Abstract
The HCLS Knowledgebase (HCLS-KB) is a biomedical knowledge base that integrates 15 distinct data sources using currently available Semantic Web Technologies such as the W3C standard Web Ontology Language (OWL) and Resource Description Framework (RDF). This report outlines which resources were integrated, how the KB was constructed using freely available triple store technology, how it can be queried using the W3C Recommended RDF query language SPARQL, and what resources and inferences are involved in answering complex queries. While the utility of the KB is illustrated by identifying a set of genes involved in Alzheimer's Disease, the approach described here can be applied to any use case that integrates data from multiple domains.
Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.
This is a First Public Working Draft of the Semantic Web in Health Care and Life Sciences Interest Group (HCLS), part of the W3C Semantic Web Activity.
This document describes the construction and use of the HCLS Knowledgebase used in the WWW2007 Banff HCLS Demo. It describes the process for creating a bilogical database on the Semantic Web. The companion document, Experiences with the conversion of SenseLab databases to RDF/OWL, describes the process for integrating new data into this Knowledgebase.
Please send all comments on either of these documents by 21 April, to public-semweb-lifesci@w3.org, a mailing list with a public archive, though the IG does not promise explicit responses to each comment. Publication of this document as an Interest Group Note is planned for May 2008; timely comments are appreciated. Areas marked with "@@" are known to be incomplete, however, any suggestions in these areas are still appreciated.
Publication as a Working Draft does not imply endorsement by the W3C Membership. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to cite this document as other than work in progress.
This document was produced by a group operating under the disclosure
obligations of the 5 February 2004 W3C Patent Policy. The group does
not expect this document to become a W3C Recommendation. An
individual who has actual knowledge of a patent which the individual
believes contains Essential Claim(s) must disclose the information to
public-semweb-lifesci@w3.org [public archive] in accordance with
in accordance with section 6 of the W3C Patent Policy.
Appendices
1 Introduction
The life sciences have a rich history of making data available on the Web, because researchers recognized the benefits of sharing data and made it available to other researchers for the benefit of greater science. However, because many of the data repositories were developed in relative isolation, they tend to use different identifier schemes, incompatible terminology, and dissimilar data formats. This makes it hard for researchers to find all data about an entity of interest and to assemble it into a useful block of knowledge. The HCLS knowledgebase was built to demonstrate how Semantic Web technologies can integrate such heterogeneous data sets and thereby help scientists to more easily answer interesting scientific questions.
The key to advancing scientific understanding is empowering scientists with the information that they need to make well-informed decisions. Scientists need to be able to easily gain access to all information about chemical compounds, biological systems, diseases, and the interactions between these entities, and this requires data to be effectively integrated in order to provide a systems level view to the user. However, achieving this goal has proven to be a formidable challenge in the life sciences, where data and models are found in a large variety of formats and scales that span from the molecular to the anatomical.
In order to overcome the challenge of gaining insight directly from the Web, a number of laboratories, organizations, and companies have built internal data warehouses from the publicly available data sources. This certainly helps scientists to more easily query for all information related to entities of interest. However, these efforts generally integrate a subset of publicly available data that is deemed to be of greatest interest, and it has proven difficult to add data sources to the data at a later point. Further, advances in scientific knowledge require regular changes to be made to the underlying data models, and this is not straightforward with a relational model. Organizations that use this approach also typically face challenges with representing data that is at different levels of abstraction, and that includes data of very different quality.
Many health care and life sciences organizations are interested in the data integration abilities promised by the Semantic Web. More specifically, the benefits include the aggregation of heterogeneous data using explicit semantics, and the expression of rich and well-defined models for data aggregation and search. Another critical aspect of the Semantic Web is the ability to more flexibly add additional data sets into the data model, and more easily reuse data in unanticipated ways. Finally, once the data has been integrated, the Semantic Web enables the application of reasoning to infer additional insights.
The HCLS Knowledgebase imports data from data sources that span multiple domains in health care and the life sciences to make cross-discipline queries and, thereby, knowledge integration possible. The use of an RDF repository to store RDF and OWL makes it possible to query, manipulate, and reason about the data with standard tools and languages such as the SPARQL Query Language for RDF, as well as OWL reasoners. Although this document addresses a specific use case, the approach described here can be applied to any use case that integrates data from multiple domains.
1.2 Document Scope and Target Audience
This document attempts to succinctly describe how the HCLS Knowledgebase was constructed so that interested parties can use the core requirements to eventually create their own knowledgebase. We have attempted to write a general description but the knowledgebase makes use of unavoidably specialized resources, such as those found in the Data Sources section. Some, but not all, of the reasoning behind design decisions is explained. Several technologies such as semantic web standards were used but we are unable to explain all aspects in the depth that would be required for those new to the area. Those interested in a general introduction to semantic web should see The Semantic Web Primer. See also the CO-ODE web site for a hands-on OWL tutorial with Protégé.
1.3 Stability of Terms
This document uses URLs to identify records about biological processes. The identifiers used in this document are the same as those used in the knowledgebase and are not yet stable. However, an accompanying appendix will index the regular expressions or scripts used to update these identifiers as they evolve. Knowledgebase implementors should use these terms whenever possible.
1.4 Document Conventions
In this document, examples assume the following namespace prefix bindings unless
otherwise stated:
| Prefix | URI | Description |
|---|
rdf: | http://www.w3.org/1999/02/22-rdf-syntax-ns# | The RDF Vocabulary |
rdfs: | http://www.w3.org/2000/01/rdf-schema# | The RDF Schema vocabulary |
xsd: | http://www.w3.org/2001/XMLSchema# | XML Schema |
sc: | http://purl.org/science/owl/sciencecommons/ | Classes and properties belonging to the ad hoc Science Commons ontology. |
pubmedRec: | http://purl.org/commons/record/pmid/ | PubMed records (not the articles themselves). |
article: | http://purl.org/science/article/pmid/ | PubMed articles. |
ncbi_gene: | http://purl.org/commons/record/ncbi_gene/ | Entrez Gene records (not the genes themselves). |
proteinsubclass: | http://purl.org/science/protein/subjects/ | Proteins of a given gene participating in a given pathway. |
go: | http://purl.org/obo/owl/GO# | temporary namespace for Gene Ontology terms |
protein: | http://purl.org/science/protein/bysequence/ | NCBI records for Genes sequences. |
ro: | http://www.obofoundry.org/ro/ro.owl# (proposed update may be more complete) | Relationships between members of OBO classes. |
obo: | http://purl.org/obo/owl/obo# | @@ don't know — contains part_of @@ |
senselab: | http://purl.org/ycmi/senselab/neuron_ontology.owl# | Neuroscience ontology derived from the SenseLab NeuronDB database. |
dnaGeneProduct: | http://purl.org/science/owl/sciencecommons/is_protein_gene_product_of_dna_ | Syntactic trick to shorten sc:is_protein...described_by |
1.5 Document Outline
1 Introduction motivates and explains this document.
2 Use Case introduces an
interesting scientific question that the knowledgebase can be used
to address.
3 Data Sources describes the data sources that have been incorporated into the knowledgebase.
4 Design Decisions explains the reasons for several design choices.
5 Importing to RDF explains the process of translating data into RDF triples.
6 Query explains the basis query that answers the scientific question.
7 Data Model explains the basics of RDF triples.
8 Adding a New Data Source explains how the SenseLab database was integrated.
9 Named Graphs discusses the use of named graphs and query details.
10 Next Steps discusses problem areas and possible improvements.
2 Use Case
Alzheimer's is a debilitating neurodegenerative disease that affects approximately 27 million people worldwide. The cause of Alzheimer's is currently unknown and no therapy is able to halt its progression. However, insight into the mechanism and potential treatment of this debilitating disease may come from the integration of neurological, biomedical and biological resources. The HCLS knowledgebase assembles several neurology-related resources alongside an array of clinical and biological resources. This makes it possible to integrate knowledge across several research domains and potentially provide insight into the mechanisms of the disease.
The scientific question under scrutiny in our use case involves several elements of putative functional importance to Alzheimer's. CA1 Pyramidal Neurons (CA1PN) are known to be particularly damaged in Alzheimer's disease and play a key role in signal transduction. Signal transduction pathways are considered to be rich in proteins that might respond to chemical therapy. By integrating information about signal transduction, pyramidal neurons, their genes, and gene products, the query corresponding to our scientific question can provide information relevant to researchers that are looking for drug target candidates that are potentially effective against Alzheimer's Disease.
3 Data Sources
In order to incorporate data from several information sources, it was necessary to convert several exported formats, each into its own RDF bundle. The largest RDF bundle of 200M triples resulted from MeSH associations with PubMed articles. In contrast, there were a number of smaller bundles ranging from 10K to 10M triples. This resulted in a total of approximately 350M triples occupying approximately 20Gb when loaded into the RDF repository. In several cases, we extracted only a subset, for example, by selecting only human, rat, and mouse data. Click on [Details] in the table below to view provenance information such as the date of the last extraction, whether the extraction was a subset, etc.
At the time of publication, the following information sources have been (sometimes partially) incorporated into the knowledgebase. This set will continue to be extended in depth (i.e., more complete inclusion of partially represented data sets) and in breadth (i.e., novel data sets):
| Allen Brain Atlas (ABA) |
Allen Brain Atlas is an interactive, genome-wide image database of gene expression in the mouse brain. A combination of RNA in situ hybridization data, detailed Reference Atlases and informatics analysis tools are integrated to provide a searchable digital atlas of gene expression. Together, these resources present a comprehensive online platform for exploration of the brain at the cellular and molecular level. |
[Details] |
| Addgene |
A catalog of plasmids from Addgene |
[Details] |
| BAMS |
The Brain Architecture Management System (BAMS) is designed to be a repository of information about brain structures from different species, and has a set of inference engines for processing the neurobiological data. BAMS contains to date five interrelated modules: Brain Parts (brain regions, major fiber tracts, and ventricles), Cell Types, Molecules, Relations (between structures from different neuroanatomical atlases), and Connections. |
[Details] |
| GALEN |
GALEN is an advanced terminology of medical concepts for clinical information systems. More on GALEN. We imported the GALEN ontology in OWL from CO-ODE |
[Details] |
| NCBI gene_info |
NCBI gene_info was imported into OWL. |
[Details] |
| Gene Ontology (GO) |
The Gene Ontology project provides a controlled vocabulary to describe gene and gene product attributes in any organism. GO terms are often used to annotate gene and protein records. |
[Details] |
| GOA |
GO annotations from NCBI and EBI. |
[Details] |
| HomoloGene |
Homologene is a system for automated detection of homologs among the annotated genes of several completely sequenced eukaryotic genomes. |
[Details] |
| MEDLINE/PubMed |
PubMed is a service of the U.S. National Library of Medicine that includes over 17 million citations from MEDLINE and other life science journals for biomedical articles back to the 1950s. PubMed includes links to full text articles and other related resources. |
[Details] |
| MeSH |
Medical Subject Headings. 2008 MeSH includes the subject descriptors appearing in MEDLINE/PubMed, the NLM catalog database, and other NLM databases. See the MeSH introduction. |
[Details] |
| Neurocommons Text Mining Pilot |
Protein/gene associations/interactions extracted from Temis software applied to 7% of Medline records (SC). Annotations were captured in RDF using the Neurocommons Annotations Schema |
[Details] |
| BerkeleyBop OBO ontologies |
All Open Biomedical Ontologies (OBO) available from BerkelyBop. |
[Details] |
| Science Commons Ontology |
An ad hoc ontology from Science Commons used by the output of several of the conversion scripts. |
[Details] |
| SenseLab |
There will be a reference here to another W3C document. |
[Details] |
| SWAN |
Semantic Web Applications in Neuromedicine |
@@ no bundle yet @@ |
| SKOS |
Simple Knowledge Organization System: specifications and standards to support the use of knowledge Organization systems (KOS) such as thesauri, classification schemes, subject heading systems and taxonomies within the framework of the Semantic Web |
- |
4 Design Decisions
A number of design decisions were made during the construction
of the HCLS Knowledgebase. Many of the decisions were pragmatic in
nature, as a consequence of the need to implement the solution on
a commodity PC within a two-month period for a demonstration at
WWW2007.
- URI Scheme
HTTP URIs were adopted as the mechanism to identify
biological entities. In particular, URIs with a Persistent URL
(PURL) were used as they provide re-direction capabilities, which
make the identifiers more robust against future change.
- Unifying terms
While data in different information sources may talk
about the same thing, one must provide a common set of identifiers
in order to get the RDF graph to connect. For instance, the named
graph PubMesh uses gene record
identifiers to relate genes to PubMed articles. It uses terms like
ncbi_gene:1812 to identify a gene
record. The Gene Ontology database
records use the same identifiers, which allows us to easily link
information contained in the two corresponding named graphs. New
databases are able to connect their data graphs to the existing
store by re-using the same terms. We accomplished this by
translating internal identifiers from the databases into URIs in
our chosen scheme.
- Ontology Design
An ontology was built with sufficient detail for the
immediate needs of the demonstration and was limited by the date
of the demo. Consequently, it contains more detail in the core
areas of focus, than in areas of more peripheral interest. The
ontology was written in OWL-DL so that we could specify statements
in an interoperable and computable way. We also wanted to verify
small subsets for consistency during development, with the hope
that in the future a more capable repository will be able to do
appropriate inferences based on the class and property
definitions. The ontology distinguishes between real world
entities and documents about real world entities. We endeavored to
follow the OBO foundry methodology, which espouses the principle
that we first identify what instances are by identifying them with
physical things, such as a molecule in some person's body. Classes
are defined as sets of those instances. For example, the class of
glutamate receptors can be defined as multimeric macromolecules
that have high binding affinity for glutamate molecules. Expressed
more formally, we can say EVERY glutamate receptor
IS_A multimeric macromolecule THAT has high binding
affinity for SOME glutamate molecule. In this way, the
class of glutamate receptors can be defined in terms of the
classes multimeric macromolecules and glutamate molecule,
something which OWL expresses quite naturally. The knowledge base
contains many such definitions of classes.
- Multiple Graphs
Once the data was converted into RDF/OWL, it was loaded into the
triple store as a number of separate graphs. This approach made
it simpler to re-load and update data, which was required often
as a consequence of iterative enhancements to the ontology. This
fast upload capability proved critical as the data reached the
scale of hundreds of millions of triples. This partitioning of
data also helped queries to be performed rapidly.
- Precomputed Inferences
Our approach has been to choose a representation in valid OWL-DL,
with the expectation that queries would be evaluated against all
answers that could be inferred from our representation. However,
our triple store has no native inferencing capabilities. To
enable querying against inferred information, we added
pre-computed inferences in the form of non-OWL-DL, direct
class-class relations, to the classrelations graph (see
Named Graphs section and @@list of named
graphs@@ in the Appendix). These non-OWL-DL relations were added
so that it would be easy to use SPARQL queries to access the
inferences, which were in some cases represented in OWL as
property restrictions, as in the case of partonomic
relations. The direct class-class relations were more compact to
represent in RDF and queries that took advantage of them were
easier to write in SPARQL.
5 Importing to RDF
A number of different approaches were used for the conversion
of data into RDF/OWL. The most commonly used approach was the use
of Lisp code to read text exports of the data and create OWL or
RDF documents. We will focus on the example of importing data
from Homologene.
The general steps required to import from an existing data source into RDF are:
- Read the data into your program. This can be accomplished by
exporting to a text format of choice (CSV, tab-delimited, XML,
etc.) or accessing the database directly with a database connector.
- Write the data into the desired RDF format. This can be in
the form of an RDF/XML file that is then loaded into the
repository. Another approach is to use software libraries that
allow you to add triples directly to your repository.
In the case of Homologene, we start with a text file that contains the exported information. The original tab delimited file is ftp://ftp.ncbi.nih.gov/build54/homologene.data. The Lisp code for the homologene conversion is also available.
It looks like this:
3 9606 34 ACADM 4557231 NP_000007.1
3 9598 469356 ACADM 114557331 XP_524741.2
3 9615 490207 ACADM 73960161 XP_547328.2
3 10090 11364 Acadm 6680618 NP_031408.1
3 10116 24158 Acadm 8392833 NP_058682.1
We are interested in the first 3 fields. The first field identifies
the homologous cluster. The second field is the species taxon. The
third field is the EntrezGene id. We are only interested in human,
mouse, rat, taxon ids: "9606" "10116" "10090".
We first iterate over the lines in the file, creating a table mapping cluster id to the pairs of taxon id, entrez id in the cluster. This is the variable homologene, created by the function read-homologene. For each of these clusters we will create an individual to represent the cluster e.g for cluster 99949:
<sciencecommons:orthology_record rdf:about="http://purl.org/science/record/homologene/cluster_r54_99949">
<sciencecommons:has_homologous_gene_record rdf:resource="http://purl.org/commons/record/ncbi_gene/678753"/>
<sciencecommons:has_homologous_gene_record rdf:resource="http://purl.org/commons/record/ncbi_gene/727759"/>
<sciencecommons:has_supporting_evidence rdf:resource="http://purl.org/science/evidence/homologene/cluster_r54_99949"/>
</sciencecommons:orthology_record>
There are two things to note about this conversion. The first is that HTTP URIs were adopted as the mechanism to identify records. Importantly, these can also be resolved using standard web technology (web browsers). PURLS for a specific format of database records redirect to web pages that describe those records in the format. It has been our experience that URIs for such web pages can change over time. PURLS were chosen because we can change what web page a PURL redirects to. Thus PURLs provide a more stable URI for a resource than the provider resources, and place control enabling one to make repairs in such situations into the hands of the HCLS community. The second is that we mapped equivalent terms from different resources to a common base URI i.e. the http://purl.org/commons/record/ncbi_gene/ prefix was used to consistently identify Entrez Gene records. This allows for trivial data integration between different resources and simplifies queries involving Entrez Gene records.
Also, the individual http://purl.org/science/evidence/homologene/cluster_r54_99949 serves as a link to the "evidence", which is not elaborated in this translation, but would include the blast scores and other evidence used to establish the orthology in future work. (see http://www.ncbi.nlm.nih.gov/sites/entrez?cmd=Retrieve&db=homologene&dopt=AlignmentScores&list_uids=99949)
6 Query
The scientific question can be answered with the following query, which
searches for gene names and processes from four data sources within the
knowledgebase. The data sources include: MeSH (Pyramidal Neurons), PubMed (Journal Articles), Entrez Gene (Genes), Gene Ontology (Signal Transduction). The query example selects the gene name of the genes involved in signal transduction that are related to pyramidal neurons. Some of the complexity in this query comes from the need to capture relevant anatomical and functional detail at the subcellular and molecular level. The portion probing the Gene Ontology queries a set of classes describing processes at the molecular level. Our query employs the SPARQL RDF query language to perform knowledge integration across the sources of the knowledgebase. Details on SPARQL can be found in the References.
[Note: The query below will not work verbatim at SPARQL endpoints. We have simplified the actual Banff demonstration query for explanatory purposes in our example below. The Banff demonstration query is discussed in more detail in Named Graphs Section. You can try running the query at the DERI installation.]
SELECT ?genename ?processname
WHERE {
?pubmed_record sc:has-as-minor-mesh mesh:D017966 .
?article sc:identified_by_pmid ?pubmed_record .
?gene_record sc:describes_gene_or_gene_product_mentioned_by ?article .
?protein rdfs:subClassOf ?restriction1 .
?restriction1 owl:onProperty ro:has_function .
?restriction1 owl:someValuesFrom ?restriction2 .
?restriction2 owl:onProperty ro:realized_as .
?restriction2 owl:someValuesFrom ?process .
?protein rdfs:subClassOf ?protein_superclass .
?protein_superclass owl:equivalentClass ?restriction3 .
?restriction3 owl:onProperty dnaGeneProduct:described_by .
?restriction3 owl:hasValue ?gene_record .
?process obo:part_of go:GO_0007166 .
?gene_record rdfs:label ?genename .
?process rdfs:label ?processname .
}
The following shows a few of the results from the query:
| gene_record_name |
processname |
| Entrez Gene record for human DRD1, 1812 |
adenylate cyclase activation |
| Entrez Gene record for human ADRB2, 154 |
adenylate cyclase activation |
| ... |
The following section describes the RDF data model and how we employed it to make our query possible.
7 Data Model
The data in the knowledgebase is modeled in OWL-DL, which has been expressed as RDF triples. Briefly, an RDF triple consists of a subject, predicate, and object. The predicate is also known as the property of the triple. Subjects and objects in the data unify to create an RDF Graph, with subjects and objects as nodes and predicates as edges. For more information about RDF and OWL, see the References section in the Appendix.
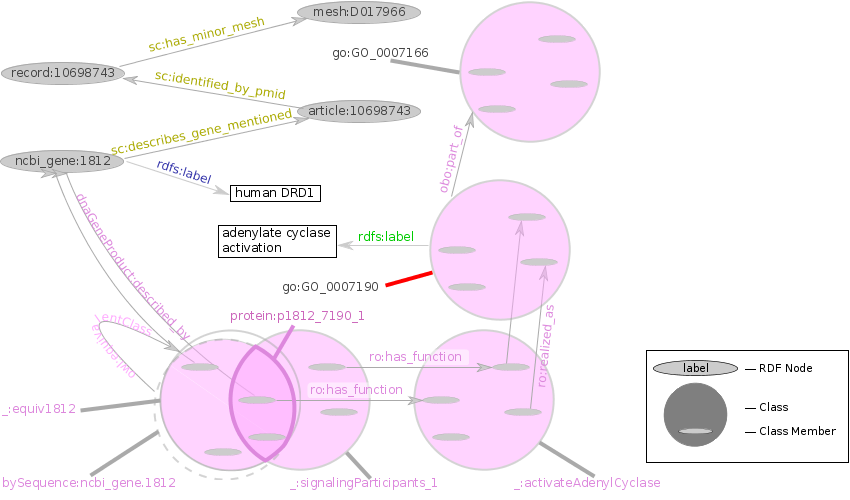
Nodes labeled with a leading "_:", e.g. proteinsubclass:p1812_7190_1, are called RDF blank nodes [CONCEPTS]. These frequently have machine-generated and therefore typically opaque to a human reader (e.g., the set of all nodes that represent protein entities linked to the GO molecular function XXX), but the purposes of explanation, here, they have been named to convey meaning to the reader. Blank nodes ending in "_1" in this document indicate this blank node is one of many in this class.
The application of a commercial text mining tool to neuroscience-related PubMed abstracts results in a set of annotations that link MeSH terms to genes (for more details on MeSH, see the table in Data Sources. An article with PubMed id 10698743 mentions ncbi_gene:1812 and that the corresponding PubMed record has a MeSH term mesh:D017966. The following three triples express this:
| subject |
predicate |
object | | |
| pubmedRec:10698743 | sc:has-as-minor-mesh | mesh:D017966 | . |
| article:10698743 | sc:identified_by_pmid | pubmedRec:10698743 | . |
| ncbi_gene:1812 | sc:describes_gene_or_gene_product_mentioned_by | article:10698743 | . |
A set of genes or gene products in human bodies are described by ncbi_gene:1812. Here, we call this set _:equiv1812.
| _:equiv1812 | owl:onProperty | dnaGeneProduct:described_by | . |
| _:equiv1812 | owl:hasValue | ncbi_gene:1812 | . |
protein:ncbi_gene.1812 has the same extension (members) as the OWL restriction _:equiv1812.
| protein:ncbi_gene.1812 | owl:equivalentClass | _:equiv1812 | . |
The expression
NamedClass equivalentClass R .
R onProperty SomeProperty .
R hasValue SomeClass
is an owl idiom to say that for every X such that
X SomeProperty SomeClass .
X is a member of the class NamedClass. See OWL Web Ontology Language Semantics and Abstract Syntax Section 4. Mapping to RDF Graphs for a formal treatment of this.
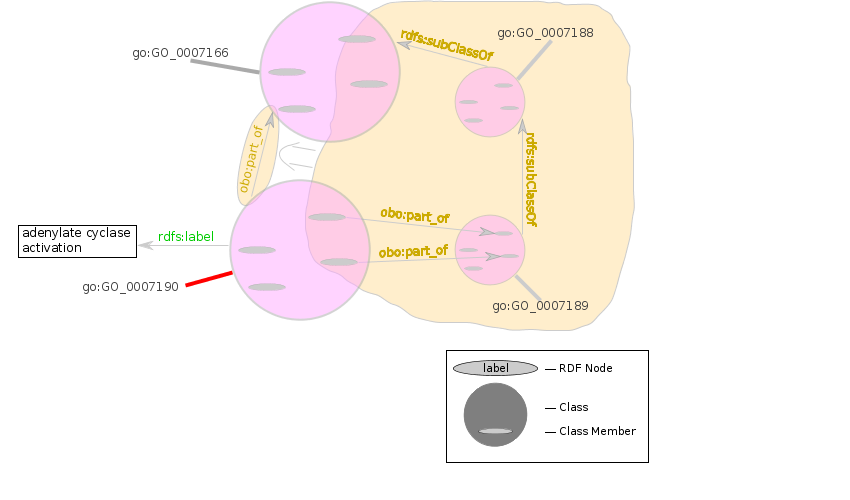
Using our other supplied constant, we note that adenylate cyclase activation, go:GO_0007190, is part of signal transduction, go:GO_0007166. Note: this simplified query matches only processes that are a sub-process of go:GO_0007166; the actual query, described in §9 Named Graphs, looks also for subclasses. The part_of relationships were inferred from the OWL class restrictions described in §7.1 Precomputing Inferences. The class of functions that are realized_as adenylate cyclase activation is here labeled _:activateAdenylCyclase.
There are many possible classes of substance participating in molecular signaling, one of which (called here _:molecularSignalers_1) is defined by the ability to activate adenyl cyclase.
| _:signalingParticipants_1 | owl:onProperty | ro:has_function | . |
| _:signalingParticipants_1 | owl:someValuesFrom | _:activateAdenylCyclase | . |
The class of proteins in the intersection of _:signalingParticipants_1 and protein:ncbi_gene.1812 is here abbreviated proteinsubclass:p1812_7190_1, though the actual identifier is proteinsubclass:product_of_ncbi_gene.1812_that_participates_in_GO_0007190_fbc49f20524727a24c7b7effa29bad4a. Note: the Venn diagram reveals that this set is potentially empty (like the intersection of cars and ice cream stands), theoretically permitting the query to range over pairs of gene/process that aren't related through any known protein. However, OWL-DL reasoners will not infer new classes, so the proteins in the intersection of ncbi_gene:1812 and the substances participating in molecular signaling is restricted to the set which have already been entered into the knowledgebase, e.g. like proteinsubclass:p1812_7190_1
| proteinsubclass:p1812_7190_1 | rdfs:subClassOf | _:signalingParticipants_1 | . |
| proteinsubclass:p1812_7190_1 | rdfs:subClassOf | protein:ncbi_gene.1812 | . |
ncbi_gene:1812 and go:GO_0007190 have human-readable labels.
The addition (@@curation (from a text media)?@@) of another MeSH record gives us another solution:
| pubmedRec:11441182 | sc:has-as-minor-mesh | mesh:D017966 | . |
| article:11441182 | sc:identified_by_pmid | pubmedRec:11441182 | . |
| ncbi_gene:1812 | sc:describes_gene_or_gene_product_mentioned_by | article:11441182 | . |
7.1 Precomputing Inferences
The demonstration query depends on the existence of an obo:part_of (or rdfs:subClassOf) relationship between any part (i.e. any subclass of any step in the sequence) of molecular signaling, and the general identifier for molecular signaling, go:GO_0007166:
This part_of relationship between _:subPart and _:parentClass is inferred from the following OWL restriction:
| _:subPart | owl:onProperty | obo:part_of | . |
| _:subPart | owl:allValuesFrom | _:subClass | . |
| _:subClass | owl:onProperty | rdfs:subClassOf | . |
| _:subClass | owl:hasValue | _:parentClass | . |
The symmetric property for rdfs:subClassOf need not be explicitly modeled because the RDF Schema Specification defines subClassOf, including its transitivity. Note that if _:subClass is a subClassOf _:parentClass, then all members of _:subClassOf are of type _:parentClass (as well as _:subClass):
| _:subClass | owl:onProperty | rdf:type | . |
| _:subClass | owl:hasValue | _:parentClass | . |
Because the knowledgebase used does not do inferencing, these triples have been pre-computed (forward-chained) and inserted into the knowledgebase. This also simplifies the query; were these triples not pre-computed, the obo:part-of part of the query would be expressed:
| ?process | rdfs:subClassOf | ?what | . |
| ?what | owl:onProperty | obo:has_part | . |
| ?what | owl:someValuesFrom | go:GO_0007166 | . |
would need to query over a transitive closure over the union of the obo:part-of and rdfs:subClassOf rules.
8 Adding a New Data Source
The last data source listed above, SenseLab, was added to an already used database. An accompanying document, Experiences with the conversion of SenseLab databases to RDF/OWL, describes the details of adding it to the KB. With this new data incorporated, the example query could be extended to extract data from the new data source, in this case, discovering the names of receptor proteins associated with the genes discovered in the previous query. In an integrative query of this sort, we can use the results as a starting point for more detailed queries of a particular repository, such as in this case SenseLab.
SELECT ?genename ?processname ?receptor_protein_name
WHERE {
?pubmed_record sc:has-as-minor-mesh mesh:D017966 .
?article sc:identified_by_pmid ?pubmed_record .
?gene_record sc:describes_gene_or_gene_product_mentioned_by ?article .
?protein rdfs:subClassOf ?restriction1 .
?restriction1 owl:onProperty ro:has_function .
?restriction1 owl:someValuesFrom ?restriction2 .
?restriction2 owl:onProperty ro:realized_as .
?restriction2 owl:someValuesFrom ?process .
?protein rdfs:subClassOf ?protein_superclass .
?protein_superclass owl:equivalentClass ?restriction3 .
?restriction3 owl:onProperty dnaGeneProduct:described_by .
?restriction3 owl:hasValue ?gene_record .
?process obo:part_of go:GO_0007166 .
?gene_record rdfs:label ?genename .
?process rdfs:label ?processname .
OPTIONAL {
?gene owl:equivalentClass ?restriction4 .
?restriction4 owl:onProperty senselab:has_nucleotide_sequence_described_by .
?restriction4 owl:hasValue ?gene_record .
?receptor_protein rdfs:subClassOf ?restriction5 .
?restriction5 owl:onProperty senselab:proteinGeneProductOf .
?restriction5 owl:someValuesFrom ?gene .
?receptor_protein rdfs:label ?receptor_protein_name
}
}
yielding another variable in our results:
| gene_record_name |
processname |
receptor_protein_name |
| Entrez Gene record for human DRD1, 1812 |
adenylate cyclase activation |
D1 receptor |
| Entrez Gene record for human ADRB2, 154 |
adenylate cyclase activation |
NULL |
| ... |
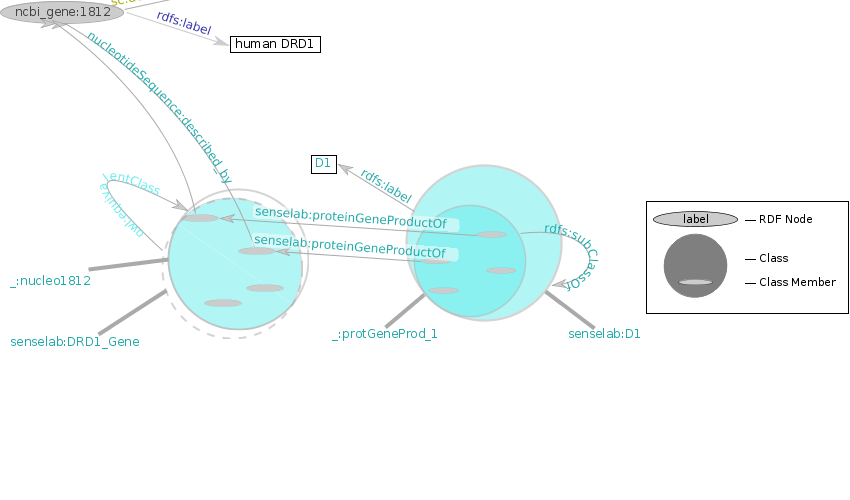
The additional triples this matched in the SenseLab knowledgebase connect to the existing data by talking about the same genes, e.g. ncbi_gene:1812.
