A global distributed Social Web requires that each person be able to control their identity, that this identity be linkable across sites - placing each person in a Web of relationships - and that it be possible to authenticate globally with such identities. By making distributed authentication easy one can allow everybody to protect their resources and enable their preferred privacy settings.
This specification outlines a simple universal identification mechanism that is distributed, openly extensible, improves privacy, security and control over how each person can identify themselves in order to allow fine grained access control to their information on the Web.
It does this by applying the best practices of Web Architecture whilst building on well established widely deployed protocols and standards including HTML, URIs, HTTP, TLS, X.509 Certificates, and RDF Semantics.
How to Read this Document
There are a number of concepts that are covered in this document that the
reader may want to be aware of before continuing. General knowledge of
public key cryptography
and RDF [RDF-PRIMER] is necessary to understand how
to implement this specification. WebID uses a number of specific technologies
like HTTP over TLS [HTTP-TLS], X.509 certificates [X509V3],
Turtle [turtle] and RDFa [RDFA-CORE].
A general Introduction is provided for all that
would like to understand why this specification is necessary to simplify usage
of the Web.
The terms used throughout this specification are listed in the section
titled Terminology.
This is an internal draft document and may not even end up being
officially published. It may also be updated, replaced or obsoleted by
other documents at any time. It is inappropriate to cite this document
as other than work in progress.
The WebID-TLS protocol enables secure, efficient and maximally user friendly authentication on the Web.
It enables people to authenticate onto any site by simply choosing one of the certificates proposed to them by their browser.
These certificates can be created by any Web Site for their users.
This specification extends the WebID Identity [WEBID] specification which defines many of the core concepts used in WebID-TLS, such as the identifier, known as the WebID, as well as the associated Profile Document.
WebIDs can be used to build a Web of trust using vocabularies such as [FOAF] by allowing people to link together their profiles in a public or protected manner.
Such a web of trust can then be used by a Service to make authorization decisions, by allowing access to resource depending on the properties of an agent, such that he/she is known by some relevant people, works at a given company, is a family member, is part of some group, ...
The WebID-TLS protocol specifies how a Service can authenticate a user after requesting his or her Certificate without needing to rely on this being signed by a well known Certificate Authority. This is done by dereferencing the WebID Profile, and checking if it describes the user as being in control of the private key related to the Public Key published in the Certificate used to authenticate.
WebID authentication can also be used for automatic authentication by robots, such as web crawlers of linked data repositories, which could be agents working on behalf of users to help them in their daily tasks.
1.1 Outline
This specification is divided in the following sections.
This section gives a high level overview of the WebID-TLS Protocol, and presents the organization of the specification and the conventions used throughout the document.
Section 2 lists the preconditions that need to be in place for any authentication sequence to be successful: which include the creation of a WebID Profile and the creation of a WebID Certificate.
Section 3 on the WebID-TLS Protocol describes in detail how a server can authenticate a user.
1.2 Terminology
WebID
A WebID is a URI with an HTTP or HTTPS scheme which denotes an Agent (Person, Organization, Group, Device, etc.).
For WebIDs with fragment identifiers (e.g. #me), the URI without the fragment denotes the Profile Document.
For WebIDs without fragment identifiers an HTTP request on the WebID MUST return a 303 with a Location header URI referring to the Profile Document. Refer to [WEBID] for the normative definition.
WebID Profile or Profile Document
A WebID Profile is an RDF document which MUST uniquely describe the Agent denoted by the WebID in relation to that WebID.
This document MUST be available as Turtle [turtle].
This document MAY be available in other RDF serialization formats, such as RDFa [[!RDFA-CORE] or RDF/XML [RDF-SYNTAX-GRAMMAR] if so requested through content negotiation.
Refer to [WEBID] for the normative definition.
Alice
Alice is an agent who owns a Server which runs a Service which Bob wishes to Access.
Bob
Bob is an agent who uses a Client to connect to Alice's Service, and who is responsible for the private key the Client uses to authenticate to Services.
If he notices the private key was compromised he needs to take action to disable the public key.
Subject
The Subject is the Agent that is identified by the WebID.
Only the Subject should be able to authenticate to a Service.
We will name him Bob throughout this document to improve readability.
The Subject is distinct from the Client which is used to connect to the Server.
Client
The Client initiates a request to a Service listening on a specific port using a given protocol on a given Server. It can request authentication credentials from a Key Store to send to a server.
Key Store
A Key Store can return certificates to authorized Clients and can sign cryptographic tokens with the corresponding key.
This protocol does not specify where the Key Store is located: it could be that the Client contains its own Key Store or it could be that the Key Store is a separate process on the Operating System, or even that it is to be found in an external device controlled by the Subject.
Server
A Server is a machine contactable at a domain name or IP address that hosts a number of globally accessible Services. Refer to [WEBID] for the normative definition.
Service
A Service is an agent listening for requests at a given IP address on a given Server. Refer to [WEBID] for the normative definition.
TLS Service
A TLS Service is a transport level service listening on the Service port.
It secures the transport layer before passing messages to the Application layer Service itself.
The TLS protocol [TLS] is applied to incoming connections: it identifies the server to the client, securing the channel and is able to request authentication credentials from the Client if needed.
Server Credentials and Client credentials traditionally take the form of X.509 Certificates containing a public key.
The TLS protocol enables the TLS Service to verify that the Client controls the private key of the Public Key published in the certificate.
Trust decisions on other attributes of the Subject published in the Certificate - such as his name - are traditionally based on the trust in the Agent that signed the Certificate - known as a Certificate Authority.
Certificate
A Certificate is a document that affirms statements about a Subject such as its public key and its name, and that is signed by a Certificate Authority using the private key that corresponds to the public key published in its certificate. The Certificate Authority's own Certificate is self signed. Certificates used by TLS are traditionally X.509 [X509V3] Certificates.
Certificate Authority (CA)
A Certificate Authority is a Subject that signs Certificates.
It is an Authority for what is written in the Certificate for any Agent that trusts it to be truthful in what it signs.
Such agents use the knowledge of the CA's public key to verify the statements made by that CA in any of the Certificates it signed.
Services usually identify themselves with Certificates signed by well known and widely deployed CAs available in all agents.
TLS-Light Service or TLS Agent
A TLS-Light Service is a standard TLS Service, without the CA Based Client Certificate Authentication.
When receiving a Client Certificate, it simply verifies that the Client knows the private key of the public key published in the Certificate.
Verification of attributes in the certificate is left to other services such as the WebID Verifier.
Guard
A Guard is an agent, usually on the Server that can look at a request from the Client and decide if it needs to be authorized by looking at the access control rules for that resource ( using the Web Access Control ontology perhaps )
If the request requires authorization, the Guard can first demand authentication of the Client and use the WebID Verifier to check any claimed identies that would allow it to come to an authorization decision.
Finally the Guard can grant or deny access according to how the verfied identities satisfy the Access Control Rules.
WebID Verifier
A WebID Verifier is an agent trusted by the Server to verify that the Subject identified by the WebID is the one that knows the private key of the given public key. The Verifier uses the procedure determined in this protocol to do the verification.
WebID Claim or Claimed WebID
A WebID Certificate can be thought of as a set of statements made and signed by a Certificate Authority.
If the Certificate Authority is not known to be one whose every statement can be trusted, then the statements in the certificate must be thought of by a suspicious guard, as claimed statements only, that is as statements which have not been verified.
In particular, statements about the Subject Alternative Names of the agent that knows the private key should not be assumed to be true until verified.
A WebID Claim then is the statement of Identity between the Subject Alternative Name and the public key in the certificate.
In Turtle this can be written as
A WebID Verifier takes a WebID Claim and checks that it is currently true, as explained in Verifying the WebIDs section.
A WebID Verification Agent MUST be able to parse documents in TURTLE [turtle], RDF/XML [RDF-SYNTAX-GRAMMAR] and RDFa [RDFA-CORE].
WebID Certificate
An X.509 [X509V3] Certificate that identifes an Agent using one or more WebIDs.
The Certificate need not be signed by a well known Certificate Authority.
Indeed it can be signed by the server which hosts the WebID Profile, or it can even be self signed.
The Certificate MUST contain a Subject Alternative Name extension with at least one URI entry identifying the Subject.
This URI SHOULD be one of the URIs with a dereferenceable secure scheme, such as https:// . Dereferencing this URI should return a representation containing RDF data.
For example, a certificate identifying the WebIDhttps://bob.example/profile#me would contain the following:
X.509v3 extensions:
...
X509v3 Subject Alternative Name:
URI:https://bob.example/profile#me
And it would have a WebID Profile at https://bob.example/profile.
Public Key
A cryptographic key that can be published and can be used to verify the possession of a private key. A public
key is always included in a WebID Certificate.
1.3 Namespaces
Examples assume the following namespace prefix bindings unless otherwise stated:
Prefix
IRI
cert
http://www.w3.org/ns/auth/cert#
xsd
http://www.w3.org/2001/XMLSchema#
foaf
http://xmlns.com/foaf/0.1/
bob
https://bob.example/profile#
The bob: namespace is a URI that refers to Bob's profile, where Bob is an imaginary character well known in security circles.
2. Preconditions
2.1 The certificate
The Key Store must have a Certificate with a Subject Alternative Name URI entry.
This URI must be one that dereferences to a WebID Profile whose graph contains a cert:key relation from the WebID to the public key published in the Certificate . (see below The WebID Profile Document)
2.1.1 Certificate example
This section is non-normative.
For example, if a user Bob controls https://bob.example/profile,
then his WebID can be https://bob.example/profile#me
When creating a certificate it is very important to choose a user friendly Common Name (CN) for the user, that will allow him to distinguish between different certificates he may have, such as a personal or a business certificate, when selecting one from his browser.
In the example below the CN is Bob (personal).
This name can then also be displayed by any server authenticating the user as a human friendly label.
The WebID URL itself should not usually be used as a visible identifier for human users, rather it should be thought of as a hyperlink in an <a href="https://..."> anchor.
That is the CN should be a label and the WebID a pointer.
