![]()
Part of:
Module Interface Homme-Machine
January 20, 2005
ESSI, Sophia-Antipolis
Because:
Therefore:
But also:
One particular kind of human-computer interface we want to support is intelligent agents. A person may have his own interface to the data in the form of an agent that, on the one hand, knows the user, and on the other hand, knows how to surf the Web. The user can, e.g., talk to the agent in natural language, and the agent will search and aggregate information.
For that to work, either the intelligent agent needs to be as intelligent as a human, or the information on the Web needs to be machine-readable and annotated with sufficient semantics. The former is rather a long-term project, the latter is what we call the Semantic Web.
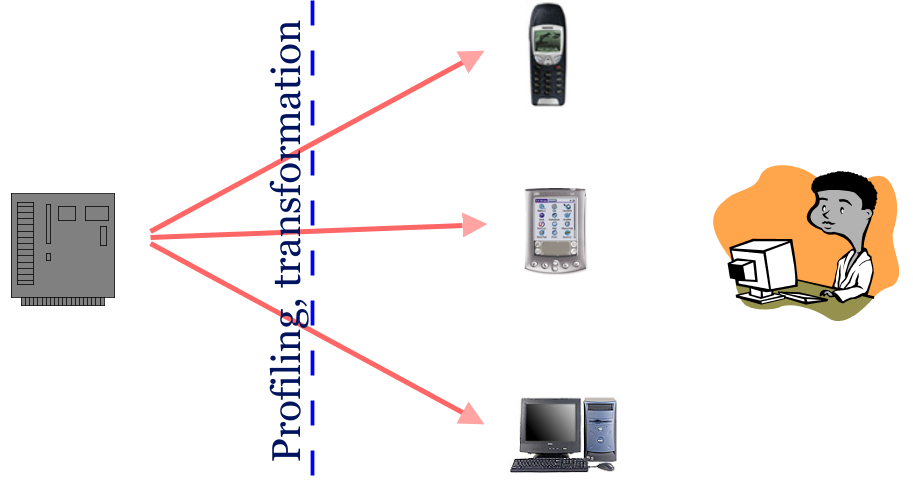
Separating the modules is nice in principle, but it leads to some new challenges, in particular in multi-modal interfaces. For example, it isn't too hard to take a well-designed HTML page and make it usable on a PC screen, on a mobile phone, on a speech browser and when printed. That can usually be done by adding some (partial) style sheets in CSS, or, if the document is complex, in XSL. The person designing the rendering for a mobile phone doesn't need to be the same as the one doing it for the PC screen. But a multimodal interface typically needs communication between devices, or support from the origin server to coordinate the devices.
In a car, e.g., you may interact with a navigation system. Depending on whether you drive or are parked, more or less of the I/O may be done via a screen and buttons vs via voice. Thus, you need not only the original information service and a few style sheets for the different devices, but also an interaction manager that can dynamically change the role played by each of the devices.
Imagine you're in a car…
![[genie]](MMI-car-genie.png)
Multi-media usually refers to simultaneous output in sound, graphics and text. Multi-modal adds the interactive aspect: simultaneous, coordinated input via multiple devices.
Imagine, e.g., that you have a device with knowledge of the train schedules, that displays a map and accepts both touch screen input and spoken input. It can compute the best route from one place to another. You just have to tell it where you want to go from and where to. The easiest for the user may be to combine modalities: he speaks "from here" and points to the map, instead of selecting the "from here" command from a menu or speaking the name of the destination. The device will have to have a “parser” that accepts input from both modalities.
Cars are interesting examples of multi-modality, because they exhibit different bahvior, based on the circumstances: normal driving, dangerous situations, or standing still.
This photo shows the screen of an in-car information system, but the screen is only a small part of it. When driving, the screen displays very little information, because the driver can't look at it for more than a fraction of a second anyway.
Instead, the system can speak to the driver. It also can make various sounds, and it controls the radio and CD player as well, so it can lower the volume if it needs to say something, or when a phone call comes in.
Input to the system can be via the touch screen, but while driving, that doesn't work. There is also a knob on the console, the controls of the radio and CD player serve as input, the hands-free set for the telephone doubles as voice input for the system, and there is input from various devices in the car: speed, GPS position, tire pressure, fuel level, outside/inside temperature, traffic information, etc.
