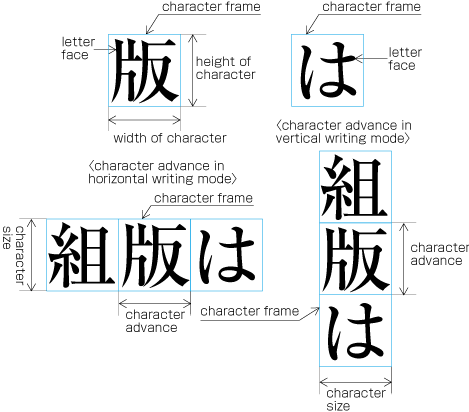
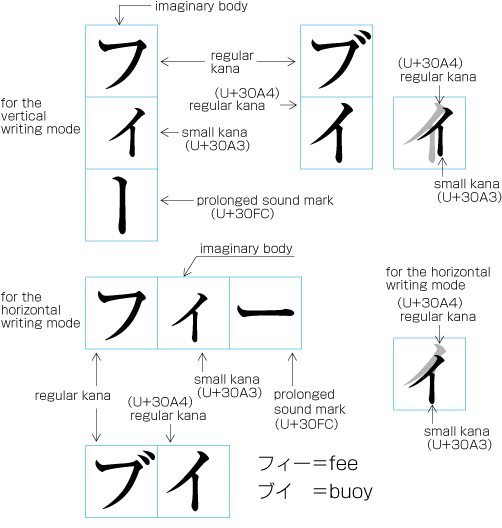
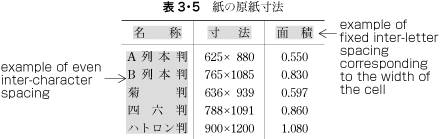
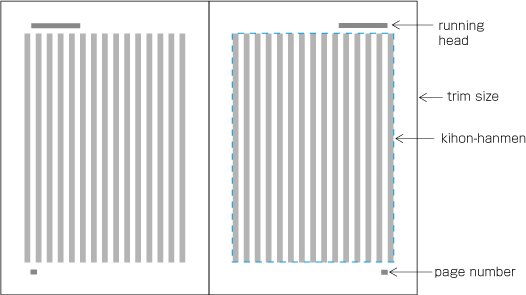
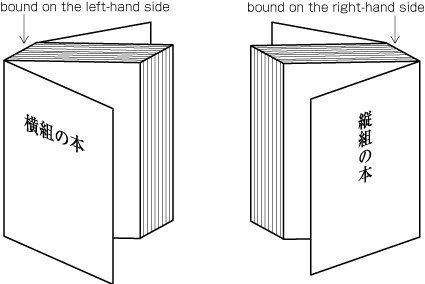
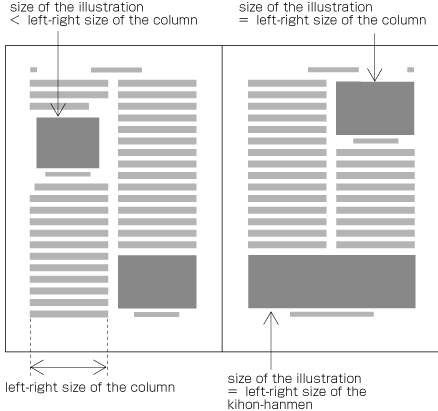
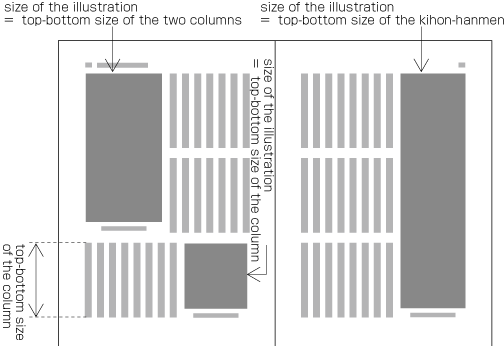
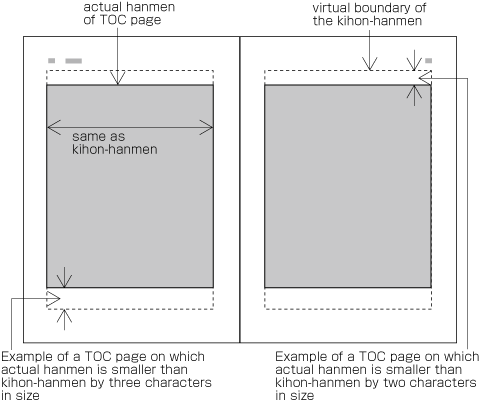
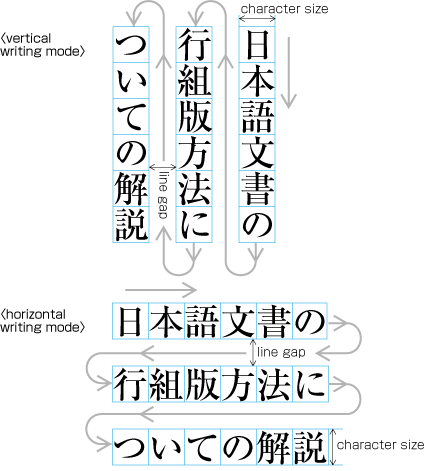
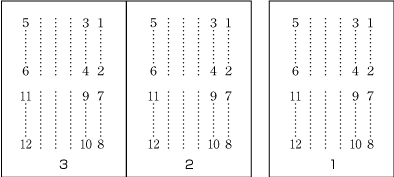
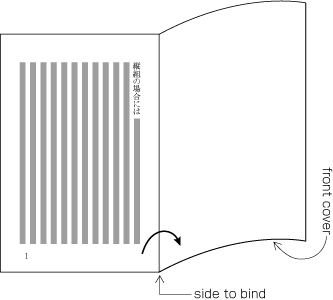
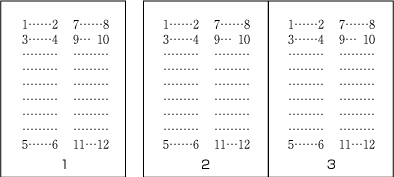
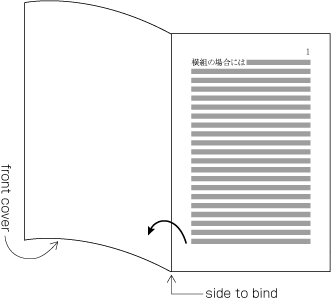
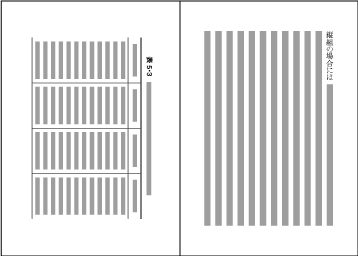
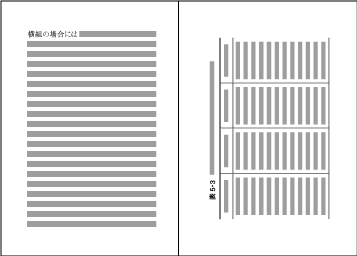
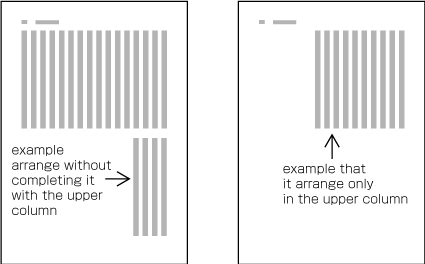
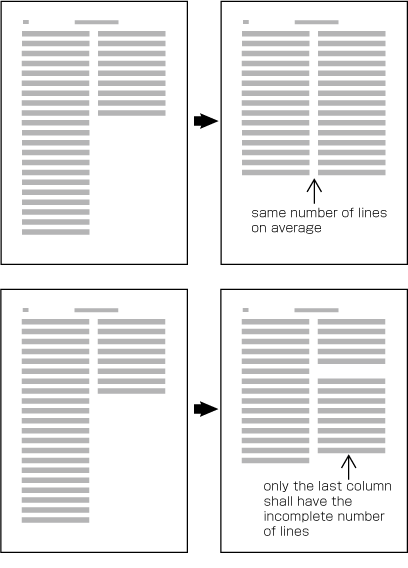
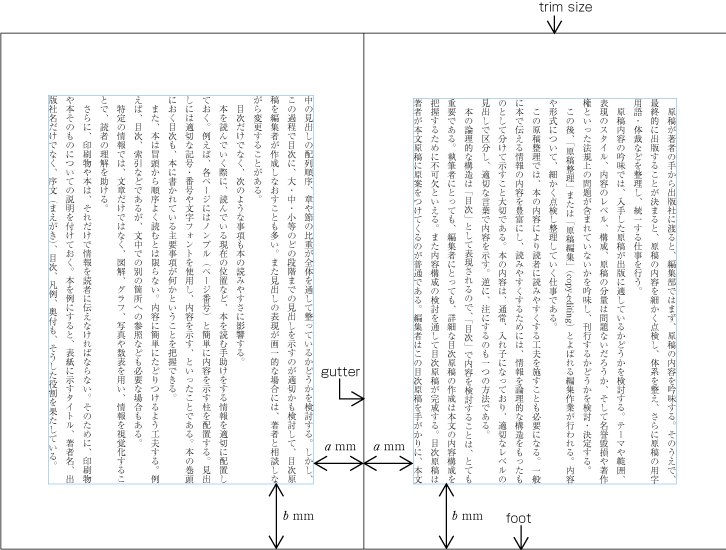
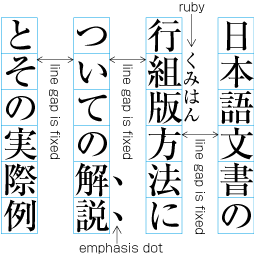
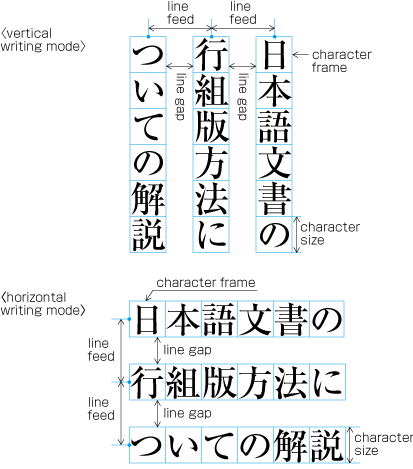
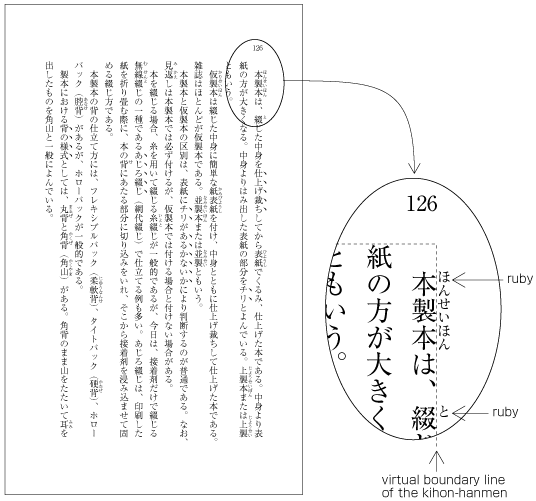
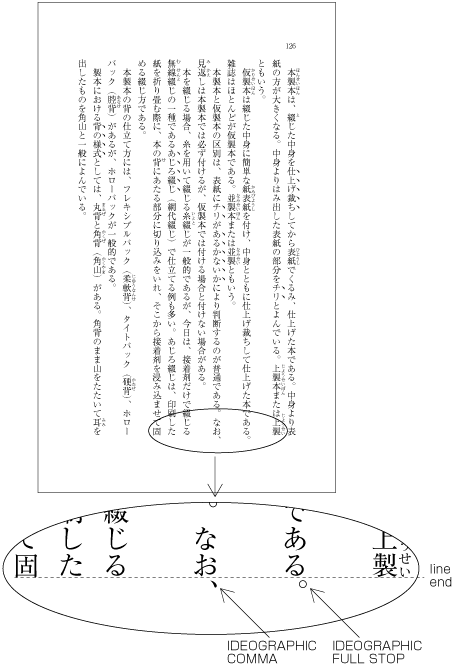
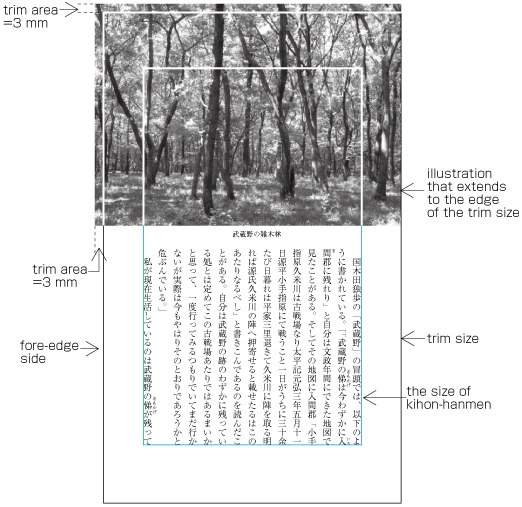
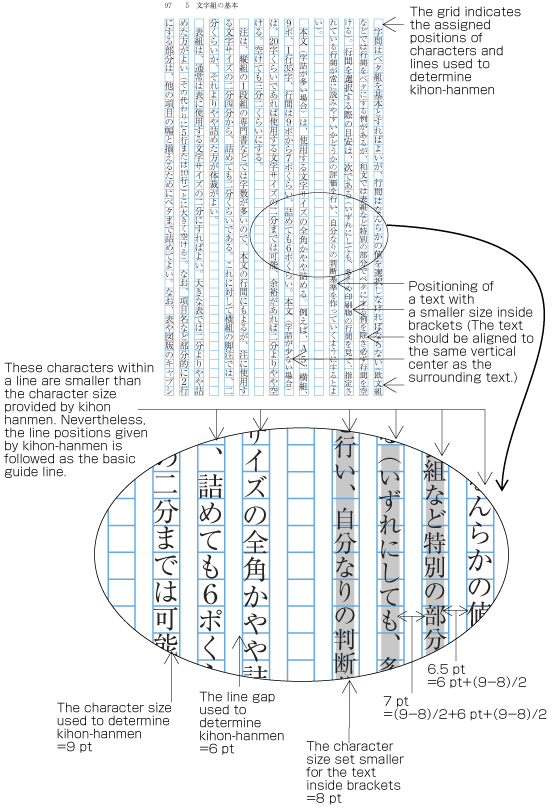
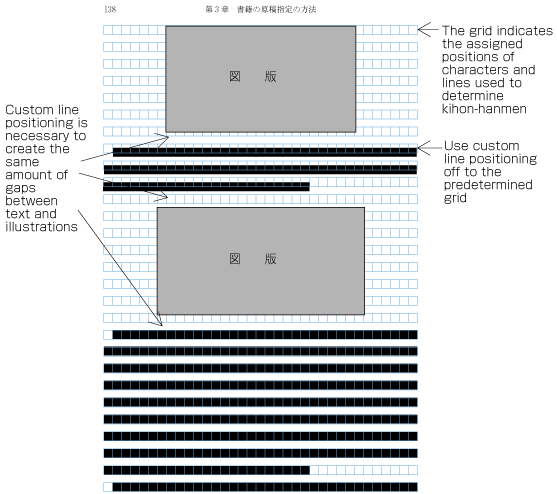
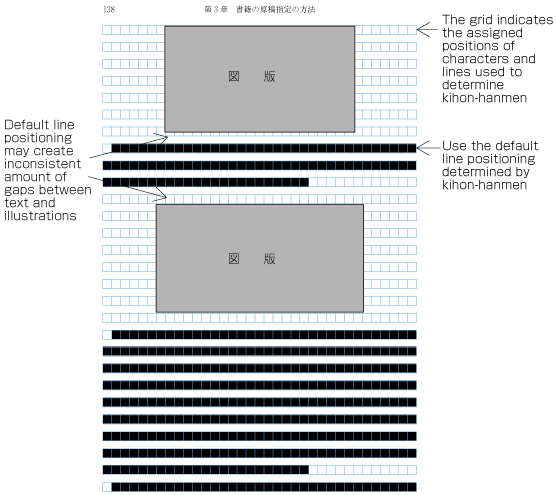
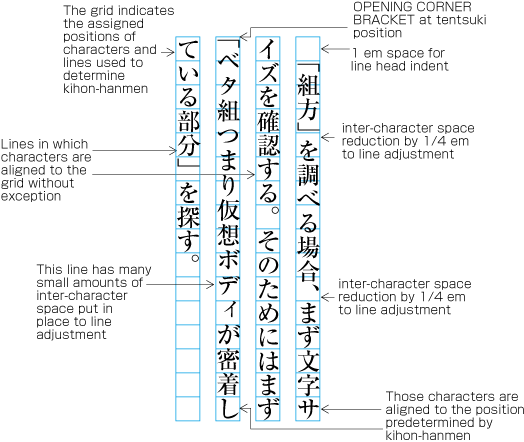
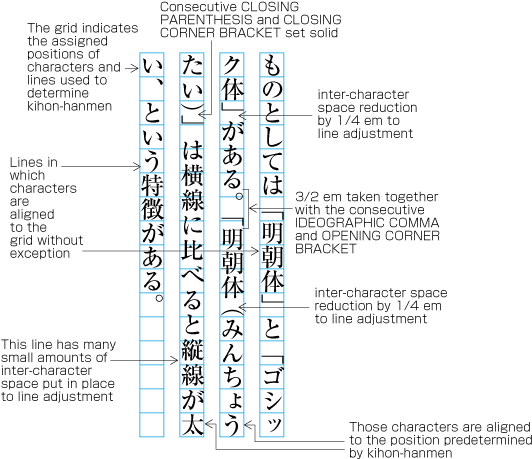
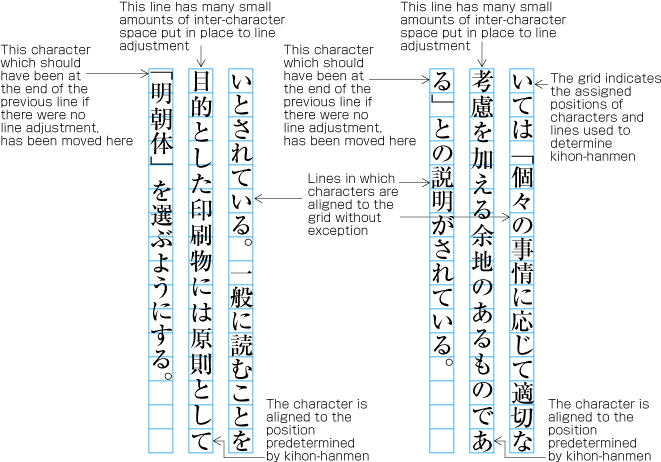
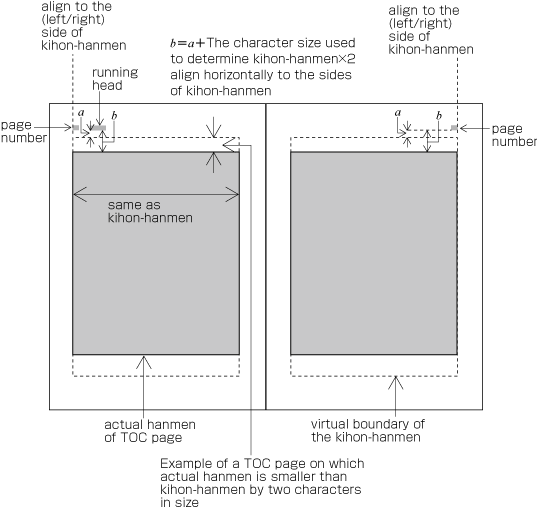
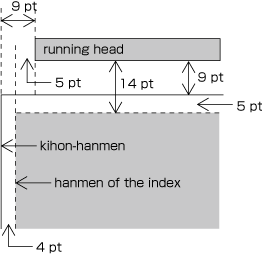
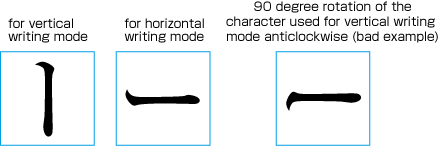
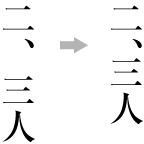
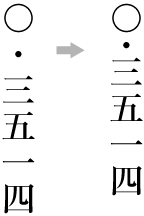
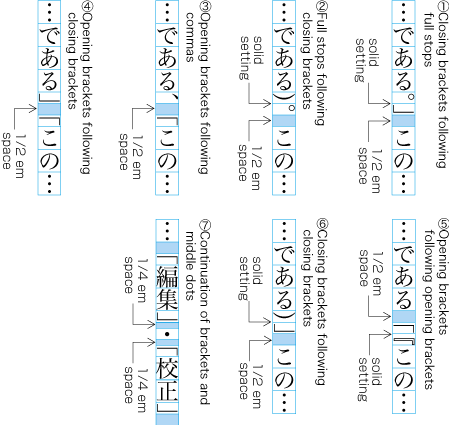
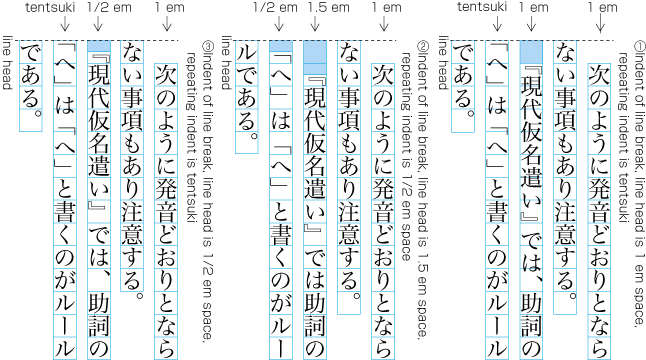
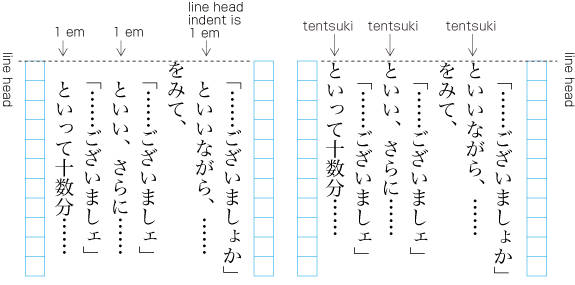
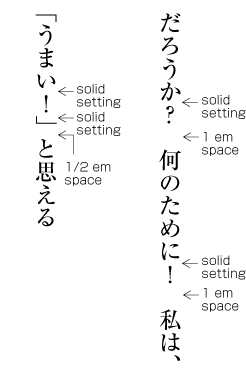
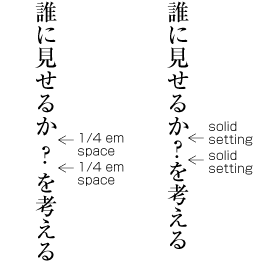
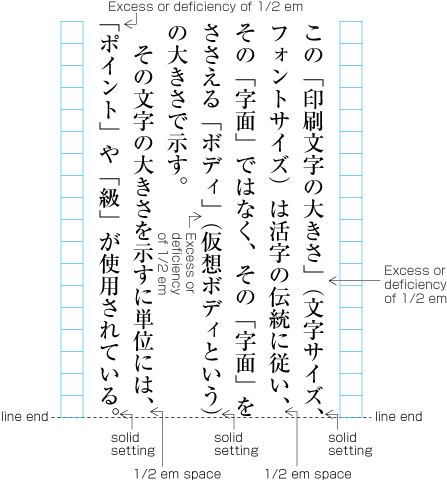
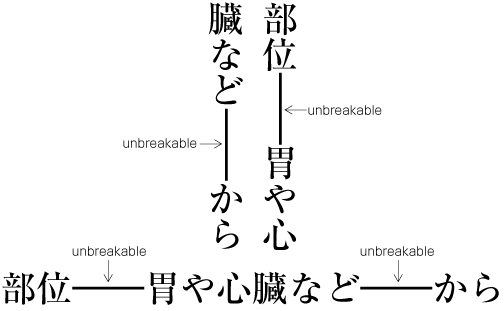
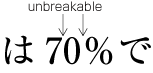
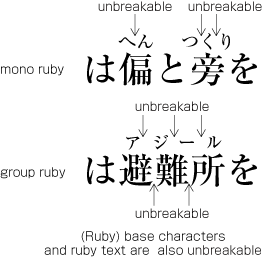
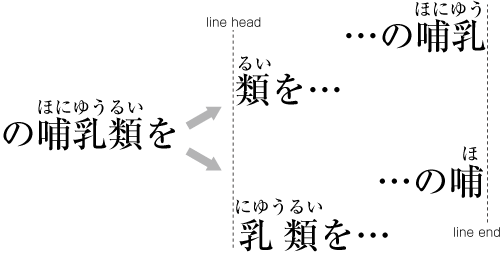
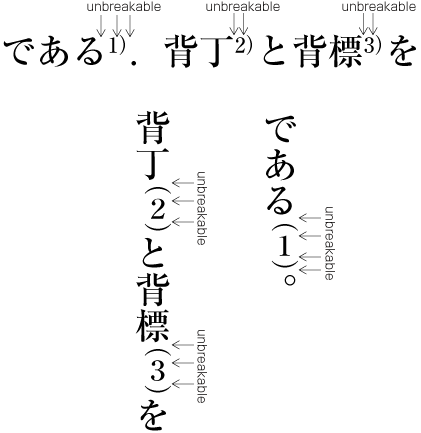
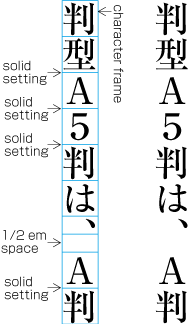
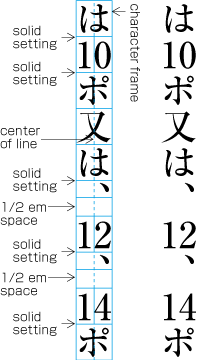
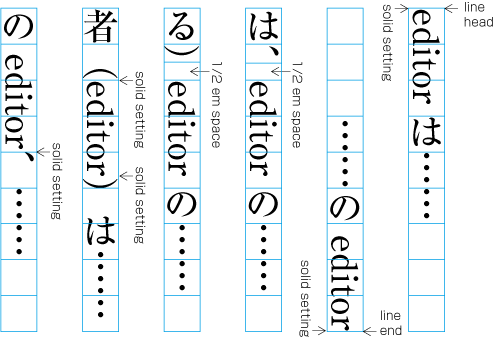
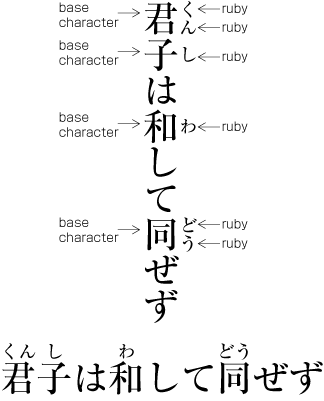
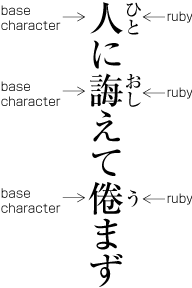
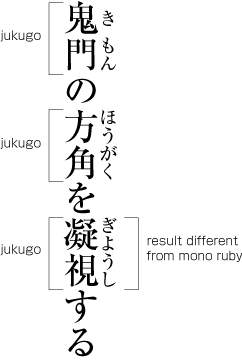
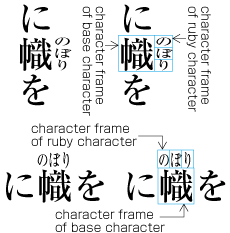
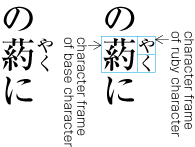
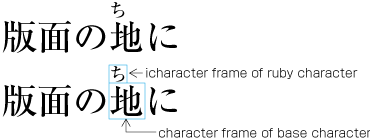
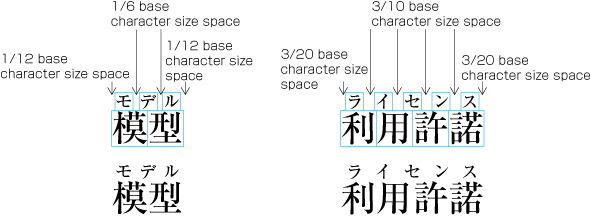
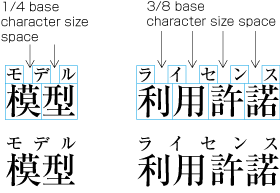
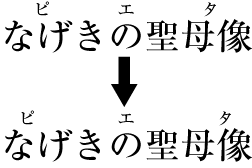
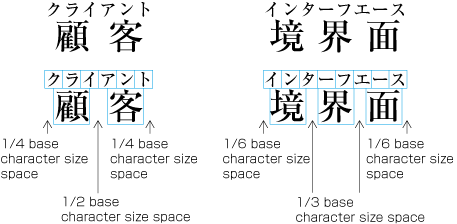
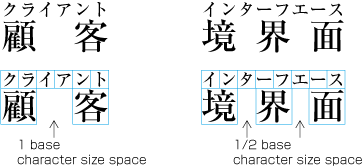
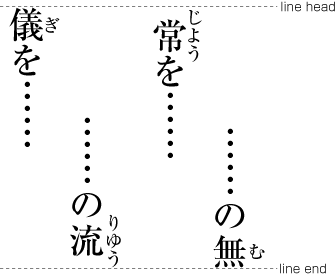
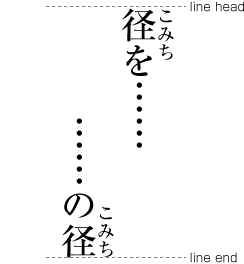
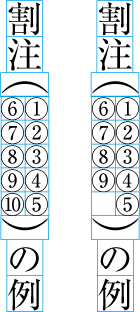
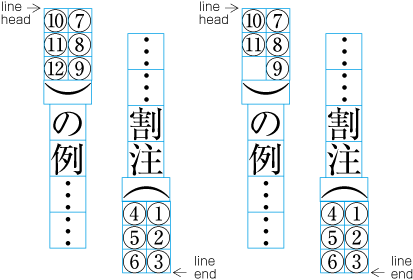
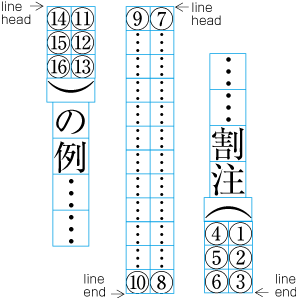
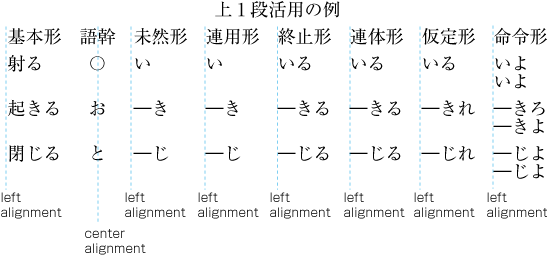
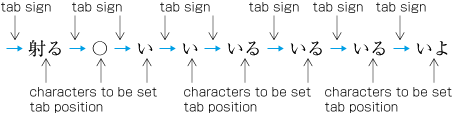
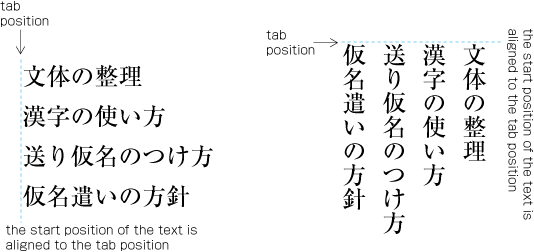
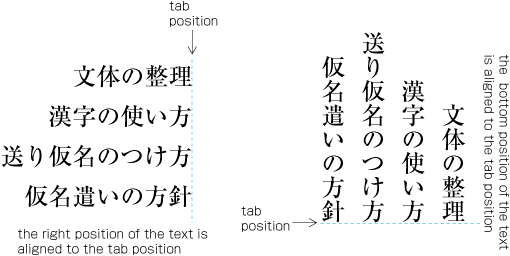
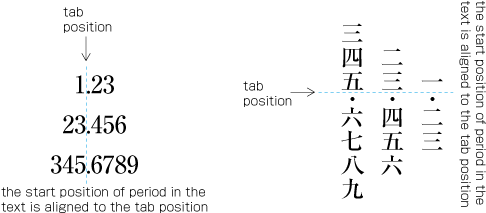
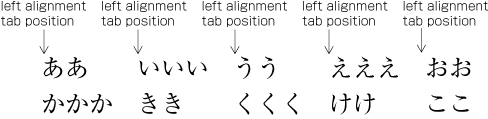
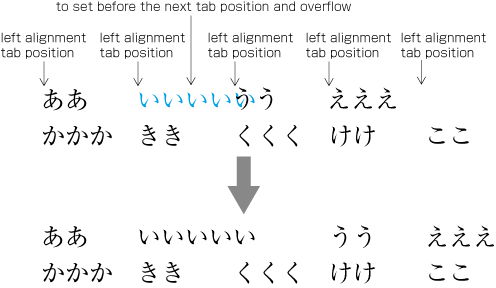
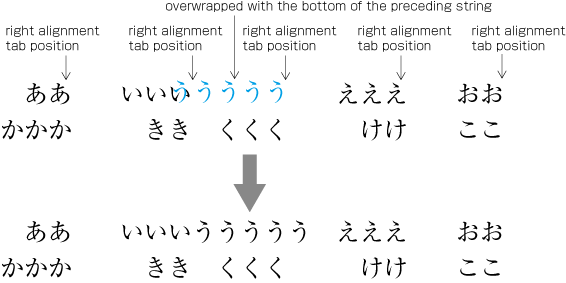
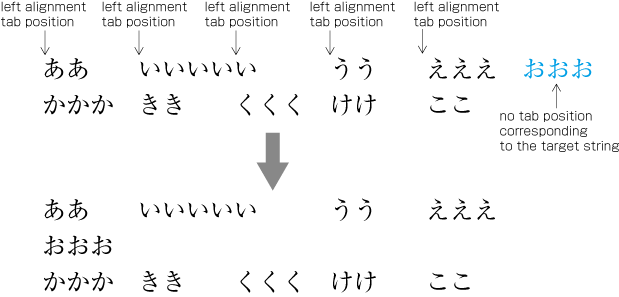
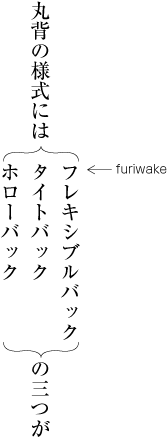
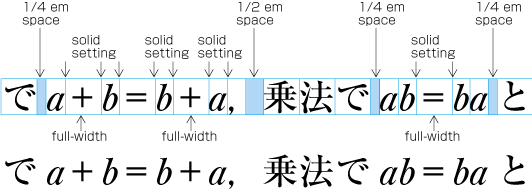
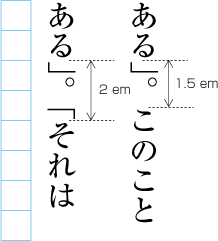
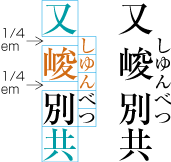
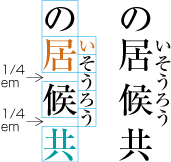
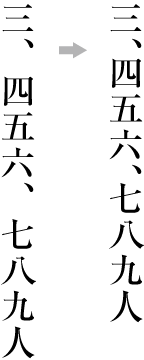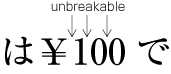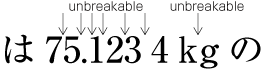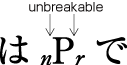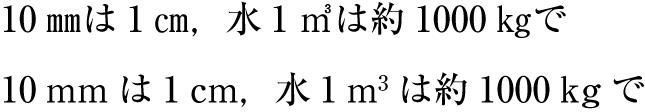| , | 002C | COMMA | proportional |
| . | 002E | FULL STOP | proportional |
| : | 003A | COLON | proportional |
| ; | 003B | SEMICOLON | proportional |
| ? | 003F | QUESTION MARK | proportional |
| ! | 0021 | EXCLAMATION MARK | proportional |
| ´ | 00B4 | ACUTE ACCENT | proportional |
| ` | 0060 | GRAVE ACCENT | proportional |
| ¨ | 00A8 | DIAERESIS | proportional |
| ^ | 005E | CIRCUMFLEX ACCENT | proportional |
| ‾ | 203E | OVERLINE | proportional |
| _ | 005F | LOW LINE | proportional |
| — | 2014 | EM DASH | proportional |
| ‐ | 2010 | HYPHEN | proportional |
| / | 002F | SOLIDUS | proportional |
| \ | 005C | REVERSE SOLIDUS | proportional |
| ‖ | 2016 | DOUBLE VERTICAL LINE | proportional |
| | | 007C | VERTICAL LINE | proportional |
| … | 2026 | HORIZONTAL ELLIPSIS | proportional |
| ‥ | 2025 | TWO DOT LEADER | proportional |
| ‘ | 2018 | LEFT SINGLE QUOTATION MARK | proportional |
| ’ | 2019 | RIGHT SINGLE QUOTATION MARK | proportional |
| “ | 201C | LEFT DOUBLE QUOTATION MARK | proportional |
| ” | 201D | RIGHT DOUBLE QUOTATION MARK | proportional |
| ( | 0028 | LEFT PARENTHESIS | proportional |
| ) | 0029 | RIGHT PARENTHESIS | proportional |
| [ | 005B | LEFT SQUARE BRACKET | proportional |
| ] | 005D | RIGHT SQUARE BRACKET | proportional |
| { | 007B | LEFT CURLY BRACKET | proportional |
| } | 007D | RIGHT CURLY BRACKET | proportional |
| + | 002B | PLUS SIGN | proportional |
| − | 2212 | MINUS SIGN | proportional |
| ± | 00B1 | PLUS-MINUS SIGN | proportional |
| × | 00D7 | MULTIPLICATION SIGN | proportional |
| ÷ | 00F7 | DIVISION SIGN | proportional |
| = | 003D | EQUALS SIGN | proportional |
| ≠ | 2260 | NOT EQUAL TO | proportional |
| < | 003C | LESS-THAN SIGN | proportional |
| > | 003E | GREATER-THAN SIGN | proportional |
| ≦ | 2266 | LESS-THAN OVER EQUAL TO | proportional |
| ≧ | 2267 | GREATER-THAN OVER EQUAL TO | proportional |
| ∴ | 2234 | THEREFORE | proportional |
| ♂ | 2642 | MALE SIGN | proportional |
| ♀ | 2640 | FEMALE SIGN | proportional |
| ° | 00B0 | DEGREE SIGN | proportional |
| ′ | 2032 | PRIME | proportional |
| ″ | 2033 | DOUBLE PRIME | proportional |
| ¥ | 00A5 | YEN SIGN | proportional |
| $ | 0024 | DOLLAR SIGN | proportional |
| ¢ | 00A2 | CENT SIGN | proportional |
| £ | 00A3 | POUND SIGN | proportional |
| % | 0025 | PERCENT SIGN | proportional |
| # | 0023 | NUMBER SIGN | proportional |
| & | 0026 | AMPERSAND | proportional |
| * | 002A | ASTERISK | proportional |
| @ | 0040 | COMMERCIAL AT | proportional |
