See also: IRC log
<edit> scribe: DanC_lap
<edit> scribenick: DanC_lap
<scribe> Scribe: DanC
proposed: to accept http://www.w3.org/2008/02/14-tagmem-minutes as a true record
RESOLUTION: to accept http://www.w3.org/2008/02/14-tagmem-minutes as a true record
PROPOSED: to cancel 6 march and meet again 13 Mar
Noah is nominated to scribe 13 Mar
RESOLUTION: to cancel 6 march and meet again 13 Mar
SKW: I had one comment to move boilerplate to the end
<ht> Minor editorial: "due a change" -> "due to a change"
<ht> "other working paper" -> "other working papers"
<ht> "on one ore more" -> "on one or more"
DC: likewise, I suggest picking the most interesting bit and making it visible in the top screenful.
SKW: ok, the number of liaison
meetings is remarkable
... OK, I'll fold in these comments...
... public or member?
DanC: more valuble public
HT: yup; tag works in public
SKW: www-tag or tag-announce?
DC: tag-announce... and/or the tag blog
action-101?
<trackbot-ng> ACTION-101 -- Dan Connolly to , Tim to produce Visio diagram to send to Leo -- due 2008-02-21 -- PENDINGREVIEW
<trackbot-ng> http://www.w3.org/2001/tag/group/track/actions/101
see also #swig discussion...
http://chatlogs.planetrdf.com/swig/2008-02-14
[15:09] * timbl refreshes
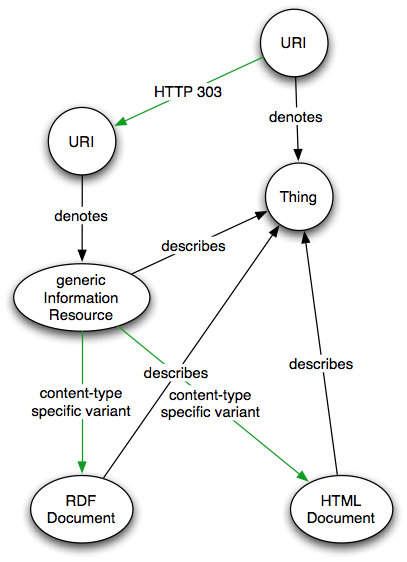
http://www.w3.org/DesignIssues/diagrams/tag/HTTP303.png
[15:11] <DanC_lap> note
http://www.w3.org/DesignIssues/diagrams/tag/HTTP303.graffle source...
close action-101
<trackbot-ng> ACTION-101 , Tim to produce Visio diagram to send to Leo closed
SKW: I did attempt to get in touch with leo and richard about joining a tag telcon; no response yet
-> http://lists.w3.org/Archives/Public/www-tag/2008Feb/0013.html [httpRedirections-57] Resource-Decription Header: a possible proposal to consider.
(wiki page? help?)
JAR: suppose you have a URI for a resource and you don't know whether it's an information resource; this header would tell you [oops; missed the gist of it]
<Stuart> There seems to be a summary of the above thread at: http://esw.w3.org/topic/FindingResourceDescriptions
JAR: the point here is go from URI of a thing to the URI of a description of the thing
<Zakim> ht, you wanted to query the intended range of use of Link-Header
Ashok: is this like discovering metadata? to the extent that it is, yes, we should see that this is standardized
HT: the negative consequence of this
approach is to say: anyone who has metadata about a resource should
put this link header in the response to GET/HEAD about the
resource
... and that's not what HTTP is designed to do, AFAIK
<noah_office> Henry, I have some sympathy for your argument that HTTP is not mainly designed for "
<Stuart> acl Danc
<Zakim> DanC_lap, you wanted to ask for elaboration of the use case(s)
HT: I think something creative in the case of a failure to give a 200 makes sense, or if the request explicitly _asks_ for metadata
<noah_office> Henry, I have some sympathy for your argument that HTTP is not mainly designed for "tell me all sorts of random stuff about the resource". How do you feel, then, about 303? Not too evil given you didn't have the goods for a 200.
<noah_office> DC: Jonathan, can you start the story at the beginning, with more recognizable players in the scenario?
JAR: suppose I have some spreadsheet
data in a .csv file...
... and I want to be able to tell people who the author of the
spreadsheet is...
... and I write { <spreadsheet.csv> dc:author "JAR" }; where
do i put the triple?
... it's not clear where that metadata belongs in HTTP
<ht> DC: Some folk have actually written code to implement Link-Header
<ht> ... What are they using it for?
<ht> DC: How does this get esclated from the 'nice to have' to the 'must have'
<ht> ... we've lived w/o it for a long time
<ht> JR: LSID protocol has this, and gets used a lot
<ht> ... From an LSID for a (fasta?) file, you can frame a request for metadata _about_ that (fasta?) file
Stuart: the stories DC evoked from
JAR cover much of what I was interested in... for a non-information
resource, the 303 mechanism allows us to find metadata, but there's
no analog for information resources
... it reminds me of something J. Borden [sp?] wrote about... a
Resource-Description header
... it's related to the Link header, or at least the rel="meta"
case... the Link header has a "swiss army knife" feel; lots of
knobs and params
<jar> MGET has been proposed (metadata get)
Stuart: and reminds me of the URIQA
[sp?] idea of adding an HTTP verb to get metadata
... I suppose methods/verbs are much higher cost than headers
Ashok: from the web services context... suppose I have a URI for an endpoint, but I don't really know what messages it supports, so I'd like to find a WSDL description of it.
<Zakim> noah_office, you wanted to ask whether these solutions scale well enough to lots of sources of metadata?
Ashok: I've seen a few mechanisms for that case; perhaps we should standardize one
Noah: I wonder if a pointer to one source is all that useful... as opposed to a list of 2 or more...
<Stuart> fwiw... there is no intention that the number of description references is 1
Noah: if we look at ordinary HTTP, when you do GET... you can imagine more complex designs, but one body works pretty well. "don't make it more complicated than it needs to be" is the answer.
<Stuart> also fwiw... powder are also looking at the link header as a way of associating POWDER labels with resources.
(yeah; where did Noah get the idea that only one pointer fits in any of the proposals so far?)
scribe: am I wrong to think the metadata story is more complicated than just one place to look?
DanC: no... most of the useful proposals allow a number of pointers
Noah: ok, but even so, I can imagine it might get more complicated than a list; and it's not clear what goes in the list and what doesn't.
<Zakim> ht, you wanted to respond to DC wrt 'good use of http'
SKW: yes, the header approach isn't exhaustive; it's those that the server operator chose to refer to
HT: I'm not comfortable having the server choose which things to pointer, if this is to generalize the 303 case
[I hadn't considered that this might obsolete the 303 mechanism. I'm getting lost, I'm afraid.]
HT: also, how do authors who don't control their servers deploy this information?
<Stuart> fwiw I think that the 303 solution has only a single redirection target (unless you chain through a bunch of them).
[simple: they don't. we'd be recommending that authors get control of this mechanism, exactly.]
<Norm> ScribeNick: Norm
HT: I want to note three categories
where we can look for solutions
... 1. the 303/linked header story where we talk about changing
responses contain based on ... who knows what at this point
... 2. add a new request, or several new requests; we may think
that's harder to deploy but the cost/benefit analysis might make it
the right thing (MGET, eg.)
... and 3. and in the ARK approach, systematic naming. URIs with
mandated syntaxes; you can ask for the document, metadata, or
something else (I forget what)
... SO there are a number of places we could look.
DaveO: I wanted to make 3 points.
... 1. Henry objected to a header, but I'm more sanguine about a
header for this. It struck me as similar to content-location.
... Whether you think of the URI for the content-location as
metadata or not is something I don't want to get into, but I think
a header is ok.
... I also wanted to support Ashok's point about metadata. WRT
Noah's question about the kinds of responses, you can get back a
metadata document that has several flavors of metadata.
... You can ask for different sorts, or you can ask for them
all.
... There are issues of scoping and paging through WSDL documents,
for example.
... This has been deployed in a bunch of interesting scenarios;
there's a motorcycle consortium using metadata discovery.
... and 3. on where we can learn things, this reminded me of the
problems that the access control folks are working on. In their
solution, they have a two-part approach where you can put the
access control in headers, or you can put it in an XML processing
instruction.
... The access control spec says that if you get a representation
that has the access control PI in it and that's a cross-site
request that should be denied, then that's supposed to stop the
processing.
... That is obviously there to allow folks w/o access to the server
to put access control in the document.
<DanC_lap> (we seem to be talking about a huge design space... I wonder if this is all in order... hmm... yup, http://www.w3.org/2001/tag/group/track/issues/57 is about "obtaining a description of a resource (typically a non-information resource) where the ")
<Zakim> DanC_lap, you wanted to report on IETF standardization (or lack thereof) status and to ask what I missed about the connection between Link: and 303
DanC: If any W3C work is going to be
based on the link header, then the current status isn't good
enough.
... That's the short version, the long version probably isn't worth
our time here.
... I believe this one has timed out. Mark Nottingham isn't
disposed to start again until he gets more support.
Stuart: I pinged Mark too.
DanC: On link and 303, I got a bunch of stories about link, but somehow the 303 and link stories aren't connecting in my brain. They seem releated, but can someone tell me how?
Stuart: I'll try.
... 303's don't work well for information resources.
... That can get you a pointer to the metadata that tells you where
the real bits are, then you have to do three round trips.
Scribe got lost.
DanC: How does link work in the non IR case?
<ht> Consider the example of the W3C home page, which we serve millions of times a day, I believe: If we go down the Resource-Description header route, we will be adding 1+ % to our traffic
Stuart: If you put a link in, then that link could point to information about the resource. So the link might be used instead of the 303.
DanC: Slowly. Let's say there's a URI for my car. What's the response code?
Stuart: Let's say it's a 303 to a
description. You might say that's enough, no link header
needed.
... You could, for good measure, put in a link ehader that points
to the same place
Henry: That duplication would be of real value, because it clarifies what the 303 is telling you, since that's what the header tells you
Stuart: Yes, maybe.
... Actually, you could think there are several relevant resources,
I might put in severl of them.
<Zakim> Stuart, you wanted to ask ashok whether this kind of approach would be a welcome addition to the WS 'armory'
<DanC_lap> ScribeNick:DanC_lap
Stuart: re web services approaches... you mentioned that there are several existing mechanisms... would one more be welcome?
Ashok: the existing mechanisms haven't been all that widely deployed/endorsed, so one that is more widely adopted might be welcome
<Stuart> also that a single widely adopted mechanism is better than several adopted in fragments.
Ashok: the web services scenarios I have in mind, and those I hear from DaveO, have very specific metadata: WSDL, policies; I hear something different from Noah. I wonder if one mechanism suits both.
<ht> HST thinks RDDL bridges the gap between what Ashok is describing and what Noah described
Ashok: in the general case, there's no way to exhaustively find all the metadata relevant to some resource.
<jar> you never know ahead of time whether there will be metadata, or what it will be
Noah: how can the server know that the client wants a WSDL policy as opposed to other stuff?
<Norm> +q to RDDL
<Norm> +1 to RDDL
<Zakim> Norm, you wanted to RDDL
HT: RDDL expresses exactly these sorts of relationships, i.e. to distinguish WSDL policies from authors, [normative references, schemas, etc.]
<Ashok> Yup, RDDL is a possible answer
[RDDL is one interesting point in the design space, but it seems to me that we're talking about query routing, one of the classic unsolved problems in computer science. this issue has expanded to be computer-science-complete]
<jar> So how does RDDL help me find the author of a CSV file?
DaveO: this sounds an awful lot like SOAP
<Stuart> I think that daves point was about mustunderstand.
<noah_office> DO: Sort of ironic. The access control folks couldn't force mustUnderstand semantics to make sure their header would be honoroed. We have SOAP. Interesting to ask why it's not good enough, or why we don't need something similar in HTTP.
DO: SOAP addresses this protocol need for the XML space; I can see room to generalize to non-XML stuff
SKW: [missed]
<jar> "good
<jar> "?
poll braintstorm: is Link: rel="meta" a good approach to finding author information for protein data?
<noah_office> FWIW, my answer would be neither "yes" nor "no", but "premature", we don't know yet.
