Our group has identified a number of features as critical and advisory recommendations. We hope these considerations inspire best practices for content creators.
Our group agreed that captioning within VR must encompass all sounds and speech so that any deaf or hard of hearing user can perceive, understand, and fully participate in the experience to the same extent as everyone else. Therefore, the captioning must include localized speech from an identified speaker (human or otherwise) and non-localized speech, i.e. “Voice of God” audio content. Captioning must include all spatial sounds including inanimate objects sounds (e.g. weapons, appliances), animate objects sounds (e.g. footsteps, animal calls), point ambience sounds (spatialized ambient sounds that are diegetic such as a river near the user), surrounding ambience sounds (diegetic non-spatialized ambient sounds such as a crowd), and music sounds (non-diegetic background music).
In 360 video, the viewer defines their own viewing area and may not be looking at the source of sound(s). It is critical in 360 space to have indicators of speaker identification and/or audio location to help equalize the experiences of all users, regardless of disabilities. One example is to provide a speaker’s identification as text ahead of each caption; users can have the option to only display the speaker identification when the source changes. In the spirit of keeping the experience similar to all users, care must also be taken to avoid caption “spoilers” such as pre-announcing the arrival of a character before they should be known. This may apply to keeping mystery around certain characters if it is appropriate in the storytelling. We noted an example where a character arrived to the film with the label “The Snitch” in the captioning long before that information was revealed to other viewers.
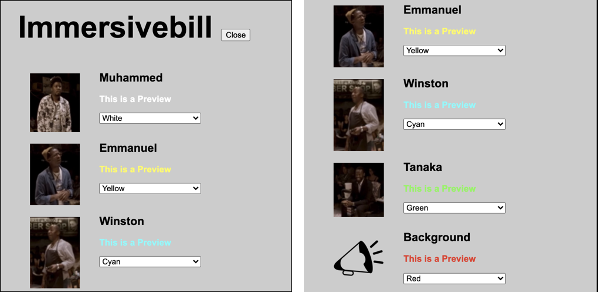
Identifying speakers is critical, but frequently using additional text in captioning affects the experience in other ways. We propose the ability for users to choose other methods for distinguishing speakers, such as options to use text labels, names, icons, and/or colors to represent each character as shown in figure 1. Note that using color representation is not enough on its own as it requires users to remember the colors and this could also affect usability for someone with color blindness.



Our prototype presents these options prior to playing the video. Our group calls this the Immersivebill feature. Inspired by Playbill’s Cast List, this feature shows pictures of the characters (speakers) before the start of the 360 video. By default, each character in the 360 video has a text color assigned to them. If a viewer wants to assign certain colors to characters or background sounds, they can customize their preferences. Users can also customize the speaker ID to represent characters by text or image. See figure 2 for a sample of the Immersivebill from our working prototype. (W. Dannels, personal communication, coined the term “immersivebill” on April 1, 2021.)
Identifying the source and location of audio besides speakers is critical to equalizing the experience for all content viewers. To assist in communicating where specific audio is coming from, one solution could be guide arrows. These helpful indicators should point towards the location of the audio, speaking character, or object. For consideration, different arrows could be used to identify different characters or sound sources, and the size and location of the arrow could be used to indicate the relative distance to the source. Content creators should consider the relative prominence of specific audio in their assistive design to ensure these visuals do not overwhelm the primary content. The key here is that the solution must provide visualization to indicate and locate sound coming from anywhere rather than just those in the user’s current field of view. Covered spatial sounds should be enabled by default with an option to disable.
Our group proposes that users have options for different captioning modes that we refer to as interactive captions (IC) and transcript view. IC, as shown in figure 3, provides a few seconds of captioned conversation that can be used as dialogue-based navigation. The user can seek backwards and forwards by caption rather than by time. Although this is not in our “critical” selections, we find that interactive captions provide an aspirational framework for truly innovative captioning.
The interactive caption feature is an intermediate between captions and full transcripts. The goal of using interactive captioning is to give the user an option to follow the conversation in a way that is less rushed because captions generally only stay on the screen for 1-2 seconds. While having full transcripts is very useful for users such as deafblind users, it is too long to display on screen for all platforms and lacks the ability to communicate spatial sound information.
Interactive captions can be enabled when a user wants to follow the conversation in more than one line of caption at a time. If a user chooses to preview 3-7 lines of captions at once, this makes it possible for each line to clearly demonstrate the unique speaker ID, speaker caption color, and the relative location of the speaker with the use of triangles pointing toward the person saying the line or other indicators. One interesting discovery was that slowing down playback makes it easier to follow captions. Currently our recommended playback speed is 75%, but a user could adjust the speed according to their needs.
A seek-by captions feature, as shown in figure 4, allows users to click on a caption to jump to the time in video or media where that specific caption occurred. Since viewers pay attention to what is said rather than time in video when that said line occurred, this feature makes it easier to find a specific part of the video. One can use the next/previous caption buttons to move between captions. Combined with interactive captions, this one-click navigation method allows users to more easily get to the section of media they wish to access. (Credit to Chris Hughes.)

2. W. Dannels (personal communication) recommended to reduce playback rate to either .50 or .75 on April 1, 2021.
In contrast, the transcript view is a scrollable view of the entire dialogue and key sounds during the entire pre-recorded media session. It is not our intention to replace transcripts. Transcripts are useful for consuming the content via other technologies like Braille displays for deafblind users and screen readers for people with low vision. The transcript should always be available separately to aid in integration with a braille display, but may also be integrated in the UI of the video. The transcript must be well-formatted with clear speaker identification and broken into reasonable-sized paragraphs. The transcript view could be modified for interactivity on its own, yet the interface must allow for easy activation of the controls and settings.
Think there needs to be a definition and explanation of headlocked and non-headlocked captions. And how is it different from "anchoring" -- next paragraph (2.8).
In terms of the visual display, our group generally preferred for the captions to persist within the user’s field of view (FOV), which allows the deaf or hard of hearing user to understand via captioning while being able to look around. However, the user needs to have the ability to customize captions and adjust them for personal needs without complex barriers to configure those choices. It is also preferable to limit the visual movement of the captions.
There is no “right” answer for how captions should be presented in immersive video experiences. Platform and experience designers should allow for maximum flexibility. In our group, some people liked having the captions headlocked, while others liked having them anchored so they knew where to look or so they could avoid physical discomfort (see section on vestibular disorders). Thus, the optimal design allowed options for the user to customize.
We experimented with a captions-anchoring feature that displayed captions next to their speaker and followed the speaker throughout the video. While adding too many moving components to a media could be overwhelming, some in our group wanted an option to “anchor” captions to the speaker rather than moving the caption with the user’s field of view. The practicality of this feature could vary depending on the type of content and the amount of motion. It’s also worth noting that most existing captioning formats do not support the type of metadata needed to include location information for captions. Still, this is an interesting opportunity to innovate existing captioning formats and add important metadata such as coordinates of characters to be able to anchor captions in immersive videos. This work could lead to other non-caption related features we haven’t even considered. (Credit to ImAc)
The user interface (UI) must allow for easy activation of each of the controls and settings, such as the ability to enable and disable both the captions and interactive captions mode. It must also provide customization for the UI including font, color, and playback speed (1.0x, 0.75x, and 0.5x). The UI for immersive captions (IC) should also have customization options for speaker identification such as through the use of text, icons, or colors.
Key recommendations also include further customization for appearance (font, color, size, background, etc.), number of lines, and length of display time (time to live - TTL), which can be set to the caption end time, a fixed time, or a fixed extension time. This can also be managed through the option to set a number of captions which can remain on the screen at one time, with the oldest only being removed once the maximum number has been exceeded. There should also be an option for a pan and scan mode, but this mode should have the option to be disabled by users who may have motion sickness.
As with any long list of options, there should be easy methods for users to set their choices. There should be logical and intuitive groupings of features that belong together so it’s easy to choose. A user experience professional could assist in these design considerations. Accessibility features should not be difficult to locate or adjust.
Captions should always comply with the guidelines for the specific display type (e.g. TV, HMD). With respect to latency, it is critical that each segment of caption starts no more than 70ms from the start of the dialogue segment. The appearance of the captions should follow the regulations of the Federal Communications Commission (FCC) which require appropriate usage of background and foreground color, text size, and positioning.
Content creators may wish to consider that reading captions when there are multiple speakers can be very challenging for caption readers because speakers can rapidly take turns in any order. This is especially true in immersive video, where the viewer has full control of their FOV but may not know where to focus their attention. The caption reader is usually focused on reading the captions and cannot anticipate who will speak next. As a result, the reader usually looks back and forth between captions and the speakers, and they become tired or distracted. Additionally, readers can feel left out of the conversation.