Deutsch English Français Italiano Nederlands Português Pусский Українська
La tecla de acceso 'n' lleva a la navegación de la página. Ir al inicio del contenido.
Este documento es una traducción. En caso de discrepancias o errores, la única versión normativa es el último original en inglés. Los derechos de autor originales corresponden al W3C, como puede verse al final de la página.
Traductor: Spanish Translation Team, Trusted Translations, Inc.s
http://www.w3.org/International/tutorials/svg-tiny-bidi/
Audiencia de destino: Autores de contenido con SVG que implementan páginas SVG Tiny en árabe y hebreo o que tienen que lidiar con textos incrustados con sistemas de escritura de derecha a izquierda. Este material se aplica en el caso de que usted cree documentos en un editor o mediante secuencia de comandos.
Los sistemas de escritura de derecha a izquierda incluyen al árabe, hebreo, thaana y N'ko y son utilizados por un gran número de personas en todo el mundo. Si es nuevo en esto de trabajar con textos bidireccionales, lograr que se visualice correctamente a veces puede resultar complicado y confuso, pero no debe serlo necesariamente. Si ha lidiado con esto o tiene que comenzar, este tutorial puede ayudarlo a adoptar el mejor método para etiquetar su contenido. También le explica lo suficiente sobre la manera en que funciona el algoritmo bidireccional para que pueda entender mejor las causas de la mayoría de los problemas. También abordaremos algunos errores conceptuales comunes acerca de las maneras de manejar las etiquetas para el contenido bidireccional.
Al finalizar el tutorial, usted será capaz de:
Observe que la especificación SVG Tiny 1.2 fue publicada como una recomendación el 22 de diciembre de 2008. La funcionalidad descripta en este tutorial se usará extensamente después de un tiempo.
Esta sección abarca lo siguiente:
Agregue direction="rtl" a la etiqueta svg para establecer la dirección de base del documento cada vez que la dirección del documento sea de derecha a izquierda. La dirección de base establece el contexto direccional general para el texto dentro del elemento donde se manifieste.
No es necesario que defina explícitamente la dirección de base de los documentos que son predominantemente de izquierda a derecha, ya que esto es lo predeterminado.
Habiendo hecho esto, es posible que no necesite ninguna otra etiqueta de dirección en su contenido. El valor de la propiedad direction configurado en el elemento svg es heredado por los elementos relacionados con el texto a lo largo de todo el documento. El Algoritmo Bidireccional Unicode ('algoritmo bidi') se encarga automáticamente de gran parte del reordenamiento que se necesita para visualizar el texto. Esto se puede ver ilustrado en el ejemplo que figura a continuación.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="fa">
<title>...</title>
<desc>...</desc>
<text x="200" y="200"
font-size="10">داستان SVG Tiny 1.2 طولا ني است.</text>
</svg>
Esto desplegará el texto en el siguiente orden (correcto), si la implementación admite el manejo de texto bidi:
![]()
Sin la propiedad direction, el texto se vería así:
![]()
Obviamente, existen situaciones donde es posible que necesite aplicar más etiquetas. A continuación, describiremos dichas situaciones. Además, agregar direction="rtl" al elemento svg derivará en algunos efectos automáticos en propiedades de text-align y text-anchor que también describiremos en breve.
Mientras está indicando la direccionalidad del documento en la etiqueta svg, no olvide indicar el idioma del documento utilizando el atributo xml:lang (consulte Etiquetas de idiomas en HTML y XML).
Sin embargo, no cometa el error de suponer que las manifestaciones de idioma indican direccionalidad, o viceversa.
Incluso si se utiliza una subetiqueta del sistema de escritura en el valor del atributo de idioma, no tiene ninguna consecuencia con respecto a la direccionalidad del texto en el agente de usuario. Siempre debe indicar la dirección utilizando el atributo dir.
El ordenamiento visual de textos en hebreo era común en los agentes de usuario de HTML antiguo que no admitían el algoritmo bidireccional Unicode. El texto se almacenaba en el código fuente en el mismo orden en el que se esperaría visualizarlo. (No era tan común en el caso de los textos con sistemas de escritura árabes dado que interfería en la forma en que los caracteres árabes se juntaban).
Con un ordenamiento lógico, el texto se almacena en la memoria en el orden en que se escribiría normalmente (y se pronunciaría generalmente). Luego el explorador aplica el algoritmo bidireccional Unicode para visualizarlo de la manera correcta. Actualmente todos los textos en la Web están en orden lógico.
Usted debería siempre escribir el contenido de derecha a izquierda en orden lógico, y confiar en que el algoritmo bidireccional y el lenguaje de etiquetas lo desplegará correctamente. Si no lo hace, no será posible buscar su texto, reutilizar el texto, mantener el contenido fácilmente, etc.
En la imagen que aparece a continuación, la frase "פעילות הבינאום, W3C" (en el margen superior, en azul) aparece de la manera en que aparecería normalmente cuando se despliega en un párrafo de derecha a izquierda. Las flechas numeradas indican la dirección de lectura. Se leen las secuencias en el orden de los números.
Orden de almacenamiento visual y lógico contrastados.

