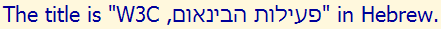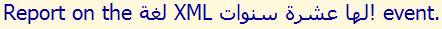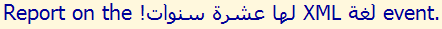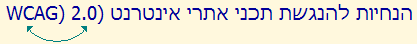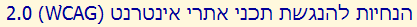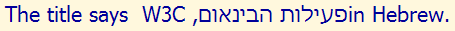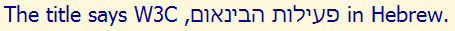When weak or neutral characters or objects appear at the wrong side of a directional run, fix it using dir if there is markup already in place, or use an RLM/LRM.
How to
If the directional run is surrounded by markup, you can simply add the dir attribute to the element surrounding it.
If not, rather than use the RLE/LRE plus PDF controls to create embedded text, place U+200F RIGHT-TO-LEFT
MARK (RLM) or U+200E LEFT-TO-RIGHT
MARK (LRM) alongside misplaced characters to produce the desired result.
The RLM/LRM characters can be added as either characters or as escapes. (But see the issues associated with escapes in the section Adding escapes to the content.)
Note: Although we talk in terms of characters in this technique, the same principles apply to objects such as checkboxes, images, radio buttons, etc, since they are treated in the same way as neutral characters.
For examples and more detailed explanations see the discussion that follows.
Discussion
You need to be familiar with the concepts in the article What you need to know about the bidi algorithm and
inline markup to understand this technique.
Weakly-typed or neutral characters between different directional runs take on the directionality of the base direction. This can be an issue if the character in question is part of, but on the edge of, a directional run which has a different direction from the current base direction.
You can deal with misplaced characters by either providing a different base direction, or by making sure the problematic character is followed by an appropriate strongly-typed character. Example 14 illustrates the problem and both of these solutions.
In the example text immediately below, the exclamation mark is part of the Arabic phrase and should have appeared to its left. It appears to the right because it falls, in memory, between an Arabic and Latin character and the overall paragraph direction is LTR. It is therefore treated as part of the English text (as is the adjacent quotation mark).


Visual ASCII version: the title is "SDRADNATS BEW OT YEK EHT!".
This is what we should have seen.

Visual ASCII version: the title is "!SDRADNATS BEW OT YEK EHT".
An easy way to fix this is to insert the Unicode character U+200F, called the RIGHT-TO-LEFT
MARK (RLM), after the exclamation mark. Now with two strong RTL characters on either side, the exclamation mark too will be treated as part of the
RTL directional run and we will get the correct result. Here's the markup that would produce it. We use a numeric character reference so that you can see the character.
<p>The title is "...‏".</p>
Note, however, that in a case such as this you are likely to have markup in place around the Arabic text to identify its semantics, assign a language tag or apply appropriate styling. If that is the case, it is equally simple to just add a dir attribute to the existing markup, as shown here.
<p>The title is "<cite lang="ar" dir="rtl">...</cite>".</p>
Although our base text for Example 14 was in Latin script, you are more likely to encounter this kind of problem in an Arabic paragraph that included English text followed by punctuation. In that case you would use U+200E LEFT-TO-RIGHT
MARK (LRM) to address the problem. Here is an example.
In the example text immediately below, the parenthesis to the left is part of the English phrase and should have appeared to its right. It appears to the left because it falls, in memory, between a Latin and Arabic character and the overall paragraph direction is RTL. It is therefore treated as part of the Arabic text. Note: the shape of the parenthesis is irrelevant, since it is a mirrored character.

Visual ASCII version: DNA NOITCUDORTNI NA ROF (web content accessibility guidelines (wcag EES
.wcag ROF LAIRETAM LANOITACUDE DNA LACINHCET OT SKNIL
This is what we should have seen.

Visual ASCII version: DNA NOITCUDORTNI NA ROF web content accessibility guidelines (wcag) EES
.wcag ROF LAIRETAM LANOITACUDE DNA LACINHCET OT SKNIL
The easy way to fix this is to insert the Unicode character U+200E, called the LEFT-TO-RIGHT
MARK (LRM), after the parenthesis that is in the wrong place. Now with two strong LTR characters on either side, the parenthesis will be treated as part of the
LTR directional run and we will get the correct result.
If, however, the text "Web Content Accessibility Guidelines (WCAG)" is surrounded by markup, it is equally simple and effective to just add a dir attribute to the existing markup, rather than insert the character.
Here is a slightly different looking example, that turns out to be the same problem. There is a major issue with this example because it is not obvious that a mistake has been made.
The first part of this MAC number has been moved to the right. This is because the characters between the Hebrew text and the 'aa' are all neutral or weak, and so they take on the base direction, and are associated with the Hebrew directional run.
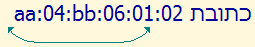
Visual ASCII version: aa:04:bb:06:01:02 REBMUN
This is what we should have seen.
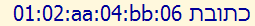
Visual ASCII version: 01:02:aa:04:bb:06 REBMUN
Again, we can produce the right ordering just by putting an LRM character immediately before the start of the number. This puts the initial digits and colons between two strong LTR characters, which associates them with the rest of the number.
Similar results can be obtained for telephone numbers with certain separators.

 Internet Explorer v6-8
Internet Explorer v6-8  Firefox v3.5.2
Firefox v3.5.2 Opera v9.64
Opera v9.64  Google Chrome v2.0.172.33
Google Chrome v2.0.172.33  Safari v4.0
Safari v4.0