Abstract
XSPARQL is a query language combining XQuery and SPARQL for transformations between RDF and XML. This document contains an overview of XSPARQL use cases within various scenarios.
Status of this document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications can be found in the W3C technical reports index at http://www.w3.org/TR/.
This document is a part of the XSPARQL Submission which comprises five documents:
- XSPARQL Language Specification
- XSPARQL: Semantics
- XSPARQL: Implementation
and Test-cases
- XSPARQL: Use cases (this document)
- Examples, Test cases and Use cases (ZIP Archive)
By publishing this document, W3C acknowledges that the Submitting Members have made a formal Submission request to W3C for discussion. Publication of this document by W3C indicates no endorsement of its content by W3C, nor that W3C has, is, or will be allocating any resources to the issues addressed by it. This document is not the product of a chartered W3C group, but is published as potential input to the W3C Process.
A W3C Team Comment has been published in conjunction with this Member Submission.
Publication of acknowledged Member Submissions at the W3C site is one of the benefits of W3C Membership. Please consult the requirements associated with Member Submissions of section 3.3 of the W3C Patent Policy. Please consult the complete list of acknowledged W3C Member Submissions.
Table of Contents
1. Introduction
This document introduces a set of use cases showing the potential of the XSPARQL language.
Especially, it focuses on how XSPARQL can be used to run tasks that usually need a complex process pipeline, such as running a query using either XQuery or SPARQL (depending on the data source) and then extending the result data or rewriting it using a particular scripting language.
2. Use cases
2.1 KML mapping: people's geolocation on a map
This use case demonstrates the capacity of XSPARQL to output OGC KML (formerly Keyhole Markup Language) format XML data.
KML is a XML-based format designed for geolocation purposes. Creating KML data using XSPARQL provides a straightforward way to build geolocation interfaces and mash-ups based on RDF data. This use case was originally motivated by the needs of the EU project inContext to locate a set of people on a map from their coordinates recorded in an RDF store.
The following query example creates a KML file regarding a set of foaf:Person instances from the FOAF ontology [FOAF] stored in a particular RDF file with their related location, using the WGS84 vocabulary [WGS84].
Figure 1: XSPARQL query: Creating KML Data from RDF
prefix foaf : <http://xmlns.com/foaf/0.1/>
prefix geo: <http://www.w3.org/2003/01/geo/wgs84_pos#>
<kml xmlns="http://www.opengis.net/kml/2.2">
{
for $person $fn $ln $long $lat
from <sample_person_geodata.rdf>
where {
$person a foaf:Person; foaf:firstName $fn;foaf:lastName $ln;
foaf:based_near [ a geo:Point; geo:long $long; geo:lat $lat ]
}
return <Placemark>
<name>{fn:concat("Location of ", $fn, " ", $ln)}</name>
<Point><coordinates>{fn:concat($long, ",", $lat, ",0")}</coordinates></Point>
</Placemark>
}
</kml>
Ideally, combined with an XSPARQL engine providing a REST interface that supports HTTP GET, one can directly pass the URL encoding of this query to an application that handles a KML input in order to get a rendering of the map. For instance, Google maps supports KML as input format. The following URI shows the encoded query to an XSPARQL server running at http://www.example.org/xsparqlrest/, which extracts geo data from an RDF file at sample_person_geodata.rdf, used as input data for Google maps:
