1 Introduction
Extending and Versioning XML Languages Part 1 described extending and versioning languages. Part 2 focuses on XML and includes schema language specific aspects of extending and versioning XML. The choices, decisions, and strategies described in Part 1 are augmented with XML and XML Schema instances herein.
1.1 XML Terminology
We will describe some key refinements to our versioning terminology for XML. An XML language has a vocabulary that may use terms from one or more XML Namespaces (or none), each of which has a namespace name. [Definition: An XML language is an where all the Texts MUST be well-formed XML.]. As XML is a markup language, the most significant parts of XML Languages are the elements and attributes. [Definition: A component is an XML element or attribute.] The Name Language - consisting of name, given, family terms - has a namespace for the terms. We use the prefix "namens" to refer to that namespace. The Name Language could consist of terms from other vocabularies, such as Dublin Core or UBL. These terms each have their own namespaces, illustrating that a language can be comprised of terms from multiple namespaces. An XML Namespace is a convenient container for collecting terms that are intended to be used together within a language or across languages. It provides a mechanism for creating globally unique names.
We use the term instance when speaking of sequences of characters (aka text) in XML. [Definition: An instance is a Text of well-formed XML and the texts are usually constrained by a schema language.] The schema language may be machine processable such as DTDs, XML Schema, Relax NG, or the schema language may be human readable text. Documents are instances of a language. In XML, they must have a root element. A name text might have a name element as the root element. Alternatively, the name vocabulary may be used by another language such as purchase orders so the purchase order texts may contain texts that can be considered name texts. Thus instances of an XML language are always at least part of a text and may be the entire text. XML instances (and all other instances of markup languages) consist of markup and content. In the name example, the given and family elements including the end markers are the markup. The values between the start and end markers are the content. An instance has an information model. There are a variety of data models within and without the W3C, and the one standardized by the W3C is the XML infoset.
The XML related terms and their relationships are shown below
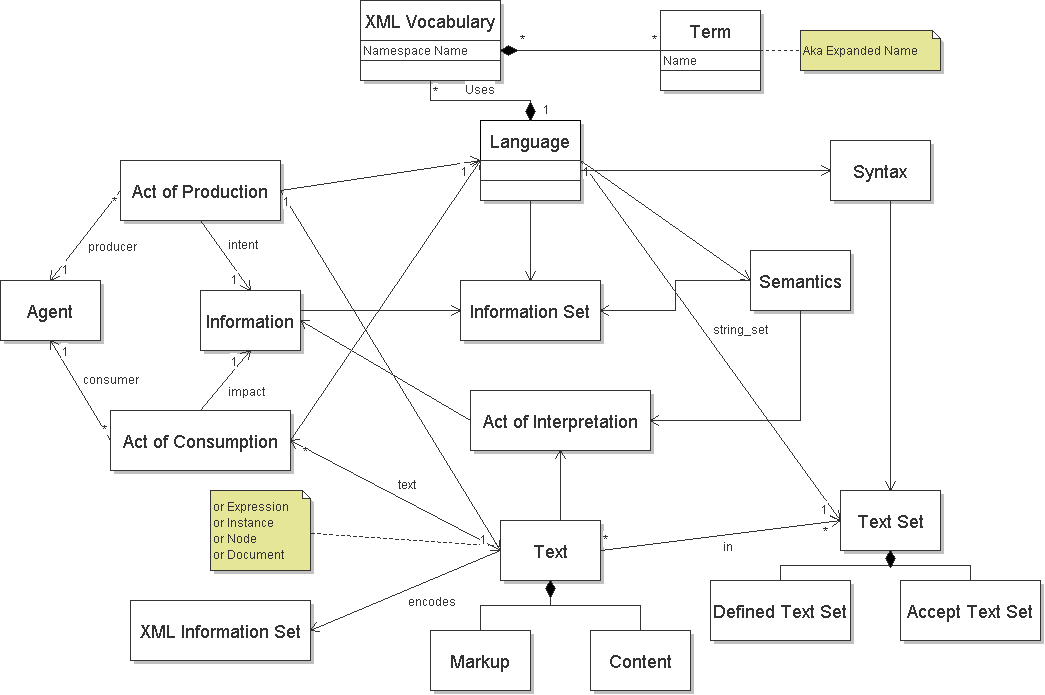
ednote: Update to final terminology version..
Some examples of XML consumers and producers are: A stylesheet processor is a
consumer of the XML text that it is processing (the producer isn't
mentioned); in the Web services context the roles of producer and
consumer alternate as messages are passed back and forth. Note that most Web service specifications provide definitions of
inputs and outputs. By our definitions, a Web service
that updates its output schema is considered a new producer. A Web service
that updates its input schema is a new consumer.
1.2 Kinds of XML Languages
Ultimately, there are different kinds of XML languages. The
versioning approaches and strategies that are appropriate for one kind
of language may not be appropriate for another. Among the various kinds
of vocabularies, we find:
Just Names: some languages don't actually identify elements
or attributes; they're just lists of names. Using QNames to identify words
in the WordNet database, for example, or the names of functions and operators
in XPath2 are examples of "just name" languages.
Standalone: languages designed to be used
more-or-less by themselves, for example XHTML, DocBook, or The TEI.
Containers: languages designed to be used as a
wrapper or framework for some other language or payload, for example
SOAP or WSDL.
Container Extensions: languages designed to extend
or augment a particular class of container. Specifications that extend SOAP by defining SOAP
header blocks, for example, to provide security, asynchrony or reliable messaging
are examples of container extension languages.
There are a few types of XML extension languages, element extension and type or attribute extension.
Element Extension. Languages that are elements. SOAP, etc. are element extensions.
Attribute or Types. Languages that define types or attributes. These languages must exist in the context of an element that is not defined by the language. Sometimes called "parasite" languages as they require a "host" element. XLink is an example.
Mixtures: languages designed for, or often used for,
encapsulating some semantics inside another language. For example, MathML
might be mixed inside of another language.
This is by no means an exhaustive list. Nor are these categories
completely clear cut. MathML can certainly be used standalone, for
example, and languages like SVG are a combination of standalone,
containers, and mixtures.
2 XML Language Requirements
The general language questions described in Part 1 Requirements (../versioning#requirements). These requirements are augmented in XML by:
Accuracy of XML Schema for the versions of the language. By accuracy, we mean the degree to which the language is described. We will see how
some designs preclude full XML Schema description. Often this results in Schemas that are incomplete at the first and subsequent versions. The options are typically: Complete in all versions, complete in first version only, incomplete in all versions.
Use of generic XML and namespace only tools (precluding vocabulary
specific versions). This itself is a trade-off because some generic XML tools (like XPath) are more difficult to use with multiple namespaces containing the same "thing", like XHTML's P element.
