Fifteenth International Unicode Conference, San Jose, CA, U.S.A., August/September 1999
WWW: World Wide Web
Base: The Internet as a heterogeneous network of computer nodes
Nodes can be (at the same time!):
The documents of the Web are structured as a global hypertext
Hypertext = Text (structured) + Links (+ Style Sheets)
Linked Web documents can be distributed worldwide
HTML: HyperText Markup Language
HTML is the format of choice (lingua franca, glue) for (hyper)texts in the Web
HTML is defined as an application of SGML
HTML is simple and easy to learn and understand
HTML is evolving
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN"
"http://www.w3.org/TR/REC-html40/strict.dtd">
<html>
<head>
<title>My first HTML document</title>
</head>
<body>
<p>Hello world!</p>
</body>
</html>
Is a rigorously defined subset of SGML (single SGML declaration)
Provides many of the advantages, but few of the headaches of SGML
Is good for: marking up parallel texts, database usage, stylesheet, hyperlinking
Current and upcoming applications of XML at W3C: MathML, SMIL, RDF, XHTML, XSL, SVG,...
Lots of applications elsewhere
<?xml version="1.0"?> <page> <title>My first XML document</title> <body> <para>Hello world!</para> </body> </page>
<h1>)
body {
color: #ffffff;
background: url("texture.jpg") #000060;
font-size: 30px;
font-family: arial, helvetica, sans-serif;
}
div.slidebody { height: 345px; }
code {
font-weight: bold;
font-family: "Courier New",courier,monospace;
}
HTTP: HyperText Transfer Protocol
Web data transfer between server and client mostly uses the HTTP protocol
General pattern:
Redirection via proxies for
| For WWW clients to receive understandable responses from a web server, no matter where they are in the world, and no matter what the language and encoding of the data being retrieved. |
The WWW is a single application
Locale independent representation
Must rely on standards
Standards are important for
Web standards generally dont specify
1991: Inception of WWW
1992: Mosaic-L10N
1993: IETF begins standardization
1994: ML-WWW, Netscape
1995: Alis Tango, Internet with an Accent
1995/6: IETF, WInter
1997: Netscape 4.0, MS IE 4.0, RFC 2070, HTML 4.0
1998: XML, CSS2
1999: XHTML
What can go wrong?
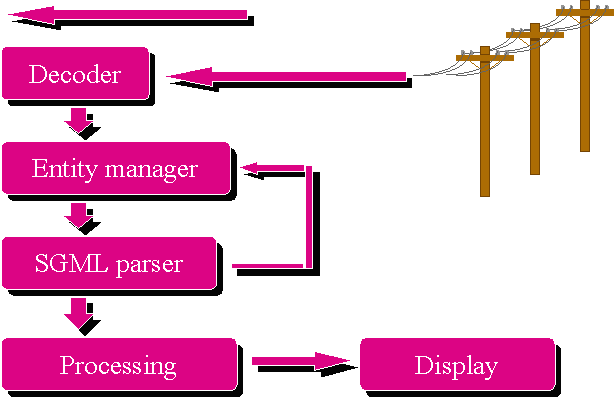
Reference processing model
Escaping and Numeric Character References
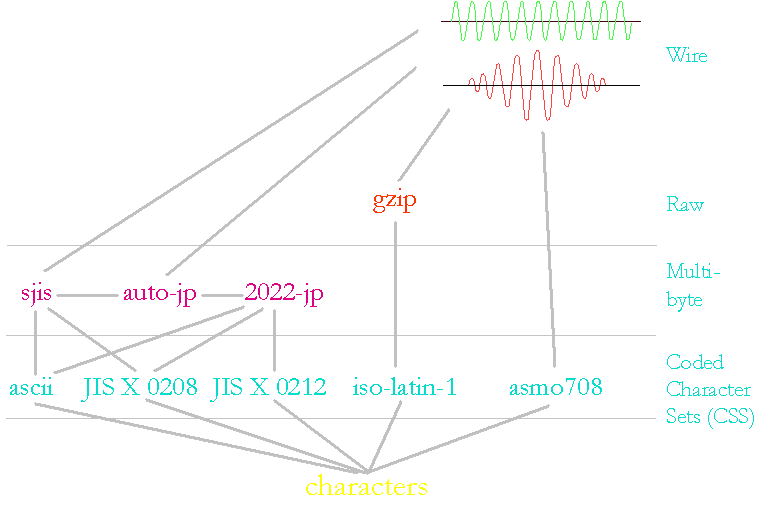
Character encoding identification
Very basic and central
Has to answer various requirements
Often leads to confusion
Internationalization:
$B$'$j$,$H$&$4$6$$$^$7$?!#O@J8$ r<h$j$K9T$-$^$7$?!#<+EY$NO@J8(J
Implementation does not have to use Unicode, only to behave as if it did
HTML and CSS do not require that all characters be displayed; XML does not speak about display
Model is backwards compatible for old HTML browsers
XML requires that a processor accept UTF-8 and UTF-16 input, so it's difficult not to use Unicode internally
Other Recommendations, e.g. DOM (API), require Unicode
