This document describes best practice recipes for publishing an RDFS or
OWL vocabulary or ontology on the Web. The features of each recipe are clearly
described, so that vocabulary or ontology creators may choose the recipe best
suited to the needs of their particular situations. Each recipe contains
an example configuration for use with an Apache HTTP server, although the
principles involved may be adapted to other environments. The recipes are all
designed to be consistent with the architecture of the Web as currently
specified.
Status of this Document
This section describes the status of this document at the time of its
publication. Other documents may supersede this document. A list of current
W3C publications and the latest revision of this technical report can be
found in the W3C
technical reports index at http://www.w3.org/TR/.
This document was prepared by the Vocabulary Management Task
Force of the Semantic
Web Best Practices and Deployment Working Group (SWBPD). This
work is part of the W3C Semantic Web Activity.
This document is a W3C First Public Working Draft published to solicit comments
from interested parties. All comments are welcome and may be sent to
public-swbp-wg@w3.org;
please include the text "comment" in the
subject line. All messages received at this address are viewable in a
public archive.
After reviewing comments and further feedback, the Working Group
may publish new versions of this document or may advance the
document to Working Group Note.
This document was produced by a group operating under the 5 February 2004 W3C Patent Policy. This document is informative only and therefore has no associated W3C Patent Policy licensing obligations. W3C has a public list of any patent disclosures made in connection with the deliverables of the SWBPD Working Group; that page also includes instructions for disclosing a patent.
Publication as a Working Draft does not imply endorsement by the W3C Membership. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to cite this document as other than work in progress.
Table of Contents
Introduction
This document is intended for the creators and maintainers
of RDFS and OWL vocabularies or ontologies. (In this document,
vocabulary and ontology are used
interchangeably.) It provides step-by-step instructions
for publishing
vocabularies on the Web, giving example configurations designed to cover the
most common cases. For more information about RDFS and OWL see [RDFS, RDFPrimer, OWLGuide, OWLFeatures].
This document is presented as a 'cookbook' of 'recipes'. Each recipe takes
the reader through the steps needed to publish a vocabulary on a Web server and
to configure the Web server to support Semantic
Web applications. The section choosing a recipe provides guidance on which recipe is
most appropriate for your situation and requirements. Once you have chosen a
recipe, follow the steps given, adapting the examples for your particular
vocabulary.
All of the recipes give example configurations for the
Apache HTTP server [APACHE20],
though the principles may of course be adapted to other
environments. For those not already familiar with Apache
configuration, the section on Apache
configuration provides a short introduction to the
Apache configuration mechanisms used in the examples and
basic information on troubleshooting.
This document is primarily intended for creators and maintainers of
existing vocabularies who are looking for guidance on how their vocabularies
should best be published on the Web. It is not intended to
provide detailed and exhaustive guidance on choosing an appropriate URI
namespace for naming a new vocabulary and its constituent terms. However,
some basic technical information about URI namespaces, including
some considerations relevant to choosing a URI namespace for a
vocabulary, is given in the section on URI
namespaces.
The recipes have all been designed to be consistent
with the architectural principles of the World Wide Web as
currently specified in the document "Architecture of the
World Wide Web" [AWWW04]. In
order to verify that they are in fact so, a set of minimum requirements
is described at the end of this document. These minimum
requirements are intended to articulate the fundamental
requirements of Semantic Web applications. All of the
recipes when correctly implemented should satisfy the minimum
requirements. A set of extended
requirements is also given. The extended requirements are
intended to articulate further practical needs of Semantic
Web application developers, such as providing documentation
about a vocabulary on Web pages in HTML. Recipes 3, 4, 5 and
6, when correctly implemented, should satisfy the extended
requirements.
In order to satisfy the extended requirements, the recipes 3, 4, 5, and 6
configure a server to perform content
negotiation. A brief explanation of this process is given in the section
on content negotiation, along with a description
of some options for coping with variability in deployed client behavior.
Appendix A describes how to adapt
the six recipes given in the main body of the document
for the special case of vocabularies identified using
"persistent URLs", or PURLs, which are resolved using
PURL services such as http://purl.org/ [PURL].
For brevity, the rationale behind each of the recipes is not described
in this document. Readers wishing to go deeper should consult
URI/Resource
Relationships in [AWWW04], fragment
identifiers in HTTP URIs [RFC3986] [RFC2616], and the W3C Technical Architecture Group's
resolution
on the range of HTTP dereferencing (aka "httpRange-14").
Apache configuration
An Apache HTTP server [APACHE20] is configured
by directives written either inside the main Apache configuration
files (usually 'httpd.conf' etc.) or inside per-directory configuration files
(usually '.htaccess'). The recipes given here assume that you do not have
access to the main Apache configuration files and that you therefore have to
use per-directory '.htaccess' configuration. In order to support this use of
per-directory configuration files, the server must be configured to allow
certain overrides for the directories you are using. The required
overrides are:
AllowOverride FileInfo Options
@@TODO verify minimal required overrides
If you are having problems getting the recipes to work, it may be because
the required override directives are not specified in the main Apache
configuration files. If you are unsure about this, contact your server
administrator.
If you do have write access to the main Apache configuration files, you
might consider writing the configuration directives directly there, as
using per-directory configuration can negatively affect server
performance, see [APACHE20].
The appropriate content type for serving RDF/XML content is
'application/rdf+xml'. An Apache server can be configured to recognize files
with the '.rdf' extension and serve them with the appropriate content type,
by adding the following directive to the main configuration file:
AddType application/rdf+xml .rdf
If you do not have write access to the main Apache configuration file, you
can also include this directive in a per-directory configuration file, as
shown in the following examples.
The configurations given here have been tested on an Apache HTTP
server version 2.0.46 only.
URI namespaces
The URI that identifies your vocabulary is referred to here as the vocabulary URI
(or ontology URI as vocabulary and
ontology are used here interchangeably). For example, the following URI
identifies the SKOS Core Vocabulary:
http://www.w3.org/2004/02/skos/core
... and the following URI identifies the FOAF ontology:
http://xmlns.com/foaf/0.1/
Vocabularies that use a 'hash namespace'
SKOS Core [SKOS] is an example of a vocabulary
that uses a hash namespace. This is an informal expression which refers to
how the URIs for the classes and properties in the
vocabulary are constructed. In this case, the URIs for the classes and
properties are constructed by appending first a hash character ('#') and then
a 'local name' to the vocabulary URI. The 'local name' is a string of
characters that uniquely identifies that class or property within the scope
of the vocabulary, also known as a 'fragment identifier' [AWWW04] (the local name must be a legal [XML-NS] token NCName).
For example, the following URIs identify a class and a property from the
SKOS Core vocabulary:
http://www.w3.org/2004/02/skos/core#Concept
http://www.w3.org/2004/02/skos/core#prefLabel
Vocabularies that use a 'slash namespace'
FOAF [FOAF] is an example of a vocabulary that
uses a slash namespace. Again, this is an informal expression which refers to
the way in which the URIs for the classes and properties defined by the
vocabulary are constructed. In this case, the vocabulary URI ends with a
forward slash character ('/'), and the URIs of classes and properties are
constructed by appending the 'local name' of the class or property directly
to the vocabulary URI. Again, the 'local name' is a string of characters that
uniquely identifies that class or property within the scope of the
vocabulary, and must be a legal [XML-NS] token NCName.