3 Version Identification technologies
Version identification of elements and attributes is often an important part of correctly processing xml documents. There are a large variety of version identification technologies in XML. The fundamental technologies available for identification of versions in an xml document are:
Qualified Names: Namespaces + Local Name
Types
Version Numbers
The decisions about which technologies to use are affected by the general language requirements and by the XML environments.
3.1 Qualified Name: Namespace + Local name
The Namespaces specification defines a Qualified Name as the Namespace and Local Name of a . From a versioning perspective, we are mainly concerned with element and attribute names, and not content. A primary motivation for Namespaces is the ability for decentralized extensibility and the resulting prevention of name collision.
3.2 Type
Many systems use type information associated with the component as part of the version identification of the component. There are generally two strategies for determining the type of a component, which we will call "Top-typing" and "Bottom-typing". Top-typing is a style where the type of the component is determined by the type of the top element. Bottom-typing is a style where the type of the component is determined by the type or types of the descendents of the top element. Bottom-typing designs can be such that a single type is not possible, rather it is effectively the composite of all the descendent types. When top-types are extended, the type becomes more difficult to specify. It could be the top-type, or it could be the top-type plus all of the extension types. A nameType extended with a middleNameType could be considered a nameType or a nameType+middleNameType. As the number of extension types grows, specifying the actual type may become equivalent to some bottom-typing designs. The extreme of this is container languages, which have a single invariable top-type and typically intended to have the type determined by the content at the "bottom" of the container.
In either typing case, the type(s) used for type determination is determined by the type associated with the qualified name of the component during type assignment. In XML Schema, this is during validation. It is also possible to specify the type in the instance. XML schema provides an xsi:type attribute that specifies the type of the component. This overrides the assocation between the qualified name of the component and the type as specified in the schema, or it provides a type where the qualified name of the component might not be resolvable into a type.
XML Schema is designed to assign type information as part of validation. Other languages, notably RelaxNG, do not assign type information and have no notion of types. The decision to use types and re-use types across components is an important factor in component version identification because the component definition and the component's type may be versioned separately.
3.3 Version Numbers
A significant downside with using version identifiers in XML is that
software that supports both versions of the name must perform special
processing on top of XML and namespaces. For example, many components
“bind” XML types into particular programming language types. Custom
software must process the version attribute before using any of the
“binding” software. In Web services, toolkits often take SOAP body
content, parse it into types and invoke methods on the types. There
are rarely “hooks” for the custom code to intercept processing between
the “SOAP” processing and the “name” processing. Further, if version
attributes are used by any 3rd party extensions—say
midns:middle has a version—then a schema cannot refer to the correct
middle type.
4 Component version identification strategies
The strategy for identifying the version of a component is perhaps the most important decision in designing an XML Language. The use of namespace names, component names, version numbers and type information are all critical in achieving the desired versioning characteristics. The strategies range from many namespaces per version of a language to only 1 namespace for all versions of a language. A few of the most common are listed below and described in more detail
later.
Whatever the design chosen, the language designer must
decide the component name, namespace name, and any version identifier for new
and all existing components.
Elaborating on these designs is illustrative.
4.1 Versioning Strategy #1: all components in new namespace(s) for each version
The following names would be valid:
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
</personName>
<personName xmlns="http://www.example.org/name/2">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
<personNameV2 xmlns="http://www.example.org/name/2">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personNameV2>
<personName xmlns="http://www.example.org/name/3">
<given>Dave</given>
<family>Orchard</family>
<midns:middle xmlns:midns="http://www.example.org/name/3/mid/1">Bryce</midns:middle>
</personName>
<personName xmlns="http://www.example.org/name/3">
<given>Dave</given>
<family>Orchard</family>
<middiffdomain:middle xmlns:middiffdomain="http://www.example.com/mid/1">Bryce</middiffdomain:middle>
</personName>
The 2nd and 3rdexamples shows all the components in the same new namespace, with the 3rd showing a new name as well.. The 4th and 5th
example show an additional middle element in 2 different namespace names. The 4th example comes from a namespace name that is
in the same domain as the name element’s new namespace name. One reason for 2 namespaces is to modularize the language. The 5th
example shows a namespace name from a different domain for the middle.
4.1.1 Advantages and Disadvantages
In this strategy, forwards compatibility is not desired. Any change or extension is an incompatible change with an existing consumer. When an older consumer receives the new texts in the new namespace, most of the software will break, such as performing schema validation without the new schema. Achieving forwards compatibility in parts of a system is possible and it requires careful selection of technologies, such as XPath expressions that are namespace agnostic. The effect of the change being an forwards incompatible change is the design goal of some systems that have adopted this strategy
4.2 Versioning Strategy #2: all new components in new namespace(s) for each compatible version
In this strategy, the following names would be valid:
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
</personName>
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<midns:middle xmlns:midns="http://www.example.org/name/mid/1">Bryce</midns:middle>
</personName>
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<middiffdomain:middle xmlns:middiffdomain="http://www.example.com/mid/1">Bryce</middiffdomain:middle>
</personName>
The 2nd and 3rd
example show an additional middle element in 2 different namespace names. The
first middle, the 2nd example, comes from a namespace name that is
in the same domain as the name element’s namespace name. The 3rd
example shows a complete different namespace name for the middle. It is
probable that the midns:middle was created by the name author, and the
middiffdomain:middle was created by a 3rd party.
4.2.1 Advantages and Disadvantages
Backwards and forwards compatibility can be supported from the first version. This design precludes the language designer from re-using a namespace name for changes, which may be desirable as introducing new namespace names can be difficult. XML Schema generally does not support more than one compatible revision of the schema in this strategy as shown in 7.2 #2: all new components in new namespace(s) for each compatible version.
4.3 Versioning Strategy #2.5: all new components in new or existing namespace(s) for each compatible version
We have called this strategy "2.5" because it is a mixture of strategy #2 and strategy #3. In this strategy, the following names would be valid:
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
</personName>
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<midns:middle xmlns:midns="http://www.example.org/name/mid/1">Bryce</midns:middle>
</personName>
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<middiffdomain:middle xmlns:middiffdomain="http://www.example.com/mid/1">Bryce</middiffdomain:middle>
</personName>
The 2nd example shows the use of the optional
middle name in the name namespace. The 3rd and 4th
example show an additional middle element in 2 different namespace names. The
first middle, the 3rd example, comes from a namespace name that is
in the same domain as the name element’s namespace name. The 4th
example shows a complete different namespace name for the middle. It is
probable that the midns:middle was created by the name author, and the
middiffdomain:middle was created by a 3rd party.
4.3.1 Advantages and Disadvantages
Backwards and forwards compatibility can be supported from the first version. Depending on the schema design, some new components do not require a namespace change. XML Schema generally does not support more than one revision of the schema in a compatible way in the new components in new namespace(s) for each compatible version strategy, as shown in 7.2 #2: all new components in new namespace(s) for each compatible version.
4.4 Versioning Strategy #3: all new components in existing namespace(s) for each compatible version
In this strategy, the following names would be valid:
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
</personName>
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<extension>
<middle>Bryce</middle>
</extension>
</personName>
<personName xmlns="http://www.example.org/name/2">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName> The 2nd example shows the use of the same namespace because the middle is optional. The 3rd example shows the use of the same namespace because the middle is optional and the middle embedded inside an "extension element". The 4th example shows the use of a new namespace for all the components, such as a
mandatory middle name.
4.4.1 Advantages and Disadvantages
Backwards and forwards compatibility can be supported from the first version without namespace changes. This means new components do not require new namespaces which generally means less chance of incompatible evolution. The use of either existing or new namespace gives the language designer greater choice in use of namespace names than just using a new namespace. As always, only the language designer has the ability to use and augment the namespace name of the first version. XML Schema does not support the 2nd example in many situations because of the Unique Particle Attribution constraint. XML Schema does support the 3rd example as shown in 7.4 #3: All new components
in existing namespace(s) for each compatible version.
4.5 Versioning Strategy #4: all new
components in existing or new namespace(s) for each version and a version
identifier
Using a version identifier, the name instances would
change to show the version of the name they use, such as:
<personName xmlns="http://www.example.org/name/1" version="1.0">
<given>Dave</given>
<family>Orchard</family>
</personName>
<personName xmlns="http://www.example.org/name/1" version="1.1">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
<personName xmlns="http://www.example.org/name/1" version="1.1">
<given>Dave</given>
<family>Orchard</family>
<midns:middle xmlns:midns="http://www.example.org/name/mid/1">Bryce</midns:middle>
</personName>
<personName xmlns="http://www.example.org/name/1" version="1.0">
<given>Dave</given>
<family>Orchard</family>
<midns:middle xmlns:midns="http://www.example.org/name/mid/1">Bryce</midns:middle>
</personName>
<personName xmlns="http://www.example.org/name/1" version="2.0">
<given>Dave</given>
<family>Orchard</family>
<midns:middle xmlns:midns="http://www.example.org/name/mid/1">Bryce</midns:middle>
</personName>
<personName xmlns="http://www.example.org/name/2" version="2.0">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
In the last two example, the version number has been changed from 1.0 to 2.0. Incrementing the major part of a version number often indicates an incompatible change. In this case, perhaps it indicates that the middle name is now mandatory where it had previously been optional.
4.5.1 Advantages and Disadvantages
Backwards and forwards compatibility can be supported from the first version without namespace changes. However, the use of version numbers means that the relationship or binding between the Qualified Name of a component and a language's interpretation requires the use of the version number. That means that general binding tools, such as XML to Java mappings, often cannot be used stand-alone.
4.6 Versioning Strategy #5: all
components in existing namespace(s) for each version and a version
identifier
Using a version identifier, the name instances would
change to show the version of the name they use, such as:
<personName xmlns="http://www.example.org/name/1" version="1.0">
<given>Dave</given>
<family>Orchard</family>
</personName>
<personName xmlns="http://www.example.org/name/1" version="1.1">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
<personName xmlns="http://www.example.org/name/1" version="2.0">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
The 2nd example shows that the middle is an optional part of the name. The last example shows that the middle is a mandatory
part of the name.
4.6.1 Advantages and Disadvantages
Backwards and forwards compatibility can be supported from the first version without namespace changes. Software that extracts the given and family name based upon the Qualified name will often not break because a new namespace name is not used. However, the use of version numbers means that the relationship or binding between the Qualified Name of a component and a language's interpretation requires the use of the version number. That means that general binding tools, such as XML to Java mappings, cannot be used stand-alone.
5 Indicating compatibility of changes or extensions
As a language designer will have chosen a component version identification strategy, they must also choose how compatible or incompatible changes will be indicated.
5.1 Compatible
As mentioned in the forwards compatibility section, forwards compatibility requires a substitution mechanism. Ignoring unknown content is a very popular model. It may be specified as the default for any extensions. It could also be specified in an instance where the default is for incompatible versioning. This could be a flag, such as ns:mayIgnore="true".
5.2 Incompatible
A version author can use new namespace names, local names, or version numbers to indicate an incompatible change. An extension author may not have these mechanisms available for indicating an incompatible extension. A language designer that wants to allow extension authors to indicate that an extension is incompatible must provide a mechanism for indicating that consumers must understand the extension, and the consumer must generate an error if it does not understand the extension. If only specific consumers must understand the extension, then the language designer must also provide a mechanism for indicating which consumers. If the language designer has allowed for forwards compatibility, then the forwards compatibility rule must be over-ridden.
Languages with forwards compatibility support MAY provide an override for indicating incompatible extensions but should only do so IF the incompatible extensions can be clearly targeted or scoped.
5.2.1 Must Understand flag
Arguably the simplest and most flexible over-ride of the Must Ignore Unknowns
technique is a Must Understand flag that
indicates whether the item must be understood. The SOAP,
WSDL, and WS-Policy
attributes and values for specifying understand are respectively: soap:mustUnderstand=”1”, wsdl:required=”1”,
wsp:Usage=”wsp:Required”. SOAP is probably
the most common case of a container that provides a Must
Understand model. The default value is 0,
which is effectively the Must Ignore rule.
A language designer can re-use an existing Must
Understand model by constraining their language to an existing Must Understand
model. A number of Web services specifications have done this by specifying
that the components are SOAP header blocks, which explicitly brings in the SOAP
Must Understand model.
A language designer can design a Must Understand model
into their language. A Must Understand flag allows the producer to insert
extensions into the container and use the Must Understand attribute to
over-ride the must
Ignore rule. This allows producers to extend instances without
changing the extension element’s parent’s namespace, retaining backwards
compatibility. Obviously the consumer must be extended to handle new extensions,
but there is now a loose coupling between the language’s processing model and
the extension’s processing model. A Must Understand flag is provided below:
An example of an instance of a 3rd party
indicating that a middle component is an incompatible change:
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<midns:middle xmlns:midns="http://www.example.org/name/mid/1"
namens:mustUnderstand="true">
Bryce
</midns:middle>
</personName> Specification of a Must Understand flag must be treated
carefully as it can be computationally expensive. Typically a processor will
either: perform a scan for Must Understand components to ensure it can process
the entire text, or incrementally process the instance and is prepared to
rollback or undo any processing if an not understood Must Understand is found.
There are other refinements related to Must Understand.
One example is providing an element that indicates which extension namespaces
must be understood, which avoids the scan of the instance for Must Understand
flags.