http://maps.google.com/maps?f=q&hl=en&geocode=&q=http:%2F%2www.example.org%2Fxsparqlrest%2F%3Fquery%3Dprefix%2Bfoaf%2B%253A%2B%253Chttp%253A%252F%252Fxmlns.com%252Ffoaf%252F0.1%252F%253E%250D%250Aprefix%2Brdf%2B%253A%2B%253Chttp%253A%252F%252Fwww.w3.org%252F1999%252F02%252F22-rdf-syntax-ns%2523%253E%250D%250Aprefix%2Bgeo%253A%2B%253Chttp%253A%252F%252Fwww.w3.org%252F2003%252F01%252Fgeo%252Fwgs84_pos%2523%253E%250D%250A%250D%250A%253Ckml%2Bxmlns%253D%2522http%253A%252F%252Fwww.opengis.net%252Fkml%252F2.2%2522%253E%250D%250A%7B%250D%250Afor%2B%2524person%2B%2524fn%2B%2524ln%2B%2524long%2B%2524lat%250D%250Afrom%2B%253Csample_person_geodata.rdf%253E%250D%250Awhere%2B%7B%250D%250A%2B%2B%2524person%2Brdf%253Atype%2Bfoaf%253APerson.%250D%250A%2B%2B%2524person%2Bfoaf%253Abased_near%2B%2524gps.%250D%250A%2B%2B%2524gps%2Brdf%253Atype%2Bgeo%253APoint.%250D%250A%2B%2B%2524gps%2Bgeo%253Along%2B%2524long.%250D%250A%2B%2B%2524gps%2Bgeo%253Alat%2B%2524lat.%250D%250A%2B%2B%2524person%2Bfoaf%253AfirstName%2B%2524fn.%250D%250A%2B%2B%2524person%2Bfoaf%253AlastName%2B%2524ln.%250D%250A%7D%250D%250Areturn%2B%253CPlacemark%253E%250D%250A%2B%2B%2B%2B%2B%2B%2B%2B%2B%253Cname%253E%7Bfn%253Aconcat(%2522Location%2Bof%2B%2522%252C%2B%2524fn%252C%2B%2522%2B%2522%252C%2B%2524ln)%7D%253C%252Fname%253E%250D%250A%2B%2B%2B%2B%2B%2B%2B%2B%2B%253CPoint%253E%253Ccoordinates%253E%7Bfn%253Aconcat(%2524long%252C%2B%2522%252C%2522%252C%2B%2524lat%252C%2B%2522%252C0%2522)%7D%253C%252Fcoordinates%253E%253C%252FPoint%253E%250D%250A%2B%2B%2B%2B%2B%2B%2B%2B%253C%252FPlacemark%253E%250D%250A%7D%250D%250A%253C%252Fkml%253E&ie=UTF8&ll=50.736455,9.140625&spn=13.252978,31.113281&t=h&z=5
This URI will not work within your browser, unless you replace http://www.example.org/xsparqlrest/ with the URI of an actual running XSPARQL server.
See a working example.
For details of an existing implementation, we refer to [XSPARQLIMPLEMENTATION].
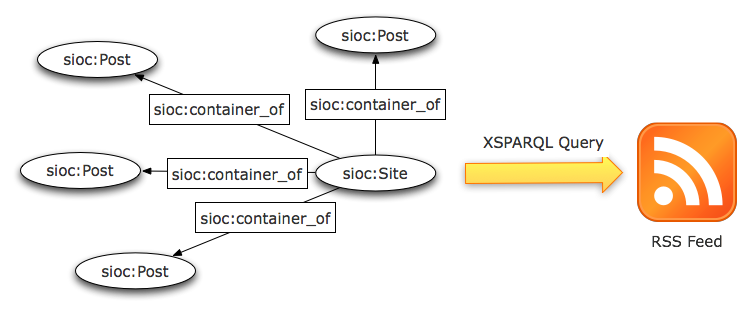
SIOC [SIOC] is an RDF vocabulary designed to describe activities of online communities such as blog posts, wiki pages, comments, etc, now used in more than 50 applications, from various Web 2.0 exporters to neuromedicine projects.
While SIOC provides a complete way to browse social data from a community, some tools may require a simple RSS feed.
The following example shows how RSS data can be created from distributed SIOC data, by using rdfs:seeAlso links to fetch related documents from a given entry point, in that case a weblog index.
declare namespace foaf = "http://xmlns.com/foaf/0.1/";
declare namespace sioc = "http://rdfs.org/sioc/ns#";
declare namespace rdfs = "http://www.w3.org/2000/01/rdf-schema#";
declare namespace dcterms = "http://purl.org/dc/terms/";
declare namespace rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#";
<rss version="2.0">
<channel>
<title>{"RSS feed for blog @ johnbreslin.org"}</title>
<link>{"http://johnbreslin.com/blog"}</link>
<description>{"RSS feed for example.org Weblog"}</description>
<generator>{"XSPARQL - xsparqler 0.1"}</generator>
{ for $blog $post $seeAlso from <http://www.johnbreslin.com/blog/index.php?sioc_type=site>
where { $blog sioc:container_of $post .
