See also: IRC log
<trackbot> Date: 12 April 2013
<MakxDekkers> shall we disconnect and try again?
<bhyland> Success!
<bhyland> or not ...
<MakxDekkers> I am back in and can hear you
<bhyland> zakim bye
<bhyland> zakim you're dismissed
<martinA> :-)
<MakxDekkers> retrying...
<HadleyBeeman> http://www.w3.org/2001/12/zakim-irc-bot
<MakxDekkers> baxk in
<HadleyBeeman> phila has arrived - we're saved!
<MakxDekkers> calling back in...
<MakxDekkers> here again on phone
<MakxDekkers> disconnecting now
<MakxDekkers> yes that was what i used, same as yesterday
<MakxDekkers> calling in...
<MakxDekkers> call connected
<MakxDekkers> yes i can hear you
<HadleyBeeman> Day 2 agenda: http://www.w3.org/2011/gld/wiki/F2F3
<MakxDekkers> I am going to sign off at lunchtime today
<DaveReynolds> Possible also delay CR exit until sandro is here, I know he has views on that
<DaveReynolds> No thanks
<MakxDekkers> i am very slow line so won't be able to do visual
<martinA> thanks
<bhyland> Ok, Deirdre is setting it up now ...
ADMS editor's draft is at https://dvcs.w3.org/hg/gld/raw-file/default/adms/index.html
<cygri> scribe: Richard
<DaveReynolds> One of the changes is the merge the advice for spatial and non-spatial objects.
<cygri> (scribe forgot that he's supposed to scribe)
<DaveReynolds> And SO will become information objects which affects http-range-14
<cygri> PhilA: Could make ADMS a DCAT profile
<cygri> …Yesterday's discussion is relevant to that, and it would work with what we resolved yesterday
<cygri> … Clean and easy to say that SemanticAsset is a subclass of Dataset
<cygri> … I'm not sure we need adms:distribution property, could just use dcat:distribution
<cygri> … We have more properties than DCAT
<cygri> … But there are very few terms that aren't either DCAT or DC Terms
<cygri> bhyland: Then why does it look so complicated?
<cygri> PhilA: More detail.
<cygri> … adms:Identifier is perhaps the most significant addition
<cygri> … Is a bit like SKOS-XL but not quite
<cygri> … Allows making statements about identifiers
<cygri> … Useful in RegOrg as well
<cygri> … Different from Org where classification is done via skos:notation
<cygri> fadmaa: One of the DCAT comments was about providing a contact point
<cygri> PhilA: ADMS has contactPoint which is a VCard
<cygri> fadmaa: We will probably add something for this to DCAT
<cygri> … Not yet sure what namespace
<cygri> PhilA: If you make dcat:contactPoint, we'd use that in ADMS
<cygri> … adms:Item is an item included in the asset
<MakxDekkers> did the call drop? i am out, calling in again
<bhyland> yes, the phone line dropped & we dialed back in again...
<MakxDekkers> ok back in again
<cygri> cygri: Instead of dcterms:hasPart, would make sense to use dcat:dataset or a subproperty
<DaveReynolds> a+
<cygri> PhilA: We also have versioning between assets, xhv:next, prev, last
<fadmaa> cygri: I don't see clear usecase for the includedItem property in ADMS seams to
<fadmaa> ... It'd be helpful to know what usecases need this property
<fadmaa> MakxDekkers: many involved stakeholders expressed their need for such a property
<cygri> cygri: I don't understand why adms:Item is needed. The use cases mentioned can be addressed by SKOS.
<fadmaa> ... I can't think of a specific usecase other than items in a codelist now
<cygri> DaveReynolds: Looks like you want to use SemanticAsset as a container and you want to talk about the items. LDP is relevant here, it has a container notion
<cygri> ACTION: MakxDekkers to describe use case for adms:Item and look into ldp:Container [recorded in http://www.w3.org/2013/04/12-gld-minutes.html#action01]
<trackbot> Error finding 'MakxDekkers'. You can review and register nicknames at <http://www.w3.org/2011/gld/track/users>.
<cygri> ACTION: Makx to describe use case for adms:Item and look into ldp:Container [recorded in http://www.w3.org/2013/04/12-gld-minutes.html#action02]
<trackbot> Created ACTION-115 - Describe use case for adms:Item and look into ldp:Container [on Makx Dekkers - due 2013-04-19].
<cygri> DaveReynolds: Can't you use dcterms:hasVersion instead of the xhv properties?
<cygri> MakxDekkers: There doesn't seem to be a standard way of doing versioning
<cygri> … dcterms:hasVersion doesn't give you a sequence
<cygri> … You could have a network of versions related to each other
<cygri> … Also a way of pointing to the last version is important
<cygri> … Didn't see anything in DC Terms that works for this
<cygri> DaveReynolds: Two notions being mixed here. There are versions, and then there are sequences.
<cygri> … XHV not necessarily a sequence of versions, could be a sequence of other things
<cygri> … Using DC Terms to say there are multiple versions, and then relating them with prev/next, would make sense
<cygri> PhilA: Would a subproperty of prev/next work?
<cygri> DaveReynolds: Yes.
<cygri> … With DC Terms you can say here's an abstract concept, and then there are specific versions of that
<DaveReynolds> http://www.w3.org/TR/rdf-concepts/ is the generic asset, http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/ is a specific version
<DaveReynolds> maybe :)
<cygri> cygri: For a generic versioning mechanism, it would be good to have a way of talking about the abstract, unversioned thing
<cygri> MakxDekkers: ADMS doesn't do that
<cygri> … next/prev can be used for things like next chapter
<cygri> … So not sure whether we want a subproperty
<cygri> cygri: I think the use of xhv here is broken; using subproperties would be better
<cygri> … Not sure how important the unversioned resource thing is. Having seen versioning modelled elsewhere, I expected to have it, but haven't thought about use cases here
<cygri> PhilA: We should say that ADMS is not designed to do that
<cygri> … So we should define subproperties of prev/next/last, and say that ADMS is not a generic versioning mechanism
<cygri> MakxDekkers: Someone should define a generic versioning mechanism, it's needed and many people do it wrong
<DaveReynolds> FWIW in the UK have a tiny version: vocab. Illustrated at top of https://raw.github.com/wiki/der/ukl-registry-poc/images/registry-diagram.png
<cygri> … Uneasy about including more ADMS-specific stuff for this
<DaveReynolds> r-
<MakxDekkers> can't realy hear
<cygri> fadmaa: Good to have ADMS as a DCAT profile. Makes sense.
<cygri> … In DCAT, we specifically left open lots of ranges, to be restricted in profiles. ADMS does that in some places
<cygri> … the PeriodOfTime modelling is in the diagram but seems to be missing from the spec
<cygri> ACTION: PhilA to update ADMS to define subproperties for prev/next/last and write text around that [recorded in http://www.w3.org/2013/04/12-gld-minutes.html#action03]
<trackbot> Created ACTION-116 - Update ADMS to define subproperties for prev/next/last and write text around that [on Phil Archer - due 2013-04-19].