It is also possible to re-use the SOAP processing model with it's mustUnderstand. Use of a SOAP header for an extension may be because the body was not designed to be extensible, or because the extension is considered semantically separate from the body and will typically be processed differently than the body.
<soap:envelope>
<soap:body>
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
</personName>
</soap:body>
</soap:envelope>
<soap:envelope>
<soap:header>
<midns:middle xmlns:midns="http://www.example.org/name/mid/1"
soap:mustUnderstand="true">
Bryce
</midns:middle>
</soap:header>
<soap:body>
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
</personName>
</soap:body>
</soap:envelope>
6 XML Schema 1.0
XML Schema provides a variety of mechanisms for extensibility and versioning: wildcards, type extension, type restriction, redefine, substitution groups, and xsi:type attributes. The wildcard construct enables authors to create schemas that are both forwards and backwards-compatible. Generally, a new schema using wildcards is backwards compatible because it will validate old and new instances. The exception is instances that have content that is legal in the wildcard but not in the new content. An example might be a middle name that has structure or digits. However, that scenario means that an author created a middle name instance in the middle name namespace according to one schema AND an author defined a new middle name in the same namespace according to a different schema. Arguably there is an authority over the namespace that will prevent such clashes and so in practice this exception won't happen. Alternatively, we can make a slightly different compatibility guarantee, which is the new schema is backwards compatible with validate old and new instance where new instances do not have any extensions in the defined namespaces. The old schema is forwards compatible because it will validate old and new instances - of course it sees these as current and future instances.
When an author creates a new version, a new schema can created by the replacement of wildcard(s) in the original, with an optional-element, optional-wildcard sequence, in the later schema. The new schema explicitly states the entire new content model, including everything from the original schema as well as the new explicit declaration for middle, and for that reason we call it a "Complete Respecification" of the type.
A new type declared using wildcards could be declared as an explicit <xs:restriction/> of the original type, because every document accepted by the new type is also accepted by the old. XML Schema's type <xs:restriction/> allows alteration of wildcards anywhere in the content model, like Complete Respecification, but allows the original type to be preserved. Alternatively, XML Schema's type extension mechanism <xs:extension/> @@provide ref to Recommendation@@ provides a different way of specifiying a modified type, in which the original content is not restated, but only the new elements are explicitly referenced. The differences are: (1) xs:extension allows new content only at the end of the model and (2) using wildcards as shown above, the original type will accept not only documents in the original language, but also documents containing the middle name, something that's not true in typical uses of xs:extension. Thus the schema author of new version of a type has 3 options outlined above: 1) Complete Respecification without explicit use of xs:restriction; 2) Complete Respecification with explicit use of xs:restriction; 3) xs:extension.
These mechanisms can be combined together. For example, a schema that supports new components in existing or new namespaces and supports multiple schema versions (described in @@) uses wildcards, type extension, and use of Extension elements in instances.
Given an extensibility point that allows different namespaces, the language designer and 3rd parties can now
use different namespaces for their versions. In general, an extension can be defined by a new
specification that makes a normative reference to the earlier specification and
then defines the new content. No permission should be needed from the authors
of the specification to make such an extension. In fact, the major design
point of XML namespaces is to allow decentralized extensions. The corollary is
that permission is required for extensions in the same namespace. A namespace
has an owner; non-owners changing the meaning of something can be harmful.
Attribute extensions can be in any namespace because in XML schema, attributes do not have non-determinism (aka Unique Particle Attribution) constraints that elements do. In XML Schema, the attributes are always unordered and the model group for attributes
uses a different mechanism for associating attributes with schema types than
the model group for elements. We will discuss this important issue later in the finding.
7 Schemas for Version Identification Strategies
7.1 #1: all components in new namespace(s) for each version
Using XML Schema 1.0, the name owner might like to write a schema such as:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute namespace="##other"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema> The next version of the schema, with middle name added, might look like
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/2"
xmlns:name2ns="http://www.example.org/name/2">
<xs:import namespace="http://www.example.org/name/1"/>
<xs:complexType name="nameType">
<xs:complexContent>
<xs:extension base="namens:nameType">
<xs:sequence>
<xs:element name="middle" type="xs:string" minOccurs="0"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:element name="personName" type="name2ns:nameType"/>
</xs:schema> This schema is not perhaps quite what is desired because there are now 2 wildcards in the content model, the original wildcard then the new middle and the new wildcard. Type extension does not replace any existing wildcard trailing wildcard with the additive content. An alternative is to not have the wildcard in the first version but that removes forwards compatible extensibility as both sides must have the new schema to understand the type. Because of the type extension problem, the language designer cannot re-use the existing name definition and force a single wildcard at the end. They must create a new schema without any re-use of the previous schema's type information by respecifying the type. They can simply respecify the type or they can use xsd:restriction. Using xsd:restriction has some extra value in that a Schema processor can guarantee that the content model is a true restriction, but in general, respecification with or without xsd:restriction are equivalent.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/2"
xmlns:namens="http://www.example.org/name/2">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element name="middle" type="xs:string" minOccurs="0"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema> The new namespace for all components does not allow compatible evolution by the language designer, unless they choose to put new components in a new namespace, which is strategy #2. Additionally, the version 2 schema cannot re-use the existing type definition.
7.2 #2: all new components in new namespace(s) for each compatible version
We previously saw how re-use by importing and extending schemas with wildcards is not possible. In this strategy, the schema designer attempts to insert the new extension in the existing schema definition, like:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element ref="midns:middle" minOccurs="0"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute namespace="##other"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/mid/1"
xmlns:midns="http://www.example.org/name/mid/1">
<xs:element name="middle" type="xs:string"/>
</xs:schema> The Unique Particle Attribution(UPA) constraint of XML Schema, described in more detail in Unique Particule Attribution, prevents this from working. The problem arises
in a version when an optional element is followed by a wildcard. In this
example, this occurs when an optional element is added and extensibility is
still desired. This is an ungentle introduction to the difference between
extensibility and versioning. An optional middle name added into a subsequent
version is a good example. Consumers should be able to continue processing if
they don’t understand an additional optional middle name, and we want to keep
the extensibility point in the new version. We can't write a schema that contains
the optional middle name and a wildcard for extensibility. The previous schema
schema is roughly what is desired using wildcards, but it is illegal because of
the UPA constraint.
