This document provides an overview of the role of delivery context in
assisting device independent presentation for the Web. It surveys current
techniques for conveying delivery context information, and identifies further
developments that would enhance the ability to adapt content for different
access mechanisms.
This section describes the status of this document at the time of its
publication. Other documents may supersede this document. The latest status
of this document series is maintained at the W3C.
This document is a public W3C Working Draft for review by W3C members and
other interested parties. It is a draft document and may be updated,
replaced, or made obsolete by other documents at any time. It is
inappropriate to use W3C Working Drafts as reference material or to cite them
as other than "work in progress". A list of current public W3C Working Drafts
can be found at http://www.w3.org/TR.
This is a working draft of a possible future W3C Note.
This document is published as part of the W3C Device Independence
Activity by the Device Independence Working Group. It is a deliverable as
defined in the Charter
of that group.
Comments on this document may be sent to the public www-di@w3.org mailing list (archived at http://lists.w3.org/Archives/Public/www-di/).
Patent disclosures relevant to this document may be found on the WG patent disclosure
page.
1 Introduction
The Device Independence Principles document [DIP] set out a number of principles that can lead to
greater device independence in delivering Web content and applications.
The term delivery context was
introduced (in [DIP]) to refer to
the set of attributes that characterize the delivery environment. Among these
attributes, the ones that are most relevant for achieving device independence
are those that characterize the presentation capabilities of the access mechanism, the delivery capabilities
of the network and the presentation preferences of the user.
Delivery context information is typically used to provide an appropriate
format, styling or other aspect of some web content that will make it
suitable for the capabilities of a presentation device. The selection or
adaptation required to achieve this may be performed by an origin server, by
an intermediary in the delivery path, or by a user agent.
From the point of view of device independence, the main concern is
accurately reflecting the capabilities of the access mechanism and the
presentation preferences of the user. Given appropriate information about the
delivery context, the presentation of the delivered content can be selected
or adapted to be functional on that device, or may be further customized to
provide a better user experience (as defined in [DIP]). The possible adaptations that could be
performed on the available content can only be determined once the delivery
context information is known.
In this document, techniques for representing, conveying and processing
delivery context are considered. Existing technologies that address these
needs are reviewed. Areas that need further work are highlighted.
1.1 Role of delivery context
The role of the delivery context in accessing web-based content and
applications is illustrated in the following diagrams.
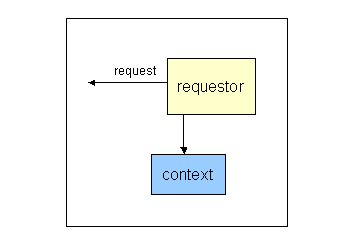
Diagram 1: Requestor provides context as well as request
The originator of a request for some web content may also define some
delivery context information which can help that request to be handled
appropriately. In the diagram, the context information is shown as a separate
box. In practice, the context information may be included as part of the
request, or some or all of it may be supplied indirectly as a reference to
information that is stored separately.
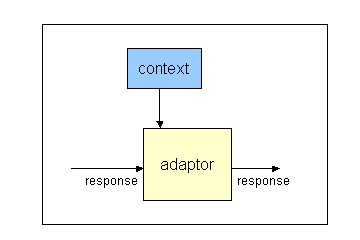
Diagram 2: Adaptor may change response based on context
The response to some request for web content may be adapted, based on the
delivery context information available at that point in the delivery chain,
to create a modified response.
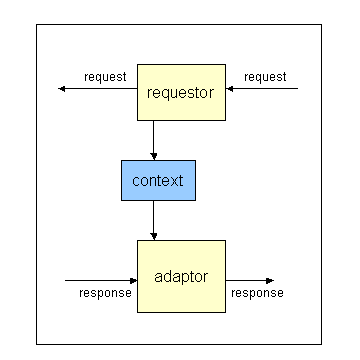
Diagram 3: Requestor and adaptor may act together as an intermediary
A requestor and adaptor may act together as an element in the delivery
path providing a specific part of the adaptation. The requestor may modify
the request, including providing new context information, in such a way that
the response can be adapted appropriately. For example, a transcoding proxy
may offer to accept a media type not included in the original request. When
the response is received by the proxy, that media type is adapted to one that
is acceptable to the originator of the request.
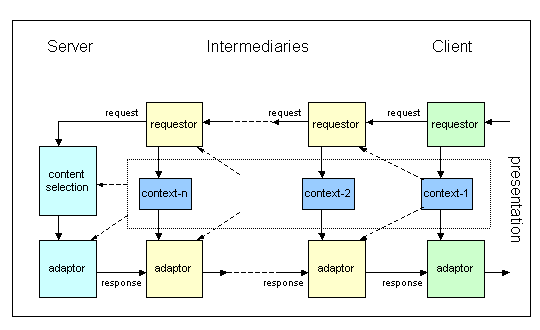
Diagram 4: Client originates the request and server originates the
response
In the most general situation, a sequence of requestors may provide
additional delivery context information at different points in the request
path from client to server. Similarly, a sequence of adaptors may modify the
response in the response path between the server and the client. The response
may be modified based on any delivery context information available at that
point in the response path.
