XSL is a language for expressing stylesheets. It consists of two
parts:
-
a language for transforming XML documents, and
-
an XML vocabulary for specifying formatting
semantics.
An XSL stylesheet specifies the presentation of a class of XML
documents by describing how an instance of the class is transformed
into an XML document that uses the formatting vocabulary.
This is a W3C Working Draft for review by W3C members and other
interested parties. This adds additional functionality to what was
described in the previous draft. It is a draft document and
may be
updated, replaced, or obsoleted by other documents at any time. The
XSL Working Group will not allow early implementation to constrain its
ability to make changes to this specification prior to final release.
It is inappropriate to use W3C Working Drafts as reference material or
to cite them as other than "work in progress". A list of
current W3C working drafts can be found at http://www.w3.org/TR/.
This document has been produced as part of the W3C Style Activity by
the XSL Working Group
(members only).
Comments may be sent to xsl-editors@w3.org. Public
discussion of XSL takes place on the XSL-List
mailing list.
1 Introduction and Overview
1.1 Processing a Stylesheet
1.1.1 Tree Transformations
1.1.2 Formatting
1.2 Benefits of XSL
1.2.1 Paging and Scrolling
1.2.2 Selectors and Tree Construction
1.2.3 An Extended Page Layout Model
1.2.4 A Comprehensive Area Model
1.2.5 Internationalization and Writing-Modes
1.2.6 Linking
2 Introduction to XSL Transformation
2.1 Tree Construction
2.2 XSL Namespace
3 Introduction to
Formatting
3.1 Conceptual Procedure
4 Area Model
4.1 Introduction
4.2 Rectangular Areas
4.2.1 Area Types
4.2.2 Common Traits
4.2.3 Geometric Definitions
4.2.4 Tree ordering
4.2.5 Stacking constraints
4.2.6 Font baseline tables
4.3 Spaces and Conditionality
4.3.1 Space-resolution rules
4.4 Block-areas
4.5 Stacked Block-areas
4.6 Line-areas
4.7 Inline-areas
4.8 Stacked Inline-areas
4.9 Glyph-areas
4.10 Line-building
4.11 Keeps and Breaks
5 Property Refinement / Resolution
5.1 Specified, Computed, and Actual Values, and Inheritance
5.1.1 Specified Values
5.1.2 Computed Values
5.1.3 Actual Values
5.1.4 Inheritance
5.2 Shorthand Expansion
5.3 Computing the Values of Corresponding Properties
5.3.1 Border and Padding Properties
5.3.2 Margin, Space, and Indent Properties
5.3.3 Height, and Width Properties
5.4 Simple Property to Trait Mapping
5.4.1 Column-number Property
5.4.2 Text-align Property
5.4.3 Text-align-last Property
5.4.4 Z-index Property
5.5 Complex Property to Trait Mapping
5.5.1 Word-spacing, and Letter-spacing Properties
5.5.2 Writing-mode Property
5.6 Non-property Based Trait Generation
5.7 Property Based Transformations
5.7.1 Text-transform Property
5.8 Expressions
5.8.1 Property Context
5.8.2 Evaluation Order
5.8.3 Basics
5.8.4 Function Calls
5.8.5 Numerics
5.8.6 Absolute Numerics
5.8.7 Relative Numerics
5.8.8 Strings
5.8.9 Colors
5.8.10 Keywords
5.8.11 Lexical Structure
5.8.12 Expression Value Conversions
5.9 Core Function Library
5.9.1 Number Functions
5.9.2 Color Functions
5.9.3 Font Functions
5.9.4 Property Value Functions
5.10 Property Datatypes
6 Formatting Objects
6.1 Introduction to Formatting Objects
6.1.1 Definitions Common to Many Formatting Objects
6.2 Formatting Object Content
6.3 Formatting Objects Summary
6.4 Pagination and Layout Formatting Objects
6.4.1 Introduction
6.4.2 fo:root
6.4.3 fo:page-sequence
6.4.4 fo:layout-master-set
6.4.5 fo:page-sequence-master
6.4.6 fo:single-page-master-reference
6.4.7 fo:repeatable-page-master-reference
6.4.8 fo:repeatable-page-master-alternatives
6.4.9 fo:conditional-page-master-reference
6.4.10 fo:simple-page-master
6.4.11 fo:title
6.4.12 fo:region-body
6.4.13 fo:region-before
6.4.14 fo:region-after
6.4.15 fo:region-start
6.4.16 fo:region-end
6.4.17 fo:flow
6.4.18 fo:static-content
6.5 Block-level Formatting Objects
6.5.1 Introduction
6.5.2 fo:block
6.5.3 fo:block-container
6.6 Inline-level Formatting Objects
6.6.1 Introduction
6.6.2 fo:bidi-override
6.6.3 fo:character
6.6.4 fo:initial-property-set
6.6.5 fo:external-graphic
6.6.6 fo:instream-foreign-object
6.6.7 fo:inline
6.6.8 fo:inline-container
6.6.9 fo:leader
6.6.10 fo:page-number
6.6.11 fo:page-number-citation
6.7 Formatting Objects for Tables
6.7.1 Introduction
6.7.2 fo:table-and-caption
6.7.3 fo:table
6.7.4 fo:table-column
6.7.5 fo:table-caption
6.7.6 fo:table-header
6.7.7 fo:table-footer
6.7.8 fo:table-body
6.7.9 fo:table-row
6.7.10 fo:table-cell
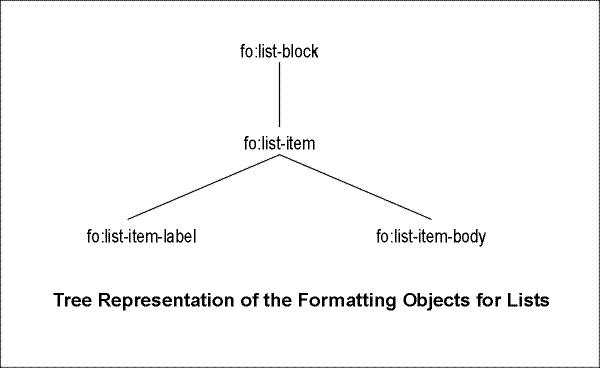
6.8 Formatting Objects for Lists
6.8.1 Introduction
6.8.2 fo:list-block
6.8.3 fo:list-item
6.8.4 fo:list-item-body
6.8.5 fo:list-item-label
6.9 Link and Multi Formatting Objects
6.9.1 Introduction
6.9.2 fo:simple-link
6.9.3 fo:multi-switch
6.9.4 fo:multi-case
6.9.5 fo:multi-toggle
6.9.6 fo:multi-properties
6.9.7 fo:multi-property-set
6.10 Out-of-Line Formatting Objects
6.10.1 Introduction
6.10.2 fo:float
6.10.3 fo:footnote
6.11 Other Formatting Objects
6.11.1 Introduction
6.11.2 fo:wrapper
7 Formatting Properties
7.1 Description of Property Groups
7.2 XSL Areas and the CSS Box Model
7.3 Common Accessibility Properties
7.3.1 source-document
7.3.2 role
7.4 Common Absolute Position Properties
7.4.1 absolute-position
7.4.2 top
7.4.3 right
7.4.4 bottom
7.4.5 left
7.5 Common Aural Properties
7.5.1 azimuth
7.5.2 cue-after
7.5.3 cue-before
7.5.4 elevation
7.5.5 pause-after
7.5.6 pause-before
7.5.7 pitch
7.5.8 pitch-range
7.5.9 play-during
7.5.10 richness
7.5.11 speak
7.5.12 speak-header
7.5.13 speak-numeral
7.5.14 speak-punctuation
7.5.15 speech-rate
7.5.16 stress
7.5.17 voice-family
7.5.18 volume
7.6 Common Border, Padding, and Background Properties
7.6.1 background-attachment
7.6.2 background-color
7.6.3 background-image
7.6.4 background-repeat
7.6.5 background-position-horizontal
7.6.6 background-position-vertical
7.6.7 border-before-color
7.6.8 border-before-style
7.6.9 border-before-width
7.6.10 border-after-color
7.6.11 border-after-style
7.6.12 border-after-width
7.6.13 border-start-color
7.6.14 border-start-style
7.6.15 border-start-width
7.6.16 border-end-color
7.6.17 border-end-style
7.6.18 border-end-width
7.6.19 border-top-color
7.6.20 border-top-style
7.6.21 border-top-width
7.6.22 border-bottom-color
7.6.23 border-bottom-style
7.6.24 border-bottom-width
7.6.25 border-left-color
7.6.26 border-left-style
7.6.27 border-left-width
7.6.28 border-right-color
7.6.29 border-right-style
7.6.30 border-right-width
7.6.31 padding-before
7.6.32 padding-after
7.6.33 padding-start
7.6.34 padding-end
7.6.35 padding-top
7.6.36 padding-bottom
7.6.37 padding-left
7.6.38 padding-right
7.7 Common Font Properties
7.7.1 font-family
7.7.2 font-size
7.7.3 font-stretch
7.7.4 font-size-adjust
7.7.5 font-style
7.7.6 font-variant
7.7.7 font-weight
7.8 Common Hyphenation
Properties
7.8.1 country
7.8.2 language
7.8.3 script
7.8.4 hyphenate
7.8.5 hyphenation-character
7.8.6 hyphenation-push-character-count
7.8.7 hyphenation-remain-character-count
7.9 Common
Keeps and Breaks Properties
7.9.1 break-after
7.9.2 break-before
7.9.3 keep-with-next
7.9.4 keep-with-previous
7.10 Common Margin
Properties-Block
7.10.1 margin-top
7.10.2 margin-bottom
7.10.3 margin-left
7.10.4 margin-right
7.10.5 space-before
7.10.6 space-after
7.10.7 start-indent
7.10.8 end-indent
7.11 Common
Margin Properties-Inline
7.11.1 space-end
7.11.2 space-start
7.12 Pagination and Layout Properties
7.12.1 column-count
7.12.2 column-gap
7.12.3 extent
7.12.4 flow-name
7.12.5 master-name
7.12.6 region-name
7.12.7 initial-page-number
7.12.8 force-page-count
7.12.9 maximum-repeats
7.12.10 page-position
7.12.11 odd-or-even
7.12.12 blank-or-not-blank
7.12.13 page-height
7.12.14 page-width
7.12.15 precedence
7.13 Table Properties
7.13.1 border-collapse
7.13.2 border-separation
7.13.3 caption-side
7.13.4 column-number
7.13.5 column-width
7.13.6 empty-cells
7.13.7 table-layout
7.13.8 table-omit-header-at-break
7.13.9 table-omit-footer-at-break
7.13.10 number-columns-spanned
7.13.11 number-rows-spanned
7.13.12 number-columns-repeated
7.13.13 ends-row
7.13.14 starts-row
7.14 Character Properties
7.14.1 character
7.14.2 letter-spacing
7.14.3 word-spacing
7.14.4 treat-as-word-space
7.14.5 suppress-at-line-break
7.14.6 text-decoration
7.14.7 text-shadow
7.14.8 text-transform
7.15 Rule and Leader Properties
7.15.1 leader-alignment
7.15.2 leader-pattern
7.15.3 leader-pattern-width
7.15.4 leader-length
7.15.5 rule-style
7.15.6 rule-thickness
7.16 Page-related Properties
7.16.1 keep-together
7.16.2 orphans
7.16.3 widows
7.17 Float-related Properties
7.17.1 float
7.17.2 clear
7.18 Properties for Number to String Conversion
7.18.1 format
7.18.2 letter-value
7.18.3 grouping-separator
7.18.4 grouping-size
7.19 Properties for Links
7.19.1 external-destination
7.19.2 internal-destination
7.19.3 show-destination
7.19.4 indicate-destination
7.19.5 destination-placement-offset
7.19.6 auto-restore
7.19.7 starting-state
7.19.8 case-name
7.19.9 case-title
7.19.10 switch-to
7.19.11 dom-state
7.20 Properties for Alignment of Areas
7.20.1 baseline-identifier
7.20.2 alignment-adjust
7.20.3 baseline-shift
7.20.4 dominant-baseline
7.20.5 display-align
7.20.6 relative-align
7.21 Miscellaneous Properties
7.21.1 clip
7.21.2 color
7.21.3 content-type
7.21.4 direction
7.21.5 unicode-bidi
7.21.6 glyph-orientation-horizontal
7.21.7 glyph-orientation-vertical
7.21.8 font-height-override-after
7.21.9 font-height-override-before
7.21.10 height
7.21.11 min-height
7.21.12 max-height
7.21.13 block-progression-dimension
7.21.14 href
7.21.15 hyphenation-keep
7.21.16 hyphenation-ladder-count
7.21.17 id
7.21.18 last-line-end-indent
7.21.19 line-height-shift-adjustment
7.21.20 line-height
7.21.21 line-stacking-strategy
7.21.22 overflow
7.21.23 provisional-label-separation
7.21.24 provisional-distance-between-starts
7.21.25 ref-id
7.21.26 reference-orientation
7.21.27 relative-position
7.21.28 scale
7.21.29 score-spaces
7.21.30 span
7.21.31 text-align
7.21.32 text-align-last
7.21.33 text-indent
7.21.34 visibility
7.21.35 width
7.21.36 min-width
7.21.37 max-width
7.21.38 inline-progression-dimension
7.21.39 linefeed-treatment
7.21.40 space-treatment
7.21.41 white-space-collapse
7.21.42 wrap-option
7.21.43 writing-mode
7.21.44 z-index
7.22 Shorthand Properties
7.22.1 background
7.22.2 background-position
7.22.3 border
7.22.4 border-bottom
7.22.5 border-color
7.22.6 border-left
7.22.7 border-right
7.22.8 border-style
7.22.9 border-spacing
7.22.10 border-top
7.22.11 border-width
7.22.12 cue
7.22.13 font
7.22.14 margin
7.22.15 padding
7.22.16 page-break-after
7.22.17 page-break-before
7.22.18 page-break-inside
7.22.19 pause
7.22.20 position
7.22.21 size
7.22.22 vertical-align
7.22.23 white-space
7.22.24 xml:lang
Appendices
A Internationalization
A.1 Additional writing-mode values
B Formatting Object Summary
B.1 Pagination and Layout Formatting Objects
B.2 Block Formatting Objects
B.3 Inline Formatting Objects
B.4 Table Formatting Objects
B.5 List Formatting Objects
B.6 Link and Multi Formatting Objects
B.7 Out-of-line Formatting Objects
B.8 Other Formatting Objects
C Property Index
C.1 Explanation of Trait Mapping Values:
C.2 Property Table: Part I
C.3 Property Table: Part II
D References
D.1 Normative References
D.2 Other References
E Acknowledgements (Non-Normative)
1 Introduction and Overview
This specification defines the Extensible Stylesheet Language
(XSL). XSL is a language for expressing stylesheets. Given a class of
arbitrarily structured XML [W3C XML]
documents or data files, designers use
an XSL stylesheet to express their intentions about how that
structured content should be presented; that is, how the source
content should be styled, laid out, and paginated onto some
presentation medium, such as a window in a Web browser or a
hand-held device, or a set of
physical pages in a catalog, report, pamphlet, or book.
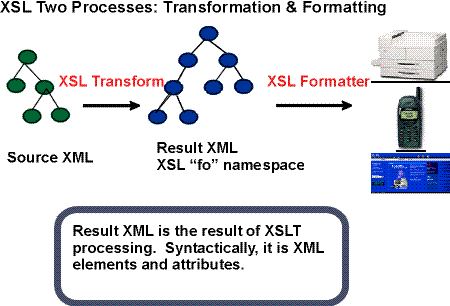
1.1 Processing a Stylesheet
An XSL stylesheet processor accepts a document
or data in XML
and an XSL stylesheet and produces the presentation of that XML source
content that was intended by the designer of that
stylesheet. There are two aspects of this
presentation process:
first, constructing a result tree from the XML source tree and second,
interpreting the result tree to produce formatted
results suitable for presentation on a
display, on paper, in speech, or onto other media. The first
aspect is called tree transformation and the
second
is called formatting. The process of formatting
is performed by the formatter. This formatter
may simply be a rendering engine inside a browser.
Tree transformation allows the structure of the result tree to be significantly
different from the structure of the source tree. For example, one could add
a table-of-contents as a filtered selection of an original source document,
or one could rearrange source data into a sorted tabular presentation.
In constructing the result tree,
the tree transformation process also adds the information necessary to
format that result tree.
Formatting is enabled by including formatting semantics
in the result tree. Formatting semantics are
expressed in terms of a catalog of classes of
formatting
objects. The nodes of the result tree are formatting
objects. The classes of formatting objects
denote typographic abstractions such as page, paragraph,
table, and so
forth. Finer control over the presentation of these abstractions is
provided by a set of formatting properties, such as
those controlling indents, word- and
letter-spacing, and widow, orphan, and hyphenation control.
In XSL, the
classes of formatting objects and
formatting properties
provide the vocabulary for expressing presentation intent.
The XSL processing model is intended to be
conceptual only. An implementation is not
mandated to provide these as separate
processes. Furthermore, implementations are free to process
the source document in any way that produces the same result
as if it were processed using the conceptual XSL processing
model. A diagram depicting the detailed conceptual model is
shown below.
1.1.1 Tree Transformations
Tree transformation constructs the result tree. In XSL,
this tree is called the element and attribute
tree, with objects primarily in the
"formatting object" namespace. In this tree, a formatting
object
is represented as an XML element, with the properties represented by a
set of XML attribute-value pairs. The content of the formatting object
is the content of the XML element. Tree
transformation is defined in the XSLT Recommendation
[XSLT].
A diagram depicting this conceptual process is
shown below.
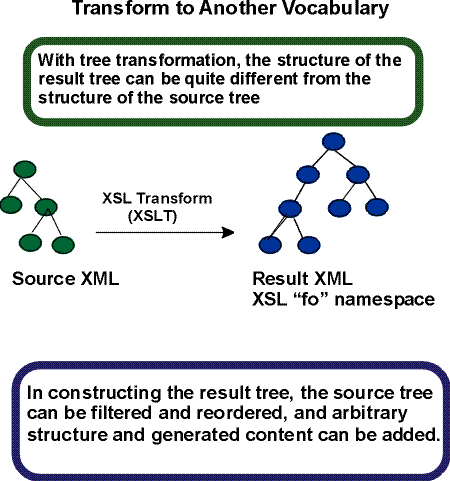
The XSL stylesheet is used in tree transformation. A stylesheet
contains a set of tree construction rules. The tree construction rules
have two parts: a pattern that is matched against elements in the
source tree and a template that constructs a portion of the result
tree. This allows a stylesheet to be applicable to a wide class of
documents that have similar source tree structures.
1.1.2 Formatting
Formatting interprets the result tree in its formatting object tree
form to produce the presentation intended by the designer
of the stylesheet from which the XML element and attribute
tree in the "fo" namespace was constructed.
The vocabulary of formatting objects supported by XSL - the set of
fo: element types - represents the set of
typographic abstractions available to the
designer. Semantically, each formatting object represents a
specification for a part of the pagination, layout, and styling
information that will be applied to the content of that formatting
object as a result of formatting the whole result tree. Each
formatting object class represents a particular kind of formatting
behavior. For example, the block formatting object class represents
the breaking of the content of a paragraph into lines. Other parts of
the specification may come from other formatting objects; for
example, the formatting of a paragraph (block formatting
object)
depends on both the specification of properties on the block
formatting object and the specification of the layout structure into
which the block is placed by the formatter.
The properties associated with an instance of a formatting object
control the formatting of that object. Some of the properties, for
example "color", directly specify the formatted result.
Other properties, for example 'space-before', only constrain the set
of possible formatted results without specifying any particular
formatted result. The formatter may make choices among other
possible considerations such as esthetics.
Formatting consists of the generation of a tree
of geometric areas, called the area tree. The
geometric areas are
positioned on a sequence of one or more pages (a browser typically
uses a single page). Each geometric area has a position on the page, a
specification of what to display in that area and may have a
background, padding, and borders. For example, formatting a
single
character generates an area sufficiently large enough to hold the
glyph that is used to present the character visually and the glyph is
what is displayed in this area. These areas may be nested. For
example, the glyph may be positioned within a line, within a
block, within a page.
Rendering
takes the area tree, the abstract model of the presentation (in terms
of pages and their collections of areas), and causes a
presentation to appear on the relevant medium, such as a browser
window on a computer display screen or sheets of paper. The semantics
of rendering are not described in detail in this specification.
The first step in formatting is to "objectify" the element
and attribute
tree obtained via an XSLT transformation.
Objectifying the tree basically consists of turning the
elements in the
tree into formatting object nodes and the
attributes into property specifications. The result of this step is
the formatting object tree.
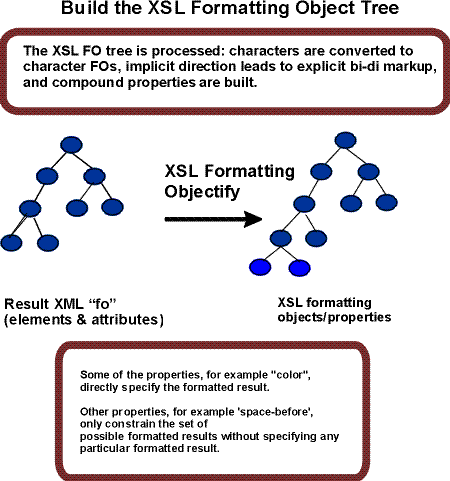
As part of the step of objectifying, the characters that occur in
the result tree are replaced by fo:character nodes. The
first phase of the
Unicode Bidirectional Algorithm is used to convert implicit Bidirectional
mark-up to explicit nodes with the appropriate directional
properties. Care is taken to insure that the introduced explicit nodes
are properly nested in the formatting object tree.
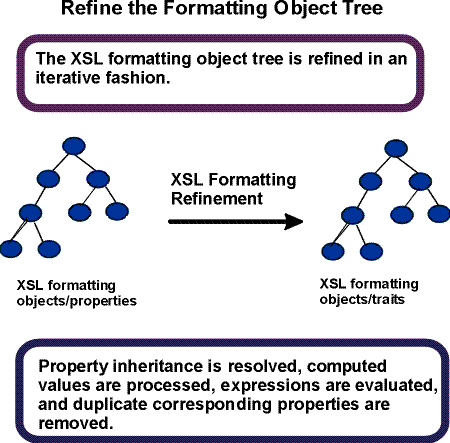
The second phase in formatting is to refine the formatting
object tree
to produce the refined formatting object tree.
The refinement process handles the mapping from properties
to traits. This consists of: (1) shorthand expansion into
individual properties, (2) mapping of corresponding
properties, (3) determining computed values (may include
expression evaluation), and (4) inheritance. Details on
refinement are found in [5 Property Refinement / Resolution].
The refinement step is depicted in the diagram below.
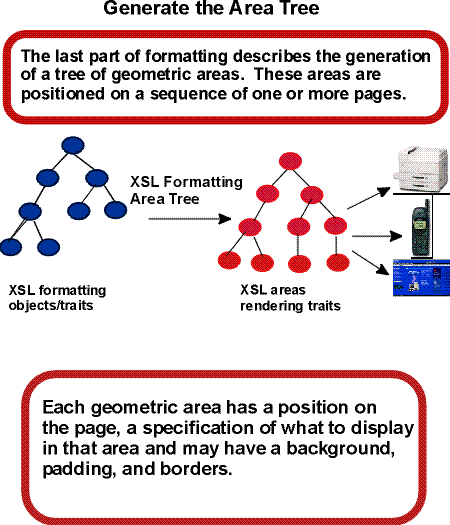
The third step in formatting is the construction of the area
tree. The
area tree is generated as described in the semantics of each
formatting object. The traits applicable to each formatting
object
class control how the areas are generated. Although every
formatting property may be specified on every formatting object, for
each formatting object class, only a subset of the formatting
properties are used to determine the traits for objects of
that class.
Area generation is depicted in the diagram below.
1.2 Benefits of XSL
Unlike the case of HTML, element names in XML have no intrinsic
presentation semantics. Absent a stylesheet, a processor could not
possibly know how to render the content of an XML document other
than as an undifferentiated string of characters. XSL provides
a comprehensive model and a vocabulary for writing such stylesheets using XML syntax.
This document is intended for implementors of such XSL processors.
Although it can be used as a reference manual for writers of XSL
style sheets, it is not tutorial in nature.
XSL builds on the prior work on Cascading Style Sheets
[CSS2] and
the Document Style Semantics and Specification Language
[DSSSL].
While many of XSL's formatting objects and properties correspond
to the common set of properties, this would not be
sufficient by
itself to accomplish all the goals of XSL. In particular, XSL introduces
a model for pagination and layout that extends what is currently available
and that can in turn be extended, in a straightforward way, to page
structures beyond the simple page models described in this specification.
1.2.1 Paging and Scrolling
Doing both scrollable document windows and pagination introduces
new complexities to the styling (and pagination) of XML content.
Because pagination introduces arbitrary boundaries
(pages or regions on pages) on the content, concepts such as
the control
of spacing at page, region, and block boundaries become
extremely important. There are also concepts related to
adjusting the spaces between lines (to adjust the page
vertically)
and between words and letters (to justify the lines of text).
These do not always arise with simple scrollable document
windows, such as those found in today's browsers. However, there
is a correspondence between a page with multiple regions, such as a body,
header, footer, and left and right side-bars, and a Web
presentation using "frames". The distribution of content into the regions
is basically the same in both cases, and XSL handles both
cases in an analogous fashion.
XSL was developed to give designers control over the features
needed when documents are paginated as well as to provide an
equivalent "frame" based structure for browsing on the Web.
To achieve this control, XSL has extended the set of formatting
objects and formatting properties. In addition, the selection
of XML source components that can be styled (elements,
attributes, text nodes, comments, and processing
instructions) is based on XSLT and XPath, thus providing the
user with an extremely powerful selection mechanism.
The design of the formatting objects and properties extensions
was first inspired by DSSSL. The actual extensions, however, do not
always look like the DSSSL constructs on which they were based. To either
conform more closely with the CSS2 specification or to
handle cases more simply than in DSSSL, some extensions have diverged from DSSSL.
There are several ways in which extensions were made. In some cases,
it sufficed to add new values, as in the case of those added to reflect
a variety of writing-modes, such as top-to-bottom and bottom-to-top, rather
than just left-to-right and right-to-left.
In other cases, common properties that are expressed in CSS2
as one property with multiple simultaneous values, are split into
several new properties to provide independent control over independent
aspects of the property. For example, the "white-space" property was
split into four properties:
a "space-treatment" property that
controls how white-space is processed, a "line-feed" property that controls
how line-feeds are processed, a "white-space-collapse" property that controls
how multiple consecutive spaces are collapsed,
and a "wrap-option" property
that controls whether lines are automatically wrapped when
they encounter a boundary, such as the edge of a column.
The effect of splitting a property into two or more
(sub-)properties is to make the equivalent existing CSS2
property a "shorthand" for the set of sub-properties it subsumes.
In still other cases, it was necessary to create new properties.
For example, there are a number of new properties that control how
hyphenation is done. These include identifying the script and country
the text is from as well as such properties as "hyphenation-character"
(which varies from script to script).
Some of the formatting objects and many of the properties in XSL
come from the CSS2 specification, ensuring compatibility
between the two.
There are four classes of XSL properties that can be identified as:
-
CSS properties by copy (unchanged from their CSS2
semantics)
-
CSS properties with extended values
-
CSS properties broken apart and/or extended
-
XSL only properties
1.2.2 Selectors and Tree Construction
As mentioned above, XSL uses XSLT and XPath for tree construction
and pattern selection, thus providing a high degree of control
over how portions of the source content are presented, and what
properties are associated with those content portions, even where
mixed namespaces are involved.
For example, the patterns of XPath allow the selection of a portion
of a string or the Nth text node in a paragraph. This allows
users to have a rule that makes all third paragraphs in
procedural steps appear in bold, for instance. In addition,
properties can be associated with a content portion based on the
numeric value of that content portion or attributes on the
containing element. This allows one to have a style rule
that makes negative values appear in "red" and positive
values appear in "black". Also, text can be generated
depending on a particular context in the source tree,
or portions of the source tree may be presented
multiple times with different styles.
1.2.3 An Extended Page Layout Model
There is a set of formatting objects in XSL to describe both the
layout structure of a page or "frame"
(how big is the body; are there multiple columns;
are there headers, footers, or side-bars; how big are these)
and the rules by which the XML source content is placed into these "containers".
The layout structure is defined in terms of one or more instances
of a "simple-page-master" formatting object. This formatting
object allows one to define independently filled regions for
the body (with multiple columns), a header, a footer, and side-bars
on a page. These simple-page-masters can be used in page sequences
that specify in which order the various simple-page-masters shall be used.
The page sequence also specifies how styled content is to fill those pages.
This model allows one to specify a sequence of simple-page-masters
for a book chapter where the page instances are automatically
generated by the formatter or an explicit sequence of pages
such as used in a magazine layout. Styled content is assigned
to the various regions on a page by associating the name of the
region with names attached to styled content in the result tree.
In addition to these layout formatting objects and properties,
there are properties designed to provide the level of control
over formatting that is typical of paginated documents.
This includes control over hyphenation, and expanding the control over
text that is kept with other text in the same line, column,
or on the same page.
1.2.4 A Comprehensive Area Model
The extension of the properties and formatting objects,
particularly in the area on control over the spacing of blocks, lines,
and page regions and within lines, necessitated an extension of the
CSS2 box formatting model. This extended model is described
in [4 Area Model] of this
specification. The CSS2 box model is a
subset of this model. See the mapping of the CSS2 box model
terminology to the XSL Area Model terminology in
[7.2 XSL Areas and the CSS Box Model].
The area model provides a vocabulary for describing
the relationships and space-adjustment between
letters, words, lines, and blocks.
1.2.5 Internationalization and Writing-Modes
There are many scripts, in particular in the Far East, that are
typically set with words proceeding from top-to-bottom and
lines proceeding either from right-to-left (most common) or
from left-to-right. Other directions are also
used. Properties expressed in terms of a fixed,
absolute frame of reference (using top, bottom, left, and right)
and which apply only to a notion of words proceeding from left to right
or right to left do not generalize well to the languages based on these scripts.
For this reason XSL (and before it DSSSL) uses a relative frame of
reference for the formatting object and property descriptions. Just as
the CSS2 frame of reference has four directions (top, bottom, left and right),
so does the XSL relative frame of reference have four directions
(before, after, start, and end), but these are relative to the "writing-mode". The
"writing-mode" property is a way of controlling the
directions needed by a formatter to correctly place
glyphs, words, lines, blocks, etc. on the page or screen.
The "writing-mode" expresses the basic directions noted
above. There are writing-modes for "left-to-right - top-to-bottom"
(denoted as "lr-tb"), "right-to-left - top-to-bottom" (denoted as "rl-tb"),
"top-to-bottom - right-to-left" (denoted as "tb-rl") and more, see [7.21.43 "writing-mode"]
for the description of the "writing-mode" property.
Typically, the writing-mode value specifies two directions,
the first is the inline-progression-direction which determines
the direction in which words will
be placed and the second is the block-progression-direction
which determines the direction in which blocks (and lines)
are placed one after another.
Besides the directions that are explicit in the name of the
value of the "writing-mode" property, the writing-mode determines
other directions needed by the formatter, such as the
shift-direction (used for sub- and super-scripts), etc.
1.2.6 Linking
Because XML, unlike HTML, has no built-in semantics,
there is no built-in notion of a hypertext link. Therefore,
XSL has a formatting object that expresses the dual semantics of
formatting the content of the link reference and the
semantics of following the link.
XSL provides a few mechanisms for changing the presentation
of a link target that is being visited. One of these mechanisms
permits indicating the link target as such;
another allows for control over the placement of the link
target in the viewing area; still another permits some degree of
control over the way the link target is displayed in relationship
to the originating link anchor.
2 Introduction to XSL Transformation
2.1 Tree Construction
The Tree Construction is described in
"XSL Transformations" [XSLT].
The provisions in "XSL Transformations" form an integral part of
this recommendation and are considered normative.
2.2 XSL Namespace
The XSL namespace has the URI http://www.w3.org/1999/XSL/Format.
NOTE:
The 1999 in the URI indicates the year in which
the URI was allocated by the W3C. It does not indicate the version of
XSL being used.
XSL processors must use the XML namespaces mechanism [W3C XML Names] to recognize elements and attributes from this
namespace. Elements from the XSL namespace are recognized only in the
stylesheet, not in the source document.
Implementors must not extend the XSL
namespace with additional elements or attributes. Instead, any
extension must be in a separate namespace.
This specification uses the prefix fo: for referring
to elements in the XSL namespace. However, XSL stylesheets are free
to use any prefix, provided that there is a namespace declaration that
binds the prefix to the URI of the XSL namespace.
An element from the XSL namespace may have any attribute not from
the XSL namespace, provided that the expanded-name of the
attribute has a non-null namespace URI. The presence of such
attributes must not change the behavior of XSL elements and functions
defined in this document. Thus, an XSL processor is always free to
ignore such attributes, and must ignore such attributes without giving
an error if it does not recognize the namespace URI. Such attributes
can provide, for example, unique identifiers, optimization hints, or
documentation.
It is an error for an element from the XSL namespace to have
attributes with expanded-names that have null namespace URIs
(i.e., attributes with unprefixed names) other than
attributes defined for the element in this document.
NOTE:
The conventions used for the names of XSL elements,
attributes, and functions are as follows:
names are all lower-case,
hyphens are used to separate words, dots are used to
separate names for the components of complex datatypes,
and abbreviations are used only if they already
appear in the syntax of a related language such as XML or
HTML.
3 Introduction to
Formatting
The aim of this section is to describe the general process
of formatting, enough to read the area model and the
formatting-object descriptions and properties and to understand the process of
refinement.
Formatting is the process of turning the result of an XSL
transformation into a tangible form for the reader or listener. This
process comprises several steps, some of which depend on others in a
non-sequential way.
Our model for formatting will be the construction of an
area tree, which is an ordered tree containing
geometric information
for the placement of every glyph, shape, and image in the document,
together with information embodying spacing constraints and other rendering
information; this information is referred to under the rubric of
traits, which are to areas what properties are to formatting objects
and attributes are to XML nodes. Section 4 (see [4 Area Model]) will
describe the area tree and
define the default placement-constraints on stacked areas. However, this is
an abstract model which need not be actually implemented in this way
in a formatter, so long as the resulting tangible form obeys the implied constraints.
Formatting objects are elements in the formatting-object tree, whose
names are from the XSL namespace; a formatting object belongs to a
class of formatting objects identified by its element name. The
formatting behavior of each class of formatting objects is described in
terms of what areas are created by a formatting object of that class, how
the traits of the areas are established, and how the areas are
structured hierarchically with respect to areas created by other formatting
objects. Sections 6 (see [6 Formatting Objects]) and
Section 7
(see [7 Formatting Properties]
describe formatting objects and their properties.
Some formatting objects are block-level and others are
inline-level. This refers to the types of areas which they generate,
which in turn refer to their default placement method. Inline-areas (for
example, glyph-areas) are collected into lines and the direction in which
they are stacked is the inline-progression-direction. Lines are a type of
block-area and these are stacked in a direction perpendicular to the
inline-progression-direction, called the block-progression-direction. See
Section 4 for detailed decriptions of these area types and
directions.
In Western writing systems, the block-progression-direction is
"top-to-bottom" and the inline-progression-direction is
"left-to-right". This specification treats other writing systems
as well and introduces the terms "block" and "inline"
instead of using absolute indicators like "vertical" and
"horizontal". Similarly this specification tries to give
relatively-specified directions ("before" and "after"
in the block-progression-direction, "start" and "end"
in the inline-progression-direction) where appropriate, either in addition
to or in place of absolutely-specified directions such as "top",
"bottom", "left", and "right". These are
interpreted according to the value of the writing-mode property.
Central to this model of formatting is refinement.
This is a computational
process which finalizes the specification of properties based on the attribute
values in the XML result tree. Though the XML result tree and the formatting-object
tree have very similar structure, it is helpful to think of them as
separate conceptual entities. Refinement involves
-
propagating the various inherited values
of properties (both implicitly and those with an attribute value of "inherit"),
-
evaluating expressions in property value specifications into actual
values, which
are then used to determine the value of the properties
-
converting relative numerics to absolute numerics,
-
constructing some composite properties from more than one attribute,
Some of these operations (particularly evaluating expressions) depend on knowledge
of the area tree. Thus refinement is not necessarily a straightforward, sequential
procedure, but may involve look-ahead, back-tracking, or control-splicing with
other processes in the formatter. Refinement is described more fully in Section 5.
See (see [5 Property Refinement / Resolution]).
To summarize, formatting proceeds by constructing an area tree
(containing areas and their traits) which satisfies constraints based on
information contained in the XML result tree (containing
element nodes and their
attributes). Conceptually, there are intermediate steps of
constructing a formatting-object tree (containing formatting objects and their
properties) and refinement;
these steps may proceed in an interleaved fashion during the
construction of the area tree.
3.1 Conceptual Procedure
This subsection contains a conceptual description of how
formatting could work. This conceptual
procedure does not mandate any particular algorithms or data structures as
long as the result obeys the implied constraints.
The procedure works by processing formatting objects. Each object,
while being processed, may initiate processing in other objects. While the
objects are hierarchically structured, the processing is not; processing of
a given object is rather like a co-routine which may pass control to other
processes, but pick up again later where it left off. The procedure starts
by initiating the processing of the fo:root
formatting object.
Unless otherwise specified, processing a formatting object creates areas
and returns
them to its parent to be placed in the area tree. Like a co-routine, it
resumes control later and initiates formatting of its own children (if
any), or some subset of them. The formatting object supplies parameters to its
children
based on the traits of areas already in the area tree, possibly including
areas generated by the formatting object or its ancestors. It then disposes of the
areas
returned by its formatting-object children. It might simply return such an area to its
parent (and will always do this if it does not generate areas itself), or
alternatively it might arrange the area in the area tree according to the
semantics of the formatting object; this may involve changing its geometric position.
It
terminates processing when all its children have terminated processing (if
initiated) and it is finished generating areas.
Some formatting objects do not themselves generate areas, instead these
formatting objects simply
return the areas returned to them by their children. Alternatively, a formatting object
may continue to generate (and return) areas based on information discovered
while formatting its own children; for example, the fo:page-sequence formatting object
will continue generating pages as long as it contains a flow with
unprocessed descendants.
Areas received by an fo:root formatting object are pages,
and are simply placed as
children of the area tree root in the order in which they are returned,
with no geometrical implications.
As a general rule, the order of the area tree parallels the order of the
formatting-object tree. That is, if one formatting object precedes another in
the depth-first
traversal of the formatting-object tree, with neither
containing the other, then
all the areas generated by the first will precede all the areas generated
by the second in the depth-first traversal of the area tree, unless
otherwise specified. Typical exceptions to this rule would be things like
inline floats, block floats, and footnotes.
At the end of the procedure, the areas and their traits have been
constructed, and they are required to satisfy constraints described in the
definitions of their associated formatting objects, and in the area model
section. In particular, size and position of the areas will be subject to
the placement and spacing constraints described in the area model, unless
the formatting-object definition indicates otherwise.
The formatting-object definitions, property descriptions, and area model
are not algorithms. Thus, the formatting-object semantics do not specify how
the line-breaking algorithm must work in collecting characters into words,
positioning words within lines, shifting lines within a container, etc.
Rather this specification assumes that the formatter has done these things
and describes the constraints which the result is supposed to
satisfy.
4 Area Model
In XSL, one creates a tree of formatting objects that serve as inputs or
specifications to a formatter. The formatter generates a hierarchical arrangement
of areas which comprise the formatted result. This section defines the general
model of areas and how they interact. The purpose is to present an abstract
framework which is used in describing the semantics of formatting objects.
It should be seen as describing a series of constraints for
conforming implementations,
and not as prescribing particular algorithms.
4.1 Introduction
The formatter generates an ordered tree, the area tree, which
describes a geometric structuring of the output medium. The terms
child, sibling, parent, descendant, and ancestor
refer to this tree structure. The tree has a root node.
Each area tree node other than the root is called an area and is
associated to a rectangular portion of the output medium. Areas are
not formatting objects; rather, a formatting object generates zero or more
rectangular areas, and normally each area is generated by a unique object in the
formatting object tree.
NOTE:
The only exceptions are when several leaf nodes of the formatting object
tree are combined
to generate a single area, for example when several characters
in sequence generate a single ligature
glyph. In all such cases, relevant properties such as
font-family and font-size are the same for
all the generating formatting objects.
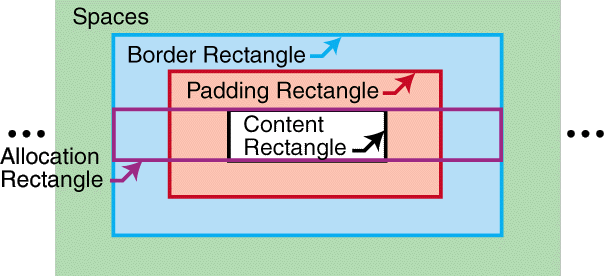
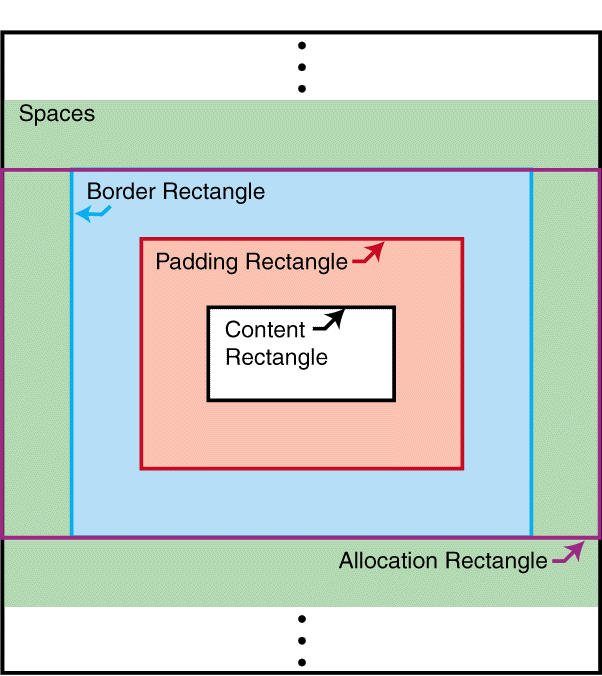
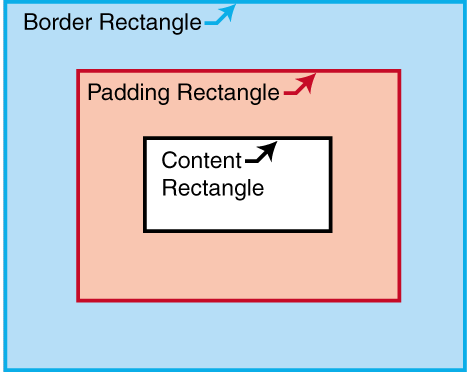
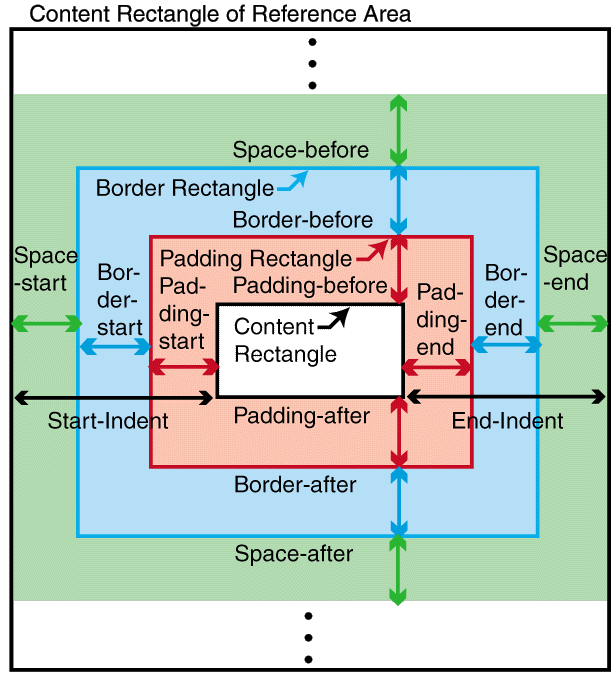
An area has a content-rectangle,
the portion in which its child areas are assigned, and optional
padding and border. The diagram shows
how these portions are related to one another. The outer bound of the border
is called the border-rectangle, and the outer
bound of the
padding is called the padding-rectangle.
Each area has a set of traits, a mapping of names to values,
in the way elements have attributes and formatting objects have properties.
Individual traits are used either
for rendering the area or for defining constraints on the result of formatting,
or both. Traits used strictly for formatting purposes or for defining
constraints may be called formatting traits, and traits used for
rendering may be called rendering traits.
For the complete list of the type of traits see [C Property Index].
The semantics of each type of formatting object that generates areas are
given in terms of which areas it generates and their place in the area-tree
hierarchy. This may be further modified by interactions between the various
types of formatting
objects. The properties of the formatting object determine what areas are
generated and how the formatting object's content is distributed among them.
(For example, a word that is not to be hyphenated may not have its glyphs
distributed into areas on two separate line-areas.)
The traits of an area are either:
1. "directly-derived" -- The values of directly-derived traits are the computed
value of a property of the same name on the generating formatting object, or
2. "indirectly-derived" -- The values of indirectly-derived traits are the
result of a computation involving the computed values of one or more properties
on the generating formatting object, other traits on this area or other
interacting areas (ancestors, parent, siblings, and/or children) and/or
one or more values constructed by the formatter. The calculation formula
may depend on the type of the formatting object.
This description assumes that refined values have been computed for all
properties of formatting objects in the result tree, i.e.,
all relative and corresponding values have been computed and the inheritable
values have been propagated as described in [5 Property Refinement / Resolution]. This
allows the
process of inheritance to be described once and avoids a need to repeat
information on computing values
in this description.
4.2 Rectangular Areas
4.2.1 Area Types
There are two types of areas: block-areas and
inline-areas. These differ according to how
they are typically stacked by the formatter. An area can have
block-area children or inline-area children as determined
by the generating formatting object, but a given area's children must all be of
one type. Although block-areas and inline-areas are
typically stacked, some areas can be explicitly positioned.
A line-area is a special kind of block-area whose children
are all inline-areas. A glyph-area is a special kind of
inline-area which has no child areas, and has a single
glyph image as content.
Typical examples would be: a paragraph rendered by using
an fo:block formatting object,
which generates block-areas,
and a character rendered by using an fo:character
formatting object,
which generates an inline-area (in fact, a glyph-area).
4.2.2 Common Traits
Associated with any area are two directions, which are derived from the
generating
formatting object's "writing-mode" and
"reference-orientation" properties: the
block-progression-direction is the direction for stacking block-area
descendants of the area, and the
inline-progression-direction is the direction for stacking inline-area
descendants of the area. Another
trait, the shift-direction, is present on inline-areas and refers to
the direction in which baseline
shifts are applied. Also the glyph-orientation defines the orientation
of glyph-images in the rendered result.
The Boolean trait is-indent-reference, determines
whether or not an area establishes a coordinate system for
specifying indents. An area for which this trait is true
is called a reference-area.
Only a reference-area may have a block-progression-direction which is different from
that of its parent.
A reference-area may be either a
block-area or an inline-area.
A set of traits describes the position and dimensions of the area.
Other traits include:
-
the is-first and is-last traits, which are Boolean traits
indicating the order in which areas are generated by a given
formatting object. is-first is true
for the first area (or only area) generated by a formatting object, and is-last
is true for the last area (or only area).
-
the amount of space outside the border-rectangle: space-before,
space-after, space-start, and space-end
(though some of these may be required to be zero on certain classes of area);
-
the thickness of each of the four sides of the padding: padding-before,
padding-after, padding-start, and padding-end;
-
the style, thickness, and color of each of the
four sides of the border: border-before, etc.; and
-
the background rendering of the
area: background-color, etc.
NOTE:
'Before', 'after', 'start',
and 'end' refer to relative directions and are defined below.
-
a nominal-font, which identifies the font that is deemed to be used
within that area.
Unless otherwise specified, the traits of an area generated by a formatting object are
present, and have the same name and value on the area.
4.2.3 Geometric Definitions
As described above, the content-rectangle is the rectangle
bounding the inside of the padding and is used to describe
the constraints on the positions of descendant areas. It is possible that
marks from glyph contents or descendant areas may appear outside the
content-rectangle.
Related to this is the allocation-rectangle
of an area,
which is used to describe the constraints on the position of
the area within its parent area. For an inline-area this extends
to the content-rectangle
in the block-progression-direction and to the border-rectangle in the
inline-progression-direction.
For a block-area, it extends to the border-rectangle in
the block-progression-direction and outside the border-rectangle
in the inline-progression-direction by an amount equal to
the end-indent,
and in the opposite direction by an amount equal to the start-indent. The traits
actual-block-progression-dimension and
actual-inline-progression-dimension of an
area apply to the content-rectangle.
NOTE:
The inclusion of space outside the border-rectangle of a block-area
in the inline-progression-direction does not affect
placement constraints, and
is intended to promote compatibility with the CSS box model.
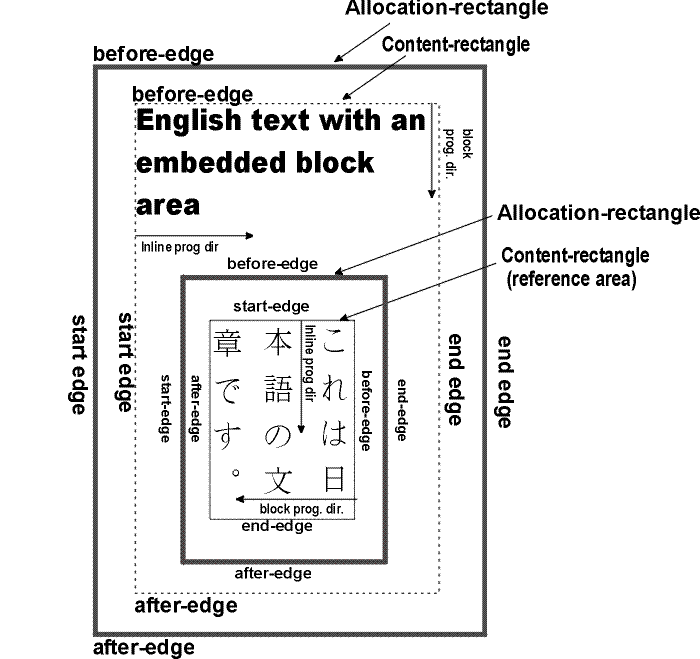
The edges of a rectangle are designated as follows:
-
the before-edge is the edge occurring first in the
block-progression-direction and perpendicular
to it;
-
the after-edge is the edge opposite
the before-edge;
-
the start-edge is the edge occurring
first in the inline-progression-direction and perpendicular
to it,
-
the end-edge is the edge opposite the
start-edge.
The following diagram shows the correspondence between the various edge
names for a mixed writing-mode example:
For purposes of this definition, the content-rectangle of an area uses the
inline-progression-direction and block-progression-direction of that area;
but the border-rectangle, padding-rectangle, and
allocation-rectangle use the
directions of its parent area. Thus the edges designated for the
content-rectangle may not correspond with the same-named edges
on the padding-, border-,
and allocation-rectangles. This is important in the case of
nested block-areas with different writing-modes.
Each inline-area has a position-point determined by the formatter,
on the start-edge
of its allocation-rectangle; for a glyph-area, this is
a point on the leading edge of the glyph on its preferred baseline (see below).
This is script-dependent and does not necessarily correspond to the
(0,0) coordinate point used for the data describing the glyph shape.
4.2.4 Tree ordering
In the area tree, the set of areas with a given parent is ordered.
The terms initial, final, preceding, and
following refer to this ordering.
In any ordered tree, this sibling order extends to an ordering of the entire tree
in at least two ways.
-
In the pre-order traversal order of a tree, the children
of each node (their order unchanged relative to one another) come after the node, but
before any following siblings of the node or of its ancestors.
-
In the post-order traversal order of a tree, the children of
each node come before the node, but after any preceding siblings of the node or of its
ancestors.
"Preceding" and "following", when applied to non-siblings, will depend on the
extension order used, which must be specified. However, in either of these given orders,
the leaves of the tree (nodes without children) are unambiguously ordered.
Given a particular order for the tree, a subset S of the tree is
contiguous if for any elements A and B of
S, S also contains any node that follows A and
precedes B in the given order.
There is a relative version of this: for a particular subset C of nodes
of a tree, if S is a subset of C, then S
is contiguous relative to C if for any elements A
and B of S, S also contains any node of
C that follows A and precedes B.
4.2.5 Stacking constraints
This section defines the notion of block-stacking constraints and
inline-stacking constraints involving areas. These are defined as
ordered relations, i.e. if A and B have a stacking constraint
it does not necessarily mean that B and A have a stacking
constraint.
The area-class trait is an enumerated value which is
xsl-normal for an area which is stacked with
other areas in sequence. A normally-sequenced area is an
area for which this trait is xsl-normal. Other
values mark an area as not following the main sequence (e.g., floats, footnotes and
absolutely positioned areas).
If P is a block-area, then there is a fence before
P if P is a reference area or if the border-before-width
or padding-before-width of P are nonzero. Similarly, there is a
fence after P if P is a reference area
or if the border-after-width or padding-after-width of P are nonzero.
If A and B are normally-sequenced areas, and S is
a sequence of space-specifiers, it is defined that A and B
have block-stacking constraint S if
any of the following conditions holds:
-
B is a block-area which is the first normally-sequenced
child of A, and S is the sequence consisting of the
space-before of B.
-
A is a block-area which is the last normally-sequenced
child of B, and S is the sequence consisting of the
space-after of A.
-
A and B are both block-areas, and either
a. B is the next normally-sequenced sibling area of A,
and S is the sequence consisting of the space-after of A
and the space-before of B;
b. B is the first normally-sequenced child of a block-area
P, there is no fence before P, A and
P have a block-stacking constraint S', and S
consists of S' followed by the space-before of B; or
c. A is the last normally-sequenced child of a block-area
P, there is no fence after P, P and
B have a block-stacking constraint S'', and S
consists of the space-after of A followed by S''.
When A and B have a block-stacking constraint, the
adjacent edges of A and B are an ordered
pair defined as:
-
In case 1, the before-edge of the content rectangle of A
and the before-edge of the allocation-rectangle of B.
-
In case 2, the after-edge of the content rectangle of A and
the after-edge of the allocation-rectangle of B.
-
In case 3a, the after-edge of the allocation rectangle of A
and the before-edge of the allocation-rectangle of B.
-
In case 3b, the first of the adjacent edges of A and P,
and the before-edge of the allocation-rectangle of B.
-
In case 3c, the after-edge of the allocation rectangle of A
and the second of the adjacent edges of P and B.
NOTE:
The intention of the definition is to identify areas at any level of the
tree which have only space between them.
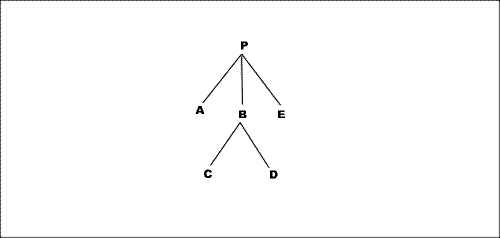
Example. In this diagram each node represents a block-area.
Assume that all padding
and border widths are zero, and none of the areas are reference-areas. Then P
and A have a block-stacking constraint, as do A
and B, A and
C, B and C, C and D,
D and B,
B and
E, D and
E, and E and
P; these
are the only pairs in the diagram having block-stacking constraints. If
B had non-zero padding-after, then D
and E would not have any block-stacking constraint (though B
and E would continue to have a block-stacking constraint).
Inline stacking constraints. This section will define the
inline-stacking-constraints between two areas, together with the notion of
fence-before and fence-after. This parallels the definition for block-stacking
constraints, but with the additional complication that we may have a stacking
constraint between inline-areas which are stacked in opposite inline-progression-directions.
(This is not an issue for block-stacking constraints because
a block-area which is not a reference area may not have block-progression-direction
different from that of its parent.)
If P and Q have an inline-stacking constraint, then
P has a fence before Q if P is
a reference area or has non-zero border width or padding width at the first
adjacent edge of P and Q. Similarly, Q has
a fence after P if Q is a reference area
or has non-zero border width or padding width at the second adjacent edge of
P and Q.
If A and B are normally-sequenced areas, and S
is a sequence of space-specifiers, it is defined that A and
B have inline-stacking constraint S if any of the
following conditions holds:
-
B is an inline-area which is the first normally-sequenced child of
A, and S is the sequence consisting of the space-start of
B.
-
A is an inline-area which is the last normally-sequenced child of
B, and S is the sequence consisting of the space-end of
A.
-
A and B are both inline-areas, and either
a. B is the next normally-sequenced sibling area of A,
and S is the sequence consisting of the space-end of A
and the space-start of B;
b. B is the first normally-sequenced child of an inline-area P,
P has no fence after A, A and P have an
inline-stacking constraint S', the inline-progression-direction of
P is the same as the inline-progression-direction of the nearest
common ancestor area of A and P, and S consists of
S' followed by the space-start of B.
c. A is the last normally-sequenced child of a block-area P,
P has no fence before B, P and B have an
inline-stacking constraint S'', the inline-progression-direction of
P is the same as the inline-progression-direction of the nearest
common ancestor area of A and P, and S consists of the
space-end of A followed by S''.
d. B is the last normally-sequenced child of an inline-area P,
P has no fence after A, A and P have an
inline-stacking constraint S', the inline-progression-direction of
P is opposite to the inline-progression-direction of the nearest
common ancestor area of A and P, and S consists of
S' followed by the space-end of B.
e. A is the first normally-sequenced child of a block-area P,
P has no fence before B, P and B have an
inline-stacking constraint S'', the inline-progression-direction of
P is opposite to the inline-progression-direction of the nearest
common ancestor area of A and P, and S consists of the
space-start of A followed by S''.
When A and B have an inline-stacking constraint,
the adjacent edges of A and B are an ordered
pair defined as:
-
In case 1, the start-edge of the content rectangle of A
and the start-edge of the allocation-rectangle of B.
-
In case 2, the end-edge of the content rectangle of A and
the end-edge of the allocation-rectangle of B.
-
In case 3a, the end-edge of the allocation rectangle of A and
the start-edge of the allocation-rectangle of B.
-
In case 3b, the first of the adjacent edges of A and
P, and the start-edge of the allocation-rectangle of B.
-
In case 3c, the end-edge of the allocation rectangle of A
and the second of the adjacent edges of P and B.
-
In case 3d, the first of the adjacent edges of A and
P, and the end-edge of the allocation-rectangle of B.
-
In case 3e, the start-edge of the allocation rectangle of A
and the second of the adjacent edges of P and B.
Two areas are adjacent if they have a block-stacking constraint
or an inline-stacking constraint. It follows from the definitions that areas of the same
type (inline or block) can be adjacent only if all their non-common descendants
are also of the same type (up to but not including their nearest common ancestor).
Thus, for example, two inline-areas which reside in different line-areas are never
adjacent.
An area A begins an area P if A is a
descendant of P and P and A have either a
block-stacking constraint or an inline-stacking constraint. In this case the
second of the adjacent edges of P and A is defined to be
a leading edge in P.
Similarly, An area A ends an area P if A is a
descendant of P and A and P have either a
block-stacking constraint or an inline-stacking constraint. In this case the
first of the adjacent edges of A and P is defined to be
a trailing edge in P.
4.2.6 Font baseline tables
Each script has its preferred "baseline" for aligning glyphs from that script.
Western scripts typically use a "alphabetic" baseline that touches at or near the
bottom of capital letters. Further, for each font there is a
preferred way of aligning embedded characters from different scripts, e.g. for a
Western font there is a separate baseline for aligning embedded ideographic or Indic
characters.
Each block-area and inline-area has a "dominant-baseline" trait which is a
baseline-type, an enumerated type corresponding to the type of alignment expected
for the nominal font for that area. Similarly, each inline-area has
a "baseline-identifier" trait, corresponding to the type of alignment preferred for
that area. The geometric line identified by this trait is called the preferred baseline
of the inline-area.
Associated to each font there is a table of baseline shifts, called the
baseline table, which associates to each pair of possible baseline types
the distance between the corresponding baselines in that font.
Example. For a Western font, the baseline table would
associate to the pair <alphabetic, hanging> a distance
approximately equal to the ascender height of the font, representing the offset
from the alphabetic baseline of the designated alignment point for embedded hanging-aligned
characters.
Some font standards, e.g. OpenType, define a baseline table as part of the
font data.
Certain baselines which are not part of the registered set of baselines are defined
as follows. The offset of the text-before-edge baseline
is determined by the height of font relative to the dominant baseline.
The determination of the text-after-edge
baseline offset is analogous; the descent of the nominal font is used for
"text-after-edge".
