Deutsch English Español Français Italiano Nederlands Pусский Українська
A tecla de acesso 'n' salta para outro local na navegação da página. Saltar para o início do conteúdo.
Este documento é uma tradução. Se ocorrerem discrepâncias ou erros, o original em inglês mais recente terá precedência. Os direitos autorais originais pertencem à W3C, como indicado abaixo.
Tradutor: Portuguese Translation Team, Trusted Translations, Inc.
http://www.w3.org/International/tutorials/svg-tiny-bidi/
Público alvo: Autories de conteúdo SVG que estejam implementando SVG Tiny pages em scripts da direita para a esquerda como árabe ou hebraico, ou que tenham que lidar com texto incorporado de script da direita para a esquerda incorporado. Este material se aplica tanto se você criar documentos em um editor, ou através de scripts.
Os scripts da direita para a esquerda incluem árabe, hebraico, thaana e n'ko, e são usados por um grande número de pessoas em todo o mundo. Caso você não tenha experiência em lidar com texto bidirecioinal, fazer com que ele seja exibido corretamente parece às vezes complexo e confuso, mas não precisa ser assim. Se você já teve dificultades com isto ou ainda poderá tê-las, este tutorial deve ajudar a adotar a melhor abordagem para fazer as marcações de seu conteúdo. Ele explicará o suficiente sobre como funciona o algorítmo bidirecional funciona para que você entenda melhor as causas fundamentais da maioria dos problemas. Nós abordaremos alguns equívocos comuns sobre formas de lidar com marcações para conteúdo bidirecional.
Acompanhando este tutorial você deverá ser capaz de:
Repare que a especificação SVG Tiny 1.2 foi publicada como uma Recomendação em 22 de dezembro de 2008. Poderá levar algum tempo até que a funcionalidade descrita neste tutorial esteja amplamente implementada.
Esta seção cobre:
Acrescente direction="rtl" à tag do svg para configurar a direção básica para o documento a qualquer momento em que a direção do documento geral seja da direita para a esquerda. A direção básica estabelece o contexto direcional geral para o texto dentro do elemento onde ela é declarada.
Não é necessário definir explicitamente a direção básica para documentos que sejam predominantemente da esquerda para a direita, já que este é o padrão.
Tendo feito isso, pode ser que não seja necessária qualquer outra marcação de direção em seu conteúdo. O valor de propriedade direction configurado no elemento svg é herdado de elementos relacionados ao texto através de todo o documento. A maior parte da reorganização necessária para exibir o texto é feita automaticamente pelo Algorítmo Bidirecional Unicode ('algorítmo bidi'). Isso pode ser ilustrado pelo exemplo abaixo.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="fa">
<title>...</title>
<desc>...</desc>
<text x="200" y="200"
font-size="10">داستان SVG Tiny 1.2 طولا ني است.</text>
</svg>
Isso exibirá o texto na ordem (correta) a seguir, caso a implementação suporte o manuseio de texto bidirecional:
![]()
Sem a propriedade direction, o texto se pareceria com o seguinte:
![]()
É claro que há situações nas quais pode ser necessário aplicar mais marcações, e as descreveremos abaixo. Além disso, a adição de direction="rtl" ao elementosvg trará alguns efeitos automáticos nas propriedades de text-align e text-anchor que também serão descritas brevemente.
Ao declarar a direção do documento na tag svg, não se esqueça de declarar o idioma do documento usando o atributo xml:lang (veja Tags de idiomas em HTML e XML).
Contudo, não cometa o erro de assumir que as declarações do idioma indicam a direção, ou vice-versa!
Mesmo que se use um sub-tag de script no valor do atributo idioma, isso não tem implicação com relação à direção do texto no agente do usuário. Você precisa sempre declarar a direção usando o atributo dir.
O ordenamento visual de texto em hebraico era comum em agentes usuários de HTML (muito) antigos que não suportavam o algorítmo bidirecional Unicode. O texto era armazenado no código fonte na mesma ordem que se esperaria vê-lo exibido. (Não era tão comum para texto de script em árabe, porque ele distorce a forma como os caracteres árabes se juntam entre si.)
Com o ordenamento lógico, o texto é armazenado na memória na ordem na qual ele seria normalmente digitado (e geralmente pronunciado). O algorítmo bidirecional Unicode é então aplicado pelo navegador para proporcionar a exibição visual correta. Hoje em dia quase todo o texto na Internet está na ordem lógica.
Você deve sempre digitar seu conteúdo da direita para a esquerda na ordem lógica, e confiar no algorítmo bidirecional e na marcação para fazê-lo ser exibido corretamente. Caso não o faça, será impossível pesquisar seu texto, reutilizar o texto, fazer a manutenção do conteúdo com facilidade, etc.
Na figura abaixo, a frase "פעילות הבינאום, W3C" (no alto em azul) aparece como normalmente apareceria quando exibida em um parágrafo da direita para a esquerda. As setas numeradas mostram a direção de leitura. As seqüências são lidas na ordem dos números.
A ordem de armazenamento visual e lógico está em contraste.

A segunda linha mostra a ordem de caracteres na memória em ordenação de codificação lógica (assumindo que o primeiro caractere na memória está à esquerda, o próximo à sua direita, e assim sucessivamente).
A terceira linha mostra a ordem de caracteres na memória em ordenação de codificação visual (com as mesmas premissas sobre a ordem na memória).
Esta seção cobre:
Havendo estabelecido a direção base no nível do elemento svg, você não deve usar a propriedade direction em outros elementos, a menos que queira mudar a direação base para aquele elemento.
O use desnecessário da propriedade direction tem impacto sobre a largura de banda e potencialmente cria trabalho adicional desnecessário para a manutenção da página.
Porém, a direção básica que é estabelecida pela propriedade direction afeta a forma como textos e a pontuação de idiomas diversos são ordenados dentro de um elemento text ou textArea (isso será descrito em detalhes um pouco adiante). De vez em quando, você pode querer alterar a direção básica para um destes elementos, se ele estiver em um idioma diferente daquele do resto da página.
Para fazê-lo, simplesmente use a propriedade direction naquele elemento, ou em um elemento de agrupamento que cerque o conteúdo relevante.
Neste exemplo, usamos um elemento de agrupamento ao redor de diversos elementos de text que precisam de uma direção básica da direita para a esquerda para parecerem corretos. Usar um elemento de agrupamento reduz a quantidade de trabalho que temos para conseguirmos o resultado desejado. O ajuste de direção é herdado pelos elementos text incorporados.
<svg xmlns="http://www.w3.org/2000/svg" width="100%" height="100%" viewBox="0 0 400 400" direction="rtl" xml:lang="fa"> <title>...</title> <desc>...</desc> <text x="200" y="20" font-size="10">כתובת לפניות באנגליה:</text> <g direction="ltr"> <text x="100" y="40" font-size="10">3, Tennyson House</text> <text x="100" y="50" font-size="10">17 Clairbourne Road,</text> <text x="100" y="60" font-size="10">Harpenden AL5 4SD</text> </g> </svg>
Sem a marcação da direção no elemento g, o texto será exhibido mais ou menos assim:
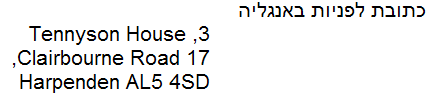
Com a propriedade direction, establecida, o texto será exibido como desejado.

Você pode ter reparado que o alinhamento de texto relacionado à coordenada x é diferente para os dois exemplos acima. Discutiremos isso a seguir.
A propriedade text-align é usada com o elemento textArea, e seus valores são start, middle e end. É importante lembrar que o primeiro e o últimos destes valores se relacionam com o texto de uma forma lógica, e não física.
start significa o lugar de onde você normalmente começaria a ler uma linha a partir da direção básica atual. Quando a direção básica é da esquerda para a direita, isso significa à esquerda do elemento textArea. Por outro lado, se a direção básica é da direita para a esquerda, isso significa à direita do elemento textArea.
Para end, apenas inverta isso.
Isso é intuitivo se você vem usando CSS com HTML, já que a propriedade direction em CSS automaticamente alinha o texto à direita em um elemento de bloco.
Neste exemplo em Urdu a direção da direita para a esquerda que é configurada no elemento svg é herdada pelo elemento textArea.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
dir="rtl" xml:lang="ur">
<title>...</title>
<desc>...</desc>
<textArea x="20" y="20" width="200">
فعالیت بینالمللیسازی، W3Cنا
عالمگیر ویب کو حقیقی طور پر عالمگیر بنانا
</textArea>
</svg>
Na exibição, o texto deve ser exibido com alinhamento à direita dentro da caixa textArea, como mostrado abaixo, já que o valor padrão de text-align é start, o qual, para uma base da direita para a esquerda, significa alinhado à direita.

