
Beijing Text Layout Workshop, Sept 2014
There are currently two groups in the Internationalization Activity. Task forces can be created under each of these groups.
In addition, anyone who can attract enough interest can set up a Community Group at the W3C. These groups are self-organizing. There are already some dealing with internationalization topics. They include:

The Internationalization Working Group contains members from and liaises with many key organizations involved in ensuring that the Web remains multilingual, including Unicode, the IETF, Ecmascript, various language industry initiatives, etc.


From the Internationalization Activity home page you can find out what's going on, how to join in, and get internationalization-related advice.

The techniques index allows you to discover how to incorporate internationalization needs into your work. It is organized by task, and helps you narrow in quickly on the information you need.
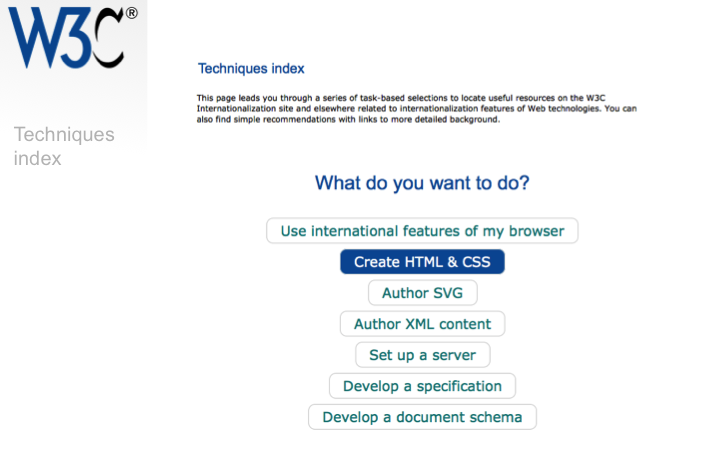


The lowest level of the index provides links to useful information, and also a set of do's and don'ts, linked to explanations and examples.
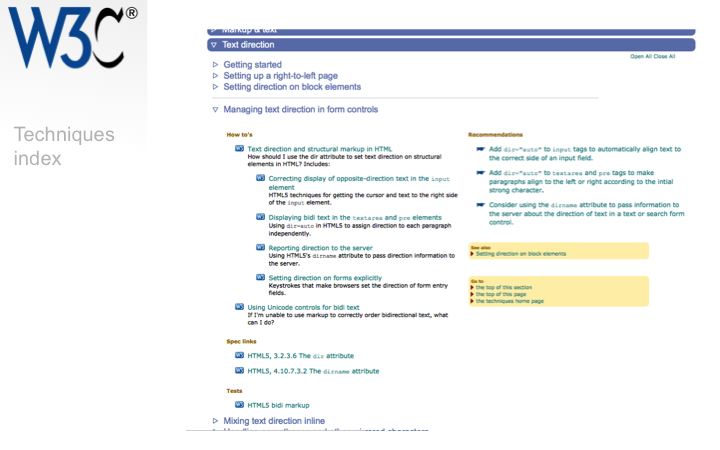
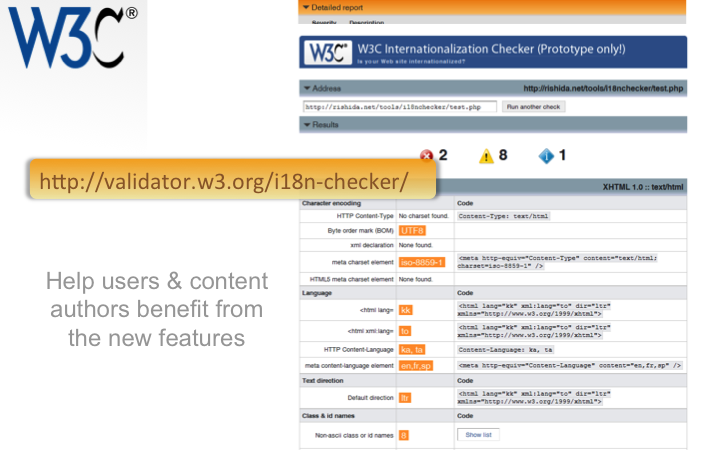
You can run your pages through the online Internationalization Checker to spot issues and find out how to fix them.
For some years we have been running very successful MultilingualWeb workshops in Europe, attracting 100-150 people, with the stated intent to bridge between disciplines and bring together people who don't typically mix, and yet who are all working on making the World Wide Web world wide.

