Deutsch English Español Français Italiano Português Pусский Українська
Met de sneltoets n gaat u rechtstreeks naar navigatie binnen de pagina. Naar begin van de inhoud gaan.
Dit document is een vertaling. In geval van afwijkingen of fouten, dient het meest recente origineel in het Engels dient als referentie te worden beschouwd. Het origineel copyright is eigendom van W3C, zoals hieronder getoond.
Vertaler: Dutch Translation Team, Trusted Translations, Inc.
http://www.w3.org/International/tutorials/svg-tiny-bidi/
Doelpubliek: Auteurs van SVG-inhoud die SVG Tiny pagina's implementeren in 'van rechts naar links' schriften zoals Arabisch en Hebreeuws, of die te maken krijgen met ingesloten 'van rechts naar links' schrifttekst. Dit materiaal is toepasbaar, of u nu documenten creëert in een tekstverwerker of via scripting werkt.
Van recht naar links schriften zoals het Arabisch, Hebreeuws, Thaana en N'ko worden door een groot aantal mensen over de hele wereld gebruikt. Als bidirectionele tekst nieuw is voor u, kan een correcte weergave soms complex en verwarrend lijken, maar dat hoeft niet zo te zijn. Indien u hiermee geworsteld heeft of nog dient te starten, kan deze tutorial u helpen bij de keuze van de beste aanpak voor de opmaak van uw inhoud. U zult genoeg leren over de werkwijze van het bidirectionele algoritme waardoor u de oorzaak van de meeste problemen beter zult begrijpen. We zullen ook enkele populaire misvattingen behandelen over de manier waarop bidirectionele inhoud kan worden opgemaakt.
Na het volgen van deze tutorial zult u in staat zijn:
Let erop dat de SVG Tiny 1.2 specificatie op 22 december 2008 gepubliceerd werd als een Aanbeveling. Het kan even duren alvorens de functionaliteit die in deze tutorial wordt beschreven overal ingezet wordt.
Dit onderdeel gaat over:
Voeg direction="rtl" toe aan de svg-tag om de basisrichting voor het document in te stellen wanneer de documentrichting van het volledige document 'van rechts naar links' is. De basisrichting stelt de algemene richtingscontext in voor de tekst in het element waar het wordt gedefinieerd.
U hoeft de basisrichting niet expliciet te definiëren voor documenten die voornamelijk van links naar rechts lopen, aangezien dit de standaardrichting is.
Het is mogelijk dat u hierna geen verdere directionele opmaak meer hoeft toe te voegen aan uw inhoud. De waarde direction die wordt ingesteld op het element svg wordt overgenomen door tekstgerelateerde elementen in het gehele document. Een aanzienlijk deel van de reorganisatie die nodig is om tekst weer te geven wordt automatisch verzorgd door het "Unicode Bidirectional Algorithm" ('bidi-algoritme'). Hieronder vindt u enkele illustratieve voorbeelden.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="fa">
<title>...</title>
<desc>...</desc>
<text x="200" y="200"
font-size="10">داستان SVG Tiny 1.2 طولا ني است.</text>
</svg>
Dit zal de tekst in de volgende (correcte) volgorde weergeven, op voorwaarde dat de implementatie bidi-tekst ondersteunt:
![]()
Zonder de eigenschap direction zou de tekst er als volgt hebben uitgezien:
![]()
Er zijn natuurlijk situaties waarin meer opmaak noodzakelijk kan zijn, deze zullen hieronder beschreven worden. Het toevoegen van direction="rtl" aan het element svg zal een aantal automatische gevolgen hebben voor de eigenschappen text-align en text-anchor, deze zullen we ook behandelen.
Vergeet terwijl u de directionaliteit aangeeft van het document in de svg-tag niet om de taal van het document in te stellen met behulp van het attribuut xml:lang (zie Taaltags in HTML en XML).
Maak echter niet de foute veronderstelling dat de taalinstellingen de directionaliteit bepalen of vice versa!
Zelfs indien er een script-subtag gebruikt wordt in de taalattribuutwaarde heeft dit geen gevolgen voor de directionaliteit van de tekst in de gebruikersagent. U moet altijd de richting aangeven met behulp van het attribuut dir.