In some situations, delivery context information may only be available to
a restricted set of adaptors. A requestor may block context information from
being passed further along the request path, or may only make it available to
an associated adaptor. For example, a phone may pass information about its
location only as far as a mobile gateway, which does not make it available to
the origin server.
2 Motivation
In this section, motivation for more effective use of delivery context
information is provided from the perspectives of users, authors and
implementers.
2.1 User perspective
From the perspective of the user, the technology for conveying delivery
context is largely invisible. For example, a user is not usually aware of the
attribute values inserted into an HTTP request header. But the user may need
a mechanism to set preferred attribute values when necessary.
Some aspects of the delivery context, such as the underlying capabilities
of the access mechanism, can be set automatically by software through
internal configuration parameters. An example of such an attribute might be
the screen size of a visual rendering device.
Other aspects of the delivery context, such as user preferences, will
usually require user configuration. User preferences related to presentation
choices, may be managed by the user agent responsible for rendering some Web
content. For example, a user may set their preferred language for delivered
text within their browser options. User preferences related to application
choices could also be transmitted as part of the delivery context, but are
outside the scope of this document.
Since the kind of content that may be delivered may depend on the
attributes that are conveyed in the delivery context, it is important that
the user is provided, through appropriate software and interaction, with
sufficient flexibility to control those attributes. This is particularly
important where the needs of the user may differ from those provided in
standard configurations.
Currently it is not clear how privacy of delivery context information is
best addressed. The user may not wish certain pieces of information contained
in the delivery context to be made available to untrusted components along
the delivery path. For example, the user may wish information about their
location to be made available to a trusted application, but not to any
intermediate node through which the delivery context information may pass.
This and other attributes in the delivery context, individually or
collectively, may indirectly constitute personally identifiable information,
and so are subject to the security and privacy concerns considered in more
detail later.
2.2 Application developer perspective
From the perspective of the application developer or content author, it is
important to be able to access delivery context information in order to
deliver the most appropriate kind of content.
In some situations, the application developer may rely on some underlying
adaptation process to select and format the appropriate content version. For
example, commercial image servers are available that can scale and convert
the format of images to suit the rendering capabilities of different
devices.
In other situations, the content author may indicate within their content
that different selections should be made according to the client
capabilities. For example, markup to express this was proposed as part of
XHTML under the name of Document Profiles [XHTMLprof], and has been included in CSS
under the name of Media Queries [MQ].
In yet other situations, the application developer may explicitly create
transformations which can adapt their content for different devices. For
example, stylesheets written in XSLT may be applied to content expressed in
XML to produce different deliverable presentation markup.
In order to make effective use of the delivery context information, the
application developer needs the attributes conveyed by the information to be
both well-defined and common across as many devices as possible. This raises
issues of the definition and re-use of vocabulary elements, as discussed later.
2.3 Implementer perspective
Delivery context support may need to be implemented in system components
such as user agents, web servers and proxy servers. From the point of view of
a delivery context system implementer, several components need to be defined
to ensure interoperable implementations:
- a data format for exchanging delivery context information
- a protocol for conveying the delivery context information
- a processing model for handling the delivery context information
Specific implementations might further define ways in which delivery
context information might be accessed via application program interfaces or
cached in data repositories.
Delivery context information may capture diverse aspects of an access
mechanism, may be augmented or processed by different kinds of
intermediaries, and may be used by different application components in an
origin server or intermediary. This means delivery context has to be
supported by many software components along the delivery path. It will not
necessarily be the case that a single software component creates the whole
delivery context, and another single component accepts it and adapts content
accordingly.
From the perspective of the implementer, software components must be able
to create a delivery context, augment an existing delivery context with their
own attributes, replace parts of a delivery context to reflect the possible
adaptation capabilities of the component, and decompose a delivery context to
extract the attributes which will control their processing.
To date, the user agent, usually based on the client, has been the
software component that has been responsible for constructing a request for
some Web content, and has therefore also assumed responsibility for creating
any client-related delivery context. However, with access mechanisms that may
increasingly include several hardware or software components, a more flexible
way of building the delivery context will be required.
For example, a mobile device may be temporarily within range of a local
LAN which provides fast Internet access as well as connection to a nearby
printer and a large screen. By interacting with their mobile device, the user
may wish to deliver some Web content on the printer or the screen. The
delivery context may include attributes, or references to attributes,
contributed by several components. Hardware attributes may be provided by the
printer, the screen and the mobile device. Software attributes may be
provided by the mobile device's operating system, user agent, and local media
handling capabilities. Network attributes may be provided relating to the LAN
connection. User preferences may be provided relating to the presentation of
the content to be accessed.
As the range of attributes made available through the delivery context
grows, so the implementer of the content adaptation process requires better
mechanisms to extract the relevant attributes from the delivery context.
For example, if multiple overlapping attributes exist within the delivery
context, such as the pixel dimensions of the presentation spaces of each of
the mobile device, the printer and the screen in the previous example,
resolution rules or other mechanisms are required to determine which
attributes should be used.
3 Existing approaches
Various approaches to defining delivery context, or at least some aspects
of it, already exist. Indeed, the need to negotiate which version of a
document should be delivered to a user was recognized in the early days of
the Web [HTTPneg].
