1 Introduction
Audio and video resources on the World Wide Web are currently treated as "foreign" objects, which can only be embedded using a plugin that is capable of decoding and interacting with the media resource. Specific media servers are generally required to provide for server-side features such as direct access to time offsets into a video without the need to retrieve the entire resource. Support for such media fragment access varies between different media formats and inhibits standard means of dealing with such content on the Web.
This specification provides for a media-format independent, standard means of addressing media fragments on the Web using Uniform Resource Identifiers (URI). In the context of this document, media fragments are regarded along three different dimensions: temporal, spatial, and tracks. Further, a fragment can be marked with a name and then addressed through a URI using that name. The specified addressing schemes apply mainly to audio and video resources - the spatial fragment addressing may also be used on images.
The aim of this specification is to enhance the Web infrastructure for supporting the addressing and retrieval of subparts of time-based Web resources, as well as the automated processing of such subparts for reuse. Example uses are the sharing of such fragment URIs with friends via email, the automated creation of such fragment URIs in a search engine interface, or the annotation of media fragments with RDF. Such use case examples as well as other side conditions on this specification and a survey of existing media fragment addressing approaches are provided in the requirements Use cases and requirements for Media Fragments document that accompanies this specification document.
The media fragment URIs specified in this document have been implemented and demonstrated to work with media resources over the HTTP and RTP/RTSP protocols. Existing media formats in their current representations and implementations provide varying degrees of support for this specification. It is expected that over time, media formats, media players, Web Browsers, media and Web servers, as well as Web proxies will be extended to adhere to the full specification. This specification will help make video a first-class citizen of the World Wide Web.
3 URI fragment and URI query
| Editorial note | |
| This section is non-normative |
To address a media fragment, one needs to find ways to convey the fragment information. This specification builds on URIs RFC 3986. Every URI is defined as consisting of four parts, as follows:
<scheme name> : <hierarchical part> [ ? <query> ] [ # <fragment> ]
There are therefore two possibilities for representing the media fragment addressing in URIs: the URI query part or the URI fragment part.
3.1 When to choose URI fragments? When to choose URI queries?
For media fragment addressing, both approaches - URI query and URI fragment - are useful.
The main difference between a URI query and a URI fragment is that a URI query produces a new resource, while a URI fragment provides a secondary resource that has a relationship to the primary resource. URI fragments are resolved from the primary resource without another retrieval action. This means that a user agent should be capable to resolve a URI fragment on a resource it has already received without having to fetch more data from the server.
A further requirement put on a URI fragment is that the media type of the retrieved fragment should be the same as the media type of the primary resource. Among other things, this means that a URI fragment that points to a single video frame out of a longer video results in a one-frame video, not in a still image. To extract a still image, one would need to create a URI query scheme - something not envisaged here, but easy to devise.
There are different types of media fragment addressing in this specification. As noted in the Use cases and requirements for Media Fragments document (section "Fitness Conditions on Media Containers/Resources"): not all container formats and codecs are "fit" for supporting the different types of fragment URIs. "Fitness" relates to the fact that a media fragment can be extracted from the primary resource without syntax element modifications or transcoding of the bitstream.
Resources that are "fit" can therefore be addressed with a URI fragment. Resources that are "conditionally fit" can be addressed with a URI fragment with an additional retrieval action that retrieves the modified syntax elements but leaves the codec data untouched. Resources that are "unfit" require transcoding. Such transcoded media fragments cannot be addressed with URI fragments, but only with URI queries.
| Editorial note: Raphael | |
| I wonder if we should not paste here the table in the Annexe B of the requirement document with the various container formats and their "fit" value for the media fragment dimensions considered |
Therefore, when addressing a media fragment with the URI mechanism, the author has to know whether this media fragment can be produced from the (primary) resource itself without any transcoding activities or whether it requires transcoding. In the latter case, the only choice is to use a URI query and to use a server that supports transcoding and delivery of a (primary) derivative resource to satisfy the query.
3.2 Resolving URI fragments within the user agent
A user agent may itself resolve and control the presentation of media fragment URIs. The simplest case arises where the user agent has
already downloaded the entire resource and can perform the extraction from its locally cached copy. For some media types, it may also be
possible to perform the extraction over the network without any special protocol assistance. For temporal fragments this requires a user
agent to be able to seek on the media resource using existing protocol mechanisms.
An example of a URI fragment used to address a media fragment is http://www.example.org/video.ogv#t=60,100. In this case,
the user agent knows that the primary resource is http://www.example.org/video.ogv and that it is only expected to display
the portion of the primary resource that relates to the fragment #t=60,100, i.e. seconds 60-100. Thus, the relationship
between the primary resource and the media fragment is maintained.
