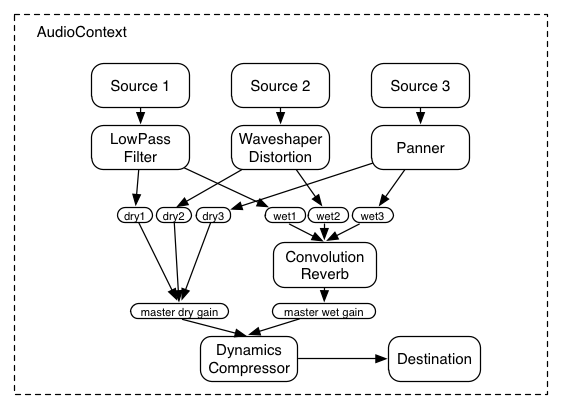
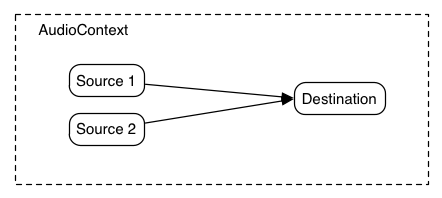
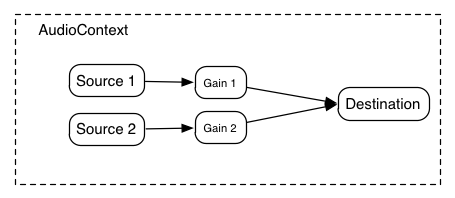
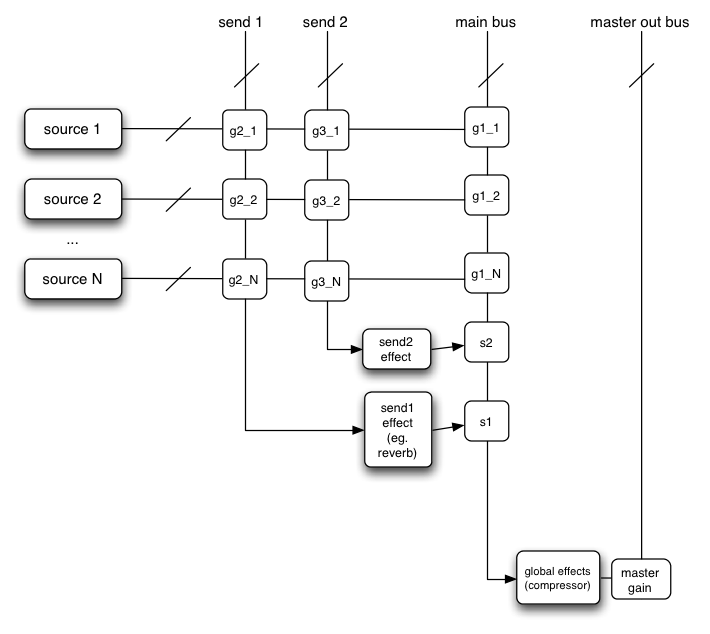
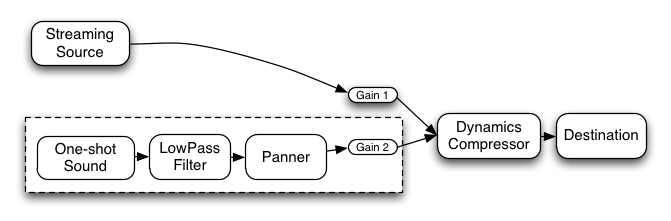
One of the most important considerations when dealing with audio processing graphs is how to adjust the gain (volume) at various points. For example, in a standard mixing board model,
each input bus has pre-gain, post-gain, and send-gains. Submix and master out busses also have gain control. The gain control described here can be used to implement
standard mixing boards as well as other architectures.
But many times, it's important to be able to control the gain for each of the output signals. The AudioGainNode gives this control:
Using these two concepts of unity gain summing junctions and AudioGainNodes, it's possible to construct simple or complex mixing scenarios.
In a routing scenario involving multiple sends and submixes, explicit control is needed over the volume or "gain" of each connection to a mixer.
Such routing topologies are very common and exist in even the simplest of electronic gear sitting around in a basic recording studio.