In this section, the main approaches that are already in use on the Web
are reviewed.
The Hypertext Transport Protocol HTTP [HTTP] is the basis for most current Web-based
information delivery. It defines a number of standard accept headers that can
be used to match the capabilities of a requesting device (or, in particular,
its user agent) to the information that is delivered from an origin server.
Standard HTTP 1.1 accept headers include:
- Accept: media types (MIME types)
- Accept-Charset: charsets
- Accept-Encoding: content coding (compression)
- Accept-Language: languages
In addition to the accept headers, the User-Agent header usually contains
a string giving information about the user agent. Typically this includes the
name of the manufacturer, the version number and a name. For mobile devices,
it often includes information about the device hardware and the browser being
used. There are no standards about how user agent information is constructed.
Nevertheless, sophisticated algorithms may use it to try to identify the
device and browser software being used. A number of existing systems use this
identification to access a repository of information about the capabilities
of the device and browser. Adaptation of content for presentation can then be
made based on knowledge of these capabilities.
While HTTP headers are currently the most widely used delivery context
information, they are difficult to extend, and have (particularly in the case
of the User-Agent header) free-form values that are difficult to
interpret.
3.2 HTTP negotiation
It is possible for a server to select content based simply on the HTTP
header information. In HTTP 1.1 [HTTP] this is called server-driven
negotiation.
In this case, the server determines which alternate to send to a user
agent as a result of examining the user agent's request header fields.
Currently HTTP 1.1 uses the following request-header fields for server-driven
negotiation:
- Accept - the MIME types accepted by the user agent.
- Accept-Charset - the character set preferred by the user.
- Accept-Encoding - the preferred encoding for the user agent.
- Accept-Language - the language preferred by the user.
Each of these fields is referred to as a dimension of negotiation. In
order to express user or browser preferences, the request-header fields may
include an associated quality value for each dimension of negotiation.
For example the following header indicates that French resources are
preferred to English resources. Accept-Language: fr; q=1.0, en;
q=0.5
There are some disadvantages associated with server-driven negotiation.
Firstly the information sent in the request header does not give a complete
description of the capabilities of the client. For example there is no way to
distinguish between images intended for handheld computers from desktop
computers if they both use the same MIME type. Secondly it is inefficient for
a user agent to describe its full capabilities to a server for every request
it makes. Finally server-driven negotiation causes problems for caches shared
by multiple devices.
It is also possible within HTTP 1.1 to support agent-driven
negotiation, in which the user agent is responsible for selecting the
most appropriate content. The server initially responds with a list of
available representations, which then allows the user agent to make another
request for the preferred representation. However, this has the disadvantage
of introducing additional delay through multiple request-response round
trips.
3.3 CC/PP
The W3C CC/PP Working Group
has specified a structure for profiles, called CC/PP (Composite Capabilities/
Preferences Profile), which is based on the XML serialized Resource
Description Framework (RDF). This profile structure is vocabulary independent
and allows the use of one or more vocabularies which may be optionally
described using RDF Schema. As CC/PP is vocabulary neutral, it allows
different vocabularies to be developed and implemented by application
developer, device manufacturer and browser developer communities.
CC/PP allows for the dynamic composition of a delivery context profile
from fragments of capability information that may be distributed among
multiple repositories on the web. Support for capabilities asserted by
intermediate proxies and gateways is also enabled.
The draft CC/PP recommendation [CCPP-struct-vocab] suggests a possible
vocabulary, but does not define a protocol for exchanging profiles, and does
not specify how the profile should be used within any mechanism for content
adaptation.
There are two associated CC/PP Implementors Guides. The Guide on Privacy
and Protocols [CCPP-trust]
discusses protocol issues as well as the way in which the privacy of profiles
could be protected, including the use of mechanisms such as those defined by
P3P [P3P]. The Guide on
Harmonizing with Existing Vocabularies and Content Transformation Heuristics
[CCPP-coordination]
discusses how different vocabularies could fit within the CC/PP framework and
suggests some approaches to content adaptation.
CC/PP is the preferred approach to communicating delivery context
information between clients, intermediaries and origin servers. Work on its
definition and implementation is continuing both in W3C and in the Java
Community Process [JSR188].
3.4 UAProf
The Open Mobile Alliance (formerly the WAP Forum) has defined a User Agent
Profile [UAProf] as an
implementation of CC/PP for WAP-enabled mobile terminals, providing
convergence of mobile web technologies with that of the classic web.
WAP 1.2.1 recommends transporting UAProf information over the Internet
using the HTTP Extension Framework [HTTPex] which was originally suggested for CC/PP
[CCPP-exchange]. WAP
defined the WSP protocol, which includes a compressed encoding, for use
between the phone and the gateway onto the Internet. Due to the lack of
implementations of HTTPex, WAP 2.0 instead defines an extension of HTTP 1.1
as an Internet protocol (W-HTTP) that uses custom headers.
The WAP Forum has also defined a profile vocabulary that includes
assertions regarding the hardware and software characteristics and WAP
specific features of the mobile terminal and associated transport network
capabilities.
Vendors of WAP proxies and browsers are beginning to offer commercial
implementations of UAProf and the 3GPP
Mobile Execution Environment (MExE) group has adopted the UAProf - CC/PP
framework for MExE terminals.
