


Report
The Open Data on the Web workshop attracted substantial interest leading to two very intensive days of input and discussion. The initial motivation for the event was a desire to engage more fully with wider open data community, in particular the section of the community that is focused on CSVs and JSON rather than linked data. To achieve this the events was organized by W3C in collaboration with two other open organizations.

The Open Data Institute is a technology-neutral body set up by Nigel Shadbolt and Tim Berners-Lee to "catalyze an open data culture that has economic, environmental and social benefits." The Open Knowledge Foundation promotes the publication and use of open data across the world and is responsible for many eye-catching initiatives as well as the widely used CKAN platform. The combination of the three organizations coming together for an event hosted by Google at Campus London gave it a very high profile and broad reach.
In numbers:
- papers submitted: 62;
- papers presented: 36 + 24 additional authors as panelists/contributors;
- no. panels: 3;
- no. national governments represented: 3;
- no. bar camp pitches: 9;
- no. registered attendees: 118 (of whom just 6 failed to attend);
- tweets tagged #odw13 sent during the workshop: 1898.
Raw minutes are available for Day 1 and Day 2. All slides are linked from the Agenda as are the papers. A separate listing of the papers is also provided.
Developing the Ecosystem

The very first presentation from John Sheridan of the UK National Archives set the scene. He talked about the importance of developing a secure foundation for open data, that is, a solid business case for the publication and use of open data. If we fail to do this we risk the whole movement collapsing (his metaphor was that we need to build our house on rock, not sand). This theme was emphasized by a number of others including, most forcefully, IBM, whose Bob Schloss talked about the need for incentives to be in place to have “economically significant” amounts of open data. He suggested that as a minimum these include:
- Recognition: the producer wants simply to be recognized for the data produced and found valuable.
- Indirect Benefit: the data producer wants the consumer to benefit using open data and credit for participating.
- Direct Benefit: the data producer wants value from usage by consumer.
He further talked about the need to put in place trust and security mechanisms for ensuring data quality, and the tracking of data ownership and provenance. This resonated particularly with Pascal Romain and Elie Sloïm's proposed checklist for open data.
There is work to be done in this sphere and to get commercial entities and the public sector working together. We, as a community, need to identify the basic datasets that will be the "streets" of open data." One possibility floated in the session on the business of open data was that commercial companies would provide the infrastructure and services to clean and harmonize public sector data that would add value for the publisher and other consumers alike. As well as this kind of opportunity there is the potential for other chargeable services such as training and consultancy too.
Conclusion: We need to do more to build a virtuous circle between publishers, developers and end users.
Tabular Data
One of the key sessions during the workshop was on tabular data formats. The Open Knowledge Foundation's Rufus Pollock presented his proposal for a simple data format - essentially a way to deliver CSV and/or JSON data and its metadata in a package (see relevant blog post). This is a very different view of the world than that taken by the linked data community and it is precisely that sort of difference in approach that the workshop was designed to address. On RDF, Rufus said:
RDF isn't natural — and therefore is barely used — by the average Web developer or data wrangler. CSV, by contrast, is. And you are going to need to win the hearts and minds of those folks for whatever approach is proposed.
Google's Omar Benjelloun asserted that tables naturally capture relations and do so better than APIs: there are no access patterns or scalability issues. RDF and common vocabularies are better than custom data models for defining schemas for DSPL, SDMX and CSVs (it is notable that Omar Benjelloun is the person responsible for DSPL at Google). He went on to say If we want to bring data together, we have to harmonize into a common model. However, that may not be the responsibility of developers. Rufus Pollock seemed to agree, suggesting that if you talk to developers about vocabularies they run for the hills.
There was general consensus around the need for a metadata format for tabular data that should probably be separate from the data itself although Tyng-Ruey Chuang (Academia Sinica) felt it would be easier to combine heterogeneous data if the metadata were embedded.
The overall theme from the session was that there is a need for simplicity and innovation - and that tables are in line with that notion; that developers and data providers can only be expected to do so much, and that the provision of good quality metadata is essential.
Panelists Stuart Williams (Epimorphics) and John Snelson (MarkLogic) both expressed a desire to get away from being tied to a particular technology and think more in terms of problems that need to be solved.
Conclusion: tabular data, notably CSV, is important and well understood by developers and people who are not data specialists. What's needed is a means to communicate metadata about the tabular data so that it can be understood and processed with a minimum of extra work. Jeni Tennison's work on Linked CSV is a potential starting point.
We Need Help!
The workshop included presentations from several organizations that are working with open data in one way or another, in particular, experimenting with linked data. The technical specifications are sufficient to create and manage the data but many presentations ended with words to the effect of "what I'm hoping is that the people in this room can help us go further in achieving our goals."