$post rdf:type sioc:Post ; rdfs:seeAlso $seeAlso .
}
return <item><link>{$post}{$seeAlso}</link>
{ for $date from $seeAlso
where { $post dcterms:created $date. }
return <date>{ $date }</date>
}
</item>
}
</channel>
</rss>
In the previous query, both sioc:container_of and rdfs:seeAlso are used to retrieve the list of related SIOC Post from the weblog homepage.
Yet, in a case where each blog post would be content-negotiated or annotated with RDFa, the sioc:container_of property will be enough to retrieve the related sioc:Post instances, thus reducing the complexity of the XSPARQL query.
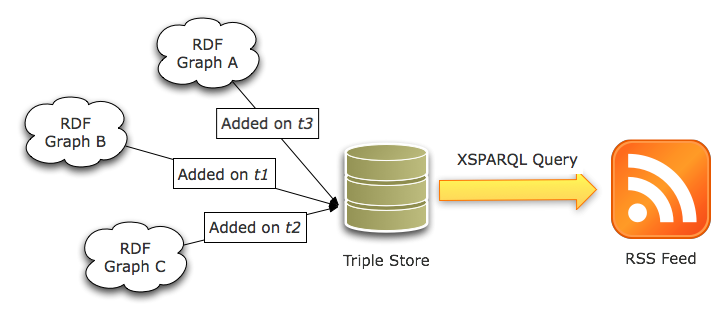
In order to build Semantic Web applications, developers generally rely on a backend system, known as a triple store, to store their RDF data.
Most of the available stores on the market supports the use of named graphs [NAMEDGRAPHS], so that each triple is contained in a particular graph, which has a given URI.
Since this URI can be used as a subject for any RDF triple, this is an efficient way to deal with information about those graphs, as provenance, retrieving date, etc, in the store itself.
Yet, there is no standard way at the moment to get an overview of the latest added / updated graph for a particular triple store.
Creating an RSS feed from a store would be the straightforward option, but cannot be easily achieved.
While using SPARQL CONSTRUCT can be used to create a RSS 1.0 feed from graphs contained in a triple store, it does not offer the ability to control the RDF/XML serialization output.
Hence, while the produced feed will be valid from a semantic point of view, it will not be readable by generic RSS aggregators, that unfortunately check the feed syntax only.
XSPARQL solves that problem by letting the user define its own RDF/XML serialization, as show by the following query that creates an RSS 2.0 feed from data contained in a triple store.
Then, any produced feed can be read through an RSS reader, so that triple store maintainers follow the activity of upcoming graphs in the storage system.
declare namespace dct = "http://purl.org/dc/terms/";
<rss version="2.0">
<channel>
<title>{"RDF Graphs @ example.org"}</title>
<link>{"http://example.org/sparql"}</link>
<description>{"RSS feed for RDF Graphs contained in example.org triple store"}</description>
<generator>{"XSPARQL - xsparqler 0.1"}</generator>
{ for $graph $date
where { graph $graph { } . $graph dct:created $date }
return <item><link>{$graph}</link><date>{$date}</date></item>
}
</channel>
</rss>
2.4 XHTML and XML document to RDF data
While some Web applications expose RDF data natively, others use different ways to structure data contained in webpages.
For instance, some providers use microformats, while other simply use XHTML templates to define a common structure for different pages of the same website.
The next example provides a way to define a set of personal relationships using the foaf:knows property from the FOAF vocabulary, thanks to a single XSPARQL query applied to an XHTML document from a microblogging platform.
This use case also shows how XSPARQL could be used to provide GRDDL [GRDDL] transformations.
Figure 6: XSPARQL query: XHTML data to RDF (FOAF)
declare namespace foaf="http://xmlns.com/foaf/0.1/";
declare default element namespace "http://www.w3.org/1999/xhtml";
let $doc := doc("http://cgi.w3.org/cgi-bin/tidy?docAddr=http%3A%2F%2Ftwitter.com%2Fterraces")
let $friends:= $doc//*[@id="friends"]/span[@class="vcard"]
for $f in $friends
let $friendsAccount := $f/*/@href
let $hp := "http://apassant.net/alex"
construct { <{$hp}> foaf:knows [ foaf:userAccount <{$friendsAccount}> ] }
While the previous example focus on creating RDF representation of a social network from an XHTML document, a similar approach can be used to convert XML data.
