Internationalization Comments on UAX #29 Unicode Text Segmentation
Version reviewed: http://www.unicode.org/reports/tr29/tr29-12.html
Lead reviewer and date of initial review: Richard Ishida, 2008-01
Subject lead in: [UAX 29]
These are comments on behalf of the Internationalization Core WG, unless otherwise stated. The "Owner" column indicates who has been assigned the responsibility of tracking discussions on a given comment.
We recommend that responses to the comments in this table use a separate email for each point. This makes it far easier to track threads. Click on the icons in the right-most column to see email discussions.
| ID | Location | Subject | Comment | Owner | Ed. / Subs. |
||
|---|---|---|---|---|---|---|---|
| 1 | 3 | Grapheme terminology |
"To avoid ambiguity with the computer use of the term character, this is called a user-perceived character or a grapheme cluster.". Section 1 para 1 replaces 'grapheme clusters ("user-perceived characters")' with 'user-perceived characters', but should probably say 'grapheme clusters (also known as user-perceived characters)'. S1 para 4 replaces 'grapheme clusters (what end users usually think of as characters)' with just 'characters'. This is incorrect. S2 para1 deletes 'grapheme clusters' and leaves 'user-perceived characters'. Later we read: "Note: Default grapheme clusters have been referred to as" This could point to a problem with terminology. Is 'default grapheme clusters' meant to include default grapheme clusters of the extended and existing types? I would have thought so, but the meaning of the text is not clear. You'd need to say 'default grapheme clusters and extended default grapheme clusters' here to be clear (and elsewhere in the text, eg. 4 paras later). We could rename the current 'default grapheme cluster' to 'minimal default grapheme cluster' and define 'default grapheme cluster' to refer to both the minimal and extended varieties, or you could simply use 'grapheme cluster' when you want to be non-specific. This is very inconsistent. We would like to see some rationalization of the terminology used throughout the section, and consistency in its application. Terms should be clearly defined, and only one term should be used for one concept. The definitions should be easy for the reader to locate visually, and compare. We suggest a mini-glossary internal to section 3 or links on terms to a glossary at the end of the document. In particular, the replacement of the term "grapheme cluster" with term "character", starting in the introduction and proceeding through the document, seems to fly in the face of standard Unicode terminology and produces a significant problem. The term "character", as usually understood in Unicode contexts, refers to a logical character i.e. a code point. By using the term interchangeably with "grapheme cluster", we introduce confusion. |
RI | E | ||
| 2 | 2 | Not just TLCJ |
The document calls out Thai and Lao in addition to Chinese and Japanese, due to the fact that they don't use spaces between words. Other similar scripts like Khmer and Myanmar should be added to the list, or it should be made clear that this is a non-exhaustive list. |
RI | E | ||
| 3 | 3 | Defining intended uses for grapheme clusters |
para starting "Grapheme clusters are important for..." We would like to see this para significantly expanded to provide a more complete list of potential applications for the grapheme cluster. This information is rather scattered around the section. Eg. mouse selection, cursor movement and backspace (and presumably delete) are mentioned later. We feel that this will not only help readers understand the concepts in the section, but to more formally list the intended applications of these rules before defining a solution for them will also help better establish the required features of default grapheme clusters that need to be defined. At the moment the document reads as if we have a solution looking for an application, rather than a set of use cases for which we are providing a solution. Note that applications we have come across recently include segmentation for vertical text and identification of boundaries for first-letter styling (which could be said to be a type of highlighting). (Segmentation of indic and south-east asian scripts for these applications is done on a syllabic basis. See examples at http://www.flickr.com/photos/ishida/2212584968/ and http://www.w3.org/International/notes/firstletter.html ) |
RI | S/E | ||
| 4 | 3 | Historically originally |
The sentence starting "Historically, the Unicode Standard originally provided for grapheme clusters" is redundant. Either say "historically" or say "originally". |
RI | E | ||
| 5 | 3.1 | Definition of EDGCs |
"Extended default grapheme clusters should be used in implementations in preference to default grapheme clusters, because it provides better results for Indic scripts such as Tamil." This should come much earlier and be easier to find. We would suggest that very near the beginning of section three the document states that it defines two types of default grapheme cluster, and that the extended one is the preferred. There also needs to be a separate section and heading for the definition of XDGCs. The current definition is difficult to find because it is just a small adjunct to the section about default grapheme clusters. |
RI | E | ||
| 6 | 3 | Indic scripts or Tamil? |
'Indic scripts such as Tamil' is ambiguous. We were expecting to read something like 'Indic scripts, such as the Tamil we saw earlier' or 'most Indic scripts'. On the other hand, this may be intentional because the XDGCs are intended to only address the needs of a simpler Indic script like Tamil that doesn't generally use conjunct forms (so the statement should say something more like "the set of Indic scripts that are like Tamil"). If this latter interpretation is true, a. there needs to be a clearer statement about the relevance of XDGCs to Indic and South-East Asian scripts in general, and b. we think the document is definitely setting its sights too low. |
RI | E/S? | ||
| 7 | 3 | Hangul stacks | One way to think of this is as a sequence of characters that form a "stack". Talking about Hangul characters "One way to think of this is as a sequence of characters that form a "stack"." Some jamos stand side by side rather than stacking. Surely the point is that this constitutes a Korean syllable. |
RI | E | ||
| 8 | 3 | Conjunct clusters |
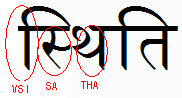
We don't think extending default grapheme clusters to just incorporate spacing marks goes far enough to actually providing better results for a very large proportion of the world's population. We feel that the Unicode TC should conduct further research on how to extend default grapheme clusters so that they incorporate the majority of indic and south-east asian syllables. Example: It is very common to have a sequence such as consonant+virama+consonant+vowel_sign, eg. 0938: स DEVANAGARI LETTER SA See this as it would be rendered. Without tailoring, the current rules would result in text wrapping the THA to the next line, or attempting to highlight only part of the conjunct. The basic unit for grapheme clusters for indic and south-east asian scripts is the syllable, and just addressing spacing marks will still leave you short of a useful solution. We would like the Unicode TC to investigate the possibility of adding a rule to say that a vowel killer character extends the grapheme cluster to any immediately adjacent base character and all its combining characters. We feel that introducing a definition of default grapheme clusters that addresses this issue will go a long way to helping ensure that implementers provide applications that can handle South Asian and South-East Asian scripts much better than now. We feel that extending default grapheme clusters to include only spacing marks may only complicate things further. We do not, however, feel that the extension of grapheme clusters should be abandoned. |
RI | S | ||
| 9 | 3 | Types of grapheme clusters |
There are many types of grapheme clusters. Examples include:... It is not clear whether this list refers to user perceived characters or different types of default grapheme cluster defined in this document. Please clarify, and if the former, please add an example of a complex indic syllable. The khmer coeng+consonant combinations do not seem to qualify as default grapheme clusters according to the rules in this section, unless the fact that they are named sequences has some bearing, though that is not made clear. Please clarify this and provide some explanatory text for the link to the named sequences list. (This is another example of poor use of terminology related to grapheme clusters.) |
RI | E/S? | ||
| 10 | 3 | Different types of grapheme cluster? |
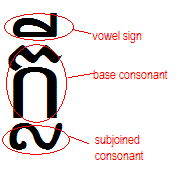
We feel that the current definition of default grapheme clusters envisages only one way in which operations interact with grapheme clusters, whereas we probably require at least two different types of behaviour. For example, in the case of Khmer, the subscript consonants are viewed as distinct letters by Cambodians. On the one hand we suspect that it would make sense to delete the subjoined consonants separately from the 'base' character above them. This may not, however, be a question of deleting a character at a time - since it may be appropriate to delete vowel signs with the subjoined consonant. On the other hand, we do not expect that it would make sense to highlight the subjoined character and its vowel sign separately from the rest of the syllable, especially since there could be some discontinuity between the subscript consonant and the following vowel sign. Nor would you expect to see parts of these clusters wrapping separately either. (Especially since vowels can appear to the left or on both sides of the stack produced by coeng combinations.) 1780: ក KHMER LETTER KA 17D2: ្ KHMER SIGN COENG 179B: ល KHMER LETTER LO 17B8: ី KHMER VOWEL SIGN II See this as it would be rendered. We find ourselves wondering whether there may be two different types of grapheme cluster, one that produces the correct behaviour for wrapping or highlighting and another to produce correct behaviour for backspace deletion. We would appreciate it if the authors of UAX 29 could point us to some discussions about this, or engage in some if they have not yet taken place. |
RI | S | ||
| 11 | 3 | for complete |
" Additional cases need to be added for complete, whereby any string of text " Syntax error ! |
RI | E | ||
| 12 | 3 | Legacy vs. desired | The whole of section 3 is written in a way that suggests that default grapheme clusters are the norm, and extended grapheme clusters are a recommended extension. We feel that this the section should be re-edited to make it clear that the extended default grapheme cluster is the standard way to do things in the future, but that you *could* find applications dealing with the former definition. To help with this, we suggest that you find a different word that 'extended' for the name of extended default grapheme clusters, and that you rename default grapheme clusters to something like legacy default grapheme clusters. |
RI | E | ||
| 14 | 3 | a key feature are | Just following the Note: "A key feature... are" | RI | E | ||
| 15 | 3 | run-on sentence | The examples for locale-specific tailorings are in a single run-on-like sentence and probably should be separated around the text: "...such as collation; Thai never breaks between..." | AP | E | ||
| 16 | 3 | Where is 9b? | Under the heading "Grapheme Cluster Boundary Rules", the text refers to a rule "9b", but no such rule exists. This appears to mean rule 9a. Note that no change bars are present here! | RI | E | ||
| 17 | 4 | Search engines | The added text about search engines, coupled with the somewhat obscure example about database queries suggests some more general rewriting is needed here. | AP | E | ||
| 18 | 4 | Scripts without spaces | All of the examples include space-separated languages. No mention is made of the fact that some languages don't use spaces between words, which I think is an extremely important point to make. It should be explicitly mentioned here and possibly an example given. | AP | E | ||
| 19 | 4 | Word break algorithm | The problem with spaces in tailored word breaking should probably be added to the text. In particular, it should be pointed out (as with the Southeast Asian languages above) that the word break algorithm provides a "pretty good" default but that some more complex mechanisms may be needed to do a perfect job (with stuff like 1_234,56, where _ represents a space type character). | AP | E | ||
| 20 | 1.1 | Carriage return typo | "and not U+000D CARRIAGE RETURN (CR)<]" We wonder if "<]" is a typo. If this is intended, shouldn't there be some explanation ? |
RI | E |
{kind=link}
{kind=link}