Within W3C standards such as CSS and HTML, style markup can be made
conditional on delivery context by using Media Queries [MQ]. These introduce another vocabulary for accessing
device attributes.
Media Queries build upon the use of 'media types' as defined in CSS2 [CSS2], which allow styles to be
conditional on a number of named categories of device: aural, braille,
embossed, handheld, print, projection, screen, tty and tv. In Media Queries,
device attributes ('media features') may be queried and combined using a
restricted expression syntax. The style used to present an element of HTML,
XHTML or XML can therefore be made conditional on the attributes of the
delivery device. By making use of the CSS 'display' property, it is also
possible to conditionally include or exclude complete elements from the
presentation.
In the future, it should therefore be possible to add device-dependent
styling to common device-independent content, at least as far as the CSS
media types and media features will allow.
Like CSS, Media Queries are typically expected to be processed directly in
user agents, based on local delivery context information. However, they could
also be fully or partially processed at servers or intermediaries in the
response path, based on delivery context information passed as part of a
request for content. This highlights the need for the vocabulary used for the
device capabilities passed in the delivery context to correspond to the
vocabulary used within Media Queries.
3.6 SMIL
A further W3C standard, the Synchronized Multimedia Integration Language
(SMIL) introduces yet another vocabulary for accessing a limited number of
device attributes.
SMIL 2.0 [SMIL] is defined as
a set of markup modules that can be integrated into specific language
profiles. In particular, it defines a BasicContentControl Module that defines
certain system attributes that may be used to control a SMIL presentation.
These attributes may be given dynamic values according to the runtime
environment. Like Media Queries, they therefore allow a user agent that
supports dynamic SMIL attributes to access local delivery context
information.
System test attributes included as part of the SMIL BasicContentControl
Module cover presentation-related capabilities such as screen size, network
bandwidth, and text and audio captions, as well as system-related attributes
such as CPU and operating system identity.
4 Other proposed approaches
The following approaches have been proposed, but have not been widely
implemented to date.
4.1 TCN
Transparent Content Negotiation [TCN], was first proposed as an experimental protocol
in RFC 2295.
Transparent negotiation uses both HTTP server-driven and agent-driven
negotiation mechanisms (as described above),
together with a caching proxy that supports content negotiation. The proxy
requests a list of all available representations from the origin server using
agent-driven negotiation, then selects the most appropriate and send it to
the client using server-driven negotiation. However, this technique has not
been widely implemented.
4.2 Conneg
The IETF Content Negotiation working group [Conneg] focused on defining the features which
could form the basis for negotiation. In particular, in RFC 2506, a procedure was
defined for registering Media Feature Tags in a central Internet Assigned
Numbers Authority (IANA) registry.
A further result of the Conneg work was a proposal for combining Media
Features Tags into Media Feature Sets [MFS]. In RFC 2533, a syntax for
expressing Boolean combinations of features is proposed and an algorithm for
feature set matching (see also [FSM]) is also described.
4.4 Document Profiles
A set of XHTML Document Profile Requirements were proposed in 1999 [XHTML-docprofile]. These
could be seen as complementary to device attributes, in that they could
define attributes that would be required of the device in order to
successfully deliver a document.
4.5 OPES
A proposed new architecture for Open Pluggable Edge Services (OPES) is
being developed within IETF [OPES]. This provides the means for a server to
delegate the content adaptation to an intermediary in such a way that it does
not break the end-to-end model of the internet. Furthermore, the intermediary
may make use of remote services to carry out the adaptation. The OPES
architecture requires extensions to the HTTP protocol that allow the server
to authorize and specify such transformations. OPES does not set out new
proposals for representing delivery context, but is concerned with ways in
which the context may relate to, or be used to control, adaptation
services.
4.6 MPEG-21
ISO/IEC is defining the MPEG-21 [MPEG-21] framework which is intended to support
transparent use of multimedia resources across a wide range of networks and
devices. The fundamental unit of distribution is the 'digital item', which is
an abstraction for some multimedia content with associated data.
One aspect of MPEG-21 is Digital Item Adaptation [MPEG-21-DIA] which is based on descriptions of
the environment (including delivery context) and adaptability of the content.
It includes the definition of vocabularies for content preferences,
presentation preferences, terminal capabilities and network
characteristics.
5 Further developments
While existing techniques provide basic support for delivery context
information, there are a number of issues that remain to be addressed. This
section summarizes some that have been raised to date.
5.1 From Device Independence Principles
Two specific principles relating to delivery context were proposed in the
Device Independence Principles [DIP].
DIP-6:
The user agent should be able to associate the characteristics of the
delivery context with a request of a particular Web page identifier.
DIP-7:
It should be possible for a user to provide or update any presentation
preferences as part of the delivery context.
In addition, in Section
3.2, an area of further work was identified.
For device independence to become widely supported, it will be necessary
to indicate how the transition can be made from existing widely supported
techniques of representing the delivery context towards future, more
complete, proposals such as CC/PP.