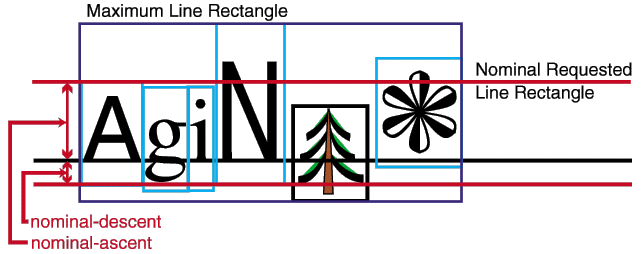
For each line area, the offset of the "before-edge" baseline is determined by ignoring
all inline areas whose baseline-identifier is "before-edge". The "before-edge" baseline
offset is set to the maximum extent in the direction opposite the block-progression-direction,
of the before-edges of the remaining inline-areas. If all
the inline-areas in an line area are aligned "before-edge" then use "text-before-edge" as the
"before-edge" alignment offset. The determination of the "after-edge" baseline is analogous.
For each area define two quantities, before-baseline-height and
after-baseline-height, as the respective distances from the area's
dominant baseline to the before-edge and after-edge baselines.
4.3 Spaces and Conditionality
A space-specifier is a compound datatype whose components are minimum, optimum,
and maximum, conditionality, and precedence.
Minimum, optimum, and maximum are lengths
and can be used to define a constraint
on a distance, namely that the distance should preferably be the optimum,
and in any case no less than the minimum nor more than the maximum. Any of these
values may be negative, which can (for
example) cause areas to overlap, but in any case the minimum should be less
than or equal to the optimum value, and the optimum less than or equal to
the maximum value.
Conditionality is an enumerated value which controls whether a
space-specifier has effect at the beginning or end of a reference-area or a
line-area. Possible values are retain and
discard;
a conditional space-specifier is one for which this value is
discard.
Precedence has a value which is either an integer or the special
token force. A forcing space-spe cifier
is one for which this value is force.
Space-specifiers occurring in sequence may interact with each other. The
constraint imposed by a sequence of space-specifiers is computed by
calculating for each space-specifier
its associated resolved space-specifier in accordance with
their conditionality and precedence, as
shown below in the space-resolution rules.
The constraint imposed on a distance by a sequence of resolved space-specifiers
is additive; that is, the distance is constrained to be no less than the
sum of the resolved minimum values and no larger than the sum of the resolved
maximum values.
4.3.1 Space-resolution rules
To compute the resolved space-specifier of a given space-specifier S,
consider the maximal inline-stacking constraint or block-stacking constraint
containing S. The resolved space-specifier of S is a
non-conditional space-specifier computed in terms of this sequence.
-
If any of the space-specifiers (in the maximal sequence) is conditional,
and begins a reference-area or line-area, then it is suppressed,
which means that its resolved space-specifier is zero. Further, any conditional
space-specifiers which consecutively follow it in the sequence are also suppressed.
If a conditional space-specifier ends a reference-area or line-area, then it
is suppressed together with any other conditional space-specifiers which
consecutively precede it in the sequence.
-
If any of the remaining space-specifiers is forcing, all non-forcing
space-specifiers are suppressed, and the value of each of the forcing space-specifiers
is taken as its resolved value.
-
Alternatively if all of the remaining space-specifiers are non-forcing,
then the resolved space-specifier is defined in terms of those space-specifiers
whose precedence is highest, and among these those whose optimum value is the
greatest. All other space-specifiers are suppressed. If there is only one of
these then its value is taken as its resolved value.
Otherwise the resolved space-specifier of the last space-specifier in the
sequence is derived from these spaces by taking their common optimum value as
its optimum, the greatest of their minimum values as its minimum,
and the least of their maximum values as its maximum, and all other space-specifiers
are suppressed.
Example. Suppose the sequence of space values occurring at the
beginning of a reference-areas is: first, a space with value 10 points (that is
minimum, optimum, and maximum all equal to 10 points) and conditionality
discard; second, a space with value 4 points and
conditionality retain; and third, a space
with value 5 points and conditionality discard;
all three spaces having precedence zero. Then the first (10 point) space is
suppressed under rule 1, and the
second (4 point) space is suppressed under rule 3. The resolved value of the
third space is a non-conditional 5 points, even though
it originally came from a conditional space.
The padding of a block-area does not interact with the any space-specifier
(except that by definition, the presence of padding at the before- or after-edge
prevents areas on either side of it from having a stacking constraint.)
The border or padding at the before-edge or after-edge of a block-area may
be specified as conditional. If so, then it is set to zero if its its associated
edge is a leading or trailing edge in a reference-area. In this case, the border
or padding is taken to be zero for purposes of the stacking constraint definitions.
4.4 Block-areas
Block-areas have several traits which typically affect the placement of their
children. The line-height is used in line placement calculations.
So is its dominant-glyph-height, which is the size (in the
block-progression-direction) of a glyph-area in the nominal-font of the
block-area. This depends only on
the font and not on which glyphs (or fonts) actually occur among
descendants of the block-area.
The line-stacking-strategy trait controls what kind of allocation
is used for descendant line-areas and has an enumerated value
(either font-height, max-height,
or line-height). This is all rigorously described below.
All areas have these traits,
but they only have relevance for areas which have stacked line-area children.
The space-before and space-after determine the
distance between the block-area and surrounding block-areas.
A block-area which is not a line-area typically has its size in the
inline-progression-direction determined
by its start-indent and end-indent and by the size of its nearest ancestor
reference-area. A
block-area which is not a line-area typically varies its
block-progression-dimension
to accommodate its descendants. Alternatively the generating
formatting object may specify a
block-progression-dimension for the block-area.
4.5 Stacked Block-areas
Block-area children of an area are typically stacked in the
block-progression-direction
within their parent area, and this is the default method of
positioning block-areas. However, formatting objects
are free to specify other methods of positioning child areas of areas which
they generate, for example list-items or tables.
For a parent area P whose children are
block-areas, P is defined to be properly
stacked if all of the following conditions hold:
-
For each block-area which is a descendant of P,
the following hold:
-
the before-edge and after-edge
of its allocation-rectangle are parallel to the before-edge and after-edges of the
content-rectangle of P,
-
the start-edge of its allocation-rectangle is parallel to the start-edge
of the content-rectangle of R (where R is the closest
ancestor reference-area of B), and offset from it
by a distance equal to
the block-area's start-indent plus its
start-intrusion-adjustment, minus its border-start,
padding-start, and space-start values, and
-
the end-edge of its allocation-rectangle is parallel to the
end-edge
of the content-rectangle of R, and offset from it
by a distance equal to
the block-area's end-indent plus its
end-intrusion-adjustment,
minus its border-end, padding-end, and space-end
values.
-
For each pair of normally-sequenced areas B and B'
in the subtree below P, if
B and B' have a block-stacking constraint S,
then the distance between the adjacent edges of B and B'
is consistent with the
constraint imposed by the
resolved values of the space-specifiers in S.
NOTE:
The start-intrusion-adjustment and
end-intrusion-adjustment are traits used to
deal with intrusions from
floats in the inline-progression-direction. The notion of indent is intended to apply to the content-rectangle, but
the constraint is written in terms of the
allocation-rectangle, because as noted earlier the edges of the
content-rectangle may not
correspond to like-named edges of the
allocation-rectangle.
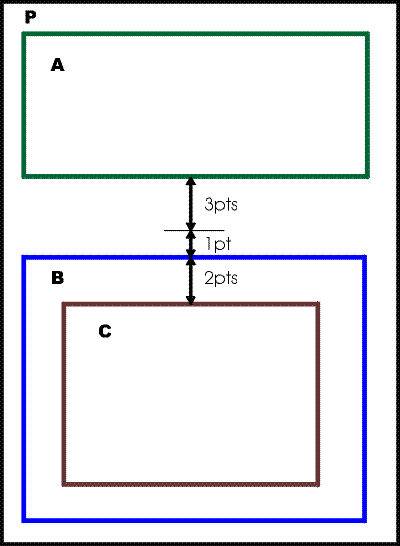
Example. In the diagram, if area
A
has a space-after value of 3 points, B a
space-before
of 1 point, and C a space-before of 2 points, all
with
precedence of force, and with zero border and padding,
then the constraints will place B's
allocation-rectangle
4 points below that of A, and C's
allocation-rectangle
6 points below that
of A. Thus the 4-point gap receives the
background color
from P, and the 2-point gap before C
receives the background color from B.
4.6 Line-areas
A line-area is a special type of block-area, and is generated by the same
formatting object which generated
its parent. Line-areas do not have borders and padding, i.e., border-before-width,
padding-before-width, etc. are all zero. Inline-areas are stacked within a line-area
relative to a baseline-start-point which is a point determined by the
formatter, on the start-edge of its content-rectangle.
The allocation-rectangle of a line is determined by the value of the
line-stacking-strategy trait: if the
value is font-height, the allocation-rectangle is
the nominal-requested-line-rectangle, defined below; if the value is
max-height, the allocation-rectangle is the
maximum-line-rectangle, defined below; and if
the value is
line-height, the allocation-rectangle is the
per-inline-height-rectangle, defined below.
The nominal-requested-line-rectangle for a line-area is the rectangle
whose start-edge and end-edge are parallel to and coincident with the start-edge
and end-edge of the content-rectangle of the parent block-area (as modified by
typographic properties such as indents), whose before-edge is separated from the
baseline-start-point by the before-baseline-height, and whose after-edge is
separated from the baseline-start-point by the after-baseline-height. It has the
same block-progression-dimension for each line-area child of a block-area.
The maximum-line-rectangle for a line-area has the same length as the
nominal-requested-line-rectangle in the inline-progression-direction. Its
block-progression-dimension is the minimum required to enclose both the
nominal-requested-line-rectangle and the allocation-rectangles of all the
inline-areas stacked within the line-area; this may vary depending on the
descendants of the line-area.
The per-inline-height-rectangle has the same length as the
nominal-requested-line-rectangle in the inline-progression-direction. For each
inline-area the half-leading is defined to be half the difference of its
line-height minus its actual-block-progression-dimension. The
expanded-rectangle of an inline-area is the rectangle with start-edge
and end-edge coincident with those of its allocation-rectangle, and whose
before-edge and after-edge are outside those of its allocation-rectangle by a
distance equal to the half-leading. The per-inline-height-rectangle is then
defined to have the minimum block-progression-dimension required to enclose both
the nominal-requested-line-rectangle and the expanded-rectangles of all the
inline-areas stacked within the line-area; this may vary depending on the
descendants of the line-area.
NOTE:
Using the nominal-requested-line-rectangle allows equal baseline-to-baseline
spacing. Using the maximum-line-rectangle allows constant space between line-areas.
Using the
per-inline-height-rectangle and zero space-before and space-after allows
CSS-style line box stacking.
4.7 Inline-areas
An inline-area has its own line-height trait, which may be
different from the line-height of its containing block-area. This may affect the
placement of its ancestor line-area when the line-stacking-strategy
is line-height. An inline-area has a baseline-table
for its nominal-font. It has
a dominant-baseline trait which determines how its stacked inline-area
descendants are to be aligned.
An inline-area may or may not have child areas, and if so it may or may not
be a reference-area. The dimensions of the content-rectangle for an inline-area
without children is computed as specified by the generating formatting object,
as are those of an inline-area with block-area children.
An inline-area with inline-area children has a content-rectangle which is
the minimum rectangle (with sides parallel to those of the content-rectangle
of its parent area) which includes the allocation-rectangles of all of its
children, and which extends from its position point by at least the
after-baseline-height in the block-progression-direction, and in the opposite
direction by at least the before-baseline-height from its position-point (these
latter quantities derived from the nominal-font of the area, as defined in
section 4.2.6).
Examples of inline-areas with children might include portions of inline
mathematical expressions or areas arising from mixed writing systems
(left-to-right within right-to-left, for example).
4.8 Stacked Inline-areas
Inline-area children of an area are typically stacked in the
inline-progression-direction
within their parent area, and this is the default method of
positioning inline-areas.
Inline-areas are stacked relative to a baseline, defined as
follows:
1. If P is a line-area, the baseline of P is defined
to be the line through the baseline-start-point which is parallel to the
inline-progression-direction;
2. If P is an inline-area, the baseline of P is defined
to be the line through the position-point of P which is parallel to
the inline-progression-direction.
For a parent area P whose children are inline-areas, P
is defined to be properly stacked if all of the following conditions
hold:
-
For each inline-area descendant I of P, the
start-edge, end-edge, before-edge and after-edge of the allocation-rectangle
of I are parallel to corresponding edges of the content-rectangle
of the nearest ancestor reference-area of I.
-
For each pair of normally-sequenced areas I and I'
in the subtree below P, if I and I' have
an inline-stacking constraint S, then the distance between the
adjacent edges of I and I' is consistent with the
constraint imposed by the resolved values of the space-specifiers in
S.
-
For any inline-area descendant I of P, the
distance in the shift-direction from the baseline of P to the
position-point of I equals the distance between the dominant-baseline
of P and the preferred baseline of I (as determined
by the dominant-baseline-table of P), plus the sum of the
baseline-shifts for I and all of its ancestors which are
descendants of P. This alignment is done with respect to the
line-area's dominant baseline, and not with respect to the baseline of any
intermediate area.
The first summand is computed to compensate for
mixed writing systems with different nominal glyph baselines, and the other
summands involve deliberate baseline shifts for things like superscripts
and subscripts.
4.9 Glyph-areas
The most common inline-area is a glyph-area, which contains the
representation for a character in a particular font.
A glyph-area has an associated font, determined by its
typographic traits, which apply to its character data.
The position-point and preferred baseline of a glyph-area are assigned
according to the writing-system in use (e.g., the glyph baseline
in Western languages), and are used to control placement of inline-areas
descendants of a line-area. The formatter may generate inline-areas with
different inline-progression-directions from their parent to accommodate
correct inline-area stacking in the case of mixed writing systems.
A glyph-area has no children. Its actual-block-progression-dimension and
baseline-table are the same for all glyphs in a font.
4.10 Line-building
This section describes tree-structure constraints on the result of
formatting a fo:block or similar block-level object.
A block-level formatting-object F which constructs lines does so by
constructing block-areas which it returns to its parent
formatting-object, and placing areas returned to F by its child
formatting-objects as children of those block-areas or of line-areas
which it constructs as children of those block-areas.
For each such formatting-object F, it must be possible to form an
ordered partition P consisting of ordered subsets S1,
S2, ..., Sn of
the normally-sequenced areas returned by the child formatting-objects,
such that the following are all satisfied:
-
Each subset consists of a sequence of inline-areas, or of a single
block-area.
-
The ordering of the the partition follows the ordering of the
formatting-object tree. Specifically, if A is in Si
and B is in Sj with
i < j, or if A and B are both in the same subset
Si with A before B in the
subset order, then either A is returned by a preceding sibling
formatting-object of B, or A and B are returned by the same
formatting-object with A being returned before B.
-
The partitioning occurs at legal line-breaks. Specifically, if A is
the last area of Si and B is the first area of
Si+1, then the rules of
the language and script in effect must permit a line break between A and
B, within the context of all areas in Si
and Si+1.
-
The partition follows the ordering of the Area Tree, except for
certain glyph substitutions and deletions. Specifically, if B1,
B2, ..., Bp are the normally-sequenced
child areas of the block-area
or block-areas returned by F, (ordered in the pre-order traversal order of the
area tree) then there is a one-one correspondence between these child areas
and the partition subsets (i.e., n = p), and for each i,
-
if Si consists of a single block-area then
Bi is that block-area, and
-
if Si consists of inline-areas then
Bi is a line-area whose child areas are the
same as the inline-areas in Si, and in the same order,
except that where the rules of the language and script in effect call
for glyph-areas to be substituted, inserted, or deleted, then the
substituted or inserted glyph-areas appear in the area tree in the
corresponding place, and the deleted glyph-areas do not appear in the
area tree. Deletions occur in the case of a glyph-area with a
remove-at-line-break value of true. Insertions and substitutions may
occur because of addition of hyphens or spelling changes due to
hyphenation, or glyph image construction from syllabilification, or
ligature formation.
Substitutions that replace a sequence of glyph-areas with a single
glyph-area should only occur when the margin, border, and padding in the
inline-progression-direction (start- and end-), baseline-shift, and
letterspacing values are zero, apply-word-spacing is false, and the
values of all other relevant traits match (i.e., color, background
traits, font traits, font-height-override-after,
font-height-override-before, glyph-orientation-horizontal,
glyph-orientation-vertical, line-height, line-height-shift-adjustment,
text-decoration, text-shadow, vertical-align).
4.11 Keeps and Breaks
Keep and break conditions apply to a class of areas, which are typically page-areas,
column-areas, and line-areas. The appropriate class for a given condition is referred
to as a context and an area in this class is a context area. As defined elsewhere
in the Model, page-areas are children of the root in the area tree. Column-areas are
children of page-areas. Line-areas are defined in another section.
A keep or break condition is an open statement about a formatting object and the
tree relationships of the areas it generates with the relevant context areas. These
tree relationships are mainly in terms of leading or trailing
areas. If A is a descendant of P, then A is defined to
be leading in P if A has no preceding sibling which
is a normally-sequenced area, nor does any of its ancestor areas up to but not including
P. Similarly, A is defined to
be trailing in P if A has no following sibling which
is a normally-sequenced area, nor does any of its ancestor areas up to but not including
P. For any given formatting object, the next formatting object
in the flow is the first formatting object following (in the pre-order traversal order)
which generates normally-sequenced areas.
Break conditions are either break-before or break-after conditions. A break-before
condition is satisfied if the first area generated by the formatting object is
leading within a context area. A break-after condition depends on the next formatting object in
the flow; it is satisfied if either there is no such next formatting object, or if the
first area generated by that formatting object is leading in a context area.
Break conditions are imposed by the break-before and break-after properties. A
refined value of page for these traits imposes a break-condition with a context
consisting of the page-areas; a value of even-page or odd-page imposes a
break-condition with a context of even-numbered page-areas or odd-numbered
page-areas, respectively; a value of column imposes a break-condition with a
context of column-areas. A value of auto in a break-before or break-after
trait imposes no break condition.
Keep conditions are either keep-with-previous, keep-with-next, or keep-together
properties. A keep-with-previous condition on an object is satisfied if the first
area generated by the formatting object is not leading within a context area, or if
there are no preceding areas in a post-order traversal of the area tree. A
keep-with-next condition is satisfied if the last area generated by the
formatting object is not trailing within a context area, or if there are
no following areas in a pre-order traversal of the area tree. A keep-together
condition is satisfied if all areas generated by the formatting object are
descendants of a single context area.
Keep conditions are imposed by the
keep-{with-previous,with-next,together}.within-{page,column,line} properties.
The refined value of each trait specifies the strength of the keep condition
imposed, with higher numbers being stronger than lower numbers and the value
always being stronger than all numeric values. A property with value auto
does not impose a keep condition. If a keep condition is imposed by a property
ending in .within-page, the context consists of the page-areas; if .within-column,
the column-areas, and if .within-line, the line areas.
The area tree is constrained to satisfy all break conditions imposed.
Each keep condition must also be satisfied, except when this would cause a
break condition or a stronger keep condition to fail to be satisfied. If not
all of a set of keep conditions of equal strength can be satisified, then some
maximal satisfiable subset must be satisfied (together with all break conditions
and stronger keep conditions, if any).
5 Property Refinement / Resolution
During refinement the set of properties that apply to a formatting
object is transformed into a set of traits that
define constraints on the result of formatting. For many traits there
is a one-to-one correspondence with a property; for other traits the
transformation is more complex. Details on the transformation are
described below.
The first step in refinement of a particular formatting object
is to obtain the effective value of each property that applies to the
object. Any shorthand property specified on the formatting object is
expanded into the individual properties. This is further described in
[5.2 Shorthand Expansion]. For any property that has not been specified
on the object the inherited (see [5.1.4 Inheritance])
or initial value, as applicable, is used as the effective value.
The second step is to transform this property set into traits.
NOTE:
Although the refinement process is described in a series of
steps, this is solely for the convenience of exposition
and does not imply they must be implemented as separate
steps in any conforming implementation. A conforming implementation
must only achieve the same effect.
5.1 Specified, Computed, and Actual Values, and Inheritance
For every property that is applicable to a given
formatting object, it is necessary to determine
the value of the property.
Three variants of the property value are
distinguished: the specified value, the computed value, and
the actual value. The "specified value" is one that is
placed on the formatting object during the tree-constuction process.
A specified value may not be in a
form that is directly usable; for example, it may be a
percentage or other expression
that must be converted into an absolute value.
A value resulting from such a conversion is called the
"computed value". Finally, the computed value may not be
realizable on the output medium and may need to be adjusted
prior to use in rendering. For example, a line width may be
adjusted to become an integral number of output
medium pixels. This adjusted value is the "actual value."
5.1.1 Specified Values
The specified value of a property is
determined using the following mechanisms
(in order of precedence):
-
If the tree-construction process placed the property
on the formatting object, use the value of that property
as the specified value. This is called "explicit
specification".
-
Otherwise, if the property is inheritable, use the value of that
property from the parent formatting object, generally the
computed value (see below).
-
Otherwise use the property's initial value, if it has one.
The initial value of each property is indicated in the
property's definition. If there is no initial value, that
property is not specifed on the formatting object.
In general, this is an error.
Since it has no parent, the root of the result tree
cannot use values from its parent formatting
object; in this case, the initial value is used if necessary.
5.1.2 Computed Values
Specified values may be absolute (i.e., they are not
specified relative to another value, as in "red" or "2mm")
or relative (i.e., they are specified relative to another value,
as in "auto", "2em", and "12%"), or they may be expressions.
For most absolute values, no
computation is needed to find the computed value. Relative values,
on the other hand, must be transformed into computed values: percentages
must be multiplied by a reference value (each property defines which value
that is), values with a relative unit (em)
must be made absolute by multiplying with the appropriate font size,
"auto" values must be computed by the formulas given with
each property, certain property
values ("smaller", "bolder") must be replaced
according to their definitions.
The computed value of any property that controls a border width
where the style of
the border is "none" is forced to be "0pt".
Some properties have more than one way in which the property value can be specified.
The simplest example of such properties are those which can be specified
either in terms of a direction relative to the writing-mode (e.g., padding-before)
or a direction in terms of the absolute geometric orientation of the viewport
(e.g., padding-top). These two properties are called the
relative property and the absolute property, respectively.
Collectively, they are called "corresponding properties".
Specifying a value for one property determines both a
computed value for the specified property and a computed value
for the corresponding property.
Which relative property corresponds to which absolute
property depends on the writing-mode. For example, if
the "writing-mode" at the top level of a document is
"lr-tb",
then "padding-start" corresponds to "padding-left", but if
the "writing-mode" is "rl-tb", then "padding-start"
corresponds to "padding-right".
The exact specification of how to compute the values of
corresponding properties is given in [5.3 Computing the Values of Corresponding Properties].
In most cases, elements inherit computed values. However,
there are some properties whose specified value may be
inherited (e.g., the value for the "line-height"
property).
In the cases where child elements do not inherit the computed value,
this is described in the property definition.
5.1.3 Actual Values
A computed value is in principle ready to be
used, but a user agent may not be able to make
use of the value in a given environment. For
example, a user agent may only be able to render
borders with integer pixel widths and may, therefore,
have to adjust the computed width to an integral number
of media pixels. The actual
value is the computed value after any such adjustments have been applied.
5.1.4 Inheritance
Some of the properties applicable to formatting objects are "inheritable."
Such properties are so identified in the property description.
The inheritable properties can be placed on any formatting
object. The inheritable properties are propagated down the
formatting object tree from a parent to each child. (These properites
are given their initial value at the root of the result tree.)
For a given inheritable property, if that property is present on a
child, then that value of the property is used for that child
(and its descendents until explicitly re-set in a lower descendent);
otherwise, the specified value of that property on the child is the
computed value of that property on the parent formatting
object. Hence there is always a specified value
defined for every inheritable property for every
formatting object.
5.2 Shorthand Expansion
In XSL there are two kinds of shorthand properties; those originating
from CSS, such as "border", and those that arise from breaking apart
and/or combining CSS properties, such as "page-break-inside". In XSL
both types of shorthands are handled in the same way.
NOTE:
Shorthands are only included in the highest XSL conformance
level; "complete".
The conformance level for each property is shown in
[C.3 Property Table: Part II].
Shorthand properties do not inherit from
the shorthand on the parent. Instead the individual properties that
the shorthand expands into may inherit.
Some CSS shorthands are interrelated; their expansion has one
or more individual properties in common.
CSS indicates that the user must specify the order of processing
for combinations of multiple interrelated shorthands and individual
interrelated properties. In XML, attributes are defined as unordered.
To resolve this issue, XSL defines a precedence order
when multiple interrelated shorthand properties or a shorthand property
and an interrelated individual property are specified:
They are processed in increasing precision (i.e. "border" is less precise
than "border-top", which is less precise than "border-top-color").
The individual properties are always more precise than any shorthand.
For the remaining ambiguous case, XSL defines the ordering to
be:
-
"border-style", "border-color", and "border-width"
is less precise than
-
"border-top", "border-bottom", "border-right",
and "border-left".
Processing is conceptually in the following steps:
-
Set the effective value of
all properties to their initial values.
-
Process all shorthands in increasing precision.
If the shorthand is set to "inherit": set the effective
value of each property that can be set by the shorthand to
the computed value of the corresponding property in the parent.
If the value of the shorthand is not "inherit": determine which
individual properties are to be set, and replace the
initial-value with the computed value derived from the specified
value.
-
Process all specified individual properties.
-
Carry out any inheritance for properties that were
not given a value other than by the first step.
NOTE:
For example,
if both the "background" property
and the "background-color" property are specified on a given
formatting object:
process the "background" shorthand then process the
"background-color" property.
5.3 Computing the Values of Corresponding Properties
Where there are corresponding properties, such as "padding-left"
and "padding-start", a computed value is determined for all the
corresponding properties. How the computed values are determined
for a given formatting object is dependent on which of
the corresponding properties are specified on the object. See description
below.
The correspondance mapping from absolute to relative property
is as follows:
If the "writing-mode" specifies a block-progression-direction of
"top-to-bottom": "top" maps to "before", and "bottom" maps to "after".
If the "writing-mode" specifies a block-progression-direction of
"bottom-to-top": "top" maps to "after", and "bottom" maps to "before".
If the "writing-mode" specifies a block-progression-direction of
"left-to-right": "left" maps to "before", and "right" maps to "after".
If the "writing-mode" specifies a block-progression-direction of
"right-to-left": "left" maps to "after", and "right" maps to "before".
If the "writing-mode" specifies an inline-progression-direction of
"left-to-right": "left" maps to "start", and "right" maps to "end".
If the "writing-mode" specifies an inline-progression-direction of
"right-to-left": "left" maps to "end", and "right" maps to "start".
If the "writing-mode" specifies an inline-progression-direction of
"top-to-bottom": "top" maps to "start", and "bottom" maps to "end".
If the "writing-mode" specifies an inline-progression-direction of
"bottom-to-top": "top" maps to "end", and "bottom" maps to "start".
If the "writing-mode" specifies an inline-progression-direction of
"left-to-right" for odd-numbered lines, and "right-to-left" for
even-numbered lined: "left" maps to "start", and "right" maps to "end".
NOTE:
"reference-orientation" is a rotation and does not influence
the correspondance mapping.
5.3.1 Border and Padding Properties
The simplest class of corresponding properties are
those for which there are only two variants in the
correspondance, an absolute property and a relative
property, and the property names differ only in the
choice of absolute or
relative designation; for example, "border-left-color" and
"border-start-color".
For this class, the computed values of the corresponding
properties are determined as follows. If the corresponding
absolute variant of the property is specified on the formatting
object, its computed value is used to set the computed value of the
corresponding relative property. If the corresponding absolute property
is not explicitly specified, then the computed
value of the absolute property is set to the computed value of the
relative property of the same name.
Note that if both the absolute and the relative
properties are not
explicitly specified, then the rules for determining the specifed
value will use either inheritance if that is defined for the property
or the initial value. The initial value must be the same for all possible
corresponding properties. If both an absolute and a corresponding relative
property are explicitly specified, then the above rule gives precedence to the
absolute property, and the specified value of the
corresponding relative property
is ignored in determining the computed value of the corresponding properties.
The (corresponding) properties that use the above rule to
determine their computed value are:
-
border-after-color
-
border-before-color
-
border-end-color
-
border-start-color
-
border-after-style
-
border-before-style
-
border-end-style
-
border-start-style
-
border-after-width
-
border-before-width
-
border-end-width
-
border-start-width
-
padding-after
-
padding-before
-
padding-end
-
padding-start
5.3.2 Margin, Space, and Indent Properties
The "space-before", and "space-after" properties (block-level
formating objects), "space-start", and "space-end" properties
(inline-level formatting objects) are handled in the same way as the
properties immediately above, but the corresponding
absolute properties are in the set: "margin-top",
"margin-bottom", "margin-left", and "margin-right".
There are two more properties, "end-indent" and
"start-indent" (block-level formatting objects),
for which the computed value may be
determined by the computed value of the
absolute margin properties. For these traits,
the calculation of the value of the trait when the
corresponding absolute property is present depends on
three computed values: the computed value of the corresponding
absolute property, the computed value of the corresponding
"padding"
property, and the computed value of the corresponding
"border-width" property.
Here the term "corresponding" has been broadened to mean
that if
"margin-left" is the corresponding absolute property
to "start-indent", then
"padding-left" (and "padding-start")
and "border-left-width" (and "border-start-width") are the
"corresponding" "padding" and "border-width" properties.
The formulae for calculating the computed value of the
"start-indent", and "end-indent" properties are as follows (where
"margin-corresponding" is a variable for the
corresponding absolute "margin" property):
end-indent = margin-corresponding + padding-end + border-end-width
start-indent = margin-corresponding + padding-start + border-start-width
If an absolute "margin" property is not explicity
specified,
these equations determine a computed value for the corresponding
"margin" property given values for the three traits
corresponding-indent,
padding-corresponding and
border-corresponding width.
5.3.3 Height, and Width Properties
Based on the writing-mode in effect for the formatting object,
either the "height", "min-height", and "max-heigth" properties, or
the "width", "min-width", and "max-width" properties are converted
to the corresponding block-progression-dimension, or
inline-progression-dimension.
The "height" properties are absolute and indicate the dimension
from "top" to "bottom"; the width properties the dimension from
"left" to "right".
If the "writing-mode" specifies a block-progression-direction of
"top-to-bottom" or "bottom-to-top" the conversion is as follows:
-
If any of "height", "min-height", or "max-height" is specified:
-
If "height" is specified then first set:
block-progression-dimension.minimum=<height>
block-progression-dimension.optimum=<height>
block-progression-dimension.maximum=<height>
-
If "height" is not specified, then first set:
block-progression-dimension.minimum=auto
block-progression-dimension.optimum=auto
block-progression-dimension.maximum=auto
-
Then, if "min-height" is specified, reset:
block-progression-dimension.minimum=<min-height>
-
Then, if "max-height" is specified, reset:
block-progression-dimension.minimum=<max-height>
-
However, if "max-height" is specified
as "none", reset:
block-progression-dimension.minimum=auto
-
If any of "width", "min-width", or "min-width" is specified:
-
If "width" is specified then first set:
inline-progression-dimension.minimum=<width>
inline-progression-dimension.optimum=<width>
inline-progression-dimension.maximum=<width>
-
If "width" is not specified, then first set:
inline-progression-dimension.minimum=auto
inline-progression-dimension.optimum=auto
inline-progression-dimension.maximum=auto
-
Then, if "min-width" is specified, reset:
inline-progression-dimension.minimum=<min-width>
-
Then, if "max-width" is specified, reset:
inline-progression-dimension.minimum=<max-width>
-
However, if "max-width" is specified
as "none", reset:
inline-progression-dimension.minimum=auto
If the "writing-mode" specifies a block-progression-direction of
"left-to-right" or "right-to-left" the conversion is as follows:
-
If any of "height", "min-height", or "max-height" is specified:
-
If "height" is specified then first set:
inline-progression-dimension.minimum=<height>
inline-progression-dimension.optimum=<height>
inline-progression-dimension.maximum=<height>
-
If "height" is not specified, then first set:
inline-progression-dimension.minimum=auto
inline-progression-dimension.optimum=auto
inline-progression-dimension.maximum=auto
-
Then, if "min-height" is specified, reset:
inline-progression-dimension.minimum=<min-height>
-
Then, if "max-height" is specified, reset:
inline-progression-dimension.minimum=<max-height>
-
However, if "max-height" is specified
as "none", reset:
inline-progression-dimension.minimum=auto
-
If any of "width", "min-width", or "min-width" is specified:
-
If "width" is specified then first set:
block-progression-dimension.minimum=<width>
block-progression-dimension.optimum=<width>
block-progression-dimension.maximum=<width>
-
If "width" is not specified, then first set:
block-progression-dimension.minimum=auto
block-progression-dimension.optimum=auto
block-progression-dimension.maximum=auto
-
Then, if "min-width" is specified, reset:
block-progression-dimension.minimum=<min-width>
-
Then, if "max-width" is specified, reset:
block-progression-dimension.minimum=<max-width>
-
However, if "max-width" is specified
as "none", reset:
block-progression-dimension.minimum=auto
5.4 Simple Property to Trait Mapping
The majority of the properties map into traits of the same name.
Most of these also simply copy the value from the property.
These are classified as "Rendering", "Formatting", "Specification",
"Font selection", "Reference", and "Action" in the property table in
[C.3 Property Table: Part II]. Some traits have a value that is different
from the value of the property. These are classified as "Value change"
in the property table. The value mapping is given below.
5.4.1 Column-number Property
If a value has not been specified on a formatting object to which
this property applies the initial value is computed as specified
in the property definition.
5.4.2 Text-align Property
A value of "left", or "right" is converted to the writing mode
relative value as specified in the property definition.
5.4.3 Text-align-last Property
A value of "left", or "right" is converted to the writing mode
relative value as specified in the property definition.
5.4.4 Z-index Property
The value is converted to one that is absolute; i.e. any local
stacking context has been converted to an absolute one.
5.5 Complex Property to Trait Mapping
A small number of properties influence traits in a more
complex manner. Detais are given below.
Issue (complex-property-mapping):
The following need
more work and coordination with the area model writeup:
absolute-position, background-position-horizontal/vertical,
starts/ends-row, text-decoration, direction, and relative-position
5.5.1 Word-spacing, and Letter-spacing Properties
These properties may set values for the start-space,
and end-space traits, as decribed in the property
definitions.
5.5.2 Writing-mode Property
The direction traits on an area are indirectly derived from the
"writing-mode", "direction" and "unicode-bidi" properties on the
formatting object that generates the area or the formatting object
ancestors of that formatting object. The exact derivation depends
on the trait.
5.6 Non-property Based Trait Generation
The "is-indent-reference" trait is set to "true" for the
following formatting objects:
"simple-page-master", "title",
"region-body", "region-before","region-after", "region-start", "region-end",
"block-container", "inline-container",
and
"table-cell".
For all other formatting objects it is set to "false".
5.7 Property Based Transformations
5.7.1 Text-transform Property
The case changes specified by this property are carried out during
refinement by changing the value of the "character" property
appropriately.
NOTE:
The use of the "text-transform" property is deprecated in XSL
due to its severe internationalization issues.
5.8 Expressions
All property value specifications in attributes within an XSL stylesheet can be expressions. These expressions represent the value of the property specified. The expression is first evaluated and then the resultant value is used to determine the value of the property.
5.8.1 Property Context
Properties are evaluated against a property-specific context. This context provides:
-
A list of allowed resultant types for a property value.
-
Conversions from resultant expression value types to an allowed type for the property.
-
The current font-size value.
-
Conversions from relative numerics by type to absolute numerics within additive expressions.
NOTE:
It is not necessary that a conversion is provided for all types. If no conversion is specified, it is an error.
When a type instance (e.g., a string, a keyword, a
numeric, etc.) is recognized in the expression it is evaluated against
the property context. This provides the ability for specific values to be
converted with the property context's specific algorithms or conversions
for use in the evaluation of the expression as a whole.
For example, the "auto" enumeration token for certain
properties is a calculated value. Such a token would be converted
into a specific type instance via an algorithm specified in the property definition.
In such a case the resulting value might be an absolute length specifying the width
of some aspect of the formatting object.
In addition, this allows certain types like relative numerics to be
resolved into absolute numerics prior to mathematical
operations.
All property contexts allow conversions as specified in
[5.8.12 Expression Value Conversions].
5.8.2 Evaluation Order
When a set of properties is being evaluated for a
specific formatting object element in the formatting object element tree
there is a specific order in which properties must be evaluated.
Essentially, the "font-size" property must be evaluated first before
all other properties. Once the "font-size" property has been evaluated,
all other properties may be evaluated in any order.
When the "font-size" property is evaluated, the current
font-size for use in evaluation is the font-size of the formatting object element's
parent. Once the "font-size" property has been evaluated,
that value is used as the
current font-size for all property contexts of all properties value expressions
being further evaluated.
5.8.3 Basics
5.8.4 Function Calls
5.8.5 Numerics
A numeric represents all the types of numbers in an XSL expression.
Some of these numbers are absolute values. Others are
relative to some other set of values. All of these values use a floating-point number to represent the number-part of their definition.
A floating-point number can have any
double-precision 64-bit format IEEE 754 value [IEEE 754].
These include a special "Not-a-Number" (NaN) value,
positive and negative infinity, and positive and negative zero. See
Section 4.2.3 of [JLS] for a summary of the key
rules of the IEEE 754 standard.
The following operators may be used with numerics:
-
+
-
Performs addition.
-
-
-
Performs subtraction or negation.
-
*
-
Performs multiplication.
-
div
-
Performs floating-point division according to IEEE 754.
-
mod
-
Returns the remainder from a truncating division.
NOTE:
Since XML allows - in names, the -
operator (when not used as a UnaryExpr negation) typically needs to be
preceded by whitespace. For example the expression 10pt - 2pt
means subtract 2 points from 10 points. The expression 10pt-2pt
means a length value of 10 with a unit of "pt-2pt".
NOTE:
The following are examples of the mod operator:
-
5 mod 2 returns 1
-
5 mod -2 returns 1
-
-5 mod 2 returns -1
-
-5 mod -2 returns -1
NOTE:
The mod operator is the same as the % operator in Java and
ECMAScript and is not the same as the IEEE remainder operation, which
returns the remainder from a rounding division.
Numeric Expressions
NOTE:
The effect of this grammar is that the order of precedence is (lowest precedence first):
and the operators are all left associative. For example, 2*3 + 4 div 5 is equivalent to (2*3) + (4 div 5).
If a non-numeric value is used in an AdditiveExpr and there is no property context conversion from that type into an absolute numeric value, the expression is invalid and considered an error.
5.8.6 Absolute Numerics
An absolute numeric is an absolute length which is a pair consisting of a Number and a UnitName raised to a power. When an absolute length is written without a unit, the unit power is assumed to be zero. Hence, all floating point numbers are a length with a power of zero.
Each unit name has associated with it an internal ratio to some common
internal unit of measure (e.g., a meter). When a value is
written in a
property expression, it is first converted to the internal unit of measure
and then mathematical operations are performed.
In
addition, only the mod,
addition, and subtraction operators require that the numerics on
either side of operation be absoluted numerics of the same unit power.
For other operations, the unit powers may be different and the result
should be mathematically consistent as with the handling of powers in algebra.
A property definition may constrain an absolute length to a particular power.
For example, when specifying font-size, the value is expected to be of power "one".
That is, it is expect to have a single powered unit specified (e.g., 10pt).
When the final value of property is calculated, the resulting power of the
absolute numeric must be either zero or one. If any other power is specified,
the value is an error.
5.8.7 Relative Numerics
Relative lengths are values that are
calculated relative to some other set of values. When written as part of an
expression, they are either converted via the property
context into an absolute numeric or passed verbatim as the property value.
It is an error if the property context has no available conversion
for the relative numeric and a conversion is required for expression
evaluation (e.g., within an add operation).
5.8.7.1 Percents
Percentages are values that are counted in 1/100 units. That is, 10%
as a percentage value is 0.10 as a floating point number.
When converting to an absolute numeric, the percentage is defined in the
property definition as being a percentage of some known
property value.
For example, a value of "110%" on a "font-size"
property
would be evaluated to mean 1.1 times the current font size.
Such a definition of the allowed conversion for percentages is specified on
the property definition. If no conversion is specified, the resulting value
is a percentage.
5.8.7.2 Relative Lengths
A relative length is a unit-based value that is measured against the
current value of the font-size property.
There is only one relative unit of measure, the "em". The
definition of "1em" is equal to the current font size. For
example, a value of "1.25em" is 1.25 times the current font
size.
When an em measurement is used in an expression, it is converted according
to the font-size value of the current property's context.
The result of the expression is an absolute length.
See [7.7.2 "font-size"]
5.8.8 Strings
Strings are represented either as literals or
as an enumeration token.
All properties contexts allow conversion from enumeration tokens to strings.
See [5.8.12 Expression Value Conversions].
5.8.9 Colors
A color is a set of values used to identify a particular color from a color space.
Currently, only RGB colors are supported by this draft.
RGB colors are directly represented in the expression language using a
hexadecimal notation. They can also be accessed through the system-color
function or through conversion from a
EnumerationToken
via the property context.
5.8.10 Keywords
Keywords are special tokens in the grammar that provide access to
calculated values or other property values.
The allowed keywords are defined in the following subsections.
5.8.10.1 inherit
The property takes the same computed value as the property
for the formatting object's parent object.
5.8.11 Lexical Structure
When processing an expression,
whitespace (ExprWhitespace) may be
allowed before or after any expression token even though it is not
explicitly defined as such in the grammar. In some cases, whitespace
is necessary to make tokens in the grammar lexically distinct.
Essentially, whitespace should be treated as if it does not exist
after tokenization of the expression has occurred.
The following special tokenization rules must be applied in the
order specified to disambiguate the grammar:
-
If the character following an
NCName (possibly after intervening
ExprWhitespace) is
"(",
then the token must be recognized as
FunctionName.
-
A number terminates at the first occurrence of a non-digit character other
than ".". This allows the unit token for
length quantities to parse properly.
-
When an NCName immediately follows a
Number, it should be recognized as a
UnitName or it is an error.
-
The Keyword values take precedence over
EnumerationToken.
-
If a NCName follows a numeric,
it should be recognized as an OperatorName or it is an error.
Expression Lexical Structure
5.8.12 Expression Value Conversions
Values that are the result of an expression evaluation may be converted
into property value types. In some instances this is a simple verification
of set membership (e.g., is the value a legal country code). In other cases,
the value is expected to be a simple type like an integer and must be converted.
It is not necessary that all types be allowed to be converted. If the
expression value cannot be converted to the necessary type for the property value,
it is an error.
The following table indicates what conversions are allowed.
| Type | Allowed Conversions | Constraints |
| NCName |
-
Color, via the system-color() function.
-
Enumeration value, as defined in the property definition.
-
To a string literal
| The value may be checked against
a legal set of values depending on the property. |
|
AbsoluteNumeric |
-
Integer, via the round() function.
-
Color, as an RGB color value.
|
If converting to an RGB color value, it must be a legal color value from the color
space. |
| RelativeLength |
|
|
The specific conversion to be applied is property specific and can be
found in the definition of each property.
5.9 Core Function Library
5.9.1 Number Functions
Function: numeric floor(
numeric)
The floor function returns the largest (closest to
positive infinity) integer that is not greater than the argument.
The numeric argument to this function must be of unit power zero.
NOTE:
If it is necessary to use the floor function for a
property where a unit power of one is expected, then an expressions
such as: "floor(1.4in/1.0in)*1.0in" must be used. This applies to the ceiling,
round, and other such functions where a unit power of zero is required.
Function: numeric ceiling(numeric)
The ceiling function returns the smallest (closest
to negative infinity) integer that is not less than the argument. The numeric
argument to this function must be of unit power zero.
Function: numeric round(numeric)
The round function returns the integer that is
closest to the argument. If there are two such
numbers, then the one that is closest to positive infinity is
returned. The numeric argument to this function must be of unit power zero.
Function: numeric min(
numeric
, numeric)
The min function returns the minimum of the
two numeric arguments. These arguments must have the same unit power.
Function: numeric max(numeric
, numeric)
The min function returns the maximum of the two
numeric arguments. These arguments must have the same unit power.
Function: numeric abs(
numeric)
The abs functions
returns the absolute value of the numeric argument.
That is, if the numeric argument is negative, it returns the negation of
the argument.
5.9.2 Color Functions
Function: color rgb(numeric
, numeric
, numeric)
The rgb function returns a specific color from the RGB
color space. The parameters to this function must be numerics (real numbers) with a
length power of zero.
Function: color system-color(
NCName)
The system-color function returns a system defined
color with a given name.
5.9.3 Font Functions
Function: object system-font(
NCName
, NCName)
The system-font funtions returns a
characteristic of a system font. The first argument is the
name of the system font and the second argument, which is optional,
names the property that specifies the characteristic. If the second
argument is omitted, then the characteristic returned is the same as
the name of the property to which the expression is being assigned.
For example, the expression
"system-font(heading,font-size)" returns the font-size
characteristic for the system font named "heading". This is equivalent to the
property assignment
'font-size="system-font(heading)"'.
5.9.4 Property Value Functions
Function: object inherited-property-value(NCName)
The inherited-property-value function returns the
inherited value of the property whose name matches the argument specified.
It is an error if this property is not an inherited property.
Function: numeric label-end()
The label-end function returns the calculated
label-end value for lists. See the definition of the
provisional-label-separation property.
Function: numeric body-start()
The body-start function returns the
calculated body-start value for lists.
See the definition of the
provisional-distance-between-starts
property.
NOTE:
When this function is used outside of a list, it still
returns a calculated value as specified.
Function: object from-parent(
NCName)
The from-parent function
returns a computed value of the property whose name matches
the argument specified.
The value returned is that for the parent of the
formatting object for which the expression is evaluated.
If there is no parent, the value returned is the initial
value. If the argument specifies a shorthand property and if
the expression only consists of the from-parent function with an
argument matching the property being computed, it is
interpreted
as an expansion of the shorthand with each property into which
the shorthand expands; each having a value of from-parent with
an argument matching the property.
It is an error if arguments matching a shorthand property are used
in any other way.
Function: object from-nearest-specified-value(
NCName)
The from-nearest-specified-value function
returns a computed value of the property whose name matches
the argument specified.
The value returned is that for the closest ancestor of the
formatting object for which the expression is evaluated on
which there
is an assignment of the property in the formatting object
element tree.
If there is no such ancestor, the value returned is the
initial value.
If the argument specifies a shorthand property and if
the expression only consists of the from-nearest-specified-value function with an
argument matching the property being computed, it is
interpreted
as an expansion of the shorthand with each property into which
the shorthand expands; each having a value of from-nearest-specified-value with
an argument matching the property.
It is an error if arguments matching a shorthand property are used
in any other way.
Function: object from-table-column(
NCName)
The from-table-column function
returns the inherited value of the property, whose name matches the
argument specified, from the fo:table-column whose column-number
matches the column for which this expression is evaluated and
whose number-columns-spanned also matches any span.
If there is no match for the number-columns-spanned, it is
matched
against a span of 1. If there is still no match, the initial
value is returned.
It is an error to use this function on formatting objects
that are not an fo:table-cell or its descendants.
5.10 Property Datatypes
Certain property values are described in terms of compound
datatypes, in terms of restrictions on permitted number values, or
strings with particular semantics.
The compound datatypes, such as space, are represented in the
result tree as multiple attributes. The names of these attributes
consist of the property name, followed by a period, followed by
the component name. For example a the "space-before" property may
be specified as:
space-before.minimum="2.0pt"
space-before.maximum="4.0pt"
space-before.optimum="3.0pt"
space-before.precedence="0"
space-before.conditionality="discard"
The following datatypes are defined:
-
<integer>
-
A signed integer value which consists of an optional '+' or '-'
character followed by a sequence of digits.
A property may define additional constraints on the value.
-
<number>
-
A signed real number which consists of an optional '+' or '-'
character followed by a sequence of digits followed by an optional '.'
character and sequence of digits.
A property may define additional constraints on the value.
-
<length>
-
A signed length value where a 'length' is a real number plus a unit
qualification.
A property may define additional constraints on the value.
-
<length-range>
-
A compound datatype, with components:
minumum, optimum, maximum. Each component is a <length>.
A property may define additional constraints on the values.
-
<length-conditional>
-
A compound datatype, with components:
length, conditionality. The length component is a <length>.
The conditionality component is either "discard" or "retain".
A property may define additional constraints on the values.
-
<length-bp-ip-direction>
-
A compound datatype, with components:
block-progression-direction, and inline-progression-direction.
Each component is a <length>.
A property may define additional constraints on the values.
-
<space>
-
A compound datatype, with components:
minumum, optimum, maximum, precedence, and conditionality.
The minumum, optimum, and maximum components are <length>s.
The precedence component is either "force" or an <integer>.
The conditionality component is either "discard" or "retain".
-
<keep>
-
A compound datatype, with components:
within-line, within-column, and within-page. The value of each
component is either "auto", "always", or an <integer>.
-
<angle>
-
An <integer> representing an angle.
-
<percentage>
-
A signed real percentage which consists of an optional '+' or '-'
character followed by a sequence of digits followed by an optional '.'
character and sequence of digits followed by '%'.
A property may define additional constraints on the value.
-
<character>
-
A single Unicode character.
-
<string>
-
A sequence of characters.
-
<name>
-
A string of characters representing a name. It must not contain
any whitespace, or space characters.
-
<family-name>
-
A string of characters identifying a font.
-
<color>
-
TBD
-
<country>
-
A string of characters conforming to an ISO 3166 country code.
-
<language>
-
A string of characters conforming to the
ISO 639 3 letter code.
-
<script>
-
A string of characters conforming to an
ISO 15924 script code.
-
<id>
-
A string of characters conforming to the XML NMTOKEN definition
that is unique within the stylesheet.
-
<idref>
-
A string of characters conforming to the XML NMTOKEN definition
that matches an ID property value used within the stylesheet.
-
<uri>
-
A sequence of characters conforming to a URI value as specified in
the URI specification.
6 Formatting Objects
6.1 Introduction to Formatting Objects
The refined formatting-object tree describes one or more
intended presentations of
the information within this tree. Formatting is the process
which converts the description into a presentation. See
[3 Introduction to
Formatting].The presentation
is represented, abstractly, by an area tree, as defined in
the area model. See [4 Area Model].
Each possible presentation
is represented by one or more area trees in which the information in
the refined formatting object tree is positioned on a two
and one-half dimensional surface.
There are three kinds of formatting objects: (1) those that generate
areas, (2) those that return areas, but do not generate
them, and (3) those that are used in the generation of
areas. The first and second kinds are typically called
flow objects. The third kind is either a
layout object or an auxilliary
object. The
kind of formatting object is indicated by the terminology used with
the object. Formatting objects of the first kind are said to "generate
one or more areas". Formatting objects of the second kind are said to
"return one or more areas". Formatting objects of the first kind may
both generate and return areas. Formatting objects of the third kind
are "used in the generation of areas"; that is, they act like
parameters to the generation process.
6.1.1 Definitions Common to Many Formatting Objects
This categorization leads to defining two traits which characterize
the relationship between an area and the formatting objects which
generate and return that area. These traits are
generated-by and
returned-by.
The value of the generated-by trait is a
single formatting
object. A formatting object F is defined to
generate an area A
if the semantics of F specify the generation of
one or more areas and A is one of the areas thus
generated.
The value of the returned-by trait is a set
of pairs, where each
pair consists of a formatting object and a positive integer. The
integer represents the position of the area in the ordering of all
areas returned by the formatting object.
A formatting object F is defined to return
the sequence of
areas A, B, C, ... if
the pair
(F,1) is a member of the
returned-by trait of A, the pair
(F,2) is a member of the
returned-by trait of B, the pair
(F,3) is a member of the
returned-by trait of C, ...
If an area is a member of the sequence of areas returned by a
formatting object, then either it was generated by the formatting
object or it was a member of the sequence of areas returned by a child
of that formatting object. Not all areas returned by a child of a
formatting object need be returned by that formatting object. A
formatting object may generate an area that has, as some of
its children areas, areas returned by the children of that
formatting
object. These children (in the area tree) of the generated area are
not returned by the formatting object to which they were returned.
A set of nodes in a tree is a lineage if:
-
there is a node N in the set such that all the
nodes in the set are ancestors of N, and
-
for every node N in the set, if the set contains
an ancestor of N, it also contains the parent of
N.
The set of formatting objects that an area is returned by is a lineage.
Areas returned by a formatting object may be either
normal or
out-of-line. Normal areas represent areas in
the
"normal flow
of text"; that is, they become area children of the areas generated by
the formatting object to which they are returned. Normal areas have a
returned-by lineage of size one. There is
only one kind of normal area.
Out-of-line areas are areas used outside the normal flow of text
either because the are absolutely positioned or they are part of a
float or footnote. Out-of-line areas may have a
returned-by lineage of size greater than one.
The area-class trait indicates which class,
normal or
out-of-line, an area belongs to. For out-of-line areas, it also
indicates the subclass of out-of-line area. The values for this trait
are: "normal", "absolute", "xsl-footnote",
"xsl-start-float", "xsl-end-float" or "xsl-top-float".
An area
is normal if and only if the value of the
area-class trait is
"normal"; otherwise, the area is an out-of-line
area.
The areas returned-by a given formatting object are ordered as
noted above. This ordering defines an ordering on the sub-sequence of
areas that are of a given area-class, such as the sub-sequence
of normal areas. An area A precedes an area B in the sub-sequence if
and only if area A precedes area B in the areas returned-by the
formatting objects.
6.2 Formatting Object Content
The content of a formatting object is described using xml content
model syntax. In some cases additional constraints, not expressable
in xml content models, are given in prose.
The parameter entity, "%block;" in the content models below,
contains the following formatting objects:
block
block-container
table-and-caption
table
list-block
The parameter entity, "%inline;" in the content models below,
contains the following formatting objects:
bidi-override
character
external-graphic
instream-foreign-object
inline
inline-container
leader
page-number
page-number-citation
simple-link
multi-toggle
The following formatting objects are "neutral" containers and
may be used anywhere where #PCDATA, %block;, or %inline; are allowed:
multi-switch
multi-properties
wrapper
The following "out-of-line" formatting objects
may be used anywhere where #PCDATA, %block;, or %inline; are allowed:
float
footnote
6.3 Formatting Objects Summary
-
bidi-override
-
The fo:bidi-override inline formatting object is used
where it is necessary to override the default Unicode-bidirectionality
algorithm writing-direction for different (or nested) inline scripts
in mixed-language documents.
-
block
-
The fo:block formatting object is commonly used for formatting paragraphs,
titles, headlines, figure and table captions,
etc.
-
block-container
-
The fo:block-container flow object is used to
generate a block-level reference-area.
-
character
-
The fo:character flow object represents a character that
is mapped to
a glyph for presentation.
-
conditional-page-master-reference
-
The fo:conditional-page-master-reference is used to identify a
page-master that is to be used when the conditions on its use are
satisfied.
-
external-graphic
-
The fo:external-graphic flow object is used for an inline
graphic where the graphics data resides outside of the fo:element tree.
-
float
-
The fo:float flow object is used to gather content of a
floating
figure, table, or sidebar.
-
flow
-
The content of the fo:flow formatting object is a
sequence of
flow objects that forms one unit of content distribution,
such as
an article, a chapter, or a section.
-
footnote
-
The fo:footnote formatting object is used to gather the
components
of a floating note.
-
initial-property-set
-
The fo:initial-property-set specifies formatting properties
for the first line of an fo:block.
-
inline
-
The fo:inline formatting object is commonly used for formatting
a portion of text with a background or enclosing it in a border.
-
inline-container
-
The fo:inline-container flow object is used to
generate an inline reference-area.
-
instream-foreign-object
-
The fo:instream-foreign-object flow object is used for an inline
graphic or other "generic" object
where the object data resides as descendants of the
fo:instream-foreign-object.
-
layout-master-set
-
The fo:layout-master-set is a wrapper around all masters used in the
document.
-
leader
-
The fo:leader formatting object is used to generate leaders consisting
either of a rule or of a row of a repeating character or cyclically
repeating pattern of characters that are used for connecting two
text formatting objects and split-quads (space-leaders).
-
list-block
-
The fo:list-block flow object is used to format a list
item or a list.
-
list-item
-
The fo:list-item formatting object contains the label and the
body of an item in a list.
-
list-item-body
-
The fo:list-item-body formatting object contains the
content
of the body of a list-item.
-
list-item-label
-
The fo:list-item-label formatting object contains the
content
of the label of a list-item; typically used to either enumerate,
identify or adorn the list-item's body.
-
multi-case
-
The fo:multi-case is used to embed flow objects, that the parent
fo:multi-switch can choose to either show or hide.
-
multi-properties
-
The fo:multi-properties is used to switch between two or more property sets that
are associated with a given portion of content.
-
multi-property-set
-
The fo:multi-property-set is used to specify an alternative
set of formatting
properties that, dependent on a DOM state, are applied to the content.
-
multi-switch
-
The fo:multi-switch is used to switch between two or more
sub-trees of formatting objects.
-
multi-toggle
-
The fo:multi-toggle is used within an fo:multi-case to
switch to another
fo:multi-case.
-
page-number
-
The fo:page-number formatting object is used to represent
the
current page-number.
-
page-number-citation
-
The fo:page-number-citation is used to reference the
page-number for the page containing the first normally sequenced
area returned by the cited formatting
object.
-
page-sequence
-
The fo:page-sequence formatting object is used to specify how to
create a (sub-)sequence of pages within a document; for example, a
chapter of a report. The content of these pages comes from flow
children of the fo:page-sequence.
-
page-sequence-master
-
The fo:page-sequence-master specifies sequences of page-masters
that are used when generating a sequence of pages.
-
region-after
-
This region defines
a viewport that is located on the "after" side of fo:region-body
region.
-
region-before
-
This region defines
a viewport that is located on the "before" side of fo:region-body
region.
-
region-body
-
This region specifies a
viewport that is located in the "center" of the
fo:simple-page-master.
-
region-end
-
This region defines
a viewport that is located on the "end" side of fo:region-body region.
-
region-start
-
This region defines
a viewport that is located on the "start" side of fo:region-body
region.
-
repeatable-page-master-alternatives
-
An
fo:repeatable-page-master-alternatives
specifies a sub-sequence consisting of
repeated instances of a set of alternative page-masters.
The number of repetitions may be bounded or
potentially unbounded.
-
repeatable-page-master-reference
-
An
fo:repeatable-page-master-reference
specifies a sub-sequence consisting of
repeated instances of a single page-master. The number of repetitions
may be bounded or potentially unbounded.
-
root
-
The fo:root node is the top node of an XSL result tree.
This tree is composed of formatting objects.
-
simple-link
-
The fo:simple-link is used for representing the start resource of a simple
link.
-
simple-page-master
-
The fo:simple-page-master is used in the generation of pages and
specifies the geometry of the page. The page may be subdivided into up
to five regions
-
single-page-master-reference
-
An fo:single-page-master-reference specifies a sub-sequence consisting
of a single instance of a single page-master.
-
static-content
-
The
fo:static-content formatting object holds a sequence or a
tree of
formatting objects that is to be presented in a single
region
or repeated in like-named regions on one or more pages in the page-sequence.
Its common use is for repeating or running headers and footers.
-
table
-
The fo:table flow object is used for formatting the
tabular material
of a table.
-
table-and-caption
-
The fo:table-and-caption flow object is used for
formatting a table
together with its caption.
-
table-body
-
The fo:table-body formatting object is used to contain
the content
of the table body.
-
table-caption
-
The fo:table-caption formatting object is used to contain block-level
formatting objects containing the caption for the table.
-
table-cell
-
The fo:table-cell formatting object is used to group
content to be
placed in a table-cell.
-
table-column
-
The fo:table-column formatting object specifies
characteristics
applicable to table cells that have the same column and span.
-
table-footer
-
The fo:table-footer formatting object is used to contain
the content
of the table footer.
-
table-header
-
The fo:table-header formatting object is used to contain
the content
of the table header.
-
table-row
-
The fo:table-row formatting object is used to group
table-cells into
rows.
-
title
-
The fo:title formatting object is used to associate a title with a given page. This title may be used by an interactive User Agent to identify the page. For examle, the content of the fo:title can be formatted and displayed in a "title" window or in a "tool tip".
-
wrapper
-
The fo:wrapper formatting object is used to
specify
inherited properties for a group of formatting objects.
It has no additional formatting semantics.
6.4 Pagination and Layout Formatting Objects
6.4.1 Introduction
The root node of the formatting object tree must be an
fo:root
formatting object. The children of the fo:root formatting object are
a single fo:layout-master-set and a sequence of one or more
fo:page-sequences. The fo:layout-master-set defines the geometry and
sequencing of the pages; the children of the fo:page-sequences, which
are called flows, provide the content that is distributed into
the pages. The process of generating the pages is done automatically
by the XSL processor formatting the result tree.