Here's an example with two send mixers and a main mixer. Although possible, for simplicity's sake, pre-gain control and insert effects are not illustrated:
This diagram is using a shorthand notation where "send 1", "send 2", and "main bus" are actually inputs to AudioNodes, but here are represented as summing busses,
where the intersections g2_1, g3_1, etc. represent the "gain" or volume for the given source on the given mixer.
In order to expose this gain, an AudioGainNode is used:
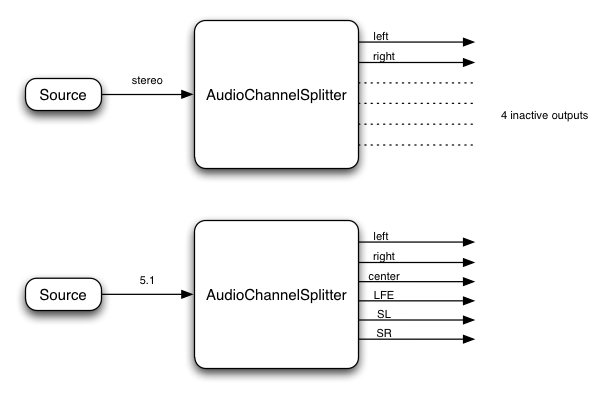
8. Channel Layouts
It's important to define the channel ordering (and define some abbreviations) for different layouts.
The channel layouts are clear:
Mono
0: M: mono
Stereo
0: L: left
1: R: right
A more advanced implementation can handle channel layouts for quad and 5.1:
Quad
0: L: left
1: R: right
2: SL: surround left
3: SR: surround right
5.1
0: L: left
1: R: right
2: C: center
3: LFE: subwoofer
4: SL: surround left
5: SR: surround right
Other layouts can also be considered.
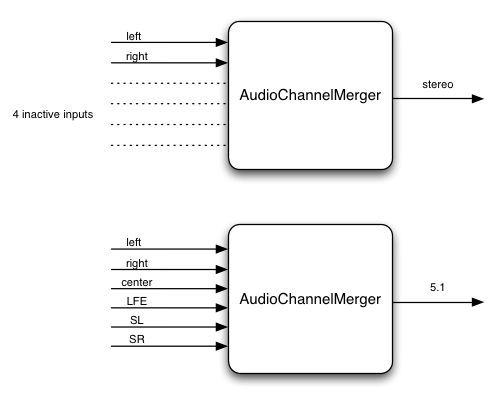
9. Channel up-mixing and down-mixing
For now, only considers cases for mono, stereo, quad, 5.1. Later other channel layouts can be defined.
Up Mixing
Consider what happens when converting an audio stream with a lower number of channels to one with a higher number of channels.
This can be necessary when mixing several outputs together where the channel layouts differ. It can also be necessary if the rendered audio
stream is played back on a system with more channels.
Mono up-mix:
1 -> 2 : equal-power up-mix from mono to stereo
output.L = 0.707 * input;
output.R = 0.707 * input;
1 -> 4 : equal-power up-mix from mono to quad
output.L = 0.707 * input;
output.R = 0.707 * input;
output.SL = 0;
output.SR = 0;
1 -> 5.1 : up-mix from mono to 5.1
output.L = 0;
output.R = 0;
output.C = input; // put in center channel
output.LFE = 0;
output.SL = 0;
output.SR = 0;
Stereo up-mix:
2 -> 4 : up-mix from stereo to quad
output.L = input.L;
output.R = input.R;
output.SL = 0;
output.SR = 0;
2 -> 5.1 : up-mix from stereo to 5.1
output.L = input.L;
output.R = input.R;
output.C = 0;
output.LFE = 0;
output.SL = 0;
output.SR = 0;
Quad up-mix:
4 -> 5.1 : up-mix from stereo to 5.1
output.L = input.L;
output.R = input.R;
output.C = 0;
output.LFE = 0;
output.SL = input.SL;
output.SR = input.SR;
Down Mixing
A down-mix will be necessary, for example, if processing 5.1 source material, but playing back stereo.
Mono down-mix:
2 -> 1 : stereo to mono
output = 0.5 * (input.L + input.R);
4 -> 1 : quad to mono
output = 0.25 * (input.L + input.R + input.SL + input.SR);
5.1 -> 1 : 5.1 to mono
???
Stereo down-mix:
4 -> 2 : quad to stereo
output.L = 0.5 * (input.L + input.SL);
output.R = 0.5 * (input.R + input.SR);
5.1 -> 2 : 5.1 to stereo
???