At a more implementation-specific level, this document has shown the
delivery context being associated with a request for a Web page. There are
several possibilities here. It is not necessary that the whole context is
sent with each request. It could be that only a reference to the context is
sent. Or that the context is managed on a session basis, or based on profiles
stored elsewhere.
CC/PP provides a possible representation for conveying delivery context
information. However, the way in which the delivery context should be
generated by the access mechanism (user agent) and the interpretation of the
delivery context by the server (and possibly also by intermediate proxies)
will need further recommendations to be developed. Ways of conveying the
delivery context in device independent ways using existing techniques, prior
to CC/PP becoming widely adopted, should also be considered.
5.2 From Delivery Context Workshop
The W3C Delivery Context Workshop held in March 2002 [DCW] gave an opportunity for presentation and
discussion about technologies associated with device independent delivery,
and delivery context in particular. The workshop identified a number of areas
relating to delivery context where further work was necessary.
For example, among some of the topics discussed were:
- device capability classes
- versioning and merging of profiles
- delivery context for multiple devices
- document profile relationship to delivery context
- standard vocabulary definition
For further details see the position papers, presentations and
workshop notes.
6 Collected issues
While it is not the purpose of this document to identify specific
requirements, it is useful to collect together open issues.
6.1 General issues
Capability information could be distributed in multiple locations on the
web. It may not be consolidated and made available all in one place. For
example, a hardware manufacturer and a software provider may make the static
capabilities of their respective parts of an access mechanism available on
their own websites, whereas network capabilities may depend on the routing of
a particular request. So it should be possible to retrieve distributed
capability information and compose or derive the delivery context at any
appropriate point in the delivery path. To do this flexibly, a delivery
context should be able to use combinations of attributes from multiple
vocabularies, or multiple versions of a single vocabulary, that relate to
different aspects of an access mechanism. For example, CC/PP uses XML
namespaces to distinguish attributes from different vocabularies.
Since a delivery context may be built from attributes provided by
different components along the delivery path, it should be possible to
accumulate delivery context information provided by different components. The
means of accumulation could simply consist of appending the information from
different sources in separate profiles, or of combining them into a single
profile. It should not be assumed that any particular component along the
path is capable of resolving the information further.
It should be possible to identify the source of delivery context
information provided by different components along the delivery path, and to
extract the information from the delivery context provided by each source. By
identifying the source of some delivery context information, it may be
possible to do a better job of adapting the content. For example, a request
for printed output made via a phone may include device capabilities for the
printer (so that the output can be formatted for it) as well as for the phone
(so that any print control or error messages can be displayed on it). It is
important that these can be distinguished and separately extracted. In
addition, it may be important for assessing the reliability of the delivery
context information, or the trust to be placed in it, for its source to be
identified.
6.2 Vocabulary issues
Delivery context information is expressed in terms of values of attributes
which may be drawn from, and are defined in, one or more vocabularies.
In the overview of existing and proposed approaches, it is clear that many
groups have started to define vocabularies that could be used to express
aspects of delivery context. For device capabilities alone, there are already
Media Features defined in the IANA registry as part of the Conneg work,
different versions of the UAProf vocabulary defined by the Open Mobile
Alliance, Media Queries as part of CSS style, and an example CC/PP
vocabulary.
Vocabularies for device capabilities need to be standardized so that
authoring and adaptation processes can use them to select or generate
suitable presentations.
It is inevitable that vocabularies for device capabilities will evolve
through a number of different versions. It is also likely that they will need
to incorporate attributes that have been defined in other approaches for
other purposes.
There is a danger that vocabularies and their versions may proliferate so
that the task of interpreting them and making appropriate adaptations to
delivered content becomes unmanageable.
For a discussion on the use of different vocabularies within the CC/PP
framework, see the CC/PP Implementors Guide [CCPP-coordination].
It seems clear there is a need for a well-defined, machine-readable, way
of declaring a vocabulary for use in a delivery context.
It should be possible to declare a set of attributes as a vocabulary
module that can be included in multiple other vocabularies. By sharing sets
of attributes between vocabularies, it should be possible to minimize the
number of different attributes that might be introduced for similar
capabilities. It is preferable to re-use attributes whenever possible during
vocabulary definition rather than have to separately identify equivalences
between attributes from different vocabularies at a later date.
Further work on Core Device Attributes is included in the charter of the
Device Independence Working Group [DI-charter].
6.3 Protocol issues
In order to implement the interoperable exchange of delivery context
information, it is necessary to specify how the information is conveyed as
part of a request protocol. Apart from the use of HTTP headers to express
some limited aspects of delivery context as described earlier, no consensus
has been reached on how more general delivery context information can be
conveyed.
For a discussion on the use of different protocols within the CC/PP
framework, see the CC/PP Implementors Guide on Privacy and Protocols [CCPP-trust].
A proposal was made for a protocol for CC/PP based on the HTTP Extension
Framework [CCPP-exchange], but in practice this
framework has not been widely implemented.
UAProf [UAProf] has defined
a protocol based on additional ad hoc HTTP header fields.
However, there is still a need to standardize an extensible way of
conveying delivery context, beyond the existing header fields, as part of an
HTTP 1.1 request.