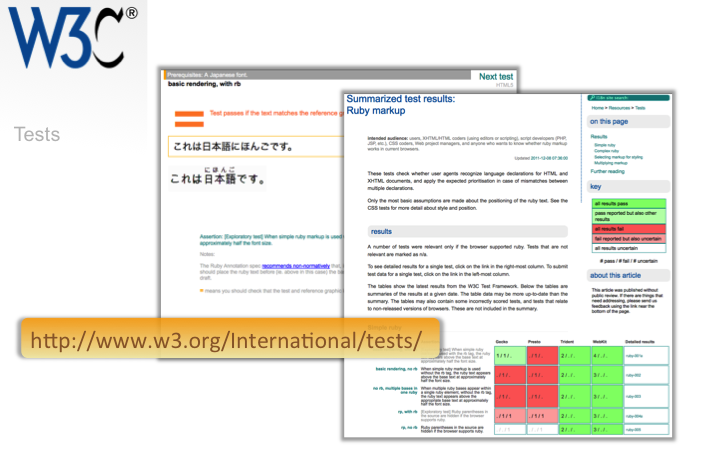
The Internationalization Working Group also develops tests for internationalization features, and adds many of those tests to the HTML and CSS test suites. These tests are useful to content developers, to give an idea of what is and is not currently supported, but they are also often used by browser implementers too, to test feature support.

Various requirements have already been fed into the development of W3C specifications. These include:
Recently a lot of work has been done to improve support for Arabic, Hebrew, and other right-to-left scripts in HTML and CSS. In particular, the document "Additional Requirements for Bidi in HTML5 & CSS" improves the ability to isolate items to significantly improved handling of text that is added to a page from an external source, as well as many normal content authoring situations.
You can learn more about how to use these techniques in the tutorial Creating HTML Pages in Arabic, Hebrew and Other Right-to-left Scripts.

The document Requirements for Japanese Text Layout showed how useful it can be to have a detailed requirements document that covers a wide range of requirements for a given script. It has been used to guide development of several major technologies of the Open Web Platform. It was made available in Japanese and English, and published also in book form.
It covers topics such as:

The basic process for producing the Japanese requirements doc was as follows:

Work has also started on a similar document for Korean requirements, Requirements for Hangul Text Layout and Typography. Topics include:

And another document, Indic Layout Requirements, is looking at requirements for languages of India. Topics include:

We have started work on Chinese Layout requirements, for both Simplified and Traditional Chinese. This will cover similar ground to the Japanese document, but will point out China-specific differences and explain the requirements for those.

We would also like to address usage of other scripts used in China, such as Mongolian, Tibetan, and the Arabic script as used for Uighur.

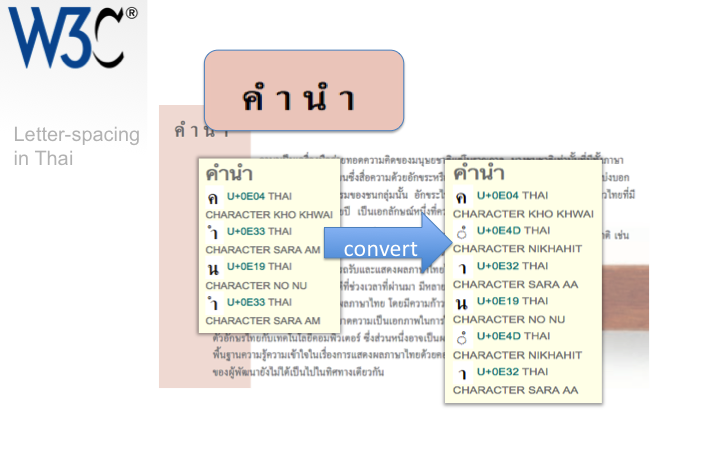
The title in the top-left corner of the Thai text on this slide has been letter-spaced.