Het visueel rangschikken van Hebreeuwse tekst was normaal in (zeer) oude HTML gebruikersagenten die het 'Unicode bidirectionele algoritme' niet ondersteunden. De tekst werd in de broncode opgeslagen in dezelfde volgorde als bij de verwachte weergave. (Het was minder gebruikelijk voor tekst in Arabisch schrift, omdat het geen rekening hield met de manier waarop Arabische tekens samengevoegd worden.)
Dankzij logisch rangschikken wordt de tekst in het geheugen opgeslagen in de volgorde waarin die normaal ingetikt (en meestal uitgesproken) zou worden. Het 'Unicode bidirectionele algoritme' wordt dan toegepast door de browser om de juiste visuele weergave te garanderen. Tegenwoordig wordt bijna alle tekst op het Internet logisch gerangschikt.
U dient de 'van rechts naar links' tekst altijd logisch te rangschikken en vertrouwen op het bidirectionele algoritme en de opmaak voor een correcte weergave. Indien u dit niet doet, zal het onmogelijk zijn om te zoeken in de tekst, deze te hergebruiken, uw inhoud vlot te onderhouden, etc.
In de afbeelding hieronder verschijnt de zin "פעילות הבינאום, W3C" (bovenaan in het blauw) zoals die normaalgesproken zou verschijnen in een paragraaf 'van rechts naar links'. De genummerde pijlen geven de leesrichting aan. U leest de reeksen in de volgorde van de nummers.
Logisch en visueel rangschikken in contrast.

De 2e lijn toont de volgorde van de karakters in het geheugen in logische coderingsvolgorde (in de veronderstelling dat het eerste karakter in het geheugen zich aan de linkerkant bevindt, het volgende rechts ernaast, enzovoort).
De 3e lijn toont de volgorde van de karakters in het geheugen in visuele coderingsvolgorde (met dezelfde veronderstellingen over de volgorde in het geheugen).
Dit onderdeel gaat over:
Nadat de basisrichting is vastgesteld op het niveau van het element svg kunt u de eigenschap direction beter niet gebruiken op andere elementen tenzij u de basisrichting voor dat element wil wijzigen.
Onnodig gebruik van de eigenschap direction beïnvloedt de bandbreedte en kan overbodig werk veroorzaken bij het onderhoud van de pagina.
De basisrichting die wordt ingesteld bij de eigenschap direction beïnvloedt echter de manier waarop tekst in verschillende talen en interpunctie gerangschikt wordt binnen een text of textArea-element (dit wordt hieronder in detail beschreven). Het is mogelijk dat u van tijd tot tijd de basisrichting van één van deze elementen wenst te wijzigen indien het een andere taal betreft dan de rest van de tekst.
Om dat te doen gebruikt u gewoon de eigenschap direction op het element of op een groepselement dat de relevante context bevat.
In dit voorbeeld gebruiken we een groepselement rond verschillende text-elementen waarvan de basisrichting 'van links naar rechts' moet zijn zodat het er correct uitziet. Het gebruik van een groepselement zorgt ervoor dat we minder werk moeten verrichten om het gewenste resultaat te verkrijgen. De richtingsinstelling wordt overgenomen door de text-elementen.
<svg xmlns="http://www.w3.org/2000/svg" width="100%" height="100%" viewBox="0 0 400 400" direction="rtl" xml:lang="he"> <title>...</title> <desc>...</desc> <text x="200" y="20" font-size="10">כתובת לפניות באנגליה:</text> <g direction="ltr"> <text x="100" y="40" font-size="10">3, Tennyson House</text> <text x="100" y="50" font-size="10">17 Clairbourne Road,</text> <text x="100" y="60" font-size="10">Harpenden AL5 4SD</text> </g> </svg>
Zonder de richtingsopmaak op het element g, wordt de tekst ongeveer als volgt weergegeven:
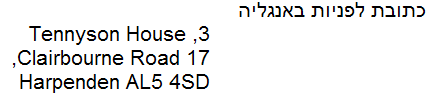
Nadat de eigenschap direction is ingesteld, zal de tekst de bedoelde weergave krijgen.

