This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.
This is the first
W3C Working Draft of the XML-binary Optimized Packaging
specification. It has been produced by the XML Protocol Working Group (WG),
which is a part of the Web Services
Activity. This specification describes a generalization of the packaging mechanism first developed in SOAP Message Transmission Optimization Mechanism (MTOM). Comments from other XML technology areas on this generalized mechanism are encouraged.
Discussion of this document takes place on the public xml-dist-app@w3.org mailing
list (public
archive) under the email communication rules in the XML Protocol Working
Group Charter .
Comments on this document are welcome. Send them to xmlp-comments@w3.org mailing
list (public
archive). Note that all resolved and outstanding issues against this
document are documented in the Working Group's Issues List.
Patent disclosures relevant to this specification may be found on the
Working Group's patent
disclosure page.
Publication as a Working Draft does not imply endorsement by the W3C Membership. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to cite this document as other than work in progress.
1. Introduction
This specification defines the XML-binary Optimized Packaging (XOP)
convention, a means of more efficiently serializing XML Query 1.0 and
XPath 2.0 Data Model [XML Query Data Model] that have certain types of
content.
A XOP package is created by placing a serialization of the XML Data
Model inside of an extensible packaging format (such as MIME
Multipart/Related, see [RFC 2387]) and then re-encoding
selected portions of its content alongside it, while marking their
locations in the XML with a special element that links to the packaged
data using URIs.
Optimization in XOP is limited to the content of those elements which
contain characters that can be interpreted as the canonical lexical
representation of the XML Schema base64Binary datatype (see
[XML Schema Part 2] 3.2.16
base64Binary and Errata in XML
Schema, E2-54). Attributes, non-base64-compatible
character data, and data not in the canonical representation of the
base64Binary datatype cannot be successfully optimized by
XOP.
| Editorial note: HR | |
|
Track change of any XML Schema spec new edition incorporating the
Erratas, to replace the double reference by only one.
|
This specification uses terminology from the XML Query 1.0 and XPath
2.0 Data Model when discussing XML content and structure, because the
Data Model allows content to be accessed both as characters and typed
values. However, it is not necessary to use or implement an XQuery
processor to create or process XOP Packages; the Data Model is used
as a convenience in specification.
XOP is designed to carry sufficient information to reconstruct with
full fidelity the supplied Data Model, including the return value of
the dm:string-value accessor for each Node in
the Data Model, except that the type property and the return
value of the dm:typed-value accessor are generally not
preserved. The type of base64Binary Element
Bodes that were optimized is in fact conveyed, but the
type of other Element Nodes as well as the
type of Attribute Nodes is in general not
preserved.
The remainder of this specification is organized in the following
fashion:
-
Section Two of this specification describes the form of the XOP
Package.
-
Section Three describes the XOP Data Model, which preserves the
non-optimized content and structure of the original Data Model.
-
Section Four specifies XOP's processing model.
-
Section Five describes how XOP Documents are identified.
-
Section Six explores the security considerations of using the XOP
convention.
-
Finally, Appendix A gives a mapping between Infosets and Data
Models, so that XOP optimization can be used with Infoset-based
formats.
1.1 Terminology
The following terms are used in this specification:
-
Original Data Model - An XML Data Model to be
optimized
-
Original XML Infoset - An XML Infoset to be optimized.
-
Extracted Content - Optimized content which has
been removed from the Data Model.
-
XOP Data Model - The Original Data Model with
any Extracted Content removed and replaced by
xop:Include elements.
-
XOP Document - A serialization of the XOP Data
Model using XML 1.0.
-
XOP Package - A package containing the XOP
Document and any Extracted Content. As a whole, the XOP Package
is an alternate serialization of the Original Data Model.
-
Reconstituted Data Model - An XML Data Model that
has been constructed from the parts of a XOP Package.
-
Reconstituted XML Infoset - An XML Infoset that has been
constructed from the parts of a XOP Package.
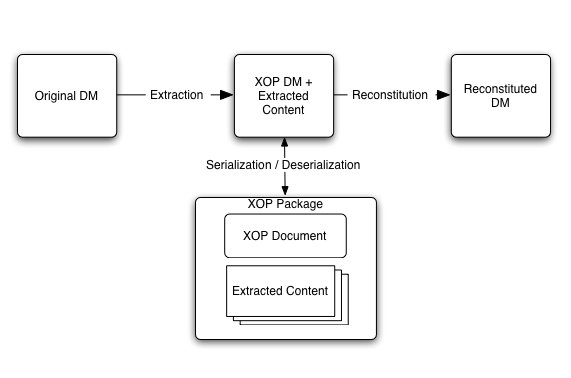
Figure 1: Architecture of the XOP framework
1.2 Example
Example 1 shows an XML Infoset prior to XOP
processing. Example 2 shows the same
Infoset, serialized using the XOP format in a MIME Multipart/Related
package. The base64-encoded content of the m:photo and
m:sig elements have been replaced by a
xop:Include element, while the binary octets have been
serialized in separate MIME parts.
Example 1: XML Infoset prior to XOP processing
<soap:Envelope
xmlns:soap='http://www.w3.org/2003/05/soap-envelope'
xmlns:xop='http://www.w3.org/2003/12/xop/include'
xmlns:xop-mime='http://www.w3.org/2003/12/xop/mime'>
<soap:Body>
<m:data xmlns:m='http://example.org/stuff'>
<m:photo xop-mime:content-type='image/png'>
/aWKKapGGyQ=
</m:photo>
<m:sig xop-mime:content-type='application/pkcs7-signature'>
Faa7vROi2VQ=
</m:sig>
</m:data>
</soap:Body>
</soap:Envelope>
Example 2: XML Infoset serialized as a XOP package
MIME-Version: 1.0
Content-Type: Multipart/Related;boundary=MIME_boundary;
type=text/xml;start="<mymessage.xml@example.org>"
Content-Description: An XML document with my picture and signature in it
--MIME_boundary
Content-Type: text/xml; charset=UTF-8
Content-Transfer-Encoding: 8bit
Content-ID: <mymessage.xml@example.org>
<soap:Envelope
xmlns:soap='http://www.w3.org/2003/05/soap-envelope'
xmlns:xop='http://www.w3.org/2003/12/xop/include'
xmlns:xop-mime='http://www.w3.org/2003/12/xop/mime'>
<soap:Body>
<m:data xmlns:m='http://example.org/stuff'>
<m:photo xop-mime:content-type='image/png'>
<xop:Include href='cid:http://example.org/me.png'/>
</m:photo>
<m:sig xop-mime:content-type='application/pkcs7-signature'>
<xbinc:Include href='cid:http://example.org/my.hsh'/>
</m:sig>
</m:data>
</soap:Body>
</soap:Envelope>
--MIME_boundary
Content-Type: image/png
Content-Transfer-Encoding: binary
Content-ID: <http://example.org/me.png>
// binary octets for png
--MIME_boundary
Content-Type: application/pkcs7-signature
Content-Transfer-Encoding: binary
Content-ID: <http://example.org/my.hsh>
// binary octets for signature
--MIME_boundary--
1.3 Notational Conventions
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT",
"SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this
document are to be interpreted as described in RFC 2119 [RFC 2119].
This specification uses a number of namespace prefixes throughout;
they are listed below. Note that the choice of any namespace prefix
is arbitrary and not semantically significant.
Table 1: Prefixes and Namespaces used in this
specification.
| Prefix |
Namespace |
| Notes |
| dm |
"Not bound to any namespace." |
|
Consistent with [XML Query Data Model], this prefix is used to
qualify accessor names in the XQuery 1.0 and XPath 2.0 Data
Model.
|
| xop |
"http://www.w3.org/2003/12/xop/include" |
|
A normative XML Schema [XML Schema Part 1], [XML Schema Part 2] document for the
"http://www.w3.org/2003/12/xop/include"
namespace can be found at http://www.w3.org/2003/12/xop/include.xsd.
|
| xop-mime |
"http://www.w3.org/2003/12/xop/mime" |
|
[TBD]
|
| xs |
"http://www.w3.org/2001/XMLSchema" |
|
The namespace of XML Schema data types [XML Schema Part 2].
|
2. XOP Packages
XOP is capable of using a variety of underlying packaging mechanisms.
This section specifies how a particular packaging mechanism, MIME
Multipart/Related, is used, but does not preclude the use of other
packaging mechanisms with the XOP convention.
2.1 MIME Multipart/Related XOP Packages
This section describes how MIME Multipart/Related packaging (as specified in
[RFC 2387]) is used with XOP.
The root MIME part is the root part of the package, and MUST be an
XML 1.0 serialization [XML 1.0] of the XOP Data Model, as
defined below, and MUST be identified with the [ TBD ] media type.
| Editorial note: HR | |
| Need to define the media type. |
Except for purposes of determining the root MIME part, as specified
by [RFC 2387], ordering of MIME parts MUST NOT be
considered significant to XOP processing or to the construction of
the XOP Data Model.
Part metadata is reflected in MIME header fields. Specifically, if
the URI used in the value of a xop:Include element's
href attribute has a 'cid' scheme, the corresponding MIME
part's Content-ID header field MUST have a corresponding field-value.
Otherwise, the MIME part's Content-Location header field MUST have a
field-value identical to the URI in the value of the href
attribute.
Furthermore, if a xop-mime:content-type header is found (as
described in 4. XOP's Processing Model), it SHOULD be
reflected in the MIME Content-Type header's field-value.
3. XOP Data Models Constructs
XOP operates by transforming the supplied Original Data Model into a
more compact XML representation, which is achieved by removing the
Text Node children of Element Nodes to be
optimized and replacing them with an Element Node named
xop:Include . The xop:Include Element
Node contains an Attribute Node with a link to
the structure that is created to carry a binary representation of the
data removed from the original Element Node. Details of
the construction and processing of XOP serializations are provided in
4. XOP's Processing Model.
The Data Model used as input to XOP processing MUST NOT
contain any Element Node with a node-name
property equal to
{http://www.w3.org/2003/12/xop/include;Include} . Data
Models containing such Element Nodes cannot be
serialized using XOP.
The following subsections provide formal definitions for the
Element Nodes and Attribute Nodes used to
construct a XOP serialization.
3.1 xop:Include Element Node
The xop:Include Element Node property values
are as follows:
-
node-name MUST be
{http://www.w3.org/2003/12/xop/include;Include} .
-
type MUST be
{http://www.w3.org/2003/12/xop/include;Include} .
-
children MUST NOT contain any Element Node.
-
There MAY be more than one Attribute Nodes comprising
attributes. Among these MUST be the following:
-
nilled MUST be false.
-
Other properties such as base-uri, parent nad
namepsaces MUST be set according to the context.
| Editorial note: Gudge | |
|
Should not allow other children either.
|
3.2 href Attribute Node
The href Attribute Node has the following
Data Model property values:
-
node-name MUST be
{;href} .
-
string-value MUST be a representation of a URI referencing
the part of the package containing the data logically included by
the parent Element Node (i.e., the
xop:Include Element Node).
-
parent MUST be the
xop:Include Element
Node which is parent of the Attribute Node.
-
type MUST be
{http://www.w3.org/2001/XMLSchema;anyURI} .
3.3 xop-mime:content-type Attribute Node
The xop-mime:content-type Attribute Node has
the following Data Model property values:
-
node-name MUST be
{http://www.w3.org/2003/12/xop/mime;content-type} .
-
string-value MUST be the content-type of the binary data
represented as base64 encoded data in the Element Node
parent of this Attribute Node.
-
parent MUST be set according to the context.
-
type MUST be
{http://www.w3.org/2003/12/xop/mime;content-type} .
| Editorial note: HR | |
|
Write the corresponding schema.
|
4. XOP's Processing Model
This section describe XOP's Processing Model, both for creating XOP
Packages and Interpreting XOP Packages. Unless otherwise stated,
processing of XOP Packages MUST be semantically equivalent to
performing the specified steps separately, and in the order given.
4.1 Creating XOP Packages
To create a XOP Package from an Original XML Infoset or an Original
Data Model:
-
If starting with an Original XML Infoset, create an Original Data
Model as described in A.1 XOP Infoset to Data Model Mapping; otherwise, proceed using
the supplied Original Data Model.
-
Ensure that the Original Data Model contains no Element
Node with a node-name of
{http://www.w3.org/2003/12/xop/include;Include} . As
discussed in 3. XOP Data Models Constructs, Data Models with
such Element Node cannot be represented using XOP.
-
Create an empty package.
-
Identify within the Original Data Model the Element
Nodes to be optimized. Such Nodes MUST have
type equal to
xs:base64Binary , and the return
value of the dm:string-value accessor of such
Nodes must be in the canonical lexical representation
of that type as described in Errata in
XML Schema, E2-54.
-
Create a XOP Data Model which is a copy of the Original Data Model,
but with the children of each Element Node
identified in the previous step replaced by a
xop:Include Element Node (see 3.1 xop:Include Element Node) constructed as follows:
-
Transform the replaced characters into binary data by
processing them as base64-encoded data.
-
Serialize the binary data into a new part of the package, with
appropriate metadata corresponding to the string-value
of the
href Attribute Node of the
xop:Include Element Node (see 3.2 href Attribute Node).
-
If the Node being optimized (i.e., the
parent of the newly inserted
xop:Include
Element Node) has a
xop-mime:content-type Attribute Node,
its value SHOULD be reflected appropriately in the part's
metadata.
-
Serialize the resulting XOP Data Model into the package as XML 1.0
and identify it as the root part according to the packaging
mechanism's convention.
Additional parts MAY be added to the package to satisfy application
specific requirements. Other content-specific metadata MAY be
reflected in the packaging metadata as appropriate.
If content cannot be successfully encoded into the XOP Data Model,
implementations SHOULD behave as if that portion of the Original Data
Model was not nominated for optimization.
4.2 Interpreting XOP Packages
To create a Reconstituted Data Model or a Reconstituted XML Infoset
from a XOP Package:
-
Parse the root part of the package as an XML 1.0 document to
construct an XML Infoset (see [XML InfoSet]). From
that, construct a Data Model using the Infoset to Data Model
mapping described in [XML Query Data Model] Construction
from an Infoset.
-
Using that Data Model, for each Element Node which has
as its children a
xop:Include Element
Node (as defined in 3.1 xop:Include Element Node):
-
Locate the part of the package corresponding to the URI in the
xop:Include 's href Attribute
Node (i.e., corresponding to the URI encoded in the
Attribute Node's string-value).
-
Replace the Element Node's children with
a Text Node containing the canonical base64
encoding of the entity body of the identified package part
(i.e., effectively replace the
xop:Include
Element Node with the data reconstructed from the
package part).
-
If a reconstructed XML Infoset is needed, use the mapping described
in A.2 XOP Data Model to Infoset Mapping to create the
required Reconstructed XML Infoset from the Reconstructed Data
Model.
5. Identifying XOP Documents
[TBD]
6. Security Considerations
[TBD]