| § | 00A7 | SECTION SIGN | proportional |
| ☆ | 2606 | WHITE STAR | proportional |
| ★ | 2605 | BLACK STAR | proportional |
| ○ | 25CB | WHITE CIRCLE | proportional |
| ● | 25CF | BLACK CIRCLE | proportional |
| ◎ | 25CE | BULLSEYE | proportional |
| ◇ | 25C7 | WHITE DIAMOND | proportional |
| ◆ | 25C6 | BLACK DIAMOND | proportional |
| □ | 25A1 | WHITE SQUARE | proportional |
| ■ | 25A0 | BLACK SQUARE | proportional |
| △ | 25B3 | WHITE UP-POINTING TRIANGLE | proportional |
| ▲ | 25B2 | BLACK UP-POINTING TRIANGLE | proportional |
| ▽ | 25BD | WHITE DOWN-POINTING TRIANGLE | proportional |
| ▼ | 25BC | BLACK DOWN-POINTING TRIANGLE | proportional |
| → | 2192 | RIGHTWARDS ARROW | proportional |
| ← | 2190 | LEFTWARDS ARROW | proportional |
| ↑ | 2191 | UPWARDS ARROW | proportional |
| ↓ | 2193 | DOWNWARDS ARROW | proportional |
| ' | 0027 | APOSTROPHE | proportional |
| " | 0022 | QUOTATION MARK | proportional |
| - | 002D | HYPHEN-MINUS | proportional |
| ~ | 007E | TILDE | proportional |
| ∞ | 221E | INFINITY | proportional |
| ∈ | 2208 | ELEMENT OF | proportional |
| ∋ | 220B | CONTAINS AS MEMBER | proportional |
| ⊆ | 2286 | SUBSET OF OR EQUAL TO | proportional |
| ⊇ | 2287 | SUPERSET OF OR EQUAL TO | proportional |
| ⊂ | 2282 | SUBSET OF | proportional |
| ⊃ | 2283 | SUPERSET OF | proportional |
| ∪ | 222A | UNION | proportional |
| ∩ | 2229 | INTERSECTION | proportional |
| ⊄ | 2284 | NOT A SUBSET OF | proportional |
| ⊅ | 2285 | NOT A SUPERSET OF | proportional |
| ⊊ | 228A | SUBSET OF WITH NOT EQUAL TO | proportional |
| ⊋ | 228B | SUPERSET OF WITH NOT EQUAL TO | proportional |
| ∉ | 2209 | NOT AN ELEMENT OF | proportional |
| ∅ | 2205 | EMPTY SET | proportional |
| ⌅ | 2305 | PROJECTIVE | proportional |
| ⌆ | 2306 | PERSPECTIVE | proportional |
| ∧ | 2227 | LOGICAL AND | proportional |
| ∨ | 2228 | LOGICAL OR | proportional |
| ¬ | 00AC | NOT SIGN | proportional |
| ⇒ | 21D2 | RIGHTWARDS DOUBLE ARROW | proportional |
| ⇔ | 21D4 | LEFT RIGHT DOUBLE ARROW | proportional |
| ∀ | 2200 | FOR ALL | proportional |
| ∃ | 2203 | THERE EXISTS | proportional |
| ⊕ | 2295 | CIRCLED PLUS | proportional |
| ⊖ | 2296 | CIRCLED MINUS | proportional |
| ⊗ | 2297 | CIRCLED TIMES | proportional |
| ∥ | 2225 | PARALLEL TO | proportional |
| ∦ | 2226 | NOT PARALLEL TO | proportional |
| ∠ | 2220 | ANGLE | proportional |
| ⊥ | 22A5 | UP TACK | proportional |
| ⌒ | 2312 | ARC | proportional |
| ∂ | 2202 | PARTIAL DIFFERENTIAL | proportional |
| ∇ | 2207 | NABLA | proportional |
| ≡ | 2261 | IDENTICAL TO | proportional |
| ≒ | 2252 | APPROXIMATELY EQUAL TO OR THE IMAGE OF | proportional |
| ≪ | 226A | MUCH LESS-THAN | proportional |
| ≫ | 226B | MUCH GREATER-THAN | proportional |
| √ | 221A | SQUARE ROOT | proportional |
| ∽ | 223D | REVERSED TILDE (lazy S) | proportional |
| ∝ | 221D | PROPORTIONAL TO | proportional |
| ∵ | 2235 | BECAUSE | proportional |
| ∫ | 222B | INTEGRAL | proportional |
| ∬ | 222C | DOUBLE INTEGRAL | proportional |
| ≢ | 2262 | NOT IDENTICAL TO | proportional |
| ≃ | 2243 | ASYMPTOTICALLY EQUAL TO | proportional |
| ≅ | 2245 | APPROXIMATELY EQUAL TO | proportional |
| ≈ | 2248 | ALMOST EQUAL TO | proportional |
| ≶ | 2276 | LESS-THAN OR GREATER-THAN | proportional |
| ≷ | 2277 | GREATER-THAN OR LESS-THAN | proportional |
| ↔ | 2194 | LEFT RIGHT ARROW | proportional |
| Å | 212B | ANGSTROM SIGN | proportional |
| ‰ | 2030 | PER MILLE SIGN | proportional |
| ♯ | 266F | MUSIC SHARP SIGN | proportional |
| ♭ | 266D | MUSIC FLAT SIGN | proportional |
| ♪ | 266A | EIGHTH NOTE | proportional |
| † | 2020 | DAGGER | proportional |
| ‡ | 2021 | DOUBLE DAGGER | proportional |
| ¶ | 00B6 | PILCROW SIGN | proportional |
| ♮ | 266E | MUSIC NATURAL SIGN | proportional |
| ♫ | 266B | BEAMED EIGHTH NOTES | proportional |
| ♬ | 266C | BEAMED SIXTEENTH NOTES | proportional |
| ♩ | 2669 | QUARTER NOTE | proportional |
| ◯ | 25EF | LARGE CIRCLE | proportional |
| ▷ | 25B7 | WHITE RIGHT-POINTING TRIANGLE | proportional |
| ▶ | 25B6 | BLACK RIGHT-POINTING TRIANGLE | proportional |
| ◁ | 25C1 | WHITE LEFT-POINTING TRIANGLE | proportional |
| ◀ | 25C0 | BLACK LEFT-POINTING TRIANGLE | proportional |
| ↗ | 2197 | NORTH EAST ARROW | proportional |
| ↘ | 2198 | SOUTH EAST ARROW | proportional |
| ↖ | 2196 | NORTH WEST ARROW | proportional |
| ↙ | 2199 | SOUTH WEST ARROW | proportional |
| ⇄ | 21C4 | RIGHTWARDS ARROW OVER LEFTWARDS ARROW | proportional |
| ⇨ | 21E8 | RIGHTWARDS WHITE ARROW | proportional |
| ⇦ | 21E6 | LEFTWARDS WHITE ARROW | proportional |
| ⇧ | 21E7 | UPWARDS WHITE ARROW | proportional |
| ⇩ | 21E9 | DOWNWARDS WHITE ARROW | proportional |
| ⤴ | 2934 | ARROW POINTING RIGHTWARDS THEN CURVING UPWARDS | proportional |
| ⤵ | 2935 | ARROW POINTING RIGHTWARDS THEN CURVING DOWNWARDS | proportional |
| 0 | 0030 | DIGIT ZERO | proportional |
| 1 | 0031 | DIGIT ONE | proportional |
| 2 | 0032 | DIGIT TWO | proportional |
| 3 | 0033 | DIGIT THREE | proportional |
| 4 | 0034 | DIGIT FOUR | proportional |
| 5 | 0035 | DIGIT FIVE | proportional |
| 6 | 0036 | DIGIT SIX | proportional |
| 7 | 0037 | DIGIT SEVEN | proportional |
| 8 | 0038 | DIGIT EIGHT | proportional |
| 9 | 0039 | DIGIT NINE | proportional |
| ◦ | 25E6 | WHITE BULLET | proportional |
| • | 2022 | BULLET | proportional |
| A | 0041 | LATIN CAPITAL LETTER A | proportional |
| B | 0042 | LATIN CAPITAL LETTER B | proportional |
| C | 0043 | LATIN CAPITAL LETTER C | proportional |
| D | 0044 | LATIN CAPITAL LETTER D | proportional |
| E | 0045 | LATIN CAPITAL LETTER E | proportional |
| F | 0046 | LATIN CAPITAL LETTER F | proportional |
| G | 0047 | LATIN CAPITAL LETTER G | proportional |
| H | 0048 | LATIN CAPITAL LETTER H | proportional |
| I | 0049 | LATIN CAPITAL LETTER I | proportional |
| J | 004A | LATIN CAPITAL LETTER J | proportional |
| K | 004B | LATIN CAPITAL LETTER K | proportional |
| L | 004C | LATIN CAPITAL LETTER L | proportional |
