Accesskey n skips to in page navigation. Skip to the content start
Terminology
In this article we refer to the value of a language attribute such as fr-CA as a language tag.
The fr and CA parts are referred to as subtags when described as parts of a tag. When
described as members of an ISO list of languages or countries, fr and CA are referred to as codes.
Language tags can be (and should be) used to indicate the language of text in HTML and XML documents. For
HTML 4, language tags are specified with the lang attribute. For
XML, language tags are given in the xml:lang attribute. In both cases, language
information is inherited along the document hierarchy, i.e. it has to be given only once if the whole document is in one language, and language
information nests, i.e. inner attributes overwrite outer attributes.
Language tags are defined in RFC 3066, which obsoletes the older RFC 1766. XML has been updated to use RFC 3066 by an erratum. RFC 3066 is based on ISO-639 two-letter and three letter language codes, and on ISO-3166 two-letter country codes. RFC 1766 did not include three-letter language codes.
Examples include:
| Code | Language | Explanation |
|---|---|---|
| en | English | ISO-639 two-letter language code |
| mas | Masai | ISO-639 three-letter language code |
| fr-CA | French as used in Canada | ISO-639 two-letter code with ISO-3166 two-letter country code |
| en-scouse | English Liverpudlian dialect known as 'Scouse' | ISO-639 two-letter language code with addition, IANA-registered |
| i-klingon | Klingon | IANA-registered language code |
| x-pig-latin | Pig Latin | Unregistered/Experimental |
Language tags starting with i- are defined in the IANA registry of
language tags. Language tags starting with x- denote experimental tags without guarantee for uniqueness. The list of
ISO-639 two-letter and three-letter language codes is provided by the
ISO 639-2 Registration Authority (Library of Congress, USA).
According to RFC 3066, for languages with both a two-letter and a three-letter code, the two-letter code must be used. This also solves the problem of those languages that have two different three-letter codes, because all of them also have a two-letter code.
XML now also provides a means to prevent inheritance of language using the empty string, ie.
xml:lang=""
Essentially, this says: I do not want to associate any language with this information.
The remainder of this article provides additional detail on how to use language tags.
RFC 3066 is the standard that defines how to use language tags to identify languages.
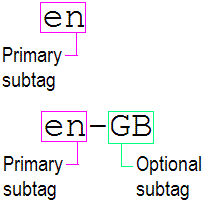
A language tag is composed of a primary subtag, followed by zero or more additional subtags, separated by hyphens.
The primary subtag represents a language (there are two possible exceptions, i- and x-, which are described below), and any following subtags serve to qualify the dialect or usage of the language. These latter subtags typically represent countries, dialects or scripts.
The following example indicates that a document is written not just in English but in British English, as opposed to, say, US English.
<html lang="en-GB">
Subtags are case insensitive; they can include the letters and digits A to Z, a to z and 0 to 9; and they must be 8 characters or less in length.
Note that the HTML specification still recommends the use of RFC 1766 for identifying language. RFC 3066 is an update of RFC 1766 that supersedes it, and there is a planned erratum in place for the HTML specification, so you should use RFC 3066 despite what the HTML specification currently says.
A proposed successor to RFC 3066 is currently being developed, but it aims to retain backwards compatibility with tags created using RFC 3066.
All subtags in initial position must be 1, 2 or 3 letters in length. All 2 and 3 letter subtags in this position must be language codes from ISO 639 part 2, which defines codes to represent languages. 1 letter subtags must be one of the prefixes i- or x- we will describe later.
Although the codes are case insensitive, they are commonly written lowercased, but this is merely a convention.
Note also that, where ISO offers a choice between 2-letter and 3-letter codes, you should choose the 2-letter one. This ensures that for each language, as far as possible, a unique code is used. Older data using two-letter codes (based on RFC 1766, which did not allow three-letter codes) does not need to be changed. Also, the question of which three-letter code to use is avoided, since the few languages that have two different three-letter codes all have a two-letter code.
Subtags can be added to indicate geographic, dialectal, script, or other refinements to the primary (language) tag. Any number of subtags can follow the primary tag, although it is unusual to see more than one.
RFC 3066 specifies that any 2-letter tags in the second subtag must be ISO 3166 country codes. There are no rules for any third and subsequent subtags that are used.
Two-letter ISO subtags indicating country are commonly written uppercase, but this is only a convention.
RFC 3066 defines a couple of instances where the language tag might not begin with an ISO language code.
A language tag that begins with i- is reserved for IANA-registered language tags. Examples include
A language tag that begins with x- provides a mechanism for user-defined language tags. The second tag must be more than one letter long, and must not be one of the following reserved subtags: AA, QM-QZ, XA-XZ, and ZZ. For example:
Of course, neither of these approaches should be used to identify a language if the approach based on initial two- or three-letter ISO codes is available. These methods restrict or prevent interoperable language tag recognition.
It is possible to register language tags with IANA using the submission process described in RFC 3066. These tags can have 3- to 8-letter subtags in the second position.