The underlying question here is not so much 'how do I do open data?' as 'what problems can open data help me solve?'
Organizations in this category included the Science Museum, the UN Development Program, DNA Digest, the European Commission's JRC, the Univeristy of Plymouth and students at the Royal College of Art.
Conclusion: we need to do more to guide potential publishers and users of open data.
Mixing My Data with Open Data
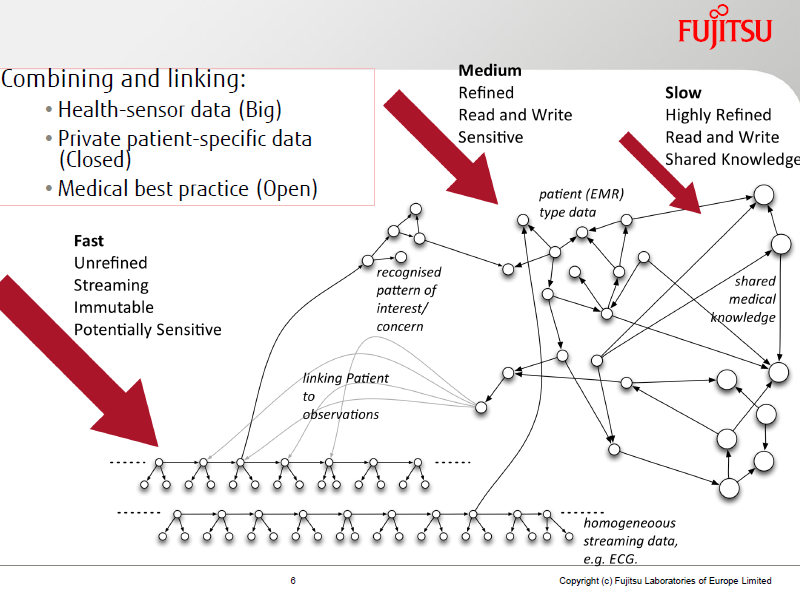
The point was made by a number of presenters that there's a lot more data behind firewalls and paywalls than there is out in the open. One can argue about whether some data should be open or not, but there is some data that unequivocally should not be open and more than simply won't be. Organizations like the BBC, Deutsche Nationalbibliothek, customers of companies like IBM and commercial entities like Pearson work primarily with what one might simply call closed data. However, that data can be augmented using open data. One area where this is particularly relevant is in health care and life sciences. Patient data is kept private (or should be!), but anonymized data, data about disease pathways and more can readily be shared for the benefit of all.
This did not prevent the room enjoying several rounds of Chris Gutteridge's Open Data Excuse Bingo, i.e. electronically shouting every time a predictable excuse is used as to why data cannot be opened.
Conclusion: the 'open data community' needs to respect and engage positively with the closed data world.
Product Data
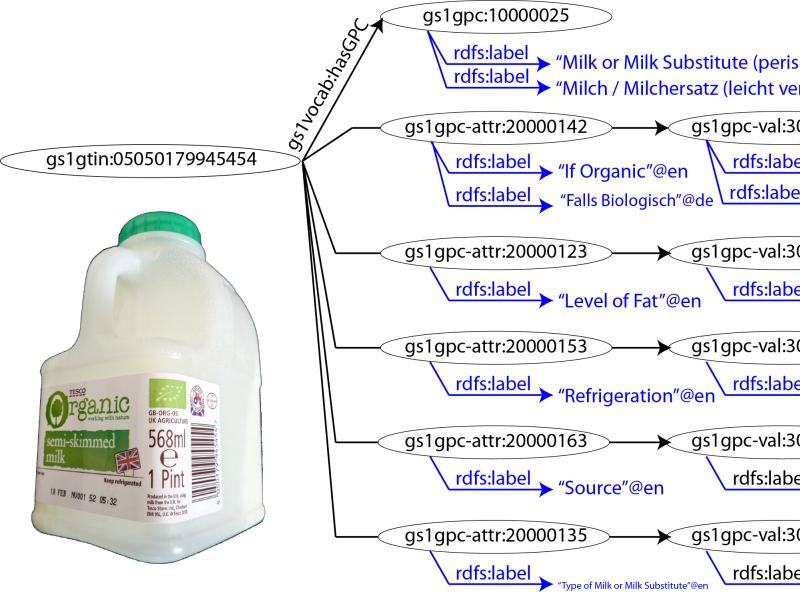
A session on product data brought together a number of organizations that have not been associated with open data until now. GS1 is the global standards body behind the number system encoded as bar codes on just about every product in the world. NXP Semiconductors is a large manufacturer that is creating a version of its product catalog as linked open data and Tesco is Britain's biggest retailer (believed to be second only in size to Wal-Mart). Joining this panel was Philippe Plagnol from the Product Open Data project - a community built around data and applications centered on products that depends entirely on identifiers. The workshop was given an exciting vision of a future where manufacturers' catalogs were readily ingested into retailers' systems whilst also being accessible to others who can build products and services that effectively promote those products.
Philippe Plagnol describes product codes as the 'latitude and longitude of planet product.' "Where's the nearest place I can buy a product of type X" is a basic query open data should soon be able to help answer. Nevertheless this is a new venture for manufacturers and retailers and so guidance is necessary and steps need to be taken to boost confidence in this area as much as in the public sector.
Conclusion from this and other sessions during the workshop: from Tesco to Pearson to Deutsche Nationalbibliothek to NXP Semiconductors, structured metadata offers substantial benefits across the supply chain and can act as an effective means of advertising.
Other Topics
The preceding sections give a very terse summary of the major discussions and thought processes that the workshop promoted. There were others of course: the use of open data in Japan was an important theme with Shuichi Tashiro's talk being particularly impressive. Among other things he reported on how the use of the limited amount of open data available at the time of the Great East Japan Earthquake enabled trains to be stopped before the quake hit, thus saving lives. This realization gave a boost to the Japanese government's open data strategy. In similar vein, although with much less drama, attendees heard of the Dutch government's efforts to prove the return on investment in open data.
Two Community Groups were promoted at the workshop: Open Linked Education and Best Practices for Multilingual Linked Open Data Community Group. The former ties in nicely with the product data session and the latter was part of a plea for more multilingual vocabularies.
Data interoperability was the theme of a specific session but was also a recurring subject throughout. Isolated data sets that make no use of common schemas will remain isolated and in some situations that's not a critical problem. For mixing and sharing, the use of common schemas is very important. In either case, metadata describing the data, its license, provenance, quality and update cycle is critical. If the metadata is structured, complete and standardized, processing the data into any format be it RDF or any other, becomes easy or at least manageable. Finally on this topic, the provision of good quality metadata is in the interests of any publisher since it aids search engine discovery directly.