Protocol design is non-trivial. Care must be taken, especially if it is to
affect many web requests, not to introduce inefficiencies. For example, to
minimize additional use of network bandwidth, a protocol should encourage
optimizations such as indirect reference to static parts of the context
information or caching of unchanging attributes. A protocol should also allow
intermediaries, if necessary, to access and augment the contextual
information with minimal overhead.
Session-based management of context could be considered, complementing the
widely implemented HTTP state management using cookies, as described in RFC 2965. If delivery context
information were associated with a session, it might not be necessary to
convey the full context with each request. Instead, it might be possible to
simply notify changes from the previous context data.
Further work on CC/PP Protocol is included in the charter of the Device
Independence Working Group [DI-charter]. This will focus on a protocol for
use with conventional stateless HTTP requests. Work on session-based
protocols is out of the current scope.
6.4 Processing issues
It is not sufficient simply to define how delivery context information can
be conveyed as part of a communication protocol. For the end-to-end semantics
of the delivery process to be well defined and predictable, it is also
necessary to consider how the context information is resolved and made
available to the adaptation or negotiation mechanisms.
Resolution rules can be used to describe how attributes may default or
override. However, if different rules are created for different attributes,
the complexity of the resolution process can quickly grow.
Delivery context attributes must also fit into authoring and adaptation
environments, and allow individual attributes to be accessed from server
pages and applications on origin servers as well as by intermediary
adaptors.
A current Java Community Process proposal [JSR188] will define a set of Java APIs for
accessing CC/PP attributes as well as provide a reference server-side
implementation.
6.5 Negotiation issues
If document profiles, or some similar mechanism, are used to describe the
capabilities required of the delivery device, there needs to be a way of
matching these to the delivery context information so that appropriate
content can be delivered.
With the modularization of markup languages such as XHTML, SVG, CSS and
SMIL, a mechanism is also required for representing and negotiating which
modules are supported by a user agent and which modules are required to
successfully deliver a document. For example, the 3GPP specification for
Packet Switched Streaming service [3GPP-PSS], which is based on SMIL, defines its
own vocabulary for capability exchange based on UAProf and includes a means
of enumerating supported SMIL modules.
Currently several standards perform capability negotiation between
devices: for example SyncML for data
synchronization or the Wireless
Village Initiative for instant messaging. These standards describe device
capabilities using profiles consisting of two types of elements: descriptive
elements and structural elements. Descriptive elements describe the
properties of the device, such as the width of the device screen in pixels.
Structural elements on the other hand may perform two roles: they either
group related elements together, or they allow disambiguation which makes it
possible to distinguish between multiple descriptive elements that refer to
the same property in a profile or a set of profiles. For example structural
elements are used to disambiguate in SyncML, where the meaning of a CTType
element is different depending on whether it is within a Tx-Pref element or a
Rx-Pref element. In the former case it refers to the MIME types that the
device datastore can send whereas in the latter case it refers to the MIME
types a device datastore can receive.
When a device involved in capability negotiation receives a profile, it
typically interprets the descriptive elements in one of three ways. If a
descriptive element has a single value, it is regarded as a constraint that
must be met by the other device. If it contains multiple values, then it is
either regarded as a choice available to the other device, or it is necessary
to perform resolution. This is done by examining the structural context of
the multiple values within the profile to see whether to select one value to
use as a constraint, or to select a subset of values to regard as a
choice.
In capability negotiation, either the resolution mechanisms may be
specific to each application, or application independent resolution
mechanisms may be used for all applications that depend on the same profile.
For example the UAProf standard specifies application independent resolution
mechanisms. CC/PP does not propose a complete set of resolution mechanisms,
so makes the assumption that application dependent resolution mechanisms will
be used.
It is also possible to make a distinction between serial or parallel
disambiguation. Serial disambiguation may be required when a number of
elements are connected in a serial chain. For example, the chain might
contain a client, and intermediary acting as a proxy and an origin server.
Here the client device and the proxy may provide different versions of the
same properties, so it is necessary to disambiguate. Similarly, there may be
a need to deal with aggregated devices, such as connecting a phone and PDA in
order to provide voice and text browsing. Here one of the devices may merge
the profiles from the phone and the PDA in order to allow the server to
provide a multimodal interface. In this case it is necessary to perform
parallel disambiguation to determine which of the client devices, and
possibly which modality or other grouping on that device, provides a
particular property.
6.6 Trust issues
Since delivery context could be used to convey user-specific information,
it is important to consider how much trust the user can place in how that
information is handled. Ultimately this could extend to providing security
measures for ensuring the privacy of sensitive information.
For a discussion on privacy issues within the CC/PP framework, see the
CC/PP Implementors Guide on Privacy and Protocols [CCPP-trust]. This includes examples of how P3P
could be used with CC/PP. It also includes an Appendix on "Basic
requirements for trust management frameworks".
Issues that relate to trust include:
- Identification, and possibly authentication, of the source of delivery
context information
- Restriction of delivery context information, under user control, only
to non-sensitive attributes
- Release of delivery context information only to trusted applications or
intermediaries
- Encryption and decryption of subsets of delivery context
information
Many of these issues are beyond the scope of device independence. If
limited information about device and network capabilities can be freely
shared, the user can benefit from receiving content better suited to the
delivery device. This is the case currently, for example, in the use of HTTP
header information. However, if such capability information is withheld, the
user should still be provided with a functional presentation.
