Abstract
This Working Draft specifies version 1.2 of the Scalable Vector Graphics (SVG) Language, a modularized language for describing two-dimensional vector and mixed vector/raster graphics in XML.
Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document.
This document is the second public working draft of this specification. It lists the potential areas of new work in version 1.2 of SVG and is not a complete language description. In most cases, the descriptions in this document are incomplete and simply show the current thoughts of the SVG Working Group on the feature. This document should in no way be considered stable. This version does not include the implementations of SVG 1.2 in either DTD or XML Schema form. Those will be included in subsequent versions, once the content of the SVG 1.2 language stabilizes.
This document has been produced by the W3C SVG Working Group as part of the W3C Graphics Activity within the Interaction Domain.
We explicitly invite comments on this specification. Please send them to www-svg@w3.org: the public email list for issues related to vector graphics on the Web. This list is archived and acceptance of this archiving policy is requested automatically upon first post. To subscribe to this list send an email to www-svg-request@w3.org with the word subscribe in the subject line.
The latest information regarding patent disclosures related to this document is available on the Web. As of this publication, the SVG Working Group are not aware of any royalty-bearing patents they believe to be essential to SVG.
Publication of this document does not imply endorsement by the W3C membership. A list of current W3C Recommendations and other technical documents can be found at http://www.w3.org/TR/. W3C publications may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to cite a W3C Working Draft as anything other than a work in progress."
1 How to read this document and give feedback
This draft of SVG 1.2 is a snapshot of a work-in-progress. The SVG Working Group believe the most of the features here are complete and stable enough for implementors to begin work and provide feedback. Some features already have multiple implementations.
This is not a complete specification of the SVG 1.2 language. Rather it is a list of features that are under consideration for SVG 1.2. In many cases the reader will have to be familiar with the SVG 1.1 language.
The main purpose of this document is to encourage public feedback. The best way to give feedback is by sending an email to www-svg@w3.org. Please include some kind of keyword that identifies the area of the specification the comment is referring to in the subject line of your message (e.g "1.2 compositing" or "1.2 audio and video formats"). If you have comments on multiple areas of this document, then it is probably best to split those comments into multiple messages.
The public are welcome to comment on any aspect in this document, but there are a few areas in which the SVG Working Group are explicitly requesting feedback. These areas are noted in place within this document. There are also a few areas related to the specification that are listed here:
-
An W3C XML Schema for SVG 1.2. We are currently developing a W3C XML
Schema, demonstrated by some of the schema snippets included in
this document. The current plan is to follow the technique of
XHTML Modularization in XML Schema for SVG.
-
How should elements be described in the specification? Previous
SVG specification have included relevant DTD snippets when defining
an element. This document has incomplete (and incorrect) XML Schema
snippets. Are these useful? As the schema becomes more complete and
as the modularization information is included, the snippets may
become longer and potentially less readable.
-
The format of the specification itself is under consideration. A
full SVG specification can be over 800 printed pages. Suggestions
are welcome on alternate ways to arrange the information, such as
separate downloads for the DOM Interfaces, DTD/Schema, etc. Note
that the complete online HTML version will always be the normative
reference, regardless of the structure of alternate downloads.
2 Text Wrapping
SVG 1.2 enables a block of text to be rendered inside a shape, while automatically wrapping the text into lines, using the flowText element. The idea is to mirror, as far as practical, the existing SVG text elements.
2.1 The flowText element
The flowText element specifies a block of text to be rendered. It contains at least one flowRegion element, defining regions in which the child flowDiv element of the flowText should be flowed into.
The following is a extract of an XML Schema that describes the flowText element.
<xs:element name="flowText">
<xs:complexType>
<xs:sequence>
<xs:element ref="flowRegion"/>
<xs:element ref="flowRegionExclude"/>
<xs:element ref="flowDiv"/>
</xs:sequence>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
</xs:complexType>
</xs:element>
2.2 The flowRegion element
The flowRegion element contains a set of shapes and exclusion regions in which the text content of a parent flowText element is drawn into. A flowRegion element has basic shapes and path elements as children, as well as a flowRegionExclude element. The children of a flowRegion element are inserted into the rendering tree before the text is drawn, and have the same rendering behavior as if they were children of a g element.
The child elements create a sequence of shapes in which the text content for the parent flowText will be drawn into. Once the text fills a shape it flows into the next shape. The flowRegionExclude child describes a set of regions in which text will not be drawn into, such as a cutout from a rectangular block of text.
The child elements of a flowRegion can be transformed as usual, but the text is always laid out in the coordinate system of the flowText element. For example, a rect child with a 45 degree rotation transformation will appear as a diamond, but the text will be axis aligned.
The following is a extract of an XML Schema that describes the flowRegion element.
<xs:element name="flowRegion">
<xs:complexType>
<xs:sequence>
<xs:choice>
<xs:group ref="ShapeElements" minOccurs="0" maxOccurs="unbounded"/>
<xs:group ref="flowRegionExclude" minOccurs="0" maxOccurs="unbounded"/>
</xs:choice>
</xs:sequence>
</xs:complexType>
</xs:element>
2.3 The flowRegionExclude element
The flowRegionExclude element contains a set of shapes defining regions in which flowed text is not drawn. It can be used to create exclusion regions from within a region of text.
If flowRegionExclude is a child of a flowRegion then it describes an exclusion region for that particular flowRegion. If it is a child of flowText then it describes exclusion regions for all flowRegion children of the flowText.
The following is a extract of an XML Schema that describes the flowRegionExclude element.
<xs:element name="flowRegionExclude">
<xs:complexType>
<xs:sequence>
<xs:group ref="ShapeElements" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
2.4 The flowDiv element
The flowDiv element specifies a block of text to be inserted into the text layout, and marks it as a division of related text. The children of the flowDiv element will be rendered as a block: offset before and after from their parent's siblings. By separating the logical order of text (in successive flowDiv elements) from the physical layout (in regions, which can be presented anywhere on the canvas) the SVG document structure encourages creation of a default, meaningful linear reading order while preserving artistic freedom for layout. This enhances accessibility.
The following is a extract of an XML Schema that describes the flowtext element.
<xs:element name="flowDiv">
<xs:complexType>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element ref="flowPara"/>
<xs:element ref="flowRegionBreak"/>
</xs:choice>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
</xs:complexType>
</xs:element>
2.5 The flowPara element
The flowPara element marks a block of text as a logical paragraph.
The following is a extract of an XML Schema that describes the flowPara element.
<xs:element name="flowPara">
<xs:complexType mixed="true">
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element ref="flowRegionBreak"/>
<xs:element ref="flowLine"/>
<xs:element ref="flowTref"/>
<xs:element ref="flowSpan"/>
</xs:choice>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
</xs:complexType>
</xs:element>
2.6 The flowSpan element
The flowSpan element specifies a block of text to be rendered inline, and marks the text as a related span of words. The flowSpan element is typically used to allow a subset of the text block, of which it is a child, to be rendered in a different style, or to mark it as being in a different language.
The following is a extract of an XML Schema that describes the flowSpan element.
<xs:element name="flowSpan">
<xs:complexType mixed="true">
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element ref="flowSpan"/>
<xs:element ref="flowLine"/>
<xs:element ref="flowRegionBreak"/>
</xs:choice>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
</xs:complexType>
</xs:element>
2.7 The flowRegionBreak element
When the flowRegionBreak element is inserted into the text stream it causes the text to stop flowing into the current region at that point. The text after the flowRegionBreak element begins in the next region. If there is no next region, then the text will stop being rendered at the point of the flowRegionBreak.
The following is a extract of an XML Schema that describes the flowRegionBreak element.
<xs:element name="flowRegionBreak">
<xs:complexType/>
</xs:element>
2.8 The flowLine element
The flowLine element is used to force a line break in the text flow. The content following the end of a flowLine element will be placed on the next available strip in the flowRegion that does not already contain text. This happens even if the flowLine element has no children.
Note that if there are no printing characters between the end of multiple flowLine elements the second and greater flowLine elements have no effect as the current line does not contain any text when they are processed.
In all other aspects, the flowLine element is functionally equivalent to the flowSpan element.
The following is a extract of an XML Schema that describes the flowLine element.
<xs:element name="flowLine">
<xs:complexType mixed="true">
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element ref="flowSpan"/>
<xs:element ref="flowLine"/>
<xs:element ref="flowRegionBreak"/>
</xs:choice>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
</xs:complexType>
</xs:element>
2.9 The flowTref element
The flowTref element is used to insert the child text content of a referenced element. It's effect is analogous to the tref element.
The following is a extract of an XML Schema that describes the flowTref element.
<xs:element name="flowTref">
<xs:complexType>
<xs:attribute ref="href" use="required"
namespace="http://www.w3.org/1999/xlink"/>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
</xs:complexType>
</xs:element>
2.10 The flowRef element
The flowRef element references a flowRegionElement. It causes the referenced element's geometry to be drawn in the current user coordinate system along with the text that was flowed into the region.
The following is a extract of an XML Schema that describes the flowRef element.
<xs:element name="flowRef">
<xs:complexType>
<xs:attribute ref="href" use="required"
namespace="http://www.w3.org/1999/xlink"/>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
</xs:complexType>
</xs:element>
2.11 Text Flow
Text flow is defined as a post processing step to the standard text layout model of SVG. At a high level the steps for flowing text are as follows:
-
The text is then processed in logical order to determine line
breaking opportunities between characters, according to Unicode
Standard Annex No. 14
-
Text layout is performed as normal, on one infinitely long line,
soft hyphens are included in the line. The result is a set of
positioned Glyphs.
-
Glyphs are associated with the word who's characters generated it.
In cases where characters from multiple words contribute to the same
glyph the words are merged and all the glyphs are treated as part of
the earliest word in logical order.
-
The glyphs from a word are collapsed into Glyph Groups. A Glyph
Group is comprised of all consecutive glyphs from the same word. In
most cases each word generates one glyph group however in some cases
the interaction between BIDI and special markup may cause glyphs
from one word to have glyphs from other words embedded in it.
-
Each Glyph Group has two extents calculated: is it's normal extent,
and it's last in text region extent. It's normal extent is the sum
of the advances of all glyphs in the group except soft hyphens. The
normal extent is the extent used when a Glyph Group from a later
word is in the same text region. The last in text region extent
includes the advance of a trailing soft hyphens but does not include
the advance of trailing whitespace or combining marks (ABC width?).
The last in text region extent is used when this glyph group is from
the last word (in logical order) in this text region.
-
The location of the first strip is determined based on the first
word in logical order (see Calculating Text Regions and determining
strip location).
-
Words are added to the current Strip in logical order. All the
Glyph Groups from a word must be in the same strip and all the
glyphs from a Glyph Group must be in the same Text Region.
When a word is added the line height may increase, it can never decrease from the first word. An increase in the line height can only reduce the space available for text placement in the span.
The span will have the maximum possible number of words.
-
The Glyphs from the Glyph Groups are then collapsed into the text
regions by placing the first selected glyph (in display order) at
the start of the text region and each subsequent glyph at the
location of the glyph following the preceding selected glyph (in
display order).
-
The next word is selected and the next strip location is determined.
Goto Step 7.
2.12 Determining Strip Location
To determine the placement of a strip the Glyph Groups from first word is used. The initial position for the strip is calculated, taking into account the end (in non text progression direction) of the previous strip and the appropriate margin properties.
The line-box is calculated using the initial position as the top/right edge of the line-box, and the line-height of the first word. The 'bottom/right' edge of the line-box must be checked against the margin properties, if it lies within the margin then processing moves to the next flow region.
Once the line-box is calculated the Strip and it's associated Text Regions are calculated (see: Calculating Text Regions). If the first word can be placed in the text regions of this Strip then this location is used for the next line of text. If the first word does not fit then the top/right edge is shifted by 'line-advance' and the new line-box is checked. This proceeds until the word fits or end of the flow region is reached at which point processing moves to the next flow region.
2.13 Calculating Text Regions
In order to flow text into arbitrary regions it is necessary to calculate what areas of the arbitrary region are available for text placement. SVG uses a fairly simple algorithm to do this.
In summary you intersect the flow region geometry with the current line-box. The result of this intersection is referred to as the strip. The strip is then split into text regions where ever a piece of geometry from the flow region 'intrudes'. It is important to ignore edges & points that are co-incident with the top or bottom of the line-box.
The diagram below shows the text strips used on a given shape.

