This document describes requirements for the layout and presentation of text in the Tibetan script for use with Web standards and technologies, such as HTML, CSS, Mobile Web, Digital Publications, and Unicode. In addition to Tibet and China, the script is widely used in Bhutan, Nepal, India and throughout the Tibetan diaspora, and requirements for these regions are also included in the scope of the document.
Status of This Document
This section describes the status of this
document at the time of its publication. Other documents may supersede
this document. A list of current W3C publications and the latest revision
of this technical report can be found in the
W3C technical reports index at
https://www.w3.org/TR/.
This document is produced by the Chinese Layout Requirement Task Force in the W3C i18n Activity, which is focusing on language layout requirements for languages used in China, but wishes to also incorporate information relevant to the use of Tibetan in other places around the world. The document contains English and Chinese versions of the text, which can be filtered using the buttons at the top right of the window. The English version is the authoritative version. The Working Group expects this document to become a Working Group Note.
To make it easier to track comments, please raise separate issues or emails for each comment, and point to the section you are commenting on using a URL for the dated version of the document.
GitHub Issues are preferred for
discussion of this specification.
Publication as a First Public Working Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or
obsoleted by other documents at any time. It is inappropriate to cite this
document as other than work in progress.
This document was produced by a group
operating under the
W3C Patent Policy.
The group does not expect this document to become a W3C Recommendation.
W3C maintains a
public list of any patent disclosures
made in connection with the deliverables of
the group; that page also includes
instructions for disclosing a patent. An individual who has actual
knowledge of a patent which the individual believes contains
Essential Claim(s)
must disclose the information in accordance with
section 6 of the W3C Patent Policy.
This document describes requirements for the layout and presentation of text in the Tibetan script for use with Web standards and technologies, such as HTML, CSS, Mobile Web, Digital Publications, and Unicode. In addition to Tibet and China, the script is widely used in Bhutan, Nepal, India and throughout the Tibetan diaspora, and requirements for these regions are also included in the scope of the document.
The document does not describe implementations or issues related to specific technologies, such as CSS. Instead it describes the typographic requirements of Tibetan in a technology-agnostic manner, so that the content remains evergreen and is equally relevant to all technologies that aim to represent Tibetan text on the Web.
In the future other documents or issues may be created by comparing the requirements in this document with the gaps in specific technologies, but that information will be documented elsewhere.
1.2 How this Document was Created
This document uses material from the web page Tibetan script notes and from a talk by Jianxin Yin to establish a base of information that will be developed and refined by discussion, including in the context of China’s National Standards, and by surveying needs from actual users and technical experts.
The following types of experts will be involved in the creation of this document:
Tibetan typography experts
International and Chinese standardization experts
Academic and industry experts
In order to facilitate contributions from the Chinese national standards groups, the text of the document will also be available in Chinese, although the English version remains the authoritative version. It is also expected that some discussions will take place in Chinese or Tibetan, and will then be translated into English during the development of the document.
The technical terms for discussing and describing the Tibetan writing system will be carefully selected after considering potential differences in nuance even if a direct translation exists, and they will be described in both English and Chinese so the discussion can be continued in the future. Also many figures are included to promote understanding for certain parts that are hard to describe.
1.3 Basic Principles for Document Development
This document describes the characteristics of the Tibetan language system along the lines of the following principles.
It does not cover every issue of Tibetan typography, but only the important differences from the Western language systems.
The technical aspects of actual implementation are not covered by this document.
In order to help readers' understanding of how Tibetan is used, typical real life examples are provided.
Text layout rules and recommendations for readable design are different matters, but it is hard to discuss these two aspects separately. In this document, these two issues are separated carefully.
2. Tibetan script overview
The Tibetan script is an abugida, ie. consonants carry an inherent vowel sound a that is overridden using vowel signs. Text runs from left to right.
The script combines consonants, vowels, superscripts, and subscripts letters in combinations that conform to the basic rules of Tibetan spelling to form syllables. Words are made up of one or more syllables.
There are various different Tibetan scripts, of two basic types: དབུ་ཅན་dbu-can, pronounced uchen (with a head), and དབུ་མེད་dbu-med, pronounced ume (headless). This document concentrates on the former. Pronunciations are based on the central, Lhasa dialect.
Traditionally, Tibetan text was written on pechas (dpe-chaདཔེ་ཆ་), loose-leaf sheets. Some of the characters used and formatting approaches are different in books and pechas.
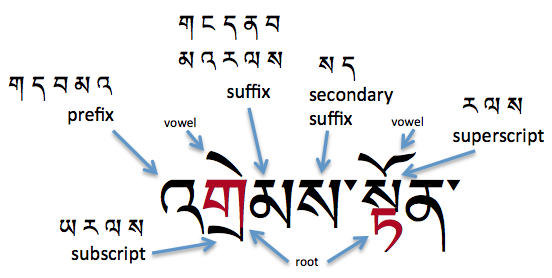
Tibetan structural elements include prefixes, root characters, subscripts, superscripts, suffixes, secondary suffixes, vowels and intersyllabic marks.
Native Tibetan words use 30 consonants, but the Unicode Tibetan block contains many more. Many of the extra consonants (and other characters) are used for transliteration of other languages, principally Sanskrit and Chinese. These include the retroflex and voiced aspirated consonants. A couple of characters are extensions for Balti.
