The World Wide Web Consortium's Voice Browser Working Group is
defining several markup languages for applications supporting
speech input and output. These markup languages will enable
speech applications across a range of hardware and software
platforms. Specifically, the Working Group is designing markup
languages for dialog, speech recognition grammar, speech
synthesis, natural language semantics, and a collection of
reusable dialog components. These markup languages make up the
W3C Speech Interface Framework. The speech community is invited
to review and comment on the working draft requirement and
specification documents.
This document describes a model architecture for speech
processing in voice browsers. It also briefly describes markup
languages for dialog, speech recognition grammar, speech
synthesis, natural language semantics, and a collection of
reusable dialog components. This document is being released as a
working draft, but is not intended to become a proposed
recommendation.
This specification is a Working Draft of the Voice Browser
working group for review by W3C members and other interested
parties. It is a draft document and may be updated, replaced, or
obsoleted by other documents at any time. It is inappropriate to
use W3C Working Drafts as reference material or to cite them as
other than "work in progress".
Publication as a Working Draft does not imply endorsement by
the W3C membership, nor of members of the Voice Browser working
groups. This is still a draft document and may be updated,
replaced or obsoleted by other documents at any time. It is
inappropriate to cite W3C Working Drafts as other than "work in
progress."
This document has been produced as part of the W3C Voice Browser Activity,
following the procedures set out for the W3C Process. The
authors of this document are members of the Voice Browser Working
Group. This document is for public review. Comments should be
sent to the public mailing list <www-voice@w3.org> (archive).
A list of current W3C Recommendations and other technical
documents can be found at http://www.w3.org/TR.
The Voice Browser Working Group was chartered
by the World Wide Web Consortium (W3C) within the User Interface
Activity in May 1999 to prepare and review markup languages that
enable voice browsers. Members meet weekly via telephone and
quarterly in face-to-face meetings.
The W3C Voice Browser
Working Group is open to any member of the W3C Consortium.
The Voice Browser Working Group has also invited experts whose
affiliations are not members of the W3C Consortium. The four
founding members of the VoiceXML Forum, as well as telelphony
applications venders, speech recognition and text to speech
engine venders, web portals, hardware venders, software venders,
telcos and appliance manufactures have representatives who
participate in the Voice Browser Working Group. Current members
include AskJeves, AT&T, Avaya, BT, Canon, Cisco, France
Telecon, General Magic, Hitachi, HP, IBM, isSound, Intel, Locus
Dialogue, Lucent, Microsoft, Mitre, Motorola, Nokia, Nortel,
Nuance, Phillips, PipeBeach, Speech Works, Sun, Telecon Italia,
TellMe.com, and Unisys, in addition to several invited
experts.
Table of Contents
A voice browser is a device (hardware and software)
that interprets voice markup languages to generate voice output,
interpret voice input, and possibly accept and produce other
modalities of input and output.
Currently the major deployment of voice browsers enable users
to speak and listen using a telephone or cell phone to access
information available on the World Wide Web. These voice browsers
accept DTMF and spoken words as input, and produce synthesized
speech or replay prerecorded speech as output. The voice markup
languages interpreted by voice browsers are also frequently
available on the World Wide Web. However, many other deployments
of voice browsers are possible.
Hardware devices may include telephones or cell phones,
hand-held computers, palm-sized computers, laptop PCs, and
desktop PCs. Voice browser hardware processors may be embedded
into appliances such as TVs, radios, VCRs, remote controls,
ovens, refrigerators, coffeepots, doorbells, and practically any
other electronic or electrical device.
Possible software applications include:
- Accessing business information, including the corporate
"front desk" asking callers who or what they want, automated
telephone ordering services, support desks, order tracking,
airline arrival and departure information, cinema and theater
booking services, and home banking services
- Accessing public information, including community information
such as weather, traffic conditions, school closures, directions
and events; local, national and international news; national and
international stock market information; and business and
e-commerce transactions
- Accessing personal information, including calendars, address
and telephone lists, to-do lists, shopping lists, and calorie
counters
- Assisting the user to communicate with other people sending
and receiving voice-mail messages
Our definition of a voice browser does not support a voice
interface to HTML pages. A voice browser processes scripts
written using voice markup languages. HTML is not among the
languages which can be interpreted by a voice browser. Some
venders are creating voice-enabled HTML browsers that produce
voice instead of displaying text on a screen display. A
voice-enabled HTML browser must determine the sequence of text to
present to the user as voice, and possibly how to verbally
present non-text data such as tables, illustrations, and
animations. A voice browser, on the other hand, interprets a
script which specifies exactly what to verbally present to the
user as well as when to present each piece of information
Voice is a very natural user interface because it
enables the user to speak and listen using skills learned during
childhood. Currently users speak and listen to telephones and
cell phones with no display to interact with voice browsers. Some
voice browsers may have small screens, such as those found on
cell phones and palm computers. In the future, voice browsers may
also support other modes and media such as pen, video, and sensor
input and graphics animation and actuator controls as output. For
example, voice and pen input would be appropriate for Asian users
whose spoken language does not lend itself to entry with
traditional QWERTY keyboards.
Some voice browsers are portable. They can be used
anywhere—at home, at work, and on the road. Information
will be available to a greater audience, especially to
people who have access to handsets, either telephones or cell
phones, but not to networked computers.
Voice browsers present a pragmatic interface for
functionally blind users or users needing Web access while
keeping their hands and eyes free for other things. Voice
browsers present an invisible user interface to the user, while
freeing workspace previously occupied by keyboards and mice.
The Voice Browser Working group has defined the W3C Speech
Interface Framework, shown in Figure 1. The white boxes
represent typical components of a speech-enabled web application.
The black arrows represent data flowing among these components.
The blue ovals indicate data specified using markup languages
used to guide components to accomplish their respective tasks. To
review the latest requirement and specification documents for
each of the markup languages, see the section entitled
Requirements and Language specification Documents on our W3C Voice Browser home web
site.
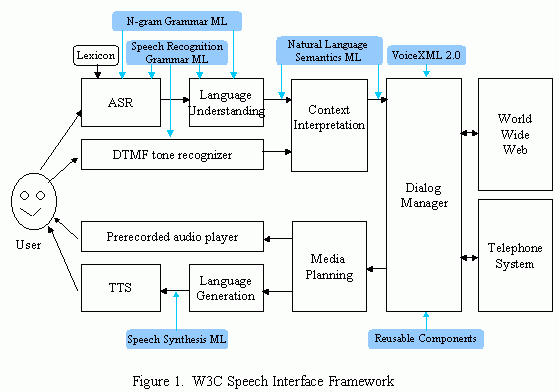
Components of the W3C Speech Interface Framework include the
following:
Automatic Speech Recognizer (ASR)—accepts speech
from the user and produces text. The ASR uses a grammar to
recognize words from the user's spoken speech. Some ASRs use
grammars specified by a developer using the Speech Grammar
Markup Language. Other ASRs use statistical grammars
generated from large corpra of speech data. These grammars are
represented using the N-gram Stochastic Grammar Markup
Language.
DTMF Tone Recognizer—accepts touch-tones produced
by a telephone when the user presses the keys on the telephone's
keypad. Telephone users may use touch-tones to enter digits or
make menu selections.
Language Understanding Component—extracts
semantics from a text string by using a prespecified grammar. The
text string may by produced by an ASR or be entered directly by a
user via a keyboard. The Language Understanding Component may
also use grammars specified using the Speech Grammar Markup
Language or the N-gram Stochastic Grammar Markup
Language. The output of the Language Understanding Component
is expressed using the Natural Language Semantics Markup
Language.
Context Interpreter—enhances the semantics from
the Language Understanding Module by obtaining context
information from a dialog history (not shown in Figure 1). For
example, the Context Interpreter may replace a pronoun by a noun
to which the pronoun referred. The input and output from the
Context Interpreter is expressed using the Natural Language
Semantics Markup Language.
Dialog Manager—prompts the user for input, makes
sense of the input, and determines what to do next according to
instructions in a dialog script specified using VoiceXML 2.0
modeled after VoiceXML 1.0. Depending upon the input received,
the dialog manager may invoke application services, or download
another dialog script from the web, or cause information to be
presented to the user. The Dialog Manager accepts input specified
using the Natural Language Semantics Markup Language.
Dialog scripts may refer to Reusable Dialog Components,
portions of another dialog script which can be reused across
multiple applications.
Media Planner—determines whether output from the
dialog manager should be presented to the user as synthetic
speech or prerecorded audio.
Recorded audio player—replays prerecorded audio
files to the user, either in conjunction with, or in place of
synthesized voices.