However, it is necessary to consider the potential misuse of any
attributes that are provided in good faith in order to achieve a better
presentation, and to balance this against the benefits. Ultimately, the user
should be given control over whether presentation-related attributes are made
available by a user agent as part of the delivery context. In addition, it
may be necessary to include in the delivery context itself, or in the
definition of its processing, rules that indicate what may or may not be
changed or acted on by intermediaries.
7 Conclusion
Delivery context information is an important foundation for providing
better adaptation of content across different access mechanisms. This
document has provided an overview of progress in representing and using
delivery context for this purpose, and has set out the issues currently seen
as important.
The W3C is proposing CC/PP as a candidate standard for representing
delivery context information.
The W3C Device Independence Working Group is currently chartered to
continue work on two key further topics in this area, a protocol
for CC/PP and a core
vocabulary for device presentation capabilities.
References
- [3GPP-PSS]
- Transparent
end-to-end packet switched streaming service (PSS) Protocols and codecs
(Release 5), 3rd Generation Partnership Project TS 26.234 V5.1.0
June 2002
- [CCPP-coordination]
- CC/PP
Implementors Guide: Harmonization with Existing Vocabularies and
Content Transformation Heuristics, W3C Note 20 December 2001
For latest version see:
http://www.w3.org/TR/CCPP-COORDINATION/
- [CCPP-exchange]
- CC/PP
exchange protocol based on HTTP Extension Framework, W3C Note 24
June 1999
For latest version see:
http://www.w3.org/TR/NOTE-CCPPexchange
- [CCPP-ra]
- Composite
Capability/Preference Profiles: Requirements and Architecture, W3C
Working Draft 21 July 2000
For latest version see: http://www.w3.org/TR/CCPP-ra/
- [CCPP-struct-vocab]
- Composite
Capability/Preference Profiles (CC/PP): Structure and Vocabularies,
W3C Working Draft 15 March 2001
For latest version see:
http://www.w3.org/TR/CCPP-struct-vocab/
- [CCPP-trust]
- CC/PP
Implementors Guide: Privacy and Protocols, W3C Working Draft 20
December 2001
For latest version see: http://www.w3.org/TR/CCPP-trust
- [Conneg]
- IETF
Content Negotiation Working Group, concluded October 2000
http://www.ietf.org/html.charters/OLD/conneg-charter.html
- [CSS2]
- Cascading
Style Sheets, level 2 CSS2 Specification, W3C Recommendation 12 May
1998
For latest version see: http://www.w3.org/TR/REC-CSS2
- [DCW]
- W3C Delivery Context
Workshop, INRIA Sophia-Antipolis, France, 4-5 March 2002
http://www.w3.org/2002/02/DIWS/
- [DI-charter]
- W3C
Device Independence Working Group Charter
http://www.w3.org/2002/06/w3c-di-wg-charter-20020612.html
- [DIP]
- Device
Independence Principles, W3C Working Draft 18 September 2001
For latest version see: http://www.w3.org/TR/di-princ/
- [FSM]
- Feature Set
Matching, sample software by Graham Klyne
http://www.ninebynine.org/Software/Conneg-FSM/
- [HTTP]
- Hypertext
Transfer Protocol -- HTTP/1.1, IETF RFC-2616 June 1999
http://www.w3.org/Protocols/rfc2616/rfc2616.html
- [HTTPex]
- An HTTP Extension
Framework, IETF RFC-2774 February 2000
http://www.ietf.org/rfc/rfc2774.txt
- [HTTPneg]
- HTTP
Negotiation algorithm, Tim Berners-Lee 1992
http://www.w3.org/Protocols/HTTP/Negotiation.html
- [JSR188]
- JSR 188: CC/PP
Processing, Java Specification Request
http://jcp.org/jsr/detail/188.jsp
- [MFS]
- A Syntax for Describing
Media Feature Sets, IETF RFC-2533 March 1999
http://www.ietf.org/rfc/rfc2533.txt
- [MMreq]
- Multimodal
Requirements for Voice Markup Languages, W3C Working Draft 10 July
2000
For latest version see: http://www.w3.org/TR/multimodal-reqs
- [MPEG-21]
- MPEG-21
Overview (v.5), ISO/IEC JTC1/SC29/WG11/N5231 October 2002
- [MPEG-21-DIA]
- MPEG-21
Digital Item Adaptation WD (v3.0), ISO/IEC JTC1/SC29/WG11/N5178
October 2002
- [MQ]
- Media
Queries, W3C Candidate Recommendation 8 July 2002
For latest version see:
http://www.w3.org/TR/css3-mediaqueries/
- [OPES]
- IETF Open Pluggable Edge Services
(OPES) working group
http://www.ietf-opes.org
- [P3P]
- Platform for Privacy Preferences
Project, W3C Initiative
http://www.w3.org/P3P/
- [SMIL]
- Synchronized
Multimedia Integration Language (SMIL 2.0), W3C Recommendation 7
August 2001
For latest version see: http://www.w3.org/TR/smil20
- [TCN]
- Transparent Content
Negotiation in HTTP, IETF RFC-2295 March 1998
http://www.ietf.org/rfc/rfc2295.txt
- [UAProf]
- User
Agent Profiling Specification, WAP Forum 20 October 2001
For latest version see:
http://www.wapforum.org/what/technical.htm
- [WAP2]
- Wireless
Application Protocol 2.0 specifications, WAP Forum 31 July 2001
For latest version see:
http://www.wapforum.org/what/technical.htm
- [XHTML-docprofile]
- XHTML
Document Profile Requirements, W3C Working Draft 6 September
1999
For latest version see: http://www.w3.org/TR/xhtml-prof-req
- [XSLT]
- XSL
Transformations (XSLT) Version 1.1, W3C Working Draft 24 August
2001
For latest version see: http://www.w3.org/TR/xslt11/
Appendices
A Glossary
The following definitions are taken from the HTTP/1.1 specification (RFC
2616) [HTTP] and from Device
Independence Principles [DIP].