10. Event Scheduling
Need more detail here, but for now:
- Audio events such as start/stop play and volume fades can be scheduled to happen in a rhythmically perfect way (sample-accurate scheduling)
- Allows sequencing applications such as drum-machines, digital-dj mixers. Ultimately, it may be useful for DAW applications.
- Allows rhythmically accurate segueways from one section of music to another (as is possible with the FMOD engine)
- Allows scheduling of sound "grains" for granular synthesis effects.
11. Spatialization / Panning
Background
A common feature requirement for modern 3D games is the ability to dynamically spatialize and move multiple audio sources in 3D space.
Game audio engines such as OpenAL, FMOD, Creative's EAX, Microsoft's XACT Audio, etc. have this ability.
Using an AudioPannerNode, an audio stream can be spatialized or positioned in space relative to an AudioListener. An AudioContext will
contain a single AudioListener. Both panners and listeners have a position in 3D space using a cartesian coordinate system.
AudioPannerNode objects (representing the source stream) have an orientation vector representing in which direction the sound is projecting.
Additionally, they have a sound cone representing how directional the sound is. For example, the sound could be omnidirectional, in which case it would be heard
anywhere regardless of its orientation, or it can be more directional and heard only if it is facing the listener.
AudioListener objects (representing a person's ears) have an orientation and up vector representing in which direction the person is facing.
Because both the source stream and the listener can be moving, they both have a velocity vector representing both the speed and direction of movement. Taken together,
these two velocities can be used to generate a doppler shift effect which changes the pitch.
Panning Algorithm
The following algorithms can be implemented:
- Equal-power (Vector-based) panning
This is a simple and relatively inexpensive algorithm which provides basic, but reasonable results.
- Sound-field (Ambisonics)
Attempts to recreate the acoustic field.
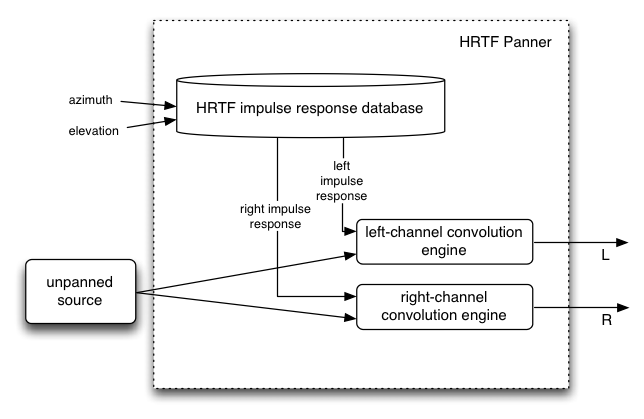
- HRTF panning (stereo only)
This requires a set of HRTF impulse responses recorded at a variety of azimuths and elevations. There are a small number of open/free impulse responses available.
The implementation requires a highly optimized convolution function. It is somewhat more costly than "equal-power", but provides a more spatialized sound.
- Pass-through
This is mostly useful for stereo sources to pass the left/right channels unpanned to the left/right speakers. Similarly for 5.0 sources,
the channels can be passed unchanged.
Distance Effects
- Sources farther away are typically quieter than nearer ones.
- Different rolloff curves are assignable per-source: linear, inverse, exponential
Sound Cones
The listener and each sound source have an orientation vector describing which way they are facing.
Each sound source's sound projection characteristics are described by an inner and outer "cone" describing the
sound intensity as a function of the source/listener angle from the source's orientation vector. Thus, a sound source
pointing directly at the listener will be louder than if it is pointed off-axis. Sound sources can also be omni-directional.
Doppler Shift
- Introduces a pitch shift which can realistically simulate moving sources
- Depends on: source / listener velocity vectors, speed of sound, doppler factor
12. Linear Effects using Convolution
Background
Convolution is a mathematical process which can be applied to an audio signal to achieve many interesting high-quality linear effects.
Very often, the effect is used to simulate an acoustic space such as a concert hall, cathedral, or outdoor amphitheater. It can also
be used for complex filter effects, like a muffled sound coming from inside a closet, sound underwater, sound coming through a telephone,
or playing through a vintage speaker cabinet. This technique is very commonly used in major motion picture and music production and is
considered to be extremely versatile and of high quality.
Each unique effect is defined by an impulse response. An impulse response can be represented as an audio file and can be recorded from
a real acoustic space such as a cave, or can be synthetically generated through a great variety of techniques.
Motivation for use as a Standard
A key feature of many game audio engines (OpenAL, FMOD, Creative's EAX, Microsoft's XACT Audio, etc.) is a reverberation effect for simulating the sound of being in an acoustic space.
But the code used to generate the effect has generally been custom and algorithmic (generally using
a hand-tweaked set of delay lines and allpass filters which feedback into each other). In nearly all cases, not only is the implementation custom, but
the code is proprietary and closed-source, each company adding its own "black magic" to achieve its unique quality.
Each implementation being custom with a different set of parameters makes it impossible to achieve a uniform desired effect. And the code
being proprietary makes it impossible to adopt a single one of the implementations as a standard. Additionally, algorithmic reverberation effects
are limited to a relatively narrow range of different effects, regardless of how the parameters are tweaked.
A convolution effect solves these problems by using a very precisely defined mathematical algorithm as the basis of its processing.
An impulse response represents an exact sound effect to be applied to an audio stream and
is easily represented by an audio file which can be referenced by URL. The range of possible effects is enormous.
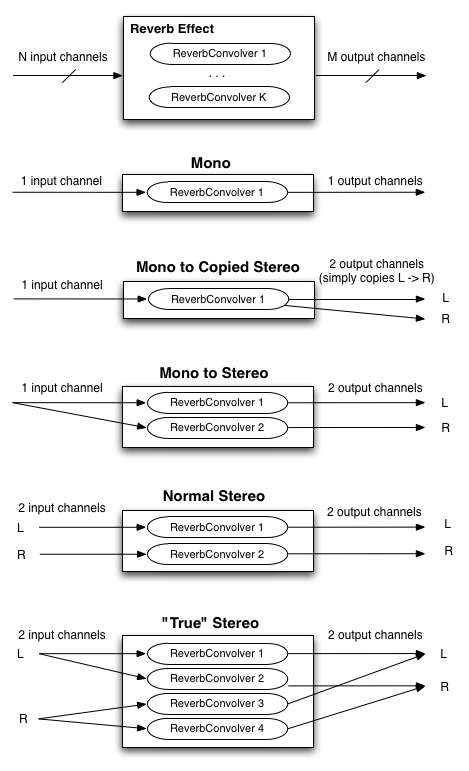
Reverb Effect (with matrixing)
Single channel convolution operates on a mono audio source, using a mono impulse response. But to achieve a more spacious sound,
multi-channel audio sources and impulse responses must be considered. Audio sources and playback systems can be stereo, 5.1, or more
channels. In the general case the source has N input channels, the impulse response has K channels, and the playback system has M output channels.
Thus it's a matter of how to matrix these channels to achieve the final result. The following diagram, illustrates the common cases for stereo
playback where N, K, and M are all less than or equal to 2. Similarly, the matrixing for 5.1 and other playback configurations can be defined.
Recording Impulse Responses
This section is informative.
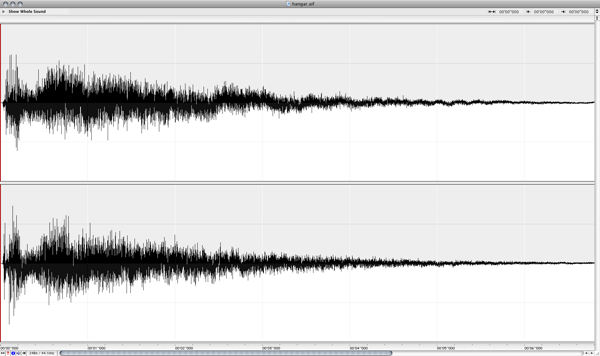
The most modern
and accurate way to record the impulse response of a real acoustic space is to use
a long exponential sine sweep. The test-tone can be as long as 20 or 30 seconds, or longer.
Several recordings of the
test tone played through a speaker can be made with microphones placed and oriented at various positions in the room. It's important
to document speaker placement/orientation, the types of microphones, their settings, placement, and orientations for each recording taken.
Post-processing is required for each of these recordings by performing an inverse-convolution with the test tone,
yielding the impulse response of the room with the corresponding microphone placement. These impulse responses are then
ready to be loaded into the convolution reverb engine to re-create the sound of being in the room.