| M | 004D | LATIN CAPITAL LETTER M | proportional |
| N | 004E | LATIN CAPITAL LETTER N | proportional |
| O | 004F | LATIN CAPITAL LETTER O | proportional |
| P | 0050 | LATIN CAPITAL LETTER P | proportional |
| Q | 0051 | LATIN CAPITAL LETTER Q | proportional |
| R | 0052 | LATIN CAPITAL LETTER R | proportional |
| S | 0053 | LATIN CAPITAL LETTER S | proportional |
| T | 0054 | LATIN CAPITAL LETTER T | proportional |
| U | 0055 | LATIN CAPITAL LETTER U | proportional |
| V | 0056 | LATIN CAPITAL LETTER V | proportional |
| W | 0057 | LATIN CAPITAL LETTER W | proportional |
| X | 0058 | LATIN CAPITAL LETTER X | proportional |
| Y | 0059 | LATIN CAPITAL LETTER Y | proportional |
| Z | 005A | LATIN CAPITAL LETTER Z | proportional |
| ∓ | 2213 | MINUS-OR-PLUS SIGN | proportional |
| ℵ | 2135 | ALEF SYMBOL | proportional |
| ℏ | 210F | PLANCK CONSTANT OVER TWO PI | proportional |
| ℧ | 2127 | INVERTED OHM SIGN | proportional |
| a | 0061 | LATIN SMALL LETTER A | proportional |
| b | 0062 | LATIN SMALL LETTER B | proportional |
| c | 0063 | LATIN SMALL LETTER C | proportional |
| d | 0064 | LATIN SMALL LETTER D | proportional |
| e | 0065 | LATIN SMALL LETTER E | proportional |
| f | 0066 | LATIN SMALL LETTER F | proportional |
| g | 0067 | LATIN SMALL LETTER G | proportional |
| h | 0068 | LATIN SMALL LETTER H | proportional |
| i | 0069 | LATIN SMALL LETTER I | proportional |
| j | 006A | LATIN SMALL LETTER J | proportional |
| k | 006B | LATIN SMALL LETTER K | proportional |
| l | 006C | LATIN SMALL LETTER L | proportional |
| m | 006D | LATIN SMALL LETTER M | proportional |
| n | 006E | LATIN SMALL LETTER N | proportional |
| o | 006F | LATIN SMALL LETTER O | proportional |
| p | 0070 | LATIN SMALL LETTER P | proportional |
| q | 0071 | LATIN SMALL LETTER Q | proportional |
| r | 0072 | LATIN SMALL LETTER R | proportional |
| s | 0073 | LATIN SMALL LETTER S | proportional |
| t | 0074 | LATIN SMALL LETTER T | proportional |
| u | 0075 | LATIN SMALL LETTER U | proportional |
| v | 0076 | LATIN SMALL LETTER V | proportional |
| w | 0077 | LATIN SMALL LETTER W | proportional |
| x | 0078 | LATIN SMALL LETTER X | proportional |
| y | 0079 | LATIN SMALL LETTER Y | proportional |
| z | 007A | LATIN SMALL LETTER Z | proportional |
| – | 2013 | EN DASH | proportional |
| ⧺ | 29FA | DOUBLE PLUS | proportional |
| ⧻ | 29FB | TRIPLE PLUS | proportional |
| Α | 0391 | GREEK CAPITAL LETTER ALPHA | proportional |
| Β | 0392 | GREEK CAPITAL LETTER BETA | proportional |
| Γ | 0393 | GREEK CAPITAL LETTER GAMMA | proportional |
| Δ | 0394 | GREEK CAPITAL LETTER DELTA | proportional |
| Ε | 0395 | GREEK CAPITAL LETTER EPSILON | proportional |
| Ζ | 0396 | GREEK CAPITAL LETTER ZETA | proportional |
| Η | 0397 | GREEK CAPITAL LETTER ETA | proportional |
| Θ | 0398 | GREEK CAPITAL LETTER THETA | proportional |
| Ι | 0399 | GREEK CAPITAL LETTER IOTA | proportional |
| Κ | 039A | GREEK CAPITAL LETTER KAPPA | proportional |
| Λ | 039B | GREEK CAPITAL LETTER LAMDA | proportional |
| Μ | 039C | GREEK CAPITAL LETTER MU | proportional |
| Ν | 039D | GREEK CAPITAL LETTER NU | proportional |
| Ξ | 039E | GREEK CAPITAL LETTER XI | proportional |
| Ο | 039F | GREEK CAPITAL LETTER OMICRON | proportional |
| Π | 03A0 | GREEK CAPITAL LETTER PI | proportional |
| Ρ | 03A1 | GREEK CAPITAL LETTER RHO | proportional |
| Σ | 03A3 | GREEK CAPITAL LETTER SIGMA | proportional |
| Τ | 03A4 | GREEK CAPITAL LETTER TAU | proportional |
| Υ | 03A5 | GREEK CAPITAL LETTER UPSILON | proportional |
| Φ | 03A6 | GREEK CAPITAL LETTER PHI | proportional |
| Χ | 03A7 | GREEK CAPITAL LETTER CHI | proportional |
| Ψ | 03A8 | GREEK CAPITAL LETTER PSI | proportional |
| Ω | 03A9 | GREEK CAPITAL LETTER OMEGA | proportional |
| ♤ | 2664 | WHITE SPADE SUIT | proportional |
| ♠ | 2660 | BLACK SPADE SUIT | proportional |
| ♢ | 2662 | WHITE DIAMOND SUIT | proportional |
| ♦ | 2666 | BLACK DIAMOND SUIT | proportional |
| ♡ | 2661 | WHITE HEART SUIT | proportional |
| ♥ | 2665 | BLACK HEART SUIT | proportional |
| ♧ | 2667 | WHITE CLUB SUIT | proportional |
| ♣ | 2663 | BLACK CLUB SUIT | proportional |
| α | 03B1 | GREEK SMALL LETTER ALPHA | proportional |
| β | 03B2 | GREEK SMALL LETTER BETA | proportional |
| γ | 03B3 | GREEK SMALL LETTER GAMMA | proportional |
| δ | 03B4 | GREEK SMALL LETTER DELTA | proportional |
| ε | 03B5 | GREEK SMALL LETTER EPSILON | proportional |
| ζ | 03B6 | GREEK SMALL LETTER ZETA | proportional |
| η | 03B7 | GREEK SMALL LETTER ETA | proportional |
| θ | 03B8 | GREEK SMALL LETTER THETA | proportional |
| ι | 03B9 | GREEK SMALL LETTER IOTA | proportional |
| κ | 03BA | GREEK SMALL LETTER KAPPA | proportional |
| λ | 03BB | GREEK SMALL LETTER LAMDA | proportional |
| μ | 03BC | GREEK SMALL LETTER MU | proportional |
| ν | 03BD | GREEK SMALL LETTER NU | proportional |
| ξ | 03BE | GREEK SMALL LETTER XI | proportional |
| ο | 03BF | GREEK SMALL LETTER OMICRON | proportional |
| π | 03C0 | GREEK SMALL LETTER PI | proportional |
| ρ | 03C1 | GREEK SMALL LETTER RHO | proportional |
| σ | 03C3 | GREEK SMALL LETTER SIGMA | proportional |
| τ | 03C4 | GREEK SMALL LETTER TAU | proportional |
| υ | 03C5 | GREEK SMALL LETTER UPSILON | proportional |
| φ | 03C6 | GREEK SMALL LETTER PHI | proportional |
| χ | 03C7 | GREEK SMALL LETTER CHI | proportional |
| ψ | 03C8 | GREEK SMALL LETTER PSI | proportional |
| ω | 03C9 | GREEK SMALL LETTER OMEGA | proportional |
| ς | 03C2 | GREEK SMALL LETTER FINAL SIGMA | proportional |
| ⓵ | 24F5 | DOUBLE CIRCLED DIGIT ONE | proportional |
| ⓶ | 24F6 | DOUBLE CIRCLED DIGIT TWO | proportional |
| ⓷ | 24F7 | DOUBLE CIRCLED DIGIT THREE | proportional |
| ⓸ | 24F8 | DOUBLE CIRCLED DIGIT FOUR | proportional |
| ⓹ | 24F9 | DOUBLE CIRCLED DIGIT FIVE | proportional |
| ⓺ | 24FA | DOUBLE CIRCLED DIGIT SIX | proportional |
| ⓻ | 24FB | DOUBLE CIRCLED DIGIT SEVEN | proportional |