- access mechanism
- A combination of hardware (including one or more devices and network
connections) and software (including one or more user agents) that
allows a user to perceive and interact with the Web using one or more
interaction modalities (sight, sound, keyboard, voice etc.). [DIP]
- client
- A program that establishes connections for the purpose of sending
requests. [HTTP]
- content negotiation
- The mechanism for selecting the appropriate representation when
servicing a request. The representation of entities in any response can
be negotiated (including error responses). [HTTP]
- device
- An apparatus through which a user can perceive and interact with the
Web. [DIP]
- delivery context
- A set of attributes that characterizes the capabilities of the access
mechanism and the preferences of the user. [DIP]
- entity
- The information transferred as the payload of a request or response.
An entity consists of metainformation in the form of entity-header
fields and content in the form of an entity-body. [HTTP]
- gateway
- A server which acts as an intermediary for some other server. Unlike
a proxy, a gateway receives requests as if it were the origin server
for the requested resource; the requesting client may not be aware that
it is communicating with a gateway. [HTTP]
- origin server
- The server on which a given resource resides or is to be created.
[HTTP]
- proxy
- An intermediary program which acts as both a server and a client for
the purpose of making requests on behalf of other clients. Requests are
serviced internally or by passing them on, with possible translation,
to other servers. A proxy must implement both the client and server
requirements of this specification. A "transparent proxy" is a proxy
that does not modify the request or response beyond what is required
for proxy authentication and identification. A "non-transparent proxy"
is a proxy that modifies the request or response in order to provide
some added service to the user agent, such as group annotation
services, media type transformation, protocol reduction, or anonymity
filtering. Except where either transparent or non-transparent behavior
is explicitly stated, the HTTP proxy requirements apply to both types
of proxies. [HTTP]
- representation
- An entity included with a response that is subject to content
negotiation. There may exist multiple representations associated with a
particular response status. [HTTP]
- request
- An HTTP request message [HTTP]
- response
- An HTTP response message [HTTP]
- resource
- A network data object or service that can be identified by a URI.
Resources may be available in multiple representations (e.g. multiple
languages, data formats, size, resolutions) or vary in other ways.
[HTTP]
- server
- An application program that accepts connections in order to service
requests by sending back responses. Any given program may be capable of
being both a client and a server; our use of these terms refers only to
the role being performed by the program for a particular connection,
rather than to the program's capabilities in general. Likewise, any
server may act as an origin server, proxy, gateway, or tunnel,
switching behavior based on the nature of each request. [HTTP]
- variant
- A resource may have one, or more than one, representation(s)
associated with it at any given instant. Each of these representations
is termed a `variant.' Use of the term `variant' does not necessarily
imply that the resource is subject to content negotiation. [HTTP]
- user agent
- The client which initiates a request. These are often browsers,
editors, spiders (web-traversing robots), or other end user tools.
[HTTP]
A process within a device that renders the presentation data for a web
page into physical effects that can be perceived and interacted with by
the user. [DIP]
B Acknowledgements
This document was produced by members of the Device Independence Working
Group, whose membership at the time of publication is shown below.
- Abbie Barbir, Nortel Networks
- Stephane Boyera, W3C Staff Contact
- Dennis Bushmitch, Panasonic
- Mark Butler, HP
- Wendy Chisholm, W3C WAI
- Steve Farowich, Boeing
- Shlomit Ritz Finkelstein
- Roger Gimson, HP (Chair)
- Yoshihisa Gonno, Sony
- Guido Grassel, Nokia
- Rotan Hanrahan, MobileAware
- Philipp Hoschka, W3C Domain Lead
- Eamonn Howe, MobileAware
- Kazuhiro Kitagawa, W3C Activity Lead
- Markus Lauff, SAP AG
- Rhys Lewis, Volantis Systems
- Roland Merrick, IBM
- Masashi Morioka, NTT DoCoMo
- Kaori Nakai, NTT DoCoMo
- Axel Spriestersbach, SAP AG
- Lalitha Suryanarayana, SBC Technology
- Ryuji Tamagawa, Sky Think System
- Luu Tran, Sun Microsystems
- Michael Wasmund, IBM
- Mark Watson, Volantis Systems
- Jason White, University of Melbourne
- Greg Ziebold, Sun Microsystems