Two command-line tools have been written:
generate_testtones generates an exponential sine-sweep test-tone and its inverse. Another
tool convolve was written for post-processing. With these tools, anybody with recording equipment can record their own impulse responses.
To test the tools in practice, several recordings were made in a warehouse space with interesting
acoustics. These were later post-processed with the command-line tools.
% generate_testtones -h
Usage: generate_testtone
[-o /Path/To/File/To/Create] Two files will be created: .tone and .inverse
[-rate <sample rate>] sample rate of the generated test tones
[-duration <duration>] The duration, in seconds, of the generated files
[-min_freq <min_freq>] The minimum frequency, in hertz, for the sine sweep
% convolve -h
Usage: convolve input_file impulse_response_file output_file
Recording Setup

Audio Interface: Metric Halo Mobile I/O 2882



Microphones: AKG 414s, Speaker: Mackie HR824
The Warehouse Space

13. JavaScript Synthesis and Processing
This section is informative.
The Mozilla project has conducted Experiments to synthesize and process audio directly in JavaScript.
This approach is interesting for a certain class of audio processing and they have produced a number of impressive demos. This specification includes
a means of synthesizing and processing directly using JavaScript by using a special subtype of AudioNode
called JavaScriptAudioNode.
Here are some interesting examples where direct JavaScript processing can be useful:
Custom DSP Effects
Unusual and interesting custom audio processing can be done directly in JS.
It's also a good test-bed for prototyping new algorithms. This is an extremely rich area.
JS processing is ideal for illustrating concepts in computer music synthesis and processing,
such as showing the de-composition of a square wave into its harmonic components, FM synthesis techniques, etc.
JavaScript has a variety of performance issues so it is not suitable for all types of audio processing.
The approach proposed in this document includes the ability to perform computationally intensive aspects of the audio processing (too expensive for JavaScript to compute in real-time)
such as multi-source 3D spatialization and convolution in optimized C++ code. Both direct JavaScript processing and C++ optimized code can be combined due to the APIs
modular approach.
14. Realtime Analysis
15.2. Audio Glitching
Audio glitches are caused by an interruption of the normal continuous audio stream, resulting in loud clicks and pops. It is considered to be
a catastrophic failure of a multi-media system and must be avoided. It can be caused by problems with the threads responsible for delivering the audio
stream to the hardware, such as scheduling latencies caused by threads not having the proper priority and time-constraints. It can also be caused by
the audio DSP trying to do more work than is possible in real-time given the CPU's speed.
15.3. Hardware Scalability
The system should gracefully degrade to allow audio processing under resource constrained conditions without dropping audio frames.
First of all, it should be clear that regardless of the platform, the audio processing load should never be enough to completely lock up the
machine. Second, the audio rendering needs to produce a clean, un-interrupted audio stream without audible
glitches.
The system should be able to run on a range of hardware, from mobile phones and tablet devices to laptop and desktop computers.
But the more limited compute resources on a phone device make it necessary to consider techniques to scale back and reduce the complexity
of the audio rendering. For example, voice-dropping algorithms can be implemented to reduce the total number of notes playing at any given time.
Here's a list of some techniques which can be used to limit CPU usage:
15.3.1. CPU monitoring
In order to avoid audio breakup, CPU usage must remain below 100%.
The relative CPU usage can be dynamically measured for each AudioNode (and chains of connected nodes) as a percentage of the rendering time
quantum. In a single-threaded implementation, overall CPU usage must remain below 100%. The measured usage may be used internally in the implementation
for dynamic adjustments to the rendering. It may also be exposed through a cpuUsage attribute of AudioNode
for use by JavaScript.
In cases where the measured CPU usage is near 100% (or whatever threshold is considered too high), then an attempt to add additional
AudioNodes into the rendering graph can trigger voice-dropping.
15.3.2. Voice Dropping
Voice-dropping is a technique which limits the number of voices (notes) playing at the same time to keep CPU usage within a reasonable range.
There can either be an upper threshold on the total number of voices allowed at any given time, or CPU usage can be dynamically monitored
and voices dropped when CPU usage exceeds a threshold. Or a combination of these two techniques can be applied. When CPU usage is monitored
for each voice, it can be measured all the way from the AudioSourceNode through any effect processing nodes which apply uniquely to that voice.
When a voice is "dropped", it
needs to happen in such a way that it doesn't introduce audible clicks or pops into the rendered audio stream. One way to achieve this is to
quickly fade-out the rendered audio for that voice before completely removing it from the rendering graph.