While the i- prefix is reserved specifically for IANA tags, not all IANA tags begin with it. For example, a number of Chinese dialects have been registered with IANA. These include zh-guoyu, zh-hakka, zh-min, zh-min-nan, zh-wuu, etc.
Registering tags with IANA is better than using user-defined tags because it maximizes the likelihood of interoperability, due to the fact that the IANA tags are visible to others. On the other hand, IANA tags may be deprecated as new codes are added to the ISO standard. For this reason, there may be some risk to long-term interoperability when using certain IANA registered tags. This is particularly likely to apply to tags beginning with the i- prefix.
IANA tags that have been deprecated at the time this tutorial was published include no-bok (Norwegian "Book language" - use ISO 639 nb), i-navajo (Navajo - use ISO 639 nv), i-lux (Luxembourgish - use ISO 639 lb), and others.
Some particularly useful tags registered with IANA allow you to specify Traditional vs. Simplified Chinese. In the past it was necessary to distinguish the two by using something like zh-CN (Mainland China) for Simplified Chinese and zh-TW (Taiwan) for Traditional Chinese. Apart from the fact that this is mislabelled, you could not guarantee that others would recognize these conventions, or even follow them. For example, some people used zh-HK to represent Traditional Chinese. Now IANA makes available the tags zh-Hans and zh-Hant for Simplified and Traditional Chinese, respectively. The following two paragraphs illustrate the use of these tags.
<p lang="zh-Hans" xml:lang="zh-Hans">当世界需要沟通时,请用Unicode!</p><p lang="zh-Hant" xml:lang="zh-Hant">當世界需要溝通時,請用統一碼(Unicode)</p>
It is expected that these tags will persist for the foreseeable future, so it would be good to use them as soon as possible in order to improve future interoperability sooner rather than later.
According to RFC3066 'en-GB' should also match 'en'. For example, the following CSS code colors all English text red in browsers that support the pseudo-attribute :lang.
:lang(en) { color: red; }
In the following code, the text described as lang="en-GB" will be red.
<p>En janvier, toutes les boutiques de Londres affichent des panneaux <span lang="en-GB">SALE</span>, mais en fait ces magasins sont bien propres!</p>
On the other hand, given the following CSS declaration,
:lang(en-GB) { color: red; }
the word 'SALE' should not be red in the following code.
<p>En janvier, toutes les boutiques de Londres affichent des panneaux <span lang="en">SALE</span>, mais en fait ces magasins sont bien propres!</p>
Note, however, that this is not the case for language negotiation on an Apache server. If you want to be automatically directed to a page example.fr.html and your browser settings only state a preference for 'fr-CA', you will need to add 'fr' to your settings. (See Setting language preferences in a browser.)
Although RFC3066 language tags work well much of the time, there are still some issues:
Many more codes are needed than those provided by ISO to cover the approximately 6,000 languages of the world.
They don't cover the needs to express general regions; for example, there is still no tag for the generalized Latin-American Spanish that many organizations use to create Spanish content.
There is some lack of clarity between the use of language tag values for designating language vs. locale. 'Locales' are combinations of language plus geographical region typically used to set such things as date and time defaults in software.
There is a need, sometimes, to distinguish the script used, in addition to the language. For example, Mongolian might be written in Mongolian script or Cyrillic; Croatian might be written in Latin or Cyrillic; ...
People are currently working on solutions to these issues, including people from ISO TC37, SIL, and W3C, etc. The proposed successor to RFC 3066 is also targeting these issues.
Language tags for HTML were first formally defined in RFC 2070, F. Yergeau, et.al. Internationalization of the Hypertext Markup Language. RFC 2070 was incorporated into HTML 4, and has been reclassified as historic.
Note changes to ISO language codes, in particular those in 1989 (withdrawing iw, in, and ji, replacing them by he, id, and yi, and adding se, iu, ug, and za).
Unicode provides cross-references to Microsoft and Apple codes.
Many other W3C and Web-related specifications use language tags:
lang attribute and the XML xml:lang attribute,
with the later taking precedence in case there should be any differences.Note also that language information can be attached to objects such as images and included audio files.
RFC 3066: Tags for the Identification of Languages http://www.ietf.org/rfc/rfc3066.txt
ISO 639: Codes for the Representation of Names of Languages http://www.loc.gov/standards/iso639-2/langcodes.html
ISO 3166: Codes for Country Names http://www.iso.org/iso/en/prods-services/iso3166ma/02iso-3166-code-lists/list-en1.html
IANA language tag registry http://www.iana.org/assignments/language-tags
Authoring Techniques for XHTML & HTML Internationalization: Specifying the language of content 1.0 http://www.w3.org/TR/i18n-html-tech-lang/
W3C I18N resource index: Language declarations and language negotiation http://www.w3.org/International/resource-index.html#lang
Last update 2005-05-13 20:06 GMT
For a summary of significant changes, search for the title in the change log.
Copyright © 2005 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements.