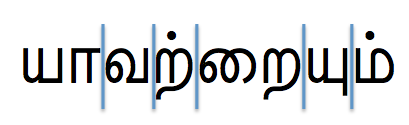This document describes requirements for the layout and presentation of text in languages that use the Tamil script when they are used by Web standards and technologies, such as HTML, CSS, Mobile Web, Digital Publications, and Unicode.
Status of This Document
This section describes the status of this
document at the time of its publication. Other documents may supersede
this document. A list of current W3C publications and the latest revision
of this technical report can be found in the
W3C technical reports index at
https://www.w3.org/TR/.
This early draft has not yet been through any review process. Please do not rely on the contents.
This document describes the basic requirements for Tamil script layout and text support on the Web and in eBooks. These requirements provide information for Web technologies such as CSS, HTML and digital publications about how to support users of Tamil scripts. Currently the document focuses on Tamil as used for the Tamil language. The information here is developed in conjunction with a document that summarises gaps in support on the Web for Tamil.
GitHub Issues are preferred for
discussion of this specification.
Publication as a First Public Working Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or
obsoleted by other documents at any time. It is inappropriate to cite this
document as other than work in progress.
This document was produced by a group
operating under the
W3C Patent Policy.
The group does not expect this document to become a W3C Recommendation.
W3C maintains a
public list of any patent disclosures
made in connection with the deliverables of
the group; that page also includes
instructions for disclosing a patent. An individual who has actual
knowledge of a patent which the individual believes contains
Essential Claim(s)
must disclose the information in accordance with
section 6 of the W3C Patent Policy.
This document provides information about the Tamil script is used for the Tamil language.
This document should contain no reference to a particular technology. For example, it should not say "CSS does/doesn't do such and such", and it should not describe how a technology, such as CSS, should implement the requirements. It is technology agnostic, so that it will be evergreen, and it simply describes how the script works. The gap analysis document is the appropriate place for all kinds of technology-specific information.
1.2 Gap analysis
This document is pointed to by a separate document, Tamil Gap Analysis, which describes gaps in support for Tamil on the Web, and prioritises and describes the impact of those gaps on the user.
Wherever an unsupported feature is indentified through the gap analysis process, the requirements for that feature need to be documented. This document is where those requirements are described.
1.3 Other related resources
Much of the content of this document has been taken or adapted from Tamil.
The document Language enablement index points to this document and others, and provides a central location for developers and implementers to find information related to various scripts.
The W3C also maintains a tracking system that has links to github issues in W3C repositories. There are separate links for (a) requests from developers to the user community for information about how scripts/languages work, (b) issues raised against a spec, and (c) browser bugs. For example, you can find out what information developers are currently seeking, and the resulting list can also be filtered by script.
Tamil is an abugida. Consonant letters have an inherent vowel sound. Combining vowel-signs are attached to the consonant to indicate that a different vowel follows the consonant.
Modern Tamil only uses two conjunct forms. Consonant clusters or consonants without a following inherent vowel are indicated by a visible virama mark, called pulli in Tamil.
The orthographic syllable is the unit for various aspects of the behaviour of the script. The alphabet is split into vowels and consonants.
Text runs horizontally, left to right, and lines typically break at the spaces between words.
The script has no upper-/lowercase distinction.
Tamil script summary can be read for a high level overview of characters used for the script, and some basic features. Text from that the latter part of that page was used for the initial versions of several sections in this document.
3. Text direction
Tamil is written horizontally, left to right.
In rare cases, Tamil text may be displayed in a vertical arrangement with upright glyphs. In such cases, words should be broken at syllable boundaries, rather than after each code point. In general this equates to breaking at grapheme cluster boundaries, because Tamil doesn't have the conjunct forms that are common in north Indian scripts. However, grapheme clusters do not
4. Structural boundaries & markers
4.1 Grapheme boundaries
For text operations including line breaking, letter spacing, cursor movement, forward delete, dropped initials, and some vertical text, the basic unit of text is the syllable, not the character.
For Tamil, the typographic units for these operations are generally equivalent to grapheme clusters as defined by the Unicode Standard, ie. a single base character and all combining character that immediately follow it. For example, a Tamil word such as யாவற்றையும் (yāvaṟṟaiyum), would be split as shown in Figure 1.
Figure 1 Grapheme cluster boundaries for the word யாவற்றையும்.
This is more straightforward than for many other Indian scripts because, rather than combining the elements of a consonant cluster into a conjunct, consonant clusters in Tamil are normally represented using the puḷḷi dot over the character(s) that are not followed by a vowel, eg. தீர்ப்புtīrppuverdict.
Notice also that the word in Figure 1 contains the sequence ற்றை (ṟṟai), where the vowel-sign is displayed immediately before the second consonant, rather than before the consonant cluster. This is also something that doesn't happen when conjunct clusters occur.
The exceptions are the sequences க்ஷkṣa, and ஶ்ரீśrī / ஸ்ரீsrī (which are synonyms). These sequences should not be broken during segmentation. Note, that the 'shri' sequence must include the i vowel to produce a conjunct. With a different vowel, the sequence of characters is displayed using a visual pulli, eg. இஶ்ரேல்iśrēlIsrael.
Correct segmentation of these conjunct-forming sequences are not supported by default by Unicode grapheme clusters (which split them in two), and requires the application of tailored rules.
4.2 Word boundaries
Words are separated by spaces.
4.3 Quotations
The default quote marks for Tamil should be “ [U+201C LEFT DOUBLE QUOTATION MARK] at the start, and ” [U+201D RIGHT DOUBLE QUOTATION MARK] at the end.
When an additional quote is embedded within the first, the quote marks should be ‘ [U+2018 LEFT SINGLE QUOTATION MARK] and ’ [U+2019 RIGHT SINGLE QUOTATION MARK]. This is according to CLDR – need to check.
4.4 Font styles
Italics and bold are not traditional feature of Tamil text.
4.5 Text decoration
Underlining is not traditional feature of Tamil text
5. Line & paragraph layout
5.1 Line breaking
The primary break opportunities for line breaking are at inter-word spaces.
Line breaking should not move a danda or double danda to the beginning of a new line, even if they are preceded by a space character. These punctuation characters should behave in the same way as a full stop does in English text.
Other characters that should not appear at the start of a line include: , . : ; । ॥ ) ] } > + * / = _ | ~ % .
5.2 Hyphenation
Because of the length of Tamil words, hyphenation is useful during layout, but it isn't easy to do because of the complexity of Tamil words.
Hyphenation must take place at syllable boundaries. A hyphen is added at the end of the line when a word is hyphenated.
Prabhakar proposes rules that single characters should be avoided at line start/end, especially characters with nukta at line start, and a word with 5 characters including 3 consecutive consonants can't be split. He says that due to the fact that Tamil is highly inflexional, morphological or pattern based approaches are needed, rather than simple dictionary lookup.
5.3 Justification
Tamil is usually justified by adjusting inter-word spacing.
Due to the length of Tamil words, this can sometimes lead to large gaps between words in narrow columns, such as in newsprint.
Paragraph features are the same as in English. Paragraphs can start with or without indents.
5.4 Counters
Counters are used to number lists, chapter headings, etc.
Modern Tamil generally uses western digits for numbering.
Some other numbering systems exist, however.
Tamil uses a numeric counter style, based on the decimal model, and using the standard Tamil digits, '௦' '௧' '௨' '௩' '௪' '௫' '௬' '௭' '௮' '௯' in a decimal pattern.
Figure 3 Examples of counter values using the Tamil alphabetic counter style.
5.5 Styling initials
It is possible to find the first letter in a paragraph styled in a distinctive way.
Initials should not just include the first character on the line, but should include any associated combining characters.
If the first character is the beginning of the sequences க்ஷk͓ʂ, and ஶ்ரீʃ͓ɾī / ஸ்ரீs͓ɾī, all of the characters making up the conjunct should be included in the styling.
Any paragraph-initial punctuation such as opening quotes and opening parentheses should also be included in the initial styling.
Sunken and raised styles are not used by South Asian languages [ilreq]. Indian languages generally use the drop style or a boxed letter. Contour-filling is also not needed for Indian text [ilreq].
Figure 4 Two example paragraphs showing dropped highlighted initials.
For the drop style, the alphabetic baseline of the highlighted letter(s) should match the bottom of the row that determines the size of the highlighted letter(s). In box examples in Figure 4 the highlighted text is set to 3 lines in height. If the highlighted text descends below the baseline, an extra line is cleared to accommodate it. Tall vowel-signs rise slightly higher than the normal character height, and slightly exceed the height of the first line of text.
The exact positioning of the normal character height relative to the characters in the rest of the first line needs further research. The examples in Figure 4 show the default result for the Safari browser.
Another common approach in Indic text is to create a box around the enlarged letter(s), often with a background colour. In this case the box dimensions are associated with the other lines in the paragraph, and the highlighted letters float within the box.
A. Acknowledgements
Special thanks to the following people who contributed to this document (contributors' names listed in in alphabetic order).