| ⓼ | 24FC | DOUBLE CIRCLED DIGIT EIGHT | proportional |
| ⓽ | 24FD | DOUBLE CIRCLED DIGIT NINE | proportional |
| ⓾ | 24FE | DOUBLE CIRCLED NUMBER TEN | proportional |
| ☎ | 260E | BLACK TELEPHONE | proportional |
| ☀ | 2600 | BLACK SUN WITH RAYS | proportional |
| ☁ | 2601 | CLOUD | proportional |
| ☂ | 2602 | UMBRELLA | proportional |
| ☃ | 2603 | SNOWMAN | proportional |
| ▱ | 25B1 | WHITE PARALLELOGRAM | proportional |
| А | 0410 | CYRILLIC CAPITAL LETTER A | proportional |
| Б | 0411 | CYRILLIC CAPITAL LETTER BE | proportional |
| В | 0412 | CYRILLIC CAPITAL LETTER VE | proportional |
| Г | 0413 | CYRILLIC CAPITAL LETTER GHE | proportional |
| Д | 0414 | CYRILLIC CAPITAL LETTER DE | proportional |
| Е | 0415 | CYRILLIC CAPITAL LETTER IE | proportional |
| Ё | 0401 | CYRILLIC CAPITAL LETTER IO | proportional |
| Ж | 0416 | CYRILLIC CAPITAL LETTER ZHE | proportional |
| З | 0417 | CYRILLIC CAPITAL LETTER ZE | proportional |
| И | 0418 | CYRILLIC CAPITAL LETTER I | proportional |
| Й | 0419 | CYRILLIC CAPITAL LETTER SHORT I | proportional |
| К | 041A | CYRILLIC CAPITAL LETTER KA | proportional |
| Л | 041B | CYRILLIC CAPITAL LETTER EL | proportional |
| М | 041C | CYRILLIC CAPITAL LETTER EM | proportional |
| Н | 041D | CYRILLIC CAPITAL LETTER EN | proportional |
| О | 041E | CYRILLIC CAPITAL LETTER O | proportional |
| П | 041F | CYRILLIC CAPITAL LETTER PE | proportional |
| Р | 0420 | CYRILLIC CAPITAL LETTER ER | proportional |
| С | 0421 | CYRILLIC CAPITAL LETTER ES | proportional |
| Т | 0422 | CYRILLIC CAPITAL LETTER TE | proportional |
| У | 0423 | CYRILLIC CAPITAL LETTER U | proportional |
| Ф | 0424 | CYRILLIC CAPITAL LETTER EF | proportional |
| Х | 0425 | CYRILLIC CAPITAL LETTER HA | proportional |
| Ц | 0426 | CYRILLIC CAPITAL LETTER TSE | proportional |
| Ч | 0427 | CYRILLIC CAPITAL LETTER CHE | proportional |
| Ш | 0428 | CYRILLIC CAPITAL LETTER SHA | proportional |
| Щ | 0429 | CYRILLIC CAPITAL LETTER SHCHA | proportional |
| Ъ | 042A | CYRILLIC CAPITAL LETTER HARD SIGN | proportional |
| Ы | 042B | CYRILLIC CAPITAL LETTER YERU | proportional |
| Ь | 042C | CYRILLIC CAPITAL LETTER SOFT SIGN | proportional |
| Э | 042D | CYRILLIC CAPITAL LETTER E | proportional |
| Ю | 042E | CYRILLIC CAPITAL LETTER YU | proportional |
| Я | 042F | CYRILLIC CAPITAL LETTER YA | proportional |
| а | 0430 | CYRILLIC SMALL LETTER A | proportional |
| б | 0431 | CYRILLIC SMALL LETTER BE | proportional |
| в | 0432 | CYRILLIC SMALL LETTER VE | proportional |
| г | 0433 | CYRILLIC SMALL LETTER GHE | proportional |
| д | 0434 | CYRILLIC SMALL LETTER DE | proportional |
| е | 0435 | CYRILLIC SMALL LETTER IE | proportional |
| ё | 0451 | CYRILLIC SMALL LETTER IO | proportional |
| ж | 0436 | CYRILLIC SMALL LETTER ZHE | proportional |
| з | 0437 | CYRILLIC SMALL LETTER ZE | proportional |
| и | 0438 | CYRILLIC SMALL LETTER I | proportional |
| й | 0439 | CYRILLIC SMALL LETTER SHORT I | proportional |
| к | 043A | CYRILLIC SMALL LETTER KA | proportional |
| л | 043B | CYRILLIC SMALL LETTER EL | proportional |
| м | 043C | CYRILLIC SMALL LETTER EM | proportional |
| н | 043D | CYRILLIC SMALL LETTER EN | proportional |
| о | 043E | CYRILLIC SMALL LETTER O | proportional |
| п | 043F | CYRILLIC SMALL LETTER PE | proportional |
| р | 0440 | CYRILLIC SMALL LETTER ER | proportional |
| с | 0441 | CYRILLIC SMALL LETTER ES | proportional |
| т | 0442 | CYRILLIC SMALL LETTER TE | proportional |
| у | 0443 | CYRILLIC SMALL LETTER U | proportional |
| ф | 0444 | CYRILLIC SMALL LETTER EF | proportional |
| х | 0445 | CYRILLIC SMALL LETTER HA | proportional |
| ц | 0446 | CYRILLIC SMALL LETTER TSE | proportional |
| ч | 0447 | CYRILLIC SMALL LETTER CHE | proportional |
| ш | 0448 | CYRILLIC SMALL LETTER SHA | proportional |
| щ | 0449 | CYRILLIC SMALL LETTER SHCHA | proportional |
| ъ | 044A | CYRILLIC SMALL LETTER HARD SIGN | proportional |
| ы | 044B | CYRILLIC SMALL LETTER YERU | proportional |
| ь | 044C | CYRILLIC SMALL LETTER SOFT SIGN | proportional |
| э | 044D | CYRILLIC SMALL LETTER E | proportional |
| ю | 044E | CYRILLIC SMALL LETTER YU | proportional |
| я | 044F | CYRILLIC SMALL LETTER YA | proportional |
| ⋚ | 22DA | LESS-THAN EQUAL TO OR GREATER-THAN | proportional |
| ⋛ | 22DB | GREATER-THAN EQUAL TO OR LESS-THAN | proportional |
| ⅓ | 2153 | VULGAR FRACTION ONE THIRD | proportional |
| ⅔ | 2154 | VULGAR FRACTION TWO THIRDS | proportional |
| ⅕ | 2155 | VULGAR FRACTION ONE FIFTH | proportional |
| ✓ | 2713 | CHECK MARK | proportional |
| ⌘ | 2318 | PLACE OF INTEREST SIGN | proportional |
| ␣ | 2423 | OPEN BOX | proportional |
| ⏎ | 23CE | RETURN SYMBOL | proportional |
| ㉑ | 3251 | CIRCLED NUMBER TWENTY ONE | proportional |
| ㉒ | 3252 | CIRCLED NUMBER TWENTY TWO | proportional |
| ㉓ | 3253 | CIRCLED NUMBER TWENTY THREE | proportional |
| ㉔ | 3254 | CIRCLED NUMBER TWENTY FOUR | proportional |
| ㉕ | 3255 | CIRCLED NUMBER TWENTY FIVE | proportional |
| ㉖ | 3256 | CIRCLED NUMBER TWENTY SIX | proportional |
| ㉗ | 3257 | CIRCLED NUMBER TWENTY SEVEN | proportional |
| ㉘ | 3258 | CIRCLED NUMBER TWENTY EIGHT | proportional |
| ㉙ | 3259 | CIRCLED NUMBER TWENTY NINE | proportional |
| ㉚ | 325A | CIRCLED NUMBER THIRTY | proportional |
| ㉛ | 325B | CIRCLED NUMBER THIRTY ONE | proportional |
| ㉜ | 325C | CIRCLED NUMBER THIRTY TWO | proportional |
| ㉝ | 325D | CIRCLED NUMBER THIRTY THREE | proportional |
| ㉞ | 325E | CIRCLED NUMBER THIRTY FOUR | proportional |
| ㉟ | 325F | CIRCLED NUMBER THIRTY FIVE | proportional |
| ㊱ | 32B1 | CIRCLED NUMBER THIRTY SIX | proportional |
| ㊲ | 32B2 | CIRCLED NUMBER THIRTY SEVEN | proportional |
| ㊳ | 32B3 | CIRCLED NUMBER THIRTY EIGHT | proportional |
| ㊴ | 32B4 | CIRCLED NUMBER THIRTY NINE | proportional |
| ㊵ | 32B5 | CIRCLED NUMBER FORTY | proportional |
| ㊶ | 32B6 | CIRCLED NUMBER FORTY ONE | proportional |
| ㊷ | 32B7 | CIRCLED NUMBER FORTY TWO | proportional |