The following is the algorithm with more detail:
The current flow region and any applicable exclude regions must be combined into one piece of geometry, simply concatenating the geometry is sufficient as this entire algorithm deals simply with segments of the paths and does not use directionality information until the inclusion tests at the end. The result of the concatenation of the geometry is referred to as the flow geometry.
Next the line-box is calculated, from the top/right edge of the line, the line-height and the bounding box of the flow region. This line-box is intersection with the flow geometry, clipping the flow geometry segments to the line box.
The bounding box is then calculated separately for each of the segments in the intersection.
The left and right (top and bottom respectively for vertical text) edges of the bounding boxes are sorted in increasing coordinate order (x for horizontal text, y for vertical text), for edges at the same location the left/top (or opening) edge is considered less than right/bottom (or closing) edges. The following pseudo code then generates the list of open areas for the current line:
Edge [] segs = ...; // The sorted list of edges.
Edge edge = segs[0];
int count = 1;
double start = 0;
for (i=1; i<segs.length; i++) {
edge = segs[i];
if (edge.open) {
// 'open' is true, this is the start of a block out region.
if (count == 0) {
// End of an open region so record it.
rgns.add(new TextRegion(start, edge.loc));
}
count++;
} else {
// 'open' is false, this edge is the end of a block out region.
count--;
if (count == 0) {
// start of an open area remember it.
start = edge.loc;
}
}
}
This gives the regions of the strip that are unobstructed by any flow geometry (from either exclusion or flow regions), however those regions may be outside the flow region (such as in a hole, such as the middle of an 'O'), or inside an exclusion region. Thus the center of each rectangle should be checked first to see if it lies inside any exclusion region if so the rectangle is removed from the list. Second it must be checked for inclusion in the flow region, if it is inside the flow region then the rectangle is available for text placement and becomes a text region for the current strip.
Once all the text regions for a strip are located left and right Margins for horizontal text (top and bottom margins for vertical) as well as indent are applied. Margins are applied to each text region. For the first span in a paragraph (flowPara for flowRegionBreak) the indent is added to the appropriate margin of the first text region. For left to right text this is the left margin of the left most text region, for right to left text this is the right margin of the right most text region, and for vertical text is the top margin of the top most text region.
this is applying margins to every Text Region we could just apply them to the first/last text regions. Perhaps have a separate property for 'internal' margins and the 'external' margins?.
If the left/right (top/bottom) edges of a text region pass each other due to the application of margins (or indent) the text region is removed from the list. If the text region removed had indent applied the indent is not applied to the next text region in text progression direction it is simply ignored.
We could have the indent move but it isn't clear that this would always be correct. The above is simpler and for the cases where indent is most commonly used, simple rectangles, it doesn't matter.
Should we restrict indent's range such that it can be no more negative than the margin it is applied to? Our feeling is no. If the user wants to shift the boxes out they should be able to - the only complication this adds is that the geometry may no longer define the bounding box of the text.
3 Rendering Arbitrary XML
3.1 Introduction
Many of the enhancements to the SVG language are based on using SVG as a presentation layer for structured data (e.g. XForms). Public feedback has also suggested that many content developers are using SVG as the graphical user interface to their XML data, either through declarative transformations such as XSLT or through scripting (loading XML data into the SVG User Agent and transforming using the DOM).
While it is already possible in SVG 1.0 to use scripting to transform XML from a private namespace into SVG, the code has to be replicated in each SVG file and modified for each namespace. It may be possible to provide more support for a declarative syntax, similar to, or using parts of, XSLT. The SVG Working Group is investigating approaches to see whether new features might be added to SVG 1.2 in order to better facilitate these techniques. This section summarizes the current status of these investigations within the Working Group, describes target use cases, proposed design requirements, discussion of some of the approaches that are being considered, and a list of some of the open issues.
The "Rendering Arbitrary XML" feature is sometimes referred to as "RAX" below.
3.2 Use Cases
One topic that came up repeatedly at SVG Open 2002 is strategies for relating semantically rich XML markup, such as GML features, with the presentation-oriented nature of SVG. Some presentations at SVG Open called on the community to architect their documents in terms of model-view-controller and argued the SVG tag set represents the "view" part of MVC. Others described the need to look at geographical markup such as GML as "data" and the corresponding SVG as "presentation", and suggested that the transformation from GML into SVG represents a styling operation. Much of the open discussion at the conference talked about how to map semantically rich user interface (UI) tagsets such as XForms UI elements into SVG.
The charter of the SVG Working Group includes determining how to combine XForms and SVG. The new RAX features may help provide the foundation for allowing implementers to create combined SVG+XForms implementations.
A large part of the SVG developer community and the SVG Working Group believe that a top priority for SVG 1.2 is enhancements that allow for easier creation of custom user interface widgets. A particular technical approach for UI widgets is to leverage XForms in various ways.
The SVG Working Group have adopted the position that SVG 1.2 should first address the low-level foundation features necessary to support fully custom UI widgets that allow sophisticated developers to leverage SVG's power in the development of graphic user interfaces. At present, the SVG Working Group is against the approach of attempting to define a full user interface system, such as MFC or Java SWING, for SVG 1.2.
One of the motivations behind RAX is to define a small number of foundation features which can help address many of the low-level UI widget features demanded by the SVG developer community.
3.2.4 More powerful use: reusable symbols, UI elements and components
One of the most common requests among SVG developers is to enhance SVG's symbol and use features to provide more flexibility. Symbols are used in many different applications of SVG, for example mapping. The use element satisfies some needs, but content creators have run into many shortcomings that force them to either abandon SVG or sacrifice the quality of the presentation or write large amounts of ECMAScript or Perl. Right now, each instance of a symbol is restricted to a simple clone-with-specified-properties operation, with the only possible difference between cloned instances coming from a different set of inherited properties (for example, one instance might inherit fill="blue" whereas another instance might inherit fill="red"). Many developers have requested the ability to create template objects which can be reused but where instances of the symbol can differ in arbitrary ways. One specific unsatisfied requirement of SVG 1.1 is the ability to define a symbol for a standard UI element such as a button and then change the text on each instance. In the more complex case, the notion of "reusable symbols" moves into the realm of "reusable components". Examples of reusable components include business graphs, schematics, process flow diagrams, GANTT charts and organization charts.
RAX may provide a mechanism which meets many of the requirements for a more powerful use element. The graphical contents of the original symbol could be cloned into the shadow tree and then any instance-specific graphics (e.g., different text on each different button) could be added via DOM manipulation of each instance's shadow tree.
One thing to note is that RAX might end up describing an entirely different mechanism than the use element. The use element really does work by reference, not by cloning. Thus, with use, there really is only one copy of the symbol. With the shadow tree approach, each instance gets its own shadow tree.
3.2.5 Graphical UI for Web Services
The traditional way of looking at the Web is from an end-user/client perspective. The end-user is the center of the universe and the entire Web exists out there to be accessed. However, there is an alternate viewpoint, which is the organization which wants to interact with other organizations and with people via the Web. For example, XYZ company looks at the Web as a means to communicate with its own computing resources, its partners computing resources, and its customers. Businesses these days are treating each of the interactions as a generic Web service, and the W3C and other standards organizations are rapidly providing the standards infrastructure for Web Services.
From the point of view of the IT department in a business, an interaction with a human should be treated exactly like an interaction with a computer. In fact, the IT team may sometimes get some information from an automated source such as a computer one day and find that it needs to get the same information the next day manually from a real person. Thus, it makes sense to treat each human-computer interaction as just another Web service.
When the Web service requires a human-computer interaction, the Web service will describe the interaction using various semantically-rich XML. However, this interaction needs to be "styled" into a human-computer interaction. Adding the ability for SVG to be able to visually render arbitrary XML enables SVG to be a key component in Web Services when a human-computer interaction is required. One application of this idea is to use SVG and XForms to populate a shadow tree within an otherwise semantically rich XML document.
3.2.6 Adaptable content
The ability to specify a transformation from Original XML into Generated Alternative SVG would provide a clean, simple, and powerful way of creating content that could adjust based on the current client environment. Right now, client-side SVG has only limited ability to adjust based on the client environment, such as the media facility in CSS-enabled SVG implementations and the few test attributes defined in the SVG language (e.g., systemLanguage).
The ability to render arbitrary XML might provide more flexibility in the styling transformation, taking into account the nature of the client: color bit depth, screen size, screen resolution, zoom level, whether a Web connection exists, which version of SVG (1.0/1.1/1.2/2.0), which profile is supported (Full or Basic, for example) and possibly user preferences. Of course, any adaptability requires the transformation specification to test for various conditions in the client, which probably means additional DOM methods, additional test attributes, and possibly some sort of expression evaluation system.
3.2.7 Expression-based attribute values
Various SVG content developers have requested the ability to use expressions such as XPath within path data, for attribute values and for property values. For example, something like <path d=" M {viewport.left+10px}, {viewport.top+10px} H {viewport.right-10px} V {viewport.bottom-10px}, H {viewport.left+10px} z" stroke-width="{2px}"/>.
If SVG includes the ability to render custom elements, then potentially the above requirement could be solved by having the SVG content developer define a custom path definition element whose behavior had the ability to perform expression evaluation on the custom element attribute values and generate alternate SVG which represented the result of all of the expression evaluations. For example, the Original XML might look like <foo:ConstrainedPath d=" M {viewport.left+10px}, {viewport.top+10px} H {viewport.right-10px} V {viewport.bottom-10px}, H {viewport.left+10px} z" stroke-width="{2px}"/> and the Generated SVG would be a regular path element with numbers (the result of the expressions) replacing all of the bracketed terms in the Original XML.
3.2.8 Dynamic layout
Related to adaptable content is the notion of dynamic layout, which provides the ability to have layout adapt to screen size, zoom level, and the relationship of the content to each other (as determined by extracting information from semantically rich markup). For example, a styling transformation could produce an organization chart from a purely hierarchical XML grammar, and the sizes and positions of the boxes could adapt to the length of the names of the various people. In fact, it might be possible to define custom layout managers via the ability to render arbitrary XML. For example, the arbitrary XML might define a dialog box layout manager which sets the position for (otherwise) standard SVG graphic objects.
Right now, legacy authoring tools do an imperfect job of roundtripping their native data models via SVG. This is understandable because these authoring tools usually were designed before SVG was defined and thus support an overlapping but different feature set. It isn't surprising that there might be some data loss when writing then reading SVG.
However, if SVG were enhanced such that arbitrary XML could be transformed into an alternate dynamically generated (and dynamically updated) SVG version of the content, then authoring tools could export two things:
-
The authoring tool's native data model expressed in XML using a
private namespace
-
A transformation from Original XML into
Generated Alternative SVG
With this approach, the original authoring tool would recognize its own namespace and read the SVG files with no data loss. Other SVG processors might or might not recognize the private namespace. If not, then these SVG processors would at least be able to faithfully process the visual representation that results from the transformation into Generated Alternative SVG.
3.2.10 Graphical UI for Semantic Web
The W3C has a vision for the Semantic Web where instead of millions of opaque, unknown web pages, mostly HTML and images, there instead is a network of metadata which describes both the content and relationships of all of the various resources that populate the web. A clear extension is that the content itself should be as semantically rich as possible rather than simply contain presentation-oriented HTML+images, presentation-oriented SVG, or other less semantically rich formats.
With RAX it would be feasible to create SVG-encoded, fully interactive Web content which retained all semantic richness. By constructing the SVG file so that it contains the original semantically rich XML tags and references an appropriate transformation from the original XML tags into SVG shadow trees that contain the final-form presentation.
3.2.11 Extending SVG
XML was built to be extensible. While the SVG 1.0/1.1 specifications have some extensibility features, in practice few people attempt to extend SVG due to limitations in the extensibility capabilities. These limitations were well-known to the SVG 1.0 Working Group who decided to proceed with SVG 1.0 as defined and address extensibility more fully in a subsequent version. Confirming evidence that SVG 1.0/1.1 have extensibility limitations is available on SVG developer newsgroups, where several developers have encountered difficulty using the SVG 1.0 extensibility features.
The ability to render arbitrary XML in SVG might provide some major benefits in the whole area of extensibility and might allow many developers who wish to extend SVG the ability to do so easily and in a highly interoperable manner (i.e., once most implementations support SVG 1.2).
One example of extensibility would be as simple as a new text element which does exactly the same things as regular SVG text except that it adds the one extra feature of drawing a rectangle around the text. This might be useful for tooltips.
Another example of extensibility is vector effects. Leading graphical authoring tools offer the ability to apply vector effects to graphical objects. Typically, this consists of taking a simpler source graphic, such as a path, and then producing a more complex result graphic which might squiggle the path or apply multiple different fills and strokes to the path. Generally, authoring tools will produce SVG which only contains the complex result graphics, loses the original source path and loses the semantics about the vector effect that was applied.
This approach would allow the original path element to be inserted as is into the SVG document, and then the styling transformation would generate the result of the vector effect within the shadow tree.
3.2.12 Z-order
One particular example of the use case for extending SVG that warrants special mention is the potential for using custom elements to provide some ability to change the drawing order of elements. It might use the ability to define custom elements to create a new grouping element such as foo:ReorderableGroup. The elements within foo:ReorderableGroup might have a custom attribute which provides a z-index value. The transformation might reorder these elements within the Alternate SVG to achieve drawing order which is different than the logical order within the Original XML.
3.3 Design requirements
The following is a very preliminary list of design requirements for the rendering arbitrary XML feature set. It is expected that this list will be adjusted significantly in subsequent versions of the SVG 1.2 specification. In the list below, must means that the item is an absolute requirement; should means that there may exist valid reasons in particular circumstances to ignore the item, but the full implications must be understood and carefully weighed before choosing a different course; may means that item will be considered, but further examination is needed to determine if the item should be treated as a requirement. The must, should and may designations are very preliminary and are thus very much subject to change in future versions. This preliminary version is being published as is to allow for early public feedback.
-
must allow for the transformation of arbitrary Original XML into
alternative SVG which provides final-form, low-level graphical
presentation and behavior.
-
must allow for re-usable widgets and/or components to be developed
by third parties and posted at Web locations for use by reference by
the SVG content developer community.
-
must be as elegant a solution as possible, where elegance is
achieved when there is lots of power yet keeping things simple.
One indicator of elegance is the ratio of enhanced language
power divided by the complexity of the new features. (Enhanced
language power might be measured by the number of use cases that
benefit from the new features. Complexity might be measured by the amount of
additional text in the SVG specification or the implementation time
required to add the new features to an existing SVG 1.0
implementation or the number of new elements, attributes and
properties added because of the new feature.)
-
must be recursive. That is, RAX can be applied to the result
of RAX.
-
must be compatible with progressive rendering (i.e., you don't need
to have the entire document downloaded before transformations from
Original XML into Generated SVG can begin)
-
should provide a foundation for developing a combined SVG+XForms
processor.
-
should be compatible with XML Events; in particular, allow for
custom events on the custom elements within the Original XML.
-
should allow for ways for bi-directional linking of original XML
data into generated SVG presentation/behavior.
-
must allow any symbols, components or template elements to be
referenced from an external file.
-
may allow for custom objects that do not actually get rendered for
requirements such as adding drag-and-drop to an element and in-place
editing. Thus, not only mapping of a model element to a widget
shadow tree but also an attribute triggering DOM calls on the
existing tree.
-
must allow for creating custom, slightly-extended versions of
existing SVG elements. One example is the ability to create an
element called foo:Layer which is nearly identical to a g, which
maps to a g within the Generated SVG Tree and whose content model
matches exactly that of a g. This custom grouping element might or
might not have custom attributes in a private namespace; even if
entirely identical to a g the simple renaming of the element might
help certain workflows recognize that this particular type of group
has special meaning (a potential accessibility benefit) or gets
special treatment in particular workflows. Another example might be
a custom element foo:MyPath which is a slight modification on a path element, perhaps allowing multiple strokes (versus the
restriction of a single stroke on SVG's existing path element).
-
should be theoretically possible to write a transformation in script
which transforms either CSS-styled arbitrary XML or MathML into
final-form SVG. These two scenarios are litmus tests to verify the
robustness of the approach.
-
should be compatible with XML Schema for validation purposes on the
SVG with Original XML
-
should avoid messy scripting problems, such as the real DOM changing
in unexpected ways as a result of the Original XML to Alternate SVG
transformation, which would make script development difficult. For
example, the application of the transformation should not cause
standard firstChild and nextSibling DOM operations to produce
different results.
-
should not have adverse effects on DOM serializations (DOM
load/save) due to the application of the transformation. Thus, if
the Original XML has not been modified by DOM operations such as
scripting, then DOM serialization should save out the original
content, not the resulting Alternate SVG.
-
must take into account accessibility concerns.
-
must take into account internationalization concerns.
-
should be able to animate any aspect of the Original XML content and
have the animated reflected in real-time in the Generated
Alternative SVG.
3.4 Possible Approaches
This section is under construction. The Working Group has not completed writing up all of the approaches which have been considered so far. The next draft of SVG 1.2 may included proposed syntaxes for RAX features.
Here are some notes on some of the approaches being considered:
-
There are advantages to a facility whereby particular element names
in particular namespaces are "registered" with the SVG user agent
such that an automatic transformation from Original XML into
Alternative SVG occurs at parse time whenever the given element name
is encountered. For example, the symbol element might be enhanced
such that it specifies an optional pair of namespace and element
name. Then, an instance of the symbol might be created either via a use element (as in SVG 1.0/1.1) or whenever the SVG user agent
parses the given custom element. (An alternative to extending symbol would be to provide a new element in the SVG language such
as registerComponent which registers custom elements.
-
There are advantages to a render-as property (available as both a
presentation attribute and within CSS style sheets) that
provides a URL to an object which specifies the transformation from
Original XML into Generated Alternative SVG.
-
The SVG Working Group recognizes that existing features from XSLT,
particularly the template element (plus value-of, for-each,
etc.) and the XPath expression facilities from XSLT might help
address many of the transformation problems. Note that XSLT
does not solve the mapping problems from Original XML
into Alternative SVG because XSLT (as defined today) is a one-time
batch operation from one document into another and doesn't take
into account the various special transformation needs in an SVG
context (e.g., the need to rerun the transformation when content
changes based on user interaction, the need to support animation,
the need for bi-directional event mapping, the need to address
performance issues so that as small a subset of the transformations
as possible get rerun upon content changes, the need to address
XForms integration, etc.).
-
Some sort of dual source tree approach looks attractive, where the
Generated SVG is a function of both the Original XML and some
additional content that is defined within the definition of the
custom element and/or the definition of the transformation.
-
In general, with SVG 1.2, the Working Group wants to give a priority
to providing a small number of low-level foundation capabilities
which allow sophisticated developers to accomplish arbitrarily
custom presentations via scripting. It would also be good if a large
percentage of common use cases could be achieved without having to
resort to scripting.
-
There might be synergy and overlap by addressing XForms integration
and rendering arbitrary XML at the same time. For example, XForms
instance data might help with the bidirectionality issues by
providing a common location for data which is shared between both
the Original XML and the Generated SVG. The ability to render
arbitrary XML might provide the foundation feature set for mapping
XForms UI widgets into SVG.
-
There has been a suggestion that the feature consists of five
component pieces:
-
the model (i.e., the Original XML)
-
the template (i.e., the symbol or prototype component used as a base
for creating an instance of the custom component)
-
the trigger (i.e., the events which cause recalculation of the
Alternate SVG from the Original XML)
-
the transformation (i.e., the definition of how to generate the
Alternate SVG given the Original XML)
-
the view (i.e., the Alternate SVG)
In Working Group discussion, the question has been raised (also listed under Open issues below): Is our primary use case "skinning" XForms, more general UI widgets, or are we going all the way and defining a way of presenting (SVG) views of arbitrary XML data? Relative to this question, here are some alternative approaches that are being considered:
-
Define RAX as a simple mechanism for skinning primarily
XForms widgets, leveraging the XForms data model.
-
Define RAX as a new templating mechanism/language. This
need not be SVG specific, and may be provided
by a separate specification document.
-
Leverage XSLT by defining extensions and mechanisms suitable for
transforming to a scripted/dynamic presentation language (SVG)
rather than a static one (XSL-FO).
-
Write an "implementation spec" that defines how to do SVG/XForms
interworking widgets that uses existing standards and scripting.
This would essentially be a library of extensible SVG UI widgets.
Some users would find SVG/XForms widgets just
as useful as a new standard.
3.5 Open Issues
Here are some of the open issues that have been raised regarding potential RAX features that allow for transformation of semantically rich arbitrary XML into presentation-rich alternative SVG. Some of these open issues are overlapping and contradictory because the Working Group has only gone so far as to collect the issues and has yet to clean up this list.
-
Where does the Alternative Generated SVG go? Does the generated SVG
become part of the real DOM (which means the generated SVG could be
reached via firstChild, nextSibling, etc. off of the main document
tree) or does the generated SVG go into some sort of shadow DOM
(which means the generated nodes can be reached, but not via
firstChild, nextSibling, etc. on the main document tree). Some of
the arguments in favor of shadow trees are:
-
SaveAs should only show original data, not result of styling
-
Philosophical: Rendering tree is a transient thing that should not
be part of real DOM
-
Scripts get messed up by modifying real DOM (new elements appear
in the wrong place)
-
Philosophical: Requirement of clean separation of model versus view
-
Philosophical: Implementers need freedom of released storage for
purge/regenerate of rendering tree
Some of the arguments against shadow trees:
-
How to style versus CSS selectors
-
Potential implementation and specification complexity
-
What events trigger a recalculation operation from Original XML into
Alternate SVG? One candidate is that by default regeneration is
triggered by DOM Mutation events.
-
How does XML Events relate to this feature?
-
Is the primary use case "skinning" XForms, more general UI widgets,
or defining a way of presenting (SVG)
views of arbitrary XML data? (This issue is discussed in more
detailed under Possible Approaches above.)
-
Is a kind of use that leverages XForm's instance model, or is it a
new templating language?
-
Should the mapping be one way or two way (ie. should there be a way
to automatically reflect changes in the transformed content when the
transformation is updated?)
-
Bidirectionality, particularly event mapping, almost certainly will
require custom scripting in some circumstances. How far should RAX go
in trying to minimize the number of situations where scripting is
required?
-
Dependency mapping (i.e., which fragments of Original XML relate to
which fragments of Generated SVG) is highly desirable but also will
likely require custom scripting in some circumstances. How much
leverage might RAX get from adopting XForms' approach to instance
data? How feasible is it for implementations to do automatic
dependency mapping? How far should RAX go in trying to define markup
which explicitly defines dependencies?
-
Should the feature be enabled by the styling system (ie. should you
be able to apply a style rule that converts all myns:pie elements
into a combination of svg:path elements?)
-
Is this an extension to the use element?
-
If a declarative syntax is used, SVG implementations may be required
to support XPath and some simple XSLT features. Will the SVGT
features be too much of an implementation burden?
-
What features are available in SVG Full vs SVG Basic vs SVG Tiny?
4 Integration with other XML formats
A number of relevant XML formats have matured since the time of the SVG 1.0 Recommendation. It is the intent of the SVG Working Group to allow easy integration with these formats, as well as to be a display format for generic XML.
XForms is a technology for describing forms in XML. It separates the model, or the information that is to be sent as the result of the form, from the abstract controls that will be used to get information from the person using the form. XForms deliberately says nothing about presentation of form controls; this is left to a styling or transformation language, to generate the actual visual (or indeed, audio) form widgets. XForms cannot be used by itself; it is designed to be integrated into a host language, such as SVG. This provides the host language with an abstract definition of form content and leaves the rendering to the host. SVG is well suited to hosting XForms, since it provides powerful rendering and interactivity APIs.
Furthermore, a generic set of user interface components has been a common request from the SVG community. By describing how SVG and XForms can be integrated that request can be answered while providing more functionality if required. For example, the tight integration with a data model of a form should allow an SVG/XForms implementation to package SOAP messages easily. It also would allow an author to provide multiple interfaces to the same form (SVG, CSS, VoiceXML).
It also should be possible to extend generic form controls to use an SVG rendering specified by the document author. Events within the SVG rendering should be linked to behavior that updates the form model.
At the time of publication, the Working Group is undecided as to whether or not the SVG specification should describe a default rendering and behavior for some form elements, such as buttons and sliders. We realise that creating widget sets is a deep topic and specifically request feedback on this matter. Would a simple set of form widgets be sufficient in most situations, or would authors prefer to always create the SVG rendering and behaviour for every element?
Readers will notice the Rendering Arbitrary XML sections make a number of references to XForms. The current feeling of the Working Group is enable XForms through this feature and by adding a small number of low-level widgets to the SVG language (such as text-entry).
4.2 Support for XML Events
XML Events is an XML syntax for integrating event listeners with DOM Event handlers. The events in SVG are hardwired into the language, such that you are required to embed the specification of event handling within the content (e.g. an element has an onclick attribute). By allowing XML Events, SVG content can specify the event listeners separately from the graphical content.
The specifics of what is meant by "allowing XML Events" is not yet clear. It may be that all event attributes from SVG 1.0/1.1 are deprecated in favor of XML events. Also, conformance has not yet been discussed - should all SVG viewers be required to support XML Events?
4.3 More SMIL Integration
SVG 1.0 used SMIL Animation for its animation syntax. It has been a common request from the public to have more features from SMIL in SVG. For that reason, SVG 1.2 will mostly likely incorporate more of SMIL 2.0. In this document the audio, video and some timing elements are described. Future revisions will expand on the SMIL integration.
The current proposal is to add more SMIL elements into the SVG language. Alternatively, the SVG Working Group may produce a W3C Note which defines an SVG+SMIL profile, similar to the XHTML+SMIL profile.
It is worth noting what parts of SMIL 2.0 are not under consideration for SVG 1.2. SVG would probably not include SMIL Layout, Linking, Structure and MetaInformation.
4.3.1 Timing and Synchronization
The SMIL2 Timing and Synchronization module allows for simpler authoring of multimedia content with multiple elements. SVG 1.2 plans to add the par and seq elements in order to create synchronized presentations.
There are a number of attributes that should be added to SVG 1.2 in order to control the synchronization of timed content. These include syncBehavior, syncTolerance, syncMaster, timeContainer, and timeAction as well as expanding the range of allowed fill attribute values.
SVG 1.2 also plans to allow timed content, such as animations, to begin before the entire document is downloaded. This may require the addition of an attribute on the root svg element that marks the document as a particular time container.
See SMIL 2.0 Timing and Synchronization for more details.
4.3.2 The audio element
The audio element specifies an audio file which is to be rendered to provide synchronized audio. The usual SMIL animation elements are used to start and stop the audio at the appropriate times. An xlink:href is used to link to the audio content. No visual representation is produced. However, content authors can if desired create graphical representations of control panels to start, stop, pause, rewind, or adjust the volume of audio content.
It is an open question what audio formats, if any, would be required for conformance. For the image element, SVG mandates support of PNG, JPEG and SVG formats and allows others. All three mandatory formats may be implemented without royalty payments. Many common audio formats, such as MP3, require payment of royalties. One option under consideration is the Vorbis audio compression in the Ogg format. Ogg/Vorbis audio files are believed to be implementable without royalty payments. Another option is to say that there are no required formats, and each implementation supports whatever format the operating system provides. Clearly, this would lead to non-interoperable, platform-dependent content.
The following is a extract of an XML Schema that describes the audio element.
<xs:element name="audio">
<xs:complexType>
<xs:complexContent>
<xs:restriction base="xsd:anyType">
</xs:restriction>
<xs:attributeGroup ref="XLinkEmbedAttrs"/>
<xs:attributeGroup ref="MediaAttrs"/>
</xs:complexType>
</xs:element>
The following example illustrates the use of the audio element. Whe the button is pushed, the audio file is played three times.
<svg width="100%" height="100%" version="1.2"
xmlns="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink">
<desc>SVG audio example</desc>
<audio xlink:href="ouch.ogg" volume="7" type="audio/vorbis"
begin="mybutton.click" repeatCount="3"/>
<g id="mybutton">
<rect width="150" height="50" x="20" y="20" rx="10"
fill="#ffd" stroke="#933" stroke-width="5"/>
<text x="95" y="55" text-anchor="middle" font-size="30"
fill="#933">Press Me</text>
</g>
<rect x="0" y="0" width="190" height="90" fill="none" stroke="#777"/>
</svg>
When rendered, this looks as follows:

4.3.3 The video element
The video element specifies a video file which is to be rendered to provide synchronised video. The usual SMIL animation elements are used to start and stop the video at the appropriate times. An xlink:href is used to link to the video content. It is assumed that the video content also includes an audio stream, since this is the usual way that video content is produced, and thus the audio is controlled by the video element's media attributes.
The video element produces a rendered result, and thus has width, height, x and y attributes.
It is an open question what video formats, if any, would be required for conformance. For the image element, SVG mandates support of PNG, JPEG and SVG formats and allows others. All three mandatory formats may be implemented without royalty payments. Many common video formats, such as RealVideo, Quicktime movies or Windows media Format video, require payment of royalties for most common codecs. W3C would be interested in suggestions for a royalty-free video format that could be used in any free or commercial SVG implementation without royalty.
The following is a extract of an XML Schema that describes the video element.
<xs:element name="audio">
<xs:complexType>
<xs:complexContent>
<xs:restriction base="xsd:anyType">
</xs:restriction>
<xs:attribute ref="x"/>
<xs:attribute ref="y"/>
<xs:attribute ref="width"/>
<xs:attribute ref="height"/>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
<xs:attributeGroup ref="XLinkEmbedAttrs"/>
<xs:attributeGroup ref="MediaAttrs"/>
</xs:complexType>
</xs:element>
The following example illustrates the use of the video element. The video content is partially obscured by other graphics elements. Experiments within the SVG working group have shown that adequate performance can be obtained by rendering the video in an offscreen buffer and then transforming and compositing it in the normal way, so that it behaves like any other graphical primitive such as an image or a rectangle. It may be scaled, rotated, skewed, displayed at various sizes, and animated.
<svg xmlns="http://www.w3.org/2000/svg" width="420" height="340" viewBox="0 0 420 340">
<desc>SVG 1.2 video example</desc>
<g>
<circle cx="0" cy="0" r="170" fill="#da4" fill-opacity="0.3"/>
<video xlink:href="myvideo.foo" volume="8" type="video/x-foo"
width="320" height="240" x="50" y="50" />
<circle cx="420" cy="340" r="170" fill="#927" fill-opacity="0.3"/>
<rect x="0" y="0" width="420" height="340" fill="none" stroke="#777"/>
</g>
</svg>
When rendered, this looks as follows:

4.3.4 More SMIL test attributes and events
SVG 1.2 is considering adding extra test attributes to better facilitate conditional content. Potential new attributes include: systemBitrate, systemCaptions, systemRequired, systemScreenDepth, systemScreenSize, systemAudioDesc, systemCPU, systemComponent, systemOperatingSystem, systemOverdubOrSubtitle.
Also, SVG 1.2 may add new events that better facilitate control of timed content. Potential new events include mediacomplete, mediaerror, outofsync, pause, reset, resume, reverse, seek, syncrestored, timerror.
4.3.5 Transition effects
SMIL 2.0 defines syntax for allowing the transition between multimedia elements to include a transition, such as a fadein/fadeout. There is a comprehensive set of transition effects defined by SMPTE and listed in an appendix of SMIL 2.0 Transition Effects
SVG 1.2 may add the SMIL transition and/or transitionFilter elements.
It is expected that this feature will be useful in multipage SVG documents, or for slideshows/presentations authored in SVG.
5 Printing
A specification related to printing SVG is being developed by the SVG Working Group. The present plan is to produce a set of authoring guidelines that meet the requirements given in the SVG Printing Requirements. Any new features needed for printing will be added to the core SVG language.
6 Multiple Pages
One of the requirements for SVG Print was adding the ability for multiple pages to be stored within a single SVG file. A user agent will only display one page at a time, the "current page", and provide the user with a method for choosing which page is the current page.
It is intended that this technique also be used to facilitate scenes in animation. That is, some animations (eg. cartoons) can be considered as a set of scenes shown in sequence. Each page is a scene in the animation. The combination of page and the streamable attribute (described below) should provide a method to stream long-running declarative animations.
Below is an pseudo-example of an SVG document with multiple pages:
<svg xmlns="http://www.w3.org/2000/svg" version="1.2"
streamable="true">
<defs>
<!-- definitions here are always available -->
</defs>
<g>
<!-- graphics here are always visible -->
</g>
<pageSet>
<page>
<!-- graphics for page 1 go here -->
</page>
<page>
<!-- graphics for page 2 go here -->
</page>
<page>
<!-- graphics for page 3 go here -->
</page>
</pageSet>
</svg>
Still need to come up with a scriptable or declarative method of moving between pages for animations
6.1 The pageSet element
<xs:element name="pageSet">
<xs:complexType>
<xs:sequence>
<xs:element ref="page" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
</xs:complexType>
</xs:element>
The pageSet element contains a set of page elements which are the pages contained within this document.
A user agent renders all content outside the pageSet in the normal manner. However, only one page child of the pageSet is to be displayed at a time, as if all pages except the current page have their display property set to "none". This enables a multiple page SVG document to have a concept of a "master" page that contains graphics to be displayed on every page. The "master" content should be included outside the pageSet element, as part of the root svg content.
6.2 The page element
The page element contains graphics that are to be rendered when the page is the current page.
<xs:element name="page">
<xs:complexType>
<xs:sequence>
<xs:group ref="GraphicsElements" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
<xs:attribute ref="viewBox"/>
<xs:attribute ref="preserveAspectRatio"/>
</xs:complexType>
</xs:element>
Conceptually, the page element is similar to an svg element, but without transformation and positioning. All pages are in coordinate system of their pageSet, which is in the coordinate system of the root svg element.
Still have to work out associated metadata such as page orientation.
7 Streaming
The SVG working group is considering streaming enhancements to the SVG language. Here are two identified uses for streaming:
-
The SVG Print specification has
relatively low-end printers as a potential target. These devices may have
various limitations such as memory. It might be a requirement of SVGP that
elements can be rendered and discarded immediately, thereby removing
the need for maintaining an in-memory DOM for the document.
-
For time-based SVG applications viewed on a display device, we would
like SVG to allow time-based elements such as animations to start
while the rest of the document is still downloading.
7.1 The streamable attribute
The streamable attribute can be set on the root svg element to mark a document as streamable.
streamable = "false | true"
-
false:
-
(The default value.) Indicates that this document has
not been specifically authored to facilitate streaming.
-
true:
-
Indicates that this document has been authored to facilitate streaming.
All internal references within the document are limited to elements that
are contained within a defs element. Elements within the document that are
not descendants of a defs element may not be referenced.
All elements within defs elements are scoped, and may only be referenced
by elements that are descendants of the defs element's parent.
Furthermore, elements may not be referenced by elements
in the same document that are after the referenced
element in document order.
There are no restrictions on external references.
If a User Agent finds a forward internal reference in a document marked as streamable, or backward internal references that are out of scope, then it can treat the reference as invalid.
The scoping mechanism has two purposes:
-
in low bandwidth scenarios, it ensures that all
content/references needed for an element have arrived at
the client before the element itself. Rendering should
be able to proceed immediately.
-
it allows User Agents in resource-limited environments
to discard elements as they are rendered.
The combination of scripting and streaming has not yet been specified. The most likely solution is that the user agent will be able to delete the elements from the DOM once they have been rendered, and scripts that reference those elements will throw exceptions.
This proposal is lacking the most difficult part — text which describes what happens to the timeline for streamed documents with animations.
8 Modifications to the Rendering Model
The SVG Working Group are considering a number of modifications to the rendering model for SVG 1.2. As the rendering model is perhaps the most important concept in the graphical representation of SVG content, any change to the model has to both fulfill a strong requirement and to be extremely carefully checked in order to not introduce inconsistencies, break existing content or have a substantial negative effect on implementations.
8.1 Enhanced Alpha Compositing
SVG 1.0 uses a simple rendering model, the Painter's Model, where a graphical object is composited onto the canvas above the objects that came before it in the document. While there is the ability to allow enhanced compositing within the filter system, there is no way to remove painting operations once they have been composited to the canvas. There are some usage scenarios where it would be advantageous to allow the enhanced compositing operations inline (ie. outside of the SVG 1.0 filter mechanism) since it may allow an implementation to perform the operation without rasterization. When placing graphical objects on the canvas, the result will be dependent on input color and opacity, the existing color and opacity on the canvas and the compositing operation. This will allow objects to remove "paint" from the canvas.
The actual technique that would allow such a feature is still under discussion. We propose two alternatives here: the first being the most complete proposal, and the second a less-complete alternative. We strongly request feedback from the public on this feature.
8.1.1 Introduction
SVG supports the following clipping/masking features:
-
alpha compositing, which may be used each time a new element is
placed on the canvas. The operation specified determines the
combination of source color / alpha and destination color / alpha.
-
clipping paths, which uses any combination of path, text and
basic shapes to serve as the outline of a (in the absence of
anti-aliasing) 1-bit mask, where everything on the "inside" of the
outline is allowed to show through but everything on the outside is
masked out
-
masks, which are container elements which can contain graphics
elements or other container elements which define a set of graphics
that is to be used as a semi-transparent mask for compositing
foreground objects into the current background.
One key distinction between a clipping path and a mask is that clipping paths are hard masks (i.e., the silhouette consists of either fully opaque pixels or fully transparent pixels, with the possible exception of anti-aliasing along the edge of the silhouette) whereas masks consist of an image where each pixel value indicates the degree of transparency vs. opacity. In a mask, each pixel value can range from fully transparent to fully opaque.
Note that masking with an element containing only color components with full luminance (e.g. r=g=b=1), will produce the equivalent result to compositing using the src_in or dst_in operators.
8.1.2 Alpha compositing
Graphics elements are composited onto the elements already rendered on the canvas based on an extended Porter-Duff compositing model, in which the resulting color and opacity at any given pixel on the canvas depend on the 'comp-op' specified. Note: that the base set of 12 Porter-Duff operations shown below always result in a value between zero and one, and as such, no clamping of output values is required.
In addition to the base set of 12 Porter-Duff operations, a number of blending operations are supported. These blending operations are extensions of the base Porter-Duff set and provide enhanced compositing behaviour. The extended operations may result in color and opacity values outside the range zero to one. The opacity value should be clamped between zero and one inclusive, and the pre-multiplied color value should be clamped between zero and the opacity value inclusive.
Implementation note: Various container elements calculate their bounds prior to rendering. For example, rendering a group generally requires an off-screen buffer, and the size of the buffer is determined by calculating the bounds of the objects contained within the group. Note: that depending on the compositing operations used to combine objects within a group, the bounds of the group may be reduced, and so, reduce the memory requirements. For example, if a group contains two objects - object A 'in' object B - then the bounds of the group would be the intersection of the bounds of objects A and B as opposed to the union of their bounds.
The following diagram shows the four different regions of a single pixel considered when compositing.
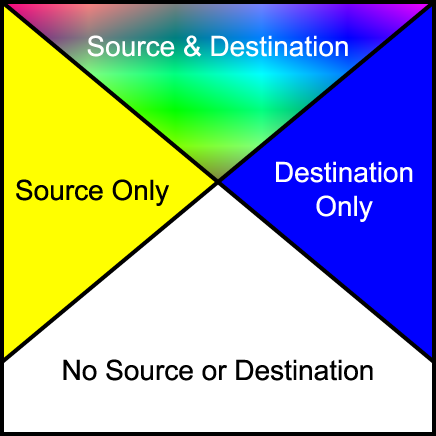
Depending on the compositing operation the resultant pixel includes input from one or more of the regions in the above diagram. For the regions where only source or destination are present, a choice of including or not including the input is available. For the region where both are present, various options are available for the combination of input data.
Depending on various attributes of a container element , the elements within the container element, are either combined to generate a single element, or the elements within the container element, are rendered onto the canvas independently. A container element, may be just a change in graphics context, or just a collection of elements, and as such the elements within the container element are rendered independently onto the canvas. Alternatively, a container element may have an opacity set to less than 100%, or an input filter applied to it, in which case the elements within the container element are first composited into a buffer, then treated as a single element to which the opacity, or an input filter is applied before the result is placed onto the canvas.
Implementation Note: Implementations may choose to implement groups using various techniques. An implementation has the option of creating buffers, and rendering as it sees fit to produce the results as described in this chapter.
Combinations of groups where background-enable is set to 'accumulate' combined with group opacity less than 1 and a comp-op other than 'src_over' requires application of a background removal technique. This needs to be incorporated into this description, either here, or as an appendix.
For groups containing compositing operators, the operation used to composite the group onto the canvas is the comp-op property of the container element itself. Other container element properties such as opacity specify operations to be performed to the group between the steps of combining the children, and compositing the group onto the background. The enable-background and knock-out properties specify the state the group buffer is initialised to prior to use, any modification to the compositing of the group's children, and in some cases a post rendering step to be performed after rendering the children and prior to any other post rendering steps.
Implementation Note: While container elements are defined as requiring an buffer to be generated, it is often the case that a user agent using various optimizations can choose not to generate this buffer. For example, a group containing a single object could be directly rendered onto the background rather than into an buffer first.
8.1.3 The clip-to-self property
-
clip-to-self
-
| Value: |
true | false | inherit
|
| Initial: |
false
|
| Applies to: |
container elements and graphics elements
|
| Inherited: |
no
|
| Percentages: |
N/A
|
| Media: |
visual
|
| Animatable: |
yes
|
The clip-to-self property determines if the object effects pixels not covered by the object. Some compositing operations effect pixels where the source graphic is completely transparent. Regions where the source graphic does not cover, one of two operations can be performed. Setting clip-to-self to true means that compositing an object only effects the pixels covered by the object. Setting clip-to-self to false means that compositing an object effects all pixels on the canvas by compositing completely transparent source onto the destination for areas not covered by the object.
The clip-to-self property provides compatibility with Java2D and PDF 1.4 transparency.
Implementation of this property will most likely require a so-called 'shape' channel in addition to an alpha channel. This may have issues regarding high-quality renderers which perform antialiasing. The group is considering issues related to the use of the shape channel for both antialiasing and container groups.
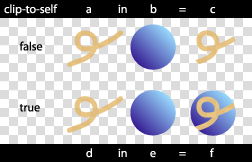
View this image as SVG (SVG-enabled browsers only)
8.1.4 The enable-background property
-
enable-background
-
| Value: |
accumulate | new [ x y width height ] | inherit
|
| Initial: |
accumulate
|
| Applies to: |
container elements
|
| Inherited: |
no
|
| Percentages: |
N/A
|
| Media: |
visual
|
| Animatable: |
no
|
For a simple group, enable-background is set to accumulate. For such groups, sub-objects are rendered directly onto the canvas.
For a complex group with enable-background set to new , the container element's buffer is initially cleared to transparent. This buffer is treated as the canvas for the complex group's children. When the complete contents of the container element are rendered onto the buffer, the buffer is composited onto the canvas, using the container element's specified compositing operation.
For a complex group with enable-background set to accumulate , the corresponding area of the canvas is copied into the container element's buffer. A second buffer which has only an opacity channel is also created. This buffer, the group opacity buffer, is initially transparent. The group buffer is treated as the canvas for the childern of the complex group as usual. Additionally, as objects are placed into the buffer, the opacity part of the operation is repeated into the group opacity buffer. Before the group buffer is composited onto the canvas, the background color, masked by the group opacity buffer, is subtracted from the group buffer. Other post rendering steps such as the opacity are performed after this step, and before compositing the result onto the canvas.
The following equation is the method used to remove the color from the background contributing to the values in the buffer.
BGc - The background color value.
BGa - The background alpha value.
Dc - The buffer color value prior to background color removal.
Da - The buffer alpha value prior to background color removal.
Da2 - The buffer secondary alpha value.
Dc' - The buffer color value post background color removal.
Da' - The buffer alpha value post background color removal.
Dc' = Dc - BGc/BGa . (Da - Da2)
Da' = Da2
Elements containing a comp-op property value of clear, src, dst, dst_over, src_in, dst_in, src_out, dst_out, src_atop, dst_atop, xor are only valid where the object's parent complex group has the enable-background property set to new. It is valid for such objects to be contained within nested simple groups, as long as the nearest ancestor that is a complex group has the enable-background property set to new. For elements without a parent complex group, or elements within a complex group where the enable-background property set to accumulate , these operations are technically an error. A user agent should ignore the operation specified and render the element using the src_over compositing operation.
Filters have access to the nearest ancestor complex group's buffer through the BackgroundImage and BackgroundAlpha images. The buffer created for the ancestor complex group element of the element referencing the filter, is passed to the filter. Where no ancestors of the element referencing the filter contain an enable-background property value of new, transparent black is passed as input to the filter.
The optional x, y, width, height parameters on the new value indicate the subregion of the container element's user space where input filters have access to the background image. These parameters enable the SVG user agent potentially to allocate smaller temporary image buffers than the effective bounds of the container element. Thus, the values x, y, width, height act as a clipping rectangle on the background image canvas. Negative values for width or height are an error. If more than zero but less than four of the values x, y, width and height are specified or if zero values are specified for width or height, BackgroundImage and BackgroundAlpha are processed as if enable-background property was set to accumulate .
Where a filter references an area of the background image outside the area specified by x, y, width, height, transparent is passed to the filter.
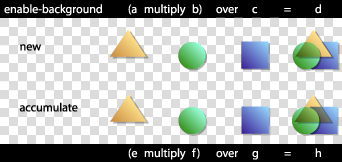
View this image as SVG (SVG-enabled browsers only)
8.1.5 The knock-out property
-
knock-out
-
| Value: |
true | false | inherit
|
| Initial: |
false
|
| Applies to: |
container elements
|
| Inherited: |
no
|
| Percentages: |
N/A
|
| Media: |
visual
|
| Animatable: |
no
|
For a complex group where the knock-out property is set, the buffer is created as usual. The initial contents of the buffer created, and whether a secondary opacity channel is created depends on the value of the enable-background property. For each object within the container element, the object color and opacity replaces that of other objects within the container element, rather than overlaying it as for normal compositing. In effect, the destination input to the compositing operations for the complex group's children is the original contents of the buffer, rather than the current buffer for the complex group.
For knock-out=false :
Dc' = f(Sc, Sa, Dc, Da)
Da' = f(Sa, Da)
For knock-out=true, enable-background=new :
Dc' = f(Sc, Sa, 0, 0)
Da' = f(Sa, 0)
For 'knock-out' =true ,'enable-background' =accumulate :
Dc' = f(Sc, Sa, BGc, BGa)
Da' = f(Sa, 0)
Note that an element in a knockout group that does not have the clip-to-self property set, in effect clears all prior elements in the group.
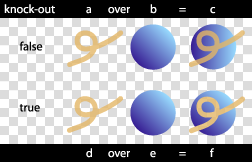
View this image as SVG (SVG-enabled browsers only)
8.1.6 The comp-op property
-
comp-op
-
| Value: |
clear | src | dst | src_over | dst_over | src_in | dst_in | src_out | dst_out | src_atop | dst_atop | xor | plus | multiply | screen | overlay | darken | lighten | color_dodge | color_burn | hard_light | soft_light | difference | exclusion | inherit
|
| Initial: |
src_over
|
| Applies to: |
container elements and graphics elements
|
| Inherited: |
no
|
| Percentages: |
N/A
|
| Media: |
visual
|
| Animatable: |
yes
|
The comp-op property determines the compositing operation used when placing elements onto the canvas. The canvas contains color components and an optional alpha component. When placing new elements onto the canvas, the resulting pixel values on the canvas are calculated using the equations listed in the sections below.
The diagram below shows the sub-pixel regions output by each of the compositing operations.
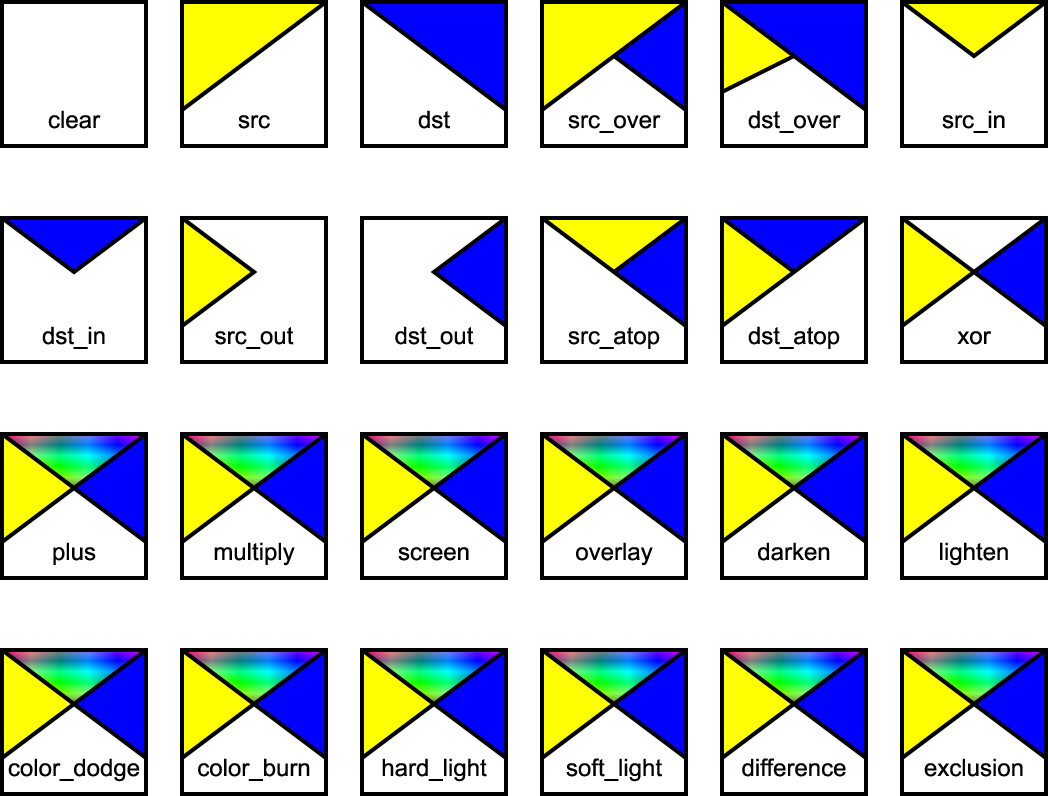
For many of the operators below, the destination is modified in regions of the image where the source is completely transparent. Pixels that the source does not touch are considered transparent, and as such may be modified, depending on the compositing operation. As discussed in the previous section, the bounds of the parent container element can be optimized to save in memory usage and hence, pixel writing requirements. Once the bounds of the parent container element have been determined, each element can only affect the pixels within those bounds.
The following operators change pixels where the source is transparent: clear src src_in dst_in src_out dst_atop
Implementation Note: The user agent may be required to create a backing store in which to generate a container element. The size of the backing store for a container element using the default compositing operator src_over is simply the union of the bounds of the sub-elements of the container element. When other compositing operators are used, the bounds of the container element are determined using the compositing operator diagram above. Starting with an empty bounds, the bounds of each successive object within the container element either replaces, is unioned with the result, or intersected depending on the compositing operatior. For most compositing operators, the bounds are unioned with the result. For clear, the current result is set to empty. For src, src_out and dst_atop, the bounds are set to the source bounds. For dst, dst_out and src_atop, the bounds are left unchanged. For src_in and dst_in the bounds are intersected with the result.
All color components listed below refer to color component information pre-multiplied by the corresponding alpha value. The following identifiers have the attached meaning in the equations below:
Sc - The source element color value.
Sa - The source element alpha value.
Dc - The canvas color value prior to compositing.
Da - The canvas alpha value prior to compositing.
Dc' - The canvas color value post compositing.
Da' - The canvas alpha value post compositing.
-
clear
-
Both the color and the alpha of the destination are cleared. Neither
the source nor the destination are used as input.
Dc' = 0
Da' = 0
-
src
-
The source is copied to the destination. The destination is not used
as input.
Dc' = Sc.Da + Sc.(1 - Da)
= Sc
Da' = Sa.Da + Sa.(1 - Da)
= Sa
-
dst
-
The destination is left untouched.
Dc' = Dc.Sa + Dc.(1 - Sa)
= Dc
Da' = Da.Sa + Da.(1 - Sa)
= Da
-
src_over
-
The source is composited over the destination.
Dc' = Sc.Da + Sc.(1 - Da) + Dc.(1 - Sa)
= Sc + Dc.(1 - Sa)
Da' = Sa.Da + Sa.(1 - Da) + Da.(1 - Sa)
= Sa + Da - Sa.Da
The following diagram shows src_over compositing:

View this image as SVG (SVG-enabled browsers only)
-
dst_over
-
The destination is composited over the source and the
result replaces the destination.
Dc' = Dc.Sa + Sc.(1 - Da) + Dc.(1 - Sa)
= Dc + Sc.(1 - Da)
Da' = Da.Sa + Sa.(1 - Da) + Da.(1 - Sa)
= Sa + Da - Sa.Da
-
src_in
-
The part of the source lying inside of the destination
replaces the destination.
Dc' = Sc.Da
Da' = Sa.Da
The following diagram shows src_in compositing:
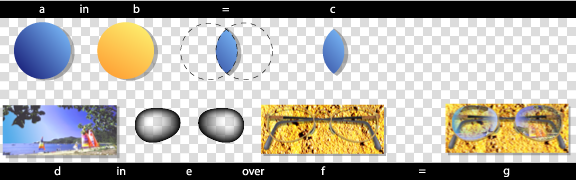
View this image as SVG (SVG-enabled browsers only)
-
dst_in
-
The part of the destination lying inside of the source
replaces the destination.
Dc' = Dc.Sa
Da' = Sa.Da
-
src_out
-
The part of the source lying outside of the destination
replaces the destination.
Dc' = Sc.(1 - Da)
Da' = Sa.(1 - Da)
The following diagram shows src_out compositing:

View this image as SVG (SVG-enabled browsers only)
-
dst_out
-
The part of the destination lying outside of the source replaces the destination.
Dc' = Dc.(1 - Sa)
Da' = Da.(1 - Sa)
-
src_atop
-
The part of the source lying inside of the destination is
composited onto the destination.
Dc' = Sc.Da + Dc(1 - Sa)
Da' = Sa.Da + Da(1 - Sa)
= Da
The following diagram shows src_atop compositing:

View this image as SVG (SVG-enabled browsers only)
-
dst_atop
-
The part of the destination lying inside of the source is composited over the source and replaces the destination.
Dc' = Dc.Sa + Sc.(1 - Da)
Da' = Da.Sa + Sa.(1 - Da)
= Sa
-
xor
-
The part of the source that lies outside of the destination is
combined with the part of the destination that lies outside of the
source.
Dc' = Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa.(1 - Da) + Da.(1 - Sa)
= Sa + Da - 2.Sa.Da
The following compositing operators add blending of source and destination colors beyond the base 12 Porter-Duff operations. The behaviour of these operators necessitates clamping of the output values after compositing.
-
plus
-
The source is added to the destination and replaces the destination. This operator is useful for animating a dissolve between two images.
Dc' = Sc.Da + Dc.Sa + Sc.(1 - Da) + Dc.(1 - Sa)
= Sc + Dc
Da' = Sa.Da + Da.Sa + Sa.(1 - Da) + Da.(1 - Sa)
= Sa + Da
-
multiply
-
The source is multiplied by the destination and replaces the destination. The resultant color is always at least as dark as either of the two constituent colors. Multiplying any color with black produces black. Multiplying any color with white leaves the original color unchanged.
Dc' = Sc.Dc + Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa.Da + Sa.(1 - Da) + Da.(1 - Sa)
= Sa + Da - Sa.Da
The following diagram shows multiply compositing:

View this image as SVG (SVG-enabled browsers only)
-
screen
-
The source and destination are complemented and then multiplied and then replace the destination. The resultant color is always at least as light as either of the two constituent colors. Screening any color with white produces white. Screening any color with black leaves the original color unchanged.
Dc' = (Sa.Da - (Da - Dc).(Sa - Sc)) + Sc.(1 - Da) + Dc.(1 - Sa)
= (Sc.Da + Dc.Sa - Sc.Dc) + Sc.(1 - Da) + Dc.(1 - Sa)
= Sc + Dc - Sc.Dc
Da' = Sa + Da - Sa.Da
The following diagram shows screen compositing:

View this image as SVG (SVG-enabled browsers only)
-
overlay
-
Multiplies or screens the colors, dependent on the destination color. Source colors overlay the destination whilst preserving its highlights and shadows. The destination color is not replaced, but is mixed with the source color to reflect the lightness or darkness of the destination.
if 2.Dc < Da
Dc' = 2.Sc.Dc + Sc.(1 - Da) + Dc.(1 - Sa)
otherwise
Dc' = Sa.Da - 2.(Da - Dc).(Sa - Sc) + Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa + Da - Sa.Da
These equations are approximations which are under review. Final equations may differ from those presented here.
The following diagram shows overlay compositing:

View this image as SVG (SVG-enabled browsers only)
-
darken
-
Selects the darker of the destination and source colors. The destination is replaced with the source when the source is darker, otherwise it is left unchanged.
Dc' = min(Sc.Da, Dc.Sa) + Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa + Da - Sa.Da
or
if Sc.Da < Dc.Sa
src_over()
otherwise
dst_over()
The following diagram shows darken compositing:

View this image as SVG (SVG-enabled browsers only)
-
lighten
-
Selects the lighter of the destination and source colors. The destination is replaced with the source when the source is lighter, otherwise it is left unchanged.
Dc' = max(Sc.Da, Dc.Sa) + Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa + Da - Sa.Da
or
if Sc.Da > Dc.Sa
src_over()
otherwise
dst_over()
The following diagram shows lighten compositing:

View this image as SVG (SVG-enabled browsers only)
-
color_dodge
-
Brightens the destination color to reflect the source color. Painting with black produces no change.
if Sc.Da + Dc.Sa >= Sa.Da
Dc' = Sa.Da + Sc.(1 - Da) + Dc.(1 - Sa)
otherwise
Dc' = Dc.Sa/(1-Sc/Sa) + Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa + Da - Sa.Da
These equations are approximations which are under review. Final equations may differ from those presented here.
The following diagram shows color_dodge compositing:

View this image as SVG (SVG-enabled browsers only)
-
color_burn
-
Darkens the destination color to reflect the source color. Painting with white produces no change.
if Sc.Da + Dc.Sa <= Sa.Da
Dc' = Sc.(1 - Da) + Dc.(1 - Sa)
otherwise
Dc' = Sa.(Sc.Da + Dc.Sa - Sa.Da)/Sc + Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa + Da - Sa.Da
These equations are approximations which are under review. Final equations may differ from those presented here.
The following diagram shows color_burn compositing:

View this image as SVG (SVG-enabled browsers only)
-
hard_light
-
Multiplies or screens the colors, dependent on the source color value. If the source color is lighter than 0.5, the destination is lightened as if it were screened. If the source color is darker than 0.5, the destination is darkened, as if it were multiplied. The degree of lightening or darkening is proportional to the difference between the source color and 0.5. If it is equal to 0.5 the destination is unchanged. Painting with pure black or white produces black or white.
if 2.Sc < Sa
Dc' = 2.Sc.Dc + Sc.(1 - Da) + Dc.(1 - Sa)
otherwise
Dc' = Sa.Da - 2.(Da - Dc).(Sa - Sc) + Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa + Da - Sa.Da
These equations are approximations which are under review. Final equations may differ from those presented here.
The following diagram shows hard_light compositing:

View this image as SVG (SVG-enabled browsers only)
-
soft_light
-
Darkens or lightens the colors, dependent on the source color value. If the source color is lighter than 0.5, the destination is lightened. If the source color is darker than 0.5, the destination is darkened, as if it were burned in. The degree of darkening or lightening is proportional to the difference between the source color and 0.5. If it is equal to 0.5, the destination is unchanged. Painting with pure black or white produces a distinctly darker or lighter area, but does not result in pure black or white.
if 2.Sc < Sa
Dc' = Dc.(Sa - (1 - Dc/Da).(2.Sc - Sa)) + Sc.(1 - Da) + Dc.(1 - Sa)
otherwise if Dc.8 <= Da
Dc' = Dc.(Sa - (1 - Dc/Da).(2.Sc - Sa).(3 - 8.Dc/Da)) + Sc.(1 - Da) + Dc.(1 - Sa)
otherwise
Dc' = (Dc.Sa + ((Dc/Da)^(0.5).Da - Dc).(2.Sc - Sa)) + Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa + Da - Sa.Da
These equations are approximations which are under review. Final equations may differ from those presented here.
The following diagram shows soft_light compositing:

View this image as SVG (SVG-enabled browsers only)
-
difference
-
Subtracts the darker of the two constituent colors from the lighter. Painting with white inverts the destination color. Painting with black produces no change.
Dc' = abs(Dc.Sa - Sc.Da) + Sc.(1 - Da) + Dc.(1 - Sa)
= Sc + Dc - 2.min(Sc.Da, Dc.Sa)
Da' = Sa + Da - Sa.Da
The following diagram shows difference compositing:

View this image as SVG (SVG-enabled browsers only)
-
exclusion
-
Produces an effect similar to that of 'difference', but appears as lower contrast. Painting with white inverts the destination color. Painting with black produces no change.
Dc' = (Sc.Da + Dc.Sa - 2.Sc.Dc) + Sc.(1 - Da) + Dc.(1 - Sa)
Da' = Sa + Da - Sa.Da
These equations are approximations which are under review. Final equations may differ from those presented here.
The following diagram shows exclusion compositing:

View this image as SVG (SVG-enabled browsers only)
8.1.7 Alternate Proposal for compositing
This is an alternate proposal for compositing syntax. It builds upon the Rendering Arbitrary XML feature described above. It is less complete than the proposal above which has been more thoroughly checked (mathematically).
The goal of this compositing proposal is to achieve the same functionality as the above proposal, but without changing the underlying rendering model. In summary:
-
No extra compositing logic is added to implementation. Rather it
uses the existing filter system and the rendering arbitrary XML
feature to map compositing operations into filters.
-
The filter logic may have to be updated to handle the clip-to-self
functionality.
-
It addresses the issue of complex groups requiring an extra channel
for shape opacity.
-
The memory allocation controls from filters are used, allowing
authors to limit the area to which compositing operations apply,
especially in the cases where offscreen buffers are necessary.
There will be two new elements added to the SVG language: composite and blend. Each has a predefined translation into a shadow tree. For example:
<composite op="over" x="0" y="0" width="100" height="100"
filterUnits="userSpaceOnUse" filterRes="100 100">
<!-- arbitrary SVG content -->
</composite>
The above example would be mapped into:
<g>
<defs>
<filter id="comp1" x="100" y="100" width="100" height="100"
filterUnits="userSpaceOnUse" filterRes="100 100">
<feComposite operator="over"/>
</filter>
</defs>
<g filter="url(#comp1)">
<!-- referenced content of 'composite' element -->
</g>
</g>
In order to facilitate clip-to-self and the shape channel, the filter mechanism should add a shape attribute to all filter primitives which provides the same functionality as the Java2D clip-to-self feature and most common PDF shape channel algorithm. If the attribute is set then there will be a single channel mask which restricts the area upon which the filter is operating.
For example:
<blend op="multiply" x="0" y="0" width="100" height="100"
filterUnits="userSpaceOnUse" filterRes="100 100"
shape="sourceShape">
<!-- arbitrary SVG content -->
</blend>
The above example gets translated into:
<g>
<defs>
<filter id="comp2" x="100" y="100" width="100" height="100"
filterUnits="userSpaceOnUse" filterRes="100 100">
<feBlend mode="multiply" shape="sourceShape"/>
</filter>
</defs>
<g filter="url(#comp2)">
<!-- referenced content of 'composite' element -->
</g>
</g>
Implementations would be able to optimize their code to directly implement composite and blend without resorting to filters or shadow trees. The shadow tree logic represents the defined correct behaviour, not the required implementation approach.
8.2 Drawing Order
There have been a number of requests to provide a mechanism that separates drawing order from document order, a feature commonly referred to as "Z index". The SVG Working Group is evaluating the need for the feature as well as several possible solutions.
It is possible to simulate such a feature at the moment either using SMIL animation and multiple use elements, or through scripting (moving an element toward the end of the document). However, both can place restrictions on document structure, and have limitations in the area of property inheritance.
The SVG Working Group requests feedback on this feature, especially any specific requirements you may have. SVG 1.2 plans to enable a drawing order independent of document order, a feature commonly referred to as Z index. This feature is in very early development - there are no further details at the moment.
9 Painting Enhancements
9.1 The solidColor Element
The solidColor element is a paint server that provides a single color with opacity. It can be referenced like the other paint servers (gradients and patterns).
<xs:element name="solidColor">
<xs:complexType>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
</xs:complexType>
</xs:element>
The solid-color property indicates what color to use for this solidColor element. The keyword currentColor and ICC colors can be specified in the same manner as within a <paint> specification for the fill and stroke properties.
-
solid-color
-
| Value: |
currentColor | <color> [icc-color( <name> [, <icccolorvalue>]* ) ] | inherit
|
| Initial: |
black
|
| Applies to: |
solidColor elements
|
| Inherited: |
no
|
| Percentages: |
N/A
|
| Media: |
visual
|
| Animatable: |
yes
|
The solid-opacity property defines the opacity of a given solid color.
-
solid-opacity
-
| Value: |
<alphavalue> | inherit
|
| Initial: |
1
|
| Applies to: |
solidColor elements
|
| Inherited: |
no
|
| Percentages: |
N/A
|
| Media: |
visual
|
| Animatable: |
yes
|
9.2 Background Fill Property
SVG 1.2 will enable the author to specify a painting operation which will be used to fill the background of any element that creates a viewport, such as the root svg element.
We are still discussing if this paint operation should be restricted to a solid color or should allow any arbitrary paint operation, such as gradients and patterns. The arbitrary paint is the preferred option, but we have to precisely define what coordinate system to use, taking into account the aspect ratio and the canvas dimensions. It may not be the initial viewport that is filled. For now, we assume that we have worked this out and allow arbitrary paint.
The background-fill property defines the paint used to fill the viewport created by a particular element.
-
background-fill
-
| Value: |
<paint>
|
| Initial: |
none
|
| Applies to: |
viewport-creating elements
|
| Inherited: |
no
|
| Percentages: |
N/A
|
| Media: |
visual
|
| Animatable: |
yes
|
The current user coordinate system used when rendering the background is the user coordinate system in place on the given viewport-creating element before any additional transformations that might be specified on that element via a viewBox or transform attribute.
For the particular case of the viewport corresponding to the outermost svg element (i.e., the initial viewport), the background is processed using the initial viewport coordinate system as the current user coordinate system. Thus, a background specified on the initial viewport will stay fixed relative to any zoom, pan and scroll actions by the user.
Note that background-fill paints the entire viewport, not just that part which might include document contents due to the viewBox attribute.
9.3 Inheritance into the shadow tree
The shadowInherit property applies to elements that establish shadow trees and controls property inheritance in those shadow trees. In SVG 1.0 and 1.1, this behavior was fixed depending on the element name. This property regularizes control over the inheritance method and gives more flexibility to content creators.
-
shadowInherit
-
| Value: |
onDefine | onUse | none | inherit
|
| Initial: |
onDefine
|
| Applies to: |
all elements that establish shadow trees
|
| Inherited: |
no
|
| Percentages: |
N/A
|
| Media: |
visual
|
| Animatable: |
no
|
-
onDefine
-
Properties inherit into the shadow tree at their point of definition,
in other words from the element that defines the shadow tree.
In SVG 1.0 and 1.1, for example, marker elements behave like this. It is easy to make red markers that are used on multiple paths, and difficult to make markers that are the color of the path on which they are used. Similarly gradient elements behave like this; it is difficult to make a gradient one of whose stops is the currentColor for example.
-
onUse
-
Properties inherit into the shadow tree at their point of use, in
other words from the element that generates the shadow tree.
In SVG 1.0 and 1.1, for example, symbols behave like this. It is easy to make symbols that are used in multiple places, and inherit from the use element that references them.
-
none
-
There is no inheritance into the shadow tree. All properties on the
root element of the shadow tree are set to their initial values, as if
the shadow tree were in a separate document. This allows SVG content
to be created and then re-used without risk of styling changes from
the surrounding context.
-
inherit
-
(This is a useless value but we need to define what happens). If the
parent element is an element that establishes shadow trees then the
value is that of the shadowInherit property on the parent element.
Otherwise, it is the same as onDefine.
The User Agent default stylesheet for SVG 1.2 user agents, to give SVG 1.0/1.1 compatible styling, includes the following rules:
symbol { shadowInherit: onUse }
image, feImage { shadowInherit: none }
9.4 Using device colors
Certain print applications can improve printing quality by specifying colors by name or in an alternative color format. This often is referred to the use of 'spot' colors, device colors or inks, and usually means that a particular ink will be used for the color when it is printed. Furthermore, there are applications in the printing press industry where presses can be set up with different inks for different jobs. This means that the content creator will need to create content tailored to the particular press setup in order to obtain the best results.
The deviceColor element can be used to indicate an alternative color for a particular paint. This element will be mostly used in closed workflows, since the names of the inks and the parameters (percentages of each ink's color components) rarely have meaning outside the domain of the target device.
<xs:element name="deviceColor">
<xs:complexType>
<xs:attribute ref="href" use="required"
namespace="http://www.w3.org/1999/xlink"/>
<xs:attribute ref="name" use="required" type="string"/>
<xs:anyAttribute namespace="##any" processContents="skip"/>
</xs:complexType>
</xs:element>
-
xlink:href
-
A URI used to identify the device-specific information included in this element. If the User Agent does not recognize the URI (ie. is not able to recognize the particular device parameters) then the element should be ignored and should not be part of the rendering process.
Animatable: no
-
name
-
The name of this device-specific color information. The name attribute is used within the device-color specification within <paint> to reference this deviceColor element.
Animatable: no
The deviceColor element uses attributes from external namespaces to define the device specific properties that are to be used when the deviceColor is referenced from a <paint>.
The following example illustrates the use of deviceColor. There are two things to note:
-
The deviceColor element describes device specific setup information.
-
The device-color keyword is used as an alternative <paint> specification,
achieving the desired <paint> when the output is the named device (or when
the User Agent is able to understand the device specific information).
<svg xmlns="http://www.w3.org/2000/svg" version="1.2"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:ecpi="http://www.example.com/press/inks">
<defs>
<!-- describe a particular output device -->
<deviceColor name="device-inks"
xlink:href="http://www.example.com/pressInks"
ecpi:value="Cyan, Magenta, Yellow, Black, Silver, Gray, Green"/>
</defs>
<text x="100" y="150" font-family="Verdana" font-size="35"
fill="rgb(22,33,44) device-color(device-inks, 11,55,66,77,0,0,88)" >
Hello, out there
</text>
</svg>
In the example above, a supplemental attribute, value, from a private namespace has been added. This example value attribute provides the definitions of colors or inks to be interpreted in the context of the URI specified. It is in a private namespace so that content and context authors can use any understood format to convey the necessary information. When the particular deviceColor element is referenced later by a device-color keyword specification, it is generally expected that the number of parameters following the name reference (1st parameter) in the function-like representation for the value of device-color alternate in a fill or stroke attribute (for example) will have an understood one-to-one correspondence with the information specified for the value attribute in the the deviceColor element. The interpretation of the parameters is implied specifically by the context set by the URI.
9.4.1 The device-color keyword
The device-color keyword for specifying device specific <paint> colors is to be used only by those agents that understand the full meaning of the context set by the URI in the referred to DeviceColor element. The keyword can only be used with a corresponding color definition, such as a color keyword or RGB definition. The color definition, with ICC Color specification when present, is used if the agent does not understand the rendering context implied by the referenced device-color URI. The priority of the use of color specifications are as follows: device-color if understood, color-profile if present and understood and finally the sRGB specification.
The first parameter in the function like representation device-color must be the name for a defined deviceColor element, in a manner similar to color-profile. The remainder of the parameters are interpreted entirely in light of the information provided in the deviceColor element. There is a correspondence between the parameters after the name in the functional representation for device-color and the external attributes on the referenced deviceColor. In the example above, the interpretation of the values meaning (ink volume to use, percent of total ink volume, or whatever) is strictly in the context of the specification or convention implied by the URI in the referenced deviceColor element.
Addition of this keyword will modify the definition of the <paint> type. For this draft, we just include the definition of the keyword. Future drafts will specify the new <paint> type in full.
9.4.2 DOM Interface
Interface SVGDeviceColorElement
provides access to the deviceColor element.
IDL Definition-
interface SVGDeviceColorElement : SVGURIReference {
readonly attribute DOMString name; // raises DOMException on setting
};
- Attributes
-
-
readonly
DOMString
name
-
Corresponds to the attribute 'name' on the given element
9.5 Controlling the rendering color space
SVG 1.2 adds a new property to give increased control over the color space used for rendering.
9.5.1 The rendering-color-space property
The rendering-color-space property defines the color space that an element's rendering operations will take place in. Conceptually this involves the creation of an offscreen buffer with color space is defined by the ICC profile referenced by the property. All fill/stroke/gradient/pattern specifications must be converted to this color space before elements are rendered. Images and the results of filtering must be color converted, when required, to the specified color space before being composited. After the object/group is rendered the offscreen image must be converted to the color space defined by the rendering-color-space property on the object/group's parent before being composited into the parent's offscreen buffer.
The ICC profile referenced must provide forward and reverse conversion, as the implementation will need to convert to and from the specified color space; most ICC profiles provide both conversions. To limit the burden on implementors only three channel ICC profiles are required to be supported. In cases where the specified ICC profile can not be used (such as not being available, or because it has more than three channels of output) the implementation must use the rendering-color-space specification from the first ancestor that has a usable profile associated (i.e. it is as if a value was not provided for this property for this element).
Note that standard SVG compositing rules are used. As a consequence highly non-linear color spaces (such as HSV) or non-orthogonal color spaces (such as CMYK) may give unintuitive results when blending colors.
-
rendering-color-space
-
| Value: |
auto | sRGB | linearRGB | <name> | <uri> |inherit
|
| Initial: |
auto
|
| Applies to: |
container elements and graphical elements
|
| Inherited: |
yes
|
| Percentages: |
N/A
|
| Media: |
visual
|
| Animatable: |
yes
|
-
auto
-
The user agent must defer to the 'color-interpolation' property.
-
sRGB
-
Specifies that the sRGB color space is to be used for rendering.
-
linearRGB
-
Specifies that the linear sRGB color space is to be used for rendering.
-
<name>
-
A name corresponding to a defined color profile that is in the user
agent's color profile description database. The user agent searches
the color profile description database for a color profile
description entry whose name descriptor matches <name> and uses the
last matching entry that is found. If no match is found then it is
as if 'sRGB' were specified.
-
<uri>
-
A URI reference to the source color profile to use for rendering.
The color-interpolation property on gradients and color-interpolation-filters property on filter primitives are also extended to support <name> and <uri> references. This enables gradients and filters where interpolation occurs in an alternate color space. When the gradient is rendered the colors must be converted to the rendering-color-space of the object the gradient is applied to (consistent with the current definition of color-interpolation).
The color-interpolation property on graphics elements will be deprecated. The current definition of color-interpolation states that when the property is set on an element it controls what color space is used when the child is composited with it's parent.
The problem with this definition is that it implicitly requires converting the content already rendered into the parents buffer to the color space specified by color-interpolation for compositing with the child. This made sense when the only supported color spaces were sRGB and linear sRGB, because presumably the compositing code would perform the conversion, composite and convert back all at once, thus preserving the fidelity of the parent buffer. However it would be extremely difficult and computationally expensive for implementations to do this for arbitrary ICC color spaces.
Given this definition, for the use of the color-interpolation property to be make sense, the property would generally have to be set on all the children of a grouping element, but not be set on the grouping element. This would allow an implementation to composite all the children in the desired color space, and only convert to the 'parent' color space at the end of the group. However having to set a property on all the children but not on the parent would be extremely fragile as well as error prone for generators of SVG content.
Thus the SVG working group has decided that rendering-color-space should replace color-interpolation for use on graphics elements, it allows a clearer expression of the authors intent, and makes costly mistakes (both in speed and quality) less likely.
The user agent will go into error if the value of rendering-color-space is anything but 'auto' when color-interpolation has a value of 'linearRGB'. If color-interpolation is removed a future version of the specification the 'auto' value for rendering-color-space will be defined to mean 'sRGB'.