A nucleotide sequence is also described by ncbi_gene:1812. Here, we call this _:nucleo1812.
| subject |
predicate |
object | | |
| _:nucleo1812 | owl:onProperty | nucleotideSequence:described_by | . |
| _:nucleo1812 | owl:hasValue | ncbi_gene:1812 | . |
The class senselab:DRD1_Gene has the same members as the OWL restriction _:nucleo1812.
| senselab:DRD1_Gene | owl:equivalentClass | _:nucleo1812 | . |
This _:protGeneProd_1 is defined by being a product of DRD1_Gene.
| _:protGeneProd_1 | owl:onProperty | senselab:proteinGeneProductOf | . |
| _:protGeneProd_1 | owl:someValuesFrom | senselab:DRD1_Gene | . |
Our solution is a subclass of _:protGeneProd_1 called senselab:D1. @@What other subclasses of _:protGeneProd_1 are there motivating this extra subclassof relationship?@@
| senselab:D1 | rdfs:subClassOf | _:protGeneProd_1 | . |
| senselab:D1 | rdfs:label | "D1" | . |
9 Named Graphs
In the Banff Demo, the resulting knowledgebase partitioned the assertions into groups called Named Graphs. This process basically consists of associating a distinct URI with a connected graph of triples, and then referring to that graph via the URI. At the time of publication, any query would be expected to include SPARQL GRAPH constraints, e.g.:
prefix go: <http://purl.org/obo/owl/GO#>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix owl: <http://www.w3.org/2002/07/owl#>
prefix mesh: <http://purl.org/commons/record/mesh/>
prefix sc: <http://purl.org/science/owl/sciencecommons/>
prefix ro: <http://www.obofoundry.org/ro/ro.owl#>
prefix senselab: <http://purl.org/ycmi/senselab/neuron_ontology.owl#>
prefix obo: <http://purl.org/obo/owl/obo#>
SELECT ?genename ?processname ?receptor_protein_name
WHERE {
GRAPH <http://purl.org/commons/hcls/pubmesh> {
?pubmed_record sc:has-as-minor-mesh mesh:D017966 .
?article sc:identified_by_pmid ?pubmed_record .
?gene_record sc:describes_gene_or_gene_product_mentioned_by ?article
}
GRAPH <http://purl.org/commons/hcls/goa> {
?protein rdfs:subClassOf ?restriction1 .
?restriction1 owl:onProperty ro:has_function .
?restriction1 owl:someValuesFrom ?restriction2 .
?restriction2 owl:onProperty ro:realized_as .
?restriction2 owl:someValuesFrom ?process .
?protein rdfs:subClassOf ?protein_superclass .
?protein_superclass owl:equivalentClass ?restriction3 .
?restriction3 owl:onProperty sc:is_protein_gene_product_of_dna_described_by .
?restriction3 owl:hasValue ?gene_record .
GRAPH <http://purl.org/commons/hcls/20070416/classrelations> {
{ ?process obo:part_of go:GO_0007166 }
UNION
{ ?process rdfs:subClassOf go:GO_0007166 }
}
}
GRAPH <http://purl.org/commons/hcls/gene> {
?gene_record rdfs:label ?genename
}
GRAPH <http://purl.org/commons/hcls/20070416> {
?process rdfs:label ?processname
}
GRAPH <http://purl.org/ycmi/senselab/neuron_ontology.owl> {
?gene owl:equivalentClass ?restriction4 .
?restriction4 owl:onProperty senselab:has_nucleotide_sequence_described_by .
?restriction4 owl:hasValue ?gene_record .
?receptor_protein rdfs:subClassOf ?restriction5 .
?restriction5 owl:onProperty senselab:proteinGeneProductOf .
?restriction5 owl:someValuesFrom ?gene .
?receptor_protein rdfs:label ?receptor_protein_name
}
}
The named graphs help with both provenance and scaling. In the current approach, each RDF bundle is imported into its own named graph. This is useful for a number of reasons. First, we know the source of each named graph, so we can control and review which data sources are being accessed by our queries. Additionally, the association of a named graph with a data source serves as data provenance and can also be employed by schemes that exploit knowledge about the data source to assign confidence measures in a model of trust. For example, one of the knowledgebase data sources resulted from text mining experiments to find protein associations. Users of the knowledgebase can choose to view this evidence of association differently than the associations provided from a protein-protein interaction database. Also, named graphs support scaling by making it possible to update selected parts of the knowledgebase, for example when the data source has new information or related ontologies are changed.
10 Next Steps
The knowledgebase was initially designed for the purposes of a live demo. The data warehousing that was performed, several design choices in the data, and the resulting queries were all aimed at simplicity and maximal performance. Many choices were guided by the desire for transparency for a broader audience of biomedical informaticists. Several areas of possible improvement are noted here:
- We would like to broaden the knowledge base to cover more of
the related domains such as structural chemistry, cells,
anatomy, physiology, behavior, protocols, and reagents.
- The sources accessed by a query could eventually be spread
across repositories in separate locations to demonstrate the
ease of integrating distributed data sources with semantic
web.
- Create dynamic visual interfaces that provide the user with
the means to create and refine a query without requiring
prerequisite knowledge of the data or query language.
There are also a number of open issues that should be addressed in future research:
- What relations should we use to connect a biological entity with artificial entities describing it, e.g. protein records, sequence records, PubMed records?
- What is the best way to model evidence so that it can be recorded in data provenance?
- How are information resources such as database entry or XML document associated with a database entry best represented in BFO-friendly ontologies?
- Mapping across terminologies: MeSH, in particular has terms that are synonymous which many terms in other ontologies, including genes, proteins, GO terms, etc. We made efforts to harmonize the representation in certain cases, such as between Senselab and GO. In other cases, we have done no harmonization so this should be reviewed for eventual corrections.
Appendix
A RDF Sources
A table of the RDF sources used to create the Knowledgebase:
B Schema
This table describes the classes and properties used in the knowledgebase:
| sc:Gene |
|---|
| sc:describes_gene_or_gene_product_mentioned_by | sc:Article |
| rdfs:label | Gene Label |
| sc:Article . |
|---|
| sc:identified_by_pmid | sc:Paper |
| sc:Paper . |
|---|
| sc:has-as-minor-mesh | sc:PubMedId |
| sc:PubMedId . |
|---|
C References
- [N3]
- Primer:
Getting into RDF and Semantic Web using N3,
http://www.w3.org/2000/10/swap/Primer .