As an example to use throughout this specification here is the
following certificate as an output of the OpenSSL program.
Should we formally require the last issuer of a chain of certificates
to be O={}, CN=WebID
This would allow the server to request only WebID enabled certificates, or even WebID enabled
certificates in addition to CA signed certificates it trusts using the certificate_authorities
field in the TLS request.
Issue 2
The above certificate is no longer valid.
2.1.2 Certificate creation
This section is non-normative.
Many tools exist to create Certificates.
Some Key Stores allow a user to create the Certificate directly with a friendly User Interface.
But using a Key Store on the client still requires the public key to be published on the server as detailed in the next section.
It is possible to combine the creation of the key with its publication in one step in such a way as to allow the server to make the decision of what the WebID should be, by using the HTML 5 keygen element which can be added to an HTML form, as shown in this example:
When the user clicks such a form, the following sequence can take place on a properly configured server:
just before it submits the form, the browser asks the Key Store to create a public and private key pair, and saves the private key in its local Key Store
the browser then sends the public part of the key in the spkac format along with any additional attribute values from the form to the certificate maker form handler with an HTTP POST
The Certificate Maker service can then create an X509 Certificate with the user's WebID filled in the Subject Alternative Name field and return this to the Client
the browser on receiving the response find the matching private key and places both in the Key Store
The private key never leaves the secure Key Store. This exchange allows the Server to make the decision about what the Certificate should say, what the WebID should be, and to simultaneously add the public key to the User's WebID Profile page. The user experience for this Certificate creation is a one click operation.
2.2 The WebID Profile Document
The WebID Profile document MUST be a [WEBID] document. It MUST also expose the relation between the WebID URI and the Subject's public keys using the cert ontology as well as the standard xsd datatypes.
Note
The cert ontology will be extended to cover DSA, Eliptic Curve Cryptography, and other cryptographic alogrithms as requests for them are made, proposals accepted, and when enough working and compatible implementations can be shown to work. Please contact the WebID Comunity Group with requests and proposals.
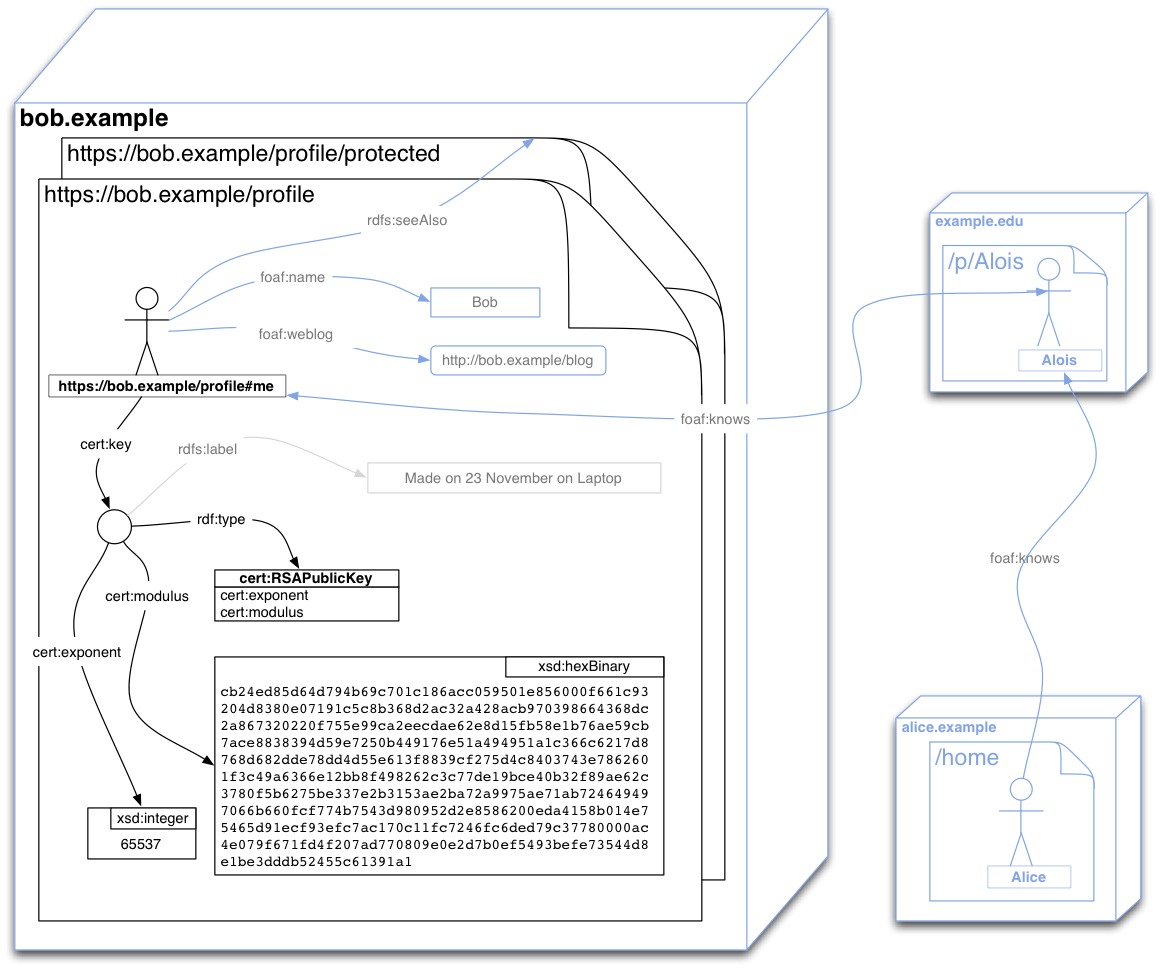
The set of relations to be published at the WebID Profile document can be presented in a graphical notation as follows.