The example query that follows then provides RDF data (using the FOAF vocabulary and some OpenSocial RDF mappings) from an XML file described using the Portable Contact schema.
Figure 8: XSPARQL query: XML data to RDF (FOAF and OpenSocial RDF mappings)
declare namespace foaf="http://xmlns.com/foaf/0.1/";
declare namespace opensocial="http://danbri.org/2008/opensocial/_latest";
declare namespace dc="http://purl.org/dc/elements/1.1/";
let $doc := doc("http://asemantics.dyndns.org/downloads/dp_contacts.xml")
let $entries := $doc//entry
return
for $entry in $entries
let $id := $entry/id
let $givenName := $entry/name/givenName
let $familyName := $entry/name/familyName
let $gender := $entry/gender
let $nickname := $entry/nickname
let $birthday := $entry/birthday
let $drinker := $entry/drinker
let $tags := $entry/tags
let $relationshipStatus := $entry/relationshipStatus
let $emails := $entry/emails
let $phones := $entry/phoneNumbers
let $ims := $entry/ims
let $accounts := $entry/accounts
let $organizations := $entry/organizations
construct
{ _:b{data($id)} a foaf:Person;
foaf:firstname {data($givenName)};
foaf:surname {data($familyName)};
foaf:gender {data($gender)};
foaf:nick {data($nickname)};
foaf:birthday {data($birthday)};
opensocial:drinker {data($drinker)};
opensocial:relationshipStatus {data($relationshipStatus)};
opensocial:tags {data($tags)}.
{
for $email in $emails
let $address := $email/value
construct
{ _:b{data($id)} foaf:mbox {data($address)};
}
}.
{
for $phoneNumber in $phones
let $phone := $phoneNumber/value
construct
{ _:b{data($id)} foaf:phone {data($phone)};
}
}.
{
let $counter := 0
for $im in $ims
let $imAccount := $im/value
let $imType := $im/type
let $counter := $counter + 1
construct
{ _:im{data($counter)} a foaf:OnlineChatAccount;
foaf:accountName {fn:concat(data($imType),":",data($imAccount))}.
_:b{data($id)} foaf:holdsAccount _:im{data($counter)};
}
}.
{
let $counter := 0
for $account in $accounts
let $accountDomain := $account/domain
let $accountUserId := $account/userid
let $counter := $counter + 1
construct
{ _:acc{data($counter)} a foaf:OnlineAccount;
foaf:accountName {data($accountUserId)};
foaf:accountServiceHomepage {data($accountDomain)}.
_:b{data($id)} foaf:holdsAccount _:acc{data($counter)};
}
}.
{
let $counter := 0
for $organization in $organizations
let $orgName := $organization/name
let $counter := $counter + 1
construct
{ _:org{data($counter)} a foaf:Organization;
dc:title {data($orgName)}.
}
}.
}
2.5 Generating ontology specification
Understanding and using an ontology is easier if comprehensive reference documentation is available.
Almost every popular vocabulary is extensively documented, otherwise, its value as element of shared understanding would be compromised.
For large ontologies, keeping the ontology and its documentation in sync is simpler if the former is generated by an automated process that exploits the logical structure of the ontology and the content of the annotation properties.
There are some tools for this task.
Some of them are plugins for the Protégé ontology editor, such as OWLDoc and ProtegeDocgen, and thus, closely tied to the use of that editor.
Another tool in use by some popular ontologies is SpecGen, which is a Python script that uses an ontology API to programmatically create a HTML report.
XSPARQL offers new opportunities to produce the reference documentation of a self-documented ontology, i.e., an ontology that contains per-term documentation as annotation properties.
With XSPARQL, no scripting language is required, and the report can be obtained independently of the application used to edit the ontology.
Moreover, the XSPARQL-based solution is highly flexible and can be easily modified to produce different kinds of reports.
The example query that follows produces a very simple HTML report with a listing of all the classes and properties of an OWL ontology.
The annotation properties provide the name and description of each term, and the name is also used to sort the terms.
The structure of the ontology is queried to show the names of the super-classes for each class.