- [OWL
Overview]
- OWL
Web Ontology Language Overview, Deborah L. McGuinness
and Frank van Harmelen, Editors, W3C Recommendation, 10 February
2004, http://www.w3.org/TR/2004/REC-owl-features-20040210/ . Latest version
available at http://www.w3.org/TR/owl-features/ .
- [OWL Guide]
- OWL Web
Ontology Language Guide, Michael K. Smith, Chris Welty,
and Deborah L. McGuinness, Editors, W3C Recommendation, 10
February 2004, http://www.w3.org/TR/2004/REC-owl-guide-20040210/
. Latest version
available at http://www.w3.org/TR/owl-guide/ .
- [OWL Semantics and Abstract Syntax]
- OWL
Web Ontology Language Semantics and Abstract Syntax,
Peter F. Patel-Schneider, Patrick Hayes, and Ian Horrocks,
Editors, W3C Recommendation, 10 February 2004,
http://www.w3.org/TR/2004/REC-owl-semantics-20040210/ .
Latest version
available at http://www.w3.org/TR/owl-semantics/ .
- [RDF]
-
Resource Description Framework (RDF) Model and Syntax Specification
,
Ora Lassila, Ralph R. Swick, Editors.
World Wide Web Consortium Recommendation, 1999,
http://www.w3.org/TR/1999/REC-rdf-syntax-19990222/.
Latest version
available at http://www.w3.org/TR/REC-rdf-syntax/.
- [RDF CONCEPTS]
- Resource Description Framework (RDF): Concepts and Abstract Syntax , G. Klyne, J. J. Carroll, Editors, W3C Recommendation, 10 February 2004, http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/ . Latest version available at http://www.w3.org/TR/rdf-concepts/ .
-
[RDFS]
-
RDF Vocabulary Description Language 1.0: RDF Schema
,
Dan Brickley and R.V. Guha, Editors.
W3C Recommendation, 10 February 2004,
http://www.w3.org/TR/2004/REC-rdf-schema-20040210/ .
Latest version
available at http://www.w3.org/TR/rdf-schema/.
- [RDF
Semantics]
- RDF
Semantics,
Pat Hayes, Editor, W3C Recommendation, 10 February 2004,
http://www.w3.org/TR/2004/REC-rdf-mt-20040210/
. Latest version available
at
http://www.w3.org/TR/rdf-mt/ .
- [RDF
Vocabulary]
- RDF
Vocabulary
Description Language 1.0: RDF Schema, Dan Brickley and R. V.
Guha,
Editors, W3C Recommendation, 10 February 2004,
http://www.w3.org/TR/2004/REC-rdf-schema-20040210/
. Latest version
available
at http://www.w3.org/TR/rdf-schema/ .
-
[SPARQL-QUERY]
-
SPARQL Query Language for RDF, E. Prud'hommeaux, A. Seaborne, Editors. World Wide Web Consortium. 19 April 2005. Work in progress. This version is http://www.w3.org/TR/2005/WD-rdf-sparql-query-20050419/. The latest version of SPARQL Query Language for RDF is available at http://www.w3.org/TR/rdf-sparql-query/.
- [SPARQL-sem-05]
- A relational
algebra for SPARQL, Richard Cyganiak, 2005
- [SPARQL-sem-06]
- Semantics of SPARQL, Jorge Pérez, Marcelo Arenas, and Claudio Gutierrez,
2006
D Additional Resources
The knowledgebase has been installed at several locations. Below are locations that also provide SPARQL query access:
Below are a few visual interfaces that make it possible to browse the results of a search on the knowledgebase:
We used the open source edition of the Openlink Virtuoso repository from http://sourceforge.net/projects/virtuoso/.
The actions and scripts that were used to create the knowledgebase on a commodity PC have been documented by several HCLS members. The necessary instructions and scripts that were used will be listed here as completely as possible:
The following resources may be of interest for future work:
E Acknowledgements (Informative)
Special thanks to Alan Ruttenberg who coordinated the assembly of the data sets and presented the initial version of the knowledgebase at the Banff demo.
Contributors:
Many contributed to the knowledgebase and its documentation, as
well as the thoughts behind it, including John Barkley (NIST),
Olivier Bodenreider (NLM, NIH), William Bug (School of Medicine,
UCSD), Huajun Chen (Zhejiang University), Paolo Ciccarese (SWAN),
Kei Cheung (SenseLab, Yale), Tim Clark (SWAN), Don Doherty
(Brainstage Research Inc.), Michel Dumontier (Carleton
University), Kerstin Forsberg (AstraZeneca), Ray Hookaway (HP),
Vipul Kashyap (Partners Healthcare), June Kinoshita (AlzForum),
Joanne Luciano (Harvard Medical School), M. Scott Marshall
(University of Amsterdam), Chris Mungall (NCBO), Eric Neumann
(Clinical Semantics Group), Eric Prud’hommeaux (W3C),
Jonathan Rees (Science Commons), Alan Ruttenberg (Science
Commons), Matthias Samwald (Medical University of Vienna), Susie
Stephens (Eli Lilly), Mike Travers, Gwen Wong (SWAN), Elizabeth Wu
(SWAN)
Data providers:
Judith Blake (MGD.), Mikail Bota (BAMS), David Hill (MGD), Oliver
Hoffman (CL), Minna Lehvaslaiho (CL), Colin Knep (Alzforum), Maryanne
Martone (CCDB), Susan McClatchy (MGD), Simon Twigger (RGD), Allen Brain
Institute.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}