The document can publish many more relations that are of interest to the WebID-TLS protocol, as shown in the above graph by the grayed out relations.
For example Bob can publish a depiction or logo, so that sites he authenticates to can personalize the user experience. He can post links to people he knows, where those have WebIDs published on other sites, in order to create a distributed Social Web.
He can also publish relations to protected documents, where he keeps more information for people who authenticate, such as his friend Alois or his friends friends who may not yet know him personally, such as Alice.
The protocol does not depend on any particular serialization of the graph, provided that agents are able to parse that serialization and obtain the graph automatically, see examples in the [WEBID] specification.
2.2.1 Vocabulary
RDF graphs are built using vocabularies defined by URIs, that can be placed in subject, predicate or object position.
The definition of each URI should be found at the namespace of the URI.
Here we detail the core cryptographic terms needed. The optional foaf vocabulary used to describe
agents can be found at the the foaf namespace vocabulary document.
Below is a short summary of the vocabulary elements to be used when conveying the relation between the
Subject and his or her key, within a WebID Profile document.
For more details please consult the cert ontology document.
Used to associate a WebID URI with any PublicKey. A WebID ProfileMUST contain at least one PublicKey that is associated with the
corresponding WebID URI.
Refers to the class of RSA Public Keys. A RSAPublicKey MUST specify both a
cert:modulus and a cert:exponent property. As the cert:modulus and cert:exponent relations both
have as domain a cert:RSAPublicKey, the type of the key can be inferred by the use of those relations
and need not be written out explicitly.
Used to relate an RSAPublic key to its modulus expressed as a hexBinary.
An RSA key MUST have one and only one modulus. The datatype of a modulus is xsd:hexBinary. The string representation of the hex:Binary MUST not contain any whitespaces in between the hex numbers.
Used to relate an RSAPublic key to its exponent expressed as a decimal integer.
An RSA key MUST have one and only one exponent. The datatype of a modulus is xsd:integer.
2.3 Turtle
This section is non-normative.
A widely used format for writing RDF graphs by hand is the Turtle [turtle] notation.
It is easy to learn, and very handy for communicating over e-mail and on mailing lists.
The syntax is very similar to the SPARQL query language.
Turtle should be served with the text/turtle mime type.
@prefixcert: <http://www.w3.org/ns/auth/cert#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rdfs: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<#me> a foaf:Person;
foaf:name "Bob";
foaf:knows <https://example.edu/p/Alois#MSc>;
foaf:img <http://bob.example/picture.jpg>;
cert:key [ a cert:RSAPublicKey;
rdfs:label "made on 23 November 2011 on my laptop";
cert:modulus "cb24ed85d64d794b69c701c186acc059501e856000f661c93204d8380e07191c5c8b368d2ac32a428acb970398664368dc2a867320220f755e99ca2eecdae62e8d15fb58e1b76ae59cb7ace8838394d59e7250b449176e51a494951a1c366c6217d8768d682dde78dd4d55e613f8839cf275d4c8403743e7862601f3c49a6366e12bb8f498262c3c77de19bce40b32f89ae62c3780f5b6275be337e2b3153ae2ba72a9975ae71ab724649497066b660fcf774b7543d980952d2e8586200eda4158b014e75465d91ecf93efc7ac170c11fc7246fc6ded79c37780000ac4e079f671fd4f207ad770809e0e2d7b0ef5493befe73544d8e1be3dddb52455c61391a1"^^xsd:hexBinary;
cert:exponent 65537 ;
] .
3. Disabling a WebID Certificate
A WebID Certificate identifies the Subject alone and no one else, if and only if that Subject is the only one to control the corresponding private key.
It is very important therefore that the Subject take care of keeping the private key secure.
This can be done by keeping it in the Key Store of a personal machine in an account that is password protected and free of viruses, or best of all on some physical device where the private key is inaccessible to be read by any software.
In the second case, having the device implies that the private key has not been lost or copied.
In the first case the user has to be more careful for signals of misuse.
In either situation if the Subject is suspicious that his private key has been taken, future authentications for that certificate can be disabled by removing the corresponding public key from the WebID Profile.
If the profile contains more than one public key for the Subject then it is suggested that each public key contain a label to help the user locate the key. In the examples above an rdfs:label with a creation date was used for this purpose.
4. The WebID Authentication Protocol
4.1 Authentication Sequence
In order to give the full context of a Client interaction with a Server we will illustrate the protocol with the following sequence diagram.
Bob initiates a connection to Alice's server via a TLS enabled protocol such as HTTPS in order to access a Protected Resource or a Protected Service.
The Protected Resource MUST be served over a TLS-Light Service, that will not do full CA authentication of ClientCertificates it receives.
The Protected Resource may be a document served over HTTPS, but it could also be a SOAP service, or some other resource.
This resource is protected by a Guard, which uses a WebID Verifier to verify the non Certified WebIDs found in the certificate.
Once the verification succeeds the Guard checks to see if the Agent identified by the WebID is allowed access to the resource, by using trusted information from the Web and access control rules.
The steps in detail are as follows:
Bob's ClientMUST open a TLS [TLS] connection with the server which authenticates itself using the standard TLS protocol.
Once the Transport Layer Security [TLS] has been set up, the application protocol exchange can start.
If the protocol is HTTP then the client can request an HTTP GET, PUT, POST, DELETE, ... action on a resource as detailed by [HTTP11].
The Guard can then intercept that request and by checking access control rules associated with that resource, determine if the client needs authorization and hence authentication for that type of request.
If the request has no access restrictions the request can be passed straight on to the resource.
If the request does have access restrictions then the Guard can proceed to the next step.
If the resource requires WebID authentication, the Guard MAY request the client to authenticate itself using public key cryptography by signing a token with its private key and have the Client send its Certificate. This has been carefully defined in the TLS protocol and can be summarized by the following steps:
The Guard requests the TLS agent to make a Certificate Request to the client. The TLS layer does this. Because the WebID-TLS protocol does not rely on Certificate Authorities to verify the contents of the Certificate, the TLS Agent can ask for any Certificate from the Client. More details in Requesting the Client Certificate
The Client asks Bob to choose a certificate if the choice has not been automated.
We will assume that Bob does choose a WebID Certificate and sends it to the client.
The TLS AgentMUST verify that the client is indeed in possession of the private key.
What is important here is that the TLS Agent need not know the Issuer of the Certificate, or need not have any trust relation with the Issuer.
Indeed if the TLS Layer could verify the signature of the Issuer and trusted the statements it signed, then step 5 and 6 would not be needed - other than perhaps as a way to verify that the key was still valid.
The WebID Certificate is then passed on to the Guard with the provision that the WebID still needs to be verified.
The Guard then MUST ask the Verification Agent to verify that the WebIDs in the WebID Certificate do identify the agent who knows the given Public Key.
The Verification AgentMUST extract the Public Key and all the URI entries contained in the Subject Alternative Name extension of the WebID Certificate.
A WebID CertificateMAY contain multiple URI entries which are considered Claimed WebIDs at this point, since they have not been verified.
The Verification Agent may verify as many or as few WebIDs it has time for.
It may do it in parallel and asynchronously.
However that is done, a Claimed WebID can only be considered verified if the following steps have been accomplished successfully:
The WebID Verifier must get access to an up to date version of the WebID Profile Graph.
If the WebID Verifier has an up to date version of the graph in its graph cache then it can return it.
Otherwise the WebID verifierMUST fetch an up to date version of the WebID Profile representation
by dereferencing the URI, using the canonical method for dereferencing a URL of that scheme.
For an https://...WebID this would be done using the [HTTP-TLS] protocol.
The dereferencing of the URI MAY use any representation caching mechanism it can to speed up the process.
The returned representation is then transformed into an RDF graph [RDF-MT] as specified in processing the WebID Profile .
This graph may be then be cached to speed up future requests.
The graph returned in the previous step is then queried as explained in Verifying the WebIDs.
If the query is answered positively, then that WebID is verified.
If the query fails and the graph was not up to date, then the Verifier MAY start again at point 6.1.2 by making
a request to an up to date graph.
With the set of verified WebIDs the Guard can then check if one of of them is authorized by the Access Control Rules found in step 2.
If access is granted, then the guard can pass on the request to the protected resource.
4.2 Authentication Sequence Details
This section covers details about each step in the authentication process.
4.2.1 Initiating a TLS Connection
This section is non-normative.
Standard SSLv3 and TLSv1 and upwards can be used to establish the connection between
the Client and the TLS Agent listening on the Service's port.
Note
Many servers allow a simple form of TLS client side authentication to be setup when configuring a TLS Agent: they require the agent to be authenticated in WANT or NEED mode before any further interaction can take place.
If the client sends a certificate, then neither of these have an impact on the WebID Verification steps (4) and (5).
Nevertheless, from a user interaction perspective both of these are problematic as they either force (NEED) or ask the user to authenticate himself even if the resource he wishes to interact with is public and requires no authentication.
Furthermore very few people will feel comfortable authenticating to a web site on the basis of reading the server certificate alone.
Most people would like to know more about what the web site claims to be about before divulging their identity.
This is usually done by reading a few web pages without being authenticated.
Hence it is important for human users that authentication be only requested on user demand.
This can be done by using TLS renegotiation and moving the authentication to the application layer Guard which can make more fine grained decisions on when authentication is required.
Please see the WebID Wiki for implementation pointers in different programming languages and platforms to learn about how this can be done and to share your experience.
4.2.2 Connecting at the Application Layer
This section is non-normative.
Once the TLS connection has been setup, the application layer protocol interaction can start.
This could be an HTTP GET request on the protected resource for example.
If the protocol permits it, the Client can let the Application layer, and especially the Guard know that the client can authenticate with a WebID Certificate, and even if it wishes to do so. This may be useful both to allow the Server to know that it can request the client certificate, and also in order to make life easier for Robots that may find it a lot more convenient to be authenticated at the TLS layer.
Issue 3
Bergi proposed a header for HTTP which could do this. Please summarise it.
4.2.3 Access Control Check
This section is non-normative.
The Guard can intercept the request and consult its access control rules for that resource, in order to determine if some the request type is access controlled.
If the request is authorized to anyone, then server can pass the request straight on to the resource.
If the request requires some authentication the Guard MAY request the client certificate as detailed
in the next section.
Because a WebID is a global linkable URI, one can build webs of trust that can be crawled the same way the web can be crawled: by following links from one document to another.
It is therefore possible to have very flexible access control rules where parts of the space of the user's machine is given access to friends and those friends' friends (FOAF), stated by them at their domains.
It is even possible to allow remote agents to define their own access control rules for parts of the machine's namespace.
4.2.4 Requesting the Client Certificate
This section is non-normative.
TLS allows the server to request a Certificate from the Client using the CertificateRequest message [Section 7.4.4] of TLS v1.1 [TLS]. Since WebID TLS authentication does not rely on CAs signing the certificate to verify the WebID Claims made therein, the Server does not need to restrict the certificate it receives by the CAs they were signed by. It can therefore leave the certificate_authorities field blank in the request.
Note
From our experience leaving the certificate_authorities field empty leads to the correct behavior on all browsers and all TLS versions.
Issue 4
Should we formally require the last issuer of a chain of certificates
to be O={}, CN=WebID
This would allow the server to request only WebID enabled certificates, or even WebID enabled
certificates in addition to CA signed certificates it trusts using the certificate_authorities
field in the TLS request.
Note
A security issue with TLS renegotiation was discovered in 2009, and an IETF fix was proposed in [RFC5746] which is widely implemented.
If the Client does not send a certificate, because either it does not have one or it does not wish to send one, other authentication procedures can be pursued at the application layer with protocols such as OpenID, OAuth, BrowserID, etc...
As much as possible it is important for the server to request the client certificate in WANT mode, not in NEED mode.
If the request is made in NEED mode then connections will be broken off if the client does not send a certificate.
This will break the connection at the application protocol layer, and so will lead to a very bad user experience. The server should therefore avoid doing this unless it can be confident that the client has a certificate - which it may be because the client advertised that in some other way to the server.
Issue 5
Is there some normative spec about what NEED and WANT refer to?
4.2.5 Verifying the WebIDs
The Verification Agent is given a list of WebIDs associated with a public key. It needs to verify that the agent identified by that WebID is indeed the agent that controls the private key of the given public key. It does this by looking up the definition of the WebID. A WebID is a URI, and its meaning can be obtained by dereferencing it using the protocol indicated in its scheme.
If we first consider WebIDs with fragment identifiers, we can explain the logic of this as follows. As is explained in the RFC defining URIs [RFC3986]:
The fragment identifier component of a URI allows indirect identification of a secondary resource by reference to a primary resource and additional identifying information.
The identified secondary resource may be some portion or subset of the primary resource, some view on representations of the primary resource, or some other resource defined or described by those representations.
[...]
The semantics of a fragment identifier are defined by the set of representations that might result from a retrieval action on the primary resource.
In order therefore to know the meaning of a WebID containing a fragment identifier, one needs to dereference the resource referred to without the fragment identifier.
This resource will describe the referent of the WebID using a syntax convertible to RDF triples.
If the document returned states that the referent of the WebID is the agent that controls the private key of the given public key, then this is a definite description that can be considered to be a definition of the WebID: it gives its meaning.
The trust that can be had in that statement is therefore the trust that one can have in one's having received the correct representation of the document that defined that WebID.
An HTTPS WebID will therefore be a lot more trustworthy than an HTTP WebID, as it reduces the likelihood of man-in-the-middle attacks.
If the authenticity of the server hosting the WebID profile document is proven through the use of HTTPS, then the trust one can have in the agent at the end of the TLS connection being the referent of the WebID is related to the trust one has in the cryptography, and the likelihood that the private key could have been stolen.
Issue 6
Add explanation for URI with redirect.
4.2.5.1 Processing the WebID Profile
The Verification Agent needs to fetch the document, if it does not have a valid one in cache.
The WebID Verification AgentMUST be able to parse documents in TURTLE [turtle], and MAY be able to also parse them in RDFa [RDFA-CORE] and RDF/XML [RDF-SYNTAX-GRAMMAR].
The result of this processing should be a graph of RDF relations that is queryable, as explained in the next section.
Note
The Verification AgentMUST set the Accept-Header to request text/turtle with a higher priority than text/html and application/rdf+xml. The reason is that it is quite likely that many sites will produce non marked up HTML and leave the graph to the pure RDF formats.
If the Guard wishes to have the most up-to-date Profile document for an HTTPS URL, it can use the HTTP cache control headers to get the latest versions.
4.2.5.2 Verifying the WebID Claim
To check a WebID Claim one has to find if the graph returned by the profile relates the WebID to the CertificatePublic Key with the cert:key relation. In other words, one has to check if those statements are present in the graph.
4.2.5.2.1 Verifying the WebID Claim with SPARQL
Testing for patterns in graphs is what the SPARQL query language is designed to do [RDF-SPARQL-QUERY]. We will first look at how to use this as it is also the simplest method, and then what some other programmatic options may be.
Below is the SPARQL Query Template which should be used for an RSA public key. It contains three variables ?webid, ?mod and ?exp that need to be replaced by the appropriate values:
The variables to be replaced for each WebID claim are:
Variable
Details on its value.
?webid
should be replaced by the WebID Resource. In the SPARQL notation that is the URL string would be placed between <...> in the position of the ?webid variable.
?mod
should be replaced by the modulus written as a xsd:hexBinary as specified by the cert:modulus relation. All leading double 0 bytes (written "00" in hexadecimal) should be removed. The resulting hexadecimal should then be placed in the space of the XXX in "XXX"^^xsd:hexBinary
?exp
should be replaced by the public exponent written as an xsd:integer typed literal. In SPARQL as in Turtle notation this can just be written directly as an integer.
Assuming that we received Bob's key whose modulus starts with cb24ed85d64d794b6... and whose exponent is 65537 then the following query should be used:
An ASK query simply returns true or false. If it returns true, then the key was found in the graph with the proper relation and the claim is verified.
When processing the queries in the above template, unexpected results may appear if the representation of a modulus or exponent contains whitespace characters in the initial and/or final position. To avoid these unexpected results, the query engine MUST support the D-entailment regime for xsd:hexBinary and xsd:integer as specified in SPARQL 1.1 Entailment Regimes.
For verifiers that do not have access to a SPARQL query engine but can query the RDF data programmatically, it is relatively easy to emulate the above SPARQL query programmatically. There are a number of ways of doing this, some more efficient than others.
4.2.5.2.2 Verifying the WebID claim without SPARQL
If the RDF library does datatype normalization of all literals before loading them, then the most efficient way to execute this would be to start by searching for all triples whose subjects have relation cert:modulus to the literal which in our example was "cb24ed..."^^xsd:hexBinary. One would then iterate through all the subjects of the relations that satisfied that condition, which would most likely never number more than one, and from there filter out all those that were the object of the cert:modulus relation of the WebID - in the example bob:me. Finally one would verify that one of the keys that had satisfied those relations also had the cert:exponent relation to the number which in the example above is "65537"^^xsd:integer.
For triples stores that do not normalize literals on loading a graph, the normalization will need to be done after the query results and before matching those with the values from the Certificate. Because one could not rely on the modulus having been normalized, one would have to start with the WebID - bob:me and find all its cert:key relations to objects - which we know to be keys - and then iterate through each of those keys' modulus and exponent, and verify if the normalized version of the value of those relation is equal to the numbers found in the certificate. If one such key is found then the answer is true, otherwise the answer will be false.
4.2.5.3 Authorization
This section is non-normative.
Once the Guard has a WebID it can lookup the access control rules for the given resource to see if the agent is allowed the required type of access.
Up to this point, we are not much more advanced than with a user name and password, except that the user did not have to create an account on Alice's server to identify himself and that the server has some claimed attributes to personalize the site for the requestor.
5. Privacy considerations
This section is non-normative.
In an WebID authentication process, three actors are involved: the authenticating Subject, the server he is authenticating to, and the server serving the WebID Profile. Different privacy considerations apply to each one of these actors.
5.1 The Authenticating Subject
This section is non-normative.
During authentication, the Subject authenticating to a server must reveal one of his identies.
As a consequence, information that is associated with that identity, found at the WebID Profile, will be tied to behavioral information that can be gathered by the site he is logging into.
Access to profile information can be restricted through access control policies, based on ontologies such as Web Access Control.
However, by aggregating user data from multiple servers that exchange information about users, attackers could in theory be able to build a complete profile of a given user.
It is therefore important that the Subject understands the privacy policies of the site to which he authenticates in order to choose the appropriate identity to use for that site.
The development of a limited number of easy to understand and machine readable privacy policies, would greatly help users make informed decisions in this space.
Further flexibility may be offered to the authenticating Subject to adapt his privacy policies to a site, allowing the user to select the group of agents with whom he wishes to share the information he generates.
5.2 Privacy considerations for the WebID Profile Server
This section is non-normative.
To avoid potential deadlock problems, where one server needs to authenticate into a second server that itself requires authentication, etc... , WebID Profile's MUST be public.
It follows that WebID Authenticating servers MUST not authenticate when fetching a WebID Profile.
Even though a WebID Profile document MUST be publicly accessible, the WebID Profile can be split among multiple resources that are linked and protected by access control rules (as explained in the privacy section of the WebID specification [WEBID]), in order to provide limited access to sensitive information.
As a consequence of dereferencing the WebID Profile during authentication, identity providers such as the server hosting the profile document are able to track the IP addresses of incoming requests for the user's profile document, and potentially match them to a list of known servers and services.
In other words, unless the user hosts her profile on a server she owns and controls, the server owner will be able to track references to the user across the Web, and effectively use this pattern to build a picture of the user's actions on the Web.
WebID Profiles that are hosted on organizational servers should therefore be used by their owners with care and responsibility.
5.3 Privacy considerations for the authenticating Server
This section is non-normative.
Servers identify themselves in any transaction, and even more so when the transactions are done over HTTPS.
A server must make sure that information is served only to Agents that are allowed access to that information - public information should be made available to anyone, and non public information be only made available to those that are allowed access.
As explained in the previous section, the WebID VerifierMUST NOT authenticate when fetching a WebID profile, as this leads to deadlock situations.
6. Security considerations
This section is non-normative.
A WebID identifies an agent via a description found in the associated WebID Profile document.
An agent that wishes to know what a WebID refers to, must rely on the description found in the WebID Profile.
An attack on the relation between the WebID and the WebID Profile can thus be used
to subvert the meaning of the WebID, and to make agents following links within the WebID Profile come to different conclusions from those intended by profile owners.
When authenticating clients identified by an http:// (as opposed to https://) WebID, the server to which the client is authenticating should take into account the potential man-in-the-middle attack or DNS poisoning attacks that may take place when fetching a non secure resource on the Web.
The server to which the client is authenticating should take these attacks into account when deciding what level of service to provide for the user, and also what type of information to allow him access to.
If such a user wants to access sensitive data or enter a serious transaction it may be important to verify his authenticity using additional channels.
For more sensitive transactions, a server authenticating https:// WebIDs may want to make sure that the WebID Profile information it obtains is recent, in order to be able to exclude the possibility that the user disabled that certificate by removing its public key from the list of cert:keys listed in the WebID Profile. A user may do that on discovering that one or more of its private keys were compromised.
A server to which the client is authenticating must remember that the contents of a WebID Profile is only a self assertion by the WebID owner.
In other words, the server can decide on the authenticity of that information when communicating with the referent of the WebID itself, but it must take care not to assume that other agents on the web will agree with those statements.
If other agents do build up relations to that WebID, then depending on the nature of those relations one may conclude to a certain overlapping of points of views, leading to a Web of trust.
The position of the WebID in the global Linked Data space may make a very big difference as to how much trust the authenticating server puts in the veracity of those relations.
The publication of a profile on a publicly listed company's web site may make the information legally binding and the legal framework may create a stronger space in which those statements can be accepted.
This details of this trust reasoning goes way beyond what can be explored by the WebID authentication protocol.
As security is constantly being challenged by new attacks, to which new responses are found, a collection of security considerations will be made available on the WebID Wiki.
A. Change History
This section is non-normative.
2013-08-01
Separated the WebID Identity and Discovery spec from the WebID Authentication over TLS protool. Updated editors and acknowledgments. Reorganised diagram to make clearer that authentication of user should depend on access control rules.
2011-12-12
Fixed several errors in examples and diagrams, clarified TLS-Light, added SSL renegotiation, key chain and cache control, updated list people in acknowledgments.
2011-11-23
Wide ranging changes: Rewrote the Verification algorithm now enhanced with a detailed sequence diagram. Moved to new ontology using xsd:hexBinary datatypes and removed rsa: ontology. Rewrote vocabulary section using clearer names. All these changes required serious rewriting everywhere.
2011-02-10
Move to W3C WebID XG.
Updates from previous unofficial WebID group include changes on
RDF/XML publishing in HTML, clarification on multiple SAN URIs and
WebID verification steps.
2010-08-09
Updates from WebID community: moved OpenID/OAuth sections to separate document,
switched to the URI terminology instead of URL, added "Creating the certificate"
and "Publishing the WebID Profile document" sections with a WebID graph and
serializations in Turtle and RDFa, improved SPARQL queries using literal
notation with cert datatypes, updated list of contributors,
and many other fixes.
The following people have been instrumental in providing thoughts, feedback,
reviews, criticism and input in the creation of this specification:
Tim Berners-Lee, Thomas Bergwinkl, Andrei Sambra, Erich Bremer, Sarven Capadisli, Melvin Carvalho, Martin Gaedke, Michael Hausenblas, Kingsley Idehen, Ian Jacobi, Nathan Rixham, Seth Russell, Jeff Sayre, Dominik Tomaszuk, Mo McRoberts, David Chadwick, Patrick Logan, Peter Williams, Mischa Tuffield, Pierre Antoine Champin, Reto Bachman Gmür, Antoine Zimmermann, Manu Sporny.
ITU-T Recommendation X.509 version 3 (1997). "Information Technology - Open Systems Interconnection - The Directory Authentication Framework" ISO/IEC 9594-8:1997.. ITU.