| ㊸ | 32B8 | CIRCLED NUMBER FORTY THREE | proportional |
| ㊹ | 32B9 | CIRCLED NUMBER FORTY FOUR | proportional |
| ㊺ | 32BA | CIRCLED NUMBER FORTY FIVE | proportional |
| ㊻ | 32BB | CIRCLED NUMBER FORTY SIX | proportional |
| ㊼ | 32BC | CIRCLED NUMBER FORTY SEVEN | proportional |
| ㊽ | 32BD | CIRCLED NUMBER FORTY EIGHT | proportional |
| ㊾ | 32BE | CIRCLED NUMBER FORTY NINE | proportional |
| ㊿ | 32BF | CIRCLED NUMBER FIFTY | proportional |
| ◐ | 25D0 | CIRCLE WITH LEFT HALF BLACK | proportional |
| ◑ | 25D1 | CIRCLE WITH RIGHT HALF BLACK | proportional |
| ◒ | 25D2 | CIRCLE WITH LOWER HALF BLACK | proportional |
| ◓ | 25D3 | CIRCLE WITH UPPER HALF BLACK | proportional |
| Ǎ | 01CD | LATIN CAPITAL LETTER A WITH CARON | proportional |
| ǎ | 01CE | LATIN SMALL LETTER A WITH CARON | proportional |
| ǐ | 01D0 | LATIN SMALL LETTER I WITH CARON | proportional |
| Ḿ | 1E3E | LATIN CAPITAL LETTER M WITH ACUTE | proportional |
| ḿ | 1E3F | LATIN SMALL LETTER M WITH ACUTE | proportional |
| Ǹ | 01F8 | LATIN CAPITAL LETTER N WITH GRAVE | proportional |
| ǹ | 01F9 | LATIN SMALL LETTER N WITH GRAVE | proportional |
| Ǒ | 01D1 | LATIN CAPITAL LETTER O WITH CARON | proportional |
| ǒ | 01D2 | LATIN SMALL LETTER O WITH CARON | proportional |
| ǔ | 01D4 | LATIN SMALL LETTER U WITH CARON | proportional |
| ǖ | 01D6 | LATIN SMALL LETTER U WITH DIAERESIS AND MACRON | proportional |
| ǘ | 01D8 | LATIN SMALL LETTER U WITH DIAERESIS AND ACUTE | proportional |
| ǚ | 01DA | LATIN SMALL LETTER U WITH DIAERESIS AND CARON | proportional |
| ǜ | 01DC | LATIN SMALL LETTER U WITH DIAERESIS AND GRAVE | proportional |
| € | 20AC | EURO SIGN | proportional |
| | 00A0 | NO-BREAK SPACE | proportional |
| ¡ | 00A1 | INVERTED EXCLAMATION MARK | proportional |
| ¤ | 00A4 | CURRENCY SIGN | proportional |
| ¦ | 00A6 | BROKEN BAR | proportional |
| © | 00A9 | COPYRIGHT SIGN | proportional |
| ª | 00AA | FEMININE ORDINAL INDICATOR | proportional |
| « | 00AB | LEFT-POINTING DOUBLE ANGLE QUOTATION MARK | proportional |
| | 00AD | SOFT HYPHEN | proportional |
| ® | 00AE | REGISTERED SIGN | proportional |
| ¯ | 00AF | MACRON | proportional |
| ² | 00B2 | SUPERSCRIPT TWO | proportional |
| ³ | 00B3 | SUPERSCRIPT THREE | proportional |
| · | 00B7 | MIDDLE DOT | proportional |
| ¸ | 00B8 | CEDILLA | proportional |
| ¹ | 00B9 | SUPERSCRIPT ONE | proportional |
| º | 00BA | MASCULINE ORDINAL INDICATOR | proportional |
| » | 00BB | RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK | proportional |
| ¼ | 00BC | VULGAR FRACTION ONE QUARTER | proportional |
| ½ | 00BD | VULGAR FRACTION ONE HALF | proportional |
| ¾ | 00BE | VULGAR FRACTION THREE QUARTERS | proportional |
| ¿ | 00BF | INVERTED QUESTION MARK | proportional |
| À | 00C0 | LATIN CAPITAL LETTER A WITH GRAVE | proportional |
| Á | 00C1 | LATIN CAPITAL LETTER A WITH ACUTE | proportional |
| Â | 00C2 | LATIN CAPITAL LETTER A WITH CIRCUMFLEX | proportional |
| Ã | 00C3 | LATIN CAPITAL LETTER A WITH TILDE | proportional |
| Ä | 00C4 | LATIN CAPITAL LETTER A WITH DIAERESIS | proportional |
| Å | 00C5 | LATIN CAPITAL LETTER A WITH RING ABOVE | proportional |
| Æ | 00C6 | LATIN CAPITAL LETTER AE (ash) | proportional |
| Ç | 00C7 | LATIN CAPITAL LETTER C WITH CEDILLA | proportional |
| È | 00C8 | LATIN CAPITAL LETTER E WITH GRAVE | proportional |
| É | 00C9 | LATIN CAPITAL LETTER E WITH ACUTE | proportional |
| Ê | 00CA | LATIN CAPITAL LETTER E WITH CIRCUMFLEX | proportional |
| Ë | 00CB | LATIN CAPITAL LETTER E WITH DIAERESIS | proportional |
| Ì | 00CC | LATIN CAPITAL LETTER I WITH GRAVE | proportional |
| Í | 00CD | LATIN CAPITAL LETTER I WITH ACUTE | proportional |
| Î | 00CE | LATIN CAPITAL LETTER I WITH CIRCUMFLEX | proportional |
| Ï | 00CF | LATIN CAPITAL LETTER I WITH DIAERESIS | proportional |
| Ð | 00D0 | LATIN CAPITAL LETTER ETH (Icelandic) | proportional |
| Ñ | 00D1 | LATIN CAPITAL LETTER N WITH TILDE | proportional |
| Ò | 00D2 | LATIN CAPITAL LETTER O WITH GRAVE | proportional |
| Ó | 00D3 | LATIN CAPITAL LETTER O WITH ACUTE | proportional |
| Ô | 00D4 | LATIN CAPITAL LETTER O WITH CIRCUMFLEX | proportional |
| Õ | 00D5 | LATIN CAPITAL LETTER O WITH TILDE | proportional |
| Ö | 00D6 | LATIN CAPITAL LETTER O WITH DIAERESIS | proportional |
| Ø | 00D8 | LATIN CAPITAL LETTER O WITH STROKE | proportional |
| Ù | 00D9 | LATIN CAPITAL LETTER U WITH GRAVE | proportional |
| Ú | 00DA | LATIN CAPITAL LETTER U WITH ACUTE | proportional |
| Û | 00DB | LATIN CAPITAL LETTER U WITH CIRCUMFLEX | proportional |
| Ü | 00DC | LATIN CAPITAL LETTER U WITH DIAERESIS | proportional |
| Ý | 00DD | LATIN CAPITAL LETTER Y WITH ACUTE | proportional |
| Þ | 00DE | LATIN CAPITAL LETTER THORN (Icelandic) | proportional |
| ß | 00DF | LATIN SMALL LETTER SHARP S (German) | proportional |
| à | 00E0 | LATIN SMALL LETTER A WITH GRAVE | proportional |
| á | 00E1 | LATIN SMALL LETTER A WITH ACUTE | proportional |
| â | 00E2 | LATIN SMALL LETTER A WITH CIRCUMFLEX | proportional |
| ã | 00E3 | LATIN SMALL LETTER A WITH TILDE | proportional |
| ä | 00E4 | LATIN SMALL LETTER A WITH DIAERESIS | proportional |
| å | 00E5 | LATIN SMALL LETTER A WITH RING ABOVE | proportional |
| æ | 00E6 | LATIN SMALL LETTER AE (ash) | proportional |
| ç | 00E7 | LATIN SMALL LETTER C WITH CEDILLA | proportional |
| è | 00E8 | LATIN SMALL LETTER E WITH GRAVE | proportional |
| é | 00E9 | LATIN SMALL LETTER E WITH ACUTE | proportional |
| ê | 00EA | LATIN SMALL LETTER E WITH CIRCUMFLEX | proportional |
| ë | 00EB | LATIN SMALL LETTER E WITH DIAERESIS | proportional |
| ì | 00EC | LATIN SMALL LETTER I WITH GRAVE | proportional |
| í | 00ED | LATIN SMALL LETTER I WITH ACUTE | proportional |
| î | 00EE | LATIN SMALL LETTER I WITH CIRCUMFLEX | proportional |
| ï | 00EF | LATIN SMALL LETTER I WITH DIAERESIS | proportional |
| ð | 00F0 | LATIN SMALL LETTER ETH (Icelandic) | proportional |
