
PROV-FAQ
Here are some answers to frequently asked questions about PROV and using it.
How do I show off my use of PROV?
You can include the PROV logo / badge provided at http://www.w3.org/2007/10/sw-logos.html.
Relationship to other vocabularies
In general, the working group decided not to adopt existing vocabularies directly, in preference for a mappings based approach, so they could be absolutely precise about their semantics.
What is the relationship between Dublin Core and PROV?
The two specifications are complementary. Dublin Core contains many provenance related terms many of which are more specific than those provided by PROV. For those terms, there is a mapping from Dublin Core Metadata Terms to PROV provided by a best practice document. If your system understands PROV, it will be able to understand the provenance terms of Dublin Core.
Why doesn't PROV use FOAF?
See #Relationship to other vocabularies
Isn't prov:Location just wgs:SpatialThing?
http://www.w3.org/2003/01/geo/wgs84_pos#SpatialThing is "Anything with spatial extent, i.e. size, shape, or position. e.g. people, places, bowling balls, as well as abstract areas like cubes."
It is reasonable to make prov:Location a subclass (or even equivalent) to wgs:SpatialThing.
OWL Time
prov:Activities could be described as time:Intervals and prov:InstantaneousEvents (prov:Start, etc) can be modeled as time:Instant. See What if my Activity started/ended at a time other than xsd:dateTime? for how OWL time can help fill in some details when an exact detail is not known.
Modeling considerations
How can I define a sub activity?
PROV contains the notion of an activity. Some people have asked how to model sub-activities. We suggest using dcterms:hasPart
When should I use prov:Agent subtypes?
If you want to denote that some Person, Organization or Software Agent has responsibility for and activity or entity use the subtypes of prov:Agent. Otherwise, we suggest that use other ontologies like FOAF.
Can I infer Derivation from Usage and Generation?
No! Consider the trivial contrived example of an activity X that uses 3 input entities, a,b,c, and generates 2 output entities, one with a value of the sum of the first two (d = a+b), and a second with a value of the second two (e = b+c). You could express that:
used(X, a) used(X, b) used(X, c) wasGeneratedBy(d, X) wasGeneratedBy(e, X)
Given our description, we would also assert that:
wasDerivedFrom(d, a) wasDerivedFrom(d, b) wasDerivedFrom(e, b) wasDerivedFrom(e, c)
But you could not infer from the Usages and Generations for activity X that:
wasDerivedFrom(d, c)
or:
wasDerivedFrom(e, a)
Should I use wasInfluencedBy, wasInformedBy, or another relation?
The names of terms in the PROV data model and ontology are chosen as carefully as possible to distinctly represent the concepts intended. However, as a generic model intended to express provenance in many settings, it is impossible to find names that, read as colloquial English, match their use precisely in each setting. The terms wasInfluencedBy and wasInformedBy have been confused, due to the similar meanings of the words 'influence' and 'inform'.
First, in choosing a relation, please read the definitions rather than relying on the names, as these will help clarify their intended use. In general, we discourage the use of the wasInfluencedBy in expressing provenance unless very little information is known about what you would like to model in the provenance. wasInfluencedBy is a super-property of the relations for common use: used, wasGeneratedBy, wasAssociatedWith, wasInformedBy, etc. These properties relate entities, activities and agents in varying combinations. wasInfluencedBy is present more to help querying provenance data, at times where you do not care about which type of provenance relation is being expressed. wasInformedBy is a more specific relation connecting one activity to another implying "the exchange of some unspecified entity by two activities, one activity using some entity generated by the other", so that one activity was in some way dependent on the other.
If you find yourself using wasInfluencedBy in your provenance model, it is preferable to check what kinds of element (entities, activities, or agents) you are trying to relate and considering using the more specific relation. For example, if you wish to express the influence of one entity on another, consider using a wasDerivedFrom relation.
Validity and Bundles
The following example shows a document containing two bundles. This document is invalid because the first bundle ex:b1 contains a cycle of derivations, which is not allowed due to the PROV Constraint derivation-generation-generation-ordering (e1 is older than e2, but e2 is older than e1).
document prefix ex <http://example.org/> bundle ex:b1 entity(ex:e1) entity(ex:e2) wasDerivedFrom(ex:e1,ex:e2) wasDerivedFrom(ex:e2,ex:e1) endBundle bundle ex:b2 entity(ex:e1) entity(ex:e2) wasDerivedFrom(ex:e2,ex:e1) endBundle endDocument
In this second example, the document is valid, since the validity of each bundle is established independently of the other bundle. While there is a cycle of derivations, this cycle is not present in any single bundle.
document prefix ex <http://example.org/> bundle ex:b1 entity(ex:e1) entity(ex:e2) wasDerivedFrom(ex:e1,ex:e2) endBundle bundle ex:b2 entity(ex:e1) entity(ex:e2) wasDerivedFrom(ex:e2,ex:e1) endBundle endDocument
Finally, in the third example, the document is not syntactically correct since descriptions in bundle ex:b2 refer to prefixes ex1 and ex2, which are neither defined in bundle ex:b2 nor at the toplevel.
document prefix ex <http://example.org/> bundle ex:b1 prefix ex1 <http://example.org/> entity(ex1:e1) entity(ex1:e2) wasDerivedFrom(ex1:e1,ex1:e2) endBundle bundle ex:b2 entity(ex1:e1) entity(ex2:e2) wasDerivedFrom(ex2:e2,ex2:e1) endBundle endDocument
How to "use" a string (e.g. when modeling a parameter)
In PROV-O, prov:used is an owl:ObjectProperty, so it's value should be a URI. Occasionally, one may want to model an prov:Activity that prov:use's a string, e.g. when a program accepts a string parameter. Because RDFS and OWL draw a distinction between rdfs:Literals and rdfs:Resources, it is not appropriate to say
:my_program prov:used "hello" .
One design that could have provided "using a string" would have been to define a parallel owl:DatatypeProperty, such as :usedLiteral. However, the WG did not conclude with this design.
The appropriate way to model the use of strings is by combining the prov:value property.
:my_program_execution a prov:Activity;
prov:used :hello_string;
prov:endedAtTime "2013-04-18T08:18:36-04:00"^^xsd:dateTime;
.
:hello_string a prov:Entity;
prov:wasAttributedTo :susie;
prov:value "hello" .
Although this may seem cluttered, it is important to consider that the :hello_string resource represents the string "hello" used within a specific context -- i.e., the context of being passed to this program. In the example above, this specific occurrence of "hello" was the one that Susie provided. Other program invocations could also be provided the string "hello", which could have been attributed to other agents. Using a resource to represent different occurrences of a string can be very helpful in establishing each occurrences' provenance.
A very common construct that occurs with prov:value is the subtype of Derivation: prov:Quotation, prov:wasQuotedFrom. These constructs can be used to model "copy-pasting" from text documents. For example, we could model the copying of the first four words of this paragraph:
:my_copied_text prov:value "A very common construct"; prov:wasAttributedTo :Tim; prov:wasQuotedFrom <http://www.w3.org/2001/sw/wiki/index.php?title=PROV-FAQ&action=edit§ion=4>; .
What if my Activity started/ended at a time other than xsd:dateTime?
The abstract PROV model is based on a partial orderings, so any property indicating a specific time is only available for practical purposes.
prov:startedAtTime, prov:endedAtTime, and prov:atTime are owl:Datatype properties whose range is xsd:dateTime, which is the most popular way to specify a specific moment. However, xsd:dateTime may not be appropriate for all modeling situations. This first example shows two acceptable and equivalent ways to model the start time of an activity.
:activity
a prov:Activity;
# Unqualified start
prov:startedAtTime "2013-04-18T08:18:36-04:00"^^xsd:dateTime;
# Qualified Start
prov:startedAt [
a prov:Start;
prov:atTime "2013-04-18T08:18:36-04:00"^^xsd:dateTime;
];
.
The full resolution of a dateTime may inappropriate for your situation. For example, you may only know the *day* that it occurred, not an exact time. You could also know a bounds for when it occurred, but just aren't sure. (Remember that PROV defines a start as being instantaneous, so a full interval is inappropriate). One approach to handling this uncertainty is to use the qualified pattern above but use a separate time-based ontology to describe the prov:start. For example, the non-Rec [OWL Time http://www.w3.org/TR/owl-time/] could be used (among others) (remember not to use bnodes in practice):
@prefix time: <http://www.w3.org/2006/time#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . @prefix prov: <http://www.w3.org/ns/prov#> . :activity_2 a prov:Activity; # Qualified Start prov:startedAt [ a prov:Start, time:Instant; time:inDateTime [ a time:DateTimeDescription; time:year "2012"^^xsd:gYear; time:month "Apr"^^xsd:gYear; time:day "18"^^xsd:gDay; ]; ]; .
Examples of Provenance
Provenance of a Car
The prov-dm document gives the example of a car, moved from Boston to Cambridge (see example 5 CR document). For this car, we identify multiple entities exposing various facets of the thing: Joe's car, Joe's car in Boston, and Joe's car in Cambridge.
entity(joe-car) entity(joe-car-boston, [prov:location="boston"]) entity(joe-car-cambridge, [prov:location="cambridge"]) alternateOf(joe-car-boston,joe-car-cambridge) specializationOf(joe-car-cambridge, joe-car) specialization(joe-car-boston, joe-car)
Joe-car-cambridge begins to exist when the car arrives is Cambridge, and Joe-car-boston ceases to exist (invalidation) once it leaves Boston. So joe-car-cambridge's generation time is defined as the time at which in arrives in Cambridge.
Provenance of Flour
If a change in a resource's state is something to be documented in the provenance, then that requires multiple entities.
If a change is to be documented in PROV, then multiple entities are used, e.g. the flour before and after baking. If it is not documented, then only one entity is required. There is no notion of a change which is "documented but not significant", because it is unclear what significance would be in general except for the decision to model/document it. As before, a general, mutable "flour" entity can exist that is connected to the flour before and after baking using prov:specializationOf. For example:
ex:baked prov:used ex:flour1 ex:flour2 prov:wasGeneratedBy ex:baked ex:flour2 prov:wasDerivedFrom ex:flour1 ex:flour1 prov:specializationOf ex:flour ex:flour2 prov:specializationOf ex:flour
Access and Query
Access and Query - arbitrary data
@@TODO: text lifted from what was section 3.4 of PROV-AQ
If a resource is represented using a data format other than HTML or RDF, and no URI for the resource is known, provenance discovery becomes trickier to achieve. This specification does not define a specific mechanism for such arbitrary resources, but this section discusses some of the options that might be considered.
For formats which have provision for including metadata within the file (e.g. JPEG images, PDF documents, etc.), use the format-specific metadata to include a <a class="internalDFN">target-URI</a>, <a class="internalDFN">provenance-URI</a> and/or <a class="internalDFN">service-URI</a>. Format-specific metadata provision might also be used to include <a class="internalDFN">provenance information</a> directly in the resource.
Use a generic packaging format that can combine an arbitrary data file with a separate metadata file in a known format such as RDF.
Access and Query - alternatives
@@TODO
The following text copied from PROV-AQ "Best Practices"
Using SPARQL for provenance queries
Simply identifying and retrieving provenance information as a resource on the Web may not always meet the requirements of a particular application or service, e.g.:
- the resource for which provenance information is required is not identified by a known URI
- the provenance information for a resource is not directly identified by a known URI
- a requirement to access provenance information for a number of distinct but related resources in a single atomic operation
- etc.
A provenance query service provides an alternative way to access provenance information and/or provenance-URIs. An application will need a URI for the provenance query service, and some relevant information about the resource whose provenance is to be accessed.
The details of a provenance query service is an implementation choice, but for interoperability between different providers and users we recommend use of SPARQL RDF-SPARQL-PROTOCOL RDF-SPARQL-QUERY. The query service URI would then be the URI of a <a href="http://www.w3.org/TR/rdf-sparql-protocol/#conformant-sparql-protocol-service" class="externalRef">SPARQL protocol service</a> (often referred to as a "SPARQL endpoint"). The following subsections provide examples for what are considered to be some plausible common scenarios for using SPARQL, and are not intended to cover all possibilities.
A SPARQL protocol service description may be published using the SPARQL 1.1 Service Description vocabulary SPARQL-SD.
The following subsections illustrate use cases for querying a SPARQL-based provenance query service.
Find a provenance-URI given a target-URI
If the requester has a <a class="internalDFN">target-URI</a>, a simple SPARQL query may be used to return the corresponding <a class="internalDFN">provenance-URI</a>. E.g., if the original resource has a target-URI http://example.org/resource:
@prefix prov: <http://www.w3.org/ns/prov#>
SELECT ?provenance_uri WHERE
{
<http://example.org/resource> prov:hasProvenance ?provenance_uri
}
Find Provenance-URI given identifying information about a resource
If the requester has identifying information that is not the URI of the original resource, then they will need to construct a more elaborate query to locate a resource description and obtain its provenance-URI(s). The nature of identifying information that can be used in this way will depend upon the third party service used, further definition of which is out of scope for this specification. For example, a query for a document identified by a DOI, say 1234.5678, using the PRISM vocabulary PRISM might look like this:
@prefix prov: <http://www.w3.org/ns/prov#>
@prefix prism: <http://prismstandard.org/namespaces/basic/2.0/>
SELECT ?provenance_uri WHERE
{
[ prism:doi "1234.5678" ] prov:hasProvenance ?provenance_uri
}
Obtain provenance information directly given a target-URI
This scenario retrieves provenance information directly given the URI of a resource, and may be useful where the provenance information has not been assigned a specific URI, or when the calling application is interested only in specific elements of provenance information.
If the original resource has a URI http://example.org/resource, a SPARQL query for provenance information might look like this:
@prefix prov: <http://www.w3.org/ns/prov#>
SELECT ?generationStartTime WHERE {
<http://example.org/resource> prov:wasGeneratedBy ?activity .
?activity prov:startedAtTime ?generationStartTime .
}
This query extracts a "generation start time" for an artifact by following links to the start time of the activity which generated it.
Incremental Provenance Retrieval
<a class="internalDFN">Provenance information</a> may be large. While this specification does not define how to implement scalable provenance systems, it does allow for publishers to make available provenance in an incremental fashion. We now discuss two possibilities for incremental provenance retrieval.
Via Web Retrieval
Publishers are not required to publish all the provenance information associated with a given resource at a particular <a class="internalDFN">provenance-URI</a>. The amount of provenance information exposed is application dependent. However, it is possible to incrementally retrieve (i.e. walk the provenance graph) by progressively looking up provenance information using HTTP. The pattern is as follows:
- For a given resource (
resource-URI) retrieve it's associatedprovenance-URI-1and its associatedtarget-URI-1using a returned HTTPLink:header field (<a href="#resource-accessed-by-http" class="sectionRef"></a>) - Dereference
provenance-URI-1 - Navigate the provenance information
- When reaching a dead-end during navigation, that is on encountering a reference to a resource (
target-URI-2) with no provided provenance information, find its provenance-URI and continue from Step 2. (Note: an HTTP HEAD request fortarget-URI-2may be used to obtain theLink:headers without retrieving the resource representation.)
To reduce the overhead of multiple HTTP requests, a provenance information publishers are encouraged to link entities to their associated provenance information using the prov:hasProvenance predicate. Thus, the same pattern above applies, except instead of having to retrieve a new Link header field, one can immediately access the resource's associated provenance.
The same approach can be adopted when using the <a class="internalDFN">provenance service</a> API (<a href="#provenance-services" class="sectionRef"></a>). However, instead of performing an HTTP HEAD or GET against a resource one queries the provenance service using the given <a class="internalDFN">target-URI</a>.
Via SPARQL Queries
Provenance information may be made available using a SPARQL endpoint (<a href="#querying-provenance-information" class="sectionRef"></a>) RDF-SPARQL-PROTOCOL RDF-SPARQL-QUERY. Using SPARQL queries, provenance can be selectively retrieved using combinations of filters and or path queries.
Can PROV-XML use GRDDL?
PROV-XML documents can include a reference to a GRDDL transformation, which -- when invoked with the document as input -- will produce a PROV-O representation of the PROV-XML. Include the xmlns:grddl and grddl:transformation attributes below, and point to any appropriate XSL stylesheet (the one shown is for demonstration purposes and is incomplete).
<prov:document xmlns:grddl="http://www.w3.org/2003/g/data-view#" grddl:transformation="https://raw.github.com/timrdf/provenanceweb/master/src/provx2o.xsl"
The WG could add a default XSL within the w3.org/ns... Adopters are encouraged to specify whichever @transformation they wish (including their own tailored to their flavor of prov).
How should I generate JAXB classes from the PROV-XML schemas?
JAXB, as of jaxb-ri-2.2.6, sometimes generates Java bindings with JAXBElement<T> types for storing elements within prov:Document and prov:BundleConstructor. These JAXBElement<T> may not be as user friendly to use. JAXB appears to do so in order to retain a round-trip marshalling/unmarshalling capability of elements--particularly when unbounded sequence of elements are used in the current prov-core.xsd.
For example, the prov:Document type:
<xs:element name="document" type="prov:Document" />
<xs:complexType name="Document">
<xs:sequence maxOccurs="unbounded">
<xs:group ref="prov:documentElements" minOccurs="0"/>
<xs:element name="bundleContent" type="prov:BundleConstructor" minOccurs="0"/>
<xs:any namespace="##other" processContents="lax" minOccurs="0" />
</xs:sequence>
</xs:complexType>
May yield the following Java bindings with JAXBElement<T> for storing the elements:
public class Document {
@XmlElementRefs({
@XmlElementRef(name = "hadPrimarySource", namespace = "http://www.w3.org/ns/prov#", type = JAXBElement.class, required = false),
@XmlElementRef(name = "agent", namespace = "http://www.w3.org/ns/prov#", type = JAXBElement.class, required = false),
@XmlElementRef(name = "activity", namespace = "http://www.w3.org/ns/prov#", type = JAXBElement.class, required = false),
@XmlElementRef(name = "organization", namespace = "http://www.w3.org/ns/prov#", type = JAXBElement.class, required = false),
@XmlElementRef(name = "softwareAgent", namespace = "http://www.w3.org/ns/prov#", type = JAXBElement.class, required = false),
....
JAXB's generation of JAXBElement<T> classes seems to be a wrapper approach to preserve sufficient information in the schema for round-trip marshaling & unmarshalling of values in XML instances. More specifically, it wraps the data with a QName and a nillable flag.
It appears that the a frequent cause of JAXB producing JAXBElement<T> is its attempt to preserve elements with both minOccurs=0 and nillable=true. JAXB needs to distinguish between the two cases where:
1. element missing, minOccurs=0, then jaxbElement==null
2. element present, xsi:nil=true, then jaxbElement.isNil()==true
It would not be possible to distinguish between these two states if the bindings were the raw types.
The repeating sequences are treated as a List<Object> of generic JAXBElements, where the JAXBElement's QName is used to distinguish elements with different names.
It would be possible to customize the JAXB bindings to ignore the full round-trip requirement. An example "bindings.xjb" customization file:
<jaxb:bindings version="2.1" xmlns:jaxb="http://java.sun.com/xml/ns/jaxb" xmlns:xjc="http://java.sun.com/xml/ns/jaxb/xjc" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <jaxb:bindings schemaLocation="prov-core.xsd" node="//xs:complexType[@name='Document']"> <jaxb:globalBindings generateElementProperty="false" /> </jaxb:bindings> </jaxb:bindings>
$ xjc.sh -b bindings.xjb prov.xsd
However, it has been noted that the "generateElementProperty=false" customization option generates an alternate developer-friendly "but lossy binding".
A more viable solution is to remove usage of the abstractElement from the sequences and to leverage the use of prov:others.
TODO: link to to inline the modified JAXB-friendly schema.
Capitalization Conventions in PROV
Various conventions are adopted by various communities, and the group itself had its own set of requirements. Hence, the following conventions were adopted, as a compromise among those sometimes conflicting constraints.
PROV-DM
1. In Figure 1 of prov-dm (http://www.w3.org/TR/prov-dm/#prov-core-structures-top) classes are capitalized.
2. Relations are expressed using a past tense verbal form (was derived from, was generated by, ...)
3. Figure 5 (http://www.w3.org/TR/prov-dm/#figure-component1) and subsequent figures show that most relations are reified (called Association Class in UML, and see Qualified Pattern in PROV-O), so in compliance with UML convention, binary association and corresponding association classes are capitalized.
4. Values that the prov:type attribute can take are classes, and therefore are capitalized prov:Bundle, prov:SoftwareAgent, etc
5. Definitions define terms informally, in English. Terms in definitions are not capitalized (unless they begin the sentence).
PROV-N
1. All expressions start with a predicate using camel case with the first letter as lower case.
agent(ex:ag) wasDerivedFrom(ex:e2, ex:e1)
2. References to types are capitalized:
entity(ex:b1, [prov:type="prov:Bundle]) agent(ex:ag1, [prov:type="prov:SoftwareAgent"])
PROV-O
1. Properties use camel case with the first letter as lower case.
2. Classes are capitalized
ex:e2 prov:wasDerivedFrom ex:e1.
ex:e2 a prov:Entity.
