Questions (and Answers) on the Semantic Web
W3C and the Semantic Web, June 20, 2005, Wien, Austria
Ivan Herman, W3C
Usually, one gives an introduction to SW…
…and then, questions are asked
But this audience already knows the introduction…
…so let us move to questions right away!
So…
Questions?
Is the Semantic Web AI on the Web?
NO!!!
RDF and OWL are relatively simple things (compared to AI, that is…)
They offer:
a simple way to express and store metadata
a way to “structure” and characterize the terms
means to make some inference within a restricted framework
and that is it!
One goal in SW is to keep things relatively simple and not necessarily seek absolute completeness (the famous 80/20 rule…)
RDF (Resource Description Framework)
Remember: RDF is a set of statements , that can be modeled (mathematically) with:
Resources : an element, a URI, a literal, …
Properties : directed relations
between two resources
Statements: “triples” of two resources bound
by a property
usual terminology: (s,p,o) for subject, property, object
RDF is a general model for such statements
OWL (Web Ontology Language)
OWL refines the usage of RDF by:
defining the terminology used in a specific context (ontologies)
imposing constraints on properties (e.g., cardinality constraints)
characterizing the logical characteristics of properties (e.g., transitivity, functionality)
defining the equivalence of terms across ontologies
etc.
(to be precise: these are done by RDFS+OWL)
OWL and Logic
OWL expresses a small subset of First Order Logic
it has a “structure” (class hierarchies, properties, datatypes…),
and “axioms” can be stated within that structure only
i.e., OWL uses FOL to describe “traditional” ontology concepts … but it is not a general logic system per se!
Inference based on OWL is within this framework only
it seems modest, but has proved to be remarkably useful…
Some things are missing
There are lots of things RDF/OWL cannot express, eg:
the “uncle” relationship: ∀x,z: ((∃y: (y parent x) ∧ (y brother z)) ⇒ (z uncle x))
temporal and spatial reasoning
fuzzy logic
…
Some of these may find their way, eventually, to SW (see later)
But AI is more…
(Some would say: if something is not yet solved in Computer Science, it is AI…)
More seriously, there are things that are not part of the SW:
associative thinking
recognition of images, text content, gestures, …
complex decision procedures (like Big Blue…)
etc.
Just as Prolog is not AI but merely a useful tool for it, SW might be a good tool for AI
Where is the “Web” in SW?
The “Web” is in the URI-s!
On the SW, resources are identified by URI-s, e.g.:
URL-s
http://www.ivan-herman.net
ftp://ftp.cwi.nl
URN-s
urn:ISBN:0-395-36341-1
urn:lsid:ensembl.org:homosapiens_gene:ensg00000002016
Anybody can create metadata on any resource on the Web
It becomes easy to merge and share metadata and ontologies
some would say: “if it is not shared, it is not on the Semantic Web…”
URI-s ground RDF into the Web
Related Question…
Q: People have misused HTML’s meta elements… why would that be different?
A: The meta elements are in the HTML source
i.e., only the authors can set them
on the SW, anybody can define metadata
so one can get around misuse…
Isn’t the RDF Model way too complex?
(look how complex RDF/XML is …)
RDF is a graph!
An (s,p,o) triple can be viewed as a labelled edge in a graph
i.e., a set of RDF statements is a directed, labelled graph
both “objects” and “subjects” are the graph nodes
“properties” are the edges
the formal semantics of RDF is also described using graphs
One should “think” in terms of graphs, and…
…RDF/XML is only a tool for practical usage!
RDF authoring tools often work with graphs, too (XML is done “behind the scenes”)
If one thinks in graphs, things become simple!
RDF/XML has its Problems
RDF/XML was developed in the “prehistory” of XML
e.g., even namespaces did not exist!
Coordination was not perfect, leading to problems
the syntax cannot be checked with XML DTD-s
XML schemas are also a problem
encoding is verbose and complex (simplifications lead to confusions…)
but there is too much legacy code
Don’t be influenced (and set back…) by the XML format
the important point is the model , XML is just syntax
other “serialization” methods may come to the fore
Other Encoding Examples…
Turtle, n3, N-triples (variants of one another):
:object :pred [:pred2 :val1; :pred3 :val2; ]
<triple>
<subject uri="..."/>
<predicate uri="..."/>
<object>A Literal</object>
</triple>
Class(animate)
Class(animateMotion)
Class(animationEntity complete
unionOf(animate animateMotion …)
)
Again: these are all just syntactic sugar!
Why should I use RDF?
(Couldn’t I simply use XML with XML Schema instead?)
(or: Couldn’t I simply use a relational database instead?)
It Depends…
XML’s model is
a tree, i.e., a strong hierarchy
applications may rely on hierarchy position (e.g., li in HTML)
relatively simple syntax and structure
not easy to combine trees
RDF’s model is
a loose collections of relations
applications may do “database”-like search
not easy to recover hierarchy
easy to combine relations in one big collection (great for the integration of heterogeneous information
RDF’s Force is its Flexibility
If you want to modify your XML structure:
you have to modify your DTD or Schema…
you may not have access and/or permission to those…
tools depending on the hierarchy (e.g., XSLT) might go wrong…
Similar problems with a DBMS:
you have to modify the database record definition
you may not have the right to do so…
In the triple store model you just merge…
Extra Bonus: OWL
You may not use OWL reasoning yet…
…but you may in future, RDF leaves the door open!
Finding New Relationships
RDF(+OWL) helps in finding new relationships
e.g., in Life Sciences:
most of the drug experiments are unsuccessful
but the information from each experiment may be valuable
by “binding” this information new insights can be gained
(currently, life sciences are very excited by the
prospects of the Semantic Web!)
Sharing and aggregation of data becomes easier
may be determinant for future R&D, for example
great tool for general community building
But... RDF Does Not Make XML Obsolete!
Do not try to describe an HTML page in terms of triplets:
it is technically doable…
but things would be much more complicated!
I.e.: the choice depends on what you want to do!
With huge ontologies on the Web, does this scale?
It May Be a Problem, But…
Yes, reasoning over huge ontologies may be a problem
combination of ontologies may lead to this
DL systems shown to work for ≈100k concepts already
albeit with a simple structure
there are already applications with large ontologies (see later)
lots of R&D is happening here… but it is indeed still a challenge
But… “a little semantics can take you far” (Jim Hendler)
i.e., small OWL ontologies may lead to useful applications
applications can also be developed with “ontology islands”
loosely connected ontologies bound by an application…
… via, e.g., a P2P architecture
(e.g., M.-C. Rousset’s paper at ISWC2004)
You Can Also Choose
OWL provides layers, namely Lite, DL, Full:
increasing expressability, though increasing complexity
choose what is right for you!
(new layers might come to the fore in future)
Applications may add their own modules to a general reasoner:
the extra module “knows” about the application’s specificities
can complement the general general reasoner
But: you are not obliged to use OWL to be a good SW citizen!
see CC/PP, RSS, thesauri with SKOS, …
Where does the metadata and ontologies come from?
(Should we really expect the author to type in all this metadata?)
It May Be Around Already…
Part of the metadata information is present in tools … but thrown away at output e.g., a business chart can be generated by a tool…
…it “knows” the structure, the
classification, etc. of the chart
…usually, this information is
lost
Storing it in metadata would be easy!
“SW-aware” authoring tools will be of a great help (e.g., Adobe’s XMP)
RDF Can Also Be Generated
There might be conventions to use in XHTML…
e.g., by using class names
… and then generate RDF automatically (e.g., via an XSLT script)
there are tools and developments in this direction, like GRDDL
An interesting direction is in XHTML2 :
it has two “metadata” modules
the metadata can then be extracted via a tool, e.g., to add Dublin Core metadata to a document:
<span property="dc:date">March 23, 2004</span>
<span property="dc:title">High-tech rollers hit casino for £1.3m</span>
By <span property="dc:creator">Steve Bird</span> …
Ontology Developement
The hard work is to create the ontologies in general
requires a good knowledge of the area to be described
some communities have good expertise already (e.g., librarians)
OWL is just a tool to formalize ontologies
Large scale ontologies are often developed in a community process
leading to versioning issues, too
OWL includes predicates for versioning, deprecation, “same-ness”, …
Sharing ontologies may be vital in the process
saves the energy of re-inventing the wheel…
There is also R&D in generating them from a corpus of data
still mostly a research subject
Isn't This Research Only?
(or: does this have any industrial relevance whatsoever?)
Not Any More…
SW has indeed a strong foundation in research results…
…but we see more and more companies embracing it!
Remember:
the Web was born at CERN…
…was first picked up by high energy physicists…
…then by academia at large…
…then by small businesses and start-ups…
“big business” came only later!
network effect kicked in early…
Semantic Web is now at #4, and moving to #5!
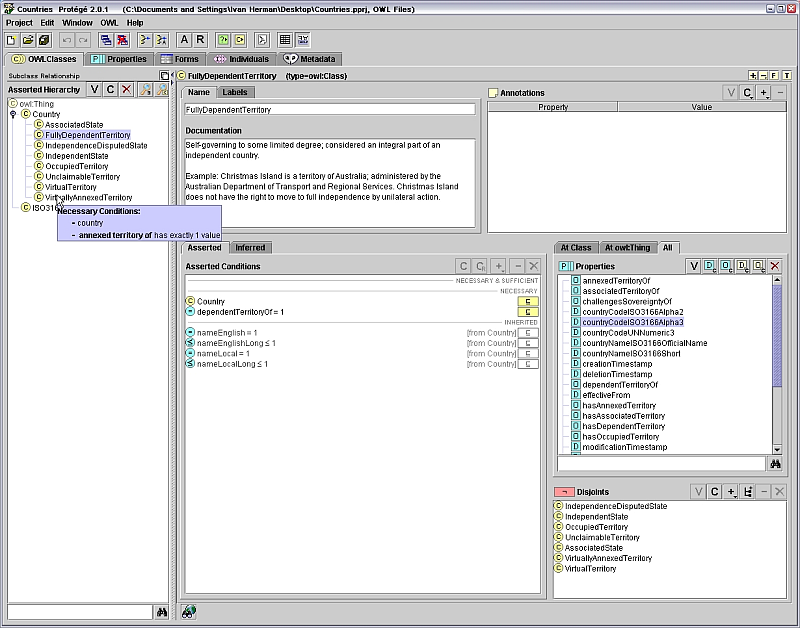
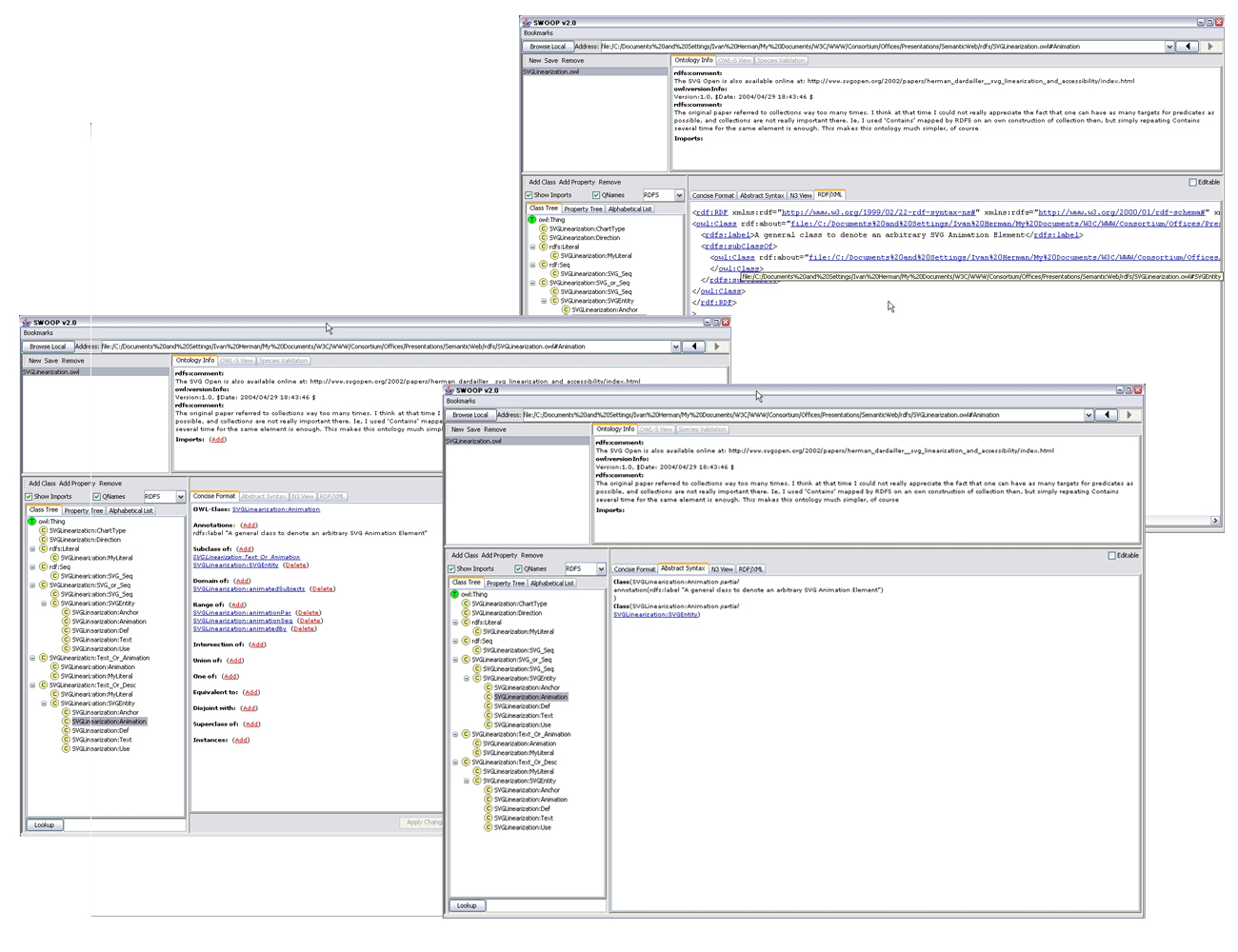
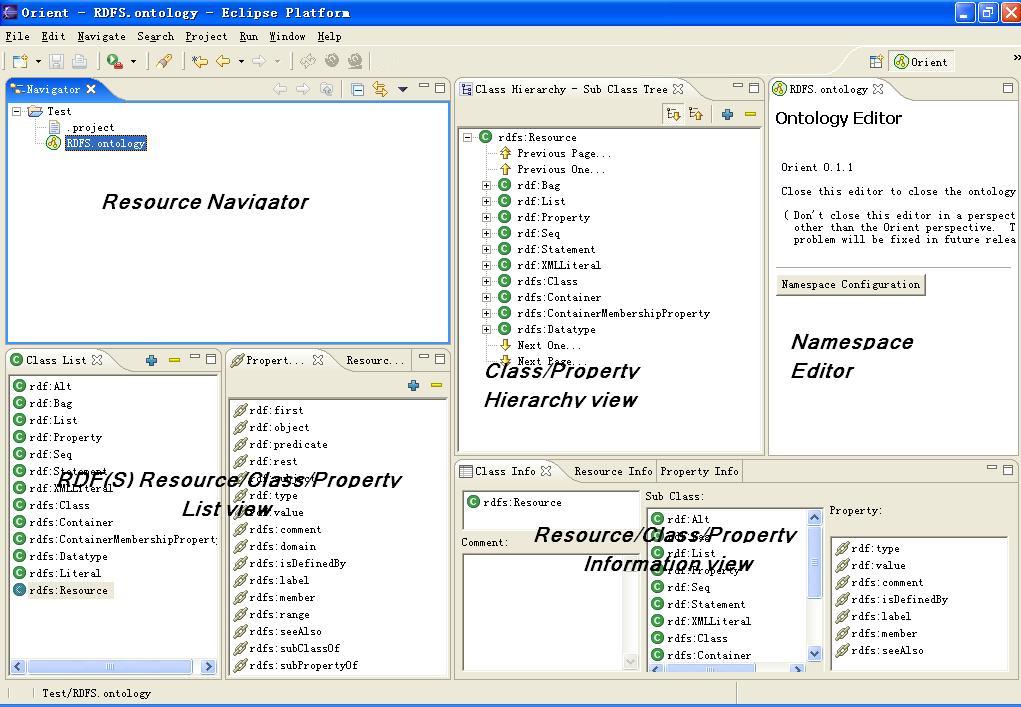
Lots of Tools
(Graphical) Editors:
Programming Environments:
Jena (for Java, includes OWL reasoning),
RDFLib (for Python),
Redland (in C, with interfaces to Tcl, Java,
PHP, Perl, Python, …), SWI-Prolog, IBM’s Semantic Toolkit, …
Jena (for Java, includes OWL reasoning),
RDFLib (for Python),
Redland (in C, with interfaces to Tcl, Java,
PHP, Perl, Python…),
SWI-Prolog, IBM’s Semantic Toolkit, …
Triple based database systems:
RDF and OWL validators:
You can always start looking at W3C’s RDF developer site
“You can take stuff from the shelf and put a prototype out fast!”
SW Applications
Large number of applications emerge:
first applications were RDF only…
…but recent ones use ontologies, too
huge number of ontologies exist already, with proprietary formats
converting them to RDF/OWL is a significant task
(but there are converters)
Most applications are still “centralized”, not many decentralized applications yet
For further examples, see, for example, the SW Technology Conference
not a scientific conference, but commercial people making real money!
Data integration
Semantic integration of corporate resources or different databases
RDF/RDFS/OWL based vocabularies as an “interlingua” among system components
(early experimentation at Boeing, see, e.g., a WWW11 paper )
Similar approaches: Sculpteur project, MITRE Corp., MuseoSuomi, …
There are companies specializing in the area
Oracle's Network Data Model
An RDF data model to store RDF statements
Java Ntriple2NDM converter for loading existing RDF data
An RDF_MATCH function which can be used in SQL to find graph patterns (similar to SPARQL)
Will be release as part of Oracle Database 10.2 later this year
Vodaphone's Live Mobile Portal
Search application (e.g. ringtone, game, picture) using RDF
better search: page views per download decreased 50%
increased revenue: ringtone up 20% in 2 months
RDF was key factor in making this possible
Sun's SwordFish
Sun provides assisted support for its products, handbooks, etc
Public queries go through an internal RDF engine for, eg:
Nokia has a somewhat similar support portal
IBM – Life Sciences and Semantic Web
IBM Internet Technology Group
focusing on general infrastructure for Semantic Web applications
Develop user-centered tools
power of Semantic Web technologies, but hide the underlying complexity
Integrated tool kit (storage, query, editing, annotation, visualization)
Common representation (RDF), unique ID-s (LSID), collaboration, …
Focus on Life Sciences (for now)
but a potential for transforming the scientific research process
Adobe's XMP
Adobe’s tool to add RDF-based metadata to all their file formats
used for more effective organization
supported in Adobe Creative Suite (over 700K desktops!)
support from 30+ major asset management vendors
The tool is available for all!
Does the SW Replace Web Services?
SW and WS are Complementary
Two facets of machine-to-machine communication
service based (“Web of applications”)
metadata based (“Web of data”)
A widely deployed Web Services infrastructure may be the most compelling business case
for the Semantic Web
The synergy of Semantic Web and Web Service will hugely benefit for the wide deployement of both!
Examples for Potential Synergies
Semantic Web based search engines for Web Services
search based on complex constraints
e.g., “find the most elegant Schrödinger equation solver”
“Match-making”
i.e., combining various services based on their semantics
Examples for Potential Synergies (cont)
RDF Database services with complex Queries
queries and query results transmitted in, e.g., SOAP
query facilities described in WSDL
Ontology services
“provide a Web Service to make logical deductions on my behalf”
(e.g., on complex metadata with an ontology)
find and manage equivalences
make logical deduction of terms
check SW description for validity
etc
“provide a Web Service to make logical deductions on my behalf”
(e.g., on complex metadata with an ontology)
find and manage equivalences
make logical deduction of terms
check SW description for validity
etc.
SW-WS Synergy Example
Baby CareLink
centre of information for the treatment of premature babies
provides an OWL service as a Web Service
combines disparate vocabularies like medical, insurance, etc
users can add new entries to ontologies
complex questions can be asked through the service
Convergence (at W3C and Elsewhere)
Lots of discussions on convergence at W3C
Both areas are represented at W3C, too
mapping of WSDL2.0 to RDF
Web Choreography development in terms of RDF
initiatives already exist, e.g., the OWL-S Member Submission
discussions on “WS Features and Properties”
there is a “Semantic Web Services” Interest Group
Workshop on “Frameworks for Semantics in Web Services” in June 2005
Discussions on UDDI being expressed in RDF
…
Are we done?
Not Yet…
The “core” infrastructure is around
New technical issues come up:
querying RDF data
specialized vocabularies (e.g., SKOS)
rules
…
There is also a need for a very strong outreach:
outreach to user communities (life sciences, geospatial information systems,
libraries and digital repositories, …)
intersection of SW with other technologies (Web Services, Privacy issues, …)
There is a separate Working Group on “Deployment and Best Practices” (see Thomas Baker’s presentation later today, including SKOS)
Querying RDF Graphs
In practice, complex queries into the RDF data are necessary
The fundamental idea: use graph patterns to define a subgraph:
a pattern contains unbound symbols
by binding the symbols, subgraphs of the RDF graph may be matched
if there is such a match, the query returns the bound resources or a subgraph
This is how SPARQL (Query Language for RDF) is defined
based on similar systems that already exist, e.g., in Jena
is programming language-independent query language
still in a working draft phase (Recommendation in 2006?)
Simple SPARQL Example
SELECT ?cat ?val
WHERE { ?x rdf:value ?val. ?x category ?cat }
Returns:
[["Total Members",100],["Total Members",200],…,["Full Members",10],…]
Note the role of ?x: it helps defining the pattern, but is not returned
Other SPARQL Features
Add functional constraints to pattern matching
Define optional patterns
Return a full subgraph (instead of a list of bound variables)
Construct a graph combining a separate pattern and the query results
Use datatypes and/or language tags when matching a pattern
…
Remember: SPARQL is still evolving!
SPARQL Usage in Practice
Locally , i.e., bound to a programming environment like RDFLib or Jena
details are language dependent
Remotely , i.e., over the network, possibly connecting to a database
very important: there are a growing number of RDF depositories…separate documents define the protocol and the result format
return is in XML: can be fed, e.g., into XSLT for direct display
An application pattern evolves: use (XHTML) forms to create a SPARQL Query to a database and display the result in HTML (eg, W3C’s Talk database)
There are lots of SPARQL implementations already!
Rules
OWL can be used for simple inferences
Applications may want to express domain-specific knowledge, e.g.:
(prem-1 ∧ prem-2 ∧ …) ⇒ (concl-1 ∧ concl-2 ∧ …)
e.g.: for any «X», «Y» and «Z»: “if «Y» is a parent of «X», and «Z» is a brother of «Y» then «Z» is the uncle of «X»”
using a logic formalism (Horn clauses): ∀x,z: ((∃y: (y parent x) ∧ (y brother z)) ⇒ (z uncle x))
Lots of research has happenend to extend RDF/OWL
(Metalog,
RuleML,
SWRL,
cwm, …)
note: cwm, for example, defines Horn predicates in terms of graph patterns
there is a connection to SPARQL here…
Interest from rule system vendors, financial services, business rules, …
the community seems to need some sort of a rule language
W3C’s Rules Workshop
W3C held a Workshop in April 2005
Lots of issues identified:
relationship to RDFS+OWL: Side by side? On the top? Replace? Independent?
open World vs. closed World assumption
“if something cannot be proved, we do not know” vs.
“if something cannot be proved, it is false”
OWL relies on the former, rule languages usually on the latter…
uncertainty/probabilitistic reasoning, fuzzy logic
syntax issues (XML? RDF? Abstract Syntax?)
declarative rules, vs. rules with functional/programmable actions
There is a public archive on further discussions
W3C may work on an “Activity Proposal”
Trust
Can I trust a metadata on the Web?
is the author the one who claims he/she is? Can I check the credentials?
can I trust the inference engine?
etc.
Some of the basic building blocks are available (e.g., XML Signature/Encryption) but
much is missing, e.g.:
how to “express” trust? (e.g., trust in context.)
how to “name” a full graph
a “canonical” form of triplets (in RDF/XML or other) (necessary for unambiguous signatures)
exhaustive tests for inference engines
protocols to check, for example, a signature
It is on the “future” stack of W3C and the SW Community …
A Number of Other Issues…
Lot of R&D is going on:
improve the inference algorithms and implementations
improve scalability, reasoning with OWL Full
temporal & spatial reasoning, fuzzy logic
better modularization (import or refer to part of ontologies)
procedural attachments
…
This mostly happens outside of W3C, though
W3C is not a research entity…
Now For Real…
Other Questions?






{kind=link}
{kind=link}
{kind=link}
{kind=link}