La segunda línea muestra el orden de los caracteres en la memoria en orden de codificación lógico (suponiendo que el primer carácter en la memoria está a la izquierda, el siguiente a la derecha, y así sucesivamente).
La tercera línea muestra el orden de los caracteres en la memoria en orden de codificación visual (con las mismas suposiciones acerca del orden en la memoria).
Esta sección abarca lo siguiente:
Una vez establecida la dirección de base al nivel del elemento svg, no debería utilizar la propiedad direction en otros elementos a menos que desee cambiar la dirección de base para ese elemento.
El uso innecesario de la propiedad direction impacta sobre el ancho de banda y crea, de manera potencial, un esfuerzo adicional para el mantenimiento de la página.
La dirección de base que se establece por la propiedad direction sí afecta, sin embargo, la manera en que se ordena la puntuación y el texto de idiomas combinados dentro de un elemento text o textArea (describiremos esto en mayor detalle más adelante). A veces, es posible que quiera cambiar la dirección de base de algunos de estos elementos, si está en un idioma diferente al del resto de la página.
Para hacerlo, simplemente use la propiedad direction en ese elemento, o en un elemento de agrupamiento que rodea el contenido importante.
En este ejemplo, utilizamos el elemento de agrupación alrededor de diversos elementos text que necesitan una dirección de base de izquierda a derecha que se vea correctamente. El uso de un elemento de agrupación reduce la cantidad de trabajo que debemos realizar para conseguir el resultado deseado. La dirección establecida es heredada por los elementos de text encerrados.
<svg xmlns="http://www.w3.org/2000/svg" width="100%" height="100%" viewBox="0 0 400 400" direction="rtl" xml:lang="he"> <title>...</title> <desc>...</desc> <text x="200" y="20" font-size="10">כתובת לפניות באנגליה:</text> <g direction="ltr"> <text x="100" y="40" font-size="10">3, Tennyson House</text> <text x="100" y="50" font-size="10">17 Clairbourne Road,</text> <text x="100" y="60" font-size="10">Harpenden AL5 4SD</text> </g> </svg>
Sin las etiquetas de dirección en el elemento g, el texto se verá de la siguiente manera:
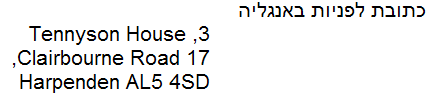
Con la propiedad direction establecida, el texto se verá como lo deseaba.

Posiblemente haya notado que la alineación del texto relacionado con la coordenada x es diferente en los dos ejemplos anteriores. Abordaremos este tema más adelante.
La propiedad text-align se utiliza para el elemento textArea, y sus valores son start, middle y end. Es importante recordar que el primero y el último de estos valores se relacionan con el texto de una manera más lógica que física.
start significa el lugar donde normalmente comenzaría a leer una línea dada la dirección básica actual. Cuando la dirección de base es de izquierda a derecha, significa que es hacia la izquierda del elemento textArea. Si, por otra parte, la dirección de base es de derecha a izquierda, significa el lateral derecho del elemento textArea.
Para end, simplemente revierta eso.
Esto es intuitivo si ha estado utilizando CSS con HTML, ya que la propiedad direction en CSS alinea el texto automáticamente a la derecha en un elemento de bloque.
En este ejemplo en Urdu la dirección de derecha a izquierda que está configurada en el elemento svg es heredada por el elemento textArea.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
dir="rtl" xml:lang="ur">
<title>...</title>
<desc>...</desc>
<textArea x="20" y="20" width="200">
فعالیت بینالمللیسازی، W3Cنا
عالمگیر ویب کو حقیقی طور پر عالمگیر بنانا
</textArea>
</svg>
En pantalla, el texto debería verse alineado a la derecha dentro de la caja textArea, como se muestra a continuación, dado que el valor predeterminado de text-align es start, lo cual significa "alineado a la derecha", en una dirección de base de derecha a izquierda.