| ñ | 00F1 | LATIN SMALL LETTER N WITH TILDE | proportional |
| ò | 00F2 | LATIN SMALL LETTER O WITH GRAVE | proportional |
| ó | 00F3 | LATIN SMALL LETTER O WITH ACUTE | proportional |
| ô | 00F4 | LATIN SMALL LETTER O WITH CIRCUMFLEX | proportional |
| õ | 00F5 | LATIN SMALL LETTER O WITH TILDE | proportional |
| ö | 00F6 | LATIN SMALL LETTER O WITH DIAERESIS | proportional |
| ø | 00F8 | LATIN SMALL LETTER O WITH STROKE | proportional |
| ù | 00F9 | LATIN SMALL LETTER U WITH GRAVE | proportional |
| ú | 00FA | LATIN SMALL LETTER U WITH ACUTE | proportional |
| û | 00FB | LATIN SMALL LETTER U WITH CIRCUMFLEX | proportional |
| ü | 00FC | LATIN SMALL LETTER U WITH DIAERESIS | proportional |
| ý | 00FD | LATIN SMALL LETTER Y WITH ACUTE | proportional |
| þ | 00FE | LATIN SMALL LETTER THORN (Icelandic) | proportional |
| ÿ | 00FF | LATIN SMALL LETTER Y WITH DIAERESIS | proportional |
| Ā | 0100 | LATIN CAPITAL LETTER A WITH MACRON | proportional |
| Ī | 012A | LATIN CAPITAL LETTER I WITH MACRON | proportional |
| Ū | 016A | LATIN CAPITAL LETTER U WITH MACRON | proportional |
| Ē | 0112 | LATIN CAPITAL LETTER E WITH MACRON | proportional |
| Ō | 014C | LATIN CAPITAL LETTER O WITH MACRON | proportional |
| ā | 0101 | LATIN SMALL LETTER A WITH MACRON | proportional |
| ī | 012B | LATIN SMALL LETTER I WITH MACRON | proportional |
| ū | 016B | LATIN SMALL LETTER U WITH MACRON | proportional |
| ē | 0113 | LATIN SMALL LETTER E WITH MACRON | proportional |
| ō | 014D | LATIN SMALL LETTER O WITH MACRON | proportional |
| Ą | 0104 | LATIN CAPITAL LETTER A WITH OGONEK | proportional |
| ˘ | 02D8 | BREVE | proportional |
| Ł | 0141 | LATIN CAPITAL LETTER L WITH STROKE | proportional |
| Ľ | 013D | LATIN CAPITAL LETTER L WITH CARON | proportional |
| Ś | 015A | LATIN CAPITAL LETTER S WITH ACUTE | proportional |
| Š | 0160 | LATIN CAPITAL LETTER S WITH CARON | proportional |
| Ş | 015E | LATIN CAPITAL LETTER S WITH CEDILLA | proportional |
| Ť | 0164 | LATIN CAPITAL LETTER T WITH CARON | proportional |
| Ź | 0179 | LATIN CAPITAL LETTER Z WITH ACUTE | proportional |
| Ž | 017D | LATIN CAPITAL LETTER Z WITH CARON | proportional |
| Ż | 017B | LATIN CAPITAL LETTER Z WITH DOT ABOVE | proportional |
| ą | 0105 | LATIN SMALL LETTER A WITH OGONEK | proportional |
| ˛ | 02DB | OGONEK | proportional |
| ł | 0142 | LATIN SMALL LETTER L WITH STROKE | proportional |
| ľ | 013E | LATIN SMALL LETTER L WITH CARON | proportional |
| ś | 015B | LATIN SMALL LETTER S WITH ACUTE | proportional |
| ˇ | 02C7 | CARON (Mandarin Chinese third tone) | proportional |
| š | 0161 | LATIN SMALL LETTER S WITH CARON | proportional |
| ş | 015F | LATIN SMALL LETTER S WITH CEDILLA | proportional |
| ť | 0165 | LATIN SMALL LETTER T WITH CARON | proportional |
| ź | 017A | LATIN SMALL LETTER Z WITH ACUTE | proportional |
| ˝ | 02DD | DOUBLE ACUTE ACCENT | proportional |
| ž | 017E | LATIN SMALL LETTER Z WITH CARON | proportional |
| ż | 017C | LATIN SMALL LETTER Z WITH DOT ABOVE | proportional |
| Ŕ | 0154 | LATIN CAPITAL LETTER R WITH ACUTE | proportional |
| Ă | 0102 | LATIN CAPITAL LETTER A WITH BREVE | proportional |
| Ĺ | 0139 | LATIN CAPITAL LETTER L WITH ACUTE | proportional |
| Ć | 0106 | LATIN CAPITAL LETTER C WITH ACUTE | proportional |
| Č | 010C | LATIN CAPITAL LETTER C WITH CARON | proportional |
| Ę | 0118 | LATIN CAPITAL LETTER E WITH OGONEK | proportional |
| Ě | 011A | LATIN CAPITAL LETTER E WITH CARON | proportional |
| Ď | 010E | LATIN CAPITAL LETTER D WITH CARON | proportional |
| Ń | 0143 | LATIN CAPITAL LETTER N WITH ACUTE | proportional |
| Ň | 0147 | LATIN CAPITAL LETTER N WITH CARON | proportional |
| Ő | 0150 | LATIN CAPITAL LETTER O WITH DOUBLE ACUTE | proportional |
| Ř | 0158 | LATIN CAPITAL LETTER R WITH CARON | proportional |
| Ů | 016E | LATIN CAPITAL LETTER U WITH RING ABOVE | proportional |
| Ű | 0170 | LATIN CAPITAL LETTER U WITH DOUBLE ACUTE | proportional |
| Ţ | 0162 | LATIN CAPITAL LETTER T WITH CEDILLA | proportional |
| ŕ | 0155 | LATIN SMALL LETTER R WITH ACUTE | proportional |
| ă | 0103 | LATIN SMALL LETTER A WITH BREVE | proportional |
| ĺ | 013A | LATIN SMALL LETTER L WITH ACUTE | proportional |
| ć | 0107 | LATIN SMALL LETTER C WITH ACUTE | proportional |
| č | 010D | LATIN SMALL LETTER C WITH CARON | proportional |
| ę | 0119 | LATIN SMALL LETTER E WITH OGONEK | proportional |
| ě | 011B | LATIN SMALL LETTER E WITH CARON | proportional |
| ď | 010F | LATIN SMALL LETTER D WITH CARON | proportional |
| đ | 0111 | LATIN SMALL LETTER D WITH STROKE | proportional |
| ń | 0144 | LATIN SMALL LETTER N WITH ACUTE | proportional |
| ň | 0148 | LATIN SMALL LETTER N WITH CARON | proportional |
| ő | 0151 | LATIN SMALL LETTER O WITH DOUBLE ACUTE | proportional |
| ř | 0159 | LATIN SMALL LETTER R WITH CARON | proportional |
| ů | 016F | LATIN SMALL LETTER U WITH RING ABOVE | proportional |
| ű | 0171 | LATIN SMALL LETTER U WITH DOUBLE ACUTE | proportional |
| ţ | 0163 | LATIN SMALL LETTER T WITH CEDILLA | proportional |
| ˙ | 02D9 | DOT ABOVE (Mandarin Chinese light tone) | proportional |
| Ĉ | 0108 | LATIN CAPITAL LETTER C WITH CIRCUMFLEX | proportional |
| Ĝ | 011C | LATIN CAPITAL LETTER G WITH CIRCUMFLEX | proportional |
| Ĥ | 0124 | LATIN CAPITAL LETTER H WITH CIRCUMFLEX | proportional |
| Ĵ | 0134 | LATIN CAPITAL LETTER J WITH CIRCUMFLEX | proportional |
| Ŝ | 015C | LATIN CAPITAL LETTER S WITH CIRCUMFLEX | proportional |
| Ŭ | 016C | LATIN CAPITAL LETTER U WITH BREVE | proportional |
| ĉ | 0109 | LATIN SMALL LETTER C WITH CIRCUMFLEX | proportional |
| ĝ | 011D | LATIN SMALL LETTER G WITH CIRCUMFLEX | proportional |
| ĥ | 0125 | LATIN SMALL LETTER H WITH CIRCUMFLEX | proportional |
| ĵ | 0135 | LATIN SMALL LETTER J WITH CIRCUMFLEX | proportional |
| ŝ | 015D | LATIN SMALL LETTER S WITH CIRCUMFLEX | proportional |
| ŭ | 016D | LATIN SMALL LETTER U WITH BREVE | proportional |
| ɱ | 0271 | LATIN SMALL LETTER M WITH HOOK | proportional |
