
advice: “Go ahead and give yourself a URI. You deserve it!”
Resource names on the Semantic Web should fulfill two requirements: First,
a description of the identified resource should be retrievable with standard
Web technologies. Second, a naming scheme should not confuse documents and
the things described by the documents.
We have described two approaches that fulfill these requirements, both
based on the HTTP URI scheme and protocol. One is to use the 303 HTTP status
code to redirect from the resource identifier to the describing document. One
is to use “hash URIs” to identify resources, exploiting the fact that
hash URIs are retrieved by dropping the part after the hash and retrieving
the other part.
The requirement to distinguish between resources and their descriptions
increases the need for coordination between multiple URIs. Some useful
techniques are: embedding links to RDF data in HTML documents, using RDF
statements to describe the relationship between the URIs, and using content
negotiation to redirect to an appropriate description of a resource.
Many thanks to Tim Berners-Lee who helped us understanding the
TAG solution by answering chat
requests and contributing e-mails with clarifications. Special thanks go to Stuart Williams (HP Labs)
and Norman Walsh from TAG,
who reviewed
this document and provided essential feedback in
June
2007 and
September 2007 about many formulations that were (accidentially) contrary to the TAG's view. Also special
thanks to the Semantic Web Deployment
Group's members Michael Hausenblas, Vit
Novacek, and Ed Summers' reviews and their review summary sent in
October 2007. We wish to
thank everyone else who has reviewed drafts of this document, especially Chris Bizer and Gunnar AAstrand Grimnes.
This work was supported by the German Federal Ministry of Education,
Science, Research and Technology (bmb+f), (Grants 01 IW C01, Project EPOS:
Evolving Personal to Organizational Memories; and 01 AK 702B, Project
InterVal: Internet and Value Chains) and by the European Union IST fund
(Grant FP6-027705, Project Nepomuk).
- [AWWW]
- Architecture of
the World Wide Web, Volume One, Ian Jacobs, Norman Walsh,
Editors. World Wide Web Consortium, 15 December 2004. This edition is
http://www.w3.org/TR/2004/REC-webarch-20041215/. The latest edition is available at
http://www.w3.org/TR/webarch/.
- [Booth]
- Four
Uses of a URL: Name, Concept, Web Location and Document
Instance, David Booth. 28 January 2003. This document is
available at
http://www.w3.org/2002/11/dbooth-names/dbooth-names_clean.htm.
- [CHIPS]
- Common
HTTP Implementation Problems, Olivier Théreaux, Editor.
World Wide Web Consortium, 28 January 2003. This edition is
http://www.w3.org/TR/2003/NOTE-chips-20030128/. The latest
edition is available at http://www.w3.org/TR/chips/.
- [Cool]
- Cool URIs don't
change, Tim Berners-Lee, 1998. This document is available at
http://www.w3.org/Provider/Style/URI.
- [ECS]
- ECS URI System
Specification, Colin Williams, Nick Gibbins. ECS
Southampton, 2006. This document is available at
http://id.ecs.soton.ac.uk/docs/.
- [FOAF]
- FOAF
Vocabulary Specification 0.9, Dan Brickley, Libby Miller. 24
May 2007. This edition is http://xmlns.com/foaf/spec/20070524.html. The
latest edition is available
at http://xmlns.com/foaf/spec/.
- [GRDDL]
- Gleaning Resource Descriptions
from Dialects of Languages (GRDDL), Dan Connolly, Editor, W3C
Recommendation 11 September 2007. This edition is http://www.w3.org/TR/2007/REC-grddl-20070911/.
The latest edition is available at
http://www.w3.org/TR/grddl/.
- [HTTP-URI2]
- What
HTTP URIs Identify, Tim Berners-Lee. 9 June 2005. This
document is available at
http://www.w3.org/DesignIssues/HTTP-URI2.html.
- [httpRange]
- [httpRange-14]
Resolved, Roy Fielding. 18 June 2005. This archived www-tag email
message is available at
http://lists.w3.org/Archives/Public/www-tag/2005Jun/0039.html.
- [N3]
- Notation
3, Tim Berners-Lee, Editor, 1998. This document is available
at http://www.w3.org/DesignIssues/Notation3.
- [RDFa Primer]
- RDFa Primer 1.0 - Embedding Structured Data in Web Pages (see http://www.w3.org/2006/07/SWD/RDFa/primer.)
- [RDFPrimer]
- RDF
Primer, Frank Manola, Eric Miller, Editors. World Wide Web
Consortium, 10 February 2004. This edition is
http://www.w3.org/TR/2004/REC-rdf-primer-20040210/. The latest edition is available
at http://www.w3.org/TR/rdf-primer/.
- [RDFXML]
- RDF/XML
Syntax Specification (Revised), Dave Beckett, Editor. World
Wide Web Consortium, 10 February 2004. This edition is
http://www.w3.org/TR/2004/REC-rdf-syntax-grammar-20040210/. The latest edition is
available at http://www.w3.org/TR/rdf-syntax-grammar/.
- [Recipes]
- Best
Practice Recipes for Publishing RDF Vocabularies, Alistair
Miles, Thomas Baker, Ralph Swick, Editors. World Wide Web Consortium,
14 March 2006. This edition is
http://www.w3.org/TR/2006/WD-swbp-vocab-pub-20060314/. It is a work in
progress. The latest
edition is available at http://www.w3.org/TR/swbp-vocab-pub/.