Figure 9: XSPARQL query: HTML documentation from ontology
declare namespace foaf = "http://xmlns.com/foaf/0.1/";
declare namespace rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#";
declare namespace rdfs = "http://www.w3.org/2000/01/rdf-schema#";
declare namespace owl = "http://www.w3.org/2002/07/owl#";
declare namespace xhtml = "http://www.w3.org/1999/xhtml";
declare default element namespace "http://www.w3.org/1999/xhtml";
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:xhtml="http://www.w3.org/1999/xhtml">
<head>
<title>{"Reference documentation"}</title>
</head>
<body>
<h1>{"Reference documentation"}</h1>
<h2>{"Classes"}</h2>
{ for $Entity $Label $Desc
from <http://rdfs.org/sioc/ns#>
where { $Entity rdf:type owl:Class .
$Entity rdfs:label $Label .
$Entity rdfs:comment $Desc }
order by $Label
return
<xhtml:div>
<h3>{"Class: "} {$Label} {" ("} {$Entity} {")"}</h3>
<p><strong>{"Description: "}</strong> {$Desc}</p>
<p><strong>{"Superclasses: "}</strong>
{ for $Super $SuperLabel
from <http://rdfs.org/sioc/ns#>
where { $Entity rdfs:subClassOf $Super .
$Super rdfs:label $SuperLabel }
order by $SuperLabel
return <span>{$SuperLabel} {", "}</span>
}
</p>
</xhtml:div>
}
<h2>{"Properties"}</h2>
{ for $Entity2 $Label2 $Desc2
from <http://rdfs.org/sioc/ns#>
where { $Entity2 rdfs:label $Label2 .
$Entity2 rdfs:comment $Desc2 .
{ { $Entity2 rdf:type owl:DatatypeProperty }
union
{ $Entity2 rdf:type owl:ObjectProperty } }
}
order by $Label2
return
<xhtml:div>
<h3>{"Property: "} {$Label2} {" ("} {$Entity2} {")"}</h3>
<p><strong>{"Description: "}</strong> {$Desc2}</p>
</xhtml:div>
}
</body>
</html>
2.6 Creating an SVG chart from RDF data
SPARQL is amazingly powerful when it comes to collecting, aggregating and querying data from the (semantic) web. However, it cannot produce nice-looking reports to present the results.
A solution to this limitation is to use a XSLT stylesheet on the outcome of the SPARQL query.
Fortunately, XSPARQL provides a more elegant and powerful solution in just one step, removing the need for an intermediate XML serialization of the query results.
Some of the most popular formats for documents and images, such as XHTML and SVG respectively, are based on XML, and therefore, can be produced by a XSPARQL query.
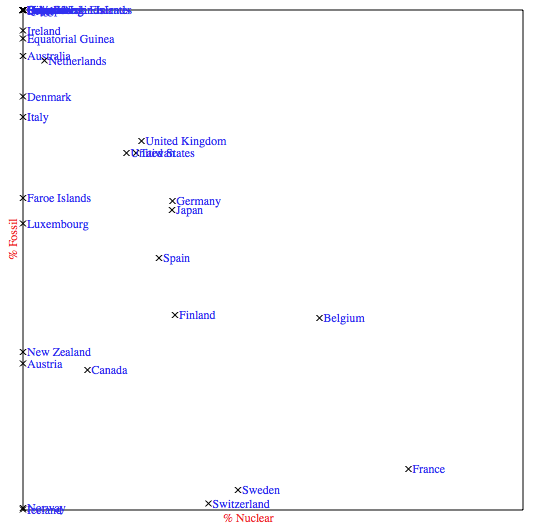
In Figure 11, we show a dispersion (X-Y) graph that depicts the source of the energy produced by rich countries.
The X axis represents the percentage of the electricity produced at nuclear power plants.
The Y axis does the same for electricity produced by burning fossil fuels.
Thus, countries that rely on greener "alternative" energies are close to the origin of coordinates (bottom-left corner).
Countries near the top of the diagram are large carbon dioxide producers due to their dependency on fossil fuels.
In order to produce this graph with XSPARQL, the data provided by the CIA Factbook is used.
The query in Figure 10 can be used with the public SPARQL endpoint of the Factbook RDF dataset to get a list of the richer countries of the world (countries with a Gross Domestic Product per capita larger than $25,000), and the information about their electrical power sources.
The "return" part of the query plots each country in the diagram using simple SVG drawing primitives.
Figure 10: XSPARQL query: RDF data to SVG
declare namespace factbook = "http://www4.wiwiss.fu-berlin.de/factbook/ns#";
declare namespace rdfs = "http://www.w3.org/2000/01/rdf-schema#";
declare namespace svg = "http://www.w3.org/2000/svg";
<svg xmlns="http://www.w3.org/2000/svg" version="1.0" width="560px" height="560px">
<g transform="translate(30,30)">
<rect width="500" height="500" x="0" y="0" style="fill:none;stroke-width:1px;stroke:#000000" />
{ ordered {
for $Name $RatioNuc $RatioFos
where {
$Country a factbook:Country .
$Country rdfs:label $Name .
$Country factbook:electricity_productionbysource_nuclear $RatioNuc .
$Country factbook:electricity_productionbysource_fossilfuel $RatioFos .
$Country factbook:GDP_percapita_PPP $GDP .
filter ($GDP > 25000)
}
return
<g>
<path d="M {$RatioNuc * 5 - 3} {500 - $RatioFos * 5 + 3} L {$RatioNuc * 5 + 3} {500 - $RatioFos * 5 - 3}"
style="fill:none;stroke-width:1px;stroke:#000000"/>
<path d="M {$RatioNuc * 5 - 3} {500 - $RatioFos * 5 - 3} L {$RatioNuc * 5 + 3} {500 - $RatioFos * 5 + 3}"
style="fill:none;stroke-width:1px;stroke:#000000"/>
<svg:text x="{$RatioNuc * 5 + 4}" y="{500 - $RatioFos * 5 + 4}"
style="font-size:12px;fill:#3030F0">{$Name}</svg:text>
</g>
} }
<svg:text x="200" y="{500 + 12}" style="font-size:12px;fill:#F03030">{"% Nuclear"}</svg:text>
<svg:text x="-250" y="-6" transform="matrix(0,-1,1,0,0,0)" style="font-size:12px;fill:#F03030">{"% Fossil"}</svg:text>
</g>
</svg>
Browse this example in SVG (only with an SVG-compliant browser).
2.7 Semantic Web Services Lifting and Lowering
In Semantic Web Service applications, such as those employing SAWSDL (Semantic Annotations for WSDL and
XML Schema), there is a strong need for translations in both directions
between XML to RDF.
Web services are software components remotely accessible using XML and Web
protocols. The stack of Web services specifications is built on SOAP and WSDL. SOAP is an XML-based protocol, and
WSDL is an XML language for capturing the machine-readable descriptions of
the interfaces and communication specifics of Web services.
On top of WSDL, SAWSDL is the first standardized specification for semantic
description of Web services. Semantic Web Services (SWS) technologies aim to
automate tasks involved in the use of Web services, such as service
discovery, composition and invocation.
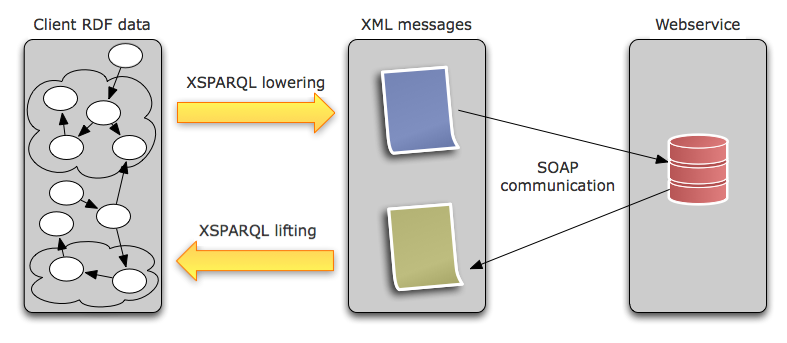
A SWS client works on the semantic level, with its data represented in RDF.
In contrast, Web services usually expect (and emit) messages in XML. In order
to enable the semantic client to communicate with actual Web services, its
semantic data must be lowered into the expected input messages, and the data
coming from the service in its output messages must be lifted back up to the
semantic level, as illustrated in next figure.
