
Community Group meeting, Friday 2 June 2023
The W3C Music Notation Community Group met with a hybrid in-person and online meeting at the Hanns Eisler Music School in Berlin, Germany as part of the MOLA Conference 2023. This post is a transcription of the meeting, edited for length and clarity.
Introduction

DANIEL:
So welcome, everybody. Thank you very much for making the time to come today. I’m going to give you a very brief introduction to the group for anybody who is new.

DANIEL:
The W3C is the World Wide Web Consortium. There are two big structures inside the W3C for getting work done. There’s working groups, which is where all the really serious work gets done. It’s where the Apples and the Microsofts and the Googles in this world go.
And then there’s the community groups where the fun stuff happens. Anything developed by a community group would have to be taken up by a working group to be implemented by any of the major browser members, for example. But nevertheless, the community group can do valuable work on standards that can then be adopted by whoever is interested in having them.
If you’re not a member of the community group already and you would like to contribute to the project in whatever way, even if it’s just participating in discussions online, and we’ll talk a bit about how those discussions work in a minute, please do join the group.
It’s very easy to do. You simply go to our home page. And you just click Join this group. You’re asked to warrant that if you represented an organization that you’re able to act on their behalf. You sign the contributor license agreement, which I’ll talk about again in a moment. That’s all there is to it.

DANIEL:
So why did we do this work under the auspices of the W3C? It’s really all about making sure that the things that are produced by the community group can be used freely by anybody who wants to implement them.
That’s really one of the benefits of being under the auspices of the W3C, is that the contributor license agreement means that anybody who makes a contribution to the projects that W3C community group is working on do so in the knowledge they’re basically giving everybody a license to use the intellectual property that’s generated by that.
So the really nice thing about that is that all the work we do in the CG is free for everybody to use. There will never be any way that anybody can charge you for implementing anything in SMuFL or in MNX or anything like that. It’s guaranteed to be not free of copyright, but you will always have a permanent royalty-free license to implement anything that the CG produces.
This is also why it’s extremely important that people who contribute to the group are members of the group, because that is how that legal protection, that everybody’s intellectual property is licensed for use in this way.

DANIEL:
How does this CG work? So there are three co-chairs. One of them is online today. Myke is joining us from Hawaii, which is not sunny at this time because it’s the middle of the night over there. So thank you, Myke, for getting up at crazy o’clock to join us. And Adrian on my left, and myself, Daniel.
The three of us, there are three main projects that the CG works on. We’re only really going to talk about them today. We do have some other ideas for things we want to work on. There’s an instrument database project, for example, that we’ve been trying to get off the ground, but haven’t yet got a spec editor and a critical mass to get that project going.
But the three main projects are MNX, which is Adrian’s specification, MusicXML, which is Myke’s specification, and SMuFL, which is my specification.
The way that the group works is that the three co-chairs, we meet regularly. We meet every two weeks or sometimes more often. We are discussing the issues that are under active review, which are the things that we’re really thinking about and each of the standards that we’re working on at the moment.
And the output of that is we produce some lovely minutes that I write every meeting that go up on our blog and which gets sent around to the mailing list. But the real work is actually done on GitHub.
GitHub is a software development environment community that is, again, free for anybody to join. Joining the community group doesn’t automatically join you to GitHub, so you still need to go and do that. But it’s free to join GitHub, and then you can participate in all of our discussions.
And so the way that it works, as a summary is given here, so we raise a particular issue with either a problem with one of the specs or a requirement that somebody’s identified. The community discusses it. Then the spec editor will determine the priority. So the issue goes in; perhaps it’s not come from one of us in the co-chair team, but it comes from a community member because they say, in MusicXML, it’s really, really important that I should be able to do x. And maybe it’s already possible, in which case maybe there’s a documentation clarification that needs to be made, or maybe it’s not possible. Then at that point, the co-chairs get together, or sometimes they’ll make the determination on their own as to the priority of an item. If it ends up going into active review, then we work on it.
At that point, the spec editor normally – it would be nice if it wasn’t always the spec editor, but normally it is the spec editor – writes the change, the specification that is needed to meet the requirements.
We then create a thing called a pull request, which is a stupid software term, but it basically means a way for you to review the changes that we’ve made in a way that allows you to see those changes very easily.
And again, there’s the opportunity for the community to discuss, and we can revise that. The pull request can be updated with any changes that need to be made. The pull request gets merged, and that’s the end of that issue. The issue gets closed, and then you go on to the next one.