U heeft misschien opgemerkt dat de uitlijning van de tekst met betrekking tot de x-coördinaat verschillend is voor de twee voorbeelden hierboven. Hieronder bespreken we dit.
De eigenschap text-align wordt gebruikt met het element textArea en de waarden hiervoor zijn start, middle en end. Het is belangrijk om te onthouden dat de eerste en de laatste van deze waarden op logische in plaats van fysieke wijze gerelateerd zijn aan de tekst.
start staat voor de plaats waar u gewoonlijk een regel zou beginnen lezen gezien de huidige basisrichting. Als de basisrichting 'van links naar rechts' is, betekent dit aan de linkerzijde van het element textArea. Indien de basisrichting 'van rechts naar links' is, wijst dit op de rechterzijde van het element textArea.
Voor end kan u dit gewoon omdraaien.
Dit zal intuïtief lijken indien u reeds bekend bent met het gebruik van CSS met HTML aangezien de eigenschap direction in CSS de tekst in een "block"-element automatisch rechts uitlijnt.
In dit voorbeeld in het Urdu wordt de richting 'van rechts naar links' die is ingesteld op het element svg overgenomen door het element textArea.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
dir="rtl" xml:lang="ur">
<title>...</title>
<desc>...</desc>
<textArea x="20" y="20" width="200">
فعالیت بینالمللیسازی، W3Cنا
عالمگیر ویب کو حقیقی طور پر عالمگیر بنانا
</textArea>
</svg>
Bij weergave zou de tekst in het vak textArea rechts uitgelijnd moeten verschijnen, zoals hieronder, aangezien de standaardwaarde van text-align start is en bij een 'van rechts naar links' basisrichting betekent dit rechts uitgelijnd.

De eigenschap text-anchor wordt gebruikt met het element text en de waarden hiervoor zijn start, middle en end. Opnieuw zijn de eerste en laatste van deze waarden op logische in plaats van fysieke wijze aan de tekst gerelateerd.
Indien u geen basisrichting heeft opgegeven of indien u direction="ltr" heeft ingesteld, en als text-anchor op start staat, zal de tekst zich uitstrekken aan de rechterzijde van de x-coördinaat. Indien u direction="rtl" heeft ingesteld dan zal de tekst zich uitstrekken aan de linkerzijde van de x-coördinaat. Standaard zal text-anchor ingesteld staan op start.
Voor end is het omgekeerde van toepassing.
In dit voorbeeld in het Nederlands/Arabisch gebruiken we twee tekstelementen, beiden met dezelfde x-coördinaat en beiden met dezelfde standaardwaarde voor text-anchor.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
xml:lang="en">
<title>...</title>
<desc>...</desc>
<text x="200" y="10"
font-size="10">Internationalization activity, W3C</text>
<text direction="rtl" x="200" y="20"
font-size="10">نشاط التدويل، W3C</text>
</svg>
Hoewel de x-coördinaat voor beide tekstelementen hetzelfde is, zal de tekst ongeveer als volgt worden weergegeven:

Houd er rekening mee dat de richting waarin de tekst zich uitstrekt weg van het punt x (zie het vorige voorbeeld) afhangt van de basisrichting, dit is de waarde van de eigenschap direction, en niet van het feit of u nu met tekst in het Latijns of Arabisch (of Hebreeuws) schrift werkt. Dit is belangrijk.
Het betekent bijvoorbeeld dat een lijst met termen die zowel woorden bevat in het Latijns schrift als een schrift uit het Midden-Oosten de items niet onverwachts verkeerd uitlijnt.
Het volgende voorbeeld bevat afwisselend regels in het Hebreeuws en Latijns schrift:
<svg xmlns="http://www.w3.org/2000/svg" width="100%" height="100%" viewBox="0 0 400 400" direction="rtl" xml:lang="he"> <title>...</title> <desc>...</desc> <text x="200" y="20" font-size="10">פעילות הבינאום, W3C</text> <text x="200" y="30" xml:lang="en" font-size="7">(Internationalization Activity, W3C)</text> <text x="200" y="50" font-size="10">ליצור מהרשת רשת כלל עולמית באמת</text> <text x="200" y="60" xml:lang="en" font-size="7">(Het World Wide Web wereldwijd maken)</text> </svg>
Al de items in de adreslijst zullen nog steeds rechts worden uitgelijnd. We hoeven niets speciaals te doen met de regels in Latijns schrift opdat deze opgesteld worden naast de rest:

Onthoud erchter wel dat indien u, om welke reden dan ook, direction="ltr" instelt voor één van de text-elementen, u ook text-anchor="end" moet specificeren voor dat item zodat het uitgelijnd blijft met de rest.
Dit onderdeel gaat over:
Hierboven hebben we reeds vermeld dat het soms niet voldoende is om gewoon de richtingsinformatie toe te voegen aan de tag svg. In dit onderdeel zullen we bekijken waarom en wanneer er meer controle nodig is, en in het bijzonder hoe de opmaak van tspan-elementen voor richting verloopt (waarvoor we eerst de eigenschapunicode-bidi moeten introduceren).
Het resultaat van de toepassing van het bidirectionele algoritme hangt af van de algemene basisrichting van de zin, de alinea, het blok of de pagina waarop het wordt toegepast. De basisrichting bepaalt een directionele context waar het bidi-algoritme op veschillende naar verwijst om te beslissen hoe de tekst moet worden behandeld.
De basisrichting wordt of bepaald door het dichtstbijzijnde "parent"-element dat de eigenschap direction gebruikt of, indien dat element afwezig is, wordt deze overgenomen van de standaarddirectionaliteit van de svg-tag, dus 'van links naar rechts'.
Let erop dat u voor 'block'-elementen de richting 'van rechts naar links' enkel kan bepalen met behulp van de eigenschap direction.
We weten reeds dat een reeks tekens in Latijns schrift één na één worden weergegeven van links naar rechts (we kunnen dat zien op deze pagina). Anderzijds zal het bidi-algoritme een reeks van "strongly typed" RTL-karakters ("right-to-left") één na één weergeven van rechts naar links.
Dit staat los van de huidige basisrichting en werkt omdat elk karakter in Unicode een directionele eigenschap toegewezen krijgt. De meeste letters zijn strongly typed als LTR. Letters in 'van rechts naar links' schriften zijn "strongly typed" als RTL.
Directioneel typen.

Wanneer tekst met verschillende directionaliteit gemengd wordt op dezelfde regel, geeft het bidi-algoritme elke reeks karakters met dezelfde directionaliteit weer als een afzonderlijke directional run.
Zo zijn er in het volgende voorbeeld er drie verschillende "directional runs":
Directional runs.

Een andere manier om het te beschouwen is dat veranderingen in richting de grens van een "directional run" bepalen. Let erop dat er geen opmaak of stilering nodig is om dit te realiseren.
Het is bijzonder belangrijk om te begrijpen dat de volgorde waarin de "directional runs" over de pagina worden weergegeven afhangt van de gangbare richtingsbasis.
De woorden op de afbeelding hieronder zijn afzonderlijke "directional runs". De bovenste regel bevindt zich in een context waar de basisrichting LTR is; de onderste RTL. De karakters op beide regels in de afbeelding worden in het geheugen opgeslagen in exact dezelfde volgorde aar de visuele rangschikking van de "directional runs" is omgekeerd wanneer deze worden weergegeven.
Het effect van de basisrichting op de weergave van de "directional runs".

Spaties en interpunctietekens worden in Unicode niet "strongly typed" als LTR of RTL omdat ze in beide soorten schrift kunnen worden gebruikt. Ze worden dan ook als neutraal geclassificeerd.
Nu begint het pas echt interessant te worden. Wanneer het bidi-algoritme op karakters stuit met neutrale richtingseigenschappen (zoals spaties en interpunctietekens) beslist het op basis van de omliggende karakters hoe behandeld moeten worden.