The basic 30 Tibetan consonants are listed below:
藏文有三十个辅音字母,具体如下表所示:
ཀ KA e
ཁ KHA e
ག GA e
ང NGA m
ཅ CA p
ཆ CHA p
ཇ JA e
ཉ NYA p
ཏ TA p
ཐ THA p
ད DA e
ན NA p
པ PA p
ཕ PHA p
བ BA e
མ MA p
ཙ TSA p
ཚ TSHA p
ཛ DZA e
ཝ WA e
ཞ ZHA p
ཟ ZA e
འ -A e
ཡ YA e
ར RA e
ལ LA e
ཤ SHA e
ས SA e
ཧ HA e
ཨ A p
Figure 1 Tibetan consonants
2.1.2 Vowels...
Standard Tibetan has five vowels, for which there are four characters, since one vowel, a, is inherent in the consonant. Non-inherent vowels are indicated by a single mark attached to and typed after a consonant or consonant stack. These are shown with the character KA in the following figure.
In the example ʧí, general, shown in Figure 3 the vowel sign that appears above the stack is typed after the three consonants that make up the stack.
Figure 3 Vowel sign position in a stack
2.1.3 A-chung and a-chen...
The phonological realisation for U+0F60 TIBETAN LETTER -Aའ (called འ་ཆུང་, 'a-chung) and U+0F68 TIBETAN LETTER Aཨ (called ཨ་ཆེན་, a-chen) is a. In the Lhasa dialect, the former has a high and the latter a low tone.
Both 'a-chung and a-chen can be used with vowel signs, in which case the a sound is replaced by that of the vowel.
'A-chung can also represent a nasal, so མཚམས་mtshams (boundary) and མཐུན་mthun (agreement) are often written འཚམས་ and འཐུན་.
'A-chung may also nasalise the juncture of two morphemes, as in དགེ་འདུན་dge-'dun (buddhist community), pronounced ɡenyn.
Other than loanwords, Tibetan only allows diphthongs in diminutive expressions. 'A-chung is used to write these, as in the following: མི་miperson → མེའུ་me'udwarf; རྡོ་rdostone → རྡེའུ་rde'upebble.
A subjoined 'a-chung is used to express long vowels in loan words (Tibetan doesn't have them natively), such as those borrowed from Chinese, Hindi and Mongolian. For example, ཏཱ་བླ་མ་tā-bla-ma (grand lama) (ta from Chinese), and ཤྲཱི་śrī (wealth) from Sanskrit. For this purpose you should use U+0F71 TIBETAN VOWEL SIGN AA ཱ, and not U+0FB0 TIBETAN SUBJOINED LETTER -A ྰ.
The Unicode Standard says of SUBJOINED LETTER -A:
U+0FB0 TIBETAN SUBJOINED LETTER -A ( a-chung ) should be used only in the very rare cases where a full-sized subjoined a-chung letter is required. The small vowel lengthening a-chung encoded as U+0F71 TIBETAN VOWEL SIGN AA is far more frequently used in Tibetan text, and it is therefore recommended that implementations treat this character (rather than U+0FB0) as the normal subjoined a-chung.
Finally, 'a-chung can be used to disambiguate the location of an inherent vowel in a syllable. The sequence དག་dagdàg (I) is interpreted as CVC. To express CCV add 'a-chung, eg. དགའ་dga'gà (virtue).
2.2 Consonant Stacking...
A salient feature of the Tibetan script is the tendency to stack consonant characters belonging to a syllable. A stack has a standard consonant character at the top (although it may actually be slightly squeezed or adapted slightly in shape), and one or more special subjoined consonant characters beneath it.
The word 'head' is often used to refer to either the top-most consonant (ie. spacially) or the root consonant of a syllable, which may be a subjoined consonant. We therefore avoid this term here, and say 'root' or 'topmost'.
The topmost consonant in a stack always uses the standard character from the Unicode Tibetan block regardless of whether it is a root consonant or not, and consonants below it always use a character from the subjoined range.
The example shows a stack with three consonants. (There is also a vowel sign above the stack.)
Figure 4 Stacked consonants in Tibetan.
Unlike Indic scripts, no virama (or halant) is used for Tibetan. Instead, just a full and subjoined form of each consonant. The subjoined forms are combining characters. Avoiding the virama makes sense because the virama is not used by Tibetans, and the approach taken makes it easier to create the large number of stacks contained in Tibetan text.
Subjoined forms of the basic 30 Tibetan consonants are listed below:
ྐ KA e
ྑ KHA e
ྒ GA e
ྔ NGA e
ྕ CA p
ྖ CHA p
ྗ JA e
ྙ NYA p
ྟ TA p
ྠ THA p
ྡ DA e
ྣ NA p
ྤ PA p
ྥ PHA p
ྦ BA e
ྨ MA p
ྩ TSA p
ྪ TSHA p
ྫ DZA e
ྭ WA e
ྮ ZHA p
ྯ ZA e
ྰ -A e
ྱ YA e
ྲ RA e
ླ LA e
ྴ SHA e
ྶ SA e
ྷ HA e
ྸ A e
Figure 5 Tibetan subjoined consonants
The following list shows the order in which characters should be typed, and stored in memory, for a set of stacked characters.
Standard consonant shape
First subjoined consonant
Any other subjoined consonants, in order of descent
Subjoined vowel 'a-chung
Standard or compound vowel sign, or virama
Some consonant characters are modified using the character U+0F39 TIBETAN MARK TSA-PHRU ༹ In these cases, the tsa-phru character should be placed in memory immediately after the consonant it modifies.