This slide shows how the normal set of characters used to produce this word have to be converted to a different set of characters in order to allow the letter-spaces to appear where expected. The list of characters on the right should only be used internally for this purpose – content authors should actually write and store the text as shown in the left-hand list.
We became aware of this issue thanks to an email from an expert on a W3C list. What other issues are out there for supporting Thai and related scripts on the Web?
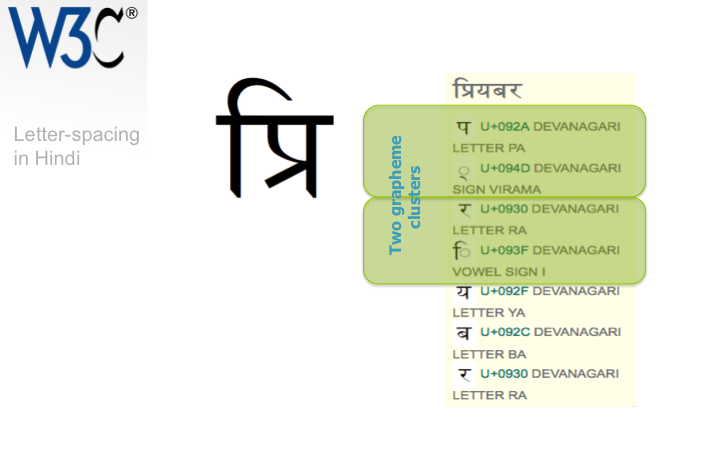
This slide shows Hindi text. Hindi can be letter-spaced, in which case you would expect it to look like the text on the second line.
However, the representation of the first syllable as a single unit depends on the availability of glyphs in the font. Change the font for a less sophisticated one and you may actually see the text as displayed on the bottom line of the slide.

The devanagari script, which is used to write Hindi, is based on syllablic structures. The list to the right shows the characters used to write the word, but note how the first four characters are combined visually to make one user-perceived unit. The characters in this unit should not be separated by letter-spacing (nor by first-letter styling, justification, line-wrapping, vertical text layout, etc).

The current wording in the CSS3 Text spec says that you should base unit boundaries for letter-spacing on 'grapheme clusters'. This is a concept defined by the Unicode Standard, which typically associates base characters with combining characters that follow it. Unfortunately, the current definition of grapheme-clusters leads to a segmentation of the Hindi word as shown on the bottom line of the slide and does not allow for the combination of all four initial characters into a single unit.
Unfortunately, it is not so straightforward to fix this by extending the definition of a grapheme cluster because the representation of the first syllable as a single unit depends on the availability of glyphs in the font. It is not clear how to automatically detect what kind of font is being used for display (ie. does it support the larger syllable or not) and thereby where to break the word during letter-spacing.
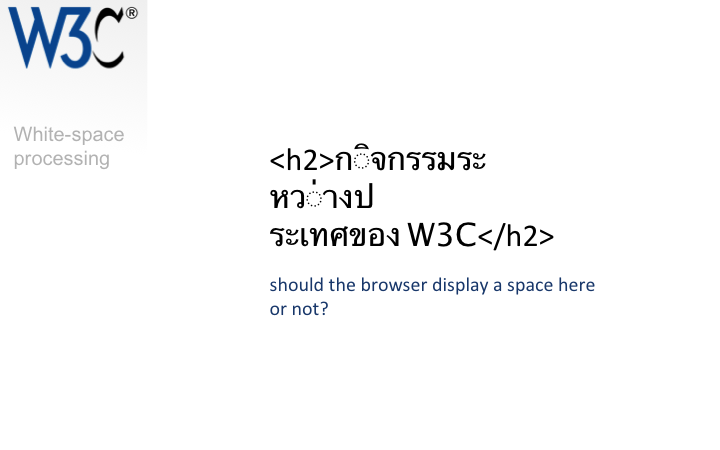
Thai is a script which doesn't use spaces to separate words. If there is content in the source code like that shown in the slide, should the two parts have a space between them when the text is displayed as part of the page? What if a line is too long to fit in the width of the editing window, but you don't want to introduce spaces?
Webkit has just this week produced support for more sophisticated drop-caps, which adds improvements for positioning but also uses grapheme-clusters as a basic unit for detecting what should be enlarged. However, use of grapheme clusters doesn't address the more complicated indic syllable which we saw earlier. What should be added? And are the positioning rules adequate for other scripts?