A propriedade text-anchor é usada com o elemento text, e seus valores são start, middle e end. Mais uma vez, o primeiro e o último destes valores se relacionam com o texto de uma forma lógica e não de uma forma física.
Se você não especificou nenhuma direção básica, ou especificou direction="ltr", e se text-anchor está configurado para start, o texto se estenderá para a direita da coordenada x. Se você configurou direction="rtl", então o texto se estenderá para a esquerda da coordenada x. Por padrão text-anchor é configurado para start.
Para end, o oposto é verdadeiro.
Neste exemplo inglês/árabe, usamos dois elementos de texto, ambos com a mesma coordenada x, e ambos usando o valor padrão para text-anchor.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
xml:lang="en">
<title>...</title>
<desc>...</desc>
<text x="200" y="10"
font-size="10">Internationalization activity, W3C</text>
<text direction="rtl" x="200" y="20"
font-size="10">نشاط التدويل، W3C</text>
</svg>
Ainda que a coordenada x para ambos elementos de texto seja a mesma, isso exibirá o texto mais ou menos assim:

Você deve se lembrar que a direção na qual o texto se estende a partir do ponto x (veja o exemplo anterior) depende da direção básica, ou seja, o valor da propriedade direction, e não se você está lidando com texto latino ou árabe (ou hebraico). Isso é importante.
Isso significa que, por exemplo, uma lista de termos contendo tanto palavras latinas como palavras do oriente médio não perde inesperadamente o alinhamento dos itens.
O exemplo seguinte contém linhas alternantes em script em hebraico e em caracteres latinos:
<svg xmlns="http://www.w3.org/2000/svg" width="100%" height="100%" viewBox="0 0 400 400" direction="rtl" xml:lang="fa"> <title>...</title> <desc>...</desc> <text x="200" y="20" font-size="10">פעילות הבינאום, W3C</text> <text x="200" y="30" xml:lang="en" font-size="7">(Internationalization Activity, W3C)</text> <text x="200" y="50" font-size="10">ליצור מהרשת רשת כלל עולמית באמת</text> <text x="200" y="60" xml:lang="en" font-size="7">(Making the World Wide Web worldwide)</text> </svg>
Todos os itens na lista de endereços ainda aparecerão alinhados à direita. Não precisamos fazer nada em especial para linhas somente com caracteres latinos para que elas se alinhem com o resto:

O que você precisa lembrar, contudo, é que se você, por algum motivo, aplicar direction="ltr" para um dos elementos text, você precisará também especificar text-anchor="end" para aquele item, para que ele continue a se alinhar com os outros.
Esta seção cobre:
Nas seções anteriores mencionamos que ocasionalmente não é suficiente apenas adicionar as informações de direção ao tag svg. Nesta seção, examinaremos porque e quando se necessita mais controle, e mostraremos, em especial, como marcar elementos tspan para direção (para os quais precisaremos introduzir a propriedade unicode-bidi).
O resultado de se aplicar o algorítmo bidirecional depende da direção básica geral da frase, parágrafo, bloco ou página na qual é aplicado. A direção básica estabelece um contexto direcional ao qual o algorítmo bidirecional se refere em diversos pontos para decidir como manusear o texto.
A direção básica é configurada pelo mais próximo elemento hierarquicamente superior que use a propriedade direction, ou, na falta de tal elemento, ela é herdada da direcionalidade padrão do tag svg, que é da esquerda para a direita.
Repare que, para elementos de bloco, uma direção básica da direita para a esquerda somente pode ser configurada usando-se a propriedade direction.
Já sabemos que uma seqüência de caracteres latinos é desenhada (ou seja, exibida) uma após a outra da esquerda para a direita (podemos ver isto nesta página). Por outro lado, o algorítmo bidirecional desenhará uma seqüência de caracteres RTL (direita para a esquerda) digitados fortemente um após o outro da direita para a esquerda.
Isso independe da direção básica atual, e só funciona porque cada caracter em Unicode tem uma propriedade direcional associada. A maioria das letras é digitada fortemente como LTR (esquerda para a direita). As letras de scripts da direita para a esquerda são digitadas fortemente como RTL.
Digitação direcional.

