Status of This Document
This section describes the status of this document at the time of its publication. Other
documents may supersede this document. A list of current W3C publications and the latest revision
of this technical report can be found in the W3C technical reports
index at http://www.w3.org/TR/.
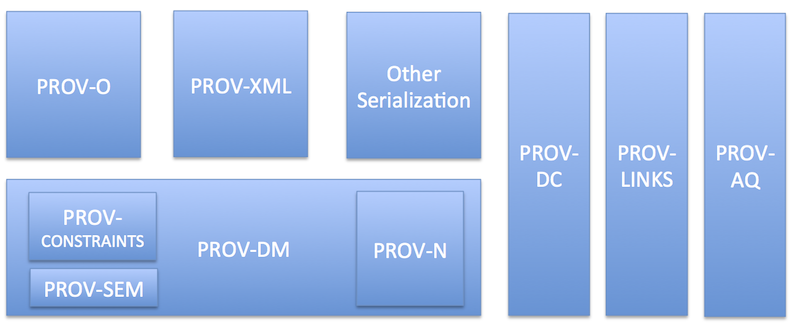
PROV Family of Documents
This document is part of the PROV family of documents, a set of documents defining various aspects that are necessary to achieve the vision of inter-operable
interchange of provenance information in heterogeneous environments such as the Web. These documents are listed below.
- PROV-OVERVIEW (To be published as Note), an overview of the PROV family of documents (this document);
- PROV-PRIMER (To be published as Note), a primer for the PROV data model [PROV-PRIMER];
- PROV-O (Proposed Recommendation), the PROV ontology, an OWL2 ontology allowing the mapping of PROV to RDF [PROV-O];
- PROV-DM (Proposed Recommendation), the PROV data model for provenance; [PROV-DM]
- PROV-N (Proposed Recommendation), a notation for provenance aimed at human consumption [PROV-N];
- PROV-CONSTRAINTS (Proposed Recommendation), a set of constraints applying to the PROV data model [PROV-CONSTRAINTS];
- PROV-XML (To be published as Note), an XML schema for the PROV data model [PROV-XML];
- PROV-AQ (To be published as Note), the mechanisms for accessing and querying provenance [PROV-AQ];
- PROV-DICTIONARY (To be published as Note) introduces a specific type of collection, consisting of key-entity pairs [PROV-DICTIONARY];
- PROV-DC (To be published as Note) provides a mapping between PROV and Dublic Core Terms [PROV-DC];
- PROV-SEM (To be published as Note), a declarative specification in terms of first-order logic of the PROV data model [PROV-SEM];
- PROV-LINKS (To be published as Note) introduces a mechanism to link across bundles [PROV-LINKS].
This document was published by the Provenance Working Group as a Working Draft.
If you wish to make comments regarding this document, please send them to
public-prov-comments@w3.org
(subscribe,
archives).
All comments are welcome.
Publication as a Working Draft does not imply endorsement by the W3C Membership.
This is a draft document and may be updated, replaced or obsoleted by other documents at
any time. It is inappropriate to cite this document as other than work in progress.
This document was produced by a group operating under the
5 February 2004 W3C Patent Policy.
The group does not expect this document to become a W3C Recommendation.
W3C maintains a public list of any patent disclosures
made in connection with the deliverables of the group; that page also includes instructions for
disclosing a patent. An individual who has actual knowledge of a patent which the individual believes contains
Essential Claim(s) must disclose the
information in accordance with section
6 of the W3C Patent Policy.
A. Acknowledgements
This document has been produced by the PROV Working Group, and its contents reflect extensive discussion within the Working Group as a whole.
Members of the PROV Working Group at the time of publication of this document were:
Ilkay Altintas (Invited expert),
Reza B'Far (Oracle Corporation),
Khalid Belhajjame (University of Manchester),
James Cheney (University of Edinburgh, School of Informatics),
Sam Coppens (IBBT),
David Corsar (University of Aberdeen, Computing Science),
Stephen Cresswell (The National Archives),
Tom De Nies (IBBT),
Helena Deus (DERI Galway at the National University of Ireland, Galway, Ireland),
Simon Dobson (Invited expert),
Martin Doerr (Foundation for Research and Technology - Hellas(FORTH)),
Kai Eckert (Invited expert),
Jean-Pierre EVAIN (European Broadcasting Union, EBU-UER),
James Frew (Invited expert),
Irini Fundulaki (Foundation for Research and Technology - Hellas(FORTH)),
Daniel Garijo (Universidad Politécnica de Madrid),
Yolanda Gil (Invited expert),
Ryan Golden (Oracle Corporation),
Paul Groth (Vrije Universiteit),
Olaf Hartig (Invited expert),
David Hau (National Cancer Institute, NCI),
Sandro Hawke (W3C/MIT),
Jörn Hees (German Research Center for Artificial Intelligence (DFKI) Gmbh),
Ivan Herman, (W3C/ERCIM),
Ralph Hodgson (TopQuadrant),
Hook Hua (Invited expert),
Trung Dong Huynh (University of Southampton),
Graham Klyne (University of Oxford),
Michael Lang (Revelytix, Inc.),
Timothy Lebo (Rensselaer Polytechnic Institute),
James McCusker (Rensselaer Polytechnic Institute),
Deborah McGuinness (Rensselaer Polytechnic Institute),
Simon Miles (Invited expert),
Paolo Missier (School of Computing Science, Newcastle university),
Luc Moreau (University of Southampton),
James Myers (Rensselaer Polytechnic Institute),
Vinh Nguyen (Wright State University),
Edoardo Pignotti (University of Aberdeen, Computing Science),
Paulo da Silva Pinheiro (Rensselaer Polytechnic Institute),
Carl Reed (Open Geospatial Consortium),
Adam Retter (Invited Expert),
Christine Runnegar (Invited expert),
Satya Sahoo (Invited expert),
David Schaengold (Revelytix, Inc.),
Daniel Schutzer (FSTC, Financial Services Technology Consortium),
Yogesh Simmhan (Invited expert),
Stian Soiland-Reyes (University of Manchester),
Eric Stephan (Pacific Northwest National Laboratory),
Linda Stewart (The National Archives),
Ed Summers (Library of Congress),
Maria Theodoridou (Foundation for Research and Technology - Hellas(FORTH)),
Ted Thibodeau (OpenLink Software Inc.),
Curt Tilmes (National Aeronautics and Space Administration),
Craig Trim (IBM Corporation),
Stephan Zednik (Rensselaer Polytechnic Institute),
Jun Zhao (University of Oxford),
Yuting Zhao (University of Aberdeen, Computing Science).