W3C | TAG | Previous: 3 May teleconf | Next: 25 May
Minutes of 12-14 May 2004 TAG FTF meeting in Boston
Nearby: Teleconference
details · issues
list (handling new
issues)· www-tag
archive
 (full-size
version)
(full-size
version)
Roll call from left: Paul Cotton, Norm Walsh, Roy Fielding, Mario
Jeckle, Chris Lilley, Tim Berners-Lee, Ian Jacobs
Paul Cotton joined the meeting 13,14 May. Also periodically
attending: Stuart Williams (by phone) and Dan Connolly (by phone, IRC,
and iChat).
1. Administrative
- Resolved to accept minutes of the 3 May teleconf
- Resolved to accept draft
monthly summary.
- Accepted this agenda
- Next meeting: 25 May 2004.
- Resolved: TAG plans to meet 5-7 Oct at a
European location.
Minutes:
Completed/moot actions from previous meetings:
- Action PC, CL 2004/05/03: Review presentation materials when DC makes
them available.
- Action CL, PC 2004/05/03: Read TBL's TLD essay on .mobi; send comments to
www-tag.
- Action TBL 2004/05/03: Send pointer to .mobi essay to www-tag.
Resources:
- Last call
issues list
- Last
Call Draft with inserted issues
- 10 May 2004
Editors' Draft
- Last
Call Draft with inserted proposals
- [IanJ]
- TBL: We need to devote time to httpRange-14
- [DanC_]
- Tim, I agree that comments from PFPS and Hayes show dissatisfaction
with our non-treatment of httpRange-14, but they don't really show
anything new that would say why spending time on it today would be
productive.
- [tim_TAG]
- The comments show that at least one more person seems to need a
separation of the concepts of InformationObject and Thing.
Issues discussed here:
See also continuation of discussion of Last Call issues.
Issue
msm2
- [IanJ]
- TBL: I like the drop shadow
- Action CL: Send IJ and SVG version of the
first illustration in the document (Done)
- Resolved: For issue msm2, we wish to
keep the drop shadow.
- [IanJ]
- RF: Delete "This categorization is derived from Roy Fielding's work
on "Representational State Transfer" [REST]."
Issue
diwg2
- [IanJ]
- IJ: I did not incorporate the proposal in the 10 May draft.
- RF: "The Spanish version" is a different resource.
- IJ: I thought both are useful: conneg and URI for the Spanish
resource.
- CL: Yes, in general, show both sides of story.
- [Roy]
- A "tiny URI" example would be easier to convey as a reasonable use of
multiple URI for one resource.
- [Chris]
- yes it would
- tinyurl is the actual name ;-)
- http://tinyurl.com/
- [IanJ]
- [General theme: when someone has said "why not this other
way", ack the other way.]
- Action IJ: Draft some text that talks
about conneg as well as individual URIs.
- TBL: Footnote perhaps.
Other changes the TAG accepted:
- s/resource owner/URI owner/
- s/URI ambiguity/URI overloading/
Issue
stickler2
At their2 March
teleconf, the TAG discussed changing the term "namespace
document" to "namespace representation". This change was incorporated into
the 10 May draft. The TAG discussed this change.
- [IanJ]
- Bug in 4.5.4
-
Namespace representation: If a namespace declaration binds a
prefix to a URI, and that URI can be dereferenced to get a
representation, then that is a namespace representation
- IJ: We don't say "namespace document" in the 10 May draft. Does the
web arch require the concept of "namespace document"
- TBL: People use "namespace" to mean set of terms; "namespace
document" to talk about those terms.
Issue
stickler4
- [IanJ]
- NW: I think people should feel guilty if they don't provide
representations!
- Resolved: Rejected stickler4
- Rationale: We meant this: people should - the community is poorer
where representations are not available.
- Action IJ - respond to reviewer.
- Issue
hawke1
- TBL: I think that SH is asking for transparency. E.g., perhaps your
agent should tell you when you are going to do a GET v. a POST. (e.g.,
change of cursor).
- RF: In my dissertation - principle of visibility.
- TBL: View source is good for other reasons - get people hacking and
extending.
- IJ: Also accessibility - emergency exit.
- TBL: Sandro's comment is also about responsibility of agent to
represent the user.
- Action RF: Provide text for hawke1. There
is general support for a visibility principle.
- Issue
dhm3
- Proposed:
- Extended language: A+B
- Extension: B
- Resolved: Agreed. Editor will
incorporate.
Issue
dhm4
"The Web follows Internet tradition in that its important interfaces are
defined in terms of protocols, by specifying the syntax, semantics, and
sequence of the messages interchanged. "
- [IanJ]
- Reviewer asks "protocols as opposed to what"
- [Chris]
- its protocols rather than apis
- [IanJ]
- TBL: There's an important point here, but not protocol v. API.
- [Chris]
- but message passing rather than apis is another distinction with
similar properties
- [IanJ]
- TBL: When we define protocols we are used to designing more resilient
interfaces than when we design software APIs. (No reason we couldn't do
the same for software.). Because protocols operate across boundaries, require
scalability, etc. we are more used to designing flexible
interfaces.
- CL: Related point - in xforms they try to avoid the dom; they use
message passing. Same rationale, even if there's no network .
- TBL: They are defining error handling processes (doing their own
operating system...) Put in a second paragraph in 1.2.4 - we do not use
convention distributed protocol approaches when designing software
APIs.
- CL: Point to the client side example since distributed is not a
requirement.
- [Chris]
- no, its not error handling at all!
- [IanJ]
- Action IJ: Add a second paragraph to
1.2.4 explaining what TBL said about resilience as typical design goal
in protocols.
- [Roy]
- http://www.ics.uci.edu/~fielding/pubs/dissertation/evaluation.htm#sec_6_5_1
Issue
rodriguez1
- [IanJ]
- Proposed: We don't think we need to address this comment in the Arch
Doc.
- [Chris]
- XDI: Weaving the "Dataweb"
- [IanJ]
- [Stuart calls in from Crete]
- Resolved: Reject rodriguez1
- [Chris]
- language for rejection (rationale)?
List of findings
The TAG did not do an update on:
2.2.1 How should the problem of identifying ID semantics in XML languages
be addressed in the absence of a DTD?
How
should the problem of identifying ID semantics in XML languages be addressed
in the absence of a DTD?
- [IanJ]
- CL: Proposal - approve this and indicate that someone else is
chartered to work on this. I've updated it as the XML Core WG has
asked. They have a first draft of a document.
- NW: Core WG will come back to TAG for review when work done.
- Resolved: Accept finding.
- Action CL: Add reference to the XML
Core's working draft and publish approved finding. Announce finding
(www-tag, public-tag-announce) (Done)
- IJ to CL: Check out status section of this one: http://www.w3.org/2001/tag/doc/mime-respect.html
- [Roy]
- I'd prefer a shorter title: ID semantics in XML
2.2.2 The use of Metadata in URIs
The
use of Metadata in URIs
- [IanJ]
- SKW: See my update,
with summary of comments. I'll try to have another draft by
mid-June
2.2.3 Versioning XML Languages
Versioning
XML Languages
- [IanJ]
- NW: DO and I were working on this. The document needs an editing pass
to incorporate comments from a DO/NW discussion a few months ago.
- [Some discussion of editing]
- Resolved: Ask Tim Bray and David
Orchard if they would be willing to act in an editor role on the TAG,
specifically on extant findings.
- Action TBL: Talk to TB and DO about
editor role.
2.2.4 Separation of semantic and presentational markup, to the extent
possible, is architecturally sound
Separation
of semantic and presentational markup, to the extent possible, is
architecturally sound
- CL: I have been working on this based on comments on arch doc section
4. I think arch doc oversimplifies; may need to say more about pros and
cons. I expect a new draft soon.
2.2.5 Abstract Component References
Abstract
Component References
- The TAG plans to wait to hear from editor David Orchard.
Resources:
Issues discussed here:
See also continuation of discussion of
TAG's general issues list.
The TAG indicated a desire to close these issues this year: 8, 14, 33,
34, 8, 15
Issue
HTTPSubstrate-16
- [IanJ]
- Action RF: "Write a response to IESG asking
whether the Web services example in the SOAP 1.2 primer is intended to
be excluded from RFC 3205"
- RF: An area director said "Yes, we intend 3205 to cover SOAP." Not
sure where to take the action item beyond this.
- TBL summarizes:
- People are tunneling through port 80
- There are benefits to one-port-per-protocol, but each time you
create a new protocol you have to ask for a new port.
- The recommendation was thus not to use port 80 for other
applications. Furthermore, there's a hint of "don't use http for
things is was not intended for", but I disagree with that - promote
reuse.
- TBL: Abusive tunneling is another question. There are lots of times
when you want HTTP functionality and you should darn well use it.
- RF: I agree with TBL. But what do we do in practice? Write the IETF
and say they are confused? (they might ignore). We could also submit a
replacement draft, or our own description. It's difficult to find
something specific now for something to respond to. I wish there were a
suitable replacement strategy, but there isn't. What about if we write
a few paragraphs expressing where we felt unease. I think Mark wants us
to write up a general critique of the RFC and present the editors with
comments from the TAG. I didn't see any way to reach consensus on that,
but I could draft some comments.
- IJ: How involved would this be?
- RF: We could put this issue in limbo until someone tries to enforce
3205.
- Resolved: Close Roy's action item on
this issue
- Resolved: Move HTTPSubstrate-16 to
deferred state.
- Action RF: Write descriptive paragraph
explaining this issue's state.
- Issue
fragmentInXML-28
- (NW: This touches on httpRange-14)
- CL summarizes the issue.
- Resolved:
- To the general question of "Do fragment identifiers refer to a
syntactic element (at least for XML content), or can they refer to
abstractions?" - see the section on fragment identifier semantics
(i.e., the media type identifies a specification, which tells you
their semantics).
- For the specific question in SVG, DC's observation is correct
since it's licensed by the SVG spec.
- Action CL: Write up a summary of the
resolution.
Issue
binaryXML-30
- [IanJ]
- Proposed: Close and state that the W3C has chartered a WG to
investigate this.
- CL's summary has been given to them as input.
- [Roy]
- The potato has been passed.
- [IanJ]
- Resolved: Move this issue to deferred
status with a note that the TAG anticipates considering the Binary
Char. WG's deliverables.
Issue
DerivedResources-43
- [IanJ]
- NW: Note that Xinclude no longer allows fragids.
- [TAG tries to understand the issue]
- Resolved: The TAG no longer understands the issue.
- Action NW: Write to DO saying that
XInclude no longer uses frag ids and the TAG is unable to construct
from its meeting record what the issue was. We will discuss this
further if we get help, but otherwise expect to close without
action.
- Issue
xmlChunk-44
- NW: Core WG and TAG discussed this in Cannes. Not sure we made
progress. I believe that there are wildly divergent ideas about what
chunk equality means.
- TBL: But we were in the same place re: URI comparison and the TAG did
reach consensus.
- NW: I hear TBL saying that he'd like a document summarizing different
comparison approaches. There is another issue regarding comparing
canonical forms.
- TBL: Issue 44 is whether a chunk of XML has meaning out of context.
Chunks only have meaning when XML is wrapped around them and there's a
media type at the top. E.g., does xml:base propagate? If a chunk had a
base in one document and it's moved, does the base move with it?
- NW: Do we want to take a stab at it?
- TBL: Note that there are two canonicalizations already. You need
another one, e.g., including:
- must have namespaces (open issue about "unused" ns)
- xml:lang
- xml:base
- TBL: If we were to propose a canonicalization, those are the sorts of
issues we'd have to address.
- CL: Note that XML doesn't have inherited attributes; they don't
appear in the infoset. You could do the following (1) propagate
attributes (2) canonicalize.
- [TBL asks whether xml:lang and xml:base are to be inherited at
the infoset level]
- RF: "XML Fragment Interchange" is a CR...
- NW: And it's been there for a long time. It's a related problem.
- MJ: I can have a private equivalence function.
- TBL: We are looking at a minimal equivalence function for all XML
applications.
- [Chris]
- ok so this would define and name *an* equivalence function
- [IanJ]
- NW: If I were asked to define an equivalence function I would: (a)
define at infoset level (b) not use the canonicalization specs and (c)
include the possibility of error - you have to perform certain
operations when you extract the chunk.
- TBL: Note also, e.g., in a particular application additional
information might need to be added to the chunk (e.g., CSS style for an
SVG chunk).
- [Chris]
- hmm... 'in scope' xl pis for stylesheets ..... hmmm
- [IanJ]
- NW: Another point - infoset includes prefixes and we don't need the
same prefixes. Let the minutes show that the TAG understands that Paul
Cotton has concerns about this issue and is not currently present.
- Action NW: Write up a named equivalence
function based on today's discussion (e.g., based on infoset, augmented
with xml:lang/xml:base, not requiring prefixes, etc.).: Write up a
named equivalence function based on today's discussion (e.g., based on
infoset, augmented with xml:lang/xml:base, not requiring prefixes,
etc.).
- NW: I don't expect to have text before mid-July.
The TAG walked through changes in the 10 May Editor's
Draft. See also continuation of discussion
of 10 May draft.
- Summary
of changes
- Diffs
- [IanJ]
- RF: Need to update RFC2396 reference
- [DanC_]
- (I skimmed one of the recent versions, only enough to realize I'd
more time to read it carefully. I saw a _lot_ of changes.)
- [IanJ]
- DC: I read 10 may draft enough to know that there are a lot of
changes and that I need to review more carefully.
- RF: I read the first half.
- [Zakim]
- DanC_, you wanted to ask if anybody has read the 10May draft
- [IanJ]
- RF: I don't like the change from "orthogonal" to "independent". They
don't mean the same thing. HTTP is dependent on the URI protocol, but
they are orthogonal protocols. "loosely coupled" not same as orthogonal
either. Orthogonality generally refers to things traveling on different
paths.
- TBL: The idea is that you change one spec without changing the other.
That's a form of independence.
- Resolved: Change "independent" back to
"orthogonal". Say "may evolve independently" instead of "independent".
Drop "loosely coupled."
- [DanC_]
- +1 "resource is a periodically updated report..."
- transition sentence sounds editorial.
- the "designers" bit seems editorial.
- [IanJ]
- RF: In 1.1.1, bullet 1, delete "i.e., " to end.
- [DanC_]
- s/document involve human activity/document that involve human
activity/
- [IanJ]
- On "Many of the examples...."
- IJ: This is from voice browser input on the doc.
- CL: In voice browsing context, you only have input device (phone),
client runs remotely.
- [Chris]
- client reporting errors is therefore much harder to do
- [IanJ]
- +1 to citing the work.
- [Zakim]
- DanC_, you wanted to suggest citing their work
Section 1.1.3
- [DanC_]
- Roy, how about citing [REST] from the acks section, ala "This
document borrows several terms and concepts from [REST]."
- ok, never mind.
Section 1.2.3 Error Handling
- [Roy]
- editorial - s/indicate through/indicate such consent through/
- [IanJ]
- TBL: I'm not happy with: "Agent recovery from error without user
consent is harmful." E.g., TCP recovery from error....
- [Norm]
- Editorially, s/specifications/specification designers/, strikes me as
not ideal
- [IanJ]
- DC: The user does give consent by using that protocol. Same as HTTP
404; that's part of the protocol.
- TBL: I think that what we are saying here is "If an error occurs and
some behavior happens which will mess up the user"; that's a bad thing.
Introducing bad data into the system is a bad idea.
- NW: We can distinguish "error correction" - error occurs and you can
fix it although the error never occurred, v. "error recovery" where you
can't correct the error...
- TBL: How do you define the set of corrections that are "bad"? [See
also issue
schema1]
- RF: I think if we distinguish correction v. recovery the problems go
away.
- TBL: User agents that correct errors without the consent of the user
are doing the user a favor.
- [DanC_]
- "User agents that mask errors in a way that is not licensed by
protocol documentation are not acting on behalf of the user."
- (trying some scribbling... hmm...)
- [IanJ]
- TBL: User agents that mask an error from which they cannot recover,
and that do so without the consent of the user, are not acting on the
user's behalf.
- Action IJ: Fix the text to make error
correction/error recovery distinction.
- [DanC_]
- (hmm... is the connection between specs and consent written down?
hmm.)
- [Roy]
- 404 (not found) instead of "404 (resource not found)"
Section 2. Identification
- [IanJ]
- "The identification mechanism for the Web is the URI."
- What about OWL/RDF methods of identification? {Comments from Sandro
Hawke}
- DC: OWL identification mechanisms don't give the same network effect
benefits.
- "Resources exist before URIs; a resource may be identified by zero
URIs."
- [DanC_]
- "References from one part of the web to another should use URIs."
- [IanJ]
- TBL: OWL uses "indirect identification" as well as through URIs.
- DC: OWL has other mechanisms, but they don't contribute to the
network effect.
- [DanC_]
- (what did timbl ask?)
- [Norm]
- Timbl asked "can we use 'name' around here"
- [IanJ]
- TBL: What's a "part of the Web"?
- [DanC_]
- section 2.7.2. Assertion that Two URIs Identify the Same Resource
discusses OWL, btw.
- [IanJ]
- TBL: How about "We refer from an information resource to
anything"
- [DanC_]
- "In order to participate in the network effects of The Web, use URIs
for naming."
- [Zakim]
- DanC_, you wanted to note "A URI must be assigned to a resource in
order for agents to be able to refer to the resource." is wrong
- [IanJ]
- IJ: I am proposing to write some text that starts off slightly more
generally with the desire to identify resources. URIs are the most
important mechanism for identifying resources; we are seeing the growth
of others. Here are the properties and benefits of the various
identification mechanisms.
- [Norm]
- 1: The primary ident. mech. is the URI
- 2. The ident. mech. that offers the benefit of the network effect is
the URI
- [Chris]
- +1 to 'primary'
- [marioj]
- what about 'preferred' or 'recommended'?
- [IanJ]
- TBL: Value of giving something a URI is that you can refer to it from
many formats.
- [DanC_]
- I much prefer to say, in the principle, what's better about URIs,
rather than just say "primary" or "recommended"
- [IanJ]
- RF: The value of the network increases exp. with the value of nodes
in the network.
- [DanC_]
- the point about formats was made in some drafts; it seems to be gone
now. I'd like to see it come back.
- [IanJ]
- RF: This increases the value of the Web to society and also the value
of specific resources by virtue of them being referred to directly by
other resources.
- TBL: People who use local ids only in their design, other people
can't connect to them.
- [DanC_]
- yes, the point is not one string versus some mechanism using 3
strings; it's global vs. local naming.
- [IanJ]
- IJ: I am hearing the question as a larger one such as "why use URIs
instead of queries"?
- DC: One issue is local naming v. global naming. When you do global
naming, you get interesting naming effects.
- [DanC_]
- "In order to participate in the network effects of The Web, use URIs
for naming."
- [IanJ]
- DC: Another issue is which global naming system. For historical
reasons, people are using URIs.
- TBL: When you use global identifiers instead of local identifiers,
you increase the potential for sharing.
- [DanC_]
- perhaps rather than "for historical reasons": "While the choice of
identifier syntax is somewhat arbitrary, there is a lot of value in the
existing network of URI-named resources"
- [IanJ]
- RF: You could rephrase as a definition: "The Web is defined as the
set of resources identified by a URI"
- TBL: "The World Wide Web is a global system and uses a set of
globally-scoped names called URIs"
- [Norm]
- What's wrong with "The World Wide Web is a global system and uses a
set of globally-scoped identifiers called URIs"
- [DanC_]
- principle: global naming leads to network effects. constraint: use
URI syntax to participate in the existing network of URI-named
resources
- [IanJ]
- The World Wide Web uses globally scoped names for resources; these
are called URIs.
- TBL: d/"for resources"/
- TBL: I agree but you have to then explain in what way "the network
effect"
- TBL: Syntax and semantics
- [DanC_]
- principle: global naming leads to network effects. constraint: use
URIs to participate in the existing network of URI-named resources
- [timbl]
- s/syntax//
- [IanJ]
- +1
- [DanC_]
- principle: global naming leads to network effects. constraint: use
URIs to participate in the existing network, i.e. the Web
- [IanJ]
- Action IJ: Incorporate DC's suggested
principle and constraint instead of constraint at beginning of section
2.
- New "Principle: URI assignment"
- [Norm]
- "A URI should be assigned to anything to which agents may wish to
refer"
- [IanJ]
- TBL: "It is beneficial to assign a URI because then others can then
refer to it by URI."
- [DanC_]
- +1 beneficial, or something like that
- [IanJ]
- RF: (principle) "Shared resources improve the network effect." (good
practice) It is beneficial to assign URIs to identify resources one
would be interested in.
- [DanC_]
- I think the good practice is about assignment, not use, no?
- [IanJ]
- [IJ to work on this]
Section 2.1 URI Comparisons
- [DanC_]
- hmm... the Constraint at the top of 2.1 is a non-constraint.
- [IanJ]
- s/people/assignment of ...
[Doesn't matter who does it]
- [DanC_]
- +1 get rid of people/resources ala ndw's suggestion
- people/agents
- [Norm]
- "Web architecture allows more than one URI to be assigned to a
resource"
- [IanJ]
- Resolved: Delete the box (i.e., no
longer a Constraint); leave the sentence.
- CL: What about "Do not make the assumption that a resource is only
identified by a single resource." Or "agents that assume..."
- [Norm]
- Constraint: URI Multiplicity; Web architecture allows a resource to
be identified by multiple URIs"
- [IanJ]
- [DC excused]
- [Norm]
- s/comparison//
- More explicitly, s/false negative comparison/false negative/
- [IanJ]
- NW: I don't think it's a good idea to draw attention to camel case of
domain name.
- IJ: What about all-caps instead of camel case?
- NW: I'm uncomfortable with discussion of case in domain part.
- RF: I suggest removing the example Example.Com and move reference to
section 6 of [URI] in its place.
- CL: Note that depending on what the agent is doing (as its job) the
agent is likely to use (or not use) the extended comparison
algorithms.
Section 2.1.1 URI aliases
- [IanJ]
- RF: Move rationale of 2.1.1 up front - talk about aliases and
bifurcation.
- [RF to suggest text]
- But: s/unofficial/official
Section 2.2 URI Overloading
- [IanJ]
- RF: I don't know any way to avoid URI overloading.
- TBL: That's a serious error.
- RF: Whether or not it's an error, how do you avoid it?
- TBL: Ownership system.
- RF: There's no question that the authority should not use the same
URI for multiple uses. This para is about user, not minter. People use
URIs without finding out the authoritative meaning of the resource. You
can't use a URI to refer to anything other than what it identifies. You
can say that an authority should not go around changing the meaning of
its resources.
- IJ: Could be rephrased as "Before you start using a URI, find out
what it identifies."
- Action IJ: Rewrite "Avoid URI
overloading" in terms of good practice for agents - avoid URI
overloading by find out what a URI identifies before using it.
- IJ: I deleted moby dick
Section 2.2.2 URIs in other roles
- [IanJ]
- RF: TBL used the phrase "indirect reference", which I prefer. TBL
said "that's ok, but that's not what we're talking about here." URIs
identify resources. In addition, URIs can be used to indirectly
identify things other than the resource.
- Action IJ: In 2.2.1, don't talk about Web
arch, talk about indirect identification and that it's ok as long as
the context is clear when it is happening. And that when we say
"identifier" we mean "direct" henceforth. (URI may be one component in
a phrase that is a series of references that strung together identify
something)
- NW: And that's one way to lead to overloading.
- IJ: I will remove distinction of web protocols world / non-web
protocols world.
Section 2.3 URI ownership
- [IanJ]
- CL: Add that domain owner can delegate URIs (i.e., domain owner is
not necessarily URI owner).
- RF: Add "For example, " before ". When the HTTP protocol is used to
provide representations, the HTTP origin server (defined in [RFC2616])
is the software agent acting on behalf of the URI owner." Move "When
the HTTP protocol is used to provide representations, the HTTP origin
server (defined in [RFC2616]) is the software agent acting on behalf of
the URI owner." to section on interactions
- [Roy]
- editorial: 2.4, remove "normative" in first para (redundant)
Section 2.7.2. Assertion that Two URIs Identify the Same Resource
- [Norm]
- s/syntactically different/that are not character-for-character the
same/
- [IanJ]
- [IJ recalls that earlier RF talked about sem web not relying on
consistency among URIs]
- RF: "One consequence of this direction is that URIs syntactically
different can be used to identify the same resource." This was true
before.
- IJ: Yes.
- [On third para of 2.7.2]
- TBL: Make the second URI in the paragraph also contain a "#".
- RF: The limits of ownership between two organizations is the same as
within one organization over time.
- Resolved: Delete third paragraph; doesn't
add anything.
- [IanJ]
- TBL: There are two questions:
- What is the Web Architecture?
- Fix things. Find a transition strategy.
- TBL: I agree with NW about the practical issue of dereferencing a
stem URI and getting back a huge representation in order to understand
the secondary reference. One suggestion to address this has been to let
people know through HTTP headers. E.g., people have suggested
generating "virtual URIs" for data in a database. You could say in
protocols "To get a document about this thing, use this other URI"
- CL: Why is this better architecturally?
- TBL: It's a way to get out of a corner case.
- [Chris]
- not clear - the uri taken stand-alone does not convey that
- problem is that we have no granularity of resources. one uri gives one
resource gives one message body ....
- [IanJ]
- NW: I can assert that a particular resource is a lake and I can make
a different assertion that the thing is a building. How is that
conflict different from the one you are describing (# v. /).
- TBL: An OWL system would put up red flag saying "inconsistent data".
RDF processor might let you go on.
- RF: It was my understanding from Pat Hayes' discussion that RDF
doesn't have any such reliance on URIs with or without a "#" (i.e., no
special meaning for # in the RDF spec).
- TBL: Right, the RDF spec doesn't tell you about URIs; but the URI and
HTTP specs do.
- NW: Is it sufficient to say "Using a URI to identify a property and a
Web page is likely to hurt."
- TBL: The problem is related to the network effect - when you share a
URI and they are used differently, you encounter problems.
- RF: The identifier doesn't identify the information. It identifies
the change in information over time. Not observable by a single
observer in the general case.
- TBL: The hope, on dereferencing, is that you get the same information
back when you do a GET. You are not concerned with consistency of
information about something, but consistency of the information
itself.
- RF: That would be true if the world did not have methods.
TBL draws this diagram on the white board (full-size image):
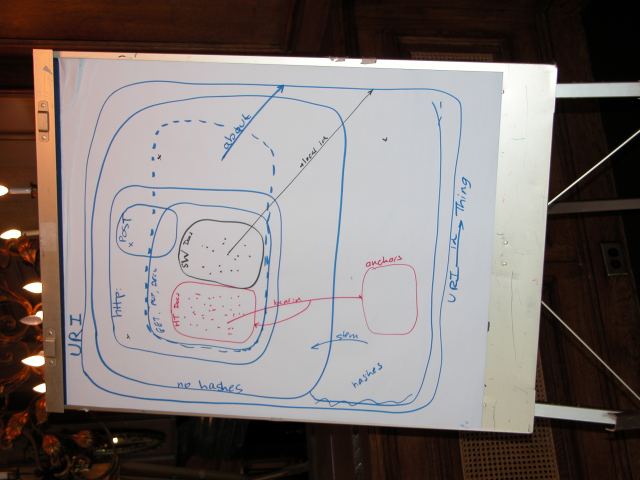
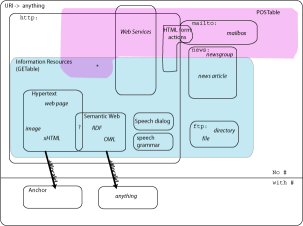
TBL later refined his diagram with a drawing tool (SVG
version, full-size
PNG version):
- [Disagreement between RF and TBL about usage of POST]
- TBL: There are some hairy things that are just post-able and that
don't quite fit in the architecture. I think it's important to explain
the architecture in a way that makes the hypertext web and the semantic
web work and that holds together. Don't let the possible corner case
disturb the depiction of the REST-ful information space.
- RF: A lot of people working with the sem web will want to be able to
deal with post operations. TBL doesn't need this entire solution, IMO.
If you use a URI consistently, you don't need more.
- TBL: This is where RF and I were in Irvine --- the thing that you
identify with an HTTP_URI is a picture of a car, and you expect to get
back a picture of the car in each case. What you are interested in is
the photo, not the car in the photo.
- RF: I said: "All identifiers refer to one resource." The URI doesn't
tell you what the representations you'll get; what is important is that
the representations are consistent.
- TBL: What do you mean about "consistency"?
- [DanC_]
- (I can't follow this because neither timbl nor roy has been able to
finish a sentence.)
- [IanJ]
- RF: I think that TBL's solution doesn't solve anything.
- TBL: The "about" relationship is not part of the architecture. It's
not important that a document is "about" a car; what is important is
the information that the document conveys.
- [Chris]
- (Dan - nor can we...)
- [IanJ]
- [impasse]
- RF: As far as I can tell, the document would be consistent if we were
to talk about individual information systems. E.g., browsers present a
particular view of the universe. Browsers provide representations that
are consistent with the state of the resources. There are other
possible systems that can make use of a Web of resources.
- TBL: I think that the hypertext web and semantic web overlap and that
we can build the sem web on the hypertext web.
- RF: My intention is that there is one web. Think of it as a common
data source and various ways of operating on that data source.
- [More discussion about consistency of information content across
representations.]
- TBL: This is about expectations when using http uris - people pass
them around and expect to plug into their browsers and get back web
pages (not "Mark Baker")
- [Secondary issue of content negotiation across the hypertext/sem web
boundary. TBL thinks it could work in some cases, but that's a
secondary question. TBL would be happy if the answer were "you can't
conneg across the boundary", more inclined to answer the primary
question.]
- RF: Another point is, in the absence of representations to
communicate meaning of resource, there's no way to gauge consistency,
and thus one could say that the URI identifies anything.
- [DanC_]
- ndw, if you're looking for compromises, there's one: if URI U has a
representation, then it refers to an information resource.
- [Norm]
- hmmm...
- [IanJ]
- And if it doesn't, you don't know.
- [DanC_]
- ... and http://markbaker.ca/ actually doesn't have any
representations; only http://markbaker.ca/index.html does, as you can tell
from the Content-Location: header on the reply.
- there are 2 axioms: { ?X log:uri [ str:notContains "#" ] } => { ?X
a :InformationResource }. # the strong position on httpRange-14
- [IanJ]
- TBL: not thrilled with DC's approach; would prefer to know from the
http scheme that those URIs identify info resources (and
representations might be available).l
- [DanC_]
- and: { ?X webarch:representation ?R } => { ?X a
:InformationResource } # a less-strong position on httpRange-14
- [Norm]
- What is webarch:representation?
- [DanC_]
- er... representation as we've defined it in webarch; e.g. the body of
a 200 reply represents the resource you were doing a GET about.
- [Norm]
- ok. that didn't seem to help with tbl
- [DanC_]
- bummer; he was more receptive to it on other days.
- [IanJ]
- RF: The two things I have a problem with:
- The gross violation of orthogonality principle.
- Existing examples which violate the modeled separation.
- TBL: I'm not telling people to change their robotic system, just how
they describe what their system does (e.g., "identifies a robot control
panel page" v. "identifies a robot")
- NW: Suppose I set up a taxi service and you click on the URI and a
taxi arrives at my door. Does the URI identify a taxi?
- TBL: That's the taxi architecture getting you a taxi. I'd like two
terms in the document (e.g., thing and information resource).
Information space consists of information resources, interconnected by
links. The web also consists of other resources, and those are not
interconnected by links. This document focuses on information
resources. Also need to say what we mean by "representation" if we do
this.
- RF: A Web browser takes any URI and treats it as though it identified
an information resource, whether or not it is. The browser thinks of
all URIs as being dereferenceable.
- IJ: I'm not sure how one defines an information resource.
- TBL: Hypertext web and sem web share some concepts: (1) identity (2)
reference (3) uri ownership But a connection like ":bob :brother :joe"
is not a "link". (Web link)
- DC: Roy, do you think it would be useful to build on people's
intuitions about Web as set of information resources?
- TBL: It's useful to say what the hypertext web and sem web have in
common.
See also continuation of discussion of httpRange-14
Paul joins the meeting today.
- IanJ
- Five issues identified yesterday for later discussion.
- URI ambiguity
- Definition of "on the Web"
- httpRange-14
- Namespace documents or Namespace representations
- Fragment identifiers
"New top level domains
considered harmful" from TBL
- IanJ
- TBL: I still have some comments to fold in. Half of my comments are
generic; about any new TLD. I am wondering whether I should send the
generic comments to other lists. There are TLDs that I think would be a
good idea , e.g., a TLD for telephone numbers. I think it's ok to
create a new TLD that offers NEW functionality; e.g., a system with a
particular persistence policy and new social arrangements. But, e.g.,
".biz" and ".info" were not really worth it. Domain namespace is flat -
people remember brand names (i.e., tree structure doesn't work). Users
don't find it useful to have acme.net, acme.info, etc.
- PC: Similar comments have been made on our own list.
- [TBL continues to summarize his proposal]
- TBL: One of the costs of change involves FUD about ownership - people
are forced to pay more money to keep their existing position. The
addition of new TLDs reduces the value of existing investments. Like
printing money. The rush to get new names creates uncertainty in the
market; also not a good thing. There's also chicanery during the rush.
A number of people also commented "Why is this a for-profit venture?"
That raises a lot of suspicion in the community. (The above comments
were generic.)
- TBL: Specific problems with ".mobi":
- If it's for mobile content, that's unsound.
- If it's for mobile carries, that's unsound.
- TBL: People use numbers for their home lines and their mobile lines.
There are many situations when the fact that something is mobile is
unimportant (or almost "in the way"). Hard to define what it means to
be "mobile" in fact. There are aspects of "moving around" but also
"small screen", etc. Creating content for a particular device profile
is an assault on the mission of W3C to create a universal Web.
- [See the proposal for more details; scribe pauses]
- TBL: Example of bookmarking and device variation according to
context.
- [Other examples of ghetto-ization through TLDs]
- CL: See my
additional comments.
- [Discussion on how to do content tailoring with existing
technologies such as CSS and CC/PP]
- CL: Authoring tools should increase support by providing support for
@media and allowing previewing in different modes.
- RF: I agree with comments from others about the line regarding
semantics of names. More confusing than helpful. Other than that I
completely support TBL's position.
- DanC
- (I wrote an analogy between semantics in names and which/that, i.e.
restrictive and non-restrictive clauses...)
- IanJ
- Action TBL: Update TLD essay for
consideration this afternoon. (Done; see below)
See also continuation of discussion of TBL's
critique of .mobi TLD proposals.
- Two topics:
- Different uses of the term "resource"
- Not requiring a name to have one meaning.
- DanC
- Re: Attributes should only be there if part of the name/address space
http://lists.w3.org/Archives/Public/uri/1997Feb/0025.html
- Chris
- +1 to ensuring we get to other issues
- Norm
- TBL: The http: space was designed specifically to create an
information space. The hooks into ftp space were designed to leverage
existing content. The hook into mailto was really to hook into a
different architecture. The REST thesis describes the architecture and
the properties that make it interesting.
Those principles are what we're trying to explain. The thesis
also tries to push the REST idea as far as you can. This allows you to
look at anything through "REST-colored" spectacles. There is an
abstraction in which everything is viewed through representations.
Those REST colored spectacles give you the property that you don't
distinguish between the car and the picture of the car. It's silly to
argue about the resource because all you see is the representations. In
the TAG architecture we need to talk about more things. Within the
dotted-line of "gettable" things REST describes all the shoulds. When
you go outside the dotted-line (mailto URIs, for example) the REST
architecture does not apply.
- RF: I wouldn't say it that way, the resources don't change...
- TBL: That's not how email works
- RF: We are talking about different information systems, not different
resources.
- TBL: I'd like you to only use the REST-colored spectacles for the
REST-based system.
- RF: There is no boundary between resources that are viewable
.........
- TBL: Please, can we put a boundary. Insisting on using the REST
spectacles for everything means we can't make use of the other systems.
We need to ack that there are other things in the Web arch that are not
REST-like. In the sem web we distinguish between the photo of someone
and the person. We distinguish the person and their email address.
There are URIs where there is no GET, just POST -- mailto URIs. I think
we can look at the URI scheme and tell some things about the identified
resources. E.g., when you see a "http" URI, it's reasonable to use GET
with it. And the value of repeated GETs is sameness of information
across the GETs.
- IanJ
- RF: what is the commonality among resources identified by http URIs?
They all have the same http interface? They all are document-like?
- TBL: The essential identity is consistency of information content
retrieved through GET. mailto is a store-and-forward system. It's
one-directional (with SMTP).
- [TBL and RF talk about pushing the REST model as far as they can
take it...and limits that TBL encounters]
- RF: I hear TBL saying he is convinced he needs a class to outline
resources identified by HTTP URIs. My experience suggests that this is
unnecessary. But it's ok to me if you do draw a line, as long as the
interface is not more constrained than it is today. If you say that
HTTP resources are all "document-like", that is problematic. E.g., what
about CGI gateways.
- [TBL goes to white board]
- TBL: When you look through the REST interface, you don't have to (or
can't) see the difference between the file on disk, the photo, or the
car. The interface hides the difference from you. But other systems do
separate these entities from you (e.g., photo of a car, car)
- [Diagram represents constancy of information
content across GET]
- TBL: E.g., info could come from a different disk; what's useful is
the same information content.
- RF: What about when you have an HTTP server running on the car
radio.
- TBL: When two people do GET with a URI associated with the car radio,
they don't want an audio stream one time and a photo back the next
time. In this case, they are interested in consistency of information
content.
- RF: In reality, there are also gateway HTTP URIs.
- TBL: I agree - HTTP URI space is big enough to identify resources
that are not information objects. But the vast majority of resources
identified by HTTP URIs are information resources.
- TBL Proposal:
- In the document, introduce the concept of resources with
consistency of information content (using http GET as an example,
used most of the time). [That section talks about value of HTTP
GET]
- HTTP has other methods (e.g., PUT, DELETE are connected to GET).
POST allows very different behaviors.
- Thus, there's an important class of objects that have info
resources that have http URIs. But there are other resources with
HTTP URIs where other methods dominate (e.g., Web services, html
forms using POST).
- timbl
- Proposal - HTTP range is the set of things which potentially support
the HTTP interface.
- IanJ
- TBL: Propose that the answer to httpRange-14 is "Those things that
potentially support the HTTP interface." Furthermore, those things that
support GET (regardless of protocol) are special and we will talk about
interesting properties. I'd like to call those things information
resources.
- timbl
- In document, specify the set of things which in HTTP potentially
support GET, or in other protocols an equivalence operation.
- IanJ
- TBL: When something supports GET, it has certain properties. When it
supports POST, it has other properties. I'm happy to raise a separate
issue about what relationships, if any, there are among those
properties (or what relationships there should be, etc.).
- IanJ
- NW summarizing:
- Range of HTTP URIs is the set of resources that may support the
HTTP interface.
- Those resources that support GET have the following interesting
properties ....; TBL calls these resources "information
resources"
- timbl
- http://lists.w3.org/Archives/Public/public-webarch-comments/2004JanMar/1057.html
- http://www.w3.org/2004/delta#insertion
- http://www.example.com/foo
- Norm
- PC: 1. what changes to the doc, 2. what impact does it have on
httpRange-14, 3. what impact does it have on new issues, and 4. what
impact does it have on public comments
- IanJ
- IJ: I would start with TBL/RF writing resolution to httpRange-14. I
can edit document given a clear statement of how to proceed.
- timbl
- Paul has been much more strict: Documentation of its effect on issues
and documents and comments, all to be reviewed and okayed by the group
- DanC
- PROPOSED: to address httpRange-14 by introducing "information
resource" for those resources that support GET, i.e. have
representations, contingent on doc changes agreed by RF, TBL, IJ
- DanC
- (paul's suggestion is fine by me too.)
- IanJ
- NW: I prefer PC's proposal. I'd like, for this particularly thorny
issue, that RF and TBL do all the parts of PC's request.
- RF: I won't get any work done on that until mid-July.
- IanJ
- Action TBL/RF: Write up a summary
position to close httpRange-14, text for document.
See also continuation of discussion of
httpRange-14.
Section 3.3.1 Using a URI to Access a Resource
- IanJ
- Added "necessarily" per TAG resolution.
- DanC
- norm, I wasn't asking Ian to point out the editorial stuff; I was
asking you to recruit reviewers for this draft
Section 3.2. Messages and Representations
- IanJ
- d/electronic
Section 3.3.1 Media Types and Fragment Identifier Semantics
- Zakim
- DanC_, you wanted to ask why the Greek letters (U and F) are still
there
- IanJ
- RF: Delete para after story in 3.3.1
- Norm
- If we want to keep the normative text in the current para 1, I
suggest: "Per [URI], given a URI with a fragment identifier, and a
representation retrieved by dereferencing that URI (which is
authoritative), the (secondary) resource identified by the URI with the
fragment identifier is determined by interpreting the fragment
identifier according to the specification associated with the Internet
media type of the representation data. Thus, in the case of Dirk and
Nadia, the authoritative interpretation of the fragment identifier is
given"
- Norm
- by the SVG specification, not the XHTML specification (i.e., the
context where the URI appears).
- DanC
- (oops; looks like it's my fault: Action DC: Write up some replacement
text for text at beginning of 3.3.1, from 15 Nov 2003
teleconf)
- IanJ
- I propose to remove this story, which is not that useful.
- DanC
- no, keep the story; but take "authoritative interpretation" out;
yeah, what PC said
- IanJ
- CL: I think the story is saying: frag id occurs in an xhtml content;
fetching happens without fragid; interpretation occurs in the SVG
context. I.e., separate occurrence and interpretation.
- DanC
- yes, elaborate the story to have the link found in XHTML and pointing
to part of an SVG thingy.
- IanJ
- Resolved: Close DC's action.
- Action CL: Rewrite story at beginning of
3.3.1. Consider deleting para that follows last sentence third para
after story in 3.3.1. "Note also that since dereferencing a URI (e.g.,
using HTTP) does not involve sending a fragment identifier to a server
or other agent, certain access methods (e.g., HTTP PUT, POST, and
DELETE) cannot be used to interact with secondary resources."
- RF: Delete "e.g." since people may interpret it as "i.e.".
- IJ: How about "for example" instead.
- RF: Ok with "for example"
- [para ok]
- DanC
- A#X refers to b
- IanJ
- IJ: so add "using that URI" (i.e., the one with the frag id)
- TBL: Say instead "You can't do POST using a URI that identifies a
secondary resource."
- DanC
- that would work. "You can't do POST using a URI that identifies a
secondary resource."
- Chris
- yes, agreed
- timbl
- +1
- IanJ
- What about: "Note also that since dereferencing a URI (e.g., using
HTTP) does not involve sending a fragment identifier to a server or
other agent, you can't do POST using a URI that identifies a secondary
resource."
- Chris
- suggest in last paragraph s/such interpretations are not
authoritative./such interpretations are not authoritative.because the
media type is not known.
- IanJ
- 3.1: "Agents may use a URI to access the referenced resource; this is
called dereferencing the URI"
- DanC
- http://www.w3.org/2001/tag/2004/webarch-20040510/#uri-dereference
- IanJ
- RF: delete "or other agent"
- DanC
- NW too
- IanJ
- What about: "Note also that since dereferencing a URI (e.g., using
HTTP) does not involve sending a fragment identifier to a server, you
can't do POST using a URI that identifies a secondary resource."
- IanJ
- What about: "Note also that since dereferencing a URI does not
involve sending a fragment identifier to a server, you can't do POST
using a URI that identifies a secondary resource."
- Norm
- How's this: Note also that since dereferencing a URI does not involve
sending a fragment identifier to a server, certain access methods
(e.g., HTTP PUT, POST, and DELETE) cannot be used with a URI that
identifies a secondary resource.
- IanJ
- Note also that since dereferencing a URI does not involve sending a
fragment identifier to a server, certain access methods (for example,
HTTP PUT, POST, and DELETE) cannot be used with a URI that identifies a
secondary resource.
- DanC
- Norm's version seems good.
- IanJ
- TBL: Say "HTTP allows interaction with a primary resource." Take out
"certain access methods"
- DanC
- hmm... "by design" has some appeal; it would be nice to say why this
is the design...
- Norm
- Drop "Note also that..." to the end of the paragraph
- IanJ
- IJ: I note that RF has good text on why it is by design. I propose to
delete "Note also that since dereferencing a URI (e.g., using HTTP)
does not involve sending a fragment identifier to a server or other
agent, certain access methods (e.g., HTTP PUT, POST, and DELETE) cannot
be used to interact with secondary resources."
- DanC
- aye, s/during a retrieval action//
- IanJ
- RF: Proposed to remove "during a retrieval action".
Resolved:
- Remove "during a retrieval action"
- Delete from "Note..." to end of paragraph.
- Zakim
- DanC_, you wanted to note that secondary resources might be
information resources; hmm... and to ask if this "Note also..." has
already been proposed to the reviewer and if it's clear who's going to
get back to the reviewer
- IanJ
- IJ: Regarding previous edit, I will go back to reviewer and say that
we think that edits to penultimate paragraph answer the question.
- Now looking at: "Parties that draw conclusions about the
interpretation of a fragment identifier without retrieving a
representation do so at their own risk; such interpretations are not
authoritative."
- CL: Note that because you can always get more representations, you
never know "for good" the full set of representations ....
- RF: Removing "Parties that draw conclusions about the interpretation
of a fragment identifier without retrieving a representation do so at
their own risk; such interpretations are not authoritative." will
satisfy stickler8 and schema4.
- Chris
- but not really a good solution
- IanJ
- IJ: Recall that this sentence was to respond to DO question - can I
assume a particular media type for particular URIs? The answer was "Yes
you can, but if you don't get a representation, you do so at your own
risk."
- Chris
- Better to say in a positive sense rather than just not discussing
it. Point is that when you retrieve *a* representation, you still
don't know if the fragment is consistent for the resource as a
whole
- DanC
- I'm quite happy with "Parties that ... do so at their own risk". why
remove it?
- IanJ
- IJ: Parties that draw conclusions about what a URI with a fragment
identifier identifies without retrieving a representation do so at
their own risk."
- [discussion of issue schema4]
- Chris
- there are no guarantees - png, jpeg, text all have no bare names:
"This is not a viable best practice recommendation, except as a
bandaid, as it tightly couples URIs to representations, and constrains
the ability of representations to evolve in untenable ways. This appears to
highlight a weakness in the Web architecture that should be explicitly
addressed."
- IanJ
- RF: I don't consider this a weakness.
- TBL: There is a weakness - you can get a failure. But I think that
the last paragraph of schema 4 is unwarranted.
- Chris
- we need to address it
- IanJ
- RF: I think that the other paragraphs added to 3.3.1 do help address
their comments
- Chris
- saying 'any rich addressing is contrary to web architecture' is
untenable, so I agree with their point
- Norm
- Many users have an absolute requirement to be able to point to parts
of XML documents (that they cannot edit) that do not have IDs. To say
that XPointer should be discarded is inflammatory.
- DanC
- I'm not familiar with such users, Norm. I wonder if there's a
documented use case somewhere.
- IanJ
- Three proposals on the table:
- Delete "Parties..."
- Edit to "Parties that draw conclusions about what a URI with a
fragment identifier identifies without retrieving a representation
do so at their own risk.""
- Append to existing sentence: "because you don't know the media
type"
- timbl
- Yes, but it is worth pointing out, as they ask us to point out, that
there is a detriment in using XPointer that you are very specific to
XML. If you can use a base local identifier it is better - also from
resilience to document editing too of course,. Norm.
- Chris
- dan, you are saying that there are no uses who consider structure to
be useful. i can see plenty of counter examples and find it hard to
believe that you assert this
- timbl
- I think Annotea uses xpointer. (But are there users of Annotea?)
- Norm
- Yeah, I'm not suggesting that xml:id won't make it better.
- Chris
- annotea would need to
- IanJ
- RF: I don't think (c) addresses stickler8.
- DanC
- re a) Delete... is it said elsewhere, RF?
- IanJ
- Might be said above: "The fragment's format and resolution is
therefore dependent on the media type [RFC2046] of a potentially
retrieved representation, even though such a retrieval is only
performed if the URI is dereferenced. If no such representation exists,
then the semantics of the fragment are considered unknown and,
effectively, unconstrained. "
- DC: You can draw conclusions that the media type spec allows.
- CL: But you don't know what the other possible representations
are.
- TBL: Recall that it's an error if the representations are
inconsistent. You have to be able to trust the system.
- Chris
- ok so the onus is on the person minting the URO to deal with the
consistency across representations - the user of the uri has to trust
that
- DanC
- If I have doc#sec1 and I fetch doc and get HTML with <a
id="sec1">, I can conclude, on the basis of the HTML spec, that
doc#sec1 refers to that <a>.
- Chris
- And thus, after retrieving any of the representations, they have
license to interpret the fragment And thus, suggested add on to the end
of the sentence *is* correct. QED
- IanJ
- RF seems to agree with " If I have doc#sec1 and I fetch doc and get
HTML with <a id="sec1">, I can conclude, on the basis of the
HTML spec, that doc#sec1 refers to that <a>." But you can't
conclude that there aren't other representations.
- DanC
- RF didn't agree, it seems to me.
- timbl
- Actually, specifically, you can hold the responsibility on the
publisher is just to agree that the meaning of the document is that the
secondary resource has the properties described in the
representation.
- IanJ
- CL: Provider is responsible for consistency. Retriever has to trust
that consistency has happened.
- Roy
- That assumes that the reader can fully comprehend the owner's
intentions in providing that reference.
- IanJ
- RF: Your perception of consistency may not be the same as the URI
owner's. The more precise you can be, the less risk there is.
- Chris
- oh ... so now its 'which consistency operator are we using' and 'why
do you want to know'
- Norm
- Does this help: Parties that draw conclusions about the
interpretation of a fragment identifier without retrieving a
representation do so at their own risk; such conclusions are not
authoritative.
- DanC
- (ugh; writing text about semantics of fragments is like coding, in
that I'd need a quiet room for at least an hour or two to draft
text.)
- IanJs
- This is from RFC2396 bis:"The semantics of a fragment identifier are
defined by the set of representations that might result from a
retrieval action on the primary resource. "
- TBL: Nothing says that you can't get information about a secondary
resource from other places.
- DanC
- (representations _rarely_ determine identity of #foo; they tell you
things about #foo, but rarely narrow it down to exactly one thing.)
- IanJ
- TBL: Therefore it's wrong to say "Don't use other information."
"People shouldn't draw conclusions about the identity of the secondary
resource from a syntactic analysis of the frag id alone; someone could,
for example, create a new media type which uses a similar syntax." If
it's obvious in the referring document, you may know what type of
object the URI is identifying. E.g.,
":ian :drives :foo" I
can conclude that :foo is a car because of my ontology.
- DanC
- (but info in the referring document has less status than info from
the server; kinda like the a/@type attribute in HTML)
- IanJ
- Action IJ: Edit "Parties that draw...."
to be about drawing conclusions from syntactic analysis.
- IanJ
- RF: In story, section 3, delete "by /satimage/oaxaca".
- Chris
- noise:signal ratio is infinite
Section 3.3.2 Fragment Identifiers and Multiple Representations, issue
msm13
Issue
msm13
- IanJ
- First para after story from RFC2396bis
- This was deleted: "On the other hand, it is considered an error if
the semantics of the fragment identifiers used in two representations
of a secondary resource are inconsistent. "
- TBL: I think you have to answer the question about what "consistent"
means differently for the sem web and the hypertext web.
- Chris
- And delete the base element. So the internal links work
- IanJ
- IJ: I will make CL's change.
- TBL: In "A resource owner who creates a URI with a fragment
identifier and who uses content negotiation to serve multiple
representations of the identified resource SHOULD NOT serve
representations with inconsistent fragment identifier semantics",
change SHOULD NOT to MUST NOT.
- CL: PNG is tough since PNG defines no frag ids. More interesting
would be CGM and SVG, both of which define frag ids. You can't conneg
SVG and CGM since they use different syntaxes.
- timbl
- I suggest 3 examples: The fragid working in both, the fragid giving
incorrect results; the fragid not being defined for one format.
- DanC
- 3 examples sound good.
- Roy
- The sentence "It is not considered an error that only one of the data
formats specifies semantics for the fragment identifier. " is
confusing.
- IanJ
- From "Common User Agent
Problems" (CUAP): 1.2 If the user attempts to follow a link that is
broken because it designates a missing anchor, let the user know it is
broken.
- RF: I agree with CUAP, this is a known bug. It's a user interface
error to not indicate that the reference was not found.
- Chris
- this is seen as a grave error in.for example, Web-based IETMs.
- DanC
- +1 s/SHOULD NOT/MUST NOT/
- IanJ
- RF: The paragraph does not say what a user agent should do when an agent
doesn't find an anchor
- IJ: I suggest we don't say anything. Or we can just point to
CUAP.
- Chris
- 3.3.2 should offer two possibilities and discuss the wins and losses
in each
- IanJ
- RF: I find this confusing: "It is not considered an error that only
one of the data formats specifies semantics for the fragment
identifier."
- IJ: Why?
- DanC
- yes, the good practice note is redundant with the para "For a given
resource, an agent may have ...". Meanwhile, they both say 'should not'
and I'm sympathetic to 'must not'.
- Chris
- one, a single object element with a conneg resource
- two, a nested set of objects pointing to different resources
- IanJ
- RF: Even though it's not considered an error for the resource
provider to provide representations that don't support frag ids, it is
an error from the perspective of the user agent.
- Zakim
- DanC_, you wanted to endorse the 3 examples timbl sketched: "The
fragid working in both, the fragid giving incorrect results; the fragid
not being defined for one format."
- IanJ
- DC: I like three examples:
- Two representations where frag id works in both
- Two representations where they conflict
- Two representations where frag ids not defined in one
representation.
- Chris
- so webcgm vs svg would be good for the second example
- DanC
- yes, note that the typical browser behavior of ignoring missing
fragments is an example of silent recovery from errors, and is bad.
- IanJ
- TBL: I think we should point out that (c) is an error; can cross-ref
to agent recovery from error.
- [Support that (c) is an error]
- And that silent recover is also an error. Proposed: Change "Should
not" to "Must not" in GPN.
- [Support from DC, NW, TBL]
- RF: I don't think it's reasonable to have "MUSTs" in GPNs.
- Chris
- reference for WebCGM fragid syntax:
- http://www.w3.org/TR/2001/REC-WebCGM-20011217/REC-03-CGM-IC.html#webcgm_3_1_1
- Ditto for SVG:
- http://www.w3.org/TR/SVG11/linking.html#SVGFragmentIdentifiers
- Chris
- CL volunteers to write these examples
- DanC
- +1 ndw
- IanJ
- TBL: I'd like to talk about "inconsistent" in two contexts - sem
web/hypertext web MSM13 - how is "consistent" used? For sem web, if you
use conneg, the two documents should contain the same information (same
semantics). But I can see where two formats would not be identical,
e.g., one more expressive than the other. And there's a subset
relationship between the two. In the hypertext web, more about the
publisher being sufficiently satisfied that the retriever is getting
sufficiently similar information. The publisher takes responsibility
for the degree of consistency. For the sem web, we can talk about
consistency mathematically.
- DanC
- (I note that the math/logic/kr world already has an established
definition of consistency)
- Roy
- overloading
is already defined in terms of consistency ;-)
- DanC
- is it Roy? I guess I better go check...
- IanJ
- "URI overloading refers to the use, in the context of Web protocols
and formats, of one URI to refer to more than one resource."
- Roy
- [I was joking]
- IanJ
- [But that text will change based on yesterday's discussion...]
- DanC
- (to my mind, RDF _does_ have resolution, btw. cf cyc paper on
context.)
- IanJ
- From msm13: "How do the responsible parties determine whether a given
plan of using fragment identifiers is or is not compliant with this
rule?"
- IanJ
- PC: They read the specs for the N representations and determine
whether the frag ids have the same semantics.
- timbl
- q+ to re-ask paul the question
- Zakim
- DanC_, you wanted to suggest that we can define "consistent" in terms
of overloading (nee ambiguity)
- IanJ
- NW: It seems to me that a given community developing media types need
to describe what "consistency" means for a given media type.
- Chris
- inconsistency if they produce URI overloading .... yes
- IanJ
- DC: I think it suffices to define consistency in terms of
overloading. Frag ids are inconsistent if they result in URI
overloading.
- TBL: How would we know when two representations are inconsistent?
What about the case of a photo of a hat and another person gets a photo
of a pair of gloves? I think that we would call those inconsistent.
- Norm
- PC steps out for 10 minutes
- Zakim
- timbl, you wanted to re-ask paul the question
- IanJ
- RF: If the reference is to "Photo of what's in my closet?" then it
could be considered consistent here.
- TBL: RF is saying that the publisher determines what is
consistent.
- CL: Consistency depends on what the resource is advertised as
doing.
- RF: The target of the consistency GPN is representation providers, so
I don't think the comment from MSM13 is irrelevant, as the comment was
about receiving agents.)
- Chris
- my part two was - the information provider defines which formats they
provide. no-one else can provide a different format at the same URI
- IanJ
- TBL: User expectations about consistency also exist.
- DanC
- (hmm... telling each other stories is something I'd expect to do
early in the game. responding to LC comments is more of an end-game
thing. But we don't seem to be able to achieve end-game mode, i.e.
reviewing text sent in advance of the meeting.)
- IanJ
- Proposal:
- Include three examples about coneg as proposed by TBL.
- State clearly that it's an error for representation providers to
provide representations with inconsistent frag id semantics.
- Talk about consistency as being in the eye of the representation
provider (not forgetting that users also have expectations).
- On the Semantic Web, formats allow a more mathematical
determination of consistency when doing coneg.
- DanC
- in order to avoid 'it is an error', perhaps: "conflicting
representations result in URI overloading, which, as discussed in
section [earlier], is EVIL.
- IanJ
- RF: I think the last point is somewhat speculative.
- TBL: I'm ok to drop last point.
- Resolved to accept these changes to
3.3.2:
- Include three examples about coneg as proposed by TBL.
- State clearly that it's an error for representation providers to
provide representations with inconsistent frag id semantics.
- Talk about consistency as being in the eye of the representation
provider (not forgetting that users also have expectations).
- Action CL: Provide three examples.
- Action IJ: Revise text for other parts of
proposal. And destiny of GPN in that section uncertain.
Section 3.4 Authoritative Representation Metadata
- IanJ
- Reviewing first paragraph
- DanC
- (I can't parse the sentence including "the design choice for the Web
is,")
- Chris
- the design choice for the Web is, in general, that .... is
unnecessarily verbose
- DanC
- (I thought we had pretty good wording in the finding... reviewing
http://www.w3.org/2001/tag/doc/mime-respect.html ...)
- IanJ
- TBL: Two problems in 3.4 first para:
- Media type is special; inseparable from representation data.
- Other metadata relates to things that relate to the resource;
need an authoritative source in that case.
- IanJ
- q+ to say that document definition of representation includes more
metadata than content type
- Zakim
- DanC_, you wanted to clarify by counter example: Bob says doc23 is
text/plain; Joe says doc23 is text/html; Bob gives URI doc23 to Fred,
then Joe gives doc23 to Fred; they've communicated different things
using the same URI. global naming breaks.
- IanJ
- [DC gives a counter-example]
- Zakim
- IanJ, you wanted to say that document definition of representation
includes more metadata than content type
- IanJ
- In counter-example, people who say "Check out this URI" provide
metadata.
- marioj
- thinks we should provide a definition for "Representation
metadata"
- IanJ
- RF: We should be talking about the proper interpretation of messages
here. Within a message you have different types of metadata. You want
to talk about how to obtain authoritative metadata.
- Chris
- CL: so who is the authority when i post to a resource I don't
own?
- Chris
- (people): we don't know
- DanC: yes
- IanJ
- TBL: The semantics of the message is a function of the data and the
metadata.
- IJ: Why is it an error to ignore the media type?
- DanC
- A: for the same reason any other deviation from a protocol is an
error
- IanJ
- IJ: What should title of 3.4 be?
- IanJ
- DC: What about "3.4 Message semantics"
- IJ: I suggest moving bits about which representations Nadia gets back
to somewhere else. Propose to elevate 3.4.1 to 3.4 and shrink rationale
to message semantics.
- Action IJ: Edit 3.4 and 3.4.1 to this
effect.
- IanJ
- "Agents MUST NOT ignore authoritative metadata without the consent of
the user."
- RF: Should say agents must not override metadata.
- IJ: Having had our previous discussion, should this GPN be about
deviating from protocols?
- RF: That should be ok.
Section 3.5. Safe Interactions
- IanJ
- New note: "Note: In this context, the word "unsafe" does not mean
"dangerous"; the term "safe" is used in section 9.1.1 of [ RFC2616 ]
and "unsafe" is the natural opposite."
- MJ: Perhaps an additional sentence about "safe" here means
"side-effect free".
- TBL: I think we arrived at "does not incur an obligation" rather than
talking about side effects due to things going on under the hood.
- Chris
- it also means that 'the TAG says filling in a form is unsafe' which
is true in our context but not a message we want to send
- IanJ
- RF: "Safe" does not *necessarily* mean dangerous. For a long
discussion on this topic, cf. Nancy Leveson.
- IJ: I may edit the note further along the same lines.
- Review of "It is a breakdown of the Web architecture if agents
cannot use URIs to reconstruct a "paper trail" of transactions,
transaction results, i.e., to refer to receipts and other evidence of
accepting an obligation."
- RF: Should be about transaction requests.
Section 3.5.1. Unsafe Interactions and Accountability
- IanJ
- RF: Say that the results of the transaction are a valuable resource,
and like all valuable resources, it would be nice to have an identifier
for it. It would be nice if one of the effects of interactions were to
populate the Web with new useful resources.
- TBL: In the story, s/commitment/commitment to fly her/
- CL: are we sure that it's "not widely deployed"?
- TBL: Two separate issues - message out and message back.
- Action IJ: Edit 3.5.1 to say:
- Useful to have a URI for requests and results
- Here are ways to do that in HTTP.
- RF: Note that a reference to a transaction result/request is not
useful for legal purposes; you need a copy.
- IJ: You could do a checksum test...
- CL: Why talk about "not widely deployed' in the story? It's worth
saying that content location will work in deployed user agents.
- Chris
- so servers should provide it
- IanJ
- MJ: Right, talk about the representation provider (not server
software).
Section 3.6. Representation Management
- IanJ
- What about "resource is unpredictable"?
- [Discussion of unreliable v. unpredictable.]
- CL: Use both terms: unreliable or unpredictable. (CL one could
provide false information daily and be very predictable about it)
Section 3.6.1. Representation availability
- IanJ
- TBL: Say in 3.6.1 that "there is a benefit to the community in
providing representations."
Section 3.6.2, issue klyne15
Issue
klyne15
- IanJ
- s/authorities servicing URI/URI owner/
- Persistence of a URI is a matter of policy and commitment on the part
of the URI owner.
- We look at text in 2.2: "This document does not address how the
benefits and responsibilities of URI ownership may be delegated to
other parties (e.g., to individuals managing an HTTP server)."
- TBL: This isn't sufficient to answer klyne15. In 2.2, change to "(for
example, to a server manager or someone who has been delegated part of
the URI space on a given Web server).
- IJ: I'll do that.
- Resolved: Close klyne15 as follows:
- Include TBL's text in section 2.2
- s/authorities servicing URIs/URI owners
Section 3.7. Future Directions for Interaction
- IanJ
- Proposed: Delete freenet and mldonkey from 3.7, as well as their
references. Leave in NNTP.
- DanC
- prolly ok... lemme look at 3.7.
- Norm
- I think you wanted those references, DanC_
- DanC
- any particular reason to delete them?
- IanJ
- I don't hear much support for them. Tim Bray wanted them gone, as I
recall.
- DanC
- I don't think NNTP is representative of the sort of p2p developments
that are coming down the pike
- IanJ
- I think we haven't discussed peer-to-peer at all. To include them
here seems very premature.
- DanC
- we have discussed them...
- Norm
- DanC_, do you object to removing the parenthetical list of
peer-to-peer systems?
- IanJ
- Or just leaving "peer-to-peer systems"
- DanC
- Can you do a quick straw poll, norm? am I the only one who wants them
in there? I.e. would the TAG prefer to appear ignorant of p2p
developments? Why leave "peer-to-peer systems" without a reference?
- IanJ
- Proposed: Delete "(including Freenet, MLdonkey, and NNTP
[RFC977])"
- Chris
- this tag member is insufficiently informed to make an informed
decision
- IanJ
- RF: Not sure that there are even future directions of p2p
systems.
- [Discussion here of whether NNTP is p2p]
- Chris
- RF says NNTP is not peer to peer, but client server
- IanJ
- TBL: Servers talk to each other.
- DanC
- No, I don't object, norm. I abstain. I'm a little surprised, given
our earlier discussions, but oh well.
- IanJ
- TBL: NNTP is peer-to-peer since no centralization.
- IanJ
- CL: I support acking p2p, but don't know enough about specific
examples of systems.
- [Nobody seems to care much]
- RF: It just adds noise.
- PC: I tend to agree that it's noise.
- DanC
- (reviewing records, my action to produce these citations came from
Action DC 2003/07/21 ...)
- IanJ
- Proposed: peer-to-peer systems "(including NNTP [RFC977])"
- Proposed: "peer-to-peer systems" [Delete parenthetical]
- mario
- +1
- IanJ
- Dan, no objections here to: "peer-to-peer systems" [Delete
parenthetical]"
- DanC
- hmm... the 2003/07/21 discussion was about future directions for
identification. mldonkey has a URI scheme that doesn't depend on
dns.
- IanJ
- NW: Any objections to "peer-to-peer systems" [Delete
parenthetical]"
- DanC
- I intended the freenet/mldonkey citations to go under 2.7. Future
Directions for Identifiers... do we acknowledge the weakness around
DNS?
- IanJ
- Yes, we do, in section 2.3: "One consequence of this approach is the
Web's heavy reliance on the central DNS registry."
- DanC
- no objection here, nw
- IanJ
- Resolved: change text in 2.7 to
"peer-to-peer systems"
Section 4
- Chris
- http://lists.w3.org/Archives/Public/www-tag/2004May/0024.html
- mario
- Change order to "XHTML, RDF/XML, SMIL, XLink, CSS and PNG". This
would be more consistent with the following section.
Issues discussed here:
See also continuation of discussion of Last Call
issues.
Issue
kopecky3
- IanJ
- "Thus, before inventing a new data format, designers should carefully
consider re-using one that is already available."
- TBL: You could dispatch on namespace, for example.
- From 4.5.8: When the media type assigned to representation data
is "application/xml", there are no semantics defined for fragment
identifiers, and authors should not make use of fragment identifiers in
such data.
- RF: There's a visibility argument.
- Chris
- Visibility is higher if the media type is different (visible in the
message metadata) as opposed to having to parse and understand the
content, looking for xmlns declarations
- IanJ
- PC: Does RFC 3023
answer kopecky3?
We review RFC 3023 section A.1: "Why not just use text/xml or
application/xml and let the XML processor dispatch to the correct
application based on the referenced DTD?".
- TBL: At the moment, there's lots of software out there that
dispatches on mime types, so you need specific mime types. When systems
start dispatching on namespaces, that situation may change. Remember
that we think that xml docs should have namespaces.
- MJ: Change title of
http://www.w3.org/2001/tag/2004/webarch-20040510/#no-text-xml (since
this is bad practice).
- Proposed::
- We prefer to restate what RFC 3023 says in A.1: Because in many
cases deployed software dispatches processing based on media type,
it is important to provide a specific media type rather than a
general in order to dispatch to a specific application.
- TBL: In a context where content is intended for presentation for the
user, and accompanied by sufficient style information, it is
appropriate to serve it as application/xml.
- timbl
- Where a resource is deigned for presentation to a human being, and
sufficient style information is referenced to allow that presentation,
then it is appropriate to serve the content as application/xml.
- IanJ
- CL: Say instead - when the content is document-like and when it's
suitable for box-model presentation...
- IJ: What about blind users?
- timbl
- Where a resource is deigned for presentation to a small pink mouse
this does not apply.
- IanJ
- TBL: I'd like to fall back on "sufficient style information". Box
model is limiting. Given content and style sheets, there's enough
available to make the presentation usable.
- RF: What about if you want someone to be able to process some xml
content as xml (and it includes links to style sheets).
- Action IJ/CL: Draft a proposal to address
kopecky3.
Issue
schema13
- IanJ
- CL: Summarizing - reviewer feels text does not communicate why
extensibility may not be appropriate in some cases. E.g., high-security
environment. I agree with reviewer; need to indicate that there are
also drawbacks.
- IanJ
- NW: Add a para to 4.2.2 about trade-offs.
- Chris
- http://lists.w3.org/Archives/Public/www-tag/2004May/0024.html
- IanJ
- TAG agrees with reviewer for that part of schema13.
- Action NW: Propose text on tradeoffs for
section 4.2.2.
- IanJ
- "For computer-to-computer mission-critical applications, "fallback
behavior" is semantically equivalent to "silently handling errors" and
the Web architecture document is thus self-contradictory."
- TBL: In general, useful to look at modularity on the inside but also
on the outside (i.e., where one's work is itself a module).
- Relevant text: "Additional strategies include prompting the user for
more input, automatically retrieving data from available links, and
falling back to default behavior."
- IJ: On their third point (extensibility in protocols as well), we do
talk about it in 1.2.2.
- Chris
- 1.2.2. covers it
- IanJ
- Proposed: Delete "falling back to default behavior"
- Chris
- agree with proposal
- IanJ
- PC: Does finding talk about fallback behavior as 4.2.3 states?
- IJ: Delete "and falling back to default behavior". This was a
mis-transcription of what was in the finding and doesn't apply here.
- Resolved: Delete "falling back to
default behavior"
- IJ: Should we talk about extensibility in protocols?
RF: Mandatory extensions was added to HTTP. Turns out nobody
wanted to use due to complexity. The desire is still there; there just
needs to be a better trade-off.
- TBL: Tell the following story:
- HTTP as designed had optional extensions but no mandatory
extensions.
- Attempts to add mandatory extensions to HTTP were not
successful.
- Second story:
- A protocol defines a series of messages.
- New protocols can be defined through new messages.
- When defining new protocols, message extensibility techniques may
be applicable.
- Thus, when you develop a SOAP system, better to use documents
than RPCs.
- Action IJ: Insert a story in the section
on extensibility about protocol extensibility.
See also open
actions by owner and open
issues.
Present: NW, MJ, IJ, CL, PC, TBL.
See also continuation of discussion of Last Call issues.
Issue
diwg4
[IanJ]
- Resuming review of section 4
- http://lists.w3.org/Archives/Public/www-tag/2004May/0024.html
- DIWG suggests more discussion of limitations of using media type
mechanism (e.g., text/html doesn't tell you whether HTML 3.2 or HTML
4)
- CL: In qs factors, when you are deciding which format to send,
difficult to adjust on a per-resource basis. We should probably say
that the media type mechanism doesn't solve all problems.
- PC: Where would such text go? Section on versioning? Section on data
formats? Want to perhaps say something about this, but without creating
new issues for ourselves.
- [Chris]
- suggest point about versioning in versioning; point on qs values in
interactions section
- [IanJ]
- TBL: I think we should lead the way, even if we can't implement
today. At the moment, people don't put version information in media
types. We could say:
- Use parameters in new media type definitions.
- Servers need to support this.
- In the section about representation management, tell server
managers to allow fine granularity (per-representation).
- [per-representation specification of parameterized media type]
- TBL: Should we encourage people to use quality factors?
- [Discussion of usability issue of specifying per-representation
media types and parameters; authoring tool support; server
support...]
- CL: Many users have no idea about what version of, say, CGM they are
using. Need tool support.
- [Chris]
- there is no standardization so the authoring tools cannot help, so in
practice the simpler the better
- [IanJ]
- PC: Should we open an issue on this and postpone changes to v1?
- [DanC_]
- DanC_ has changed the topic to: 14May http://www.w3.org/2001/tag/ going over updates to
section 4
- [IanJ]
- Resolved: accept new issue
mediaTypeManagement-45: "What is the appropriate level of granularity
of the media type mechanism."
- [DanC_]
- mime type versioning is hairy. I'm very wary of "leading the way",
which is really: waving our hands without sufficient implementation
experience.
- ah; yes, good to make it an issue. I concur.
- [DanC_]
- connect it to uriMediaType-9,
pls, ian.
- [IanJ]
- Action CL: Write draft finding on this
issue.
- Action IJ: Add a bit of text to the
document about media type limitations, versioning, and link to
issue.
Issue
msm14
- [Chris]
- Issue msm14: WD-webarch-20031209, Section 4.2.2, Story: Allowing
extra
- attributes does change the conformance of existing data
- Not really, given that in the story they deliberately chose that
- extensibility policy. The point is valid in general but not for
this
- particular story.
- [IanJ]
- CL: I don't think the document needs to change; the claim is true in
the document because we are explaining our story.
- Resolved: Agree with the general case
but it doesn't apply to this specific instance. The TAG does not feel
changes are required.
Issue
manola29
- [Chris]
- Question: What's a language instance?
instance - see xml spec for meaning of instance
- [IanJ]
- NW: Proposed to revise language to avoid the word "instance".
- IJ: Proposed "in content".
- Currently reads: "A format specification SHOULD provide for version
information in language instances."
- PC Proposed: "A format specification SHOULD provide for version
information."
- IJ Proposed: "A format specification SHOULD allow content authors to
identify format version."
- PC Proposed: "A format specification SHOULD allow content authors to
identify the format version."
- [Norm]
- A format spec SHOULD allow content authors to identify the version of
format being used"?
- [IanJ]
- Resolved to accept this change: A
format specification SHOULD provide for version information.
- [Thus closeth manola29]
Stuart joins by telephone. Dan joins by iChat and IRC.
Issue
schema14
- [IanJ]
- PC: Note that some of these changes in the spec might lead to some
updates in findings.
- CL: A format specification SHOULD allow content authors to indicate
the extensibility policy used This is one step further than the
reviewer requested.
- PC: Your change is stronger than what the reviewer requests.
- [DanC_imac]
- (I conclude this is pretty complete access to the meeting. this could
save a lot of plane trips ;-)
- [IanJ]
- CL: Reviewer asked for indication of trade-offs; I proposed one
way.
- PC: HTML ("liberal in what you accept") had policy in the
documentation, not a schema for example.
- CL: We may have oversimplified when moving bits of finding to arch
doc; we could respond by saying "see finding for more details".
- [DanC_imac]
- (are we still going over IJ's 10May changes? how did we get to
schema14? I don't see it in webArchWithProposals)
Issue
manola30
- [Chris]
- issue manola30: Difference between "setting expectations" and
"specifying"?
- Yes, its wooly language. All instances of "set expectations" could be
changed to "specify", I think.
- [IanJ]
- Action NW: Write some text to address
schema14 (e.g., by reviewing finding).
- CL suggests to s/set expectations/specify
- IJ Proposal: Delete: "As part of defining an extensibility mechanism,
a specification should set expectations about agent behavior in the
face of unrecognized extensions." since redundant.
- CL: Look for other instances of "set expectations"; consider changing
them.
- [DanC_imac]
- manola30 is editorial, for my money.
- [IanJ]
- Resolved: Delete "As part of defining
..." sentence.
Issue
schema15
Roy joins meeting. DanC leaves meeting.
- [Chris]
- Yes; regardless of what MIFFY/MTOM might do, a quick s/JPEG/SVG would
make the statement true.
- [IanJ]
- schema15 already closed as suggested by reviewer in 10 May draft.
Issue
klyne19
- [Chris]
- issue klyne19: Unclear statement about mixing RDF vocabularies "RDF
allows well-defined mixing of vocabularies, and allows text and
- XML to be used as a data type values within a statement having
clearly defined semantics. I couldn't figure precisely what this was
trying to say."
- Me either. (Either 'as data type values' or 'as a data type value',
too). But see the next issue. "used as a data type values" is
grammatically incorrect anyhow.
- [IanJ]
- [We review in context of 4.2.4]
- In particular " and allows text and XML to be used as a data type
values within a statement having clearly defined semantics."
- TBL: Two points here:
- You can mix RDF ontologies; mixing is well-defined for RDF.
- You can remove RDF statements and preserve the truth value of the
set of assertions.
- [timbl]
- You can add stuff in nd somebody else can strip it out. You can
remove statements *because* the semantics of the RDF graph is defined to
be the conjunction of the semantics of the statements.
- [IanJ]
- PC: Add a reference to an RDF specification?
- [timbl]
- RDF allows the mixing of information in the vocabularies from
different application, with well-defined semantics.
- RDF allows the mixing of information in the vocabularies from
different application, with well-defined semantics. [ See RDFMS1.0]
- [IanJ]
- The semantics of combining RDF documents (i.e., sets of assertions)
is well-defined.
- The semantics of combining RDF assertions from multiple vocabularies
is well-defined.
- The semantics of combining RDF statements from multiple vocabularies
is well-defined.
- The semantics of combining RDF documents with multiple vocabularies
is well-defined.
- Resolved: Change third bullet to: "The
semantics of combining RDF documents with multiple vocabularies is
well-defined."
- Resolved: Delete "and allows text and
XML to be used as a data type values within a statement having clearly
defined semantics."
Issue
manola31
- Resolved: Closed by virtue of text
being deleted.
Issue
klyne20
- [Chris]
- issue klyne20: "Say something about relationship between Hypertext
Web and Semantic Web?"
CL: So the SW uses the 'Hypertext Web' or parts thereof to make
statements about. But it also makes a statement about cars, and things,
so that boiled down to 'the semantic Web makes statements' or 'the
Semantic Web is about semantics' (tautology) or 'the non-SW has no
semantics' (not true either). So okay say something, but what? SW is at
a different level of abstraction, layered on top?
- [IanJ]
- TBL: The simple answer to klyne 20 is "Yes."
- IJ: Yesterday we came close to a definition of "information space"
(related to information resources).
- [Chris]
- information space is the network effect applied to information
resources
- [TBL goes to white board; see image from
yesterday]
- TBL: There are at least two subsets of the information space:
hypertext web and semantic web. There can be others.
- RF: How does a transforming proxy fit into TBL's model? The
transforming proxy is taking the universe of information and
transforming it.
- TBL: In case of gateway, the gateway provides an annotated view of
resources (including those outside the gateway). There are services
that, in effect, provide mirrors of the hypertext space.
- NW: Maybe we need a new section at top of document?
- IJ: What about a section on information space?
- PC: I thought we had agreed that we were going to push discussion of
the Semantic Web to another version of the arch doc.
- TBL: We don't have to "go into the SW bubble" in v1 of the arch doc.
We can put one liners about both sem web and web services to state
where they are (in the diagram). In short, explain how they relate, but
don't describe their architecture.
- [Chris]
- CL reiterates what the reviewer said originally: So okay say something, but
what? SW is at a different level of abstraction, layered on top?
- [Stuart]
- Hmmm... does application/xml+svg create a new application? I don't
see at an architectural level you distinguish media-types that
do/do-not give rise to new 'applications'. Also... are applications an
'architectural' concept that we talk about anywhere else?
- [IanJ]
- NW: I think the way to address klyne20 is to say that this document
does not attempt to describe the relationship between these systems in
detail.
- TBL: 3.7 is currently wrong and misleading. Remove the semantic Web
because that's not about interaction. Sem web uses the same interaction
mode (e.g., GET).
Resolved to accept this proposal (SW
abstaining):
- Create a new section 4.6 about use of media types to build new
applications that make use of the information space. Explain that
you create new "applications" such as the semantic web through new
media type definitions.
"Above we describe a global hypertext application which has been
defined using specific Media types. The creation of other media
types allows new applications to be build in the same space, using
the same information space infrastructure. The semantic web is one
such application, which is not described in detail in this version
of this document. We expect future versions of the Arch doc to
describe the semantic web in more detail."
- Remove sem web from discussion in 3.7
- Respond to reviewer that we expect future versions of the arch
doc to go into more detail about the relationships among various
systems.
Issue
clark6
- [Chris]
- issue clark6: Separating Presentation From Content. "This is often
harder than the AWWW lets on, and sometimes it's simply not possible at
all. I think the language should be modulated to reflect that reality;
see proposed text..."
- [IanJ]
- CL: This is another instance of oversimplification; needs more
discourse on trade-offs. I agree with reviewer.
- [Chris]
- Absolutely. Again the finding conveys this trade off but WebArch over
simplifies and presents as a single choice without trade-offs.
- [IanJ]
- Action CL: Proposed additional text that
includes more about tradeoffs.
Issue
gilman1
- [Chris]
- issue gilman1: 'legal requirement' as justification for 'particular
presentation' misses 'leading Web to highest' mark This is another
occurrence of meta-issue-1 "its a trade off, not clear-cut".
- [IanJ]
- IJ: The new text is "Designers should consider appropriate
technologies for limiting the audience. For instance digital signature
technology, access control, and other technologies are appropriate for
controlling access to content."
- Resolved: We believe that 10 May draft
addresses gilman1.
- Issue
klyne21
- [Chris]
- issue klyne21: "Add statement about scalability concerns." Good
point, scalability in for example client side vs server side image maps.
Pushing computation to the client increases server throughput.
- [IanJ]
- PC: Stored procedures on databases - scalability by pushing
computations to server. This is about light v. heavy clients. This is
clearly a time when one considers tradeoffs. Largest increases in
scalability of database applications has involved putting triggers on
the server; stored procedures (which trigger a bunch of actions), etc.
Scalability of SQL databases is about moving computation to the
server.
- [Chris]
- and cutting down communication
- [IanJ]
- PC: Security architecture scales better as well when procedures
stored on server.
- CL: The example I was thinking of was moving server-side images to
client-side images. Improved load on server and network lag.
- PC: Counter-example - there are cases where you want to filter a view
of data, and you should filter on the server side in order to ship less
data.
- Action CL: Draft a little text to explain
that there's a tradeoff in this situation.
Issue
clark4a
- [Chris]
- issue clark4a: "Hypertext Good Practice Redundancies". No, these are
not equivalent. There have been hypertext systems that allowed only
linking within a small set of documents, and SGML allowed
within-document linking (id/idref) without actually being a hypertext
system. The second good practice note is a scalability note, and is
needed. However, it should be broadened not only to hypertext links but
other sorts of links as well.
- [IanJ]
- CL: I think the two are not redundant. First motivates hyperlinks,
second motivates global hyperlinking. idref should be changed to
anyuri.
- NW: idref should be changed to anyuri
- Resolved: We believe that the
statements say different things and both are justified.
"New top level domains
considered harmful" from TBL
- [IanJ]
- Proposed: That the TAG send TBL's revised TLD text to the ICANN
comments list.
- SW summarizing what he thinks: There are some potential benefits and
potential harms to the proposal. I do not think there is an essential
need to create a TLD to provide the potential benefits. The way to give
clients with small devices more tailored content is not through TLDs. I
have not seen technical arguments that support the need to create a
TLD.
- [Roy]
- I have read and support Tim's TLD document.
- [timbl]
- DRAFT: This document comes with the support of the W3C TAG with Norm
Walsh of Sun Microsystems abstaining, and Paul Cotton of Microsoft
recusing himself.
- [DanC_]
- (I haven't looked at /TLD.html very carefully, but I'm satisfied that
it's gotten enough review and endorsement that I should have spoken up
if there was stuff I objected to. If the TAG records "concur" votes,
then that's what I'd like the record to show. Otherwise, show me as not
objecting nor abstaining, i.e. in support)
- [IanJ]
- Resolved: The TAG supports sending
TBL's revised TLD text to the ICANN comments list. Support from CL, MJ,
RF, TBL, SW. DC concurs. NW abstains. PC recuses himself (citing charter).
Action TBL: Send his text to the ICANN
comments list today.
Action TBL: Send the link to his posting to
www-tag.
Two questions re: patent policy:
- Should TAG Recs be covered by the policy?
- What should the licensing obligation of participants be?
See draft
charter.
- [DanC_]
- hmm... "TAG findings have no normative status and must not be
referenced normatively from a W3C Recommendation Track document."
- [IanJ]
- PC: IJ sent out proposed text; IJ responded to them and sent
refinements.
- TBL: I propose that some folks from the AB, the TAG, and DJW hold a
discussion on the TAG and the patent policy.
- Would prefer to be counted as an invited expert: SW, PC, RF, MJ,
NW.
- (RF: I think PC should be an invited expert)
- PC: Note that if Day Software were to join, RF's obligation would
change.
- IJ: I note the same is true for any WG.
- PC: The difference with the TAG is the election process for
participation.
- [Discussion postponed to another meeting]
- List of actions
by owner
Issues with actions discussed here:
Issue
uriMediaType-9
- Propose CL's three changes to registration process to Ned Freed.
- CL: Ned has not responded.
- [Chris]
- My action is completed, though a new action could be assigned for
followup
- [IanJ]
- Proposed to close CL's action on uriMediaType-9
- CL: My charmod review actions are all done.
- Resolved: Close charmod review actions
for CL.
- Issue
xlinkScope-23
- Resolved: Close CL's action regarding
xlinkScope-23.
Issue
contentPresentation-26
- Action CL: Talk with others about aspects of this finding and revise
it.
Resolved: Close CL's action for
contentPresentation-26
- Issue
namespaceDocument-8
- Action PC: Prepare finding to answer this issue, pointing to the RDDL
Note. See comments from Paul regarding TB theses. Per 23 Feb 2004
teleconf, modified into an action to produce a bulleted list of
points.
- PC: Still pending
- Issue
URIGoodPractice-40
- Action RF: Draft a finding for this issue.
- RF: No progress other than the URI spec.
Issue
URIEquivalence-15
- Action SW: Track RFC2396bis where Tim Bray text has been integrated.
Comment within the IETF process.
SW: I am reviewing this within the week.
Issue
metadataInURI-31
- Action SW: Produce a revision of this finding based on Vancouver ftf
meeting discussion.
- SW: I hope to have by mid-June.
Issue
IRIEverywhere-27
- Action TBL: Explain how existing specifications that handle IRIs are
inconsistent. TBL
draft not yet available on www-tag.
- TBL: Please continue.
- Issue
RDFinXHTML-35
- Action TBL State the issue with a reference to XML Core work. See email
from TimBL capturing some of the issues.
- TBL: Lots has happened since then. I think that GRDDL changes that
landscape.
See email
from DC on Syntax and Semantics for embedding RDF in XHTML.
- Action IJ: Add GRDDL to background list
in issues list.
- [IanJ]
- IJ: Who is working on this?
- [timbl]
- http://www.w3.org/2002/04/htmlrdf
- [IanJ]
- [Stuart leaves]
- Action IJ: Add this to background
materials - http://www.w3.org/2002/04/htmlrdf
Resolved to drop TBL action
regarding stating this issue w.r.t. XML Core work.
- PC: When we report to the AC we should explicitly tell them that we
are preferring to close LC issues in preference to closing general
issues.
Issue
XMLVersioning-41
- Action TBL: Suggest changes to section about extensibility related to
"when to tunnel".
- Resolved to drop this action.
4.5.1 Next Editor's Draft, Next WD
- [IanJ]
- DC: Likely to go back to WD status. I'd like to publish a new TR page
WD soon.
- [Zakim]
- DanC_, you wanted to note we owe a /TR/ publication. it's been >5
months.
- [IanJ]
- DC: IJ has feedback queued up on 10 May draft. I'd like to see a
draft in the next 3-4 weeks that at least IJ and two others have looked
at.
- [Discussion of next Editor's draft publication date - first week
of June]
- IJ: I'd shoot for 8 June.
- Regrets for 14 June: IJ, TBL, MJ. At risk: RF
- Support for:
- Next editor's draft 8 June
- At 14 June teleconf, if at least 2 thumbs up and no thumbs down,
IJ will request publication thereafter.
Commit to reading the 8 June Editor's Draft: NW, CL, PC
4.5.2 Meeting planning
Next scheduled ftf meeting: 9-11 August in Ottawa. IJ unlikely to be in
Ottawa but might be able to attend part-time by phone or IRC.
- [IanJ]
- NW: I heard people say "do LC comments until we're done"
- [DanC_]
- PC: looks like a LC will be Sep at earliest, following our Aug ftf.
DC: sigh. true.
- [DanC_]
- rather: (eek! minute taking and issue tracking!)
Issues discussed here:
See also continuation of discussion of Last Call issues.
Issue
schema17
- [IanJ]
- CL: I think their point was that a ns URI is not a globally unique
name.
- DC: I disagree.
- [Norm]
- http://lists.w3.org/Archives/Public/public-webarch-comments/2004JanMar/0005.html
- [Roy]
- Suggest: a mechanism that may be used to establish globally-unique
names.
- [IanJ]
- CL: I think the argument is "You can pick http://normwalsh.org/foo" as a ns URI, and so can
I.
- [Zakim]
- DanC_, you wanted to recall a comment that {uri, lname} may refer to
more than one thing
- [IanJ]
- NW: It's important to point out that it's true that the ns spec lets
you to create globally unique names, no matter how they are used.
- DC: The comment I heard was that "globally unique" suggested to
someone that it could only be bound to one thing. There is an
architecture of global uniqueness and then there are bugs. The
architecture assumes that the domain owner is competent. Sometimes they
are and sometimes they are not.
- [Roy]
- instead: "a mechanism that reduces the likelihood of name
collisions."
- [DanC_]
- I think s/that can be understood in any context// is responsive to
the commenter. let's try that and see if they're satisfied.
- [IanJ]
- or: "reduces the risk of URI overloading"
- [DanC_]
- there should be a link to 2.2. URI Ownership from this section
somehow...
- [IanJ]
- RF: Namespaces in xml use URIs in order to obtain the properties of a
global namespace.
- [DanC_]
- perhaps "... perhaps of a global namespace discussed in 2.2. URI
Ownership"
- [IanJ]
Resolved:
- Continue to delete "that can be understood in any context"
- Modify remaining sentence to say: "Namespaces in xml use URIs in
order to obtain the properties of a global namespace."
- Include a reference to 2.2 URI ownership.
Issue
schema18
- About 4.5.3...
- "The xsi:type attribute..."
- CL: I prefer "type attribute from XML Schema"
- MJ: Also, state the namespace that it's in.
- [Norm]
- The type attribute from the W3C XML Schema instance namespace, "http://...".
- [DanC_]
- [[
- "The type attribute from W3C XML Schema namespace is an example of a
global
- attribute."
- ]] is one of their suggestions
- ... and is OK by me
- [IanJ]
- IJ: And a ref to the schema spec.
- [IanJ]
- Resolved: IJ to make changes to point
to XML Schema spec (possibly with ns URI in text).
Resolved: The TAG agreed with the reviewer
about issue
schema19
Resolved: The TAG believes that with the 10
May draft it has satisfied the reviewer for issue
booth3
Editorial in section 2.7.2
- [DanC_]
- "Nadia is requesting the namespace document." -- http://www.w3.org/2001/tag/2003/lc1209/webarchWithProposals.html
- [IanJ]
- 2.7.2. Assertion that Two URIs Identify the Same Resource
- [DanC_]
- editorial: "owl:sameAs" vs sameAs. Pick one.
- [IanJ]
- NW: Replace ns prefixes with clear references.
- DC: Pick one of the above tokens: "owl:sameAs" vs sameAs
- IJ: I added one sentence.
- DC: Satisfied
Resolved: The TAG accepted the change in the
10 May 2004 Editor's Draft for issue
kopecky6.
Issue
schema20
- Added as well: "In practice, applications may have independent means
of specifying ID-ness as provided for and specified in the XPointer
specification."
- NW: Change to "such as the means provide for..." I'm concerned that
bullet 4 is incorrect. It does not establish ID-ness; it allows you to
point to things that are not identified by ID.
- [DanC_]
- [[
- In practice, applications may have independent means of specifying
IDness as
- provided for and specified in XPointer. XPointer carefully
- discusses these options at
- http://www.w3.org/TR/2003/REC-xptr-framework-20030325/#shorthand
- ]]
- [Norm]
- In practice, applications may have independent means of locating
identifiers inside a document such as provided for and specified in the
XPointer specification.
- [IanJ]
- TBL: Do we have any examples of this?
- [Chris]
- http://www.w3.org/TR/2003/REC-xptr-framework-20030325/#shorthand
- [DanC_]
- (I'm writing them to ask where their implementation experience for
this feature is recorded: see email
externally-determined ID implementation experience?)
- [Chris]
- its a pointer cursor not a hand cursor
- [IanJ]
- DC: +1 to NW's text; please refer to section 3.2 of XPointer.
- Resolved: For the fourth bullet, adopt
NW's proposal as amended to include ref to 3.2. The TAG believes it has
closed schema20 with these changes.