Quando se mescla alinhamento de texto com direcionalidades diferentes, o algorítmo bidirecional desenha cada seqüência de caracteres como uma seqüência direcional separada.
Então, no exemplo seguinte, há três seqüências direcionais:
Seqüências direcionais.

Outra forma de olhar para isto é que as mudanças na direção marcam os limites das seqüências direcionais. Repare que você não precisa de nenhuma marcação ou estilo para fazer que isso aconteça.
É especialmente importante compreender que a ordem na qual as seqüências direcionais são exibidas em uma página depende da direção básica predominante.
As palavras na imagem abaixo são seqüências direcionais separadas. A linha superior está em um contexto onde a direção básica é LTR; a inferior, RTL. Os caracteres em ambas as linhas na imagem estão armazenados na memória exatamente na mesma ordem, mas a disposição visual das seqüências direcionais, quando exibida, é invertida.
O efeito da direção básica na exibição de seqüências direcionais.

Os espaços e a pontuação não são digitados fortemente como LTR ou RTL em Unicode, porque eles podem ser usados em qualquer tipo de script. Portanto, eles são classificados como neutros.
Aqui é onde as coisas começam a ficar interessantes. Quando o algortítimo bidirecional encontra caracteres com propriedaes direcionais neutras (como espaços e pontuação) ele resolve como lidar com eles examinando os caracteres ao redor.
Um caractere neutro, entre dois caracteres digitados fortemente com o mesmo tipo direcional, também assumirá essa direcionalidade. Então um caractere neutro entre dois caracteres RTL digitados fortemente será tratado como se fosse um caractere RTL, e terá o efeito de expandir a seqüência direcional. É por isso que as três palavras em árabe nesta frase LTR (separada somente por espaços, que têm direcionalidade neutra) são lidas da direita para a esquerda como uma única seqüência direcional. (A primeira palavra árabe que se lê é مفتاح então معايير então الويب.)
Caracteres neutros como parte da seqüência direcional.

Repare que você ainda não precisa de nenhuma marcação ou estilo para isto. E que ainda há apenas três seqüências direcionais aqui.
A parte realmente interessante acontece quando um espaço ou pontuação cai entre dois caracteres digitados fortemente com direcionalidades diferentes, ou seja, no limite entre seqüências direcionais. Nesse caso, o caractere ou caracteres neutros serão tratados como se tivessem a direcionalidade da direção básica.
Mesmo que haja vários caracteres neutros entre dois caracteres digitados fortemetne, eles todos serão tratados da mesma forma.
Caracteres neutros.

Os números nos scripts RTL seguem da esquerda para a direita dentro do fluxo da direita para a esquerda, mas são manuseados de forma um pouco diferente das palavras pelo algorítmo bidirecional. Diz-se que eles têm uma direcionalidade fraca. Os dois exemplos na imagem ilustram esta diferença.
Numerais.
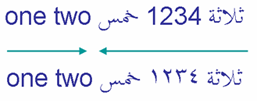
O primeiro exemplo usa numerais europeus, '1234', o segundo expressa o mesmo número usando numerais árabes-índicos, ١٢٣٤. Em ambos os casos, os dígitos do numerais são lidos da esquerda para a direita.
Por serem digitados sem força, o número é visto como parte do texto árabe, então as duas palavras em árabe que estão ao lado do número são tratadas como parte da mesma seqüência direcional, ainda que a seqüência de numerais siga LTR na tela.
Repare também, que junto com um número, certos caracteres considerados neutros, como os símbolos de moedas, serão tratados como parte do número ao invés de neutros.
O algorítmo bidirecional manuseará o texto perfeitamente na maioria das situações, e tipicamente nenhuma marcação especial ou qualquer outro dispositivo serão necessários além do ajuste da direção geral para o documento. Seria muita sorte conseguir livrar-se assim facilmente o tempo todo. Aqui está nosso primeiro exemplo de uma situação onde o algorítmo bidirecional precisa de um pouco de ajuda.
A primeira linha nesta imagem mostra um ponto de exclamação, que é parte do texto árabe incorporado, aparecendo no lugar errado. A segunda linha mostra o resultado desejado.
Os elementos neutros entre seqüências direcionais podem acabar aparecendo onde não deveriam.
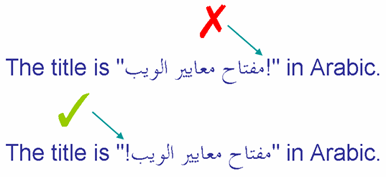
Dada nossa discussão anterior do algorítmo bidir4cional, podemos facilmente compreender porque isso aconteceu. Como esse ponto de exclamação foi digitado entre a útlima letra RTL 'ب' (à esquerda) e a letra LTR 'i' (da palavra 'in') sua direcionalidade é determinada pela direção básica do parágrafo (aqui LTR). Repare que não faz difererença o fato de haver dois caracteres de pontuação e um espaço nessa posição - todos são neutros e então todos são afetados da mesma forma. Como o ponto de exclamação é visto como LTR ele se une à seqüência direcional que inclui o texto "em árabe".
Então como colocamos a pontuação no lugar certo?
Uma resposta é colocar a citação (aspas) em árabe em um elemento tspan e usar a propriedade direction para mudar a direção básica dentro do tspan para RTL.
Diferentemente dos elementos containers que examinamos anteriormente, o tspan requer que se especifique a propriedade unicode-bidi, assim como a propriedade direction, para que a mudança na direção básica seja eficiente. O valor que você necessita é embed. (Veremos o uso de bidi-override mais tarde.)
<text>The title is "<tspan direction="rtl" unicode-bidi="embed" xml:lang="ar"> ... !</tspan>" in Arabic.</text>O ambiente de edição que você usa pode não mostrar o ponto de exclamação no lugar certo no código fonte, mas deve parecer correto quando exibido.
Repare com atenção como o tag span cai dentro das aspas - as aspas são parte do texto em inglês ao redor.
Outra possibilidade seria digitar um caracteres invisível RTL, digitado fortemente depois do ponto de exclamação. Dessa forma o ponto de exclamação seria interpretado como RTL e unido à seqüência direcional árabe.
Ocorre que há um certo caractere - o caractere Unicode U+200F, chamado de MARCA DIREITA PARA A ESQUERDA (RIGHT-TO-LEFT MARK - RLM). Há um caractere semelhante, U+200E, chamado MARCA ESQUERDA PARA A DIREITA (LEFT-TO-RIGHT MARK - LRM). Como o caractere é invisível, você pode preferir digitar uma referência de caractere numérico ()
Adicionar este caractere imediatamente após o ponto de exclamação produzirá o resultado desejado.
<text>The title is "... !" in Arabic.</text>Se já houver marcação ao redor das aspas, provavelmente faz sentido apenas usar direction nela, ao invés do caractere de controle. Por outro lado, pode ser mais fácil usar o caractere de controle.
A linha superior da imagem a seguir mostra o que aconteceria com uma lista de itens RTL dentro de uma sentença LTR se confiássemos apenas no algorítmo bidirecional (ou seja, se não usássemos a propriedade direction para estabelecer a direção básica). Em nosso exemplo, a ordem da lista está incorreta porque as primeiras duas palavras árabes deveriam estar invertidas e a vírgula entre elas, que é parte do texto em inglês, deveria aparecer imediatamente à direita da primeira palavra.
A segunda linha na imagem mostra o resultado desejado.
Elementos neutros entre texto de mesma direção podem não ser interpretados apropriadamente como parte de uma única seqüência.

O motivo dessa falha é que, com um caractere digitado fortemente da direita para a esquerda (RTL) em cada lado, o algorítmo bidirecional enxerga a vírgula* neutra como parte do texto em árabe. Ele está interpretando as duas primeiras palavras em árabe e a vírgula como uma lista em árabe. Na verdade, a vírgula é parte do texto em inglês, e deveria marcar o limite de duas seqüências direcionais em árabe.
Na seção anterior, o caractere neutro imaginou que fosse parte do contexto direcional estabelecido pela direção básica, mas não era; nesta seção, o caractere neutro imagina que é parte da seqüência direcional, quando de fato é parte do contexto da direcional geral.
Uma solução simple é usar outro caractere Unicode invisível, desta vez a MARCA ESQUERDA PARA A DIREITA junto à virgula. Isso coloca nossa pontuação neutra entre caracteres RTL e LTR digitados fortemente e a força a tomar a direcionalidade da direção básica, que é da esquerda para a direita no texto em inglês. Isso quebra as palavras em árabe em duas seqüências direcionais separadas, que são ordenadas como LTR de acordo com a direção que prevalece no parágrafo.
<text>The names of these states in Arabic are ..., ... and ... respectively.</text>Mais uma vez, você pode preferir usar um caractere neutro - NCR () para fins de visibilidade.
A próxima imagem mostra outro exemplo onde a marcação não é necessária, e um caractere de controle Unicode desempenha a função de uma maneira muito mais simples. Mais uma vez, a linha azul superior na figura mostra o resultado de se confiar apenas no algorítmo bidirecional, e a segunda linha mostra o resultado desejado.
O resultado desejado foi conseguido colocando-se junto dos perênteses que deveriam ser parte do contexto em hebraico, mas que aparece entre dois blocos de texto em caracteres latinos. O efeito da marcação RLM é quebrar o texto em caracteres latinos em três seqüências direcionais separadas, que são ordenadas de acordo com a direção básica RTL.
Outro exemplo do uso de RLM ou LRM, desta vez em um contexto em hebraico.

Você pode ter reparado que, além de ter mudado de posição, um dos parênteses no exemplo anterior também mudou de formato. Isso foi completamente automático, e ocorreu porque esses caracteres são o que se conhece como caracteres espelhados em Unicode.
Os caracteres espelhados são geralmente pares de caracteres, como parênteses, colchetes, etc., cujo formato, quando exibido, depende de serem parte de um contexto LTR ou RTL. Você não precisa mudar o caractere para que o formato mude. O fechamento de um parênteses sendo aberto sempre fica de frente para a direção do fluxo do texto. Na figura abaixo, o parêntese circulado em vermelho está de frente para a direita na linha de cima porque está sendo tratado como a abertura de parênteses de algum texto em caracteres latinos. Na versão inferior do texto, o mesmo caractere (novamente circulado em vermelho) é tratado como a abertura de parênteses relacionada ao texto hebraico (ou seja, o nome expandido segue a sigla na ordem de leitura), e, portanto, fica de frente para o outro lado.
Caracteres espelhados.

Isso quer dizer que, quer o conteúdo armazenado esteja em script em caracteres árabes/hebraicos ou latinos, você usaria o mesmo caractere de PARÊNTESE ESQUERDO no começo do texto entre parênteses. Em outras palavras, trate caracteres espelhados com se fossem qualquer outra palavra left no com significado "abrir", e right no significado "fechar".
O algorítmo bidirecional Unicode e as marcações LRM/RLM funcionam bastante bem quando há apenas um único nível de texto mesclado. Se você tiver uma situação onde há dois ou mais níveis combinados de textos direcionais, você precisará de uma solução diferente. Esta imagem mostra uma seqüência em caracteres latinos que contém uma citação em hebraico que, por sua vez, contém texto tanto em caracteres hebraicos como texto em caracteres latinos ('W3C').
A ordem de duas palavras em hebraico está correta, mas o texto 'W3C' deveria aparecer à esquerda da citação e a vírgula deveria aparecer entre o texto em caracteres hebraicos e 'W3C'.
Obter a exibição desejada usando-se marcação para abrir um novo nível de incorporação.

O problema surge porque os fluxos direcionais estão sendo ordenados de acordo com a direção básica LTR do parágrafo. Porém, dentro da citação em hebraico, o ordenamento padrão correto seria RTL.
Para resolver este problema precisamos abrir um novo nível de incorporação. Para fazer isso, você precisa envolver a citação com um elemento tspan e atribuir uma direcionalidade de RTL usando as propriedades direction e unicode-bidi.
<text>The title says "<tspan direction="rtl" unicode-bidi="embed"> ... </tspan>" in Hebrew.</text>Também há caracteres de controle Unicode que poderiam ser usados para conseguir o mesmo resultado, mas, como eles estabelecem uma direção básica para um segmento de texto com limites invisíveis isso não é recomendado.
Em resumo, onde você usa apenas a propriedade direction em elementos container como svg, g, text e textArea, você precisa usar ambos os elementos direction e unicode-bidi="embed" em elementos tspan, já que são inline.
O outro valor útil de unicode-bidi é bidi-override. Você não precisará usá-lo muito freqüentemente. Sua descrição é dada na próxima seção.
Pode haver ocasiões nas quais não se queira que o algorítmo bidirecional faça seu trabalho de reordenamento. Nesses casos você precisa de alguma marcação adicional para cercar o texto que você quer deixar sem ordenamento.
Em SVG isso se consegue usando-se o valor bidi-override da propriedade unicode-bidi junto com a propriedade direction. Mais uma vez, há caracteres de controle Unicode que podem ser usados para se obter o mesmo resultado, mas como eles criam estados com limites invisíveis, isso não é recomendado.
Um exemplo de texto onde se deseja sobrepujar o algorítmo bidirecional.
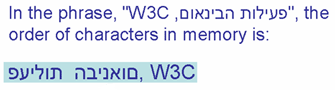
O exemplo na imagem mostra texto em hebraico como ordenado na memória. Pode-se usar a propriedade unicode-bidi para se obter esse efeito, ou seja,
<text x="20" y="80" direction="ltr" unicode-bidi="bidi-override"> ... </text>O Unicode oferece códigos de formatação invisíveis, especiais, para se establecer ou sobrepujar o resultado do algorítmo bidirecional em texto simples, da mesma forma que a marcação SVG descrita neste tutorial.
Há diversos caracteres de controle em Unicode que podem ser usados para criar o mesmo efeito que a marcação para texto bidirecional alinhado. Eles estão listados na tabela a seguir:
| Caractere | Código | Marcação equivalente |
|---|---|---|
| RLE | U+202B | <tspan direction="rtl" unicode-bidi="embed"> |
| LRE | U+202A | <tspan direction="ltr" unicode-bidi="embed" |
| RLO | U+202E | <tspan direction="rtl" unicode-bidi="bidi-override" |
| LRO | U+202D | <tspan direction="ltr" unicode-bidi="bidi-override" |
| U+202C | </tspan> |
O Unicode em linguagens de Marcação aconselha contra o uso destes quando a marcação estiver disponível, e aconselha especialmente contra a mescla de códigos de controle e marcação.
Para mais informações sobre este tópico veja Unicode controls vs. markup for bidi support (Controles Unicode versus marcação para suporte bidirecional) no site de internacionalização da W3C.
Contudo, há algumas situações onde os caracteres de controle Unicode oferecem a única forma de se expressar a direcionalidade. Esse é o caso de elementos de texto simples como title e desc. Esses elementos são definidos para suportar apenas caracteres, e não marcação. Portanto, não possível usar as propriedades direction ou unicode-bidi em uma parte do conteúdo do elemento.
Os atributos de texto tampouco podem ser marcados para direcionalidade, então os caracteres de controle Unicode têm que ser usados para indicar a direcionalidade.
Repare que, outras coisas, como idioma, não podem ser marcadas para partes de conteúdo de texto simples, nem atribuir valores.
Dê-nos a sua opinião (em inglês).
Traduzido de conteúdo em inglês datado de 2009-01-07. Última versão traduzida modificada 2009-06-17 12:10 GMT
Para obter o histórico de alterações do documento, procure tutorial-svg-tiny-bidi no blog da i18n.
Copyright © 2009 W3C® (MIT, ERCIM, Keio, Beihang), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}