<DanC_> (who else scribed yesterday? shall we rock-scissors-paper for the editing?)
<DKA> Scribe: Dan A
<DKA> ScribeNick: DKA
Noah: We could find half-hour to
an hour for discussion of mobile stuff.
... we could also discuss "what is the form of the work we do"
we've got into a mode of doing things in the small, e.g.
finding issues in other specs.
... working with other working groups. We have also discussed
doing writing, other things. Should we have a session to
discuss such meta-issues.
[agreement to go on with agenda as planned]
Issue-31?
<trackbot> ISSUE-31 -- Should metadata (e.g., versioning information) beencoded in URIs? -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/issues/31
Noah: a lot of work done on this is in action-278 now closed.
ACTION-394?
<trackbot> ACTION-394 -- John Kemp to compare Noah and Tyler's proposals on this subject -- due 2010-03-17 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/394
<DanC_> (let's not use bare issue numbers; always put a technical keyword with them. issue-31 is metadataInURI-31)
<DanC_> (so please edit the TOC)
<noah> http://www.w3.org/2001/tag/2010/02/action-278-notes.txt
John: I wrote an email which I haven't sent on keeping secrets including in URIs and I have taken Jonathan Rees's material.
<johnk> http://www.w3.org/2001/tag/2010/02/action-278-notes.html
Noah: Given that we're here f2f,
could we frame this for discussion here?
... Is there a way to take advantage of f2f to turn the
corner?
<DanC_> (ah... the topic in the agenda has both "secrets in URIs" and "metadataInURI": ISSUE-31 (metadatainURI-31): Secrets in URIs )
Noah: We also have action-341 which is for me stay in touch with Thomas about security.
<DanC_> (er... can he mail this to www-archive or something?)
John: [goes through material to be sent to working group]
<masinter> "Secrets and Lies: Digital Security in a Networked World"
<DanC_> http://www.schneier.com/book-sandl.html
<masinter> recommended reading
http://lists.w3.org/Archives/Public/www-tag/2010Mar/0115.html
[discussion on "are cookies secret?"]
Jonathan: Adam Barth is doing some work on cookie security.
Larry: There is an IETF working group working on "how cookies work."
<DanC_> the note says "A cookie is a secret", which suggests "all cookies are secrets"; I asked and John clarified that he only means to say that at least _some_ cookies are secrets
<masinter> http://tools.ietf.org/wg/httpstate/charters
<masinter> The HTTP State Management Mechanism (aka Cookies) was originally
<masinter> created by Netscape Communications in their informal Netscape cookie
<masinter> specification ("cookie_spec.html"), from which formal specifications
<masinter> RFC 2109 and RFC 2965 evolved. The formal specifications, however,
<masinter> were never fully implemented in practice; RFC 2109, in addition to
<masinter> cookie_spec.html, more closely resemble real-world implementations
<masinter> than RFC 2965, even though RFC 2965 officially obsoletes the former.
<masinter> Compounding the problem are undocumented features (such as HTTPOnly),
<masinter> and varying behaviors among real-world implementations.
Tim: In my model of how the web works, a UA [is one with] the user. So a user-agent should not keep secrets from the user.
Raman: There are redirects happening under the covers which are confusing to the user - only if you look at the address bar do you realize that you are somewhere else.
John: Very often the user doesn't
know that: site a redirects the browser to site b.
... So site a is making the cookie go to site b without
[getting the user's permission]
<masinter> i don't understand relationship of cookies to http://dev.w3.org/html5/webstorage/
<DanC_> I think it's confusing/backwards to say "my cookie" where "me" is the user... the cookie is made up by the origin
<DanC_> (photo, please? Noah?)
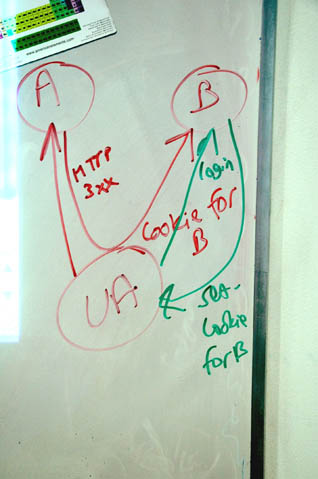
John: The UA already has a site B
cookie. Now when the user goes to Site A but Site a redirects
to Site B. Now the user goes back to Site B but the user
doesn't know that and has not instructed the UA to do
this.
... This is called ambient authority or "the confused deputy
attack."
<DanC_> (seems to me this A/B pattern is used in both positive and negative ways)
Raman: interesting aspect: the
browser can write to a page but can't read it.
... The Json-P hack: you request an html page from someone; you
make a subsequent request, they send you back a call-back
function that you can run on the page; google suggest API works
this way.
John: That's a hack around the same-origin policy.
<masinter> http://visitmix.com/opinions/json-p-an-elegant-hack
Raman: Yes.
Henry: How does that hack same-origin?
Raman: In your page, you want to use google auto-suggest in the search box. Auto-suggest needs to make a json call to google.
John: [back to "secrets" email]
<raman> jsonp: http://en.wikipedia.org/wiki/JSON#jsonp
<DanC_> (no, I don't see anything in json-p-an-elegant-hack about getting around the same-origin restriction, masinter )
<raman> I didn't say jsonp was inelegant --- I said that design pattern was introduced after some of the more obvious same/cross-origin vulnerabilities were closed off
Noah: At some level, the whole reason we're talking about passwords is that we are making an assumption that they are unguessable. So - possession of the password in some way does mean "its' you."
Tim: There are different
protocols - e.g. I am given a password from a bank and told "do
not give it away" ; another situation is: this is your password
for box.net - and you can give it to anyone you want to have
access to box.net.
... People get confused. They have what seems to be a similar
relationship with their bank's password as with facebook but
[these are different things.]
<DanC_> (I hear a pattern language forming... is it BankPIN? or is there a more general name for that pattern? and DropBox sounds like the Capability pattern)
John: But in the bank case - what happens if the password given by the bank is a URI and contains a pseudo-random number?
Noah: John - you have a sentence:
"an http URI can be a secret, shared between a UA and one or
more websites"
... for me, saying this is only slightly more appealing than "a
get request can confirm your subscription to a magazine."
... I mostly don't want to take responsibility for keeping URIs
secret. I'd prefer the phrase: there is a controversy -
[whether or not this is true].
<DanC_> I'm not bothered by "An HTTP URI can be a secret"
<DanC_> perhaps that's because of my position on the issue
Jonathan: There are 2 issues - one is that one [Noah], but another is CSRF attacks. Take the security you already have and add another level to it to prevent these veunerabilities.
Tim: So - part of this that gets overlooked - the way the UI is built. The normal protocol for a URI is - you are expected to bookmark it, etc...
DanC: Tyler has said that software shouldn't do that without your express permission.
Tim: you should be able to drag these URIs and drop them into something else...
Noah: If javascript goes in and
finds links on the page [without your express permission]
should that be prevented?
... You stated as a fact something with some controversy.
... It's not clear to me that "http URIs is a secret" is a
desirable design point for the Web.
... we have a finding - the metadata in URI finding - which
says "don't put secrets in URIs".
Tim: Let's talk about design patterns. I think it's fine for Noah to talk about a design pattern to that does involve secrets in URIs and for [John] to define a pattern that does include that and then for us [to discuss.]
Noah: The question is- should we change the finding?
Tim: I suggest we should change the finding to say that there are two ways of working.
Noah: I'm less convinced.
... We could change it to "do this at your own risk"
Tim: I note that banks -always- put random junk in my URIs. Means I can't bookmark any page from my bank's website. Because they are using URIs as a secret that will not work without my cookies, etc...
Larry: Could we add a footnote to the finding noting that though we support the finding, there may be some alternatives.
<DanC_> nope; I don't think the capability pattern should be relegated to a footnote. I think it's a regular old 1st class pattern.
Tim: as a user I would love to be able to tell the difference when I'm dragging a dropping a secret URI and when I'm not.
<masinter> mainly, i want to get to the point where we publish this analysis -- perhaps in a TAG blog post?
Tim: [accounts experience using box.net]
Noah: The google docs case is a "bearer token" thing. My concern is that sometimes user agent is not a browser. Taken to its conclusion we've got to look at all the email user agents.
Larry: In Adobe buzzword you can check a box to allow people who know the URI.
<DanC_> masinter, each of us has his own analysis (maybe with some overlap). are you aiming for a blog item with just one analysis? I think maybe 3 or 4 posts would make sense.
<DanC_> I also think a pattern language wiki might work
<masinter> a blog which identifies the different positions, what we agree on and what we don't.
<DanC_> that's one analysis
<DanC_> hard work
John: Already we have a case where "unguessable" URIs are used today. e.g. Craig's list where you make a post up and you get a URL back by email to allow you to edit your post and there is no other access control.
Noah: That is my concern.
<DanC_> I wonder if we have write access to http://www.w3.org/Security/wiki/Main_Page
<masinter> i think it's possible to summarize the discussion in a way that we could all agree with the summary. listing pros & cons
John: I agree with that concern
but I don't think *we* need to solve it.
... Unguessable URIs also form part of a defence against
clickjacking and XSRF attacks...
<masinter> DanC, maybe editing a wiki or ... a Google Docs document? :)
Noah: Any particular URI may or may not be secret but ... "the bad guy makes up URIs not used before" is different from "reusing URIs found in the address bar".
John: We explicitly say [in the
finding
... ] don't put secrets in URIs. Because of this issue we need
to say something different than that.
... What is the downside? Potential 404 because URIs do change.
E.g. craigslist gives me a URI to edit my post on craig's list
which is only valid for 30 days unless renewed.
Noah: It could return a message saying the resource is locket.
John: Is it ok to recommend
putting the unguessable portion in the fragment id of the
url?
... On the client, the client knows that and adds it to the
query parameter making a second URI...
... [e.g. using javascript]
... so - Jonathan's note has put the history in some notes -
could be a good place to go.
<johnk> http://www.w3.org/2001/tag/2010/02/action-278-notes.html
[going through Jonathan's notes]
John: Tyler's best practice statement is probably good (adding the word "guessable") is good but needs more supporting text.
Noah: Should we look at all the practices that are useful?
[looking at Tyler's original email]
<DanC_> (tim, I'm experimenting with the pattern approach at http://www.w3.org/Security/wiki/Main_Page#Ongoing_issues )
http://lists.w3.org/Archives/Public/www-tag/2010Feb/0081.html
Noah: What we said was "don't put things you need to keep secret" in a URI.
<masinter> "kept" implies "kept for a long time". maybe finding just needs 'clarification'
Jonathan: There's [one kind of] confidential that is like a random number with a timeout and there's a case where you can learn something by looking at the URI. E.g. a social security number or a birthday you're getting information that might be applied in a different setting.
Noah: Which was the justification for the original best practice. Guessability to me is confusing.
Larry: finding says "to be kept
confidential" by kept we mean kept over a certain period of
time. If you have information that only needs to be kept
confidential for 10ns it's OK to put it in a URI. We need to
clarify that all of the exceptional use cases are where "kept
confidential" is time limited.
... [finer points of naval safe-cracking]
<DanC_> (navy safe example is an interesting pattern...)
Larry: What we're trying to do is clarify what "kept confidential" means. That it means for a reasonably long period of time.
<masinter> was told that a safe is measured by "how long does it take to break in" where you have both a minimum and a maximum
John: My actual bank account account number which I use off-line vs. the hash of my bank account number which I use online and gives me access in one specific setting.
Noah: I thought the TAG said: access control is orthogonal to identification.
DanC: Yes, and we were wrong.
Noah: I think we were
right.
... What I like [architecturally] is that URIs are
identifiers...
John: What I hear is that we can roughly agree on something that looks like Tyler's first best practice - the TAG can agree roughly on this with some kind of supporting text.
Larry: I think "guessable" confuses the issue because of the time issue.
<DanC_> (I'm not interested in the finding genre, nor the good practice note mechanism. I'm interested in the pattern genre)
Larry: There are other access control methods. I think we need to re-interpret the finding as written - [going back to the meaning of "kept" in "kept confidential]
<masinter> there are some usage patterns where metadata only needs to be kept confidential for a very short period of time, or where disclosure of the information (i.e., not keeping it confidential) doesn't have serious consequences
Noah: URIs are used by many systems. Nothing we say in the architecture can restrict where URIs go. We could say: In certain practical situations URIs are distributed through systems that are sufficiently [secure] ....
<masinter> where the time-period requirement for confidentiality is shorter than any reasonable period of accidential disclosure
<noah> I agree with Larry, but I'm unconvinced that focusing on time unscrambles the particular problem we have here. In principle, I can imagine an attack that finds a URI in my email system within milliseconds and empties my bank account.
Larry: You get something confidential - it's valid only for a short time - the possiblity for information leakage is low.
<johnk> to be honest, I can see writing a whole finding on "secrets in URIs"
Larry: The second type is where the consequence of the information getting out is not...
Jonathan: The finding could be read to [say] not do the CSRF defence.
<Zakim> DKA, you wanted to note that "kept" is not only bound by time but also by the kind of information (which is somewhat subjective and social).
<DanC_> (kind of information? oh... how sensitive it is.)
Raman: There will be multiple readings to anything we write. Just add an appendix saying "we were asked this question and ..."
<masinter> well, that's how "confidential" it is.... something isn't really "confidential" because there is no serious consequence to its disclosure
<DanC_> interesting idea, raman
<DanC_> i.e. just answering clarification questions
[discussion on proposals from http://www.w3.org/2001/tag/2010/02/action-278-notes.html
Tim: I prefer to have a document with two sections - two design patterns.
<masinter> i don't like Noah's formulation because "risk of disclosure" is time varying
<DanC_> "Q: Does the 'SHOULD not put confidential...' good practice note say that [the CSRF protection pattern involving unguessable URIs] is bad practice?'
Tim: There are 3 types of URI - one has no security; one is a token that will grant access; one is a URI with crypto-gunk in it to add extra security not designed to be passed on as a token;
Noah: There's a 4th: a URI that is meant for identity where someone has stuck [e.g.] your social-security number in it. We have a best practice note that was intended to say "don't do this."... Should we get rid of this?
Tim: No. That's an anti-pattern. It's a "bad practice" note. It's not a design pattern.
<DanC_> "A: the unguessable URI pattern, in combination with other mechanisms, is a good CSRF attack, but it involves creating aliases; see [cite] for implications of aliases'
<johnk> does "confidential" include "unguessable"?
Larry: I think there are [more] ways of designing...
<masinter> "guessable" always comes with "over how much time and effort"
Tim: If you're telling pattern one then you should tell pattern two and three as well.
John: I like Tim's idea of documenting two design patterns and not say anything that favors one pattern over another...
Tim: we could list the pros and cons.
<Zakim> DanC_, you wanted to offer to take ACTION DanC: try the clarification question approach to metadata-in-uris vs CSRF
DanC: Raman asked about a clarification or blog item. I'm willing to give that a try. I'm trying to do the pattern approach as well...
Noah: You could first put it on www-tag for discussion.
Larry: [supports Dan's action]
<masinter> i like blogging with public comment on the blog before updating the finding
John: One approach is to do a lot more writing. Another approach is to write something in the metadata in URIs finding that says something based on Noah's and Tyler's proposals.
<masinter> Should "IRIEverywhere" mean that we update the Use of Metadata in URIs to address metadata in IRIs?
Tim: The concern about a good practice note is that people quote it out of context.
John: We could say not very much more at all....
Tim: I dislike [that] approach.
<masinter> i think people need to understand "kept" and "confidential" and we should hyperlink those
Noah: I welcome DanC doing anything he wants. I wonder if we can't make a short list of points. e.g. 1 document the antipatern; 2 good reasons why people want to do [x,y,z]; ....
q
<johnk> ACTION-394?
<trackbot> ACTION-394 -- John Kemp to compare Noah and Tyler's proposals on this subject -- due 2010-03-17 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/394
<DanC_> . http://www.w3.org/Security/wiki/Main_Page#Ongoing_issues
<Zakim> DanC_, you wanted to noodle on patterns a la http://www.w3.org/Security/wiki/Main_Page#Ongoing_issues
DanC: Do you know their names? Pattern languages are really powerful. You start talking about the names and discover a lot through that.
<masinter> FWIW, I don't like "design patterns" very much, if people take them too seriously as categories rather than just examples and inspiration
[discussion on patterns]
<masinter> "It's better if access control is orthogonal to identification but it often isn't"
<masinter> secrets in URIs design pattern started with http://www.guardians.net/hawass/articles/secret_doors_inside_the_great_pyramid.htm
Jonathan: Public URIs; URIs that authorize; URIs that protect
Noah: Anti-pattern: URIs that disclose secrets
DanC: You could call it "social security number in the URI"
<Zakim> noah, you wanted to say we need a story on who needs to restrict copying of URIs
Noah: I think you've well covered this - I'd like to see some patterns and antipatterns on what are the responsibilities of software and people that handle URIs?
<DanC_> (anti-pattern for giving out a URI without user's consent... i.e. another mechanism like referrer)
<DanC_> action-394?
<trackbot> ACTION-394 -- John Kemp to compare Noah and Tyler's proposals on this subject -- due 2010-03-17 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/394
John: ACTION-394 was for me to compare Tyler's and Noah's proposal. Have I completed that action/
<johnk> close action-394
<trackbot> ACTION-394 Compare Noah and Tyler's proposals on this subject closed
<DanC_> . ACTION DanC: try the clarification question, blog item, or wiki approach to metadata-in-uris vs CSRF
[general agreement]
<Zakim> johnk, you wanted to ask about disposition on ACTION-394
<DanC_> ACTION: DanC to try the clarification question, blog item, or wiki approach to metadata-in-uris vs CSRF [recorded in http://www.w3.org/2010/03/25-tagmem-irc]
<trackbot> Created ACTION-412 - Try the clarification question, blog item, or wiki approach to metadata-in-uris vs CSRF [on Dan Connolly - due 2010-04-01].
<DanC_> action-394: see action-412 for follow-up
<trackbot> ACTION-394 Compare Noah and Tyler's proposals on this subject notes added
<DanC_> action-412: see action-394 for background
<trackbot> ACTION-412 Try the clarification question, blog item, or wiki approach to metadata-in-uris vs CSRF notes added
[break till 10:50]
ISSUE-24
ISSUE-24?
<trackbot> ISSUE-24 -- Can a specification include rules for overriding HTTPcontent type parameters? -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/issues/24
ACTION-370?
<trackbot> ACTION-370 -- Henry S. Thompson to hST to send a revised-as-amended version of http://lists.w3.org/Archives/Public/www-tag/2009Dec/0068.html to the HTTP bis list on behalf of the TAG -- due 2010-03-09 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/370
Henry: Yes, I finally did that a
few days ago.
... We should look at response...
John: Would it help to provide some background?
<DanC_> (how is this background distinct from ACTION-399? maybe it's not)
<johnk> http://www.w3.org/2001/tag/2009/09/24-minutes.html#item03
John: Background: we had a meeting here in Sept last year where we had a call regarding sniffing - in HTTP BIS they were loosening the rules around sniffing. We decided that if they were to do something like that then we should update "authoritative metadata" and "self-describing web" findings to acknowledge the reality of sniffing.
<Zakim> DanC_, you wanted to offer to take ACTION DanC: try the clarification question, blog item, or wiki approach to metadata-in-uris vs CSRF
John: basic issue is that in general, as discussed in [findings] and the http spec, unless content type http header is blank (missing) you cannot look into the data and guess the content type.
<jar> Fresh email from Yves Lafon of httpbis, 14 hours ago: http://lists.w3.org/Archives/Public/www-tag/2010Mar/0114.html
John: Adam Barth wrote a draft of
an algorithm for secure sniffing. specified in an ietf draft
which has no owner or standing. We decided "the draft looks
reasonable - modulo certain remarks about whether it was good
enough - let's update the findings to say 'if you're going to
sniff do it this way'"
... I wrote some material. Larry wrote some comments on the
Barth sniffing draft.
Larry: The main thrust of my
comments were not addressed.
... The future of the draft is uncertain.
... there's a discussion of how to move it forward - the
"venue" has not been decided.
Noah: One more clarification: if we go back to TPAC in 2008 there were a whole bunch of discussions with HTML about refactoring spec. If there is some hope that this finds a home in IETF would HTML draft would HTML reference it?
Larry: There's a question about the change proposal... ISSUE-104 in the HTML working group.
<masinter> http://www.w3.org/html/wg/tracker/issues/104
<masinter> HTML working group issue on whether sniffing is optional or mandatory
<DanC_> (fyi, I'm telling tracker about the status of actions; see http://www.w3.org/2001/tag/group/track/agenda )
Noah: We have a number of actions.
<DanC_> (repeat? pointer?)
Larry: Request for assistance for reviewing Barth draft on sniffing (vers. 4) and discussing - [to help formulate response.]
<Zakim> johnk, you wanted to offer help for Larry _only_ after we describe the general thrust of what we want to do here
<masinter> I don't think the TAG should have a reference to a draft that we haven't reviewed
John: I've done the work n my
action but now in the intervening period our position has
changed... If we're going to do something it has to do
something regarding our findings (self describing web and
authoritative metadata).
... I'd be inclined to [not change] the authoritative metadata
findings.
<DanC_> (larry, I can't find your review comments on the sniffing draft from http://www.w3.org/2001/tag/group/track/actions/386 ; help?)
<masinter> http://www.ietf.org/mail-archive/web/apps-discuss/current/msg01250.html
Henry: Continuing on - we turned our attention in December to the section on sniffing and the concept of sniffing in http bis draft. Doing what they proposed to do - which was to say nothing about sniffing - in http bis was not acceptable. Attention needed to be drawn to the potential downside - in the http bis spec. With the group's help, I crafted an email messages which was sent in the beginning of January.
<DanC_> (ah; the action says to cc www-tag, but looks like you didn't larry ;-)
Henry: Some positive response to it. Mark N. declined to act.
<DanC_> action-386: comments 20 Jan on draft 3 http://www.ietf.org/mail-archive/web/apps-discuss/current/msg01250.html
<trackbot> ACTION-386 Review draft-barth-sniff-4 and send comments, cc TAG notes added
Jonathan: I've pasted in the URL of their latest offer.
http://lists.w3.org/Archives/Public/www-tag/2010Mar/0114.html
Jonathan: this is Yves's latest offer.
<noah> Discussing: http://lists.w3.org/Archives/Public/www-tag/2010Mar/0114.html
<masinter> action-386?
<trackbot> ACTION-386 -- Larry Masinter to review draft-barth-sniff-4 and send comments, cc TAG -- due 2010-04-08 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/386
Henry: Can we compare the two?
<noah> I suggest "identify" ==> "describe"
<noah> or
<noah> I suggest "identify" ==> "specify the type of"
Henry: He's damaged it.
<masinter> I think the "right" thing to do would be to fix up barth-mime-sniff so that it can go onto IETF standards track, and that HTTPBIS could make normative reference to that. Wordsmithing things that make reference (or implied reference) to the document without actually getting the document right... is wrong.