In traditional URI fragment retrieval, a user agent requests the complete primary resource from the server and then applies the
fragmentation locally. In the media fragment case, this would result in a retrieval action on the complete media resource, on which the
user agent would then locally perform its fragment extraction.
Media resources are not always retrieved over HTTP using a single request. They may be retrieved as a sequence of byte range requests
on the original resource URI, or may be retrieved as a sequence of requests to different URIs each representing a small part of the
media. The reasons for such mechanisms include bandwidth conservation, where a client chooses to space requests out over time during
playback in order to maximize bandwidth available for other activities, and bandwidth adaptation, where a client selects among various
representations with varying bitrate depending on the current bandwidth availability.
A user agent that knows how to map media fragments to byte ranges will be able to satisfy a URI fragment request such as the above example
by itself. This is typically the case for user agents that know how to seek to media fragments over the network.
For example, a user agent that deals with a media file that includes an index of its seekable structures can resolve the media fragment
addresses to byte ranges from the index. This is the case e.g. with seekable QuickTime files. Another example is a user agent that
knows how to seek on a media file through a sequence of byte range requests and eventually receives the correct media fragment. This is
the case e.g. with Ogg files in Firefox versions above 3.5.
Similarly, a user agent that knows how to map media fragments to a sequence of URIs can satisfy a URI fragment request by itself. This
is typically the case for user agents that perform adaptive streaming. For example, a user agent that deals with a media resource that
contains a sequence of URIs, each a media file of a few seconds duration, can resolve the media fragment addresses to a subsequence of
those URIs. This is the case with QuickTime adaptive bitrate streaming or IIS Smooth Streaming.
If such a user agent natively supports the media fragment syntax as specified in this document, it is deemed conformant to this
specification for fragments and for the particular dimension.
3.3 Resolving URI fragments with server help
For user agents that natively support the media fragment syntax, but have to use their own seeking approach, this specification provides
an optimisation that can make the byte offset seeking more efficient. It requires a conformant server with which the user agent will follow
a protocol defined later in this document.
In this approach, the user agent asks the server to do the byte range mapping for the media fragment address itself and send back the
appropriate byte ranges. This can not be done through the URI, but has to be done through adding protocol headers. User agents that
interact with a conformant server to follow this protocol will receive the appropriate byte ranges directly and will not need to do costly
seeking over the network.
Note that it is important that the server also informs the user agent what actual media fragment range it was able to retrieve. This is
important since in the compressed domain it is not possible to extract data at an arbitrary resolution, but only at the resolution
that the data was packaged in. For example, even if a user asked for http://www.example.org/video.ogv#t=60,100 and the
user agent sent a range request of t=60,100 to the server, the server may only be able to return the range
t=58,103 as the closest decodable range that encapsulates all the required data.
Note that if done right, the native user agent support for media fragments and the improved server support can be integrated without
problems: the user agent just needs to include the byte range and the media fragment range request in one request. A server that does not
understand the media fragment range request will only react to the byte ranges, while a server that understands them will ignore the
byte range request and only reply with the correct byte ranges. The user agent will understand from the response whether it received a
reply to the byte ranges or the media fragment ranges request and can react accordingly.
3.4 Resolving URI fragments in a proxy cacheable manner
The current setup of the World Wide Web relies heavily on the use of caching Web proxies to speed up the delivery of content. In the
case of URI fragments that are resolved by the server as indicated in the previous section, existing Web proxies have no means of
caching these requests since they only understand byte ranges.
To make use of the existing Web proxy infrastructure of the Web, we need to make sure that the user agent only asks for byte ranges,
so they can be served from the cache. This is possible if the server - instead of replying with the actual data - replies with the mapped
byte ranges for the requested media fragment range. Then, the user agent is able to resend his range request this time with bytes only,
which can possibly already be satisfied from the cache. Details of this will be specified later.
| Editorial note: Raphael | |
| Should we not foresee future "smart" media caches that would be able to actually cache range request in other units than bytes?
|
3.5 Resolving URI queries
The described URI fragment addressing methods only work for byte-identical segments of a media resource, since we assume a simple mapping
between the media fragment and bytes that each infrastructure element can deal with. Where it is impossible to maintain byte-identity
and some sort of transcoding of the resource is necessary, the user agent is not able to resolve the fragmentation by itself and a
server interaction is required. In this case, URI queries have to be used since they result in a server interaction and can deliver a
transcoded resource.
| Editorial note: Raphael | |
|
Weak argument? I would rather argue that if we cannot maintain byte-identity, then the fragment part of a URI is simply not suitable per
TAG finding that we would need to request. The argument that the server has to do some complex processing seems to me weaker.
|
Another use for URI queries is when a user agent actually wants to receive a completely new resource instead of just a byte range from
an existing (primary) resource. This is, for example, the case for playlists of media fragment resources. Even if a media fragment
could be resolved through a URI fragment, the URI query may be more desirable since it does not carry with itself the burden
of the original primary resource - its file headers may be smaller, its duration may be smaller, and it does not automatically allow
access to the remainder of the original primary resource.