2.3 Tibetan Syllables藏文音节
Word boundaries within a section are not indicated, only 'syllables', known as tsheg-bartsek bar. Syllable boundaries are usually separated by the tsek character, U+0F0B TIBETAN MARK INTER-SYLLABIC TSHEG་.
The pronunciation of Tibetan words is typically much simpler than the orthography, which involves patterns of consonants. These patterns reduce ambiguity and can affect pronunciation and tone.
The following diagram shows characters in all of the syllabic positions, and lists the characters that can appear in each of the non-root locations. The two-syllable word in the example is འགྲེམས་སྟོན་'grems-stonɖɹem-ton (exhibition).
Figure 6 Syllable composition in Tibetan
2.3.1 Structural Rules结构规则
The primary consonant in a syllable is called the root consonant (or radical) (མིང་བཞི་), and the other consonants in the syllable ( normally up to 6 in total) annotate or modify it. The following rules help identify the root:
要分析藏文结构必须先得找出根字母,然后其他的部分根据结构规则就能找到。根字母的判断方法如下:
A consonant with a vowel is always the root, unless it is the phrase connector འི, and letters with superscripts or subscripts are root consonants.
一个辅音上有元音字母,那就是根字母,除非是འི如下上面是元音字母下面是辅音字母,在此中是根字母。
In a 2-consonant syllable with no vowel, the first consonant is always the root.
一个辅音上有上标字或者下标字那么这个辅音字母也是根字母。
在一个具有两个辅音字母且没有元音字母的字中,第一个字母是根字母。
例如:
In a 3-consonant syllable where the last consonant is not ས, the second consonant is likely to be the root.
Characters in the prefix position are not pronounced, but de-aspirate aspirated root characters and give a higher tone value to nasal root characters. The consonant ག g may occur before 11 root characters, དd before 6, བ b before 10, མ m before 11, and འ a before 10.
Only two characters can appear in the secondary suffix location, according to Tibetan grammar, ས and ད, and the latter is no longer officially found in modern Tibetan. A character in this position adds no sound and nor does it affect the sounds in the rest of the syllable.
Examples: བསྒྲུབས་bsgrubsɖɹúb (established), and གྱུརད་gyurdkjùr (became).
2.3.2.4 Superscripts...
A superscript (མགོ་ཅན་) appears above the syllable's root, and is one of the following characters: ར ལ ས
The three characters that appear in the superscript location raise the tone pitch of the syllable, but are not pronounced themselves. Each superscript character can only be used with a specified set of root characters.
ར
རྐ
ka
རྒ
ga
རྔ
ŋa
རྗ
ʤa
རྙ
ɲa
རྟ
ta
རྡ
da
རྣ
na
རྦ
ba
རྨ
ma
རྩ
tsa
རྫ
dza
ལ
ལྐ
ka
ལྒ
ga
ལྔ
ŋa
ལྕ
ca
ལྗ
ʤa
ལྟ
ta
ལྡ
da
ལྤ
pa
ལྦ
ba
ལྷ
lha
ས
སྐ
ka
སྒ
ga
སྔ
ŋa
སྙ
ɲa
སྟ
ta
སྡ
da
སྡ
na
སྤ
pa
སྦ
ba
སྨ
ma
སྩ
tsa
Figure 7 Tibetan superscripts.
Note that RA has a shape slightly different from its nominal shape in all combinations except རྙ and རླ. You should still use the normal RA Unicode character for the superscript. The font will make the needed adjustments to the shape.
2.3.2.5 Subscripts...
A subscript (འདོགས་ཅན་) can be one of the following four characters: ྲ ྱ ླ ྭ
འདོགས་ཅན་ 即下标字(subscript),放在根字母下面。即右边两个: ྲ ྱ ླ ྭ
The four characters that can appear in the subscript location are also each combined with a particular subset of root characters and have different effects.
ྱ
ཀྱ
kja
ཁྱ
kʰja
གྱ
gja
པྱ
cja
ཕྱ
cʰja
བྱ
ʤja
མྱ
ɲa
ཧྱ
hja
ྲ
ཀྲ
tra
ཁྲ
tʰra
གྲ
dra
ཏྲ
tra
ཐྲ
tʰra
དྲ
dra
ནྲ
na
པྲ
tra
ཕྲ
tʰra
བྲ
tra
མྲ
ma
སྲ
sa
ཧྲ
hra
ླ
ཀླ
la
གླ
la
བླ
la
རླ
la
སླ
la
ཟླ
da
ྭ
ཀྭ
ka
ཁྭ
ka
གྭ
ga
ཉྭ
ɲa
དྭ
da
ཙྭ
tsa
ཚྭ
ʧa
ཞྭ
zʰa
ཟྭ
za
རྭ
ra
ལྭ
la
ཤྭ
ʃa
ཧྭ
ha
Figure 8 Tibetan subscripts
Note that three of the subscripts have shapes that are significantly different from the nominal shape of the character they represent.
Uniquely, WA can also appear as a sub-subscript as in གྲྭ་grwa.
2.5 Tibetan Characters used for Transliteration...
Many of the characters in the Tibetan block are there for transcribing or transliterating non-Tibetan text. The Tibetan script provides for perfect mappings between Sanskrit and Tibetan, but Tibetan is also used to transliterate other languages, such as Chinese, Mongolian and English.