Larry: I think the right thing to do is to get the Barth document so that we like it. So it says when to sniff and when not to and is the authority on sniffing. And then get HTTP BIS to point to it.
John: Right. [Agreement]
Noah: we should defer discussions of changing our own findings until after we get the Barth draft right.
DanC: Barth is documenting current practice and I think that's broken.
John: I think current practice is broken too.
<Zakim> DanC_, you wanted to say that "not correctly" is critically wrong for me
<Zakim> noah, you wanted to suggest changing identify
DanC: both drafts say "however currently deployed servers send an [incorrect] content type" but server is correct by definition so that's not correct.
Noah: I have a problem with the
word "identify".
... Purpose of the header is not to identify the content - it
is to identify the type...
<DanC_> +1 "identify the type"
<Zakim> masinter, you wanted to note that it is possible to write an alternative proposal if we can't convince Barth
Larry: Procedurally - it isn't necessary to convince Adam Barth. We could also propose an alternative draft. One way of fixing the Barth draft is to create a derivative work.
<Zakim> johnk, you wanted to agree with DanC, but...
<DanC_> ht, do you remember when we came up what you sent? I'm pretty sure I suggested other words in that meeting
John: I like "authoritative metadata" - it accurately describes the situation and people should not sniff unless the content type is empty. But some servers are misconfigured. Is there anything we can do to fix current practice - so that servers send the correct metadata and correctly send empty content type if it doesn't know.
<Zakim> DanC_, you wanted to say we could not progress on getting less sniffing; e.g. apache changes
<DanC_> +1 note the change to the apache default in the authoritative metadata finding (and/or a blog finding)
John: One thing we could do is to issue some steps to implement the authoritative metadata findings. Writing code or writing a blog.
DanC: Yes. Do that.
<Zakim> noah, you wanted to remind of ISP use case
<DanC_> (today, I'm in the mood to "chip at the mountain". yes, I go back and forth. re decade/year, the future is longer than the past, by just about any measure.)
Noah: I'm sympathetic. I'm in
favor if we can find practical things to do. But the decay
curve on bad practice looks more like a decade than a
year.
... We still have some work to do on TAG findings, RFCs, etc...
need to be fixed...
<Zakim> ht, you wanted to try to focus on HTTP-bis
<johnk> totally agree with Henry
Henry: There are two different
things on the table. We decided (correctly) that having HTTP
BIS published in its current form is not acceptable. I don't
want to make fixing that hostage to fixing the Barth paper.
Fixing HTTP BIS should not be dependent on Barth.
... Until I know whether this [message from Yves] is from the
HTTP working group, not sure how to proceed. I would like to
[wordsmith] our recommendation.
... I'm happy to take an action to draft a response to
Yves.
<masinter> I think Henry is rejecting my proposal?
Larry: I don't think patching
http bis will be effective.
... I don't think that it is helpful.
<Zakim> masinter, you wanted to argue once more for working on alternate formulation of mime-sniff and publishing in IETF
<masinter> or likely to be successful
Tim: We have this authoritative metadata finding. This the TAG's best work on this topic. Suggest a way out of this would be to send a competitive internet draft [to Barth] which is exactly our authoritative metadata finding.
<Zakim> timbl, you wanted to suggest we take any good bits from mine-sniff a d put it in out in our auth metadata finding
Larry: The sniffing draft that I
would like to see puts a maximum bound on sniffing.
... and limit the cases on where that is recommended.
... the barth draft has done some good work on "where sniffing
appears to be necessary." I would like to correct the draft to
make each instance of sniffing "opt in" only when you are
confident of overriding the content type that you are
given.
John: That may end up weakening authoritative metadata.
<timbl> I still find the design pattern language works
DanC: I don't think we should put
effort into that. I'd rather say "don't sniff - and here is all
the ways that things are getting better..."
... As long as there is one test case - images served as
text/plain treated as images - as long as there is one such
case in the barth draft then it's [incorrect.]
<Zakim> noah, you wanted to talk about browsers vs. Web in general
<DanC_> s/[incorrect.]/not something I want to work on/
Noah: Larry said "the barth draft
said - do all this stuff" - the barth draft risks trying to
serve two masters - the people in the future who are writing
clients, etc and to be reference by the HTML5 spec.
... For the specific purpose of HTML5 user agents, I think
they've done it the right way: specifying exactly when to use
sniffing.
<DanC_> (I the odds that implementations will converge on the HTML5/barth spec are dubious. implementations might get more strict about sniffing in the name of security, or they might get worse in response to some huge deployment of crappy content/servers)
Tim: is there any possibility in
this new world at tilting at windmills. - We've got the browser
to reject bad stuff - I've also suggested that browsers should
have a way of telling you how your website could be better -
built in validators.
... They might say: "This website is broken - should I tell you
about this again?"
<Zakim> johnk, you wanted to ask about ACTION-308
<johnk> ACTION-308?
<trackbot> ACTION-308 -- John Kemp to propose updates to Authoritative Metadata and Self-Describing Web to acknowledge the reality of sniffing -- due 2010-01-14 -- CLOSED
<trackbot> http://www.w3.org/2001/tag/group/track/actions/308
<DanC_> +1 do a lazyweb request for the "show me errors about _my_ site" deely
<masinter> whitelisting, show error only on first view, thinks that big-switch opt-in doesn't actually make sense
John: Asking about proposing updates to "authoritative metadata" - I proposed the very minimum updates, pointing to the Barth draft. Do we still want to do anything about this in the finding?
Noah: Let's put those questions aside - help the community - I assume we move discussions away from how to tweak the findings in the short term.
Larry: I would be happy to the update to the metadata finding if I were happy with the Barth draft.
ACTION-370?
<trackbot> ACTION-370 -- Henry S. Thompson to hST to send a revised-as-amended version of http://lists.w3.org/Archives/Public/www-tag/2009Dec/0068.html to the HTTP bis list on behalf of the TAG -- due 2010-03-09 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/370
Henry: I will draft a response - leave it under ACTION-370.
<DanC_> ACTION-370 due +2 weeks
<trackbot> ACTION-370 HST to send a revised-as-amended version of http://lists.w3.org/Archives/Public/www-tag/2009Dec/0068.html to the HTTP bis list on behalf of the TAG due date now +2 weeks
ACTION-308?
<trackbot> ACTION-308 -- John Kemp to propose updates to Authoritative Metadata and Self-Describing Web to acknowledge the reality of sniffing -- due 2010-01-14 -- CLOSED
<trackbot> http://www.w3.org/2001/tag/group/track/actions/308
ACTION-376?
<trackbot> ACTION-376 -- Daniel Appelquist to send to www-tag a pointer to and brief summary of Mobile Web Best Practices working group's "Guidelines for Web Content Transformation Proxies" and its implications for content sniffing : http://www.w3.org/TR/ct-guidelines/ -- due 2010-03-17 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/376
DanA: I sent a note.It's only orthogonally related to sniffing.
<masinter> there was an IETF working group OPES on middleware gateways
<DanC_> DanA: e.g. there are proxies in mobile networks that take pages designed for PC screens...
<masinter> https://datatracker.ietf.org/doc/rfc4236/
<DanC_> ... and optimizing them, perhaps even splitting into multiple pages...
<Zakim> noah, you wanted to ask again whether they sniff
<DanC_> ... so they look into the content to see how it'll render... and they sometimes re-write the user agent header in order to get more high-fidelity versions of the page
<Zakim> masinter, you wanted to talk about IETF OPES working group and point at all of the RFCs in the area
<DanC_> NM: I see that "4.1.5.1 Content Tasting " is orthogonal to sniffing, but...
<DanC_> ... I expect that in practice, such gateways do sniff
<DanC_> [missed some...]