SAWSDL provides a fine-grained mechanism for "semantic adornments" of XML
Schemas. In WSDL, schemas are used to describe the input and output messages
of Web service operations, and SAWSDL can annotate messages or parts of them
with pointers to relevant semantic concepts plus links to lifting and
lowering transformations. These links are captured using the
sawsdl:liftingSchemaMapping and
sawsdl:loweringSchemaMapping attributes which reference the
transformations from within the schema components (xs:element,
xs:attribute, etc.) that describe the respective message parts.
SAWSDL's schema annotations for lifting and lowering are not only useful for
communication with web services from an RDF-based client, but for service
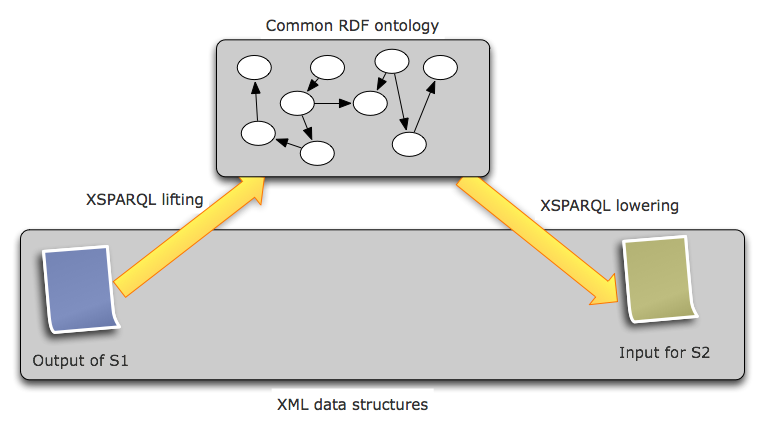
data mediation in general. For example, given two services S1 and S2, if the
output of S1 uses a different message format than S2 expects as input, but
the meaning of the data is compatible, then the data can be transformed
automatically if services S1 and S2 provide the respective lifting and
lowering schema mappings as shown in the following figure. The
transformations would presumably map from/to the same ontology, or,
alternatively, to two different ontologies that can be aligned via ontology
mediation techniques.
To illustrate XSPARQL lifting and lowering transformations, we use an example
travel (train ticket) reservation service with its message schemas shown in
Figure 14 and the respective data
ontology shown in Figure 15.
We need a lowering transformation for the booking request element so that a
semantic client can transform the data of the user goal (booking a train
trip) into the appropriate XML/SOAP message. Further, we need a
lifting transformation for the reservation response element.
For the purpose of SWS data lowering, we define <input.rdf> to be a
special graph that contains the input RDF data that the semantic client
intends to send to the service. When a semantic client performs lowering, it
calls the XSPARQL engine and makes sure that the relevant data is available
as <input.rdf>. This special graph should also be available when doing
lifting on the response message that comes from the service, so that the
lifting transformation can correlate the incoming data with the appropriate
knowledge of the client. Both the lifting and the lowering transformations
described below use the <input.rdf> graph.
The lowering transformation, shown in Figure 16, takes parts of the
request data (starting after the function declaration in the lower half) and mostly puts it into the resulting XML
structure in a straightforward way. For the start and destination locations,
which may be a train station or a city, the function
locationLowering puts the respective place names in the
corresponding XML structure.
The lifting transformation, shown in Figure 17, is even simpler, and it
uses the input data together with the incoming message and constructs the
reservation graph in RDF.
<xs:schema targetNamespace="http://example.com/bookTicket.xsd"
xmlns="http://example.com/bookTicket.xsd"
xmlns:sawsdl="http://www.w3.org/ns/sawsdl#"
xmlns:xs="http://www.w3.org/2001/XMLSchema" >
<xs:element name="BookingRequest"
sawsdl:modelReference="http://example.org/bookTicket#ReservationRequest"
sawsdl:loweringSchemaMapping="http://example.org/BookingRequestLowering.xsp" >
<xs:complexType>
<xs:all>
<xs:element name="start" type="location"/>
<xs:element name="destination" type="location"/>
<xs:element name="dateTime" type="xs:dateTime"/>
<xs:element name="passengerCount" type="xs:short"/>
</xs:all>
</xs:complexType>
</xs:element>
<xs:complexType name="location">
<xs:all>
<xs:element name="country" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
<xs:element name="station" type="xs:string" minOccurs="0"/>
</xs:all>
</xs:complexType>
<xs:element name="Reservation"
sawsdl:modelReference="http://example.org/bookTicket#Reservation"
sawsdl:liftingSchemaMapping="http://example.org/ReservationLifting.xsp" >
<xs:all>
<xs:element name="confirmationID" type="xs:string"/>
<xs:element name="description" type="xs:string"/>
</xs:all>
</xs:element>
</xs:schema>
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xs: <http://www.w3.org/2001/XMLSchema#> .