The author has 5 options for the v2 schema for name and middle, listed below and detailed
subsequently:
the new middle is defined, extensibility is retained, and the new name type does not refer to the new middle;
the new middle is defined, extensibility is lost, and the new name type refers to the new middle as optional;
the new middle is defined, extensibility is retained, and the new name type refers to the new middle as required - the result is that compatibility is lost (essentially strategy #1);
the new middle is defined, extensibility is retained, and there is no new name type
no update to the Schema
If they leave the middle as optional and retain the
extensibility point, the best schema that they can write is:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute namespace="##other"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/mid/1"
xmlns:midns="http://www.example.org/name/mid/1">
<xs:element name="middle" type="xs:string"/>
</xs:schema> This is not a very helpful XML Schema change. The problem is that
they cannot insert the reference to the optional midns:middle element
in the name schema and retain the extensibility point because of the
aforementioned Unique Particle Attribution Constraint.
The core of the problem is that there is no mechanism for
constraining the content of a wildcard. For example, imagine that ns1 contains
foo and bar. It is not possible to take the SOAP schema—an example of a
schema with a wildcard - and require that ns1:foo element must be a child of
the header element and ns1:bar must not be a child of the header element using
just W3C XML Schema constructs. Indeed, the need for this functionality
spawned some of the WSDL functionality.
They could decide to lose the extensibility point (option
#2), such as
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1"
xmlns:midns="http://www.example.org/name/mid/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element ref="midns:middle" type="xs:string" minOccurs="0"/>
</xs:sequence>
<xs:anyAttribute namespace="##other"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/mid/1"
xmlns:midns="http://www.example.org/name/mid/1">
<xs:element name="middle" type="xs:string"/>
</xs:schema> This does lose the possibility for forwards-compatible evolution.
Option #3 is adding a required middle. They
must indicate the change is incompatible. A new namespace name for the name
element can be created. This is essentially strategy #1, new namespace for all components.
The downsides of the 3 options for new components in new
namespace name(s) design have been described. Additionally, the design can
result in specifications and namespaces that are inappropriately factored, as
related constructs will be in separate namespaces.
7.2.1 Redefine
Redefine allows incompatible and incompatible changes to be made to a type. Unlike other schema extension mechanisms which provide new names for extended or restricted types, redefine changes the definition of a type without changing its name. This means that the name alone is no longer sufficient to determine of two types are really the same. The schema author must take some caution to ensure that compatible changes are made. However, there are scenarios where redefine may be the right mechanism. In particular, an extension author may want to create a schema that is based upon a schema that they cannot change. In the previous examples, the middle author cannot change the nameType. However, they cannot use redefine to help them define a schema. Redefine using respecification, restriction, or extension do not allow a component in a new namespace to be added to the end of a sequence and retain the extensibility model. We showed the scenarios of adding the content at the end and the limitations of UPA hold true with and without Redefine. Redefine is usable when the extension author chooses to make an incompatible change (#3) or they can accept losing the extension point (#2).
7.3 #2.5: All new components
in existing or new namespace(s) for each compatible version
It is possible to create Schemas with additional optional
components. This requires re-using the namespace name for optional components where possible, and use a new namespace where re-using the namespace is not possible. The re-using namespace rule is:
Good Practice
Re-use namespace names Rule: If a backwards
compatible change can be made to a specification, then the old
namespace name SHOULD be used in conjunction with XML’s extensibility
model.
Strategy #1 uses a new namespace for all existing components and any additions, strategy #2 uses a new namespace for all additions (compatible and incompatible). strategy #3 re-uses namespaces for compatible extensions and uses a new namespace for all incompatible additions. Said slightly differently, strategies #1 and #2 use a new namespace name for any extension and strategy # 3 uses a new namespace only for incompatible change is made.
Earlier examples showed that it is not possible to have a
wildcard with ##any (or even ##targetnamespace) following optional elements in
the targetnamespace. This strategy is a "middle-ground" strategy, where the ##any is used wherever possible and ##other is used where ##any cannot be used. ##any can be used after mandatory elements or for attributes.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:any namespace="##any" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema>
</xs:schema> The addition of an optional middle can be done in the same namespace, but the wildcard must change to ##other.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element name="middle" type="xs:string" minOccurs="0"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute namespace="##other"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema>
</xs:schema> After the 2nd version has been deployed, the versioning strategy is now Versioning Strategy #2: all new components in new namespace(s).
7.4 #3: All new components
in existing namespace(s) for each compatible version
It is possible to create Schemas with additional optional
components. This requires re-using the namespace name for optional components
and special schema design techniques. The re-using namespace rule is:
Good Practice
Re-use namespace names Rule: If a backwards
compatible change can be made to a specification, then the old
namespace name SHOULD be used in conjunction with XML’s extensibility
model.
Strategy #1 uses a new namespace for all existing components and any additions, strategy #2 uses a new namespace for all additions (compatible and incompatible). strategy #3 re-uses namespaces for compatible extensions and uses a new namespace for all incompatible additions. Said slightly differently, strategies #1 and #2 use a new namespace name for any extension and strategy # 3 uses a new namespace only for incompatible change is made.
Good Practice
New namespaces to break Rule: A new namespace name
is used when backwards compatibility is not permitted, that is
software SHOULD reject texts if it does not understand the new language
components.
Earlier examples showed that it is not possible to have a
wildcard with ##any (or even ##targetnamespace) following optional elements in
the targetnamespace. The solution to this problem is to introduce an element
in the schema that will always appear if the extension appears. The content
model of the extensibility point is the element + the extension. There
are two styles for this. The first, which we will call Extension element style, was published in an earlier version of this
Finding in December 2003. It uses an Extensibility element with the extensions
nested inside. The second, which we weill call Sentry style, was published in July 2004, then updated on MSDN.
It uses a Sentry or Marker element with extensions following it.
A name type
with extension elements is
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element name="Extension" type="namens:ExtensionType"
minOccurs="0" maxOccurs="1"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:complexType name="ExtensionType">
<xs:sequence>
<xs:any processContents="lax" minOccurs="1"
maxOccurs="unbounded" namespace="##targetnamespace"/>
</xs:sequence>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema> Because each extension in the targetnamespace is inside an
Extension element, each subsequent target namespace extensions will
increase nesting by another layer. While this layer of nesting per
extension is not desirable, it is what can be accomplished today when
applying strict XML Schema validation. It seems to at least this
author that potentially having multiple nested elements is worthwhile
if multiple compatible revisions can be made to a language. This
technique allows validation of extensions in the targetnamespace and
retaining validation of the targetnamespace itself.
The previous schema allows the following sample namens:
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<Extension>
<middle>Bryce</middle>
</Extension>
</personName> The namespace author can create a schema for this type
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<s:element name="Extension" type="namens:middleExtensionType"
minOccurs="0" maxOccurs="1"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:complexType name="middleExtensionType">
<xs:sequence>
<xs:element name="middle" type="xs:string"/>
<xs:element name="Extension" type="namens:middleExtensionType"
minOccurs="0" maxOccurs="1"/>
</xs:sequence>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:complexType name="ExtensionType">
<xs:sequence>
<xs:any processContents="lax" minOccurs="1"
maxOccurs="unbounded" namespace="##targetnamespace"/>
</xs:sequence>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema> The advantage of this design technique is that a forwards
and backwards compatible Schema V2 can be written. The V2 schema can validate
documents with or without the middle, and the V1 schema can validate documents
with or without the middle. This is the only schema design that enables all versions of the language to have complete schemas.