PROV-XML
1. Elements use camel case with the first letter as lower case.
2. Classes in the XML schema are capitalized
<prov:agent id="ex:ag">
<prov:type="prov:SoftwareAgent"/>
</prov:agent>
How does PROV address the recommendations of the Provenance Incubator Group
Seven of the eight recommendations defined by the Provenance Incubator are directly addressed by PROV specification:
- Core concepts (recommendation #1) addressed by Entity, Agent, Person, id, Activity in the PROV data model
- Provenance publishing (recommendation #3) addressed by prov-aq
- Provenance of provenance (recommendation #4) addressed by bundles in prov-dm
- Reproducibility (recommendation #5) addressed by Activity, Usage, Generation, etc in the PROV data model
- Versioning (recommendation #6) addressed by Derivation, Revision, Specialization, Alternate in the PROV data model
- Procedure (recommendation #7) addressed by Activity and Plan in the PROV data model
- Derivation (recommendation #8) addressed by Derivation in the PROV data model
Recommendation #2 was out of scope for standardization of activity of the working group, but it is believed that it can be supported by PROV extensibility points.
How can PROV-N, PROV-O (RDF) and PROV-XML be converted to one another?
The PROV Toolbox supports all of these conversions; however, there is no formal specification of these mappings in PROV. Appendix A of PROV-DM contains a table that cross-references the terminology used in PROV-N, PROV-O and PROV-DM.
The mapping from PROV-N to PROV-XML and back is straightforward, while the mapping between PROV-O in RDF and PROV-N is more involved. During the development of PROV, the working group maintained the ProvRDF page to help keep track of the mapping between PROV-N and PROV-O/RDF. This page is out of date and does not reflect the final version of PROV
Héctor Pérez-Urbina submitted some notes similar to the ProvRDF page's material, adapted to a near-final version of PROV (45 days before PROV was published as a Recommendation). These may be useful as a starting point for specification of a mapping from PROV-N to RDF and back.
Future developments on this topic may be posted here.
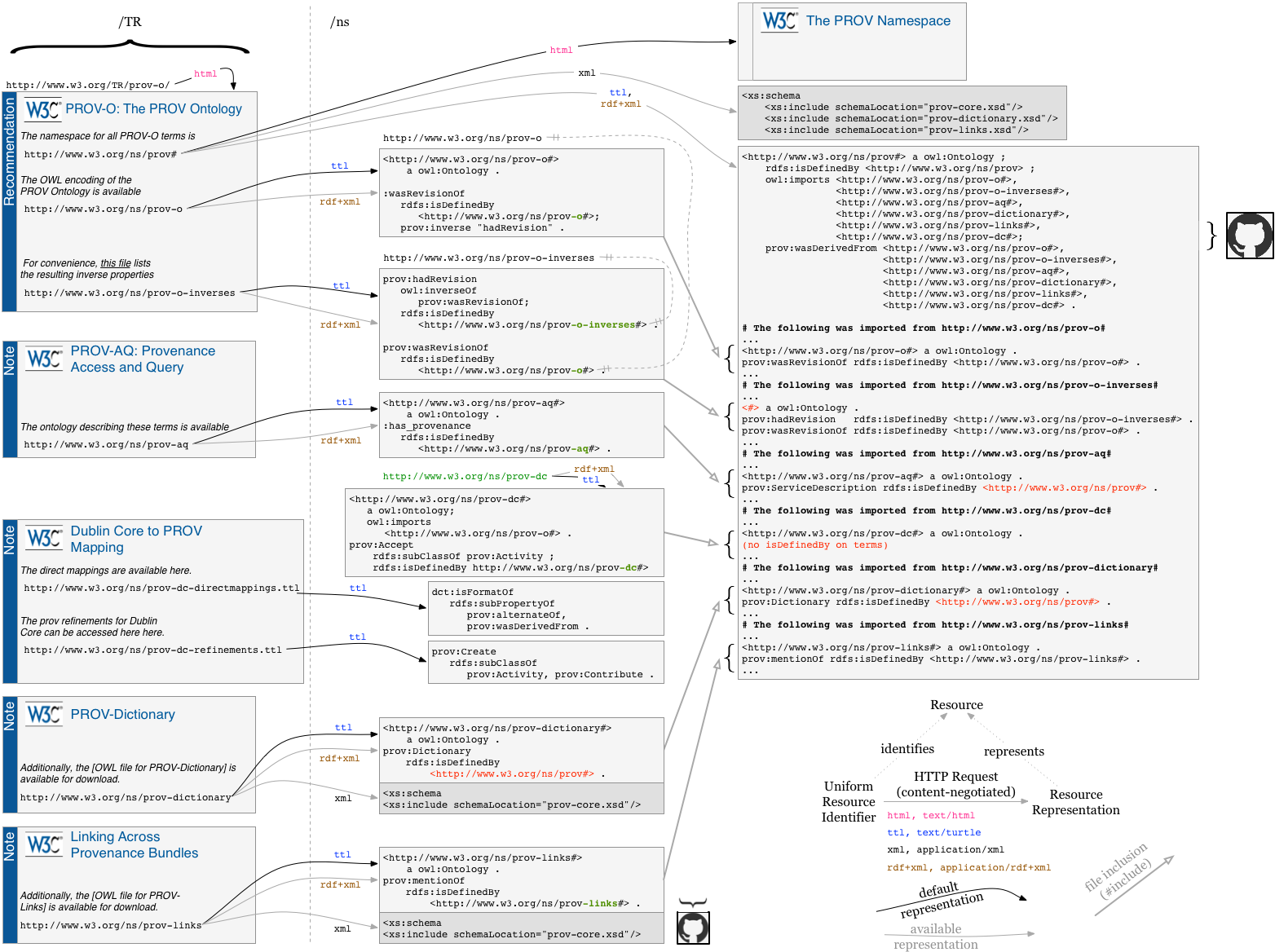
The PROV URIs
This section describes the design for the URIs chosen for the different parts of PROV.
