This document is also available in these non-normative formats: XML.
Copyright © 2006, 2007, 2008 W3C® (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use, and software licensing rules apply.
The Web is designed to support flexible exploration of information by human users and by automated agents. For such exploration to be productive, information published by many different sources and for a variety of purposes must be comprehensible to a wide range of Web client software. HTTP and other Web technologies can be used to deploy resources that are grounded in the web, in the sense that the apropriate interpretation of a document follows by following a series of references in the web. Starting with a URI, there is a standard algorithm that a user agent can apply to retrieve and interpret a representation of such resources. Furthermore, when such web-grounded resources are linked together, the Web as a whole can support reliable, ad hoc discovery of information. This finding describes how document formats, markup conventions, attribute values, and other data formats can be designed to facilitate the deployment of web-grounded Web content.
This document is an editors' copy that has no official standing.
This document has been produced for the W3C Technical Architecture Group (TAG). It is an editor's draft that has not been approved by the TAG, and it includes revisions motivated by discussions held at the May 2008 Face to Face Meeting of the TAG .
Additional TAG findings, both accepted and in draft state, may also be available. The TAG may incorporate this and other findings into future versions of the [AWWW].
Please send comments on this finding to the publicly archived TAG mailing list www-tag@w3.org (archive).
1 Introduction
2 The Web's Standard Retrieval Algorithm
3 Use of Widely Deployed Standards and Formats
4 Creating New Formats and Standards
4.1 Use Existing URI Schemes, Protocols, and
Media Types
4.2 URI-based Extensibility
4.2.1 Example: The Atom Syndication
Format
4.2.2 Example: Microformats
4.2.3 web-grounded XML Documents
5 RDF and the web-grounded Semantic Web
5.1 Using RDFa To Produce web-grounded
HTML
5.2 Using GRDDL to Bridge From XML To RDF
6 Conclusions
7 References
The World Wide Web has at least two characteristics that distinguish it from many other shared information spaces:
The Web is global: the documents on the Web are contributed by and accessed by a very large number of users.
Supporting ad-hoc exploration is a goal of the Web. Users must therefore be able to get useful information from documents prepared by people whom they don't know, and with whom they have not coordinated in advance.
Documents used as Web resource representations should be encoded
using widely deployed formats such as text/html and
image/jpeg, and deployed using HTTP.
Each representation should include standard machine-readable indications, such as HTTP Content-type headers, XML encoding declarations, etc., of the standards and conventions used to encode it.
Machine-processable specifications for interpreting new formats should be provided on the Web, and linked from representations that use the formats. Examples of linkable specifications include OWL ontologies, RDDL documents, GRDDL transformations, etc. By following links to such specifications, user agents can dynamically obtain information needed to process new representation formats.
For integration with the Semantic Web, web-grounded representations
should convey RDF triples, either directly in the representation, by
linking to the triples (perhaps using <link> elements
in HTML or the link: header in HTTP), or by linking to
transformations using technologies such as GRDDL.
A standard HTTP-based algorithm is used to deploy, retrieve and interpret web-grounded Web resource representations.
Principle
web-grounded resources promote ad hoc discovery of information.
Good Practice
Web resource representations should be web-grounded.
The sections below discuss in more detail the techniques needed to create web-grounded content for the Web, how to extend the Web with new formats that are themselves web-grounded, how to publish web-grounded Semantic Web data, and how a standard HTTP-based algorithm enables users to retrieve and interpret web-grounded resource representations.
HTTP is the most widely deployed protocol on the Web, and it is designed to facilitate the deployment of web-grounded Web resource representations. Indeed, there is a standard algorithm that a user agent can employ to attempt to obtain and interpret the representation of any Web resource that is accessible using the HTTP protocol. Consider the following example, which is representative of many simple Web interactions:
Bob is reading a Web page which includes a link to
http://example.com/todaysnews. Bob has had no previous contact
with the owner of the referenced resource, and his browser has not been
specially configured for access to it. The steps taken by Bob's browser when
he clicks the link illustrate a typical path through the standard retrieval
algorithm of the Web (readers unfamiliar with the HTTP protocol may find it
useful to consult either [HTTP], or one of the many HTTP
introductions available on the Web). Bob's browser...
parses the URI and, from the http: at the beginning,
determines that the http scheme has been used — this tells the browser
that a representation retrieved using the HTTP protocol is authoritative.
looks up the DNS name [DNS]
example.com to determine the associated IP address
opens a TCP stream to port 80 at the IP address determined above
formats an HTTP GET request for resource /todaysnews,
and sends that to the server:
GET /todaysnews HTTP/1.1 Host: example.com User-Agent: TAG Sample HttpClient v1.0 Accept: */* Accept-language: en-us
reads this response from the server:
HTTP/1.1 200 OK
Date: Tue, 28 Aug 2007 01:49:33 GMT
Server: Apache
Content-Type: text/html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Today's news</title>
</head>
<body>
<h1>Today's News: Oh boy!!</h1>
[HTML FOR NEWS REPORT HERE]
</body>
</html>
from the status code (200) determines that the request has been
successfully processed, and that a representation of the resource is
available in the Content-Type and the
entity-body
inspects the returned Content-Type and determines that
it is text/html, a standard media type that the browser
supports
passes the entity-body to its HTML rendering engine,
which uses the markup in the HTML to determine the title of the page
(Today's News), the rest of the document's structure, and so on — the
browser presents the page to Bob
Neither Bob nor his browser has any advance knowledge of the nature of the
resource or the fact that its representation is provided in HTML, yet the
browser successfully retrieves the representation, determines its format, and
renders it for him. The link could have been to an image/jpeg
picture, an application/atom+xml feed, or to a document
containing application/rdf+xml data. Bob's browser could in each
case determine the format. Indeed, as Bob continues to browse the Web, his
browser is able to determine the format of each representation that is
retrieved, and can determine how to present it to him. This example shows how
HTTP enables the deployment of web-grounded Web resources.
Consider instead a different example, in which Bob clicks on a link to
ftp://example.com/todaysnews. Although Bob's browser can easily
open an FTP connection to retrieve a file, there is no way for the browser to
reliably determine the nature of the information received. Even if the URI
were ftp://example.com/todaysnews.html the browser would be
guessing if it assumed that the file's contents were HTML, since no normative
specification ensures that data from ftp URIs ending in .html is
in any particular format.
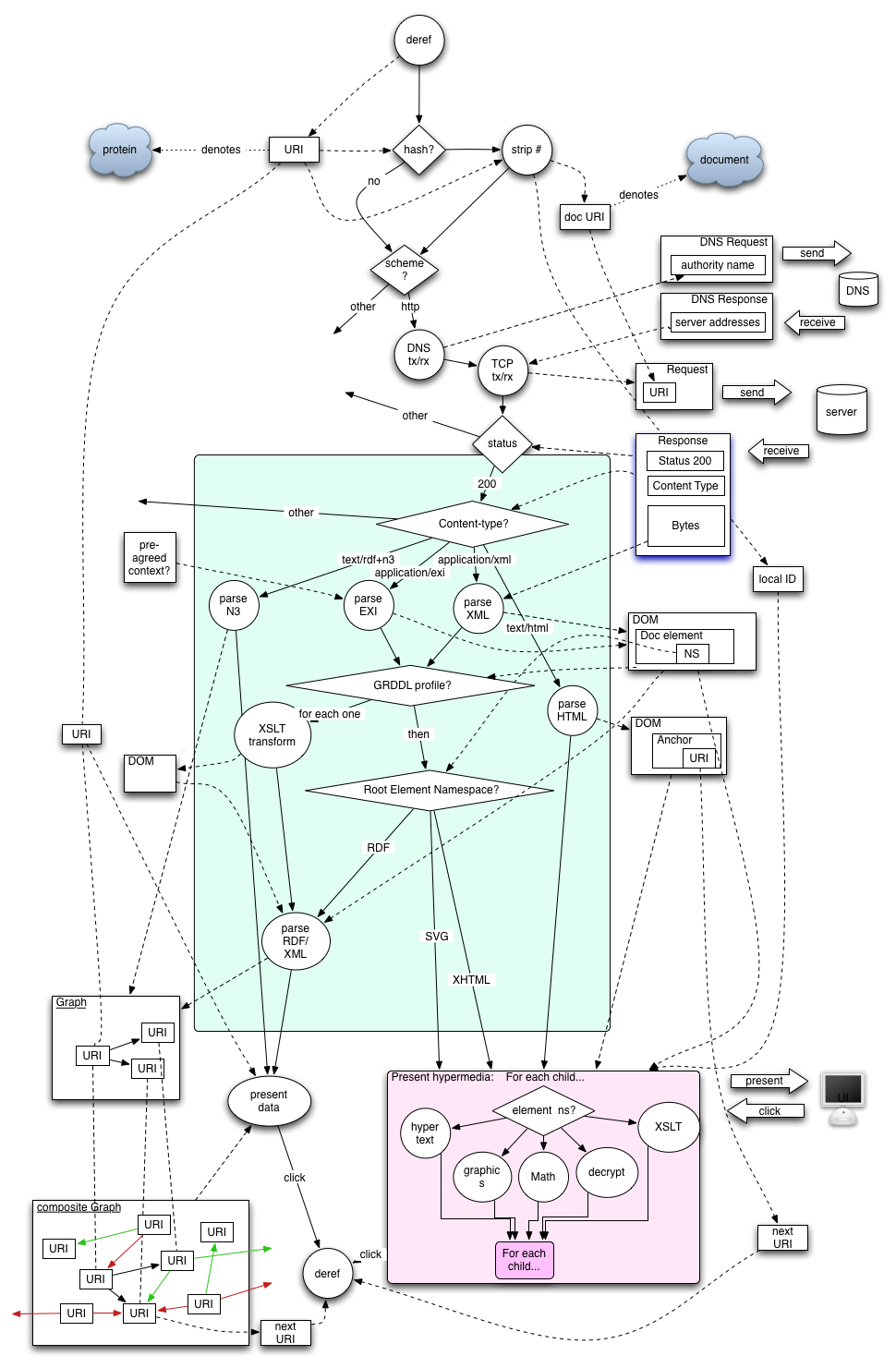
The Web's retrieval algorithm works best when used with the core suite of protocols and formats that are most widely deployed, and that are capable of supporting retrieval of web-grounded representations. These core technologies include: DNS, HTTP 1.1, HTML 4, XML, as well as widely deployed image formats such as image/jpeg and image/gif. As discussed in 5 RDF and the web-grounded Semantic Web, RDF, OWL and GRDDL are among the additional core technologies that enable web-grounded Semantic Web content. A flow diagram illustrating more details of the Web's standard retrieval algorithm is provided in A Diagram of the Web's Retrieval Algorithm.