<DanC_> NM: how about something like "based on a quick look, we don't see any sniffing concerns in "4.1.5.1 Content Tasting ", but...
<DanC_> ... the mobile web BP WG should familiarize itself with [related work]"
<DanC_> DanC: I'm inclined to decline "I'm also requesting general feedback on this document from the TAG." and ask for a more specific question
<DanC_> LMM: there's been a lot of work in this middeware/OPES area; their work should know about it
<DanC_> DKA: in fact the document does cite the OPES spec
<DanC_> break 'till lunch until 1pm
http://www.w3.org/TR/2010/WD-ct-guidelines-20100211/#sec-iab-considerations
<noah> Yeah, what I said was, maybe we should encourage them to consider the sniffing that transform proxies do, track http-bis, Barth draft, TAG findings, etc., and when things settle, reference the pertinent stuff. They should give explicit guidance on sniffing (my personal opinion)
<noah> ADJOURNED FOR LUNCH
<masinter> https://datatracker.ietf.org/doc/rfc4236/
<johnk> 10.2.4 203 Non-Authoritative Information
<johnk> The returned metainformation in the entity-header is not the
<johnk> definitive set as available from the origin server, but is gathered
<johnk> from a local or a third-party copy. The set presented MAY be a subset
<johnk> or superset of the original version. For example, including local
<johnk> annotation information about the resource might result in a superset
<johnk> of the metainformation known by the origin server. Use of this
<johnk> response code is not required and is only appropriate when the
<johnk> response would otherwise be 200 (OK).
<jar> [For projection:] http://www.w3.org/2001/tag/2010/03/metadata-notes.txt
<timbl> scribenick: Timbl
JAR Presents metadata-notes.txt
<DanC_> (does HTTP DELETE delete resources? I'm not so sure; I think it might just delete bindings between URIs and resources or something.)
jar: The HTTP spec talks about things like "resides at" and other things I don't deal with here.
This note, like Roy's writings, takes the view that the HTTP protocol expresses something about [resources].
There is a distinction -- which is prior?
The correspondence between representation and resource, or the behavior of a server? Maybe a bit subtle.
jar: Note dbooth may disagree with some of this?
The resource is [implies] a set of constraints on what consitutes a valid representation of a [the] resource.
timbl: unhappy about treting the resource as an agent.
<DanC_> (timbl, you didn't say that to the meeting)
Noah: Surely the server is an agent not hte resource
<masinter> I'm missing the model theory which resolves the boundary of what is a 'resource': http://masinter.blogspot.com/2010/03/resources-are-angels-urls-are-pins.html
jar: There is a view in which the resource is an agent; that is not my view.
<DanC_> HT: ah... interesting... in the case of a resource that comes from somebody typing in a file, the server is constrained to just about 1 representation, but in the case of ...
<DanC_> ... sensor networks and database cells and such, then the server may choose from lots and lots of representations
Jk: When there is file written by a person hen there is agency but is not the resources.
Ashok: Translations?
jar: You can have multiple resources, or one resource which exists [has representations] in five translations.
<Zakim> johnk, you wanted to note Henry's point again about creator of a resource
jar: Can you authorize a proxy to
do translations? It would have to be authorized out of band,
you can't negotiate that within HTTP.
... There is no way to negotiate that a proxy can do extra
translations within HTTP.
DA: Does this account for the serving of a special version of a blog page for a mobile phone?
timbl: That is fine. All is OK in that scenario. The blog os the resource
<DanC_> [t1,t2) ::= { x : x >= t1 and x < t2 }
jar: The over_interval* stuff is about a commitment that a given correspondence between resource and representation holds for a period of time.
ht: I am not sure the signature of W() makes sense to me, it is in tension with the signatures of the redirects, seeOther() etc.
<ht> ht: the server needs URIs to manage redirects
<DanC_> (ht, I too suspect things may fall apart without getting the URIs into the theory, but we're not far enough to tell)
<ht> JAR: I'm trying to be faithful to the spec, which talks about resources not URIs
jar: This is close to being a private theory, but the goal is that one can actually infer something in all this.
<ht> DC: Show me the spec.
<johnk> some language from RFC 2616
<masinter> I can't read this unless I think of R as "URI" and not as "Resource"
<johnk> 10.3.1 300 Multiple Choices - "If the server has a preferred choice of representation, it SHOULD include the specific URI for that representation in the Location field;"
<masinter> "for a resource whose sole representation is the representation given ..."
jar: When a redirect happens,
some properties of the first resource are "taken from" the
second -- specifically representations of B are also
representations of A. And the seeOthers are also shared.
... The seeOther rule is interesting in that it is consistent
with some sem web clients but not others.
<johnk> other text from 2616 3XX status explanation talks about redirection from one resource to another, or about multiple URIs to the same resource
jar: For example, there are ontologies deployed on purl.org with a 302 redirect. There is a 302 on purl.org for example whcih might be broken [in some clients].
<johnk> 3xx response codes: http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3
noah: Really this property rule works for real properties?
timbl: Yes, e.g. with a 200 on B then assume both A and B represent a document in the tabulator.
jar: Roy says that the mapping is from [time to set of representation].
<masinter> please reference HTTPBIS rather 2616 since we might actually fix wording problems
jar: A change in a resource would be observed as a withdrawal of a licence to deliver a representation.
[search for a information resource which is "not restful". ]
jar: Are there [information] resources which are not RESTful?
<johnk> "in particular, the convention has been established that the GET and HEAD methods SHOULD NOT have the significance of taking an action other than retrieval."
<masinter> is there room in this discussion for believing that "resource" is being misused
<johnk> from http://www.apps.ietf.org/rfc/rfc2616.html#sec-9.1
jar: Are there changes in
representations without change [in the] resource?
... But -- which happens first? Is the web stable and then
described by metadata? or the other way around -- we know what
it is from metadata and that drives the web? [the scribe
thought jar was setting up an ordering or exclusion, but he
wasn't.]
ht: In case (1) you are trying to get to where we can form the disagreement that Larry has had with much of these discussion in more concrete terms, that if we can't talk about authoritativeness then we can't talk of anything.
jar: In case (1), you get
authoritative onfo from the protocol, and you can actually
synthesize information from the protocol itself.
... Can you infer anything about a resource frm the
representation? I don't know?
... Possible sources of metadata.
... [discusses the note]
<masinter> and http://tools.ietf.org/html/draft-masinter-dated-uri-06 as the only really "universal" URI scheme
<masinter> want metadata theory to have provenance, and be couched in terms of "party A asserts B about C", never to divorce the authority from the statement
<masinter> including model of trust, A trusts B implies process A uses to believe statements (metadata) by B
<DanC_> "FRBR: Functional Requirements for Bibliographic Records" http://www.frbr.org/
<DanC_> see also http://vocab.org/frbr/core Expression of Core FRBR Concepts in RDF
jar: An frbr:Item is
... not an information resource, as it is made of atoms.
... Do you want to use a DOI URI for [to name the article]?
Normally it dereferences to a page about paying money for the
article.
<ht> HST: The question of which [timbl: any] of the FRBR terms is right for Z respectively R is, to me, interesting
timbl: Another thing which is interesting is which FRBR Classes are such that membership of that class are properties which carry over in the property redirect rule. [for example, does 302 imply same Work? Same Expression? etc]
<DanC_> (where's the dang definition of frbr:Item?)
<Zakim> masinter, you wanted to talk about http://masinter.blogspot.com/2010/03/resources-are-angels-urls-are-pins.html and thinking about the intrinsic ambiguity
<DanC_> (I can't find any evidence that they're physical)
DanC, click on it!
<DanC_> I did
<DanC_> well, I clicked on a schema by Ian Davis, but I don't think he speaks for the FRBR folks
masinter: I have been thinking
about whether resources exist. Where I have come to is for my
web page, is it the web page of then HTML, or is it the entire
site, and the answer which is most appealing is "yes". It is in
a way all of those things. find I need ambiguity about what it
exists or I end up talking about angels on the head of a pin.
Most communication is ambiguous.
... You can't use set theory on these things unless you have
equality, and we don't even have a theory of equality for
resources.
jar: We can do a lot without this -- look at what I am doing with FOL without that
<masinter> http://tools.ietf.org/html/draft-masinter-dated-uri-06
masinter: The URI document is not a good one as a basis for making logical systems.
<DanC_> (http://www.ietf.org/rfc/rfc3986.txt Uniform Resource Identifier (URI): Generic Syntax Fielding, Berners-Lee, and Masinter)
<DanC_> (tim, you didn't mean a 1-1 mapping between Us and Rs, I hope)
<noah> +1 Dan
<DanC_> (to accept a premise that names are ambiguous is to abandon first-order-logic. I'm not sure that's a good idea.)
masinter: It is important to record the provenance of metadata.
<DanC_> (meanwhile, my attempt to fit the Lampson speaks_for stuff into FOL over the last few months sorta failed. so... hmm.)
(he's not anbandoning that -- i think he is just saying persoanlly he can't copye with trying to define what a [information] resource is)
<DanC_> http://www.ietf.org/rfc/rfc3986.txt
Noah: I kinda buy 3986 as a basis for a communication protoocl but not a logic -- is that what you said?
masinter: not quite
... I can't beleive that the semantic web works by reading more
into an existing spec.
timbl: That's too bad
<DanC_> (huh? timbl, you didn't speak)
(very quietly)
masinter: it would step back from the sem web if it stepped back to use an ambiguius stance as to what a URI identified.
<DanC_> DanC: the semantic web doesn't rely on certain readings of the URI spec; it specifies the 1 URI identifies one resource in separate specs.
ashok: By "ambiguous" do you really mean "not knowabout"
<masinter> larry: yes.... (except for "tdb")
<Ashok> s/nowknowabout/not knowable/
<Ashok> s/not knowabout/not knowable/
<jar> masinter: Semweb has a postulate that you don't need, that http responses are meaningful
timbl: Are you saying the web web is broken or it works and you have a better plane/
masinter: the latter
<masinter> i don't think it's broken insofar as the assumption isn't really necessary
<masinter> that the meaning of assertions is tied somehow to the operational behavior of HTTP servers
<Zakim> jar, you wanted to ask larry how metadata subjects should be designated
jar: A core problem. When you
write metadata, how should you designate the subject?
... The RDF project was started as a metadata project, and used
HTTP URIs as the things you are talking about, [when they] are
on the web.
masinter: Adobe products use RDF using sometimes withe HTTP URIs and sometimes not.
<masinter> sometimes using a GUID-based URI scheme that identifies resources that aren't on the web.
<Ashok> ... sometimes using GUIDs because the items have not been published yet
<masinter> in XMP
<masinter> jonathan's formalism works for me using URIs
jar: The RDF semantics covers all the stuff you brought up Larry.
<DanC_> larry, even if you track provenance and such, you do so a la "Bob thinks asset:123 is blue". FOL doesn't assume one universal referent of asset:123; it has a framework of interpretations that map names (functionally) to referents
<masinter> so you're assuming http://www.w3.org/TR/rdf-mt/ ?
<jar> yes
<jar> also known as FOL. RDF is just a vector for FOL
<noah> Break
<masinter> I'd like the semantic web to work for content that is delivered over bittorrent or FTP or broadcast on television, and where there are no HTTP status codes to be found anywhere
<masinter> and i think the second-order logics about belief, trust, provenance are really important
<Zakim> timbl, you wanted to say that I don't see why jar needs to have (1) or (2) to have a causality between the two separate types of activity which hcan happen in parallel.
<DanC_> masinter, I think the semantic web should be able to take advantage of (i.e. exploit) http status codes, but it doesn't depend on them.
<DanC_> i.e. the RDF specs treat http URIs and ftp URIs the same.
<jar> and tag: URIs
masinter: I don't like this
account, particularly when we start modeling and talking about
who said what.
... There is an alternative which is pretty consistent with
what you (jar) are saying but taking a different gloss.
<Zakim> ht, you wanted to try to be optimistic on getting to the modal version of this
masinter: For a model of trust we
need this too, and it helps fro example for me when tallking ag
about Cross-Site Request Forgeries.
... (CSRF)
ht: I am sympathetic to your
goals, Larry, but getting the "if what everybody said was true
logic" under control is a good dtart, and then proceede to the
intentional one.
... Otherwise the step function to get off te ground is too
high.
<DanC_> (cyc microtheries are kinda cool for saying "in a world with fixed time..." or "in the harry potter world...")
<ht> TimBL: Doing the who-said-what stuff needs something like Jonathan's starting point
(lets work in the HP world for now ;-)
<ht> ... I would add that just as not doing the intentional part right away, we don't need time either
<ht> ... it can be added later
<ht> s/intentional/modal/g
<ht> [Where by 'modal' above I mean, adding an 'according-to-whom' argument to everything, or wrapping everything in belief/authority modal operators, or. . .
<ht> ]
Timbl: It is really inconvenient to always consider the possibility of people having misunderstood each ther -- we move faster if we assume that there are things and things which identify them
noah: Are you sayin gthe sem web is broken, or are you saying Jono's model is approaching things in a way which I think could be done differently?
masinter: There is a setof toolsw
which have been devised which make sume assumptions -- if you
look at the tool in a different way you may finf them more
useful. The tools worl for a set of examples.
... Like when we are doing inference from metadata.
... We have a movie nd a script which wwas makde from the
movie, and therte is no HTTP in sight, and no status code. Thge
more they tools rely on HTTP, the kless useful they are to me.
I need other ways of making tose systems.
timbl: We have sem web tools liek the ones i have been using for 9 years which will allow you to do all the things you were jsut describing. DO go ahead an duse them. Without using the semantcis of HTTP expklicitly.
danc: Some people think that there are no constraints, some want fewwe. There are diosagreements
noah: This is nt aboyt the sem web only. or mainly. The HTTP protocol is a really imporant protcol, and this will allow us to answer questions abouyt what HTTP, given the right formalism.
masinter: I think there is some level of abstraction which is missing.
<noah> s/only. or mainly./only./
masinter: Some way of darwing assertions about it. With that level of abstraction, you wouldn't deep-ending on what HTTP status codes mean.
<noah> s/aboyt/about/
<noah> 5 mins
<noah> s/darwing/drawing/
jar: That is one of the positions taken by my presentation. But it has consequences.
<noah> 4 mins
masinter: Good
consequences.
... It would be good to be able challenging these assumptions
without being asked whether I am challenging the entire
semantic web.
ht: Let's , as several of us had a naîve reflex to keep trying to read R as U, and as the assertion was made that there is justification for this in the RFC, remind outrselfves -- I have just remind myself the first few lines:- '
<noah> 3- mins
<noah> 2 mins
<ht> RFC3986 says "This specification does not limit the scope of what might be a
<ht> resource; rather, the term "resource" is used in a general sense
<ht> for whatever might be identified by a URI.
<johnk> 3xx response codes: http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3
<ht> 10.3.3 302 Found
<ht> The requested resource resides temporarily under a different URI.
<DanC_> noah, I think we're trying to do formalism without some of the basic tools in our toolset. Jonathan mentioned the possibility of an RDF semantics tutorial. That might speed things up.
<ht> THat's a relation between R1 and U2, not R1 and R2
<DanC_> a risk: it took me not an afternoon but 18months to grok it.
<DanC_> so I'm sympathetic to the view that this is an interesting book/research topic, but not cost-effective for the TAG
<noah> Dan, suggestion on what I do about it?