When URI queries are used, the retrieval action has to additionally make sure to create a fully valid new resource. For example, for the
Ogg format, this implies a reconstruction of Ogg headers to accurately describe the new resource (e.g. a non-zero start-time or different
encoding parameters). Such a resource will be cached in Web proxies as a different resource to the original primary resource.
An example URI query that includes a media fragment specification is http://www.example.org/video.ogv?t=60,100. This results
in a video of duration 40s (assuming the original video was more than 100s long).
Note that this resource has no per-se relationship to the original primary resource. As a user agent uses such a URI with e.g. a HTML5
video element, the browser has no knowledge about the original resource and can only display this video as a 40s long video starting at 0s.
The context of the original resource is lost.
A user agent may want to display the original start time of the resource as the start time of the video in order to be consistent with the
information in the URI. It is possible to achieve this in one of two ways: either the video file itself has some knowledge that it is an
extract from a different file and starts at an offset - or the user agent is told through the retrieval action which original primary
resource the retrieved resource relates to and can find out information about it through another retrieval action. This latter option
will be regarded later in this document.
An example for a media resource that has knowledge about itself of the required kind are Ogg files. Ogg files that have a skeleton
track and were created correctly from the primary resource will know that their start time is not 0s but 60s in the above example.
The browser can simply parse this information out of the received bitstream and may display a timeline that starts at 60s and ends at 100s
in the video controls if it so desires.
Another option is that the browser parses the URI and knows about how media resources have a fragment specification that follows a standard.
Then the browser can interpret the query parameters and extract the correct start and end times and also the original primary resource.
It can then also display a timeline that starts at 60s and ends at 100s in the video controls. Further it can allow a right-click menu to
click through to the original resource if required.
A use case where the video controls may neither start at 0s nor at 60s is a mashed-up video created through a list of media fragment URIs.
In such a playlist, the user agent may prefer to display a single continuous timeline across all the media fragments rather than a
collection of individual timelines for each fragment. Thus, the 60s to 100s fragment may e.g. be mapped to an interval at 3min20 to 4min.
No new protocol headers are required to execute a URI query for media fragment retrieval. Some optional protocol headers that improve the
information exchange will be recommended later in this document.
3.6 Combining URI fragments and URI queries
A combination of a URI query for a media fragment with a URI fragment yields a URI fragment resolution on top of the newly created resource.
Since a URI with a query part creates a new resource, we have to do the fragment offset on the new resource. This is simply a conformant
behaviour to the URI standard RFC 3986.
For example, http://www.example.org/video.ogv?t=60,100#t=20 will lead to the 20s fragment offset being applied to the new
resource starting at 60 going to 100. Thus, the reply to this is a 40s long resource whose playback will start at an offset of 20s.
| Editorial note: Silvia | |
|
We should at the end of the document set up a table with all the different addressing types and http headers and say what we deem
is conformant and how to find out whether a server or user agent is conformant or not.
|
5 Media Fragments Processing
There are many open questions about how to resolve a media fragment URI that are not being answered simply from the specification of the syntax. An implementer will need to know all of these. This starts with issues around standardisation and uptake, followed by issues of interpretation of the syntax, followed by concrete protocol exchange scenarios for the different situations explained above in section 3 URI fragment and URI query.
| Editorial note: Silvia | |
| NOTE to implementers: if you come across some (not yet mentioned) issues here, please email to public-media-fragment@w3.org. |
5.1 Overview
| Editorial note: Raphael | |
| Rephrase this section. Some bits might end up in other sections. |
This is a list of hints to implementers on how to interpret media fragment URIs. There is no particular order to them.
Media type: The media type of a resource retrieved through a URI fragment request is the same as that of the primary resource. Thus, retrieval of e.g. a single frame from a video will result in a one-frame-long video. Or, retrieval of all the audio tracks from a video resource will result in a video and not a audio resource. When using a URI query approach, media type changes are possible. E.g. a spatial fragment from a video at a certain time offset could be retrieved as a jpeg using a specific HTTP "Accept" header in the request.
Synchronisation: Synchronisation between different tracks of a media resource needs to be maintained when retrieving media fragments of that resource. This is true for both, URI fragment and URI query retrieval. With URI queries, when transcoding is required, a non-perceivable change in the synchronisation is acceptable.
Embedded Timecodes: When a media resource contains embedded time codes, these need to be maintained for media fragment retrieval, in particular when the URI fragment method is used. When URI queries are used and transcoding takes place, the embedded time codes should remain when they are useful and required.
Resolution Order: Where multiple dimensions are combined in one URI fragment request, implementations are expected to first do track and temporal selection on the container level, and then do spatial clipping on the codec level. Named selection is done for whatever the name stands for: a track, a temporal section, or a spatial region.
Reasonable Byte Clipping: A media fragment that is retrieved using URI fragment requests needs to be implementable without transcoding solely based on byte ranges. Temporal or spatial clipping needs to be as close as reasonably possible to what the media fragment specified. "Reasonably close" means the nearest compression entity to the requested fragment that completely contains the requested fragment. This means, e.g. for temporal fragments if a request is made for http://www.example.org/video.ogv#t=60,100, but the closest decodable range is t=58,102 because this is where a packet boundary lies for audio and video, then it will be this range that is returned. Similarly for spatial ranges. The UA is then capable of displaying only the requested subpart, and should also just do that. For some container formats this is a non-issue, because the container format allows specification of logical begin and end.
External Clipping: There is no obligatory resolution method for a situation where a media fragment URI is being used in the context of another clipping method. Formally, it is up to the context embedding the media fragment URI to decide whether the outside clipping method overrides the media fragment URI or cascades, i.e. is defined on the resulting resource. In the absence of strong reasons to do otherwise we suggest cascading. An example is a SMIL element as follows: <smil:video clipBegin="5" clipEnd="15" src="http://www.example.com/example.mp4#t=100,200"/>. This should start playback of the original media resource at second 105, and stop at 115.
5.2 Protocol for URI fragment Resolution in HTTP
This section defines what protocol steps are necessary in HTTP RFC 2616 to resolve and deliver a media fragment specified as a URI fragment.
| Editorial note: Silvia | |
|
We could do RTSP as well, as mentioned earlier.
|
5.2.1 UA mapped byte ranges
| Editorial note | |
|
This section is ready to implement.
|
As described in section 3.2 Resolving URI fragments within the user agent, the most optimal case is a user agent that knows how to map media fragments to byte ranges. This is the case typically where a user agent has already downloaded those parts of a media resource that allow it to do or guess the mapping, e.g. headers or a resource, or an index of a resource.
In this case, the HTTP exchanges are exactly the same as for any other Web resource where byte ranges are requested RFC 2616.
How the UA retrieves the byte ranges is dependent on the media type of the media resource.
We here show examples with only one byte range retrieval per time range, which may
in practice turn into several such retrieval actions necessary to acquire the correct
time range.
Here are the three principle cases a media fragment enabled UA and a media Server will encounter:
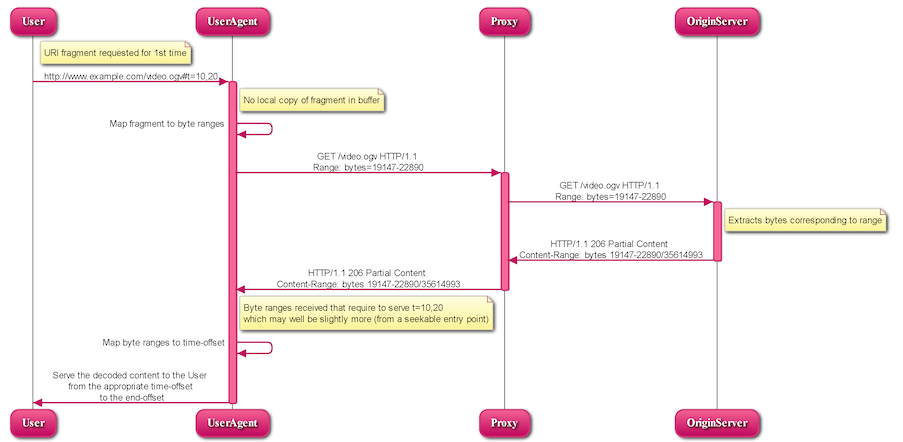
5.2.1.1 UA requests URI fragment for the first time
A user requests a media fragment URI:
User → UA (1):
http://www.example.com/video.ogv#t=10,20
The UA has to check if a local copy of the requested fragment is available in its buffer - not in this case. But it knows how to map the fragment to byte ranges: 19147 - 22890. So, it requests these byte ranges from the server:
The server extracts the bytes corresponding to the requested range and replies in a 206 HTTP response:
Assuming the UA has received the byte ranges that it requires to serve t=10,20, which may well be slightly more, it will serve the decoded content to the User from the appropriate time offset. Otherwise it may keep requesting byte ranges to retrieve the required time segments.
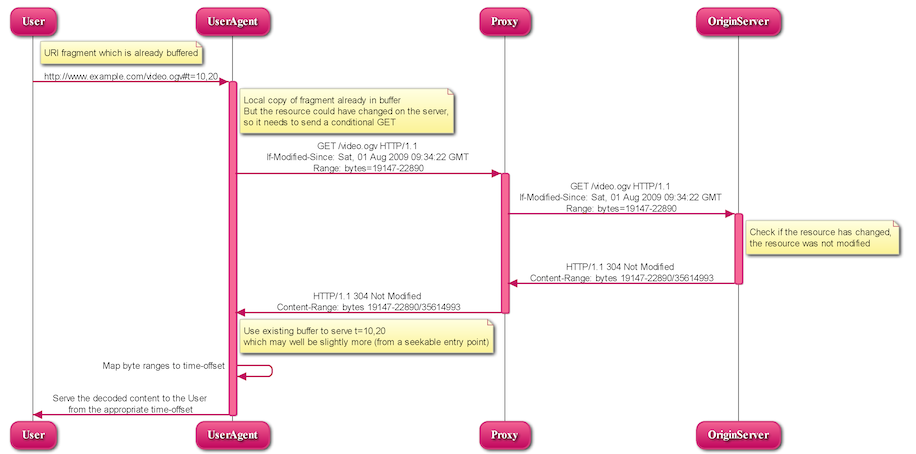
5.2.1.2 UA requests URI fragment it already has buffered
A user requests a media fragment URI:
User → UA (1):
http://www.example.com/video.ogv#t=10,20
The UA has to check if a local copy of the requested fragment is available in its buffer - it is in this case. But the resource could have changed on the server, so it needs to send a conditional GET. It knows the byte ranges: 19147 - 22890. So, it requests these byte ranges from the server under condition of it having changed:
The server checks if the resource has changed by checking the date - in this case, the resource was not modified. So, the server replies with a 304 HTTP response. (Note that a If-Range header cannot be used, because if the entity has changed, the entire resource would be sent.)
So, the UA serves the decoded resource to the User our of its existing buffer.
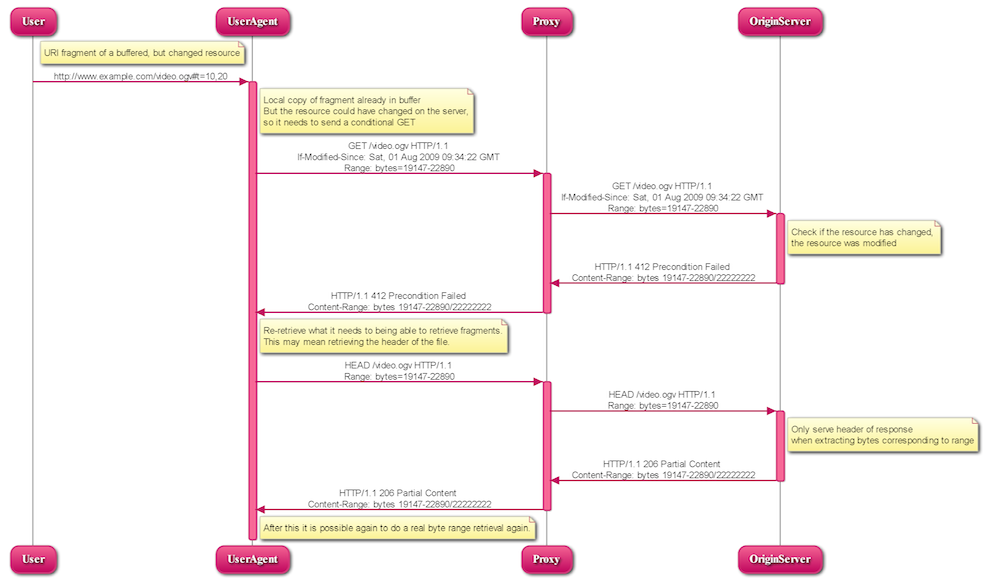
5.2.1.3 UA requests URI fragment of a changed resource
A user requests a media fragment URI and the UA sends the exact same GET request as described in the previous subsection.
This time, the server checks if the resource has changed by checking the date and it has been modified. Since the byte mapping may not be correct any longer, the server can only tell the UA that the resource has changed and leave all further actions to the UA. So, it sends a 412 HTTP response:
So, the UA can only assume the resource has changed and re-retrieve what it needs to get back to being able to retrieve fragments. For most resources this may mean retrieving the header of the file. After this it is possible again to do a byte range retrieval.
5.2.2 Server mapped byte ranges
As described in section 3.3 Resolving URI fragments with server help, some User Agents cannot undertake the framgent-to-byte mapping themselves, because the mapping is not obvious. This typically applies to media formats where the setup of the decoding pipeline does not imply knowledge of how to map fragments to byte ranges, e.g. Ogg without OggIndex. Thus, the User Agent would be capable of decoding a continuous resource, but would not know which bytes to request for a media fragment.