- [RFC2616]
- RFC 2616:
Hypertext Transfer Protocol - HTTP/1.1, J. Gettys, J. Mogul,
H. Frystyk, L. Masinter, P. Leach, T. Berners-Lee. IETF, 1999. This
document is available at http://www.ietf.org/rfc/rfc2616.txt.
- [RFC3986]
- RFC 3986: Uniform
Resource Identifier (URI): Generic Syntax, T. Berners-Lee,
R. Fielding, L. Masinter. IETF, 2005. This document is available at
http://www.ietf.org/rfc/rfc3986.txt.
- [SMW]
- Semantic
Wikipedia, Max Völkel, Markus Krötzsch, Denny Vrandecic,
Heiko Haller, Rudi Studer. University of Karlsruhe, 2006. This document
is available at
http://www.aifb.uni-karlsruhe.de/WBS/hha/papers/SemanticWikipedia.pdf.
- [TAG-Alt]
- On
Linking Alternative Representations To Enable Discovery And
Publishing, T.V. Raman. World Wide Web Consortium, 1
November 2006. This edition is
http://www.w3.org/2001/tag/doc/alternatives-discovery-20061101.html.
The latest
edition is available at
http://www.w3.org/2001/tag/doc/alternatives-discovery.html.
- [TAG-URNs]
- URNs,
Namespaces and Registries, Henry S. Thompson, David Orchard.
World Wide Web Consortium, 17 August 2006. This edition is
http://www.w3.org/2001/tag/doc/URNsAndRegistries-50-2006-08-17.html. It
is a work in progress. The latest
edition is available at
http://www.w3.org/2001/tag/doc/URNsAndRegistries-50.html.
- [TriX]
- RDF
Triples in XML, Jeremy J. Carroll, Patrick Stickler, 2004.
This document is available at
http://www.mulberrytech.com/Extreme/Proceedings/html/2004/Stickler01/EML2004Stickler01.html.
- [WP-HTTP]
- Hypertext Transfer
Protocol, Wikipedia contributors. Wikipedia, 8 October 2007.
The latest version of this document is available at
http://en.wikipedia.org/wiki/HTTP.
- 29 November 2006
- 1.0 Initial Version.
- 9 August 2007
- 1.1 Revised Version. Changes based on TAG
review.
- 28 November 2007
- Leo Sauermann included more feedback from reviews contributed by TAG,
SWD, and Tim Berners-Lee.
- 8 December 2007
- Danny Ayers did proofreading, minor grammar/idiomatic/editorial changes (I've tried not
to make any changes that substantively modify the content, though some
come close...). XHMTL validated with nxml-mode emacs
- 12 December 2007
- Leo Sauermann included link to GRDDL as suggested by Danny Ayers, minor
changes of todo notes. Document was remodelled to Working Draft status - all
feedback by SWD, TAG, and Tim Berners Lee either has been addressed or is
listed in this document as todos using @@-symbols and the css class "todo".
Non-addressed issues and general handling of issues
The editors
collected all recognized feedback in a
SVN folder, with more
notes on the editing status.
Some issues
found by reviewers were intentionally not addressed by the editors. They are
marked with red-colored backgrounds in these documents:
TODO
@@ pubrules were checked on 12.12.2007 by Leo Sauermann, repeated checking is good once the document is on the /TR location.
@@ TAG suggested
a replacement for the first graphic in their review. Not done yet
(12.12.2007)
@@ issue of using the terms "non-informationresource", "information resource" or "web document".
Leo Sauermann: The term "web document" is not common in W3Cs standardization language.
Nevertheless it is understandable by the target audience, web developers.
Tim Berners lee indicated positive feedback (link needed) towards the term "web document",
both the SWD and TAG are critisising "web document" and required better explanations or dropping the term. As this is W3C note, we
should think about dropping the term "web document".
Richard Cyganiak, Thu, 29 Nov 2007: I'm strongly opposed to changing
this terminology. "Non-information resource" is possibly the most
unfortunate term ever used in discussions of web architecture, and we should
quickly forget that it ever existed. ... Information
resource" is an official engineering term, but inappropriate for an
introductory document. The terms we currently use, "thing"/"other resource"
and "web document" are appropriate, sufficiently well-explained and correct.
The terminology has support from key TAG members, including Tim Berners Lee. I don't
think that anything needs to be changed with regard to these terms.
@@ Reviewers asked for example rules of thumb how to distinguish between document identifiers
and concept identifiers (information and non-information resources). Write some
wget examples that do that? Leo Sauermann agrees that we did not cover the crucial point yet:
what is the definitive test to verify that a URI identifies a non-information resource?
Range-14 says: "If an "http" resource responds to a GET request with a 303 (See
Other) response, then the resource identified by that URI could be any
resource;" Or is this such a problem at all? At the end the RDF:type indicates the nature of a resource.
If we find a script example, I would put that into the 4.6. implementation section.
@@ Danny Ayers: style - Abstract and much of the content uses 1st person
plural "we..." - is that ok? Leo Sauermann: Its typical for scientists (the authors) to use this wording, and acceptable outside scientific publications.
@@ Danny Ayers: style - Web/web, web site/website - consistency needed
@@ Danny Ayers: Status will probably need editing for W3C-conformance
@@ Danny Ayers: "follow-your-nose" might be a useful phrase to include somewhere