Een neutraal karakter dat zich tussen twee "strongly typed"-karakters met hetzelfde richtingstype bevindt, zal tevens die directionaliteit overnemen. Dus een neutraal karakter dat zich tussen twee "strongly typed" RTL-karakters bevindt, zal zelf behandeld worden als een RTL-karakter en zal de "directional run" verlengen. Daarom worden de drie Arabisch woorden in deze LTR-zin (enkel gescheiden door spaties, die een neutrale directionaliteit hebben) gelezen van rechts naar links als één enkele "directional run". (Het eerste Arabische woord dat u leest is مفتاح dan معايير dan الويب.)
Neutrale karakters als onderdeel van de "directional run".

Let erop dat u hier nog steeds geen opmaak of stilering nodig heeft. En dat er hier nog steeds slechts drie "directional runs" zijn.
Het wordt zeer interessant wanneer een spatie of interpunctieteken tussen twee "strongly typed"-karakter valt met verschillende directionaliteit, m.a.w. aan de grens tussen twee "directional runs". In dergelijke gevallen zal het neutraal karakter/zullen de neutrale karakters behandeld worden alsof het/ze de directionaliteit van de basisrichting heeft/hebben.
Zelfs indien er zich verschillende neutrale karakters bevinden tussen twee "strongly typed"-karakters, zullen deze allemaal op dezelfde wijze behandeld worden.
Neutrale karakters.

Nummers in RTL-schriften lopen 'van links naar rechts' binnen de normale beweging 'van rechts naar links' maar worden net iets anders behandeld door het bidi-algoritme. Men zegt dat ze zwakke directionaliteit hebben. De twee voorbeelden in de afbeelding illustreren dit verschil.
Cijfers.
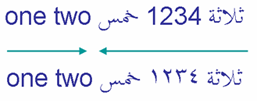
Het eerste voorbeeld gebruikt Europese cijfers, '1234', het tweede drukt hetzelfde nummer uit in Arabisch-Indische cijfers, ١٢٣٤. In beide gevallen worden de cijfers 'van links naar rechts' gelezen.
Omdat het "weakly typed" is, wordt het nummer gezien als onderdeel van de Arabische tekst, dus de twee Arabische woorden die het nummer omringen worden behandeld als deel van dezelfde "directional run" - zelfs als de cijferreeks op het scherm als LTR verschijnt.
Merk ook op dat, bepaalde anders neutrale karakters die naast een nummer verschijnen, zoals valutasymbolen, als deel van het nummer behandeld zullen worden in plaats van als een neutraal element.
Het bidi-algoritme zal in de meeste situaties tekst perfect behandelen en meestal is er geen speciale opmaak of andere handeling nodig naast het instellen van de algemene richting van het document. U zou echter veel geluk hebben indien het altijd zo eenvoudig ging. Hier is het eerste voorbeeld van een situatie waarin het bidirectionele algoritme een beetje hulp nodig heeft.
De eerste regel in deze afbeelding vertoont een uitroepteken dat deel uitmaakt van de ingesloten Arabische tekst en dus op de verkeerde plaats verschijnt. De tweede regel vertoont het gewenste resultaat.
Neutrale elementen tussen "directional runs" kunnen op de verkeerde plaats verschijnen.
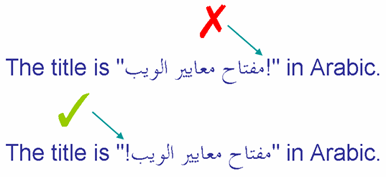
Gezien onze voorgaande bespreking van het bidi-algoritme kunnen we gemakkelijk begrijpen waarom dit gebeurt. Omdat het uitroepteken tussen de laatste RTL-letter 'ب' (aan de linkerzijde) en de LTR-letter 'i' (van het woord 'in') werd ingetikt, wordt zijn directionaliteit bepaald door de basisrichting van de alinea (hier: LTR). Merk op dat het geen verschil uitmaakt dat er twee interpunctietekens en een spatie op deze plaats staan - het zijn allemaal neutrale elementen en deze worden dus allemaal op dezelfde wijze beïnvloedt. Omdat het uitroepteken gezien wordt als LTR maakt het deel uit van de "directional run" die de tekst 'in het Arabisch' bevat.