In this case, the User Agent could either guess at what byte ranges it has to retrieve and the retrieval action would follow the previous case. Or it could hope that the server provides a special service, which would allow it to retrieve the byte ranges with a simple request of the media fragment ranges. Thus, the HTTP request of the User Agent will include a request for the fragment hoping that the server can do the byte range mapping and send back the appropriate byte ranges.
We'll go through the protocol exchange action step by step. It starts with a user's request for a media fragment URI:
User → UA (1):
http://www.example.com/video.ogv#t=10,20
The UA has to check if a local copy of the requested fragment is available in its buffer. If it is, we revert back to the processing described in sections 5.2.1.2 UA requests URI fragment it already has buffered and 5.2.1.3 UA requests URI fragment of a changed resource, since the UA already knows the mapping to byte ranges.
When the UA doesn't know how to map time to bytes, it tries requesting this time range from the server:
The example shows a temporal Range request, which introduces the "t" dimension and the "npt" unit. The specification for all new Range dimensions is given through:
temporal: t:<unit>=<start> - <end>
spatial: xywh:<unit>=<topleftx>,<toplefty>,<width>,<height>
track: track=<trackname> [; <trackname>]*
name: id=<name>
The unit is not optional. It can be "npt", "smpte", "smpte-25", "smpte-30", "smpte-30-drop" or "clock" for temporal and "pixel" or "percent" for spatial. Where "ntp" is used for a temporal Range, only specification in seconds is possible without the "s". Where "clocktime" is used for a temporal Range, only "datetime" is possible and "walltime" is fully specified in HHMMSS with fraction and full timezone. Indeed, all optional elements in the URI specification become required in the Range header.
| Editorial note: Silvia | |
|
Somebody should create an ABNF for these new Range dimensions.
|
If the server doesn't understand a Range header, it MUST ignore the header field that includes that range-set. This is in sync to the HTTP RFC RFC 2616. This means that where a server doesn't support media fragments, the complete resource will be delivered. It also means that we can combine both, byte range and fragment range headers in one request, since the server will only react to the Range header it understands.
Assuming the server can map the given Range to one or more byte ranges, it will reply with these in a 206 HTTP response. Where multiple byte ranges are required to satisfy the Range request, these are transmitted as a multipart message-body. The media type for this purpose is called "multipart/byteranges". This is in sync with the HTTP RFC RFC 2616.
Here is the reply to the example above, assuming a single byte range is sufficient:
Note that there is a new header called Content-Range-Mapping, which provides the mapping of the retrieved byte range to the original Content-Range request, which was not in bytes. In comparison to the specification in the request Range header, the reply Content-Range-Mapping header also adds the instance-length after a slash "/" character in analogy to the Content-Range header. Also note that through the extended list in the Accept-Ranges it is possible to identify which fragment schemes a server supports.
temporal: t:<unit>=<start> - <end>/<duration>
spatial: xywh:<unit>=<topleftx>,<toplefty>,<width>,<height>/<total_width>,<total_height>
track: track=<trackname1>[; <trackname2>]*/<duration>
name: id=<name>/*
For temporal it is the total duration in seconds, for spatial the total width and height dimension, for track again the total duration in seconds, for id just "*" since it could be any of the other dimensions.
Also note that, as we return both, byte and temporal ranges, the UA and any intermediate caching proxy is enabled to map byte positions with time offsets and fall back to byte range request where the fragment is re-requested.
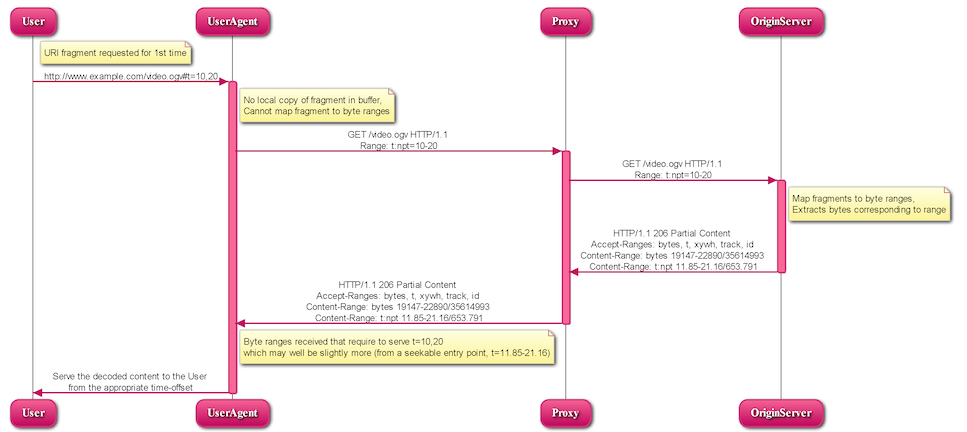
In the case where a media fragment results in a multipart message-body, the bytes Content-Range headers will be spread throughout the binary data ranges, but the Content-Range-Mapping of the media fragment will only be with the main header. For example:
Note that a caching proxy that does not understand a Range header must not cache "206 Partial Content" responses as per HTTP RFC RFC 2616. Thus, the new Range requests won't be cached by legacy Web proxies.
| Editorial note: Silvia | |
|
There is discussion in the group still whether "track" and "id" dimension can actually be handled in the same way as temporal and spatial, see Conrad's Fragment proposal.
Need to specify the ABNF for the Content-Range-Mapping header.
|
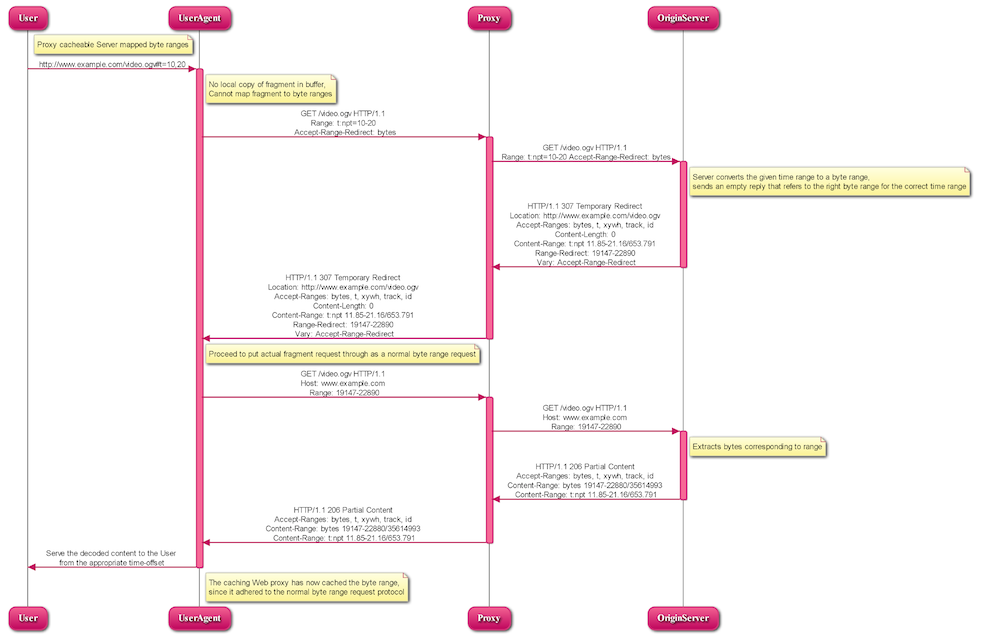
5.2.3 Proxy cacheable Server mapped byte ranges
As described in section 3.4 Resolving URI fragments in a proxy cacheable manner, the server mapped byte ranges approach can be extended to play with existing caching Web proxy infrastructure. This is important, since video is a huge bandwidth eater in the current Internet and falling back to using existing Web proxy infrastructure is important, particularly since progressive download and direct access mechanisms for video rely heavily on this functionality. Over time, the proxy infrastructure will learn how to cache media fragment URIs directly as described in the previous section and then will not require this extra effort.
To enable media-fragment-URI-supporting UAs to make their retrieval cachable, we introduce some extra HTTP headers, which will help tell the server and the proxy what to do.
Let's play it through on an example. A user requests a media fragment URI:
User → UA (1):
http://www.example.com/video.ogv#t=10,20
The UA has to check if a local copy of the requested fragment is available in its buffer. In our case here, it is not. If it was, we would revert back to the processing described in sections 5.2.1.2 UA requests URI fragment it already has buffered and 5.2.1.3 UA requests URI fragment of a changed resource, since the UA already knows the mapping to byte ranges. The UA issues a HTTP GET request with the fragment and requesting to retrieve just the mapping to byte ranges:
The server converts the given time range to a byte range and sends an empty reply that refers the UA to the right byte range for the correct time range. The message body of this answer contains the control section of fragf2f.mp4#12,21 (if required).
| Editorial note: Silvia | |
|
I have removed X-Accept-Range-Redirect - the X-Range-Redirect header already indicates that a mapping to byte ranges has been undertaken and the Accept-Ranges header shows which fragment addressing types the server can resolve. Need to discuss.
I have also removed the delivery of header information - for a URI fragment resolution, that's not necessary. When applying this to a URI query, however, it will be necessary, since the URI query delivers a completely new resource.
I further added the Content-Range-Mapping header, because it will tell the client what actual fragment data is being delivered, so this is required for the UA to get the actual mapping between fragment and byte ranges.
I am using "307 Temporary Redirect" and thus Range-Redirect (rather than Range-Refer) to return the reply without data in the reply.
We need an ABNF specification for Range-Redirect, which could contain a large number of ranges, then to be separated by comma.
|
The UA proceeds to put the actual fragment request through as a normal byte range request as in section 5.2.1.1 UA requests URI fragment for the first time:
The Origin Server puts the data together and sends it to the UA:
The UA decodes the data and displays it from the requested offset. The caching Web proxy in the middle has now cached the byte range, since it adhered to the normal byte range request protocol. All existing caching proxies will work with this. New caching Web proxies may learn to interpret media fragments natively, so won't require the extra packet exchange described in this section.
5.3 Protocol for URI query Resolution in HTTP
This section describes the protocol steps used in HTTP RFC 2616 to resolve and deliver a media fragment specified as a URI query.
A user requests a media fragment URI using a URI query:
User → UA (1):
http://www.example.com/video.ogv?t=10,20
This is a full resource, so it is a simple HTTP retrieval process. The UA has to check if a local copy of the requested resource is available in its buffer. If yes, it does a conditional GET with e.g. an If-Modified-Since and If-None-Match HTTP header.
Assuming the resource has not been retrieved before, the following is sent to the server:
If the server doesn't understand these query parameters, it typically ignores them and returns the complete resource. This is not a requirement by the URI or the HTTP standard, but the way it is typically implemented in Web browsers.
A media fragment supporting server has to create a complete media resource for the URI query, which in the case of Ogg requires creation of a new resource by adapting the existing Ogg file headers and combining them with the extracted byte range that relates to the given fragment. Some of the codec data may also need to be re-encoded since, e.g. t=10 does not fall clearly on a decoding boundary, but the retrieved resource must match as closely as possible the URI query. This new resource is sent back as a reply:
The UA serves the decoded resource to the User. Caching in Web proxies works as it has always worked - most modern Web servers and UAs implement a caching strategy for URIs that contain a query using one of the three methods for marking freshness: heuristic freshness analysis, the Cache-Control header, or the Expires header. In this case, many copies of different segments of the original resource video.ogv may end up in proxy caches. An intelligent media proxy in future may devise a strategy to buffer such resources in a more efficient manner, where headers and byte ranges are stored differently.
It is possible to add an additional HTTP response header called "Link" that refers the new resource back to the original resource and enables the UA to retrieve further information about the original resource, such as its full length. In this case, the user agent is also enable to choose to display the dimensions of the primary resource or the one created by the query.
Further, media fragment URI queries can be extended to enable UAs to use the Range-Redirect HTTP header to also revert back to a byte range request. This is analogous to section 5.2.3 Proxy cacheable Server mapped byte ranges.
Not that a server that doesn't support media fragments through either URI fragment or query addressing, will return the full resource in either case. It is therefore not possible to first try URI fragment addressing, and when that fails to try URI query addressing.
| Editorial note: Silvia | |
|
somebody should paint time-sequence diagrams for the protocol action.
|
7 Displaying Media Fragments
When dealing with media fragments, there is a question whether to display the media fragment in context or without context.
In general, it is recommended to display a URI fragment in context since it is part of a larger resource.
On the other hand, a URI query results in a new resource, so it is recommended to display it as a complete resource without context.
The next paragraphs discuss for each axis the context of a media fragment and provides suggestions regarding the visualization of the URI fragment within its context.
For a temporal URI fragment, it is recommended to start playback at a time offset that equals to the start of the fragment and pause at the end of the fragment. When the "play" button is hit again,
the resource will continue loading and play back beyond the end of the fragment. When seeking to specific offsets, the resource will load and play back from those seek points. It is also recommended
to introduce a "reload" button to replay just the URI fragment. In this way, a URI fragment basically stands for "focusing attention". Additionally, temporal URI fragments could be highlighted on the
transport bar.
For a spatial URI fragment, it is recommended to emphasize the spatial region during playback. For instance, the spatial region could be indicated by means of a bounding box or the background
(i.e., all the pixels that are not contained within the region) could be blurred or darkened.
Finally, for track URI fragments, it is recommended to play only the tracks identified by the track URI fragment. If no tracks are specified, the default tracks should be played.
Different tracks could be selected using dropdown boxes or buttons; the selected tracks are then highlighted during playback. The way the UA retrieves information regarding the available tracks of
a particular resource is out of scope for this specification.