Which information is given when and how depends on various factors. Some information is permanently visible (speed, fuel level), some is visible when the user asks for it (song title, outside temperature), some is visible when the system thinks it is necessary (low-fuel warning, traffic info).



There are various ways to interact with the system, and some are more appropriate than others, based on the circumstances.
On a large screen, a session is typically a window. You can “interrupt” the session by putting another window in front of it. The computer has little management to do. It keeps all sessions opens, but it is the user who manages them, thanks to his “external memory,” which is the screen.
When the devices are smaller, you don't have the luxury if using the screen as a visual memory. When the voice synthesizer and the screen in the car were being used for navigation and an important message interrupts the session, or the user changes channels on the radio, it is the user's own memory that needs to keep track of what was happening in each session. In other words, there can be only a small number of parallel sessions, unless the system can help the user recall the history and context of each session.
The system also needs session management to move sessions from one device to another. E.g., when you are driving and using the hands-free set for a telephone call, you may wish to continue the call outside the car using the handset, as soon as you are parked.
When there is one central unit and several fairly uninitelligent devices (a screen, a voice synthesizer, some buttons and handles, etc.), that is still manageable, but when the devices themselves are intelligent (the telephone handset is in fact a smartphone, the GPS device can be used stand-alone as well), there is the added complexity of deciding which device is best suited to do which part of the computation and which one controls the less intelligent devices.
 Input | → | Speech | → | grammars | → | interpretation | → | EMMA | → | integration | → | Interaction Manager | ←→ | application functions | 
|
| → | Handwriting | → | → | → | EMMA | → | |||||||||
| → | Keyboard | → | → | → | EMMA | → | |||||||||
| → | Mouse | → | → | → | EMMA | → | ←→ | session component | |||||||
| → | Etc. | → | → | → | EMMA | → | |||||||||
| → | System-generated | → | EMMA | → | ←→ | system & environment | |||||||||
| ← | (output) | ← | |||||||||||||
MMI isn't the same as "input," (the "I" means "Interaction") but it fits nicely in my talk this way.
Output | → | (input) | → | Interaction Manager | ←→ | application functions |
| ||||
| ← | Audio | ← | styling (CSS) (XSL) | ← | adaptation (DISelect) (Media Queries) | ← | |||||
| ← | Voice | ← | ← | ||||||||
| ← | Graphics | ← | ← | ←→ | session component | ||||||
| ← | Text | ← | ← | ||||||||
| ← | ← | ← | ←→ | system & environment | |||||||
| ← | Etc. | ← | ← | ||||||||
Under "etc." you can think of media like print, braille, force feedback, and other physical effects, such as movement, heat and coffee…
Most steps can be either on a server or on a client.
Usually, diagram of Web technology include some "cloud" that represents the Web. Where is the Web in this schema?
Case-by-case. Some factors:
The network can be in various places. It is good to offload calculations to clients, to free up the server to handle more connections at the same time. That puts the Web "cloud" on some of the arrows far to the right side of the diagrams. But some client devices are only small and slow, and they can only handle contents that needs very little processing. Which puts the Web nearer to the left side.
And there are other reasons for doing more or less of the processing on the client side:

Imagine browsing on a cell phone
But printer is different from phone.
("Best viewed with…"!?)
The layout should probably be changed (multiple columns?), the images resized or replaced with other ones, interactive parts such as a tabbed display should now be displayed without requiring interaction.
The phone may already have received all the information the printer needs (text, images, style sheets) and it may thus be a matter of recalculating the rendering in a different context.
On the other hand, the server may have indicated to the phone that in case of printing, it has alternative content, that is better adapted. In that case, the phone, or the printer itself, may request that adapted content from the server.
Extensible MultiModal Annotation markup language
<one-of id="r1"> <interpretation id="int1" confidence="0.75"> <x:origin>Boston</x:origin> <x:destination>Denver</x:destination> </interpretation> <interpretation id="int2" confidence="0.68"> <x:origin>Austin</x:origin> <x:destination>Denver</x:destination> </interpretation> </one-of>
Ink Markup Language

<ink>
<trace>
10 0 9 14 8 28 7 42 6 56 6 70
8 84 8 98 8 112 9 126 10 140
13 154 14 168 17 182 18 188
23 174 30 160 38 147 49 135
58 124 72 121 77 135 80 149
82 163 84 177 87 191 93 205
</trace>
<ink>
Scalable Vector Graphics
Speech Synthesis Markup Language
http://www.w3.org/TR/speech-synthesis
Qu'est-ce que l'indépendance vis-a-vis des terminaux ?