Escaping used to represent:
é" = "é"With the reference processing model, escapes become unambiguous:
NCRs are decimal (A is A) or, in HTML 4.0 and XML,
hexadecimal (A is A); now in SGML corrigendum
One character = one escape, not two for surrogate pairs
In HTML • is sometimes used (mostly based on CP 1252),
but is illegal, because it does not exist in Unicode
Replace with correct NCR (named entities also provided in HTML 4.0):
| wrong number | correct NCR | character | named entity |
| 132 | „ | „ | „ |
| 133 | … | … | … |
| 134 | † | † | † |
| 135 | ‡ | ‡ | ‡ |
| 139 | ‹ | ‹ | ‹ |
| 140 | Π| Π| Π|
| 145 | ‘ | ‘ | ‘ |
| 146 | ’ | ’ | ’ |
| 147 | “ | “ | “ |
| 148 | ” | ” | ” |
| 149 | • | • | • |
| 151 | — | — | — |
| 153 | ™ | ™ | ™ |
| 155 | › | › | › |
| 156 | œ | œ | œ |
| € | ¬ | € |
<script> and
<style> contents
Transcoding always works from smaller repertoire to larger repertoire, but not the other way round
Character identity depends on UCS codepoint, which depends only on character encoding and encoded value, not font
Do not use <FONT FACE="..."> to cheat on characters (e.g. Symbol font)
Do not use character entities(e.g. á) or NCR if you can just type the character as is (e.g. á):
IANA charset registry
'charset' negotiation
Fallbacks
Priorities
Failure cases
MIME: Multipurpose Internet Mail Extensions
Designed for Email, used in HTTP
MIME headers indicate resource types (text/image/audio/...),...
'charset' parameter
MIME charsets registered with IANA (Internet assigned numbers authority [RFC1790])
IANA registry is polluted by useless charsets and aliases
Unregistered charsets preceeded by x- (e.g.
x-iscii-devan)
Generate most important charsets:
These identifiers are case-insensitive
use only 'MIME preferred' values, maybe accept others
Client sends Accept-Charset HTTP header (most HTTP/1.1 browsers do)
Accept-Charset: UTF-8,ISO-8859-1;q=0.9,*;q=0.1
Server knows encoding for each document and sends 'charset' parameter in HTTP header
Content-Type: text/html; charset="UTF-8"
Problem: Difficult on most servers to configure this
Difficult to tell the server about the character encoding of a document
'Self-identifying' document:
<meta http-equiv="Content-Type" content="text/html;
charset=UTF-8"><head>
<?xml version="1.0" encoding="UTF-16BE"?>@charset "UTF-8";
Additional mechanism in HTML:
<a> and
<link>):
<a href=...
charset="UTF-8">...</a>(highest priority first)
1. [Per-document user override]
2. HTTP header (or other protocol information)
3. Self-identification (<meta> for HTML,
encoding for XML, @charset for CSS)
4. 'charset' parameter on links
5. [User preferences/heuristics]
<meta>, but charset is in
<meta> ! (Works only if <meta> is ASCII
and nothing before gets the parser disturbed.)<meta> as early as possible
Transcoders don't change self-identification
URI Internationalization
Identifiers are element and attribute names, CSS selectors and properties, etc.
In HTML, all identifiers are restricted to a subset of ASCII (-_:.A-Za-z0-9). Case insensivity is the rule, but there are exceptions
In CSS, identifiers are almost unrestricted (-A-Za-z0-9 + any char > 160); in fact, all identifers are ASCII. Almost everything is case-insensitive.
In XML, identifiers may be formed from a very large subset of Unicode; non-ASCII identifiers are widely used. Everything is case-sensitive.
In XHTML, the identifiers are those of HTML in lower-case and everything is case-sensitive (from XML).
Currently: URIs encode bytes, not characters
Most ASCII bytes expressed as ASCII chars, other byte values as %HH
No standard way to use non-ASCII characters (no defined character encoding)
Converging to use UTF-8 (implemented in IE 5.0)
Up to date references:
Internationalization of URIs and other identifiers http://www.w3.org/International/O-URL-and-ident.html
The "Send back as received" convention
The Hidden Field solution
The Accept-Charset attribute
Internationalized URIs
Data entered in forms is sent back as URIs or as a URL-encoded body
Problem: Reliable character encoding identification
Various provisions, none of them fully established:
<form>
Basic idea: If document is received in iso-2022-jp, send back iso-2022-jp
'charset' of document received has to be correctly identified (assure reader can check)
Fails with transcoding proxies
Fails with multiple forms handled by single CGI
Character repertoire may be limited
Not working on all older browsers
Form fields can be hidden (like cookies)
Easy way to identify the encoding sent (because text is known and chosen carefully)
Allows to track transcodings
Needs analysis in CGI script
accept-charset attribute on <form>
Allows wider character repertoire
Comma-separated list of charsets
Example:
<form action="..."accept-charset="iso-8859-1,utf-8">
Note: was on <input> and
<textarea> in RFC 2070, is on
<form> in HTML 4.0
Use only UTF-8 for query parts: no charset identification problems anymore
Backwards compatibility problems:
Author-triggered with accept-charset on
<form>
Needs work in CGI script
Language tag syntax
Nesting
Stylesheets
Limitations
Language tagging helps to:
Language is largely orthogonal to character encoding
HTML: All elements (exceptions: param, base, script) can carry the
lang attribute:
<span lang="it">Grazie</span>
<span> is a generic container, phrase-level, with meaning
only from its attributes (lang, dir, id and class)
XML: xml:lang attribute, can go on any element but
must be declared in DTD for strict validation.
XHTML (HTML expressed in XML syntax): use both lang and
xml:lang
Value is language tag per RFC 1766:
'fr' ISO 639 'en-US' ISO 639 + 3166 'no-nynorsk' additional qualifier 'i-navajo' IANA registry 'x-anything' "experimental"
Case is irrelevant
Do not use period or underline as separator
RFC 1766 will be updated with ISO 639-2
(see
draft-alvestrand-lang-tags-v2-00.txt)
Inner tag overrides outer, which overrides HTTP header
<p lang="en">He said <q
lang="it">Grazie</q> and left.</p>
[Language info sometimes may be derived heuristically from charset]
Language-dependent styling allows to fine-tune presentation
*:lang(xx) {
<something> }*[lang|=yy] { <something
else> }
Matches any element whose lang attribute has a
hyphen-separated list of tokens beginning with "yy" (hierarchical matching).
Dialects, idioms, translitteration,...
Creoles, pidgins,...
Names (what language is "Martin")
Text not associated to any language (e.g. programming text, math,...)