| ʋ | 028B | LATIN SMALL LETTER V WITH HOOK | proportional |
| ɾ | 027E | LATIN SMALL LETTER R WITH FISHHOOK | proportional |
| ʃ | 0283 | LATIN SMALL LETTER ESH | proportional |
| ʒ | 0292 | LATIN SMALL LETTER EZH | proportional |
| ɬ | 026C | LATIN SMALL LETTER L WITH BELT | proportional |
| ɮ | 026E | LATIN SMALL LETTER LEZH | proportional |
| ɹ | 0279 | LATIN SMALL LETTER TURNED R | proportional |
| ʈ | 0288 | LATIN SMALL LETTER T WITH RETROFLEX HOOK | proportional |
| ɖ | 0256 | LATIN SMALL LETTER D WITH TAIL | proportional |
| ɳ | 0273 | LATIN SMALL LETTER N WITH RETROFLEX HOOK | proportional |
| ɽ | 027D | LATIN SMALL LETTER R WITH TAIL | proportional |
| ʂ | 0282 | LATIN SMALL LETTER S WITH HOOK | proportional |
| ʐ | 0290 | LATIN SMALL LETTER Z WITH RETROFLEX HOOK | proportional |
| ɻ | 027B | LATIN SMALL LETTER TURNED R WITH HOOK | proportional |
| ɭ | 026D | LATIN SMALL LETTER L WITH RETROFLEX HOOK | proportional |
| ɟ | 025F | LATIN SMALL LETTER DOTLESS J WITH STROKE | proportional |
| ɲ | 0272 | LATIN SMALL LETTER N WITH LEFT HOOK | proportional |
| ʝ | 029D | LATIN SMALL LETTER J WITH CROSSED-TAIL | proportional |
| ʎ | 028E | LATIN SMALL LETTER TURNED Y | proportional |
| ɡ | 0261 | LATIN SMALL LETTER SCRIPT G | proportional |
| ŋ | 014B | LATIN SMALL LETTER ENG (Sami) | proportional |
| ɰ | 0270 | LATIN SMALL LETTER TURNED M WITH LONG LEG | proportional |
| ʁ | 0281 | LATIN LETTER SMALL CAPITAL INVERTED R | proportional |
| ħ | 0127 | LATIN SMALL LETTER H WITH STROKE | proportional |
| ʕ | 0295 | LATIN LETTER PHARYNGEAL VOICED FRICATIVE | proportional |
| ʔ | 0294 | LATIN LETTER GLOTTAL STOP | proportional |
| ɦ | 0266 | LATIN SMALL LETTER H WITH HOOK | proportional |
| ʘ | 0298 | LATIN LETTER BILABIAL CLICK | proportional |
| ǂ | 01C2 | LATIN LETTER ALVEOLAR CLICK | proportional |
| ɓ | 0253 | LATIN SMALL LETTER B WITH HOOK | proportional |
| ɗ | 0257 | LATIN SMALL LETTER D WITH HOOK | proportional |
| ʄ | 0284 | LATIN SMALL LETTER DOTLESS J WITH STROKE AND HOOK | proportional |
| ɠ | 0260 | LATIN SMALL LETTER G WITH HOOK | proportional |
| Ɠ | 0193 | LATIN CAPITAL LETTER G WITH HOOK | proportional |
| œ | 0153 | LATIN SMALL LIGATURE OE | proportional |
| Π| 0152 | LATIN CAPITAL LIGATURE OE | proportional |
| ɨ | 0268 | LATIN SMALL LETTER I WITH STROKE | proportional |
| ʉ | 0289 | LATIN SMALL LETTER U BAR | proportional |
| ɘ | 0258 | LATIN SMALL LETTER REVERSED E | proportional |
| ɵ | 0275 | LATIN SMALL LETTER BARRED O | proportional |
| ə | 0259 | LATIN SMALL LETTER SCHWA | proportional |
| ɜ | 025C | LATIN SMALL LETTER REVERSED OPEN E | proportional |
| ɞ | 025E | LATIN SMALL LETTER CLOSED REVERSED OPEN E | proportional |
| ɐ | 0250 | LATIN SMALL LETTER TURNED A | proportional |
| ɯ | 026F | LATIN SMALL LETTER TURNED M | proportional |
| ʊ | 028A | LATIN SMALL LETTER UPSILON | proportional |
| ɤ | 0264 | LATIN SMALL LETTER RAMS HORN | proportional |
| ʌ | 028C | LATIN SMALL LETTER TURNED V | proportional |
| ɔ | 0254 | LATIN SMALL LETTER OPEN O | proportional |
| ɑ | 0251 | LATIN SMALL LETTER ALPHA | proportional |
| ɒ | 0252 | LATIN SMALL LETTER TURNED ALPHA | proportional |
| ʍ | 028D | LATIN SMALL LETTER TURNED W | proportional |
| ɥ | 0265 | LATIN SMALL LETTER TURNED H | proportional |
| ʢ | 02A2 | LATIN LETTER REVERSED GLOTTAL STOP WITH STROKE | proportional |
| ʡ | 02A1 | LATIN LETTER GLOTTAL STOP WITH STROKE | proportional |
| ɕ | 0255 | LATIN SMALL LETTER C WITH CURL | proportional |
| ʑ | 0291 | LATIN SMALL LETTER Z WITH CURL | proportional |
| ɺ | 027A | LATIN SMALL LETTER TURNED R WITH LONG LEG | proportional |
| ɧ | 0267 | LATIN SMALL LETTER HENG WITH HOOK | proportional |
| ɚ | 025A | LATIN SMALL LETTER SCHWA WITH HOOK | proportional |
| æ̀ | <00E6, 0300> | <LATIN SMALL LETTER AE, COMBINING GRAVE ACCENT> | proportional |
| ǽ | 01FD | LATIN SMALL LETTER AE WITH ACUTE (ash) | proportional |
| ὰ | 1F70 | GREEK SMALL LETTER ALPHA WITH VARIA | proportional |
| ά | 1F71 | GREEK SMALL LETTER ALPHA WITH OXIA | proportional |
| ɔ̀ | <0254, 0300> | <LATIN SMALL LETTER OPEN O, COMBINING GRAVE ACCENT> | proportional |
| ɔ́ | <0254, 0301> | <LATIN SMALL LETTER OPEN O, COMBINING ACUTE ACCENT> | proportional |
| ʌ̀ | <028C, 0300> | <LATIN SMALL LETTER TURNED V, COMBINING GRAVE ACCENT> | proportional |
| ʌ́ | <028C, 0301> | <LATIN SMALL LETTER TURNED V, COMBINING ACUTE ACCENT> | proportional |
| ə̀ | <0259, 0300> | <LATIN SMALL LETTER SCHWA, COMBINING GRAVE ACCENT> | proportional |
| ə́ | <0259, 0301> | <LATIN SMALL LETTER SCHWA, COMBINING ACUTE ACCENT> | proportional |
| ɚ̀ | <025A, 0300> | <LATIN SMALL LETTER SCHWA WITH HOOK, COMBINING GRAVE ACCENT> | proportional |
| ɚ́ | <025A, 0301> | <LATIN SMALL LETTER SCHWA WITH HOOK, COMBINING ACUTE ACCENT> | proportional |
| ὲ | 1F72 | GREEK SMALL LETTER EPSILON WITH VARIA | proportional |
| έ | 1F73 | GREEK SMALL LETTER EPSILON WITH OXIA | proportional |
| ͡ | 0361 | COMBINING DOUBLE INVERTED BREVE | proportional |
| ˈ | 02C8 | MODIFIER LETTER VERTICAL LINE | proportional |
| ˌ | 02CC | MODIFIER LETTER LOW VERTICAL LINE | proportional |
| ː | 02D0 | MODIFIER LETTER TRIANGULAR COLON | proportional |
| ˑ | 02D1 | MODIFIER LETTER HALF TRIANGULAR COLON | proportional |
| ̆ | 0306 | COMBINING BREVE (Vrachy) | proportional |
| ‿ | 203F | UNDERTIE (Enotikon) | proportional |
| ̋ | 030B | COMBINING DOUBLE ACUTE ACCENT | proportional |
| ́ | 0301 | COMBINING ACUTE ACCENT (Oxia, Tonos) | proportional |
| ̄ | 0304 | COMBINING MACRON | proportional |
| ̀ | 0300 | COMBINING GRAVE ACCENT (Varia) | proportional |
| ̏ | 030F | COMBINING DOUBLE GRAVE ACCENT | proportional |
| ̌ | 030C | COMBINING CARON | proportional |
| ̂ | 0302 | COMBINING CIRCUMFLEX ACCENT | proportional |
| ˥ | 02E5 | MODIFIER LETTER EXTRA-HIGH TONE BAR | proportional |
| ˦ | 02E6 | MODIFIER LETTER HIGH TONE BAR | proportional |