@prefix bkrdf: <http://example.org/bookTicket#> .
bkrdf:Reservation a rdfs:Class .
bkrdf:ReservationRequest a rdfs:Class .
bkrdf:time a rdf:Property .
# domain: either a reservation request or reservation
# range: xs:dateTime
bkrdf:from a rdf:Property .
# domain: either a reservation request or reservation
# range: either city or a train station
bkrdf:to a rdf:Property .
# domain: either a reservation request or reservation
# range: either city or a train station
bkrdf:passengerCount a rdf:Property .
# domain: either a reservation request or reservation
# range: xs:short
bkrdf:requestedBy a rdf:Property ;
rdfs:domain bkrdf:Reservation ;
rdfs:range bkrdf:ReservationRequest .
bkrdf:description a rdf:Property ;
rdfs:subPropertyOf rdfs:comment .
bkrdf:confirmationID a rdf:Property .
# range: xs:string
bkrdf:TrainStation a rdfs:Class .
bkrdf:isInCity a rdf:Property ;
rdfs:domain bkrdf:TrainStation ;
rdfs:range bkrdf:City .
bkrdf:City a rdfs:Class .
bkrdf:isInCountry a rdf:Property ;
rdfs:domain bkrdf:City ;
rdfs:range bkrdf:Country .
bkrdf:Country a rdfs:Class .
bkrdf:name a rdf:Property .
# domain: train station, city, country
# range: xs:string
declare namespace bkrdf="http://example.org/bookTicket#";
declare namespace bkxml="http://example.com/bookTicket.xsd";
declare namespace tool="http://example.com/tools";
declare function tool:locationLowering ($node, $name) {
for $city $country $station from <input.rdf>
where { optional { $node a bkrdf:TrainStation ;
bkrdf:name $station ;
bkrdf:isInCity $cityNode .
$cityNode bkrdf:name $city ;
bkrdf:isInCountry $countryNode .
$countryNode bkrdf:name $country . }
optional { $node a bkrdf:City ;
bkrdf:name $city ;
bkrdf:isInCountry $countryNode .
$countryNode bkrdf:name $country . } }
return
element { $name } {
<bkrdf:location>
<bkxml:country>{$country}</bkxml:country>
<bkxml:city>{$city}</bkxml:city>
{ if ($station) then <bkxml:station>{$station}</bkxml:station> else () }
</bkrdf:location>
}
};
for $date $count $from $to from <input.rdf>
where { $req a bkrdf:ReservationRequest ;
bkrdf:time $date ;
bkrdf:from $from ;
bkrdf:to $to ;
bkrdf:passengerCount $count . }
return
<bkxml:BookingRequest>
<bkxml:dateTime>{$date}</bkxml:dateTime>
<bkxml:passengerCount>{$count}</bkxml:passengerCount>
{ tool:locationLowering($from, bkxml:start) }
{ tool:locationLowering($to, bkxml:destination) }
</bkxml:BookingRequest>
declare namespace bkrdf="http://example.org/bookTicket#";
declare namespace bkxml="http://example.com/bookTicket.xsd";
let $reservation := /bkxml:Reservation
for $req $date $count $from $to from <input.rdf>
where { $req a bkrdf:ReservationRequest ;
bkrdf:time $date ;
bkrdf:from $from ;
bkrdf:to $to ;
bkrdf:passengerCount $count . }
construct {
_:a a bkrdf:Reservation ;
bkrdf:requestedBy $req ;
bkrdf:time $date ;
bkrdf:from $from ;
bkrdf:to $to;
bkrdf:passengerCount $count ;
bkrdf:description { $reservation/description } ;
bkrdf:confirmationID { $reservation/confirmationID } .
}
{kind=link}