Mixed uses (e.g. hyphenation according to one language, voice synthesis according to another)
List styles
Text transformations
Font specification
Font description
Quoting style depends on language:
»Dansk ’da’ Danish«
„Deutsch ‘de’ German”
“English ‘en’ English”
« Français « fr » French »
«Italiano «it» Italian»
«Norsk ’no’ Norwegian»
« CAA:89 „ru” Russian»
HTML has the <q> element, which adds quotation
marks before and after
The quoting style is controlled by CSS properties and values
[lang|=no] > * { quotes: "«" "»" "\2019" "\2019" }
q:before { content: open-quote }
q:after { content: close-quote }
CSS has a list-style-type property with the following values
disc|circle|square|decimal|decimal-leading-zero| lower-roman|upper-roman|lower-greek|lower-alpha| lower-latin|upper-alpha|upper-latin|hebrew| armenian|georgian|cjk-ideographic|hiragana| katakana|hiragana-iroha|katakana-iroha
text-transform: uppercase, lowercase
body { font-family: Baskerville, "Heisei Mincho
W3",Symbol,serif }
Fallback mechanism:
serif is a
<generic-family>, last resort
Language-dependent styling allows to fine-tune font combinations
*:lang(ja) { font: 900 14pt/16pt
"Heisei Mincho W9", serif }
*:lang(zh-tw) { font: 800 14pt/16pt
"Li Sung", serif }
'WebFonts' capabilities enable client-side font matching, font synthesis and progressive rendering, font download
font-family, font-style,
font-weight,...
unicode-range descriptor:
unicode-range: U+??, U+AC00-D7F
Meaning: this font covers (some of) Latin-1 and Hangul
Unicode algorithm vs Markup
DIR attribute
<BDO> element
Useful entities
Bidi in CSS
Bidirectional text: Mixture of right-to-left and left-to-right text for Arabic, Hebrew,...
Bidirectional text is stored in logical (reading) order
Needs reordering for display
Unicode algorithm components:
HTML is a "higher level protocol"
BIDI embeddings are usually in sync with document structure (paragraphs, citations, emphasis,...)
BIDI markup maps directly to the Unicode algorithm or to corresponding Unicode characters
dir='ltr' or dir='rtl'
Default is ltr
On block elements (<div>, <p>,
<li>, <td>, etc.), gives base direction
Is inherited from enclosing elements
Affects default value of align
Put one on <html> to establish base for whole document,
including title
On in-line elements (<span>,
<em>,<strong>, etc.), the dir attribute
creates a new embedding level
he said: <span dir=rtl>«HE SAID: «hello» AND SHUT
UP»</span> and shut up.
<bdo> element
Bidi override: Overrides implicit directional properties of contents
Requires dir attribute
Useful for part numbers (and for including visually formated text)
<bdo dir=ltr>ABab12DE</bdo>
Correct: ABab12DE
Wrong: BAab12ED
‎ and ‏provide directional context
for neutrals, symmetric swapping, etc.
Example:
‏(‏ ==>
)
NO other effect (invisible, no word break, etc.)
‍ and ‌ force or prevent joining
in cursive scripts
This is syntactic sugar for actual Unicode characters, but helps with editing source
Not needed for HTML, but for XML
Many things in CSS2 have defaults that are directionality-dependent: tables, alignment, lists, etc.
Exception : background-position
direction:ltr|rtl|inherit
unicode-bidi: normal|embed|bidi-override
Preserve HTML bidi semantics
bdo[dir="ltr"] { direction: ltr; unicode-bidi: bidi-override }
*[dir="ltr"] { direction: ltr; unicode-bidi: embed }
Block-level elements { unicode-bidi: embed }
(the last line is only relevant if a block-level element is reformatted as an inline element)
RFC 2070 is IETF Proposed Standard
HTML 4.0 is W3C Recommendation
CSS2 is W3C Recommendation
XML 1.0 is W3C Recommendation
XHTML 1.0 is W3C Proposed Recommendation
I18n features of HTML 4.0 incorporated in ISO HTML
Support increasing in browsers
Support for UTF-8 in Tango, Netscape 4.0 (needs Unicode font) and MSIE 4.0 (needs language packs)
Markup enabling locale-sensitive rendering and/or form input of date, time, monetary, etc. values
Ruby (HTML, CSS, XSL)
Hyphenation, vertical writing (CSS, XSL)
Generic I18N markup for XML
Ruby characters are small annotations set on top of ideographic characters to indicate pronunciation

<ruby>
<rb> </rb>
</rb>
<rt>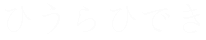 </rt>
</rt>
</ruby>
Working on details: Ruby on both sides, association details, line breaking (see http://www.w3.org/TR/WD-ruby/)
Various levels of complexity
­, often not correctly
implemented)
XSL (Extensible Stylesheet Language)
Missing Characters
What is good ML typography?