| ˧ | 02E7 | MODIFIER LETTER MID TONE BAR | proportional |
| ˨ | 02E8 | MODIFIER LETTER LOW TONE BAR | proportional |
| ˩ | 02E9 | MODIFIER LETTER EXTRA-LOW TONE BAR | proportional |
| ˩˥ | <02E9, 02E5> | <MODIFIER LETTER EXTRA-LOW TONE BAR, MODIFIER LETTER EXTRA-HIGH TONE BAR> | proportional |
| ˥˩ | <02E5, 02E9> | <MODIFIER LETTER EXTRA-HIGH TONE BAR, MODIFIER LETTER EXTRA-LOW TONE BAR> | proportional |
| ̥ | 0325 | COMBINING RING BELOW | proportional |
| ̬ | 032C | COMBINING CARON BELOW | proportional |
| ̹ | 0339 | COMBINING RIGHT HALF RING BELOW | proportional |
| ̜ | 031C | COMBINING LEFT HALF RING BELOW | proportional |
| ̟ | 031F | COMBINING PLUS SIGN BELOW | proportional |
| ̠ | 0320 | COMBINING MINUS SIGN BELOW | proportional |
| ̈ | 0308 | COMBINING DIAERESIS (Dialytika) | proportional |
| ̽ | 033D | COMBINING X ABOVE | proportional |
| ̩ | 0329 | COMBINING VERTICAL LINE BELOW | proportional |
| ̯ | 032F | COMBINING INVERTED BREVE BELOW | proportional |
| ˞ | 02DE | MODIFIER LETTER RHOTIC HOOK | proportional |
| ̤ | 0324 | COMBINING DIAERESIS BELOW | proportional |
| ̰ | 0330 | COMBINING TILDE BELOW | proportional |
| ̼ | 033C | COMBINING SEAGULL BELOW | proportional |
| ̴ | 0334 | COMBINING TILDE OVERLAY | proportional |
| ̝ | 031D | COMBINING UP TACK BELOW | proportional |
| ̞ | 031E | COMBINING DOWN TACK BELOW | proportional |
| ̘ | 0318 | COMBINING LEFT TACK BELOW | proportional |
| ̙ | 0319 | COMBINING RIGHT TACK BELOW | proportional |
| ̪ | 032A | COMBINING BRIDGE BELOW | proportional |
| ̺ | 033A | COMBINING INVERTED BRIDGE BELOW | proportional |
| ̻ | 033B | COMBINING SQUARE BELOW | proportional |
| ̃ | 0303 | COMBINING TILDE | proportional |
| ̚ | 031A | COMBINING LEFT ANGLE ABOVE | proportional |
| ❶ | 2776 | DINGBAT NEGATIVE CIRCLED DIGIT ONE | proportional |
| ❷ | 2777 | DINGBAT NEGATIVE CIRCLED DIGIT TWO | proportional |
| ❸ | 2778 | DINGBAT NEGATIVE CIRCLED DIGIT THREE | proportional |
| ❹ | 2779 | DINGBAT NEGATIVE CIRCLED DIGIT FOUR | proportional |
| ❺ | 277A | DINGBAT NEGATIVE CIRCLED DIGIT FIVE | proportional |
| ❻ | 277B | DINGBAT NEGATIVE CIRCLED DIGIT SIX | proportional |
| ❼ | 277C | DINGBAT NEGATIVE CIRCLED DIGIT SEVEN | proportional |
| ❽ | 277D | DINGBAT NEGATIVE CIRCLED DIGIT EIGHT | proportional |
| ❾ | 277E | DINGBAT NEGATIVE CIRCLED DIGIT NINE | proportional |
| ❿ | 277F | DINGBAT NEGATIVE CIRCLED NUMBER TEN | proportional |
| ⓫ | 24EB | NEGATIVE CIRCLED NUMBER ELEVEN | proportional |
| ⓬ | 24EC | NEGATIVE CIRCLED NUMBER TWELVE | proportional |
| ⓭ | 24ED | NEGATIVE CIRCLED NUMBER THIRTEEN | proportional |
| ⓮ | 24EE | NEGATIVE CIRCLED NUMBER FOURTEEN | proportional |
| ⓯ | 24EF | NEGATIVE CIRCLED NUMBER FIFTEEN | proportional |
| ⓰ | 24F0 | NEGATIVE CIRCLED NUMBER SIXTEEN | proportional |
| ⓱ | 24F1 | NEGATIVE CIRCLED NUMBER SEVENTEEN | proportional |
| ⓲ | 24F2 | NEGATIVE CIRCLED NUMBER EIGHTEEN | proportional |
| ⓳ | 24F3 | NEGATIVE CIRCLED NUMBER NINETEEN | proportional |
| ⓴ | 24F4 | NEGATIVE CIRCLED NUMBER TWENTY | proportional |
| ⓐ | 24D0 | CIRCLED LATIN SMALL LETTER A | proportional |
| ⓑ | 24D1 | CIRCLED LATIN SMALL LETTER B | proportional |
| ⓒ | 24D2 | CIRCLED LATIN SMALL LETTER C | proportional |
| ⓓ | 24D3 | CIRCLED LATIN SMALL LETTER D | proportional |
| ⓔ | 24D4 | CIRCLED LATIN SMALL LETTER E | proportional |
| ⓕ | 24D5 | CIRCLED LATIN SMALL LETTER F | proportional |
| ⓖ | 24D6 | CIRCLED LATIN SMALL LETTER G | proportional |
| ⓗ | 24D7 | CIRCLED LATIN SMALL LETTER H | proportional |
| ⓘ | 24D8 | CIRCLED LATIN SMALL LETTER I | proportional |
| ⓙ | 24D9 | CIRCLED LATIN SMALL LETTER J | proportional |
| ⓚ | 24DA | CIRCLED LATIN SMALL LETTER K | proportional |
| ⓛ | 24DB | CIRCLED LATIN SMALL LETTER L | proportional |
| ⓜ | 24DC | CIRCLED LATIN SMALL LETTER M | proportional |
| ⓝ | 24DD | CIRCLED LATIN SMALL LETTER N | proportional |
| ⓞ | 24DE | CIRCLED LATIN SMALL LETTER O | proportional |
| ⓟ | 24DF | CIRCLED LATIN SMALL LETTER P | proportional |
| ⓠ | 24E0 | CIRCLED LATIN SMALL LETTER Q | proportional |
| ⓡ | 24E1 | CIRCLED LATIN SMALL LETTER R | proportional |
| ⓢ | 24E2 | CIRCLED LATIN SMALL LETTER S | proportional |
| ⓣ | 24E3 | CIRCLED LATIN SMALL LETTER T | proportional |
| ⓤ | 24E4 | CIRCLED LATIN SMALL LETTER U | proportional |
| ⓥ | 24E5 | CIRCLED LATIN SMALL LETTER V | proportional |
| ⓦ | 24E6 | CIRCLED LATIN SMALL LETTER W | proportional |
| ⓧ | 24E7 | CIRCLED LATIN SMALL LETTER X | proportional |
| ⓨ | 24E8 | CIRCLED LATIN SMALL LETTER Y | proportional |
| ⓩ | 24E9 | CIRCLED LATIN SMALL LETTER Z | proportional |
| ⁑ | 2051 | TWO ASTERISKS ALIGNED VERTICALLY | proportional |
| ⁂ | 2042 | ASTERISM | proportional |
| ① | 2460 | CIRCLED DIGIT ONE | proportional |
| ② | 2461 | CIRCLED DIGIT TWO | proportional |
| ③ | 2462 | CIRCLED DIGIT THREE | proportional |
| ④ | 2463 | CIRCLED DIGIT FOUR | proportional |
| ⑤ | 2464 | CIRCLED DIGIT FIVE | proportional |
| ⑥ | 2465 | CIRCLED DIGIT SIX | proportional |
| ⑦ | 2466 | CIRCLED DIGIT SEVEN | proportional |
| ⑧ | 2467 | CIRCLED DIGIT EIGHT | proportional |
| ⑨ | 2468 | CIRCLED DIGIT NINE | proportional |
| ⑩ | 2469 | CIRCLED NUMBER TEN | proportional |
| ⑪ | 246A | CIRCLED NUMBER ELEVEN | proportional |
| ⑫ | 246B | CIRCLED NUMBER TWELVE | proportional |
| ⑬ | 246C | CIRCLED NUMBER THIRTEEN | proportional |
| ⑭ | 246D | CIRCLED NUMBER FOURTEEN | proportional |
| ⑮ | 246E | CIRCLED NUMBER FIFTEEN | proportional |
| ⑯ | 246F | CIRCLED NUMBER SIXTEEN | proportional |
| ⑰ | 2470 | CIRCLED NUMBER SEVENTEEN | proportional |
| ⑱ | 2471 | CIRCLED NUMBER EIGHTEEN | proportional |
| ⑲ | 2472 | CIRCLED NUMBER NINETEEN | proportional |
| ⑳ | 2473 | CIRCLED NUMBER TWENTY | proportional |
| ∮ | 222E | CONTOUR INTEGRAL | proportional |
| ∟ | 221F | RIGHT ANGLE | proportional |
| ❖ | 2756 | BLACK DIAMOND MINUS WHITE X | proportional |
| ☞ | 261E | WHITE RIGHT POINTING INDEX | proportional |