<cygri> ACTION: PhilA to update ADMS to use DCAT properties instead of adms:distribution and dct:hasPart [recorded in http://www.w3.org/2013/04/12-gld-minutes.html#action04]
<trackbot> Created ACTION-117 - Update ADMS to use DCAT properties instead of adms:distribution and dct:hasPart [on Phil Archer - due 2013-04-19].
<Gofran_Shukair> I am back to the call again
<cygri> (discussion on whether DCAT catalog->dataset is hasPart or not)
<cygri> fadmaa: (going through ADMS comments)
<Gofran_Shukair> I have addressed 1. All typos reported were fixed 2. Clarifying the first part of the introduction that defines semantic asset 3. Move the description of the original development of ADMS to a new acknowledgments section
<cygri> … James suggested to use foaf:page instead of adms:relatedWebPage
<cygri> … James suggested to rename representationTechnique, although no proposal
<cygri> PhilA: It's horrible, but already implemented, and if no one can think of anything better we should just leave it
<DaveReynolds> Presumably could publish as an updated WD even if not ready to go to Note.
<fadmaa> PhilA: We have to wait for a couple of issues on DCAT to be resolved before being able to come to the group with a ready version of the ADMS as a note
<fadmaa> cygri: Few issues on DCAT that could affect ADMS might take some time to be resolved
<MakxDekkers> better to wait and publishe a note that is consistent with final DCAT
<fadmaa> ... ADMS can wait till DCAT is ready but I think it is better to publish it as it is now and then update it when DCAT is ready
<MakxDekkers> as long as it is versioned ;-)
<DaveReynolds> Sandro yesterday recommended for BP that if there's going to be multple versions then publish as WD (with status saying it would be a note)
<MakxDekkers> agree with Dave WD until DCAT is ready
<cygri> PhilA: Could either publish ADMS Note now, and update it when DCAT is ready; or wait until DCAT is done and only publish ADMS then
<cygri> HadleyBeeman: My preference is to get something out now
<cygri> cygri: Agree with HadleyBeeman
<Gofran_Shukair> +1
<DaveReynolds> Is you want a WG vote for a Note, as opposed to WD, then we'll need adequate time to review. That's not likely to be possible for next Thursday.
<cygri> ACTION: cygri to raise issue on adms:includedAssed vs adms:includedItem [recorded in http://www.w3.org/2013/04/12-gld-minutes.html#action05]
<trackbot> Created ACTION-118 - Raise issue on adms:includedAssed vs adms:includedItem [on Richard Cyganiak - due 2013-04-19].
<cygri> PhilA: Reasonable to take this comment back to ISA
<cygri> DaveReynolds: A draft should be available ahead of date where vote will be taken so that WG members can review it
<cygri> PhilA: Notice had been given
<cygri> … And things that will still be updated have been discussed today
<Gofran_Shukair> I have to le
<Gofran_Shukair> I have to leave now sorry
<Gofran_Shukair> talk to you later
<Gofran_Shukair> bye
<Gofran_Shukair> thanks to you Phil
<DaveReynolds> http://www.w3.org/2011/gld/wiki/ORG_LC_comments
<HadleyBeeman> scribe: phila
<HadleyBeeman> DaveReynolds: From original last call for ORG, we had a number of comments which we've addressed.
<HadleyBeeman> … Since then, we've had this accidentally extended period for last call, we've had 2 more comments.
<HadleyBeeman> … Resolved Bill Roberts's comment, he is satisfied.
<HadleyBeeman> … All comments have been addressed, we have evidence of that.
<cygri> DaveReynolds, our call dropped
<HadleyBeeman> DaveReynolds: Question: whether the changes we made after the first last call were substantive, and should we have done another last call? The document was edited, but the second last call pointed to the original document without those changes in.
<HadleyBeeman> … The changes we made, I would argue, wouldn't have invalidated existing implementations.
<HadleyBeeman> … Assuming we're happy with that, and the transition meeting will be happy with that, we're fine.
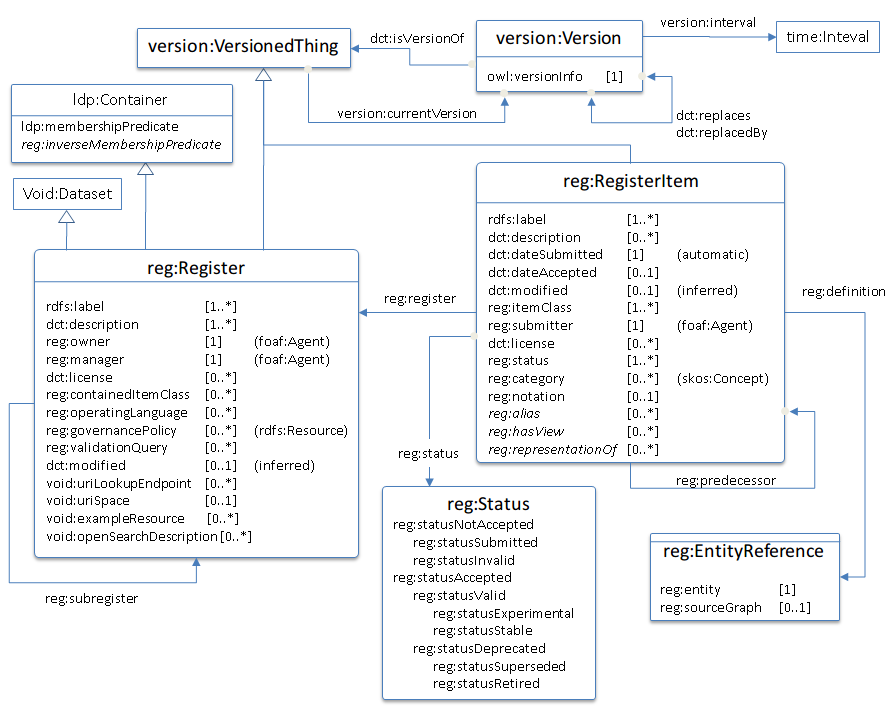
<HadleyBeeman> … One more comment from Joao-Paulo says that the diagram isn't normative, doesn't cover all features of ORG; he'd prefer it to be complete and in proper UML style. I prefer the current diagram, but I won't object if someone wants to provide that. No response. This is purely an editorial thing, but we need to decide to have one or decide we don't need one.
<HadleyBeeman> … Next step: put things together for a transition meeting.
<HadleyBeeman> Cygri: Comment on the diagram (general comment on all our vocabulary documents). IT would be terrific if in those diagrams, I could click on things and go to the definition of the thing that was clicked. I understand this is difficult to do. Do we as a working group want to do this for all our specs?
<HadleyBeeman> PhilA: clickable schema leading to an SVG diagram? that would be great.
<HadleyBeeman> Bartvanleeuwen: All the vocabularies have different types of diagrams. I agree, but I'm not sure we should take our time right now.
<HadleyBeeman> cygri: It is purely an editorial comment. Could be updated in the future.
<HadleyBeeman> davereynolds: It would be great. It would just take time to do it.
<MakxDekkers> yes I
<HadleyBeeman> Hadleybeeman: How is this not addressed by other working groups?
<MakxDekkers> sorry slip of keyboard
<HadleyBeeman> cygri: This is something we could raise on the mailing list.
<HadleyBeeman> davereynolds: there was a version of RDF Gravity that could visualise our ontologies. But the clickable diagram and low cost requirements are challenging.
<DaveReynolds> http://www.w3.org/2011/gld/wiki/ORG_Timetable
<HadleyBeeman> DaveReynolds: If we're happy that we don't need another Last Call, then we just need to packing things up for transition to CR. Should take a few weeks to pull together that documentation (I'm guessing). I'm tied up next week, so two weeks after puts it into early may. Then a few weeks to transition/publication.
<HadleyBeeman> PROPOSED: having examined the summary for ORG comments, another iteration of Last Call for ORG is not needed.
+1
<DaveReynolds> +1
<bhyland1> +1
<fadmaa> +1
<gatemezi> +1
<BartvanLeeuwen> +1
<HadleyBeeman> RESOLVED: having examined the summary for ORG comments, another iteration of Last Call for ORG is not needed.
<DeirdreLee> +1
<MakxDekkers> +1
<martinA> +1
<HadleyBeeman> Sandro: Someone should review the editorial changes to ORG before we vote to go to CR
<HadleyBeeman> … (two people)
<cygri> +1
<HadleyBeeman> Sandro: review could happen today?
<HadleyBeeman> DaveReynolds: Last change to ORG was in response to the response to the PROV WG. Has anyone looked at it since then?
<HadleyBeeman> … Could we have a volunteer to do that?
<HadleyBeeman> … We can then vote when that's done and we have the exit criteria for CR.
<fadmaa> I can do that
<cygri> me too
<HadleyBeeman> 5 min break
<bhyland1> Resuming at 11.15AM Dublin time
<MakxDekkers> i am back in
<martinA> Back
<HadleyBeeman> http://www.w3.org/TR/2013/WD-vocab-regorg-20130108/
<HadleyBeeman> PhilA: RegORG, we've previously decided, is a profile of ORG.
<HadleyBeeman> … We have no open Tracker issues on RegORG
<sandro> +Sandro
<BartvanLeeuwen> :)
<HadleyBeeman> … I need to reconcile dcterms:type as aproplert on adms:identifier, or should it just be a type:literal on adms:notation. (This is a new issue on regORG: alignment on ADMS identifier)
<HadleyBeeman> davereynolds: noticed adms:schemaAgency ?
<HadleyBeeman> phila: It's a literal. I need to make that clearer.
<HadleyBeeman> phila: best practice doesn't say anything about encoding skos?
<HadleyBeeman> DaveReynolds: SDMS attribute code. Published as XML, using Jena. Mechanical translation. Info may be in the google group.
<HadleyBeeman> PhilA: that is an example on how to do it; would be nice to have it as documentation.
<HadleyBeeman> … I'd like to do something on how to create a SKOS concept scheme from a PDF of a vocabulary. We haven't got time to do it though.
<HadleyBeeman> bhyland: I'm making a note to see about addressing this in Best Practices. People always ask how to do that.
<HadleyBeeman> philA: in mapping between ORG and RegORG: it should be a vertical list (to be mobile-friendly). I'll get rid of the table.
<HadleyBeeman> … Want to point from org:organization to the registeredOrganization. We should just keep the domain of registeredOrganization as foaf:agent
<HadleyBeeman> … Marios, as co-editor, will be helping with this.
<HadleyBeeman> … I will fix the issue re adms:identifier. Next version to group, which will be the final note. Bottom line, nothing huge on it. We haven't received many comments (though we may not have asked them for it.)
<HadleyBeeman> scribe: deirdrelee
sandro: requirement that at least 2 systems have to pass the test suite is to prove that the spec could be implemented and could be implemented interoperably
<HadleyBeeman> Each item in a test suite needs to be passed by two implementations
sandro: if there is no software
consuming the data, it is difficult to identify if data is
being published incorrectly
... therefore there's a need to show data consumption as well
as publication
... should every term be used? I would say so, as that is the
only way we can show that the term is being correctly
utilised
... so every term in spec should be used in 2 publication
implementations, and most terms in 2 consumption
implementations
<bhyland1> q
DaveReynolds: agrees that this is
a high bar. it would require people on our side to record all
implementations and to see if every term is being used from
every vocab
... to show that we pass the exit criteria test
<MakxDekkers> I wonder whether things like dcterms and foaf would pass the test?
DaveReynolds: if consumption is
to prove that terms are being interpreted in the same way, we
would need a consumption implementation from a different
publisher implementer
... another point: if we have no evidence of a given term being
used, should the term be deleted?
... DaveReynolds does not think so
... it may be useful in the future
sandro: we could argue for a lower bar
DaveReynolds: difficulty with a lower bar is that it is more difficult to define
PhilA: PhilA has done some work
iwht the Greek gov using google refine, suggesting it could be
plugged into the organogram
... organogram from data.gov.uk
<sandro> +1 phil Yeah, it's probably enough to have multiple instance data files and inspect them by hand to make sure the terms are being used consistently
PhilA: so for org ontology, PhilA
proposes....?
... for dcat, we could look at data.gov.fr to see how they're
using it
<MakxDekkers> daon't forget the spanish DCAT profile
<HadleyBeeman> draft http://www.w3.org/2011/gld/wiki/ORG_CR_transition
PhilA: for dcat, we have a wide range of people looking at it & implementations,which we can use to see how it is being used, how the terms are being understood
<martinA> Not for the English version yet
<DaveReynolds> PROV did a very high bar process
HadleyBeeman: are there any other groups that have gone through this CR process, who we can learn from
cygri: skos & prov
DaveReynolds: sparql
<PhilA> Prov CR Exit Criteria http://www.w3.org/2011/prov/wiki/ProvCRExitCriteria#PROV_CR_Exit_Criteria
<martinA> technical specification on PSI reuse in Spain: http://www.boe.es/boe/dias/2013/03/04/pdfs/BOE-A-2013-2380.pdf
<gatemezi> Some uses of ORG: http://stats.lod2.eu/vocabularies/149
bhyland1: would question if existing rec would reach the high bar
<PhilA> For the record http://www.boe.es/boe/dias/2013/03/04/pdfs/BOE-A-2013-2380.pdf is a profile of DCAT as used in Spain (doc is in Spanish)
sandro: happy to lower bar to what DaveReynolds suggested, that implementations could be manually inspected
<HadleyBeeman> for reference, the exit criteria for SKOS to get to CR: 1. At least two implementations have been demonstrated that use
<HadleyBeeman> features of the SKOS vocabulary. Other vocabularies that use
<HadleyBeeman> SKOS are candidates for inclusion in the implementation report.
<HadleyBeeman> 2. All issues raised during the CR period against this document
<HadleyBeeman> have received formal responses.
<MakxDekkers> the European AP draft is at https://joinup.ec.europa.eu/asset/dcat_application_profile/asset_release/dcat-application-profile-data-portals-europe-draft-1
sandro: this is not uncommon, WEBIDL has been stuck in CR for over a year, although it is widely used
<martinA> Also for the record, this is a draft with a guide for using the Spanish DCAT Profile and other best practices on PSI publication using Linked Data: http://administracionelectronica.gob.es/recursos/pae_000023387.pdf (also in Spanish, I'm sorry)
HadleyBeeman: the skos exit criteria is much less laborious
PhilA: prov-o exit criteria is very complex
HadleyBeeman: have we settled on 2 implementations?
PhilA: we should at least have one publication implementation for every term, and if a term is used in multiple implementations, it should be used in a common way
<HadleyBeeman> sandro: do we need example files? Not a full test suite, but evidence it works?
BartvanLeeuwen: is publication of org data for the community directory count as a valid implementation (using or not using diromatic)
bhyland1: yes
PhilA: we could use the Community Directory as an implementation
BartvanLeeuwen: could we describe the comm directory using dcat?
fadmaa: comm directory is not a data catalogue
<MakxDekkers> anything can be a dataset
PhilA: comm directory could be a data catalogue
<gatemezi> An attempt of using DCAT by the city of Montpellier.. http://opendata.montpelliernumerique.fr/datastore/villeMTP_MTP_Opendata.zip
<gatemezi> They are still using an old version of DCAT
<martinA> http://dadesobertes.gencat.cat/recursos/datasets/cataleg.rdf (Catalonia)
cygri: calling a publisher an
implemtation of a vocab is not a very useful way of showing
that a vocab is right
... anyone can throw something together, but this does not show
that this facilitates successful interoperability
<bhyland1> +10 to a test suite that consumes a given vocabulary and does something basic & simple.
cygri: a better way might be to create a test suite that uses the vocabulary, and show that there are two consumers can do something useful with these 'agreed upon' published data
<martinA> I'm sorry, I have to leave. Enjoy the rest of the meeting. I'll read the minutes. See you soon.
<bhyland1> That would help vocab designers, publishers & consumers.
<martinA> Thanks
cygri: this way we have a testing ecosystem and would be much stronger evidence that the vocabs are interoperable
<bhyland1> FTR - I'm much more comfortable with what cygri just decribed.
bhyland1: much more consistent approach, it compares apples with apples
<DaveReynolds> Yes!!!!!
bhyland1: if a simple client can use the data, as a simple visualisation, listing or whatever, it would be more consistent
Sandro: isn't this bar higher than what was initially proposed?
bhyland1: to have something like
an RDF validator, this being a vocab validator, would prove
usefulness of vocab
... simply publishing data using a vocab does not show the
usefulness or the interoperability of the vocab
DaveReynolds: we do not have the option of automatic vocab validation
<bhyland1> This is a suggestion for future vocabulary efforts to validate fitness for use.
<cygri> (I agree with DaveReynolds, automatic validation is not really possible here. appropriate use can't be automatically validated.)
<sandro> DaveReynolds: We could validate at some low level, like types, but we can't automatically tell whether this person is really the manager vs subordinate
DaveReynolds: but validation of
apropriateness of use would take manual inspection
... a visualisation of data would also not be a
validation
... therefore we should define what we mean by 'consumption'
for the CR exit criteria
PhilA: to clarify what DaveReynolds said, a tool can be built to visualise data modelled by a vocab, but it does not demonstrate that the vocab and its terms have been understood and used consistently
bhyland1: if there is a sample of test publication data, there will be consistency with the consumption approach
<gatemezi> Yes PhilA.. a conformance-validator vocab
<sandro> (I'm so confused at bhyland1 switching from bar-1 is too high and bar-2 is great, when bar-2 is higher than bar-1)
bhyland1: the point is to show data interoperability
<Zakim> sandro, you wanted to ask about grad students and interns
<fadmaa> scribe: fadmaa
sandro: cygri's bar seams to be higher than the one I set
<bhyland1> Yes Sandro, I agree that the vocab validator in a way is higher than what you described, but it responds to the suggestion that I understood Richard was making about a test harness.
sandro, would you consider having a student or an intern working on a project as an implementation
<sandro> fadmaa, yes,
cygri: I am not so interested in who is using these vocabularies because you can use it but you might be using it wrongly
<bhyland1> cyrgi: A developer could "use" a vocab but do it all wrong. Thus, use alone doesn't mean the vocab is "good".
cygri: the testcase can be something like I have an organization and it contains a department named X. if this is expressed in triples using org
<sandro> imagining "org-check" which checks for things like loops in the hierarchy
cygri: if a consumer can
understand the existence of an organization and department by
looking into the triples that can be called a success
... this doesn't have to be automatic
<bhyland1> FTR - I wasn't suggesting painting a picture of class names & properties as a harness. That would be useless IMO.
cygri: regarding the issue of consuming the triples via some visualizations of the data, this is actually just another way of presenting the triple and not really understanding the vocabulary
<Zakim> PhilA, you wanted to look at the conformance criteria such as http://www.w3.org/TR/vocab-org/#conformance
PhilA,we should look into the conformance sections we added to all the vocabularies
scribe: the conformance states
that you use the proper term from the vocabulary when one
exists
... it doesn't have to be a use of the whole vocabulary
... we can use the conformance as exit criteria
... I did some work on the org vocabulary
<MakxDekkers> had that discussion at DCMI; the questions was: can you conform to Dublin Core if you use only one of the terms?
scribe: in the spirit of using data represented in the ORG vocabulary based on the conformance criteria
<PhilA> The pilot study on ORG done under the ISA Programme is at https://joinup.ec.europa.eu/sites/default/files/D5.2.1%20-Report%20on%20the%20Greek%20Linked%20Open%20Government%20Data%20Pilot%20-%20v0.06.pdf
DaveReynolds, It'll be very hard to write some criteria of correct consumption of a vocabulary
DaveReynolds, what is the criteria of how independent the implementations should be
sandro, there is no restriction on this
<Zakim> cygri, you wanted to respond to DaveReynolds' point about generic RDF consumers
cygri: negative test cases is the
answer to the generic RDF consumer
... a conforming implementation shouldn't use terms from
outside the vocabulary when one exists in it
... an ORG implementation will consume non-conformant data
differently than the conformant data
<PhilA> HadleyBeeman: It's important for us to be able to demonstrate that consuming implementations are useful. But we need to show that the vocab is useful. is ORG useful?
HadleyBeeman: it is important to be able to demonstrate that what we have done is useful but am worried about putting too much emphasis about the existence of implementation
<HadleyBeeman> Yes. Also that there are reasons that might stop implementations consuming ORG, for example, that might not mean that ORG is useful and well-constructed. (Market activities, etc.) There are other dependencies that are not just "have we built ORG well and usefully?"
DaveReynolds: vocabularies are
extensible. if the vocabulary was extended by subclassing for
example an implementation would pass the testcase only if it
does RDFS inference
... Cube can be mechanically processed while ORG and DCAT are
more targeted for visualizations and the like
... criteria for cube might need to be different than those for
ORG and DCAT
... we have a checking criteria for Cube
sandro: we have two opinions regarding the exit criteria
<HadleyBeeman> sandro: the question seems to be: do we need code written to consume the vocabularies, or not?
<DaveReynolds> DaveReynolds: QB includes explicit integrity constraints. The exit criteria may need to include validation of publications against those constraints.
PhilA: reading the conformance section of Data Cube, you still need a human being to confirm conformance
sandro: the RDF validator checks part automatically but asks human input for other parts
PhilA: a tool is useful but you still need a human judgement
<bhyland1> +1
<MakxDekkers> +1
PhilA: it'd be great to have a tool but it is not mandatory
sandro: agree
<sandro> PROPOSED-1: Our Exit Criteria for our Vocabs is: each term in the vocab used in at least two government data sources and two humans have inspected each data source and confirmed they are used in conformance to the spec.
<sandro> PROPOSED: Our Exit Criteria for our Vocabs is: each term in the vocab used in at least two data sources (ideally governments) and two humans have inspected each data source and confirmed they are used in conformance to the spec.
MakxDekkers: what about the terms we are reusing from other vocabularies
<cygri> "each term whose use is recommended in the spec"
<HadleyBeeman> I like that: "ideally government". Keeps us out of the grey areas of who is government and who isn't, and what to do with suppliers hosting on behalf of government, etc.
MakxDekkers: e.g. the DCTerms reused in DCAT
<sandro> MakxDekkers:Are we only looking at dcat:* or also dc:* stuff that's in DCAT?
PhilA: we are looking at all of the properties
<sandro> PhilA: I think we're looking at all of them. Everything used in the diagram.
<sandro> PROPOSED: Our Exit Criteria for our Vocabs is: each term in the vocab used in at least two data sources and two humans have inspected each data source and confirmed they are used in conformance to the spec.
<PhilA> fadmaa: What if someone is using the vocabulary in the wrong way?
sandro: we also have to report on all implementations we are aware of
<bhyland1> abstain - I think use of each term in 2 different data sources remains a very difficult bar.
<sandro> If you don't like this bar, but can live with it, vote "-0" or "0"
cygri: I don't like checking
conformance by having two humans checking for it
... would it be any two humans?
sandro: do you want to restrict this to members of the WG?
cygri: maybe
... but I think we need to do the possible automatic
checking
... this can be done on both the consuming and publishing
sides
... I can write a SPARQL query to check a producer
implementation
... for example
<sandro> PROPOSED: Our Exit Criteria for our Vocabs is: each term in the vocab used in at least two data sources and two people (selected by the WG for their expertise) have inspected each data source and confirmed they are used in conformance to the spec. Inspection should use appropriate software tools to assist in their work.
<sandro> this doesn't say whether we will or wont make a test suite.
<sandro> exit criteria is not based on test suite, correct.
<sandro> I hear cygri volunteering to develop a test suite and tools.....
HadleyBeeman: asking sandro about
reporting on all implementations we find
... even the non-compliant ones
sandro: I think so
<Zakim> PhilA, you wanted to support SPARQL
<sandro> sandro: The Transition Request includes an Implementation Report (describing what we know about all implementations)
PhilA: I agree that there are
things we can test and provide results reports. This can be
done via SPARQL queries and doesn't necessarily require
building tools
... and we publish the SPARQL queries so human reviewers can
use that
<MakxDekkers> by the way, my time is running out.
bhyland1: practically, given the time restriction, we can't build tools
<Zakim> sandro, you wanted to say yes there is time to build tools
<PhilA> PROPOSED: Our Exit Criteria for our Vocabs is: each term in the vocab used in at least two data sources and two people (selected by the WG for their expertise) have inspected each data source and confirmed they are used in conformance to the spec. Inspection should use appropriate software tools to assist in their work and will include one or more SPARQL queries that, in the WG's view, SHOULD return useful data from conformant data. Reporting will
<PhilA> include any data that doesn't conform as well as that which does.
bhyland1: the best we can do is have people identify implementations and find a practical way to define exit criteria and conformance testing
<PhilA> In our defence m'lud, we did discuss conformance more than 6 months ago, which is closely related.
bhyland1: discussing tools building should have taken place long time ago
cygri: I ask for testcases and
not for tools
... on the consumer side, testcases are example RDF graphs that
uses the vocabularies and others that misuse
... on the producer side, SPARQL queries can be used
... potentially, the evaluator of some implementation might do
some scripting to run queries or load the graphs
... that seems to be smaller burden than writing the
testcase
<MakxDekkers> sorry, have to leave now. good luck, talk to you again next week at our regular time.
<sandro> PROPOSED: We'll build a test suite for each vocab. This will consist of example conforming and non-conforming uses of the vocab, and SPARQL queries which highlight conformance and non-conformance issues.
PhilA: we need to run the SPARQL queries against external data as well not only the ones we created
cygri: asking for two people to
confirm the conformance of some RDF data to a vocabulary is
hard to be done
... there are cases where you need to be familiar with the
reality the data describes
sandro: do you want to lower that and ask people to run the SPARQL queries on their data?
cygri: there is the general issue
of how you test an implementation of a vocabulary
... if we have time and resources, how would we do it
... I'd like to discuss this regardless of time constraints we
have
<sandro> cygri: I'd to understand how to do it properly, and how well we can do it in the time we have.
cygri: then moving to discuss a possible compromise giving the WG time constraints
<bhyland1> @PhilA, Agree, we did talk about conformance criteria and we also spoke about 2 ref implementations. However, the penny only dropped (for me) today about what it means for each term in the vocab to be used in at least two data sources by two people.
<bhyland1> … Further do we have two people, (selected by the WG for their expertise), who have time to inspect each data source and confirm they are used in conformance to the spec … all in the time we have remaining. I'm trying to be realistic.
<sandro> test suite, something like: PositiveConsumerTest, NegativeConsumerTest (turtle files) PositiveProducerTest, NegativeConsumerTest (sparql files)
<HadleyBeeman> lunch for one hour
<HadleyBeeman> Shall we come back together?
<BartvanLeeuwen> zakim is still lost
<PhilA> http://www.w3.org/2013/02/vrc.html
<PhilA> http://www.w3.org/2013/02/vrc.html
PhilA: There is an indication that Rec track might not be the proper way to handle vocabularies.
<sandro> phil: People who want something on schema.org come to public-vocabs@w3.org and suggest it
PhilA: schema.org exists and has
its own process of extention
... we have the plan to emulate this process
... the basic idea is to allow community groups to work on
vocabulary. if the work proves successful
... the community group can submit a vocabulary for official
W3C support
... if they can have consensus
... the upcoming group will be an advisory group not a decision
group
... a community group can have a vocabulary under w3.org/ns
namespace
... consistency is a concern
... deprecation will be allowed but not deletion
... if there is no consensus, the reserved namespace can be
used for other vocabularies
... I hope to see multilingualism support in the tool that
manages w3.org/ns
<sandro> PhilA: We have the multilanguage expertise in the group; it's not hard.
sandro; in the version one of the tool, it will accept a Turtle file
<DeirdreLee> Google hangout is on if anyone wants to join visually
HadleyBeeman: building a validator for vocabulary could be one thing that the vocabulary review committee works on
BartvanLeeuwen: a validator can be based on a set of SAPRQL queries
PhilA: sounds a better fit of the validation group
<gatemezi> fadmaa: Is there any limit of scope of the vocab in the new group?
fadmaa: wil the group have restriction on the scope of the vocabularies
PhilA: no
bhyland: external vocabularies
deployed on non-production machines frequently cause
problems
... when the machine is down
... having some redundancies to back-up this is very
important
... ack me
gatemezi: LOV currently has a
number of versions per vocabularies which are hosted on the
OKFN
... you always can get a differnet version of the vocabulary if
one is unavailable
bhyland: I suggest also talking to George Thomas who is behind vocab.data.gov
PhilA: there is an increasing
need for validation as well.
... Makx is working on a profile of DCAT that will be
recommended to the EC
... a workshop on validation will probably take place on
validation
<bhyland> FWIW, re: VRC - this is a very useful & needed service offering from the W3C and I see huge value/alignment with what is needed for persistence of vocabs & namespace and orgs (starting with US Government ) who should look to W3C for advice on 'how to' and possibly services beyond just strategic advice.
PhilA: in the London workshop
next week, we want to break the silos between linked data,
Json, and XML worlds
... the workshop is not specific to linked data but with open
data in general
... Horizon 2020 will require funded projects to publish
generated data in an open way
... the plan for the subsequent WG is not to be specific
neither to linked data nor to government data
... but open data in general
... the workshop next week will provide us more input to help
working on the charter
HadleyBeeman: you might want to
consider, 1) versioing as it is not solved anywhere yet 2)
quality which related to provenance but not only provenance.
adding the ability to describe the data quality
... to point out the status of the data quality even when it is
not perfect e.g. this data is 95% accurate but be aware that
...
... 3) the issue of discovery
<HadleyBeeman> http://www.w3.org/2012/Talks/0417-LD-Tutorial/Practice.pdf slide 17
<sandro> my ears perk up.... discovery of vocabs or of data sources?
HadleyBeeman: in the early days
of the Web, people rely on maintaining lists of good quality
web sites in an adhoc manner
... then search engines changes the scene
... it seems that having a list of datasets sounds similar to
the inefficient method of early days of the Web
<PhilA> See agenda for London http://www.w3.org/2013/04/odw/agenda#discovery
HadleyBeeman: Dan Brickley will be chairing a panel on discovery during the London workshop
bhyland asks cygri about the process of populating the LOD cloud
cygri: it is a manual process and
it doesn't address discovery
... only parts relevant to the diagram are recorded there
<bhyland> NB: Open Data on the Web agenda, see http://www.w3.org/2013/04/odw/
BartvanLeeuwen: I think there is
much focus on the publication side of open and linked data but
not on the consumption
... especially within the government itself
PhilA: we had a workshop last
year on use of open data
... we are working on that within project proposals and planned
workshops
... ... one of them is called "the business of open data"
BartvanLeeuwen: I am interested in consumption in general not necessarily making money out of data
<PhilA> The business of open data http://www.w3.org/2013/04/odw/agenda#bus
BartvanLeeuwen: I am aware of a number of duplicated offers within government
cygri: what would the expected
output, in terms of W3C recommendations, of the group be?
... open data is a broad topic and it will be challenging to
get consensus about what set of documents this group will
produce
... we have experienced this to a certain degree in this group
(vocabs, directory, best practices).
... with broad scope, It is challenging to sustain sufficient
resources for all planned results
... It is helpful to have strands of works so that people can
join the WG and work on a particular strand
PhilA: it is generally hard to sustain interest within working groups
<PhilA> Possible topics for the new WG
<PhilA> Open Data WG Charter notes
<PhilA> Head for Persistent URI Recommendation
<PhilA> - Input from GLD BPs
<PhilA> - Input from UKGovLD
<PhilA> - Other policies, such as Dutch
<PhilA> - Identify an differences in sectors, e.g. government, enterprise, retail
<PhilA> Guidance on what it means to conformance to a vocabulary.
<PhilA> Description language for APIs? Ref DCAT discussion.
<PhilA> Granularity vocabularies - frequency of updates, scale of map etc. ?
<PhilA> Versioning?
<PhilA> Publishing vocabs, clickable diagrams? schema -> SVG
<PhilA> From UKGovCamp...
<PhilA> Versioning, new version of old data
<PhilA> Corrections to existing
<PhilA> Quality related to provenance. Not the same as prov. It's not perfect but here it is.
<PhilA> Discovery. We're still in the midset of repositories, lists. Indexing? DCAT?
<PhilA> Barrier is not being able to find the data you need.
<PhilA> Automatic generation of something like the LOD cloud.
HadleyBeeman: maybe also APIs for usage of personal data
BartvanLeeuwen: I agree this is a hot topic
cygri: who do you expect to join?
PhilA: when drafting the charter will keep in mind who will be interested to do something not only whether it is interesting or not
bhyland: the workshop will help clarify possible interest and topics
<HadleyBeeman> From before lunch… cygri: there is the general issue of how you test an implementation of a vocabulary
<HadleyBeeman> (and from before) cygri: I'd to understand how to do it properly, and how well we can do it in the time we have.
<HadleyBeeman> 5 min break
<HadleyBeeman> Aaaand… we're back.
<PhilA> scribe: PhilA
<scribe> scribeNick: PhilA
HadleyBeeman: We started to talk about how we can test our vocabs... Bart?
BartvanLeeuwen: Richard said
before lunch that we could create some queries that could be
used by people to evaluate whether data has used the vocabulary
properly
... we thought over lunch that it shouldn't be too hard to
create a Web service that would run queries against data
<DaveReynolds> WG shouldn't set up test server, should be done by implementation reporters
BartvanLeeuwen: with the proviso
that the editors should provide the SPARQL queries
... And then after the GLD, maybe a future WG could take this
on to generalise it
... So something like "this SPARQL query should list your
organisations and the people within them"
HadleyBeeman: Are the implementation reports not all WG members?
DaveReynolds: Ideally not
bhyland: Who would run the tests?
DaveReynolds: For ORG we have several (UK, IT, EL etc.)
<HadleyBeeman> draft table http://www.w3.org/2011/gld/wiki/ORG_CR_transition
HadleyBeeman: For that point Dave that table above can be tailored to the specific example
cygri: I don't see where automation is necessary
DaveReynolds: You need a way of people saying that a given term has been tested
cygri: With our vocabs we could probbaly do it manually as the vocabs are so small
DaveReynolds: One clarification - implementation reports get you from CR to PR, not into CR
sandro: We're supposed to mention any examples when we go into CR
HadleyBeeman: The list I have there comes from the process Doc
<HadleyBeeman> "Are there any implementation requirements beyond the defaults of the Process Document? For instance, is the expectation to show two complete implementations (e.g., there are two software instances, each of which conforms) or to show that each feature is implemented twice in some piece of software?"
HadleyBeeman: Having said that...
hang on. We need to express any deviation from the standard
ones in the process doc
... we have to say what we will be showing, not what we can
show now
<DaveReynolds> To quote from Sandro's email "Is there a preliminary implementation report? The implementation report should be a detailed matrix showing which software implements each feature of the specification."
<DaveReynolds> I'm saying we should list known implementations but not provide a preliminary implementation report at CR transition.
cygri: If we want to create a
test suite and base the exit criteria on that, then what we
have to do now is to create the tests
... Then to get from CR to PR we need implementations that pass
(at least 2 or whatever we specify)
HadleyBeeman: So we need to lay out our exit criteria and our methodology
cygri: We can also say now that we know about implementation A, B and C...
<sandro> +1 DaveReynolds WG members don't have to do any testing.
DaveReynolds: This worries me. Other WGs don't do testing, they provide tools for implementors to do the tests
HadleyBeeman: That makes sense to me. And removes some of the burden from us
cygri: So if there is a broken
implementation, that doesn't create a probelm from a process
POV
... if someone else has got it wrong then that shouldn't derail
the process
bhyland: What's the incentive to run the tests?
cygri: Because the publishers
want to promote the fact that they conform to the
stnandard
... looking back to RDB2RDF test suite, people started using it
as soon as we published it
... I don't know if it's governments that will do this, it
could be others
bhyland: I think it will take a
little out reach on the part of the WG
... It's not trivial or insignificant
sandro: Quick story - SPARQL was stuck on some bits that no one was interested to do. The I saw someone at a conference and a day later it was done...
<HadleyBeeman> scribe:hadleybeeman
bhyland: we should have an action item on this, one of us do the outreach of finding people to run implementation reports on their implementations for us
phila: PwC will want to run tests against ORG and DCAT, for example
http://www.w3.org/2011/gld/wiki/ORG_CR_transition#Implementations
cygri: the last bullet point is the most interesting one (re metrics to show that stuff has been implemented).
<PhilA2> scribe: PhilA2
<PhilA> scribe: PhilA
HadleyBeeman: So are we happy with the proposal?
cygri: I'm not particularly happy
with it
... I think we should make an attempt to create some test
data
<sandro> (Earlier Test-Suite )PROPOSED: We'll build a test suite for each vocab. This will consist of example conforming and non-conforming uses of the vocab, and SPARQL queries which highlight conformance and non-conformance issues.
DaveReynolds: My comment was about QB. It doesn't fit this pattern. I don't want people to run a server that people could run 1 million triples in QB when some queries are quadratic or more
bhyland: So QBG is a unique animal. But Hadley has put together a template that seems to work well
The burden of http://www.w3.org/2011/gld/wiki/ORG_CR_transition should not be on the WG members to do the test, but someone does need to facilitate recording the test result in the page
bhyland: Someone needs to take an action item to facilitate the testing of each vocab
cygri: Creating the test data is
not trivial
... Asking people to run the tests aginst their data is
mino
... By committing to creating a test suite we create a
significant amount of work
bhyland: Yes, that's why I think
the bar is high and I'm abstainin
... But Bart said he could build a service
BartvanLeeuwen: Yep, I can host a service but the editors need to create the SPARQL queries
bhyland: Not sure we're going to resolve this today, but it's clearly an issue
sandro: I think we should try and decide
bhyland: I agree there's an urgency
sandro: I think there's consensus, if not enthusiasm, that we can do the human comparison thing
cygri: I have to disagree here.
The exit criteria about 2 humans checking doesn't work for
me
... It's very subjective and it eitehr puts the burden on the
Wg to do that or it puts the burden on the implementers
... asking them to assert that their data conforms is too low a
bar
... not happy
sandro: I see the editors doing this but not with reading millions of triples
DaveReynolds: I think I may be
seconded with what Richard said.
... who are those humans and what are their criteria
... the danger is that the humans are me and Richard
... I took a lot of time interpreting the conformance
constraints for QB...
... manbe there are some queries that we could write that would
check for obvious problems
... an unbounded amount of work is not good, no work isn't
enough
HadleyBeeman: So would it help
you and Richard to keep in our WG advice that the inspection
and confirmation process should be defined and documented case
by case by the editors
... I'm trying to put enough in the text to allow us to move
forward without being too restrictive
<HadleyBeeman> I'm suggesting we agree that the exact methodology to confirm each vocabulary is left to the editors to work out. They will find some combination of objective testing (e.g., SPARQL queries) and some subjective checking, as resources permit.
PhilA: I've built a validator forJoinup's ADMS profile
cygri: You can't give a complete test
HadleyBeeman: But you can sample
cygri: Yes
... I agree that we need a mix of using a test suite and a
human
... So regarding the manual inspection and confirming that they
conform... it would be good to write a script that the tester
could use to spot specific errors, and we should publish that
as part of our documentation
... if we're doing a good job then we could perhaps ask
implementers to do this themselves.
... that would shift the burden. I'd rather write a checklist
for others to use rather than check an unlimited number of data
sets
DeirdreLee: Would it be possible to use Gofran's tester that tests interoperability tester?
fadmaa: I know it makes some assumptions about the communication that may not be valid
DaveReynolds: One of the things
you want in the implementation report is a report on "we found
it easy to use..." and we saw no use for ... etc
... that's what's helpful
... I think we should include the means to add some descriptive
text
... I think I'd find that more useful than eyeballs on
triples
cygri: Checking whether terms
have been used at all can be automated
... Commenting on the usability or usefulness... are there
examples of others who have done
<DaveReynolds> DaveReynolds: written feedback from implementers seems to me to be an important feature of implementation reports, what was hard to understand, what was useful, what didn't have value
+1 to DaveReynolds
DeirdreLee: Wouldn't that be the same as the comments from LC
PhilA: Yes
cygri: The difference about CR is that we want to know how it was actually used, not just thought about
<HadleyBeeman> http://www.w3.org/2011/gld/wiki/ORG_CR_transition#Implementations
cygri: I'm thinking of some sort of script that we want implementers to work through. That shifts the burden from the nebulous 2 humans to the implementers
HadleyBeeman: proposes revised text...
<HadleyBeeman> proposes: Each term in the vocab used in at least two data sources (ideally governments) and, using the test methodology, inspected each data source and
<HadleyBeeman> confirmed they are used in conformance to the spec.
cygri: Org is the one where we're hitting these things first
DaveReynolds: No... the current timetable has Org and QB at the same time
cygri: I hear consensus on having
SPARQL queries for each vocab
... These are about chekcing conformance on the publishing
side. Do we need to worry about the consumer side as well
<DaveReynolds> Data for unit tests are different from data for system tests
<HadleyBeeman> PhilA: creating the SPARQL query alone will force the tester to create conformant and non-conformant data. That creates a reasonable test suite, useful for publishers and consumers.
<HadleyBeeman> PhilA: It'd be nice to get implementation reports from consuming applications, but not necessary for our exit criteria.
DaveReynolds: I think it's a
binary decision on whether we have to test consumers. We need
to be clear whether we're including them or not
... It's not a trivial side efeect, or it certainly wasn't for
QB
cygri: That's right for QB, yes,
but for Org it can be much simpler
... A well formed Cube is a much more complicated structure
DaveReynolds: true - but I didn't need to create a test for every aspect of it
cygri: No one suggests that the
queries or the test data shoujld provide complete
coverage
... we prob want data in the reports that tell us whether each
term has been used but we don't need a test for it
... It's not necessary to cover everything. It is useful to
cover most of it
HadleyBeeman: You were talking about the queries (the 80/20 thing). does that also apply to the human review?
cygri: If you show me an RDF
graph and asked is this conformant. I'd take a look and
eventually come up with an answer but it may be hard to come up
with an explanataion
... is it using the right properties? is it extending it
correctly?
... I don't know how I'd quantify my thinking
... I'm suggesting a script or checklist
... with binary answers
... some questions might be like "are there any terms with the
same semantics as an org term?"
... some inspectors will be more thorough?
<HadleyBeeman> Can we look at this again? http://www.w3.org/2011/gld/wiki/ORG_CR_transition#Implementations
cygri: Will we have a test for
every term?
... Each term is used by at least 2 data sources
... There are 2 data sources that pass manual inspection
... there are two sources that pass the test suite which
consists of the queries and the human inspection
DaveReynolds: I am confused now
<HadleyBeeman> PhilA: exit criteria: we will show that weher terms have been used, they have been used at least twice in line with the conformance criteria.
<HadleyBeeman> … methodology is how we prove that
<sandro> PhilA: Exit Criteria: (1) We will show that our terms have been used in conformance with the spec, and (2) at least two datasets have used each term
<sandro> cygri: 1. We should show that every single term in the vocab has been used in at least two data sources. When doing this, we don't check if it's been used correctly.
<sandro> cygri: 2. We will have a set of SPARQL queries, and each query comes with a description of the expected results. Like: this is a list of all the orgs mentioned in your data. We'll run these SPARQL queries and see if the results seem to match the description. We want to have two publishers that pass all of these.
<sandro> cygri: Where it's really the Implementors running the queries, and reporting back to use about whether the results look correct.
<sandro> cygri: 3. We in the WG will prepare a checklist or script saying which things need to be checked. Implementors will look at their data to see if it meets those criteria. For example: none of the non-org term has the same semantics as an org term. We'll say "look at your data and check for this".
<sandro> HadleyBeeman: We need to define these test to go into CR.
<sandro> cygri: Right, and we need two passing data sources.
<sandro> cygri: I think these threee approaches, taken together, will give us an Implementation Report where it's not too much work on anybody, but we have confidence.
<sandro> _+1
<sandro> +1
<DaveReynolds> +0
<fadmaa> +1
<HadleyBeeman> PROPOSED: To adopt cygri's three points as above to be our exit criteria for the vocabularies
<DeirdreLee> +1
<sandro> +1
<BartvanLeeuwen> +1
<DaveReynolds> +0
+1
<fadmaa> +1
<HadleyBeeman> PROPOSED: To adopt these as our exit criteria for vocabularies:
<HadleyBeeman> 1. We should show that every single term in the vocab has been used in at least two data sources. When doing this, we don't check if it's been used correctly.
<HadleyBeeman> PROPOSED: To adopt these three points (as described by cygri) as our exit criteria for vocabularies http://www.w3.org/2013/04/12-gld-irc#T15-35-40
<DaveReynolds> +0
<BartvanLeeuwen> +1
<fadmaa> +1
+1
<bhyland> +1
<sandro> +1
<DaveReynolds> +0 (seems confused, for some vocabs the SPARQL queries will be yes/no, the boundary between inspection of SPARQL results and inspection of data seems awkward)
<sandro> https://www.w3.org/2013/meeting/gld/2013-04-12
<HadleyBeeman> RESOLVED: To adopt these three points (as described by cygri) as our exit criteria for vocabularies http://www.w3.org/2013/04/12-gld-irc#T15-35-40
<DaveReynolds> DaveReynolds: Overall seems to lead to an unconvincing result and a lot of work for the editors.
<sandro> https://www.w3.org/2013/meeting/gld/2013-04-12#resolution_2
<DaveReynolds> DaveReynolds: but current lack a better concrete proposal.
<DaveReynolds> DaveReynolds: except that, as stated, QB will be different because of the existing IC tests and the need to test the normalization
<HadleyBeeman> http://www.w3.org/2011/gld/wiki/ORG_CR_transition#Implementations
<cygri> DaveReynolds, I agree that QB should be different. Was really thinking about ORG here
HadleyBeeman: declares topic
closed!
... I will create CR pages for the other Rec Track documents.
It would be good if editors cold start to populate those
pages
... if you haven't updated the timetable page for your docs,
please do
<DaveReynolds> Timetable will need to further extended given above resolution :(
HadleyBeeman: and is that it?
bhyland: Wraps up and thanks
everyone for coming
... Thanks DeirdreLee for organising the hosting
<DaveReynolds> Bye all
BartvanLeeuwen: I'd rather have 6 fires in a day - less exhausting than this
This is scribe.perl Revision: 1.137 of Date: 2012/09/20 20:19:01 Check for newer version at http://dev.w3.org/cvsweb/~checkout~/2002/scribe/ Guessing input format: RRSAgent_Text_Format (score 1.00) Succeeded: s/arms/adms/ Succeeded: s/admsscheme:agency/adms:schemaAgency/ Succeeded: s/PhillA/PhilA/ Succeeded: s/sandro:/sandro,/ Succeeded: s/PhilA: /PhilA,/ Succeeded: s/disagree/agree/ Succeeded: s/seams/seems/ Succeeded: s/sandro:/sandro;/ Succeeded: s/hadleybeeman/phila/ Succeeded: s/havie/have/ Succeeded: s/9/(/ Succeeded: s/problem/process/ Succeeded: s/from/for/ Succeeded: s/sued/used/ Found Scribe: Richard Found Scribe: phila Inferring ScribeNick: PhilA Found Scribe: deirdrelee Inferring ScribeNick: DeirdreLee Found Scribe: fadmaa Inferring ScribeNick: fadmaa Found Scribe: PhilA Inferring ScribeNick: PhilA Found ScribeNick: PhilA Found Scribe: hadleybeeman Inferring ScribeNick: HadleyBeeman Found Scribe: PhilA2 Found Scribe: PhilA Inferring ScribeNick: PhilA Scribes: Richard, phila, deirdrelee, fadmaa, hadleybeeman, PhilA2 ScribeNicks: PhilA, DeirdreLee, fadmaa, HadleyBeeman Present: MakxDekkers DaveReynolds martinA WARNING: No meeting chair found! You should specify the meeting chair like this: <dbooth> Chair: dbooth Found Date: 12 Apr 2013 Guessing minutes URL: http://www.w3.org/2013/04/12-gld-minutes.html People with action items: cygri makx makxdekkers phila[End of scribe.perl diagnostic output]
{kind=link}