Further, the re-use of the same namespace has better
tooling support. Many applications use a single schema to create the
equivalent programming constructs. These tools often work best with single
namespace support for the “generated” constructs. The re-use of the namespace
name allows at least the namespace author to make changes to the namespace and
perform validation of the extensions.
An obvious downside of this approach is the complexity of
the schema design. Another downside is that changes are linear, so 2
potentially parallel extensions must be nested rather than parallel.
7.4.1 Redefine
The author could use redefine to add the middle in the same namespace. However, the first version does not allow extensions in the same namespace, so this is an incompatible change.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute ref="namens:mustUnderstand"/>
<xs:anyAttribute namespace="##other"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:redefine schemaLocation="./Name.xsd"/>
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element name="middle" type="xs:string" minOccurs="0"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:redefine>
</xs:schema> In the previous example, the author of the redefined schema replaced the type with an update. If the author of the nameType wanted to make the change, they could presumably just change the type without using redefine. In cases where the author of the extension is not the author of the base type, then redefine allows them to change the type. Some people may consider this an illegal redefinition of the nameType because they believe that only the namespace owner of the nameType should make changes to the type. Redefine also allows extension and restriction, subject to the limitations of them. Redefine does not help the nameType owner or an extension author create a revised type that refers to any new construct.
7.5 #4: all new
components in existing or new namespace(s) for each version and a version
identifier
Using a version identifier, the name instances would
change to show the version of the name they use, such as:
<personName xmlns="http://www.example.org/name/1" version="1.0">
<given>Dave</given>
<family>Orchard</family>
</personName>
<personName xmlns="http://www.example.org/name/1" version="1.0">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
<personName xmlns="http://www.example.org/name/1" version="1.1">
<given>Dave</given>
<family>Orchard</family>
<pref1:middle xmlns:mid1="http://www.example.org/name/mid/1">Bryce</pref1:middle>
</personName>
<personName xmlns="http://www.example.org/name/1" version="1.0">
<given>Dave</given>
<family>Orchard</family>
<pref2:middle xmlns:mid2="http://www.example.org/name/mid/1">Bryce</pref2:middle>
</personName>
<personName xmlns="http://www.example.org/name/1" version="2.0">
<given>Dave</given>
<family>Orchard</family>
<pref1:middle xmlns:mid1="http://www.example.org/name/mid/1">Bryce</pref1:middle>
</personName>
The last example shows a middle that is a mandatory part of the name, which is indicated by the use of a new major version number. As with Design #2, the schema for the optional middle cannot fully express the content model. A schema for the mandatory middle is
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1"
xmlns:midns="http://www.example.org/name/mid/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element name="middle" type="xs:string" minOccurs="0"/>
<xs:element ref="midns:middle"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="version" type="xs:float"/>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/mid/1"
xmlns:midns="http://www.example.org/name/mid/1">
<xs:element name="middle" type="xs:string"/>
</xs:schema> A significant downside with using version identifiers is that
software that supports both versions of the name must perform special
processing on top of XML and namespaces. For example, many components
“bind” XML types into particular programming language types. Custom
software must process the version attribute before using any of the
“binding” software. In Web services, toolkits often take SOAP body
content, parse it into types and invoke methods on the types. There
are rarely “hooks” for the custom code to intercept processing between
the “SOAP” processing and the “name” processing. Further, if version
attributes are used by any 3rd party extensions—say
midns:middle has a version—then the schema cannot refer to the correct
middle.
7.6 #5: all components in existing namespace(s) for each version and a version
identifier
Using a version identifier, the name instances would
change to show the version of the name they use, such as:
<personName xmlns="http://www.example.org/name/1" version="1.0">
<given>Dave</given>
<family>Orchard</family>
</personName>
<personName xmlns="http://www.example.org/name/1" version="1.0">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
<personName xmlns="http://www.example.org/name/1" version="1.1">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
<personName xmlns="http://www.example.org/name/1" version="2.0">
<given>Dave</given>
<family>Orchard</family>
<middle>Bryce</middle>
</personName>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:any namespace="##any" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:element name="middle" type="xs:string"/>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema> This is not a very helpful XML Schema change. The problem is that
they cannot insert the reference to the optional midns:middle element
in the name schema and retain the extensibility point because of the
aforementioned Unique Particle Attribution Constraint.
The last example shows that the middle is now a mandatory
part of the name. As with Design #2, the schema for the optional middle cannot
fully express the content model. A schema for the mandatory middle is
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1"
xmlns:midns="http://www.example.org/name/mid/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element name="middle" type="xs:string">
<xs:any namespace="##any" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="version" type="xs:float"/>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema> This design has the significant drawback that XML Schema cannot be used for many of the changes. Because the same namespace is used for all versions of the language, then the wildcard namespace attribute must contain ##any. This means that any changes that are compatible, such as the addition of an optional middle in the 2nd example, cannot be completely modeled in XML Schema.
8 Indicating Incompatible changes
A new qualified name can be created by specifying standalone content, respecifying existing content or by some kind of relationship with existing content. A variety of compatible extension mechanisms have been shown. There are more mechanism for incompatible changes in Schema 1.0
8.1 Type extension
A common option for indicating an incompatible change is to use type extension.
The language designer allows for type
extension, and they must specify that type extensions must be understood. Strategy #1 (all components in new namespace) shows a type extension schemas.
8.2 Substitution Groups
Another mechanism for extending a type in XML Schema is
substitution groups. Substitution groups enable an element to be declared as
substitutable for another. This can only be used for incompatible extensions
as the consumer must understand the new element and the schema that contains the substitution type. Substitution groups
require that elements are available for substitution, so the name designer must
have provided a name element in addition to the name type.
A schema for a substitution group is provided below:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute namespace="##other"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/middle/1"
xmlns:midns="http://www.example.org/middle/1">
<xs:import namespace="http://www.example.org/name/1" schemaLocation="NameTypeWithOther.xsd"/>
<xs:complexType name="nameWithMiddleType">
<xs:complextContent>
<xs:restriction base="namens:nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element name="middle" type="xs:string" minOccurs="0"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:restriction>
</xs:complextContent>
<xs:anyAttribute namespace="##other"/>
</xs:complexType>
<xs:element name="personNameWithMiddle" type="midns:nameWithMiddleType"
substitutionGroup="namens:nameType/>
</xs:schema> Substitution groups do allow a single extension author to
indicate that their changes are mandatory. The limitations are that the
extension author has now taken over the type’s extensibility. A visual way of
imagining this is that the type tree has now been moved from the language designer
over to the extensions author. And the language designer probably does not
want their type to be “hijacked”.