Glyph: Shape in font used for display
Character: Basic logical text component
Missing glyph: Appropriate font resource not available
Missing character: Not clear how to transmit character
Provide full Unicode support with at least one font
Use font downloading/encapsulation mechanisms (CSS2 WebFonts)
Use conversion server (converts characters to inline images)
Only for well-defined communities
Use markup (not defined yet)
Caveat: HTML mostly shows structure, not presentation (=> style sheets and client-side issue)
Readability first, typography next
Typography differs for each language
Typography needs time to develop
Some bilingual examples,but almost no multilingual examples
Font availability
Font matching
Relation of multilingual text pieces
Interaction between styles and lang
lang as a selector for style (CSS2)
class
Translation servers
Translation Helper Applications
Parallel Documents
Servers that can perform encoding conversion
Other servers can redirect a client to them (shared objects)
Can also perform transliteration
Two primary categories:
Applications that "plug in" to clients, and provide machine translation services.
Already widely available in Japan
Limited by client machine capabilities
So far, do not produce good results
Same text in different languages
Important in legal contexts (e.g. EU)
Alignment levels: document, sentence
Tools should provide:
Xlink is going to help
Language selectors
Site structure
File naming
Page encoding
Text as graphics
World-wide accessibility does not make a site international
An international site needs:
Synergy between broadcasting and narrowcasting
Better understanding of information in multicultural or foreign environments
Enhancement of corporate image
Better response time
Text, images, etc.
Cultural differences in the interpretation of images, colors, symbols


Use content negotiation
Provide controls
| Flags (distributed sites only)  |
List box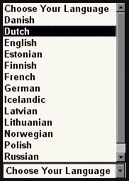 Mistake! |
Text (as images)  |
Organization by contents:
Organization by languages:
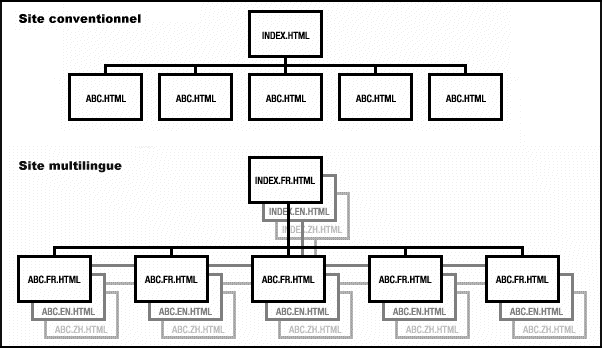
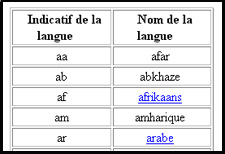
Insert ISO language code between file name and extension:
index.am.html
Allows language negotiation
Beware of intuition
Do not translate file name!
http://babel.alis.com/langues/iso639.htm
Use appropriate character set
Do provide charset identification
Do not use entities, esp. falsely
Multilingual tools make for easier editing
Make your pages processable:
Make your pages lasting, reusable
Make your pages universal
Ask whether it works on multiple platforms: not everyone has the same system as yours
More attractive for navigation elements
May help respect corporate image
Art costs add up to translation
Fast update difficult
Avoid absolutely for headings and paragraphs
When designing pages, beware that text size and direction will vary in translation, affecting:
Many images must be localized and/or translated

Beware of text expansion !
SVG will make things easier
Thread carefully with scripts: charset issues, hard-coded messages
Java, ActiveX may require full localization by experts
Sound, movies may require dubbing, localization. Multimedia localization firms have expertise that can be leveraged on the Web.
| A1: 10:00 - 10:40 Multilingual Application Server Yamasaki - Netscape |
A3: 11:30 - 12:10 Globalization of Amaya Guetari - W3C |
| A2: 10:45 - 11:25 Int'l Features of MSIE Suignard - Microsoft |
A4: 13:20 - 14:00 Character Model Dürst - W3C |
| A5: 14:05 - 15:30 Panel: i18n of the Internet |