When it is determined that one or more voices must be dropped, there are various strategies for picking which voice(s) to drop out of the
total ensemble of voices currently playing. Here are some of the factors which can be used in combination to help with this decision:
- Older voices, which have been playing the longest can be dropped instead of more recent voices.
- Quieter voices, which are contributing less to the overall mix may be dropped instead of louder ones.
- Voices which are consuming relatively more CPU resources may be dropped instead of less "expensive" voices.
- An AudioNode can have a
priority attribute to help determine the relative importance of the voices.
15.3.3. Simplification of Effects Processing
Most of the effects described in this document are relatively inexpensive and will likely be able to run even on the slower mobile devices.
However, the convolution effect can be configured with a variety of impulse responses, some of which
will likely be too heavy for mobile devices. Generally speaking, CPU usage scales with the length of the impulse response and the number of channels it has. Thus, it is reasonable to consider that impulse responses which exceed a certain length will not be allowed to run.
The exact limit can be determined based on the speed of the device. Instead of outright rejecting convolution with these long responses,
it may be interesting to consider truncating the impulse responses to the maximum allowed length and/or reducing the number of channels
of the impulse response.
In addition to the convolution effect. The AudioPannerNode may also be expensive
if using the HRTF panning model. For slower devices, a cheaper algorithm such as EQUALPOWER can be used to conserve compute resources.
15.3.4. Sample Rate
For very slow devices, it may be worth considering running the rendering at a lower sample-rate than normal. For example, the sample-rate
can be reduced from 44.1KHz to 22.05KHz. This decision must be made when the AudioContext is created, because changing the sample-rate on-the-fly can be difficult
to implement and will result in audible glitching when the transition is made.
15.3.5. Pre-flighting
It should be possible to invoke some kind of "pre-flighting" code (through JavaScript) to roughly determine the power of the machine.
The JavaScript code can then use this information to scale back any more intensive processing it may normally run on a more powerful machine.
Also, the underlying implementation may be able to factor in this information in the voice-dropping algorithm.
TODO: add specification and more detail here
15.3.6. Authoring for different user agents
JavaScript code can use information about user-agent to scale back any more intensive processing it may normally run on a more powerful machine.
15.3.7. Scalability of Direct JavaScript Synthesis / Processing
Any audio DSP / processing code done directly in JavaScript should also be concerned about scalability. To the extent possible, the JavaScript
code itself needs to monitor CPU usage and scale back any more ambitious processing when run on less powerful devices. If it's an "all or nothing" type of processing, then user-agent check or pre-flighting should be done to avoid generating an audio stream with audio breakup.
16. Example Applications
This section is informative.
Please see the demo page for working examples.
Here are some of the types of applications a web audio system should be able to support:
Basic Sound Playback
Simple and low-latency playback of sound effects in response to simple user actions such as mouse click, roll-over, key press.
3D Environments and Games


An HTML5 version of Quake has already been created. Audio features such as 3D spatialization and convolution for room simulation could be used to great effect.
3D environments with audio are common in games made for desktop applications and game consoles.
Imagine a 3D island environment with spatialized audio, seagulls flying overhead, the waves crashing against the shore, the
crackling of the fire, the creaking of the bridge, and the rustling of the trees in the wind. The sounds can be positioned
naturally as one moves through the scene. Even going underwater, low-pass filters can be tweaked for just the right underwater sound.

Box2D is an interesting open-source library for 2D game physics. It has various implementations, including one
based on Canvas 2D. A demo has been created with dynamic sound effects for each of the object collisions, taking into account the velocities vectors and
positions to spatialize the sound events, and modulate audio effect parameters such as filter cutoff.
A virtual pool game with multi-sampled sound effects has also been created.
Musical Applications


Many music composition and production applications are possible. Applications requiring tight scheduling of audio events can be implemented and can be both educational and entertaining. Drum machines, digital DJ applications, and even timeline-based digital music production software with some of the features of
GarageBand can be written.
Music Visualizers

When combined with WebGL GLSL shaders, realtime analysis data can be presented in entertaining ways. These can be as advanced as any found in iTunes.
Educational Applications

A variety of educational applications can be written, illustrating concepts in music theory and computer music synthesis and processing.
Artistic Audio Exploration
There are many creative possibilites for artistic sonic environments for installation pieces.