The children of the fo:layout-master-set are the pagination and layout
specifications. The names of these specifications end in
"-master". There are two types of pagination and layout
specifications: page-masters and page-sequence-masters. Page-masters
have the role of describing the intended subdivisions of a page and
the geometry of these subdivisions. Page-sequence-masters have the
role of describing the sequence of page-masters that will be used to
generate pages during the formatting of an fo:page-sequence.
6.4.1.1 Page-sequence-masters
Each fo:page-sequence-master characterizes a set of possible sequences
of page-masters. For any given fo:page-sequence, only one of the
possible set of sequences will be used. The sequence that is used is
the smallest sequence that satisfies the constraints determined by the
individual page-masters, the flows which generate pages from the
page-masters and the fo:page-sequence-master itself.
The fo:page-sequence-master is used to determine which page-masters
are used and in which order. The children of the
fo:page-sequence-master are a sequence of sub-sequence specifications.
The page-masters in a sub-sequence may be specified by a reference
to a single page-master or as a repetition of one or more
page-masters. For example, a sequence might begin with several
explicit page-masters and continue with a repetition of some other
page-master (or masters).
The fo:single-page-master-reference is used to specify a sub-sequence
consisting of a single page-master.
There are two ways to specify a sub-sequence that is a repetition. The
fo:repeatable-page-master-reference specifies a repetition of a single
page-master. The fo:repeatable-page-master-alternatives specifies
the repetition of a set of page-masters. Which of the alternative
page-masters is used at a given point in the sub-sequence is
conditional and may depend on whether the page number is odd or even,
is the first page, is the last page, or is blank. The
"maximum"
property on the repetition specification controls the number of
repetitions. If this property is not specified, there is no limit on
the number of repetitions.
6.4.1.2 Page-masters
A page-master is a master that is
used to generate a page. A page is a combination of two
(nested) reference-areas: the media reference-area and the page-level
reference-area. Both of these reference-areas belong to the class
of block-areas.
The media reference-area is defined by the output medium; the
page-level reference-area defined by the content-rectangle of the
media reference-area and is a child (in the area tree) of the media
reference-area. This has the affect of positioning the page-level
reference-area on the output media.
NOTE:
The content-rectangle of the media reference-area can be
viewed as
being the trim or clipping rectangle of the medium on which the page
is presented. This is the trimmed size of the sheet for sheet media
and the window size for display media. The content of the page-level
reference-area may bleed outside the content-rectangle of
the media
reference-area. Bleeds are typical when the author of the content
wants to insure that some of the content, usually an image, will not
accidentally get a media color border when the
content-rectangle of
the media reference-area is not positioned exactly as intended or when
its size is different than intended.
The term page is used ambiguously to refer to both the
media reference-area, the page-level reference-area, or both
together. The intended referent is clear from context. Most references
to page will be referring either to both reference-areas or to the
page-level reference-area. The media reference-area is used only when
defining the position of the page-level reference-area on the output
medium. Children of the page are always children of the page-level
reference-area and the parent of the page is always the parent of the
media reference-area. Where confusion would arise, as when
distinguishing which of the two refence-areas a given trait is on, the
term "page" will not be used, and, instead, the appropriate
reference-area will be explicity identified.
A single page-master may be used multiple times, each time it is used
it generates a single page; for example, a page-master that is
referenced from an fo:repeatable-page-master-reference will generate
one page for each occurrence of the reference in the specified
sub-sequence.
NOTE:
When pages are used with a user agent such as a Web
Browser, it is common that the each document has only one page. The
viewport used to view the page determines the size of the page. When
pages are placed on non-interactive media, such as sheets of paper,
pages correspond to one or more of the surfaces of the paper. The size
of the paper determines the size of the page.
In this specification, there is only one kind of page-master, the
fo:simple-page-master. Future versions of this specification may add
additional kinds of page-masters.
An fo:simple-page-master has, as children, specifications for one or more
regions.
A region specification is used as a master, the region-master,
when generating both a viewport reference-area and a region
reference-area. The region reference-area is the only area child
of the viewport reference-area. The viewport reference-area represents
an opening in the page-level reference-area through which the region
reference-area can be viewed. Scrolling and clipping is
controlled in
terms of the viewport reference-area.
We will say a viewport/region
area corresponds to a region if the viewport reference-area/region reference-area
was generated using the region-master specified by that region. Both
the viewport reference-area and the region reference-area belong to
the class of block-areas.
NOTE:
The regions on the page are analogous to "frames" in an
HTML document. Typically, at least one of these regions is of
indefinite length in one of its dimensions. For languages with a lr-tb
(or rl-tb) writing-mode, this region is typically of indefinite length
in the top-to-bottom direction. The viewport represents the
visible
part of the frame. The flow assigned to the region is viewed by scrolling
the region reference-area through the viewport.
Each region is defined by a region formatting object. Each
region formatting object has a name and a definite position. In
addition, the region's height or width is fixed and the other
dimension may be either fixed or indefinite. For example, a region
that is the body of a Web page may have indefinite height.
The specification of the region determines the size and position of
the viewport associated with the region. The positioning of the
viewport is relative to the page-level reference-area that is
generated using the page-master that is the parent of the region. The
region reference-area takes its position from the viewport and size
from the size specification of the region.
For version 1.0 of this recommendation, a page-master will
consist of up to five regions: "region-body" and four other regions,
one on each side of the body. To allow the side regions to correspond
to the current writing-mode, these regions are named "region-before"
(which corresponds to "header" in the "lr-tb" writing-mode),
"region-after" (which corresponds to "footer" in the "lr-tb"
writing-mode), "region-start" (which corresponds to a "left-sidebar"
in the "lr-tb" writing-mode) and "region-end" (which corresponds
to a "right-sidebar" in the "lr-tb" writing-mode). It is
expected, that a future version of the recommendation will introduce a
mechanism that allows a page-master to contain an arbitrary number of
arbitrarily sized and positioned regions.
6.4.1.3 Page Generation
Pages are generated
automatically by the formatting of fo:page-sequences. As noted above,
each page is a combination of a media reference-area and a page-level
reference-area. The parent of each page is the area tree root. Each
page is generated by using a page-master to define the viewport areas
and region reference-areas that correspond to the regions specified by
that page-master.
Each fo:page-sequence references either an fo:page-sequence-master or
an fo:page-master. If the reference is to an fo:page-master, this is
interpreted as if it were a reference to an fo:page-sequence-master
that repeats the referenced fo:page-master an unbounded number of
times. We will say an fo:page-sequence references a page-master if
either the fo:page-sequence directly references the page-master via
the "master-name" property or that property references an
fo:page-sequence-master that references the page-master.
6.4.1.4 Flows and Flow Mapping
There are two kinds of flows: fo:static-content and fo:flow. An
fo:static-content flow holds content, such as the text that goes
into headers and footers, that is repeated on many of the pages. The
fo:flow flow holds content that is distributed across a sequence of
pages. The processing of the fo:flow flow is what determines how many
pages are generated to hold the fo:page-sequence. The
fo:page-sequence-master is used as the generator of the sequence of
page-masters into which the flow children content is distributed.
The children of a flow are a sequence of block-level flow objects.
Each flow has a name, and no two fo:flow or fo:static-content
formatting objects in the same page-sequence may have the same
name.
The assignment of flows to regions on a page-master is determined by
an implicit flow-map. The flow-map specifies an association
between the flow children of the fo:page-sequence and regions defined
within the page-masters referenced by that fo:page-sequence.
In version 1.0 of XSL, the flow-map is implicit. The
"flow-name" property of a flow specifies to which region
that flow is assigned. Each region has a "region-name"
property. The implicit flow-map assigns a flow to the region that has
the same name. In future versions of XSL, the flow map is expected to
become an explicit formatting object.
To avoid requiring users to generate region-names, the regions all
have default values for the "region-name" property. The
region-names all begin with the prefix, "xsl-" and the
suffix is the element name of the region formatting object. For
example, the region that has the element name, "region-body"
would have "xsl-region-body" as its default region-name.
6.4.1.5 Constraints on Page Generation
The areas that are descendant from a page are constrained by the
page-master used to generate the page and the flows that are assigned
to the regions specified on the page-master. For fo:static-content
flows, the processing of the flow is repeated for each page generated
using a page-master having the region to which the flow is assigned. For
fo:flow flows, the areas generated by the descendants of the flow are
distributed across the pages in the sequence that were generated using
page-masters having the
region to which the flow is assigned.
There may be many area trees that would satisfy the constraints
determined by the formatting objects in the result tree. There are two
concepts which help choose among these trees.
The first is that area trees with the least number of pages needed to meet
the constraints are preferred. The second is
that area trees with the least number of lines are preferred.
6.4.1.6 Area Generated by Descendants of a Given Flow
The areas generated by the descendants of a flow are called
flow-descendant-areas.
Every flow-descendant-area is in two relationships: an
area-descendant
relationship and a generation-descendant
relationship.
As an area, a flow-descendant-area is an immediate area
descendant of its parent area in the area tree. In addition, a
flow-descendant-area is, necessarily, a descendant of some page in the
area tree. That is, there is some page for which the
flow-descendant-area is an area-descendant.
The flow-descendant-area is also a
generation-descendant of the
flow that is an ancestor of the flow object that generated that
area. That is, the flow objects that are the descendants of a given
flow generate areas which are generation descendants of that flow.
In the sequel, the qualifiers "area" and "generation" will normally be
omitted before the term "descendant" because the qualifier (and,
therefore, the relationship) is implied by whether the area is
described as descendant from an area or from a flow.
6.4.1.7 Pagination Tree Structure
The result tree structure is shown below.
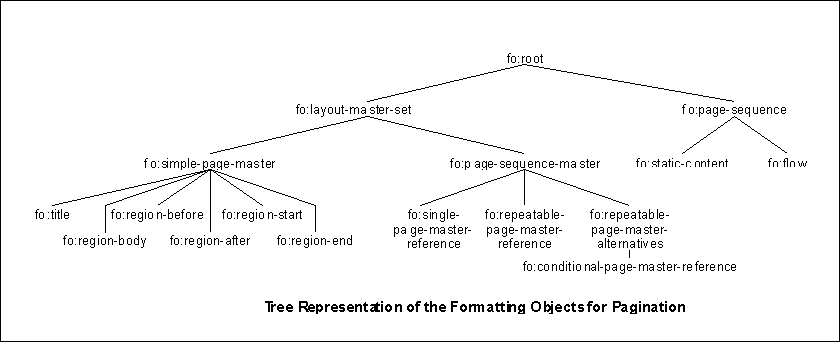
6.4.1.8 Examples
TBD
6.4.2 fo:root
-
Common Usage:
This is the top node of the formatting object tree. It holds an
fo:layout-master-set formatting object (which holds all masters used
in the document) and one or more fo:page-sequence objects. Each
fo:page-sequence represents a sequence of pages that result from
formatting the content children of the fo:page-sequence.
NOTE:
A document can contain multiple fo:page-sequences. For example,
each chapter of a document could be a separate fo:page-sequence; this
would allow chapter-specific content, such as the chapter
title, to be placed within a header or footer.
-
Areas:
Page-level areas are returned by the fo:page-sequence children of the
fo:root formatting object. The fo:root does not generate any areas.
-
Constraints:
The children of the root of the area tree consist solely of, and totally of, the
page-level areas returned by the fo:page-sequence children of the
fo:root. The ordering of area children (a) preserves the ordering of areas
returned by each fo:page-sequence child and (b) orders all page-level areas
returned by a given fo:page-sequence child before all of
the page-level areas
returned by all of its following sibling fo:page-sequences.
-
Contents:
(layout-master-set,page-sequence+)
6.4.3 fo:page-sequence
-
Common Usage:
The fo:page-sequence formatting object is used to specify how to
create a (sub-)sequence of pages within a document; for example, a
chapter of a report. The content of these pages comes from flow
children of the fo:page-sequence. The layout of these pages comes from
the fo:page-sequence-master referenced by the master-name
trait on the fo:page-sequence. The sequence of areas returned by
each of the flow-object children of the fo:page-sequence are
made descendants of the generated pages as described below.
-
Areas:
The fo:page-sequence formatting object generates
and returns a sequence of pages. For each page, and each region
specified in the page-master used to generate that page, the
fo:page-sequence object also generates the viewport reference-area and
region reference-area for the occurrence of that region on
that page.
If the region allows conditional regions within it, then the regions
that are children of the region reference-area are also generated. The
generation of the viewport reference-areas, the region reference-areas
and their children reference-areas, if any, are described
under the fo:simple-page-master and the region-masters.
-
Constraints:
The sequence of pages has as its descendants, in the area tree, the
areas returned by the flows that are the children of the
fo:page-sequence.
Each page in the page-sequence is constrained to be generated using a
page-master that satisfies the constraints of the
page-sequence-master
identified by the master-name trait of the fo:page-sequence.
For a given page, the viewport reference-areas and region
reference-areas generated for that page are constrained to correspond
to the regions that are descendants of the
fo:simple-page-master that
was used to generate the page. In addition, for
flow-descendant-areas
of a given flow, the areas must be descendants of a region
reference-area that corresponds to the region to which the flow was
assigned. The assignment of flows to regions is discussed in
Section [6.4.1.4 Flows and Flow Mapping].
There are a set of ordering constraints on the flow-descendant-areas
of the pages:
We will say that a flow is assigned to a page if
the flow is assigned to a region specified in the page-master that is
used to generate that page.
For each page returned-by the fo:page-sequence and each
fo:static-content formatting object that is a child of the
fo:page-sequence,
either the fo:static-content is assigned to the page or the
fo:static-content is not used with that page. If the fo:static-content
is not assigned to the page then none of the areas returned by the
fo:static-content formatting object are flow-descendant
areas of the
page. If the fo:static-content is assigned to the page, then the treatment
of, and constraints on, the returned areas are covered in
the
descriptions of the fo:simple-page-master and the associated
region-masters.
For flow-descendant areas of an fo:flow formatting
object,
-
For this version of the specification, for any two pages
P and Q in
the page-sequence returned by fo:page-sequence, if an
fo:flow is
assigned to page P, then the fo:flow must either be
assigned to the same region in the page-master used to generate Q or
it must not be assigned to any region in the page-master used to
generate Q.
-
If a fo:flow is assigned to pages P and Q, and
page P precedes page Q
in the ordering of pages,
-
then all normal flow-descendant-areas of that fo:flow that are area
descendants of page P must be generation
ordered before all normal
flow-descendant-areas of that fo:flow that are area descendants of
page Q.
-
and, for out-of-line flow-descendant-areas of that fo:flow that are area
descendants of page P and for which the
value of the area-class
trait is "xsl-footnote", "xsl-start-float",
"xsl-end-float" and "xsl-top-float", then within each
class, all flow-descendant-areas of that fo:flow that are area
descendants of page P must be generation ordered before all
flow-descendant-areas of that fo:flow that are area descendants of
page Q.
The flow-descendant-areas descendant from a given page returned by the
fo:page-sequence must, for each area-class, be
contiguous relative to that area-class (see section 4.2.4 of the area
model). In addition, if A and B are areas in the
same area-class and if B precedes
A in the sub-sequence of areas for that
area-class and if B is not a
flow-descendant-area of the page from which A is a
descendant, then area B must be a flow-descendant area of
some page that precedes that page from which A is a
descendant.
NOTE:
These constraints insure that all of the areas
returned-by a given fo:flow are placed on some page and that the order
of the areas is preserved. The normal areas are placed sequentially on
sequential pages (on which the region to which that flow is assigned
appears). Footnotes and floats in the block-progression-direction are
also placed sequentailly, but, it is not necessary that the sequence
be place in sequential pages. For example, some pages may have not
footnotes or floats and a sequence of floats that is too big to fit on
one page may be distributed across a sequence of pages.
-
Contents:
(static-content*,flow)
-
Properties:
6.4.4 fo:layout-master-set
-
Common Usage:
The fo:layout-master-set is a wrapper around all masters used in the
document. This includes page-sequence masters, page-masters and
region-masters.
-
Areas:
The fo:layout-master-set formatting object generates no area directly.
The masters that are the children of the fo:layout-master-set are
used by the fo:page-sequence to generate pages.
-
Constraints:
The value of the master-name trait on each
child of the fo:layout-master-set must be unique within the set.
-
Contents:
(simple-page-master|page-sequence-master)+
6.4.5 fo:page-sequence-master
-
Common Usage:
The fo:page-sequence-master is used to specify the constraints on and
the order in which a given set of page-masters will be used in
generating a sequence of pages. Pages are automatically generated when
the fo:page-sequence-master is used in formatting an fo:page-sequence.
NOTE:
There are several ways of specifying a potential
sequence of pages. One can specify a sequence of references to
particular page-masters. This yields a bounded sequence of potential
pages. Alternatively, one can specify a repeating sub-sequence of one
or more page-masters. This sub-sequence can be bounded or
unbounded. Finally one can intermix the two kinds of sub-sequence
specifiers.
-
Areas:
The fo:page-sequence-master formatting object generates no area directly.
It is used by the
fo:page-sequence formatting object to generate pages.
-
Constraints:
The children of the fo:page-sequence-master are a sequence of
sub-sequence-specifiers. A page-sequence
satisfies the constraint
determined by an fo:page-sequence-master if (a) it can be partitioned
into sub-sequences of pages that map one-to-one, in order,
to the
sub-sequence of sub-sequence-specifiers that are the
children of the
fo:page-sequence specification and, (b) for each sub-sequence of pages, that
sub-sequence satisfies the constraints of the corresponding
sub-sequence
specifier. Note that the mapping of sub-sequences of the sequence
of pages to sub-sequence-specifiers need not be onto; that
is, the
sequence of sub-sequences of pages can be shorter than the sequence of
sub-sequence-specifiers.
-
Contents:
(single-page-master-reference|repeatable-page-master-reference|repeatable-page-master-alternatives)+
-
Properties:
6.4.6 fo:single-page-master-reference
-
Common Usage:
An fo:single-page-master-reference is the
simplest sub-sequence-specifier. It specifies a sub-sequence consisting
of a single instance of a single page-master. It is used to specify
the use of a particular page-master at a given point in the sequence
of pages that would be generated using the fo:page-sequence-master
that is the parent of the fo:single-page-master-reference.
-
Areas:
The fo:single-page-master-reference formatting object generates no area directly.
It is used by the fo:page-sequence formatting
object to generate pages.
-
Constraints:
The fo:single-page-master-reference has a reference to the
fo:simple-page-master which has the same master-name as the
master-name trait on the
fo:single-page-master-reference.
The sub-sequence of pages mapped to this
sub-sequence-specifier satisfies
the constraints of this sub-sequence-specifier if (a) the
sub-sequence of pages consists of a single page and (b) that page is
constrained to have been generated using the fo:simple-page-master
referenced by the fo:single-page-master-reference.
-
Contents:
EMPTY
-
Properties:
6.4.7 fo:repeatable-page-master-reference
-
Common Usage:
An fo:repeatable-page-master-reference is the next simplest
sub-sequence-specifier. It specifies a sub-sequence
consisting of
repeated instances of a single page-master. The number of repetitions
may be bounded or potentially unbounded.
-
Areas:
The fo:repeatable-page-master-reference formatting object generates no area directly.
It is used by the fo:page-sequence formatting object to generate
pages.
-
Constraints:
The fo:repeatable-page-master-reference has a reference to the
fo:simple-page-master which has the same master-name as the
master-name trait on the
fo:repeatable-page-master-reference.
The maximum-repeats trait determines how many repeats
of the referenced page-master are allowed. A sub-sequence of pages that
has a length that is less than or equal to the value of the
maximum-repeats trait satisfies this trait; a
sub-sequence of pages that has a length that is greater does not.
The sub-sequence of pages mapped to this
sub-sequence-specifier satisfies
the constraints of this sub-sequence-specifier if (a) the
sub-sequence of pages consist of zero or more pages, (b) each page is
constrained to have been generated using the fo:simple-page-master
referenced by the fo:repeatable-page-master-reference, and (c) the
constraint determined by the maximum-repeats trait is
satisfied.
-
Contents:
EMPTY
-
Properties:
6.4.8 fo:repeatable-page-master-alternatives
-
Common Usage:
The fo:repeatable-page-master-alternatives
formatting object is the most complex
sub-sequence-specifier. It
specifies a sub-sequence consisting of repeated instances of a set of
alternative page-masters. The number of repetitions may be bounded or
potentially unbounded. Which of the alternative page-masters is used
at any point in the sequence depends on the evaluation of a condition
on the use of the alternative. Typical conditions include, testing
whether the page which is generated using the alternative is the first
or last page in a page-sequence or is the page blank. The full set of
conditions allows different page-masters to be used for the first
page, for odd and even pages, for blank pages.
NOTE:
Because the conditions are tested in order from the
beginning of the sequence of children, the last alternative in the
sequence usually has a condition that is always true and this
alternative references the page-master that is used for all pages that
do not receive some specialized layout.
-
Areas:
The fo:repeatable-page-master-alternatives
formatting object generates no area directly. This formatting object
is used by the fo:page-sequence formatting object to generate pages.
-
Constraints:
The children of the fo:repeatable-page-master-alternatives are
fo:conditional-page-master-references. These children will be called
alternatives.
The maximum-repeats trait determines how many repeats
of the referenced page-master are allowed. A sub-sequence of pages that
has a length that is less than or equal to the value of the
maximum-repeats trait satisfies this trait; a
sub-sequence of pages that has a length that is greater does not.
The sub-sequence of pages mapped to this
sub-sequence-specifier satisfies
the constraints of this sub-sequence-specifier if (a) the
sub-sequence of pages consist of zero or more pages, (b) each page is
constrained to have been generated using the fo:simple-page-master
referenced by the one of the alternatives that
are the children of the fo:repeatable-page-master-alternatives, (c)
the conditions on that alternative are "true", (d) that
alternative is the first alternative in the sequence of children for
which all the conditions are "true", and (e) the constraint
determined by the maximum-repeats trait is satisfied.
-
Contents:
(conditional-page-master-reference+)
-
Properties:
6.4.9 fo:conditional-page-master-reference
-
Common Usage:
The fo:conditional-page-master-reference is used to identify a
page-master that is to be used when the conditions on its use are
satisfied. This allows different page-masters to be used, for example,
for even and odd pages, for the first page in a page-sequence, or for
blank pages. This usage is typical in chapters of a book or report
where the first page has a different layout than the rest of the
chapter and the headings and footings on even and odd pages
may different as well.
-
Areas:
The fo:conditional-page-master-reference formatting object generates no area directly.
It is used by
the fo:page-sequence formatting object to generate pages.
-
Constraints:
The fo:conditional-page-master-reference has a reference to the
fo:simple-page-master which has the same master-name as
the master-name trait on the fo:conditional-page-master-reference.
There are three traits, page-position,
odd-or-even, and blank-or-not-blank that
specify the
sub-conditions on the use of the referenced page-master. All three
sub-conditions must be "true" for the condition on the
fo:conditional-page-master-reference to be "true". Since,
the properties from which these traits are derived are not inherited and the initial value of all the
properties makes the corresponding sub-condition "true", this
really means that the subset of traits that are derived from properties with specified values must make the corresponding
sub-condition "true".
The sub-condition corresponding to the page-position
trait is "true", if the page generated using the
fo:conditional-page-master-reference has the specifed position in
sequence of pages generated by the referencing page-sequence; namely,
"first", "last", "rest" (not first) or
"any" (all of the previous). The referencing
page-sequence is the fo:page-sequence that referenced the
fo:page-sequence-master from which this
fo:conditional-page-master-referenece is a descendant.
The sub-condition corresponding to the odd-or-even
trait is "true", if the value of the "odd-or-even"
trait is "any" or if the value matches the parity of the
page number of the page generated using the
fo:conditional-page-master-reference.
The sub-condition corresponding to the blank-or-not-blank trait is
"true", (1) if value of the trait is
"not-blank" and the page generated using the
fo:conditional-page-master-reference has flow-desecendant areas from
the fo:flow formatting object; (2) if value of the trait is
"blank" and the page generated using the
fo:conditional-page-master-reference is such that there are
no areas from the fo:flow to be put on that page (e.g.,
(a) to maintain proper page parity due to (i) a break-after
or break-before value of "even-page" or "odd-page" or (ii) at the
start or end of the page sequence or (b) because the constraints
on the flow-descendant areas of the fo:flow formatting object would
not be satisfied if they were descendant from this page); or (3)
if value of the trait is "any".
NOTE:
If any page-master referenced from a conditional-page-master-reference
with blank-or-not-blank="true" provides a region in which to put fo:flow content, no
content is put in that region.
-
Contents:
EMPTY
-
Properties:
6.4.10 fo:simple-page-master
-
Common Usage:
The fo:simple-page-master is used in the generation of pages and
specifies the geometry of the page. The page may be subdivided into up
to five regions: region-body, region-before, region-after,
region-start, and region-end.
NOTE:
For example, if the writing-mode of the
fo:simple-page-master is "lr-tb", then these regions
correspond to to the body of a document, the header, the footer, the
left sidebar and the right sidebar.
NOTE:
The simple-page-master is intended for systems that wish to provide
a simple page layout facility. Future versions of this specification
will support more complex page layouts constructed using the
fo:page-master formatting object.
-
Areas:
The fo:simple-page-master formatting object generates no area directly.
It is used in the generation of pages by an
fo:page-sequence.
When the fo:simple-page-master is used to generate a page, two
reference-areas area generated: the media reference area and the
page-level reference-area. The page-level reference-area is a child of
the media reference-area. The media reference-area represents the
physical bounds of the output medium. The page-level reference-area
represents the portion of the page on which content is intended to
appear; that is, the area inside the page margins.
In addition, when the fo:simple-page-master is used to generate a
page, reference-areas that correspond to the regions that are the
children of the fo:simple-page-master are also generated. For each
such region, the region-master is used to generate a viewport-area and
a region reference-area. (See the formatting object specifications for
the five regions for the details on the generation of these areas.)
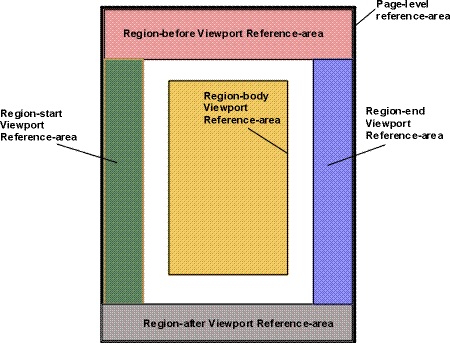
-
Trait Derivation:
In this version of this specification, borders and padding are not
allowed with a page-area. The remaining traits on the page-area are
set according to normal rules for determining the values of
traits.
-
Constraints:
When a page-master is used in the generation of a page, the
height and width of the
content-rectangle of the media reference-area are determined using the computed values of the
"page-height" and "page-width" properties.
If the
"page-height" and "page-width" properties have
explicit values, they are used to set the corresponding
height and width trait on the media
reference-area. If the "page-height" and/or
"page-width" are set to "auto", the size of the
media reference-area will be determined from the size of the media. If
the media has a fixed size, then the size of the media is used. In the
case of continuous media, the size of the user agent window is used.
NOTE:
The above size calculations are intended to match
the handling of a frameset in a browser window when the media is
continuous and to match pages when the media is paged.
A User Agent may provide a way to declare the media for which
formatting is to be done. This may be different from the media on
which the formatted result is viewed. For example, a browser User
Agent may be used to preview pages that are formatted for sheet
media. In that case, the size calculation is based on the media for
which formatting is done rather than the media being currently used.
The traits derived from the margin properties determine the size
and position of the content-rectangle of the media reference-area.
The traits derived from the "margin-top",
"margin-bottom", "margin-left" and
"margin-right" properties are used to indent the page-level
reference-area content-rectangle from the corresponding edge of the
media page. Here "top", "bottom", "left"
and "right" are determined by the computed values of the
"page-height" and "page-width" properties. For
sheet media, these values determine the orientation of the sheet;
"page-height" is measured from "top" to
"bottom" For display media, the display window is always
upright; the top of the display screen is "top".
NOTE:
The reference points for the media reference-area content rectangle
are in terms of the "top", "bottom",
"left" and "right" rather than
"before-edge", "after-edge",
"start-edge" and "end-edge" because users see the
media relative to its orientation and not relative to the
writing-mode currently in use.
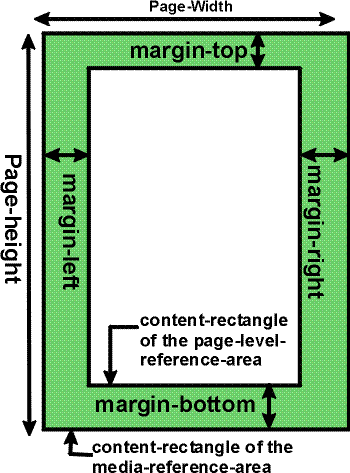
The fo:simple-page-master may have an fo:title formatting object as a child.
The user agent may use this information to help identify
the page,
for example, present the information in its "title bar".
The value of the page-number trait on the
first page returned by the
fo:page-sequence is constrained to equal the value of the
initial-page-number trait. The value of the
page-number
trait on subsequent pages is constrained to be one greater than the
value on the immediately preceding page.
The format, letter-value,
grouping-separator, grouping-size,
country, and
language traits are used to format the number into a
string form, as specified in XSLT, section 7.7.1. This formatted
number is used as the value of the fo:page-number flow object.
-
Constraints applicable to regions:
There are a number of constraints that apply to all the
regions that are specified within a given fo:simple-page-master.
Flow-descendant-areas descendant from the region reference-area must
also be generation descendant from the flow
assigned to the
region-master used to generate the region reference-area. In
addition, the sub-sequence of normal areas returned by the flow object
assigned to the corresponding region and descendant from the region
reference area (or in the case of the fo:region-body from the
remaining region-body reference-area) must be properly stacked
in that reference-area.
The inline-progression-dimension of the region
reference-area that corresponds to a given region-master is determined
by the "inline-progression-dimension" property on the flow
object that is assigned to the corresponding region. If the value of
the "inline-progression-dimension" property is
"auto", then the inline-progression-dimension of the region
reference-area is determined from the inline-progression-dimension of
the corresponding viewport reference-area. (See each region-master for
further information on how the inline-progression-dimension of the
corresponding viewport reference-area is determined.) Otherwise, the
inline-progression-dimension of the region reference-area is taken
from the inline-progression-dimension of the flow object.
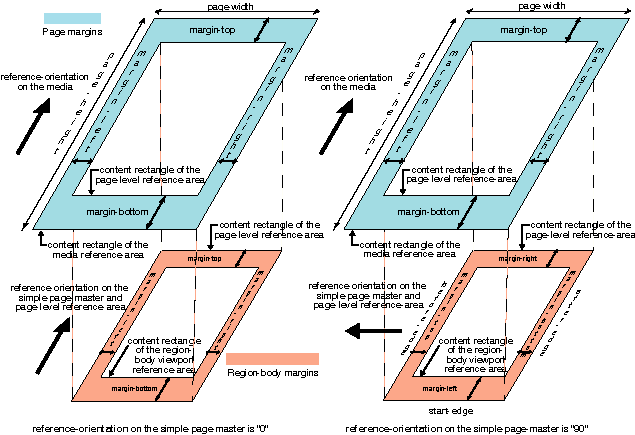
If the block-progression-dimension of the properly stacked region
reference-area is less than or equal to the
block-progression-dimension of the viewport reference-area that is its
parent, then the padding-after trait of the region
reference-area shall be such that the block-progression-dimension of
the content rectangle of the region reference-area plus the
padding-after of that area equal the block-progression-dimension of
the viewport reference-area.
NOTE:
Adding padding after the content-rectangle of the region
reference-area insures that the background of the region
reference-area will fill the entire viewport.
If the block-progression-dimension of the properly stacked region
reference-area is greater than the block-progression-dimension of the
viewport reference-area that is its parent, then the constraints on
the relationship between the viewport reference-area and the region
reference area depend on values of the overflow trait
on the region formatting object and the kind of flow
assigned to the region.
If the flow assigned to the corresponding region is an
fo:static-content flow object, then
-
If the value of the overflow trait is
"scroll" or "visible", then there is no constraint
on the block-progression-dimension of the region reference-area.
-
If the value of the overflow trait is
"hidden", then the block-progression-dimension of the region
reference-area is constrained to be no greater than the
block-progression-dimension of the viewport reference-area.
If the flow assigned to the corresponding region is an fo:flow formatting
object, then
-
If the value of the overflow trait is
"scroll", then there is no constraint on the
block-progression-dimension of the region reference-area.
-
If the value of the overflow trait is
"hidden"or "visible", then the
block-progression-dimension of the region reference-area is
constrained to be no greater than the block-progression-dimension of
the viewport reference-area.
The block-progression-dimension of a region-area that
corresponds to a
given region-master depends on the value of the
overflow trait on that region-master.
-
Contents:
(title?,region-body,region-before?,region-after?,region-start?,region-end?)
-
Properties:
6.4.11 fo:title
-
Common Usage:
The fo:title formatting object is used to associate a title with a
given page. This title may be used by an interactive User Agent to
identify the page. For examle, the content of the fo:title can be
formatted and displayed in a "title" window or in a "tool tip".
-
Areas:
This formatting object returns the sequence of areas returned by the
flow children of this formatting object.
-
Constraints:
The sequence of returned areas must be the concatenation of the
sub-sequences of areas returned by each of the flow children of the
fo:title formatting object in the order in which the children occur.
-
Contents:
((%inline;)*(%inline;))+
-
Properties:
6.4.12 fo:region-body
-
Common Usage:
Used in constructing a simple-page-master. This region specifies a
viewport that is located in the "center" of the
fo:simple-page-master. The overflow trait controls how
much of the underlying region reference-area is visible; that is, is
the reference-area clipped by the viewport-area that
corresponds to the region-master or not.
NOTE:
Typically, for paged media, the flow-descendant-areas
returned by the fo:flow formatting object in a
fo:page-sequence are made to be
descendants of a sequence of region reference-areas that
correspond to
the region-body. These region reference-areas are all area descendants
of pages for which the page-master included an fo:region-body. For
continuous media, the flow-descendant areas all descend from a single
region reference-area that usually corresponds to the region-body. If
the fo:flow flow is assigned to some other region, then its
flow-descendant-areas are constrained to be descendants of
region
reference-areas that correspond to the assigned region.
NOTE:
The body region should be sized and positioned within the
content-rectangle of the fo:simple-page-master so that there is room
for the flow-descendant-areas from the flow that is assigned to the
fo:region-body and for any desired side regions, that is,
fo:region-before, fo:region-after, fo:region-start and fo:region-end's
that are to be placed on the same page. These side regions are
positioned within the content-rectangle of the media reference-area. The
margins on the fo:region-body are used to position the viewport-area
for the fo:region-body and to leave space for the other regions that
surround the fo:region-body.
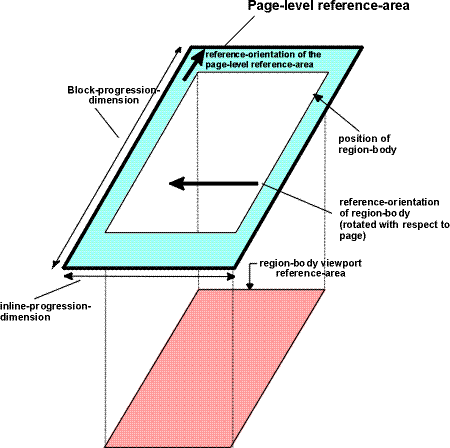
The spacing between the last four regions and the fo:region-body is
determined by subtracting the relevant extent trait on
the side regions from the trait that corresponds to the
"margin-x" property on the fo:region-body.
The fo:region-body may be also be used to provide multiple
columns. When the column-count trait is greater than one, then
the region-body will be subdivided into multiple columns.
-
Areas:
The fo:region-body formatting object is used to generate one viewport
reference-area and one region reference-area whenever an
fo:simple-page-master that has an fo:region-body as a child
is used to
generate a page.
A scrolling mechanism shall be provided, in an implementation
defined manner, if the value of the
overflow trait is "scroll".
The position and size of the viewport-area is
specified relative to the content-rectangle of the
page-level
reference-area generated by fo:simple-page-master. The content-rectangle
of the viewport-area is indented from the content-rectangle
of the page-level reference-area by the values of the "margin-top",
"margin-bottom", "margin-left" and "margin-right" properties. In this
version of this specification, the values of the padding
and border-width traits must be "0".
The region reference-area generated using an fo:region-body is a child
of the viewport-area. The reference-orientation trait
of the fo:region-body is used to orient the coordinate system of the
region reference-area generated by the fo:region-body relative to the
coordinate system of the reference-area generated by
fo:simple-page-master (and, therefore, relative to the viewport
positioned in that latter coordinate system).
In addition to the the viewport reference-area and its descendant
region reference-area, when the region-body is used to
generate areas,
at least one and up to three additional reference-areas are
generated. These reference-areas correspond to the conditional
reference-area for "xsl-top-float"s, the conditional
reference-area for "xsl-footnote"s and the remaining
region-body reference-area. The latter reference-area comprises
the space left after space is borrowed for the two conditional
reference-areas. The remaining region-body reference-area has no
padding, border, or space associated with it.
NOTE:
If there are no conditional regions that are children of
the region-body reference area, then the content rectangle of the
remaining region-body reference-area is co-terminus with the content
rectangle of the region-body region reference area. If there are
conditional reference areas that are children of the region-body
region reference-area, then the content rectangle of the remaining
region-body reference-area is reduced by the space consumed by the
conditional reference-areas.
Types of areas when column-count is greater than 1:
If the column-count trait has a value other than 1,
for example, N, then N
additional reference-areas are generated as children of the remaining
region-body reference-area generated using the fo:region-body. These N
reference-areas are the column reference-areas.
It is an error to specify "column-count" other than "1" if the "overflow"
property has the value "scroll". Other valus will be interpreted as
if "1" had been specified.
The inline-progression-dimension of each
of these column
reference-areas is determined by subtracting (N-1) times the column-gap trait from the
inline-progression-dimension of the remaining region-body
reference-area generated using the fo:region-body and dividing that
result by N. Using "body-in-size" for the name of the
inline-progression-dimension of the remaining region-body
reference-area and "column-in-size" for the name of the size of the column
reference-areas in the inline-progression-direction, the formula
is:
column-in-size = (body-in-size - (N - 1)*column-gap)/N
The size of the column reference-areas in the
block-progression-direction is the same as the size of the containing
reference-area in the block-progression-direction.
NOTE:
As noted above, the size of the containing reference-area in the
block-progression direction may be less than the size of the region
reference-area if conditional reference-areas are children of the
region reference-area.
The column reference-areas are positioned within the reference-area
generated by the fo:region-body as follows: The first column is
positioned with its before-edge and start-edge coincident
with the before-edge and
start-edge
of the remaining region-body reference-area. The Jth
column reference-area is positioned with its before-edge
coincident
with the before-edge of the remaining region-body
reference-area and
with is start-edge at ((J-1)*(column-in-size + column-gap)) in the
inline-direction. This results in the end-edge of the Nth
column
reference-area being coincident with the end-edge of the
remaining region-body reference-area.
NOTE:
If the writing-mode is "rl-tb", the
above description means that the columns are ordered from right-to-left
as would be expected. This follows because the start-edge is on
the right in an "rl-tb"writing-mode.
-
Trait Derivation:
The reference-orientation of the viewport
reference-area is taken from the value the
reference-orientation trait on the region-master which
specifies the region. reference-orientation of the
region reference-area is set to "0" and is, therefore,the
same as the orientation established by the viewport reference-area.
-
Constraints:
The constraints applicable to all regions (see
fo:simple-page-master) all apply.
The inline-progression-dimension of the viewport reference-area is
determined by the inline-progression-dimension of the
content-rectangle for the page-level reference area minus the values
of the start-indent and end-indent
traits of the region-master. The start-edge and end-edge of the
region-master are determined by the
reference-orientation trait on the page-master.
The block-progression-dimension of the viewport reference-area is
determined by the block-progression-dimension of the content-rectangle
for the page-level reference area minus the values of the
space-before and space-after traits of
the region-master. The before-edge and after-edge of the region-master
are determined by the reference-orientation trait on
the page-master.
The values of the space-before and
start-indent traits are used to position the viewport
reference-area relative to the page-level reference-areas before-edge
and start-edge.
The constraints on the size and position of the region reference-area
generated using the fo:region-body are covered in the "Constraints
applicable to regions" section of the description of
fo:simple-page-master.
If the remaining region-body reference-area is subdivided into more
than one column, then for any two coluns C and
D:
If column C precedes column D
in the ordering of columns,
-
then all normal flow-descendant-areas of that fo:flow that are area
descendants of page P must be generation ordered before all normal
flow-descendant-areas of that fo:flow that are area descendants of
page Q.
-
and, for out-of-line flow-descendant-areas of that fo:flow that are area
descendants of page P and for which the value of the
area-class
trait is "xsl-footnote", "xsl-start-float",
"xsl-end-float" and "xsl-top-float", then within each
class, all flow-descendant-areas of that fo:flow that are area
descendants of page P must be generation ordered before all
flow-descendant-areas of that fo:flow that are area descendants of
page Q.
NOTE:
This is sometimes called, "snaking columns".
-
Contents:
EMPTY
-
Properties:
6.4.13 fo:region-before
-
Common Usage:
Used in constructing a simple-page-master. This region defines
a viewport that is located on the "before" side of
the page-level reference-area.
In lr-tb writing-mode, this region corresponds to
the header
region. The visibility of the content that is bound to the region
by an fo:page-sequence is controlled by the overflow
trait on
the region.
-
Areas:
The fo:region-before formatting object is used to generate one
viewport reference-area
and one region reference-area.
This viewport is positioned with its before edge coincident with the
before edge of the content-rectangle of the page-level reference-area
generated using the parent fo:simple-page-master. In the direction
perpendicular to the before edge, the size of the viewport is
determined by the extent trait on the fo:region-before
formatting object.
In the direction parallel to the before
edge, the size of the viewport is determined by the
precedence trait on the fo:region-before. If the value
of the precedence trait is "true", then the
region-before viewport extends up to the start and after edges of the
content rectangle of the page-level reference-area. In this case, the
area generated by the region-before acts like a float into areas
generated by the region-start (respectively, the region-end). If the
value of the precedence trait on the fo:region-before
is "false", then these adjacent regions float into the area
generated by the fo:region-before and the extent of the
fo:region-before is (effectively) reduced by the incursions of the
adjacent regions.
The reference-area generated by fo:region-before lies on a canvas
underneath the above viewport. The
reference-orientation trait is used to orient the
coordinate system of the reference-area generated by the
fo:region-before relative to the coordinate system of the
reference-area generated by fo:simple-page-master (and, therefore, the
viewport positioned in that latter coordinate system).
The size of the reference-area depends on the setting of the
overflow trait on the region. If the value of that
trait
is "auto", "hidden" or "visible" then the size of the area
container
is the same as the size of the viewport. If the value of the
overflow
trait is "scroll", the size of the reference-area is
equal
to the size of the viewport in the
inline-progression-direction in the
writing-mode for the region and is long enough in the
block-progression-direction
to hold the distribution of all the content bound to the region.
-
Constraints:
The constraints on the size and position of the region reference-area
generated using the fo:region-body are covered in the "Constraints
applicable to regions" section of the description of
fo:simple-page-master.
-
Contents:
EMPTY
-
Properties:
6.4.14 fo:region-after
-
Common Usage:
Used in constructing a simple-page-master. This region defines
a viewport that is located on the "after" side of
the page-level reference-area.
In lr-tb writing-mode, this region corresponds to the footer
region. The visibility of the content that is bound to the region
by an fo:page-sequence is controlled by the overflow
trait on
the region.
-
Areas:
The fo:region-after formatting object is used to generate one
viewport reference-area
and one region reference-area.
This viewport is positioned with its after edge coincident with the
after edge of the content-rectangle of the page-level reference-area
generated using the parent fo:simple-page-master.
In the direction perpendicular to the after edge, the size of the
viewport is determined by the extent trait on the
fo:region-after formatting object.
In the direction parallel to the after edge, the size of the
viewport is determined by the precedence trait on the fo:region-after.
If the value of the precedence trait is "true", then
the region-after
viewport extends up to the start and after edges of the content
rectangle of the page-level reference-area. In this case, the area
generated by the region-after acts like a float into areas generated
by the region-start (respectively, the region-end). If the value
of the precedence trait on the fo:region-after is
"false",
then these adjacent regions float into the area generated by the
fo:region-after and the extent of the fo:region-after is (effectively)
reduced by the incursions of the adjacent regions.
The reference-area generated by fo:region-after lies on a canvas
underneath the above viewport. The reference-orientation
trait
is used to orient the coordinate system of the reference-area generated
by the fo:region-after relative to the coordinate system of the
reference-area generated by fo:simple-page-master (and, therefore,
the viewport positioned in that latter coordinate system).
The size of the reference-area depends on the setting of the
overflow trait on the region. If the value of that
trait
is "auto", "hidden" or "visible" then the size of the reference-area
is the same as the size of the viewport. If the value of the
overflow
trait is "scroll", the size of the reference-area is
equal
to the size of the viewport in the
inline-progression-direction in the
writing-mode for the region and is long enough in the
block-progression-direction
to hold the distribution of all the content bound to the region.
-
Constraints:
The constraints on the size and position of the region reference-area
generated using the fo:region-body are covered in the "Constraints
applicable to regions" section of the description of
fo:simple-page-master.
-
Contents:
EMPTY
-
Properties:
6.4.15 fo:region-start
-
Common Usage:
Used in constructing a simple-page-master. This region defines
a viewport that is located on the "start" side of
the page-level reference-area.
In lr-tb writing-mode, this region corresponds to a left
sidebar. The visibility of the content that is bound to the region
by an fo:page-sequence is controlled by the overflow
trait on
the region.
-
Areas:
The fo:region-start formatting object is used to generate one
viewport reference-area
and one region reference-area.
This viewport is positioned with its start edge coincident with the
start edge of the content-rectangle of the page-level reference-area
generated using the parent fo:simple-page-master. In the
direction perpendicular to the start edge, the size of the viewport is
determined by the extent trait on the fo:region-start formatting
object.
In the direction parallel to the start edge, the size
of the viewport is determined by the precedence trait on the
adjacent fo:region-before and the fo:region-after. If the value of the
precedence trait is "false", then the region-start viewport
extends up to the before (or, respectively, after) edge of the
content-rectangle of the page-level reference-area. In this case, the
area generated by the region-start acts like a float into areas
generated by the region-before (respectively, the region-after). If
the value of the precedence trait on the adjacent regions is
"true", then these adjacent regions float into the area generated by
the fo:region-start and the extent of the fo:region-start is
(effectively) reduced by the incursions of the adjacent regions with
the value of the precedence trait equal to "true".
The
reference-area generated by fo:region-start lies on a canvas
underneath the above viewport. The reference-orientation trait is
used to orient the coordinate system of the reference-area generated
by the fo:region-start relative to the coordinate system of the
reference-area generated by fo:simple-page-master (and, therefore, the
viewport positioned in that latter coordinate system).
The
size of the reference-area depends on the setting of the overflow
trait on the region. If the value of that trait is "auto",
"hidden" or "visible" then the size of the area container is the same
as the size of the viewport. If the value of the overflow trait
is "scroll", the size of the reference-area is equal to the size of
the viewport in the inline-progression-direction in the writing-mode
for the region and is long enough in the block-progression-direction
to hold the distribution of all the content bound to the region.
-
Constraints:
The constraints on the size and position of the region reference-area
generated using the fo:region-body are covered in the "Constraints
applicable to regions" section of the description of
fo:simple-page-master.
-
Contents:
EMPTY
-
Properties:
6.4.16 fo:region-end
-
Common Usage:
Used in constructing a simple-page-master. This region defines
a viewport that is located on the "end" side of
the page-level reference-area.
In lr-tb writing-mode, this region corresponds to a right sidebar.
The visibility of the content that is bound to the region by an fo:page-sequence
is controlled by the overflow trait on the region.
-
Areas:
The fo:region-end formatting object is used to generate one
viewport reference-area
and one region reference-area.
This viewport is positioned with its end edge coincident with the
end edge of the content-rectangle of the page-level reference-area
generated using the parent fo:simple-page-master.
In the direction perpendicular
to the end edge, the size of the viewport is determined by the extent
trait on the fo:region-end formatting object.
In the direction parallel to the end edge, the size of the viewport
is determined by the precedence trait on the adjacent fo:region-before
and the fo:region-after. If the value of the precedence
trait
is "false", then the region-end viewport extends up to the
before
(or, respectively, after) edge of the content-rectangle of
the
page-level reference-area. In this case, the area generated by the
region-end acts like a float into areas generated by the region-before
(respectively, the region-after). If the value of the
precedence
trait on the adjacent regions is "true", then these
adjacent
regions float into the area generated by the region-end and the
extent of the region end is (effectively) reduced by the incursions
of the adjacent regions with the value of the precedence
trait equal to "true".
-
Constraints:
The constraints on the size and position of the region reference-area
generated using the fo:region-body are covered in the "Constraints
applicable to regions" section of the description of
fo:simple-page-master.
-
Contents:
EMPTY
-
Properties:
6.4.17 fo:flow
-
Common Usage:
The content of the fo:flow formatting object is a sequence of flow
objects that forms one "unit of content", such as an article, a
chapter, or a section. The result of formatting this "unit of
content" is distributed across the pages generated by the
fo:page-sequence which is the parent of the fo:flow.
-
Areas:
The fo:flow formatting object does not generate any areas. The
fo:flow formatting object returns sequence of areas created by
concatenating the sequences of areas returned by each of the children
of the fo:flow. The order of concatenation is the same order as the
children are ordered under the fo:flow.
-
Constraints:
The (implicit) flow-map determines the assignment of the content
of the fo:flow to a region.
-
Contents:
(%block;)+
-
Properties:
6.4.18 fo:static-content
-
Common Usage:
The fo:static-content formatting object is used to group a "unit of content" that may be used on more than one page, such as the content of a header or footer. This "unit of content" is repeated, in its entirety, on every page to which it is assigned.
-
Areas:
The fo:staic-content formatting object does not generate any areas.
The fo:static-content formatting object returns the sequence of areas
created by concatenating the sequences of areas returned by each of
the children of the fo:flow. The order of concatenation is the same
order as the children are ordered under the fo:static-content.
-
Constraints:
The (implicit) flow-map determines the assignment of the content
of the fo:static-content to a region.
-
Contents:
(%block;)+
-
Properties:
6.5 Block-level Formatting Objects
6.5.1 Introduction
The fo:block formatting object is used for formatting
paragraphs, titles, figure captions, table titles, etc. The
following example illustrates the usage of the fo:block in a
style sheet.
6.5.1.1 Example
6.5.1.1.1 Chapter and Section Titles, Paragraphs
Input sample:
<doc>
<chapter><title>Chapter</title>
<p>Text</p>
<section><title>Section</title>
<p>Text</p>
</section>
<section><title>Section</title>
<p>Text</p>
</section>
</chapter>
<chapter><title>Chapter</title>
<p>Text</p>
<section><title>Section</title>
<p>Text</p>
</section>
<section><title>Section</title>
<p>Text</p>
</section>
</chapter>
</doc>
In this example the
Chapter title appears at the top of the page
(its "space-before" is discarded).
Space between Chapter title and first section title
is (8pt,8pt,8pt): the chapter title's "space-after" has
a higher precedence than the section title's
"space-before" (which takes on the initial value
of zero), so the latter is discarded
Space between the first section title and Section one's
first paragraph is (6pt,6pt,6pt): the section title's
"space-after"
has higher precedence than the paragraph's "space-before",
so the latter is discarded.
Space between the two paragraphs is (6pt,8pt,10pt): the
"space-after"
the first paragraph is discarded because its precedence is equal
to that of the "space-before" the next paragraph, and the
optimum
of the "space-after" of the first paragraph is greater than
the optimum of the "space-before" of the second
paragraph.
Space between the second paragraph of the first section and the
title of the second section is (12pt,12pt,12pt): the
"space-after"
the paragraph is discarded because its precedence is equal
to that of the "space-before" of the section title, and the
optimum
of the "space-after" of the paragraph is less than the
optimum of the "space-before" of the section title.
The indent on the first line of the first paragraph in section
one and the only paragraph in section two is 2pc; the indent on
the first line of the second paragraph in section one is zero.
XSL Stylesheet:
<?xml version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
version='1.0'>
<xsl:template match="chapter">
<fo:block break-before="page">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="chapter/title">
<fo:block text-align="center" space-after="8pt"
space-before="16pt" space-after.precedence="3">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="section/title">
<fo:block text-align="center" space-after="6pt"
space-before="12pt" space-before.precedence="0"
space-after.precedence="3">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="p[1]" priority="1">
<fo:block text-indent="0pc" space-after="7pt"
space-before.minimum="6pt" space-before.optimum="8pt"
space-before.maximum="10pt">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="p">
<fo:block text-indent="2pc" space-after="7pt"
space-before.minimum="6pt" space-before.optimum="8pt"
space-before.maximum="10pt">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
</xsl:stylesheet>
Result Instance: elements and attributes in the fo:
namespace
<fo:block break-before="page">
<fo:block text-align="center" space-after="8pt"
space-before="16pt" space-after.precedence="3">Chapter
</fo:block>
<fo:block text-indent="0pc" space-after="7pt"
space-before.minimum="6pt" space-before.optimum="8pt"
space-before.maximum="10pt">Text
</fo:block>
<fo:block text-align="center" space-after="6pt"
space-before="12pt" space-before.precedence="0"
space-after.precedence="3">Section
</fo:block>
<fo:block text-indent="0pc" space-after="7pt"
space-before.minimum="6pt" space-before.optimum="8pt"
space-before.maximum="10pt">Text
</fo:block>
<fo:block text-align="center" space-after="6pt"
space-before="12pt" space-before.precedence="0"
space-after.precedence="3">Section
</fo:block>
<fo:block text-indent="0pc" space-after="7pt"
space-before.minimum="6pt" space-before.optimum="8pt"
space-before.maximum="10pt">Text
</fo:block>
</fo:block>
<fo:block break-before="page">
<fo:block text-align="center" space-after="8pt"
space-before="16pt" space-after.precedence="3">Chapter
</fo:block>
<fo:block text-indent="0pc" space-after="7pt"
space-before.minimum="6pt" space-before.optimum="8pt"
space-before.maximum="10pt">Text
</fo:block>
<fo:block text-align="center" space-after="6pt"
space-before="12pt" space-before.precedence="0"
space-after.precedence="3">Section
</fo:block>
<fo:block text-indent="0pc" space-after="7pt"
space-before.minimum="6pt" space-before.optimum="8pt"
space-before.maximum="10pt">Text
</fo:block>
<fo:block text-align="center" space-after="6pt"
space-before="12pt" space-before.precedence="0"
space-after.precedence="3">Section
</fo:block>
<fo:block text-indent="0pc" space-after="7pt"
space-before.minimum="6pt" space-before.optimum="8pt"
space-before.maximum="10pt">Text
</fo:block>
</fo:block>
6.5.2 fo:block
-
Common Usage:
The fo:block formatting object is commonly used for formatting paragraphs,
titles, headlines, figure and table captions, etc.
-
Areas:
Each fo:block formatting object returns a sequence of one or more
areas, including at least one normal area. Each of the normal areas
returned by an fo:block formatting object F is a block area
and is generated by F.
-
Trait Derivation:
The nominal-glyph-height trait is set from the computed value of the
"font-size" property. The half-leading trait is set to 1/2
the computed
value of the "line-height" property minus the "font-size"
property.
-
Constraints:
The children of each normal area returned by an fo:block formatting
object must be properly stacked.
No area may have more than one normal child area returned by the
same fo:block formatting object.
For each child of a normal area returned by an fo:block formatting
object F, either
-
the area is a normal area returned by a child of
F, or
-
the area is a line area that was generated by
F
For each area generated by an fo:block formatting object
F, either
-
the area is returned by F, or
-
the area is a line area that is a child of a normal area
returned by F, or
-
the area is child of a line area generated by F,
and has a non-null composed-by trait
The original area sequence of a line area ia a
sequence of areas produced from the sequence of child areas by
replacing each child area that has a non-null
composed-from trait by the sequence of areas that is the
value of the composed-from trait.
The original area sequences of the line areas generated by a
fo:block formatting object F must correspond to the normal inline
areas returned by children of F. More precisely, the original area
sequence of a fo:block formatting object F is defined as follows.
The original area sequence of F must be the same as the concatenation
of the normal areas in the sequences returned by the children of
F.
An area with a non-null composed-by trait can be
generated in the following circumstances:
-
inserting hyphens at the end of a line
-
dropping spaces at the end of a line
-
substituting and reordering glyphs based on font
information
-
Contents:
(#PCDATA|%inline;|%block;)*
In addition an optional fo:initial-property-set may be the first
child of the fo:block.
-
Properties:
6.5.3 fo:block-container
-
Common use:
The fo:block-container flow object is used to
generate a block-level reference-area; typically containing
text blocks with a different writing-mode. In addition, it
can also be used with a different reference-orientation to
rotate its content.
NOTE:
The use of this flow object is not required for
changing
the inline-progression-direction only; in that case the Unicode bidi
algorithm and the fo:bidi-override are sufficient.
-
Area type:
The fo:block-container flow object results in
a block-area.
If the block-area will not fit in the remaining space in
the containing area, one (or more) additional areas may be generated
by the formatter, consistent with the constraints given by the
properties of the content of this flow object. The area is
a reference-area.
-
Content distribution:
The size of the reference-area has to be fixed in the
inline-progression-direction.
It must be specified
unless the inline-progression-direction is parallel to the
inline-progression-direction of the reference-area into
which
the areas resulting from this flow object are placed.
The size in the block-progression-direction is determined
by the content of this flow object.
-
Content:
(%block;)+
-
Properties:
6.6 Inline-level Formatting Objects
6.6.1 Introduction
Inline formatting objects are most commonly used to
format
a portion of text or for generating rules and leaders. There
are many other uses. The following examples illustrate
some of these uses of inline-level formatting objects.
-
putting the first line of a paragraph into
small-caps,
-
turning a normally inline formatting object, fo:external-graphic, into
a block by "wrapping" with an fo:block formatting
object,
-
formatting a running footer containing the word
"Page" followed by a page number.
6.6.1.1 Examples
6.6.1.1.1 First Line of Paragraph in Small-caps
Input sample:
<doc>
<p>This is the text of a paragraph that is going to be
presented with the first line in small-caps.</p>
</doc>
XSL Stylesheet:
<?xml version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
version='1.0'>
<xsl:template match="p">
<fo:block>
<fo:initial-property-set font-variant="small-caps"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
</xsl:stylesheet>
Result instance: elements and attributes in the fo:
namespace
<fo:block>
<fo:initial-property-set font-variant="small-caps">
</fo:initial-property-set>This is the text of a paragraph that is going to be
presented with the first line in small-caps.
</fo:block>
6.6.1.1.2 Figure with a Photograph
Input sample:
<doc>
<figure>
<photo image="TH0317A.jpg"/>
<caption>C'ieng Tamlung of C'ieng Mai</caption>
</figure>
</doc>
In this example the image (an fo:external-graphic) is
placed as a centered block-level object.
The caption is centered with 10mm indents.
XSL Stylesheet:
<?xml version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
version='1.0'>
<xsl:template match="figure">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="photo">
<fo:block text-align="center">
<fo:external-graphic href="{@image}"/>
</fo:block>
</xsl:template>
<xsl:template match="caption">
<fo:block space-before="3pt" text-align="center"
start-indent="10mm" end-indent="10mm">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
</xsl:stylesheet>
fo: element and attribute tree:
<fo:block>
<fo:block text-align="center">
<fo:external-graphic href="TH0317A.jpg"/>
</fo:block>
<fo:block space-before="3pt" text-align="center" start-indent="10mm"
end-indent="10mm">C'ieng Tamlung of C'ieng Mai</fo:block>
</fo:block>
6.6.1.1.3 Page numbering and page number reference
Input sample:
<!DOCTYPE doc SYSTEM "pgref.dtd">
<doc>
<chapter id="x"><title>Chapter</title>
<p>Text</p>
</chapter>
<chapter><title>Chapter</title>
<p>For a description of X see <ref refid="x"/>.</p>
</chapter>
</doc>
In this example each page has a running footer containing the word
"Page" followed by the page number. The "ref" element generates the
word "see" followed by the page number of the page on which the
referenced by the "refid" attribute was placed.
XSL Stylesheet:
<?xml version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
version='1.0'>
<xsl:template match="doc">
<fo:root>
<fo:layout-master-set>
<fo:simple-page-master master-name="page"
page-height="297mm" page-width="210mm"
margin-top="20mm" margin-bottom="10mm"
margin-left="25mm" margin-right="25mm">
<fo:region-body
margin-top="0mm" margin-bottom="15mm"
margin-left="0mm" margin-right="0mm"/>
<fo:region-after extent="10mm"/>
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence master-name="page">
<fo:static-content flow-name="xsl-region-after">
<fo:block>
<xsl:text>Page </xsl:text>
<fo:page-number/>
</fo:block>
</fo:static-content>
<fo:flow flow-name="xsl-region-body">
<xsl:apply-templates/>
</fo:flow>
</fo:page-sequence>
</fo:root>
</xsl:template>
<xsl:template match="chapter/title">
<fo:block id="{generate-id(.)}">
<xsl:number level="multiple" count="chapter" format="1. "/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="p">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="ref">
<xsl:text>page </xsl:text>
<fo:page-number-citation refid="{generate-id(id(@refid)/title)}"/>
</xsl:template>
</xsl:stylesheet>
Result Instance: elements and attributes in the fo:
namespace
<fo:root>
<fo:layout-master-set>
<fo:simple-page-master master-name="page"
page-height="297mm" page-width="210mm"
margin-top="20mm" margin-bottom="10mm"
margin-left="25mm" margin-right="25mm">
<fo:region-body margin-top="0mm" margin-bottom="15mm"
margin-left="0mm" margin-right="0mm"/>
<fo:region-after extent="10mm"/>
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence master-name="page">
<fo:static-content flow-name="xsl-region-after">
<fo:block>Page <fo:page-number/>
</fo:block>
</fo:static-content>
<fo:flow flow-name="xsl-region-body">
<fo:block id="N5">1. Chapter</fo:block>
<fo:block>Text</fo:block>
<fo:block id="N13">2. Chapter</fo:block>
<fo:block>For a description of X see page <fo:page-number-citation refid="N5"/>
</fo:block>
</fo:flow>
</fo:page-sequence>
</fo:root>
6.6.2 fo:bidi-override
-
Common use:
The fo:bidi-override formatting object is used when the Unicode-bidi
algorithm fails. It forces a string of text to be written in a specific
direction.
-
Area type:
The fo:bidi-override formatting object produces an inline-area.
-
Area size:
The size of the area is determined
in the same manner as all other inline-areas.
-
Determination of trait values:
The "direction" property is combined with the "writing-mode"
to determine the new writing-direction.
-
Content:
(#PCDATA|%inline;)*
-
Properties:
6.6.3 fo:character
-
Common use:
The fo:character flow object represents a character that
is mapped to
a glyph for presentation. It is an atomic unit to the formatter.
When the result tree is interpreted as a tree of formatting objects,
a character in the result tree is treated as if it were an empty
element of type fo:character with a character attribute
equal to the Unicode representation of the character.
The semantic of an "auto" value for character properties, which is
typically their initial value,
are based on the Unicode codepoint. Overrides may be specified in
an implementation-specific manner.
NOTE:
In a stylesheet the explicit creation of an fo:character may be
used to explicitly override the default mapping.
-
Area type:
The fo:character flow object results in a single inline
area.
-
Content distribution:
The width and height of the area is determined by the font
metrics for the glyph.
When formatting an fo:character with a "treat-as-wordspace" value
of "yes", the User Agent may use a different method for determining
the actual-inline-progression-dimension of the area.
-
Content:
EMPTY
-
Properties:
6.6.4 fo:initial-property-set
-
Common use:
The fo:initial-property-set specifies formatting properties
for the first line of an fo:block.
NOTE:
It is analogous to the CSS first-line pseudo-element.
In future verions of this recommendation a property controlling
the number of lines, or the "depth" that these initial properties
apply to may be added.
-
Area type:
The fo:initial-property-set object does not directly produce any area.
-
Determination of trait values:
The properties specified on the fo:initial-property-set are taken into
account as if the inline formatting objects, or parts of
them in the
case of a line break, that were used in formatting
the first line were enclosed by and fo:inline-sequence, as a direct
child of the fo:block, with those properties specified.
-
Content:
EMPTY
-
Properties:
6.6.5 fo:external-graphic
Issue (scaling-properties-for-graphics):
For scaling we want:
- scale factor for x and y
- individual for x and y
- max-width and height
- min-width and height
- height and width
Use cases:
- intrinsic size of graphic: just get it as is
- scale by a specified factor
- scale to a specified size
- put constraints on the scaling to be between
- Note fallback for graphics formats that do not have an intrinsic size.
- For the case of fixing the height of a graphic and caption and
aligning the in x and y: use the fo:block-container.
CSS questions: is the graphic rescaled when its intrinsic height
differs from the height property (and the height property is not "auto")
-
Common use:
The fo:external-graphic flow object is used for an inline
graphic where the graphics data resides outside of the fo:element tree.
-
Area type:
The fo:external-graphic flow object results in a single
inline-area.
-
Content distribution:
In the simple case, the "height" and "width" properties
are used
to set this object's size. If they are not specified, the
"min-height" or "max-height"
and "min-width" or "max-width" properties and the
"scale-graphic" property (combined
with any size specified by the content) are used to derive a size
between the limits specified.
-
Content and its placement:
The fo:external-graphic flow object has no children.
-
Content:
EMPTY
-
Properties:
6.6.6 fo:instream-foreign-object
-
Common use:
The fo:instream-foreign-object flow object is used for an inline
graphic or other "generic" object
where the object data resides as descendants of the
fo:instream-foreign-object; typically as an XML element subtree in
a non-XSL namespace.
NOTE:
A common format is SVG.
-
Area type:
The fo:instream-foreign-object flow object results in a single
inline-area.
-
Content distribution:
In the simple case, the "height" and "width" properties
are used
to set this object's size. If they are not specified, the
"min-height" or "max-height"
and "min-width" or "max-width" properties and the
"scale-graphic" property (combined
with any size specified by the content) are used to derive a size
between the limits specified.
-
Content:
The fo:instream-foreign-object flow object has children from a non-XSL
namespace. The permitted structure of these children is that
defined for that namespace.
The fo:instream-foreign-object flow object may have additional attributes
in the non-XSL namespace. These are made available to the processor
of the content of the flow object. Their semantics is defined by that
namespace.
-
Properties:
6.6.7 fo:inline
-
Common Usage:
The fo:inline formatting object is commonly used for formatting
a portion of text with a background or enclosing it in a border.
-
Areas:
Each fo:inline formatting object returns a sequence of one or more
areas, including at least one normal area. Each of the normal areas
returned by an fo:inline formatting object F is an inline area
and is generated by F.
-
Constraints:
The children of each normal area returned by an fo:block formatting
object must be properly stacked.
No area may have more than one normal child area returned by the
same fo:inline formatting object.
-
Contents:
(#PCDATA|%inline;)*
-
Properties:
6.6.8 fo:inline-container
-
Common use:
The fo:inline-container flow object is used to
generate an inline reference-area; typically containing
text blocks with a different writing-mode.
NOTE:
The use of this flow object is not required for
bidirectional text;
in this case the Unicode bidi
algorithm and the fo:bidi-override are sufficient.
-
Area type:
The fo:inline-container flow object results in
an inline-area.
If the inline-area will not fit in the remaining space in
the containing area, one (or more) additional areas may be generated
by the formatter, consistent with the constraints given by the
properties of the content of this flow object. The area is
a reference-area.
-
Content distribution:
The size of the reference-area has to be fixed in the
inline-progression-direction;
it must be specified.
The size in the block-progression-direction is determined
by the content of this flow object.
-
Content:
(%block;)+
-
Properties:
6.6.9 fo:leader
-
Common use:
The fo:leader formatting object is often used:
-
in TOCs to generate sequences of "." glyphs that separate
titles from page numbers
-
to create entry fields in fill-in-the-blank forms
-
to create horizontal rules for use as separators
-
Area type:
The fo:leader formatting object results in a single inline-area.
-
Content distribution:
A leader is atomic and may not break/wrap across multiple lines.
The height of the content-rectangle is the "line-height", determined
in the usual manner for inline-areas.
The width of the leader is determined as described in the "leader-length"
property.
If the leader's minimum length is too long to place in the current
line, the leader will begin a new line. If it is too long to be
placed in a line by itself, it will overflow the line and potentially
overflow the reference-area in accordance with that container's "overflow"
property.
-
Content and its placement:
The fo:leader formatting object can have any inline formatting objects
or PCDATA as its children, except that fo:leaders may not be nested. Its children
are ignored unless the value of the "leader-pattern" property is "use-content".
NOTE:
If the "leader-pattern" property is "use-content" and the fo:leader has
no children, the leader shall be filled with blank space.
The inline-area generated by the fo:leader has a dimension in the
inline-progression-direction which shall be at least the
"leader-length.minimum" and at most the "leader-length.maximum".
For lines-areas that have been specified to be justified, the justified
line-area must honor the "leader-alignment" property of any inline-areas
generated by fo:leaders.
If the value of the "leader-pattern" property is "dots" or "use-content",
the following constraints apply:
-
The inline-area generated by the fo:leader has as its children the areas
returned by children of the fo:leader, or obtained by formatting the pattern
specified in the "leader-pattern" property, repeated an integral number of
times. If the width of even a single repetition is larger than the dimension
of the inline-area in the inline-progression-direction, the inline-area shall
be filled with blank space. The space-start and space-end of the child areas
is set to account for the constraints specified in the "leader-pattern-width"
and "leader-alignment" properties.
-
The "leader-pattern-width" property is ignored if its value is
less than the width obtained by formatting the specified leader pattern.
-
Content:
(#PCDATA|%inline;)*
The content must not contain an fo:leader, or fo:inline-container,
either as a direct child or as a descendant.
-
Properties:
NOTE:
If it is desired that the leader should stretch to fill all available space
on a line, the maximum length of the leader should be specified to be at least as
large as the column width.
NOTE:
The alignment of the leader may be script specific and may require indicating
what aligment point is required, because it is different from the default alignment for
the script. For example, in some usage of Indic scripts the leader is aligned at the
baseline.
NOTE:
An fo:leader can be wrapped in an fo:block to create a rule for separating
or decorating block-areas.
6.6.10 fo:page-number
-
Common use:
The fo:page-number flow object is used to obtain an
inline-area
whose content is
the page number for the page on which the inline-area is
placed.
-
Area type:
The fo:page-number flow object results in a single
inline-area.
The content of this inline-area is the same as the result of formatting
a result-tree fragment consisting of fo:character flow
objects; one
for each character in the page number string.
The page number string is obtained by converting the page number
on which the inline-area is placed in accordance with the
number to string conversion properties specified on the page master
used for instantiating the page.
-
Content distribution:
Height and width are determined in the usual manner for inline-areas.
-
Content:
EMPTY
-
Properties:
6.6.11 fo:page-number-citation
-
Common use:
The fo:page-number-citation is used to reference the
page-number for the page containing the first normally sequenced
area returned by the cited formatting
object.
NOTE:
It may be used to provide the page numbers in the table of contents,
cross-references, and index entries.
-
Area type:
The fo:page-number-citation flow object results in an
inline-area
in a manner analogous to that of the fo:page-number flow
object.
-
Content distribution:
Height and width are determined in the usual manner for inline-areas.
-
Determination of trait values:
The "ref-id" property is used to locate the item being referenced.
The page-number of the page containing the first area resulting from
this item is then acquired as an unstyled
text string and the character-level properties
are applied to that string in the same manner as for
fo:inline.
-
Content:
EMPTY
-
Properties:
6.7 Formatting Objects for Tables
6.7.1 Introduction
There are nine formatting objects used to construct tables:
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row, and
fo:table-cell.
The result tree structure is shown below.
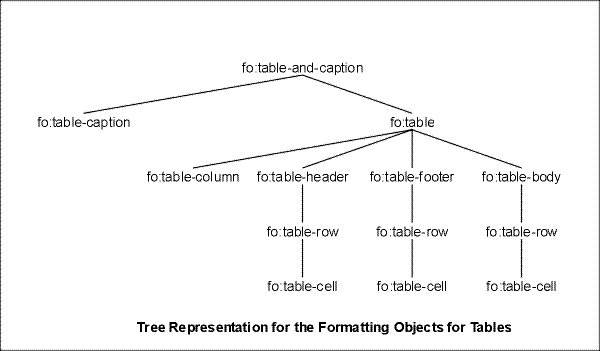
6.7.1.1 Examples
TBD
6.7.2 fo:table-and-caption
NOTE:
This formatting object corresponds to the CSS anonymous
box that encloses the table caption and the table.
-
Common use:
The fo:table-and-caption flow object is used for
formatting a table
together with its caption.
NOTE:
A fo:table-and-caption may be placed inline by enclosing
it in an fo:inline-container.
-
Area type:
The fo:table-and-caption flow object results in a block-area.
If the block-area will not fit in the remaining space in the containing
area, one (or more) additional areas may be generated by the formatter,
consistent with the constraints given by the properties of the content,
to accommodate the content.
-
Content distribution:
The width of the content-rectangle of the resulting
block-area is the
width of the content-rectangle of the containing
reference-area
less than the "start-indent" and "end-indent".
The height is determined by the height of the content.
-
Content and its placement:
The content of the table-and-caption flow object is one
or two areas,
acting as reference-areas;
one for the table caption and one for the table itself.
These are positioned relative to each other as specified by the
"caption-side" property.
They are placed relative to the content-rectangle as
specified by the
"text-align" property.
-
Content:
(table-caption?,table)
-
Properties:
6.7.3 fo:table
-
Common use:
The fo:table flow object is used for formatting the
tabular material
of a table.
The fo:table flow object and its child flow objects
model the
visual layout of a table in a "row primary" manner. A complete table
may be seen as consisting of a grid of rows and columns where each
cell occupies one or more grid units in the row-progression-direction
and column-progression-direction.
The table content is divided into a header (optional), footer (optional),
and one or more bodies. Properties specify if the headers and footers
should be repeated at a break in the table. Each of these parts occupies
of one or more rows in the table grid.
-
Area type:
The fo:table flow object results in a block-area.
If the block-area will not fit in the remaining space in the containing
area, one (or more) additional areas may be generated by the formatter,
consistent with the constraints given by the properties of the rows, cells,
and their content.
-
Determination of trait values:
The column-progression-direction and row-progression-direction are governed by
the
"writing-mode" property.
The width of the content-rectangle of the table is the
sum of the widths
of the columns in the table grid. The method used to determine these
widths is specified by values of the "table-layout" and
the "width" properties in the following manner:
-
width="auto" table-layout="auto"
-
The automatic table layout shall be used.
-
width="auto" table-layout="fixed"
-
The automatic table layout shall be used.
-
width=<length> table-layout="auto"
-
The automatic table layout shall be used.
-
width=<length> table-layout="fixed"
-
The fixed table layout shall be used.
The automatic table layout and fixed table layout is defined in
17.5.2 of the CSS2 specification.
The method for determining the height of the table is
governed by the "height" property.
NOTE:
The CSS2 specification explicitly does not specify
what the behavior
should be if there is a mismatch between an explicitly
specified table height and the height of the content.
The method for deriving the border trait for a table is
specified by the "border-collapse" property.
If the value of the "border-collapse" property is
"separate" the border
is composed of two components. The first, which is placed
with the inside edge coincident with the outermost table grid boundary line,
has the width of half the value for the "border-separation" property.
It is filled in accordance with the "background" property of the fo:table.
Outside the outermost table grid boundary line
is placed, for each side of the table, a border based
on a border specified on the table.
If the value of the "border-collapse" property is "collapse" the border
is determined, for each segment, at the cell level.
NOTE:
By specifying an appropriately high priority on the border
specification for the fo:table one may ensure that this specification
is the one used on all border segments.
The background color of a cell is determined in accordance with
17.5.1 of the CSS2 specification.
-
Content:
(table-column*,table-header?,table-footer?,table-body+)
-
Properties:
6.7.4 fo:table-column
-
Common use:
The fo:table-column formatting object specifies
characteristics
applicable to table cells that have the same column and span.
The most important property is the "column-width" property.
-
Type of Area:
This formatting object does not directly generate any area.
-
Content:
EMPTY
-
Properties:
6.7.5 fo:table-caption
-
Common use:
The fo:table-caption formatting object is used to contain block-level
formatting objects containing the caption for the table.
-
Type of Area:
The fo:table-caption generates a reference-area.
-
Content Distribution and Size:
For the case when the value of the "caption-side" property is "before"
or "after" the width of the reference-area is equal to the
width of
the content-rectangle of the reference-area that encloses
it.
When the value is "start" or "end" the width of the
reference-area is given by the "caption-width"
property.
-
Content:
(%block;)+
-
Properties:
6.7.6 fo:table-header
-
Common use:
The fo:table-header formatting object is used to contain
the content
of the table header.
-
Type of Area:
This formatting object does not directly create any area.
-
Content:
(table-row+|table-cell+)
The fo:table-header has fo:table-row (one or more) as
its children,
or alternatively fo:table-cell (one or more). In the latter case
cells are grouped into rows using the starts-row and ends-row properties.
-
Properties:
6.7.7 fo:table-footer
-
Common use:
The fo:table-footer formatting object is used to contain
the content
of the table footer.
-
Type of Area:
This formatting object does not directly create any area.
-
Content:
(table-row+|table-cell+)
The fo:table-footer has fo:table-row (one or more) as
its children,
or alternatively fo:table-cell (one or more). In the latter case
cells are grouped into rows using the starts-row and ends-row properties.
-
Properties:
6.7.8 fo:table-body
-
Common use:
The fo:table-body formatting object is used to contain
the content
of the table body.
-
Type of Area:
This formatting object does not directly create any area.
-
Content:
(table-row+|table-cell+)
The fo:table-body has fo:table-row (one or more) as its
children,
or alternatively fo:table-cell (one or more). In the latter case
cells are grouped into rows using the starts-row and ends-row properties.
-
Properties:
6.7.9 fo:table-row
-
Common use:
The fo:table-row formatting object is used to group
table-cells into
rows; all table-cells in a table-row start in the same geometric row on
the table grid.
-
Type of Area:
This formatting object does not directly create any area.
-
Content Distribution and Size:
The method for determining the height of the row in the grid is
governed by the "row-height" property.
-
Content:
(table-cell+)
-
Properties:
6.7.10 fo:table-cell
-
Common use:
The fo:table-cell formatting object is used to group
content to be
placed in a table-cell.
-
Type of Area:
A table-cell occupies one or more grid units in the
row-progression-direction and
column-progression-direction and acts as a reference-area.
The content-rectangle of the cell is the size of the portion
of the grid
the cell occupies minus, for each of the four sides:
-
If the value of the "border-collapse" property is "separate":
half the value of the "border-separation" property; otherwise 0.
-
If the value of the "border-collapse" property is "separate":
the thickness of the cell-border; otherwise half the thickness of the
effective border.
-
The cell padding.
-
Content Distribution and Size:
The method for determining the height of the cell in the grid is
governed by the "row-height" property.
-
Determination of Trait Values:
-
background: in accordance with the CSS2 inheritance rules
specified in 17.5.1.
NOTE:
A cell that is spanned may have a different background in each
of the grid units it occupies.
-
border: the method for deriving the border for a cell is
specified by the "border-collapse" property.
If the value of the "border-collapse" property is "separate" the border
is composed of two components. The first, which is placed
with the outside edge coincident with the table grid boundary line,
has the width of half the value for the "border-separation" property.
It is filled in accordance with the "background" property of the fo:table.
Inside this border is placed, for each side of the cell, a border based
on a border specified on the cell or inherited.
If the value of the "border-collapse" property is "collapse" the border
for each side of the cell is determined by, for each segment of a border,
selecting, from all border specifications for that segment, the border
that has the highest priority. It is an error if there are two such
borders that have the same priority but are not identical.
Each border segment is placed centered on the table grid boundary line.
-
padding: the value for the table-cell; either specified or
inherited.
-
Content:
(%block;)+
-
Properties:
6.8 Formatting Objects for Lists
6.8.1 Introduction
There are four formatting objects used to construct lists:
fo:list-block, fo:list-item, fo:list-item-label, and fo:list-item-body.
The fo:list-block has the role of containing the complete list and
to specify values used for the list geometry in the
inline-progression-direction (see details below).
The children of the fo:list-block are one or more fo:list-item, each
containing a pair of fo:list-item-label and fo:list-item-body.
The fo:list-item has the role of containing each item in a list.
The fo:list-item-label has the role of containing the content,
block-level formatting objects, of the label for the
list-item; typically an fo:block containing
a number, a ding-bat character, or a term.
The fo:list-item-body has the role of containing the content,
block-level formatting objects, of the body of the
list-item; typically one or more fo:block.
The placement, in the block-progression-direction, of the
label with respect to the body is made in accordance with the
"vertical-align" property of the fo:list-item.
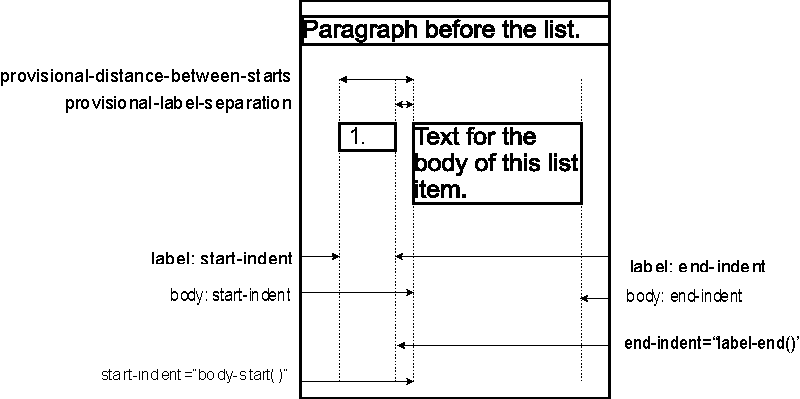
The specification of the list geometry in the
inline-progression-direction is achieved by:
-
Specifying appropiate values of the "provisional-distance-between-starts"
and "provisional-label-separation" properties.
The "provisional-distance-between-starts" specifies the desired
distance between the start-indents of the label and the body of
the list item.
The "provisional-label-separation" specifies the desired
separation between the end-indent of the label and the start-indent
of the body of the list item.
-
Specifying end-indent="label-end()" on the fo:list-item-label.
Specifying start-indent="body-start()" on the fo:list-item-body.
NOTE:
These list specific functions are defined below.
The start-indent of the list item label and end-indent of the
list item body, if desired, are typically specified as a length.
6.8.1.1 Examples
6.8.1.1.1 Numbered List
The list-items are contained in an "ol"
element. The items are
contained in "item" elements and contain text (as opposed to
paragraphs).
The style is to number the items alphabetically with a dot at
the end of the number.
XSL Stylesheet:
<?xml version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
version='1.0'>
<xsl:template match="ol">
<fo:list-block provisional-distance-between-starts="15mm"
provisional-label-separation="5mm">
<xsl:apply-templates/>
</fo:list-block>
</xsl:template>
<xsl:template match="ol/item">
<fo:list-item>
<fo:list-item-label start-indent="5mm" end-indent="label-end()">
<fo:block>
<xsl:number format="a."/>
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</fo:list-item-body>
</fo:list-item>
</xsl:template>
</xsl:stylesheet>
Input sample:
<ol>
<item>List item 1.</item>
<item>List item 2.</item>
<item>List item 3.</item>
</ol>
Result Instance: elements and attributes in the fo:
namespace
<fo:list-block provisional-distance-between-starts="15mm"
provisional-label-separation="5mm">
<fo:list-item>
<fo:list-item-label start-indent="5mm" end-indent="label-end()">
<fo:block>a.
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>List item 1.
</fo:block>
</fo:list-item-body>
</fo:list-item>
<fo:list-item>
<fo:list-item-label start-indent="5mm" end-indent="label-end()">
<fo:block>b.
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>List item 2.
</fo:block>
</fo:list-item-body>
</fo:list-item>
<fo:list-item>
<fo:list-item-label start-indent="5mm" end-indent="label-end()">
<fo:block>c.
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>List item 3.
</fo:block>
</fo:list-item-body>
</fo:list-item>
</fo:list-block>
6.8.1.1.2 HTML-style "dl" lists
In this example the stylesheet processes HTML-style "dl" lists, which
contain unwrapped pairs of "dt" and "dd" elements, transforming
them into fo:list-blocks.
Balanced pairs of "dt"/"dd"s are converted into fo:list-items.
For unbalanced "dt"/"dd"s, the stylesheet makes the
following assumptions:
In other words, given a structure like this:
<doc>
<dl>
<dt>term</dt>
<dd>definition</dd>
<dt>term</dt>
<dt>term</dt>
<dd>definition</dd>
<dt>term</dt>
<dd>definition</dd>
<dd>definition</dd>
</dl>
</doc>
If $allow-naked-dd is true, the result instance: elements
and attributes in the fo: namespace is:
<fo:list-block provisional-distance-between-starts="35mm"
provisional-label-separation="5mm">
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<fo:block>term
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>definition
</fo:block>
</fo:list-item-body>
</fo:list-item>
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<fo:block>term
</fo:block>
<fo:block>term
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>definition
</fo:block>
</fo:list-item-body>
</fo:list-item>
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<fo:block>term
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>definition
</fo:block>
</fo:list-item-body>
</fo:list-item>
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>definition
</fo:block>
</fo:list-item-body>
</fo:list-item>
</fo:list-block>
If $allow-naked-dd is false, the result instance:
elements and attributes in the fo: namespace is:
<fo:list-block provisional-distance-between-starts="35mm"
provisional-label-separation="5mm">
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<fo:block>term
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>definition
</fo:block>
</fo:list-item-body>
</fo:list-item>
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<fo:block>term
</fo:block>
<fo:block>term
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>definition
</fo:block>
</fo:list-item-body>
</fo:list-item>
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<fo:block>term
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>definition
</fo:block>
<fo:block>definition
</fo:block>
</fo:list-item-body>
</fo:list-item>
</fo:list-block>
XSL Stylesheet:
<?xml version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
version='1.0'>
<xsl:include href="dtdd.xsl"/>
<xsl:template match="doc">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="dl">
<xsl:call-template name="process.dl"/>
</xsl:template>
<xsl:template match="dt|dd">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
</xsl:stylesheet>
Included stylesheet "dtdd.xsl"
<?xml version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
version='1.0'>
<xsl:variable name="allow-naked-dd" select="true()"/>
<xsl:template name="process.dl">
<fo:list-block provisional-distance-between-starts="35mm"
provisional-label-separation="5mm">
<xsl:choose>
<xsl:when test="$allow-naked-dd">
<xsl:call-template name="process.dl.content.with.naked.dd"/>
</xsl:when>
<xsl:otherwise>
<xsl:call-template name="process.dl.content"/>
</xsl:otherwise>
</xsl:choose>
</fo:list-block>
</xsl:template>
<xsl:template name="process.dl.content.with.naked.dd">
<xsl:param name="dts" select="./force-list-to-be-empty"/>
<xsl:param name="nodes" select="*"/>
<xsl:choose>
<xsl:when test="count($nodes)=0">
<!-- Out of nodes, output any pending DTs -->
<xsl:if test="count($dts)>0">
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<xsl:apply-templates select="$dts"/>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()"/>
</fo:list-item>
</xsl:if>
</xsl:when>
<xsl:when test="name($nodes[1])='dd'">
<!-- We found a DD, output the DTs and the DD -->
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<xsl:apply-templates select="$dts"/>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<xsl:apply-templates select="$nodes[1]"/>
</fo:list-item-body>
</fo:list-item>
<xsl:call-template name="process.dl.content.with.naked.dd">
<xsl:with-param name="nodes" select="$nodes[position()>1]"/>
</xsl:call-template>
</xsl:when>
<xsl:when test="name($nodes[1])='dt'">
<!-- We found a DT, add it to the list of DTs and loop -->
<xsl:call-template name="process.dl.content.with.naked.dd">
<xsl:with-param name="dts" select="$dts|$nodes[1]"/>
<xsl:with-param name="nodes" select="$nodes[position()>1]"/>
</xsl:call-template>
</xsl:when>
<xsl:otherwise>
<!-- This shouldn't happen -->
<xsl:message>
<xsl:text>DT/DD list contained something bogus (</xsl:text>
<xsl:value-of select="name($nodes[1])"/>
<xsl:text>).</xsl:text>
</xsl:message>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
<xsl:template name="process.dl.content">
<xsl:param name="dts" select="./force-list-to-be-empty"/>
<xsl:param name="dds" select="./force-list-to-be-empty"/>
<xsl:param name="output-on"></xsl:param>
<xsl:param name="nodes" select="*"/>
<!-- The algorithm here is to build up a list of DTs and DDs, -->
<!-- outputing them only on the transition from DD back to DT -->
<xsl:choose>
<xsl:when test="count($nodes)=0">
<!-- Out of nodes, output any pending elements -->
<xsl:if test="count($dts)>0 or count($dds)>0">
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<xsl:apply-templates select="$dts"/>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<xsl:apply-templates select="$dds"/>
</fo:list-item-body>
</fo:list-item>
</xsl:if>
</xsl:when>
<xsl:when test="name($nodes[1])=$output-on">
<!-- We're making the transition from DD back to DT -->
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<xsl:apply-templates select="$dts"/>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<xsl:apply-templates select="$dds"/>
</fo:list-item-body>
</fo:list-item>
<!-- Reprocess this node (and the rest of the node list) -->
<!-- resetting the output-on state to nil -->
<xsl:call-template name="process.dl.content">
<xsl:with-param name="nodes" select="$nodes"/>
</xsl:call-template>
</xsl:when>
<xsl:when test="name($nodes[1])='dt'">
<!-- We found a DT, add it to the list and loop -->
<xsl:call-template name="process.dl.content">
<xsl:with-param name="dts" select="$dts|$nodes[1]"/>
<xsl:with-param name="dds" select="$dds"/>
<xsl:with-param name="nodes" select="$nodes[position()>1]"/>
</xsl:call-template>
</xsl:when>
<xsl:when test="name($nodes[1])='dd'">
<!-- We found a DD, add it to the list and loop, noting that -->
<!-- the next time we cross back to DT's, we need to output the -->
<!-- current DT/DDs. -->
<xsl:call-template name="process.dl.content">
<xsl:with-param name="dts" select="$dts"/>
<xsl:with-param name="dds" select="$dds|$nodes[1]"/>
<xsl:with-param name="output-on">dt</xsl:with-param>
<xsl:with-param name="nodes" select="$nodes[position()>1]"/>
</xsl:call-template>
</xsl:when>
<xsl:otherwise>
<!-- This shouldn't happen -->
<xsl:message>
<xsl:text>DT/DD list contained something bogus (</xsl:text>
<xsl:value-of select="name($nodes[1])"/>
<xsl:text>).</xsl:text>
</xsl:message>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>
The "dtdd.xsl" stylesheet may be customized in the following ways:
-
Set the value of $allow-naked-dd to control the processing of unbalanced
"dd"s.
-
Change "dt" to the name of the element
which is a term in the list.
-
Change "dd" to the name of the element
which is a definition in the list.
-
In the, perhaps unlikely, event that the documents may contain
an element named "force-list-to-be-empty", that element name
should be changed to a name that is not used in the documents.
In the stylesheet using the "dtdd.xsl" stylesheet change the "dl"
to the name of the element which is the wrapper for the list.
6.8.2 fo:list-block
-
Common use:
The fo:list-block flow object is used to format a list
item or a list.
-
Type of Area:
The fo:list-block flow object results in a block-area.
If the block-area will not fit in the remaining space in
the containing area, one (or more) additional areas may be generated
by the formatter, consistent with the constraints given by the
content of the list-block.
-
Content and its Placement:
The list-block must have one or more fo:list-item formatting objects
as children.
The areas produced by these are placed one after the other in the
block-progression-direction.
-
Content:
(list-item+)
-
Properties:
6.8.3 fo:list-item
-
Common use:
The fo:list-item formatting object contains the label and the
body of an item in a list.
-
Type of Area:
The fo:list-item flow object results in a block-area.
If the block-area will not fit in the remaining space in
the containing area, one (or more) additional areas may be generated
by the formatter, consistent with the constraints given by the
content of the list-item.
-
Content Distribution and Size:
The width of the content-rectangle of the block-area is
the width of the
reference-area into which it is placed minus the
start-indent and end-indent.
The height is determined by the content of the fo:list-item.
-
Content and its Placement:
The placement of the areas produced by formatting the fo:list-item-label
and fo:list-item-body objects are positioned with respect to each
other in the following manner:
-
In the block-progression-direction
these areas are positioned according to the "relative-align" property.
-
In the inline-progression-direction
these areas are positioned according to the start-indent and end-indent
properties of the content of the fo:list-item-label and fo:list-item-body
formatting objects.
It is an error if the areas overlap.
NOTE:
These areas are not reference-areas, hence the indents on all
objects within them are measured relative to the reference-area that
holds the content of the fo:list-block.
-
Content:
(list-item-label,list-item-body)
-
Properties:
6.8.4 fo:list-item-body
6.8.5 fo:list-item-label
-
Common use:
The fo:list-item-label formatting object contains the
content
of the label of a list-item; typically used to either enumerate,
identify or adorn the list-item's body.
-
Type of Area:
The fo:list-item-label formatting object does not
directly create any
area.
-
Content:
(%block;)+
-
Properties:
6.9 Link and Multi Formatting Objects
6.9.1 Introduction
The following classes of "dynamic" effects are covered by the
formatting objects included in this section:
-
One-directional single-target links.
-
The ability to switch between the display of two or more
formatting object subtrees. This can be used for, e.g.,
expandable/collapsible table of contents, display of an icon or
a full table or graphic.
-
The ability to switch between different property values, such
as color or font-weight, depending on DOM state, such as "mouse-over".
The switching between subtrees is achieved by using the
following three formatting objects:
fo:multi-switch,
fo:multi-case, and
fo:multi-toggle.
The result tree structure is shown below.
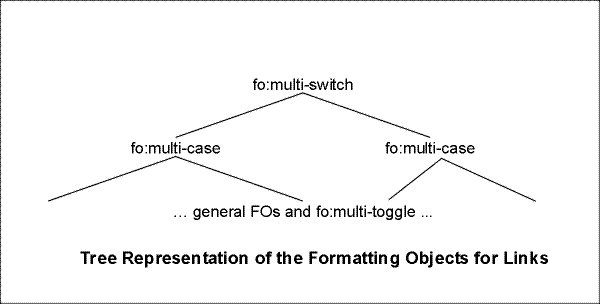
The role of the fo:multi-switch is to wrap fo:multi-case
formatting objects, each containing a subtree. Each subtree is
given a name on the fo:multi-case formatting object. Activating,
for example implemented as clicking on,
an fo:multi-toggle causes a named subtree, the previous, the next, or
"any" subtree to be displayed; controlled by the "switch-to" property.
For "any", an implementation would typically
present a list of choices each labeled using the "case-title" property
of the fo:multi-case.
The initial subtree displayed is controlled by the "starting-state"
property on the fo:multi-case.
6.9.1.1 Examples
6.9.1.1.1 Expandable/Collapsible Table of Contents
Input sample:
<doc>
<chapter><title>Chapter</title>
<p>Text</p>
<section><title>Section</title>
<p>Text</p>
</section>
<section><title>Section</title>
<p>Text</p>
</section>
</chapter>
<chapter><title>Chapter</title>
<p>Text</p>
<section><title>Section</title>
<p>Text</p>
</section>
<section><title>Section</title>
<p>Text</p>
</section>
</chapter>
</doc>
In this example
the chapter and section titles are extracted into a table of contents
placed at the front of the result. The chapter titles are preceeded
by an icon indicating either collapsed or expanded state. The section
titles are only shown in the expanded state. Furthermore,there are
links from the titles in the table of contents to the corresponding
titles in the body of the document.
The two states are achieved by, for each chapter title, using
an fo:multi-switch with a fo:multi-case for each state. The icon
is contained in an fo:multi-toggle with the appropriate fo:multi-case
"switch-to" property to select the other state.
The links in the table of contents are achieved by
adding a unique id on the title text in the body of the document
and wrapping the title text in the table of contents in an
fo:simple-link referring to that id.
XSL Stylesheet:
<?xml version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
version='1.0'>
<xsl:template match="doc">
<!-- create the table of contents -->
<xsl:apply-templates select="chapter/title" mode="toc"/>
<!-- do the document -->
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="chapter/title" mode="toc">
<fo:multi-switch>
<fo:multi-case case-name="collapsed" case-title="collapsed"
starting-state="show">
<fo:block>
<fo:multi-toggle switch-to="expanded">
<fo:external-graphic href="plus-icon.gif"/>
</fo:multi-toggle>
<fo:simple-link internal-destination="{generate-id(.)}">
<xsl:number level="multiple" count="chapter" format="1. "/>
<xsl:apply-templates mode="toc"/>
</fo:simple-link>
</fo:block>
</fo:multi-case>
<fo:multi-case case-name="expanded" case-title="expanded"
starting-state="hide">
<fo:block>
<fo:multi-toggle switch-to="collapsed">
<fo:external-graphic href="minus-icon.gif"/>
</fo:multi-toggle>
<fo:simple-link internal-destination="{generate-id(.)}">
<xsl:number level="multiple" count="chapter" format="1. "/>
<xsl:apply-templates mode="toc"/>
</fo:simple-link>
</fo:block>
<xsl:apply-templates select="../section/title" mode="toc"/>
</fo:multi-case>
</fo:multi-switch>
</xsl:template>
<xsl:template match="section/title" mode="toc">
<fo:block start-indent="10mm">
<fo:simple-link internal-destination="{generate-id(.)}">
<xsl:number level="multiple" count="chapter|section" format="1.1 "/>
<xsl:apply-templates/>
</fo:simple-link>
</fo:block>
</xsl:template>
<xsl:template match="chapter/title">
<fo:block id="{generate-id(.)}">
<xsl:number level="multiple" count="chapter" format="1. "/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="section/title">
<fo:block id="{generate-id(.)}">
<xsl:number level="multiple" count="chapter|section" format="1.1 "/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="p">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
</xsl:stylesheet>
Result Instance: elements and attributes in the fo:
namespace
<fo:multi-switch>
<fo:multi-case case-name="collapsed" case-title="collapsed" starting-state="show">
<fo:block>
<fo:multi-toggle switch-to="expanded">
<fo:external-graphic href="plus-icon.gif">
</fo:external-graphic>
</fo:multi-toggle>
<fo:simple-link internal-destination="N4">1. Chapter
</fo:simple-link>
</fo:block>
</fo:multi-case>
<fo:multi-case case-name="expanded" case-title="expanded" starting-state="hide">
<fo:block>
<fo:multi-toggle switch-to="collapsed">
<fo:external-graphic href="minus-icon.gif">
</fo:external-graphic>
</fo:multi-toggle>
<fo:simple-link internal-destination="N4">1. Chapter
</fo:simple-link>
</fo:block>
<fo:block start-indent="10mm">
<fo:simple-link internal-destination="N11">1.1 Section
</fo:simple-link>
</fo:block>
<fo:block start-indent="10mm">
<fo:simple-link internal-destination="N19">1.2 Section
</fo:simple-link>
</fo:block>
</fo:multi-case>
</fo:multi-switch>
<fo:multi-switch>
<fo:multi-case case-name="collapsed" case-title="collapsed" starting-state="show">
<fo:block>
<fo:multi-toggle switch-to="expanded">
<fo:external-graphic href="plus-icon.gif">
</fo:external-graphic>
</fo:multi-toggle>
<fo:simple-link internal-destination="N28">2. Chapter
</fo:simple-link>
</fo:block>
</fo:multi-case>
<fo:multi-case case-name="expanded" case-title="expanded" starting-state="hide">
<fo:block>
<fo:multi-toggle switch-to="collapsed">
<fo:external-graphic href="minus-icon.gif">
</fo:external-graphic>
</fo:multi-toggle>
<fo:simple-link internal-destination="N28">2. Chapter
</fo:simple-link>
</fo:block>
<fo:block start-indent="10mm">
<fo:simple-link internal-destination="N35">2.1 Section
</fo:simple-link>
</fo:block>
<fo:block start-indent="10mm">
<fo:simple-link internal-destination="N43">2.2 Section
</fo:simple-link>
</fo:block>
</fo:multi-case>
</fo:multi-switch>
<fo:block id="N4">1. Chapter
</fo:block>
<fo:block>Text
</fo:block>
<fo:block id="N11">1.1 Section
</fo:block>
<fo:block>Text
</fo:block>
<fo:block id="N19">1.2 Section
</fo:block>
<fo:block>Text
</fo:block>
<fo:block id="N28">2. Chapter
</fo:block>
<fo:block>Text
</fo:block>
<fo:block id="N35">2.1 Section
</fo:block>
<fo:block>Text
</fo:block>
<fo:block id="N43">2.2 Section
</fo:block>
<fo:block>Text
</fo:block>
6.9.2 fo:simple-link
-
Common use:
The fo:simple-link is used for representing the start resource of a simple
one-directional single-target link. The object allows for traversal to the
destination resource, typically by clicking on any of the containing areas.
-
Type of Area:
The fo:simple-link flow object results in an
inline-area.
If the inline-area will not fit in the remaining space in
the containing
line-area, one (or more) additional areas may be generated
by the formatter,
consistent with the constraints given by the properties of the content,
to accommodate the content.
NOTE:
An fo:simple-link may be displayed by enclosing
it in an fo:block.
-
Content Distribution and Size:
The width is determined by the content.
The height is determined by the height of the content.
The content is formatted in the general manner of inlines.
-
Content:
(#PCDATA|%inline;|%block;)*
-
Properties:
6.9.3 fo:multi-switch
-
Common use:
The fo:multi-switch is used to switch between two or more
sub-trees of formatting objects.
The direct children of an fo:multi-switch object are
fo:multi-case objects.
Only a single fo:multi-case may be visible at a single time. The user may
switch between the available multi-cases.
Each fo:multi-case may contain one or more fo:multi-toggle objects, which
controls the fo:multi-case switching of the fo:multi-switch.
NOTE:
An fo:multi-switch can be used for many interactive tasks, such as
table-of-content views, embedding link targets, or generalized (even
multi-layered hierarchical), next/previous views. The
latter are today
normally handled in HTML by next/previous links to other
documents, forcing
the whole document to be replaced whenever the users decides to
move on.
The fo:multi-switch shall initially display the first fo:multi-case child
that has the property "starting-state" assigned to "show".
-
Type of Area:
The fo:multi-switch does not directly
create any areas, but acts as an transparent
container, and is (conceptually) replaced by the currently visible
flow objects.
-
Content:
(multi-case+)
-
Properties:
6.9.4 fo:multi-case
-
Common use:
The fo:multi-case is used to embed flow objects, that the parent
fo:multi-switch can choose to either show or hide.
-
Type of Area:
The fo:multi-case does not directly create any areas,
but acts as a transparent
container, and is (conceptually) replaced by the flow
objects it contains.
-
Content:
(#PCDATA|%inline;|%block;)*
The fo:multi-case may contain any formatting objects that
are permitted as a replacement of the fo:multi-switch formatting object.
In particular,
it can contain fo:multi-toggle objects (at any depth), which controls the
fo:multi-case switching.
-
Properties:
6.9.5 fo:multi-toggle
-
Common use:
The fo:multi-toggle is typically used to create an area that when "clicked,"
has the
effect of switching from one fo:multi-case to another. The "switch-to"
property
value of the fo:multi-toggle typically matches the "case-name" property
value of
the fo:multi-case to switch to.
-
Type of Area:
The fo:multi-toggle results in the sequence of areas obtained
by formatting the content of the fo:multi-toggle formatting
object.
-
Content:
(#PCDATA|%inline;|%block;)*
-
Properties:
6.9.6 fo:multi-properties
-
Common use:
The fo:multi-properties is used to switch between two or more property sets that
are associated with a given portion of content.
The direct children of an fo:multi-properties
formatting object
is an ordered set of fo:multi-property-set formatting objects
followed by any character, inline, and block-level formatting objects.
The specified
properties of all fo:multi-property-set formatting objects
for states that apply are merged. In this merger, properties specified
in later fo:multi-property-set objects replace any values set in
earlier fo:multi-property-set objects. This assembled set of property
specifications are added to the inheritable properties for all
the child formatting objects of the fo:multi-properties
formatting object that are not of the class
fo:multi-property-set. This has the same effect
as if an fo:wrapper formatting object with the
assembled set of property specifications had enclosed them.
If no states apply, there is no change to the inheritable
properties.
The states on the fo:multi-property-set are the states (and events)
that are identified by the DOM.
NOTE:
An fo:multi-properties formatting object can be
used to give different
appearances to a given portion of content. For example, when
a link changes
from the not-yet-visited state to the visited-state, this
could change the
set of properties that would be used to format the content. Designers
should be careful in choosing which properties they change, because many
property changes could cause reflowing of the text which may
not be
desired in many circumstances. Changing properties such as
"color" or
"text-decoration" should not require re-flowing the text.
-
Type of Area:
The fo:multi-properties does not directly result in any areas.
Areas may be generated by formatting the content of the
fo:multi-properties formatting object.
-
Content:
(multi-property-set+,wrapper)
The properties that should take a merged value shall be specified
with a value of "from-parent()". This function, when applied on
an fo:wrapper
that is a direct child of an fo:multi-properties, merges the applicable
property definitions on the fo:multi-property-set siblings.
-
Properties:
6.9.7 fo:multi-property-set
-
Common use:
The fo:multi-property-set is used to specify an alternative
set of formatting
properties that can be used to provide an alternate presentation of the
children flow objects of the parent of this fo:multi-property-set that are not of the
fo:multi-property-set class.
-
Type of Area:
The fo:multi-property-set does not generate any area, but
simply holds a set of properties.
-
Content:
EMPTY
-
Properties:
6.10 Out-of-Line Formatting Objects
Issue (out-of-line):
This section is incomplete and may be inconsistent with
other sections of this draft.
6.10.1 Introduction
6.10.1.1 Conditional Regions
Conditional regions specify region-masters that are used to generate region
reference-areas. These region reference-areas are called conditional
reference-areas. Conditional reference-areas are generated only
when one or more areas that would be descendant from these
reference-areas are present on the page from which the conditional
reference-area is descendant. The descendants of a conditional
reference-area are out-of-line areas that are returned by formatting
objects, such as footnotes and floats, which have children that
generate areas that are not placed in the normal flow of areas.
Conditional regions are subdivisions of a region. They specify how
space can be borrowed from that region either at the top or bottom of
that region. The region from which the conditional region borrows
space is called the containing region. When a region-master
that contains conditional regions is used to generate a
reference-area, some of the region reference-areas that
correspond to the
conditional regions may be generated as well.
Whether a conditional reference-area is generated depends on the
presence of out-of-line areas that should be descendent from that
conditional reference-area. If there are out-of-line areas, such as
areas generated by an fo:footnote or fo:float, then the conditional
reference-areas may be generated. Whether or not the conditional
reference-areas are actually generated depends, additionally, on
whether there is sufficient space left in the reference-area from
which the space is being borrowed and whether constraints on the
relationship between the placement of the out-of-line areas and the
normal areas generated by the same formatting object are met. For
example, a constraint on footnotes requires that the footnote begin on
the same page as the reference to the footnote. In addition,
constraints on other portions of the content on the page may produce
an over-constrained situation; for example, if there is a long,
unbreakable paragraph that contains the footnote reference and just
fits on a page.
When one or more conditional reference-areas are generated, the parent
reference-area must be subdivided. This subdivision gives meaning to
the phrase, "a conditional region borrows space from the containing
region". The subdivision preserves the original reference-area
generated using the region-master. This original area is the
parent area of the subdivision areas. Subdivision generates two or
more reference-areas that are children of the original
reference-area. All but one of these reference-areas are conditional
reference-areas. These conditional reference-areas are aligned with
the before-edge or after-edge, respectively of the
content-rectangle of the parent reference-area.
The remaining reference-area corresponds to the
remaining space after the
borrowing done by the conditional regions. The traits of the
remaining reference-area are set as they would be if the
reference-area were generated by a region with no specified properties
that was the child of the containing region. This insures that there
is a transparent background and no margin, border, or
padding; and that
inherited properties are set as they would be when the region-master
for the containing region is used to generate a
reference-area. The
block-progression-dimension (this is "height"
when the writing-mode is "lr-tb") of the remaining
reference-area is set
equal to the block-progression-dimension of the parent reference-area
minus the sum of the sizes in the block-progression-direction of the
allocation-rectangles of the conditional reference-areas.
The
remaining reference-area is positioned to immediately follow the after
edge of the allocation-rectangle of the last of the
conditional
reference-areas that are before the remaining reference-area. This
positions the after-edge of the remaining reference-area to coincide
with the before-edge of the allocation-rectangle of the
first of the
conditional reference-areas that are after the remaining
reference-area. The areas that would have been children of the parent
reference-area are made children of the remaining reference-area. In
addition to the constraints normally determined by the original
region, the inline-progression-dimension (this is "width"
when the writing-mode is "lr-tb") of
that region is constrained
to match inline-progression-dimension of the remaining reference-area.
Issue (out-of-line-intro-space):
Should space-before and space-after be taken into account for the
space consumed by the conditional regions.
The allocation-rectangle size in the
block-progression-direction does not include these.
There may be limits on how much space
conditional regions can borrow from the containing region.
The association of out-of-line content (areas) with particular
conditional regions (areas) is specified in the descriptions of the
formatting objects that initially return the out-of-line content
(areas).
6.10.1.2 Floats and Footnotes
The region-body region has an implicit conditional float region at the
before-edge of the region and an implicit conditional footnote region at the
after-edge of the region.
When an fo:footnote formatting object appears in a flow, it returns at
least two kinds of areas. One kind of area is a normal
inline-area to accommodate the footnote
citation. This inline-area is
generated in sequence with the areas generated by the flow
objects
preceding and following the fo:footnote formatting object.
It is, therefore, assigned to the reference-area
generated using the region-master associated with the flow in which
the fo:footnote occurs.
The second kind of area that is
returned by the fo:footnote formatting object is an
out-of-line area.
It becomes a descendant of the reference-area
generated by the implicit conditional footnote region
associated with the region to which the flow in which the
fo:footnote occurs is assigned.
The conditional reference-area which has as its descendant the first
(and usually only) out-of-line area returned by the fo:footnote is
constrained to be a sibling of the reference-area which has as its
descendant the first of normal areas returned by the fo:footnote. That
is, the footnote must begin in the same instance of the
containing region in which the footnote citation occurs.
NOTE:
The actual areas generated by the descendants of the fo:footnote
formatting object are determined by the formatting objects
that comprise the
descendant subtree. For example, if one wanted to format the footnote
with a label and an indented body, then one could use the
fo:list-block formatting object to format the content of the
footnote.
When an fo:float formatting object appears in a flow, it returns
out-of-line areas. These areas become descendants of
reference-areas generated by the
implicit conditional float region associated with the region to which
the flow in which the fo:float occurs is assigned.
Issue (out-of-sequence-intro-error):
Should it be an error if an fo:float occurs in a flow that is
not assigned to a region that has an implicit conditional "float"
region. If it is an error is there a reasonable fallback, say put
the float inline at the point of occurrence. This issue also applies
to footnotes. Note that this would consistent with the
fallback listed in
the conformance summary since footnotes and floats are not
in the "basic" formatting object set.
The constraint on the areas returned by an fo:float is that they may
only be descendant from conditional reference-areas that are (a)
descendant from areas generated using the region-masters for the region to
which the flow that has the fo:float as a descendant is assigned, and
(b) are descendent from the same page as the page in which normal
areas returned by the fo:float would be descendants, or descendant from a
page following that page in the sequence of pages that are children of
the area tree root.
NOTE:
Future versions of this specification will describe the
above semantics as special cases of a more general mechanism that
allows out-of-line areas to be assigned to conditional regions and the
expression of constraints between the occurrences of normal areas and
out-of-line areas.
6.10.1.3 Examples
TBD
6.10.2 fo:float
-
Common Usage:
The fo:float formatting object holds a sequence
formatting objects
that is to be presented in a conditional-area at the top of an instance
of a region with the same name as the region into which the fo:float
flow object is distributed. The content of the fo:float
flow object
is not placed where the flow object is distributed, but is
instead placed,
out-of-line, in the next instance of the region with the same name
for which there is room for the content of the fo:float. Such content
might be a figure, a table or other chunk of content that is to
be kept together and need not disrupt the flow of the content around
it.
NOTE:
Issue: Floating to the top of the same page should not
be prohibited for systems that can support it.
-
Areas:
The fo:float flow object generates a block-area that is
placed
in a conditional-area anchored on the before edge of the region
into which the fo:float flow object is distributed. The
placement
of the block-area generated by the fo:float into the conditional
regions is called, "out-of-line" placement.
NOTE:
Issue: Does it generate a block-area?!
-
Trait Derivation:
The coordinate system for the conditional-area for floats is
set to the same orientation as the coordinate system of the region
that contains the conditional-area. The writing-mode for the conditional-rererence-area
is similarly copied from the region which contains it. Currently,
there is no way to specify any of the common-border-padding-and-background-properties
so the conditional region has no padding, borders or background.
-
Constraints:
The fo:floats which are distributed into a given region all generate
a float block-area in a conditional-area for floats in the region
into which they are distributed or in some subsequent instance of
a region with the same name. That is, the content of the fo:float flow object
is not distributed where the fo:float is distributed, but is instead
formatted into a block-area that is placed, out-of-line, in
the
same or a subsequent region of the same name as the one in which
the fo:float flow object was distributed.
The size of the conditional-area for floats, in the block-progression-direction,
shall not exceed the computed value of the "max-height"
property
on the fo:float flow object.
The content of each fo:float is distributed into a single block-area
whose height and width is determined by the common-margin-properties-block
and the common-border-padding-and-background-properties. The conditional-area
for floats is the reference-area into which this block-area is placed.
The normal rules for space resolution apply to these blocks. The
block-areas for floats are placed in conditional-areas for floats
in the order in which the fo:float flow objects were
distributed
in the content distribution of the flow in which they occur. If
a the block-area for a given float will not fit into the current
conditional-area for floats, then it will be distributed into a conditional
area for floats in a subsequent region of the same name as the current region.
Instances of page-masters with a region of the same name will continue
to be generated as long as there are float block-areas to be placed.
NOTE:
Issue: What is to happen if there is a float that can never fit
within the "max-height" of the conditional-area for floats. Should
that float be split? Should it be ignored?
-
Contents:
(%block;)+
-
Properties:
6.10.3 fo:footnote
-
Common Usage:
The fo:footnote formatting object represents both the
place of
occurrence of the footnote reference (or citation) and the content
of the footnote itself. The footnote citation occurs where the fo:footnote
flow object occurs; that is, the footnote citation is
formatted
inline. The footnote itself is formatted out of line; it is floated
to the bottom of the page on which the footnote citation occurs.
The content of the fo:footnote is structured into two pieces.
There is an fo:footnote-citation flow object which is an
inline flow object
that is used to specify the properties to be used in formatting
the footnote citation. The remaining content of the fo:footnote flow object
is the content of the footnote itself. If the footnote itself is
to have a label and a body, then this content should be structured
using the fo:list-block flow object containing an
fo:list-label and
an fo:list-body.
NOTE:
Issue: The last sentence should be moved to a note and also
stress that the use of list formatting objects is only when such
a layout is desired.
-
Areas:
The fo:footnote formatting object generates two areas.
The citation
generates at least one inline-area into which the content of the
fo:footnote-citation is distributed. This distribution into one
or more inline-areas shall be consistent with the constraints determined
by the properties applicable to the fo:footnote-citation flow object.
The fo:footnote flow object generates a block-area that
is placed
in a conditional-area anchored on the after edge of the region into
which the fo:footnote-citation is distributed. The placement of
the block-area generated by the fo:footnote into the conditional
regions is called, "out-of-line" placement.
NOTE:
Issue: Does it generate a block-area?!
-
Trait Derivation:
The coordinate system for the conditional-area for footnotes
is set to the same orientation as the coordinate system of the region
that contains the conditional-area. The writing-mode for the conditional-reference-area
is similarly copied from the region which contains it. Currently,
there is no way to specify any of the common-border-padding-and-background-properties
so the conditional region has no padding, borders or background.
NOTE:
Issue: Should there be a way to establish borders and/or padding
and backgrounds for the conditional footnote areas?
-
Constraints:
The content of the fo:footnote-citation is distributed as specified
in the description of the fo:footnote-citation flow
object.
The fo:footnotes which have a citation distributed into a given
region all generate a footnote block-area in the conditional-area
for footnotes for the region into which they are distributed. One
condition on the distribution of the footnote-citation inline-areas into
a region is that footnote conditional-area for that region is large
enough to hold the footnote block-areas for all the footnote-citations
distributed to that region. In addition, the size of that conditional-area
in the block-progression-direction shall not exceed the computed
value of the "max-height" property on the fo:footnote flow
object.
The content of each fo:footnote, excluding the fo:footnote-citation,
is distributed into a single block-area whose height and width is
determined by the common-margin-properties-block and the common-border-padding-and-background-properties.
The conditional-area for footnotes is the reference-area into which
this block-area is placed. The normal rules for space resolution
apply to these blocks which are placed in the conditional-area for
footnotes in the order in which the fo:footnote flow objects occurred
in the content distributed into the region to which the footnote
is attached.
-
Contents:
(%block;)+
-
Properties:
6.11 Other Formatting Objects
6.11.1 Introduction
The following example shows the use of the fo:wrapper
formatting object that has no semantics but acts as a
"carrier" for inherited properties.
6.11.1.1 Example
Input sample:
<doc>
<p>This is an <emph>important word</emph> in this
sentence that also refers to a <code>variable</code>.</p>
</doc>
The "emph" elements are to be presented using a
bold
font and the "code" elements are using a Courier
font.
XSL Stylesheet:
<?xml version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
version='1.0'>
<xsl:template match="p">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="emph">
<fo:wrapper font-weight="bold">
<xsl:apply-templates/>
</fo:wrapper>
</xsl:template>
<xsl:template match="code">
<fo:wrapper font-family="Courier">
<xsl:apply-templates/>
</fo:wrapper>
</xsl:template>
</xsl:stylesheet>
fo: element and attribute tree:
<fo:block xmlns:fo="http://www.w3.org/1999/XSL/Format">This is an
<fo:wrapper font-weight="bold">important word</fo:wrapper>
in this sentence that also refers to a
<fo:wrapper font-family="Courier">variable</fo:wrapper>.
</fo:block>
6.11.2 fo:wrapper
-
Common use:
The fo:wrapper formatting object is used to
specify
inherited properties for a group of formatting objects.
-
Area type:
The fo:wrapper formatting object does not directly
generate any area.
However, each of its children is individually formatted to produce a series
of areas.
-
Determination of trait values:
The fo:wrapper has no properties that are directly used
by it. However, it does serve as a carrier to hold inheritable properties
that are utilized by its children.
-
Content:
(#PCDATA|%inline;|%block;)*
-
Properties:
7 Formatting Properties
7.1 Description of Property Groups
The following sections describe the properties of the XSL
formatting objects.
-
The first eight sets of property definitions have been
arranged into groups based on similar functionality
and the fact that they apply to many formatting objects.
In the formatting-object descriptions the group name is
referred
to rather than referring to the individual properties.
-
Common Absolute Position Properties
This set of properties controls the position and size of formatted
areas with absolute or relative positioning (areas displaced from
the default positioning in the text block).
-
Common Aural Properties
This group of properties controls the aural rendition of the
content of a formatting object. They appear on all formatting objects
that contain content and other formatting objects that group other
formatting objects and where that grouping is necessary for
the understanding of the aural rendition. An example of the latter
is fo:table-and-caption.
-
Common Border, Padding, and Background Properties
This set of properties controls the backgrounds and borders on
the block-areas and inline-areas. This property group
appears on
all formatting objects that produce visible renderings.
-
Common Font Properties
This set of properties controls the font selection on all formatting objects
that can contain text. Appears on fo:block, fo:first-line-marker,
and on inline formatting objects that contain or generate
text.
-
Common Hyphenation Properties
Low-level control of line-breaking, including hyphenation and
language selection. Appears on fo:block and fo:title.
-
Common Keeps and Breaks Properties
Controls page/column breaks before/after block-level formatting
objects. Appears on most block-level formatting objects.
-
Common Margin Properties-Block
These properties set the spacing and indents surrounding block-level
formatting objects.
-
Common Margin Properties-Inline
These properties set the spacing surrounding inline formatting objects.
-
The remaining properties are used on a small number of
formatting objects. These are arranged into clusters of similar
functionality to
organize the property descriptions. In the formatting object description
the individual properties are referenced.
-
Pagination Properties
These properties govern the sequencing, layout, and instantiation
of pages, including: the page size and orientation, sizes of regions
on the page-master, the identification and selection of page-masters,
division of the body region into columns, and the assignment of
content flows to layout regions.
-
Table Properties
Properties governing the layout and presentation
of tables.
-
Character Properties
Properties governing the presentation of text-characters.
-
Leader Properties
Properties governing the construction of leaders and
horizontal rules.