There are a number of consonants, including a range of aspirated consonants, and the following range of retroflex consonants.
GHA
DDHA
DHA
BHA
DZHA
KSSA
TTA
TTHA
DDA
NNA
SSA
head
subjoined
Figure 10 Additional consonant characters for transliteration.
The retroflex consonants, which are reversed versions of Tibetan consonant shapes, are often used to distinguish loan words from sequences of Tibetan syllables. For example, ཁ་ཎ་ཌ་kha-ṇa-ḍa (Canada), མོ་ཊ་mo-ṭa (car).
In transliterated text consonants are sometimes stacked in ways that are not allowed in native Tibetan text.
There are also additional vowel signs between U+0F71 and U+0F7D for Sanskrit transcriptions, and several are compound shapes. The component parts of these compounds should normally be typed individually, rather than using the compound codepoints. The table below shows the characters, and indicates those whose use is discouraged and strongly discouraged.
II
EE
OO
Rev I
V R
V L
II
UU
Rev II
V RR
V LL
Ok
Discouraged
Deprecated &
strongly discouraged
Figure 11 Additional vowel sign characters for transliteration.
U+0F7F TIBETAN SIGN RNAM BCADཿ ( nam chay ) is the visarga, and U+0F7E TIBETAN SIGN RJES SU NGA RO ཾ ( ngaro ) is the anusvara.
2.5.1 Compound Consonants
The six compound consonants GHA, DDHA, DHA, BHA, DZHA and KSSA in the table above, used to represent the Indic consonants during transliteration, can be created by combining a head consonant with a subjoined HA, but the Unicode Standard recommends that the precomposed characters be used in order to maximise effectiveness of transmission and searching. I have suggested that this recommendation be changed in version 7, since many applications silently normalise text to the decomposed sequence.
2.5.2 Fixed Form Letters
U+0F62 TIBETAN LETTER RA at the top of a stack usually has a reduced form, eg. རྐrka. For transliterations it is sometimes desirable to retain the full form of RA where in Tibetan words it would be reduced. To do this use U+0F6A TIBETAN LETTER FIXED-FORM RAཪ instead of the normal RA, but only where the normal RA would not produce the full form anyway, ie. do not use eg. རྙrnya, which has the full form already.
There are also fixed form variants of subjoined RA, YA and WA.
2.6 Tibetan Numerals藏文的数字
Tibetan has its own set of digits, although publications may also use European numerals. The basic Tibetan numbers are used in the same way as European numerals. They differ only in shape.
The Unicode Tibetan block also contains a set of half-numbers. These are very rarely used, and there is some ambiguity about how they are used. By some interpretations, the following shapes each have the value of 0.5 less than the number within which it appears. Used only in some traditional contexts, they appear as the last digit of a multidigit number, eg. ༤༬ represents 42.5.
In traditional, loose-leaf Tibetan pechas a head mark or yig-mgo (yig go) is used at the beginning of the front of the folio so that you can tell which is the front.
Head marks are also used in both pechas and books to indicate the start of a headline or the start of the first paragraph in a longer text.
Head marks differ from text to text. The Unicode Standard provides a number of characters to give some basic coverage, but may not meet all needs.
A common head mark is U+0F04 TIBETAN MARK INITIAL YIG MGO MDUN MA༄, and there is also the extension character U+0F05 TIBETAN MARK CLOSING YIG MGO SGAB MA༅. A head mark can be written alone, or can be followed by as many as three closing marks; head marks are also followed by two shads, eg.༄༅། །.
Three less common head marks, used in Nyingmapa and Bonpo literature, are also represented in the Tibetan block, namely:
U+0F01 TIBETAN MARK GTER YIG MGO TRUNCATED A༁
U+0F02 TIBETAN MARK GTER YIG MGO -UM RNAM BCAD MA༂
U+0F03 TIBETAN MARK GTER YIG MGO -UM GTER TSHEG MA༃
2.8 Tibetan Punctuation藏文的标点符号
2.8.1 Syllable Breaks音节符
The U+0F0B TIBETAN MARK INTER-SYLLABIC TSHEG [་] is used to indicate syllable boundaries. Note that this is not necessarily equivalent to word boundaries.
音节符U+0F0B TIBETAN MARK INTER-SYLLABIC TSHEG [་] ,加在每个音节之后,起划分音节的作用,让读者正确读出文字。如果缺少音节符文字混论无法读出正确的字,也不构成字。
Key divisions of the text are sections (or expressions (brjod-pa)) and topics (don-tshan), which do not necessarily equate to English phrases, sentences and paragraphs. Sections normally end with a shay, U+0F0D TIBETAN MARK SHAD།, followed by a space. Topics (eg. headlines, verses, and longer paragraphs) are often terminated or separated with shay+space+shay.
Over and above that just described, traditional Tibetan text uses very little punctuation, but there a number of signs and symbols to choose from.
U+0F08 TIBETAN MARK SBRUL SHAD༈ is used to separate texts that are equivalent to topics and subtopics, such as the start of a smaller text, the start of a prayer, a chapter boundary, or to mark the beginning and end of insertions into text in pechas.
This drul-shay is usually surrounded on both sides by the equivalent of about three non-breaking spaces (though no rule is specified). The drul-shay should not appear at the beginning of a new line and the whole structure of spacing-plus- shay needs to be kept together.
U+0F3C TIBETAN MARK ANG KHANG GYON༼ and U+0F3D TIBETAN MARK ANG KHANG GYAS༽ are paired punctuation used to form a roof over one or more digits or words. The right-hand character can also be used much like a single parenthesis in list counters.
U+0F3E TIBETAN SIGN YAR TSHES༾ and U+0F3F TIBETAN SIGN MAR TSHES༿ are also paired characters used in combination with digits.
U+0F34 TIBETAN MARK BSDUS RTAGS༴ means 'etc.', and is used after the first few tsek-bar of a recurring phrase.
U+0FBE TIBETAN KU RU KHA྾ (often repeated three times) indicates a refrain.
U+0F36 TIBETAN MARK CARET -DZUD RTAGS BZHI MIG CAN༶ and U+0FBF TIBETAN KU RU KHA BZHI MIG CAN྿ are used to indicate where text should be inserted within other text or as references to footnotes and marginal notes.
U+2638 WHEEL OF DHARMA☸ which occurs sometimes in Tibetan texts is encoded in the Miscellaneous Symbols block.
Issue 1
How are quotations demarcated in Tibetan?
3. Typography for Tibetan characters
3.1 Text Segmentation in Tibetan...
Key divisions of the text are sections (or expressions (brjod-pa)) and topics (don-tshan), which do not necessarily equate to English phrases, sentences and paragraphs. Sections normally end with a shay, U+0F0D TIBETAN MARK SHAD།, followed by a space. Topics (eg. headlines, verses, and longer paragraphs) are often terminated or separated with shay+space+shay.
Unicode provides U+0F0E TIBETAN MARK NYIS SHAD༎ as a means of regularising the spacing between the two shad marks, which tends to be slightly bigger than a normal space. The space between the shad marks can be stretched during justification, however, and it's not clear how that would work when using NYIS SHAD.
Note
In Chinese magazine publications articles may contain no double shay as a delimiter. (The text is formatted in paragraphs.) The double shay may still be found at the very end of some articles, or at the end of each line on a page containing some verse-formatted folk literature. The applies for large parts of Bhutanese newspapers, however there are other pages with plenty of double shays - some at the end of paragraphs, some inside paragraphs.
A line that ends with the root consonant U+0F40 TIBETAN LETTER KAཀ or U+0F42 TIBETAN LETTER GAག will normally swallow up the shay that immediately follows it, even if there is a vowel sign. For example, where you might expect to see a double shay, you might see ཀུ ། and སྐུ །. However, the shad is not omitted if these characters have a subscript, eg. གྲུ། །.
Figure 16 Example of GA swallowing up a shay at the end of a section.
Word boundaries within a section are not indicated. Only 'syllables', known as tsheg-bartsek bar, are separated by the tsek character, U+0F0B TIBETAN MARK INTER-SYLLABIC TSHEG་.
The tsek is not used before a shay, except after U+0F44 TIBETAN LETTER NGAང. For example, note the end of the three sections in this example:
Figure 17 Examples of tsek not being used before shay, and of U+0F0C being used between NGA and shay.
Users may use an ordinary TSHEG between NGA and SHAD, but Unicode also provides a special non-breaking character that can be used instead, U+0F0C TIBETAN MARK DELIMITER TSHEG BSTAR༌. The word 'delimiter' in the name is a misnomer.
Figure 18 Example of U+0F0C being used between NGA and shay.
Whitespace in Tibetan text should use U+00A0 NO-BREAK SPACE. Spaces in Tibetan text are usually wider than spaces in English text, and typically only occur after one of the following: །, ༑, ༔ or ཿ. However, numbers and embedded Western text are surrounded by smaller spaces, eg. ལོ་ ༢༠༠༡ ཤིང་བྱ་ཟླ་ ༩ ཚེས་ ༥ ཉིན་.
Issue 3
What effect should double-clicking on text produce? Should the whole syllable be selected? Does that include the tsek? Or should the application just highlight the grapheme clusters?
3.2 Text Emphasis and Highlighting...
U+0F35 TIBETAN MARK NGAS BZUNG NYI ZLA ༵ and U+0F37 TIBETAN MARK NGAS BZUNG SGOR RTAGS ༷ can be used to create a similar effect to underlining or to mark emphasis.
These marks attach to a syllable rather than a character and therefore to place them correctly it is necessary to take syllable boundary positions into account. If entered as combining characters they can be added after the vowel-sign in a stack.
Application software has to ignore these characters for text processing operations such as search and collation.
Alternative methods of emphasis include use of a different colour, or the use of the prefix ༸.
སྐལ་ལྡན་གདུལ་བྱར་སྣང་བའི་བསོ༵ད་ནམ༵ས་གཟུགས།
Figure 19 Use of colour and diacritics to emphasise text.
These characters may also be used in interspersed commentaries to tag the root text that is being commented on. An alternative is to set the tsek-bar being commented on in large type and the commentary in small type.
སྐུ༷་གསུ༷ང་ཐུག༷ས།.
Figure 20 Marks being used to identify root text.
Modern texts tend to bold text for emphasis.
3.3 Baseline alignment...
When text in smaller annotations or larger heading text is mixed with normal text, the letter-heads of all characters should align to the same height.
4. Typography for Tibetan paragraphs
4.1 Tibetan Writing Mode藏文的书写方式
Tibetan is written horizontally and read from left to right.
藏文文字为“从左至右”书写、“从上向下”显示,也简称为横排从左至右排版。
Issue 4
Is Tibetan written vertically with upright glyphs at all (eg. in table headings, in pictures, etc.)? If so, does it require that all elements composing a syllable be kept together in horizontal fashion, placing just syllables one above the other? Or does each non-subjoined/combining character move to the next line? etc.
4.2 Line breaking...
Normally, Tibetan only breaks after a tsek (U+0F0B TIBETAN MARK INTER-SYLLABIC TSHEG་), and doesn't break after spaces.
Line breaks do not occur after a tsek
when it follows U+0F44 TIBETAN LETTER NGAང (with or without a vowel sign) and precedes a shay (U+0F0D TIBETAN MARK SHAD།).
Issue 5
The Unicode Standard also talks of other instances where Tibetan grammatical rules do not permit a break, but it isn't clear what those are.
If the character after NGA is an ordinary tsek, then lines should not break between the tsek and the shay. Text is likely to be more portable if content authors use the TSHEG BSTAR in these locations, instead of the normal tsek.
Line breaks are also possible after:
U+0F0D TIBETAN MARK SHAD། - as long as the next line starts with a consonant (ie. not a second shad).
U+0F14 TIBETAN MARK GTER TSHEG༔
U+0F7F TIBETAN SIGN RNAM BCADཿ (used to represent the visarga in transliterations). There is never a tsek after this character, eg. ཨོཾ་ཨཱཿཧཱུྃ་.
Tibetan never breaks inside a syllable, and has no hyphenation. If a word is composed of multiple syllables, it is also preferable to avoid breaking a line in the middle of the word.
A line must never start with a shad.
4.2.1 Line breaks and rin chen spungs shad...
In Tibetan, especially in pechas, it is considered a special case if the last syllable of an expression that is terminated by a shay breaks onto a new line. In that case the shay or double shay is replaced by rin chen spungs shad, U+0F11 TIBETAN MARK RIN CHEN SPUNGS SHAD༑.
At the end of a topic the rules say that only one shay should be converted, ie. ༑ །, however it is moderately popular to convert both, ie. ༑ ༑. This change serves as an optical indication that there is a left-over syllable at the beginning of the line that actually belongs to the preceding line.
This varies in the following cases:
when a line starts with ལེའུ། །, no rin chen spungs shad would be used, since le'u is pronounced as two syllables.
sometimes only the first of two shays is replaced, ie. ༑ །, but this style is considered less attractive.
some printed books do not use rin chen spungs shad replacements, however the majority of books apply the same rules as are used with pechas.
In an environment where the width or content of the page can change, this feature poses a problem for the content author. The application needs to be able to automatically switch between the two styles of shad as a syllable moves on or off a new line when the page is resized or when preceding content is modified.
The Unicode Standard adds: "Not only is rin-chen-spungs-shad used as the replacement for the shay but a whole class of “ornamental shays ” are used for the same purpose. All are scribal variants on a rin-chen-spungs-shad, which is correctly written with three dots above it."
Issue 6
What are the rules for line-wrap for other symbols? Are there rules about certain characters not starting/ending a line?
4.3 Justification...
There are two alternative methods of justification.
4.3.1 Inter-character spacing...
Spacing between all characters should be adapted equally. Note that the width of the white-space character should not be changed significantly, so Tibetan texts use the non-breaking space mentioned above, which doesn't change width on justification.
4.3.2 Tsek padding...
While hand writing, authors add small spaces across the text to get the line end as near as possible to the right margin. Where space remains at the margin, it may be left as is, if it is short. Otherwise, the remaining space will be filled with tseks to make the line as flush as possible with the right margin (there will usually still be a slight raggedness to the right edge of the text).
Figure 21 A page of a booklet showing tsek padding.
There are a couple of detailed rules about the use of tsek padding.
Justifying tseks are almost always used when the line ends in a tsek. If, however, the line ends in a shay, there are a number of alternatives.
If the line ends with a single shay the shay is followed by spaces. Tsek padding is never applied after spaces. (See examples in the figure above.)
If the line ends in a double shay (with space between), it is unusual (though possible) to add tsek padding. Instead, the space between the shays is stretched or narrowed. (See examples in the figure below.) The same applies if the second shay was removed because it was preceded by a KA or GA.
Figure 22 Booklet pages showing double shay usage at the end of a line.
4.4 Lists and counters...
Note
This section needs attention. Questions include: Is a space expected after the counter? If so, is it a non-break space? Is any other punctuation needed after a Tibetan counter? How common is the Tibetan vs European counter?
Tibetan numerals can be used for list counters. The Tibetan numbers are used in a simple decimal notation, ie. in the same way as European numerals. They differ only in shape.
This document has been developed with contributions from participants of the Chinese Layout Requirement Task Force, with kind help from experts from 信标委中文信息处理分技术委员会及藏文信息处理工作组.
D. Character List
This appendix lists the characters in the Unicode Tibetan block, and sorts them into various groups that describe how they are used.