Hoe kunnen we de interpunctie op de juiste plaats krijgen?
Een oplossing is om het Arabische citaat in een tspan-element te plaatsen en de eigenschap direction te gebruiken om de basisrichting binnen die tspante veranderen naar RTL .
In tegenstelling tot de "container"-elementen die we hierboven hebben besproken, vereist tspan dat u de eigenschap unicode-bidi specificeert, evenals de eigenschap direction, opdat de verandering van basisrichting zou plaatsnemen. De waarde die u nodig heeft is embed. (We zullen het gebruik van bidi-override later bekijken.)
<text>De titel is "<tspan direction="rtl" unicode-bidi="embed" xml:lang="ar"> ... !</tspan>" in het Arabisch.</text>De redactie-omgeving die u gebruikt zal het uitroepteken misschien niet op de juist plaats tonen in de codebron maar bij weergave zou het correct moeten verschijnen.
Merk op dat de tag "span" binnen de aanhalingstekens valt - het citaat maakt deel uit van de omringende Nederlandstalige tekst.
Een andere mogelijke oplossing is om een onzichtbaar, "strongly typed" RTL-karakter in te tikken na het uitroepteken. In dat geval wordt het uitroepteken geïnterpreteerd als RTL en bij de Arabische "directional run" gevoegd.
Het toeval wil nu dat er een dergelijk karakter bestaat - het Unicode-karakter U+200F dat het RIGHT-TO-LEFT MARK (RLM) genoemd wordt. Er is een gelijkaardig karakter, U+200E, dat het LEFT-TO-RIGHT MARK (LRM) genoemd wordt. Aangezien het karakter onzichtbaar is, kan u misschien beter daadwerkelijk een numerieke referentie invoeren ()
Door dit karakter net na het uitroepteken toe te voegen zal u het gewenste resultaat bekomen.
<text>De titel is "... !" in het Arabisch.</text>Indien er zich rond het citaat reeds opmaak bevindt, is het waarschijnlijk zinvol om enkel direction te gebruiken in plaats van het controlekarakter. Anderzijds kan het gemakkelijker zijn om het controlekarakter te gebruiken.
De bovenste regel in onderstaande afbeelding toont wat er zou gebeuren met een lijst van RTL-items binnen een LTR-zin indien we enkel vertrouwden op het bidirectionele algoritme (m.a.w. als we geen gebruik maakten van de eigenschap direction om de basisrichting vast te leggen). In ons voorbeeld is de lijstvolgorde onjuist omdat de eerste twee Arabische woorden omgekeerd zouden moeten verschijnen en de tussenliggende komma, die deel uitmaakt van de Nederlandstalige tekst, onmiddellijk rechts naast het eerste woord zou moeten staan.
De tweede regel in de afbeelding vertoont het gewenste resultaat.
Neutrale elementen tussen tekst met dezelfde richting kunnen onterecht gezien worden als onderdeel van één "run".

De oorzaak van deze fout is dat, met een "strongly typed" karakter 'van rechts naar links' (RTL) aan beide zijden, het bidirectionele algoritme de neutrale komma* ziet als onderdeel van de Arabische tekst. Het interpreteert de eerste twee Arabische woorden en de komma als een lijst in het Arabisch. In feite maakt de komma deel uit van de Nederlandstalige tekst en zou de grens moeten aanduiden tussen de twee "directional runs" in het Arabisch.
In het voorgaande onderdeel dacht het neutrale karakter dat het deel uitmaakte van de directionele context die werd gedefinieerd door de basisrichting maar dat was niet zo; in deze context denkt het neutrale karakter dat het deel uitmaakt van de "directional run" terwijl het eigenlijk deel uitmaakt van de algemene directionele context.
Een eenvoudige oplossing is om naast de komma een ander onzichtbaar Unicode-karakter in te voegen, deze keer het LEFT-TO-RIGHT MARK. Dit plaatst ons neutraal interpunctieteken tussen "strongly typed" RTL- en LTR-karakters en dwingt het de directionaliteit van de basisrichting op, die 'van links naar rechts' is voor de Nederlandstalige tekst. Dit breekt de Arabische woorden op in twee afzonderlijke "directional runs" die 'van links naar recht' gerangschikt worden volgens de gangbare richting in deze alinea.