It’s a software development methodology that’s followed in the community group, but it’s a really, really good way of making sure that the work of the group is transparent because everything is done in public on GitHub or in our co-chairs meetings where I keep very detailed minutes so that even though those are just the three of us, we always record whatever it is we have.

DANIEL:
Just to give a very quick summary of our three main projects, I already mentioned them: MusicXML is the de facto standard for the digital sheet music interchange. Michael Good was the inventor and longtime maintainer of the MusicXML specification. He retired in January of this year, richly deserved retirement. So he’s still pretty busy as far as I can tell, but he’s at least nominally retired. And so Myke has taken on the stewardship of the MusicXML specification as the new spec editor. We are planning on continuing to develop MusicXML as a group. Myke will say a few words about that in a minute on a slide he hasn’t seen, so he’ll enjoy talking about that slide when it appears on the screen.
But it is a mature standard, and so the majority of our effort in that direction is going to MNX, which we’ll talk about in much more detail a bit later on.
The Standard Music Font Layout, or SMuFL, is my spec. The idea behind that is that it provides a way of describing the symbols that are used in Western music notation and providing a means for people who want to use them in applications, whether on the web, on the desktop, or wherever it might be, have a way for them to have access to the symbols, to know what they are, and to know how to use them if they’re a software developer, in terms of how to then get them into the right place on the screen.
It specifies the code points for the fonts and the guidelines for how to implement them if you’re a font designer and how to use them if you’re a software developer. And a whole bunch of applications are using SMUFL these days, including our own ones, those of us who are on the co-chair team.
And then MNX, which Adrian will talk about in lots more detail in a minute, is the idea behind that. It is the successor to MusicXML. It addresses different use cases, which we’ll talk about a bit as we go along. And we’re deep into development of that. But we are really making good strides towards a version 1 now, and we’ll talk about some of those specific.
So just to give you, because the meat of this meeting is going to focus on MNX, although there will be an opportunity later on for anybody who wants to talk about anything else to do so.
SMuFL 1.5

DANIEL:
The SMuFL 1.5 update is in progress. I’ve done some work on it so far. As I say here on the slide, the main goal of this version, because we’ve got a pretty good glyph coverage now, there’s not too many more things that are coming up, although there have been a couple of interesting proposals made just recently that I haven’t yet had a chance to really look at.
But the main focus of our next development effort is on improving the usefulness of the SMuFL metadata files for software developers and ultimately for end users. At the moment, we’ve got lots of these metadata files that describe things like ranges of glyphs or the names of glyphs.
But for example, they’re all only in English. So one of the things we want to do is to make it possible to translate those into different European languages or other languages if that would be useful. Because again, that will allow software developers who want to then show those names in their software to not have to localize them themselves. We have a Transifex project. If anybody’s interested in doing some translation work on SMuFL, it would be wonderful to have some more contributors. There was a little flurry of activity when we started that last year. There hasn’t been a great deal of activity since. So I’m saying it here in this public forum.
And there’s also, beyond the naming of things, there’s also some issues around why optional glyphs exist. So at the moment in the metadata, all you can say is that this glyph is a variant of this glyph. It’s an optional version of this one. But what it doesn’t say is why. And so that would be really useful for software applications to know.
So the idea is that we should be able to provide a kind of, probably in the end, it’ll be an enumeration of uses or types of these optional glyphs, again, which will hopefully have translated names so that then software developers can expose that data to end users.
And then the last thing on that little list there is ordering the glyph ranges. At the moment, when software programs list the ranges, they tend to either do them alphabetically, which is very sensible, or by code point, which is also very sensible. Although maybe neither of those is perfect, because although when we started out with SMuFL, we tried to put things in some kind of sensible, almost like, sort of like a semantic order. It starts with things that happen at the left-hand side of the stage, like braces. And then it moves on to class. And then it moves on to time signatures, and then accidentals, and then noteheads, and so on.
But that quickly broke down when we had to go back and add stuff in the middle. So another proposal is that we should provide a specification for how the glyph ranges could be ordered so that there’s a useful order that software developers can use.
The other big thing is to look at the fonts for text-based application. When we started SMuFL many, many years ago, 10 years ago now, one of the things that was quite popular at that time was fonts like Bach, the musicological font, which you use to put together short music examples in text-based documents.
And so when we decided that we should have not only symbolic fonts for using music notation software and related things like that, we should also have versions that you could use in a word processor. But in fact, nobody’s ever really implemented that, apart from Bravura. Even Bravura’s implementation isn’t very good.
And it has downsides in that it is not intended to just show a musical symbol in a run of text, which would actually be a more common use case that people really need much more often than they need to create in a very detailed way little musical examples using font characters, which is, for goodness sakes, stuff we were doing in the 90s. We have many better solutions for that these days than that.
So the idea is that we would deprecate that way of using the text fonts and instead focus on a set of guidelines that are about how do you make a font that contains all these musical symbols which have various registration possibilities? Where are they in the box that the character sits in? Where are they vertically? Where are they horizontally? How wide are they? How do we do that in such a way that we can then also show those symbols in a Word document, say, without it mucking up all the spacing and so on? How do you scale them? How do you position them?
So it’s basically an alternative set of registration and scaling guidelines is what we’re going to come up with there.
There are a few more glyphs that we need to add to the repertoire. As I say, there are some open issues with good suggestions for glyphs that we will take care of. And it is expected to be completed at some point.
That is the SMuFL update.
MusicXML 4.1
MYKE:
I’m Michael Cuthbert. I’m following on Michael Good’s amazing work for a very long time. And I just want to say I’m primarily learning all the XML tooling for things. So if I’ve been a little bit slow on getting things out, I have tool chains on my own system that I’m thinking of working.
But one of the differences from what we’ll hear with MNX is that MusicXML has been around for a very long time. And any changes need to make sure not to break existing ecosystems. So I’m testing out my first couple of changes in as many formats as you can.
They’re mostly Michael Good gave me some of the things that were missing in the spec or that we had already known had problems. So I’m trying to get those out.
We’re focusing on score-partwise, which is a version of MusicXML everybody has. There were crickets on the notion of deprecating the timewise format, which if you, there’s still time to save that if you’d like.
But there was also the DTD version of MusicXML has been deprecated. But enough people have said that don’t remove that, that it will continue to be updated.
Most of my work has been on trying to come up with guidelines for ambiguous cases and best practices. So not in this case that has been ambiguous for a very long time, such as some of the beaming over rests, for example. Trying to make it not changing the specifications that saying you’ve been doing forever is wrong, but trying to come up with guidelines that people who are implementing new ways of supporting MusicXML will be able to not have ambiguity there.
A lot of also what I’m doing is, I’ll tell this group, I came in as an MNX skeptic about this time last year. I was still, yeah, I’m not, MNX is really great, but will it ever become the next format? Will anything knock MusicXML off of its throne?
And now I’m an MNX convert and believer, and I really think that the project is going to be the future. So I’m shifting some of my work, which was before on the supports tag and on other things useful to make sure that MusicXML has everything that other formats like MEI are supporting, and really going forward to try to make MusicXML 4.1 a better bridge to the great things that are happening in MNX.
So that’s where I’m going to yield most of my time so that Adrian and MNX can have their time.
MNX

ADRIAN:
Hi, I’m Adrian. And the MNX project was originally started by Joe Berkovitz from Noteflight years ago. And he retired, and I came in to take over the project. The idea is to provide a next generation MusicXML successor with the thinking being that when MusicXML was originally designed, it didn’t intend for the various ways that people actually are using it these days. One key use case there is to be a native format.
There are applications that use MusicXML as their native format. And any more technical people among you will know that’s kind of crazy.
So yeah, one of the primary goals of MNX is to make a format that a developer would be very happy to use sort of ergonomically as their native format for their notation app.
Because one of the highest value things that we do in designing these formats, all three of them actually, is just figuring out the entire scope of what’s possible.
What a decent chunk of the time that we spend in our biweekly co-chairs meetings is, would a slur ever be in this one particular case? And Daniel inevitably says, yeah, yeah, I’ve seen that. And so then that forces us to think of how we design the format to accommodate that.
So speaking as somebody who’s built a notation rendering engine and product, I wish I had had even 10% of this knowledge that we’re gaining now by just having access to these people and everybody in the community pointing out what’s sort of the breadth of Common Western Music Notation.
So that’s sort of the meta goal is to scope out what actually is possible in Common Western Music Notation.
Of course, with the knowledge that you have to draw the line somewhere. But hopefully the line is broad enough that basically all mainstream apps will be able to support it.
And then once we’ve defined that scope, then we figure out how to encode that in digital formats so that notation applications can use it. So that’s the quick overview. We want to make something that’s wide ranging and is a native format. And also something that can do what MusicXML has traditionally done, which is to serve as an interchange format.
So the goal is to take some inspiration from Python programming language, which has as one of its mottos, there’s one and only one way to do it – which is not always possible with music notation, but we can do a better job.
Now, the biggest thing that’s happened since our last meeting is probably the biggest thing that’s happened in the history of the project, which is we have changed it from an XML-based format to JSON.