<noah_office> I suppose the conservative approach would be for me to vote "no"
DanC: it's the best I've seen, though I'm not sure it's so good as to be worth all the blue-helmets standardization cost
Stuart: it's a useful approach,
though rel="meta" should be grounded in URI-space...
... that would let you distinguish WSDL from POWDER desciriptions
from others
Ashok: not sure yet...
HT: looks like it would work, but I wouldn't recommend it
Noah: would like to look at the
larger picture first
... where metadata lives and who wants to know about which parts
when
JAR: I think it's better than
nothing; there's a pretty powerful need for something like this,
and Link is probably an 80% solution
... I can see how it's not particularly tasteful[/elegant]
... but [the perfect is the enemy of the good]
Norm: maybe; too early to tell
Dave: yes, too early to pick a
winner, but ...
... I can see the point that something is better than nothing
[HT: no progress on curie; I gotta go; there's some urgency; hope to get something for you tues]
<Stuart> http://www.w3.org/2001/tag/2008/02/26-agenda
next step seems to be discussion at the ftf on Thu. http://www.w3.org/2001/tag/2008/02/26-agenda#httpRedirections-57 "@@ Jonathan and/or Stuart please provide additional structure for this session."
HT: no progress on curie; I gotta go; there's some urgency; hope to get something for you tues
SKW: Swick has invited the TAG to participate in RDFa last call review
NM: re the self-describing web draft,
TimBL pointed out a gap between the media type registry and
RDFa
... and I'm not clear on the follow-your-nose story
<Stuart> fwiw RDFa LC looks scheduled to end on 21 Mar
DanC: yes, I'd like to go slowly thru some RDFa examples/tests, presuming nothing but ubiquitously deployed stuff and see if we can follow our nose
<scribe> ACTION: Norman review RDFa LC spec by 21 Mar [recorded in http://www.w3.org/2001/tag/2008/02/21-minutes#action01]
<trackbot-ng> Created ACTION-102 - Review RDFa LC spec by 21 Mar [on Norman Walsh - due 2008-02-28].
<scribe> ACTION: Jonathan review RDFa LC spec by 21 Mar [recorded in http://www.w3.org/2001/tag/2008/02/21-minutes#action02]
<trackbot-ng> Created ACTION-103 - Review RDFa LC spec by 21 Mar [on Jonathan Rees - due 2008-02-28].
<jar> what if we changed the value space?
<jar> e.g. qname value space is pair of prefix, suffix
<Stuart> the valuespce for CURIEs *is* URIs and the mapping will be context specific as currentlt specifief
<jar> hmm. could change the way the spec is written... blah
-> http://lists.w3.org/Archives/Public/www-tag/2008Feb/0075 NewsML-G2 QCode message from Misha Wolf
<jar> qnames *are* curies
<Stuart> jar, no they aren't
<jar> hmm. offline i guess
<Stuart> :-)
DanC: I wonder if the NewsML design process is done? can't tell.
action-99?
<trackbot-ng> ACTION-99 -- David Orchard to revise the finding and publish it directly, unless he feels the need for more review before publication -- due 2008-02-14 -- CLOSED
<trackbot-ng> http://www.w3.org/2001/tag/group/track/actions/99
oops; that's maybe not relevant
DO: I see a variety of positions; haven't finished digesting them.
trackbot-ng, status
<scribe> ACTION: David summarize feedback on passwords-in-the-clear draft of 11 Feb [recorded in http://www.w3.org/2001/tag/2008/02/21-minutes#action03]
<trackbot-ng> Created ACTION-104 - Summarize feedback on passwords-in-the-clear draft of 11 Feb [on David Orchard - due 2008-02-28].
not really due 28 Feb
<Stuart> http://www.w3.org/2001/tag/doc/passwordsInTheClear-52-20080211.html
<jar> bye all, sorry i have to go 2 mins early
is this it? http://www.oasis-open.org/archives/xri-comment/200802/msg00001.html
<noah_office> XRI Comments list: http://lists.oasis-open.org/archives/xri-comment/200802/msg00001.html
Date: Wed, 13 Feb 2008 15:17:00 +0000 / Date: Fri, 1 Feb 2008 14:04:22 -0500
ADJOURN
{kind=link}