-
Page-related Properties
These properties augment the common-keeps-and-breaks-properties
group by adding controls for widows, orphans, and page/column/line keeps.
-
Float-related properties
Properties governing the placement of floats and controlling
the wrapping (runaround) of text that may be adjacent to the float.
-
Properties for Number-to-String Conversions
Properties used in the construction of page-numbers and
other formatter-based numbering.
-
Properties for Links
Properties governing the presentation and actions associated
with links.
-
Miscellaneous Properties
These properties did not reasonably fit into any of the other
categories.
7.2 XSL Areas and the CSS Box Model
This section describes how to interpret property descriptions which
incorporate the CSS2 definition of the same property. In CSS2, "boxes"
are generated by "elements" in the same way that XSL areas are generated
by formatting objects. Any references in the CSS2 definition to "boxes"
are to be taken as referring to "areas" in the XSL area model, and where
"element" appears in a CSS2 definition it should be taken to refer to a
"formatting object".
The position and size of a box are normally taken to refer to the
position and size of the area's content rectangle. Additional
correspondences between the CSS2 Box Model and the XSL Area Model are
contained in the following table.
| Box | Area |
| top content edge | top edge of the content rectangle |
| padding edge | padding rectangle |
| content area | interior of the content rectangle |
| padding area | region between the content rectangle and the padding rectangle |
| border area | region between the padding rectangle and the border rectangle |
| background | background |
| containing block | closest ancestor block area |
| caption | area generated by fo:table-caption |
| inline box | inline-area |
| line box | line-area |
| block box | block-area which is not a line-area |
| page box | page-area |
Box margins map to area traits in accordance with the description of how
area traits are computed from property values
in[5 Property Refinement / Resolution].
7.3 Common Accessibility Properties
7.3.1 "source-document"
XSL Definition:
| Value: | <uri>+ | none | inherit |
| Initial: | none |
| Applies to: | fo:root |
| Inherited: | no |
| Percentages: | N/A |
| Media: | all |
Values have the following meanings:
-
none
-
The source document is transient, unknown, or unspecified.
-
<uri>
-
A list of space-separated URIs, indicating the XML document(s)
used as input to the stylesheet.
This property provides a pointer back to the original XML
document(s) used to create this formatting-object tree. It is useful
for for alternate renderers (aural readers, etc) whenever the structure
of the formatting-object tree is inappropriate for that renderer.
7.3.2 "role"
XSL Definition:
| Value: | <string> | none | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | all |
It is used by all formatting objects that can be
contained in fo:flow
or fo:static-content (all formatting objects that can be
directly created from an XML source element).
Values have the following meanings:
-
none
-
Indicates that no semantic tag is cited by this
formatting object.
-
<string>
-
The value is a string representing a semantic that
may be used in rendering this formatting object. It can,
for example, be an element name in some known semantic
vocabulary, such as HTML, or a particular Web Accessibility
Initiative (WAI) semantic vocabulary.
This provides a hint for alternate renderers (aural readers,
etc) as to the role and potential alternate presentation of the
content of this formatting
object.
This property is not inherited, but all subsidiary nodes of this
formatting object that do not bear a role property should
utilize
the same alternate presentation properties. (It is not inherited
because knowledge of the start and end of the formatting-object
subtree generated by the element may be needed by the renderer.)
7.4 Common Absolute Position Properties
7.4.1 "absolute-position"
XSL Definition:
| Value: | auto | absolute | fixed | inherit |
| Initial: | auto |
| Applies to: | fo:block-container |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
auto
-
There is no absolute-positioning constraint. Positioning is
in accordance with the relative-position property.
-
absolute
-
The area's position (and possibly size) is specified with
the "left", "right", "top", and "bottom" properties. These properties
specify offsets with respect to the area's containing area. Absolutely
positioned areas are taken out of the normal flow. This means they
have no impact on the layout of later siblings. Also, though absolutely
positioned areas have margins, they do not collapse with any other margins.
-
fixed
-
The area's position is calculated according to the "absolute"
model, but in addition, the area is fixed with respect to some reference.
In the case of continuous media, the area is fixed with respect to
the viewport (and doesn't move when scrolled). In the case of paged
media, the area is fixed with respect to the page, even if that page is
seen through a viewport (in the case of a print-preview, for example).
Authors may wish to specify "fixed" in a media-dependent way. For
instance, an author may want an area to remain at the top the viewport
on the screen, but not at the top of each printed page.
The following additional restrictions apply for paged
presentations:
-
Only objects with absolute-position="auto"
may have page/column breaks.
For other values any
keep and break properties are ignored.
-
The area generated is a descendant of the page-area where the
first area from the object would have been placed had the object had
absolute-posiiton="auto" specified.
7.4.2 "top"
CSS2 Definition:
| Value: | <length> | <percentage> | auto | inherit |
| Initial: | auto |
| Applies to: | positioned elements |
| Inherited: | no |
| Percentages: | refer to height of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-top.
The "top" property specifies how far a box's top content edge
is offset below the top edge of the box's containing block.
XSL modifications to the CSS definition:
See definition of property left ([7.4.5 "left"]).
7.4.3 "right"
CSS2 Definition:
| Value: | <length> | <percentage> | auto | inherit |
| Initial: | auto |
| Applies to: | positioned elements |
| Inherited: | no |
| Percentages: | refer to height of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-right.
The "right" property specifies how far a box's right content
edge is offset to the left of the right edge of the box's containing
block.
XSL modifications to the CSS definition:
See definition of property left ([7.4.5 "left"]).
7.4.4 "bottom"
CSS2 Definition:
| Value: | <length> | <percentage> | auto | inherit |
| Initial: | auto |
| Applies to: | positioned elements |
| Inherited: | no |
| Percentages: | refer to height of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-bottom.
The "bottom" property specifies how far a box's bottom content
edge is offset above the bottom of the box's containing block.
XSL modifications to the CSS definition:
See definition of property left ([7.4.5 "left"]).
7.4.5 "left"
CSS2 Definition:
| Value: | <length> | <percentage> | auto | inherit |
| Initial: | auto |
| Applies to: | positioned elements |
| Inherited: | no |
| Percentages: | refer to height of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-left.
The "left" property specifies how far a box's left content edge
is offset to the right of the left edge of the box's containing
block.
The values of the four (position offset) properties have the
following meanings:
-
auto
-
The effect of this value depends on which of related properties
have the value "auto" as well. See the sections on the width and
height of absolutely positioned, non-replaced elements for details.
-
<length>
-
The offset is a fixed distance from the reference edge.
-
<percentage>
-
The offset is a percentage of the containing block's width
(for "left" or "right") or "height" (for "top" and "bottom"). For
"top" and "bottom", if the "height" of the containing block is not
specified explicitly (i.e., it depends on content height), the percentage
value is interpreted like "auto".
For absolutely positioned boxes, the offsets are with respect
to the box's containing block. For relatively positioned boxes,
the offsets are with respect to the outer edges of the box itself
(i.e., the box is given a position in the normal flow, then offset
from that position according to these properties).
XSL modifications to the CSS definition:
These properties set the position of the content-rectangle
of the associated area.
If both "top" and "bottom" are specified, the height of the content
rectangle is overridden. If both "left" and "right" are specified,
the width of the content-rectangle is overridden.
7.5 Common Aural Properties
7.5.1 "azimuth"
CSS2 Definition:
| Value: | <angle> | [[ left-side | far-left | left
| center-left | center | center-right | right | far-right | right-side
] || behind ] | leftwards | rightwards | inherit |
| Initial: | center |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | aural |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/aural.html#propdef-azimuth.
7.5.2 "cue-after"
7.5.3 "cue-before"
7.5.4 "elevation"
7.5.5 "pause-after"
7.5.6 "pause-before"
7.5.7 "pitch"
7.5.8 "pitch-range"
7.5.9 "play-during"
7.5.10 "richness"
7.5.11 "speak"
7.5.12 "speak-header"
7.5.13 "speak-numeral"
7.5.14 "speak-punctuation"
7.5.15 "speech-rate"
7.5.16 "stress"
7.5.17 "voice-family"
7.5.18 "volume"
CSS2 Definition:
| Value: | <number> | <percentage> | silent | x-soft
| soft | medium | loud | x-loud | inherit |
| Initial: | medium |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | refer to inherited value |
| Media: | aural |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/aural.html#propdef-volume.
7.6 Common Border, Padding, and Background Properties
The following common-border-padding-and-background-properties
are taken from CSS2. Those "border", "padding", and "background"
properties that have a before, after, start, or end suffix are writing-mode
relative and are XSL-only properties.
7.6.1 "background-attachment"
CSS2 Definition:
| Value: | scroll | fixed | inherit |
| Initial: | scroll |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/colors.html#propdef-background-attachment.
-
scroll
-
The background-image may scroll with the enclosing object.
-
fixed
-
The background-image is to be fixed within the viewable
area of the enclosing object.
If a background-image is specified, this property specifies
whether it is fixed with regard to the viewport (fixed) or scrolls
along with the document (scroll).
Even if the image is fixed, it is still only visible when it
is in the background or padding area of the element. Thus, unless
the image is tiled ("background-repeat: repeat"), it may be invisible.
User agents may treat fixed as scroll. However, it is recommended
they interpret fixed correctly, at least for the HTML and BODY elements,
since there is no way for an author to provide an image only for
those browsers that support fixed. See the section on conformance
for details.
XSL modifications to the CSS definition:
The last paragraph in the CSS description does not apply.
7.6.2 "background-color"
CSS2 Definition:
| Value: | <color> | transparent | inherit |
| Initial: | transparent |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/colors.html#propdef-background-color.
This property sets the background color of an element, either
a <color> value or the keyword transparent, to make the underlying
colors shine through.
-
transparent
-
The underlying colors will shine through.
-
<color>
-
Any valid color specification.
XSL modifications to the CSS definition:
Issue (color-props):
We plan to
include two proposed SVG properties: color-profile
and rendering-intent in XSL. We are investigating if there
is an extended syntax to specify both ICC
and SVG color.
7.6.3 "background-image"
CSS2 Definition:
| Value: | <uri> | none | inherit |
| Initial: | none |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/colors.html#propdef-background-image.
This property sets the background image of an element. When setting
a "background-image", authors should also specify a background-color
that will be used when the image is unavailable. When the image
is available, it is rendered on top of the background color. (Thus,
the color is visible in the transparent parts of the image).
Values for this property are either <uri>, to specify the
image, or "none", when no image is used.
-
none
-
No image is specified.
-
<uri>
-
7.6.4 "background-repeat"
CSS2 Definition:
| Value: | repeat | repeat-x | repeat-y | no-repeat | inherit |
| Initial: | repeat |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/colors.html#propdef-background-repeat.
If a background image is specified, this property specifies whether
the image is repeated (tiled), and how. All tiling covers the content
and padding areas of a box. Values have the following meanings:
-
repeat
-
The image is repeated both horizontally and vertically.
-
repeat-x
-
The image is repeated horizontally only.
-
repeat-y
-
The image is repeated vertically only.
-
no-repeat
-
The image is not repeated: only one copy of the image is
drawn.
XSL modifications to the CSS definition:
"Horizontal" and "vertical" are defined relative to the reference
orientation; "horizontal" is "left" to "right", and "vertical" is
"top" to "bottom".
NOTE:
Thus for a rotated area the tiling is also rotated.
It is, however, independent of the writing mode.
7.6.5 "background-position-horizontal"
XSL Definition:
| Value: | <percentage> | <length> |
left | center | right | inherit |
| Initial: | 0% |
| Applies to: | block-level and replaced elements |
| Inherited: | no |
| Percentages: | refer to the size of the padding rectangle |
| Media: | visual |
If a "background-image" has been specified, this property specifies
its initial position horizontally.
-
<percentage>
-
Specifies that a point, at the given percentage across the image
from left to right, shall be placed at a point at the given percentage
across, from left to right, the area's padding rectangle.
NOTE:
For example
with a value of 0%, the left edge of the
image is aligned with the left edge of the area's padding
rectangle. A value of 100% places the right edge of
the image aligned with the right edge of the padding rectangle.
With a value
of 14%, a point 14% across the image is
to be placed at a point 14% across the padding rectangle.
-
<length>
-
Specifies that the left edge of the image shall be placed
at the specified length to the right of the left edge of the
padding rectangle.
NOTE:
For example
with a value of 2cm, the left edge of the
image is placed 2cm to the right of the left edge of the padding
rectangle.
-
left
-
Same as 0%.
-
center
-
Same as 50%.
-
right
-
Same as 100%.
7.6.6 "background-position-vertical"
XSL Definition:
| Value: | <percentage> | <length> |
top | center | bottom | inherit |
| Initial: | 0% |
| Applies to: | block-level and replaced elements |
| Inherited: | no |
| Percentages: | refer to the size of the padding rectangle |
| Media: | visual |
If a "background-image" has been specified, this property specifies
its initial position vertically.
-
<percentage>
-
Specifies that a point, at the given percentage down the image
from top to bottom, shall be placed at a point at the given percentage
down, from top to bottom, the area's padding rectangle.
NOTE:
For example
with a value of 0%, the top edge of the
image is aligned with the top edge of the area's padding
rectangle. A value of 100% places the bottom edge of
the image aligned with the bottom edge of the padding rectangle.
With a value
of 84%, a point 84% down the image is
to be placed at a point 84% down the padding rectangle.
-
<length>
-
Specifies that the top edge of the image shall be placed
at the specified length below the top edge of the
padding rectangle.
NOTE:
For example
with a value of 2cm, the top edge of the
image is placed 2cm below the top edge of the padding
rectangle.
-
top
-
Same as 0%.
-
center
-
Same as 50%.
-
bottom
-
Same as 100%.
7.6.7 "border-before-color"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <color> | inherit |
| Initial: | the value of the 'color' property |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the color of the border
on the before-edge of a block-area or inline-area.
See definition of property border-top-color ([7.6.19 "border-top-color"]).
7.6.8 "border-before-style"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <border-style> | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the border style for the before-edge.
See definition of property border-top-style ([7.6.20 "border-top-style"]).
7.6.9 "border-before-width"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <border-width> | <length-conditional> | inherit |
| Initial: | medium |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the border width for the before-edge.
See definition of property border-top-width ([7.6.21 "border-top-width"]).
XSL modifications to the CSS definition:
The following value type has been added for XSL:
-
<length-conditional>
-
A compound value specifying the width and any conditionality
of the border for the before-edge.
The .length component is a <length>.
The .conditionality component may be set to "discard" or "retain" to
control if the border should be 0 or retained if it's associated
edge is a leading edge in a reference-area for areas generated from
this formatting object that have an is-first value
of "false". See [4.3 Spaces and Conditionality] for further details.
The initial value of the .conditionality component is "retain".
NOTE:
If the border style is "none" the computed value of the width
is forced to "0pt".
7.6.10 "border-after-color"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <color> | inherit |
| Initial: | the value of the 'color' property |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the color of the border
on the after-edge of a block-area or inline-area.
See definition of property border-top-color ([7.6.19 "border-top-color"]).
7.6.11 "border-after-style"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <border-style> | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the border style for the after-edge.
See definition of property border-top-style ([7.6.20 "border-top-style"]).
7.6.12 "border-after-width"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <border-width> | <length-conditional> | inherit |
| Initial: | medium |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the border width for the after-edge.
See definition of property border-top-width ([7.6.21 "border-top-width"]).
XSL modifications to the CSS definition:
The following value type has been added for XSL:
-
<length-conditional>
-
A compound value specifying the width and any conditionality
of the border for the after-edge.
The .length component is a <length>.
The .conditionality component may be set to "discard" or "retain" to
control if the border should be 0 or retained if it's associated
edge is a trailing edge in a reference-area for areas generated from
this formatting object that have an is-last value
of "false". See [4.3 Spaces and Conditionality] for further details.
The initial value of the .conditionality component is "retain".
NOTE:
If the border style is "none" the computed value of the width
is forced to "0pt".
7.6.13 "border-start-color"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <color> | inherit |
| Initial: | the value of the 'color' property |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the color of the border
on the start-edge of a block-area or inline-area.
See definition of property border-top-color ([7.6.19 "border-top-color"]).
7.6.14 "border-start-style"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <border-style> | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the border style for the start-edge.
See definition of property border-top-style ([7.6.20 "border-top-style"]).
7.6.15 "border-start-width"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <border-width> | inherit |
| Initial: | medium |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the border width for the start-edge.
NOTE:
If the border style is "none" the computed value of the width
is forced to "0pt".
See definition of property border-top-width ([7.6.21 "border-top-width"]).
7.6.16 "border-end-color"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <color> | inherit |
| Initial: | the value of the 'color' property |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the color of the border
on the end-edge of a block-area or inline-area.
See definition of property border-top-color ([7.6.19 "border-top-color"]).
7.6.17 "border-end-style"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <border-style> | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the border style for the end-edge.
See definition of property border-top-style ([7.6.20 "border-top-style"]).
7.6.18 "border-end-width"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <border-width> | inherit |
| Initial: | medium |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Specifies the border width for the end-edge.
NOTE:
If the border style is "none" the computed value of the width
is forced to "0pt".
See definition of property border-top-width ([7.6.21 "border-top-width"]).
7.6.19 "border-top-color"
CSS2 Definition:
| Value: | <color> | inherit |
| Initial: | the value of the 'color' property |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-top-color.
The 'border-color' property sets the color of the four borders.
Values have the following meanings:
-
<color>
-
Any valid color specification.
If an element's border color is not
specified with a "border" property, user agents must use the value
of the element's "color" property as the computed value for the
border color.
7.6.20 "border-top-style"
CSS2 Definition:
| Value: | <border-style> | inherit |
| Initial: | none |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-top-style.
The border style properties specify the line style of a box's
border (solid, double, dashed, etc.).
The properties defined in this section refer to the <border-style>
value type, which may take one of the following:
-
none
-
No border. This value forces the computed value of 'border-width'
to be '0'.
-
hidden
-
Same as 'none', except in terms of border conflict resolution
for table elements.
-
dotted
-
The border is a series of dots.
-
dashed
-
The border is a series of short line segments.
-
solid
-
The border is a single line segment.
-
double
-
The border is two solid lines. The sum of the two lines
and the space between them equals the value of 'border-width'.
-
groove
-
The border looks as though it were carved into the canvas.
-
ridge
-
The opposite of 'groove': the border looks as
though it were coming out of the canvas.
-
inset
-
The border makes the entire box look as though it were
embedded in the canvas.
-
outset
-
The opposite of 'inset': the border makes the entire box
look as though it were coming out of the canvas.
All borders are drawn on top of the box's background. The
color of borders drawn for values of 'groove', 'ridge', 'inset',
and 'outset' depends on the element's 'color' property.
Conforming HTML user agents may interpret 'dotted', 'dashed',
'double', 'groove', 'ridge', 'inset', and 'outset' to be 'solid'.
XSL modifications to the CSS definition:
For fallback, a conforming implementation may
interpret 'dotted', 'dashed', 'double', 'groove', 'ridge', 'inset',
and 'outset' to be 'solid'.
7.6.21 "border-top-width"
CSS2 Definition:
| Value: | <border-width> | inherit |
| Initial: | medium |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-top-width.
The border width properties specify the width of the border area.
The properties defined in this section refer to the <border-width>
value type, which may take one of the following values:
-
thin
-
A thin border.
-
medium
-
A medium border.
-
thick
-
A thick border.
-
<length>
-
The border's thickness has an explicit value. Explicit
border widths cannot be negative.
The interpretation of the first three values depends on
the user agent. The following relationships must hold, however:
7.6.22 "border-bottom-color"
7.6.23 "border-bottom-style"
7.6.24 "border-bottom-width"
7.6.25 "border-left-color"
7.6.26 "border-left-style"
7.6.27 "border-left-width"
7.6.28 "border-right-color"
7.6.29 "border-right-style"
7.6.30 "border-right-width"
7.6.31 "padding-before"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <padding-width> | <length-conditional> | inherit |
| Initial: | 0pt |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
Specifies the width of the padding
on the before-edge of a block-area or inline-area.
See definition of property padding-top ([7.6.35 "padding-top"]).
XSL modifications to the CSS definition:
The following value type has been added for XSL:
-
<length-conditional>
-
A compound value specifying the width and any conditionality
of the padding for the before-edge.
The .length component is a <length>.
The .conditionality component may be set to "discard" or "retain" to
control if the padding should be 0 or retained if it's associated
edge is a leading edge in a reference-area for areas generated from
this formatting object that have an is-first value
of "false". See [4.3 Spaces and Conditionality] for further details.
The initial value of the .conditionality component is "retain".
7.6.32 "padding-after"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <padding-width> | <length-conditional> | inherit |
| Initial: | 0pt |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
Specifies the width of the padding
on the after-edge of a block-area or inline-area.
See definition of property padding-top ([7.6.35 "padding-top"]).
XSL modifications to the CSS definition:
The following value type has been added for XSL:
-
<length-conditional>
-
A compound value specifying the width and any conditionality
of the padding for the after-edge.
The .length component is a <length>.
The .conditionality component may be set to "discard" or "retain" to
control if the padding should be 0 or retained if it's associated
edge is a trailing edge in a reference-area for areas generated from
this formatting object that have an is-last value
of "false". See [4.3 Spaces and Conditionality] for further details.
The initial value of the .conditionality component is "retain".
7.6.33 "padding-start"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <padding-width> | inherit |
| Initial: | 0pt |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
Specifies the width of the padding
on the start-edge of a block-area or inline-area.
See definition of property padding-top ([7.6.35 "padding-top"]).
7.6.34 "padding-end"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | <padding-width> | inherit |
| Initial: | 0pt |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
Specifies the width of the padding
on the end-edge of a block-area or inline-area.
See definition of property padding-top ([7.6.35 "padding-top"]).
7.6.35 "padding-top"
CSS2 Definition:
| Value: | <padding-width> | inherit |
| Initial: | 0pt |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-padding-top.
-
<length>
Specifies the width of the padding
on the top-edge of a block-area or inline-area.
7.6.36 "padding-bottom"
7.6.37 "padding-left"
7.6.38 "padding-right"
7.7 Common Font Properties
The following common-font-properties all are taken from
CSS2. The reference to CSS2 is: http://www.w3.org/TR/REC-CSS2/fonts.html
NOTE:
Although these properties reference the individual properties
in the CSS specification, it is recommended that you read the entire
font section of the CSS2 specification.
7.7.1 "font-family"
CSS2 Definition:
| Value: | [[ <family-name> | <generic-family>
],]* [<family-name> | <generic-family>] | inherit |
| Initial: | depends on user agent |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/fonts.html#propdef-font-family.
This property specifies a prioritized list of font family names
and/or generic family names. To deal with the problem that a single
font may not contain glyphs to display all the characters in a document,
or that not all fonts are available on all systems, this property allows
authors to specify a list of fonts, all of the same style and size,
that are tried in sequence to see if they contain a glyph for a
certain character. This list is called a font set.
The generic font family will be used if one or more of the other
fonts in a font set is unavailable. Although many fonts provide
the "missing character" glyph, typically an open box, as its name
implies this should not be considered a match except for the last
font in a font set.
There are two types of font family names:
-
<family-name>
-
The name of a font-family of choice. In the previous example,
"Baskerville", "Heisi Mincho W3", and "Symbol" are font families.
Font family names containing whitespace should be quoted. If quoting
is omitted, any whitespace characters before and after the font
name are ignored and any sequence of whitespace characters inside the
font name is converted to a single space.
-
<generic-family>
-
The following generic families are defined: "serif", "sans-serif",
"cursive", "fantasy", and "monospace". Please see the section on
generic font families for descriptions of these families. Generic
font family names are keywords, and therefore must not be quoted.
XSL modifications to the CSS definition:
-
<string>
-
The names are syntactically expressed as
strings.
NOTE:
See the expression language for a two argument
"system-font" function that returns a characteristic of a system font.
This may be used, instead of the "font" shorthand, to specify e.g.
the name of a system font.
7.7.2 "font-size"
CSS2 Definition:
| Value: | <absolute-size> | <relative-size> | <length>
| <percentage> | inherit |
| Initial: | medium |
| Applies to: | all elements |
| Inherited: | yes, the computed value is inherited |
| Percentages: | refer to parent element's font size |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/fonts.html#propdef-font-size.
This property describes the size of the font when set solid.
Values have the following meanings:
-
<absolute-size>
-
An <absolute-size> keyword refers to an entry in a table
of font sizes computed and kept by the user agent. Possible values
are:
[ xx-small | x-small | small | medium | large | x-large | xx-large
]
On a computer screen a scaling factor of 1.2 is suggested between
adjacent indexes; if the "medium" font is 12pt, the "large" font
could be 14.4pt. Different media may need different scaling factors.
Also, the user agent should take the quality and availability of fonts
into account when computing the table. The table may be different
from one font family to another. Note. In CSS1, the suggested scaling
factor between adjacent indexes was 1.5 which user experience proved
to be too large.
-
<relative-size>
-
A <relative-size> keyword is interpreted relative to
the table of font sizes and the font size of the parent element.
Possible values are:
[ larger | smaller ]
For example, if the parent element has a font size of "medium",
a value of "larger" will make the font size of the current element
be "large". If the parent element's size is not close to a table
entry, the user agent is free to interpolate between table entries
or round off to the closest one. The user agent may have to extrapolate
table values if the numerical value goes beyond the keywords.
-
<length>
-
A length value specifies an absolute font size (that is
independent of the user agent's font table). Negative lengths are
illegal.
-
<percentage>
-
A percentage value specifies an absolute font size relative
to the parent element's font size. Use of percentage values, or
values in "em's", leads to more robust and cascadable stylesheets.
The actual value of this property may differ from the computed
value due a numerical value on 'font-size-adjust' and the unavailability
of certain font sizes.
Child elements inherit the computed 'font-size' value (otherwise,
the effect of 'font-size-adjust' would compound).
7.7.3 "font-stretch"
CSS2 Definition:
| Value: | normal | wider | narrower | ultra-condensed
| extra-condensed | condensed | semi-condensed | semi-expanded |
expanded | extra-expanded | ultra-expanded |inherit |
| Initial: | normal |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/fonts.html#font-styling.
The 'font-stretch' property selects a normal, condensed, or extended
face from a font family.
-
ultra-condensed
-
extra-condensed
-
condensed
-
semi-condensed
-
normal
-
semi-expanded
-
expanded
-
extra-expanded
-
ultra-expanded
-
Absolute keyword values have the following ordering, from
narrowest to widest :
-
ultra-condensed
-
extra-condensed
-
condensed
-
semi-condensed
-
normal
-
semi-expanded
-
expanded
-
extra-expanded
-
ultra-expanded
-
wider
-
The relative keyword "wider" sets the value to the next
expanded value above the inherited value (while not increasing it
above "ultra-expanded").
-
narrower
-
The relative keyword "narrower" sets the value to the next
condensed value below the inherited value (while not decreasing
it below "ultra-condensed").
7.7.4 "font-size-adjust"
CSS2 Definition:
| Value: | <number> | none | inherit |
| Initial: | none |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/fonts.html#font-size-props.
In bicameral scripts, the subjective apparent size and legibility
of a font are less dependent on their 'font-size' value than on
the value of their 'x-height', or, more usefully, on the ratio of
these two values, called the aspect value (font size divided by
x-height). The higher the aspect value, the more likely it is that
a font at smaller sizes will be legible. Inversely, faces with a
lower aspect value will become illegible more rapidly below a given threshold
size than faces with a higher aspect value. Straightforward font
substitution that relies on font size alone may lead to illegible
characters.
For example, the popular font Verdana has an aspect value of
0.58; when Verdana's font size 100 units, its x-height is 58 units.
For comparison, Times New Roman has an aspect value of 0.46. Verdana
will therefore tend to remain legible at smaller sizes than Times New
Roman. Conversely, Verdana will often look 'too big' if substituted
for Times New Roman at a chosen size.
This property allows authors to specify an aspect value for an
element that will preserve the x-height of the first choice font
in the substitute font. Values have the following meanings:
-
none
-
Do not preserve the font's x-height.
-
<number>
-
Specifies the aspect value. The number refers to the aspect
value of the first choice font. The scaling factor for available
fonts is computed according to the following formula:
y(a/a') = c
where:
y="font-size" of first-choice font
a' = aspect value of available font
c="font-size" to apply to available font
This property allows authors to specify an aspect value
for an element that will preserve the x-height of the first choice
font in the substitute font.
Font size adjustments take place when computing the actual value
of "font-size". Since inheritance is based on the computed value,
child elements will inherit unadjusted values.
7.7.5 "font-style"
CSS2 Definition:
| Value: | normal | italic | oblique | backslant | inherit |
| Initial: | normal |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/fonts.html#font-styling.
The "font-style" property requests normal (sometimes referred
to as "roman" or "upright"), italic, and oblique faces within a
font family. Values have the following meanings:
-
normal
-
Specifies a font that is classified as "normal" in the
UA's font database.
-
oblique
-
Specifies a font that is classified as "oblique" in the
UA's font database. Fonts with Oblique, Slanted, or Incline in their
names will typically be labeled "oblique" in the font database.
A font that is labeled "oblique" in the UA's font database may actually
have been generated by electronically slanting a normal font.
-
italic
-
Specifies a font that is classified as "italic" in the
UA's font database, or, if that is not available, one labeled 'oblique'.
Fonts with Italic, Cursive, or Kursiv in their names will typically
be labeled "italic".
XSL modifications to the CSS definition:
The following value type has been added for XSL:
-
backslant
-
Specifies a font that is classified as "backslant"
in the UA's font database.
7.7.6 "font-variant"
CSS2 Definition:
| Value: | normal | small-caps | inherit |
| Initial: | normal |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/fonts.html#font-styling.
In a small-caps font, the glyphs for lowercase letters look similar
to the uppercase ones, but in a smaller size and with slightly different
proportions. The "font-variant" property requests such a font for
bicameral (having two cases, as with Roman script). This property has
no visible effect for scripts that are unicameral (having only one
case, as with most of the world's writing systems). Values have
the following meanings:
-
normal
-
Specifies a font that is not labeled as a small-caps font.
-
small-caps
-
Specifies a font that is labeled as a small-caps font.
If a genuine small-caps font is not available, user agents should
simulate a small-caps font, for example by taking a normal font
and replacing the lowercase letters by scaled uppercase characters. As
a last resort, unscaled uppercase letter glyphs in a normal font
may replace glyphs in a small-caps font so that the text appears
in all uppercase letters.
Insofar as this property causes text to be transformed
to uppercase, the same considerations as for "text-transform" apply.
7.7.7 "font-weight"
CSS2 Definition:
| Value: | normal | bold | bolder | lighter | 100 | 200
| 300 | 400 | 500 | 600 | 700 | 800 | 900 | inherit |
| Initial: | normal |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/fonts.html#font-styling.
The "font-weight" property specifies the weight of the font.
-
normal
-
Same as "400".
-
bold
-
Same as "700".
-
bolder
-
Specifies the next weight that is assigned to a font that
is darker than the inherited one. If there is no such weight, it
simply results in the next darker numerical value (and the font
remains unchanged), unless the inherited value was "900", in which case
the resulting weight is also "900".
-
lighter
-
Specifies the next weight that is assigned to a font that
is lighter than the inherited one. If there is no such weight, it
simply results in the next lighter numerical value (and the font
remains unchanged), unless the inherited value was "100", in which case
the resulting weight is also "100".
-
<integer>
-
These values form an ordered sequence, where each number
indicates a weight that is at least as dark as its predecessor.
Child elements inherit the computed value of the weight.
7.8 Common Hyphenation
Properties
7.8.1 "country"
XSL Definition:
| Value: | none | <country> | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
none
-
Indicates the country is unknown or
is not significant to the proper formatting of this object.
-
<country>
-
A country specifier in conformance with RFC 1766.
Specifies the country to be used by
the formatter in language-/locale-coupled services (line-justification
strategy, line-breaking and hyphenation).
NOTE:
This may affects line composition in
a system-dependent way.
The country may be the country component of any RFC 1766 code
(these are derived from ISO 3166).
7.8.2 "language"
XSL Definition:
| Value: | none | <language> | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
none
-
Indicates the language is unknown
or is not significant to the proper formatting of this object.
-
<language>
-
A language specifier in conformance with RFC 1766.
Specifies the language to be used
by the formatter in language-/locale-coupled services (line-justification
strategy, line-breaking, and hyphenation).
NOTE:
This may affect line composition in
a system-dependent way.
The language may be the language component of any RFC 1766 code
(these are derived from the ISO 639 language codes).
7.8.3 "script"
XSL Definition:
| Value: | none | auto | <script> | inherit |
| Initial: | auto |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
auto
-
Indicates that the script is determined
using codepoint ranges in the text of the document.
NOTE:
This provides
the automatic differentiation between Kanji, Katakana,
Hiragana, and Romanji
used in JIS-4051 and similar services in some other countries/languages.
-
none
-
Indicates the script is unknown or
is not significant to the proper formatting of this object.
-
<script>
-
A script specifier in conformance with ISO 15924.
Specifies the script to be used by
the formatter in language-/locale-coupled services (line-justification
strategy, line-breaking and hyphenation).
NOTE:
This may affect line composition
in a system-dependent way.
The script may be any ISO 15924 script code.
7.8.4 "hyphenate"
XSL Definition:
| Value: | false | true | inherit |
| Initial: | false |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
false
-
Hyphenation may not be used in the line-breaking algorithm
for the text contained in this object.
-
true
-
Hyphenation may be used in the line-breaking algorithm
for the text contained in this object.
Specifies whether hyphenation is allowed
during line-breaking when the formatter is formatting this formatting
object.
7.8.5 "hyphenation-character"
XSL Definition:
| Value: | <character> | inherit |
| Initial: | The unicode hyphen character u+2010 |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
<character>
Specifies the character to be displayed
when a hyphenation break occurs. The styling properties of this
character are those inherited from its containing flow object.
7.8.6 "hyphenation-push-character-count"
XSL Definition:
| Value: | <number> | inherit |
| Initial: | 2 |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
<integer>
-
If a negative or non-integer value is specified, it will
be rounded to the nearest integer greater than zero.
The hyphenation-push-character-count
is a positive integer specifying the minimum number of characters
in a hyphenated word after the hyphenation character. This is the minimum
number of characters in the word pushed to the next line after the
line ending with the hyphenation character.
7.8.7 "hyphenation-remain-character-count"
XSL Definition:
| Value: | <number> | inherit |
| Initial: | 2 |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
<integer>
-
If a negative or non-integer value is specified, it will
be rounded to the nearest integer greater than zero.
The hyphenation-remain-character-count
is a positive integer specifying the minimum number of characters
in a hyphenated word before the hyphenation character. This is the minimum
number of characters in the word left on the line ending with the
hyphenation character.
7.9 Common
Keeps and Breaks Properties
Page breaks only apply to descendants of the fo:flow
formatting object, and not within absolutely
positioned areas, or out-of-sequence areas.
In descendants of fo:flow formatting objects, column breaks apply,
and a column break in the last (or only) column implies a page break;
column breaks in static content apply except for those in
the last (or only) column which are ignored.
The semantics of keeps and breaks are further described in
[4.11 Keeps and Breaks].
7.9.1 "break-after"
XSL Definition:
| Value: | auto | column | page | even-page | odd-page | inherit |
| Initial: | auto |
| Applies to: | block-level formatting objects, fo:list-item, and
fo:table-row. |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values for these properties have the following meanings:
-
auto
-
No break shall be forced.
NOTE:
Page breaks may occur as determined by the formatter's
processing as affected by the "widow",
"orphan", "keep-with-next", "keep-with-previous", and "keep-together"
properties.
-
column
-
Imposes a break-after condition with a context
consisting of column-areas.
-
page
-
Imposes a break-after condition with a context
consisting of page-areas.
-
even-page
-
Imposes a break-after condition with a context consisting
of even page-areas (a blank page may be generated if necessary).
-
odd-page
-
Imposes a break-after condition with a context consisting of odd
page-areas (a blank page may be generated if necessary).
Specifies that the last area generated by formatting this
formatting object shall be the last one placed in a
particular context (e.g. page-area, column-area).
This property has no effect when it appears on an fo:table-row
formatting object in which there is any row spanning occurring
that includes both the current fo:table-row and the subsequent one.
7.9.2 "break-before"
XSL Definition:
| Value: | auto | column | page | even-page | odd-page | inherit |
| Initial: | auto |
| Applies to: | block-level formatting objects, fo:list-item, and
fo:table-row. |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
auto
-
No break shall be forced.
NOTE:
Page breaks may occur as determined by the formatter's processing
as affected by the "widow", "orphan", "keep-with-next",
"keep-with-previous",
and "keep-together" properties.
-
column
-
Imposes a break-before condition with a context
consisting of column-areas.
-
page
-
Imposes a break-before condition with a context
consisting of page-areas.
-
even-page
-
Imposes a break-before condition with a context consisting of even
page-areas (a blank page may be generated if necessary).
-
odd-page
-
Imposes a break-before condition with a context consisting of odd
page-areas (a blank page may be generated if necessary).
Specifies that the first area generated by
formatting this formatting object shall be the first one
placed in a particular context (e.g., page-area, column-area).
This property has no effect when it appears on an fo:table-row
formatting object in which there is any row spanning occurring
that includes both the current fo:table-row and the previous one.
7.9.3 "keep-with-next"
XSL Definition:
| Value: | <keep> | inherit |
| Initial: | .within-line=auto, .within-column=auto, .within-page=auto |
| Applies to: | block-level formatting objects, inline formating objects,
fo:list-item, and fo:table-row |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
This property imposes keep-with-next conditions on formatting objects.
The <keep> datatype is composed of three components: within-line,
within-column, and within-page. Different components apply to
different classes of formatting objects and provide keep conditions
relative to different contexts. In the case of the
within-line component, the keep context consists of line areas;
for the within-column component, the keep context consists of
column-areas;
for the within-page component, the keep context consists of page-areas.
In the descriptions
below, the term "appropriate context"
should be interpreted in terms of the previous sentence.
Any assignment to this property unqualified by a specific component
shall cause the ".within-column" component to be set to the given
value and the ".within-line" and ".within-page" components to be set to
"auto".
Values of the components have the following meanings:
-
auto
-
There are no keep-with-next conditions
imposed by this property.
-
always
-
Imposes a keep-with-next condition with strength "always" in the
appropriate context.
-
<integer>
-
Imposes a keep-with-next condition with strength of the given
<integer> in the appropriate context.
The semantics of keeps and breaks are further described in
[4.11 Keeps and Breaks].
7.9.4 "keep-with-previous"
XSL Definition:
| Value: | <keep> | inherit |
| Initial: | false |
| Applies to: | block-level formatting objects, inline formatting objects,
fo:list-item, and fo:table-row |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
This property imposes keep-with-previous conditions on formatting objects.
The <keep> datatype is composed of three components: within-line,
within-column, and within-page. Different components apply to
different classes of formatting objects and provide keep conditions
relative to different contexts. In the case of the
within-line component, the keep context consists of line areas;
for the within-column component, the keep context consists of
column-areas;
for the within-page component, the keep context consists of page-areas.
In the descriptions
below, the term "appropriate context"
should be interpreted in terms of the previous sentence.
Any assignment to this property unqualified by a specific component
shall cause the ".within-column" component to be set to the given
value and the ".within-line" and ".within-page" components to be set to
"auto".
Values of the components have the following meanings:
-
auto
-
There are no keep-with-previous conditions
imposed by this property.
-
always
-
Imposes a keep-with-previous condition with strength "always" in
the appropriate context.
-
<integer>
-
Imposes a keep-with-previous condition with strength of the given
<integer> in the appropriate context.
The semantics of keeps and breaks are further described in
[4.11 Keeps and Breaks].
7.10 Common Margin
Properties-Block
7.10.1 "margin-top"
CSS2 Definition:
| Value: | <margin-width> | inherit |
| Initial: | 0 |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-margin-top.
Margin-width may be one of the following:
-
auto
-
See the CSS2 section on computing
widths and margins for behavior.
-
<length>
-
Specifies a fixed width.
-
<percentage>
-
The percentage is calculated with respect to the width
of the generated box's containing block. This is true for 'margin-top'
and 'margin-bottom', except in the page context, where percentages
refer to page box height.
Negative values for margin properties
are allowed, but there may be implementation-specific limits.
Sets the top margin of a box.
XSL modifications to the CSS definition:
7.10.2 "margin-bottom"
CSS2 Definition:
| Value: | <margin-width> | inherit |
| Initial: | 0 |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-margin-bottom.
Margin-width may be one of the
following:
-
auto
-
See the CSS2 section on computing
widths and margins for behavior.
-
<length>
-
Specifies a fixed width.
-
<percentage>
-
The percentage is calculated with respect to the width
of the generated box's containing block. This is true for 'margin-top'
and 'margin-bottom', except in the page context, where percentages
refer to page box height.
Negative values for margin properties
are allowed, but there may be implementation-specific limits.
Sets the bottom margin of a box.
XSL modifications to the CSS definition:
7.10.3 "margin-left"
CSS2 Definition:
| Value: | <margin-width> | inherit |
| Initial: | 0pt |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-margin-left.
Margin-width may be one of the
following:
-
auto
-
See the CSS2 section on computing
widths and margins for behavior.
-
<length>
-
Specifies a fixed width.
-
<percentage>
-
The percentage is calculated with respect to the width
of the generated box's containing block. This is true for 'margin-top'
and 'margin-bottom', except in the page context, where percentages
refer to page box height.
Negative values for margin properties
are allowed, but there may be implementation-specific limits.
Sets the left margin of a box.
XSL modifications to the CSS definition:
7.10.4 "margin-right"
CSS2 Definition:
| Value: | <margin-width> | inherit |
| Initial: | 0pt |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-margin-right.
Margin-width may be one of the
following:
-
auto
-
See the CSS2 section on computing
widths and margins for behavior.
-
<length>
-
Specifies a fixed width.
-
<percentage>
-
The percentage is calculated with respect to the width
of the generated box's containing block. This is true for 'margin-top'
and 'margin-bottom', except in the page context, where percentages
refer to page box height.
Negative values for margin properties
are allowed, but there may be implementation-specific limits.
Sets the right margin of a box.
XSL modifications to the CSS definition:
7.10.5 "space-before"
XSL Definition:
| Value: | <space> | inherit |
| Initial: | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 |
| Applies to: | all block-level formatting objects |
| Inherited: | no |
| Percentages: | N/A (Differs from margin-top in CSS) |
| Media: | visual |
Values have the following meanings:
-
<space>
-
Specifies the minimum, optimum, and maximum values
for the space before any areas generated by this formatting object
and the conditionality and precedence of this space.
Specifies the value of the space-specifier for the space before
the areas generated by this formatting object.
A definition of space-specifiers, and
the interaction between space-specifiers occuring in sequence are
given in [4.3 Spaces and Conditionality].
NOTE:
A common example of such a sequence is the "space-after" on
one area and the "space-before" of its next sibling.
7.10.6 "space-after"
XSL Definition:
| Value: | <space> | inherit |
| Initial: | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 |
| Applies to: | all block-level formatting objects |
| Inherited: | no |
| Percentages: | N/A (Differs from margin-bottom in CSS) |
| Media: | visual |
Values have the following meanings:
-
<space>
-
Specifies the minimum, optimum, and maximum values
for the space after any areas generated by this formatting object
and the conditionality and precedence of this space.
Specifies the value of the space-specifier for the space after
the areas generated by this formatting object.
A definition of space-specifiers, and
the interaction between space-specifiers occuring in sequence are
given in [4.3 Spaces and Conditionality].
NOTE:
A common example of such a sequence is the "space-after" on
one area and the "space-before" of its next sibling.
7.10.7 "start-indent"
XSL Definition:
| Value: | <length> | inherit |
| Initial: | 0pt |
| Applies to: | all block-level formatting objects |
| Inherited: | yes |
| Percentages: | refer to width of containing reference-area |
| Media: | visual |
Values have the following meanings:
-
<length>
-
For each block-area generated by this formatting object, specifies the
distance from the start-edge of the content-rectangle of the containing
reference-area to the start-edge of the content-rectangle of that
block-area.
This property may have a negative value, which indicates an outdent.
7.10.8 "end-indent"
XSL Definition:
| Value: | <length> | inherit |
| Initial: | 0pt |
| Applies to: | all block-level formatting objects |
| Inherited: | yes |
| Percentages: | refer to width of containing reference-area |
| Media: | visual |
Values have the following meanings:
-
<length>
-
For each block-area generated by this formatting object, specifies the
distance from the end-edge of the content-rectangle of
that block-area
to the end-edge of the content-rectangle of the containing
reference-area.
This property may have a negative value, which indicates an outdent.
7.11 Common
Margin Properties-Inline
This group also includes all the properties in the common-margin-properties-block
group except space-before, space-after, start-indent, and
end-indent.
7.11.1 "space-end"
XSL Definition:
| Value: | <space> | inherit |
| Initial: | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 |
| Applies to: | all inline-level formatting objects |
| Inherited: | no |
| Percentages: | refer to the width of the containing area |
| Media: | visual |
Values have the following meanings:
-
<space>
-
Specifies the minimum, optimum, and maximum values
for the space after any areas generated by this formatting object
and the conditionality and precedence of this space.
Specifies the value of the space-specifier for the space after
the areas generated by this formatting object.
A definition of space-specifiers, and
the interaction between space-specifiers occuring in sequence are
given in [4.3 Spaces and Conditionality].
NOTE:
A common example of such a sequence is the "space-end" on
one area and the "space-start" of its next sibling.
7.11.2 "space-start"
XSL Definition:
| Value: | <space> | inherit |
| Initial: | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 |
| Applies to: | all inline-level formatting objects |
| Inherited: | no |
| Percentages: | refer to the width of the containing area |
| Media: | visual |
Values have the following meanings:
-
<space>
-
Specifies the minimum, optimum, and maximum values
for the space before any areas generated by this formatting object
and the conditionality and precedence of this space.
Specifies the value of the space-specifier for the space before
the areas generated by this formatting object.
A definition of space-specifiers, and
the interaction between space-specifiers occuring in sequence are
given in [4.3 Spaces and Conditionality].
NOTE:
A common example of such a sequence is the "space-end" on
one area and the "space-start" of its next sibling.
7.12 Pagination and Layout Properties
The following pagination and layout properties are all
XSL only.
7.12.1 "column-count"
XSL Definition:
| Value: | <number> | inherit |
| Initial: | 1 |
| Applies to: | fo:body-region |
| Inherited: | no |
| Percentages: | N/A |
| Media: | paged |
Values have the following meanings:
-
<integer>
-
A positive integer. If a negative or non-integer value
is provided, the value will be rounded to the nearest integer value
greater than or equal to 1.
Specifies the number of columns in
the region.
A value of 1 indicates that this is not a multi-column region.
7.12.2 "column-gap"
XSL Definition:
| Value: | <length> | <percentage> | inherit |
| Initial: | 12.0pt |
| Applies to: | fo:region-body |
| Inherited: | no |
| Percentages: | refer to width of the region being divided into columns. |
| Media: | paged |
Values have the following meanings:
-
<length>
-
This is an unsigned length. If a negative value has been
specified a value of 0pt will be used.
-
<percentage>
-
The value is a percentage of the inline-progression-dimension
of the content rectangle of the region.
Specifies the width of the
separation between adjacent columns in a multi-column region.
See the description in [6.4.12 fo:region-body] for further details.
7.12.3 "extent"
XSL Definition:
| Value: | <length> | <percentage> | inherit |
| Initial: | 0.0pt |
| Applies to: | fo:region-before, fo:region-after, fo:region-start, fo:region-end |
| Inherited: | no |
| Percentages: | refer to the corresponding height or width of the page
region. |
| Media: | paged |
Values have the following meanings:
-
<length>
-
This is an unsigned length. If a negative value has been
specified a value of 0pt will be used.
-
<percentage>
-
The value is a percentage of corresponding height or width of
the page.
Specifies the
width
of the region-start
or region-end or the
height
of the region-before or region-after.
7.12.4 "flow-name"
XSL Definition:
| Value: | <name> |
| Initial: | an empty name |
| Applies to: | fo:flow, fo:static-content |
| Inherited: | no, a value is required |
| Percentages: | N/A |
| Media: | paged |
Values have the following meanings:
-
<name>
-
Names used as identifiers must be unique within
an fo:page-sequence.
If the name is empty or if a name-conflict is
encountered, an
error shall be reported. A
processor may then
continue processing.
Defines the name of the flow.
The flow-name and region-name are used to assign the flow's content
(or static-content's content) to a specific region or series of
regions in the layout. In XSL this is done by specifying
the name of the target region as the flow-name. (For example, text placed
in the body-region would specify
flow-name="xsl-region-body".)
7.12.5 "master-name"
XSL Definition:
| Value: | <name> |
| Initial: | an empty name |
| Applies to: | fo:page-sequence,
fo:simple-page-master,
fo:page-sequence-master, fo:single-page-master-reference,
fo:repeatable-page-master-reference, fo:conditional-page-master-reference |
| Inherited: | no, a value is required |
| Percentages: | N/A |
| Media: | paged |
Values have the following meanings:
-
<name>
-
Names used as master identifiers may not be empty and must
be unique.
Uses of the name to reference a given named object need not be
unique, but may not be empty and must refer to a master-name that
exists within the document.
This property is used for two purposes:
-
Identifying a master:
If this property is specified on an fo:simple-page-master, it
provides an identifying name of the master. This name is subsequently
referenced as the value of properties on the following formatting objects:
fo:single-page-master-reference, fo:repeatable-page-master-reference,
and fo:conditional-page-master-reference to request the use of this master
when creating a page instance. It may also be used on an fo:page-sequence
to specify the use of this master when creating page instances.
If this property is specifed on an fo:page-sequence-master, it
provides an identifying name of the master. This name is
subsequently referenced as the value of properties on the fo:page-sequence
to request the use of this page-sequence-master when creating page instances.
A master-name must be unique across all page-masters,
and page-sequence-masters.
If the name is empty or if a name-conflict is
encountered, an
error shall be reported. A
processor may then
continue processing.
-
Selecting a master:
-
If this property is specified on the fo:page-sequence
it specifies the name of the page-sequence-master or page-master
to be used to create pages in the sequence.
-
If this property is specified on the fo:single-page-master-reference,
it specifies the name of the page-master to be used to create a
single page instance.
-
If this property is specified on the fo:repeatable-page-master-reference,
it specifies the name of the page-master to be used in repetition
until the content is exhausted or the maximum-repeats limit is reached,
whichever occurs first.
-
If this property is specified on the fo:conditional-page-master-reference,
it specifies the name of the page-master to be used whenever this
alternative is chosen.
If the name is empty or if a name-conflict is
encountered, an
error shall be reported. A
processor may then
continue processing.
7.12.6 "region-name"
XSL Definition:
| Value: | xsl-region-body | xsl-region-start | xsl-region-end
| xsl-region-before | xsl-region-after | <name> |
| Initial: | see prose |
| Applies to: | fo:region-body, fo:region-start, fo:region-end, fo:region-before,
and fo:region-after |
| Inherited: | no, a value is required |
| Percentages: | N/A |
| Media: | paged |
Values have the following meanings:
-
xsl-region-body
-
Reserved region-name for use as default name of fo:region-body.
This name may not be used on any other class of region.
-
xsl-region-start
-
Reserved region-name for use as default name of fo:region-start.
This name may not be used on any other class of region.
-
xsl-region-end
-
Reserved region-name for use as default name of fo:region-end.
This name may not be used on any other class of region.
-
xsl-region-before
-
Reserved region-name for use as default name of fo:region-before.
This name may not be used on any other class of region.
-
xsl-region-after
-
Reserved region-name for use as default name of fo:region-after.
This name may not be used on any other class of region.
-
<name>
-
Names used as identifiers must be unique within a page master.
This property is used to identify
a region within a simple-page-master.
The "region-name" may be used to differentiate a region that
lies on a page-master for an odd page from a region that
lies on a page-master for an even page. In this usage, once a name is used
for a specific class
of region (start, end, before, after, or body), that name may only
be used for regions of the same class in any other page-master.
The reserved names may only be used in the manner described above.
7.12.7 "initial-page-number"
XSL Definition:
| Value: | auto | auto-odd | auto-even | <number> | inherit |
| Initial: | auto |
| Applies to: | fo:page-sequence |
| Inherited: | no |
| Percentages: | N/A |
| Media: | paged |
Values have the following meanings:
-
auto
-
The initial number shall be set to 1 if no previous fo:page-sequence
exists in the document.
If a preceding page-sequence exists, the initial number
will
be one greater than the last number for that sequence.
-
auto-odd
-
A value is determined in the same manner as for "auto".
If that value is an even number 1 is added.
-
auto-even
-
A value is determined in the same manner as for "auto".
If that value is an odd number 1 is added.
-
<integer>
-
A positive integer. If a negative or non-integer value
is provided, the value will be rounded to the nearest integer value
greater than or equal to 1.
Sets the initial page number to be used on this page-sequence.
7.12.8 "force-page-count"
XSL Definition:
| Value: | auto | even | odd | end-on-even | end-on-odd | no-force
| inherit |
| Initial: | auto |
| Applies to: | fo:page-sequence |
| Inherited: | no |
| Percentages: | N/A |
| Media: | paged |
Force-page-count is used to impose a constraint on
the
number of pages in a page-sequence. In the event that this
constraint
is not satisfied, an additional page will be added to the end of
the sequence. This page becomes the "last" page of that sequence.
The values have the following meanings:
-
auto
-
Force the last page in this page-sequence to be an odd page
if the initial-page-number of the next page-sequence is even.
Force it to be an even page if the initial-page-number of the
next page-sequence is odd. If there is no next page-sequence or if the
value of its initial-page-number is "auto" do not force any page.
-
even
-
Force an even number of pages in this
page-sequence.
-
odd
-
Force an odd number of pages in this
page-sequence.
-
end-on-even
-
Force the last page in this page-sequence to be an even page.
-
end-on-odd
-
Force the last page in this page-sequence to be an odd page.
-
no-force
-
Do not force either an even or an odd number of pages in
this page-sequence
7.12.9 "maximum-repeats"
XSL Definition:
| Value: | <number> | no-limit | inherit |
| Initial: | no-limit |
| Applies to: | fo:repeatable-page-master-reference, fo:repeatable-page-master-alternatives |
| Inherited: | no |
| Percentages: | N/A |
| Media: | paged |
Specifies the constraint on the maximum number of pages
in the subsequence of pages that may be generated by an
fo:page-sequence
that uses the fo:repeatable-page-master-reference or
fo:repeatable-page-master-alternatives
on which this property is specified.
The values have the following meanings:
-
no-limit
-
No constraint is specified.
-
<integer>
-
The maximum number of pages in the subsequence.
The value is an integer greater than or equal to 0.
If a fractional value or a value less than 0 is specified, it
will be rounded to the nearest integer greater than or equal to
0.
A value of 0 indicates this master-reference will not be used.
If this property is not supported, it shall be treated
as if "no-limit" had been specified.
7.12.10 "page-position"
XSL Definition:
| Value: | first | last | rest | any | inherit |
| Initial: | any |
| Applies to: | fo:conditional-page-master-reference |
| Inherited: | no |
| Percentages: | N/A |
| Media: | paged |
This property forms part of a selection rule to determine
if the referenced page-master is eligible for selection at
this point in the page-sequence.
The values have the following meanings:
-
first
-
This master is eligible for selection if this is the first
page in the page-sequence.
-
last
-
This master is eligible for selection if this is the last
page in the page-sequence.
-
rest
-
This master is eligible for selection if this is not the
first page nor the last page in the page-sequence.
-
any
-
This master is eligible for selection regardless of page
positioning within the page-sequence.
If this property is not supported, it shall be treated
as if "any" had been specified.
7.12.11 "odd-or-even"
XSL Definition:
| Value: | odd | even | any | inherit |
| Initial: | any |
| Applies to: | fo:conditional-page-master-reference |
| Inherited: | no |
| Percentages: | N/A |
| Media: | paged |
This property forms part of a selection rule to determine
if the referenced page-master is eligible for selection at
this point in the page-sequence.
The values have the following meanings:
-
odd
-
This master is eligible for selection if the page number is
odd.
-
even
-
This master is eligible for selection if the page number is
even.
-
any
-
This master is eligible for selection regardless of whether
the page number is odd or even.
If this property is not supported, it shall be treated
as if "any" had been specified.
7.12.12 "blank-or-not-blank"
XSL Definition:
| Value: | blank | not-blank | any | inherit |
| Initial: | any |
| Applies to: | fo:conditional-page-master-reference |
| Inherited: | no |
| Percentages: | N/A |
| Media: | paged |
This property forms part of a selection rule to determine
if the referenced page-master is eligible for selection at
this point in the page-sequence.
The values have the following meanings:
-
blank
-
This master is eligible for selection if a page
must be generated (e.g., to maintain proper page parity
at the start or end of the page sequence) and there are
no areas from the fo:flow to be put on that page.
-
not-blank
-
This master is eligible for selection if this page
contains areas from the fo:flow.
-
any
-
This master is always eligible for selection.
7.12.13 "page-height"
XSL Definition:
| Value: | auto | indefinite | <length> | inherit |
| Initial: | auto |
| Applies to: | fo:simple-page-master |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
auto
-
The "page-height" shall be determined
by the formatter from the height of the media or browser window.
If media information is not available this dimension shall be implementation
defined.
NOTE:
A fallback to 11.0in would fit
on both 8+1/2x11 and A4 pages).
-
indefinite
-
The height of the page is determined
from the size of the laid-out content.
"Page-width" and "page-height" may not both be set to "indefinite".
Should that occur,
the dimension that is parallel to the block-progression-direction,
as determined by the "reference-oritentation" and "writing-mode"
on the fo:simple-page-master, of the page-level reference-area
will remain "indefinite" and the other will revert to "auto".
-
<length>
-
Specifies a fixed height for the page.
Specifies the height of a page-area.
7.12.14 "page-width"
XSL Definition:
| Value: | auto | indefinite | <length> | inherit |
| Initial: | auto |
| Applies to: | fo:simple-page-master |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
auto
-
The "page-width" shall be determined
by the formatter from the width of the media or browser window.
If media information is not available this dimension shall be implementation
defined.
NOTE:
A fallback to 8.26in would fit
on both 8+1/2x11 and A4 pages).
-
indefinite
-
The width of the page is determined
from the size of the laid-out content.
"Page-width" and "page-height" properties may not both be set
to "indefinite". Should that occur,
the dimension that is parallel to the block-progression-direction,
as determined by the "reference-oritentation" and "writing-mode"
on the fo:simple-page-master, of the page-level reference-area
will remain "indefinite" and the other will revert to "auto".
-
<length>
-
Specifies a fixed width for the
page-area.
Specifies the width of a page-area.
7.12.15 "precedence"
XSL Definition:
| Value: | true | false | inherit |
| Initial: | false |
| Applies to: | fo:before-region, fo:after-region, fo:start-region, fo:end-region |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
false
-
A value of false specifies that this region does not extend
to the page margins. This region has the same width or height as
the body.
-
true
-
A value of true specifies that this region takes precedence
and extends across the full size of the page or view.
Specifies which region (i.e., region-before,
region-after, region-start, or region-end) takes precedence in terms
of which may extend into the corners of the simple-page-master.
If both adjacent regions have equal precedence, the before-region
or after-region is treated as if 'true' had been specified and the
start-region or end-region will be treated as if 'false' had been
specified.
7.13 Table Properties
7.13.1 "border-collapse"
CSS2 Definition:
| Value: | collapse | separate | inherit |
| Initial: | collapse |
| Applies to: | table |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/tables.html#propdef-border-collapse.
-
collapse
-
The value "collapse" selects the collapsing borders model.
-
separate
-
The value "separate" selects the separated borders border
model.
This property selects a table's border model. The value "separate"
selects the separated borders border model. The value "collapse"
selects the collapsing borders model.
7.13.2 "border-separation"
XSL Definition:
| Value: | <length-bp-ip-direction> | inherit |
| Initial: | .block-progression-direction="0pt" .inline-progression-direction="0pt" |
| Applies to: | table |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
-
<length>
The lengths specify the distance that separates adjacent cell
borders in the row stacking direction
(given by the block-progression-direction of the table),
and in the column stacking direction
(given by the inline-progression-direction of the table).
In the separate borders model, each cell has an individual border.
The "border-separation" property specifies the distance between the
borders of adjacent cells. This space is filled with the background
of the table element. Rows, columns, row groups, and column groups cannot
have borders (i.e., user agents must ignore the border properties
for those elements).
7.13.3 "caption-side"
CSS2 Definition:
| Value: | before | after | start | end | top | bottom | left | right | inherit |
| Initial: | before |
| Applies to: | fo:table-caption |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/tables.html#q6.
-
top
-
Positions the caption box above the table box.
-
bottom
-
Positions the caption box below the table box.
-
left
-
Positions the caption box to the left of the table box.
-
right
-
Positions the caption box to the right of the table box.
This property specifies the position of the caption box with
respect to the table box.
Captions above or below a "table" element are formatted very
much as if they were a block element before or after the table,
except that (1) they inherit inheritable properties from the table,
and (2) they are not considered to be a block box for the purposes
of any "compact" or "run-in" element that may precede the table.
A caption that is above or below a table box also behaves like
a block box for width calculations; the width is computed with respect
to the width of the table box's containing block.
For a caption that is on the left or right side of a table box,
on the other hand, a value other than "auto" for "width" sets the
width explicitly, but "auto" tells the user agent to chose a "reasonable
width". This may vary between "the narrowest possible box" to "a
single line", so we recommend that users do not specify "auto" for
left and right caption widths.
To align caption content horizontally within the caption box,
use the "text-align" property. For vertical alignment of a left
or right caption box with respect to the table box, use the "vertical-align"
property. The only meaningful values in this case are "top", "middle",
and "bottom". All other values are treated the same as "top".
XSL modifications to the CSS definition:
Insert the following writing-mode relative values:
-
before
-
Positions the caption before the table in the block-progression-direction.
-
after
-
Positions the caption after the table in the block-progression-direction.
-
start
-
Positions the caption before the table in the inline-progression-direction.
-
end
-
Positions the caption after the table in the inline-progression-direction.
The CSS qualifications (1) and (2) do not apply.
7.13.4 "column-number"
XSL Definition:
| Value: | <number> |
| Initial: | see prose |
| Applies to: | fo:table-column, fo:table-cell |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
-
<integer>
-
A positive integer. If a negative or non-integer value
is provided, the value will be rounded to the nearest integer value
greater than or equal to 1.
For an fo:table-column formatting object, it
specifies
the column-number of the table cells that may use
properties
from this fo:table-column formatting object by using
the from-table-column() function.
The initial
value is
1 plus the column-number of the previous table-column, if there
is a previous table-column, and otherwise 1.
For an fo:table-cell it specifies the number of the first column
to be spanned by the table-cell. The initial value is the current
column-number. For the first table-cell in a table-row, the
current
column number is 1. For other table-cells, the current column-number
is the column-number of the previous table-cell in the row plus
the number of columns spanned by that previous cell.
7.13.5 "column-width"
XSL Definition:
| Value: | <length> |
| Initial: | undefined |
| Applies to: | fo:table-column |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
-
<length>
The "column-width" property specifies the width of the
column whose value is given by the "column-number" property. This
property, if present, is ignored if the "number-columns-spanned" property
is greater than 1. The "width" property must be specified for every column,
unless the automatic table layout is used.
7.13.6 "empty-cells"
CSS2 Definition:
| Value: | show | hide | inherit |
| Initial: | show |
| Applies to: | table-cell |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/tables.html#propdef-empty-cells.
-
show
-
When this property has the value "show", borders are drawn
around empty cells (like normal cells).
-
hide
-
A value of "hide" means that no borders are drawn around
empty cells. Furthermore, if all the cells in a row have a value
of "hide" and have no visible content, the entire row behaves as
if it had "display: none".
In the separated borders model, this property controls the rendering
of borders around cells that have no visible content. Empty cells
and cells with the "visibility" property set to "hidden" are considered
to have no visible content. Visible content includes "& " (non-breaking-space)
and other whitespace except ASCII CR ("\0D"), LF ("\0A"), tab ("\09"),
and space ("\20").
7.13.7 "table-layout"
CSS2 Definition:
| Value: | auto | fixed | inherit |
| Initial: | auto |
| Applies to: | table |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/tables.html#propdef-table-layout.
-
fixed
-
Use the fixed table layout algorithm
-
auto
-
Use any automatic table layout algorithm
The "table-layout" property controls the algorithm used to lay
out the table cells, rows, and columns.
7.13.8 "table-omit-header-at-break"
XSL Definition:
| Value: | yes | no |
| Initial: | no |
| Applies to: | fo:table |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
-
yes
-
This property specifies that the header should be omitted.
-
no
-
This property specifies that the header should not be omitted.
The "table-omit-header-at-break" property
specifies if a
table whose first area is not at the beginning of an area produced
by the table should start with the content of the fo:table-header
formatting object or not.
7.13.9 "table-omit-footer-at-break"
XSL Definition:
| Value: | yes | no |
| Initial: | no |
| Applies to: | fo:table |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
-
yes
-
This property specifies that the footer should be omitted.
-
no
-
This property specifies that the footer should not be omitted.
The "table-omit-footer-at-break" property
specifies if a
table whose last area is not at the end of an area produced by the
table should end with the content of the fo:table-header formatting object
or not.
7.13.10 "number-columns-spanned"
XSL Definition:
| Value: | <number> |
| Initial: | 1 |
| Applies to: | fo:table-column, fo:table-cell |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
-
<integer>
-
A positive integer. If a negative or non-integer value
is provided, the value will be rounded to the nearest integer value
greater than or equal to 1.
For an fo:table-column the "number-columns-spanned" property
specifies the number of columns spanned by table-cells that may use
properties from this fo:table-column
formatting object using the from-table-column() function.
For an fo:table-cell the "number-columns-spanned" property specifies
the number of columns which this cell spans in the column-progression-direction
starting with the current column.
7.13.11 "number-rows-spanned"
XSL Definition:
| Value: | <number> |
| Initial: | 1 |
| Applies to: | fo:table-cell |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
-
<integer>
-
A positive integer. If a negative or non-integer value
is provided, the value will be rounded to the nearest integer value
greater than or equal to 1.
The "number-rows-spanned" property specifies the number of rows
which this cell spans in the row-progression-direction starting
with the current row.
7.13.12 "number-columns-repeated"
XSL Definition:
| Value: | <number> |
| Initial: | 1 |
| Applies to: | fo:table-column |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
-
<integer>
-
A positive integer. If a negative or non-integer value
is provided, the value will be rounded to the nearest integer value
greater than or equal to 1.
The "number-columns-repeated" property specifies the repetition
of a table-column specification n times; with the same effect as
if the fo:table-column formatting object had been repeated n times
in the result tree. The "column-number" property, for all but the
first, is the column-number of the previous one plus its value of
the "number-columns-spanned" property.
NOTE:
This handles HTML's "colgroup" element.
7.13.13 "ends-row"
XSL Definition:
| Value: | yes | no |
| Initial: | no |
| Applies to: | fo:table-cell |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
-
yes
-
This cell ends a row.
-
no
-
This cell does not end a row.
Specifies whether this cell ends a row. This is only allowed
for table-cells that are not in table-rows.
7.13.14 "starts-row"
XSL Definition:
| Value: | yes | no |
| Initial: | no |
| Applies to: | fo:table-cell |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
-
yes
-
This cell starts a row.
-
no
-
This cell does not start a row.
Specifies whether this cell starts a row. This is only
allowed for table-cells that are not in table-rows.
NOTE:
The "starts-row" and "ends-row" properties
with a "yes" value are
typically used when the input data does not have elements containing
the cells in each row, but instead, for example, each row starts
at elements of a particular type.
7.14 Character Properties
7.14.1 "character"
XSL Definition:
| Value: | <string> |
| Initial: | N/A, value is required |
| Applies to: | fo:character |
| Inherited: | no, a value is required |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
<character>
Specifies the Unicode character
to be presented.
7.14.2 "letter-spacing"
CSS2 Definition:
| Value: | normal | <length> | <space> | inherit |
| Initial: | normal |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/text.html#propdef-letter-spacing.
This property specifies spacing behavior between text
characters. Values have the following meanings:
-
normal
-
The spacing is the normal spacing for the current font.
This value allows the user agent to alter the space between characters
in order to justify text.
-
<length>
-
This value indicates inter-character space in addition
to the default space between characters. Values may be negative,
but there may be implementation-specific limits. User agents may
not further increase or decrease the inter-character space in order
to justify text.
Character-spacing algorithms are user agent
dependent.
Character spacing may also be influenced by justification (see the
"text-align" property).
When the resultant space between two characters is not the same
as the default space, user agents should not use ligatures.
Conforming user agents may consider the value of the 'letter-spacing'
property to be 'normal'.
XSL modifications to the CSS definition:
The following value type has been added for XSL:
-
<space>
-
This allows the user to specify a range of adjustments
in addition to the default space between characters.
The minimum
and maximum values specify the limits of the adjustment.
Default space between characters is defined to be 0pt, i.e.
glyph areas stacked with no extra space between the allocation
rectangles of the glyph areas.
The actual-inline-progression-dimension
of the glyph area is obtained by formatting the fo:character.
For an fo:character that in the Unicode database is
classified as "Alphabetic"
the start-space and end-space traits are each set to a value
as follows:
-
For "normal":
.optimum = "the normal spacing for the current font" / 2,
.maximum = auto,
.minimum = auto,
.precedence = force, and
.conditionality = discard. A value of auto for a component implies
that the limits are User Agent specific.
-
For a <length>:
.optimum = <length> / 2,
.maximum = .optimum,
.minimum = .optimum,
.precedence = force, and
.conditionality = discard.
-
For a <space>:
a value that is half the value of the "letter-spacing"
property
for the numeric components and the value for the .precedence and
.conditionality components.
The initial values for .precedence is "force" and
for .conditionality "discard".
The CSS statement that "Conforming user agents may consider the
value of the 'letter-spacing' property to be 'normal'." does not apply
in XSL, if the User Agent implements the "Extended" property set.
NOTE:
If it is desired that the letter-space combine with other spaces that have
less than forcing precedence, then the value of the letter-space should
be specified as a <space> with precedence less than force which
implies that space combines according to the space resolution
rules described in [4.3 Spaces and Conditionality].
The algorithm for resolving the adjusted values between word-spacing
and letter-spacing is user agent dependent.
7.14.3 "word-spacing"
CSS2 Definition:
| Value: | normal | <length> | <space> | inherit |
| Initial: | normal |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/text.html#propdef-word-spacing.
This property specifies spacing behavior between words.
Values have the following meanings:
-
normal
-
The normal inter-word space, as defined by the current
font and/or the UA.
-
<length>
-
This value indicates inter-word space in addition to the
default space between words. Values may be negative, but there may
be implementation-specific limits.
Word spacing algorithms are user agent-dependent. Word
spacing is also influenced by justification (see the 'text-align'
property).
XSL modifications to the CSS definition:
The following value type has been added for XSL:
-
<space>
-
This allows the user to specify a range of adjustments
in addition to the default space between words.
The minimum
and maximum values specify the limits of the adjustment.
Default space between words is defined to be
the actual-inline-progression-dimension
of the glyph area obtained by formatting the current
fo:character whose
treat-as-wordspace trait has the value "yes".
For fo:character whose treat-as-word-space trait has the value "yes",
the start-space and end-space traits are each set to a value
as follows:
-
For "normal":
.optimum = ("the normal inter-word-space, as defined by the
current font and/or the UA" - "the actual-inline-progression-dimension
of the glyph area obtained by formatting the fo:character") / 2,
.maximum = .optimum,
.minimum = .optimum,
.precedence = force, and
.conditionality = discard.
-
For a <length>:
.optimum = <length> / 2,
.maximum = .optimum,
.minimum = .optimum,
.precedence = force, and
.conditionality = discard.
-
For a <space>:
a value that is half the value of the "word-spacing"
property
for the numeric components and the value for the .precedence and
.conditionality components.
The initial values for .precedence is "force" and
for .conditionality "discard".
NOTE:
If it is desired that the word-space combine with other spaces that have
less than forcing precedence, then the value of the word-space should
be specified as a <space> with precedence less than force which
implies that space combines according to the space resolution
rules described in [4.3 Spaces and Conditionality].
The algorithm for resolving the adjusted values between word-spacing
and letter-spacing is user agent dependent.
NOTE:
The "word-spacing" property only affects the
placement of glyphs
and not the shape that may be associated with the characters. For example,
adjusting a "_" treated as a word-space does not lengthen or
shorten the
"_" glyph.
7.14.4 "treat-as-word-space"
XSL Definition:
| Value: | auto | yes | no | inherit |
| Initial: | auto |
| Applies to: | fo:character |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
This property determines if the character shall be treated
as a word-space or as a normal letter.
This property has the following values:
-
auto
-
The value of this property is determined by the Unicode
codepoint for the character.
As the default behavior:
-
The characters at codepoints u+0020 and u+00a0 are
treated as if 'yes' had been specified. All other characters are
treated as if 'no' had been specified.
-
This property does not automatically apply word-spacing
to the fixed spaces (u+2000 through u+200a) or the ideographic-space
(u+3000).
-
This default behavior can be overridden by
information in the font used for formatting the character,
which can specify additional characters that may be
treated as "word-spaces".
-
yes
-
This inline-progression-dimension of the character
shall be adjusted as described in
the "word-spacing" property.
-
no
-
This character shall not have a word-spacing adjustment
applied.
7.14.5 "suppress-at-line-break"
XSL Definition:
| Value: | auto | suppress | retain | inherit |
| Initial: | auto |
| Applies to: | fo:character |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Issue (suppress-at-line-break):
This property needs review and rewording
to fit in with the model.
This property determines if the character's presentation
shall be suppressed if it appears as the last non-control character
in a line.
This property has the following values:
-
auto
-
The value of this property is determined by the Unicode
codepoint for the character. The character at codepoints u+0020
is treated as if 'yes' had been specified. All other characters
are treated as if 'no' had been specified.
This property does not automatically suppress the presentation
of the non-breaking-space (u+00a0), the fixed spaces (U+2000 through
u+200a), or the ideographic-space (u+3000).
-
suppress
-
If this character is the last visibly renderable (non-control)
character in the line (preceding either a hard or a soft line-break),
then its glyph representation shall not be presented and its width
shall not be considered in the line justification.
If multiple suppressible characters are present at the end of
the line, the are all suppressed.
-
retain
-
This character shall be presented if it is the last visibly
renderable (non-control) character in the line.
7.14.6 "text-decoration"
CSS2 Definition:
| Value: | none | [ underline || overline || line-through
|| blink ] | inherit |
| Initial: | none |
| Applies to: | all elements |
| Inherited: | no, but see prose |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/text.html#propdef-text-decoration.
This property describes decorations that are added to
the text of an element. If the property is specified for a block-level
element, it affects all inline-level descendants of the element. If
it is specified for (or affects) an inline-level element, it affects
all boxes generated by the element. If the element has no content
or no text content (e.g., the IMG element in HTML), user agents
must ignore this property.
Values have the following meanings:
-
none
-
Produces no text decoration.
-
underline
-
Each line of text is underlined.
-
overline
-
Each line of text has a line above it.
-
line-through
-
Each line of text has a line through the middle
-
blink
-
Text blinks (alternates between visible and invisible).
Conforming user agents are not required to support this value.
The color(s) required for the text decoration should be
derived from the "color" property value.
This property is not inherited, but descendant boxes of a block
box should be formatted with the same decoration (e.g., they should
all be underlined). The color of decorations should remain the same
even if descendant elements have different "color" values.
XSL modifications to the CSS definition:
NOTE:
To specify multiple text-decorations on the same span of text,
use nested fo:inline objects.
7.14.7 "text-shadow"
CSS2 Definition:
| Value: | none | [<color> || <length> <length> <length>?
,]* [<color> || <length> <length> <length>?] | inherit |
| Initial: | none |
| Applies to: | all elements |
| Inherited: | no, see prose |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/text.html#propdef-text-shadow.
This property accepts a comma-separated list of shadow
effects to be applied to the text of the element. The shadow effects
are applied in the order specified and may thus overlay each other,
but they will never overlay the text itself. Shadow effects do not
alter the size of a box, but may extend beyond its boundaries. The
stack level of the shadow effects is the same as for the element
itself.
Each shadow effect must specify a shadow offset and may optionally
specify a blur radius and a shadow color.
A shadow offset is specified with two "length" values that indicate
the distance from the text. The first length value specifies the
horizontal distance to the right of the text. A negative horizontal
length value places the shadow to the left of the text. The second length
value specifies the vertical distance below the text. A negative
vertical length value places the shadow above the text.
A blur radius may optionally be specified after the shadow offset.
The blur radius is a length value that indicates the boundaries
of the blur effect. The exact algorithm for computing the blur effect
is not specified.
A color value may optionally be specified before or after the
length values of the shadow effect. The color value will be used
as the basis for the shadow effect. If no color is specified, the
value of the "color" property will be used instead.
7.14.8 "text-transform"
CSS2 Definition:
| Value: | capitalize | uppercase | lowercase | none | |
| Initial: | none |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/text.html#propdef-text-transform.
This property controls capitalization effects of an element's
text. Values have the following meanings:
-
capitalize
-
Puts the first character of each word in uppercase.
-
uppercase
-
Puts all characters of each word in uppercase.
-
lowercase
-
Puts all characters of each word in lowercase.
-
none
-
No capitalization effects.
The actual transformation in each case is written language
dependent. See RFC 2070 ([RFC2070]) for ways to find the language
of an element.
Conforming user agents may consider the value of "text-transform"
to be "none" for characters that are not from the ISO Latin-1 repertoire
and for elements in languages for which the transformation is different
from that specified by the case-conversion tables of Unicode or
ISO 10646.
XSL modifications to the CSS definition:
There are severe internationalization issues with the use
of this property. It has been retained for CSS compatibility, but
its use is not recommended in XSL.
7.15 Rule and Leader Properties
7.15.1 "leader-alignment"
XSL Definition:
| Value: | none | reference-area | page | inherit |
| Initial: | none |
| Applies to: | fo:leader |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
none
-
Leader-pattern has no special alignment.
-
reference-area
-
Leader-pattern is aligned as if it began on the current
reference-area's content-rectangle start-edge.
-
page
-
Leader-pattern is aligned as if it began on the current
page's start-edge.
Specifies whether fo:leaders having identical content and property values
shall have their patterns aligned with each other, with respect to their
common reference-area or page.
For fo:leaders where the "leader-pattern" property is specified as
"dot" or as "use-content", this property will be honored. For leaders
with a "leader-pattern" of "rule", if the "rule-style" property
has a patterned structure, the user agent may choose to honor the this
property.
If the fo:leader is aligned, the start-edge of each cycle of the
repeated pattern will be placed on the start-edge of the next cycle
in the appropriate pattern-alignment grid.
7.15.2 "leader-pattern"
XSL Definition:
| Value: | space | rule | dots | use-content | inherit |
| Initial: | space |
| Applies to: | fo:leader |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
space
-
Leader is to be filled with blank space.
-
rule
-
Leader is to be filled with a rule.
If this choice is selected, the rule-thickness and rule-style
properties are used to set the leader's style.
-
dots
-
Leader is to be filled with a repeating sequence of dots.
The choice of dot character is dependent on the user agent.
-
use-content
-
Leader is to be filled with a repeating pattern as specified
by the children of the fo:leader.
Provides the specification of how to fill in the leader.
If the leader is aligned, the start-edge of each cycle of each
repeating pattern component will be placed on the start-edge of
the next cycle in the pattern-alignment grid.
7.15.3 "leader-pattern-width"
XSL Definition:
| Value: | use-font-metrics | <length> | inherit |
| Initial: | use-font-metrics |
| Applies to: | fo:leader |
| Inherited: | yes |
| Percentages: | Refer to width of containing box |
| Media: | visual |
Values have the following meanings:
-
use-font-metrics
-
Use the width of the leader-pattern as determined from
its font metrics.
-
<length>
-
Sets length for leader-pattern-repeating.
The leader will have an inline-space inserted after each pattern
cycle to account for any difference between the width of the pattern
as determined by the font metrics and the width specified in this
property.
If the length specified is less than the value that would be
determined via the use-font-metrics choice, this value will be treated
as if use-font-metrics choice had been specified.
Specifies the length of each repeat cycle in a repeating leader.
For leaders where the "leader-pattern" property is specified as
"dot" or as "use-content", this property will be honored. For leaders
with a leader-pattern of "rule", if the rule-style has a patterned
structure, the user agent may choose to honor this property.
7.15.4 "leader-length"
XSL Definition:
| Value: | <length-range> | inherit |
| Initial: | leader-length.minimum=0pt, .optimum=12.0pt, .maximum=100% |
| Applies to: | fo:leader |
| Inherited: | yes |
| Percentages: | refer to width of content rectangle of parent area |
| Media: | visual |
Values have the following meanings:
-
<length-range>
-
leader-length.minimum=sets minimum length for a leader
leader-length.optimum=sets optimum length for a leader
leader-length.maximum=sets maximum length for a leader
Specifies the minimum, optimum, and maximum length of an fo:leader.
The specification of a minimum and maximum range of lengths allows
leaders and inline rules to be used to "fill" or "justify" a line.
It also allows
for specification of how multiple leaders appearing in a given line-area
are to be balanced.
7.15.5 "rule-style"
XSL Definition:
| Value: | none | dotted | dashed | solid | double | groove
| ridge | inherit |
| Initial: | solid |
| Applies to: | fo:leader |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Specifies the style (pattern) of the rule.
This property applies only if the "leader-pattern" property is
specified as "rule".
Values have the following meanings:
-
none
-
No rule, forces rule-thickness to 0.
-
dotted
-
The rule is a series of dots.
-
dashed
-
The rule is a series of short line segments.
-
solid
-
The rule is a single line segment.
-
double
-
The rule is two solid lines. The sum of the two lines and
the space between them equals the value of "rule-thickness".
-
groove
-
The rule looks as though it were carved into the canvas.
(Top/left half of the rule's thickness is the color specified, the
other half is white.)
-
ridge
-
The opposite of "groove", the rule looks as though it were
coming out of the canvas. (Bottom/right half of the rule's thickness
is the color specified, the other half is white.)
7.15.6 "rule-thickness"
XSL Definition:
| Value: | <length> |
| Initial: | 1.0pt |
| Applies to: | fo:leader |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Specifies the overall thickness of the rule.
This property applies only if the "leader-pattern" property is
specified as "rule".
Values have the following meanings:
-
<length>
-
The "rule-thickness" is always perpendicular
to its length-axis.
The the rule is thickened equally above and below the line's
alignment position. This can be adjusted through the "baseline-shift"
property.
7.16 Page-related Properties
The following are page-related properties that are not
common to all formatting objects. See
common-keep-and-breaks-properties.
7.16.1 "keep-together"
XSL Definition:
| Value: | <keep> | inherit |
| Initial: | .within-line=auto, .within-column=auto, .within-page=auto |
| Applies to: | block-level formatting objects, inline formatting objects,
fo:title, fo:list-item, fo:list-item-label, and fo:list-item-body |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
This property imposes keep-together conditions on formatting objects.
The <keep> datatype is composed of three components: within-line,
within-column, and within-page. Different components apply to different
classes of formatting objects and provide keep conditions relative to
different contexts. In the case of the within-line
component, the keep context consists of line areas;
for the within-column component, the keep
context consists of column-areas;
for the within-page component, the keep context consists of page-areas.
In the descriptions below, the term
"appropriate context" should be
interpreted in terms of the previous sentence.
Any assignment to this property unqualified by a specific component shall
cause the ".within-column" component to be set to the given value and the
".within-line" and ".within-page" components to be set to "auto".
Values of the components have the following meanings:
-
auto
-
There are no keep-together conditions
imposed by this property.
-
always
-
Imposes a keep-together condition with strength "always" in the
appropriate context.
-
<integer>
-
Imposes a keep-together condition with strength of the given
<integer> in the appropriate context.
The semantics of keeps and breaks are further described in
[4.11 Keeps and Breaks].
7.16.2 "orphans"
7.16.3 "widows"
CSS2 Definition:
| Value: | <integer> | inherit |
| Initial: | 2 |
| Applies to: | block-level elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/page.html#propdef-widows.
The "orphans" property specifies the minimum number of
lines of a paragraph that must be left at the bottom of a page.
The "widows" property specifies the minimum number of lines of a
paragraph that must be left at the top of a page.
XSL modifications to the CSS definition:
In XSL the "orphans" property specifies the minimum number of
line areas in the first area generated by the formatting object.
The "widows" property specifies the minimum number of line areas
in the last area generated by the formatting object.
7.17 Float-related Properties
The following properties are all taken from CSS2. The reference
is: http://www.w3.org/TR/REC-CSS2/visuren.html#floats
7.17.1 "float"
CSS2 Definition:
| Value: | left | right | none | inherit |
| Initial: | none |
| Applies to: | all but positioned elements and generated content |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-float.
This property specifies whether a box should float to
the left, right, or not at all. It may be set for elements that
generate boxes that are not absolutely positioned. Values have the following
meanings:
-
left
-
The element generates a block box that is floated to the
left. Content flows on the right side of the box, starting at the
top (subject to the "clear" property). The "display" is ignored,
unless it has the value "none".
-
right
-
Same as "left", but content flows on the left side of the
box, starting at the top.
-
none
-
The box is not floated.
Here are the precise rules that govern the behavior of floats:
1.The left outer edge of a left-floating box may not be to the
left of the left edge of its containing block. An analogous rule
holds for right-floating elements.
2.If the current box is left-floating, and there are any left
floating boxes generated by elements earlier in the source document,
then for each such earlier box, either the left outer edge of the
current box must be to the right of the right outer edge of the
earlier box, or its top must be lower than the bottom of the earlier
box. Analogous rules hold for right-floating boxes.
3.The right outer edge of a left-floating box may not be to the
right of the left outer edge of any right-floating box that is to
the right of it. Analogous rules hold for right-floating elements.
4.A floating box's outer top may not be higher than the top of
its containing block.
5.The outer top of a floating box may not be higher than the
outer top of any block or floated box generated by an element earlier
in the source document.
6.The outer top of an element's floating box may not be higher
than the top of any line-box containing a box generated by an element
earlier in the source document.
7.A left-floating box that has another left-floating box to its
left may not have its right outer edge to the right of its containing
block's right edge. (Loosely: a left float may not stick out at
the right edge, unless it is already as far to the left as possible.)
An analogous rule holds for right-floating elements.
8.A floating box must be placed as high as possible.
9.A left-floating box must be put as far to the left as possible,
a right-floating box as far to the right as possible. A higher position
is preferred over one that is further to the left/right.
XSL modifications to the CSS definition:
7.17.2 "clear"
CSS2 Definition:
| Value: | none | left | right | both | inherit |
| Initial: | none |
| Applies to: | block-level elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-clear.
This property indicates which sides of an element's box(es) may
not be adjacent to an earlier floating box. (It may be that the
element itself has floating descendants; the 'clear' property has
no effect on those.)
This property may only be specified for block-level elements
(including floats). For compact and run-in boxes, this property
applies to the final block box to which the compact or run-in box
belongs.
Values have the following meanings when applied to non-floating
block boxes:
-
left
-
The top margin of the generated box is increased enough
that the top border edge is below the bottom outer edge of any left-floating
boxes that resulted from elements earlier in the source document.
-
right
-
The top margin of the generated box is increased enough
that the top border edge is below the bottom outer edge of any right-floating
boxes that resulted from elements earlier in the source document.
-
both
-
The generated box is moved below all floating boxes of
earlier elements in the source document.
-
none
-
No constraint on the box's position with respect to floats.
When the property is set on floating elements, it results in
a modification of the rules for positioning the float. An extra
constraint (#10) is added [to those specified in the description
of the 'float' property]:
10. The top outer edge of the float must be below the bottom
outer edge of all earlier left-floating boxes (in the case of 'clear:
left'), or all earlier right-floating boxes (in the case of 'clear:
right'), or both ('clear: both').
XSL modifications to the CSS definition:
7.18 Properties for Number to String Conversion
7.18.1 "format"
XSL Definition:
| Value: | <string> |
| Initial: | 1. |
| Applies to: | fo:page-sequence |
| Inherited: | no |
| Percentages: | N/A |
| Media: | all |
This property is defined in XSLT: Number to String Conversion
Attributes.
7.18.2 "letter-value"
XSL Definition:
| Value: | alpabetic | traditional |
| Initial: | no value |
| Applies to: | fo:page-sequence |
| Inherited: | no |
| Percentages: | N/A |
| Media: | all |
This property is defined in XSLT: Number to String Conversion
Attributes.
7.18.3 "grouping-separator"
XSL Definition:
| Value: | <character> |
| Initial: | no separator |
| Applies to: | fo:page-sequence |
| Inherited: | no |
| Percentages: | N/A |
| Media: | all |
This property is defined in XSLT: Number to String Conversion
Attributes.
7.18.4 "grouping-size"
XSL Definition:
| Value: | <number> |
| Initial: | no grouping |
| Applies to: | fo:page-sequence |
| Inherited: | no |
| Percentages: | N/A |
| Media: | all |
This property is defined in XSLT: Number to String Conversion
Attributes.
7.19 Properties for Links
7.19.1 "external-destination"
XSL Definition:
| Value: | <uri> |
| Initial: | null string |
| Applies to: | fo:simple-link |
| Inherited: | no |
| Percentages: | N/A |
| Media: | interactive |
-
<uri>
Specifies the destination resource of an fo:simple-link. The
URI part specifies the destination document. If the URI is unspecified,
the destination document defaults to the current source document.
NOTE:
In this context, a "document" is any resource that can be identified
by a URI.
The fragment identifier (portion of the URI following the # symbol)
specifies the destination node. If the fragment identifier is unspecified,
or that part of the source is not present in the rendered document,
the destination node defaults to the root node of the destination
document.
The destination node has to be mapped to objects in the result
tree.
The destination flow objects are the nodes in the result tree
that were generated when the destination node was processed, including
all descendant flow objects.
NOTE:
This will give target objects even if no flow objects were directly
created when processing the destination node.
If the node was never processed, the system should inform the
user.
If the node was processed, but no areas were created, the target
is the (empty) point in the flow object tree where the destination
node was processed.
If the node was processed at several places in the flow object
tree, which one of them is chosen as the target is implementation dependent.
The areas created from the destination flow object are the destination
areas.
At least one of the external-destination and internal-destination
properties should be assigned. If both are assigned, the system
may either report the error, or use the internal-destination property.
7.19.2 "internal-destination"
XSL Definition:
| Value: | <idref> |
| Initial: | null string |
| Applies to: | fo:simple-link |
| Inherited: | no |
| Percentages: | N/A |
| Media: | interactive |
-
<idref>
Specifies the destination flow object of an an fo:simple-link.
This property allows the destination flow object node to be explicitly
specified.
At least one of the external-destination and internal-destination
properties should be assigned. If both are assigned, the system
may either report the error, or use the internal-destination property.
7.19.3 "show-destination"
XSL Definition:
| Value: | replace | new |
| Initial: | replace |
| Applies to: | fo:simple-link |
| Inherited: | no |
| Percentages: | N/A |
| Media: | interactive |
-
replace
-
The current document view should be replaced. However,
if the destination area(s) are already available in a page/region,
those areas should simply be moved/scrolled "into sight".
-
new
-
A new (additional) document view should always be opened.
Specifies where the destination resource should be displayed.
7.19.4 "indicate-destination"
XSL Definition:
| Value: | yes | no |
| Initial: | no |
| Applies to: | fo:simple-link |
| Inherited: | no |
| Percentages: | N/A |
| Media: | interactive |
-
yes
-
The areas that belong to the link target
when traversed should, in a system-dependent manner, be indicated.
-
no
-
No special indication should be made.
NOTE:
This could be indicated in any feasible way, e.g., by reversed
video, etc.
7.19.5 "destination-placement-offset"
XSL Definition:
| Value: | <length> |
| Initial: | 0pt |
| Applies to: | fo:simple-link |
| Inherited: | no |
| Percentages: | N/A |
| Media: | interactive |
-
<length>
The "destination-placement-offset" property specifies
the distance from the beginning (top) of the page to the innermost
line-area that contains the first destination area. If the first
destination area is not contained in a line-area, the "destination-placement-offset" property
instead directly specifies the distance to the top of the destination
area.
If the specification of destination-placement-offset would
result in a distance longer than the distance from the start of
the document, the distance from the start of the document should
be used.
If the specified distance would push the first destination area
below the page-area, the distance should be decreased so the whole
first destination area becomes visible, if possible. If the first
destination area is higher than the page, the top of the area should
be aligned with the top of the page.
7.19.6 "auto-restore"
XSL Definition:
| Value: | yes | no |
| Initial: | no |
| Applies to: | fo:multi-switch |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | interactive |
-
yes
-
If this fo:multi-switch
is contained in another fo:multi-switch, and that fo:multi-switch
changes the active fo:multi-case (hiding this fo:multi-switch),
then this fo:multi-switch should restore its initial fo:multi-case.
-
no
-
This fo:multi-switch
should retain its current fo:multi-case.
Specifies if the initial fo:multi-case should be restored
when the fo:multi-switch gets hidden by an ancestor fo:multi-switch.
NOTE:
A common case of using this property with a "yes" value
is when several nested fo:multi-switch objects
builds an expandable/collapsible table-of-contents view. If the
table-of-contents is expanded far down the hierarchy, and an (far
above) ancestor is closed, one would want all sub-titles to have
restored to their original state when that ancestor is opened again.
7.19.7 "starting-state"
XSL Definition:
| Value: | show | hide |
| Initial: | show |
| Applies to: | fo:multi-case |
| Inherited: | no |
| Percentages: | N/A |
| Media: | interactive |
-
show
-
The content of the fo:multi-case is a candidate for being
displayed initially.
-
hide
-
The content of the fo:multi-case is not a candidate for being
displayed initially.
Specifies if the fo:multi-case can be initially displayed.
The parent fo:multi-switch shall choose the first fo:multi-case
child where the property "starting-state" has the value equal to "show".
NOTE:
Any number of the fo:multi-case objects may assign "starting-state"
to "show".
If no fo:multi-case has "starting-state" property value of "show", the
contents of no fo:multi-case should be displayed.
NOTE:
If no multi-case is displayed, the entire fo:multi-switch will
effectively be hidden.
7.19.8 "case-name"
XSL Definition:
| Value: | <name> |
| Initial: | none, a value is required |
| Applies to: | fo:multi-case |
| Inherited: | no, a value is required |
| Percentages: | N/A |
| Media: | interactive |
-
<name>
-
Specifies a name for an fo:multi-case. The name must be unique
among the current fo:multi-case siblings, i.e., in the scope of
the fo:multi-switch object that (directly) contains them. Other
instances of fo:multi-switch objects may use the same names for
its fo:multi-case objects.
The purpose of this property is to allow fo:multi-toggle objects
to select fo:multi-case objects to switch to.
7.19.9 "case-title"
XSL Definition:
| Value: | <string> |
| Initial: | none, a value is required |
| Applies to: | fo:multi-case |
| Inherited: | no, a value is required |
| Percentages: | N/A |
| Media: | interactive |
-
<string>
-
Specifies a descriptive title for the fo:multi-case. The title
can be displayed in a menu to represent this fo:multi-case when
an fo:multi-toggle object names several fo:multi-case objects as
allowed destinations.
7.19.10 "switch-to"
XSL Definition:
| Value: | xsl-preceding | xsl-following | xsl-any | <name>[ <name>]* |
| Initial: | xsl-any |
| Applies to: | fo:multi-toggle |
| Inherited: | no |
| Percentages: | N/A |
| Media: | interactive |
-
xsl-preceding
-
Activating the switch should result in that the current
fo:multi-case is replaced by its preceding sibling.
NOTE:
The current fo:multi-case is the closest ancestor fo:multi-case.
In other words, the current fo:multi-switch should switch to
the previous sibling of the fo:multi-case that is currently selected.
NOTE:
The current fo:multi-switch is the closest ancestor fo:multi-switch.
It the current fo:multi-case is the first sibling, xsl-preceding
should switch to the last fo:multi-case sibling.
-
xsl-following
-
Activating the switch should result in that the current
fo:multi-case is replaced by its next sibling.
It the current fo:multi-case is the last sibling, xsl-following
should switch to the first fo:multi-case sibling.
-
xsl-any
-
Activating the switch should allow the user to select any
other fo:multi-case sibling.
If there is only a single other fo:multi-case, the toggle should
immediately switch to it (and not show that single choice to the
user).
-
<name>
-
A name matching a case-name of an fo:multi-case.
Specifies what fo:multi-case object(s) this fo:multi-toggle
shall switch to.
If switch-to is a name list, the user can switch to any of the
named multi-case objects. If a multi-toggle with a single name is
activated, it should immediately switch to the named multi-case.
NOTE:
How to actually select the multi-case from a list
is system dependent.
7.19.11 "dom-state"
XSL Definition:
| Value: | TBD |
| Initial: | TBD |
| Applies to: | fo:multi-properties |
| Inherited: | no |
| Percentages: | N/A |
| Media: | interactive |
-
a DOM state (or event)
The "dom-state" property is used to control which of the
fo:multi-property-sets
are used to format the child flow objects within an
fo:multi-properties
formatting object. The states (or at least the events that
cause the state to be entered) are defined by the DOM.
Issue (dom-states):
We need to identify the semantics for events, such as "mouse over",
"visited link", etc. When this is completed the datatypes may need
updating.
7.20 Properties for Alignment of Areas
7.20.1 "baseline-identifier"
XSL Definition:
| Value: | baseline | before-edge
| text-before-edge | middle | after-edge
| text-after-edge | ideographic | alphabetic | hanging | mathematical
| inherit |
| Initial: | see prose |
| Applies to: | all inline formatting objects |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
This property specifies how an object is aligned with respect to
its parent. It also determines a default alignment point for the
object, which may be adjusted by other properties.
The initial value of the "baseline-identifier" property depends on the
kind of object on which it is being used. For fo:character, the initial value
is the dominant baseline of the script to which the character belongs.
If there is no unambigous script identifier then the initial value
is the dominant baseline of the parent area.
For all other objects, the initial value is "baseline".
For the values below, the alignment-point defaults to the baseline
with the same name as the value. That is, for the value "ideographic"
the alignment-point is the "ideographic" baseline of the object being
aligned. (See "alignment-adjust" below
for a description of how the alignment point is determined.)
Values have the following meanings:
-
baseline
-
The alignment-point of the object being aligned is aligned with the
dominant baseline of the parent area.
-
before-edge
-
The alignment-point of the object being aligned is aligned with the "before-edge"
baseline of the parent area.
-
text-before-edge
-
The alignment-point of the object being aligned is aligned with the
"text-before-edge" baseline of the parent area.
-
middle
-
The alignment-point of the object being aligned is aligned with the
"middle" baseline of the parent area.
-
after-edge
-
The alignment-point of the object being aligned is aligned with the "after-edge" baseline of
the parent area.
-
text-after-edge
-
The alignment-point of the object being aligned is aligned with the
"text-after-edge" baseline of the parent area.
-
ideographic
-
The alignment-point of the object being aligned is aligned with the
"ideographic" baseline of the parent area.
-
alphabetic
-
The alignment-point of the object being aligned is aligned with the
"alphabetic" baseline of the parent area.
-
hanging
-
The alignment-point of the object being aligned is aligned with the
"hanging" baseline of the parent area.
-
mathematical
-
The alignment-point of the object being aligned is aligned with the
"mathematical" baseline of the parent area.
7.20.2 "alignment-adjust"
XSL Definition:
| Value: | auto | <percentage> | <length>
| inherit |
| Initial: | auto |
| Applies to: | all inline formatting objects |
| Inherited: | no |
| Percentages: | see prose |
| Media: | visual |
The "alignment-adjust" property allows more precise alignment of
elements, such as graphics, that do not have a baseline-table
or lack the desired baseline in their baseline-table. With the
"alignment-adjust" property, the position of the baseline identified
by the "baseline-identifier" can be explicity determined.
Values for the property have the following meaning:
-
auto
-
For a glyph, the alignment-point is the intersection of the start-edge
of the allocation rectangle of the glyph area
and the baseline identified by the "baseline-identifier"
property if this baseline exists in the font from which the glyph
comes. For other inline areas, the alignment-point is at the
intersection of the start-edge of the border rectangle and the
baseline identified by the "baseline-identifier" property if this
baseline exists in the baseline-table for the dominant baseline for
the inline area. If the baseline-identifier does not exist in the
baseline-table for the glyph or other inline area, then the user agent
may either use heuristics to determine where that missing baseline
would be or may use the dominant baseline as a fall back. For
areas generated by a fo:external-graphic, or fo:instream-foreign-object,
the alignment point is at the intersection of the
start-edge and after-edge of the allocation rectangle of the
area.
-
<percentage>
-
The computed value of the property is this percentage multiplied by
the area's computed "height" if the area is generated by a
fo:external-graphic, or fo:instream-foreign-object,
the "font-size" if the area was generated by an fo:character and the "line-height"
otherwise. The alignment-point is on the start-edge of the allocation
rectangle of the area
being aligned. Its position along the start edge relative to the
intersection of the dominant-baseline and the start-edge is offset by
the computed value. The offset is opposite to the shift-direction if
that value is positive and in the shift-direction if that value is
negative value). A value of "0%" makes the dominant-baseline the
alignment point.
-
<length>
-
The alignment-point is on the start-edge of the
allocation rectangle of the area being
aligned. Its position along the start-edge relative to the
intersection of the dominant-baseline and the start-edge is offset by
<length> value. The offset is opposite to the shift-direction if
that value is positive and in the shift-direction if that value is
negative. A value of "0cm" makes the dominant-baseline the
alignment point.
7.20.3 "baseline-shift"
XSL Definition:
| Value: | baseline | sub | super | <percentage> | <length>
| inherit |
| Initial: | baseline |
| Applies to: | all inline formatting objects |
| Inherited: | no |
| Percentages: | refers to the "line-height" of the parent area |
| Media: | visual |
The "baseline-shift" property allows repositioning of the
dominant-baseline relative to the dominant-baseline of the parent area. The
shifted object might be a sub- or superscript. Within the shifted
object, the whole baseline table is offset; not just a single
baseline. The amount of the shift is determined from information from
the parent area, the sub- or superscript offset from the nominal font of
the parent area, percent of the "line-height" of the parent area or an absolute
value.
Values for the property have the following meaning:
-
baseline
-
There is no baseline shift; the dominant baseline remains in its original position.
-
sub
-
The dominant baseline is shifted to the default position for
subscripts. The offset to this position is determined by the font data
for the nominal font as adjusted by the dominant baseline-table font-size.
If there is no applicable font data the User Agent may use heuristics
to determine the offset.
-
super
-
The dominant baseline is shifted to the default position for
superscripts. The offset to this position is determined by the font
data for the nominal font as adjusted by the dominant baseline-table
font-size.
If there is no applicable font data the User Agent may use heuristics
to determine the offset.
-
<percentage>
-
The computed value of the property is this percentage multiplied by
the computed "line-height" of the parent area. The dominant baseline
is shifted in the shift-direction (positive value) or opposite to the
shift-direction (negative value) of the parent area by the computed
value. A value of "0%" is equivalent to "baseline".
-
<length>
-
The dominant baseline is shifted in the shift-direction (positive
value) or opposite to the shift-direction (negative value) of the
parent area by the <length> value. A value of "0cm" is equivalent
to "baseline".
NOTE:
Although it may seem that "baseline-shift" and "alignment-adjust"
properties are doing the same thing, there is an important although,
perhaps, subtle difference. For "alignment-adjust" the percentage
values refer to the "line-height" of the element being aligned. For
"baseline-shift" the percentage values refer to the "line-height" of
the parent. Similarly, it is the "sub" and "super" offsets of the
parent that are used to align the shifted baseline rather than the
"sub" or "super" offsets of the element being positioned. To ensure a
consistent sub- or superscript position, it makes more sense to use
the parent as the reference rather than the subscript element which
may have a changed "line-height" due to "font-size" changes in the
sub- or superscript element.
Using the "alignment-adjust" property is more suitable for positioning
objects, such as graphics, that have no internal textual
structure. Using the "baseline-shift" property is intended for sub-
and superscripts where the positioned object may itself be a textual
object. The baseline-shift provides a way to define a specific
baseline offset other than the named offsets that are defined relative
to the dominant baseline. In addition, having "baseline-shift" makes
it easier for tool to generate the relevant properties; many
formatting programs already have a notion of (temporary) baseline
shift.
7.20.4 "dominant-baseline"
XSL Definition:
| Value: | auto | autosense-script | no-change | reset-size
| ideographic | alphabetic | hanging | mathematical
| inherit |
| Initial: | auto |
| Applies to: | all inline formatting objects |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
The "dominant-baseline" property is used to re-determine the dominant
baseline and re-establish the font-size used with the baseline-table.
This property can also be used to explicitly set the
dominant baseline when the "auto" value would give an incorrect
result.
Values for the property have the following meaning:
-
auto
-
If this property occurs on a block level formatting object, the
dominant-baseline is set using the rules for "autosense-script"
below. Otherwise, the dominant baseline and the baseline-table remain
the same as that of the parent area. If the "baseline-shift" value actually
shifts the baseline, then the baseline-table font-size is set to the
current "font-size", otherwise the baseline-table font-size remains
the same as that of the parent area. If there is no parent area, the
dominant-baseline is set to be the "lower" baseline, the
baseline-table is set for that baseline and the baseline-table
font-size is set to the current "font-size".
-
autosense-script
-
The dominant baseline and the baseline-table are set as follows. Use
the first character descendant, as determined by the post-order
traversal of the refined formatting object tree, which has an
unambiguous script identifier to determine the dominant script of the
element's content. Using the nominal font for the element, set the
"dominant-baseline" (and, correspondingly, the dominant
baseline-table) to the default baseline, in the current writing-mode,
for the dominant script. If there is no such character, then set the
"alphabetic" baseline as the dominant-baseline.
-
no-change
-
The dominant baseline, the baseline-table and the baseline-table
font-size remain the same as that of the parent area.
-
reset-size
-
The dominant baseline and the baseline table remain the same, but the
baseline-table font-size is changed to the value of the "font-size"
property on this formatting object. This re-scales the baseline table for the
current "font-size".
-
ideographic
-
The dominant baseline is set to the "ideographic" baseline using the
baseline-table and baseline-table font-size of the parent area, the
baseline table is changed to correspond to the "ideographic" baseline,
and the baseline-table font-size is changed to the value of the
"font-size" property on this formatting object.
-
alphabetic
-
The dominant baseline is set to the "alphabetic" baseline using the
baseline-table and baseline-table font-size of the parent area, the
baseline table is changed to correspond to the "alphabetic" baseline, and
the baseline-table font-size is changed to the value of the
"font-size" property on this formatting object.
-
hanging
-
The dominant baseline is set to the "hanging" baseline using the
baseline-table and baseline-table font-size of the parent area, the
baseline table is changed to correspond to the "hanging" baseline, and
the baseline-table font-size is changed to the value of the
"font-size" property on this formatting object.
-
mathematical
-
The dominant baseline is set to the "mathematical" baseline using the
baseline-table and baseline-table font-size of the parent area, the
baseline table is changed to correspond to the "mathematical"
baseline, and the baseline-table font-size is changed to the value of
the "font-size" property on this formatting object.
If there is no baseline-table in the nominal font or if the
baseline-table lacks an entry for the desired baseline, then the User
Agent may use heuristics to determine the position of the desired
baseline.
7.20.5 "display-align"
XSL Definition:
| Value: | auto | before | center | after
| inherit |
| Initial: | auto |
| Applies to: | fo:table-cell, fo:region-body, fo:region-before, fo:region-after, fo:region-start, fo:region-end
|
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
This property specifies the alignment, in the block-progression direction,
of the areas that are the children of a reference area.
Values for the property have the following meaning:
-
auto
-
If the "relative-align" property applies to this formatting object
the "relative-align" property is used. If not this value is treated
as if "before" had been specified.
-
before
-
The before-edge of the allocation rectangle of the first
child area is placed coincident with the before-edge of the content
rectangle of the reference area.
-
center
-
The child areas are placed such that the
distance
between the before-edge of the allocation rectangle of the
first child area and the before-edge of the content rectangle
of the reference area
is the same as the distance
between the after-edge of the allocation rectangle of the
last child adea and the after-edge of the content rectangle
of the reference area.
-
after
-
The after-edge of the allocation rectangle of the last
child area is placed coincident with the after-edge of the content
rectangle of the reference area.
7.20.6 "relative-align"
XSL Definition:
| Value: | before | baseline
| inherit |
| Initial: | before |
| Applies to: | fo:list-item, fo:table-cell |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
This property specifies the alignment, in the block progression direction,
between two or more areas.
If the "display-align" property applies to this formatting object and
has a value other than "auto" this property is ignored.
Values for the property have the following meaning:
-
before
-
For an fo:table-cell: for each row, the first child area of
all the cells that start in the row and that have this value is placed
such that the before-edge of the content rectangle
is placed at
the same distance from the row grid. In addition, at least, one
of these first child areas of the cells
has to be placed with the before-edge of its allocation
rectangle coincident with the before-edge of the content rectangle
of the table-cell.
For an fo:list-item the before-edge of the first area decendant
generated by the fo:list-item-label is placed coincident with the
before-edge of the area generated by the fo:list-item.
Similarly the before-edge of the first
area decendant generated by the fo:list-item-body is placed coincident
with the before-edge of the area generated by the fo:list-item.
-
baseline
-
For an fo:table-cell: for each row, the first child area of
all the cells that start in the row and that have this value is placed
such that the dominant baseline, as specified on the fo:table-row,
of the first line is placed at
the same distance from the row grid. In addition, at least, one
of these first child areas of the cells
has to be placed with the before-edge of its allocation
rectangle coincident with the before-edge of the content rectangle
of the table-cell.
NOTE:
That is; for all applicable cells the baseline of all the first
lines are all aligned and placed the minimum distance down in the
block-progression direction. It should be noted that the start-edges
of the content rectangles of the cells need not align.
For an fo:list-item the distance between the baseline of
the first line area of the first area decendant generated by the
fo:list-item-label is the same as the distance between
the baseline of the
first line area of the first area decendant generated by the
fo:list-item-body. In addition, at least, one of these first
area decendants has to be placed such that the before-edge of its
allocation rectangle is coincident with the before-edge of the
content rectangle of the list-item.
7.21 Miscellaneous Properties
7.21.1 "clip"
CSS2 Definition:
| Value: | <shape> | auto | inherit |
| Initial: | auto |
| Applies to: | block-level and replaced elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visufx.html#propdef-clip.
The 'clip' property applies to elements that have a 'overflow'
property with a value other than 'visible'. Values have the following
meanings:
-
auto
-
The clipping region has the same size and location as the
element's box(es).
-
<shape>
-
In CSS2, the only valid <shape> value is: rect (<top> <right> <bottom> <left>) where <top>, <bottom> <right>,
and <left> specify offsets from the respective sides of the
box.
<top>, <right>, <bottom>, and <left> may either
have a <length> value or "auto". Negative lengths are permitted.
The value "auto" means that a given edge of the clipping region
will be the same as the edge of the element's generated box (i.e., "auto"
means the same as "0".)
When coordinates are rounded to pixel coordinates, care should
be taken that no pixels remain visible when <left> + <right>
is equal to the element's width (or <top> + <bottom> equals
the element's height), and conversely that no pixels remain hidden
when these values are 0.
The element's ancestors may also have clipping regions
(in case their "overflow" property is not "visible"); what is rendered
is the intersection of the various clipping regions.
If the clipping region exceeds the bounds of the UA's document
window, content may be clipped to that window by the native operating
environment.
7.21.2 "color"
CSS2 Definition:
| Value: | <color> | inherit |
| Initial: | depends on user agent |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/colors.html#propdef-color.
EdNote: Changed datatype to <color> from <unknown>
-
<color>
-
Any valid color specification.
This property describes the foreground color of an element's
text content.
XSL modifications to the CSS definition:
NOTE:
For XSL, do we want to add:
-
Basic named colors:
transparent, red, green, blue, cyan, magenta, yellow, black,
white,
-
Colorspaces other than sRGB.
7.21.3 "content-type"
XSL Definition:
| Value: | <string> | auto |
| Initial: | auto |
| Applies to: | fo:external-graphic, fo:instream-foreign-object |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
This property specifies the content-type and may be used
by a User Agent to select a rendering processor for the object.
Values for this property have the following meanings:
-
auto
-
No identification of the content-type. The User Agent
may determine it by "sniffing" or by other means.
-
<string>
-
A specification of the content-type in terms of either a
mime-type or a namespace.
A mime-type specification has the form "content-type:" followed
by a mime content-type, e.g. content-type="content-type:xml/svg".
A namespace specification has the form "namespace-prefix:" followed
by a declared namespace prefix, e.g. content-type="namespace-prefix:svg".
If the namespace prefix is null the content-type refers to the
default namespace.
7.21.4 "direction"
CSS2 Definition:
| Value: | ltr | rtl | inherit |
| Initial: | ltr |
| Applies to: | all elements, but see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-direction.
This property still needs further updating due to
continued discussions with I18N, CSS, and SVG.
This property specifies the base writing direction of blocks
and the direction of embeddings and overrides (see 'unicode-bidi')
for the Unicode bidirectional algorithm. In addition, it specifies
the direction of table column layout, the direction of horizontal overflow,
and the position of an incomplete last line in a block in case of
'text-align: justify'.
Values for this property have the following meanings:
-
ltr
-
Left to right direction.
-
rtl
-
Right to left direction.
For the 'direction' property to have any effect on inline-level
elements, the 'unicode-bidi' property's value must be 'embed' or
'override'.
NOTE:
The 'direction' property, when specified for table column elements,
is not inherited by cells in the column since columns don't exist
in the document tree. Thus, CSS cannot easily capture the "dir"
attribute inheritance rules described in [HTML40], section 11.3.2.1.
XSL modifications to the CSS definition:
-
This property overrides the inline-progression-direction
determined by the current writing-mode and the Unicode bidirectional
algorithm.
-
This property only has an effect on text in which the glyph-orientation
is perpendicular to the inline-progression-direction. Therefore,
vertical ideographic text is not affected by this property, but
rotated non-ideographic text is.
-
Except for the specific use of "direction" and "unicode-bidi"
on inline objects solely to override the Unicode bidi algorithm,
all uses of the "direction" property from CSS are deprecated for
use in XSL. The following is the proper handling of "direction"
and "writing-mode" in XSL:
-
Block stacking is governed by "writing-mode" on
the fo:region, fo:table, fo:table-cell, fo:display-included-container,
and fo:inline-included-container, fo:table, and/or fo:table-cell
-
Inline stacking, except as described for fo:bidi-override
and as overridden through the combination of the "unicode-bidi" & "direction"
properties at the inline-level, is governed by XSL's "writing-mode"
on the fo:region, fo:table, fo:table-cell, fo:display-included-container,
and fo:inline-included-container, fo:table, and/or fo:table-cell
-
Table column layout is governed by the "writing-mode" on
the fo:table (columns use the inline-progression-direction, and
rows use the block-progression-direction),
-
Horizontal overflow is governed by the "writing-mode" and
"text-align" in effect on the overflowing area.
-
Position of an incompletely filled last line in a block
in the case of "text-align='justify'" with "text-align-last='relative'"
is governed by the "writing-mode" in effect on the block. (Note
this is not the "writing-mode" or direction of the inlines of the
last line, since there could be a mixture within the line.)
-
When mapping CSS to XSL, the XSL "writing-mode" property
should be used rather than the "direction" property for all block-level
directionality control. XSL's "writing-mode" should also be used
for any inline-included-container or display-included-container
objects. The "direction" property should be used only for control/overrides of
the Unicode-bidi algorithm on inline-* formatting
objects.
7.21.5 "unicode-bidi"
CSS2 Definition:
| Value: | normal | embed | bidi-override | inherit |
| Initial: | normal |
| Applies to: | all elements, but see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-unicode-bidi.
Values have the following meanings:
-
normal
-
The element does not open an additional
level of embedding with respect to the bidirectional algorithm.
For inline-level elements, implicit reordering works across element
boundaries.
-
embed
-
If the element is inline-level, this
value opens an additional level of embedding with respect to the
bidirectional algorithm. The direction of this embedding level is given
by the 'direction' property. Inside the element, reordering is done
implicitly. This corresponds to adding a LRE (U+202A; for 'direction:
ltr') or RLE (U+202B; for 'direction: rtl') at the start of the
element and a PDF (U+202C) at the end of the element.
-
bidi-override
-
If the element is inline-level or
a block-level element that contains only inline-level elements,
this creates an override. This means that inside the element, reordering
is strictly in sequence according to the 'direction' property; the
implicit part of the bidirectional algorithm is ignored. This corresponds
to adding a LRO (U+202D; for 'direction: ltr') or RLO (U+202E; for
'direction: rtl') at the start of the element and a PDF (U+202C)
at the end of the element.
The final order of characters in each
block-level element is the same as if the bidi control codes had
been added as described above, markup had been stripped, and the
resulting character sequence had been passed to an implementation
of the Unicode bidirectional algorithm for plain text that produced
the same line-breaks as the styled text. In this process, non-textual
entities such as images are treated as neutral characters, unless
their 'unicode-bidi' property has a value other than 'normal', in
which case they are treated as strong characters in the 'direction'
specified for the element.
Please note that in order to be able to flow inline boxes in
a uniform direction (either entirely left-to-right or entirely right-to-left),
more inline boxes (including anonymous inline boxes) may have to
be created, and some inline boxes may have to be split up and reordered
before flowing.
Because the Unicode algorithm has a limit of 15 levels of embedding,
care should be taken not to use 'unicode-bidi' with a value other
than 'normal' unless appropriate. In particular, a value of 'inherit'
should be used with extreme caution. However, for elements that
are, in general, intended to be displayed as blocks, a setting of
'unicode-bidi: embed' is preferred to keep the element together
in case display is changed to inline.
XSL modifications to the CSS definition:
The phasing of the first paragraph of the general description
(following the value breakouts) should read "The final order of
presentation of the characters...".
In Unicode 3.0, the Unicode Consortium has increased the limit of
the levels of embedding to 61 (definition BD2 in Unicode TR 9).
7.21.6 "glyph-orientation-horizontal"
XSL Definition:
| Value: | <angle> | inherit |
| Initial: | 0 |
| Applies to: | fo:character |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
<angle>
-
The angle is restricted to a range
of -360 to +360 in 90-degree increments.
A value of "0" indicates that all glyphs are set with the top
of the glyphs toward the top of the reference-area. Top of the reference-area
is defined by the reference-area's 'reference-orientation'.
A value of "90" indicates a rotation of 90-degrees clockwise
from the "0" orientation.
The angle value is computed modulo 360; thus a value of "-90"
or a value of "270" indicates a rotation of 90-degrees counter-clockwise
from the "0" orientation.
This property specifies the orientation
of text glyphs relative to the path direction specified by the 'writing-mode'.
This property is applied only to horizontally written text.
Fallback: If not supported the behavior shall be as if "glyph-orientation='0'"
had been specified.
7.21.7 "glyph-orientation-vertical"
XSL Definition:
| Value: | auto | <angle> | inherit |
| Initial: | auto |
| Applies to: | fo:character |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
auto
-
-
Fullwidth ideographic
and fullwidth Roman text (excluding ideographic punctuation) will
be set with a glyph-orientation of 0.
Ideographic punctuation and other ideographic characters having
alternate horizontal and vertical forms will use the vertical form
of the glyph.
-
Text which is not fullwidth will be set with a glyph-orientation
of 90.
This reorientation rule applies only to the first-level non-ideographic
text. All futher embedding of writing-modes or bi-di processing
will be based on the first-level rotation.
NOTE:
-
This is equivalent to having set the non-ideographic
text string horizontally honoring the bidi-rule, then rotating the
resultant sequence of inline-areas (one area for each change of
glyph direction) 90-degrees clockwise.
It should be noted that text set in this "rotated" manner may
contain ligatures or other glyph combining and reordering common
to the language and script. (This "rotated" presentation form does
not disable auto-ligature formation or similar context-driven variations.)
-
The determination of which characters should be auto-rotated
may vary across user agents. The determination is based on a complex
interaction between country, language, script, character properties,
font, and character context. It is suggested that one consult the
Unicode consortium's UTR #11 and the various JIS or other national
standards.
-
<angle>
-
The angle is restricted to a range
of -360 to +360 in 90-degree increments.
A value of "0" indicates that all glyphs are set with the top
of the glyphs toward the top of the reference-area. Top of the reference-area
is defined by the reference-area's 'reference-orientation'.
A value of "90" indicates a rotation of 90-degrees clockwise
from the "0" orientation.
The angle value is computed modulo 360; thus a value of "-90"
or a value of "270" indicates a rotation of 90-degrees counter-clockwise
from the "0" orientation.
This property specifies the orientation
of text glyphs relative to the path direction specified by the writing-mode.
This property is applied only to vertically written text.
Its most common usage is to differentiate between the preferred
orientation of Roman text in vertically written Japanese documents
(glyph-orientation="auto") vs. the orientation of Roman text in
western signage and advertising (glyph-orientation="0").
Fallback: If not supported the behavior
shall be as if "glyph-orientation='0'" had been specified.
7.21.8 "font-height-override-after"
XSL Definition:
| Value: | use-font-metrics | <length> | inherit |
| Initial: | use-font-metrics |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | refer to font's em-height |
| Media: | visual |
Values have the following meanings:
-
use-font-metrics
-
Uses the font's value for the height
of the font below the baseline.
-
<length>
-
Replaces the height value found in the font.
Specifies the height to be used for
line-spacing that lies below/after the font's reference-position
(baseline).
7.21.9 "font-height-override-before"
XSL Definition:
| Value: | use-font-metrics | <length> | inherit |
| Initial: | use-font-metrics |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | refer to font's em-height |
| Media: | visual |
Values have the following meanings:
-
use-font-metrics
-
Uses the font's value for the height
of the font above the baseline.
-
<length>
-
Replaces the height value found in the font.
Specifies the height to be used for
line-spacing that lies above/before the font's reference-position
(baseline).
7.21.10 "height"
CSS2 Definition:
| Value: | <length> | <percentage> | auto | inherit |
| Initial: | auto |
| Applies to: | all elements but non-replaced inline elements, table columns,
and column groups |
| Inherited: | no |
| Percentages: | see prose |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visudet.html#propdef-height.
This property specifies the content height of boxes generated
by block-level and replaced elements.
This property does not apply to non-replaced inline-level elements.
The height of a non replaced inline element's boxes is given by
the element's (possibly inherited) 'line-height' value.
Values have the following meanings:
-
auto
-
The height depends on the values of other properties.
-
<length>
-
Specifies a fixed height.
-
<percentage>
-
Specifies a percentage height. The percentage is calculated
with respect to the height of the generated box's containing block.
If the height of the containing block is not specified explicitly
(i.e., it depends on content height), the value is interpreted like
"auto".
Negative values for 'height' are illegal.
XSL modifications to the CSS definition:
In XSL, this property is mapped to either "inline-progression-dimension"
or "block-progression-dimension", based on the applicable values
of the "writing-mode" and "reference-orientation" properties.
Details on the mapping are given in [5 Property Refinement / Resolution].
For a discussion of the "height" property in tables see:
http://www.w3.org/TR/REC-CSS2/tables.html
Issue (height-width-rel):
Not all references to height
and width in the document have been made consistent with the
introduction of the writing mode relative ones. This is work to be done.
7.21.11 "min-height"
CSS2 Definition:
| Value: | <length> | <percentage> | inherit |
| Initial: | 0pt |
| Applies to: | all elements except non-replaced inline elements and table
elements |
| Inherited: | no |
| Percentages: | refer to height of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visudet.html#propdef-min-height.
XSL modifications to the CSS definition:
In XSL, this property is mapped to either "inline-progression-dimension"
or "block-progression-dimension", based on the applicable values
of the "writing-mode" and "reference-orientation" properties.
Details on the mapping are given in [5 Property Refinement / Resolution].
7.21.12 "max-height"
CSS2 Definition:
| Value: | <length> | <percentage> | none | inherit |
| Initial: | 0pt |
| Applies to: | all elements except non-replaced inline elements and table
elements |
| Inherited: | no |
| Percentages: | refer to height of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visudet.html#propdef-max-height.
These two properties allow authors to constrain box heights to
a certain range. Values have the following meanings:
-
none
-
(Only on "max-height") No limit on the height of the box.
-
<length>
-
Specifies a fixed minimum or maximum computed height.
-
<percentage>
-
Specifies a percentage for determining the computed value.
The percentage is calculated with respect to the height of the generated
box's containing block. If the height of the containing block is
not specified explicitly (i.e., it depends on content height), the
percentage value is interpreted like "auto".
XSL modifications to the CSS definition:
In XSL, this property is mapped to either "inline-progression-dimension"
or "block-progression-dimension", based on the applicable values
of the "writing-mode" and "reference-orientation" properties.
Details on the mapping are given in [5 Property Refinement / Resolution].
7.21.13 "block-progression-dimension"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | auto | <length> | <percentage> | <length-range>
| inherit |
| Initial: | auto |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | see prose |
| Media: | visual |
This property specifies the block-progression-dimension
of the content rectangle.
The user
may specify an explicit size (<length> or <percentage>)
or a <length-range>, allowing the size to be adjusted by the formatter.
This property does not apply when the "line-height" property
applies to the same dimension of the
areas generate by this formatting object.
Values have the following meanings:
-
auto
-
No constraint is imposed by this property.
The block-progression-dimension is determined by the formatter
taking all other constraints into account.
Specifying block-progression-dimension=auto will set:
-
block-progression-dimension.minimum=auto
-
block-progression-dimension.optimum=auto
-
block-progression-dimension.maximum=auto
-
<length>
-
Specifies a fixed block-progression-dimension.
Specifying block-progression-dimension=<length> will set:
-
block-progression-dimension.minimum=<length>
-
block-progression-dimension.optimum=<length>
-
block-progression-dimension.maximum=<length>
-
<percentage>
-
Specifies a percentage block-progression-dimension. The
percentage is calculated with respect to the corresponding dimension
of the closest area ancestor that was generated by a block-level
formatting object.
If that dimension
is not specified explicitly (i.e., it depends
on content's block-progression-dimension), the value is interpreted
as "auto".
Specifying block-progression-dimension=<percentage> will
set:
-
block-progression-dimension.minimum=<percentage>
-
block-progression-dimension.optimum=<percentage>
-
block-progression-dimension.maximum=<percentage>
-
<length-range>
-
Specifies the dimension as a length-range, consisting
of:
-
block-progression-dimension.optimum
This is the preferred dimension of the area created, if minimum and
maximum are identical, the area is of a fixed dimension. If they are, respectively,
smaller and larger than optimum, then the area may be adjusted in
dimension within that range.
A value of "auto" may be specified for optimum, indicating that
there is no preferred dimension, but that the intrisic or resolved dimension
of the area should be used. If minimum and/or maximum are not also
auto, then the dimension shall be constrained between those limits.
-
block-progression-dimension.minimum
-
block-progression-dimension.maximum
A value of "auto" may be specified for block-progression-dimension.maximum.
This indicates that there is no absolute maximum limit, and the
object may be sized to its intrinsic size.
Negative values for block-progression-dimension.minimum, block-progression-dimension.optimum,
and block-progression-dimension.maximum are invalid and are treated
as if "0pt" had been specified.
If the computed value of block-progression-dimension.maximum
is less than the computed value of block-progression-dimension.optimum,
it is treated as if the value of block-progression-dimension.optimum
had been specified.
If the computed value of block-progression-dimension.minimum
is greater than the computed value of block-progression-dimension.optimum,
it is treated as if the value of block-progression-dimension.optimum
had been specified.
7.21.14 "href"
XSL Definition:
| Value: | <url> | inherit |
| Initial: | none, value required |
| Applies to: | fo:external-graphic |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
<uri>
Specifies the URL to locate a link
destination or the image/graphic data to be included as the content
of this object.
7.21.15 "hyphenation-keep"
XSL Definition:
| Value: | none | column | page | spread | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
none
-
No restriction applies. The word may
be hyphenated at the end of any region.
-
column
-
Both parts of a hyphenated word shall
lie within a single column.
-
page
-
Both parts of a hyphenated word shall
lie within a single page.
-
spread
-
Both parts of a hyphenated word shall
lie within a single spread.
Controls whether hyphenation can be
performed on the last line that fits in a given reference-area.
7.21.16 "hyphenation-ladder-count"
XSL Definition:
| Value: | none | <number> | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
none
-
Any number of successive lines may
be hyphenated.
-
<integer>
-
An integer greater than or equal to 1.
1 means that if a line is hyphenated, the immediately-subsequent
and immediately-preceding lines within the same block may not be
hyphenated.
2 means you may have 2 hyphenated lines in succession, if there
are more than 1 immediately-subsequent line in the block, the 2
hyphenataed lines must be followed by at least 1 non-hyphenated
line, before any subsequent hyphenated lines may occur.
Limits the number of successive hyphenated
line-areas the formatter may generate in a
block-area.
7.21.17 "id"
XSL Definition:
| Value: | <id> |
| Initial: | see prose |
| Applies to: | all formatting objects |
| Inherited: | no, see prose |
| Percentages: | N/A |
| Media: | all |
Values have the following meanings:
-
<id>
An identifier unique within all objects
in the result tree with the fo: namespace. It allows references
to this formatting object by other objects.
The "inherit" value is not allowed on this property.
The
initial value of this property is random and unique
identifier. The algorithm to generate this identifier is
system-dependent.
7.21.18 "last-line-end-indent"
XSL Definition:
| Value: | <length> | <percentage> | inherit |
| Initial: | 0pt |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | width of containing block |
| Media: | visual |
Values have the following meanings:
-
<length>
-
The "last-line-end-indent" is specified as a length.
-
<percentage>
-
The "last-line-end-indent" is specified as a percentage
of the current-block's content-rectangle
width.
Specifies an indent to be applied
to the end-edge of the last (or only) line of a block-area.
It is
added to the current block's end-edge. Positive values indent the
edge, negative values outdent the edge. Unlike 'text-indent', the
actual result depends on how much flexibility there is in the block
of text, except when 'last-line-align' is 'justify'.
This is often used with a negative value specified for generating
a table-of-contents with the page number hanging in an "outdent"
and in similar semi-tabular material.
7.21.19 "line-height-shift-adjustment"
XSL Definition:
| Value: | consider-shifts | disregard-shifts | inherit |
| Initial: | consider-shifts |
| Applies to: | fo:block |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
consider-shifts
-
In determining the line-height, include
the adjusted top-edge and bottom-edge of any characters that have
a baseline-shift.
-
disregard-shifts
-
In determining the line-height, include
the unshifted top-edge and bottom-edge of any characters that have
a baseline-shift.
This property is used to control if
the line-height is adjusted for content that has a baseline-shift.
NOTE:
This property can be used to prevent superscript and subscript
characters from disrupting the line spacing.
7.21.20 "line-height"
CSS2 Definition:
| Value: | normal | <length> | <number> | <percentage> | <space>
| inherit |
| Initial: | normal |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | refer to the font size of the element itself |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visudet.html#propdef-line-height.
Values have the following meanings:
-
normal
-
Tells user agents to set the computed value to a "reasonable"
value based on the font size of the element. The value has the same
meaning as <number>. We recommend a computed value for "normal"
between 1.0 to 1.2.
-
<length>
-
The box height is set to this length. Negative values are
illegal.
-
<number>
-
The computed value of the property is this number multiplied
by the element's font size. Negative values are illegal. However,
the number, not the computed value, is inherited.
-
<percentage>
-
The computed value of the property is this percentage multiplied
by the element's computed font size. Negative values are illegal.
If the property is set on a block-level element whose content
is composed of inline-level elements, it specifies the minimal height
of each generated inline box.
If the property is set on an inline-level element, it specifies
the exact height of each box generated by the element. (Except for
inline replaced elements, where the height of the box is given by
the "height" property.)
When an element contains text that is rendered in more than one
font, user agents should determine the "line-height" value according
to the largest font size.
Generally, when there is only one value of "line-height" for
all inline boxes in a paragraph (and no tall images), the above
will ensure that baselines of successive lines are exactly "line-height"
apart. This is important when columns of text in different fonts
have to be aligned, for example in a table.
Note that replaced elements have a "font-size" and a "line-height"
property, even if they are not used directly to determine the height
of the box. The "font-size" is, however, used to define the "em"
and "ex" units, and the "line-height" has a role in the "vertical-align" property.
XSL modifications to the CSS definition:
XSL adds the following value with the following meanings:
-
<space>
-
The difference between the inline-area's actual height and the
line-height's space-specifier's three lengths are each divided by 2.0 and
the result is used to set three half-leading
values (optimum, minimum, and maximum).
Negative values for line-height.minimum, line-height.optimum,
and line-height.maximum are invalid and will be interpreted as 0pt.
If the value of line-height.maximum is less than the value of
line-height.optimum, it is treated as if the value of line-height.optimum
had been specified. If the value of line-height.minimum is greater
than the value of line-height.optimum, it is treated as if the value
of line-height.optimum had been specified.
The line-height.conditionality setting
can be used to control the half-leading above the first line or
after the last line that is placed in a reference area.
The line-height.precedence setting can be used to control the
merging of the half-leading with other spaces.
The space-before and space-after
space-specifiers are set to the value of the half-leading.
A definition of space-specifiers, and
the interaction between space-specifiers occuring in sequence are
given in [4.3 Spaces and Conditionality].
If line-height is specified using <length>, <percentage>
or <number>; the formatter shall convert the single value to a
space-specifier with the subfields interpreted as follows:
-
line-height.minimum: the resultant computed value
(as a length) of the <length>, <percentage>, or <number>.
-
line-height.optimum: the resultant computed value (as a
length) of the <length>, <percentage>, or <number>.
-
line-height.maximum: the resultant computed value (as a
length) of the <length>, <percentage>, or <number>.
-
line-height.precedence: force.
-
line-height.conditionality: retain
7.21.21 "line-stacking-strategy"
XSL Definition:
| Value: | line-height | font-height | max-height | inherit |
| Initial: | line-height |
| Applies to: | fo:block |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
line-height
-
Matches CSS's line height and positioning
strategy. (Uses the per-inline-height-rectangle as described in
the area-model.)
-
font-height
-
Uses the block's font height as adjusted
by the font-height-override-before and font-height-override-after
properties. (Uses the nominal-requested-line-rectangle as described
in the area-model.)
-
max-height
-
Uses the adjusted maximum ascender-heights
and maximum descender-depth for the actual fonts and inline-areas
placed on the line. This value may be further influenced by the
line-height-shift-adjustment property. (Uses the maximal-line-rectangle
as described in the area-model).
Selects the strategy for positioning
adjacent lines, relative to each other.
7.21.22 "overflow"
CSS2 Definition:
| Value: | visible | hidden | scroll | auto | inherit |
| Initial: | auto |
| Applies to: | block-level and replaced elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visufx.html#propdef-overflow.
This property specifies whether the content of a block-level
element is clipped when it overflows the element's box (which is
acting as a containing block for the content). Values have the following
meanings:
-
visible
-
This value indicates that content is not clipped, i.e.,
it may be rendered outside the block box.
-
hidden
-
This value indicates that the content is clipped and that
no scrolling mechanism should be provided to view the content outside
the clipping region; users will not have access to clipped content.
The size and shape of the clipping region is specified by the "clip"
property.
-
scroll
-
This value indicates that the content is clipped and that
if the user agent uses scrolling mechanism that is visible on the
screen (such as a scroll bar or a panner), that mechanism should
be displayed for a box whether or not any of its content is clipped.
This avoids any problem with scrollbars appearing and disappearing
in a dynamic environment. When this value is specified and the target
medium is "print" or 'projection', overflowing content should be
printed.
-
auto
-
The behavior of the "auto" value is user agent
dependent,
but should cause a scrolling mechanism to be provided for overflowing
boxes.
Even if "overflow" is set to "visible", content may be
clipped to a UA's document window by the native operating environment.
XSL modifications to the CSS definition:
The initial value for the overflow property has been
changed from "visible" to "auto"
Two more values are defined and the definition of the CSS "auto"
value is augmented as follows:
-
error-if-overflow
-
This value implies the same semantics as the value "hidden" with the
additional semantic that an error shall be indicated; implementations may
recover by clipping the region.
-
paginate
-
When overflow occurs while directing content to a target region on a
page-master, new instances of the presentation medium shall be generated
as necessary to contain the overflow. When applied to a non-region
formatting object, this value specifies, in the case of overflow, that more
areas shall be generated as necessary to contain the overflow.
This property value has conformance level "extended".
-
auto
-
The behavior of the "auto" value is user agent dependent, but should cause
a scrolling mechanism to be provided for overflowing boxes if the user
agent if the user agent is capable of doing so. If the user agent cannot
provide a scrolling mechanism, then (1) when applied to the region to which
fo:flow is assigned, this value implies the same semantics as "paginate"; (2)
when applied to a region to which fo:static-content is assigned, this value
implies the same semantics as "error-if-overflow"; and (3) when applied to
a non-region formatting object, this value implies the same semantics as
"error-if-overflow".
7.21.23 "provisional-label-separation"
XSL Definition:
| Value: | <length> | inherit |
| Initial: | 6.0pt |
| Applies to: | fo:list-block |
| Inherited: | yes |
| Percentages: | refer to width of the containing box |
| Media: | visual |
Values have the following meanings:
-
<length>
-
Specifies the provisional distance between the end of the
list-item-label and the start of the list-item-body. The value is
not directly used during formatting, but is used in the computation
of the value of the label-end variable.
NOTE:
label-end() = width of the content-rectangle of the
reference-area into
which the list-block is placed - (the value of the provisional-distance-between-starts
+ the value of the start-indent - the value of the provisional-label-separation)
of the closest ancestor fo:list-block.
7.21.24 "provisional-distance-between-starts"
XSL Definition:
| Value: | <length> | inherit |
| Initial: | 24.0pt |
| Applies to: | fo:list-block |
| Inherited: | yes |
| Percentages: | refer to width of the containing box |
| Media: | visual |
Values have the following meanings:
-
<length>
-
Specifies the provisional distance between the start-indents
of the list-item-label and the list-item-body. The value is not
directly used during formatting, but is used in the computation
of the value of the body-start variable.
NOTE:
body-start() = the value of the start-indent + the value
of the
provisional-distance-between-starts of the closest ancestor fo:list-block.
7.21.25 "ref-id"
XSL Definition:
| Value: | <idref> | inherit |
| Initial: | none, value required |
| Applies to: | fo:page-number-citations |
| Inherited: | no |
| Percentages: | N/A |
| Media: | all |
Values have the following meanings:
-
<idref>
-
The "id" of an object in the formatting-object
tree.
Reference to the object having the
specified unique identifier.
7.21.26 "reference-orientation"
XSL Definition:
| Value: | 0 | 90 | 180 | 270 | -90 | -180 | -270 | inherit |
| Initial: | 0 |
| Applies to: | see prose |
| Inherited: | yes (see prose) |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
0
-
The reference-orientation of this
reference-area has the same reference-orientation as
the containing reference-area.
-
90
-
The reference-orientation of this
reference-area is rotated 90 degrees counter-clockwise from the
reference-orientation of the containing reference-area.
-
180
-
The reference-orientation of this
reference-area is rotated 180 degrees counter-clockwise from the
reference-orientation of the containing reference-area.
-
270
-
The reference-orientation of this
reference-area is rotated 270 degrees counter-clockwise from the
reference-orientation of the containing reference-area.
-
-90
-
The reference-orientation of this
reference-area is rotated 270 degrees counter-clockwise from the
reference-orientation of the containing reference-area.
NOTE:
This is equivalent to specifying "270".
-
-180
-
The reference-orientation of this
reference-area is rotated 180 degrees counter-clockwise from the
reference-orientation of the containing reference-area.
NOTE:
This is equivalent to specifying "180".
-
-270
-
The reference-orientation of this
reference-area is rotated 90 degrees counter-clockwise from the
reference-orientation of the containing reference-area.
NOTE:
This is equivalent to specifying "90".
The reference-orientation specifies
the direction for "top" for the content-rectangle of the "reference-area".
This is used as the reference for deriving directions, such as the
block-progression-direction, inline-progression-direction,
etc.
as specified by the "writing-mode" and "direction" properties.
The "reference-orientation" property is applied only on formatting objects
that set up a reference-area (for XSL these are: fo:simple-page-master,
fo:*-region, fo:flow, fo:static-content, fo:table, fo:table-cell,
fo:display-included-container, & fo:inline-included-container).
Each value of "reference-orientation" sets the absolute direction
for "top", "left", "bottom", and "right"; which is used by "writing-mode",
"direction", and all positioning operations that are referenced
to the reference-area or are nested within it.
The "reference-orientation" trait on an area are indirectly derived
from the "reference-orientation" property on the formatting object
that generates the area or the formatting object ancestors of that
formatting object. The exact derivation is as follows:
Conformance:
-
The user agent may implement only "0". This
is the minimum (core) implementation.
Fallback: The unimplemented values are to be treated as "0".
-
If the user agent implements any other value for reference-orientation,
the user agent must implement all other
orientations.
7.21.27 "relative-position"
XSL Definition:
| Value: | auto | static | relative | inherit |
| Initial: | static |
| Applies to: | all block-level and inline-level formatting objects |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
static
-
The area is normally stacked.
-
relative
-
The area's position is determined as if it was normally
stacked. Only during rendering is the area
rendered offset relative to this position.
The fact that one area is relatively positioned does not
influence the position on any other area.
For areas that break over a page boundary,
only the portion that would have been on a given page originally
is included in the repositioned area on that page. Any portion
of the repositioned area that was originally on the current page, but
falls off the current page due to repositioning is "off" (typically
clipped), thus does not fall onto any other page.
7.21.28 "scale"
XSL Definition:
| Value: | <number>{1,2} | maximum | maximum-uniform
| inherit |
| Initial: | 1.0 |
| Applies to: | fo:external-graphic,
fo:instream-foreign-object |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
maximum
-
The content of the graphic shall be scaled independently
in each direction so that its size in the horizontal and vertical
directions is as large as allowed.
-
maximum-uniform
-
The content of the graphic shall be scaled uniformly
in the horizontal and vertical directions so that its size in either
the horizontal or vertical direction is as large as allowed. The
"non-fitting" axis will under-fill the available size.
-
<number>
-
Specifies a scaling factor to be applied to the content
of the graphic. Numbers less than 1 shall make the content smaller.
Numbers greater than 1 shall make it larger. The value must be greater
than zero.
-
If 1 number is specified, it sets both x-scale & y-scale
to same value
-
If 2 numbers are specified, the first sets the x-scale
(inline-progression-direction) and the second sets the y-scale (block-progression-direction).
Sets the scale factor for an embedded
graphic.
7.21.29 "score-spaces"
XSL Definition:
| Value: | true | false | inherit |
| Initial: | true |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | see prose |
| Media: | visual |
Values have the following meanings:
-
true
-
Text-decoration will be applied to spaces
-
false
-
Text-decoration will not be applied to spaces
Specifies whether the text-decoration
property shall be applied to spaces.
7.21.30 "span"
XSL Definition:
| Value: | none | all | inherit |
| Initial: | none |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
none
-
This object does not span multiple
columns.
-
all
-
The areas resulting from this flow
object shall span all the columns of a multi-column region.
Specifies if a block-level object
should be placed in the current column or should span all columns
of a multi-column region.
7.21.31 "text-align"
CSS2 Definition:
| Value: | start | center | end | justify | inside | outside
| left | right | <string> | inherit |
| Initial: | start |
| Applies to: | block-level elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/text.html#propdef-text-align.
This property describes how inline content of a block is aligned.
Values have the following meanings:
-
left
-
center
-
right
-
justify
-
Left, right, center, and double justify text, respectively.
-
<string>
-
Specifies a string on which cells in a table column will
align (see the section on horizontal alignment in a column for details
and an example). This value applies only to table cells. If set
on other elements, it will be treated as 'left' or 'right', depending
on whether 'direction' is 'ltr', or 'rtl', respectively.
A block of text is a stack of line boxes. In the case of
'left', 'right' and 'center', this property specifies how the inline
boxes within each line box align with respect to the line box's
left and right sides; alignment is not with respect to the viewport.
In the case of 'justify', the UA may stretch the inline boxes in
addition to adjusting their positions. (See also 'letter-spacing'
and 'word-spacing'.)
NOTE:
The actual justification algorithm used is user agent and written
language dependent.
Conforming user agents may interpret the value 'justify' as 'left'
or 'right', depending on whether the element's default writing direction
is left-to-right or right-to-left, respectively.
XSL modifications to the CSS definition:
Values have the following meanings:
-
start
-
Specifies that the contents is to be start-aligned in the
inline-progression-direction. Any overflow is placed onto the end
edge of the contents.
-
center
-
Specifies that the contents is to
be centered in the inline-progression-direction. Any overflow is
distributed equally onto the start and end edges of the contents.
-
end
-
Specifies that the contents is to
be end-aligned in the inline-progression-direction. Any overflow
placed onto the start edge of the contents.
-
justify
-
Specifies that the contents is to
be expanded to fill the available width in the inline-progression-direction.
Any overflow is placed onto the end edge of the contents.
The last (or only) line of any block will be set start-aligned.
If you wish to force-justify the line, you must specify "text-align-last='justify'".
-
inside
-
If the page binding edge is the start-side,
the alignment will be start. If the binding-edge is the end-side,
the alignment will be end. If neither, use start-side.
-
outside
-
If the page binding edge is the start-side,
the alignment will be end. If the binding-edge is the end-side the
alignment will be start. If neither, use end alignment.
-
left
-
Interpreted as "text-align='start'".
-
right
-
Interpreted as "text-align='end'".
-
<string>
-
Specifies a string on which cells in a table column will
align (see the section on horizontal alignment in a column for details
and an example). This value applies only to table cells. If set
on other elements, it will be treated as "start".
This property describes how inline content of a block is
aligned.
7.21.32 "text-align-last"
XSL Definition:
| Value: | relative | start | center | end | justify | inside
| outside | left | right | <string> | inherit |
| Initial: | start |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
relative
-
If text-align is justify, then the
alignment of the last line will be start. If text-align is not justify,
text-align-last will use the value of text-align.
-
start
-
Specifies that the contents is to be start-aligned in the
inline-progression-direction. Any overflow is placed onto the end
edge of the contents.
-
center
-
Specifies that the contents is to
be centered in the inline-progression-direction. Any overflow is
distributed equally onto the start and end edges of the contents.
-
end
-
Specifies that the contents is to
be end-aligned in the inline-progression-direction. Any overflow
placed onto the start edge of the contents.
-
justify
-
Specifies that the contents is to
be expanded to fill the available width in the inline-progression-direction.
Any overflow is placed onto the end edge of the contents.
This setting will force-justify the last (or only) line of a
block.
-
inside
-
If the page binding edge is the start-side,
the alignment will be start. If the binding-edge is the end-side,
the alignment will be end. If neither, use start-side.
-
outside
-
If the page binding edge is the start-side,
the alignment will be end. If the binding-edge is the end-side the
alignment will be start. If neither, use end alignment.
-
left
-
Interpreted as "text-align='start'".
-
right
-
Interpreted as "text-align='end'".
-
<string>
-
Specifies a string on which cells in a table column will
align (see the section on horizontal alignment in a column for details
and an example). This value applies only to table cells. If set
on other elements, it will be treated as "start".
Specifies the alignment of the last
textline in the block.
A value of relative specifies that the value of the text-align
property shall be used, except when that value is justify, in which
case a value of start shall be used.
7.21.33 "text-indent"
CSS2 Definition:
| Value: | <length> | <percentage> | inherit |
| Initial: | 0pt |
| Applies to: | block-level elements |
| Inherited: | yes |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/text.html#propdef-text-indent.
This property specifies the indentation of the first line of
text in a block. More precisely, it specifies the indentation of
the first box that flows into the block's first line box. The box is
indented with respect to the left (or right, for right-to-left layout)
edge of the line box. User agents should render this indentation
as blank space.
Values have the following meanings:
-
<length>
-
The indentation is a fixed length.
-
<percentage>
-
The indentation is a percentage of the containing block
width
The value of 'text-indent' may be negative, but there may
be implementation-specific limits.
XSL modifications to the CSS definition:
The "text-indent" property specifies an adjustment to the
start-indent of the first line of text in a block-area. This indent
is added to the block's start-indent.
A negative value specifies a hanging indent (outdent) on the
first line.
7.21.34 "visibility"
CSS2 Definition:
| Value: | visible | hidden | collapse | inherit |
| Initial: | visible |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visufx.html#propdef-visibility.
The 'visibility' property specifies whether the boxes generated
by an element are rendered. Invisible boxes still affect layout
(set the 'display' property to 'none' to suppress box generation
altogether). Values have the following meanings:
-
visible
-
The generated box is visible.
-
hidden
-
The generated box is invisible (fully transparent), but
still affects layout.
-
collapse
-
Please consult the section on dynamic row and column effects
in tables. If used on elements other than rows or columns, "collapse"
has the same meaning as "hidden".
This property may be used in conjunction with scripts to
create dynamic effects.
XSL modifications to the CSS definition:
Changed initial value to visible (is "inherit" in
CSS).
7.21.35 "width"
CSS2 Definition:
| Value: | <length> | <percentage> | auto | inherit |
| Initial: | auto |
| Applies to: | all elements but non-replaced inline elements, table-rows,
and row groups |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visudet.html#propdef-width.
This property specifies the content width of boxes generated
by block-level and replaced elements.
This property does not apply to non-replaced inline-level elements.
The width of a non-replaced inline element's boxes is that of the
rendered content within them (before any relative offset of children).
Recall that inline boxes flow into line boxes. The width of line boxes
is given by the their containing block, but may be shorted by the
presence of floats.
The width of a replaced element's box is intrinsic and may be
scaled by the user agent if the value of this property is different
than 'auto'.
Values have the following meanings:
-
auto
-
The width depends on the values of other properties.
-
<length>
-
Specifies a fixed width.
-
<percentage>
-
Specifies a percentage width. The percentage is calculated
with respect to the width of the generated box's containing block.
Negative values for "width" are illegal.
XSL modifications to the CSS definition:
In XSL, this property is mapped to either "inline-progression-dimension"
or "block-progression-dimension", based on the applicable values
of the "writing-mode" and "reference-orientation" properties.
Details on the mapping are given in [5 Property Refinement / Resolution].
7.21.36 "min-width"
CSS2 Definition:
| Value: | <length> | <percentage> | inherit |
| Initial: | depends on UA |
| Applies to: | all elements except non-replaced inline elements and table
elements |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visudet.html#propdef-min-width.
XSL modifications to the CSS definition:
In XSL, this property is mapped to either "inline-progression-dimension"
or "block-progression-dimension", based on the applicable values
of the "writing-mode" and "reference-orientation" properties.
Details on the mapping are given in [5 Property Refinement / Resolution].
7.21.37 "max-width"
CSS2 Definition:
| Value: | <length> | <percentage> | none | inherit |
| Initial: | none |
| Applies to: | all elements except non-replaced inline elements and table
elements |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visudet.html#propdef-max-width.
These two properties allow authors to constrain box widths to
a certain range. Values have the following meanings:
-
none
-
(Only on "max-width") No limit on the width of the box.
-
<length>
-
Specifies a fixed minimum or maximum computed width.
-
<percentage>
-
Specifies a percentage for determining the computed value.
The percentage is calculated with respect to the width of the generated
box's containing block.
XSL modifications to the CSS definition:
In XSL, this property is mapped to either "inline-progression-dimension"
or "block-progression-dimension", based on the applicable values
of the "writing-mode" and "reference-orientation" properties.
Details on the mapping are given in [5 Property Refinement / Resolution].
7.21.38 "inline-progression-dimension"
Writing-mode Relative Equivalent of CSS2 Property.
| Value: | auto | <length> | <percentage> | <length-range>
| inherit |
| Initial: | auto |
| Applies to: | see prose |
| Inherited: | no |
| Percentages: | see prose |
| Media: | visual |
This property specifies the inline-progression-dimension
of the content rectangle. The user
may specify an explicit size (<length> or <percentage>)
or a <length-range>, allowing the size to be adjusted by the formatter.
This property does not apply when the "line-height" property
applies to the same dimension of the
areas generate by this formatting object.
Values have the following meanings:
-
auto
-
No constraint is imposed by this property.
The block-progression-dimension is determined by the formatter
taking all other constraints into account.
Specifying inline-progression-dimension=auto will set:
-
inline-progression-dimension.minimum=auto
-
inline-progression-dimension.optimum=auto
-
inline-progression-dimension.maximum=auto
-
<length>
-
Specifies a fixed inline-progression-dimension.
Specifying inline-progression-dimension=<length> will set:
-
inline-progression-dimension.minimum=<length>
-
inline-progression-dimension.optimum=<length>
-
inline-progression-dimension.maximum=<length>
-
<percentage>
-
Specifies a percentage inline-progression-dimension. The
percentage is calculated with respect to the corresponding dimension
of the closest area ancestor that was generated by a block-level
formatting object.
If that dimension
is not specified explicitly (i.e., it depends
on content's inline-progression-dimension), the value is interpreted
as "auto".
Specifying inline-progression-dimension=<percentage> will
set:
-
inline-progression-dimension.minimum=<percentage>
-
inline-progression-dimension.optimum=<percentage>
-
inline-progression-dimension.maximum=<percentage>
-
<length-range>
-
Specifies the dimension as a length-range, consisting
of:
-
inline-progression-dimension.optimum
This is the preferred dimension of the area created, if minimum and
maximum are identical, the area is of a fixed dimension. If they are, respectively,
smaller and larger than optimum, then the area may be adjusted in
dimension within that range.
A value of "auto" may be specified for optimum, indicating that
there is no preferred dimension, but that the intrisic or resolved dimension
of the area should be used. If minimum and/or maximum are not also
auto, then the dimension shall be constrained between those limits.
-
inline-progression-dimension.minimum
-
inline-progression-dimension.maximum
A value of "auto" may be specified for inline-progression-dimension.maximum.
This indicates that there is no absolute maximum limit, and the
object may be sized to its intrinsic size.
Negative values for inline-progression-dimension.minimum, inline-progression-dimension.optimum,
and inline-progression-dimension.maximum are invalid and are treated
as if "0pt" had been specified.
If the computed value of inline-progression-dimension.maximum
is less than the computed value of inline-progression-dimension.optimum,
it is treated as if the value of inline-progression-dimension.optimum
had been specified.
If the computed value of inline-progression-dimension.minimum
is greater than the computed value of inline-progression-dimension.optimum,
it is treated as if the value of inline-progression-dimension.optimum
had been specified.
7.21.39 "linefeed-treatment"
XSL Definition:
| Value: | ignore | preserve | treat-as-space | inherit |
| Initial: | treat-as-space |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
ignore
-
Specifies that any character flow object whose Unicode
character code is #xA shall be discarded.
-
preserve
-
Specifies no special action.
-
treat-as-space
-
Specifies that any character flow object
whose Unicode character code is #xA shall be treated by subsequent XSL processing
(including collapsing) and the formatter as if its Unicode character code
were #x20.
The "linefeed-treatment" property specifies the treatment of linefeeds (#xA
characters).
7.21.40 "space-treatment"
XSL Definition:
| Value: | ignore | preserve | inherit |
| Initial: | preserve |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
ignore
-
Specifies that any character flow object whose character
is of Unicode character class "whitespace", except for #xA (linefeed) characters
(since their treatment is determine by the linefeed-treatment
property), shall be discarded.
-
preserve
-
Specifies no special action.
The "space-treatment" property specifies the treatment of space
(#x20) and other whitespace characters except for linefeeds (#xA characters).
7.21.41 "white-space-collapse"
XSL Definition:
| Value: | false | true | inherit |
| Initial: | true |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
false
-
Specifies no special action.
-
true
-
Specifies, for any character flow object such
that:
-
its character is of the Unicode character class "whitespace",
and
Issue (white-space-Unicode-or-XML):
Should this be the
Unicode defined whitespace classified characters or those designated
as whitespace in XML?
-
it is not a preserved linefeed (due to linefeed-treatment="preserve"
), and
-
the immediately preceding (non-ignored) flow object was a character flow
object also with a character of class whitespace or the immediately
following (non-ignored) flow object is a preserved linefeed,
that flow object shall be ignored.
The "white-space-collapse" property specifies the treatment of
consecutive whitespace. The effect is as follows: after all ignored whitespace
is discarded and all "treat-as-space" whitespace is turned into a space, all
resulting runs of two or more consecutive spaces are replaced by a single
space, then any remaining space immediately adjacent to a remaining linefeed
is also discarded. An implementation is free to use any algorithm to achieve
an equivalent effect.
7.21.42 "wrap-option"
XSL Definition:
| Value: | no-wrap | wrap | inherit |
| Initial: | wrap |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
nowrap
-
No line-wrapping will be performed.
In the case when lines are longer than the available width of
the content-rectangle, the overflow will be treated in accordance
with the "overflow" property specified on the reference-area.
-
wrap
-
Line-breaking will occur if the line
overflows the available block width. No special markers or other
treatment will occur.
Specifies how line-wrapping (line-breaking)
of the content of the formatting object is to be
handled.
7.21.43 "writing-mode"
XSL Definition:
| Value: | lr-tb | rl-tb | tb-rl | lr | rl | tb | inherit |
| Initial: | lr-tb |
| Applies to: | see prose |
| Inherited: | yes (see prose) |
| Percentages: | N/A |
| Media: | visual |
NOTE:
This version of the writing-mode property covers the base writing-modes
that are used as the official languages of the United Nations. For
information regarding additional writing-modes, please see the "Internationalization
Appendix".
Values have the following meanings:
-
lr-tb
-
Inline components and text within
a line are written left-to-right. Lines and blocks are placed top-to-bottom.
NOTE:
Typically, this is the writing-mode for normal Roman text.
Establishes the following directions:
-
inline-progression-direction to left-to-right
If any right-to-left reading characters are present in the text,
the inline-progression-direction for glyph-areas may be
further modified by the Unicode bidi algorithm.
-
block-progression-direction to top-to-bottom
-
shift-direction to bottom-to-top
See "Conformance" section if the Unicode bidi algorithm is supported.
-
rl-tb
-
Inline components and text within
a line are written right-to-left. Lines and blocks are placed top-to-bottom.
NOTE:
Typically, this writing mode is used in Arabic and Hebrew text.
Establishes the following directions:
-
inline-progression-direction to right-to-left
If any left-to-right reading characters or numbers are present
in the text, the inline-progression-direction for
glyph-areas may
be further modified by the Unicode bidi algorithm.
-
block-progression-direction to top-to-bottom
-
shift-direction to bottom-to-top
See "Conformance" section if it is not possible to fully support
the rl-tb setting of 'writing-mode'.
-
tb-rl
-
Inline components and text within
a line are written top-to-bottom. Lines and blocks are placed right-to-left.
NOTE:
Typically, this writing mode is used in Chinese and Japanese
text.
Establishes the following directions:
-
inline-progression-direction to top-to-bottom
-
block-progression-direction to right-to-left
-
shift-direction to left-to-right
See "Conformance" section if it is not possible to fully support
the tb-rl setting of 'writing-mode'.
-
lr
-
Shorthand for lr-tb.
-
rl
-
Shorthand for rl-tb.
-
tb
-
Shorthand for tb-rl.
The "writing-mode" property is applied (processed and converted
to the 3 direction traits) only on formatting objects that
set up
a reference-area (for XSL these are: fo:simple-page-master, fo:*-region,
fo:table, fo:table-cell, fo:display-included-container, and fo:inline-included-container.
Each value of writing-mode sets all 3 of the direction
traits indicated in each of the value descriptions above on the
reference-area. (See the area model for a description of the direction
traits and their usage.)
-
When "writing-mode" is applied to the simple-page-master,
it is used to determine the placement of the 5 regions on the master.
-
When "writing-mode" is applied to the fo:*-region, it defines
the column-progression within each region. The inline-progression-direction
is used to determine the stacking direction for columns (and the
default flow order of text from column-to-column).
-
To change the "writing-mode" within an fo:flow or fo:static-content,
either the fo:display-included-container or the fo:inline-included-container,
as appropriate, should be used.
If one only wishes to change the inline-progression-direction
to override the Unicode bidi-rule, one need not use an fo:inline-included
container. Instead, one may use the the "direction" property on
any block-level formatting object or the "direction" and
"unicode-bidi"
properties on any inline formatting object.
-
When "writing-mode" is applied to the fo:table, it controls
the layout of the rows and columns. Table-rows use the
block-progression-direction
as the row stacking direction. The inline-progression-direction
is used to determine the stacking direction for columns (and cell
order within the row).
-
When "writing-mode" is applied to an fo:table-cell, it
governs the placement of blocks in the cell.
Conformance:
-
Fallback:
The unimplemented value choices are to be treated as lr-tb, however,
if there are are characters within the content that are identified
as being right-to-left either by the Unicode Bidi Algorithm or by
explicit mark-up, these characters must be presented in right-to-left
order (as glyphs). If it is not possible to present the characters
in right-to-left order, then the User Agent should display either
an "unsupported character glyph" or display some indication that
the content cannot be correctly rendered.
Notes:
-
The phrase "identified as being right-to-left by
Unicode Bidi Algorithm" means that the character has a resolved
level that is odd after steps I1 and I2 of the Unicode Bidi Algorithm.
-
It is assumed that the User Agent has a glyph that it normally
uses for "unsupported characters"; this specification does not define
what that glyph is.
-
The phrase "display some indication" could mean display
a message that "this page could not be rendered" or "this paragraph
could not be rendered" or ...
-
The user agent may implement only lr-tb and the corresponding
lr shorthand. This is the minimum (core) implementation.
-
If the user agent implements rl-tb then the user agent
must also implement the rl shorthand, lr-tb, and the lr shorthand.
-
If the user agent implements any vertical writing mode,
then the user agent must implement all 3 base modes (lr-tb, rl-tb, & tb-rl)
and the corresponding 3 shorthands (lr, rl, & tb).
7.21.44 "z-index"
CSS2 Definition:
| Value: | auto | <integer> | inherit |
| Initial: | auto |
| Applies to: | positioned elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-z-index.
For a positioned box, the "z-index" property specifies:
1. The stack level of the box in the current stacking context.
2. Whether the box establishes a local stacking context.
Values have the following meanings:
-
auto
-
The stack level of the generated box in the current stacking
context is the same as its parent's box. The box does not establish
a new local stacking context.
-
<integer>
-
This integer is the stack level of the generated box in
the current stacking context. The box also establishes a local stacking
context in which its stack level is "0".
This example [see the CSS specification] demonstrates the
notion of transparency. The default behavior of a box is to allow
boxes behind it to be visible through transparent areas in its content.
In the example, each box transparently overlays the boxes below
it. This behavior can be overridden by using one of the existing
background properties.
7.22 Shorthand Properties
The following properties are all shorthand properties.
Shorthands are only included in the highest XSL conformance
level; "complete".
7.22.1 "background"
CSS2 Definition:
| Value: | [<background-color> ||
<background-image>
|| <background-repeat> || <background-attachment> || <background-position>
| ]]inherit |
| Initial: | not defined for shorthand properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | allowed on 'background-position' |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/colors.html#propdef-background.
The "background" property is a shorthand property for setting
the individual background properties (i.e., background-color, background-image,
background-repeat, background-attachment and background-position)
at the same place in the stylesheet.
The "background" property first sets all the individual background
properties to their initial values, then assigns explicit values
given in the declaration.
7.22.2 "background-position"
CSS2 Definition:
| Value: | [ [<percentage> | <length> ]{1,2} |
[ [top | center | bottom] || [left | center | right] ] ] | inherit |
| Initial: | 0% 0% |
| Applies to: | block-level and replaced elements |
| Inherited: | no |
| Percentages: | refer to the size of the box itself |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/colors.html#propdef-background-position.
If a "background-image" has been specified, this property specifies
its initial position.
-
<percentage> <percentage>
-
With a value pair of 0% 0%, the upper left corner of the
image is aligned with the upper left corner of the box's padding
edge. A value pair of 100% 100% places the lower right corner of
the image in the lower right corner of padding area. With a value
pair of 14% 84%, the point 14% across and 84% down the image is
to be placed at the point 14% across and 84% down the padding area.
-
<length> <length>
-
With a value pair of 2cm 2cm, the upper left corner of the
image is placed 2cm to the right and 2cm below the upper left corner
of the padding area.
-
top left and left top
-
Same as 0% 0%.
-
top, top center, and center top
-
Same as 50% 0%.
-
right top and top right
-
Same as 100% 0%.
-
left, left center, and center left
-
Same as 0% 50%.
-
center and center center
-
Same as 50% 50%.
-
right, right center, and center right
-
Same as 100% 50%.
-
bottom left and left bottom
-
Same as 0% 100%.
-
bottom, bottom center, and center bottom
-
Same as 50% 100%.
-
bottom right and right bottom
-
Same as 100% 100%.
If only one percentage or length value is given, it sets
the horizontal position only, the vertical position will be 50%.
If two values are given, the horizontal position comes first. Combinations
of length and percentage values are allowed, (e.g., 50% 2cm). Negative positions
are allowed. Keywords cannot be combined with percentage values
or length values (all possible combinations are given above).
If the background image is fixed within the viewport (see the
"background-attachment" property), the image is placed relative
to the viewport instead of the elements padding area.
XSL modifications to the CSS definition:
The CSS property shall be treated as a shorthand by XSL
and maps as follows:
-
<percentage>
-
background-position-horizontal="<percentage>"
background-position-vertical="50%"
-
<percentage1> <percentage2>
-
background-position-horizontal="<percentage1>"
background-position-vertical="<percentage2>"
-
<length>
-
background-position-horizontal="<length>"
background-position-vertical="50%"
-
<length1> <length2>
-
background-position-horizontal="<length1>"
background-position-vertical="<length2>"
-
<length> <percentage>
-
background-position-horizontal="<length>"
background-position-vertical="<percentage>"
-
<percentage> <length>
-
background-position-horizontal="<percentage>"
background-position-vertical="<length>"
-
top left and left top
-
background-position-horizontal="0%"
background-position-vertical="0%"
-
top, top center, and center top
-
background-position-horizontal="50%"
background-position-vertical="0%"
-
right top and top right
-
background-position-horizontal="100%"
background-position-vertical="0%"
-
left, left center, and center left
-
background-position-horizontal="0%"
background-position-vertical="50%"
-
center and center center
-
background-position-horizontal="50%"
background-position-vertical="50%"
-
right, right center, and center right
-
background-position-horizontal="100%"
background-position-vertical="50%"
-
bottom left and left bottom
-
background-position-horizontal="0%"
background-position-vertical="100%"
-
bottom, bottom center, and center bottom
-
background-position-horizontal="50%"
background-position-vertical="100%"
-
bottom right and right bottom
-
background-position-horizontal="100%"
background-position-vertical="100%"
7.22.3 "border"
CSS2 Definition:
| Value: | [ <border-width> || <border-style>
|| <color> ] | inherit |
| Initial: | see individual properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border.
The "border" property is a shorthand
property for setting the same width, color, and style for all four
borders, top, bottom, left, and right, of a box. Unlike the shorthand
"margin" and "padding" properties, the "border" property cannot
set different values on the four borders. To do so, one or more
of the other border properties must be used.
XSL modifications to the CSS definition:
Refer to the introduction to the Section "Common Border,
Padding, and Background Properties" for information on the precedence
order of properties.
7.22.4 "border-bottom"
CSS2 Definition:
| Value: | [ <border-top-width> || <border-style>
|| <color> ] | inherit |
| Initial: | see individual properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-bottom.
A shorthand property for setting the
width, style, and color of the bottom border of a block-area or inline-area.
7.22.5 "border-color"
CSS2 Definition:
| Value: | <color>{1,4} | transparent | inherit |
| Initial: | see individual properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-color.
The 'border-color' property sets the color of the four
borders. Values have the following meanings:
-
transparent
-
The border is transparent (though it may have width).
-
<color>
-
Any valid color specification.
The "border-color" property can have
from one to four values, and the values are set on the different
sides as for "border-width".
If an element's border color is not specified with a "border"
property, user agents must use the value of the element's "color"
property as the computed value for the border color.
XSL modifications to the CSS definition:
See the 'border-width' property for a description of how
this property is interpreted when one through four values are
provided.
7.22.6 "border-left"
CSS2 Definition:
| Value: | [ <border-top-width> || <border-style>
|| <color> ] | inherit |
| Initial: | see individual properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-left.
A shorthand property for setting the
width, style, and color of the left border of a block-area or inline-area.
7.22.7 "border-right"
CSS2 Definition:
| Value: | [ <border-top-width> || <border-style>
|| <color> ] | inherit |
| Initial: | see individual properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-right.
A shorthand property for setting the
width, style, and color of the right border of a block-area or inline-area.
7.22.8 "border-style"
CSS2 Definition:
| Value: | <border-style>{1,4} | inherit |
| Initial: | see individual properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-style.
The "border-style" property sets the
style of the four borders.
It can have from one to four values, and the values are set on
the different sides.
XSL modifications to the CSS definition:
See the 'border-width' property for a description of how
this property is interpreted when one through four values are
provided.
7.22.9 "border-spacing"
CSS2 Definition:
| Value: | <length> <length>? | inherit |
| Initial: | 0pt |
| Applies to: | table |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/tables.html#propdef-border-spacing.
-
<length>
The lengths specify the distance that separates adjacent cell
borders. If one length is specified, it gives both the horizontal
and vertical spacing. If two are specified, the first gives the
horizontal spacing and the second the vertical spacing. Lengths
may not be negative.
In the separate borders model, each cell has an individual border.
The "border-spacing" property specifies the distance between the
borders of adjacent cells. This space is filled with the background
of the table element. Rows, columns, row groups, and column groups cannot
have borders (i.e., user agents must ignore the border properties
for those elements).
XSL modifications to the CSS definition:
The CSS property shall be treated as a shorthand by XSL
and maps as follows:
If one value is specified the "border-separation.block-progression-direction"
and "border-separation.inline-progression-direction" are both set to
that value.
If two values are specified the "border-separation.block-progression-direction"
is set to the second value
and "border-separation.inline-progression-direction" are both set to
the first value.
7.22.10 "border-top"
CSS2 Definition:
| Value: | [ <border-top-width> || <border-style>
|| <color> ] | inherit |
| Initial: | see individual properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-top.
A shorthand property for setting the
width, style, and color of the top border of a block-area or inline-area.
7.22.11 "border-width"
CSS2 Definition:
| Value: | <border-width>{1,4} | inherit |
| Initial: | see individual properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-border-width.
This property is a shorthand property
for setting "border-top-width", "border-right-width", "border-bottom-width",
and "border-left-width" at the same place in the stylesheet.
If there is only one value, it applies to all sides. If there
are two values, the top and bottom borders are set to the first
value and the right and left are set to the second. If there are three
values, the top is set to the first value, the left and right are
set to the second, and the bottom is set to the third. If there
are four values, they apply to the top, right, bottom, and left,
respectively.
7.22.12 "cue"
7.22.13 "font"
CSS2 Definition:
| Value: | [ [ <font-style> || <font-variant>
|| <font-weight> ]? <font-size> [ / <line-height>]? <font-family>
] | caption | icon | menu | message-box | small-caption | status-bar
| inherit |
| Initial: | see individual properties |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/fonts.html#propdef-font.
The "font" property is, except as described below, a shorthand
property for setting "font-style", "font-variant", "font-weight",
"font-size", "line-height", and "font-family", at the same place
in the stylesheet. The syntax of this property is based on a traditional typographical
shorthand notation to set multiple properties related to fonts.
All font-related properties are first reset to their initial
values, including those listed in the preceding paragraph plus "font-stretch"
and "font-size-adjust". Then, those properties that are given explicit
values in the "font" shorthand are set to those values. For a definition
of allowed and initial values, see the previously defined properties.
For reasons of backward compatibility, it is not possible to set
"font-stretch" and "font-size-adjust" to other than their initial
values using the "font" shorthand property; instead, set the individual properties.
The following [first six] values refer to system
fonts:
-
caption
-
The font used for captioned controls (e.g., buttons, drop-downs,
etc.).
-
icon
-
The font used to label icons.
-
menu
-
The font used in menus (e.g., dropdown menus and menu lists).
-
message-box
-
The font used in dialog boxes.
-
small-caption
-
The font used for labeling small controls.
-
status-bar
-
The font used in window status bars.
System fonts may only be set as a whole; that is, the "font-family",
"size", "weight", "style", etc. are all set at the same time. These
values may then be altered individually if desired. If no font with
the indicated characteristics exists on a given platform, the user agent
should either intelligently substitute (e.g., a smaller version
of the "caption" font might be used for the "smallcaption" font),
or substitute a user agent default font. As for regular fonts, if,
for a system font, any of the individual properties are not part
of the operating system's available user preferences, those properties
should be set to their initial values.
That is why this property is "almost" a shorthand property: system
fonts can only be specified with this property, not with "font-family"
itself, so "font" allows authors to do more than the sum of its
sub-properties. However, the individual properties such as "font-weight"
are still given values taken from the system font, which can be
independently varied.
XSL modifications to the CSS definition:
In XSL the "font" property is a pure shorthand property. System
font characteristics, such as font-family, and font-size, may be
obtained by the use of the "system-font" function in the expression
language.
7.22.14 "margin"
CSS2 Definition:
| Value: | <margin-width>{1,4} | inherit |
| Initial: | not defined for shorthand properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-margin.
A shorthand property for setting margin-top,
margin-right, margin-bottom, and margin-left of a block-area or
inline-area.
If there is only one value, it applies to all sides. If there
are two values, the top and bottom margins are set to the first
value and the right and left margins are set to the second. If there
are three values, the top is set to the first value, the left and
right are set to the second, and the bottom is set to the third.
If there are four values, they apply to the top, right, bottom,
and left, respectively.
XSL modifications to the CSS definition:
7.22.15 "padding"
CSS2 Definition:
| Value: | <padding-width>{1,4} | inherit |
| Initial: | not defined for shorthand properties |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | refer to width of containing block |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/box.html#propdef-padding.
A shorthand property for setting padding-top,
padding-bottom, padding-left, and padding-right of a block-area
or inline-area.
If there is only one value, it applies to all sides. If there
are two values, the top and bottom paddings are set to the first
value and the right and left paddings are set to the second. If there
are three values, the top is set to the first value, the left and
right are set to the second, and the bottom is set to the third.
If there are four values, they apply to the top, right, bottom,
and left, respectively.
The surface color or image of the padding area is specified via
the "background" property.
7.22.16 "page-break-after"
CSS2 Definition:
| Value: | auto | always | avoid | left | right | inherit |
| Initial: | auto |
| Applies to: | block-level elements, list-item, and table-row. |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/page.html#propdef-page-break-after.
Values for these properties have the following meanings:
-
auto
-
Neither force nor forbid a page break before (after, inside)
the generated box.
-
always
-
Always force a page break before (after) the generated
box.
-
avoid
-
Avoid a page break before (after, inside) the generated
box.
-
left
-
Force one or two page breaks before (after) the generated
box so that the next page is formatted as a left page.
-
right
-
Force one or two page breaks before (after) the generated
box so that the next page is formatted as a right page.
A potential page break location is typically under the
influence of the parent element's 'page-break-inside' property,
the 'page-break-after' property of the preceding element, and the
'page-break-before' property of the following element. When these
properties have values other than 'auto', the values 'always', 'left',
and 'right' take precedence over 'avoid'. See the section on allowed
page breaks for the exact rules on how these properties may force
or suppress a page break.
XSL modifications to the CSS definition:
The CSS property shall be treated as a shorthand by XSL
and maps as follows:
-
auto
-
break-after = "auto"
keep-with-next = "auto"
-
always
-
break-after = "page"
keep-with-next = "auto"
-
avoid
-
break-after = "auto"
keep-with-next = "always"
-
left
-
break-after = "even-page"
keep-with-next = "auto"
-
right
-
break-after = "odd-page"
keep-with-next = "auto"
7.22.17 "page-break-before"
CSS2 Definition:
| Value: | auto | always | avoid | left | right | inherit |
| Initial: | auto |
| Applies to: | block-level elements, list-item, and table-row. |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/page.html#propdef-page-break-before.
Values for these properties have the following meanings:
-
auto
-
Neither force nor forbid a page break before (after, inside)
the generated box.
-
always
-
Always force a page break before (after) the generated
box.
-
avoid
-
Avoid a page break before (after, inside) the generated
box.
-
left
-
Force one or two page breaks before (after) the generated
box so that the next page is formatted as a left page.
-
right
-
Force one or two page breaks before (after) the generated
box so that the next page is formatted as a right page.
A potential page break location is typically under the
influence of the parent element's 'page-break-inside' property,
the 'page-break-after' property of the preceding element, and the
'page-break-before' property of the following element. When these
properties have values other than 'auto', the values 'always', 'left',
and 'right' take precedence over 'avoid'. See the section on allowed
page breaks for the exact rules on how these properties may force
or suppress a page break.
XSL modifications to the CSS definition:
The CSS property shall be treated as a shorthand by XSL
and maps as follows:
-
auto
-
break-before = "auto"
keep-with-previous = "auto"
-
always
-
break-before = "page"
keep-with-previous = "auto"
-
avoid
-
break-before = "auto"
keep-with-previous = "always"
-
left
-
break-before = "even-page"
keep-with-previous = "auto"
-
right
-
break-before = "odd-page"
keep-with-previous = "auto"
7.22.18 "page-break-inside"
CSS2 Definition:
| Value: | avoid | auto | inherit |
| Initial: | auto |
| Applies to: | block-level elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/page.html#propdef-page-break-inside.
NOTE:
The CSS definition for page-break-inside was shared with the
definitions of page-break-before and page-break-after. The text
here has been edited to include only the value choices valid for
page-break-inside and to remove the before/after/inside triplet.
Values for this property have the following meanings:
-
auto
-
Neither force nor forbid a page break inside the generated
box.
-
avoid
-
Avoid a page break inside the generated box.
A potential page break location is typically under the
influence of the parent element's 'page-break-inside' property,
the 'page-break-after' property of the preceding element, and the
'page-break-before' property of the following element. When these
properties have values other than 'auto', values 'always', 'left',
and 'right' take precedence over 'avoid'. See the section on allowed
page breaks for the exact rules on how these properties may force or
suppress a page break.
XSL modifications to the CSS definition:
XSL treats this as a shorthand and maps it as follows.
-
auto
-
keep-together = "auto"
-
avoid
-
keep-together = "always"
7.22.19 "pause"
CSS2 Definition:
| Value: | [<time> | <percentage>]{1,2} | inherit |
| Initial: | depends on user agent |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | see descriptions of 'pause-before' and 'pause-after' |
| Media: | aural |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/aural.html#propdef-pause.
7.22.20 "position"
CSS2 Definition:
| Value: | static | relative | absolute | fixed | inherit |
| Initial: | static |
| Applies to: | all elements, but not to generated content |
| Inherited: | no |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visuren.html#propdef-position.
Values have the following meanings:
-
static
-
The box is a normal box, laid out according to the normal
flow. The "left" and "top" properties do not apply.
-
relative
-
The box's position is calculated according to the normal
flow (this is called the position in normal flow). Then the box
is offset relative to its normal position. When a box B is relatively
positioned, the position of the following box is calculated as though
B were not offset.
-
absolute
-
The box's position (and possibly size) is specified with
the "left", "right", "top", and "bottom" properties. These properties
specify offsets with respect to the box's containing block. Absolutely
positioned boxes are taken out of the normal flow. This means they
have no impact on the layout of later siblings. Also, though absolutely
positioned boxes have margins, they do not collapse with any other margins.
-
fixed
-
The box's position is calculated according to the "absolute"
model, but in addition, the box is fixed with respect to some reference.
In the case of continuous media, the box is fixed with respect to
the viewport (and doesn't move when scrolled). In the case of paged
media, the box is fixed with respect to the page, even if that page is
seen through a viewport (in the case of a print-preview, for example).
Authors may wish to specify "fixed" in a media-dependent way. For
instance, an author may want a box to remain at the top the viewport
on the screen, but not at the top of each printed page.
Specifies the positioning scheme to be used.
XSL modifications to the CSS definition:
The CSS property shall be treated as a shorthand by XSL
and maps as follows:
-
static
-
relative-position="static"
absolute-position="auto"
-
relative
-
relative-position="relative"
absolute-position="auto"
-
absolute
-
relative-position="static"
absolute-position="absolute"
-
fixed
-
relative-position="static"
absolute-position="fixed"
7.22.21 "size"
CSS2 Definition:
| Value: | <length>{1,2} | auto | landscape | portrait
| inherit |
| Initial: | auto |
| Applies to: | the page context |
| Inherited: | N/A [XSL:no, is optional] |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/page.html#propdef-size.
Restructured to use Ccc-text/Xsl-mod wrappers and intro before
datatype breakout.
Changed datatype to remove [unknown] and moved descriptions into
each datatype.
Added all of the <Desc> content (all text after after datatype
breakout).
Issue: If 2 lengths are specified, which is height?
This property specifies the size and orientation of a page box.
The size of a page box may either be "absolute" (fixed size)
or "relative" (scalable, i.e., fitting available sheet sizes). Relative
page boxes allow user agents to scale a document and make optimal
use of the target size.
[The first] Three values for the 'size' property create a relative
page box:
-
auto
-
The page box will be set to the size and orientation of
the target sheet.
-
landscape
-
Overrides the target's orientation. The page box is the
same size as the target, and the longer sides are horizontal.
-
portrait
-
Overrides the target's orientation. The page box is the
same size as the target, and the shorter sides are horizontal.
-
<length>
-
Length values for the "size" property create an absolute
page box. If only one length value is specified, it sets both the
width and height of the page box (i.e., the box is a square). Since
the page box is the initial containing block, percentage values
are not allowed for the "size" property.
User agents may allow users to control the transfer of
the page box to the sheet (e.g., rotating an absolute page box that's
being printed).
-
Rendering page boxes that do not fit a target sheet
If a page box does not fit the target sheet dimensions, the user
agent may choose to:
The user agent should consult the user before performing these
operations.
-
Positioning the page box on the sheet
When the page box is smaller than the target size, the user agent
is free to place the page box anywhere on the sheet. However, it
is recommended that the page box be centered on the sheet since
this will align double-sided pages and avoid accidental loss of
information that is printed near the edge of the sheet.