So some quick history about that is when I took over the projects, I assumed that it was too late that the train had left the station, that the ship had sailed, whatever metaphor you want to add.
But then we got some fresh blood. When Myke took over the MusicXML, he just went for it. He said, why isn’t MNX JSON? And I gave the explanation that, yeah, I kind of assumed that it was too late to make any changes. But he made some very good persuasive arguments, and frankly, if I were starting it from scratch, I would have picked JSON in a heartbeat because I much prefer working with it to working with XML. And over the years, as I’ve told fellow developers about MNX, a high percentage of them say, sometimes more rudely and in other cases, have you considered JSON for this?
On the top of this slide, we have the older XML version of an event, which you can think of as a beat, something that contains more than 0 to 1 notes. Could also be a rest. So it used to look like the top, and now it looks like the bottom.

ADRIAN:
So for those of you who are not so technical, you might think, what is even the point of this? Some quick bullets on why we’re doing this.
It’s easier to deal with as a developer, both in creating it and in consuming it. Now there is a fair amount of opinion here. But it’s sort of the stance that we’ve taken.
Number two is it’s kind of a clear differentiator. Myke was pretty adamant about this point. I think it’s a good one.
If MNX were XML, it’s sort of yet another XML music notation format. It would be at least the third. And it’s not yet another XML format, Y-A-X-F.
Another advantage of JSON is there’s built-in types: you get arrays and Booleans by default. In XML, you kind of have to do that on your own unless you rely on a schema. And it’s just a little bit more work.
JSON has more mind share these days. This is, again, something that is perhaps controversial. It depends on which segment of developers you’re talking about. But this is the case that we’re making.
And for an internal file format, it’s more appropriate, which is, again, a matter of opinion.
And for more of these ideas and rationale, check out GitHub issue #290, which has the full discussion.

ADRIAN:
The best way to get a sense of MNX is to go to the MNX documentation, which does exist, and look at the example documents page.
We’ve tried to take an example-first approach, where anytime we’re adding a new feature, some new notation that we want to encode, we will actually just create the document preferably with a screenshot of how that should be rapidly rendered. And then we talk about it on GitHub and say, oh, can we, maybe we should consider doing this instead.
Well, on the parts of MNX that are relatively stable, we have a list of sample documents. And you can click on each one, and you’ll see the graphically rendered notation, and you’ll see the full MNX document, so you can really get the sense of it.
And my hope is that these examples are plentiful enough over time that developers dealing with MNX will just rely on them instead of diving into documentation. Of course, documentation, the documentation itself beyond the examples will be complete. But I know speaking as a developer, I’d always rather see an example first, because that really helps me understand how things work.
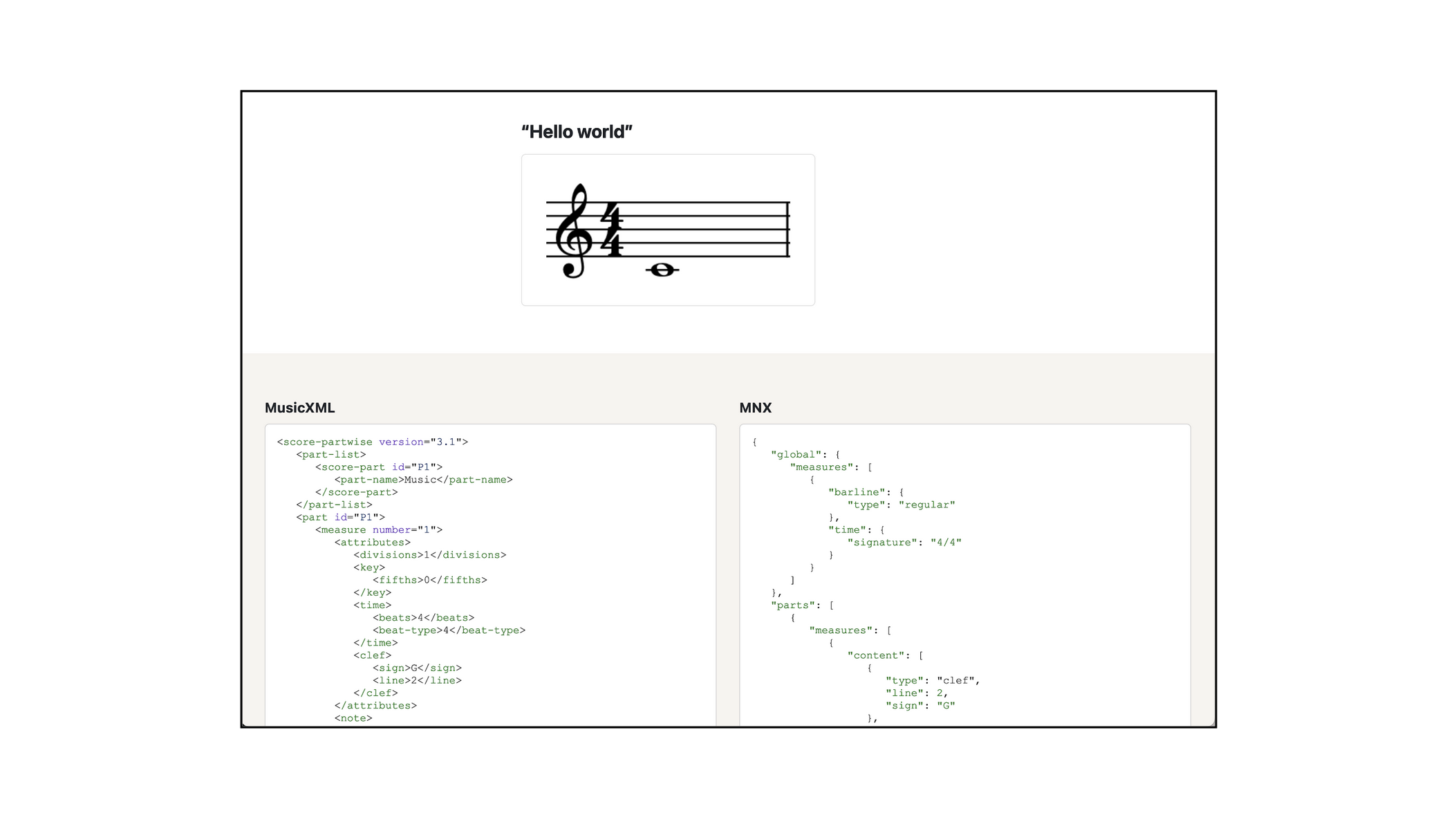
ADRIAN:
There’s also another page called MNX compared to MusicXML, which gives several examples of music that are all pretty simple with the MusicXML version on the left and the MNX on the right. And you can hopefully, especially if you’re already familiar with MusicXML, you already know the ideas.

ADRIAN:
Now, the move to JSON is pretty new. And when I did it, I had to make some calls. I didn’t want this to be in this forever limbo case, forever limbo situation where I was waiting for community input on every single thing before we actually just did it. So my approach there was I just made a bunch of calls and then documented all of them in GitHub issues posted a few days ago.
Here are the issue numbers. I encourage all of you, and we were technically inclined and interested, to contribute to these. So there’s some pretty fundamental questions that will inform how MNX works in JSON. I won’t really go into details, because it’s pretty obscure stuff. But those particular issue numbers are definitely worth checking out.
So yeah, again, the idea was I just wholesale converted all the documentation and examples to JSON in a way that kind of felt like it honored the ideas of what we’ve done in MNX so far, but also honored the usability of JSON.
But here’s some stuff that came up. So I definitely didn’t mean to do it unilaterally. It’s just a means of getting something done.
A question is asked in the room.
ADRIAN:
A disadvantage of JSON is there’s no comments. One idea that people had about comments was, well, it’s a more general idea, which is that for any object in the JSON structure in MNX, we will allow certain key or certain pattern of keys that you can use for whatever you want. And that’s what we’re doing.
So we’re not going to be using the same object for every single JSON structure. We’re going to be using a different pattern of keys that you can use for whatever you want. And I think that’s essential if people are going to use this as a native format. You can always put in your application-specific stuff. That could be a place to put comments as well.
If we don’t want to do syntactically, then you have to parse them, yeah. Probably the philosophy would be this isn’t really intended to be read by a human. It’s intended to be machine-readable stuff. So comments, those types of comments aren’t in scope.
It would be better treated as just data within there, with underscore, underscore comments, blah, blah, blah. But that is for sure a downside. It’s a trade-off that we made.

ADRIAN:
So an upcoming/current discussion that Myke has spearheaded is, do we really need microformats? In Joe’s original MNX vision, he had five-ish, maybe a few more, microformats. And there are two examples here.
One is this note value. That means, in case you, for some reason, are not well-versed in MNX microformats, this slash 4D means it’s a quarter note that’s dotted. The D means the dot. And the idea would be that you have to further parse that after you parse the MNX document.
And Myke has made the great point that it kind of made sense in an XML world because you didn’t have as rich of data types. But in JSON, if you look at that, it’s kind of like, why don’t we just go the full 100% and just turn that into actual parsed data in the document itself, hence saving music developers time?
Same thing goes for that pitch. We have the pitch D5. Why isn’t that two separate things, hence saving developers from having to parse that?

ADRIAN:
So one, this is just kind of a toy example. But you could envision, instead of that micro-syntax, having actual structured data for it.
This is just not even a formal proposal, I just made it up for the slide. But there are several nice things there. You get type checking built in because the number of dots will only ever be integers. So you don’t have to deal with Ds.
You also can get some easier validation. You don’t have to deal with regular expressions. And it also would enable things like microtonal accidentals as sort of an optional add-on that notation programs that don’t support them, they can just sort of ignore it.
And that’s a lot harder to do with the micro-syntax. So this is an open discussion. It’s on GitHub discussion number 293. That was just opened a few weeks ago. There hasn’t been a lot of chatter on there. So I’d encourage you to put your thoughts in. Even if it’s just a thumbs up, that’s very useful to know that we’re on the right track with this.

ADRIAN:
Some next milestones are to finalize those JSON questions that I listed on a few slides ago. And we want to, so we have this open source tool called the MNX converter that converts MusicXML to MNX. And that’s intended to be kind of a test case for people. It’s also intended to possibly even be integrated in applications. You can add MusicXML support for free by just running it through the MNX converter before going into your app.
And the intention is to make it two-way. So we also convert from MNX to MusicXML. It’s an open source Python application, but it’s still doing the XML version, so I need to update that to JSON.
And then the continue encoding aspects of music notation. So this is what we’ve been doing, is we’ll take a new concept like octave shifts. And we’ll say, all right, let’s figure out how octave shifts will work. And we really want to think about the crazy ways, like I was talking about earlier, the crazy ways that the data can be used. For instance, an octave shift that’s only applicable to a part; it’s not in the conductor’s score. That’s something that legitimately is not really possible with MusicXML.
So we want to design these things one by one, one notation, one aspect of notation at a time, and continue going forward.
I wish I could work on this full time. I also wish there were more people who would contribute more actively. So there’s always an open invitation for more contributions.
Q&A
Question from the room about how tuplets are encoded.
Triplets: how do you make them? There’s what you can think of as a voice in MNX, that’s called a sequence. It’s an ordered list of events, an event or a tuplet. And a tuplet is treated as its own sequence. A tuplet knows it has an outer and an inner. The outer is its rhythmic duration, and the outer scope and then the inner.
When it comes to being unambiguous, one thing that that makes me think of is different and harmonic spellings for notes between a part and a score. That’s a tricky one. MNX has a thing called layouts, which is really cool. It’s definitely something that was never possible in MusicXML. A single document can contain multiple layouts. And we have one layout may be trumpet part, one layout may be piano part. Another layout may be voice plus piano plus just this one voice of a multi-voice soprano alto thing.
You can really combine data in powerful ways. And I think it’s going to make a lot of really nice applications possible.
This is an example of how we try to minimize redundancy, because the layout is looking at the same notation data that is defined in only one place in the document. There’s only one place where you say, yeah, here’s a C4 note. And then the layouts are sort of like the, you can think of them as a graphical instantiation of the semantic music. And you can have as many layouts as you want. And they can each have their own different page breaks, stave breaks.
Question from the room about ambiguities in MusicXML could be addressed in MNX.
Well, any text is a great example in this case, right? Adrian already gave the example of five different ways of trying to find the fingering.
Well, there is a fingering element that’s the most semantic way of doing it. But then there’s also, for some application, it’s very subtle because it’s not necessarily the fault of MusicXML. It’s also the fault of the implementation of the app that’s generating MusicXML. At a higher level, it could be the limitation in how that app thinks about notation.
So fingering, in the ideal case, I think, is tied to the note that it applies to, or notes in the case of a little bracket around it. But some applications don’t have that level of sophistication. And they treat it just as text that just so happens to be very close to the note.
But the application doesn’t actually know that the fingering and the note are linked together. So that’s the kind of ambiguity.
MYKE:
I wanted to say one of the big things that MNX will be enabling because of the semantic disambiguation is a lot of accessibility features that are possible, but require a lot of applications to implement themselves in MusicXML.
And I think this was one of the things, in case anybody’s wondering how I went from a doubter to a convert, seeing that MNX will create a much more accessible format that layouts will be more easily reflowed for low vision or blind users.
Question from the room about whether Adrian has implemented MNX in SoundSlice.
ADRIAN:
So the question for Zoom is, have I tried actually implementing MNX for SoundSlice, which is the product I work on? I haven’t, although I might implement a subset of it. And the reason is we recently added a copy feature – it’s a web application, and people wanted the ability to copy and paste some notation from one web browser window to the other. So we need a way of serializing notation data in order to do that.