Has CSS correctly captured the needs for underlining of scripts, especially those where an uninterrupted line would obscure important elements of the text? What about underlining in Tibetan. Similar issues for overlines and strike-through.
What are the rules for emphasis, and how do they differ in horizontal and vertical texts? Here we see two alternative methods for Japanese, but the top one is specifically for horizontal text – there are different glyphs for vertical text. The Tibetan text at the bottom uses small symbols below a syllable to create emphasis (or sometimes as part of an annotation for commentaries). Placement is not always as straighforward as shown here, since the signs need to be centred on the syllable as a whole, rather than attached to a particular letter.

Some scripts or collections of scripts have unique typographic features, such as kumimoji and warichu in Japanese. How important is support for these? And what are the rules for use?

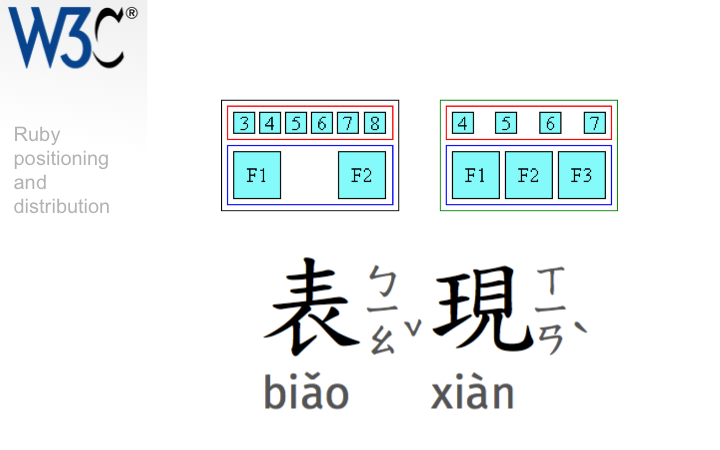
Ruby markup support has been making good progress in browsers, but now the styling implementations must follow, and the rules need to be clarified. What are the various styles of alignment that the user will need to control? How will browsers implement bopomofo ruby, and what are the exact rules for positioning of the bopomofo and its tone marks?
The logo on the left shows a colour change between two joining characters. There was recently a discussion about how to handle this in CSS. In particular, questions centered on whether style changes including font changes should be allowed. Or what to do if the CSS changes two blocks of text to inline runs.

There are slight differences listed in the CSS Text spec for line-breaking in Japanese and Chinese. Korean shares some of the line breaking rules, but are there specific Korean differences to take into account?

There are different opinions among experts about the right way to justify Arabic text – do you stretch spaces, or do you stretch baselines? Or both? Many of the current views are based on fixed-sized pages, but we need a strategy that will survive as users stretch and shrink windows.
If cursive elongation is proposed (and it is certainly used in other contexts) what are the rules for application? And how do you handle differences between font-styles such as naskh, nastaliq and ruq'ah, when the text can switch between these depending on what font and rendering is available on their system?

Does CSS need to allow users to apply tsek padding at the end of lines for Tibetan justification? If so, what are the detailed rules for it's application, since its appropriateness varies, depending on things such as what ends the line?

We need to get data from other countries
Organizational issues
The W3C is not a 'magic box' that miraculously produces standards, requirements, and other information. We need people to volunteer to make this happen. There needs to be one or more chairs to manage the group, and a representative body of regular participants contributing content and reviewing the work.

We also need to ensure that newly specified features make it into browsers


Always remember that community involvement is crucial to development of W3C specifications. The W3C does not simply decide in an ivory tower to develop specifications and impose them on the public. The process only starts when we have support from the W3C member companies, experts and industry participants who will compose the Working Group. If you feel that this work is valuable, please consider participating in the Working Group.

Content created September, 2014. Last update 2016-03-02 20:30 GMT
Copyright © 2014 W3C® (MIT, ERCIM, Keio, Beihang), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements.