
| Up: Table of Contents | Working Draft 6-Jan-98 |
This chapter introduces the basic ideas of MathML. The first section describes the overall design of MathML. The second section present a number of motivating examples, to give the reader something concrete to refer to while reading subsequent chapters of the MathML Specification. The final section describes basic features of the MathML syntax and grammar, which apply to all MathML markup. In particular, section 2.3 should be read before chapters 3, 4 and 5.
A fundamental challenge in defining a mathematics markup language for the Web is reconciling the need to encode both the presentation of a mathematical notation and the content of the mathematical idea or object which it represents.
The relationship between a mathematical notation and a mathematical idea is subtle and deep. On a formal level, the results of mathematical logic raise unsettling questions about the correspondence between symbolic logic systems and the phenomena they model. At a more intuitive level, anyone who uses mathematical notation knows the difference that a good choice of notation can make; the symbolic structure of the notation suggests the logical structure. For example, the Leibniz notation for derivatives "suggests" the chain rule of calculus through the symbolic cancellation of fractions:
Mathematicians and teachers understand this very well; part of their expertise lies in choosing notation that emphasizes key aspects of a problem while hiding or diminishing extraneous aspects. It is commonplace in math and science to write one thing when technically something else is meant, because long experience shows this actually communicates the idea better at some higher level.
In many other settings, though, mathematical notation is used to encode the full, precise meaning of a mathematical object. Mathematical notation is capable of prodigious rigor, and when used carefully, it is virtually free of ambiguity. Moreover, it is precisely this lack of ambiguity which makes it possible to describe mathematical objects so that they can be used by software applications such as computer algebra systems and voice renderers. In situations where such inter-application communication is of paramount importance, the nuances of visual presentation generally play a minimal role.
MathML allows authors to encode both the notation which represents a mathematical object and the mathematical structure of the object itself. Moreover, authors can mix both kinds of encoding in order to specify both the presentation and content of a mathematical idea. The remainder of this section gives a basic overview of how MathML can be used in each of these ways.
All MathML elements fall into one of three categories: presentation elements, content elements and interface elements. Each of these categories is described in detail in chapters 3, 4 and 7 respectively.
Presentation elements describe mathematical notation structure. Typical examples are the mrow element, which is used to indicate a horizontal row of characters, and the msup element, which is used to indicate a base and superscript. As a general rule, each presentation element corresponds to a single kind of notational "schema" such as a row, a superscript, an underscript and so on. Since many notational schemata have a number of frequently occuring variants, most presentation elements accept a number of attributes which can be used to select between variants. For example, the superscript element accepts a "superscript shift" attribute which specifies the minimum amount the superscript should shift upward.
Content elements describe mathematical objects directly, as opposed to describing the notation which represents them. Typical examples include the plus element, which denotes the usual addition operator for real numbers, and the vector element, which denotes a vector from linear algebra. Each content element corresponds to a carefully defined mathematical concept. Some elements represent mathematical objects like vectors, while others represent functions or operations like addition.
All but one MathML element is either a presentation element or a content element. The math element is neither, since its role is to serve as a top-level, interface element. One function of the math element is to pass on parameters to a MathML processor that affect an entire expression, such as style preferences. A second function is to communicate parameters to a Web browser about what software to use to render a MathML expression, and how the expression should be integrated into the surrounding HTML page. (As XML support is added to browsers, it may ultimately be necessary to introduce one or two more interface elements, to handle these functions separately. See chapter 7 for details.)
Presentation and content expressions both share a number of formal properties. In both cases, most expressions naturally decompose into pieces, or subexpressions. For example, the expression
(a + b)2
naturally breaks into a "base," the (a + b), and a
"script," which is the single character '2' in this case.
Furthermore, as this example shows, the subexpressions may
themselves decompose into further subexpressions, and so on. Of
course, the decomposition process eventually terminates with
indivisible expressions such as digits, letters, or other symbol
characters.
Although this particular example involves mathematical notation, and hence presentation markup, the same observation applies equally well to abstract mathematical objects, and hence to content markup. For example, our superscript example would typically denote an exponentiation operation that would require two operands: a "base" and an "exponent." This is no coincidence, since as a general rule, mathematical notation closely mirrors the logical structure of the underlying mathematical objects.
The recursive nature of mathematical objects and notation is strongly reflected in MathML markup. Most presentation or content elements contain some number of other MathML elements corresponding to the consituent pieces out of which the the original object is recursively built. The original schema is commonly called the parent schema, and the constituent pieces are called children schemata. More generally, MathML expressions can be regarded as trees, where each node corresponds to a MathML element, the branches under a "parent" node correspond to its "children", and the leaves in the tree correspond to indivisible notation or content units such as numbers, characters, etc.
The leaf nodes in a MathML expression tree are called token elements. MathML token elements are the only MathML elements permitted to directly contain character data. The character data may consist of ASCII characters and MathML entities, which are escape sequences of the form &entity_name;. MathML entities typically denote non-ASCII Unicode characters such as α, → and ∑.
The most important presentation token elements are mi, mn and mo for representing identifiers, numbers and operators respectively. Typically a renderer will employ slightly different typesetting styles for each of these kinds of character data: numbers are usually in upright font, identifiers in italics, and operators have extra space around them. In content markup, there are only two tokens, ci and cn for identifiers and numbers respectively. In content markup, functions and operations correspond to separate elements, and consequently no operator token is necessary.
In terms of markup, most MathML elements have a begin tag and an end tag, which enclosed the markup for their contents. In the case of tokens, the content is character data, and in most other cases, the content is the markup for child elements. A third category of elements, called empty elements, don't require any contents, and are marked up using a single tag of the form <element_name/>. An example of this kind of markup is the content element <plus/>.
Returning to the example of (a + b)2, we can now see how the principles discussed above play out in practice. The presentation markup might be:
<msup>
<mfenced>
<mi>a</mi>
<mo>+</mo>
<mi>b</mi>
</mfenced>
<mn>2</mn>
</msup>
The content markup for the same exmple might be:
<apply>
<power/>
<apply>
<plus/>
<ci>a</ci>
<ci>b</ci>
</apply>
<cn>2</cn>
</apply>
While a full discussion of presentation and content markup must
wait until chapters 3 and 4, the main features of these sample
encodings should now be relatively clear.
MathML presentation markup consists of 28 elements which accept over 50 attributes. Most of the elements correspond to layout schemata, which have other presentation elements as their content. Each layout schema corresponds to a 2-dimensional notational device, such as a script, fraction or table. In addition, there a the presentation token elements mi, mn and mo introduced above, as well as several other less commonly used token elements. The remaining few presentation elements are empty elements, and are used mostly in connection with alignment.
The layout schemata fall into several classes. One group of elements is concerned with scripts, and contains elements such as msub, munder, and mmultiscripts. Another group focuses on more general layout schema and includes mrow, mstyle, and mfrac. A third group deals with tables. The maction element is a category by itself, and represents various kinds of interactive notation, such as an expression which toggles between two pieces of notation.
An important feature of many layout schemata is that the order of children schemata is significant. For example, the first child of an mfrac element is the numerator and the second child is the denominator. Since the order of children schemata cannot be enforced by an XML DTD, the information added by ordering is only available to a MathML processor, as opposed to a generic XML processor. When we want to emphasize that a MathML element such as mfrac requires children in a specific order, we will refer to them as arguments, and think of the mfrac element as a notational "constructor".
Content markup consists of 75 elements accepting roughly a dozen attributes. The majority of these elements are empty elements corresponding to a wide variety of operators, relations and named functions. Examples of this sort include <partialdiff/>, <leq/> and <tan/>. Others such as matrix and set are used to encode various mathematical data types, and a third, important category of content elements such as apply are used to make new mathematical objects from others.
The apply elements is perhaps the single most important content element. It is used to apply a function to a collection of arguments. The postion of the children schemata is again significant, with the first child denoting the function to be applied, and the remaining children denoting the arguments of the function, with order preserved. Note that the apply construct always uses prefix notation, like the programming language lisp. In particular, even binary operations like subtraction are marked up by applying a prefix subtraction operator to two arguments. For example, a - b would be marked up as
<apply>
<minus/>
<ci>a</ci>
<ci>b</ci>
</apply>
A number of functions and operations require one or more quantifiers to be well-defined. For example, in addition to an integrand, an definite integral must specify the limits of integration and the bound variable. For this reason, there are several quantifier schemata such as bvar and lowlimit. They are used with operators such as diff such int.
The declare construct is especially important for content markup that is may be evaluated in a computer algebra system. The declare element provides a basic assignment mechanism, where a variable can be declared to be of a certain type, with a certain value. Typically, declarations are ignored for visual rendering, and are used when an expression is evaluated.
Different kinds of markup will be most appropriate for different kinds of tasks. Legacy data is probably best translated into pure presentation markup, since semantic information about what the author meant can only be guessed at heuristically. By contrast, some mathematical applications and pedagogically-oriented authoring tools will likely choose to be entirely content-based. However, the majority of applications fall somewhere in between these extremes. For these applications, the most appropriate markup is a mixture of both presentation and content markup.
The rules for mixing presentation and content markup derive from the general principle that mixed content should only be allowed in places where it makes sense. For content markup embedded in presentation markup this basically means that any content fragments should be semantically meaningful, and should not require additional arguments or quantifiers to be fully specified. For presentation markup embedded in content markup, this usually means that presentation markup must be contained in a content token element, so that it will be treated as an indivisible notational unit used as a variable or function name, etc. Another option is to use a semantics element.
The semantics element is used to bind MathML expressions to various kinds of annotations. One common use for the semantics element is to bind a content expression to a presentation expression as a semantic annotation. In this way, an author can specify a non-standard notation be used when displaying a particular content expression. Another use of the semantics element is to bind some other kind of semantic specification, such as an OpenMath expression, to a MathML expression. In this way, the semantics element can be used to extend the scope of MathML content markup.
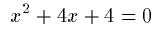
Markup:
<mrow>
<mrow>
<msup>
<mi>x</mi>
<mn>2</mn>
</msup>
<mo>+</mo>
<mrow>
<mn>4</mn>
<mo>&invisibletimes;</mo>
<mi>x</mi>
</mrow>
<mo>+</mo>
<mn>4</mn>
</mrow>
<mo>=</mo>
<mn>0</mn>
</mrow>
Note the use of nested mrow elements to denote terms, in
this case the left-hand side of the equation functioning as an
operand of "=". Marking terms greatly facilitates things like
spacing for visual rendering, voice rendering, and line breaking.
Notation: 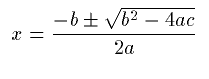
Markup:
<mrow>
<mi>x</mi>
<mo>=</mo>
<mfrac>
<mrow>
<mrow>
<mo>-</mo>
<mi>b</mi>
</mrow>
<mo>±</mo>
<msqrt>
<mrow>
<msup>
<mi>b</mi>
<mn>2</mn>
</msup>
<mo>-</mo>
<mrow>
<mn>4</mn>
<mo></mo>
<mi>a</mi>
<mo></mo>
<mi>c</mi>
</mrow>
</mrow>
</msqrt>
</mrow>
<mrow>
<mn>2</mn>
<mo></mo>
<mi>a</mi>
</mrow>
</mfrac>
</mrow>
Notice that the plus/minus sign is given by a special named entity
±. MathML provides a very comprehensive list of entity
names for mathematical symbols. In addition to the mathematical
symbols needed for screen and print rendering, MathML provides
symbols to facilitate audio rendering. For audio rendering, it is
important to be able to automatically determine whether
<mrow>
<mi>z</mi>
<mfenced>
<mi>x</mi>
<mo>+</mo>
<mi>y</mi>
</mfenced>
</mrow>
should be read as "z times the quantity x plus y" or "z of x plus
y". The entities and provide a way
for authors to directly encode the distinction for audio renderers.
For instance, in the first case should be inserted
after the line containing the z. MathML also introduces entities
like ⅆ which represents a "differential d" which renders with
slightly different spacing in print, and is usually rendered as
"with respect to" in speech. Unless content tags, or some other
mechanism, are used to eliminate the ambiguity, authors should
always use these entities, in order to make their documents more
accessible.
Notation: 
Markup:
<mrow>
<mi>A</mi>
<mo>=</mo>
<mfenced open="[" close="]">
<mtable>
<mtr>
<mtd><mi>x</mi></mtd>
<mtd><mi>y</mi></mtd>
</mtr>
<mtr>
<mtd><mi>z</mi></mtd>
<mtd><mi>w</mi></mtd>
</mtr>
</mtable>
</mfenced>
</mrow>
Most elements have a number of attributes that control the details
of their screen and print rendering. For example, there are several
attributes for the mfenced element that control what
delimiters should be used at the beginning and the end of the
expression. The attributes for entities are set to default values
determined by a dictionary. (For the standard MathML default
dictionary, see appendix C.)
Notation:
Markup:
<relation>
<eq/>
<apply>
<plus/>
<apply>
<power/>
<ci>x</ci>
<cn>2</cn>
</apply>
<apply>
<times/>
<cn>4</cn>
<ci>x</ci>
</apply>
<cn>4</cn>
</apply>
<cn>0</cn>
</relation>
Note that the relation element is used much like the
apply element, except that it is used with relations instead of
operators and function.
Notation:
Markup:
<relation>
<eq/>
<ci>x</ci>
<apply>
<over/>
<apply>
<fn occurence="infix"><mo>±</mo></fn>
<apply>
<minus/>
<ci>b</ci>
</apply>
<apply>
<root/>
<apply>
<minus/>
<apply>
<power/>
<ci>b</ci>
<cn>2</cn>
</apply>
<apply>
<times/>
<cn>4</cn>
<ci>a</ci>
<ci>c</ci>
<apply>
</apply>
<cn>2</cn>
</apply>
</apply>
<apply>
<times/>
<cn>2</cn>
<ci>a</ci>
</apply>
</apply>
</relation>
MathML content markup does not directly contain an element for the
"plus or minus" operation. Therefore, we use the fn element
to declare that we want the presentation markup for this operator
to act as a content operator. This is a simple example of how
presentation and content markup can be mixed to extend content
markup.
Notation:
Markup:
<relation>
<eq/>
<ci>A</ci>
<matrix>
<matrixrow>
<ci>x</ci>
<ci>y</ci>
</matrixrow>
<matrixrow>
<ci>z</ci>
<ci>w</ci>
</matrixrow>
</matrix>
</relation>
Note that by default, the rendering of the content element
matrix includes enclosing parentheses, so we need not directly
encode them. This is quite different from the presentation element
mtable which may or may not refer to a matrix, and hence
requires explicit encoding of the parenthese if they are desired.
Notation: 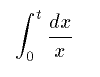
Markup:
<semantics>
<mrow>
<msubsup>
<mo>∫</mo>
<mn>0</mn>
<mi>t</mi>
</msubsup>
<mfrac>
<mrow>
<mo>ⅆ</mo>
<mi>x</mi>
</mrow>
<mi>x</mi>
</mfrac>
</mrow>
<apply>
<int>
<apply>
<over/>
<cn>1</cn>
<ci>x</ci>
</apply>
<lowlimit><cn>0</cn></lowlimit>
<uplimit><ci>t</ci></uplimit>
<bvar><ci>x</ci></bvar>
</apply>
</semantics>
In this example, we use the semantics element to give one
MathML expression for display, and another for the content
encoding. This is necessary because the default rendering of the
content expression would not place the "dx" in the numerator.
MathML is an application of XML, or Extenstible Markup Language, and as such, it's syntax is governed by the rules of XML syntax, and its grammar is in part specified by a DTD, or Document Type Definition. In other words, the details of using tags, attributes, entity references and so on are defined in the XML language specification, and the details about MathML element and attribute names, which elements can be nested inside each other, and so on are specified in the MathML DTD.
However, MathML also specifies some syntax and grammar rules in addition to the general rules it inherits as an XML application. These rules allow MathML to encode a great deal more information than would ordinarily be possible with pure XML, without introducing many more elements, and using a substantially more complex DTD. Of course, one drawback to using MathML specific rules is that they are invisible to generic XML processors and validators.
There are basically two kinds of additional MathML grammar and syntax rules. One kind involves placing additional criteria on attribute values. For example, it is not possible in pure XML to require that an attribute value be a positive integer. The second kind of rule involves specifying an ordering for children elements. For example, it is not possible in XML to specify that the first child be interpreted one way, and the second in another.
The following sections discuss features both of XML syntax and grammar in general, and of MathML in particular. Throughout the remainder of the MathML specification, we will usually take care to distinguish between usage required by XML syntax and the MathML DTD and usage required by MathML specific rules. However, we will frequently allude to "MathML errors" without identifying which part of the specification is being violated.
Since MathML is an application of XML, the MathML Specification
uses the terminology of XML to describe it. Briefly, XML data is
composed of Unicode characters (which include ordinary ASCII
characters), "entity references" (informally called "entities")
such as " " which usually represent "extended characters", and
"elements" such as <mi fontslant="plain"> x
</mi>. Elements enclose other XML data called their
"content" between a "begin tag" and an "end tag" much like in HTML.
There are also "empty elements" such as <plus/>,
whose begin tag ends with /> to indicate that the
element has no content or end tag. The begin tag can contain named
parameters called "attributes", such as
fontslant="plain" in the example above. For further details
on XML, consult the XML
specification.
Because XML is case-sensitive, MathML element and attribute names are case-sensitive and all lowercase. Note, however, that all MathML element and attribute names consist solely of ASCII characters, for which case insensitivity is trivially well-defined, and do not need to be distinguished by case. MathML is expected to often be embedded in HTML, and therefore its element and attribute names should be as case-insensitive as possible, for familiarity to users of HTML.
In formal discussions of XML markup a distinction is maintained between an element, such as an mrow element, and the tags <mrow> and </mrow> marking it. What is between the <mrow> begin tag and the </mrow> end tag is the mrow element's content. An "empty element" such as none is defined to have no content and so has a single tag of the form <none/>. Usually, the distinction between elements and tags will not be so finely drawn in this specification. For instance, we will sometimes refer to the <mrow> and <none/> elements, really meaning the elements whose tags these are, in order that references to elements are visually distinguishable from references to attributes. However, the words "element" and "tag" themselves will be used strictly in accordance with XML terminology.
Many MathML elements require a specific number of children element and/or attach addition meaning to children in certain positions. As noted above, these kinds of requirements are MathML specific, and cannot be specified entirely in terms of XML syntax and grammar. When the children schemata of a given MathML element are subject to these kinds of additional conditions, we will often refer to them as arguments instead of merely children in order to emphasize their MathML specific usage. Note that especially in Chapter 3 the term "argument" is usually used in this technical sense, unless otherwise noted, and therefore refers a child element.
In the detailed discussions of element syntax given with each element throughout the MathML specification, the number of required arguments and their order is implicitly indicated by giving names for the arguments at various positions. In the case of content elements, this information is also given in the EBNF grammar for content markup in appendix E.
A few elements have other requirements on the number or type of arguments. Examples include default behaviors when an incorrect numbers or types of arguments are encountered, and ignoring certain kinds of markup (typically encoding whitespace) for purposes of determining argument positions. These additional requirements are described together with the individual elements.
According to the XML language specification, attributes given to elements must have the form:
attribute-name = "
value"Attribute names are generally shown in bold within descriptive text in this specification, but not within examples.
The attribute value, which in general in XML can be a string of arbitrary characters
MathML uses a more complicated syntax for attribute values than the generic XML syntax required by the MathML DTD. These additional rules are intended for use by MathML applications, and are not enforced by XML processing. For example, most attribute values are declared in the MathML DTD as #IMPLIED, which means that default values are generated by the processing application. However, MathML specifies an explicit nheritance mechanism which MathML applications are expected to use.
The MathML syntax of attribute values is specified together with the descriptions of individual elements, using a notation described below. In MathML applications these attribute values should be further processed as follows, unless otherwise specified: the case of letters is ignored in matching to literal words within the attribute value syntax; whitespace is ignored except to separate letter and/or digit sequences into individual words or numbers; and the same entity references (listed in Chapter 6) which can be used within token elements to represent characters can be used to represent those characters in attribute values (whenever those characters would be permitted by that attribute value's syntax).
In particular, the characters ", ',
and & can be included in MathML attribute values
(when permitted by the attribute value syntax) using the entity
references ", ', and
&, respectively. (< can also be used for
<, but this is not required in attribute values, only in token element content.)
This additional processing of attribute values is done, in part, to provide for compatibility with potential DTDs for MathML stricter than the one in Appendix A, which declare as many of these attributes as possible using enumerated lists of permissible values, although the MathML DTD provided in Appendix A declares them as strings (in order to permit increased interoperability with existing SGML software).
To describe the MathML-specific syntax of permissible attribute values, the following conventions and notations are used in the MathML specifications for most attributes.
| Notation | what it matches | |
| number | decimal integer or real number (digits with one decimal point), optionally starting with '-' | |
| unsigned-number | decimal integer or real number, no sign | |
| integer | decimal integer, optionally starting with '-' | |
| positive-integer | decimal integer, unsigned, not 0 | |
| string | arbitrary string (always used as entire value; whitespace trimmed and collapsed) | |
| character | single non-whitespace character, or MathML entity reference; whitespace separation not required | |
| #rrggbb | RGB color value | |
| other italicized words | explained in the text for each attribute | |
| form + | one or more instances of form | |
| form * | zero or more instances of form | |
| f1 f2 ... fn | one instance of each form, in sequence, perhaps separated by whitespace | |
| f1 | f2 | ... | fn | any one of the specified forms | |
| [ form ] | optional instance of form | |
| ( form ) | same as form (except for units, e.g. (ems); see below) | |
| word in plain text | that word, literally present in attribute value (unless it is obviously part of an explanatory phrase) | |
| quoted symbol | that symbol, literally present in attribute value (e.g. "+" or '+') |
The order of precedence of the syntax notation operators is, from highest to lowest precedence:
form + or form *
f1 f2 ... fn (sequence of forms)
f1 | f2 | ... | fn (alternative forms)
A string can contain arbitrary characters which are specifiable within XML CDATA attribute values, except whitespace; it must use entity references for certain characters, as described earlier. It can also contain XML-format entity or character references for any of the characters listed in Chapter 6. A character consists of a single non-whitespace character or entity reference.
As a simple example, the permissible values of boolean
attributes are specified as true | false, meaning that
the entire attribute value should be either "true" or "false".
Note that (as mentioned above) literal words in attribute syntax
specifications are not case-sensitive, and adjacent literal words
and/or numbers must be separated by whitespace in the actual
values. Whitespace is not otherwise required, but is permitted
between any of the tokens listed above, and between the signs and
digits of signed numbers, but not between # and
rrggbb.
Numeric attribute values for dimensions that should depend upon the current font are given in font-related units. Horizontal dimensions are given in "ems", and vertical dimensions in "exs", unless otherwise specified. For example, the horizontal spacing around an operator such as "+" is given in "ems". Using font-related units allows MathML renderings to grow or shrink proportionately to the current font size.
Use of the units "ems" or "exs" is sometimes indicated in the syntax for an attribute by including the notation (ems) or (exs) after the number it applies to; the words "ems" or "exs" should not be included in the actual attribute values themselves. The same applies to the notations (ems exs) and (points). This is an exception to the syntax notation for literal words, listed above. For some attributes, the use of these or other units is described in the text but not in the syntax specification.
For most numeric attributes, only those in a subset of the expressible values are sensible; values outside this subset are not errors, unless otherwise specified, but rather are rounded up or down (at the discretion of the renderer) to the closest value within the allowed subset. The set of allowed values may depend on the renderer, and is not specified by MathML.
If a numeric value within an attribute value syntax description is declared to allow a minus sign ('-'), e.g. number or integer, it is not a syntax error to provide one, even if a negative value is not sensible. Instead, the value should be handled by the processing application as described in the preceding paragraph. An explicit plus sign ('+') is not allowed as part of a numeric value except when it is specifically listed in the syntax (as a quoted '+' or "+").
Default values for MathML attributes are in general given along with the detailed descriptions of specific elements in the text. Default values are literal words when shown in plain text (unless they are obviously explanatory phrases), but when italicized are descriptions of how default values can be computed.
Default values described as inherited are taken from the rendering environment, as described under <mstyle>, or in some cases (described individually) from the values of other attributes of surrounding elements, or from certain parts of those values. The value used will always be one which could have been specified explicitly, had it been known; it will never depend on the content or attributes of the same element, only on its environment. (What it means when used may, however, depend on those.)
Default values described as automatic should be computed by a MathML renderer in a way which will produce a high-quality rendering; how to do this is not specified by MathML. The value computed will always be one which could have been specified explicitly, had it been known, but it will usually depend on the element content and/or the rendering environment.
Note that, in general, there is no value which can be given explicitly for a MathML attribute which will simulate the effect of not specifying the attribute at all, for attributes which are inherited or automatic. Giving the words "inherited" or "automatic" explicitly will not work, and is not generally allowed. Therefore, the MathML DTD declares such attributes as #IMPLIED, which prevents XML preprocessors from adding them with any default value. (Note that attributes of all elements which can be set with the <mstyle> element are declared as #IMPLIED for the same reason.)
Other descriptions of default values are explained for each attribute individually.
The single or double quotes which are required around attribute values in an XML begin tag are not shown in the tables of attribute value syntax given with each element, but are shown with example attribute values in the text.
In an XML DTD, allowed attribute values can be declared as general strings (subject only to trimming of whitespace from the beginning and end, or they can be constrained in various ways, either by enumerating the possible values, or by declaring them to be certain special data types. The choice of an XML attribute type affects the extent to which validity checks can be performed using a DTD.
The MathML DTD specifies formal XML attribute types for all MathML attributes, including enumerations of legitimate values in some cases. In general, however, the MathML DTD is relatively permissive, frequently declaring attribute values as strings; this is done to provide for interoperability with SGML parsers while allowing multiple attributes on one MathML element to accept the same values (such as "true" and "false").
At the same time, even though an attribute value may be declared as a string in the DTD, only certain values are legitimate in MathML, as described above and in the rest of this specification. For example, many attributes expect numerical values. In the sections which follow, the allowed attribute values are described for each element. To determine when these constraints are actually enforced in the MathML DTD, consult Appendix A. However, lack of enforcement of a requirement in the DTD does not imply that the requirement is not part of the MathML language itself, or that it will not be enforced by a particular MathML renderer. (See Section 7.2.2 for a description of how MathML renderers should respond to MathML errors.)
Furthermore, the MathML DTD is provided for convenience; although it is intended to be fully compatible with the text of the specification, the text should be taken as definitive if there is a contradiction.
In order to facilitate compatibility with Cascading Style Sheets, Level 1 ( CSS1 ), all MathML elements accept class and style attributes in addition to those shown specifically for each element.
At present, many MathML properties that would be desirable to control via style sheets are not defined in CSS1. Conversely, CSS1 properties which are applicable to MathML may not be accessible to embedded MathML renderers in the immediate future. Also, MathML is not required to be embedded in an environment which supports CSS such as HTML. For these reasons, MathML renderers are not required to respond to the CLASS and STYLE attributes, though they are encouraged to do so whenever practical. Allowing these attributes provides some degree of CSS compatibility now, and may provide much greater compatibility in the future.
There is a great deal of work underway on the problem of controlling the layout of XML extensions to HTML via style sheet mechanisms. The HTML-Math working group will be coordinating its efforts with other groups to insure that MathML will be compatible with emerging style sheet mechanisms.
Every MathML element also accepts the attribute other (Section 7.2.3) for passing non-standard attributes without violating the MathML DTD. MathML renderers are only required to process this attribute if they respond to any attributes which are not standard in MathML.
See also Section 3.2.1 for a list of MathML attributes which can be used on most token elements.
MathML ignores whitespace (as defined for attributes in Section 3.1.3) occurring between the arguments of layout schemata. (Non-whitespace characters are not allowed there.) Whitespace occurring within the content of token elements is "trimmed" from the ends (i.e. all whitespace at the beginning and end of the content is ignored), and "collapsed" internally (i.e. each sequence of 1 or more whitespace characters is replaced with one blank character).
For example, <mo> ( </mo> is equivalent
to <mo>(</mo>, and
<mtext>
Theorem
1:
</mtext>
is equivalent to <mtext>Theorem
1:</mtext>.
Authors wishing to encode whitespace characters at the start or end of the content of a token, or in sequences other than a single blank, without having them ignored, must use entity references for these characters.