Successful communication depends on the supplier and the consumer(s) of a document having a shared understanding of the information conveyed, and that in turn requires at least some shared assumptions about the form in which the information is represented. The simplest way to achieve this is if the media type, the document encoding, and any other conventions used for the representation are standards and are widely deployed.
Consider Susan, who buys a new digital camera. The software supplied with
her camera uploads photos to the Web using the widely-deployed
image/jpeg media type, and her Web server correctly labels
served representations with that Content-Type. Millions of user
agents deployed around the world are preconfigured to display Susan's
photographs and to extract metadata such as camera settings from them. Search
engines are likely to index them in helpful ways too.
Now consider instead Mary, who buys a different camera with software that
does not use widely deployed Web formats. Indeed, the camera's
manufacturer has invented a new "raw" file format that takes advantage of the
camera's special features. The provided photo management software not only
uses that format locally, it also uploads photos to Mary's Web server in that
same form. Indeed, it even uploads a .htaccess
file, configuring the server to label served representations with the
proprietary Content-Type image/x-fancyrawphotoformat. In this
example, there are no outright violations of Web architecture, but the
decision to use an uncommon, proprietary, unregistered and apparently
experimental media type is unfortunate. No existing Web user agents recognize
the image/x-fancyrawphotoformat media type, search engine
spiders are unlikely to extract useful information from pictures in that
format, and so on. Unlike Susan's, which can be viewed by almost anyone,
Mary's photos are at best useful to a few people who have the proprietary
software needed to decode them.
Good Practice
Web resource representations should be published using widely deployed standards and formats.
The techniques described above apply in the many cases where widely
deployed media types such as image/jpeg are sufficient, but the
Web is used for a broad and continually growing range of information. No
fixed set of formats and standards can fully meet the need to encode all such
information for machine processing. Of course, ways can be found to convey
almost any information using standard media types. An employment record, for
example, can be transmitted as either text/plain or
text/html. The resulting document may be quite suitable for
browsing, but it might not facilitate automated discovery of the employee's
name, his or her date of hire, and so on. To meet such needs, new standards
must be created, e.g. for marking up the names and dates. Similarly, the need
may arise to use new values for individual fields such as rel
attributes on HTML link elements (see [TAGIssue51]).
So, although the Web requires web-grounded documents that can be understood using only widely deployed standards, there is also a continual need for new formats and encoding conventions. How can new formats and encodings be deployed in a manner that is web-grounded? The following sections explore ways of creating new formats and encoding conventions that maximize interoperability with existing Web infrastructure, and that can be used to create web-grounded documents.
Innovations can be introduced to the Web at many different architectural layers. For example:
New URI schemas can be introduced
New transfer protocols can be deployed
New media types can be introduced
New namespace-qualified markup can be defined for XML
New RDF properties and ontologies can be defined for the Semantic Web
Often, a given capability could in principle be deployed at any of several different layers. For example, new sorts of content, such as movies, could be made available using new URI schemes and/or with new protocols, but doing so would require updating hundreds of millions of user agents, servers, proxies, and so on to understand these changes to the core mechanisms of the Web. Usually it is preferable to leverage the existing core mechanisms of the Web, such as http-scheme URIs and the HTTP protocol, as these are widely deployed. Indeed, one should usually leverage as many existing layers of the Web's architecture as is practical when introducing new function.
Good Practice
When extending the Web with new formats and functions, use existing URI schemes, protocols, and media types wherever practical.
One way to do this is to use URI-based extensibility within existing media types, as described in the sections below.
Many documents, particularly those that convey machine-readable data or messages, encode information using specifications that are specialized to particular purposes. Such specifications may cover details of particular data formats such as lists of customers or inventory records, results of scientific experiments, listings for television shows, details of university course offerings, information about molecular structures or drug tests, etc. Because of the great variety and number of such formats and their specifications, it's not practical to assume that even most of them will be directly implemented by typical Web user agents. Instead, the Web provides means by which the necessary specifications can be discovered, and to a significant degree implemented, dynamically and automatically. This is done by:
ensuring that every specification, and in many cases each markup tag name or data value used, is identified with a URI
ensuring that such URIs are used in the instance either directly as data values or tag names, or else to identify the encodings used
including in Web representations URIs that identify the specifications needed to interpret those representations
Good Practice
Web representations should link to the information needed to support automatic processing of those representations.
The Atom Syndication Format [ATOM] is an XML-based
format for syndicating information about blogs and other Web resources. ATOM
entries can include <atom:link> elements such as the
following:
<entry>
<title>An interesting picture</title>
<link rel="enclosure" type="image/jpeg" length="12345"
href="http://example.org/interestingPic"/>
<content type="xhtml" xml:lang="en"
xml:base="http://example.org/">
<div xmlns="http://www.w3.org/1999/xhtml">
<p><[Update: Here's an interesting picture.]</p>
</div>
</content>
</link>
</entry>
The link elements identify external resources, in this case an
image/jpeg photograph. Furthermore, each link can carry a
rel attribute which specifies the relationship between the
linked resource and the ATOM entry that links it. In the example above, the
relationship is specified as enclosure which, according to the
ATOM specification, indicates that the linked photograph may have been too
large for inline processing with the rest of the feed.
What's of interest for this finding is the fact that values of the
rel attribute are URIs (actually [IRI]s,
which are the internationalized form of URIs), or else the values can be
mapped to URIs. This means that anyone, anywhere can invent a new sort of
link relationship, can assign a URI to identify that relationship, and can
use that value in the rel attribute. For example:
<entry>
<title>An interesting picture</title>
<link rel="http://example.org/SomeNewATOMRelationship"
type="image/jpeg" length="12345"
href="http://example.org/interestingPic"/>
<content type="xhtml" xml:lang="en"
xml:base="http://example.org/">
<div xmlns="http://www.w3.org/1999/xhtml">
<p><[Update: Here's an interesting picture.]</p>
</div>
</content>
</link>
</entry>
Furthermore, anyone doing this can (and indeed should) provide information
about that new relationship via HTTP from the assigned URI. For convenience,
the ATOM specification also provides that short form names such as
enclosure in the first example can be registered with IANA, and
ATOM provides a deterministic mapping to a URI for each of these. These URIs
are formed by prepending the fixed base URI
http://www.iana.org/assignments/relation/ to the short form.
Thus, the first example above is in fact using the relationship
http://www.iana.org/assignments/relation/enclosure.
This example shows how use of URIs for data values enables distributed assignment of new values. More importantly for this finding, the use of URIs for such values provides the opportunity for information about those values to be discovered dynamically on the Web.
[Microformats] provide a simple means of
marking up data in HTML Web pages. The presence of a microformat is typically
indicated by the appearance of an identifying value such as vcard
in an HTML class attribute, and particular data items are usually marked with
other class values. For example, this hCard provides contact information for
the North American office of the W3C:
<div class="vcard">
<a class="fn org url" href="http://www.w3.org/">World Wide Web Consortium</a>
<div class="adr">
<span class="type">Work</span>:
<div class="street-address">32 Vassar Street</div>
<span class="locality">Cambridge</span>,
<abbr class="region" title="Massachusetts">MA</abbr>
<span class="postal-code">02139</span>
<div class="country-name">USA</div>
</div>
<div class="tel">
<span class="type">Work</span> +1-617-253-2613
</div>
<div class="tel">
<span class="type">Fax</span> +1-617-258-5999
</div>
</div>
In general, microformats such as hCard are not web-grounded, because there
is no requirement in the HTML media type specifications that class attribute
values such as vcard or type be interpreted per the
hCard specification. Indeed, lacking any specific indication that the
resource owner has intended this interpretation, it is dangerous for clients
to assume hCard semantics — there is a real risk that some HTML Web pages
use values like type, value or even in principle
vcard for other purposes.
Unlike some other microformats, hCard does provide an option for deploying
in a way that is web-grounded. The hCard profile specifies
a value for the profile
attribute of the HTML 4.01 [HTML 4.01]
<HEAD> element:
<head profile='http://www.w3.org/2006/03/hcard'>and presence of this profile value indicates that class attributes can be reliably interpreted per the hCard specification. (Note, however, that there is ongoing discussion as to whether the profile attribute will be included as part of HTML 5, and if not, whether some other mechanism will be provided for signaling the use of extensions such as microformats.)
So, microformats are web-grounded only when profiles or other means
licensed by a pertinent media type specification are used to enable them.
Unfortunately, few microformats have such profiles, and even when profiles
are available, evidence suggests that they are not universally applied. User
agents that infer the presence of microformats without reliable indicators
such as <HEAD> element profiles are at risk of extracting
incorrect data from Web pages.
XML Namespaces [XMLNamespaces] facilitate the
creation of web-grounded XML documents. Given that a Web document is of media
type application/xml, or in the family of media types
application/____+xml, recursive processing from the root element
may be applied to determine not just the overall nature of the document, but
also the meaning in context of all sub-elements. Doing this, however,
requires understanding of the semantics of each named element. Although a few
specific XML variants such as application/xhtml+xml may be
directly supported by some user agents, no user agent can build in support
for the ever growing set of XML languages used for Web representations. This
section describes how namespace documents, discoverable from the XML tag
names in the markup, can be used to make such languages web-grounded, and to
enable automated processing of them.
When XML namespaces are used, each XML element is named with a qualified name,
consisting of a prefix and a local name. In the following example, the root
element has the qualified name <inventory:inventoryItem>:
<inventory:inventoryItem
xmlns:inventory="http://example.org/inventoryNamespace">
<inventory:itemNumber>
87354
</inventory:itemNumber>
<inventory:quantityAvailable>
152
</inventory:quantityAvailable>
</inventory:inventoryItem>
Qualified names map to expanded names such
as {http://example.org/inventoryNamespace,inventoryItem},
comprised of a namespace name URI
(http://example.org/inventoryNamespace) and a local name
(inventoryItem). The namespace name URI serves at least two
roles: the most obvious and the most widely understood is to distinguish
expanded names in one namespace from those in another; the other role, and
the one that is most important for purposes of this finding, is that it
provides Web identification for the namespace itself. The namespace is a Web
resource, and like any other resource, it can and should provide
representations using HTTP. A user agent processing an XML document can
retrieve descriptions of the namespaces used in that document, and can use
that retrieved information to determine how to correctly process the XML
markup. The TAG Finding "Associating Resources with Namespaces" [NamespaceDocuments], recommends the use of [RDDL] as a preferred means of documenting namespaces. RDDL
is itself extensible, but it is commonly used to suggest XML Schemas (in any
of several languages), XSLT Stylesheets, etc. that are usable with markup
from the namespace being described.
Example: assume that user Bob is browsing the Web, and that he follows a
link to a resource that returns the XML above as its representation.
Specifically, Bob's browser uses 2 The Web's Standard
Retrieval Algorithm to retrieve the representation, to determine its
character encoding, and to discover that its Content-type is
application/inventory+xml. Of course, it's very unlikely that
Bob's browser has built in knowledge of the inventory XML language, but the
Content-type makes clear [XMLMediaType] that the
representation can be interpreted as XML with Namespaces. The root element
tag is from namespace http://example.org/inventoryNamespace,
which uses the http scheme, so Bob's browser does an HTTP GET from that URI.
What comes back is a RDDL document containing the following
<rddl:resource> element:
<rddl:resource xlink:role="http://www.w3.org/1999/XSL/Transform" xlink:arcrole="http://www.w3.org/1999/xhtml" xlink:href="http://example.org/InventoryToBrowsableHTML.xslt" xlink:title="Transform Inventory XML to HTML for Browsing"> </rddl:resource>
This designates a stylesheet
(http://example.org/InventoryToBrowsableHTML.xslt) that can be
applied to format the inventory XML as HTML — the browser automatically
retrieves and applies the stylesheet, producing HTML that is rendered on the
screen. Without any manual intervention from Bob, his browser automatically
displays the inventory record in a format that is convenient to read and
print. Bob's browser may also be enabled for XML validation, in which case it
can look in the RDDL for a link to a schema to validate the inventory markup.
Bob's browser has, in an important sense, extended itself for processing of the inventory markup language. Unless the RDDL provides a link to one or more executable programs that process inventory records, it's unlikely that Bob's browser can automatically discover everything that one might reasonably want to know about processing inventory markup. Still, even the limited automatic function described above is very useful, and RDDL is an extensible framework that can be easily adapted to provide new kinds of information about namespaces. Note that because RDDL documents are themselves XML, GRDDL can be applied to derive RDF statements from them (see 5.2 Using GRDDL to Bridge From XML To RDF). In this way, web-grounded XML documents can be integrated with the web-grounded Semantic web. [NamespaceDocuments] describes this technique in more detail.
RDF [RDF] provides an interoperable means of publishing and linking web-grounded Web data resources, and for integrating representations rendered using other technologies such as XML. The result is a single, global web-grounded Semantic Web that integrates not only resources that are themselves built or represented using RDF, but also the other Web resources to which that RDF links, as well as those that can be mapped to RDF using technologies such as [GRDDL] . Readers unfamiliar with RDF should consult the RDF primer [RDFPrimer] as a prerequisite to understanding the discussion below.
Each RDF statement is a triple consisting of a subject, a predicate
(typically the identifier for a property, or for a relationship between two
Web resources), and an object (the value of the property or the referent of
the relationship). The subject, the predicate, and often the object as well,
are themselves identified by URIs, enabling the dynamic discovery introduced
in 4.2 URI-based Extensibility above
— if a user agent has no built in knowledge of some particular RDF subject,
relationship, or object, it can often use the URI to retrieve the information
necessary for processing. Indeed, RDF's Schema [RDFSchema] and OWL Ontology technologies [OWL] together offer a standard, machine-processable means of
describing relationships between RDF statements, e.g. that two seemingly
differing predicates are the "owl:sameAs" each other.
As described in 2 The Web's Standard Retrieval Algorithm, the principal purpose of the Web's core retrieval algorithm is to obtain web-grounded representations of Web resources. For the web-grounded Semantic Web, the algorithm is extended to achieve a more particular goal: to directly obtain RDF triples that represent or indirectly obtain RDF triples that describe the referenced resource.
| Editorial note | |
| The early drafts of this finding used RDF/XML in the example below. I have received a comment from Stuart Williams recommending use of N3 instead. For now I'm offering both versions, and I ask that reviewers let me know which is more effective. Only one of the two will be retained in the final draft. Here's the RDF/XML: | |
Consider Amy, who uses an RDF-enabled user agent to retrieve an RDF/XML document containing the following element:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:employeeData="http://example.org/EmployeeInformation#">
<employeeData:employee rdf:about="http://example.org/Employees#BobSmith">
<employeeData:name>Bob Smith</employeeData:name>
<employeeData:email rdf:resource="mailto:BobSmith@example.org"/>
</employeeData:employee>
</rdf:RDF>
| Editorial note | |
| ...and here's the alternative version using N3: | |
Consider Amy, who uses an RDF-enabled user agent to retrieve an N3 document containing the following element:
@prefix employeeData: <http://example.org/EmployeeInformation#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<http://example.org/Employees#BobSmith>
a employeeData:employee ;
employeeData:email <mailto:BobSmith@example.org> ;
employeeData:name "Bob Smith" .
The user agent is general purpose, and although it has rules for certain
commonly used ontologies, it has no built in code to handle the
employeeData properties in the above example. To dynamically
acquire the necessary function, the agent does an HTTP GET for
http://example.org/EmployeeInformation. The GET returns an OWL
ontology, from which the agent discovers that
http://example.org/EmployeeInformation#email is
rdfs:subPropertyOf the
http://www.w3.org/2001/vcard-rdf/3.0#email property, one that
the agent recognizes as designating a person's e-mail address. The agent
offers Amy the option to send e-mail to Bob Smith. Amy's browser has, like
Bob's in the example above, automatically extended itself for processing the
employee data.
Good Practice
Representations provided directly in RDF, or those for which automated means can be used to discover corresponding RDF, contribute to the web-grounded Semantic Web.
Because its model is uniform, because all of its self-description is provided in the same model as the data itself, and because all RDF information is linked into the Web as a whole, RDF provides uniquely powerful facilities for dynamic integration of a web-grounded Web. Therefore, it's particularly important that information not originally supplied in an RDF-specific format be convertible into RDF. The sections below discuss two means of doing this: the first shows how RDFa can integrate HTML documents into the Semantic Web, and the second illustrates the use of GRDDL to extract RDF from XML documents.
| Editorial note | |
As of now, the pertinent RDFa specification is in Proposed Recommendation status, and the specific plans for updating XHTML namespace documentation, requiring or recommending use of DOCTYPEs, profile attributes, etc., are still being discussed. The following is based in part on the latest editors drafts of RDFa. As we prepare to publish this finding, we should convince ourselves that we are comfortable referencing RDFa specifications as working drafts, or else decide to wait for RDFa to reach a more stable status. (Speaking for myself, I would prefer not to delay this finding very long, but rather to just reference the latest working drafts if necessary. Noah) |
|
[RDFa] is a W3C draft Recommendation for embedding Semantic Web statements into XHTML Web pages (see also [RDFaSyntax]). This example illustrates how RDFa can integrate HTML into the web-grounded Semantic Web:
Mary is exploring the Web using a browser that has been enhanced with capabilities for interpreting RDFa. Her browser knows to look through each XHTML Web page that she browses, picking out information from the RDFa, and helping her to use it. For example, the page might contain the following HTML, which represents an [RDFVCard]-style contact listing. (This example is adapted from one in [RDFa]):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN"
"http://www.w3.org/MarkUp/DTD/xhtml-rdfa-1.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
version="XHTML+RDFa 1.0"
<body>
<p class="contactinfo"
xmlns:contact="http://www.w3.org/2001/vcard-rdf/3.0#"
about="http://example.org/staff/joseph">
My name is
<span property="contact:fn">
Joseph Smith
</span>
I'm a
<span property="contact:title">
distinguished web engineer
</span>
at
<a rel="contact:org" href="http://example.org">
Example.org
</a>.
You can contact me
<a rel="contact:email" href="mailto:joe@example.org">
via email
</a>.
</p>
</body>
</html>
Even though this document is of media type
application/xhtml+xml [XHTMLMediaType], which is not a member of the RDF
family of media types, an RDFa-enabled user agent can extract RDF from this
document. This document conveys as RDF a set of semantic Web statements about
the Web resource http://example.org/staff/joseph. The predicates
are all named with the same base URI
http://www.w3.org/2001/vcard-rdf/3.0#, for which the shorthand
prefix contact is established in the HTML. Using this syntax,
the RDFa carries triples for relationships such as the full name of the
contact (http://www.w3.org/2001/vcard-rdf/3.0#fn), which is
Joseph Smith, the e-mail address
(http://www.w3.org/2001/vcard-rdf/3.0#email) which is
mailto:joe@example.org, and so on.
An RDFa-enabled user agent can extract these triples and use them to help
Mary work with the data they contain, or to integrate with other Semantic Web
information. Indeed RDF is designed for such use because, as discussed above
in 5 RDF and the web-grounded Semantic Web,
Semantic Web triples are inherently web-grounded. If a user agent needs more
information about the processing of the email triple it can, like Amy's user
agent, do an HTTP GET for URI
http://www.w3.org/2001/vcard-rdf/3.0, and use the results to get
more information. With luck, that information will lead the agent to
automatically discover that, in the example,
mailto:joe@example.org can indeed be used to send mail to the
person named Joseph Smith. The browser can then offer Mary the
option to send e-mail to Joe, or to add Joe to her address book.
Good Practice
RDFa should be used to make information conveyed in HTML web-grounded.
For this example document to be web-grounded, the pertinent media type and
the specifications on which it depends must provide for the use of RDFa in
XHTML; at the time of this writing, they do not. Those who are working on
RDFa specifications have suggested that the specification for the XHTML
namespace will soon be updated to provide explicitly for the use of RDFa in
XHTML. When this happens, documents such as the one shown above will be
web-grounded when served with the Content-type
application/xhtml+xml, since the specification for that media
type refers to the specification for the XHTML namespace. Similarly, the
media type specification for text/html [XHTMLMediaType] allows for certain XHTML content,
and presumably such content would similarly be enabled for RDFa once the
XHTML namespace documentation was revised.
| Editorial note | |
In informal discussions with those working on RDFa, they have referred to "updating the specification for the XHTML namespace". Is it really the specification for the namespace that matters? I would have thought it would be the specification(s) for one or more of the languages that use elements from that namespace as markup. |
|
RDFa provides a standard means of encoding RDF information in XHTML documents, but many other XML variants lack that capability. Furthermore, RDFa requires explicit encoding of each triple in the XHTML instance, and that may in some cases be impractical. [GRDDL] provides a standard means of extracting triples from a broad range of XML document formats. Each GRDDL-enabled XML document links to a transformation that, when applied to the document, produces RDF triples. Typically, the same GRDDL transformation can be used on entire families of similar XML documents.
For example, assume that Albert uses a GRDDL-enabled user agent to retrieve an XML document containing the following fragment:
<employees xmlns="http://example.org/employeeNS">
<employee name="Bob Smith">
<email>BobSmith@example.org</email>
</employee>
</employees>
Note that, unlike the earlier examples, this is neither in HTML nor in
RDF; we can assume that http://example.org/employeeNS is a
namespace created by some particular business for use in its own busines
documents. Albert's agent has no built in knowledge of this namespace, and so
can not do much with it. Now assume that Albert instead retrieves a different
document. Most of the markup and data in it is identical to the first, but
this document is GRDDL enabled:
<employees xmlns="http://example.org/employeeNS"
xmlns:grddl="http://www.w3.org/2003/g/data-view#"
grddl:transformation=
"http://example.org/GRDDL_For_employeeNS.xsl>
<employee name="Bob Smith">
<email>BobSmith@example.org</email>
</employee>
</employees>
Albert's user agent is GRDDL aware, so it transforms the
<employees> information to RDF using the supplied
GRDDL_For_employeeNS.xsl transformation. If Albert is lucky,
that transformation produces RDF triples that the agent understands, or that
the agent can dynamically discover how to process using the techniques
described above in 5 RDF and the web-grounded Semantic
Web. As in the earlier examples, Albert's user agent offers to send
mail to Bob Smith.
Good Practice
GRDDL should be used to integrate XML documents into the web-grounded Semantic Web.
Ad hoc exploration of the Web is possible only if resource representations are web-grounded. Using the techniques described above and starting with an http- or https-scheme URI, a user agent can proceed step by step to retrieve a representation, reliably discover the conventions that have been used to encode it, and if necessary, dynamically find instructions for processing it. Those who invent new document formats, new markup tags, or new conventions for encoding particular data values should use the techniques described above to make those formats web-grounded. When these techniques are used, and when web-grounded representations are linked together, the Web as a whole can support reliable, ad hoc discovery of information.