However, this is not substantially different than an
extension being marked with a “Must Understand”. In either case—with the
extensions higher up in the tree (sometimes called top-typing) or lower in the
tree (bottom-typing)—a new type is effectively created.
The difference is that there can only be 1 element at the
top of an element hierarchy. If multiple mandatory extensions are added, then
the only way to compose them together is at the bottom of the type because that
is where the extensibility is.
Substitution groups do not allow a language designer and
an extension author to incompatibly change the language as they end up
conflicting over what to call the name element. Thus substitution groups are a
poor mechanism for allowing an extension author to indicate that their changes
are incompatible. A Must Understand flag is a superior method because it
allows multiple extension authors to mix their mandatory extensions with a
language designer’s versioning strategy. Hence language designers should
prevent substitution groups and provide a Must Understand flag or other model
when they wish to allow 3rd parties to make incompatible changes.
In some cases, a language does not provide a Must Understand
mechanism. In the absence of a Must Understand model, the only way to force consumers
to reject a message if they don’t understand the extension namespace is to
change the namespace name of the root element, but this is rarely desirable.
8.3 Must Understand
Each of the various component identification schemes can support a mustUnderstand flag. Two schema for a Must Understand flag are provided below:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute ref="namens:mustUnderstand"/>
<xs:anyAttribute namespace="##other"/>
</xs:complexType>
<xs:attribute name="mustUnderstand" type="xs:boolean"/>
<xs:element name="personName" type="namens:nameType"/>
</xs:schema>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/name/1"
xmlns:namens="http://www.example.org/name/1">
<xs:complexType name="nameType">
<xs:sequence>
<xs:element name="given" type="xs:string"/>
<xs:element name="family" type="xs:string"/>
<xs:element name="middle" type="xs:string" minOccurs="0"/>
<s:element name="Extension" type="namens:ExtensionType"
minOccurs="0" maxOccurs="1"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute ref="namens:mustUnderstand"/>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:element name="personName" type="namens:nameType"/>
<xs:complexType name="ExtensionType">
<xs:sequence>
<xs:any processContents="lax" minOccurs="1"
maxOccurs="unbounded" namespace="##targetnamespace"/>
</xs:sequence>
<xs:anyAttribute namespace="##any"/>
</xs:complexType>
<xs:attribute name="mustUnderstand" type="xs:boolean"/>
</xs:schema> An example of an instance of a 3rd party
indicating that a middle component is an incompatible change:
<personName xmlns="http://www.example.org/name/1">
<given>Dave</given>
<family>Orchard</family>
<mid2:middle xmlns:mid2="http://www.example.org/name/mid/1"
namens:mustUnderstand="true">
Bryce
</mid2:middle>
</personName>
9 Survey of Languages Versioning Strategies
We can examine a variety of languages for their versioning strategies.
| Requirement | [Docbook 4.5] | [XHTML 1.0] | [SVG 1.1] | [WS-Policy 1.2] |
|---|
| Schema Lang | RelaxNG | XML Schema | DTD | XML Schema |
|---|
| 3rd party compatibly extend | Yes | Yes | Yes | Yes |
|---|
| 3rd party incompatibly extend | No | No | Yes | Yes |
|---|
| stand-alone | Yes | Yes and No | Yes or in xhtml | Yes |
|---|
| Schema design | open content, patterns | Modularization, Redefine | DTD extensibility | Schema wildcards |
|---|
| Substitution Mechanism | N/A | Must Accept Unknowns | Must Accept Unknowns and fallback | Must Accept Unknowns |
|---|
| Component Identification | #5 | #2 | #2.5 | #2.5 |
|---|
| Incompatible Ext identification | No | N/A | requiredFeatures and requiredExtensions attributes | QName of Required assertion |
|---|
| Schema Completeness | N/A | Complete including extensions | Yes | partial |
|---|
Notes
WS-Policy 1.5 uses ##any for attributes and PolicyReference element extensibility, and ##other for other extensibility points.
SVG specifies an extension entity for extending most of the SVG elements, it specifies that fallbacks can be provided for unknown elements and that processing can be aborted.
| Requirement | [Atom Format] | [UBL Naming and Design] | [Reach Interoperability Guidelines] | [XSLT 2.0] |
|---|
| Schema Lang | XML Schema, RelaxNG | XML Schema, RelaxNG | XML Schema | HTML |
|---|
| 3rd party compatibly extend | Yes | No | Yes | Yes |
|---|
| 3rd party incompatibly extend | No | No | Yes | Yes |
|---|
| stand-alone | Yes | Yes | Yes | Yes |
|---|
| Schema design | Wildcards | ? | Wildcards | N/A |
|---|
| Substitution Mechanism | Must Accept Unknowns | Must Not Accept Unknowns | Must Accept Unknowns | Must Accept Unknowns and Fallback provided |
|---|
| Component Identification | #4 | #1 | #3 | #5 |
|---|
| Incompatible Ext identification | None | N/A(See Note) | MustUnderstand | <xsl:message terminate="true"> |
|---|
| Schema Completeness | ? | Complete for all | Complete for all | N/A |
|---|
UBL extensions are incompatible by UBL definition
XSLT 2.0 has very powerful versioning features. The version of the processor can be tested, fallbacks can be provided for unknown elements and processing can be aborted.
10 Unique Particle Attribution
This Finding has spent considerable material describing
content models valid under Unique Particle Attribution constraints, and so it is worth describing the W3C XML
Schema Unique Particle Attribution constraint in more detail. The reader is reminded that these
rules are unique to W3C XML Schema and that other XML Schema languages like RELAX NG
do not use these rules and so do not suffer from the contortions one is forced
through when using W3C XML Schema. XML DTDs and W3C XML Schema have a rule
that requires schemas to have content models valid under the Unique Particle Attribution constraint. From the XML 1.0
specification,
“For example, the content model ((b, c) | (b, d)) is
non-deterministic, because given an initial b the XML processor cannot
know which b in the model is being matched without looking ahead to
see which element follows the b.”
The use of ##any means there are some schemas that we might like to
express, but that aren’t allowed.
Wildcards with ##any, where minOccurs does not equal
maxOccurs, are not allowed before an element declaration. An instance
of the element would be valid for the ##any or the element. ##other
could be used.
The element before a wildcard with ##any must have
cardinality of maxOccurs equals its minOccurs. If these were
different, say minOccurs=”1” and maxOccurs=”2”, then the optional
occurrences could match either the element definition or the ##any. As
a result of this rule, the minOccurs must be greater than zero.
