This document contains examples in another language or script.
Accesskey n skips to in page navigation. Skip to the content start
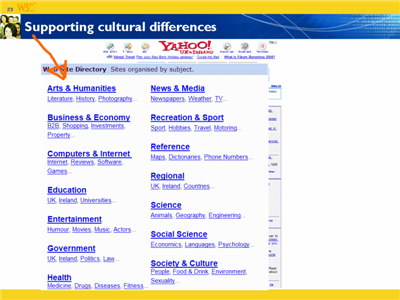
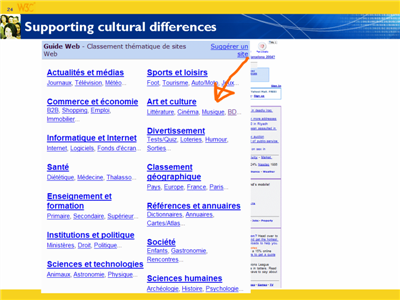
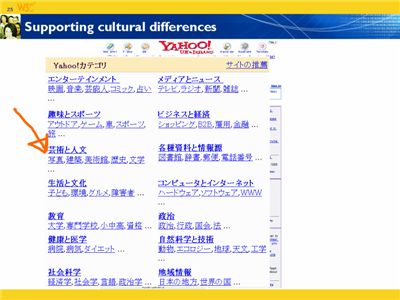
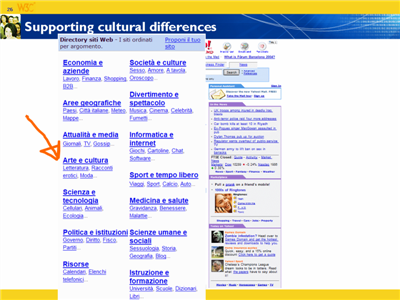
This talk was delivered by Richard Ishida at the meeting to celebrate the 10th anniversary of the World Wide Web Consortium in Europe, in June 2005.
Additional commentary will be added shortly to convey the messages on the slides.
Please send any comments to ishida@w3.org.