Should this property apply (or not) to implementations with more than 3 channels?
The current tspan element does not have a 'transform' attribute. This means that some animations of text are required to split related text chunks into separate text elements. By adding a 'transform' attribute, it should be possible to keep the related text content within one text element.
We will have to carefully examine what effect this has on the other attributes such as x, y, dx, dy and rotate, as well as the current text position.
10 Alternate content based on display resolutions
An image may be placed at any location in userspace, and be subject to any set of affine transformations. In many cases, the resolution at which a raster image is rendered, whether to screen or another device, may not be a good match to the resolution of the image itself. For example, it is not efficient to load a 4000 by 4000 pixel image to be eventually rendered in a 10 pixel by 10 pixel region if an appropriate thumbnail was available at that size.
For this reason, SVG 1.2 will add enhancements to images which will allow multiple resources to be used for a single image. The choice of resource is governed by the output resolution.
At the moment there are two proposals for this functionality. Both proposals are given here and the Working Group explicitly requests feedback on the topic. One proposal is specific to raster images, the other is an attempt to provide a general solution that could be used for any graphical content.
10.1 Proposal 1: Images with multiple resolutions
This section can be considered a replacement for Section 5.7 — The image element of SVG 1.1.
10.1.1 The image element
The image element indicates that a given rectangle within the current user coordinate system is to be filled by referenced content. The image element and its child subimage elements can refer to raster image files such as PNG or JPEG or to files with MIME type of "image/svg+xml" or to elements of type symbol .Conforming SVG viewers need to support at least PNG, JPEG and SVG format files.
The result of processing an image is always a four-channel RGBA result. When an image element or its child subimage elements reference a raster image file such as PNG or JPEG files which only has three channels (RGB), then the effect is as if the object were converted into a 4-channel RGBA image with the alpha channel uniformly set to 1. For a single-channel raster image, the effect is as if the object were converted into a 4-channel RGBA image, where the single channel from the referenced object is used to compute the three color channels and the alpha channel is uniformly set to 1.
An image element establishes a new viewport for the referenced content as described in Establishing a new viewport. The bounds for the new viewport are defined by attributes x, y, width and height. The placement and scaling of the referenced content are controlled by the preserveAspectRatio attribute on the image element.
When an image element or its child subimage elements references an SVG image, or a symbol element then the preserveAspectRatio attribute as well as the clip and overflow properties on the root element in the referenced SVG image or symbol element are ignored (in the same manner as the x, y, width and height attributes are ignored). Instead, the preserveAspectRatio attribute on the referencing image element defines how the referenced content is fitted into the viewport and the clip and overflow properties on the image element define how the referenced content is clipped (or not) relative to the viewport.
The value of the viewBox attribute to use when evaluating the preserveAspectRatio attribute is defined by the referenced content. For content that clearly identifies a viewBox (e.g. an SVG file with the viewBox attribute on the outermost svg element, or a symbol element) that value should be used. For most raster content (PNG, JPEG) the bounds of the image should be used (i.e. the image element has an implicit viewBox of "0 0 raster-image-width raster-image-height"). Where no value is readily available (e.g. an SVG file with no viewBox attribute on the outermost svg element) the preserveAspectRatio attribute is ignored, and only the translate due to the x & y attributes of the viewport is used to display the content.
For example, if the image element referenced a PNG or JPEG and preserveAspectRatio has the value "xMinYMin meet", then the aspect ratio of the raster would be preserved (which means that the scale factor from image's coordinates to current user space coordinates would be the same for both X and Y), the raster would be sized as large as possible while ensuring that the entire raster fits within the viewport, and the top/left of the raster would be aligned with the top/left of the viewport as defined by the attributes x, y, width and height on the image element. If the value of preserveAspectRatio was 'none' then aspect ratio of the image would not be preserved. The image would be fitted such that the top/left corner of the raster exactly aligns with coordinate (x,y) and the bottom/right corner of the raster exactly aligns with coordinate (x+width ,y+height ).
Except when the referenced resource is a symbol element the resource referenced by the image element represents a separate document which generates its own parse tree and document object model (if the resource is XML). Thus, there is no inheritance of properties into the image.
When the referenced resource is a symbol element the image element behaves much like the 'use' element and there is inheritance of properties into the referenced symbol element.
Unlike use, the image element cannot reference arbitrary elements within an SVG file, it is only allowed to reference symbol.
<xs:element name="image">
<xs:complexType>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
<xs:attributeGroup ref="XLinkEmbedAttrs"/>
<xs:attribute ref="viewBox"/>
<xs:attribute ref="preserveAspectRatio"/>
<xs:attribute ref="transform"/>
<xs:attribute ref="x"/>
<xs:attribute ref="y"/>
<xs:attribute ref="width"/>
<xs:attribute ref="height"/>
<xs:attribute ref="min-pixel-size"/>
<xs:attribute ref="max-pixel-size"/>
</xs:complexType>
</xs:element>
There are two new attributes on the image element: min-pixel-size and max-pixel-size. They are described below in "Selecting the image for rendering". The other attributes retain the same meaning as SVG 1.1.
10.1.2 The subImage element
The subImage element is used to provide alternate resources to use for this image depending on rendering conditions. The subImage provides alternate resource references to be used for a range of rendering scales as defined by min-pixel-size and max-pixel-size.
<xs:element name="subImage">
<xs:complexType>
<xs:attributeGroup ref="XLinkEmbedAttrs"/>
<xs:attribute ref="min-pixel-size"/>
<xs:attribute ref="max-pixel-size"/>
</xs:complexType>
</xs:element>
10.1.3 Selecting the image for rendering
For 'image' elements that have one or more child 'subImage' elements the viewer has a choice between several possible sources of data to use to fill the image element. The choice is made based on the current rendering conditions and the values of the 'min-pixel-size' and 'max-pixel-size' on the elements.
The 'min-pixel-size' and 'max-pixel-size' attributes both describe the size of a pixel in the current coordinate system. They are allowed to provide one value or two. If two values are provided then the first refers to the size of a pixel in the horizontal direction and the second value refers to the size of a pixel in the vertical direction. If one value is provided it is used for both horizontal and vertical. If the attribute is not provided then the resource's range is considered unbounded on that side.
Thus 'min-pixel-size' and 'max-pixel-size' define a range of resolutions that the resource from the associated 'xlink:href' is considered applicable to.
In cases where the current rendering resolution lies outside of any specified range, the viewer is given wide latitude in selecting the resource to display, however implementations are encouraged to select the resource whose range is closest to the current rendering resolution. Likewise in cases where the current rendering resolution lies within multiple ranges the viewer is given wide latitude in selecting the resource to display, however implementations are encouraged to select the resource whose range is closest to the current rendering although the immediate availability of a resource should also be heavily considered.
Authors are strongly recommended to provide 'min-pixel-size' and 'max-pixel-size' attributes on the image element when they provide 'subImage' elements, as otherwise viewers may ignore that resource entirely in preference to the 'subImage' elements that must provide 'min-pixel-size' and 'max-pixel-size' attributes.
An example of using subImage:
<svg width="4in" height="3in" version="1.2"
xmlns="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink">
<desc>This graphic links to a list of possible external images
</desc>
<image x="200" y="200" width="100px" height="100px"
min-pixel-size="1" max-pixel-size="2"
xlink:href="myimage.png">
<title>My mult-resolution image</title>
<desc>'myimage.png' is a 100x100 pixel image</desc>
<subImage xlink:href="myimage-lg.png"
min-pixel-size=".5" max-pixel-size="1">
<desc>'myimage-lg.png' is a 200x200 pixel image</desc>
</subImage>
<subImage xlink:href="myimage-sm.png"
min-pixel-size="2" max-pixel-size="4">
<desc>'myimage-sm.png' is a 50x50 pixel image</desc>
</subImage>
</image>
</svg>
10.2 Proposal 2: Conditional content based on resolution
The following proposal creates additional elements for resolution-dependent content, unlike the above proposal which modified the image element.
10.2.1 The renderSwitch element
The renderSwitch element indicates that a given rectangle within the current user coordinate system is to be filled by one of its children based on rendering conditions. Unlike the switch element the child chosen for rendering is evaluated every time the element is rendered.
A renderSwitch element establishes a new viewport for the contained content as described in Establishing a new viewport . The bounds for the new viewport are defined by attributes x, y, width and height. The placement and scaling of the referenced content are controlled by the preserveAspectRatio attribute on the renderSwitch element.
The renderSwitch element may have one or more resolution elements as children. Each resolution element provides content that should be rendered for a particular range of display resolutions. The range is specified through the min-pixel-size and max-pixel-size attributes. The resolution elements are evaluated in order until the current rendering conditions satisfy one the children's min/max Pixel size attributes, at which time that element's content is selected as the content to render. The resolution element may have any combination of min and max pixel size's specified including neither of them, in which case when processing reaches that element it will always be selected. In cases where no element is selected the implementation much choose one by selecting the element with the closest specified resolution.
Here is an alternative to the above paragraph: The renderSwitch element may have one or more resolution elements as children. Each resolution element provides content that should be rendered for a particular range of display resolutions. The range is specified through the min-pixel-size and max-pixel-size attributes. These attributes describe recommended ranges that the content be used for. The implementation is strongly encouraged to adhere to these recommended ranges however because all the content is considered semantically equivalent, the viewer is allowed to consider factors other than just resolution (such as having an alternate branch ready for viewing, or available network bandwidth/connectivity).
<xs:element name="renderSwitch">
<xs:complexType>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
<xs:attribute ref="viewBox"/>
<xs:attribute ref="preserveAspectRatio"/>
<xs:attribute ref="transform"/>
<xs:attribute ref="x"/>
<xs:attribute ref="y"/>
<xs:attribute ref="width"/>
<xs:attribute ref="height"/>
</xs:complexType>
</xs:element>
-
x = " <coordinate>"
-
The x-axis coordinate of one corner of the rectangular region into
which the child content is placed. If the attribute is not
specified, the effect is as if a value of "0" were specified.
Animatable : yes.
-
y = " <coordinate>"
-
The y-axis coordinate of one corner of the rectangular region into
which the child content is placed. If the attribute is not
specified, the effect is as if a value of "0" were specified.
Animatable : yes.
-
width = " <length>"
-
The width of the rectangular region into which the child content is rendered
A negative value is an error. A value of
zero disables rendering of the element.
Animatable : yes.
-
height = " <length>"
-
The height of the rectangular region into which the child content is
rendered. A negative value is an error. A
value of zero disables rendering of the element.
Animatable : yes.
10.2.2 The resolution element
The resolution element is used to provide content intended for use with a particular range of display resolutions specified by its min-pixel-size and max-pixel-size attributes.
Aside from the addition of the min-pixel-size and max-pixel-size attributes the resolution element acts as a g element and if referenced directly by content the min-pixel-size and max-pixel-size attributes are ignored.
<xs:element name="resolution">
<xs:complexType>
<xs:attributeGroup ref="PresentationAttrs"/>
<xs:attributeGroup ref="StyleAttrs"/>
<xs:attribute ref="transform"/>
<xs:attribute ref="min-pixel-size"/>
<xs:attribute ref="max-pixel-size"/>
</xs:complexType>
</xs:element>
-
min-pixel-size = " <number-optional-number>"
-
See following section
-
max-pixel-size = " <number-optional-number>"
-
See following section
10.2.3 The min-pixel-size and max-pixel-size attributes
The min-pixel-size and max-pixel-size attributes refer to the size of a pixel in the user coordinate system of the resolution element. These attributes are allowed to provide one or two values. If two values are provided then the first refers to the size of a pixel in the horizontal direction and the second value refers to the size of a pixel in the vertical direction. If one value is provided it is used for both the horizontal and vertical size of the pixel. When implementations evaluate these attributes they should pay attention to the possibility that the content is being rendered in a filter using the filterRes attribute when calculating the size of a pixel in the current coordinate system.
If the min-pixel-size or max-pixel-size attribute is not provided then the resolution's range is considered unbounded on that side. If neither is provided it is considered an error.
In cases where the current rendering resolution lies outside of any specified range, the viewer is given wide latitude in selecting the resource to display, however implementations are encouraged to select the child whose range is closest to the current rendering resolution. Likewise in cases where the current rendering resolution lies within the ranges specified on multiple children the viewer is given wide latitude in selecting the resource to display, however implementations are encouraged to select the resource whose range is closest to the current rendering although having a child ready for immediate display should also be heavily considered.
The following example demonstrates renderSwitch and resolution:
<svg width="400" height="300" version="1.2"
xmlns="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink">
<desc>This changes from a rectangle to an ellipse depending
on display resolution.
</desc>
<renderSwitch x="100" y="100" width="200" height="100">
<resolution min-pixel-size="1">
<desc>The rect is displayed when zoomed out
</desc>
<rect x="0%" y="0%" width="100%" height="100%"
fill="yellow" stroke="purple"/>
</resolution>
<resolution max-pixel-size="1">
<desc>The ellipse is displayed when zoomed in
</desc>
<ellipse cx="50%" cy="50%" rx="50%" ry="50%"
fill="yellow" stroke="purple"/>
</resolution>
</image>
</svg>
11 DOM Enhancements
11.1 DOM Access to Images
There is an oversight in the SVG 1.0 DOM in that the SVGImage interface does not allow access to the DOM of the image it refers to (if that image is an SVG document). It should also be possible to access whatever DOM, if any, is provided by the non-SVG images. Examples could be an XML representation of the metadata associated with an image from a digital camera (e.g. EXIF) or other XML image formats.
To provide this functionality, SVG 1.2 will add a getImageDocument() method to the SVGImageElement interface. This method should return the Document DOM interface of the referenced image, if one is available. It is unlikely that the SVG specification will describe the format for the returned Document except in the case of a referenced SVG image.
Although the names of elements, interfaces and methods have been listed here, they are not yet finalized. The functionality will be added, however it may not be named exactly as specified above.
11.2 Conversion of Mouse Coordinates
It is quite difficult to convert the client space coordinates in a mouse event into the corresponding user space coordinates in the SVG document, taking into account nested viewBoxes, aspect ratio and the dimensions of the user agent. For this reason, SVG 1.2 will add convenience methods to the SVG DOM which provide the client space to user space coordinate conversion (and visa-versa).
11.3 DOM 3 Events
The SVG Working Group plans to incorporate DOM Level 3 Events into SVG 1.2. The most significant change this entails is the addition of Text Events (ie. events that encapsulate some form of textual content, such as text entry, or function key being pressed).
Early drafts of SVG 1.0 included keyboard events from the draft DOM level 2 specification. Some SVG viewers implemented this, and the functionality is used in content today. However, due to severe problems with the internationalization aspect, DOM Level 2 dropped the keyboard events before it became a Recommendation. In consequence, SVG 1.0 had nothing to refer to and also dropped these keyboard events.
The improved DOM Level 3 Text Events addresses the internationalization aspects. In particular, the programmer will not need to worry whether a particular character was entered using the keyboard, or using an Input Method Editor (IME) as is commonly done for Chinese and Japanese, or by some other method such as an on-screen virtual keyboard; nor do all the different national keyboard layouts matter. It no longer matters if the letter "n" was entered by pressing the "n" key, or by pressing shift plus "n" when caps lock was on. The event merely returns the text that was entered. Of course, keypress information is also available for applications that need this and for keys that do not generate text.
11.4 Window Interface
The majority of scripted SVG documents in existence make use of the browser specific Window interface, which includes methods such as setTimeout and clearInterval. SVG 1.2 will most likely specify an SVGWindow interface, taking into account the de-facto standard that already exists.
A method will be added to the SVGDocument interface to enable access to the SVGWindow interface. The following is the current proposed Window interface in IDL.
Interface SVGWindow
provides a global object for scripts embedded in a SVG
document.
IDL Definition-
interface SVGWindow {
readonly attribute StyleSheet defaultStyleSheet
readonly attribute SVGDocument document
readonly attribute Event evt
readonly attribute long innerHeight
readonly attribute long innerWidth
attribute DOMString src
void clearInterval ( in object interval );
void clearTimeout ( in object timeout );
void getURL ( in DOMString uri, in EventListener callback );
DocumentFragment parseXML ( in DOMString source, in Document document );
void postURL ( in DOMString uri, in DOMString data, in EventListener callback,
in DOMString mimeType, in DOMString contentEncoding );
DOMString printNode ( in Node node );
Object setInterval ( in DOMString code, in long delay );
Object setTimeout ( in DOMString code, in long delay );
void alert ( in DOMString message );
boolean confirm ( in DOMString message );
DOMString prompt ( in DOMString message, in DOMString default );
};
interface SVGDocument {
readonly attribute SVGWindow window
};
- Attributes
-
-
readonly
StyleSheet
defaultStyleSheet
-
The user agent style sheet.
-
-
readonly
SVGDocument
document
-
The
SVGDocument.
-
-
readonly
Event
evt
-
The event currently being dispatched. Null if there is no currently processed event.
-
-
readonly
long
innerHeight
-
Viewport height in pixels.
-
-
readonly
long
innerWidth
-
Viewport width in pixels.
-
-
DOMString
src
-
The URI of the current document. On setting, the new document pointed to by the URI is loaded by the user agent.
- Methods
-
- clearInterval
-
Cancels a time-out that was set with the setInterval method.
- Parameters
-
|
in
object
interval
|
|
An object that specifies the time-out setting returned by a previous call to the setInterval method
|
- No Return Value
- No Exceptions
- clearTimeout
-
Cancels a time-out that was set with the setTimeout method.
- Parameters
-
|
in
object
timeout
|
|
An object that specifies the time-out setting returned by a previous call to the setTimeout method.
|
- No Return Value
- No Exceptions
- getURL
-
Get data from the given URL using the HTTP GET method.
Notify the callback when done.
- Parameters
-
|
in
DOMString
url
|
|
The URI reference for the data to be loaded.
|
|
in
EventListener
callback
|
|
The method to be invoked when the data is
available. The argument passed to
the function is an ECMAScript Object with 3
properties:
- success:
- true if the data is available, false otherwise
- contentType:
- the content type of the data, if the information is known by the user agent
- content:
- A string representing the data. If the response
was compressed, this property contains the decompressed value.
|
- No Return Value
- No Exceptions
- parseXML
-
Convert the given source string into
DocumentFragment that
belongs to the given XML document. This document
fragment does not get inserted in the tree; this can be
done with DOM methods like appendChild or
insertBefore. If the second parameter is null, a new XML
document is created and the given string is parsed as a
standalone XML document.
- Parameters
-
|
in
DOMString
source
|
|
A string containing a XML document fragment.
|
|
in
Document
document
|
|
The Document context for parsing the XML fragment.
|
- Return Value
-
|
DocumentFragment
|
|
An XML Fragment converted from the original DOMString.
|
- No Exceptions
- postURL
-
Send data to the given URL using the HTTP POST
method. Notify the callback when done. One can also
specify MIME type to be reported to server and
encoding to be used (valid values are null, "gzip" and
"deflate", some browsers cannot post binary data and
will ignore encoding).
- Parameters
-
|
in
DOMString
url
|
|
The URI reference of the application that will receive the data.
|
|
in
DOMString
data
|
|
The data to be sent to the server.
|
|
in
EventListener
callback
|
|
The method to be invoked when the data is
available. The argument passed to
the function is an ECMAScript Object with 3
properties:
- success:
- true if the data is available, false otherwise
- contentType:
- the content type of the data, if the information is known by the user agent
- content:
- A string representing the data. If the response was compressed, this property holds the decompressed value.
|
|
in
DOMString
mimeType
|
|
MIME type to be reported to the server.
|
|
in
DOMString
contentEncoding
|
|
Encoding to be used.
|
- No Return Value
- No Exceptions
- printNode
-
Converts a Node into a DOMString. The string is an XML representation of the Node.
- Parameters
-
|
in
Node
node
|
|
The Node to be converted.
|
- Return Value
-
|
DOMString
|
|
A serialized version of the original Node.
|
- No Exceptions
- setInterval
-
Evaluates an expression after a specified number of milliseconds has elapsed.
- Parameters
-
|
in
DOMString
code
|
|
A string that indicates the code to be executed when the specified interval has elapsed.
|
|
in
long
delay
|
|
An integer that specifies the number of milliseconds.
|
- Return Value
-
|
object
|
|
An object that is used to cancel the interval with the setInterval method.
|
- No Exceptions
- setTimeout
-
Evaluates an expression after a specified number of milliseconds has elapsed.
- Parameters
-
|
in
DOMString
code
|
|
A string that indicates the code to be executed when the specified interval has elapsed.
|
|
in
long
delay
|
|
An integer that specifies the number of milliseconds.
|
- Return Value
-
|
object
|
|
An object that is used to cancel the timeout with the setTimeout method.
|
- No Exceptions
- alert
-
Displays a modal synchronous message to the user if possible
in the current user environment. Commonly, this message takes
the form of a pop-up window with a single dispose button.
- Parameters
-
|
in
DOMString
message
|
|
The message to be displayed.
|
- No Return Value
-
- No Exceptions
- confirm
-
Displays a modal synchronous message to the user if possible
in the current user environment. The user is able
to accept or reject the message. Commonly, this message takes
the form of a pop-up window with either a Yes/No or
OK/Cancel button pair.
- Parameters
-
|
in
DOMString
message
|
|
The message to be displayed.
|
- Return Value
-
|
boolean
|
|
A boolean indicating the user's response. True for
accept, False for reject.
|
- No Exceptions
- prompt
-
Displays a modal synchronous message to the user if possible
in the current user environment. The user is able
to enter a response to the message.
Commonly, this message takes
the form of a pop-up window with a single text entry field.
- Parameters
-
|
in
DOMString
message
|
|
The message to be displayed.
|
|
in
DOMString
default
|
|
The default response to suggest to the user. This can be displayed
in the text field and be modified by the user.
|
- Return Value
-
|
DOMString
|
|
A string representing the response that the user entered.
|
- No Exceptions
12 Other new features
12.1 Monitoring download progress
Many resources, such as raster images, movies and complex SVG content can take a substantial amount of time to download. In some use cases the author would prefer to delay the display of content or the beginning of an animation until the entire contents of a file have been downloaded. In other cases, the author may wish to give the viewer some feedback that a download is in progress (e.g. a loading progress screen).
12.1.1 The Progress event
The ProgressEvent occurs when the user agent makes progress loading a resource (local or external) referenced by an xlink:href attribute.
The user agent must dispatch a ProgressEvent at the beginning of a load operation (i.e., just before starting to access the resource). This event is of type 'preload'. The value of the 'preload' event's progress property is 0.
The user agent must dispatch a ProgressEvent at the end of a load operation (i.e. after load is complete and the user agent is ready to render the corresponding resource). This event is of type 'postload' event. The value of the 'postload' event's progress property is 1.
The user agent may dispatch a loadProgress event between the 'preload' event and the 'postload' events. Such events are of type 'loadprogress'.
All 'loadprogress' events must follow to the following constraints:
-
the progress property on an 'intermediate progress'
event is strictly greater than zero and strictly
smaller than one.
-
for two consecutive 'loadprogress' events,
if provided, the progress property of an event must be strictly
bigger than the value of the progress property on the
preceding event.
-
for two consecutive 'loadprogress' events, the loaded
property of an event must be strictly bigger than the
value of the loaded property on the preceding event.
The ProgressEvent has three corresponding event attributes on elements: onpreload, onpostload and onloadprogress.
IDL Definition-
interface ProgressEvent : events::Event {
readonly attribute DOMString typeArg;
readonly attribute unsigned long loaded;
readonly attribute unsigned long total;
void initProgressEvent(in DOMString typeArg,
in unsigned long loaded,
in unsigned long total);
};
- Attributes
-
-
readonly
DOMString
typeArg
-
Specifies the event type. One of 'preload', 'loadprogress' or
'postload'.
-
-
readonly
unsigned long
total
-
Specifies the expected total number of bytes expected
in a load operation. This value
is ignored for a 'preload' and a 'postload' event. For a
'loadprogress' event, it should specify the total number of bytes
expected or be
-1 which means that it cannot be computed (for example when
the size of the downloaded resource is unknown).
-
-
readonly
unsigned long
loaded
-
Specifies the number of bytes downloaded since the begining
of the download. This value is ignored for a 'preload' or
'postload' event. For a 'loadprogress' event, this value
must be positive.
- Methods
-
- initProgressEvent
-
The initProgressEvent method is used to initialize the value of a
ProgressEvent created through the DocumentEvent interface. This method
may only be called before the ProgressEvent has been dispatched via the
dispatchEvent method, though it may be called multiple times during that
phase if necessary. If called multiple times, the final invocation takes
precedence.
- Parameters
-
|
in
DOMString
typeArg
|
|
Specifies the event type.
|
|
in
unsigned long
loaded
|
|
Specifies the number of bytes that have been
retrieved. This is a positive value.
|
|
in
unsigned long
total
|
|
Specifies the expected total number of bytes in
this load operation.
|
- No Return Value
- No Exceptions
12.2 Prefetching resources
SVG 1.2 adds functionality (adapted from Section 4.4 of SMIL 2.0 — The PrefetchControl Module) to allow content developers to suggest fetching content from the server before it is needed to improve the rendering performance of the document.
12.2.1 The prefetch element
The prefetch element will give a suggestion or hint to a user agent that a media resource will be used in the future and the author would like part or all of the resource fetched ahead of time to make the document playback smoother. User-agents can ignore prefetch elements, though doing so may cause an interruption in the document playback when the resource is needed. It gives authoring tools or savvy authors the ability to schedule retrieval of resources when they think that there is available bandwidth or time to do it.
The prefetch element is a particular type of animation element. The full details of how prefetch fits into the animation model of SVG is not described in this draft. As SVG 1.2 adds more of the planned SMIL features, such as video, audio, par and seq, the behaviour of the prefetch element will be described in full.
<xs:element name="prefetch">
<xs:complexType>
<xs:attribute ref="href" use="required"
namespace="http://www.w3.org/1999/xlink"/>
<xs:attributeGroup ref="StdAttrs"/>
<xs:attribute ref="mediaSize"/>
<xs:attribute ref="mediaTime"/>
<xs:attribute ref="bandwidth"/>
</xs:complexType>
</xs:element>
-
mediaSize = " <number> | <percentage>"
-
Defines how much of the resource to fetch as a function of the file
size of the resource. To fetch the entire resource without knowing
its size, specify 100%. The default is 100%.
-
mediaTime = " <clock> | <percentage>"
-
Defines how much of the resource to fetch as a function of the
duration of the resource. To fetch the entire resource without
knowing its duration, specify 100%. The default is 100%. For
discrete media (non-time based media like image/png)
using this attribute causes the entire resource to be fetched.
-
bandwidth = " <number> | <percentage>"
-
Defines how much network bandwidth the user agent should use when
doing the prefetch. To use all that is available, specify 100%. The
default is 100%.
Any attribute with a value of "0%" is ignored and treated as if the attribute wasn't specified.
If both mediaSize and mediaTime are specified, mediaSize is used and mediaTime is ignored.
Below is an example of the prefetch element:
<svg width="400" height="300" version="1.2"
xmlns="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink">
<desc>
Prefetch the large images before starting the animation
if possible.
</desc>
<defs>
<prefetch id="pf1" xlink:href="http://www.example.com/images/huge1.png"/>
<prefetch id="pf2" xlink:href="http://www.example.com/images/huge2.png"/>
<prefetch id="pf3" xlink:href="http://www.example.com/images/huge3.png"/>
</defs>
<image x="0" y="0" width="400" height="300"
xlink:href="http://www.example.com/images/huge1.png"
display="none">
<set attributeName="display" to="inline" begin="10s"/>
<animate attributeName="xlink:href" values="
http://www.example.com/images/huge1.png;
http://www.example.com/images/huge2.png;
http://www.example.com/images/huge3.png"
begin="15s" dur="30s"/>
</image>
</svg>
12.3 Navigating between elements
SVG 1.2 plans to add the ability to navigate between elements using an input device, such as a keyboard. In order to do this, the specification will describe what it means to focus on an element (text or graphical), as well as provide a language feature that allows the author to specify the order of navigation, which may be independent of the document order.
These features are useful in a number of applications, including accessibility and user interfaces.
The most likely solution for specifying navigation order is to add a navIndex attribute, similar to XForms, or a nav-index property.
12.4 Hinting SVG Fonts
When displaying text on low-resolution devices or at very small sizes on higher-resolution devices it is common for a User Agent to use what is called a 'hinted' version of a scalable font. Many popular font formats, such as TrueType and Postscript, allow hinting. Typically this is a set of instructions to the text layout system that, when followed, will produce optimum legibility. This could include instructions on placing parts of the glyph on pixel boundaries or instructions on keeping the width of adjecent glyph stems constant.
The font format included in SVG 1.1 does not allow hinting. This is seen as a shortcoming in situations where the available resolution is insufficient to display the glyphs well, and where legibility of the text is considered more important than preserving the typographic color of the font used. This has meant that authors are embedding fonts in other formats inside SVG documents.
SVG 1.2 plans to add hinting as an optional feature on SVG fonts in order to give authors the choice of a pure SVG solution. The main requirements are that the hinting technology be declarative, work on non axis aligned text (eg. rotated text) and available royalty-free to SVG implementations. The most likely solution is a variation of Postscript Type 1 hinting.
13 Authors
The authors of this specification are the participants of the W3C SVG Working Group.
-
Ola Andersson, ZOOMON AB
-
Henric Axelsson, Ericsson AB
-
Phil Armstrong, Corel Corporation
-
Benoît Bézaire, Corel Corporation
-
Robin Berjon, Expway
-
Gordon Bowman, Corel Corporation
-
Craig Brown, Canon Information Systems Research Australia
-
Mike Bultrowicz, Savage Software
-
Tolga Capin, Nokia Inc.
-
Mathias Larsson Carlander, Ericsson AB
-
Jakob Cederquist, ZOOMON AB
-
Charilaos Christopoulos, Ericsson AB
-
Lee Cole, Quark
-
Don Cone, America Online Inc.
-
Alex Danilo, Canon Information Systems Research Australia
-
Thomas DeWeese, Eastman Kodak
-
Jon Ferraiolo, Adobe Systems Inc.
-
Darryl Fuller, Schema Software
-
藤沢 淳 (FUJISAWA Jun), Canon
-
Rick Graham, BitFlash
-
Vincent Hardy, Sun Microsystems Inc.
-
端山 貴也 (HAYAMA Takanari), KDDI Research Labs
-
Scott Hayman, Research In Motion Limited
-
Lofton Henderson, OASIS
-
Ivan Herman, W3C
-
石川 雅康 (ISHIKAWA Masayasu), W3C
-
Dean Jackson, W3C/CSIRO (W3C Team Contact)
-
Christophe Jolif, ILOG S.A.
-
Lee Klosterman, Hewlett-Packard
-
小林 亜令 (KOBAYASHI Arei), KDDI Research Labs
-
Thierry Kormann, ILOG S.A.
-
Yuri Khramov, Schema Software
-
Chris Lilley, W3C (Working Group Chair)
-
Philip Mansfield, Schema Software
-
水口 充 (MINAKUCHI Mitsuru), Sharp Corporation
-
Luc Minnebo, Agfa-Gevaert N.V.
-
小野 修一郎 (ONO Shuichiro), Sharp Corporation
-
Antoine Quint, Fuchsia Design (formerly of ILOG)
-
相良 毅 (SAGARA Takeshi), KDDI Research Labs
-
Brad Sipes, ZOOMON AB
-
Peter Sorotokin, Adobe Systems Inc.
-
上田 宏高 (UEDA Hirotaka), Sharp Corporation
-
Rick Yardumian, Canon Development Americas
-
Charles Ying, Openwave Systems Inc.
14 References
-
SVG11
-
Scalable Vector Graphics (SVG) 1.1 Specification, Jon
Ferraiolo, Jun Fujisawa, Dean Jackson editors, W3C,
14 January 2003 (Recommendation). See
http://www.w3.org/TR/2003/REC-SVG11-20030114/
-
SVG2Reqs
-
SVG 1.1/1.2/2.0 Requirements, Dean Jackson editor,
W3C,
22 April 2002 (Working Draft). See
http://www.w3.org/TR/2002/WD-SVG2Reqs-20020422/
-
SVGPrintReqs
-
SVG Printing Requirements, Jun Fujisawa, Lee Klosterman
Craig Brown, Alex Danilo editors, W3C,
18 February 2003 (Working Draft). See
http://www.w3.org/TR/2003/WD-SVGPrintReqs-20030218/
-
SMIL20
-
Synchronized Multimedia Integration Language (SMIL 2.0),
Jeff Ayars et al editors, W3C,
7 August 2001 (Recommendation). See
http://www.w3.org/TR/2001/REC-smil20-20010807/
-
XMLEvents
-
XML Events, Shane McCarron, Steven Pemberton, T.V. Raman
editors, W3C,
7 February 2003 (Candidate Recommendation). See
http://www.w3.org/TR/2003/CR-xml-events-20030207/
-
XForms
-
XForms 1.0, Micah Dubinko, Leigh Klotz, Roland Merrick, T.V. Raman
editors, W3C,
12 November 2002 (Candidate Recommendation). See
http://www.w3.org/TR/2002/CR-xforms-20021112/
-
XHTMLMod
-
Modularization of XHTML in XML Schema,
Daniel Austin, Shane McCarron, Masayasu Ishikawa
editors, W3C,
9 December 2002 (Working Draft). See
http://www.w3.org/TR/2002/WD-xhtml-m12n-schema-20021209/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}