Derived types that add element definitions after a wildcard
with ##any must be avoided. A derived type might add an element
definition after the wildcard, then an instance of the added element
definition could match either the wildcard or the derived element
definition.
Good Practice
Follow Unique Particle Attribution constraint: Use of wildcards MUST be
follow the Unique Particle Attribution constraint. Location of wildcards, namespace of wildcard
extensions, minOccurs and maxOccurs values are constrained, and type
restriction is controlled.
As shown earlier, a common design pattern is to provide
an extensibility point—not an element - allowing any namespace at the end of
a type. This is typically done with <xs:any
namespace=”##any”>.
Unique Particle Attribution makes this unworkable as a complete solution
in many cases. Firstly, the extensibility point can only occur after required
elements in the original schema, limiting the scope of extensibility in the
original schema. Secondly, backwards compatible changes require that the added
element is optional, which means a minOccurs=”0”.
The Unique Particle Attribution constraint prevents us from placing a minOccurs=”0”
before an extensibility point of ##any. Thus, when adding an element at an
extensibility point, the author can make the element optional and lose the
extensibility point, or the author can make the element required and lose
backwards compatibility.
11 Other technologies
The W3C XML Schema Working has heard and taken to heart
many of these concerns. They have plans to remedy some of these issues in XML
Schema 1.1. A Working Draft[@@] and a Guide 2 versioning using the new XML Schema 1.1 features [@@] are available.
A simple analysis of doing compatible extensibility and
versioning using RDF and OWL is available [21].
In general, RDF and OWL offer superior mechanisms for extensibility and
versioning. RDF and OWL explicitly allow extension components to be added to
components. And further, the RDF and OWL model builds in the notion of “Must
Ignore Unknowns” as an RDF/OWL processor will absorb the extra components but
do nothing with them. An extension author can require that consumers
understand the extension by changing the type using a type extension
mechanism.
RELAX NG is another schema language. It explicitly allows
extension components to be added to other components as it does not have the
Unique Particle Attribution constraint.
12 Conclusion
This Finding describes a number of questions, decisions
and rules for using XML, W3C XML Schema, and XML Namespaces in language
construction and extension. The main goal of the set of rules is to allow
language designers to know their options for language design, and ideally make backwards-
and forwards-compatible changes to their languages to achieve loose coupling
between systems.
13 References
- Atom Format
- RFC 4287, the Atom Syndication Format (See http://www.ietf.org/rfc/rfc4287.txt.)
- Docbook 4.5
- The Docbook Document Type (See http://www.docbook.org/specs/docbook-4.5-spec.html.)
- FlexXMLP
- Flexible XML Processing Profile.
(See http://www.upnp.org/download/draft-goland-fxpp-01.txt.)
- WebDAV XMLIgnore post
- Yaron GolandXML Ignore proposed for WebDAV (See http://lists.w3.org/Archives/Public/w3c-dist-auth/1997AprJun/0190.html.)
- WebDAV
- RFC 2518, WebDAV (See http://www.ietf.org/rfc/rfc2518.txt.)
- SVG 1.1
- W3C Recommendation, SVG 1.1 (See http://www.w3.org/TR/SVG11/.)
- UBL Naming and Design
- Universal Business Language (UBL) Naming and Design Rules (See http://www.oasis-open.org/committees/download.php/20093/cd-UBL-NDR-2.0.pdf.)
- XHTML 1.0
- XHTML 1.0.
(See http://www.w3.org/TR/xhtml1/.)
- Reach Interoperability Guidelines
- Reach Interoperability Guidelines (See http://sdec.reach.ie/rigs/rig0006/.)
- TBL Mandatory Extensions
- Berners-Lee.
Web Architecture: Mandatory extensions.
(See http://www.w3.org/DesignIssues/Mandatory.html.)
- TBL Extensible languages
- Berners-Lee.
Web Architecture: Extensible languages.
(See http://www.w3.org/DesignIssues/Extensible.html.)
- TBL Evolution
- Berners-Lee.
Web Architecture: Evolvability.
(See http://www.w3.org/DesignIssues/Evolution.html.)
- Web Architecture: Extensible Languages
- Berners-Lee and Connolly, ed.
Web Architecture: Extensible Languages
World Wide Web Consortium, 1998. (See http://www.w3.org/TR/1998/NOTE-webarch-extlang-19980210.)
- HTML Document types
- Connolly, ed.
HTML Document dialects
World Wide Web Consortium, 1996. (See http://www.w3.org/MarkUp/WD-doctypes.)
- SOAP 1.2
- W3C
Recommendation, SOAP 1.2 Part 1: Messaging Framework (See http://www.w3.org/TR/SOAP/.)
- WSDL 1.1
- W3C Note, WSDL 1.1 (See http://www.w3.org/TR/WSDL/.)
- WS-Policy 1.2
- W3C Note, WS-Policy 1.2 (See http://www.w3.org/Submissions/WS-Policy/.)
- XML 1.0
- W3C Recommendation, XML 1.0 (See http://www.w3.org/TR/REC-xml.)
- xhtmlmodularization
- W3C Working Draft, XHTML Modularization (See http://www.w3.org/TR/xhtml-modularization/.)
- XInclude
- W3C Working Draft, XML Inclusions (See http://www.w3.org/TR-Xinclude.)
- XML Namespaces
- W3C Recommendation, XML Namespaces (See http://www.w3.org/TR/REC-xml-names.)
- XML Schema Part 2
- W3C Recommendation, XML Schema, Part 2 (See http://www.w3.org/TR/xmlschema-2.)
- XSLT 2.0
- W3C Recommendation, XSLT 2.0 (See http://www.w3.org/TR/xslt20/.)
- XML Schema Wildcard Test Collection
- XML Schema Wildcard Test collection (See http://www.w3.org/XML/2001/05/xmlschema-test-collection/result-ms-wildcards.htm.)
- XFront Schema Best Practices
- XFront Schema Best Practices (See http://www.xfront.com/BestPracticesHomepage.html.)
- XML.com Schema Design Patterns
- Dare ObasanjoXML.com Schema design patterns (See http://www.xml.com/pub/a/2002/07/03/schema_design.html.)
- Dave Orchard writings on Extensibility and Versioning
- Dave Orchard writings on extensibility and versioning (See http://www.pacificspirit.com/Authoring/Compatibility.)
14 Acknowledgements
The author thanks the many reviewers that have
contributed to the article, particularly David Bau, William Cox, Ed Dumbill,
Chris Ferris, Yaron Goland, Hal Lockhart, Mark Nottingham, Jeffrey Schlimmer,
Cliff Schmidt, and Norman Walsh.