1 Introduction
This is an old issue, and people are tired of it. — Sandro Hawke, January 2003 [disambiguating]
In any kind of discourse it is very useful for an agent to be able to provide documentation for a term, in such a way that other agents can discover and use that documentation in order to make sense of utterances that use that term, and to compose new utterances that use it.
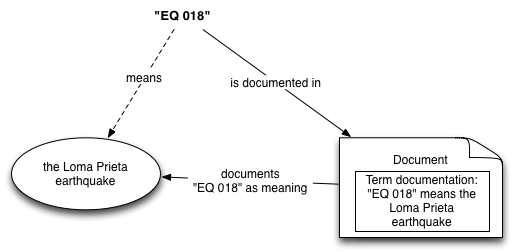
Suppose that Alice, in communication with Bob, uses the term "EQ 018" to mean the Loma Prieta earthquake, as in "Alice was in the laboratory during EQ 018". If Bob does not know what "EQ 018" means, he will have to find out. He might be able to ask Alice directly, although this may be impossible, as Alice might be too busy, or otherwise unavailable. Lacking that option he does some research, consulting a dictionary or similar resource (reference book, database, search engine) in order to obtain the explanation of Alice's use of the term "EQ 018".
In this report, the terms to be documented are assumed to be URIs. URIs can be used to mean all sorts of things in many different technical contexts. Contexts of special interest to this report are those processed by machine, including the RDF and OWL family of languages. The question may appear to be limited to RDF and its derivatives, but to the extent that there is supposed to be a single meaning for each URI common to RDF and Web architecture [webarch], the issue transcends RDF.
The nature of URI documentation need not concern us here - many forms are familiar, including translation between languages (e.g. providing an English or Spanish phrase equivalent to a URI), descriptions (the URI refers to an entity possessing some set of properties), explanation by example, axiomatic method, and so on. Also not of concern here are the many ways in which meaning can fail as a result of what URI documentation says or doesn't say about the URI in question, or the particular way in which a URI is used. Our concern is only with the method by which documentation is conveyed, and with meaning only to the extent the method impinges on interpretation.
URI documentation is typically carried in documents. No assumptions are made about what else might be in such a document; there could be additional related information, documentation for other URIs, and so on. Nor is it important here that URI documentation be delimited or set off from the other information in the document. As in an encyclopedia, the URI documentation part blurs into the other-information parts of the document.
URI documentation discovery methods include, in addition to those already mentioned, network protocols such as HTTP that involve the URI as a protocol element. Henceforth, in a URI documentation discovery scenario, the URI whose URI documentation is to be discovered will be called the probe URI.
URI documentation discovery is similar to Web retrieval in that in both cases one can start with a URI and end with a document. The two must not be confused, however, since retrieval often yields information that does not document the URI, is not recognized as doing so, or is not intended to do so.
The reason we define URI documentation discovery methods is interoperability: so that there is agreement on how each URI is to be understood. In principle, we only need consensus on methods, such as the ones surveyed here, for URIs that are to be shared widely. If agents in one community never use the URI in communication with agents in another community, then it is OK for the URI to have distinct senses in the two communities, and there is no problem to be solved. Each community can use the URI in its own way, and there will be no confusion.
The operative word here is "if". Isolation is fragile and means lost opportunities for synergy and unintended reuse. All the arguments in favor of a World Wide Web, which depends on the global nature of the URI vocabulary, apply here.
This report presents discovery methods in current use, reports some criticisms of them, and describes some additional discovery methods that have been proposed to address the criticisms.
1.1 Desiderata
No consensus on criteria for judging success of a discovery method has emerged from the discussion of this question. The following properties have been articulated as desirable by various parties to the discussion. Unfortunately they apparently form a mutually inconsistent set.
- Uniform
- The URI, considered as a reference to something, should make sense on its own, independent of context or community of use. Its meaning or "identification" should be uniform regardless whether it's used as a protocol element, hyperlink, or name. This property cannot necessarily be enforced through technical design, but a discovery solution should not depend on non-uniform meaning. [rfc3986]
- Retrieval-friendly
- It should be possible to configure a URI that has discoverable documentation so that a retrieval request using the URI yields information (such as URI documentation) that is relevant and useful, especially in a Web browser context.
- Easy to deploy using a current widely deployed protocol stack
- Discovery should employ a widely deployed network protocol such as HTTP in order to avoid the need to deploy a new protocol stack. (This would likely be implied by "retrieval friendly".)
- Easy to deploy on Web hosting services
- Uptake of linked data depends on the technology being accessible to as many Web publishers as possible, so discovery should not require control over Web server behavior that is not provided by typical hosting services. For example, some hosting services provide no way to deliver a 303 redirect.
- Efficient
- (a) Accessing URI documentation should require at most one network round trip, and (b) URI documentation should be cacheable.
- Substitution resistant
- A URI should be conveyed unmodified through typical client and server side data flows, so that it retains its utility (such as for bookmarking). Difficulties might include (a) content management systems that strip fragment ids off of URIs at inopportune moments, and (b) Web browsers that replace a redirected URI with its redirect target. Also (c) misspellings yielding invalid URIs should become evident through routine error checks.
- Compatible with use of URI as metadata subject
- Convention 1 (below) is widely observed, and it would be nice if discovery methods didn't interfere with it.
- Compatible with inference
- URIs should participate gracefully in deployed frameworks for ontologies and logical inference, specifically RDF and OWL.
It is not certain that all of these goals can be met simultaneously.
As any overall discovery solution will combine of a number of methods, avoiding conflict between adopted methods is also a goal for any solution.
2 Use case scenarios
Use cases need to be presented as being independent of any particular solution to be used, in order that the solution space can be explored without bias. This leads to some frustrating vagueness in the following, but the vagueness is intentional and necessary.
2.1 Choose a URI, provide documentation for the URI, then use the URI
Alice wants to refer to a particular earthquake. Alice "mints" a new URI (one that is not yet in use) with the purpose of using that URI to refer to the earthquake. Alice publishes a document containing documentation for the URI, i.e. a document that would lead a reader to understand that the URI refers to the earthquake.
Bob then learns of Alice's URI and its documentation, and uses the URI in a document of his own.
Subsequently Carol encounters Bob's document. Wanting to know what the URI means, she is led somehow to Alice's published URI documentation, which she reads. She is enlightened.
Any method for implementing this use case would need to explain: what kind of URI Alice should use (syntactic constraints); where and how should Alice should publish the documentation so that it can be found; and how Carol might come to discover Alice's documentation, given the URI.
2.2 Using a document as URI documentation by reference to its primary topic
| Editorial note | 2011-04-14 |
| Consider dropping this use case, and explain the situation in some less prominent way. The only evidence we have for this situation is from Hugh Glaser's message, and most of the discussion in this document does not apply to this case. On the other hand it is important to understand the distinction being made. | |
Bob desires to refer to Chicago. He finds a Web page on the Web at 'http://example/about-chicago' (provided by, say, Alice) that consists of a description of Chicago, and wants to use it for the purpose of referring to Chicago. He chooses a URI and associates it with Alice's Web page in such a way that Bob's URI will be understood as referring to Chicago.
Carol encounters Bob's URI, is led to 'http://example/about-chicago' and thence to Alice's description of Chicago, and then somehow understands that Bob's URI is meant to refer to Chicago.
Any method for implementing this use case would need to explain: what are the syntactic constraints on the URI Bob chooses; what Bob needs to do to associate his URI with the document about Chicago; and how Carol comes to discover and use that association.
(This differs from the previous use case in that the document about Chicago was not written with the purpose of documenting Bob's URI. In fact Bob's URI doesn't even occur in it. Rather than look in the document for URI documentation for Bob's URI, Carol must determine the topic of the document and take the topic as the meaning of Bob's URI.)
2.3 Find instances of a resource at a URI, then refer to the resource in metadata
Alice finds interesting retrieval responses at a URI and wants to talk to Bob about them. In communication with Bob, Alice uses some agreed syntax (such as the URI itself, if Alice and Bob so agree) to refer the resource of which these responses are instances. (An instance is a particular kind of "representation," in the sense of [rfc3986], that may share properties such as title or subject with a resource of which it is an instance. See [generic] for discussion of instances and generic resources.)
Upon receipt of this syntax, Bob attempts retrieval of an instance using the URI. If this succeeds then Bob understands Alice to be referring to the resource of which it is an instance, not to something else.
3 URI documentation discovery methods in current general use
This section describes currently accepted methods for providing and discovering URI documentation.
3.1 Colocate URI documentation and use
One way to lead someone encountering a URI to documentation for the URI is to make sure that the URI documentation occurs in each document in which the URI occurs. This makes the URI documentation easy to find, since anyone who encounters the URI will already have it in hand. The form of the URI in this case is arbitrary.
This method treats URIs similarly to blank nodes in RDF, which have to stay close to their own documentation, since they are scoped to a graph. An example of the application of this approach would be the use of a URI in an OWL ontology file that carries the URI documentation.
Criticism: In RDF, this method is fragile in the same way as are blank nodes, because use and documentation can get separated, e.g. when uses of the URI are deposited into a triple store and then retrieved by a query. Carrying documentation around with a reference does not help in the common case where an out-of-context reference is needed (as one would want in, say, a Semantic Web). (Desideratum: [ Uniform ].)
3.2 Specifically point (link) to the URI documentation
When using a URI, provide, again in the document in which the URI occurs, a recognizable reference to a document that carries the URI documentation. This is the approach taken by OWL; the document containing the URI is related to the one from which the URI documentation should be obtained via the owl:imports relation.[1]
The rdfs:isDefinedBy property might also be used for this purpose, but it probably isn't.
Criticism: Like the previous approach, this one is good so far as it goes, but it suffers in similar ways. The URI and the link to its documentation can get separated, or keeping the documentation link close to the occurrence of the URI may prove to be too difficult for applications. (Desideratum: [ Uniform ].)
3.3 Use non-http: URIs and a non-HTTP protocol
It is possible to create a new URI scheme or URN namespace equipped with its own URI documentation discovery regime. A recent example is RFC 5870 for URIs documented as naming geographic locations, where the RFC itself constitutes URI documentation for all of its URIs. Another is the URI documentation for the URI about:blank and other about: URIs, which is in progress as of this writing. A "tdb:" (thing-described-by) URI scheme has also been proposed, [TBD: cite Masinter] as has "xri:" for "extensible resource identifiers" (n.b. xri: has been deprecated in favor of http: and Web Linking). See [rfc4395] and [rfc3406] for details.
The most fully developed and widely implemented such design is the 'lsid' URN namespace. URIs beginning 'urn:lsid:' are called LSIDs. [lsid] LSIDs have an associated SOAP-based protocol that has separate methods for retrieval (getData) and discovery (getMetadata). According to the LSID specification, an LSID for which the getData method yields nonempty content refers to a representation, while the LSID could refer to anything at all if getData yields empty content. In the latter case the information yielded by the getMetadata method generally constitutes, or at least contains, documentation for the LSID.
For clients lacking an LSID protocol implementation, HTTP/LSID gateways are available, suggesting the possible applicability of the 5.1 Global rule yielding documentation URI discovery method as an alternative to the LSID protocol.
Criticism: The LSID protocol itself is not widely deployed, and LSIDs are not currently processed in any useful way by most Web clients. (Desiderata: [ Retrieval-friendly ], [ Easy to deploy using a current widely deployed protocol stack ], [ Easy to deploy on Web hosting services ].)
3.4 'Hash URI'
With this method, the probe URI must be a 'hash URI', i.e. must contain a hash character '#'. The URI documentation is placed in the document on the Web at the stem (where stem URI = the pre-hash prefix of the URI).
For historical reasons the part of the URI following '#' is called the 'fragment identifier', even when it is null. We will call these 'local identifiers' in recognition of their uses beyond just references to document fragments.
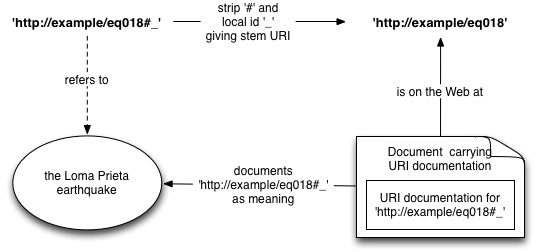
The interpretation of a 'hash URI', say 'http://example/eq018#_', depends (according to [rfc3986]) on the media types of representations of the resource on the Web at its stem URI 'http://example/eq018'. For media type application/rdf+xml, the media type registration defers to the content of the representation — that is, the representation itself of the stem URI gets to document what the probe URI means.[2]
Because of the dependence on media type, care must be taken to ensure that content negotiation does not muddy the meaning of the probe URI. Fortunately any of three approaches may be used: (1) avoid content negotiation, (2) make sure that all representations provide the same documentation (following section 3.2.2 of [webarch]), or (3) institute, as a new consensus practice, a priority ordering on media types, so that, say, media type application/rdf+xml deterministically takes priority over text/html (or vice versa). (The latter in turn requires modifications to discovery clients, so this would would be in effect a new discovery method.)
Similar considerations apply for competing use of local identifiers as script-defined or as document fragment identifiers: any potential conflicts must be either avoided or resolved.
A second caveat around hash URIs is that when a number of hash URIs are formed by combining a fixed namespace prefix (stem) with many different suffixes using hash as a connector, there must be a single underlying document at the stem URI that provides URI documentation for all of the URIs. This leads to a number of annoyances, including inefficiency (repeated retrieval of a large document is an unacceptable performance hit for the server, the network, and the client), analytics imprecision, and unavailability of HTTP methods such as DELETE specific to the particular URI.
The answer to this difficulty has been reported a number of times (e.g. [degraauw]) and might be called the "single-hash-URI-per-stem-URI pattern" of use of hash URIs. For a set of namespace members a, b, c, ... instead of using URIs
http://example/ns#a http://example/ns#b http://example/ns#c ...
use URIs that look like
http://example/ns/a#_ http://example/ns/b#_ http://example/ns/c#_ ...
where _ is a common suffix of your choice.
3.4.1 Local identifier misspellings go undetected
Criticism: A hashless URI that is misspelled, when submitted to an HTTP server, would normally evoke a 404 Not Found response, alerting a user quickly to a misspelling. A hash URI, on the other hand, isn't sent to an HTTP server. Any misspelling in the local identifier may go undetected for a long time, since it would only be detected as a failure to recover expected information from the content that was supposed to document it. (Desideratum: [ Substitution resistant ].)
Response: This is hard to argue with. Mitigations such as use of Javascript for error checking might be possible.
3.4.2 Local identifiers are easily lost
Criticism: Harry Halpin [halpin] reports that local identifiers are often lost during document preparation and cut/paste operations.
Rumor has it that some MVC-based web frameworks (Django?, Sinatra?) are not good about preserving local identifiers. This needs to be verified. (Desideratum: [ Substitution resistant ].)
Response: More information needed; it's not obvious [to the editor] that this should be the case. Concrete scenarios would help.
3.5 Hashless URI with HTTP 303 'See Other' redirect
Initially (around 2000) 'hash URIs' were advanced as the recommended method for URI documentation provision and discovery. In the 2002-2005 time period demand arose for a discovery method applicable to hashless URIs. This led to the invention of a new protocol for use in situations where 'hash URIs' are considered unacceptable.
In this approach, one mints an absolute hashless http: URI, puts documentation for it on the Web at a second URI, and then arranges for a GET request of the first (probe) URI to redirect, using a 303 'See Other' status code, to the second URI. The probe URI is not retrieval-enabled, and therefore does not name the resource at that URI according to Convention 1 (since there is none). The probe URI then gets its meaning by interpreting the document on the Web at the second URI, which presumably contains documentation for the first URI. The document may carry documentation for other URIs as well, so the referent of the URI is not necessarily the document's primary topic - it may be only one of many things "described by" the document. [Draft note: TBD: cite HTTPbis]
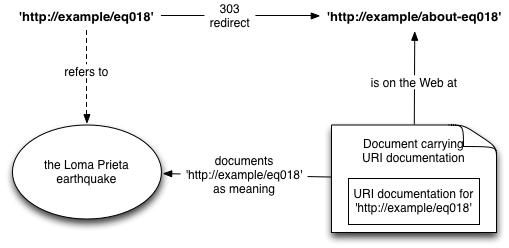
Alice chooses 'http://example/eq018' as the way she will refer to a particular earthquake. At 'http://example/about-eq018' she publishes text and/or RDF that carries URI documentation for 'http://example/eq018', explaining the URI's meaning by providing details about the earthquake (date, location). For the URI 'http://example/eq018', which will not be retrieval-enabled (since otherwise, it would, by Convention 1, refer to the resource on the Web at that URI [generic], not the earthquake), she arranges that a GET request yields a 303 redirect with a Location: header specifying 'http://example/eq018' as the redirect target.
Those encountering 'http://example/eq018' will attempt a retrieval, but this will fail, with a 303 redirect delivered instead. The 303 redirect indicates that the document at 'http://example/about-eq018' provides documentation of the URI 'http://example/eq018'.
Another pattern is to use a 303 redirect to a document whose primary topic is the intended referent, similar to the Chicago use case (2.2 Using a document as URI documentation by reference to its primary topic). This could, in theory, lead to ambiguities, as the entity to which the URI refers in the document may not be the document's primary topic.
Again, a number of objections to this approach have been raised:
3.5.1 303 is difficult, sometimes impossible, to deploy
Criticism: Deploying a 303 redirect requires giving the correct directive to a web server, for example adding a Redirect line to .htaccess in Apache HTTPD. Unfortunately many hosting solutions do not allow this, putting this manner of publishing URI documentation off limits to many who would otherwise like to use it. (Desideratum: [ Easy to deploy on Web hosting services ].)
Response: Web publishers whose ISP does not permit them to set up a 303 redirect, or for whom the overhead such as expertise acquisition is prohibitive in some other way, could choose to use a service that provides 303 redirects to a location of their choosing. One such service is purl.org, operated by OCLC, which permits anyone to set up a 303 or other redirect from their domain. The URI to be documented would have to have the form http://purl.org/..., while the URI for the document carrying the URI documentation could be anything at all.
Unfortunately, use of a redirect service makes one dependent on two service providers instead of one, making one's URI documentation more vulnerable than if only one provider were involved.
3.5.2 303 leads to too many round trips
Criticism: To get URI documentation for N URIs by redirecting through 303 responses, you need to do 2N HTTP requests (in the absence of cache hits). This is a frustrating and apparently gratuitous performance hit for those interested in publishing and accessing large numbers of URI documentation-carrying documents. (Desideratum: [ Efficient ].)
Response: See 5.1 Global rule yielding documentation URI.
3.5.3 303 responses aren't cached
Criticism: RFC 2616 [rfc2616] says that 303 responses shouldn't be cached. Some caching software obeys this directive, with negative consequences for the performance of GET/303 exchanges. (Desideratum: [ Efficient ].)
Response: This problem was recognized quite early on as a mistake in RFC 2616 [rfc2616], and an erratum was circulated. This is one of many changes made in HTTPbis, which is being developed by the IETF HTTP working group and should be published some time soon. Any software that fails to cache 303 responses when allowed to by HTTPbis needs to be fixed.
3.5.4 303 makes the URI difficult to bookmark
Criticism: "The user enters one URI into their browser and ends up at a different one, causing confusion when they want to reuse the URI ... Often they use the document URI by mistake." [davis]
"Redirection has in fact very confusing side effects; as we expect the semantic web to work seamlessly with the web, it is very odd that a semantic web uri cannot be copy pasted to a browser without seeing it change to something that is not the same as before." [tumarello] (Desideratum: [ Substitution resistant ])
Response: The location bar issue is discussed here. [TBD: citation] The content from the redirect target does not originate from the referent of the original URI, so an interface that suggests otherwise is guilty of misattribution. The best answer to this is that an additional user interface element should be added to browsers that provides access to the original URI. Accomplishing this would be a challenge.
3.6 Retrieval as equivalent to instance relationship
Widely observed convention relating retrieval to meaning is the following:
Convention 1: A retrieval-enabled hashless URI refers to the resource on the Web at that URI (see [generic]), independent of anything that the retrieval results (representations) say about what the URI means.
In effect, a response to a retrieval request is equivalent, according to Convention 1, to URI documentation that says that the response is an instance of the thing named by the URI. This in turn implies (as explained in [generic]) that the response (or rather its representation payload) may resemble that thing in properties such as title, author, subject, creation date, and so on. The URI is then useful as the subject of a statement of metadata, which is understood as applying to the instance. (See use case 2.3 Find instances of a resource at a URI, then refer to the resource in metadata .)
Criticism: From the fact that a response is an instance of the URI's referent, you learn from this that the referent is of a kind that might have properties characteristic of a retrieval response. But it's not obvious what in particular the response tells you about the referent of the URI, since most relevant properties, such as length, creation date, or even author, can vary among responses. According to the theory in [generic], a property will hold if it holds of all potential responses, but whether it does would have to be either conjectured or learned through other channels.
4 Don't do it: Potential workarounds
If issues around 'hash URIs' and 303 redirects render them unacceptable, it is worth considering alternatives. In this section we reconsider ways in which URI documentation discovery can be bypassed altogether. In the following secion potential new discovery methods are considered.
4.1 Use something other than a URI
| Editorial note | 2011-04-14 |
| This section derives from JAR's TAG F2F presentation slides. The purpose of talking about this idea would be mainly to remind people that the problem is one of notational engineering, not philosophy. I have been asked to remove this section. | |
URIs are just one kind of term that might be used to refer to something. If defining a URI is too difficult or costly, then perhaps one might do without. In RDF serializations such as Turtle, for example, we have blank node notation:
[ foaf:isPrimaryTopicOf <http://example/about-chicago> ]
Here we have managed to refer to Chicago without defining a new URI; we have simply referred indirectly using a URI that refers to the resource on the Web at that URI according to a generic method (see [generic]).
A concise alternative would be syntactic sugar:
*<http://example/about-chicago>
which might be supported in a hypothetical new RDF serialization as a shorthand for the previous example. (The asterisk is meant to be suggestive of indirection in the C programming language.)
Criticism: These are good as far as they go, but they do not meet the demand for documented URIs. In particular, it is possible but difficult to detect that blank nodes in separate graphs are meant to refer to the same thing. Data integration is easier when shared URIs are used.
In the case of syntactic sugar, there would be adoption overhead in publishing new RDF serialization specifications and getting them implemented.
4.2 Express data in terms of named documents (parallel properties)
The idea here is that you don't need to document a URI if you are willing to use properties that are defined or understood as indirecting through documents. Instead, just use a URI that refers to the document on the Web at that URI, and use it as the subject of such properties.
Assume that each named document (i.e. document+name pair) can have an associated entity, which we'll call its "designated subject".[3] Information about the designated subject is expressed using properties whose subject is the document.
Suppose that Alice wants to record some information about an earthquake. She publishes URI documentation containing the following so that it's on the Web at the URI 'http://example/eq018':
<http://example/eq018> eq:magnitude 6.9. <http://example/eq018> eq:epicenter <geo:37.040,-121.877>.
Bob then comes along and writes the following metadata about OW@('http://example/eq018') in the usual way, i.e. using the URI to refer to that resource, based on what information is accessed via that URI:
<http://example/eq018> dc:creator "Alice".
<http://example/eq018> dc:title
"Documentation for Loma Prieta earthquake URI".Suppose that Carol encounters both bits of RDF (or either) and needs to make sense of them. She is aware that 'http://example/eq018' might be used in both kinds of statement - in metadata, with the intent that the metadata is about OW@('http://example/eq018'); and also in statements that relate to an eathquake.
Instead of defining eq:epicenter to be a property relating an earthquake to its epicenter, one documents eq:epicenter to be a property that relates a document to the epicenter of its designated subject. Then, as long as you have a URI for the IR, you don't need a URI for the earthquake. If property eq:epicenter has domain eq:Earthquake, then the members of eq:Earthquake are IRs whose designated subjects are earthquakes.
The nature of the designated subject is inferred from information found in the IR. For example, if the IR says that its eq:epicenter is E, then you can infer that the designated subject has epicenter E.
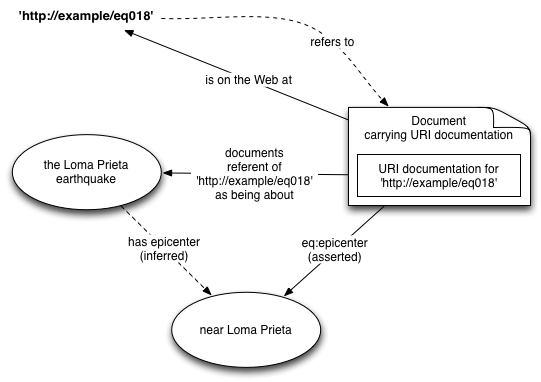
The overall effect when reading the RDF is that the documents, being ubiquitous, seem to disappear, and one focuses naturally on information about their designated subjects without being aware of the indirection.
All considerations that apply to the subject of a property also apply to the object, making the situation more complex in ways that we won't work out in detail here.
[via TimBL?] This pattern has some degree of uptake. Using the open graph protocol on Facebook, you can get a page about a movie. The RDF references <>, which is of class Movie. (<> is equivalent to a reference via the base URI, the one from which the page was retrieved, and therefore refers to a document.) The members of class Movie are documents whose designated subjects are movies. [is this message on topic?]
Criticism: If a property that refers directly to movies also needs to be used, then two properties have to be defined (with distinct URIs), one relating to the movie and one relating to the Movie. This results in clerical overhead and potential user confusion.
5 Some potential new discovery methods
All rules presented in this section assume that the probe URI is a hashless http: URI.
For compatibility with clients that are not aware of new method(s) for hashless URIs, a complete discovery solution should grandfather discovery methods that are currently widely known, such as 303 redirects. A current method should be deployed when possible, redundantly. Lacking this a 404 should be returned, and if the content of the 404 response can be controlled it should provide suitable information such as a link to the URI documentation. Agents would be faced with the problem of which method to attempt first, since if the the new method doesn't yield URI documentation, a retrieval using the probe URI might have to be attempted (in hope of either success or a See Also), resulting in one or two extra retrieval requests. It is the editor's belief that this problem is not insurmountable, but the details would have to be worked out.
5.1 Global rule yielding documentation URI
The network round-trip (303 redirect) used to map the probe URI to the URI of the document that carries its URI documentation can be avoided if we know a general rule that maps the one kind of URI to the other, as such a rule can be applied on the client without server involvement.
The "well known URIs" specification [rfc5988] provides a solution to this problem. For any origin (the part of the URI preceding the path part) we can prefix the path of URIs with a fixed string, say, '/.well-known/meta', to obtain the URI documentation URI. For example, if the URI is 'http://example/eq018', then its URI documentation would be found by retrieval using the URI 'http://example/.well-known/meta/eq018'.
(There is nothing special about the string 'meta'; it could as easily be, say, 'about' or 'seealso'.)
Criticism: Web publishers without the ability to control retrieval results for the /.well-known/meta/... URIs would not be able to take advantage of this method. (Desideratum: [ Easy to deploy on Web hosting services ].)
Criticism: Jeni Tennison says: "the disadvantage is that you lose the distinction between status codes for the thing [described] and the document [instantiated]". [But the editor doesn't understand this. Any information that would have been conveyed by the status code from a GET on the probe URI, could be conveyed in the document retrieved by URI documentation discovery?]
5.2 Site-specific rule yielding documentation URI
Considering the transformation rule idea of the previous section, it is probably too much to hope for that a single rule could work uniformly for hosts whose documentation might be sought, but each individual host may have a rule that applies for URIs at that host.
To support site-specific rules, a a file containing such rules can be provided [rfc5988] using a well-known path, say '/.well-known/documentation-rule', e.g. 'http://example/.well-known/documentation-rule'. To obtain documentation for 'http://example/eq018', first retrieve (and cache) the documentation-rule document for its host. Then if the rule says to map 'http://example/{path}' to, say, 'http://example/{path}.about', documentation for 'http://example/eq018' can be sought by a retrieval request using 'http://example/eq018.about'.
When the mapping rule is cached, the number of round trips is one instead of two.
Although it would not be difficult to specify a new .well-known path and syntax for the documentation-rule document, it might be possible to use the link-template feature of the host-meta file. There are pros and cons for each approach.
This approach is essentially the same as the ARK design, [TBD: reference https://wiki.ucop.edu/display/Curation/ARK or something better] which uses as its global URI transformation appending a '?' to the URI. The main differences are that the ARK rule only works when the path begins 'ark:', and that the risk of 'squatting' on part of a domain owner's URI space (not all '?'-ended URIs are for URI documentation discovery) is somewhat higher than in the case of /.well-known/meta/, which would be sanctioned by [rfc5988].
Criticism: Web publishers without the ability to control retrieval results for /.well-known/meta/documentation-rule would not be able to take advantage of this method. (Desideratum: [ Easy to deploy on Web hosting services ].)
Criticism: Jeni Tennison says: "in some cases the mapping from thing URI to document URI can be complex or change over time in ways that make it hard to use a documentation rule file; in legislation.gov.uk for example, we return a 303 redirection from a legislation item to either an as-enacted version or the most recently revised version, depending on what is available for that particular item of legislation (which changes as new revised versions are added). It would be quite hard to create a documentation-rule file in those circumstances (we would have to solve it by having a simple mapping with some URIs 307 redirecting to others)."
5.3 HTTP response header that links to documentation
The Link: HTTP header [rfc5988] is useful for indicating a metadata source for an information resource (see POWDER spec [citation needed]). (Although well documented by its normative specifications, this method is not listed in this document under "methods in current use" because the editor is not aware of any deployment.) The URI needn't be retrieval-enabled, as Link: could be used in any non-success response for directing a client to documentation for the URI.
Criticism: The advantage of Link: over a 303 redirect in the non-retrieval-enabled case is unclear, since a second network round trip would be required either way. (Desideratum: [ Efficient ].)
5.4 New HTTP request method eliciting documentation
To reduce the number of round trips relative to the 303 redirect, we might have HTTP requests that are somehow understood as signalling a request for URI documentation, as opposed to retrieval of an instance of a resource on the Web at the URI, with the documentation coming back in the HTTP response. Such a request could be distinguished from a retrieval or other request by its method, headers, and/or content.
The URIQA specification [uriqa] defines MGET, a new HTTP request method. An MGET request on a URI yields a response containing information about the referent of the URI. If the URI is retrieval-enabled, then (by Convention 1) the URI refers to the resource on the Web at that URI, so the MGET result is metadata for that resource. Otherwise, the MGET result might be documentation for the URI. In that case a GET request should yield a 303 See Other linking to the same URI documentation obtained by MGET, or maybe to a 405 Method Not Allowed response.
Criticism: Not possible to deploy on many hosting services. (Desideratum: [ Easy to deploy on Web hosting services ].)
5.5 New HTTP response status code
In response to GET of a URI, a server might provide documentation for the URI directly in a non-200 response, as opposed to indirectly via a 303 redirect. (The URI documentation can't go in a successful GET response since that would mean that the URI refers to the resource on the Web at the URI.) Possibilities for HTTP response status codes that might signal this situation: 203 Non-Authoritative Information; a new 2xx status (maybe 209); a new 3xx status (maybe 309); or a variety of 4xx codes. Placing the URI documentation in the content of a redirect response (status code 301, 302, 303, and 307) is unsatisfactory as the content would not be displayed in a Web browser; the same situation might apply to any 3xx or 4xx response, making a 2xx status code the most attractive.
Criticism: Probably impossible for many hosting services. Not clear whether proxies, caches, and Web clients do something reasonable with the proposed status code. (Desiderata: [ Retrieval-friendly ], [ Easy to deploy on Web hosting services ].)
6 Discovery methods where some retrieval responses carry URI documentation
A range of discovery method designs involve having clients interpret parts of retrieval (HTTP GET/200 or equivalent) responses, or entire responses, as URI documentation. Depending on design details, any particular response might be treated as carrying URI documentation (or expected to do so), treated as an instance (per Convention 1), both (instance with embedded metadata), or neither.
The following illustration diagrams the case where all retrieval responses are treated as carrying URI documentation, i.e. all responses are instances of something different from what the URI refers to that carries URI documentation.
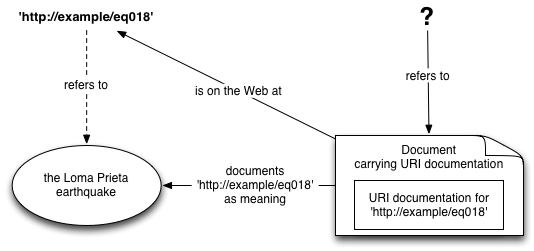
These designs have in common that at most a single HTTP round trip is required, when discovery uses the HTTP protocol.
After surveying the design choices that have to be made, a few representative method designs are presented. The entire space of possibilities is too broad to cover here.
6.1 Design space overview
Designs in this space differ in important ways:
-
Which kinds of retrieval responses are recognized as carrying
applicable URI documentation? Possible design elements
(not mutually exclusive):
- all responses (client may just fail to understand it)
- only responses with particular media types (see [davis])
- only responses possessing some other special indicator (response header)
- only responses that contain URI documentation for the probe URI (e.g. response header)
- only responses to rerieval requests that explicitly request documentation (e.g. using HTTP request headers, see [thompson], which has a detailed analysis)
- only responses in which the probe URI occurs (e.g. as an RDF subject), or has some other distinguishing syntactic property
- (n.b. "no responses" would put the design outside this space; see the other discovery methods, above)
-
How is URI documentation found inside such a response?
- consider the entire response to be potential documentation for the probe URI (no need to find it)
- somehow select some relevant part of it, such as statements that use the probe URI
-
Which kinds of retrieval responses are recognized as carrying
instances of what the URI names?
- all of them (any embedded URI documentation is metadata)
- none of them
- those not recognized as containing URI documentation for the probe URI treat it as an instance
- those responses the truth of which implies that the URI refers to a kind of thing that can have instances then treat is as an instance
- if the response is consistent with the URI documentation, then treat is as an instance
-
When the probe URI does not refer to what's on the Web
at that URI (when all retrieval responses carry
documentation, that would be the a URI documentation
carrier), how does
one refer to what's on the Web at the URI?
- this case does not arise - all URI documentation carriers are also instances
- using a second URI found via some method
- using blank node notation [generic]
- using syntactic sugar
- using the URI, distinguishing between cases based on context of use of the URI
- not specified
Regarding the last question, any method that conflicts with Convention 1 makes some URIs unavailable for expressing what the URIs mean according to Convention 1. There are many applications that need a method for writing a reference to the resource at an arbitrary retrieval-enabled hashless URI, including those concerned with metadata (including licensing), provenance, Web site testing, validation, text processing, text annotation, and access control. Therefore any complete discovery solution that includes some a discovery method that preempts Convention 1 for any URI should include a way to write such references.
The workaround 4.2 Express data in terms of named documents (parallel properties) described above falls in this design space, but as it can be used immediately with no new consensus, it is not listed here.
Criticism: Designs requiring new request or response headers fail desideratum [ Easy to deploy on Web hosting services ]. Designs in which some responses are non-instances fail desideratum [ Compatible with use of URI as metadata subject ] since metadata might be interpreted to be about the URI documentation. Designs in which URI interpretation is context sensitive fail [ Uniform ].
6.2 A "take it at face value" discovery method design
One particular point in the design space is presented in [davis], and will be taken as representative.
For discovery, do a GET requesting media type application/rdf+xml. If the result is application/rdf+xml, then assume no retrieval response is an instance of the referent (?), and assume the result carries URI documentation for the probe URI. To refer to the URI documentation, use the URI in the Content-location: header of the response.
If there is no application/rdf+xml variant then assume the URI refers to what's on the Web at the probe URI.
When an instance is sought (application/rdf+xml not requested), and the result is application/rdf+xml, it is not clear [to the editor] how the result should be classified: as both instance and URI documentation, just an instance, or just URI documentation.
Criticism: Designs in which some responses are non-instances fail desideratum [ Compatible with use of URI as metadata subject ] since metadata might be interpreted to be about the URI documentation.
Criticism: This design does not seem to support other URI documentation formats such as RDFa or Turtle.
6.3 Rely on implicit coercion from a named document its intended subject
If one's domain of discourse mixes documents with entities that might be their designated subjects, then maintaining parallel properties (see 4.2 Express data in terms of named documents (parallel properties)), one set that applies the 'designated subject' coercion and one that doesn't, might be considered an unacceptable cognitive and clerical burden. (There is quite a lot of variation in opinion on this point.) In this case one might try combining the two properties into a single property that can be used in either way. Suppose that P is the initial property (not defined via designated subject coercion) and Q is the overloaded property we'd like to define and write. Then obvious documentation for Q would be
Q(x,y)
if and only if
P(x,y) OR P(designated-subject(x),y)
For example, taking P = dc:creator as defined by the Dublin Core documentation, and Q = dc:creator as overloaded, the statement
<http://example/eq018> dc:creator "Alice".
could be taken to imply that P(<http://example/eq018>, "Alice") as long as it is agreed ahead of time that earthquakes don't have creators.
This manner of overloading can make correct recovery of P-relationships impossible when a designated subject is a document, so it's probably better use a "tie breaking" rule such as
Q(x,y)
if and only if
P(x,y) OR {P(designated-subject(x),y) AND designated-subject(x) is not a document}
There may be better tie-breakers than this one; this is just for illustration.
All considerations that apply to the subject of a property also apply to the object, making the coercion rules that much more complex.
Criticism: Any tie-breaking rule is going to be fragile and will make the "losing" side of the race difficult to express. One can expect many mistakes where the designated subject was the intended subject of some metadata but the tie-breaking rule implicated the other resource. (Desideratum: [ Compatible with use of URI as metadata subject ])
Criticism: This method, by design, creates the illusion that the URI actually refers to the designated subject, not the resource at the URI. If predicates that already possess meaning are being reinterpreted as overloaded properties, there is risk that an agent will draw unsound conclusions. For example, if two URIs u, v refer to distinct resources with the same designated subject, and one then writes <u> owl:sameAs <v> having their designated subjects in mind, then one can incorrectly impute that the two resources are identical. A similar situation holds with functional properties, which induce equations. (Desideratum: [ Compatible with inference ])
6.4 Boundary cases
Designers of discovery methods based on this idea should consider what the specified outcome is to be in the following test scenarios. Assume that U is a hashless http: URI and Z is the payload ("entity" in [rfc2616] terms) of a response to a successful retrieval request (GET/200 in HTTP). The outcome could be that Z is seen as carrying URI documentation for U, Z is seen as an instance of what U refers to / identifies, both of these, neither of these, or not specified by the method definition (answer is out of scope).
- Z has media type application/rdf+xml, but U does not occur in the RDF graph
- Z has media type text/turtle
- Z has media type text/plain and carries URI documentation for U
- Z has media type text/html and contains RDFa markup in which U occurs in the equivalent RDF graph
- Z has media type text/html and contains RDFa markup in which U does not occur in the equivalent RDF graph, or no RDFa markup at all
- Z has a media type specifying an equivalent RDF graph, but the type is not registered with IANA
- one content negotiation variant is recognized to have URI documentation for U but another isn't
- URI documentation for U in Z is consistent with U "identifying" an unspecified document
- URI documentation for U in Z is consistent with U "identifying" a document that carries no URI documentation for U (i.e. an information resource but not the one at U)
- Z has a primary topic that is inconsistent with URI documentation for U contained in Z
- URI documentation for U in Z is internally inconsistent (meaning U would not refer to anything)
- Z carries information that would be harmful if considered true
7 Summary
The following table summarizes some of the current and proposed URI documentation discovery methods, evaluating each against the desiderata stated in the introduction, as explained in the key below.
A complete discovery solution would combine methods in some way, conceivably resulting in an overall approach possessing more or fewer virtues than any of its individual constituent methods.
A table entry of '?' means that the answer depends on the details of the method design, while '~' means it depends on the interpretation of the desideratum statement (i.e. the vagueness of the desideratum statement makes it hard to say).
Refer to 1.1 Desiderata, as follows, for explanations of each column in the table:
- uniform
- Uniform.
- retrieval
- Retrieval-friendly.
- easy
- Easy to deploy using existing widely deployed protocol stacks.
- hosting
- Easy to deploy on Web hosting services.
- round trips
- Efficient. The table gives the number of network round trips are needed, at minimum, to find URI documentation, assuming (a) the URI documentation is not cached and (b) the /.well-known/host-meta cache misses with probability ε.
- resistant
- Substitution resistant.
- metadata
- Compatible with use of Web metadata per Convention 1.
- inference
- Compatible with inference.
| Editorial note | 2011-04-11 |
| For reference, here's a similar analysis — not the same problem, but a closely related one — with its own matrix. | |
8 Glossary
This section defines terms that are used in this report. An attempt has been made to avoid gratuitous differences from the way these terms are used elsewhere, but in a few cases choice of terminology has been difficult and words with other meanings are given technical definitions. These definitions are not being proposed for general adoption.
[Draft comment: All terminology choices are provisional; for most of them I am testing the waters to see how well the word works, and am prepared to change.]
- hashless
- A URI is hashless if it contains no hash '#' sign.
- http: URI
- A URI whose scheme (the part before the colon) is 'http' or 'https'.
- local identifier
- The part of a URI that follows a '#' character (perhaps null); fragment identifier.
- metadata
- Information about information, i.e. a document, image, audio recording, etc. In RDF, metadata might be written using vocabularies such as Dublin Core, FOAF, or CC REL.
- named document
- A document that has a particular URI associated with it. Two named documents might have identical content, but be distinguishable by virtue of having distinct associated URIs.
- on the Web at
- When a URI is retrieval-enabled, "the resource on the Web at a URI" (abbreviated OW@(that URI), see below) is the resource whose associated representations are the ones obtained by retrieval requests using that URI (or more precisely, the ones that are authorized for retrievals using that URI). Note that without Convention 1 "the resource on the Web at u" may be different from what u refers to. See [generic] for a rigorous definition.
- OW@(u)
- OW@(u) is shorthand for the generic resource (generic information entity) on the Web at URI u.
- refer
- For the purposes of this report, reference is just one way to mean. There may be ways to mean other than to refer, but none are specified here.
- representation
- Content (an octet sequence) tagged with media type and perhaps other information meant to guide interpretation of the content. "Representation" is used as a term of art; these representations don't necessarily "represent" anything at all. Similar to "entity" in RFC 2616. [rfc2616] See [generic] for a treatment of representations and their resources.
- retrieval-enabled
- A URI is "retrieval-enabled" iff a retrieval request could legitimately lead to a successful response. (Source: [rfc3986] section 1.2.2.) In particular, hashless http: URIs are retrieval-enabled if an HTTP GET method or equivalent correctly is, or could be, successful (yields a 2xx response). Some URIs belonging to some other URI schemes are also retrieval-enabled.
- URI documentation
- A document or document part that provides information about the meaning of a URI. This term is not meant to be either rigorous or exclusive. The "information" could be provided in any human-readable or machine-readable language, or combination of languages. [Draft note: Alan R: Is a sound recording possible documentation?]
9 Acknowledgments
AWWSW Task Group members David Booth, Michael Hausenblas, Nathan Rixham, and Alan Ruttenberg contributed to the creation of this report. Pat Hayes and Henry S. Thompson participated in discussions. Timothy Danford gave some helpful suggestions on a draft. Dave Reynolds gave detailed advice the handling of desiderata throughout the document, and other valuable comments. Jeni Tennison and the rest of the TAG gave many helpful comments. Martin J. Dürst clarified the technical meaning of the term "absolute URI".
10 References
- ark
- John Kunze. ARK: Archival Resource Key. Web page, January 2012, accessed 30 January 2012. (See https://wiki.ucop.edu/display/Curation/ARK.)
- davis
- Ian Davis. A guide to publishing linked data without redirects. Blog post, November 2010, accessed 27 January 2012. (See http://blog.iandavis.com/2010/11/07/a-guide-to-publishing-linked-data-without-redirects/.)
- degraauw
- Marc de Graauw. The #referent convention. Blog post, 2007, accessed 20 January 2012. (See http://www.marcdegraauw.com/2007/02/20/the-referent-convention/.)
- disambiguating
- Sandro Hawke. Disambiguating RDF Identifiers. W3C, January 2003. (See http://www.w3.org/2002/12/rdf-identifiers/.)
- halpin
- Harry Halpin. Reversing HTTP Range 14 and SemWeb Cool URIs decision. Email to public-awwsw list, 2011. (See http://lists.w3.org/Archives/Public/public-awwsw/2011Jan/0021.html.)
- hostmeta
- E. Hammer-Lahav. Web Host Metadata. Internet-draft, IETF, 2010. (See http://tools.ietf.org/html/draft-hammer-hostmeta-13.)
- generic
- Jonathan A. Rees, editor. Generic resources and Web metadata. Editor's draft, W3C, 2012. (See http://www.w3.org/2001/tag/awwsw/ir/20120127/.)
- issue-14-resolved
- Roy Fielding. [httpRange-14] Resolved. Email to www-tag list, 2005. (See http://lists.w3.org/Archives/Public/www-tag/2005Jun/0039.html.)
- issue-57
- Issue 57. W3C Technical Architecture Group, 2007-2012. (See http://www.w3.org/2001/tag/group/track/issues/57.)
- lsid
- Life Sciences Identifiers Specification. Object Management Group, 2004. (See http://www.omg.org/cgi-bin/doc?dtc/04-05-01.pdf.)
- rfc2616
- R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, and T. Berners-Lee. Hypertext Transfer Protocol -- HTTP/1.1. RFC 2616, IETF, 1999. (See http://www.ietf.org/rfc/rfc2616.txt.)
- rfc3406
- L. Daigle, D.W. can Gulik, R. Iannella, and P. Faltstrom. Uniform Resource Names (URN) Namespace Definition Mechanisms. RFC 3406, IETF, 2002. (See http://www.ietf.org/html/rfc3406.txt.)
- rfc3986
- T. Berners-Lee, R. Fielding, L. Masinter. Uniform Resource Identifier (URI): Generic Syntax. RFC 3986, IETF, 2005. (See http://www.ietf.org/rfc/rfc3986.txt.)
- rfc4395
- T. Hansen, T. Hardie, and L. Masinter. Guidelines and Registration Procedures for New URI Schemes. RFC 4395, IETF, 2006. (See http://www.ietf.org/rfc/rfc4395.txt.)
- rfc5988
- M. Nottingham. Web linking. RFC 5988, IETF, 2010. (See http://www.ietf.org/rfc/rfc5988.txt.)
- sporny
- Manu Sporny. Reversing HTTP Range 14 and SemWeb Cool URIs decision. Email to public-awwsw list, 2011. (See http://lists.w3.org/Archives/Public/public-awwsw/2011Jan/0012.html.)
- thompson
- Henry S. Thompson. Yet another workaround for definition discovery. W3C informal memo, 19 September 2011. (See http://www.ltg.ed.ac.uk/~ht/wantOther.html.)
- tumarello
- Giovanni Tumarello. http-range-14 303 issue, request for reopening the discussion. Email to www-tag list, 2007. (See http://lists.w3.org/Archives/Public/www-tag/2007Jul/0034.html.)
- uriqa
- Patrick Stickler. The URI Query Agent Protocol. Nokia, 2010. (See http://sw.nokia.com/uriqa/URIQA.html.)
- webarch
- Ian Jacobs and Norman Walsh, editors. Architecture of the World Wide Web, Volume One. W3C Recommendation, December 2004. (See http://www.w3.org/TR/webarch/.)
11 Change log
- 2011-11-07 Terminology correction: "absolute" to "hashless"
- 2011-11-07 Added new material on scripts, 3.4.1 Local identifier misspellings go undetected, and analytics
- 2012-01-19 Terminology change: "definition" to "URI documentation"
- 2012-01-19 Terminology correction: "dereferenceable" to "retrieval-enabled"
- 2012-01-19 Added new section 5.1 Global rule yielding documentation URI
- 2012-01-20 Terminology change: "fragment identifier" to "local identifier"
- 2012-01-20 Defined "convention 1" and introduced more care regarding the question of how widespread observance of httpRange-14(a) is.
- 2012-01-24 Changed "criteria" to "desiderata".
- 2012-01-24 Removed "unattractive, silly, and/or vestigial" criticism of hash URIs pending better documentation.
- 2012-01-24 Removed unfair criticism of LSID.
- 2012-01-24 Moved new-status-code method into its own section.
- 2012-01-24 Overhauled treatment of desiderata in intro and summary.
- 2012-01-27 Purged the term "information resource" from the document. Cross-referenced criticisms to desiderata. Some reorganization.
- 2012-01-28 Hash URI section reorg; recast 2xx ("convention 1") as a discovery method, and added criticism.
- 2012-01-30 Added comment about ARK
- 2012-01-30 Reorganized "face value" again; expanded design space overview
- 2012-01-30 Removed section "This use of 303 has no consensus specification" since all discovery solutions (other than hash and Link:) have this problem.
- 2012-02-02 Added use case for discovering that a URI refers to the generic resource at that URI.
- 2012-02-02 Added section listing boundary cases.