For example, the following URIs identify a class and a property from the
FOAF vocabulary:
http://xmlns.com/foaf/0.1/Person
http://xmlns.com/foaf/0.1/maker
Note that a vocabulary whose URI ends with a forward slash character
doesn't necessarily use a slash namespace. It could use a hash
namespace, for example the vocabulary
http://example.com/myvocabulary/ could define classes
http://example.com/myvocabulary/#Foo and
http://example.com/myvocabulary/#Bar.
Both hash namespaces and slash
namespaces are supported within the architecture of the Web. However,
certain behaviors are required of the Web server that differ between these
two choices. Because both the requests received by the server and the
responses returned by the server are different in each case, the mechanics of
setting up an HTTP server to satisfy some or all of the requirements given below also differ, and hence
these two cases are treated separately.
Vocabularies that use other types of namespace
Readers should be aware of a third type of
vocabulary URI under discussion at the time of
writing: URIs based on a 303-redirect service
such as http://thing-described-by.org.
Though simpler to implement
than approaches described in this document, the 303-redirect
approach has not yet been implemented for stable, published RDF
vocabularies and is not used in any of the following recipes.
Appendix B describes this approach in
more detail.
Some considerations when choosing a URI namespace
This document is intended for creators and maintainers of
existing vocabularies. Proper guidance on choosing the best URI namespace for any given situation is beyond the scope
of this document. However, the recipes given here make
assumptions and involve trade-offs with respect to
functionality, so some considerations relevant to
choosing a URI namespace are described in this section. If you have already chosen a
URI namespace, skip to the section choosing a
recipe.
The URI namespace you choose for your vocabulary should be a Web address
(a URI) to which you have write access. Others who use your vocabulary will
expect to be able to dereference both the vocabulary URI itself as well as
the URIs of properties and classes defined by your vocabulary. The choice of
URI namespace is a fundamental decision you make early in the design of your
vocabulary.
While RDF permits a namespace name to start with any valid URI scheme,
best practice for the Semantic Web is to use a URI scheme that can be
resolved by any client without requiring the use of additional plug-ins or
client setup configuration. The http
URI scheme is the best known of these and is recognized by all Web clients.
This document focuses exclusively on vocabularies whose namespace name begins
with http:.
Best practice dictates that all RDF vocabularies use either a hash namespace or a slash namespace
(see above). Which you choose depends in part on how big you expect your
vocabulary to become, how often you expect to add new terms (i.e., properties
or classes), and how you expect users to access
information about individual terms in your vocabulary.
For small vocabularies, it may be most convenient to serve the entire
vocabulary in a single Web access. Such a
vocabulary would typically use a hash namespace, and a
Web access (i.e., an HTTP GET request) for any term in the vocabulary would
return a single information
resource describing all of the terms in the vocabulary.
A vocabulary that is large, to which additions are anticipated frequently,
or that defines more data than a typical user application will want to
access at one time, should be arranged so that progressively greater detail
about the terms in the vocabulary may be retrieved through multiple Web
accesses. The full description of all of the terms may be divided among many
information resources, or may be managed via a query service (e.g. [SPARQL]).
Such a vocabulary would typically use a slash namespace,
which allows for the possibility that a Web access for any term in the
vocabulary may return information principally about just that one term. (Such
a configuration is not possible for a vocabulary that uses a hash namespace, because of the mechanics of the HTTP
protocol.)
Choosing a recipe
The choice of recipe depends primarily on what types of content you wish
to provide from your vocabulary URI and the URIs of the classes and
properties defined by your vocabulary.
Simple configuration
The simplest recipes configure your server to provide only
machine-processable (RDF) content from the vocabulary URI.
If you are using a hash namespace see recipe 1 or, if using PURLs, recipe
1a.
If you are using a slash namespace see recipe 2 or, if using PURLs, recipe
2a.
Extended configuration
The extended recipes configure your server to provide both
machine-processable (RDF) and human-readable (HTML) content (see also the
section content negotiation below). These recipes
are easily extended to serve additional content types.
If you are using a hash namespace and want to provide
both RDF and HTML content, see recipe 3 or, if using
PURLs, recipe 3a.
If you are using a slash namespace and want to
provide both RDF and HTML content, where the HTML content is contained in a
single document, see recipe 4 or, if using PURLs, recipe 4a.
If you are using a slash namespace and want to
provide both RDF and HTML content, where the HTML content is served as
individual hyperlinked documents for each class or property, with an overview
(e.g. a table of contents or an index) at the vocabulary URI, see recipe 5 or, if using PURLs, recipe
5a.
If you are using a slash namespace and want to
provide both RDF and HTML content, where the HTML content is served as
individual hyperlinked documents for each class or property, and where the RDF
is served as bounded descriptions of each class or property, see recipe 6 (@@TODO).
Content negotiation
When an HTTP client attempts to dereference a URI, it can specify which
type (or types) of content it would prefer to receive in response. It does this by
including an 'Accept:' field in the header of the request message, the value
of which gives MIME types corresponding to preferred
content types. For example, an HTTP client that prefers RDF/XML content might
include the following field in the header of each request:
Accept: application/rdf+xml
Similarly, an HTTP client that prefers HTML content, such as a Web
browser, might include something like the following field in the header of
each request:
Accept: application/xhtml+xml,text/html
It is accepted as a principle of good practice that HTTP clients SHOULD
include an 'Accept:' field in a request header, explicitly specifying those
content types that may be handled.
When the server receives a request, it can use the value(s) of the
'Accept:' field to select the most appropriate response from those available,
attempting to meet the preference of the client as closely as possible. This
process is an example of content negotiation [AWWW04].
Recipes 1 and 2 below
do not configure the server to perform any content
negotiation. RDF/XML is the only representation type available, and is
provided irrespective of the value of the 'Accept:' header sent by the
client.
Recipes 3, 4, 5 and 6 below do
configure the server to perform content negotiation based on the value of the
'Accept:' header field sent by the client.
Default behavior
Note that where the server is to be configured to perform content
negotiation, a 'default behavior' must be specified. The server must be
able to determine which response should be sent in the case where the client
does not include an 'Accept:' field in the request message header (i.e. the
client doesn't specify a preference), or where the values of the 'Accept:'
field do not match any of the available content types (i.e. the client asks
for something other than RDF/XML or HTML).
In recipes 3, 4, 5, and 6 below, RDF/XML is configured as the default
response. This is chosen to minimize the impact on deployed Semantic Web
applications that do not currently send appropriate 'Accept:' header field
values for RDF content. Note that, however, with RDF as the default response,
a 'hack' has to be included in the rewrite directives to ensure the URIs
remain 'clickable' in Internet Explorer 6, due to the peculiar 'Accept:'
header field values sent by IE6. This 'hack' consists of a rewrite condition
based on the value of the 'User-agent:' header field. Performing content
negotiation based on the value of the 'User-agent:' header field is not
generally considered good practice, @@TODO why. If you don't want to
implement this hack, then you should (1) remove the following line from all
directives whever it appears:
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
... and (2) remove the '[OR]' from the end of the preceding rewrite
condition. Additionally, if you also want to retain 'clickable' URIs in IE6,
you must (3) set HTML as the default response (see comments in examples for
instructions on how to do this). Bear in mind that if HTML is configured as
the default response, some existing Semantic Web applications expecting to
receive RDF content will receive HTML content instead, and will break.
[For the sake of the developers and maintainers of Semantic Web
applications that expect to process RDF content, and that do not currently
provide an 'Accept:' header field in HTTP requests, a suitable value of the
'Accept:' field is as follows:]
Accept: application/rdf+xml,application/xml;q=0.5
Recipe 1. Minimal configuration for a 'hash namespace'
Jump straight to: Example configuration | Testing the configuration
This recipe gives an example of the simplest possible
configuration for a vocabulary that uses a hash
namespace. The recipe configures the server to provide machine-processable
(RDF) content from the vocabulary URI, thereby satisfying the minimum requirements. This is illustrated by
the following diagram:
Dereference the vocabulary URI

(Serve the RDF description of the vocabulary, encoded as RDF/XML.)
Example Configuration
For vocabulary ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example1
... defining classes ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example1#ClassA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example1#ClassB
... and properties ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example1#propA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example1#propB
Step 1
Create a file called example1.rdf that
contains a complete RDF/XML serialization of the
vocabulary. I.e. all resources defined by the
vocabulary are described in this file.
Step 2
Copy the example1.rdf file to the /apachedocumentroot/VM/http-examples/ directory on
the server.
Step 3
Add the following directives to the .htaccess file in the /apachedocumentroot/VM/http-examples/directory on
the server:
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
# Rewrite engine setup
RewriteEngine On
RewriteBase /VM/http-examples
# Rewrite rule to serve RDF/XML content from the vocabulary URI
RewriteRule ^example1$ example1.rdf
(N.B. If a .htaccess file does not exist,
create one.)
Testing the Configuration
If this configuration is working, it should support the following
interactions:
Dereference the vocabulary URI
Test message (substitute correct path and host for your vocabulary
URI):
GET /VM/http-examples/example1 HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Response header should contain the following fields:
HTTP/1.x 200 OK
Content-Type: application/rdf+xml
Recipe 2. Minimal configuration for a 'slash namespace'
Jump straight to: Example configuration | Testing the configuration
This recipe gives an example of the simplest possible
configuration for a vocabulary that uses a slash
namespace. The recipe configures the server to provide machine-processable
(RDF) content from the vocabulary URI, and to redirect the client to the
vocabulary URI from class and property URIs, thereby satisfying the minimum requirements. This is illustrated by
the following diagrams:
Dereference the vocabulary URI
(Serve the RDF description of the vocabulary, encoded as RDF/XML.)
Dereference the URI of a class or property
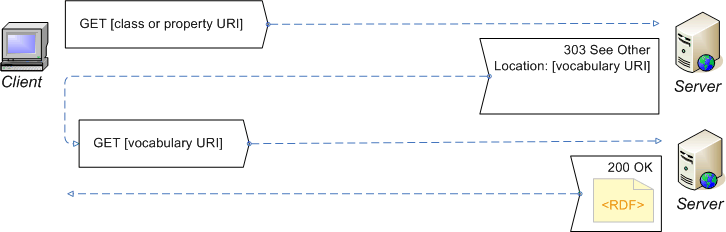
(Redirect the client to the vocabulary URI.)
Example Configuration
For vocabulary ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example2/
... defining classes ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example2/ClassA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example2/ClassB
... and properties ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example2/propA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example2/propB
Step 1
Create a file called example2.rdf that
contains a complete RDF/XML serialization of the
vocabulary. I.e. all resources defined by the
vocabulary are described in this file.
Step 2
Copy the example2.rdf file to the /apachedocumentroot/VM/http-examples/ directory on
the server.
Step 3
Add the following directives to the .htaccess file in the /apachedocumentroot/VM/http-examples/directory on
the server:
# Turn off MultiViews
Options -MultiViews
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
# Rewrite engine setup
RewriteEngine On
RewriteBase /VM/http-examples
# Rewrite rule to redirect 303 from any class or prop URI
RewriteRule ^example2/.+ example2/ [R=303]
# Rewrite rule to serve RDF/XML content from the vocabulary URI
RewriteRule ^example2/$ example2.rdf
(N.B. If a .htaccess file does not exist,
create one.)
The directory option 'MultiViews' must be disabled for this configuration
to work, and a directory called /apachedocumentroot/VM/http-example/example2/ must
not actually exist on the server's file system.
Testing the Configuration
If this configuration is working, it should support the following
interactions:
Dereference the vocabulary URI
Test message (substitute correct path and host for your vocabulary URI):
GET /VM/http-examples/example2/ HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Response header should contain the following fields:
HTTP/1.x 200 OK
Content-Type: application/rdf+xml
Dereference the URI of a class or property
Test message (substitute correct path and host for your class or property
URI):
GET /VM/http-examples/example2/ClassA HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Response header should contain the following fields, with your vocabulary
URI as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example2/
Recipe 3. Extended configuration for a 'hash namespace'
Jump straight to: Example configuration | Testing the configuration | Notes
This recipe gives an example of an extended configuration
for a vocabulary with a hash namespace. The recipe
configures the server to provide either human-readable (HTML) or
machine-processable (RDF) content from the vocabulary URI, depending on what is
requested, thereby satisfying the extended
requirements. This is illustrated by the following diagrams:
Dereference the vocabulary URI, requesting HTML content
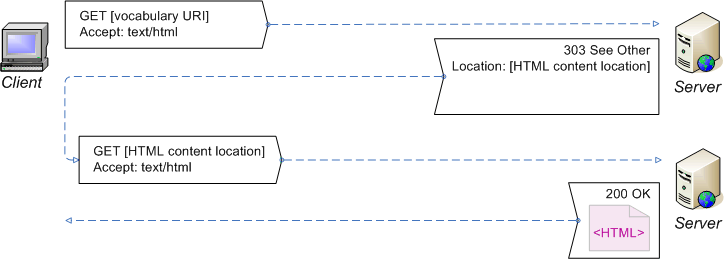
(Redirect the client to current HTML documentation for the vocabulary.)
Dereference the vocabulary URI, requesting RDF content
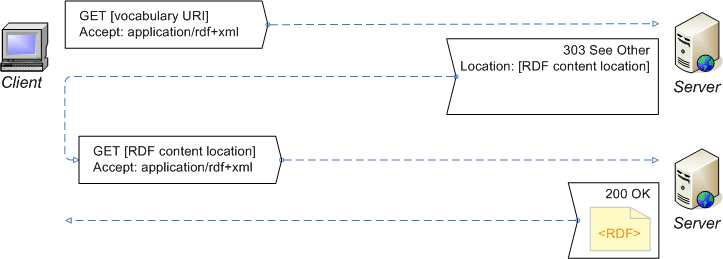
(Redirect the client to the current RDF description of the vocabulary.)
Example Configuration
For vocabulary ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example3
... defining classes ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example3#ClassA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example3#ClassB
... and properties ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example3#propA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example3#propB
Step 1
Create a file called 2005-10-31.rdf that
contains a complete RDF/XML serialization of the
vocabulary, as at 2005-10-31 (or whatever the current date is). I.e.
all resources defined by the vocabulary are
described in this file, and this file represents a 'snapshot' or 'version' of
the vocabulary.
Step 2
Create a file called 2005-10-31.html that
contains HTML content documentation about all classes and properties defined
by the vocabulary as at 2005-10-31 (or whatever the current date is). This
document may include sections for each of the classes/properties documented,
each section being headed by an HTML anchor whose name is identical to the
fragment identifier of the documented class or property.
Step 3
Copy 2005-10-31.rdf and 2005-10-31.html to the directory /apachedocumentroot/VM/http-examples/example3-content/
on the server.
Step 4
Add the following directives to the .htaccess file in the /apachedocumentroot/VM/http-examples/ directory:
# Turn off MultiViews
Options -MultiViews
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
# Rewrite engine setup
RewriteEngine On
RewriteBase /VM/http-examples
# Rewrite rule to serve HTML content from the vocabulary URI if requested
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^example3$ example3-content/2005-10-31.html [R=303]
# Rewrite rule to serve RDF/XML content from the vocabulary URI if requested
RewriteCond %{HTTP_ACCEPT} application/rdf\+xml
RewriteRule ^example3$ example3-content/2005-10-31.rdf [R=303]
# Choose the default response
# ---------------------------
# Rewrite rule to serve the RDF/XML content from the vocabulary URI by default
RewriteRule ^example3$ example3-content/2005-10-31.rdf [R=303]
# Rewrite rule to serve HTML content from the vocabulary URI by default (disabled)
# (To enable this option, uncomment the rewrite rule below, and comment
# out the rewrite rule directly above)
# RewriteRule ^example3$ example3-content/2005-10-31.html [R=303]
(N.B. If a .htaccess file does not exist,
create one.)
Testing the Configuration
If this configuration is working, it should support the following
interactions:
Dereference the vocabulary URI, requesting HTML content
Test message (substitute correct path and host for your vocabulary
URI):
GET /VM/http-examples/example3 HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Accept: text/html
Response header should contain the following fields, with your HTML
content location as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example3-content/2005-10-31.html
Dereference the vocabulary URI, requesting RDF content
Test message (substitute correct path and host for your vocabulary
URI):
GET /VM/http-examples/example3 HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Accept: application/rdf+xml
Response header should contain the following fields, with your current RDF
content location as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example3-content/2005-10-31.rdf
Dereference the vocabulary URI, default case
Test message (substitute correct path and host for your vocabulary
URI):
GET /VM/http-examples/example3 HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Response header should contain the following fields, with your current RDF
content location as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example3-content/2005-10-31.rdf
Notes
This example uses the modification date of the vocabulary version to
create file names. It would also be possible to use version numbers (e.g.
'1.01') instead of dates for this purpose, or indeed any convention that
makes it possible to differentiate between vocabulary versions, and helps to
keep track of version history.
See also the section on content negotiation.
Recipe 4. Extended configuration for a 'slash namespace',
using a single HTML document
Jump straight to: Example configuration | Testing the configuration | Notes
This recipe gives an example of an extended configuration
for a vocabulary with a slash namespace. The recipe
configures the server to provide either human-readable (HTML) or
machine-processable (RDF) content from the vocabulary URI, depending on what is
requested, and to redirect the client from class and property URIs to the
appropriate content locations, again depending on what is requested, thereby
satisfying the extended requirements. The
HTML documentation is served as a single file. This behavior is illustrated
by the following diagrams:
Dereference the vocabulary URI, requesting HTML content
(As per recipe 3, redirect the client to current
HTML documentation for the vocabulary.)
Dereference the vocabulary URI, requesting RDF content
(As per recipe 3, redirect the client to the
current RDF description of the vocabulary.)
Dereference the URI of a class or property, requesting HTML content
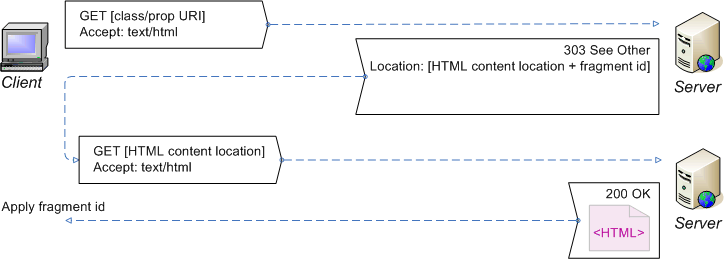
(Redirect the client to the fragment of current HTML documentation for the
vocabulary relevant to the class or property.)
Dereference the URI of a class or property, requesting RDF content
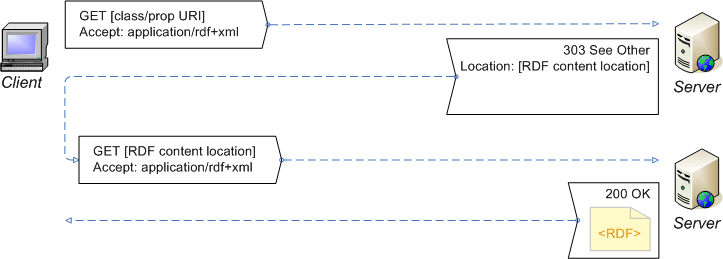
(Redirect the client to the current RDF description of the vocabulary.)
Example Configuration
For vocabulary ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example4/
... defining classes ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example4/ClassA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example4/ClassB
... and properties ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example4/propA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example4/propB
Step 1
Create a file called 2005-10-31.rdf that
contains a complete RDF/XML serialization of the
vocabulary, as at 2005-10-31 (or whatever the current date is). I.e.
all resources defined by the vocabulary are
described in this file, and this file represents a 'snapshot' or 'version' of
the vocabulary.
Step 2
Create a file called 2005-10-31.html that
contains HTML content documentation about all classes and properties defined
by the vocabulary as at 2005-10-31 (or whatever the current date is). This
document may include sections for each of the classes/properties documented,
each section being headed by an HTML anchor whose name is identical to the
fragment identifier of the documented class or property.
Step 3
Copy 2005-10-31.rdf and 2005-10-31.html to the directory /apachedocumentroot/VM/http-examples/example4-content/
on the server.
Step 4
Add the following directives to the .htaccess file in the /apachedocumentroot/VM/http-examples/ directory:
# Turn off MultiViews
Options -MultiViews
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
# Rewrite engine setup
RewriteEngine On
RewriteBase /VM/http-examples
# Rewrite rule to serve HTML content from the vocabulary URI if requested
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^example4/$ example4-content/2005-10-31.html [R=303]
# Rewrite rule to serve directed HTML content from class/prop URIs
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^example4/(.+) example4-content/2005-10-31.html#$1 [R=303,NE]
# Rewrite rule to serve RDF/XML content if requested
RewriteCond %{HTTP_ACCEPT} application/rdf\+xml
RewriteRule ^example4/ example4-content/2005-10-31.rdf [R=303]
# Choose the default response
# ---------------------------
# Rewrite rule to serve RDF/XML content by default
RewriteRule ^example4/ example4-content/2005-10-31.rdf [R=303]
# Rewrite rules to serve HTML content by default (disabled)
# (To enable this option, uncomment the two rewrite rules below,
# and comment out the rewrite rule directly above)
# RewriteRule ^example4/$ example4-content/2005-10-31.html [R=303]
# RewriteRule ^example4/(.+) example4-content/2005-10-31.html#$1 [R=303,NE]
(N.B. If a .htaccess file does not exist,
create one.)
For this configuration to work, the directory option 'MultiViews' must be
disabled, and a directory called /apachedocumentroot/VM/http-example/example4/ must
not actually exist on the server's file system.
Testing the Configuration
If this configuration is working, it should support the following
interactions:
Dereference the vocabulary URI, requesting HTML content
Test message (substitute correct path and host for your vocabulary
URI):
GET /VM/http-examples/example4/ HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Accept: text/html
Response header should contain the following fields, with your HTML
content location as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example4-content/2005-10-31.html
Dereference the vocabulary URI, requesting RDF content
Test message (substitute correct path and host for your vocabulary
URI):
GET /VM/http-examples/example4/ HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Accept: application/rdf+xml
Response header should contain the following fields, with your RDF content
location as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example4-content/2005-10-31.rdf
Dereference the vocabulary URI, default case
Test message (substitute correct path and host for your vocabulary
URI):
GET /VM/http-examples/example4/ HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Response header should contain the following fields, with your RDF content
location as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example4-content/2005-10-31.rdf
Dereference the URI of a class or property, requesting HTML content
Test message (substitute correct path and host for your class or property
URI):
GET /VM/http-examples/example4/ClassA HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Accept: text/html
Response header should contain the following fields, with your HTML
content location (plus appropriate fragment identifier) as the value of the
'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example4-content/2005-10-31.html#ClassA
Dereference the URI of a class or property, requesting RDF content
Test message (substitute correct path and host for your class or property
URI):
GET /VM/http-examples/example4/ClassA HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Accept: application/rdf+xml
Response header should contain the following fields, with your RDF content
location as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example4-content/2005-10-31.rdf
Dereference the URI of a class or property, default case
Test message (substitute correct path and host for your class or property
URI):
GET /VM/http-examples/example4/ClassA HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Response header should contain the following fields, with your RDF content
location as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example4-content/2005-10-31.rdf
Notes
As with recipe 3, this example uses the
modification date of the vocabulary version to create file names. It would
also be possible to use version numbers (e.g. '1.01') instead of dates for
this purpose, or indeed any convention that makes it possible to
differentiate between vocabulary versions, and helps to keep track of version
history.
See also the section on content negotiation.
Recipe 5. Extended configuration for a 'slash namespace',
using multiple HTML documents
Jump straight to: Example configuration | Testing the configuration | Notes
This recipe gives an example of an extended configuration
for a vocabulary with a slash namespace. The recipe
configures the server to provide both machine-processable (RDF) and
human-readable (HTML) content, depending on what is requested, with the HTML
documentation being given as multiple hyperlinked HTML documents plus an
overview document. This behavior is illustrated by the following
diagrams:
Dereference the vocabulary URI, requesting HTML content
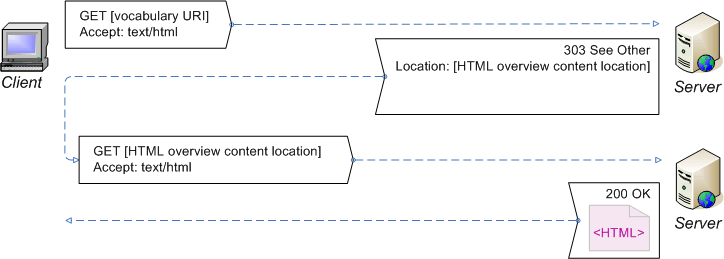
(Redirect the client to current HTML overview documentation for the
vocabulary.)
Dereference the vocabulary URI, requesting RDF content
(As per recipe 3 and recipe
4, redirect the client to the current RDF description of the
vocabulary.)
Dereference the URI of a class or property, requesting HTML content
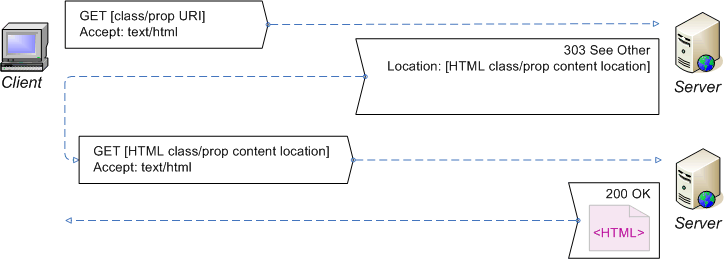
(Redirect the client to current HTML documentation for the class or
property.)
Dereference the URI of a class or property, requesting RDF content
(As per recipe 4, redirect the client to the
current RDF description of the vocabulary.)
Example Configuration
For vocabulary ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example5/
... defining classes ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example5/ClassA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example5/ClassB
... and properties ...
http://isegserv.itd.rl.ac.uk/VM/http-examples/example5/propA
http://isegserv.itd.rl.ac.uk/VM/http-examples/example5/propB
Step 1
Create a file called 2005-10-31.rdf that
contains a complete RDF/XML serialization of the
vocabulary, as at 2005-10-31 (or whatever the current date is). I.e.
all resources defined by the vocabulary are
described in this file, and this file represents a 'snapshot' or 'version' of
the vocabulary.
Step 2
Copy 2005-10-31.rdf to the directory /apachedocumentroot/VM/http-examples/example5-content/
on the server.
Step 3
Create files ClassA.html ClassB.html propA.html propB.html each of which contains HTML content
documentation relevant to the class or property with the corresponding local
name, as at 2005-10-31 (or whatever the current date is). Create a file index.html that contains HTML content documentation
about the vocabulary itself, with hyperlinks to all class or property
documentation.
Step 4
Copy ClassA.html ClassB.html propA.html propB.html and index.html to the directory /apachedocumentroot/VM/http-examples/example5-content/2005-10-31-docs/
on the server.
Step 5
Add the following directives to the .htaccess file in the /apachedocumentroot/VM/http-examples/ directory:
# Turn off MultiViews
Options -MultiViews
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
# Rewrite engine setup
RewriteEngine On
RewriteBase /VM/http-examples
# Rewrite rule to serve HTML content from the namespace URI if requested
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^example5/$ example5-content/2005-10-31-docs/index.html [R=303]
# Rewrite rule to serve HTML content from class or prop URIs if requested
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^example5/(.+) example5-content/2005-10-31-docs/$1.html [R=303]
# Rewrite rule to serve RDF content is requested
RewriteCond %{HTTP_ACCEPT} application/rdf\+xml
RewriteRule ^example5/ example5-content/2005-10-31.rdf [R=303]
# Choose the default response
# ---------------------------
# Rewrite rule to serve RDF/XML content by default
RewriteRule ^example5/ example5-content/2005-10-31.rdf [R=303]
# Rewrite rules to serve HTML content by default (disabled)
# (To enable this option, uncomment the two rewrite rules below,
# and comment out the rewrite rule directly above)
# RewriteRule ^example5/$ example5-content/2005-10-31-docs/index.html [R=303]
# RewriteRule ^example5/(.+) example5-content/2005-10-31-docs/$1.html [R=303]
(N.B. If a .htaccess file does not exist,
create one.)
Testing the Configuration
If this configuration is working, it should support the following
interactions:
Dereference the vocabulary URI, requesting HTML content
Test message (substitute correct path and host for your vocabulary
URI):
GET /VM/http-examples/example5/ HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Accept: text/html
Response header should contain the following fields, with your HTML
overview content location as the value of the 'Location' field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example5-content/2005-10-31-docs/index.html
Dereference the vocabulary URI, requesting RDF content
Same as recipe 4.
Dereference the vocabulary URI, default case
Same as recipe 4.
Dereference the URI of a class or property, requesting HTML content
Test message (substitute correct path and host for your class or property
URI):
GET /VM/http-examples/example5/ClassA HTTP/1.1
Host: isegserv.itd.rl.ac.uk
Accept: text/html
Response header should contain the following fields, with the HTML content
location for the given class or property as the value of the 'Location'
field:
HTTP/1.x 303 See Other
Location: http://isegserv.itd.rl.ac.uk/VM/http-examples/example5-content/2005-10-31-docs/ClassA.html
Dereference the URI of a class or property, requesting RDF content
Same as recipe 4.
Dereference the URI of a class or property, default case
Same as recipe 4.
Notes
See also the section on content negotiation.
As with recipe 3, this example uses the
modification date of the vocabulary version to create file names. It would
also be possible to use version numbers (e.g. '1.01') instead of dates for
this purpose, or indeed any convention that makes it possible to
differentiate between vocabulary versions, and helps to keep track of version
history.
If you have the directory options Indexes and MultiViews enabled for the
directory /apachedocumentroot/VM/http-examples/example5-content/2005-10-31-docs/
then you can replace the first two rewrite rules with one single rewrite rule:
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^example5/(.*) example5-content/2005-10-31-docs/$1 [R=303]
This configuration is particularly suited to the use of documentation
generated by the OWLDoc plugin for Protege.
Recipe 6
This recipe gives an example of an extended configuration
for a vocabulary with a slash namespace. The recipe
configures the server to provide both machine-processable (RDF) and
human-readable (HTML) content, depending on what is requested, with the HTML
documentation being given as multiple hyperlinked HTML documents plus an
overview document, and the RDF content being made available via some sort of
query service such that clients can obtain a partial RDF description of the
vocabulary as appropriate.
@@TODO this recipe is included as a placeholder, as its best practice
implementation currently requires further investigation, discussion and
testing, but is anticipated to be an import part of this document,
'completing the set' of the most commonly needed configurations.
Requirements
This section attempts to articulate the requirements and expectations of
Semantic Web applications and application developers with respect to the
HTTP behavior of vocabularies, classes, and properties denoted by
HTTP URIs (i.e., URIs from the http: URI space).
It is intended as a benchmark against which the
example configurations given in the recipes above may be verified.
Minimum Requirements
M1. The 'authoritative' RDF description of a vocabulary, class,
or property denoted by an HTTP URI can be obtained by dereferencing the URI
of that vocabulary, class, or property.
An HTTP client can obtain the 'authoritative' RDF description of a
vocabulary, class, or property by performing an HTTP GET request
against the URI of that vocabulary, class or property. The RDF
description is returned as an HTTP response whose content type is a
registered MIME type for RDF content (currently only
'application/rdf+xml').
This is the default behavior in the case that some form of
content negotiation has been implemented for these URIs. I.e. an HTTP GET
request without an 'Accept:' header field will result in a response
with content type 'application/rdf+xml', which is a serialization of a set of
RDF statements, including those statements that constitute the
'authoritative' RDF description of the denoted resource.
N.B. it is reasonable for an attempt to dereference the URI of an RDF
property or class to result in an RDF description of more than just that
property or class.
M2. The behavior of an HTTP URI denoting an RDFS/OWL
vocabulary, class or property, does not lead to inconsistency in the
interpretation of the nature of the denoted resource.
Currently the architecture of the Web allows applications to draw
inferences about the nature of a resource denoted by an HTTP URI,
based on the following:
(i) The HTTP response code obtained when dereferencing the URI (see resolution
of TAG issue 'httpRange-14'),
... and ...
(ii) Where the URI contains a fragment identifier, the content type(s) of
the available representations [AWWW04].
Given these constraints, for each HTTP URI denoting an RDFS/OWL
vocabulary, class or property, the range of possible responses to
HTTP requests against that URI will not lead applications to draw any
inconsistent conclusions.
Extended Requirements
These requirements are an extension of the minimum requirements.
E1. 'Human-readable' documentation about an RDF vocabulary,
class or property, denoted by an HTTP URI, can be obtained by dereferencing
the URI of that vocabulary, class or property.
An HTTP client such as a Web browser can obtain 'human-readable'
documentation relating to an RDFS/OWL vocabulary, class or property,
by performing an HTTP GET request against the URI of that
vocabulary, class or property, specifying 'Accept:' headers
appropriate to the desired content type in the request.
E2. Applications are able to differentiate between 'versions'
of a vocabulary.
Vocabularies change over time as properties or
classes are added or their descriptions are editorially
changed. Applications need a way to differentiate between
successive 'snapshots' of the vocabularies over time. To be
precise, what is "versioned" is the description of a
property -- i.e., a set of RDF statements about the property
-- rather than the property itself, the URI of which does
not change.
Conventions in common use for distinguishing successive
descriptions include the use of version-number strings or
date strings in filenames (e.g., 1.01.rdf
or 2005-10-31.rdf) or in pathnames (e.g.,
http://dublincore.org/2003/02/04/dces#title).
It should be noted that, at present, there are no generally
accepted conventions for using date or version-number strings
in this way.
Acknowledgments
The examples attempt to distill elements of good practice from currently
deployed Semantic Web vocabularies, especially the Dublin Core
Metadata Terms, the Friend of a Friend Ontology, and the SKOS Core
Vocabulary. All those who contributed to the development of these practices
are gratefully acknowledged.
References
This bibliography as: BibTex | BibTeXML | RDF
- APACHE20
- Apache HTTP
Server Version 2.0 Documentation, The Apache Software
Foundation.
Available at http://httpd.apache.org/docs/2.0/
- AWWW04
- Architecture
of the World Wide Web, Volume One, Ian Jacobs and
Norman Walsh, World Wide Web Consortium, W3C Recommendation, December
2004.
Available at http://www.w3.org/TR/2004/REC-webarch-20041215/
- FOAF
- FOAF Vocabulary
Specification, Dan Brickley and Libby Miller.
Available at http://xmlns.com/foaf/0.1/
- OWLFeatures
- OWL
Web Ontology Language Overview, Deborah L. McGuinness
and Frank van Harmelen, World Wide Web Consortium, W3C Recommendation,
February 2004.
Available at http://www.w3.org/TR/2004/REC-owl-features-20040210/
- OWLGuide
- OWL Web
Ontology Language Guide, Michael K. Smith, Chris Welty
and Deborah L. McGuinness, World Wide Web Consortium, W3C
Recommendation, February 2004.
Available at http://www.w3.org/TR/2004/REC-owl-guide-20040210/
- PURL
- Introduction to
Persistent Uniform Resource Locators, Kieth Shafer,
Stuart Weibel, Erik Jul and Jon Fausey, 6565 Frantz Road, Dublin, Ohio
43017-3395: OCLC Online Computer Library Center, Inc., 1996.
Available at http://purl.oclc.org/docs/inet96.html
- RDFPrimer
- RDF
Primer, Frank Manola and Eric Miller, World Wide Web
Consortium, W3C Recommendation, February 2004.
Available at http://www.w3.org/TR/2004/REC-rdf-primer-20040210/
- RDFS
- RDF
Vocabulary Description Language 1.0: RDF Schema, Dan
Brickley and R. V. Guha, World Wide Web Consortium, W3C Recommendation,
February 2004.
Available at http://www.w3.org/TR/2004/REC-rdf-schema-20040210/
- RFC2616
- Hypertext
Transfer Protocol - HTTP/1.1, R. Fielding, J. Gettys,
J. Mogul, H. Frystyk, L. Masinter, P. Leach and T. Berners-Lee,
Internet Engineering Task Force, RFC (2616), June 1999.
Available at http://www.ietf.org/rfc/rfc2616.txt
- RFC3986
- Uniform
Resource Identifier (URI): Generic Syntax, T.
Berners-Lee, R. Fielding and L. Masinter, Internet Engineering Task
Force, RFC (3986), January 2005.
Available at http://www.ietf.org/rfc/rfc3986.txt
- SKOS
- SKOS
Core Vocabulary Specification, Alistair Miles and Dan
Brickley, World Wide Web Consortium, W3C Working Draft, November
2005.
Available at
http://www.w3.org/TR/2005/WD-swbp-skos-core-spec-20051102/
- XMLNames
- Namespaces
in XML, Tim Bray, Dave Hollander and Andrew Layman,
World Wide Web Consortium, W3C Recommendation, January 1999.
Available at http://www.w3.org/TR/1999/REC-xml-names-19990114
Appendix A. Vocabularies that use PURLs for naming
PURLs ('Persistent URLs') are URIs from the http://purl.org/ URI space.
PURLs are supported by a PURL resolution service, which
allows the registered owners of a PURL domain to redirect
HTTP requests against a PURL to an arbitrary resource URL.
Registered owners of PURLs may not configure the central PURL
server other than to specify the redirect URL for each PURL.
When the central PURL server was originally developed in
the 1990s, the standard response of an HTTP to a request
against a PURL was to return a response code of 302
("temporarily moved"). Web architecture has evolved since
then, and the Technical Architecture Group (TAG) of W3C has
resolved that, for the purpose of such redirects, the response
code 303 ("see other") should be returned (see the TAG resolution
on httpRange-14.
As PURL servers use a 302 response code and there is
currently no way to configure them to use 303 response codes,
existing vocabularies with http://purl.org
slash namespaces servers do not strictly conform to the
current TAG recommendations. These cases are treated in the
following recipes.
Recipe 1a. | Recipe 2a. |
Recipe 3a. | Recipe 4a. | Recipe 5a.
Recipe 1a. Minimal configuration for a PURL 'hash
namespace'
This recipe gives an example configuration that satisfies the minimum requirements for a vocabulary with a
hash namespace within the http://purl.org/ URI space. Only
machine-processable (RDF) content is served at the namespace URI.
For vocabulary ...
http://purl.org/net/swbp-vm/example6
... defining classes ...
http://purl.org/net/swbp-vm/example6#ClassA
http://purl.org/net/swbp-vm/example6#ClassB
... and properties ...
http://purl.org/net/swbp-vm/example6#propA
http://purl.org/net/swbp-vm/example6#propB
Step 1
Create a file called example6.rdf that
contains a complete RDF/XML serialization of the
vocabulary. I.e. all resources defined by the
vocabulary are described in this file.
Step 2
Copy example6.rdf to the directory /apachedocumentroot/VM/http-examples/ on the server
from which you wish to serve the content (in this example the server is isegserv.itd.rl.ac.uk).
Step 3
Set up the following PURL:
PURL: http://purl.org/net/swbp-vm/example6
URL: http://isegserv.itd.rl.ac.uk/VM/http-examples/example6.rdf
Notes
If the server is already configured to serve files with the .rdf extension as content type application/rdf+xml then you don't have to do
anything further. If this is not the case, you will need to add the following directive:
AddType application/rdf+xml .rdf
... either to the main apache configuration files, or if you don't have
access to these, to the per-directory configuration file (.htaccess) for the directory /apachedocumentroot/VM/http-examples/ on the
server.
Recipe 2a. Minimal configuration for a PURL 'slash
namespace'
This recipe gives an example configuration that satisfies the minimum requirements for a vocabulary with a
slash namespace within the http://purl.org/ URI space. Only
machine-processable (RDF) content is served at the namespace URI.
N.B. this example does not strictly conform with the TAG resolution on
httpRange-14 because the purl.org servers use a 302 redirect code, and
not a 303.
For vocabulary ...
http://purl.org/net/swbp-vm/ex7/
... defining classes ...
http://purl.org/net/swbp-vm/ex7/ClassA
http://purl.org/net/swbp-vm/ex7/ClassB
... and properties ...
http://purl.org/net/swbp-vm/ex7/propA
http://purl.org/net/swbp-vm/ex7/propB
Step 1
Create a file called ex7.rdf that contains
a complete RDF/XML serialization of the vocabulary.
I.e. all resources defined by the vocabulary are
described in this file.
Step 2
Copy ex7.rdf to the directory /apachedocumentroot/VM/http-examples/ on the server
from which you wish to serve the content (in this example the server is isegserv.itd.rl.ac.uk).
Step 3
Set up the following Partial Redirect PURL:
PR PURL: http://purl.org/net/swbp-vm/ex7/
Root URL: http://isegserv.itd.rl.ac.uk/VM/http-examples/ex7/
Step 4
Add the following directives to the .htaccess file in the /apachedocumentroot/VM/http-examples/directory on
the server:
# Turn off MultiViews
Options -MultiViews
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
# Rewrite engine setup
RewriteEngine On
RewriteBase /VM/http-examples
# Rewrite rule to serve RDF/XML content from all partially redirected URIs
RewriteRule ^ex7/ ex7.rdf
(N.B. If a .htaccess file does not exist,
create one.)
Notes
In the above recipe the single rewrite rule is an internal
redirect. This minimises the number of external (i.e HTTP) redirects
involved in the dereference action. However, you could also implement this
rewrite rule as an external redirect, by replacing the above rule with the following:
# Rewrite rule to serve RDF/XML content from all partially redirected URIs
RewriteRule ^ex7/ ex7.rdf [R=303]
This creates an additional HTTP redirect in the dereference action,
but possibly makes it clearer to the client that attempts to dereference
vocabulary, class or property URIs all end up at the same place.
It is also possible to avoid any server configuration by creating
individual PURLs for each class and property of the vocabulary, all
referencing the same URL (rather than a Partial Redirect PURL). However, if
the content were subsequently to be moved, each PURL would need to be updated --
a cumbersome and impractical task for medium- to large-size ontologies.
Recipe 3a. Extended configuration for a PURL 'hash
namespace'
This recipe gives an example configuration that satisfies the extended requirements for a vocabulary
with a hash namespace within the http://purl.org/ URI space. Both
machine-processable (RDF) and human-readable (HTML) content is served at the
namespace URI.
For vocabulary ...
http://purl.org/net/swbp-vm/example8
... defining classes ...
http://purl.org/net/swbp-vm/example8#ClassA
http://purl.org/net/swbp-vm/example8#ClassB
... and properties ...
http://purl.org/net/swbp-vm/example8#propA
http://purl.org/net/swbp-vm/example8#propB
Step 1
Create a file called 2005-10-31.rdf that
contains a complete RDF/XML serialization of the
vocabulary, as at 2005-10-31 (or whatever the current date is). I.e.
all resources defined by the vocabulary are
described in this file, and this file represents a 'snapshot' or 'version' of
the vocabulary.
Step 2
Create a file called 2005-10-31.html that
contains HTML content documentation about all classes and properties defined
by the vocabulary as at 2005-10-31 (or whatever the current date is). This
document may include sections for each of the classes/properties documented,
each section being headed by an HTML anchor whose name is identical to the
fragment identifier of the documented class or property.
Step 3
Copy 2005-10-31.rdf and 2005-10-31.html to the directory /apachedocumentroot/VM/http-examples/example8-content/
on the server from which you wish to serve the content (in this example the
server is isegserv.itd.rl.ac.uk).
Step 4
Add the following directives to the .htaccess file in the /apachedocumentroot/VM/http-examples/ directory:
# Turn off MultiViews
Options -MultiViews
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
# Rewrite engine setup
RewriteEngine On
RewriteBase /VM/http-examples
# Rewrite rule to make sure we serve HTML content from the namespace URI if requested
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^example8$ example8-content/2005-10-31.html [R=303]
# Rewrite rule to make sure we serve the RDF/XML content from the namespace URI by default
RewriteRule ^example8$ example8-content/2005-10-31.rdf [R=303]
Step 5
Setup the following PURL:
PURL: http://purl.org/net/swbp-vm/example8
URL: http://isegserv.itd.rl.ac.uk/VM/http-examples/example8
Notes
Because we can't configure the PURL server for content negotiation, this
example configures the content server to perform negotiation after
the 302 redirect from the PURL server.
Recipe 4a. Extended configuration for a PURL 'slash
namespace', single HTML document
This recipe gives an example configuration that satisfies the extended requirements for a vocabulary with
a slash namespace within the http://purl.org/ URI space. Both
machine-processable (RDF) and human-readable (HTML) content is served at the
namespace URI. The HTML documentation is served as a single file.
N.B. this example does not strictly conform with the TAG resolution on
httpRange-14 because the purl.org servers use a 302 redirect code, and
not a 303.
For vocabulary ...
http://purl.org/net/swbp-vm/ex9/
... defining classes ...
http://purl.org/net/swbp-vm/ex9/ClassA
http://purl.org/net/swbp-vm/ex9/ClassB
... and properties ...
http://purl.org/net/swbp-vm/ex9/propA
http://purl.org/net/swbp-vm/ex9/propB
Step 1
Create a file called 2005-10-31.rdf that
contains a complete RDF/XML serialization of the
vocabulary, as at 2005-10-31 (or whatever the current date is). I.e.
all resources defined by the vocabulary are
described in this file, and this file represents a 'snapshot' or 'version' of
the vocabulary.
Step 2
Create a file called 2005-10-31.html that
contains HTML content documentation about all classes and properties defined
by the vocabulary as at 2005-10-31 (or whatever the current date is). This
document may include sections for each of the classes/properties documented,
each section being headed by an HTML anchor whose name is identical to the
fragment identifier of the documented class or property.
Step 3
Copy 2005-10-31.rdf and 2005-10-31.html to the directory /apachedocumentroot/VM/http-examples/ex9-content/
on the server from which you wish to serve the content (in this example the
server is isegserv.itd.rl.ac.uk)..
Step 4
Add the following directives to the .htaccess file in the /apachedocumentroot/VM/http-examples/ directory:
# Turn off MultiViews
Options -MultiViews
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
# Rewrite engine setup
RewriteEngine On
RewriteBase /VM/http-examples
# Rewrite rule to serve HTML content from the namespace URI if requested
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^ex9/$ ex9-content/2005-10-31.html [R=303]
# Rewrite rule to serve directed HTML content from class/prop URIs
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^ex9/(.+) ex9-content/2005-10-31.html#$1 [R=303,NE]
# Rewrite rule to serve RDF/XML content from the namespace URI by default
RewriteRule ^ex9/ ex9-content/2005-10-31.rdf [R=303]
(N.B. If a .htaccess file does not exist,
create one.)
Step 5
Set up the following Partial Redirect PURL:
PR PURL: http://purl.oclc.org/net/swbp-vm/ex9/
URL Root: http://isegserv.itd.rl.ac.uk/VM/http-examples/ex9/
Notes
This configuration would be the most appropriate for Dublin Core Metadata
Terms.
Recipe 5a. Extended configuration for a PURL 'slash
namespace', using multiple HTML documents
This recipe gives an example configuration that satisfies the extended requirements for a vocabulary with
a slash namespace within the http://purl.org/ URI space. Both
machine-processable (RDF) and human-readable (HTML) content is served at the
namespace URI with the HTML documentation being given as multiple hyperlinked
HTML documents plus an overview document.
N.B. this example does not strictly conform with the TAG resolution on
httpRange-14 because the purl.org servers use a 302 redirect code, and
not a 303.
For vocabulary ...
http://purl.org/net/swbp-vm/ex10/
... defining classes ...
http://purl.org/net/swbp-vm/ex10/ClassA
http://purl.org/net/swbp-vm/ex10/ClassB
... and properties ...
http://purl.org/net/swbp-vm/ex10/propA
http://purl.org/net/swbp-vm/ex10/propB
Step 1
Create a file called 2005-10-31.rdf that
contains a complete RDF/XML serialization of the
vocabulary, as at 2005-10-31 (or whatever the current date is). I.e.
all resources defined by the vocabulary are
described in this file, and this file represents a 'snapshot' or 'version' of
the vocabulary.
Step 2
Copy 2005-10-31.rdf to the directory /apachedocumentroot/VM/http-examples/ex10-content/
on the server from which you wish to serve the content (in this example the
server is isegserv.itd.rl.ac.uk).
Step 3
Create files ClassA.html ClassB.html propA.html propB.html each of which contains HTML content
documentation relevant to the class or property with the corresponding local
name, as at 2005-10-31 (or whatever the current date is). Create a file index.html that contains HTML content documentation
about the vocabulary itself, with hyperlinks to all class or property
documentation.
Step 4
Copy ClassA.html ClassB.html propA.html propB.html and index.html to the directory /apachedocumentroot/VM/http-examples/ex10-content/2005-10-31-docs/
on the server from which you wish to serve the content (in this example the
server is isegserv.itd.rl.ac.uk).
Step 5
Add the following directives to the .htaccess file in the /apachedocumentroot/VM/http-examples/ directory:
# Turn off MultiViews
Options -MultiViews
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
# Rewrite engine setup
RewriteEngine On
RewriteBase /VM/http-examples
# Rewrite rule to serve HTML content from the namespace URI if requested
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^ex10/$ ex10-content/2005-10-31-docs/index.html [R=303]
# Rewrite rule to serve HTML content from class or prop URIs if requested
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^ex10/(.+) ex10-content/2005-10-31-docs/$1.html [R=303]
# Rewrite rule to serve RDF/XML content from the namespace URI by default
RewriteRule ^ex10/ ex10-content/2005-10-31.rdf [R=303]
(N.B. If a .htaccess file does not exist,
create one.)
Step 6
Set up the following Partial Redirect PURLs:
PR PURL: http://purl.org/net/swbp-vm/ex10/
Root URL: http://isegserv.itd.rl.ac.uk/VM/http-examples/ex10/
Appendix B. Vocabulary URIs based on
a 303-redirect service
URIs of this type are formed by appending the URI of a
descriptive resource as a query string to the base URI of a
303-redirect service such as
http://thing-described-by.org.
The domain thing-described-by.org delegates authority for
defining the meaning of such a query URI to the domain cited
in the query string (i.e., the part following a question
mark).
In principle, then, one might coin the URI
http://thing-described-by.org?http://example.org/foo
as an identifier for the Foo vocabulary. An HTTP
GET request against the URI for the Foo vocabulary, or
against a property or class in the Foo vocabulary, would
result in a response code of 303, thus conforming to the
second of the two minimum
requirements articulated in this document for the
publication of RDF vocabularies. If, in addition,
the URI http://example.org/foo were to identify an
authoritative RDF description for the vocabulary, and the
server providing that description were to return a MIME
type properly identifying it as such, then the use of
http://thing-described-by.org?http://example.org/foo
could be said to conform to first of the minimum requirements
as well.