Language Generator—Accepts text from the media
planner and prepares it for presentation to the user as spoken
voice via a text-to-speech synthesizer (TTS). The text may
contain markup tags expressed using the Speech Synthesis
Markup Language which provides hints and suggestions for how
acoustic sounds should be produced. These tags may be produced
automatically by the Language Generator or manually inserted by a
developer.
Text-to-Speech Synthesizer (TTS)—Accepts text
from the Language Generator and produces acoustic signals which
the user hears as a human-like voice according to hints specified
using the Speech Synthesis Markup Language.
The components of any specific voice browser may differ
significantly from the Components shown in Figure 1. For example,
the Context Interpretation, Language Generation and Media
Planning components may be incorporated into the Dialog Manager,
or the tone recognizer may be incorporated into the Context
Interpretation. However, most voice browser implementations will
still be able to use of the various markup languages defined in
the W3C Speech Interface Framework.
The Voice Browser Working Group is not defining the components
in the W3C Speech Interface Framework. It is defining markup
languages for representing data in each of the blue ovals in
Figure 1. Specifically, the Voice Browser Working Group is
defining the following markup languages:
-
Speech Recognition Grammar Specification
-
N-gram Grammar Markup Language
-
Speech Synthesis Markup Language
-
Dialog Markup Language
The Voice Browser Working Group is also defining packaged
dialogs which we call Reusable Components. As their name
suggests, reusable components can be reused in other dialog
scripts, decreasing the implementation effort and increasing user
interface consistency. The Working Group may also define a
collection of reusable components such as solicit the user's
credit card number and exploration date, solicit the user's
address, etc.
Just as HTML formats data for screen-based interactions over
the Internet, an XML-based language is needed to format data for
voice-based interactions over the Internet. All markup languages
recommended by the Working Group will be XML-based, so XML
language processors can process any of the W3C Speech Interface
Framework markup languages.
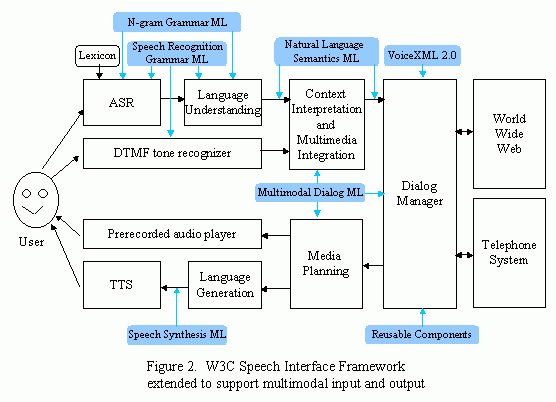
Figure 2 illustrates the W3C Speech Interface Framework
extended to support multiple modes of input and output. It is
anticipated that another working group will be formed to specify
the Multimodal Dialog Language, an extension of the Dialog
Language. We anticipate that another Working Group will be
established to take over our current work in defining the
Multimodal Dialog Language.
Markup languages also may be used in applications not usually
associated with voice browsers. The following applications also
may benefit from the use of voice browser markup languages:
- Text-based Information Storage and
Retrieval—Acceptance of text from a keyboard and
presents the text on a display. It uses neither ASR nor TTS, but
makes heavy use of the language understanding module and the
natural language semantic markup language.
- Robot Command and Control—Users speak commands
that control a mechanical robot. This application may use both
Speech Recognition Grammar Specification and dialog markup
languages.
- Medical Transcription—A complex, specialized
speech recognition grammar is used to extract medical information
from text produced by the ASR. A human editor corrects the
resulting text before printing.
- Newsreader—A language generator produces
marked-up text for presenting voice to the user. This application
uses a special language generator to markup text from news wire
services for verbal presentation.
To review the latest requirement and specification documents
for each of the following languages, see the section titled
Requirements and Language specification Documents on our W3C Voice Browser home web
site
The Speech Recognition Grammar Specification supports the
definition of Context-Free Grammars (CFG) and, by subsumption,
Finite-State Grammars (FSG). The specification defines an XML
Grammar Markup Language, and an optional Augmented Backus-Naur
Format (ABNF) Markup Language. Automatic transformations between
the two formats is possible, for example, by XSLT to convert the
XML format to ABNF. We anticipate that development tools will be
constructed that provide the familiar ABNF format to developers,
and enable XML software to manipulate the XML grammar format. The
ABNF and XML languages are modeled after Sun's JSpeech Grammar
Format. Some of the interesting features of the draft
specification:
-
Ability to cross-reference grammars by URI and to use this
ability to define libraries of useful grammars.
-
Internationalized.
-
Semantic tagging mechanism for interpretation of spoken input
(under development).
-
Applicable to non-speech input modalities, e.g. DTMF input or
parsing and interpretation of typed input.
A complementary speech recognition grammar language
specification is defined for N-Gram language models.
Terms used in the Speech Grammar Markup Language requirements
and specification documents include:
| CFG |
Context-Free Grammar. A formal computer science
term for a language that permits embedded recursion. |
| BNF |
Backus-Naur Format. A language used widely in
computer science for textural representations of CFGs. |
| ABNF |
Augmented Backus-Naur Format. The language
defined in the grammar specification that extends a conventional
BNF representation with regular grammar capabilities, syntax for
cross-referencing between grammars and other useful syntactic
features |
| Grammar |
The representation of constraints defining the
set of allowable sentences in a language. E.g. a grammar for
describing a set of sentences for ordering a pizza. |
| Language |
A formal computer science term for the collection
of set of sentences associated with a particular domain. Language
may refer to natural or program language. |
A text document may be produced automatically, authored by
people, or a combination of both. The Speech Synthesis Markup
Language supports high-level specifications, including the
selection of voice characteristics (name, gender, and age) and
the speed, volume, and emphasis of individual words. The language
also may describe how to pronounce acronyms, such as "Nasa" for
NASA, or spelled, such as "N, double A, C, P," for NAACP. At a
lower level, designers may specify prosodic control, which
includes pitch, timing, pausing, and speaking rate. The Speech
Synthesis Markup Language is modeled on Sun's
Java Speech Markup Language.
There is some variance in the use of terminology in the speech
synthesis community. The following definitions establish a common
understanding
| Prosody |
Features of speech such as pitch, pitch range,
speaking rate and volume. |
| Speech Synthesis |
The process of automatic generation of speech
output from data input which may include plain text, formatted text or binary objects. |
| Text-To-Speech |
The process of automatic generation of speech
output from text or annotated text input. |
VoiceXML 2.0 Markup supports four I/O modes: speech
recognition and DTMF as input with synthesized speech and
prerecorded speech as output. VoiceXML 2.0 supports
system-directed speech dialogs where the system prompts the user
for responses, makes sense of the input, and determines what to
do next. VoiceXML 2.0 also supports mixed initiative speech
dialogs. In addition, VoiceXML also supports task switching and
the handling of events, such as recognition errors, incomplete
information entered by the user, timeouts, barge-in, and
developer-defined events. Barge-in allows users to speak while
the browser is speaking. VoiceXML 2.0 is modeled after VoiceXML 1.0
designed by the VoiceXML
Forum, whose founding members are AT&T, IBM, Lucent, and
Motorola.
Terms used in the Dialog Markup Language requirements and
specification documents include:
| Dialog Markup Language |
a language in which voice dialog behavior is specified. The
language may include reference to scripting elements which can
also determine dialog behavior. |
| Voice Browser |
a software device which interprets a voice markup language
and generates a dialog with voice output and possibly other
output modalities and/or voice input and possibly other
modalities. |
| Dialog |
a model of interactive behavior underlying the interpretation
of the markup language. The model consists of states, variables,
events, event handlers, inputs and outputs. |
| Utterance |
Used in this document generally to refer to a meaningful user
input in any modality supported by the platform, not limited to
spoken inputs. For example, speech, DTMF, pointing, handwriting,
text and OCR. |
| Mixed initiative dialog |
A type of dialog in which either they system or the user can
take the initiative at any point in the dialog by failing to
respond directly to the previous utterance. For example, the user
can make corrections, volunteer additional information, etc.
Systems support mixed initiative dialog to various degrees.
Compare to "directed dialog." |
| Directed dialog |
Also referred to as "system initiative" or "system led." A
type of dialog in which the user is permitted only direct literal
responses to the system's prompts. |
| State |
the basic interact ional unit defined in the markup language.
A state can specify variables, event handlers, outputs and
inputs. A state may describe output content to be presented to
the user, input which the user can enter, event handlers
describing, for example, which variables to bind and which state
to transition to when an event occurs. |
| Events |
generated when a state is executed by the voice browser; for
example, when outputs or inputs in a state are rendered or
interpreted. Events are typed and may include information; for
example, an input event generated when an utterance is recognized
may include the string recognized, an interpretation, confidence
score, and so on. |
| Event Handlers |
are specified in the voice markup language and describe how
events generated by the voice browser are to be handled.
Interpretation of events may bind variables, or map the current
state into another state (possibly itself). |
| Output |
content specified in an element of the markup language for
presentation to the user. The content is rendered by the voice
browser; for example, audio files or text rendered by a TTS.
Output can also contain parameters for the output device; for
example, volume of audio file playback, language for TTS, etc.
Events are generated when, for example, the audio file has been
played. |
| Input |
content (and its interpretation) specified in an element of
the markup language which can be given as input by a user; for
example, a grammar for DTMF and speech input. Events are
generated by the voice browser when, for example, the user has
spoken an utterance and variables may be bound to information
contained in the event. Input can also specify parameters for the
input device; for example, timeout parameters, etc. |
The Natural Language Semantics Markup Language supports XML
semantic representations. For application-specific information,
it is based on the W3C XForms.
The Natural Language Semantics Markup Language also includes
application-independent elements defined by the W3C Voice Browser
group. This application-independent information includes
confidences, the grammar matched by the interpretation, speech
recognizer input, and timestamps. The Natural Language Semantics
Markup Language combines elements from the XForms, natural
language semantics, and application-specific namespaces. For
example, the text, "I want to fly from New York to Boston, and,
then, to Washington, DC", could be represented as:
<result xmlns:xf="http://www.w3.org/2000/xforms"
x-model="http://flight-model"
grammar="http://flight-grammar">
<interpretation confidence=100>
<xf:instance>
<flight:trip>
<leg1>
<from>New York</from>
<to>Boston</to>
</leg1>
<leg2>
<from>Boston</from>
<to>DC</to>
</leg2>
</flight:trip>
</xf:instance>
<input mode="speech">
I want to fly from New York to Boston, and,
then, to Washington, DC
</input>
</interpretation>
</result>
Terms used in the Natural Language Semantics Markup Language
requirements and specification documents include:
| Natural language interpreter |
A device which produces a representation of the
meaning of a natural language expression. |
| Natural language expression |
An unformatted spoken or written utterance in a
human language such as English, French, Japanese, etc. |
Reusable Dialog Components are dialog components (chunks of
dialog script or platform-specific objects that pose frequently
asked questions in dialog scripts, and can be invoked from any
dialog script) that are reusable (can be used multiple times
within an application or used by multiple applications) and that
meet specific interface (configuration parameter and return value
format) requirements. The purpose of reusable components is to
reduce the effort to implement a dialog by reusing encapsulations
of common dialog tasks, and to promote consistency across
applications. The W3C Voice Browser Working Group is defining the
interface for Reusable Dialog Components. Future specifications
will define standard reusable dialog components for designated
tasks that are portable across platforms.
The following speech dialog fragment illustrates the use of
the speech synthesis, Speech Recognition Grammar Specification,
and speech dialog markup languages:
<menu>
<!-- This is an example of a menu which present the user -->
<!-- with a prompt and listens for the user to utter a choice -->
<prompt>
<!-- This text is presented to the user as synthetic speech -->
<!-- The emphasisis element adds emphasis to its content -->
Welcome to Ajax Travel Do you want to fly to
<emphasis>New York, Boston</emphasis> or
<emphasis>Washington DC</emphasis>
</prompt>
<!-- When the user speaks an utterance that matches the grammar -->
<!-- control is transferred to the "next" VoiceXML document -->
<choice next="http://www.NY...">
<!-- The Grammar element indicates the words which -->
<!-- the user may utter to select this choice -->
<grammar>
<choice>
<item> New York </item>
<item> The Big Apple </item>
</choice>
</grammar>
</choice>
<choice next="http://www.Boston...">
<grammar>
<choice>
<item> Boston </item>
<item> Beantown </item>
</choice>
</grammar>
</choice>
<choice next="http://www.Wash....">
<grammar>
<choice>
<item> Washington D.C. </item>
<item> Washington </item>
<item> The U.S. Capital </item>
</choice>
</grammar>
</choice>
</menu>
In the example above, the Dialog Markup Language describes
when a voice menu which contains a prompt to be presented to the
user. The user may respond by saying and of several choices. When
the user speech matches a particular grammar, control is
transferred to the dialog fragment at the "next" location.
The Speech Synthesis Markup Language describes how text is
rendered to the user. The Speech Synthesis Markup Language
includes <emphasis> element. When rendered to the user, the
word "you" will be emphasized, and the end of the sentence will
raise in pitch to indicate a question.
The Speech Recognition Grammar Specification describes the
words that the user must say when making a choice. The
<grammar> element is shown within the <choice>
element. The language understanding module will recognize "New
York" or "The Big Apple" to mean New York, "Boston" or "Beantown"
to mean Boston, and "Washington, D.C.," "Washington," or "The
U.S. Capital" to mean Washington.
An example user-computer dialog resulting from interpreting
the above dialog script is
Computer: Welcome to Ajax Travel Do you want to fly
to New York, Boston, or Washington DC?
User: Beantown
Computer: (transfers to dialog script associated with Boston)
W3C has acknowledged the JSGF and JSML
submission from the Sun
Microsystems. The W3C Voice Browser Working Group plans to
develop specifications for its Speech Synthesis Markup Language
and Speech Grammar Specification using JSGF and JSML as a
model.
W3C has acknowledged the VoiceXML 1.0
submission from the VoiceXML Forum. The W3C Voice Browser Working
Group plans to adopt VoiceXML 1.0 as the basis for developing
a Dialog Markup Language for interactive voice response
applications. See
ZDNet's article covering the announcement
The following resources are related to the efforts of the
Voice Browser working group.
- Aural
CSS
- The aural rendering of a document, already commonly used by
the blind and print-impaired communities, combines speech
synthesis and "auditory icons." Often such aural presentation
occurs by converting the document to plain text and feeding this
to a screen reader -- software or hardware that simply reads all
the characters on the screen. This results in less effective
presentation than would be the case if the document structure
were retained. Style sheet properties for aural presentation may
be used together with visual properties (mixed media) or as an
aural alternative to visual presentation.
The European Telecommunications
Standards Institute (ETSI)- The European Telecommunications Standards Institute (ETSI)
ETSI is a non-profit organization whose mission is "to determine
and produce the telecommunications standards that will be used
for decades to come". ETSI's work is complementary to W3C's. The
ETSI STQ Aurora DSR Working Group standardizes algorithms for
Distributed Speech Recognition (DSR). The idea is to preprocess
speech signals before transmission to a server connected to a
speech recognition engine. Navigate to http://www.etsi.org/stq/
for more details.
Java Speech Grammar Format- The Java™ Speech Grammar Format is used for defining
context free grammars for speech recognition. JSGF adopts the
style and conventions of the Java programming language in
addition to use of traditional grammar notations.
- Microsoft Speech
Site
- This site describes the Microsoft speech API, and
contains a recognizer and synthesizer that can be
downloaded.
NOTE-voice- This note describes features needed for effective interaction
with Web browsers that are based upon voice input and output.
Some extensions are proposed to HTML 4.0 and CSS2 to support
voice browsing, and some work is proposed in the area of speech
recognition and synthesis to make voice browsers more
effective.
SABLE- SABLE is a markup language for controlling text to speech
engines. It has evolved out of work on combining three existing
text to speech languages: SSML, STML and JSML.
SpeechML- (IBM's server precludes a simple URL for this, but you can
reach the SpeechML site by following the link for Speech
Recognition in the left frame) SpeechML plays a similar role
to VoxML, defining a markup language written in XML for IVR
systems. SpeechML features close integration with Java.
TalkML- This is an experimental markup language from HP Labs, written
in XML, and aimed at describing spoken dialogs in terms of
prompts, speech grammars and production rules for acting on
responses. It is being used to explore ideas for object-oriented
dialog structures, and for next generation aural style
sheets.
Voice Browsers
and Style Sheets- Presentation by Dave Raggett on May 13th 1999 as part of the
Style stack of Developer's Day in WWW8. The presentation makes
suggestions for extensions to ACSS.
VoiceXML site- The VoiceXML Forum formed by AT&, IBM, Lucent and
Motorola to pool their experience. The Forum has published an
early version of the VoiceXML specification. This builds on
earlier work on PML, VoxML and SpeechML.
The W3C Voice Browser Working Group is defining markup
languages for speech recognition grammars, speech dialog, natural
language semantics, multimodal dialogs, and speech synthesis, as
well as a collection of reusable dialog components. In addition
to voice browsers, these languages can also support a wide range
of applications including information storage and retrieval,
robot command and control, medical transcription, and newsreader
applications. The speech community is invited to review and
comment on working draft requirement and specification
documents.