<text>De namen van deze staten in het Arabisch zijn respectievelijk ..., ... en ... .</text>Opnieuw kan u ervoor kiezen om een NCR () te gebruiken, met het oog op de zichtbaarheid.
In de volgende afbeelding vindt u nog een voorbeeld waar opmaak niet nodig is en een Unicode controlekarakter het veel eenvoudiger maakt. Opnieuw toont de bovenste, blauwe regel in de afbeelding het resultaat van blind vertrouwen op het bidirectionele algoritme en toont de twee regel het gewenst resultaat.
Het gewenste resultaat werd verkregen door te plaatsen naast de tekst tussen haakjes die deel moesten uitmaken van de Hebreeuwse context maar die tussen twee segmenten in Latijns schrift verschijnt. Het gevolg van het RLM-teken is dat de tekst in Latijns schrift wordt onderverdeeld in drie aparte "directional runs", die gerangschikt worden volgens de basisrichting RTL.
Nog een voorbeeld van het gebruik van RLM of LRM, deze keer in een Hebreeuwse context.

U heeft misschien opgemerkt dat, naast een verandering in positie, een van de haakjes in het vorige voorbeeld ook van vorm veranderde. Dit was volstrekt automatisch en gebeurde omdat het ging om zogenaamde gespiegelde karakters in Unicode.
Gespiegelde karakters zijn meestal karakterparen, zoals haakjes, accolades en dergelijke, waarvan de vorm afhangt of deze onderdeel is van een LTR-context of RTL-context. U hoeft het karakter niet te wijzigen om de vorm te wijzigen. De uiteindes van een openend haakje wijzen altijd in de richting van de "text flow". In de afbeelding hieronder wijst het rood omcirkeld haakje in de bovenste regel naar rechts omdat deze behandeld wordt als het openend haakje van een tekst in het Latijns schrift. In de onderste versie van de tekst wordt hetzelfde karakter (opnieuw rood omcirkeld) behandeld als een openend haakje met betrekking tot de Hebreeuwse tekst (m.a.w. de volledige naam volgt het acroniem wat betreft leesvolgorde) en wijst daarom de andere kant op.
Gespiegelde karakters.

Dit betekent dat, ongeacht of de opgeslagen inhoud nu in het Arabisch/Hebreeuws of Latijns schrift is opgemaakt, u steeds hetzelfde teken LINKERHAAKJE gebruikt aan het begin van de tekst tussen haakjes. Met andere woorden, behandel gespiegelde karakters alsof elk woord left in de naam 'opening' betekent en right 'sluiting' betekent.
Het Unicode bidi-algoritme en de LRM/RLM-tekens werken vrij goed samen wanneer er slechts één niveau gemengde tekst is. In de situatie met twee of meer vastgezette niveau's directionele tekst zal u een andere oplossing nodig hebben. In deze afbeelding ziet u een zin in Latijns schrift die een citaat in het Hebreeuws bevat, dat op zijn beurt zowel Hebreeuws als Latijnse tekst bevat ('W3C').
De volgorde van de Hebreeuwse woorden is correct maar de tekst 'W3C' zou aan de linkerzijde van het citaat moeten verschijnen en de komma zou tussen de Hebreeuwse tekst en 'W3C' moeten staan.
Het gewenste resultaat bereiken door het gebruik van opmaak om een nieuw "embedding"-niveau te openen.

Het probleem doet zich voor omdat de tekstrichtingen bepaald worden volgens de basisrichting LTR van de alinea. Echter, binnen het Hebreeuwse citaat zou de correcte standaardrichting RTL moeten zijn.
Om dit probleem op te lossen moeten we een nieuw "embedding"-niveau openen. Hiervoor moet u het citaat omsluiten door een tspan-element en het de RTL-richting toewijzen met behulp van de eigenschappen direction en unicode-bidi.