Accéder au Web qui que vous soyez, ou que vous soyez, quand vous le voulez, et quel que soit le moyen utilisé
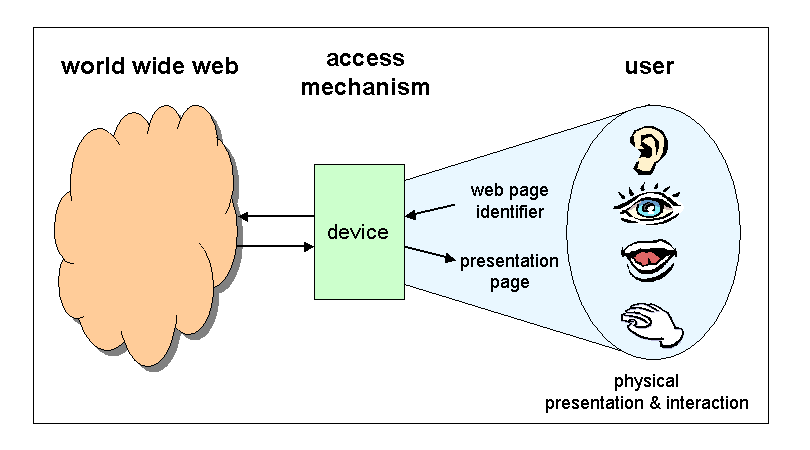

| ←→ | Interaction Manager | ←→ | application |
| |
| ←→ | session | ||||
| ←→ | system & environment |
Ecrire un seul contenu accessible par tous
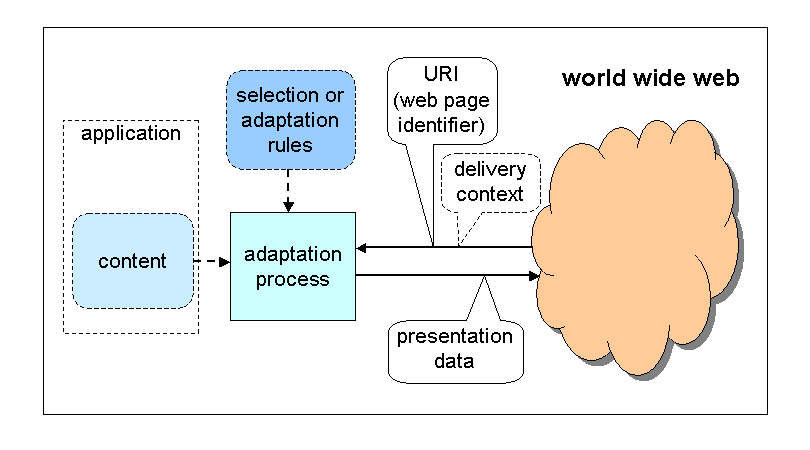
Objectif: Définir une architecture incluant ces 2 aspects
Point Central: La chaine d'adaptation (du serveur jusqu'au client) à la rencontre des points de vue
Elements Cles :
Donner au moteur d'adaptation des informations sur le contexte de présentation
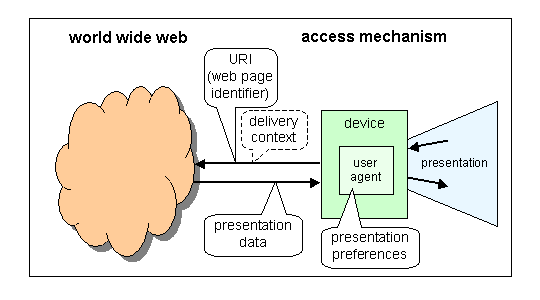
Possibilite de fournir un facteur de qualite
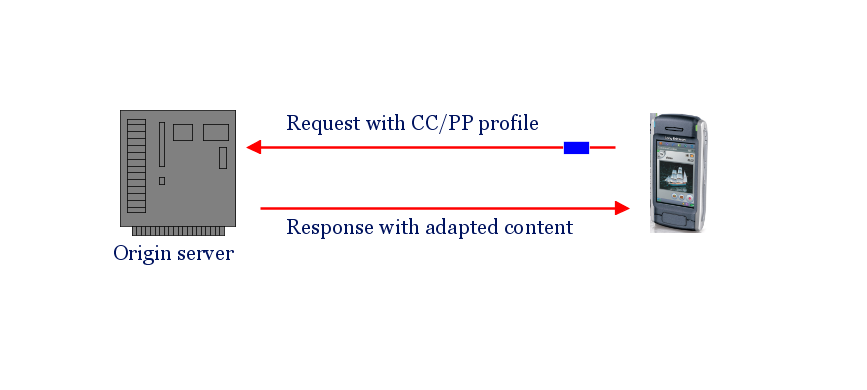
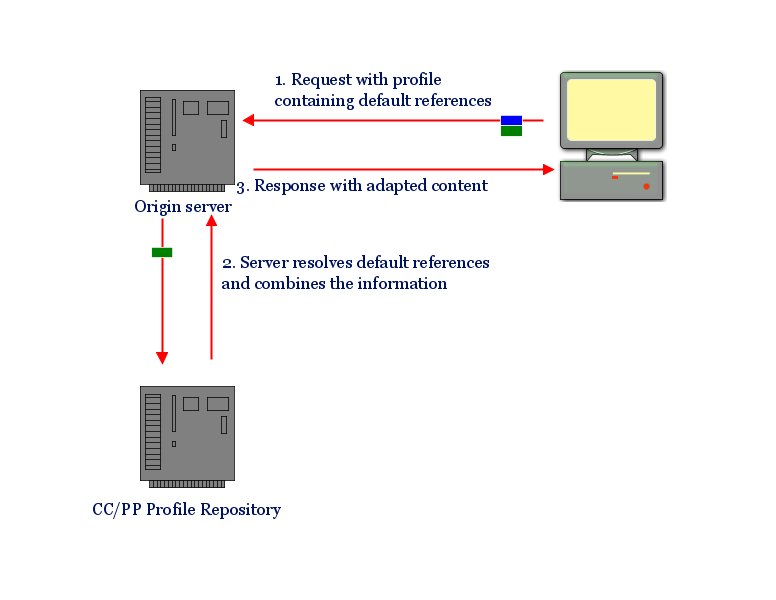
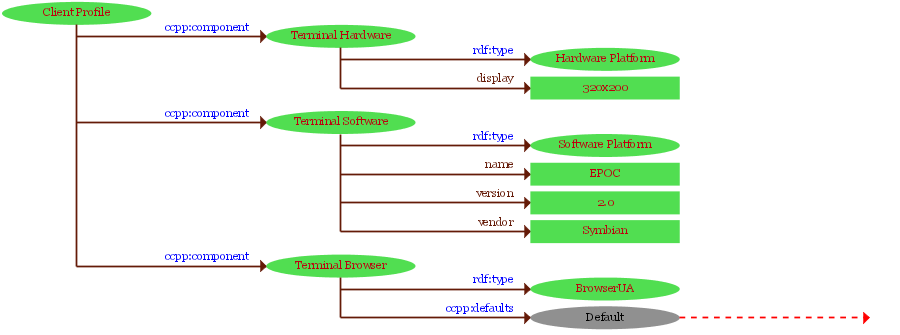
Composite Capability/Preference Profiles
Framework générique permettant à un terminal de décrire ses caractéristiques, son contexte, les préférences de l'utilisateur
| Device | → | CC/PP | → | adaptation | ← | DISelect, Media Query | ← | App. |
Extensible (XML/RDF).
Necessary if adaptation not done by device itself.
Complement to Media Queries and DISelect.
Small file with device characteristics & user's prefs.
May be stored and identified by a URL.
4 briques de base:
Scenario de base :
Principe :
<html> <head> <link rel=stylesheet href="bigcss.css" media="screen and (min-device-height: 600px)"> <link rel=stylesheet media="handheld" href="pda.css"> </head> <body> <h1 name="title" class="title">This is…</h1> <p class="summary"> This is a short summary <p class="extra"> This is very long extra… <p class="link"><a href="myling.html">More…</a>
Ici, la negotiation entre serveur et client est integrée dans le HTML. Tous les client reçoivent le même HTML, mais si le client est un “handheld” (un PDA, un telephone portable), il laisse le premier lien (bigcss.css) de côté est n'utilise que le deuxième (pda.css).
Probablement, le pda.css va ensuite supprimer l'alinea qui est labelisé “extra”. (Supprimer de l'interface seulement. L'alinea a déjà été téléchargé.)
Un PC classique, par contre, prend la feuille de style pour grand ecran (screen). Dans l'exemple, il y a une condition suplementaire: bigcss.css est conçu que pour des ecran d'au moins 600 pixels.
L'expression dans l'attribut MEDIA s'appele un Media Query.
http://www.w3.org/TR/css3-mediaqueries
HTML:
<link href="style1.css"
media="handheld and (color)
and (min-width: 400px)">
CSS:
@import "s1.css" handheld and (color);
@media screen and (max-width: 800px) {…}
<xforms>
<model>
<instance>
<person>
<fname/>
<lname/>
</person>
</instance>
<submission id="form1" method="get"
action="submit.asp"/>
</model>
<input ref="fname">
<label>First Name</label></input><br />
<input ref="lname">
<label>Last Name</label></input><br /><br />
<submit submission="form1">
<label>Submit</label></submit>
</xforms>
Pro
Cons
Definition d'un langage XML approprie a l'application :
<cd>
<artist>Aatabou, Najat</artist>
<title>The Voice of the Atlas</title>
<catalog>CDORBD 069</catalog>
<time>61.15</time>
<filed>C05 World</filed>
<playlist>
<work>Baghi narajah</work>
<work>Finetriki</work>
<work>Shouffi rhirou</work>
<work>Lila ya s'haba</work>
</playlist>
</cd>
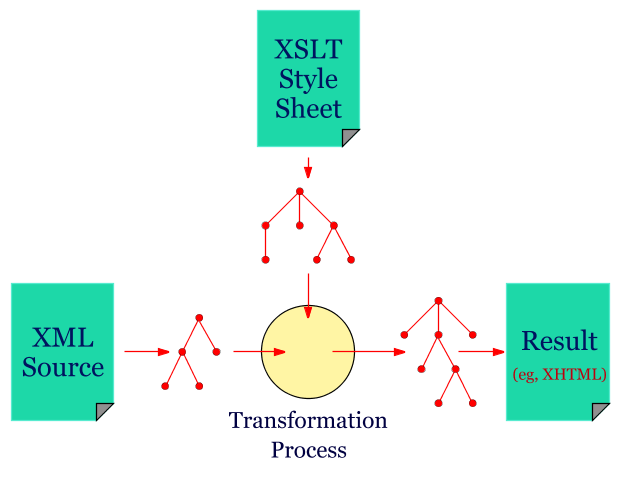
<xsl:template match="/"> <html> <xsl:for-each select="cd"> <h1><xsl:value-of select="artist"/></h1> <hr /> <p…
The Voice of the Atlas
Label: , Number: CDORBD 069 , Time: 61.15
Stored at: C05 World
Playlist:
<sel:select>
<sel:when sel:expr="screen-width > 400px
and available-colors > 4">
<img alt="Many people evacuated" src="imagebig"/>
</sel:when>
<sel:when sel:expr="screen-width > 100px and
available-colors > 4">
<img alt="Many people evacuated" src="imagesmall"/>
</sel:when>
<sel:otherwise>
<p>Many people had to be evacuated.</p>
</sel:otherwise>
| (banner) | ||
| (navigation) | (body) | |
| (copyright) | ||
<div role="copyright">
<p>Copyright © 1994-2005…
</div>
Si le sujet vous interesse, contactez-nous pour des stages de fin d'etudes !
W3C:
Cadre général DI:
Contexte de présentation
Edition Unique de document
W3C doesn't standardize Human-Computer Interfaces, but tries to define levels of abstraction, modules for various kinds of information & services, and the interfaces between them, so that you can replace the human-computer interface for some information or service with as little impact on the other modules as possible.
One classic example is separation of style and structure in documents. Most documents lend themselves well to that. That's why we have separate technologies (modules) for the structure of the content (HTML) and for the style (CSS and XSL).
It should be possible for the reader to choose his own interface to some data, depending on his preferences and the devices he has access to. But in some cases the best results are obtained if the provider of the data and the consumer negotiate the best interface. Some of the work of the Device Independent working group consists of identifying the situations in which negotiations is necessary (or desirable) and developing the protocols for negotiation.
CC/PP and Media Queries are two examples of such protocols. Usually, such protocols are fairly simple. There is only one round of negotiation: either the server gives a list of what it has and the client selects what it wants, or the client gives a list of abstract preferences and the server sends what best matches that list. A bit of both is also possible.