Consonants
U+0F40 TIBETAN LETTER KA ཀ
U+0F41 TIBETAN LETTER KHA ཁ
U+0F42 TIBETAN LETTER GA ག
U+0F44 TIBETAN LETTER NGA ང
U+0F90 TIBETAN SUBJOINED LETTER KA ྐ
U+0F91 TIBETAN SUBJOINED LETTER KHA ྑ
U+0F92 TIBETAN SUBJOINED LETTER GA ྒ
U+0F94 TIBETAN SUBJOINED LETTER NGA ྔ
U+0F45 TIBETAN LETTER CA ཅ
U+0F46 TIBETAN LETTER CHA ཆ
U+0F47 TIBETAN LETTER JA ཇ
U+0F49 TIBETAN LETTER NYA ཉ
U+0F95 TIBETAN SUBJOINED LETTER CA ྕ
U+0F96 TIBETAN SUBJOINED LETTER CHA ྖ
U+0F97 TIBETAN SUBJOINED LETTER JA ྗ
U+0F99 TIBETAN SUBJOINED LETTER NYA ྙ
U+0F4F TIBETAN LETTER TA ཏ
U+0F50 TIBETAN LETTER THA ཐ
U+0F51 TIBETAN LETTER DA ད
U+0F53 TIBETAN LETTER NA ན
U+0F9F TIBETAN SUBJOINED LETTER TA ྟ
U+0FA0 TIBETAN SUBJOINED LETTER THA ྠ
U+0FA1 TIBETAN SUBJOINED LETTER DA ྡ
U+0FA3 TIBETAN SUBJOINED LETTER NA ྣ
U+0F54 TIBETAN LETTER PA པ
U+0F55 TIBETAN LETTER PHA ཕ
U+0F56 TIBETAN LETTER BA བ
U+0F58 TIBETAN LETTER MA མ
U+0FA4 TIBETAN SUBJOINED LETTER PA ྤ
U+0FA5 TIBETAN SUBJOINED LETTER PHA ྥ
U+0FA6 TIBETAN SUBJOINED LETTER BA ྦ
U+0FA8 TIBETAN SUBJOINED LETTER MA ྨ
U+0F59 TIBETAN LETTER TSA ཙ
U+0F5A TIBETAN LETTER TSHA ཚ
U+0F5B TIBETAN LETTER DZA ཛ
U+0F5D TIBETAN LETTER WA ཝ
U+0FA9 TIBETAN SUBJOINED LETTER TSA ྩ
U+0FAA TIBETAN SUBJOINED LETTER TSHA ྪ
U+0FAB TIBETAN SUBJOINED LETTER DZA ྫ
U+0FAD TIBETAN SUBJOINED LETTER WA ྭ
U+0F5E TIBETAN LETTER ZHA ཞ
U+0F5F TIBETAN LETTER ZA ཟ
U+0F60 TIBETAN LETTER -A འ
U+0F61 TIBETAN LETTER YA ཡ
U+0FAE TIBETAN SUBJOINED LETTER ZHA ྮ
U+0FAF TIBETAN SUBJOINED LETTER ZA ྯ
U+0FB0 TIBETAN SUBJOINED LETTER -A ྰ
U+0FB1 TIBETAN SUBJOINED LETTER YA ྱ
U+0F62 TIBETAN LETTER RA ར
U+0F63 TIBETAN LETTER LA ལ
U+0F64 TIBETAN LETTER SHA ཤ
U+0F66 TIBETAN LETTER SA ས
U+0FB2 TIBETAN SUBJOINED LETTER RA ྲ
U+0FB3 TIBETAN SUBJOINED LETTER LA ླ
U+0FB4 TIBETAN SUBJOINED LETTER SHA ྴ
U+0FB6 TIBETAN SUBJOINED LETTER SA ྶ
U+0F67 TIBETAN LETTER HA ཧ
U+0F68 TIBETAN LETTER A ཨ
U+0FB7 TIBETAN SUBJOINED LETTER HA ྷ
U+0FB8 TIBETAN SUBJOINED LETTER A ྸ
Extensions for Balti
U+0F6B TIBETAN LETTER KKA ཫ
U+0F6C TIBETAN LETTER RRA ཬ
Dependent vowel signs
U+0F72 TIBETAN VOWEL SIGN I ི
U+0F74 TIBETAN VOWEL SIGN U ུ
U+0F7A TIBETAN VOWEL SIGN E ེ
U+0F7C TIBETAN VOWEL SIGN O ོ
U+0F71 TIBETAN VOWEL SIGN AA ཱ
Additional consonants for transliteration
U+0F4A TIBETAN LETTER TTA ཊ
U+0F4B TIBETAN LETTER TTHA ཋ
U+0F4C TIBETAN LETTER DDA ཌ
U+0F4E TIBETAN LETTER NNA ཎ
U+0F65 TIBETAN LETTER SSA ཥ
U+0F9A TIBETAN SUBJOINED LETTER TTA ྚ
U+0F9B TIBETAN SUBJOINED LETTER TTHA ྛ
U+0F9C TIBETAN SUBJOINED LETTER DDA ྜ
U+0F9E TIBETAN SUBJOINED LETTER NNA ྞ
U+0FB5 TIBETAN SUBJOINED LETTER SSA ྵ
U+0F43 TIBETAN LETTER GHA གྷ
U+0F4D TIBETAN LETTER DDHA ཌྷ
U+0F52 TIBETAN LETTER DHA དྷ
U+0F57 TIBETAN LETTER BHA བྷ
U+0F5C TIBETAN LETTER DZHA ཛྷ
U+0F69 TIBETAN LETTER KSSA ཀྵ
