B.1 Notation
The notation defined here builds on the XPointer element() scheme. However, where element() can only identify a whole element node in an XML Infoset, the notation defined here can also identify any point or range. This notation is intended to be easy to understand and to provide a clear way to explicate the sometimes-complex ordering relationships of document locations. It also has advantageous properties such as that many useful properties of document locations can be determined merely by examining their representation in this notation, and without having to resort to the actual document or Infoset.
The initial portion of the notation is identical to
element(): a list of child numbers separated by
the slash character ("/"). Such a list is called a [Definition: child sequence]. The following XML source corresponds to the diagram below it and shows the element() scheme's child sequence number above each node:
<p>hello, <emph>big </emph>world.</p>
ROOT
|
1
|
p
----------------------------------
| | |
1/1 1/2 1/3
| | |
txt emph txt
------------- ------- -----------
h e l l o , _ | w o r l d .
1/2/1
|
txt
-------
b i g _
Figure 2: Structure diagram with child sequences for all nodes.
"ROOT" here indicates the root node, "txt" indicates text nodes, "_" indicates the space character, and "p" and "emph" indicate element nodes.
For example:
element(1) identifies the p element (the document element; note that the root node has no number).
element(1/2/1) identifies the (only) text node within the emph element, which contains the text "big ".
Points, ranges, and non-element nodes cannot be identified by the numbering mechanism. However, the DOM 2: Range[DOM2] specification (http://www.w3.org/TR/DOM-Level-2-Traversal-Range/ranges.html) defines points in terms of a containing node and an offset within it. This numbering covers all the points adjacent to nodes of all ordered node types, and all the points adjacent to characters within the text-containing node types (not only text nodes, but also comments, processing instructions, namespace and attribute nodes).
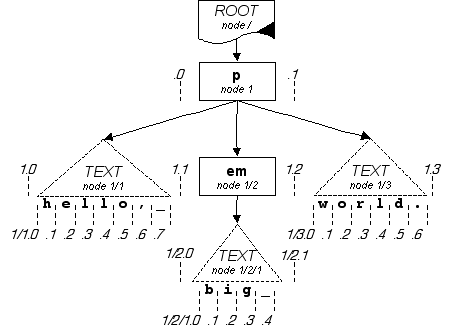
For the exact same structure shown above, those points are numbered as shown below.
ROOT
|
|
^ p ^
0 | 1
|
----------------------------------
| | |
| | |
| | |
^ txt ^ emph ^ txt ^
0 ^ 1 | 2 ^ 3
/ \ | / \
/ \ | / \
/ \ | / \
------------- txt -----------
h e l l o , _ ^ w o r l d .
^ ^ ^ ^ ^ ^ ^ ^ / \ ^ ^ ^ ^ ^ ^ ^
0 1 2 3 4 5 6 7 / \ 0 1 2 3 4 5 6
/ \
-------
b i g _
^ ^ ^ ^ ^
0 1 2 3 4
Figure 3: Structure diagram with points numbered.
For example:
the point just before the first text node is offset 0 within the p element
the point after the "r" of "world" is offset 3 within the last text node.
the point between the emph element and the following text node is offset 2 within the p element
Note:
Implementors must take care regarding a difference in how
XPath [XPath] and DOM 2: Range [DOM2] count characters. XPath and (and hence this specification) count UCS characters; DOM instead counts UTF-16 code points.
A point is always within some node, but a point cannot have children as a node can. Thus, a point can always be identified by the child sequence of the node it is in, plus the offset of the point within that node.
This specification therefore defines the [Definition: point sequence] notation to be like the element() scheme syntax except that:
the slash-separated numbers are determined not by counting only element nodes, but by counting nodes of all types
an integer is appended when representing a point, to represent the point's offset within the node specified by the preceding child sequence
the final integer is separated from the preceding ones by "." instead of "/", to distinguish its different meaning
the child sequence may be empty, meaning that the point is directly within the root node
the notation is not named "element", but "point"
For example:
the point sequence to identify the point immediately following the period within the last text node above is point(1/3.6). "1/3" identifies the last text node, while ".6" indicates the offset with that node.
the point immediately preceding the p element has point sequence point(.0).
The last component must be delimited by "." instead of "/" in order to distinguish specifying a point from specifying a node at the same level. For example, point(1/2) is a child sequence that identifies the emph element above, but point(1.2) identifies the point immediately following it. Thus the XPointer startpoint() and endpoint() functions can be easily implemented in terms of this representation.
The point preceding the root node itself is identified as ".0"; the point after the root node itself is identified as ".1". The sequence "/" refers to the root node itself and may optionally be written before the first numeric component.
For an expression range(S, E) in which S and E are both points: If S precedes E in document order the expression represents the range beginning at S and ending at E; if S is equal to E in document order, the expression represents the collapsed range (equivalent to the point) at S (and equally at E); if S follows E in documents order, the expression is in error and results are undefined.
An expression point(P) in which P is not a point, is treated as point(start-point(P)).
An expression range(S) is treated as range(S,S).
An expression range(S, E) in which either S or E is not a point, is equivalent to range(start-point(S),end-point(E)).
The name of the point notation is "point", and its formal grammar is:
[1] PointSchemeData ::= (NCName PointSequence?) | PointSequence
[2] PointSequence ::= (ChildSequence Offset?) | (Root Offset?) | Offset
[3] ChildSequence ::= ('/' [1-9] [0-9]*)+
[4] Root ::= '/'
[5] Offset ::= ('.' [0-9]+)
The name of the range notation is "range", and its formal grammar is:
[6] RangeSchemeData ::= PointSchemeData s* ("," s* PointSchemeData)?
The diagram in the section "Document Ordering" above, shows the point sequences to all points in its example, omitting the "point(" and ")" to save space.
Note:
As noted earlier, the point immediately before (or after) a text node occurs at the same place in an XML source document as the point immediately before (or after) that text node's first (or last) character. This specification defines those locations as distinct; they do not compare as equal. For example, the point at offset 2 within the p element above is not equal to the point at offset 0 within the text node containing "world." It is beyond the scope of this specification to define editing operations such as insertion, but we note that the permissible operations at such points may differ. For example, an interface might reject inserting a node within a text node even at offset 0, or inserting characters at the corresponding offset within the containing element.
Since a range is defined in terms of a starting point and an ending point, a range is uniquely identified by two point sequences. For example, the range extending from before the 2nd "l" of "hello", to immediately after the emph element, is from point(1/1.3) to point(1.2) and is here written range(1/1.3, 1.2).