Issue
stickler3
- [marioj]
- originally occurred @ 3.1. Using a URI to Access a Resource
- [IanJ]
- Current definition: "Dereference a URI: Access the resource
identified by the URI."
- Patrick recommends: "Indirectly access the resource identified by the
URI via a representation of that resource."
Resolved: Keep the text in the
glossary.
Action IJ: Ask the commenter if the
definition in context (in section 3.1) explains the way we use the
terms to his satisfaction.
- [Roy]
- rfc2396bis: URI "resolution" is the process of determining an access
mechanism and the appropriate parameters necessary to dereference a
URI; such resolution may require several iterations. To use that access
mechanism to perform an action on the URI's resource is to
"dereference" the URI.
Issue
diwg1
- [IanJ]
- RF: IMO, the commenter misunderstands the concept of "URI
persistence".
- Action IJ: Ask the reviewer to clarify
the question.
- TBL: I think this is more about .html v. .asp (for example).
Issue
clark1a, Issue
clark1b
- [IanJ]
RF: One indirection always suffices.
TBL: Reviewer only thinking about hypertext; no constraint to just
hypertext. I do note that "secondary resource" is not a subclass of
"resource". "Secondary" is a relationship ("something referred to by
the primary resource"). In fact it is a "referenced resource".
- RF: Rather, it's "defined by". The secondary resource is "defined by"
the primary resource.
- TBL: Note that "a#b" and "c" can identify the same resource; "b" is
just a local name within the context of the representation of a.
- RF: Within the global set of resources, there are subsets
(primary/secondary) which may be the same sets or overlap. I don't know
where to place resources not yet assigned a URI.]
- IJ Proposed: "resource" and "resource with a local name"
- [That is an attempt to move towards naming and to avoid thinking
about subclassing resources]
- TBL: You can never establish whether something is a secondary
resource because you don't know whether someone has created a URI that
designates it.
- RF: I do not expect to change the terms in RFC2396.
- DC: Best to describe secondary resources as a relationship between
the two resources.
- [Norm]
- Can someone post the URI for the most recent 2396bis?
- [IanJ]
- PC: Explain to the reviewer that the definitions of primary/secondary
are in RFC2396. Include a reference to the RFC2396bis for info about
the definitions.
- [DanC_]
- (just because a term is defined elsewhere doesn't make our reviewers
happy about it. to wit: Hayes and 'resource')
- [Norm]
- (point taken)
- [IanJ]
- TBL: The response to the reviewer can say (at least) that we mean
"Just a relationship."
- Resolved for issue clark1a:
- No change to document other than inclusion of a ref. to
RFC2396.
- Respond to reviewer indicating this and answering "(1)".
- [timbl]
- From clark1b: "Let's assume however, that these are mutually
incompatible representational semantics. The question arises then,
which of the several, mutually incompatible secondary resources is
identified by a primary resource with a fragment identifier? In other
words, the answer to the claim that "the secondary resource identified
by a URI with a fragment identifier is expected to be the same across
all representations" is yes, but which one?"
- [IanJ]
- [Sentiment that new text will address clark1b as well.]
- PC: Ask commenter at next draft to review the revised text.
More on clark1b.
TBL: In the case of, say, SVG and HTML. You can create named anchors
that correspond - and consistency from the point of view of the
publisher.
- [IanJ]
- TBL: I propose a new issue.
- DC: I think the long discussion we had yesterday suffices.
- TBL: There's a discrepancy between what you can do with an html
anchor and an rdf anchor. There is a real need to be able to write a
resource and to provide both html and rdf representations.
- [DanC_]
- this is issue http://www.w3.org/2001/tag/issues.html#fragmentInXML-28
, no?
- [IanJ]
- TBL: There are cases where, e.g., HTML is generated from the RDF. In
that case, if someone asks for a representation and gets back html
instead of RDF, and for every concept named in the RDF representation,
there is an anchor in the HTML document, it's reasonable for coneg to
work (from RDF-> HTML). There are pitfalls but also a need. The
answer to "Can RDF be consistent with HTML?" is "That's a long story."
Is the move from "reality" to a "description of reality" a reasonable
downgrading of information that a publisher could be happy with
sufficient to do coneg?
- [Zakim]
- DanC_, you wanted to ask if fragmentInXML-28 is close enough
- [IanJ]
- RF: How is an RDF description of a car different from an HTML
description?
- DC: See fragmentInXML-28.
- [IanJ]
- PC: Why not have a parameter on a fragment to provide different text
on a per-media type basis?
- [DanC_]
- e.g. foo#if-HTML(sec3);if-RDF(car12)
- [IanJ]
- RF: There is a reason - makes it easier for people to create
implementation-names instead of implementation-independent names.
People in general don't do this; they don't create names in different
representations that are incompatible, and then use URIs to refer to
them.
- TBL: Ken Clark is operating in a space where he wants to be able to
use both RDF and HTML representations.
- [IanJ]
- NW: I do this today - you can get either HTML or RDF files back; I
assert they are consistent (see example from NW
site)
- IJ: I believe that I can incorporate what Kendall and TBL want into
text that we agreed to yesterday: namely that the architecture licenses
publishers to serve both RDF and HTML representations when the
publisher believes they are suitably consistent (despite switching
semantic "levels"). However, need to proceed with caution when doing
this (nothing new!).
- [NW's URI is an example of doing this.]
See TBL's electronic version of diagram as well (SVG version,
PNG
version)
- [timbl]
- See my proposed
text regarding HTTPRange-14
- [DanC_]
- which part of the document does that text go in, timbl?
- [timbl]
- I'll leave that to Ian?
- [DanC_]
- I'd rather you didn't, timbl. I'd much rather you carefully
considered where the text goes and how it flows.
- [IanJ]
- MJ: [For TBL's graphic] Why not enlarge the Web services box to
overlap with the Semantic Web ("semantic web services")
- CL: Also, not all web services work over http.
- [DanC_]
- See my slides
for AC meeting.
- [IanJ]
- CL: I agree to them.
- NW: Please add a Note that the TAG will be focussing on LC comments.
Who will present these slides?
- DC and PC will split slides.
- Resolved: TAG happy to have DC and PC
present slides at AC meeting.
Issues discussed here:
Issue
clark3.
Resolvedto refer reviewer to
3.6.2, no change to document.
Issue
clark4b
- [DanC_]
- [[ The real problem here is that there is no real formalization of
"hypertext link" in the AWWW. ]] er... isn't hypertext link discussed
in 4.x?
- ah... he's aware of that... [[ But if, as seems likely from Section
4.5.2. ]]
- [IanJ]
- IJ: I understand the question to mean "why not allow hypertext links
in the format even when there is a different paradigm (non hypertext
UI)
- NW: But this section is explicitly about hypertext.
- DC: I think that the reviewer means "Use hypertext links even if you
expect machines to be using the data."
- NW: We've said "Identify things with URIs". We could also say "Format
designers should allow people to create references in formats using
URIs."
- DC: I think that this is more about: Create a network using URIs.
- NW: I suggest pointing reviewer to "A specification SHOULD provide
mechanisms that allow Web-wide linking, not just internal document
linking."
- [Zakim]
- DanC_, you wanted to suggest tweaking "Formats that allow content
authors to use URIs instead of local identifiers foster the "network
effect": the value of these formats grows with the size of the deployed
Web."
- [timbl]
- Chris, what do Web Services use when they don't use http:?
- [Chris]
- sockets?
- [DanC_]
- not only do Formats foster the network effects, but also collections
of representations that refer to each other.
- [IanJ]
Action IJ: Incorporate DC suggested
tweak for section 2.
- [DanC_]
- they use SMTP or other message-passing infrastructures.
(MQseries?)
- [IanJ]
- TBL: We should include some references to materials that define
"hypertext".
- [timbl]
- http://portal.acm.org/citation.cfm?id=175237&coll=portal&dl=ACM&CFID=21545401&CFTOKEN=39367008
- [IanJ]
- CL: I'd like to nail down a bit more a definition of hypertext
link.
- [timbl]
- The Dexter hypertext reference model
- [IanJ]
- NW: I'd like to see if we can address the reviewer's comment by
virtue of IJ's action to incorporate DC's proposal.
- [timbl]
- RF: [sotto voce] The web isn't based on dexter
The TAG did not discuss the topics below this line.
5. Other action items
- Action DC 2003/11/15: Follow up on KeepPOSTRecords with Janet Daly on
how to raise awareness of this point (which is in CUAP).
- Action CL 2003/10/27: Draft XML mime type thingy with Murata-san
Ian Jacobs for Stuart Williams and TimBL
Last modified: $Date: 2004/05/27 14:59:46 $
{kind=link}
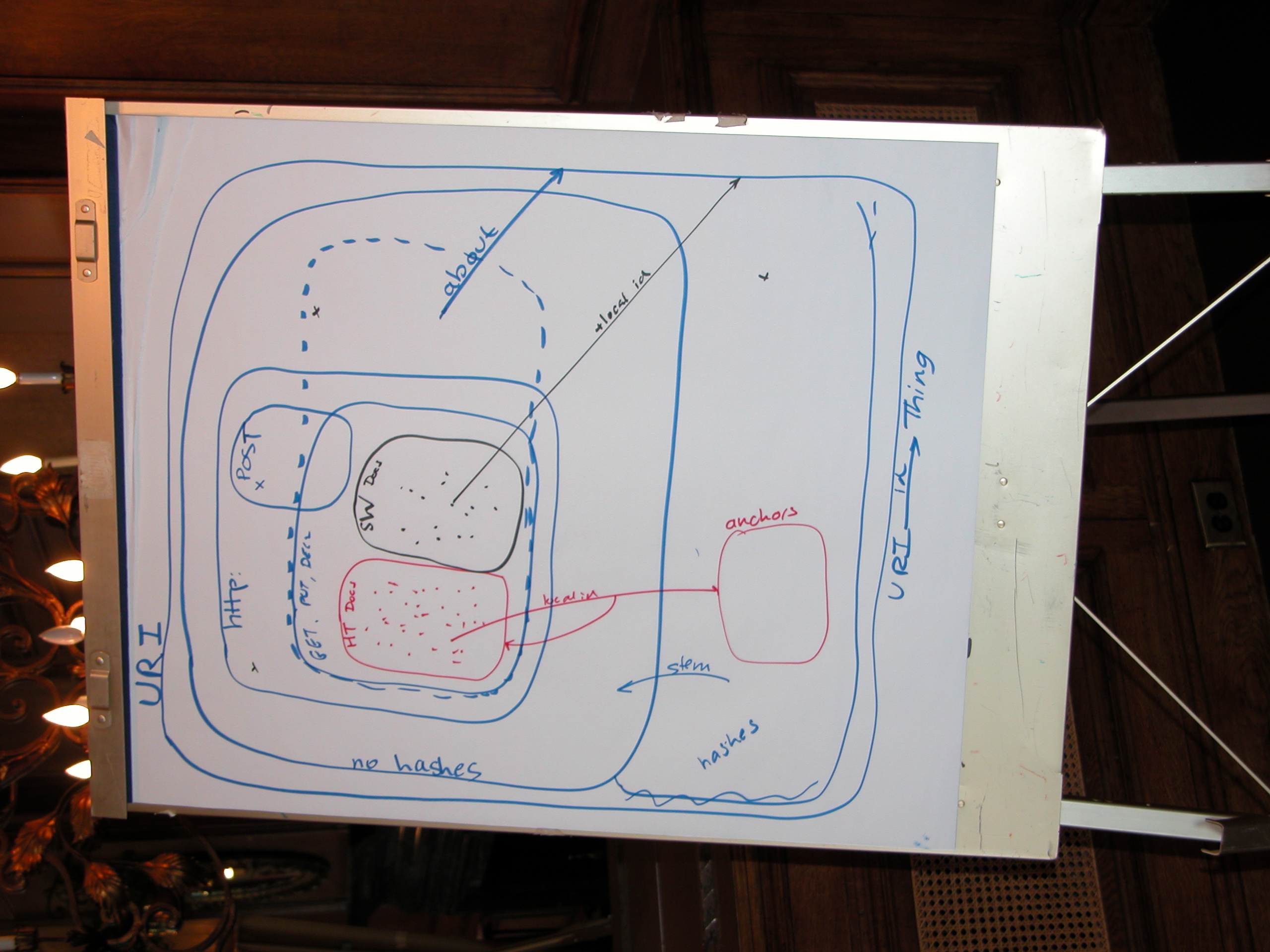{kind=link}
{kind=link}
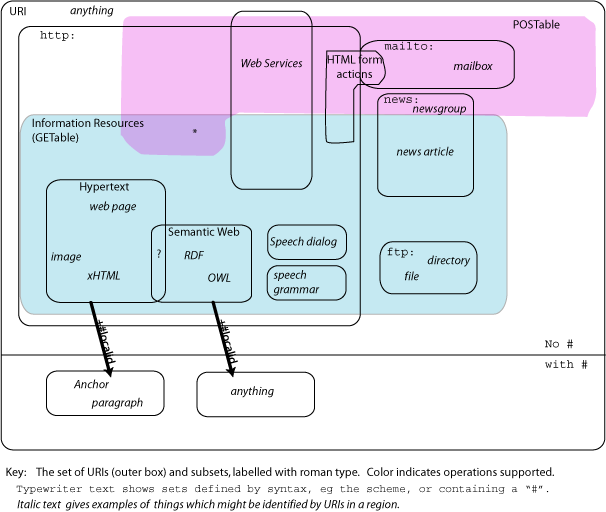{kind=link}