La propiedad text-anchor se utiliza para el elemento text, y sus valores son start, middle y end. Nuevamente, el primero y último de estos valores se relacionan con el texto de una manera más lógica que física.
Si no especificó ninguna dirección de base, o especificó direction="ltr", y si el text-anchor está configurado en start, el texto se extenderá hacia la derecha de la coordenada x. Si configuró direction="rtl", el texto se extenderá hacia la izquierda de la coordenada x. El text-anchor está configurado en start de manera predeterminada.
En el caso de end, sucede lo contrario.
En este ejemplo de inglés/árabe, usamos dos elementos de texto, ambos con la misma coordenada x y con el valor predeterminado para text-anchor.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
xml:lang="en">
<title>...</title>
<desc>...</desc>
<text x="200" y="10"
font-size="10">Internationalization activity, W3C</text>
<text direction="rtl" x="200" y="20"
font-size="10">نشاط التدويل، W3C</text>
</svg>
Aunque la coordenada x para ambos elementos de texto es la misma, el texto se verá de la siguiente manera:

Debe tener en cuenta que la dirección en la que el texto se extiende desde el punto x (vea el ejemplo anterior) depende de la dirección de base, es decir, el valor de la propiedad direction, y no si se trata de texto en latín o árabe (o hebreo). Esto es importante.
Significa que, por ejemplo, una lista de términos que contiene palabras en latín y del Oriente Medio no desalinea los ítems de manera inesperada.
El siguiente ejemplo contiene líneas alternantes en sistemas de escritura hebreo y latín:
<svg xmlns="http://www.w3.org/2000/svg" width="100%" height="100%" viewBox="0 0 400 400" direction="rtl" xml:lang="he"> <title>...</title> <desc>...</desc> <text x="200" y="20" font-size="10">פעילות הבינאום, W3C</text> <text x="200" y="30" xml:lang="en" font-size="7">(Internationalization Activity, W3C)</text> <text x="200" y="50" font-size="10">ליצור מהרשת רשת כלל עולמית באמת</text> <text x="200" y="60" xml:lang="en" font-size="7">(Making the World Wide Web worldwide)</text> </svg>
Todos los ítems en la lista de direcciones seguirán apareciendo alineados a la derecha. No tenemos que hacer nada especial para las líneas solamente en latín a fin de que se alineen con el resto.

Sin embargo, lo que sí debe recordar es que si por alguna razón aplica direction="ltr" para uno de los elementos text, también debe especificar el text-anchor="end" para ese ítem, para que siga alineándose con los demás.
Esta sección abarca lo siguiente:
En secciones anteriores hemos mencionado que en ocasiones no es suficiente simplemente agregar información sobre la dirección a la etiqueta svg. En esta sección observaremos por qué y cuándo se requiere mayor control, y nos abocaremos particularmente a la manera de etiquetar elementos tspan para indicar dirección (para lo cual necesitamos presentar la propiedad unicode-bidi).
El resultado de aplicar el algoritmo bidireccional depende de la dirección de base general de la frase, el párrafo, el bloque o la página en la cual se aplica. La dirección de base determina el contexto direccional al cual se refiere el algoritmo bidi en diversos puntos para decidir cómo manejar el texto.
La dirección de base se configura explícitamente por el elemento padre más cercano que usa la propiedad direction, o bien, en ausencia de dicho padre, es heredada desde la direccionalidad predeterminada de la etiqueta svg, que es de izquierda a derecha.
Observe que para los elementos de bloque se puede configurar solamente una dirección de base de derecha a izquierda por medio de la propiedad direction.
Ya sabemos que una secuencia de caracteres en latín se despliega uno tras otro de izquierda a derecha (podemos verlo en esta página). Por otro lado, el algoritmo bidi desplegará una secuencia de caracteres RTL (de derecha a izquierda) fuertemente tipados uno tras otro de derecha a izquierda.
Esto es independiente de la dirección de base actual y funciona ya que cada carácter en Unicode tiene una propiedad direccional asociada. La mayoría de las letras son fuertemente tipadas como LTR (de izquierda a derecha). Las letras de los sistemas de escritura de derecha a izquierda son fuertemente tipadas como RTL.
Escritura direccional.