Another cross-session issue was the importance and value of URIs as a technology-neutral means of publishing authoritative data. An area of increasing importance to the community is research data. The Research Data Alliance has been founded to act as a standards body to accelerate and facilitate data exchange in this area. Working groups have already been established for topics such as persistent identifiers, metadata, provenance and quality… the familiar themes.
Finally a word about PDF - often referred to as the format where data goes to die. In the open data world, PDF has a bad name as it is not deemed machine processable. As Adobe's Jim King pointed out in his presentation, this is perhaps unfair. PDF can include structured tables, can carry associated metadata, extractable text and more. It is the way that PDFs are generated - using basic tools that don't support all the features - that renders PDF documents opaque to machine processes.
Conclusions:
- public sector use of open data is maturing and important;
- true interoperability can only be achieved if vocabularies are multilingual;
- high quality metadata is crucial;
- URI sets are important technology-neutral means of providing authoritative data;
- research is joining the public sector and the GLAM community in the datasphere.
Next Steps
The Open Data on the Web workshop covered a great many topics and the summaries presented here do little justice to the quality of papers, presentations and discussions. From a W3C perspective, two new working groups designed to take on the challenges raised are in the early stages of planning.
CSV on the Web

This working group will tackle the issue of metadata for tabular data, specifically CSV data. The group is likely to develop a metadata vocabulary for describing tabular data and a set of standard mapping to alternative formats such as RDF, JSON and XML. Such mappings will form a template to be used for mapping to any number of other formats.
Data Best Practices

This working group will focus on developing the ecosystem in which open data operates, whether that is done entirely in the open or mixed with closed data sets. Vocabularies will be designed to allow data publishers to express the quality of their data and developers to cite the data set(s) used and purpose of their applications. Best practices will be developed that, if followed, will maximize the potential of published data and minimize the effort required to use such data.
Details of both working groups are being developed for review by the W3C membership and will be made public as soon as possible.
Acknowledgements
The success of the workshop was due to the support of the Open Data Institute and the Open Knowledge Foundation. Particular thanks are due to Dan Brickley of Google/schema.org for arranging the hosting of the event at Campus London (see forthcoming events).
The first day ended with a networking reception at the ODI to which several other groups of people in London at that time were invited. Sincere thanks are due to the ODI for supporting and hosting that event, in particular Olivia Burman and Jade Croucher. A separate review of the event including an audio recording of the speeches is available.

All images on this page are available for re-use without restriction. All photographs except that of Tom Scott were taken by Naomi Yoshizawa (W3C).
Important Dates
Today
Expression of interest — please send a short e-mail to Phil Archer ASAP.
3 March 2013:
Deadline for Position Papers
(EasyChair submission)
26 March 2013:
Acceptance notification and registration instructions sent.
Program and position papers posted on the workshop website.
22nd April 2013, 19:00
Open Data Meetup – London
23rd April 2013, 09:30
Workshop begins
18:00 - 20:00 ODI Networking Evening Sold Out!
24th April 17:00
Workshop ends
Questions? E-mail Phil Archer
Photo source;
credit: Richard Young via Flickr.
![]()
![]()
![]() Some rights reserved
Some rights reserved
Thanks to Chris Gutteridge for fixing a weird Firefox-only bug in my JavaScript.