The namespace for all PROV terms -- regardless of serialization -- is http://www.w3.org/ns/prov#. For example, http://www.w3.org/ns/prov#Entity and http://www.w3.org/ns/prov#Activity.
Content negotiation is used to determine which representation to return when the namespace is requested.
Six owl:Ontologies
- http://www.w3.org/ns/prov# is an owl:Ontology that contains ANY term from ANY PROV-WG document, regardless of Rec or Note (see http://www.w3.org/ns/prov#)
The owl:Ontology above is an aggregation of the owl:Ontology below.
- http://www.w3.org/ns/prov-o# is an owl:Ontology that contains the Recommendation terms. (see http://www.w3.org/TR/prov-o/)
- http://www.w3.org/ns/prov-aq# is an owl:Ontology that contains the Note terms for access and query. (see http://www.w3.org/TR/prov-aq/)
- http://www.w3.org/ns/prov-dictionary# is an owl:Ontology that contains the Note terms for dictionaries (see http://www.w3.org/TR/prov-dictionary/#dictionary-ontological-definition)
- http://www.w3.org/ns/prov-links# is an owl:Ontology that contains the Note terms for bundling linking (see http://www.w3.org/TR/prov-links/)
- http://www.w3.org/ns/prov-dc# is an owl:Ontology that contains the Note terms for mapping to Dublin Core (see http://www.w3.org/TR/prov-dc/#bib-refinements)
GET'ing an RDF description of a PROV term
When requesting the namespace http://www.w3.org/ns/prov in a web browser, it does not dereference to the OWL ontology, but to a general documentation page about various documents using the namespace, including the ontology itself. How am I supposed to GET the RDF description of e.g., http://www.w3.org/ns/prov#Activity, from the namespace URI?
To get an RDF description of the PROV namespace, use content negotiation by including an "Accept" header whose value is any recognized RDF serialization mimetype. For example, using curl:
curl -H "Accept: application/rdf+xml" -L http://www.w3.org/ns/prov
or
curl -H "Accept: text/turtle" -L http://www.w3.org/ns/prov
Alternatively, use the ".rdf" or ".ttl" extensions to access them: http://www.w3.org/ns/prov.rdf and http://www.w3.org/ns/prov.ttl
PROV namespace map
https://github.com/timrdf/prov-wg/wiki/namespace-map provides an illustration (pdf, png) of how the Technical Reports each have their own OWL definitions for the terms they introduce, and how they are all combined for the OWL definition of the PROV namespace.
{kind=link}