And I actually was thinking, well, the current way that notes are defined in MNX is kind of maybe 80% of what we need. But otherwise, the answer is no: the main implementation is that MNX converter.
And that, indeed, did surface some stuff that needed to be addressed; for example, a problem with beams, Originally, MNX, in that sequence, you could have event, event, event, to flip, which has its inner events. But then beams were, for some reason, at that same level.
And when I implemented the first bit of the MNX converter, I realized that’s mixing things in a weird way. So that resulted in moving the beam information to a separate structure that references objects by their IDs.
And the nice thing about that is that we can have different beaming just by switching that beams function.
So to your point that I completely agree with your point that actual implementation is when you find out all the problems. That’s kind of why we want to go with examples also, because they shed a horrible light on horrible situations.
Question from the room about IDs in MNX.
ADRIAN:
So the question is, are IDs in MNX implicit? No, you have to explicitly state them. It’s just a string, so it’s whatever.
Question from the room about custom data in MNX files.
ADRIAN:
So the question is, regarding custom data that you put in your MNX JSON file, are there any ideas on how that would work? In XML, we have namespaces, but how would that work in a JSON context?
The answer is that we haven’t thought about that yet. My initial five-second hot take would be, yeah, we say, we promise that our format will never create a JSON key that starts with an underscore, so that will always be an open area.
And you can always put stuff in there. And yeah, beyond that, I’m inclined to leave it at that and see what happens. But more discussion needed.
This introduces the possibility that different applications use the same custom key. I think what that tells me is that is a feature that should be in MNX proper: if more than one application is trying to encode the same thing that MNX doesn’t handle, that means we’ve got to handle it.
DANIEL:
But I think that at the same time, don’t forget that even though namespaces and so on, and processing instructions were possible in MNX, hardly anybody, and I’m using scare quotes here, but hardly anybody ever used them.
So I think that we have to, again, and it’s kind of a part of our philosophy with MNX is that we try to design for the majority case. That also goes as far as our philosophy of what we even encode.
And so although because it was never a goal of MusicXML to make it able to be a native format. So in a way, the fact that, as Adrian so rightly said earlier on, it was kind of crazy that people actually ever did that. And we want to make it decidedly non-crazy for MNX to do that with MNX.
But we also want to keep the hurdles as low as possible while not creating mayhem. But we need to think about it lots more, I think, is the answer.
ADRIAN:
I think the biggest hurdle, this is maybe a different topic, but I think it’s maybe something interesting for people to ponder.
The biggest hurdle is that MNX, if we achieve our goal of one and only one way of doing things and having that be the most semantic, proper way of encoding things, there are probably 100% of music notation programs are not thinking about the data in that way.
So what are they going to do? Like if they, for fingering, if they only, if they don’t know that a fingering is attached to a node and it’s just some text flying, do we just say, no, you can’t use MNX because you’re not proper? Obviously, we need to provide a freeform text way of encoding that.
But I think it’s similar to what happened with the Python programming language when they moved from version 2 to 3. They forced you in version 3 to deal with Unicode, to think about any time you have a string of characters, you have to understand what encoding that is. Is it UTF-8? Is it the Windows encoding?
And in previous versions of Python, it was just the Wild West. You just kind of dealt with it. But Python 3 forced the issue. And I think that there’s some parallels there with forcing developers to really think about the nature of their data and not just throw some stuff in there and hope that it works.
That’s one of my biggest worries when it comes to adoption So part of me telling you this is so that you, as application developers, can start thinking about it and preparing yourselves.
MYKE:
I think that vendor, or what we call application prefixes, will, I think will be fine. But I don’t think there’ll be too much domain squatting if the major browsers were able to do it without getting on each other’s cases.
But I also think one of the advantages about the native format approach for somebody starting off a new project, I mean, obviously, we don’t expect the Finales and Doricos and giant consumers of the world to start over and rethink what their native formats are.
But if you are coming up with a new project, or it’s a niche project, or a smaller project, and you, or music is, notation is one small part of a much bigger project, the notion that you can use as an internal format also means that it’s much easier to round trip things that you don’t understand, that your project doesn’t care about, like perhaps fingerings, or my weird, broke fingered bases, and things like that.
So that there’s a higher probability, I believe, with the JSON and the native formats for data to come into an application that does one particular thing and come out of it with that one particular thing done properly and everything else still there.
Question from the room about the implementation of MNX in commercial software.
DANIEL:
So the question from Bob was, so are the big commercial companies going to implement MNX support? And obviously, I can’t speak for anybody other than Steinberg, but we’re very interested in doing it.
I mean, I think our challenges on MusicXML are still quite bad. So we still have a bit of work to do on MusicXML to make it up to scratch with the other applications in that area.
Adrian said earlier that 100% of music notation apps are not taking the semantic approach that MNX does. And that’s probably true, but if there is one that’s getting closest to it, it’s probably Dorico. From that point of view, a lot of MNX concepts are mapped relatively cleanly into Dorico concepts, which means that in theory, it wouldn’t be so hard for us to support MNX imports and exports.
We’re highly unlikely to use it as our native format, of course. There would be no chance of that, really. But certainly, we would want to put our money where our mouth is and work on it. But actually, we still have to think about, when is it going to deliver value to the end user?
And obviously, to some point, this is, and I alluded to this earlier on when I was speaking about Michael Good, is that Michael took the bull by the horns. And he made it work by implementing it for the major platforms to start with.
And certainly, we want to, in our group, we want to do the best that we can to give MNX the kick up, the kick down the ramp that it needs to sail beautifully off over the horizon, picking up adherence as it goes.
So yeah, we will certainly look at it. But we have to do it at the right time. And at the moment, I don’t know when that will be.
Question from Zoom: what would define the commercial value of MNX?
DANIEL:
Well, I mean, it’s when people want to exchange files with it, frankly. I think that that’s really it. Obviously, if we do our job correctly, and we address the things that Adrian’s been talking about, like an ambiguity, one way and one way only to do something, that will provide enough value on its own that you would think that applications that want to achieve those things would then attach themselves to it.
And then at that point, it becomes an ecosystem. And then the value of the ecosystem is in the interoperability of those things. So I mean, obviously, when we started MNX donkeys years ago, it was because there is commercial value in MusicXML. Clearly: there’s 350 implementations of it. And a lot of people make a lot of very valuable use out of it. But it has these limitations.
So why not try to solve, improve, reduce those limitations, and then ultimately, gently move MusicXML into a different role and have MNX fulfilling at least some of those things where people are deriving commercial value from MusicXML.
Comment from Zoom about only hearing about the shift to JSON today.
DANIEL:
So Reinhold is saying that he’s only heard about JSON for the first time today. And that’s what we expect to some degree.
Obviously, if you’re following closely the work we’re doing in the group, then you’ll see us talking about it in the weekly or bi-weekly minutes. You’ll see it on GitHub. But that’s why these meetings are really important, because it gives us a chance to reach outside the people who are really engaged with the project. It’s another point where people can re-engage with the project and understand the things that we’re doing.
I think for us desktop software development people, JSON is maybe not quite so comfortable, perhaps. But it’s definitely worth talking to your developers about it, because they will definitely have an opinion and probably some experience about it by now.
MYKE:
Just to say that JSON does have schema and schema validators. So we’re not losing that part of the XML ecosystem. They’re not as well-developed as XML schemas or XSL style sheet transforms. But they are stable. And that’s probably the big change between why JSON is viable today in a way that it wasn’t eight years ago.
Community member presentation
Klaus Rettinghaus of eNote took the floor.
KLAUS:
Hi, I’m Klaus, from here in Berlin, and I work at a startup called eNote. And we are developing an app, not just another app, but in the end, it is another app for showing notation to the user.
And the end goal of the idea behind that is to have everything fully digital so that you have the possibility to choose different layouts, scale the music, and the layout is done fluently. And transpose everything and so on. And we are looking at many, many, many, many, many, many, many scores and find really strange things from all the different epochs in music history.
And so over the last two and a half years, I tried to find everything and collect everything that is not in SMuFL yet and opened a couple of issues there.
The format we are using for delivering the digital music is MEI. And because most of the music that is already out there and can be exported from whatever, Dorico or MuseScore or whatever, is in MusicXML, of course. So we are also looking what is possible in each format and also trying to push MEI forward that it is at least on par with MusicXML. It has some advantages, some disadvantages.
MYKE:
Klaus, just from Zoom, I just wanted to say thanks for bringing MEI into this discussion. My day job, at least until two days ago, was a professional musicologist. One of the few places where MEI is the dominant format over MusicXML is in musicology. So I’m always interested in, A, keep bringing musicologists into this fold or at least into a compatible fold.
I’d love to talk with you about issues that are possible or easy in MEI that are impossible or difficult in MusicXML. And that’s one of the things I’d like to make sure that we have in 4.1.
So don’t just open up things on SMuFL – please open issues on MusicXML where you see problems.
Meeting closed.