XSL modifications to the CSS definition:
This is treated as a CSS shorthand property that is mapped
to XSL's "page-height" and "page-width" properties.
Issue: We should describe the mapping of landscape & portrait
into XSL.
7.22.22 "vertical-align"
CSS2 Definition:
| Value: | baseline | middle | sub | super | text-top |
text-bottom | <percentage> | <length> | top | bottom | inherit |
| Initial: | baseline |
| Applies to: | inline-level and 'table-cell' elements |
| Inherited: | no |
| Percentages: | refer to the 'line-height' of the element itself |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/visudet.html#propdef-vertical-align.
This property affects the vertical positioning inside a line
box of the boxes generated by an inline-level element. The following
values only have meaning with respect to a parent inline-level element,
or to a parent block-level element, if that element generates anonymous
inline boxes; they have no effect if no such parent exists.
NOTE:
Values of this property have slightly different meanings in the
context of tables. Please consult the section on table height algorithms
for details.
Values have the following meanings:
-
baseline
-
Align the baseline of the box with the baseline of the
parent box. If the box doesn't have a baseline, align the bottom
of the box with the parent's baseline.
-
middle
-
Align the vertical midpoint of the box with the baseline
of the parent box plus half the x-height of the parent.
-
sub
-
Lower the baseline of the box to the proper position for
subscripts of the parent's box. (This value has no effect on the
font size of the element's text.)
-
super
-
Raise the baseline of the box to the proper position for
superscripts of the parent's box. (This value has no effect on the
font size of the element's text.)
-
text-top
-
Align the top of the box with the top of the parent element's
font.
-
text-bottom
-
Align the bottom of the box with the bottom of the parent
element's font.
-
top
-
Align the top of the box with the top of the line box.
-
bottom
-
Align the bottom of the box with the bottom of the line
box.
-
<percentage>
-
Raise (positive value) or lower (negative value) the box
by this distance (a percentage of the "line-height" value). The
value "0%" means the same as "baseline".
-
<length>
-
Raise (positive value) or lower (negative value) the box
by this distance. The value "0cm" means the same as "baseline".
NOTE:
Values of this property have slightly different meanings in the
context of tables. Please consult the section on table height algorithms
for details.
XSL modifications to the CSS definition:
The CSS property shall be treated as a shorthand by XSL
and maps as follows:
-
baseline
-
baseline-identifier="baseline"
alignment-adjust="auto"
baseline-shift="baseline"
dominant-baseline="auto"
-
top
-
baseline-identifier="top"
alignment-adjust="auto"
baseline-shift="baseline"
dominant-baseline="auto"
-
text-top
-
baseline-identifier="text-top"
alignment-adjust="auto"
baseline-shift="baseline"
dominant-baseline="auto"
-
middle
-
baseline-identifier="middle"
alignment-adjust="auto"
baseline-shift="baseline"
dominant-baseline="auto"
-
bottom
-
baseline-identifier="bottom"
alignment-adjust="auto"
baseline-shift="baseline"
dominant-baseline="auto"
-
text-bottom
-
baseline-identifier="text-bottom"
alignment-adjust="auto"
baseline-shift="baseline"
dominant-baseline="auto"
-
sub
-
baseline-identifier="baseline"
alignment-adjust="auto"
baseline-shift="sub"
dominant-baseline="auto"
-
super
-
baseline-identifier="baseline"
alignment-adjust="auto"
baseline-shift="super"
dominant-baseline="auto"
-
<percentage>
-
baseline-identifier="baseline"
alignment-adjust="<percentage>"
baseline-shift="baseline"
dominant-baseline="auto"
-
<length>
-
baseline-identifier="baseline"
alignment-adjust="<length>"
baseline-shift="baseline"
dominant-baseline="auto"
7.22.23 "white-space"
CSS2 Definition:
| Value: | normal | pre | nowrap | inherit |
| Initial: | normal |
| Applies to: | block-level elements |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
CSS2 Reference:
http://www.w3.org/TR/REC-CSS2/text.html#propdef-white-space.
This property declares how whitespace inside the element is handled.
Values have the following meanings:
-
normal
-
This value directs user agents to collapse sequences of
whitespace, and break lines as necessary to fill line boxes. Additional
line breaks may be created by occurrences of "\A" in generated content (e.g.,
for the BR element in HTML).
-
pre
-
This value prevents user agents from collapsing sequences
of whitespace. Lines are only broken at newlines in the source,
or at occurrences of "\A" in generated content.
-
nowrap
-
This value collapses whitespace as for 'normal', but suppresses
line breaks within text except for those created by "\A" in generated
content (e.g., for the BR element in HTML).
Conforming user agents may ignore the 'white-space' property
in author and user style sheets but must specify a value for it
in the default style sheet.
XSL modifications to the CSS definition:
XSL splits control of whitespace collapsing, space and linefeed
handling, and wrapping into separate properties.
The CSS property shall be treated as a shorthand by XSL
and maps as follows:
-
normal
-
linefeed-treatment="treat-as-space"
white-space-collapse="true"
space-treatment="preserve"
wrap-option="wrap"
-
pre
-
linefeed-treatment="preserve"
white-space-collapse="false"
space-treatment="preserve"
wrap-option="no-wrap"
-
nowrap
-
linefeed-treatment="treat-as-space"
white-space-collapse="true"
space-treatment="preserve"
wrap-option="no-wrap"
7.22.24 "xml:lang"
XSL Definition:
| Value: | <country-language> | inherit |
| Initial: | not defined for shorthand properties |
| Applies to: | see prose |
| Inherited: | yes |
| Percentages: | N/A |
| Media: | visual |
Values have the following meanings:
-
<string>
-
A language and/or country specifier in conformance with
RFC-1766.
Specifies the language and country
to be used by the formatter in linguistic services (such as hyphenation)
and in the determination of line breaks. This affects line composition
in a system-dependent way.
The string may be any RFC 1766 code.
XSL treats xml:lang as a shorthand and uses it to set the country
and language properties.
NOTE:
In general, linguistic services (line-justification strategy,
line-breaking and hyphenation) may depend on a combination
of the "language", "script", and "country" properties.
A Internationalization
A.1 Additional "writing-mode" values
The following additional values for the "writing-mode" property
provide for more extensive internationalization support.
The values have the following meanings:
-
tb-lr
-
Inline components and text within a line are stacked top-to-bottom.
Lines and blocks are stacked left-to-right.
Establishes the following directions:
-
inline-progression-direction to top-to-bottom
-
block-progression-direction to left-to-right
-
shift-direction to right-to-left
-
bt-lr
-
Inline components and text within a line are stacked bottom-to-top.
Lines and blocks are stacked left-to-right.
Establishes the following directions:
-
inline-progression-direction to bottom-to-top
-
block-progression-direction to left-to-right
-
shift-direction to right-to-left
-
bt-rl
-
Inline components and text within a line are stacked bottom-to-top.
Lines and blocks are stacked right-to-left.
Establishes the following directions:
-
inline-progression-direction to bottom-to-top
-
block-progression-direction to right-to-left
-
shift-direction to left-to-right
-
lr-bt
-
Inline components and text within a line are stacked left-to-right.
Lines and blocks are stacked bottom-to-top.
Establishes the following directions:
-
inline-progression-direction to left-to-right
-
block-progression-direction to bottom-to-top
-
shift-direction to bottom-to-top
-
rl-bt
-
Inline components and text within a line are stacked right-to-left.
Lines and blocks are stacked bottom-to-top.
Establishes the following directions:
-
inline-progression-direction to right-to-left
-
block-progression-direction to bottom-to-top
-
shift-direction to bottom-to-top
-
lr-alternating-rl-bt
-
Inline components and text within the first
line are stacked left-to-right, within the second line
they are stacked right-to-left; continuing in alternation.
Lines and blocks are stacked bottom-to-top.
Establishes the following directions:
-
inline-progression-direction to
left-to-right for odd-numbered lines,
right-to-left for even-numbered lines
-
block-progression-direction to bottom-to-top
-
shift-direction to bottom-to-top
-
lr-alternating-rl-tb
-
Inline components and text within the first
line are stacked left-to-right, within the second line
they are stacked right-to-left; continuing in alternation.
Lines and blocks are stacked top-to-bottom.
Establishes the following directions:
-
inline-progression-direction to
left-to-right for odd-numbered lines,
right-to-left for even-numbered lines
-
block-progression-direction to top-to-bottom
-
shift-direction to bottom-to-top
-
lr-inverting-rl-bt
-
Inline components and text within the first
line are stacked left-to-right, within the second line
they inverted and are stacked right-to-left; continuing in alternation.
Lines and blocks are stacked bottom-to-top.
Establishes the following directions:
-
inline-progression-direction to
left-to-right for odd-numbered lines,
right-to-left for even-numbered lines
-
block-progression-direction to bottom-to-top
-
shift-direction to
bottom-to-top for odd-numbered lines,
top-to-bottom for even-numbered lines
-
lr-inverting-rl-tb
-
Inline components and text within the first
line are stacked left-to-right, within the second line
they inverted and are stacked right-to-left; continuing in alternation.
Lines and blocks are stacked top-to-bottom.
Establishes the following directions:
-
inline-progression-direction to
left-to-right for odd-numbered lines,
right-to-left for even-numbered lines
-
block-progression-direction to top-to-bottom
-
shift-direction to
bottom-to-top for odd-numbered lines,
top-to-bottom for even-numbered lines
-
tb-rl-in-rl-pairs
-
Text is written in two character, right-to-left pairs. The pairs
are then stacked top-to-bottom to form a line.
Lines and blocks are stacked right-to-left.
Establishes the following directions:
-
inline-progression-direction to top-to-bottom
-
block-progression-direction to right-to-left
-
shift-direction to left-to-right
B Formatting Object Summary
This section contains tables summarizing the
conformance level of each of the defined formatting objects.
Included with each formatting object name is a designation
of its inclusion or exclusion from the basic set of
formatting objects for
the particular class, e.g., aural. A proposed fallback
treatment is specified wherever possible.
B.1 Pagination and Layout Formatting Objects
| Formatting Object | Visual | Aural |
| fo:root |
basic |
basic |
| fo:page-sequence |
basic |
basic |
| fo:page-sequence-master |
basic |
basic |
| fo:single-page-master-reference |
basic |
basic |
| fo:repeatable-page-master-reference |
basic |
basic |
| fo:repeatable-page-master-alternatives |
extended
fallback: use the page-master referenced in the first fo:conditional-page-master-reference child
|
extended
fallback: use the page-master referenced in the first fo:conditional-page-master-reference child
|
| fo:conditional-page-master-reference |
extended
fallback: use the page-master referenced in the first fo:conditional-page-master-reference child
|
extended
fallback: use the page-master referenced in the first fo:conditional-page-master-reference child
|
| fo:layout-master-set |
basic |
basic |
| fo:simple-page-master |
basic |
basic |
| fo:region-body |
basic |
basic |
| fo:region-before |
extended
fallback: include after content of body region is placed
|
extended
fallback: include after content of body region is spoken
|
| fo:region-after |
extended
fallback: include after content of body region is placed
|
extended
fallback: include after content of body region is spoken
|
| fo:region-start |
extended
fallback: include after content of body region is placed
|
extended
fallback: include after content of body region is spoken
|
| fo:region-end |
extended
fallback: include after content of body region is placed
|
extended
fallback: include after content of body region is spoken
|
| fo:flow |
basic |
basic |
| fo:static-content |
extended
fallback: include after content of body region is placed
|
extended
fallback: include after content of body region is spoken
|
B.2 Block Formatting Objects
| Formatting Object | Visual | Aural |
| fo:block |
basic |
basic |
| fo:block-container |
extended
fallback: display
indication that content cannot be correctly
rendered
|
basic |
B.3 Inline Formatting Objects
| Formatting Object | Visual | Aural |
| fo:bidi-override |
extended
fallback: display indication that content cannot be correctly rendered.
|
basic |
| fo:character |
basic |
basic |
| fo:initial-property-set |
extended
fallback: ignore any properties specified on this object.
|
basic
|
| fo:external-graphic |
basic |
basic |
| fo:instream-foreign-object |
extended
fallback: display an indication that content cannot be correctly rendered.
|
extended
fallback: speak an indication that
content cannot be correctly spoken.
|
| fo:inline-container |
extended
fallback: display indication that content cannot be correctly rendered.
|
extended
fallback: speak an indication that
content cannot be correctly spoken.
|
| fo:leader |
basic |
basic |
| fo:page-number |
basic |
extended
fallback: speak an indication that
content cannot be correctly spoken.
|
| fo:page-number-citation |
extended
fallback: display an indication that content cannot be correctly rendered.
|
extended
fallback: speak an indication that
content cannot be correctly spoken.
|
B.4 Table Formatting Objects
| Formatting Object | Visual | Aural |
| fo:table-and-caption |
basic |
basic |
| fo:table |
basic |
basic |
| fo:table-column |
basic |
basic |
| fo:table-caption |
extended
fallback:
-
caption-side="start" becomes caption-side="before"
-
caption-side="end" becomes caption-side="after"
-
caption-side="left" becomes caption-side="before"
-
caption-side="right" becomes caption-side="after"
|
extended
fallback:
-
caption-side="start" becomes caption-side="before"
-
caption-side="end" becomes caption-side="after"
-
caption-side="left" becomes caption-side="before"
-
caption-side="right" becomes caption-side="after"
|
| fo:table-header |
basic |
basic |
| fo:table-footer |
extended
fallback: place at end of table.
|
extended
fallback: speak at end of table
|
| fo:table-body |
basic |
basic |
| fo:table-row |
basic |
basic |
| fo:table-cell |
basic |
basic |
B.5 List Formatting Objects
| Formatting Object | Visual | Aural |
| fo:list-block |
basic |
basic |
| fo:list-item |
basic |
basic |
| fo:list-item-body |
basic |
basic |
| fo:list-item-label |
extended
fallback: labels that
break across multiple lines
are treated as separate blocks before
list-item-body.
|
basic |
B.6 Link and Multi Formatting Objects
| Formatting Object | Visual | Aural |
| fo:simple-link |
extended
fallback: promote content
to parent formatting object.
|
extended
fallback: promote content
to parent formatting object..
|
| fo:multi-switch |
extended
fallback: utilize the contents of the first eligible
multi-case formatting object.
|
extended
fallback: utilize the contents of the first eligible
multi-case formatting object.
|
| fo:multi-case |
basic: needed as wrapper for fallback for
multi-switch |
basic: needed as wrapper for fallback for
multi-switch |
| fo:multi-toggle |
extended
fallback: promote
content to parent formatting object.
|
extended
fallback: promote
content to parent formatting object.
|
| fo:multi-properties |
extended
fallback: promote
content to parent formatting object.
|
extended
fallback: promote
content to parent formatting object.
|
| fo:multi-property-set |
extended
fallback: ignore.
|
extended
fallback: ignore.
|
B.7 Out-of-line Formatting Objects
| Formatting Object | Visual | Aural |
| fo:float |
extended
fallback: place inline.
|
extended
fallback: place inline.
|
| fo:footnote |
extended
fallback: place inline.
|
extended
fallback: place inline..
|
| fo:footnote-body |
extended
fallback: place inline.
|
extended
fallback: place inline.
|
B.8 Other Formatting Objects
| Formatting Object | Visual | Aural |
| fo:wrapper |
basic |
basic |
C Property Index
C.1 Explanation of Trait Mapping Values:
-
Rendering
-
Maps directly into a rendering trait of the same name.
-
Disappears
-
There is no trait mapping.
-
Shorthand
-
A shorthand that is mapped into one or more properties.
There are no traits associated with a shorthand property.
The traits are associated with the individual
properties.
-
Refine
-
Disappears in Refinement. During refinement it sets
up one or more other traits.
-
Formatting
-
Maps directly into a formatting trait of the same name.
-
Specification
-
Sub-class of formatting. It is the same
as a formatting trait, but is specified on formatting
objects that are referenced.
-
See prose
-
Used to calculate a formatting trait, which does not have the
same name as the property. Other properties may also influence the
trait value. See the property description for
details.
-
Font selection
-
Property that participates in font selection.
-
Value change
-
Maps to a trait of the same name, but the value is not just
copied.
-
Reference
-
An association between two names. Establishes a
reference within the formatting-object tree.
-
Action
-
Behavior trait.
-
Magic
-
Handled by the formatter in an
implementation-defined way.
There are no specific traits for this property.
C.2 Property Table: Part I
| Name | Values | Initial Value | Inherited | Percentages |
| absolute-position | auto | absolute | fixed | inherit | auto | no | N/A |
| alignment-adjust | auto | <percentage> | <length>
| inherit | auto | no | see prose |
| auto-restore | yes | no | no | yes | N/A |
| azimuth | <angle> | [[ left-side | far-left | left
| center-left | center | center-right | right | far-right | right-side
] || behind ] | leftwards | rightwards | inherit | center | yes | N/A |
| background | [<background-color> ||
<background-image>
|| <background-repeat> || <background-attachment> || <background-position>
| ]]inherit | not defined for shorthand properties | no | allowed on 'background-position' |
| background-attachment | scroll | fixed | inherit | scroll | no | N/A |
| background-color | <color> | transparent | inherit | transparent | no | N/A |
| background-image | <uri> | none | inherit | none | no | N/A |
| background-position | [ [<percentage> | <length> ]{1,2} |
[ [top | center | bottom] || [left | center | right] ] ] | inherit | 0% 0% | no | refer to the size of the box itself |
| background-position-horizontal | <percentage> | <length> |
left | center | right | inherit | 0% | no | refer to the size of the padding rectangle |
| background-position-vertical | <percentage> | <length> |
top | center | bottom | inherit | 0% | no | refer to the size of the padding rectangle |
| background-repeat | repeat | repeat-x | repeat-y | no-repeat | inherit | repeat | no | N/A |
| baseline-identifier | baseline | before-edge
| text-before-edge | middle | after-edge
| text-after-edge | ideographic | alphabetic | hanging | mathematical
| inherit | see prose | no | N/A |
| baseline-shift | baseline | sub | super | <percentage> | <length>
| inherit | baseline | no | refers to the "line-height" of the parent area |
| blank-or-not-blank | blank | not-blank | any | inherit | any | no | N/A |
| block-progression-dimension | auto | <length> | <percentage> | <length-range>
| inherit | auto | no | see prose |
| border | [ <border-width> || <border-style>
|| <color> ] | inherit | see individual properties | no | N/A |
| border-after-color | <color> | inherit | the value of the 'color' property | no | N/A |
| border-after-style | <border-style> | inherit | none | no | N/A |
| border-after-width | <border-width> | <length-conditional> | inherit | medium | no | N/A |
| border-before-color | <color> | inherit | the value of the 'color' property | no | N/A |
| border-before-style | <border-style> | inherit | none | no | N/A |
| border-before-width | <border-width> | <length-conditional> | inherit | medium | no | N/A |
| border-bottom | [ <border-top-width> || <border-style>
|| <color> ] | inherit | see individual properties | no | N/A |
| border-bottom-color | <color> | inherit | the value of the 'color' property | no | N/A |
| border-bottom-style | <border-style> | inherit | none | no | N/A |
| border-bottom-width | <border-width> | inherit | medium | no | N/A |
| border-collapse | collapse | separate | inherit | collapse | yes | N/A |
| border-color | <color>{1,4} | transparent | inherit | see individual properties | no | N/A |
| border-end-color | <color> | inherit | the value of the 'color' property | no | N/A |
| border-end-style | <border-style> | inherit | none | no | N/A |
| border-end-width | <border-width> | inherit | medium | no | N/A |
| border-left | [ <border-top-width> || <border-style>
|| <color> ] | inherit | see individual properties | no | N/A |
| border-left-color | <color> | inherit | the value of the 'color' property | no | N/A |
| border-left-style | <border-style> | inherit | none | no | N/A |
| border-left-width | <border-width> | inherit | medium | no | N/A |
| border-right | [ <border-top-width> || <border-style>
|| <color> ] | inherit | see individual properties | no | N/A |
| border-right-color | <color> | inherit | the value of the 'color' property | no | N/A |
| border-right-style | <border-style> | inherit | none | no | N/A |
| border-right-width | <border-width> | inherit | medium | no | N/A |
| border-separation | <length-bp-ip-direction> | inherit | .block-progression-direction="0pt" .inline-progression-direction="0pt" | yes | N/A |
| border-spacing | <length> <length>? | inherit | 0pt | yes | N/A |
| border-start-color | <color> | inherit | the value of the 'color' property | no | N/A |
| border-start-style | <border-style> | inherit | none | no | N/A |
| border-start-width | <border-width> | inherit | medium | no | N/A |
| border-style | <border-style>{1,4} | inherit | see individual properties | no | N/A |
| border-top | [ <border-top-width> || <border-style>
|| <color> ] | inherit | see individual properties | no | N/A |
| border-top-color | <color> | inherit | the value of the 'color' property | no | N/A |
| border-top-style | <border-style> | inherit | none | no | N/A |
| border-top-width | <border-width> | inherit | medium | no | N/A |
| border-width | <border-width>{1,4} | inherit | see individual properties | no | N/A |
| bottom | <length> | <percentage> | auto | inherit | auto | no | refer to height of containing block |
| break-after | auto | column | page | even-page | odd-page | inherit | auto | no | N/A |
| break-before | auto | column | page | even-page | odd-page | inherit | auto | no | N/A |
| caption-side | before | after | start | end | top | bottom | left | right | inherit | before | yes | N/A |
| case-name | <name> | none, a value is required | no, a value is required | N/A |
| case-title | <string> | none, a value is required | no, a value is required | N/A |
| character | <string> | N/A, value is required | no, a value is required | N/A |
| clear | none | left | right | both | inherit | none | no | N/A |
| clip | <shape> | auto | inherit | auto | no | N/A |
| color | <color> | inherit | depends on user agent | yes | N/A |
| column-count | <number> | inherit | 1 | no | N/A |
| column-gap | <length> | <percentage> | inherit | 12.0pt | no | refer to width of the region being divided into columns. |
| column-number | <number> | see prose | no | N/A |
| column-width | <length> | undefined | no | N/A |
| content-type | <string> | auto | auto | no | N/A |
| country | none | <country> | inherit | none | yes | N/A |
| cue | <cue-before> || <cue-after> | inherit | not defined for shorthand properties | no | N/A |
| cue-after | <uri> | none | inherit | none | no | N/A |
| cue-before | <uri> | none | inherit | none | no | N/A |
| destination-placement-offset | <length> | 0pt | no | N/A |
| direction | ltr | rtl | inherit | ltr | yes | N/A |
| display-align | auto | before | center | after
| inherit | auto | yes | N/A |
| dominant-baseline | auto | autosense-script | no-change | reset-size
| ideographic | alphabetic | hanging | mathematical
| inherit | auto | no | N/A |
| dom-state | TBD | TBD | no | N/A |
| elevation | <angle> | below | level | above | higher
| lower | inherit | level | yes | N/A |
| empty-cells | show | hide | inherit | show | yes | N/A |
| end-indent | <length> | inherit | 0pt | yes | refer to width of containing reference-area |
| ends-row | yes | no | no | no | N/A |
| extent | <length> | <percentage> | inherit | 0.0pt | no | refer to the corresponding height or width of the page
region. |
| external-destination | <uri> | null string | no | N/A |
| float | left | right | none | inherit | none | no | N/A |
| flow-name | <name> | an empty name | no, a value is required | N/A |
| font | [ [ <font-style> || <font-variant>
|| <font-weight> ]? <font-size> [ / <line-height>]? <font-family>
] | caption | icon | menu | message-box | small-caption | status-bar
| inherit | see individual properties | yes | N/A |
| font-family | [[ <family-name> | <generic-family>
],]* [<family-name> | <generic-family>] | inherit | depends on user agent | yes | N/A |
| font-height-override-after | use-font-metrics | <length> | inherit | use-font-metrics | no | refer to font's em-height |
| font-height-override-before | use-font-metrics | <length> | inherit | use-font-metrics | no | refer to font's em-height |
| font-size | <absolute-size> | <relative-size> | <length>
| <percentage> | inherit | medium | yes, the computed value is inherited | refer to parent element's font size |
| font-size-adjust | <number> | none | inherit | none | yes | N/A |
| font-stretch | normal | wider | narrower | ultra-condensed
| extra-condensed | condensed | semi-condensed | semi-expanded |
expanded | extra-expanded | ultra-expanded |inherit | normal | yes | N/A |
| font-style | normal | italic | oblique | backslant | inherit | normal | yes | N/A |
| font-variant | normal | small-caps | inherit | normal | yes | N/A |
| font-weight | normal | bold | bolder | lighter | 100 | 200
| 300 | 400 | 500 | 600 | 700 | 800 | 900 | inherit | normal | yes | N/A |
| force-page-count | auto | even | odd | end-on-even | end-on-odd | no-force
| inherit | auto | no | N/A |
| format | <string> | 1. | no | N/A |
| glyph-orientation-horizontal | <angle> | inherit | 0 | yes | N/A |
| glyph-orientation-vertical | auto | <angle> | inherit | auto | yes | N/A |
| grouping-separator | <character> | no separator | no | N/A |
| grouping-size | <number> | no grouping | no | N/A |
| height | <length> | <percentage> | auto | inherit | auto | no | see prose |
| href | <url> | inherit | none, value required | no | N/A |
| hyphenate | false | true | inherit | false | yes | N/A |
| hyphenation-character | <character> | inherit | The unicode hyphen character u+2010 | yes | N/A |
| hyphenation-keep | none | column | page | spread | inherit | none | yes | N/A |
| hyphenation-ladder-count | none | <number> | inherit | none | yes | N/A |
| hyphenation-push-character-count | <number> | inherit | 2 | yes | N/A |
| hyphenation-remain-character-count | <number> | inherit | 2 | yes | N/A |
| id | <id> | see prose | no, see prose | N/A |
| indicate-destination | yes | no | no | no | N/A |
| initial-page-number | auto | auto-odd | auto-even | <number> | inherit | auto | no | N/A |
| inline-progression-dimension | auto | <length> | <percentage> | <length-range>
| inherit | auto | no | see prose |
| internal-destination | <idref> | null string | no | N/A |
| keep-together | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | yes | N/A |
| keep-with-next | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | no | N/A |
| keep-with-previous | <keep> | inherit | false | no | N/A |
| language | none | <language> | inherit | none | yes | N/A |
| last-line-end-indent | <length> | <percentage> | inherit | 0pt | yes | width of containing block |
| leader-alignment | none | reference-area | page | inherit | none | yes | N/A |
| leader-length | <length-range> | inherit | leader-length.minimum=0pt, .optimum=12.0pt, .maximum=100% | yes | refer to width of content rectangle of parent area |
| leader-pattern | space | rule | dots | use-content | inherit | space | yes | N/A |
| leader-pattern-width | use-font-metrics | <length> | inherit | use-font-metrics | yes | Refer to width of containing box |
| left | <length> | <percentage> | auto | inherit | auto | no | refer to height of containing block |
| letter-spacing | normal | <length> | <space> | inherit | normal | yes | N/A |
| letter-value | alpabetic | traditional | no value | no | N/A |
| linefeed-treatment | ignore | preserve | treat-as-space | inherit | treat-as-space | yes | N/A |
| line-height | normal | <length> | <number> | <percentage> | <space>
| inherit | normal | yes | refer to the font size of the element itself |
| line-height-shift-adjustment | consider-shifts | disregard-shifts | inherit | consider-shifts | yes | N/A |
| line-stacking-strategy | line-height | font-height | max-height | inherit | line-height | yes | N/A |
| margin | <margin-width>{1,4} | inherit | not defined for shorthand properties | no | refer to width of containing block |
| margin-bottom | <margin-width> | inherit | 0 | no | refer to width of containing block |
| margin-left | <margin-width> | inherit | 0pt | no | refer to width of containing block |
| margin-right | <margin-width> | inherit | 0pt | no | refer to width of containing block |
| margin-top | <margin-width> | inherit | 0 | no | refer to width of containing block |
| master-name | <name> | an empty name | no, a value is required | N/A |
| max-height | <length> | <percentage> | none | inherit | 0pt | no | refer to height of containing block |
| maximum-repeats | <number> | no-limit | inherit | no-limit | no | N/A |
| max-width | <length> | <percentage> | none | inherit | none | no | refer to width of containing block |
| min-height | <length> | <percentage> | inherit | 0pt | no | refer to height of containing block |
| min-width | <length> | <percentage> | inherit | depends on UA | no | refer to width of containing block |
| number-columns-repeated | <number> | 1 | no | N/A |
| number-columns-spanned | <number> | 1 | no | N/A |
| number-rows-spanned | <number> | 1 | no | N/A |
| odd-or-even | odd | even | any | inherit | any | no | N/A |
| orphans | <integer> | inherit | 2 | yes | N/A |
| overflow | visible | hidden | scroll | auto | inherit | auto | no | N/A |
| padding | <padding-width>{1,4} | inherit | not defined for shorthand properties | no | refer to width of containing block |
| padding-after | <padding-width> | <length-conditional> | inherit | 0pt | no | refer to width of containing block |
| padding-before | <padding-width> | <length-conditional> | inherit | 0pt | no | refer to width of containing block |
| padding-bottom | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| padding-end | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| padding-left | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| padding-right | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| padding-start | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| padding-top | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| page-break-after | auto | always | avoid | left | right | inherit | auto | no | N/A |
| page-break-before | auto | always | avoid | left | right | inherit | auto | no | N/A |
| page-break-inside | avoid | auto | inherit | auto | yes | N/A |
| page-height | auto | indefinite | <length> | inherit | auto | no | N/A |
| page-position | first | last | rest | any | inherit | any | no | N/A |
| page-width | auto | indefinite | <length> | inherit | auto | no | N/A |
| pause | [<time> | <percentage>]{1,2} | inherit | depends on user agent | no | see descriptions of 'pause-before' and 'pause-after' |
| pause-after | <time> | <percentage> | inherit | depends on user agent | no | see prose |
| pause-before | <time> | <percentage> | inherit | depends on user agent | no | see prose |
| pitch | <frequency> | x-low | low | medium | high
| x-high | inherit | medium | yes | N/A |
| pitch-range | <number> | inherit | 50 | yes | N/A |
| play-during | <uri> mix? repeat? | auto | none | inherit | auto | no | N/A |
| position | static | relative | absolute | fixed | inherit | static | no | N/A |
| precedence | true | false | inherit | false | no | N/A |
| provisional-distance-between-starts | <length> | inherit | 24.0pt | yes | refer to width of the containing box |
| provisional-label-separation | <length> | inherit | 6.0pt | yes | refer to width of the containing box |
| reference-orientation | 0 | 90 | 180 | 270 | -90 | -180 | -270 | inherit | 0 | yes (see prose) | N/A |
| ref-id | <idref> | inherit | none, value required | no | N/A |
| region-name | xsl-region-body | xsl-region-start | xsl-region-end
| xsl-region-before | xsl-region-after | <name> | see prose | no, a value is required | N/A |
| relative-align | before | baseline
| inherit | before | yes | N/A |
| relative-position | auto | static | relative | inherit | static | no | N/A |
| richness | <number> | inherit | 50 | yes | N/A |
| right | <length> | <percentage> | auto | inherit | auto | no | refer to height of containing block |
| role | <string> | none | inherit | none | no | N/A |
| rule-style | none | dotted | dashed | solid | double | groove
| ridge | inherit | solid | yes | N/A |
| rule-thickness | <length> | 1.0pt | yes | N/A |
| scale | <number>{1,2} | maximum | maximum-uniform
| inherit | 1.0 | no | N/A |
| score-spaces | true | false | inherit | true | yes | see prose |
| script | none | auto | <script> | inherit | auto | yes | N/A |
| show-destination | replace | new | replace | no | N/A |
| size | <length>{1,2} | auto | landscape | portrait
| inherit | auto | N/A [XSL:no, is optional] | N/A |
| source-document | <uri>+ | none | inherit | none | no | N/A |
| space-after | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | no | N/A (Differs from margin-bottom in CSS) |
| space-before | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | no | N/A (Differs from margin-top in CSS) |
| space-end | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | no | refer to the width of the containing area |
| space-start | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | no | refer to the width of the containing area |
| space-treatment | ignore | preserve | inherit | preserve | yes | N/A |
| span | none | all | inherit | none | no | N/A |
| speak | normal | none | spell-out | inherit | normal | yes | N/A |
| speak-header | once | always | inherit | once | yes | N/A |
| speak-numeral | digits | continuous | inherit | continuous | yes | N/A |
| speak-punctuation | code | none | inherit | none | yes | N/A |
| speech-rate | <number> | x-slow | slow | medium | fast
| x-fast | faster | slower | inherit | medium | yes | N/A |
| start-indent | <length> | inherit | 0pt | yes | refer to width of containing reference-area |
| starting-state | show | hide | show | no | N/A |
| starts-row | yes | no | no | no | N/A |
| stress | <number> | inherit | 50 | yes | N/A |
| suppress-at-line-break | auto | suppress | retain | inherit | auto | no | N/A |
| switch-to | xsl-preceding | xsl-following | xsl-any | <name>[ <name>]* | xsl-any | no | N/A |
| table-layout | auto | fixed | inherit | auto | no | N/A |
| table-omit-footer-at-break | yes | no | no | no | N/A |
| table-omit-header-at-break | yes | no | no | no | N/A |
| text-align | start | center | end | justify | inside | outside
| left | right | <string> | inherit | start | yes | N/A |
| text-align-last | relative | start | center | end | justify | inside
| outside | left | right | <string> | inherit | start | yes | N/A |
| text-decoration | none | [ underline || overline || line-through
|| blink ] | inherit | none | no, but see prose | N/A |
| text-indent | <length> | <percentage> | inherit | 0pt | yes | refer to width of containing block |
| text-shadow | none | [<color> || <length> <length> <length>?
,]* [<color> || <length> <length> <length>?] | inherit | none | no, see prose | N/A |
| text-transform | capitalize | uppercase | lowercase | none | | none | yes | N/A |
| top | <length> | <percentage> | auto | inherit | auto | no | refer to height of containing block |
| treat-as-word-space | auto | yes | no | inherit | auto | no | N/A |
| unicode-bidi | normal | embed | bidi-override | inherit | normal | no | N/A |
| vertical-align | baseline | middle | sub | super | text-top |
text-bottom | <percentage> | <length> | top | bottom | inherit | baseline | no | refer to the 'line-height' of the element itself |
| visibility | visible | hidden | collapse | inherit | visible | no | N/A |
| voice-family | [[<specific-voice> | <generic-voice>
],]* [<specific-voice> | <generic-voice> ] | inherit | depends on user agent | yes | N/A |
| volume | <number> | <percentage> | silent | x-soft
| soft | medium | loud | x-loud | inherit | medium | yes | refer to inherited value |
| white-space | normal | pre | nowrap | inherit | normal | yes | N/A |
| white-space-collapse | false | true | inherit | true | yes | N/A |
| widows | <integer> | inherit | 2 | yes | N/A |
| width | <length> | <percentage> | auto | inherit | auto | no | refer to width of containing block |
| word-spacing | normal | <length> | <space> | inherit | normal | yes | N/A |
| wrap-option | no-wrap | wrap | inherit | wrap | yes | N/A |
| writing-mode | lr-tb | rl-tb | tb-rl | lr | rl | tb | inherit | lr-tb | yes (see prose) | N/A |
| xml:lang | <country-language> | inherit | not defined for shorthand properties | yes | N/A |
| z-index | auto | <integer> | inherit | auto | no | N/A |
C.3 Property Table: Part II
The Trait Mapping Values are explained in [C.1 Explanation of Trait Mapping Values:].
| Name | Values | Initial Value | Trait mapping | Core |
| absolute-position | auto | absolute | fixed | inherit | auto | See prose. Traits influenced: | Complete |
| alignment-adjust | auto | <percentage> | <length>
| inherit | auto | Formatting | Basic |
| auto-restore | yes | no | no | Action | Extended |
| azimuth | <angle> | [[ left-side | far-left | left
| center-left | center | center-right | right | far-right | right-side
] || behind ] | leftwards | rightwards | inherit | center | Rendering | Basic |
| background | [<background-color> ||
<background-image>
|| <background-repeat> || <background-attachment> || <background-position>
| ]]inherit | not defined for shorthand properties | Shorthand | Complete |
| background-attachment | scroll | fixed | inherit | scroll | Rendering | Extended |
| background-color | <color> | transparent | inherit | transparent | Rendering | Basic |
| background-image | <uri> | none | inherit | none | Rendering | Extended |
| background-position | [ [<percentage> | <length> ]{1,2} |
[ [top | center | bottom] || [left | center | right] ] ] | inherit | 0% 0% | Shorthand | Complete |
| background-position-horizontal | <percentage> | <length> |
left | center | right | inherit | 0% | See prose. Traits influenced: | Extended |
| background-position-vertical | <percentage> | <length> |
top | center | bottom | inherit | 0% | See prose. Traits influenced: | Extended |
| background-repeat | repeat | repeat-x | repeat-y | no-repeat | inherit | repeat | Rendering | Extended |
| baseline-identifier | baseline | before-edge
| text-before-edge | middle | after-edge
| text-after-edge | ideographic | alphabetic | hanging | mathematical
| inherit | see prose | Formatting | Basic |
| baseline-shift | baseline | sub | super | <percentage> | <length>
| inherit | baseline | Formatting | Basic |
| blank-or-not-blank | blank | not-blank | any | inherit | any | Specification | Extended |
| block-progression-dimension | auto | <length> | <percentage> | <length-range>
| inherit | auto | Formatting | Basic |
| border | [ <border-width> || <border-style>
|| <color> ] | inherit | see individual properties | Shorthand | Complete |
| border-after-color | <color> | inherit | the value of the 'color' property | Rendering | Basic |
| border-after-style | <border-style> | inherit | none | Rendering | Basic |
| border-after-width | <border-width> | <length-conditional> | inherit | medium | Formatting and Rendering | Basic |
| border-before-color | <color> | inherit | the value of the 'color' property | Rendering | Basic |
| border-before-style | <border-style> | inherit | none | Rendering | Basic |
| border-before-width | <border-width> | <length-conditional> | inherit | medium | Formatting and Rendering | Basic |
| border-bottom | [ <border-top-width> || <border-style>
|| <color> ] | inherit | see individual properties | Shorthand | Complete |
| border-bottom-color | <color> | inherit | the value of the 'color' property | Disappears | Basic |
| border-bottom-style | <border-style> | inherit | none | Disappears | Basic |
| border-bottom-width | <border-width> | inherit | medium | Disappears | Basic |
| border-collapse | collapse | separate | inherit | collapse | Formatting | Extended |
| border-color | <color>{1,4} | transparent | inherit | see individual properties | Shorthand | Complete |
| border-end-color | <color> | inherit | the value of the 'color' property | Rendering | Basic |
| border-end-style | <border-style> | inherit | none | Rendering | Basic |
| border-end-width | <border-width> | inherit | medium | Formatting and Rendering | Basic |
| border-left | [ <border-top-width> || <border-style>
|| <color> ] | inherit | see individual properties | Shorthand | Complete |
| border-left-color | <color> | inherit | the value of the 'color' property | Disappears | Basic |
| border-left-style | <border-style> | inherit | none | Disappears | Basic |
| border-left-width | <border-width> | inherit | medium | Disappears | Basic |
| border-right | [ <border-top-width> || <border-style>
|| <color> ] | inherit | see individual properties | Shorthand | Complete |
| border-right-color | <color> | inherit | the value of the 'color' property | Disappears | Basic |
| border-right-style | <border-style> | inherit | none | Disappears | Basic |
| border-right-width | <border-width> | inherit | medium | Disappears | Basic |
| border-separation | <length-bp-ip-direction> | inherit | .block-progression-direction="0pt" .inline-progression-direction="0pt" | Formatting | Extended |
| border-spacing | <length> <length>? | inherit | 0pt | Shorthand | Complete |
| border-start-color | <color> | inherit | the value of the 'color' property | Rendering | Basic |
| border-start-style | <border-style> | inherit | none | Rendering | Basic |
| border-start-width | <border-width> | inherit | medium | Formatting and Rendering | Basic |
| border-style | <border-style>{1,4} | inherit | see individual properties | Shorthand | Complete |
| border-top | [ <border-top-width> || <border-style>
|| <color> ] | inherit | see individual properties | Shorthand | Complete |
| border-top-color | <color> | inherit | the value of the 'color' property | Disappears | Basic |
| border-top-style | <border-style> | inherit | none | Disappears | Basic |
| border-top-width | <border-width> | inherit | medium | Disappears | Basic |
| border-width | <border-width>{1,4} | inherit | see individual properties | Shorthand | Complete |
| bottom | <length> | <percentage> | auto | inherit | auto | Formatting | Extended |
| break-after | auto | column | page | even-page | odd-page | inherit | auto | Formatting | Basic |
| break-before | auto | column | page | even-page | odd-page | inherit | auto | Formatting | Basic |
| caption-side | before | after | start | end | top | bottom | left | right | inherit | before | Formatting | Complete |
| case-name | <name> | none, a value is required | Action | Extended |
| case-title | <string> | none, a value is required | Action | Extended |
| character | <string> | N/A, value is required | Formatting | Basic |
| clear | none | left | right | both | inherit | none | Formatting | Extended |
| clip | <shape> | auto | inherit | auto | Rendering | Basic |
| color | <color> | inherit | depends on user agent | Rendering | Basic |
| column-count | <number> | inherit | 1 | Specification | Extended |
| column-gap | <length> | <percentage> | inherit | 12.0pt | Specification | Extended |
| column-number | <number> | see prose | Value change | Basic |
| column-width | <length> | undefined | Specification | Basic |
| content-type | <string> | auto | auto | Formatting | Basic |
| country | none | <country> | inherit | none | Formatting | Extended |
| cue | <cue-before> || <cue-after> | inherit | not defined for shorthand properties | Shorthand | Complete |
| cue-after | <uri> | none | inherit | none | Rendering | Basic |
| cue-before | <uri> | none | inherit | none | Rendering | Basic |
| destination-placement-offset | <length> | 0pt | Action | Extended |
| direction | ltr | rtl | inherit | ltr | See prose. Traits influenced: | Basic |
| display-align | auto | before | center | after
| inherit | auto | Formatting | Basic |
| dominant-baseline | auto | autosense-script | no-change | reset-size
| ideographic | alphabetic | hanging | mathematical
| inherit | auto | Formatting | Basic |
| dom-state | TBD | TBD | Action | Extended |
| elevation | <angle> | below | level | above | higher
| lower | inherit | level | Rendering | Basic |
| empty-cells | show | hide | inherit | show | Formatting | Extended |
| end-indent | <length> | inherit | 0pt | Formatting | Basic |
| ends-row | yes | no | no | See prose. Traits influenced: | Extended |
| extent | <length> | <percentage> | inherit | 0.0pt | Specification | Extended |
| external-destination | <uri> | null string | Action | Extended |
| float | left | right | none | inherit | none | Formatting | Extended |
| flow-name | <name> | an empty name | Reference | Basic |
| font | [ [ <font-style> || <font-variant>
|| <font-weight> ]? <font-size> [ / <line-height>]? <font-family>
] | caption | icon | menu | message-box | small-caption | status-bar
| inherit | see individual properties | Shorthand | Complete |
| font-family | [[ <family-name> | <generic-family>
],]* [<family-name> | <generic-family>] | inherit | depends on user agent | Font selection | Basic |
| font-height-override-after | use-font-metrics | <length> | inherit | use-font-metrics | Formatting | Complete |
| font-height-override-before | use-font-metrics | <length> | inherit | use-font-metrics | Formatting | Complete |
| font-size | <absolute-size> | <relative-size> | <length>
| <percentage> | inherit | medium | Formatting and Rendering | Basic |
| font-size-adjust | <number> | none | inherit | none | Font selection | Extended |
| font-stretch | normal | wider | narrower | ultra-condensed
| extra-condensed | condensed | semi-condensed | semi-expanded |
expanded | extra-expanded | ultra-expanded |inherit | normal | Font selection | Extended |
| font-style | normal | italic | oblique | backslant | inherit | normal | Font selection | Basic |
| font-variant | normal | small-caps | inherit | normal | Font selection | Basic |
| font-weight | normal | bold | bolder | lighter | 100 | 200
| 300 | 400 | 500 | 600 | 700 | 800 | 900 | inherit | normal | Font selection | Basic |
| force-page-count | auto | even | odd | end-on-even | end-on-odd | no-force
| inherit | auto | Specification | Extended |
| format | <string> | 1. | Formatting | Basic |
| glyph-orientation-horizontal | <angle> | inherit | 0 | Formatting | Extended |
| glyph-orientation-vertical | auto | <angle> | inherit | auto | Formatting | Extended |
| grouping-separator | <character> | no separator | Formatting | Basic |
| grouping-size | <number> | no grouping | Formatting | Basic |
| height | <length> | <percentage> | auto | inherit | auto | Disappears | Basic |
| href | <url> | inherit | none, value required | Reference | Basic |
| hyphenate | false | true | inherit | false | Formatting | Extended |
| hyphenation-character | <character> | inherit | The unicode hyphen character u+2010 | Formatting | Extended |
| hyphenation-keep | none | column | page | spread | inherit | none | Formatting | Extended |
| hyphenation-ladder-count | none | <number> | inherit | none | Formatting | Extended |
| hyphenation-push-character-count | <number> | inherit | 2 | Formatting | Extended |
| hyphenation-remain-character-count | <number> | inherit | 2 | Formatting | Extended |
| id | <id> | see prose | Reference | Basic |
| indicate-destination | yes | no | no | Action | Extended |
| initial-page-number | auto | auto-odd | auto-even | <number> | inherit | auto | Formatting | Basic |
| inline-progression-dimension | auto | <length> | <percentage> | <length-range>
| inherit | auto | Formatting | Basic |
| internal-destination | <idref> | null string | Action | Extended |
| keep-together | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | Formatting | Extended |
| keep-with-next | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | Formatting | Basic |
| keep-with-previous | <keep> | inherit | false | Formatting | Basic |
| language | none | <language> | inherit | none | Formatting | Extended |
| last-line-end-indent | <length> | <percentage> | inherit | 0pt | Formatting | Extended |
| leader-alignment | none | reference-area | page | inherit | none | Formatting | Extended |
| leader-length | <length-range> | inherit | leader-length.minimum=0pt, .optimum=12.0pt, .maximum=100% | Formatting | Basic |
| leader-pattern | space | rule | dots | use-content | inherit | space | Formatting | Basic |
| leader-pattern-width | use-font-metrics | <length> | inherit | use-font-metrics | Formatting | Extended |
| left | <length> | <percentage> | auto | inherit | auto | Formatting | Extended |
| letter-spacing | normal | <length> | <space> | inherit | normal | Disappears | Extended |
| letter-value | alpabetic | traditional | no value | Formatting | Basic |
| linefeed-treatment | ignore | preserve | treat-as-space | inherit | treat-as-space | Formatting | Extended |
| line-height | normal | <length> | <number> | <percentage> | <space>
| inherit | normal | Formatting | Basic |
| line-height-shift-adjustment | consider-shifts | disregard-shifts | inherit | consider-shifts | Formatting | Extended |
| line-stacking-strategy | line-height | font-height | max-height | inherit | line-height | Formatting | Basic |
| margin | <margin-width>{1,4} | inherit | not defined for shorthand properties | Shorthand | Complete |
| margin-bottom | <margin-width> | inherit | 0 | Disappears | Basic |
| margin-left | <margin-width> | inherit | 0pt | Disappears | Basic |
| margin-right | <margin-width> | inherit | 0pt | Disappears | Basic |
| margin-top | <margin-width> | inherit | 0 | Disappears | Basic |
| master-name | <name> | an empty name | Specification | Basic |
| max-height | <length> | <percentage> | none | inherit | 0pt | Disappears | Basic |
| maximum-repeats | <number> | no-limit | inherit | no-limit | Specification | Extended |
| max-width | <length> | <percentage> | none | inherit | none | Disappears | Basic |
| min-height | <length> | <percentage> | inherit | 0pt | Disappears | Basic |
| min-width | <length> | <percentage> | inherit | depends on UA | Disappears | Basic |
| number-columns-repeated | <number> | 1 | Specification | Basic |
| number-columns-spanned | <number> | 1 | Formatting | Basic |
| number-rows-spanned | <number> | 1 | Formatting | Basic |
| odd-or-even | odd | even | any | inherit | any | Specification | Extended |
| orphans | <integer> | inherit | 2 | Formatting | Basic |
| overflow | visible | hidden | scroll | auto | inherit | auto | Formatting | Basic |
| padding | <padding-width>{1,4} | inherit | not defined for shorthand properties | Shorthand | Complete |
| padding-after | <padding-width> | <length-conditional> | inherit | 0pt | Formatting and Rendering | Basic |
| padding-before | <padding-width> | <length-conditional> | inherit | 0pt | Formatting and Rendering | Basic |
| padding-bottom | <padding-width> | inherit | 0pt | Disappears | Basic |
| padding-end | <padding-width> | inherit | 0pt | Formatting and Rendering | Basic |
| padding-left | <padding-width> | inherit | 0pt | Disappears | Basic |
| padding-right | <padding-width> | inherit | 0pt | Disappears | Basic |
| padding-start | <padding-width> | inherit | 0pt | Formatting and Rendering | Basic |
| padding-top | <padding-width> | inherit | 0pt | Disappears | Basic |
| page-break-after | auto | always | avoid | left | right | inherit | auto | Shorthand | Basic |
| page-break-before | auto | always | avoid | left | right | inherit | auto | Shorthand | Basic |
| page-break-inside | avoid | auto | inherit | auto | Shorthand | Complete |
| page-height | auto | indefinite | <length> | inherit | auto | Specification | Basic |
| page-position | first | last | rest | any | inherit | any | Specification | Extended |
| page-width | auto | indefinite | <length> | inherit | auto | Specification | Basic |
| pause | [<time> | <percentage>]{1,2} | inherit | depends on user agent | Shorthand | Complete |
| pause-after | <time> | <percentage> | inherit | depends on user agent | Rendering | Basic |
| pause-before | <time> | <percentage> | inherit | depends on user agent | Rendering | Basic |
| pitch | <frequency> | x-low | low | medium | high
| x-high | inherit | medium | Rendering | Basic |
| pitch-range | <number> | inherit | 50 | Rendering | Basic |
| play-during | <uri> mix? repeat? | auto | none | inherit | auto | Rendering | Basic |
| position | static | relative | absolute | fixed | inherit | static | Shorthand | Complete |
| precedence | true | false | inherit | false | Specification | Basic |
| provisional-distance-between-starts | <length> | inherit | 24.0pt | Specification | Basic |
| provisional-label-separation | <length> | inherit | 6.0pt | Specification | Basic |
| reference-orientation | 0 | 90 | 180 | 270 | -90 | -180 | -270 | inherit | 0 | Formatting | Basic |
| ref-id | <idref> | inherit | none, value required | Reference | Basic |
| region-name | xsl-region-body | xsl-region-start | xsl-region-end
| xsl-region-before | xsl-region-after | <name> | see prose | Specification | Extended |
| relative-align | before | baseline
| inherit | before | Formatting | Basic |
| relative-position | auto | static | relative | inherit | static | See prose. Traits influenced: | Extended |
| richness | <number> | inherit | 50 | Rendering | Basic |
| right | <length> | <percentage> | auto | inherit | auto | Formatting | Extended |
| role | <string> | none | inherit | none | Rendering | Basic |
| rule-style | none | dotted | dashed | solid | double | groove
| ridge | inherit | solid | Rendering | Basic |
| rule-thickness | <length> | 1.0pt | Rendering | Basic |
| scale | <number>{1,2} | maximum | maximum-uniform
| inherit | 1.0 | Formatting and Rendering | Extended |
| score-spaces | true | false | inherit | true | Formatting | Extended |
| script | none | auto | <script> | inherit | auto | Formatting | Extended |
| show-destination | replace | new | replace | Action | Extended |
| size | <length>{1,2} | auto | landscape | portrait
| inherit | auto | Shorthand | Complete |
| source-document | <uri>+ | none | inherit | none | Rendering | Basic |
| space-after | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | Formatting | Basic |
| space-before | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | Formatting | Basic |
| space-end | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | Formatting | Basic |
| space-start | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | Formatting | Basic |
| space-treatment | ignore | preserve | inherit | preserve | Formatting | Extended |
| span | none | all | inherit | none | Formatting | Extended |
| speak | normal | none | spell-out | inherit | normal | Rendering | Basic |
| speak-header | once | always | inherit | once | Rendering | Basic |
| speak-numeral | digits | continuous | inherit | continuous | Rendering | Basic |
| speak-punctuation | code | none | inherit | none | Rendering | Basic |
| speech-rate | <number> | x-slow | slow | medium | fast
| x-fast | faster | slower | inherit | medium | Rendering | Basic |
| start-indent | <length> | inherit | 0pt | Formatting | Basic |
| starting-state | show | hide | show | Action | Extended |
| starts-row | yes | no | no | See prose. Traits influenced: | Extended |
| stress | <number> | inherit | 50 | Rendering | Basic |
| suppress-at-line-break | auto | suppress | retain | inherit | auto | Formatting | Extended |
| switch-to | xsl-preceding | xsl-following | xsl-any | <name>[ <name>]* | xsl-any | Action | Extended |
| table-layout | auto | fixed | inherit | auto | Formatting | Extended |
| table-omit-footer-at-break | yes | no | no | Formatting | Extended |
| table-omit-header-at-break | yes | no | no | Formatting | Extended |
| text-align | start | center | end | justify | inside | outside
| left | right | <string> | inherit | start | Value change | Basic |
| text-align-last | relative | start | center | end | justify | inside
| outside | left | right | <string> | inherit | start | Value change | Extended |
| text-decoration | none | [ underline || overline || line-through
|| blink ] | inherit | none | See prose. Traits influenced: | Extended |
| text-indent | <length> | <percentage> | inherit | 0pt | Formatting | Basic |
| text-shadow | none | [<color> || <length> <length> <length>?
,]* [<color> || <length> <length> <length>?] | inherit | none | Rendering | Extended |
| text-transform | capitalize | uppercase | lowercase | none | | none | Refine | Extended |
| top | <length> | <percentage> | auto | inherit | auto | Formatting | Extended |
| treat-as-word-space | auto | yes | no | inherit | auto | Formatting | Extended |
| unicode-bidi | normal | embed | bidi-override | inherit | normal | Formatting | Extended |
| vertical-align | baseline | middle | sub | super | text-top |
text-bottom | <percentage> | <length> | top | bottom | inherit | baseline | Shorthand | Extended |
| visibility | visible | hidden | collapse | inherit | visible | Magic | Basic |
| voice-family | [[<specific-voice> | <generic-voice>
],]* [<specific-voice> | <generic-voice> ] | inherit | depends on user agent | Rendering | Basic |
| volume | <number> | <percentage> | silent | x-soft
| soft | medium | loud | x-loud | inherit | medium | Rendering | Basic |
| white-space | normal | pre | nowrap | inherit | normal | Shorthand | Complete |
| white-space-collapse | false | true | inherit | true | Formatting | Extended |
| widows | <integer> | inherit | 2 | Formatting | Basic |
| width | <length> | <percentage> | auto | inherit | auto | Disappears | Basic |
| word-spacing | normal | <length> | <space> | inherit | normal | Disappears | Extended |
| wrap-option | no-wrap | wrap | inherit | wrap | Formatting | Basic |
| writing-mode | lr-tb | rl-tb | tb-rl | lr | rl | tb | inherit | lr-tb | See prose. Traits influenced: | Basic |
| xml:lang | <country-language> | inherit | not defined for shorthand properties | Shorthand | Complete |
| z-index | auto | <integer> | inherit | auto | Value change | Basic |
D References
D.1 Normative References
-
W3C XML
- World Wide Web Consortium. Extensible
Markup Language (XML) 1.0. W3C Recommendation. See http://www.w3.org/TR/1998/REC-xml-19980210
-
W3C XML Names
- World Wide Web
Consortium. Namespaces in XML. W3C Recommendation. See
http://www.w3.org/TR/REC-xml-names/
-
XSLT
- World Wide Web Consortium.
XSL Transformations (XSLT).
W3C Recommendation. See http://www.w3.org/TR/xslt
-
XPath
- World Wide Web Consortium. XML Path
Language. W3C Recommendation. See http://www.w3.org/TR/xpath
-
IEEE 754
- Institute of Electrical and
Electronics Engineers. IEEE Standard for Binary Floating-Point
Arithmetic. ANSI/IEEE Std 754-1985.
-
ISO639
- International Organization
for Standardization.
ISO 639:1998. Code for the representation of names of languages
International Standard.
-
ISO639-2
- International Organization
for Standardization.
ISO 639-2:1998. Codes for the representation of names of languages — Part 2: Alpha-3 code.
International Standard.
-
ISO3166-1
- International Organization
for Standardization.
ISO 3166-1:1997. Codes for the representation of names of countries and their subdivisions — Part 1: Country codes.
International Standard.
-
ISO3166-2
- International Organization
for Standardization.
ISO 3166-2:1998. Codes for the representation of names of countries and their subdivisions — Part 2: Country subdivision code.
International Standard.
-
ISO3166-3
- International Organization
for Standardization.
ISO 3166-3:1999. Codes for the representation of names of countries and their subdivisions — Part 3: Code for formerly used names of countries.
International Standard.
-
SCRIPTS
- International Organization
for Standardization.
ISO 15924:1998. Code for the representation of names of
scripts. Draft International Standard.
-
ISO10646
- International Organization
for Standardization, International Electrotechnical Commission.
ISO/IEC 10646:1993. Information technology — Universal Multiple-Octet Coded Character Set (UCS) —
Part 1: Architecture and Basic Multilingual Plane with 2 corrigenda, and 23 amendments.
International Standard.
-
RFC1766
- IETF.
RFC 1766. Tags for the Identification of Languages.
See http://www.ietf.org/rfc/rfc1766.txt.
-
RFC2070
- IETF.
RFC 2070. Internationalization of the Hypertext Markup Language.
See http://www.ietf.org/rfc/rfc2070.txt.
-
UNICODE TR9
- Unicode Consortium.
Unicode Technical Report #9. Unicode 3.0 Bidirectional Algorithm.
Unicode Technical Report. See http://www.unicode.org/unicode/reports/tr9/index.html.
-
OpenType
- Microsoft, Adobe.
OpenType specification v.1.2.
See http://www.microsoft.com/truetype/tt/tt.htm.
D.2 Other References
-
CSS2
- World Wide Web Consortium. Cascading
Style Sheets, level 2 (CSS2), as amended by Errata document 1999/11/04.
W3C Recommendation. See http://www.w3.org/TR/1998/REC-CSS2-19980512/ and
http://www.w3.org/Style/css2-updates/REC-CSS2-19980512-errata.html.
-
DSSSL
- International Organization
for Standardization, International Electrotechnical Commission.
ISO/IEC 10179:1996. Document Style Semantics and Specification
Language (DSSSL). International Standard.
-
UNICODE TR10
- Unicode Consortium. Draft
Unicode Technical Report #10. Unicode Collation Algorithm.
Draft Unicode Technical Report. See http://www.unicode.org/unicode/reports/tr10/index.html.
-
W3C XML Stylesheet
- World Wide Web
Consortium. Associating stylesheets with XML documents.
W3C Working Draft. See http://www.w3.org/TR/WD-xml-stylesheet
-
JLS
- J. Gosling, B. Joy, and G. Steele. The
Java Language Specification. See http://java.sun.com/docs/books/jls/index.html.
E Acknowledgements (Non-Normative)
This specification was developed and approved for publication by the
W3C XSL Working Group (WG). WG approval of this specification does not
necessarily imply that all WG members voted for its approval. The
current members of the XSL WG are:
Sharon Adler, IBM (Co-Chair); Anders Berglund, IBM;
Perin Blanchard, Novell; Scott Boag, Lotus;
Larry Cable, Sun; Jeff Caruso, Bitstream; James Clark;
Peter Danielsen, Bell Labs; Don Day, IBM; Stephen Deach, Adobe;
Dwayne Dicks, SoftQuad; Andrew Greene, Bitstream;
Paul Grosso, Arbortext; Eduardo Gutentag, Sun;
Juliane Harbarth, Software AG; Mickey Kimchi, Enigma;
Chris Lilley, W3C; Chris Maden, Exemplary Technologies;
Jonathan Marsh, Microsoft; Alex Milowski, Lexica;
Boris Moore, RivCom; Steve Muench, Oracle; Scott Parnell, Xerox;
Jeremy Richman, Interleaf;
Vincent Quint, W3C;
Dan Rapp, Novell; Gregg Reynolds, Datalogics;
Jonathan Robie, Software AG; Mark Scardina, Oracle;
Henry Thompson, University of Edinburgh; Philip Wadler, Bell Labs;
Norman Walsh, Arbortext; Sanjiva Weerawarana, IBM;
Steve Zilles, Adobe (Co-Chair)