Cuando se mezcla texto con direccionalidad diferente en línea, el algoritmo bidi representa cada secuencia de caracteres con la misma direccionalidad como una secuencia direccional ("directional run", en inglés) separada.
En el siguiente ejemplo hay tres secuencias direccionales:
Secuencias direccionales.

Otra manera de observar esto es que los cambios de dirección marcan los límites de las secuencias direccionales. Observe que no es necesario agregar etiquetas o estilos para que esto suceda.
Es sumamente importante entender que el orden en que se visualizan las secuencias direccionales en toda la página depende de la dirección de base predominante.
Las palabras en la imagen que aparece abajo corresponden a secuencias direccionales separadas. La línea superior se encuentra dentro de un contexto donde la dirección de base es de izquierda a derecha; el botón, de derecha a izquierda. Los caracteres en ambas líneas de la imagen se almacenan en la memoria en exactamente el mismo orden, pero el orden visual de las secuencias direccionales, cuando se visualizan, es el inverso.
El efecto de la dirección de base al visualizarse las secuencias direccionales.

Los espacios y la puntuación no son fuertemente tipados como LTR o RTL en Unicode, ya que pueden utilizarse en cualquier tipo de sistema de escritura. Están clasificados como neutros.
Aquí es donde las cosas empiezan a ponerse interesantes. Cuando el algoritmo bidi encuentra caracteres con propiedades direccionales neutras (como los espacios y la puntuación) deduce cómo debe manejarlos al observar los caracteres circundantes.
Un carácter neutro entre dos caracteres fuertemente tipados con el mismo tipo de dirección también adoptarán la misma direccionalidad. Por lo tanto, un carácter neutro entre dos caracteres RTL fuertemente tipados se tratará como un carácter RTL en sí, y tendrá el efecto de extención de la secuencia direccional. Por esta razón, las tres palabras árabes en esta frase LTR (separadas sólo por espacios, los cuales tienen direccionalidad neutra) se leen de derecha a izquierda como una única secuencia direccional. (La primera palabra en árabe que lee es مفتاح luego معايير luego الويب).
Caracteres neutros como parte de la secuencia direccional.

Observe que no es necesario agregar etiquetas o estilos para esto, y que sólo hay tres secuencias direccionales aquí.
La parte realmente interesante viene cuando un espacio o signo de puntuación cae entre dos caracteres fuertemente tipados con direccionalidad diferente, es decir, en el límite entre secuencias direccionales. En dicho caso, los caracteres neutros se tratarán como si tuvieran la direccionalidad de la dirección de base.
Incluso si hay diversos caracteres neutros entre los dos caracteres fuertemente tipados, todos serán tratados de la misma manera.
Caracteres neutros.

Los números en sistemas de escritura RTL se leen de izquierda a derecha dentro del flujo de derecha a izquierda, pero el algoritmo bidi los trata de una manera un tanto diferente que a las palabras. Se dice que tienen una direccionalidad débil. Los dos ejemplos en la imagen ilustran esta diferencia.
Dígitos.
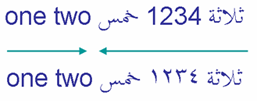
En el primer ejemplo, se usan dígitos europeos '1234'; en el segundo, se expresa el mismo número utilizando dígitos arábigo-índicos, ١٢٣٤. En ambos casos, los dígitos en el número se leen de izquierda a derecha.
Dado que es débilmente tipado, el número se ve como parte del texto en árabe, por lo tanto, las dos palabras árabes que rodean el número son tratadas como parte de la misma secuencia direccional, aunque la secuencia de dígitos vaya de izquierda a derecha en la pantalla.
Observe también que, al lado de un número, ciertos caracteres neutros, de otra manera, como los símbolos de divisa serán tratados como parte del número en vez de neutros.
El algoritmo bidi manejará el texto perfectamente bien en la mayoría de las situaciones. Generalmente no será necesario aplicar etiquetas especiales u otro dispositivo además de la dirección general del documento. Sin embargo, considérese muy afortunado si empieza así de fácil todo el tiempo. A continuación presentamos nuestro primer ejemplo de una situación en la cual el algoritmo bidireccional necesita un poco de ayuda.
La primera línea en esta imagen muestra un signo de exclamación, que es parte del texto en árabe incrustado, ubicado en el lugar incorrecto. La segunda línea muestra el resultado deseado.
Los caracteres neutros entre secuencias direccionales pueden terminar donde no deberían.
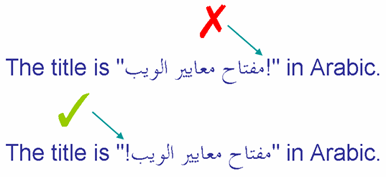
De acuerdo con lo que comentamos anteriormente sobre el algoritmo bidi, podemos comprender fácilmente por qué sucedió esto. Dado que el signo de exclamación fue escrito entre la última letra RTL 'ب' (a la izquierda) y la letra LTR 'i' (de la palabra 'in') su direccionalidad es determinada por la dirección de base del párrafo (aquí LTR). Observe que no hace ninguna diferencia que haya en realidad dos caracteres de puntuación y un espacio en esta posición: son todos neutros y, por ende, todos se ven afectados de la misma manera. Dado que el signo de exclamación se ve como LTR, se une a la secuencia direccional que incluye el texto 'en árabe'.
Entonces, ¿cómo hacemos para que la puntuación se ubique en el lugar correcto?
Una respuesta es poner la cita en árabe en un elemento tspan y usar la propiedad direction para cambiar la dirección de base dentro del tspan a RTL.
A diferencia de los elementos contenedores que observamos antes, el tspan requiere que usted especifique la propiedad unicode-bidi, como así también la propiedad direction, a fin de que el cambio de la dirección de base sea efectivo. El valor que necesita es embed. (Abordaremos el tema del uso de bidi-override más adelante).
<text>El título es "<tspan direction="rtl" unicode-bidi="embed" xml:lang="ar"> ... !</tspan>" en árabe.</text>El entorno de edición que utiliza tal vez no muestre el signo de exclamación en el lugar correcto en el código fuente, pero debería verse bien al visualizarse.
Preste mucha atención a la manera en que la etiqueta <span> cae dentro de las comillas (las comillas son parte del texto en inglés circundante).
Otra posibilidad sería ingresar un carácter RTL invisible fuertemente tipado después del signo de exclamación. De esta manera, el signo de exclamación se interpretaría como RTL y se uniría a la secuencia direccional en árabe.
Lo que sucede es que hay sólo un carácter de ese tipo: el carácter Unicode U+200F, denominado RIGHT-TO-LEFT MARK (signo de derecha a izquierda) o RLM. Existe un carácter similar, U+200E, denominado LEFT-TO-RIGHT MARK (signo de izquierda a derecha) o LRM. Dado que el carácter es invisible, es aconsejable escribir una referencia numérica de carácter ()
Agregar este carácter justo después del signo de exclamación producirá el resultado deseado.
<text>El título es "... !" en árabe.</text>Si ya hay etiquetas alrededor de la cita, probablemente tenga sentido usar direction en ella, en lugar del carácter de control. De lo contrario, sería más fácil usar el carácter de control.
La línea superior de la siguiente imagen muestra qué le sucedería a una lista de ítems RTL dentro de una oración LTR si confiaramos únicamente en el algoritmo bidireccional (es decir, si no hubiésemos usado la propiedad direction para establecer la dirección de base). En nuestro ejemplo, el orden de la lista es incorrecto porque las dos primeras palabras en árabe deberían invertirse, y la coma interpuesta, la cual es parte del texto en inglés, debería aparecer inmediatamente a la derecha de la primera palabra.
La segunda línea en la imagen muestra el resultado deseado.
Los caracteres neutros entre los textos con la misma dirección pueden interpretarse incorrectamente como parte de una única secuencia.

El motivo de la falla es que, con un carácter fuertemente tipado de derecha a izquierda (RTL) en cualquiera de los extremos, el algoritmo bidireccional considera la coma* neutra parte del texto en árabe. Está interpretando las dos primeras palabras en árabe y la coma como una lista en árabe. De hecho, la coma es parte del texto en inglés, y debería marcar el límite de las dos secuencias direccionales en árabe.
En la sección anterior, el carácter neutro consideró que era parte del contexto direccional establecido por la dirección de base, pero no lo era; en esta sección, el carácter neutro considera que es parte de la secuencia direccional, cuando en realidad es parte del contexto direccional general.
Una solución simple es usar otro carácter Unicode invisible, esta vez la LEFT-TO-RIGHT MARK, al lado de la coma. Esto coloca nuestra puntuación neutra entre los caracteres RTL y LTR fuertemente tipados y la obliga a tomar una direccionalidad de la dirección de base, la cual es de izquierda a derecha del texto en inglés. Esto divide las palabras en árabe en dos secuencias direccionales separadas, las cuales se ordenan de izquierda a derecha de acuerdo con la dirección que prevalece en el párrafo.
<text>Los nombres de estos estados en árabe son ..., ... y ... respectivamente.</text>Una vez más, es aconsejable usar una referencia numérica de caracter o NCR () por motivos de visibilidad.
La siguiente imagen muestra otro ejemplo donde no es necesario el lenguaje de etiquetas, y un carácter de control Unicode cumple la función de una manera más simple. Nuevamente, la línea azul superior muestra el resultado del hecho de confiar únicamente en el algoritmo bidireccional, y la segunda línea muestra el resultado deseado.
El resultado deseado se logró al colocar al lado del paréntesis que se suponía parte del contexto en hebreo, pero que aparece entre dos extensiones de texto en latín. El efecto de la marca RLM es la división del texto en latín en tres secuencias direccionales separadas, las cuales se ordenan de acuerdo con la dirección de base de derecha a izquierda.
Otro ejemplo del uso del RLM o LRM; esta vez dentro de un contexto en hebreo.

Posiblemente haya notado que, además de cambiar la posición, uno de los paréntesis en el ejemplo anterior de hecho cambió de forma también. Esto fue completamente automático, y sucedió ya que estos caracteres son los que en Unicode se conocen como "caracteres espejados".
Los caracteres espejados son generalmente pares de caracteres, como paréntesis, corchetes, etc., cuya forma al visualizarse depende de si es parte de un contexto LTR o RTL. No es necesario cambiar el carácter para que cambie la forma. Los extremos de un paréntesis de apertura siempre se orientan en la dirección del flujo del texto. En la imagen que aparece a continuación, el paréntesis encerrado en un círculo rojo está orientado hacia la derecha en la línea superior ya que se lo está tratando como el paréntesis de apertura de algún texto en latín. En la versión del texto de más abajo, el mismo carácter (también encerrado en un círculo en red) es tratado como un paréntesis de apertura relacionado con el texto en hebreo (es decir, el nombre expandido sigue a la sigla en orden de lectura) y, por lo tanto, está orientado hacia el otro lado.
Caracteres espejados.

Esto significa que, ya sea que el contenido almacenado esté en un sistema de escritura árabe/hebreo o latín, usted debería usar el mismo carácter PARéNTESIS IZQUIERDO al comienzo del texto entre paréntesis. En otras palabras, debe tratar a los caracteres espejados como si cualquier palabra left en el nombre significara apertura', y right significara 'cierre'.
El algoritmo bidi Unicode y los signos LRM/RLM funcionan bastante bien cuando hay un solo nivel de texto combinado. Si se encuentra en una situación en la cual hay dos o más niveles anidados de texto direccional, necesitará una solución diferente. Esta imagen muestra una oración en latín que contiene una cita en hebreo que, a su vez, contiene texto en hebreo y latín ('W3C').
El orden de las dos palabras en hebreo es correcto, pero el texto 'W3C' debería aparecer al costado izquierdo de la cita y la coma debería aparecer entre el texto en hebreo y el 'W3C'.
Cómo obtener la visualización deseada utilizando etiquetas para abrir un nuevo nivel de incrustación.

El problema surge porque los flujos direccionales están siendo ordenados de acuerdo con la dirección de base LTR del párrafo. Dentro de la cita en hebreo, sin embargo, el orden correcto predeterminado debería ser RTL.
Para resolver este problema debemos abrir un nuevo nivel de incrustación. Para hacerlo, debe encerrar la cita con un elemento tspan y asignarle direccionalidad de derecha a izquierda por medio de las propiedades direction y unicode-bidi.
<text>El título dice "<tspan direction="rtl" unicode-bidi="embed"> ... </tspan>" en hebreo.</text>También existen caracteres de control Unicode que puede utilizar para conseguir el mismo resultado, pero dado que éstos establecen la dirección de base para una extensión de texto con límites invisibles, no se recomienda su uso.
En resumen, visto que simplemente usa la propiedad direction en elementos contenedores, como svg, g, text y textArea, usted debe usar direction y unicode-bidi="embed" en elementos tspan, ya que están en línea.
El otro valor útil de unicode-bidi es bidi-override. No será necesario utilizarlo muy a menudo. Lo describiremos en la próxima sección.
Es posible que se presenten situaciones en las cuales no desee que el algoritmo bidi realice su trabajo de reordenamiento de ningún modo. En estos casos, necesita utilizar etiquetado adicional para rodear el texto que desea dejar desordenado.
En SVG esto se logra utilizando el valor bidi-override de la propiedad unicode-bidi junto con la propiedad direction. Una vez más, existen caracteres de control Unicode que puede utilizar para obtener el mismo resultado, pero dado que éstos crean estados con límites invisibles, no se recomienda su uso.
Un ejemplo de texto en donde desea anular el algoritmo bidireccional.
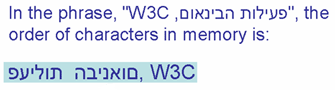
El ejemplo en la imagen muestra texto en hebreo como se encuentra ordenado en la memoria. Para lograr ese efecto, puede usar la propiedad unicode-bidi, es decir:
<text x="20" y="80" direction="ltr" unicode-bidi="bidi-override"> ... </text>Unicode proporciona códigos de formato invisibles y especiales para continuar o anular el resultado del algoritmo bidireccional en texto plano, de la misma manera que el etiquetado SVG descrito en este tutorial.
Existen diversos caracteres de control en Unicode que pueden usarse para crear el mismo efecto que el etiquetado para texto bidireccional en línea. éstos se encuentran enumerados en la siguiente tabla:
| Carácter | Código | Etiquetado equivalente |
|---|---|---|
| RLE | U+202B | <tspan direction="rtl" unicode-bidi="embed"> |
| LRE | U+202A | <tspan direction="ltr" unicode-bidi="embed" |
| RLO | U+202E | <tspan direction="rtl" unicode-bidi="bidi-override" |
| LRO | U+202D | <tspan direction="ltr" unicode-bidi="bidi-override" |
| U+202C | </tspan> |
Unicode en lenguajes de etiquetas desaconseja su uso cuando hay etiquetado disponible, y desaconseja particularmente la mezcla de códigos de control y etiquetas.
Para obtener más información sobre este tema, consulte Caracteres de control Unicode en contraposición al uso de etiquetas para el control de la bidireccionalidad en el sitio W3C Internationalization.
Sin embargo, surgen ciertas situaciones donde los caracteres de control Unicode proporcionan el único medio para expresar direccionalidad. éste es el caso de elementos de texto plano, como title y desc. Estos elementos se definen para admitir sólo caracteres, no etiquetas. Por lo tanto, no es posible usar las propiedades direction o unicode-bidi en una parte del contenido del elemento.
El texto de atributo tampoco puede ser etiquetado para indicar direccionalidad, por ende, se deben utilizar los caracteres de control Unicode.
Observe que no se puede aplicar etiquetas a otras cosas, como el idioma, para partes con contenido de texto plano ni valores de atributo.
Dinos qué piensas (en inglés).
Traducido del inglés con fecha 2009-01-07. Traducción modificada por última vez el 2009-06-17 12:10 GMT.
Para ver el historial de cambios del documento, busque tutorial-svg-tiny-bidi en la bitácora de internacionalización.
Copyright © 2009 W3C® (MIT, ERCIM, Keio, Beihang), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}