<noah> s/I/we/
<DanC_> I gave 2 different suggestions; I lean toward the latter, I guess.
<noah> OK, I'll go with the latter. What is it?
<ht> Have JAR write a book :-)
<DanC_> um... shall I type it LOUDER? ;-)
<noah> Thought you said "have" 2 suggs. Sorry.
<DanC_> (a) tutorial (b) drop it.
<noah> Tnx
<DanC_> "Have JAR write a book" falls under (b) drop it from the TAG agenda.
<DanC_> ACTION: DanC to suggest a path thru some logic terminology that might speed up httpSemantics discussions [recorded in http://www.w3.org/2010/03/25-tagmem-irc]
<trackbot> Created ACTION-413 - Suggest a path thru some logic terminology that might speed up httpSemantics discussions [on Dan Connolly - due 2010-04-01].
[a discussion of future directions ensues. DanC proposes that we would make more progress if we had a common understanding of FOL and wonders whether a talk from Pat or HT might add the necessary commonality]
<DanC_> (DKA, the compositional deely HT mentioned is http://www.ltg.ed.ac.uk/~ht/compositional.pdf from http://www.w3.org/2001/tag/group/track/issues/34 )
<noah> Suggest 24 May
a discussion of future directions ensues. DanC proposes that we would make more progress if we had a common understanding of FOL and wonders whether a talk from Pat or member:HT might add the necessary commonality
<DanC_> action-201?
<trackbot> ACTION-201 -- Jonathan Rees to report on status of AWWSW discussions -- due 2010-04-24 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/201
[Exeunt, pursued by a bear]
<ht> [Exeunt, stage left, pursued by bear]
ht: Possibilities include having a half-day meeting in June with peopl eoutside the TAG
nm: from anywhere in the world?
ht: From the UK
... That is where ACTION-351 rests.
... There was a suggestion to line it up with another big
meeting
jonathan: Like DCC
ht: OCLC are heavility onvolved
with a European meeting once a year.
... a please come and join us one afternoon would be good to
brainstorm about this.
... Where "this" means range of things including say a new
top-level domain, special dispensation from IANA, etc.
<ht> s/European meeting/meeting/
<ht> s/year./year, and OCLC do something as well, I think./
<Zakim> noah, you wanted to talk about time frames
<Zakim> DanC_, you wanted to remind Noah that my suggestion is that he doesn't have to track this at all, but rather to have HT pursue this as a W3C workshop with the staff and to remind
<ht> The director of the DCC "Chris Rusbridge"
danc: Larry sugested not pursued in the TAG.
jar: I think this ought to be a TAG thing -- I see this is important. Unfortunate that HTTP URIs are marginalised and treated no better than phone numbers.
The W3C should care about this.
<DanC_> (gee... phone numbers are treated with considerable respect; "no better than phone numbers" is pretty not bad)
timbl: This is important, and i don't think anyone else in the tag is doing it.
<ht> I heard JohnK say "It's an architectural issue"
jonathan: This is important to me. I take issue with the Crossref folks for some of what they are doing. It would be good to have this workshop.
<jar> (sorry Geoff)
timbl: I also feel this is important and do and will put time into it talkingto people.
<DanC_> s/or what/for what/
ht: I will take an action to propose an agenda for an afternoon session.
<ht> ACTION Henry to prepare a draft agenda, including goals and means, for a proposed afternoon session with invited guests, and circulate for discussion prior to a decision, on the subject of addressing the persistence of domain names
<trackbot> Created ACTION-414 - Prepare a draft agenda, including goals and means, for a proposed afternoon session with invited guests, and circulate for discussion prior to a decision, on the subject of addressing the persistence of domain names [on Henry S. Thompson - due 2010-04-01].
at the June face-face
<ht> ACTION-414 due Apr 15
<trackbot> ACTION-414 Prepare a draft agenda, including goals and means, for a proposed afternoon session with invited guests, and circulate for discussion prior to a decision, on the subject of addressing the persistence of domain names due date now Apr 15
<ht> close action-351
<trackbot> ACTION-351 Look into a workshop on persistence... perhaps the June 2010 timeframe closed
<DanC_> ACTION-351: see action-414 for follow-up
<trackbot> ACTION-351 Look into a workshop on persistence... perhaps the June 2010 timeframe notes added
<ht> action-414: The proposed afternoon meeting would be during the TAG's June 2010 f2f
<trackbot> ACTION-414 Prepare a draft agenda, including goals and means, for a proposed afternoon session with invited guests, and circulate for discussion prior to a decision, on the subject of addressing the persistence of domain names notes added
________________________________________
<noah> http://lists.w3.org/Archives/Public/www-tag/2010Mar/0073.html
jar: I will explain my idea. This
may relate to some stuff DanC was talking about baout p2p and
HTTP.
... Comparing what reliable naming systems to to what the web
does, compare and contrast.
... In the message, I have two examples.
... 1) species name -> description
... 2) description of description of doc -> document
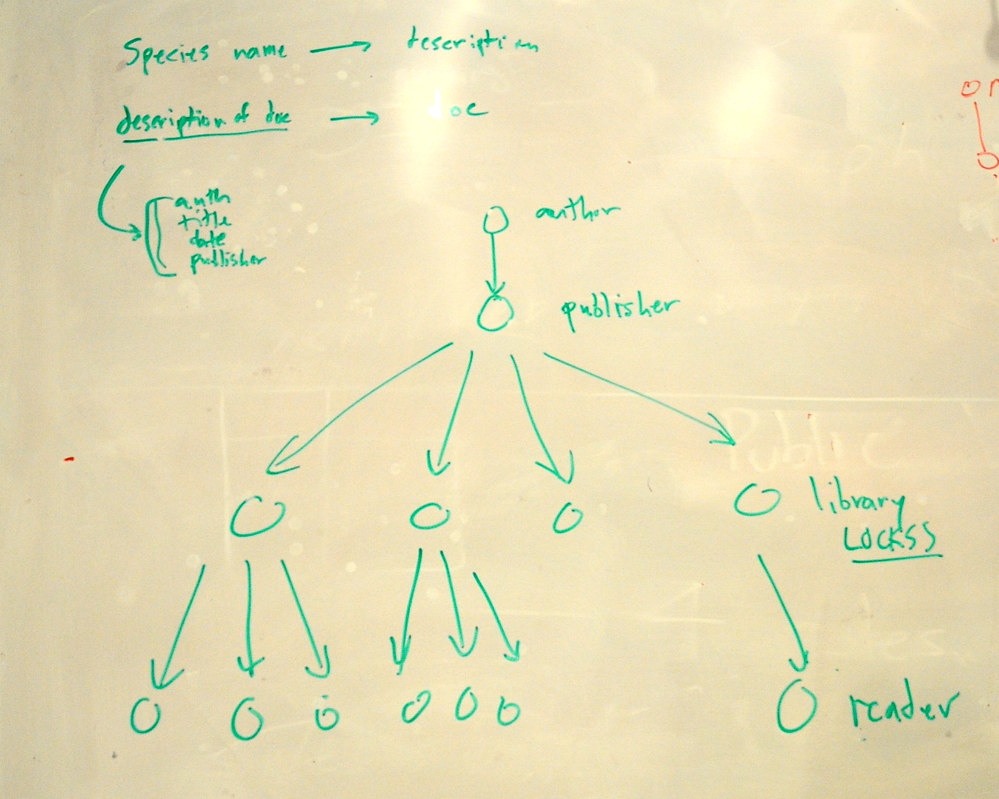
(description being title and author, etc)
danc: In fact the puplisher often wants money
ht: suppose though the publisher went out of business long ago
jar: You have an author then who does some speech act, and ships [a document] to a publisher, who then deistributes copies to shops [libraries] which distribute them to readers.