U+0F93 TIBETAN SUBJOINED LETTER GHA ྒྷ
U+0F9D TIBETAN SUBJOINED LETTER DDHA ྜྷ
U+0FA2 TIBETAN SUBJOINED LETTER DHA ྡྷ
U+0FA7 TIBETAN SUBJOINED LETTER BHA ྦྷ
U+0FAC TIBETAN SUBJOINED LETTER DZHA ྫྷ
U+0FB9 TIBETAN SUBJOINED LETTER KSSA ྐྵ
Transliteration, fixed-form consonants
U+0F6A TIBETAN LETTER FIXED-FORM RA ཪ
U+0FBA TIBETAN SUBJOINED LETTER FIXED-FORM WA ྺ
U+0FBB TIBETAN SUBJOINED LETTER FIXED-FORM YA ྻ
U+0FBC TIBETAN SUBJOINED LETTER FIXED-FORM RA ྼ
Additional vowel signs for transliteration
U+0F73 TIBETAN VOWEL SIGN II ཱི
U+0F75 TIBETAN VOWEL SIGN UU ཱུ
U+0F76 TIBETAN VOWEL SIGN VOCALIC R ྲྀ
U+0F77 TIBETAN VOWEL SIGN VOCALIC RR ཷ
U+0F78 TIBETAN VOWEL SIGN VOCALIC L ླྀ
U+0F79 TIBETAN VOWEL SIGN VOCALIC LL ཹ
U+0F7B TIBETAN VOWEL SIGN EE ཻ
U+0F7D TIBETAN VOWEL SIGN OO ཽ
U+0F80 TIBETAN VOWEL SIGN REVERSED I ྀ
U+0F81 TIBETAN VOWEL SIGN REVERSED II ཱྀ
Transliteration, vocalic modification
U+0F7E TIBETAN SIGN RJES SU NGA RO ཾ
U+0F7F TIBETAN SIGN RNAM BCAD ཿ
U+0F84 TIBETAN MARK HALANTA ྄
Transliteration, head letters
U+0F88 TIBETAN SIGN LCE TSA CAN ྈ
U+0F89 TIBETAN SIGN MCHU CAN ྉ
U+0F8A TIBETAN SIGN GRU CAN RGYINGS ྊ
U+0F8B TIBETAN SUBJOINED SIGN GRU MED RGYINGS ྋ
U+0F8C TIBETAN SUBJOINED SIGN INVERTED MCHU CAN ྌ
Transliteration, subjoined signs
U+0F8D TIBETAN SUBJOINED SIGN LCE TSA CAN ྍ
U+0F8E TIBETAN SUBJOINED SIGN MCHU CAN ྎ
U+0F8F TIBETAN SUBJOINED SIGN INVERTED MCHU CAN ྏ
Head marks
U+0F01 TIBETAN MARK GTER YIG MGO TRUNCATED A ༁
U+0F02 TIBETAN MARK GTER YIG MGO -UM RNAM BCAD MA ༂
U+0F03 TIBETAN MARK GTER YIG MGO -UM GTER TSHEG MA ༃
U+0F04 TIBETAN MARK INITIAL YIG MGO MDUN MA ༄
U+0F05 TIBETAN MARK CLOSING YIG MGO SGAB MA ༅
U+0F06 TIBETAN MARK CARET YIG MGO PHUR SHAD MA ༆
U+0F07 TIBETAN MARK YIG MGO TSHEG SHAD MA ༇
Punctuation
U+0F0B TIBETAN MARK INTERSYLLABIC TSHEG ་
U+0F0C TIBETAN MARK DELIMITER TSHEG BSTAR ༌
U+0F0D TIBETAN MARK SHAD །
U+0F0E TIBETAN MARK NYIS SHAD ༎
U+0F0F TIBETAN MARK TSHEG SHAD ༏
U+0F10 TIBETAN MARK NYIS TSHEG SHAD ༐
U+0F11 TIBETAN MARK RIN CHEN SPUNGS SHAD ༑
U+0F08 TIBETAN MARK SBRUL SHAD ༈
U+0F14 TIBETAN MARK GTER TSHEG ༔
U+0F34 TIBETAN MARK BSDUS RTAGS ༴
U+0F35 TIBETAN MARK NGAS BZUNG NYI ZLA ༵
U+0F37 TIBETAN MARK NGAS BZUNG SGOR RTAGS ༷
Paired punctuation
U+0F3A TIBETAN MARK GUG RTAGS GYON ༺
U+0F3B TIBETAN MARK GUG RTAGS GYAS ༻
U+0F3C TIBETAN MARK ANG KHANG GYON ༼
U+0F3D TIBETAN MARK ANG KHANG GYAS ༽
Annotation marks
U+0FD9 TIBETAN MARK LEADING MCHAN RTAGS ࿙
U+0FDA TIBETAN MARK TRAILING MCHAN RTAGS ࿚
Om
U+0F00 TIBETAN SYLLABLE OM ༀ
Various marks, signs & symbols
U+0F09 TIBETAN MARK BSKUR YIG MGO ༉
U+0F0A TIBETAN MARK BKA- SHOG YIG MGO ༊
U+0F12 TIBETAN MARK RGYA GRAM SHAD ༒
U+0F13 TIBETAN MARK CARET -DZUD RTAGS ME LONG CAN ༓
U+0F36 TIBETAN MARK CARET -DZUD RTAGS BZHI MIG CAN ༶