<text>De titel is "<tspan direction="rtl" unicode-bidi="embed"> ... </tspan>" in het Hebreeuws.</text>Er zijn ook Unicode-controlekarakters die u kan gebruiken om hetzelfde resultaat te bereiken maar omdat deze een basisrichting instellen voor een stuk tekst met onzichtbare grenzen, is dit niet aan te bevelen.
Samengevat, waar u enkel de eigenschap direction gebruikt voor "container"-elementen zoals svg, g, text en textArea, moet u zowel direction en unicode-bidi="embed" gebruiken voor tspan-elementen aangezien het inline-elementen zijn.
De andere nuttige waarde van unicode-bidi is bidi-override. U zal deze niet zo vaak moeten gebruiken. Deze wordt beschreven in het volgende onderdeel.
Er kunnen zich gelegenheden voordoen waarop u wilt dat het bidi-algoritme helemaal niks herschikt. In deze gevallen zal u wat extra opmaak moeten aanbrengen rond de tekst die u onveranderd wilt houden.
In SVG kan u dit bereiken met behulp van de waarde bidi-override voor de eigenschap unicode-bidi samen met de eigenschap direction. Opnieuw zijn er Unicode-controlekarakters die u kan gebruiken om hetzelfde resultaat te bereiken maar omdat deze segmenten creëren met onzichtbare grenzen is ditniet aan te bevelen.
Een voorbeeld van een tekst waar u het bidirectionele algoritme wenst te onderdrukken.
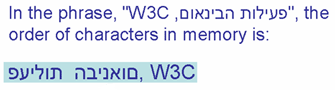
Het voorbeeld in de afbeelding toont Hebreeuwse tekst zoals die wordt gerangschikt in het geheugen. U kan de eigenschap unicode-bidi gebruiken om dat effect te bereiken:
<text x="20" y="80" direction="ltr" unicode-bidi="bidi-override"> ... </text>Unicode gebruikt speciale, onzichtbare formateringscodes om de resultaten van het bidirectioneel algoritme in platte tekst te onderdrukken op dezelfde wijze als de SVG-opmaak die wordt beschreven in deze tutorial.
Er zijn een aantal controlekarakters in Unicode die kunnen worden gebruikt om hetzelfde effect te creëren als bij opmaak voor inline bidirectionele tekst. Deze staan in de onderstaande tabel:
| Karakter | Code | Opmaakequivalent |
|---|---|---|
| RLE | U+202B | <tspan direction="rtl" unicode-bidi="embed"> |
| LRE | U+202A | <tspan direction="ltr" unicode-bidi="embed" |
| RLO | U+202E | <tspan direction="rtl" unicode-bidi="bidi-override" |
| LRO | U+202D | <tspan direction="ltr" unicode-bidi="bidi-override" |
| U+202C | </tspan> |
Unicode in Opmaaktalen raadt het gebruik van deze karakters af wanneer opmaak beschikbaar is en raadt het vermengen van controlecodes en opmaak ten zeerste af.
Ga voor meer informatie hierover naar Unicode-controles vs. opmaak voor bidi-ondersteuning op de website van W3C Internationalization.
Er zijn echter een aantal situaties waarin Unicode controlekarakters de enige manier zijn om directionaliteit uit te drukken. Dit is het geval voor plattetekstelementen zoals title en desc. Deze elementen zijn bepaald om alleen karakters te ondersteunen, geen opmaak. Het is dan ook onmogelijk om de eigenschappen direction of unicode-bidi te gebruiken op een deel van hun inhoud.
Ook attribuuttekst kan niet worden opgemaakt voor directionaliteit dus moeten Unicode-controlekarakters gebruikt worden om de directionaliteit aan te duiden.
Merk op dat andere dingen, zoals taal, ook niet kunnen worden opgemaakt als deel van platte tekst of attribuutwaarden.
Vertel ons wat u ervan denkt (Engels).
Vertaald vanuit de Engelse inhoud met datum 2009-01-07. Vertaalde versie laatst gewijzigd op 2009-01-07 21:09 GMT
Zoek naar tutorial-svg-tiny-bidi in het i18n-blog voor een geschiedenis van de veranderingen in het document.
Copyright © 2009 W3C® (MIT, ERCIM, Keio, Beihang), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}