<ht> s/ht: suppose though/jar: In fact in many cases/
<ht> ht: but libraries have copies
jar: We have the same picture on
the web, but the only different is timescales. We have an
author, a hosting service, and caches and various
readers.
... In the first picture, the library is the bridge in time, as
the difference between the writer and reader is 200
years.
... However with the web, [well] we don't know what happens in
the future.

ht: Actually the national libraries are worrying about the web.
<ht> The British Library on web archiving: http://www.bl.uk/aboutus/stratpolprog/digi/webarch/
<ht> An example from the British Library web archive pilot project: http://www.webarchive.org.uk/wayback/archive/20050808102339/http://robincook.org.uk/index.htm
jar: If you look at LOCKSS, the system used by libraries to back up journals, it is an extension of this system.
ht: In many cases like the
Internet Archives, they really are archives of the web.
... these people worry about this question for the web.
... The librarians are indeed trying to solve this problem.
jar: There is little role for the URI in that model
ht: Oh yes there is
danc: Yes
... There are lots of web caches and lots of things
... i was talking to John Bosak about the fact that the XML
spec had no URN: he was worried about it but I pointed out that
at any time there are many machines with copies of that spec on
them.
NM: Can I just tell your story quickly and see if it is what you mean. Do you mean that in the first system , there is no linnean identifier at all? That in the existing case there is nothing which we would use as a URI - in that case the first one what is the role of the URI of preserving that association? Explain how this picture gives them comfort... I think yuo will tell me that the linneans wil have a time-oriented algorithm -- so the purpose of these ...
... things it to preseve the input to that algoroithm? how for case 2, we have a dfferentc ommunity fo people you dodn't ahve a little string name, so they work o a soirt of best effort approach? In taht case thyis is a little less like a a UTI case. o in that case with autjros and cacshes I a m trying to say what dioes that pe=resvera about what you want?
[Noah, please correct the script]
I am just trying to make
sure I understand how this works. The URIS work like the Linean
system, but have a way fo breaking ambiguities. This is just a
hope, nut it may happens.
... and with these case hte reason taht the persstence is
impoirtant is [lost[ .. s ll tese thinsg ahve a systme which
takes you from [...] to what exists [...]
idealy a URI resouyrec(in th second case) and the author puts somethingup opn a web server and that stuff ends up in a lot fo caches and now what?
Lets thtake the case taht everything is in the cashe and nmes i nthe nbashe ... so yo would find all teh caches in the world and see which which have a given name ... liek I would find soemthng ...
[...]
danc: But that is quite outside this model
nm: So that is valuable to know -- it mean that other things whcih are not coverd by the model
DanC: On the left (paper) the system is only solved for static documents.
DanA: There may be an author who creates an SGML hich generates difefrent forms, one hosteed by hosted by nature, but some oethr s are preprinst distributed n fvarious ways, and even put in Paul Ginsparg's archive.
jar: What would it take to make URLs so strong that sceptical entities like archivists would use them?
dana: The advantage of a citation is you get an idea of what the thing is.
danC: I concluded that the archivist's requirements can't be met with completely opaque URIs. But if you make a domain such as .academy whose URIs by policy/definition transparently encode the citation information including year and journal and publisher and author and title in such a way as you can extract those things, that's just as good
<ht> GET http://www.theacademy.org/ ==> 403 :-)
nm: What if acandemy.org has their domain name taken away?
jar: There is no central authority for libraries.
<ht> NM: and then how do you tell new ones (post identity theft) from old ones (pre identity theft)
<DanC_> (jar, what was your last question to me? I'm trying to mull it, but it's leaking out)
<ht> TimBL: There's an authority, the publisher, via the name of the journal, even if there's no _central_ authority
<ht> ... So if you don't know, you can go to the publisher
<ht> ... Publishers do now use ISBNs for books
<ht> JAR: But they're not universally trusted, because the database isn't open
<ht> TimBL: People are quoting DOIs or ISBNs via http://...doi.../39585.287
<ht> JAR: There's no need for any trust, except that there are no conspiracies
<ht> ... You have to believe that ten libraries would all change their copies
<jar> If you don't trust the owner of academy.org, then either you need to be prepared to secede from ICANN, or you commit to attempting to enlist ICANN's help in ensuring stability
<Zakim> ht, you wanted to gloss "It hasn't been solved"
<jar> "administrative single point of failure"
ht: Scholarly communities refuse point blank to use DNS-based identifiers on the grounds that their constituency extends for hundreds of years and the DNS system can't guarantee any more than a few years. They believe that argument.
<Zakim> DanC_, you wanted to emphasize a point I heard timbl make: there _is_ a central authority for journals, publishers, etc; when one is created, there's a serious effort to make its name unique
<jar> danc: It's fixed in an important way
danc: What i mean by fixed is 99%
of the world getting 99% reliability -- there is 1% of 1% of
the world getting failure
... there is a trust that there is no duplication of the
publisher and journal names
jar: ISBNs are not trusted because the database is not open.
raman: The person who solves this problem will want money for it
jar: Exactly. That is what DOI do. They charge money. They keep the database closed. That is why they can't [shouldn't] be trusted.
<jar> database is open, after registration, for single queries. what you can't do is host it yourself (2nd sourcing)
danc: I am starting to see the appeal of the idea of a domain which starts with date; e.g. 2009.arc
<DanC_> s/getting failure/who wants more reliability than that/
<jar> muguet
jar: If you are on a space
station and the world blows up, you will re-assemble everything
using the indexes [?] of the URIs
... the person Muguet who passed away recently was talking
about the politics of te top-level domains.
dana: There may be a strong push-back from existing interests
danc: The web has grown in $$ value much faster than the governance models have evolved.
<DanC_> (and dana and I were talking about the DNS as much as the Web)
ht: We got an consensus of curators etc who use lots of DOIs that all proposed persistent identifier schemes should publish a clear statement of how to produce an HTTP version of all their identfiers.
ht: It takes the consensus we
hammered ou with all the XRI people over many years.
... Paul Walk summed it up in one great sentence.
<ht> Blog about the London persistent identifier meeting I mentioned: http://blogs.cetis.ac.uk/lmc/2010/02/09/jisc-persistent-identifier-meeting-general-discussion/
<DanC_> we should get that in a TAG blog or tweet stream or something, ht. hmm.
<ht> Not mine!
<ht> Sorry, that is, the blog is not mine
<DanC_> right; it's by Lorna
<ht> The tweet stream at the meeting is the only available record, and as of now it's . . . not available!
<DanC_> huh? I don't follow you
--
jar: About Trust.
... To make a system trustworthy, one has to make sure there is
no single point of failure.
... So you have to make the system open so that anyone can
replicate it.
danc: What is different between the web and the journal case -- we have to trust ICANN
ht: ICANN have specifically stated that they will take admian away from them The book worlks has no such problem
[missed]
[discussion of relative likelyg=hod and worry about failure mode with people stealing names in each system]
<jar> timbl: concern about ICANN failure... many people are watching it, are concerned. if it behaved badly, there's a process, it would be replaced. so much depends on it that it would be replaced by a compatible system.
<johnk> timbl: lots of people want to run their own DNS root
<jar> timbl: if we get a special deal for some part of DNS space, then... [we would get independent buyin]
s/[we would get independent buyin]/then we woudl be wise to get agreeement for the terms to be respected by all ICANN statekholders too
dka: I remember that there is a political process for top-level domain names that teh US dept of commerce was involved. Suppose the administration of some authoritarian regime wants to eleiminate say a Journal of Eviolution?
<DanC_> (that would mean closing ACTION-402 and ACTION-33 on Henry S. Thompson: revise naming challenges story ...)
<DanC_> close ACTION-402
<trackbot> ACTION-402 Summarize JAR's message to HT re HTTP-based naming and put it(?) on the agenda closed